
Multi-Resolution Population Mapping Based on a Stepwise Downscaling Approach Using Multisource Data


Abstract
:1. Introduction
2. Materials and Methods
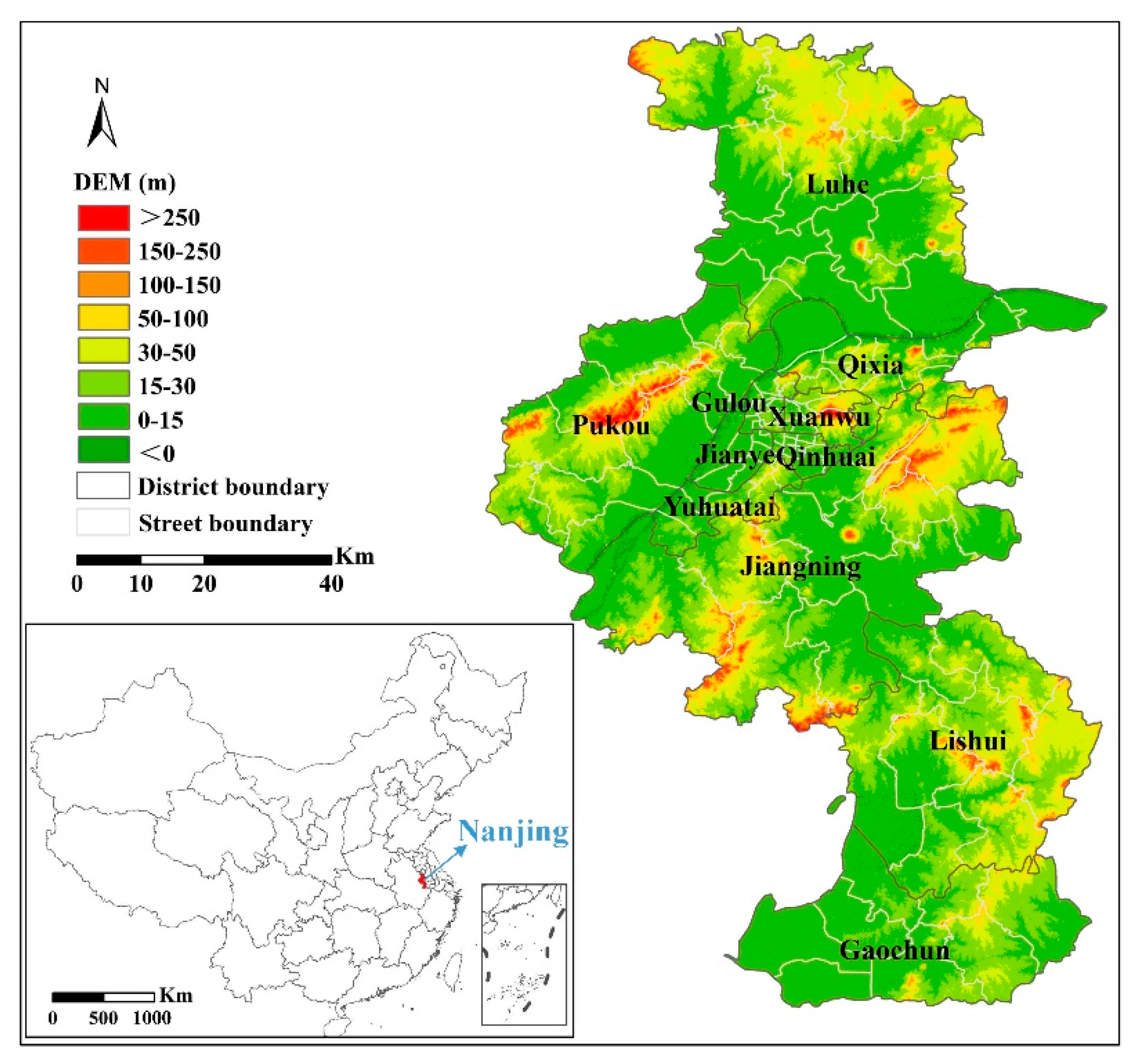
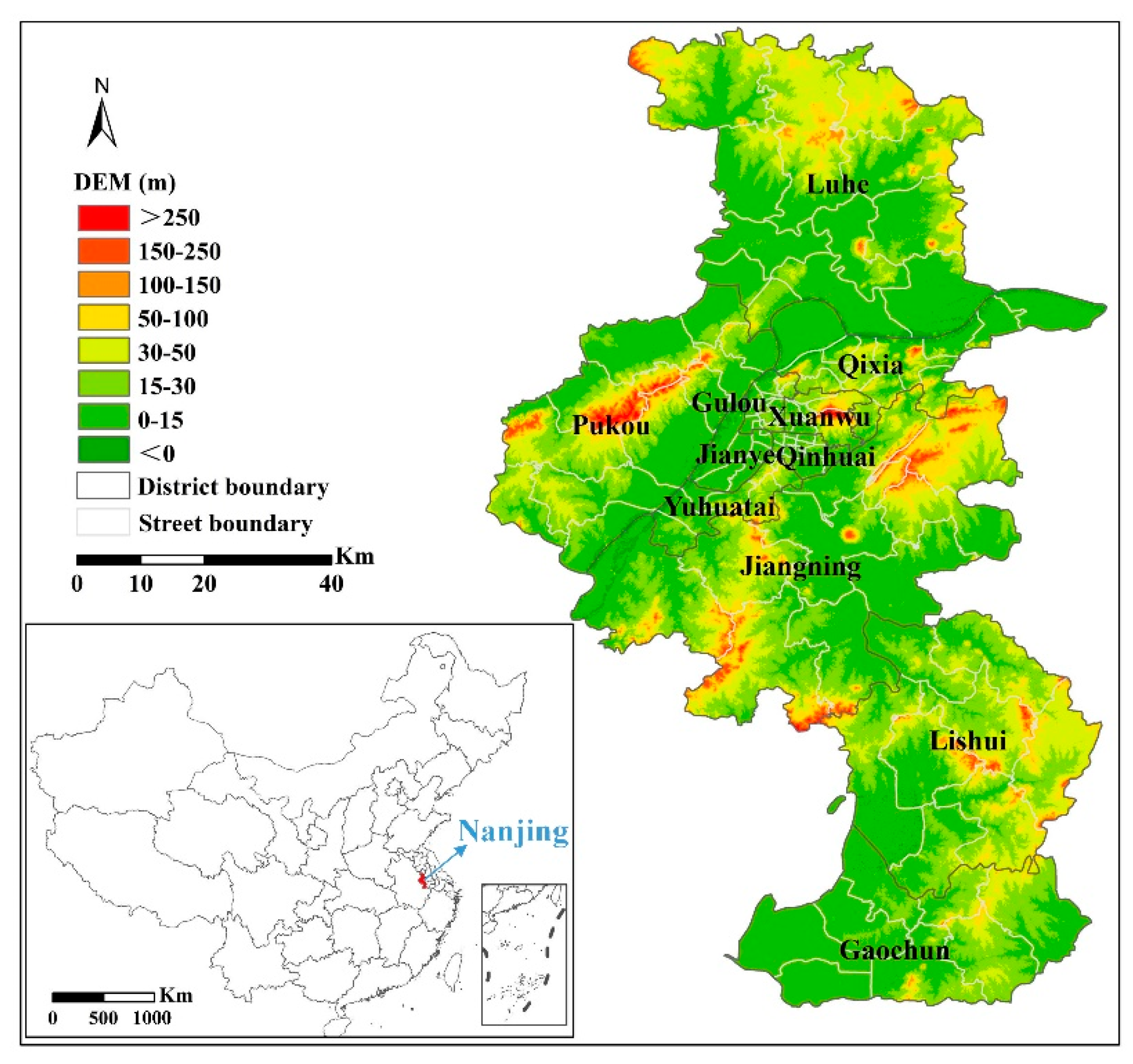
2.1. Study Area
2.2. Materials and Data Processing
2.2.1. Geospatial Data
2.2.2. Remote Sensing Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Sources | Time | Spatial Resolution | Indicators | Resampling |
|---|---|---|---|---|---|
| Census data | Nanjing Government, China | 2010 2020 | District level Street level | / | / |
| WorldPop | WorldPop Mainland China | 2010 2020 | 3 arc-seconds 30 arc-seconds | / | 1 km × 1 km 100 m × 100 m |
