1. Introduction
Latent heat flux (LE) or evapotranspiration (ET) is an important process of hydrological cycle and surface energy balance [
1,
2,
3], including soil and open water evaporation, plant transpiration, and canopy interception evaporation. LE is vital for climate change, which accounts for about 60% of global precipitation [
4]. As irrigation water use increases, so does competition for water across regions. The basin-scale LE plays a crucial role in directing the efficient distribution and administration of water resources.
Currently, the methods of obtaining LE mainly include lysimeters, eddy covariance (EC) systems, large aperture scintillometers (LASs) and optical-microwave scintillometers (OMSs) at the site scale or field scale [
5,
6,
7]. The regional-scale LE can be acquired through remote sensing estimation methods such as empirical statistical method [
8,
9], energy balance method [
10,
11,
12], and variational data assimilation method [
13,
14,
15]. However, most of the methods are still only applicable to small scales, and some errors will occur when the study area is extended to watershed or global scale. In addition, many parameters in the models cannot be measured directly due to the limitations of ground-based observations unless they are obtained by empirical estimation or parameter optimization, which will result in a strong geographical variability of the final calculated LE.
To acquire the accurate regional LE, many researchers have made numerous attempts at upscaling approaches based on ground-measured observations. The common upscaling methods include four major groupings, and the detailed descriptions are as follow. The first group averages the values of the ground sampling points directly [
16] or weights them according to the area or footprint range [
17,
18]. It is easy and effective to obtain the regional information from site data through these methods, but limited by the spatial heterogeneity and reasonable sampling strategy. Establishing empirical regression models is another widely used method, which involves creating a correlation between land surface variables and the target variable based on site-scale datasets, and subsequently extrapolating the relationship to a basin-scale level [
19]. Nevertheless, the empirical regression method, although useful for small areas, may not be suitable for extrapolation to larger areas. The third group, called “geostatistical methods”, mainly studies the natural phenomena with spatial correlation based on kriging theoretical framework or Bayesian theory framework, and it is widely used in the study of spatial scale expansion from point scale to regional scale [
20,
21]. The fourth group is based on machine learning techniques such as artificial neural networks [
22], random forests [
23], and so on [
24,
25,
26,
27]. However, what is captured by machine learning is limited to the training set that is input to the model. As a result, predictions in ranges outside the training set are not as effective, especially for extreme weather [
28].
Although previous methods have elevated the site-scale LE to regional scale to some extent, these methods have mostly considered data within regions or near sites but not in other similar regions, and the advent of transfer learning provides a new perspective. Transfer learning is inspired by the ability to transfer knowledge across domains and aims to use knowledge from the source domain to improve the learning performance of the target domain or to reduce the number of labeled examples required for the target domain [
29]. It can be divided into instance transfer, feature-representation transfer, parameter transfer, and relational-knowledge transfer based on the content of the transfer [
30]. Instance transfer means that the dataset of the source domain can be reused together with the data of the target domain after corresponding processing, and has a wide range of applications due to its relatively simple principle. Wu and Dietterich [
31] integrated source domain data into the support vector machine framework to improve classification performance. Feature-representation transfer aims to find the good feature representation and minimize the error of classification or regression model in the target domain. Parameter transfer is essentially the migration of parameters or weights from the source task to the target task to save the training time of the model. As the weights of the loss functions may vary, assigning larger weights to the loss functions in the target domain ensures better performance in the target domain. Lawrence and Platt [
32] proposed an efficient method for learning the parameters of a Gaussian process (GP), called multi-task informative vector machine (MT-IVM), for handling multi-task learning situations. Schwaighofer and Kai Yu [
33] combined hierarchical Bayesian (HB) with GP for multi-task learning. Unlike the above three transfer learning methods, the relational-knowledge transfer deals with the transfer learning problems in the relational domain and involves the non-independent and identically distributed data. Mihalkova et al. [
34] proposed transfer via automatic mapping and revision (TAMAR), which uses Markov logic networks (MLNs) to transfer relational knowledge across relational domains. Zhao et al. [
35] introduced transfer learning into the field of natural hazards, providing a new idea for improving machine learning-based assessment methods by transferring prior knowledge of different catchments.