| LandScan | LandScan Mainland China | 2010 2020 | 30 arc-seconds | / | 1 km × 1 km |
| Population mapping | Ye et al. [48] | 2010 | 100 m | / | 100 m × 100 m |
| OSM data | OSM project | 2013 2020 | Vector | POIs, Trans, Rail, Road | Street level 1 km × 1 km 500 m × 500 m 100 m × 100 m |
| Basic geospatial data | National Geomatics Center of China | 2021 | Vector | Water area, Rail, Road, Partial POIs | |
| Department of Natural Resources of Jiangsu Province | 2019 | Vector | Rail, Road, Boundary | ||
| DEM | ASTER Global Digital Elevation Model V003 | 2010 2020 | 30 m Raster | Four slope directions, Slope ≤ 5° | |
| Vegetation | MOD13A2 | 2010 2020 | 1 km Raster | Annual maximum NDVI, EVI, NIRv | |
| LST | MOD11A1 | 2010 2020 | 1 km Raster | Annual maximum LST | |
| Night light | Global NPP-VIIRS-like NL product | 2010 2020 | 500 m Raster | Nlave, CNLI | |
| Land cover | GlobeLand30 | 2010 2020 | 30 m Raster | Cropland, forest, grass, wetland, water, artificial land, bare land |
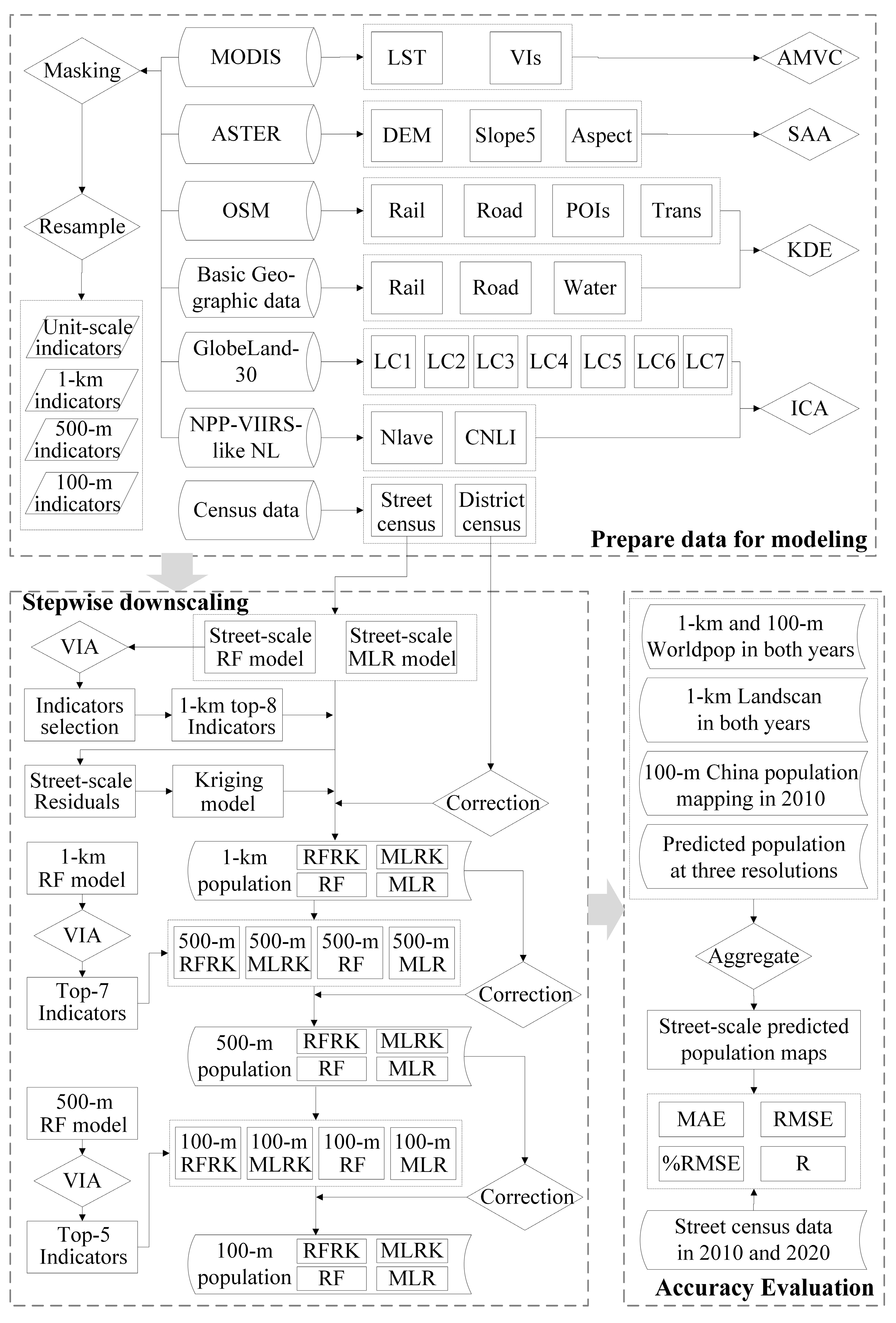
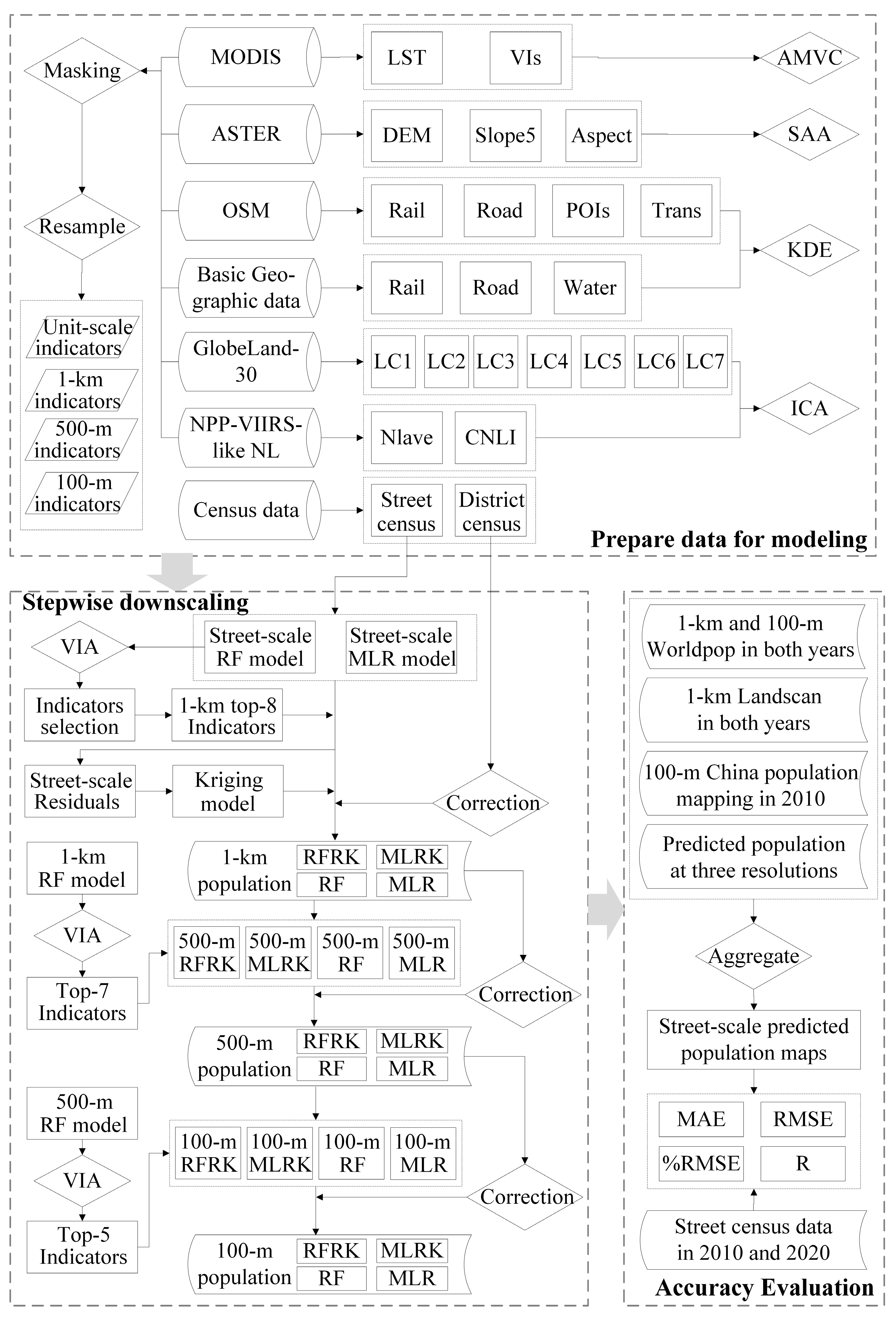
2.3. Stepwise Downscaling
2.3.1. Stepwise Downscaling Model
2.3.2. Flowchart of Multi-Resolution Population Mapping
3. Results
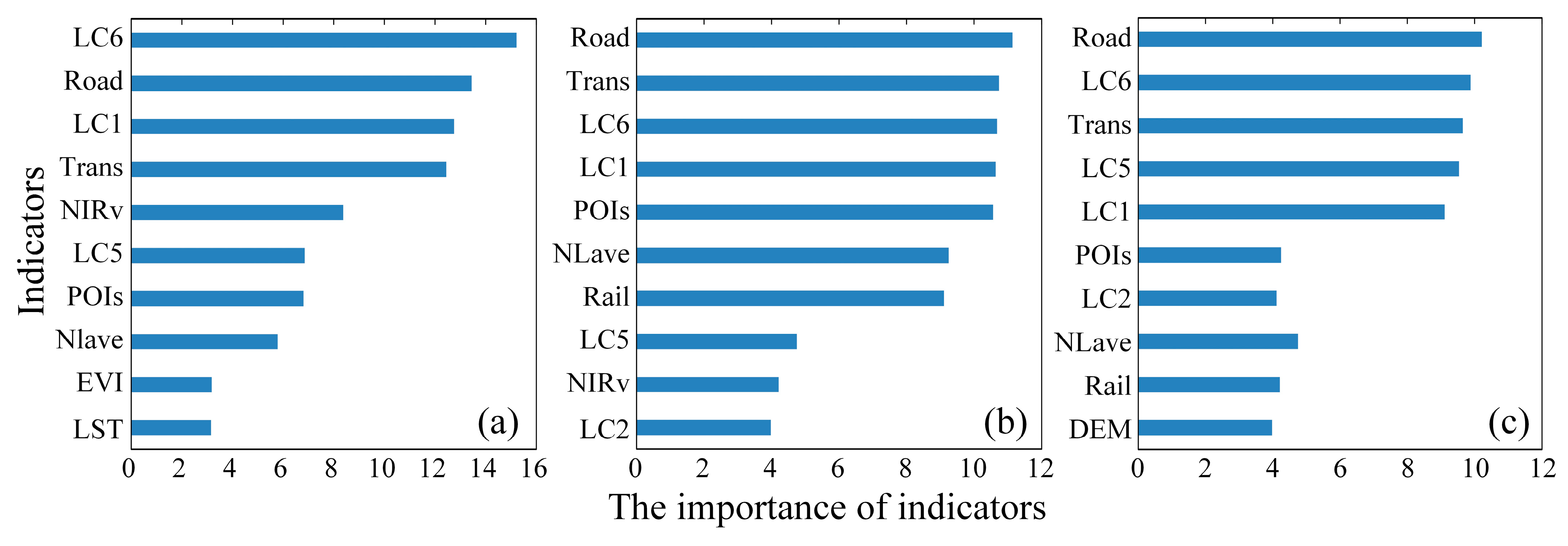
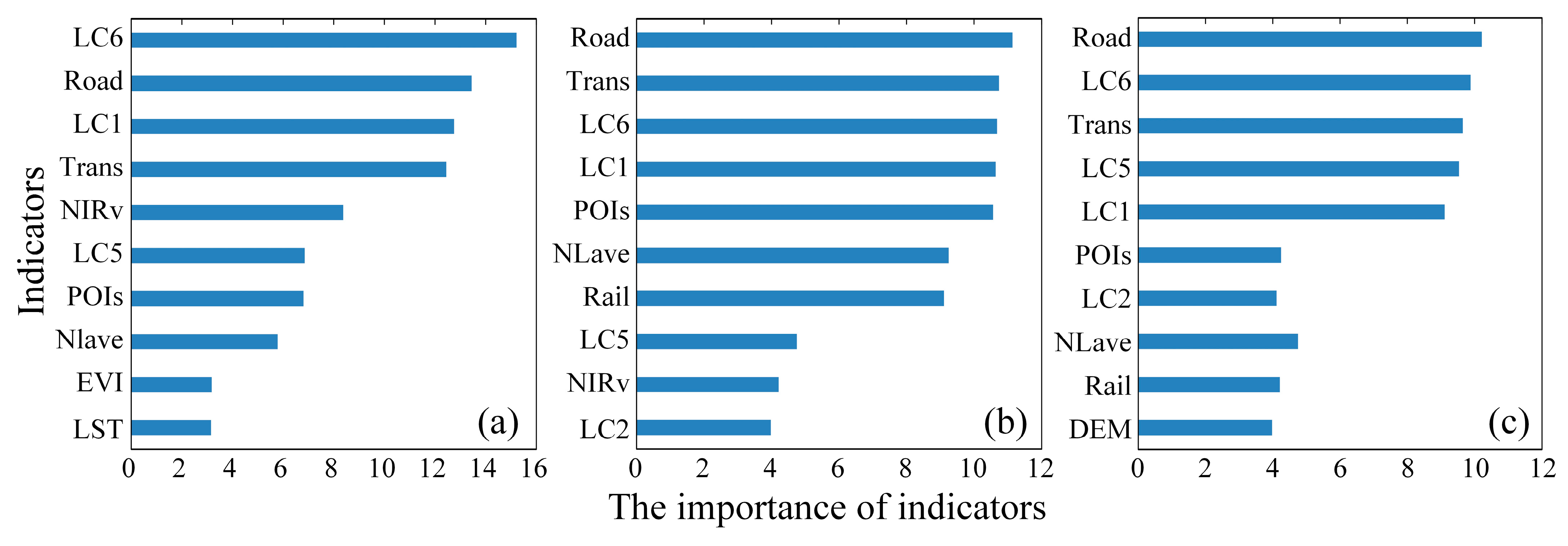
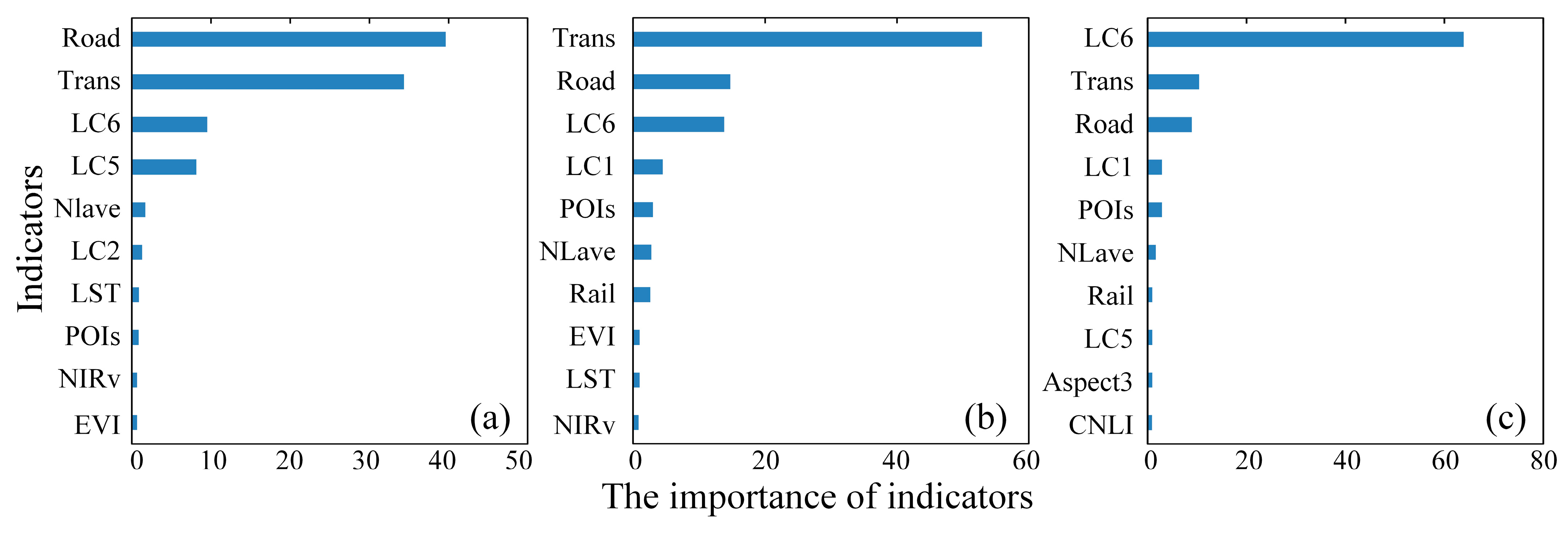
3.1. The Results of Indicators Selections
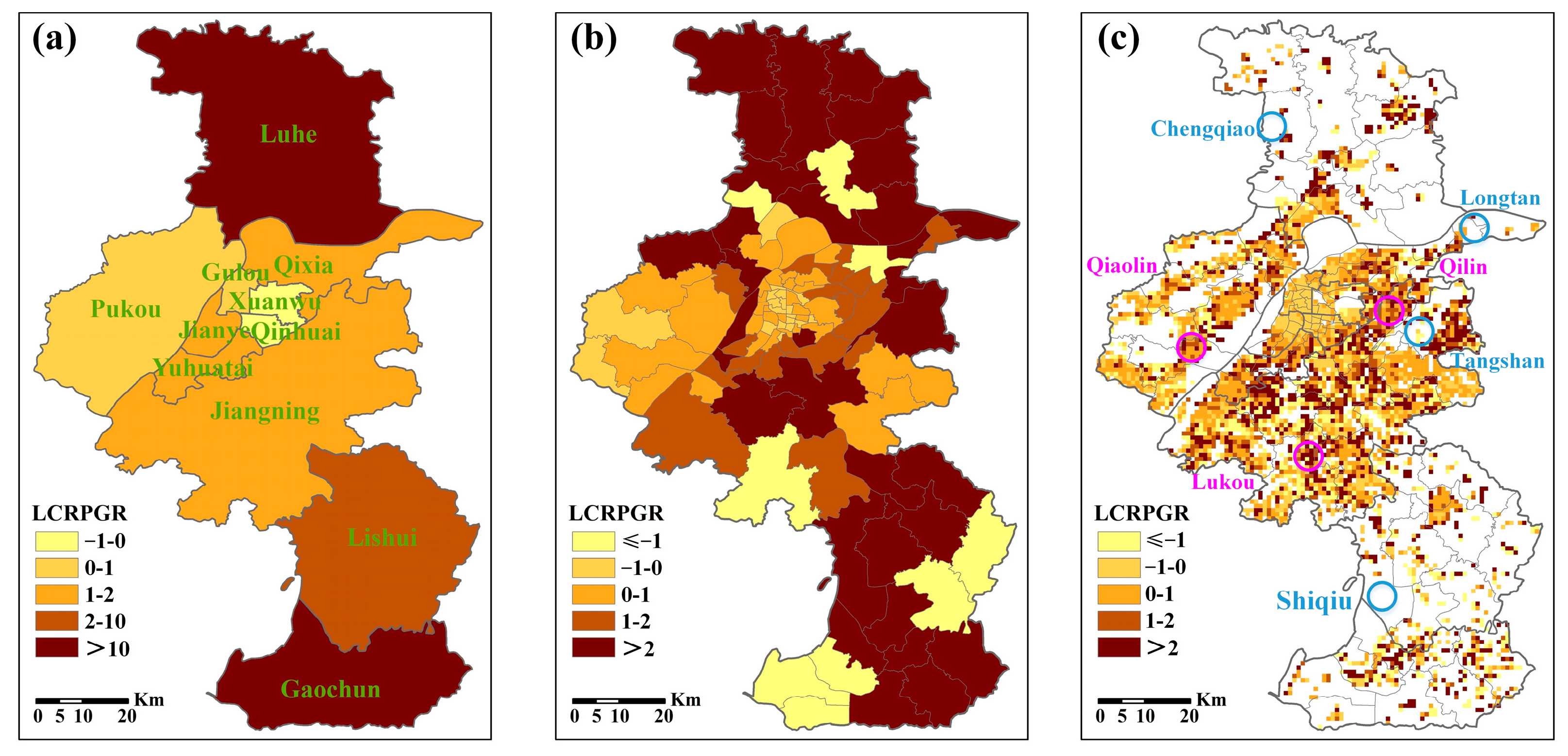