Sometimes, the capability of an individual transfer learning model is limited due to the limitation of the number of sites and land cover types, in which case the fusion of multiple models seems to solve this problem. In contrast to other fusion methods [
36,
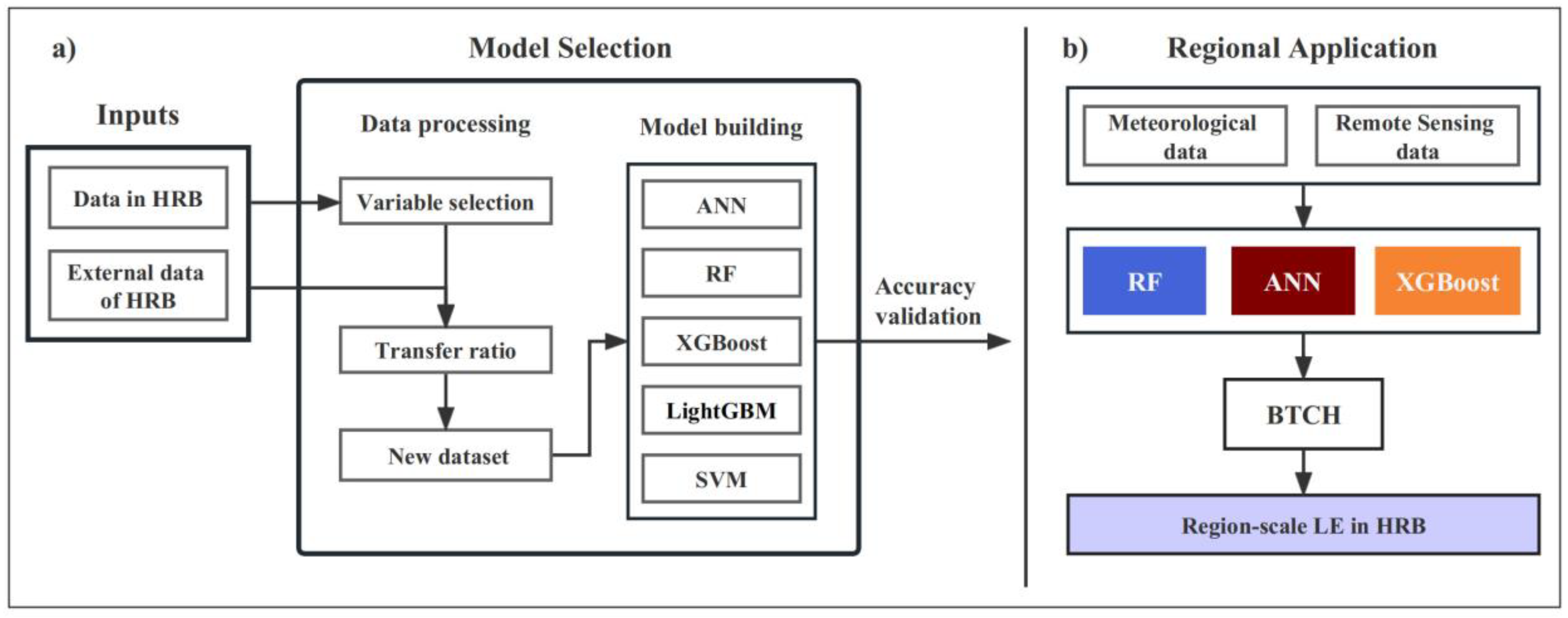
37], the Bayesian-based three-cornered hat (BTCH) approach enables the integration of products without using any a priori knowledge, and optimizes the use of available information, ultimately enhancing the quality and accuracy of data fusion. Given the robustness of machine learning models and the effectiveness of fusion algorithm, this study investigated the performance of five transfer learning methods and the BTCH fusion method based on the observed data from the Heihe River basin (HRB) sites and similar external datasets. Five machine learning algorithms are employed in this research, which are artificial neural networks (ANNs), random forests (RFs), support vector machine (SVM), extreme gradient boosting (XGBoost, version 1.3.1, Python 3.6), and light gradient boosting machine (LightGBM), respectively, and the best three of them are selected for fusion to obtain the optimal upscaled daily LE with the spatial resolution of 1 km in 2018.
4. Results and Discussion
4.1. Effectiveness of External Data for Upscaling Model
Considering that LE is influenced by a variety of factors, in order to obtain the best performance of transfer learning model, PPMCC was used to evaluate the similarity of the driving variables under four different land cover types, which are BSV, CRO, CSH, and GRA, respectively.
Table 5 shows a strong correlation between Rn, ET
0, and LE under all four land cover types, which is consistent with the physical mechanism in the P-M equation. The correlations between LE and vegetation factors, as well as Ta, were found to be stronger at sites with high vegetation cover compared to those at BSV sites. In contrast, the correlation with SM was more significant at the BSV sites than CRO sites, due to the fact that vegetation transpiration can utilize deeper soil moisture. Finally, for each land cover type, the five driving variables (bolded) with the highest correlation coefficients were selected.
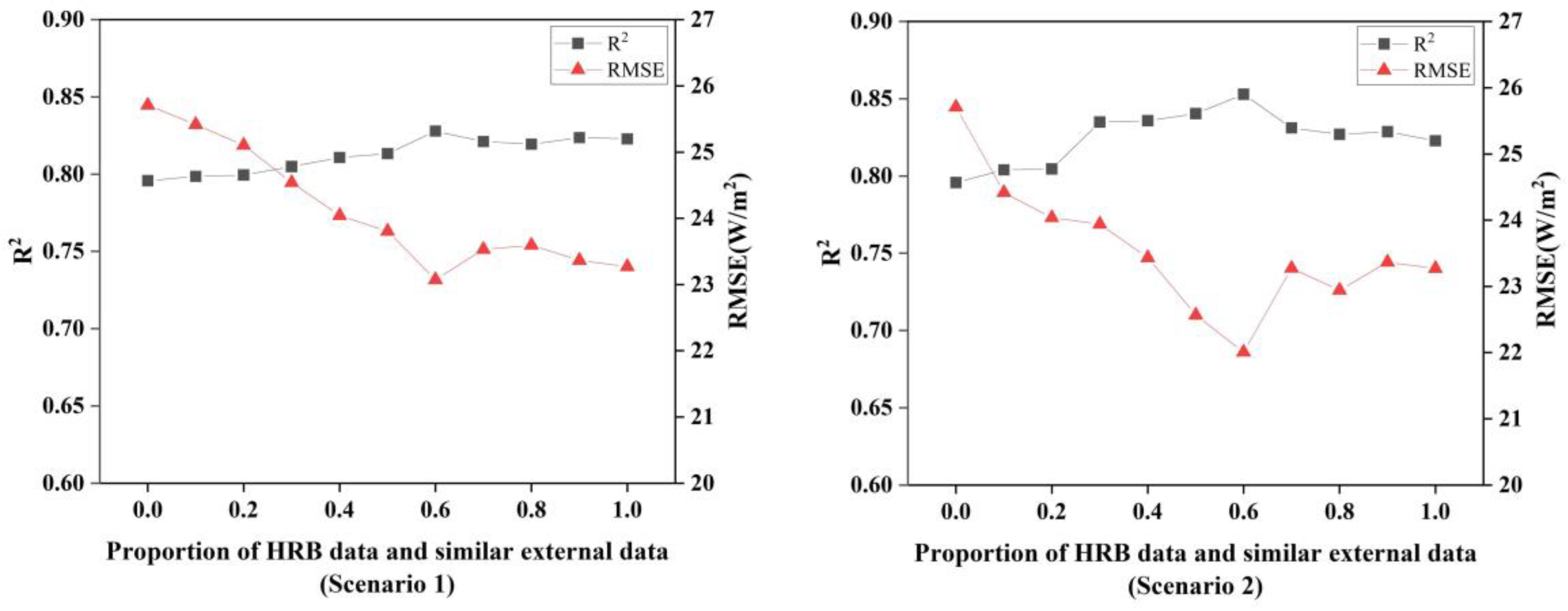
On the basis of the five variables, data were introduced from similar external data using the two scenarios already mentioned. The difference between the two scenarios is that the second ensures that the data extracted every time is the most similar to the HRB dataset.
Figure 3 shows that the second scenario performs better overall than the former. For the first one, the inclusion of data resulted in a flatter change in ANN model performance. When the incorporation ratio (the data samples ratio between HRB and external dataset) is 5:3 (transfer ratio is 0.6), the model achieves the best RMSE and R
2 in both cases, but the second has a lower RMSE and a higher R
2. Therefore, the model was constructed by introducing external data according to the law of increasing NED.
When calculating the proportion of external data introduced, the ANN model performs best when data sample transfer ratio is 0.6 (RMSE = 22.00 W/m2, R2 = 0.85), comparing with the original ANN results without external data (RMSE = 25.71 W/m2, R2 = 0.80). From this point, the performance on the test set decreases slightly before settling into a range that is still better than when no similar external data is added. It also suggests that the training set plays a role in the final performance of the machine learning model, with the more comprehensive the data in the training set, the better the generalization ability of the model. When the ratio exceeded 0.6, the model did not work well instead, probably because the ratio of similar external data was too large and the model did not capture enough key features of the data in HRB, which eventually led to some errors in the test set.
4.2. Comparison of the Results from Five Transfer Learning Models
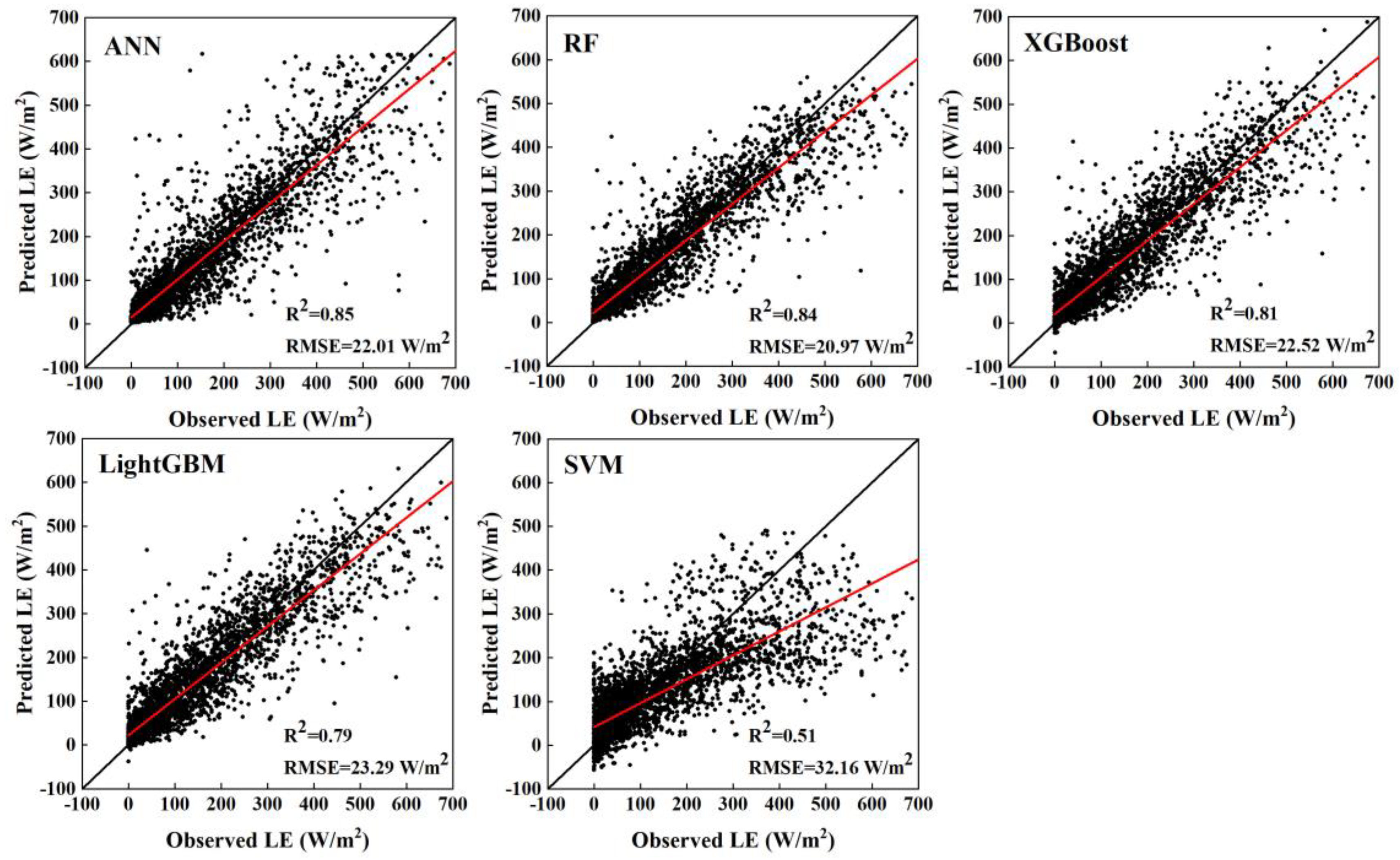
In this study, the performances of the five transfer learning models were evaluated and analyzed using the hold-out method, where the ratio of the training set to the test set is 8:2. The scatterplots of predicted LE versus observed LE for the five models over the test set were plotted in