3.2. Gridded Population Mapping
3.3. Accuracy Assessment
3.4. Comparison with Population Products
4. Discussion
4.1. The Influences of Variables
4.2. Errors in Stepwise Downscaling
4.3. Potential Application of Gridded Population
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Vörösmarty, C.J.; Green, P.; Salisbury, J.; Lammers, R.B. Global Water Resources: Vulnerability from Climate Change and Population Growth. Science 2000, 289, 284–288. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Smith, A.; Bates, P.D.; Wing, O.; Sampson, C.; Quinn, N.; Neal, J. New Estimates of Flood Exposure in Developing Countries Using High-Resolution Population Data. Nat. Commun. 2019, 10, 1814. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Palacios-Lopez, D.; Bachofer, F.; Esch, T.; Marconcini, M.; MacManus, K.; Sorichetta, A.; Zeidler, J.; Dech, S.; Tatem, A.J.; Reinartz, P. High-Resolution Gridded Population Datasets: Exploring the Capabilities of the World Settlement Footprint 2019 Imperviousness Layer for the African Continent. Remote Sens. 2021, 13, 1142. [Google Scholar] [CrossRef]
- Xu, Y.; Song, Y.; Cai, J.; Zhu, H. Population mapping in China with Tencent social user and remote sensing data. Appl. Geogr. 2021, 130, 102450. [Google Scholar] [CrossRef]
- Sorichetta, A.; Hornby, G.M.; Stevens, F.R.; Gaughan, A.E.; Linard, C.; Tatem, A.J. High-Resolution Gridded Population Datasets