Figure 4. As shown, ANN and RF algorithms outperformed the other models significantly. The ANN model has the largest R
2 of 0.85 and the RF model has the lowest RMSE of 20.97 W/m
2. Compared to the RF model, the slope of the fitted line for the ANN model is closer to 1, but when some of the data in the training set is small (LE < 200 W/m
2), the ANN model has a simulated value of 400–600 W/m
2, which results in a larger RMSE for the ANN model than the RF model. As the SVM model is essentially a linear simulation with the least effective, the scatter points of models other than itself are generally distributed around the 1:1 line. A common problem with the XGBoost and LightGBM models, however, is that for models trained on a training set with no negative values, negative values exist in the predictions. Non-negative site observations of LE values can be predicted to a maximum of around −20 W/m
2, especially in the LightGBM model.
Based on the results of the five models, it can be found that the models cannot perform well when the LE observations are at higher or lower values. The main reason for this phenomenon may be that evaporation and transpiration require a certain time process, and there may be a certain lag in the relationship between LE and precipitation and soil moisture.
4.3. Accuracy Validation and Time Series Analysis
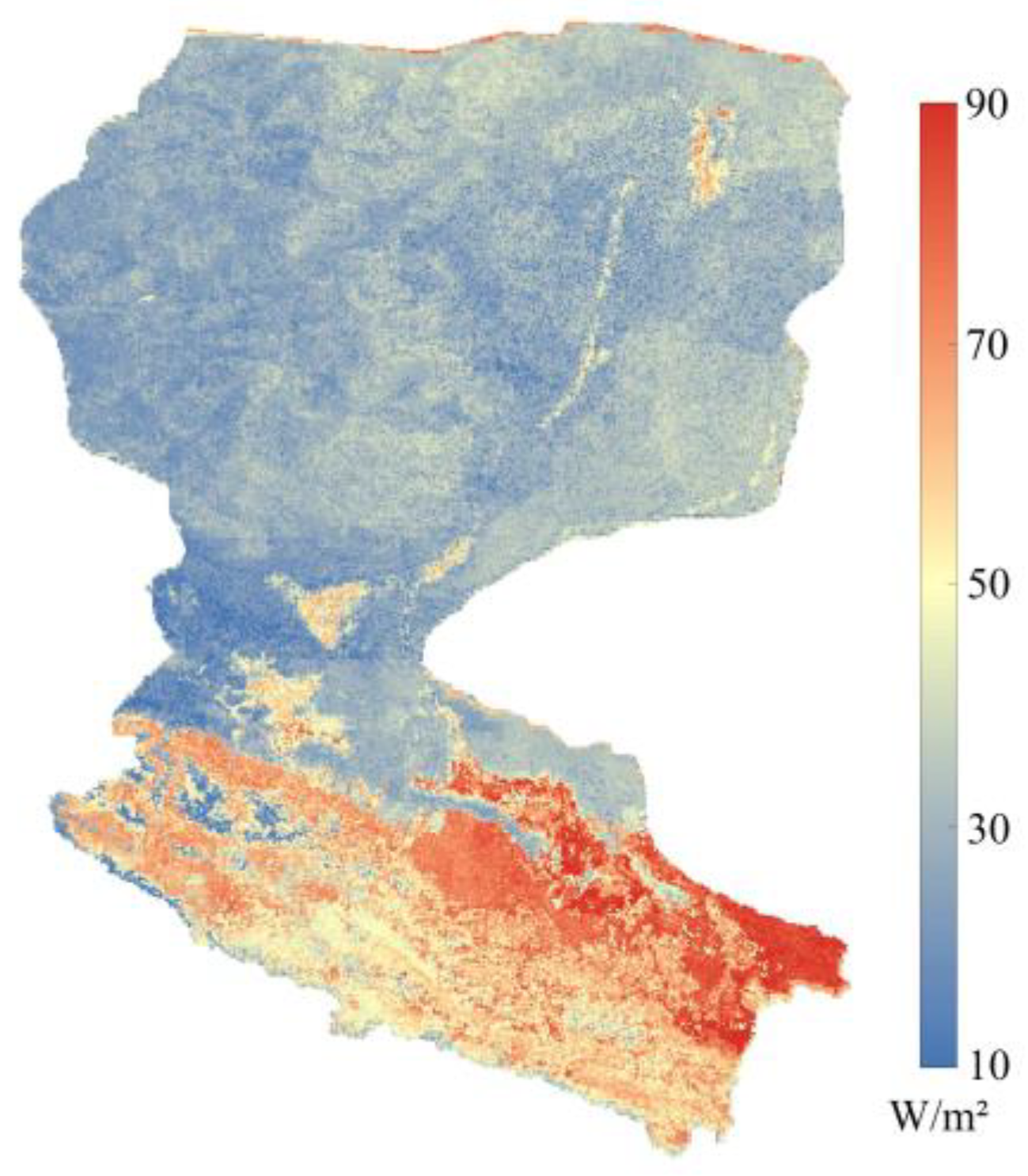
The best three models, ANN, RF, and XGBoost, were used to produce 1 km×1 km daily LE over HRB throughout 2018, using meteorological and remote sensing forcing data as input. The results of the three models were then fused using the BTCH method to obtain a new set of daily maps of LE. The spatial distribution of the fusion result can be found in
Figure 5.
The daily LE obtained from the three single transfer learning models and their fusion were compared with LAS observations in HRB. Results (
Table 6) show that the calculation accuracies of the Arou (RMSE = 19.80 W/m
2, R
2 = 0.80), Daman (RMSE = 21.48 W/m
2, R
2 = 0.77), and Sidaoqiao (RMSE = 22.69 W/m
2, R
2 = 0.76) sites are consistent with the heterogeneity of the underlying surface at the upper, middle and lower reaches of HRB sites. The underlying surface of the Arou station is relatively homogeneous and the main land cover type is grassland. For Daman station, there are roads, villages, and orchards in addition to maize farmland. The underlying surface of the Sidaoqiao station is the most complex and fragmented, with high spatial heterogeneity, and the land cover types include tamarisk, Populus euphratica, crop land, desert, etc. For model algorithms, RF and ANN are significantly better than XGBoost, while the XGBoost model has the worst performance. The BTCH model has the best simulation result, with R
2 and RMSE better than others. The fusion approach retains the advantages of three transfer learning models and also provides some improvement to the phenomenon of overestimation of low values at Daman station.
The discrepancies between transfer learning models and fusion model were mainly caused by model algorithms, observation data uncertainty, limitations of the training set, and land surface heterogeneity. Firstly, machine learning algorithms are essentially learning about data and the underlying relationships among data through continuous iterative learning of the training set. The differences in model principles lead to different areas of expertise for each model, with the RF model performing the most consistently in this study and the ANN model being more accurate in some extreme cases. The BTCH approach retains the strengths of three models through data fusion and the shortcomings of the models are compensated for. Secondly, the observed and inverse accuracy of the HRB data is not exactly the same as the true values, while differences in processing methods and different spatial and temporal resolutions can also introduce some errors. Thirdly, the training set is mainly derived from site observations, which are spread over a relatively concentrated farmlands and oases, so the model learns a limited amount of knowledge, probably causing some errors during the process of upscaling. Finally, LE is determined by numbers of factors, and verification accuracy is usually high over homogeneous stations (i.e., Arou) than heterogeneous stations (i.e., Sidaoqiao).
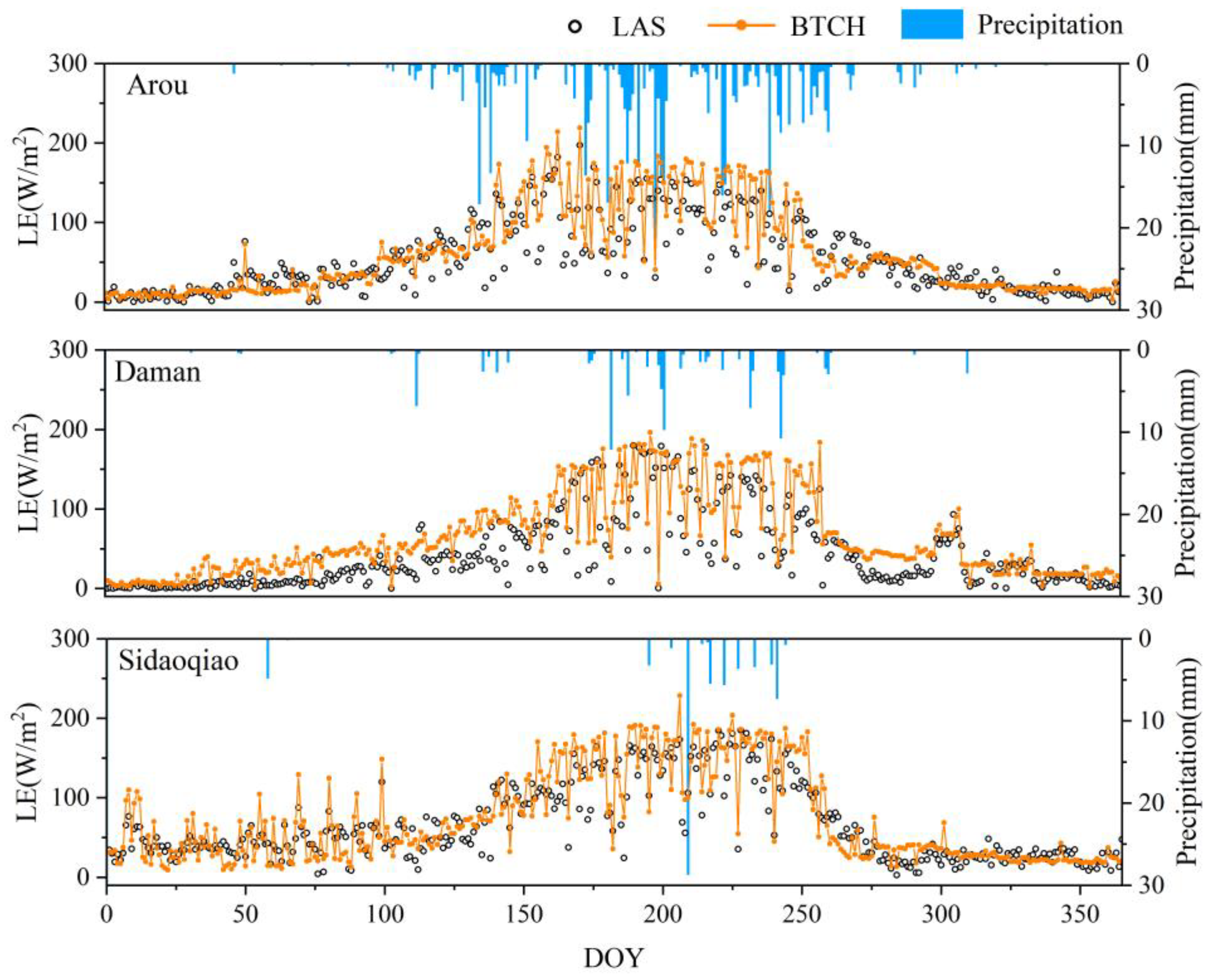
Moreover, this study also validated the temporal trends of LE simulated by the BTCH method using LAS observations (
Figure 6). The simulation results for the upper, middle, and lower reaches are generally consistent with the LAS observations trends, especially when there were significant precipitation processes at the Arou station from DOY 125 to 154, the Daman station from DOY 175 to 200, and the Sidaoqiao station from DOY 225 to 250. However, mainly influenced by the worst performance of the XGBoost model at the Daman station (RMSE = 26.41 W/m
2, R
2 = 0.67), the time series fitting of the fusion result overestimated at the Daman station, especially when the values of LAS observations are low. Overall, the BTCH method combines the strengths of the three models and can simulate well when precipitation events occur.
4.4. Spatio-Temporal Characteristics of Fused Latent Heat Flux Upscaling Results
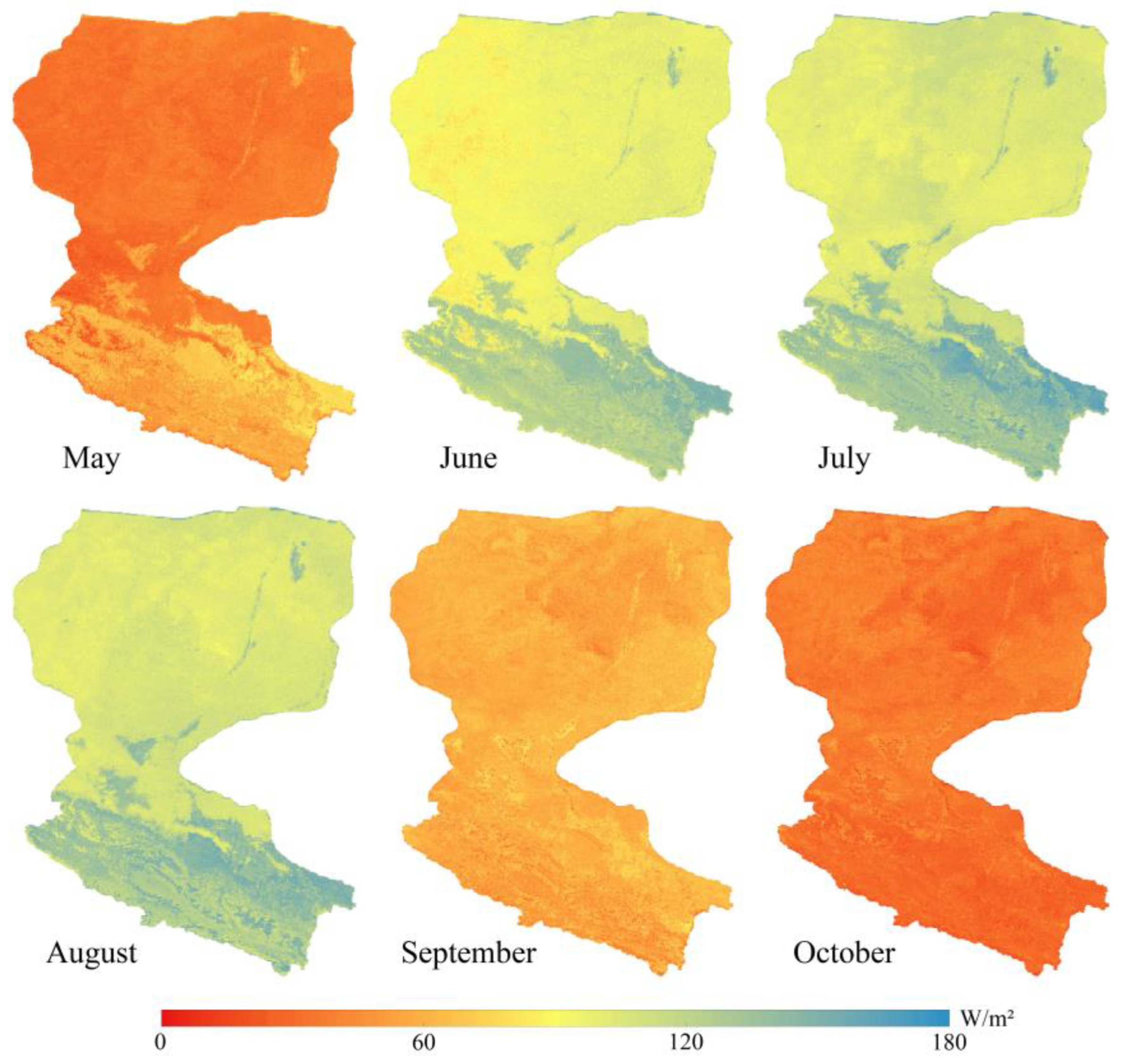
To investigate the value of the fused LE, we explored the spatial and temporal distribution of LE in HRB during the growing season (May to October) in 2018 (
Figure 7). In terms of time scale, LE over all land cover types is greatest in July or August, with a decreasing trend in the upstream to downstream direction, which is also consistent with site observations. The LE in the oasis zone of the basin rises continuously from May to August and decreases from August to October mainly due to the influence of the temperate continental monsoon climate, which is also verified by the precipitation histograms. At the spatial scale, the maximum values of LE are found in the woodlands and grasslands of the upper reaches, the farmlands of the middle reaches, the oases of the lower reaches, and the area around the HRB, while the minimum values are mainly in the desert and bare land of the lower reaches. The main reason is the difference in vegetation cover and wetness of the underlying surface in the basin, where transpiration and surface evaporation are stronger in densely vegetated areas resulting in higher LE. The LE is significantly higher in the farmlands (mostly maize) of the midstream than in other land cover types, mainly owing to the higher transpiration capacity of the crops and artificial irrigation. Grassland, woodland, and scrub have lower evapotranspiration than the above vegetation types, which is related to the relatively weak transpiration capacity of grassland and the low cover of woodland. In addition, evapotranspiration is also very high in the wetland due to the abundant natural water supply. In addition, the LE in the desert bare ground is generally lower in the downstream than in the midstream.
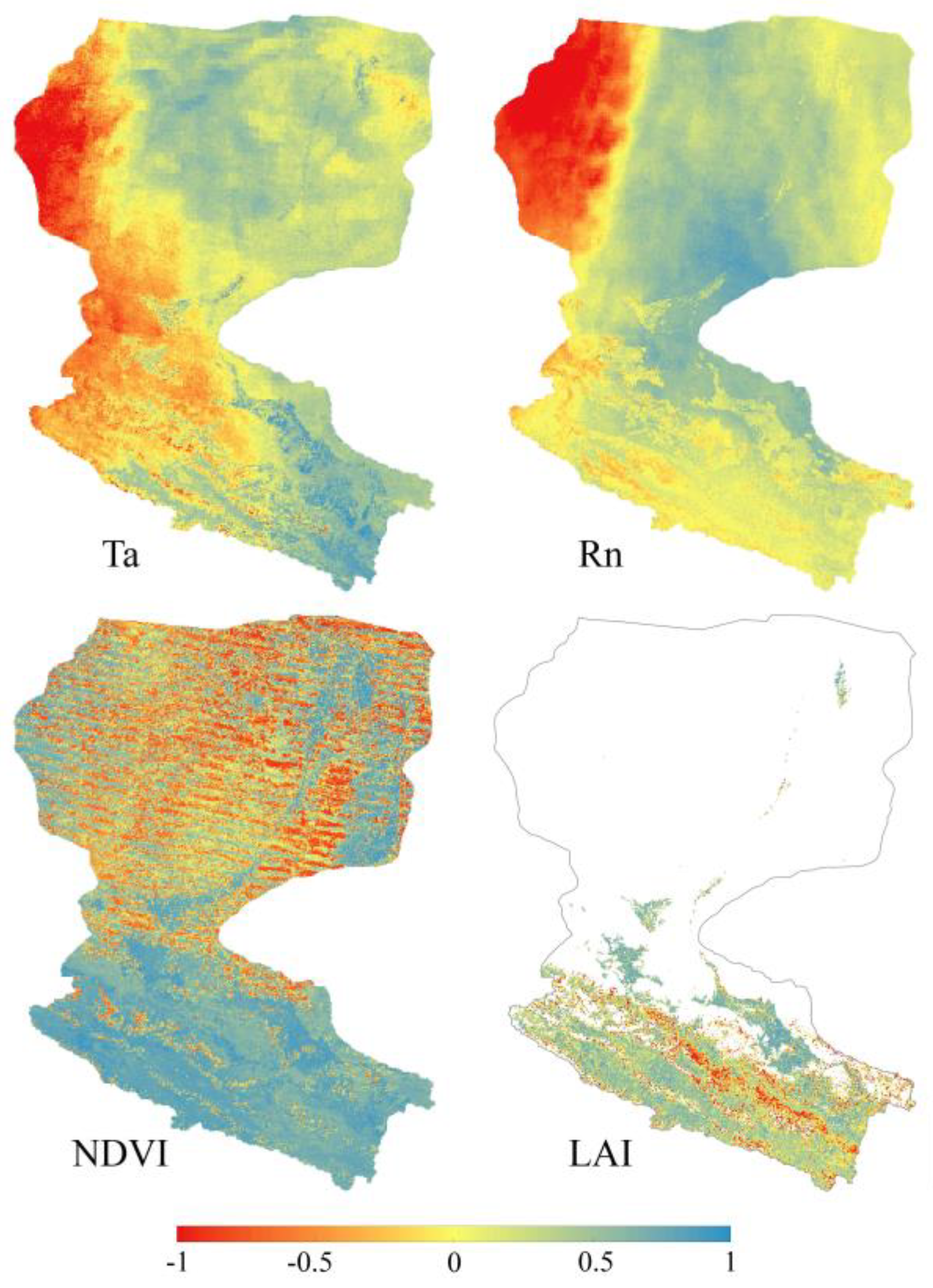
In addition, Ta, Rn, NDVI, and LAI were selected to calculate the PPMCC with the fusion result separately to analyze the reasonableness of the spatial and temporal trends.
Figure 8 shows that Ta and Rn have good positive correlations with LE throughout the eastern part of HRB, especially in the oases of the upstream and the farmland of midstream, where the PPMCC is close to 1. However, there is a clear boundary between the eastern and western parts of the downstream in the two plots, with west of the boundary the PPMCC between Ta/Rn and LE decreasing and then showing a strong negative correlation. The main reason is that the majority of the sites selected for the study are located east of the boundary, with a scarcity of sites in the west. In farmland, NDVI and LAI have a very strong positive correlation with LE, due to the fact that there is an adequate supply of water in irrigated farmland, making LE more controlled by vegetation growth and energy factors. However, in the desert areas of the downstream, the spatial distributions of NDVI and LE correlation are less regular with many zero values, probably due to some errors introduced during interpolation of NDVI data. Furthermore, the PPMCC could not be calculated due to the missing LAI data in these areas for a long time.
5. Conclusions
In order to upscale LE from site scale to regional scale with the spatial resolution of 1 km in HRB, this study introduced five transfer learning models and the BTCH fusion method. Specifically, five machine learning algorithms were utilized to construct the upscaling framework, namely ANN, RF, SVM, XGBoost, and LightGBM. Then, the three best upscaled results were selected to fuse based on the BTCH method. Finally, the upscaled results before and after fusion were validated against the LAS observations, and the main conclusions are as follows.
Introducing the idea of instance transfer to upscale LE has improved the accuracy of the machine learning models to some extent. By selecting proper variables from external datasets under different land cover types and establishing a transfer ratio of 0.6 between external and internal datasets, the upscaling model can grasp more effective information, resulting in an improvement or reduction of 6% and 17% in the R2 and RMSE values, respectively, for the ANN model. Among the five models, ANN, RF, and XGBoost models are the most suitable to upscale LE from site scale to regional scale in HRB, with the best fit of the simulated values to the site observations, the smallest errors, and less outliers.
Generally speaking, different algorithms utilized to develop upscaling models may show some differences in temporal and spatial distribution. To integrate their strengths, this study applied the BTCH fusion approach to obtain the final upscaling LE product in HRB. The verification results with precipitation and observed LE indicate that the fusion dataset retains the advantages of the different results, with reasonable time trends and the highest accuracy (R2 = 0.83, RMSE = 18.84 W/m2). Moreover, the fusion results also show that the maximum values of LE on a temporal scale occur in July and August, with increasing from May to August and decreasing from August to October in the oases of upper and middle-lower reaches. From the perspective of spatial scale, the maximum values of LE are found in the upstream woodlands and grasslands, the midstream farmlands, the downstream oases, and the area around the HRB. However, the minimum values are mainly in the downstream desert and bare ground, with a decreasing trend in the upstream to downstream direction.



 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}