for Latin America and the Caribbean in 2010, 2015, and 2020. Sci. Data 2015, 2, 150045. [Google Scholar] [CrossRef] [Green Version]
- Leyk, S.; Gaughan, A.E.; Adamo, S.B.; de Sherbinin, A.; Balk, D.; Freire, S.; Rose, A.; Stevens, F.R.; Blankespoor, B.; Frye, C.; et al. The Spatial Allocation of Population: A Review of Large-Scale Gridded Population Data Products and Their Fitness for Use. Earth Syst. Sci. Data 2019, 11, 1385–1409. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Chen, Y.; Li, Y. The Random Forest-Based Method of Fine-Resolution Population Spatialization by Using the International Space Station Nighttime Photography and Social Sensing Data. Remote Sens. 2018, 10, 1650. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Huang, C.; Zhao, M.; Hou, J.; Zhang, Y.; Gu, J. Mapping the Population Density in Mainland China Using NPP/VIIRS and Points-Of-Interest Data Based on a Random Forests Model. Remote Sens. 2020, 12, 3645. [Google Scholar] [CrossRef]
- Stokes, E.; Seto, K. Characterizing urban infrastructural transitions for the Sustainable Development Goals using multi-temporal land, population, and nighttime light data. Remote Sens. Environ. 2019, 234, 111430. [Google Scholar] [CrossRef]
- Tuholske, C.; Gaughan, A.E.; Sorichetta, A.; de Sherbinin, A.; Bucherie, A.; Hultquist, C.; Stevens, F.; Kruczkiewicz, A.; Huyck, C.; Yetman, G. Implications for Tracking SDG Indicator Metrics with Gridded Population Data. Sustainability 2021, 13, 7329. [Google Scholar] [CrossRef]
- Wu, S.; Qiu, X.; Wang, L. Population Estimation Methods in GIS and Remote Sensing: A Review. GIScience Remote Sens. 2005, 42, 80–96. [Google Scholar] [CrossRef]
- Bo, Z.Q.; Wang, J.L.; Yang, F. Research progress in spatialization of population data. Prog. Geogr. 2013, 32, 1692–1702. [Google Scholar] [CrossRef]
- Bhaduri, B.; Bright, E.; Coleman, P.; Urban, M.L. LandScan USA: A High-Resolution Geospatial and Temporal Modeling Approach for Population Distribution and Dynamics. GeoJournal 2007, 69, 103–117. [Google Scholar] [CrossRef]
- Murakami, D.; Yamagata, Y. Estimation of Gridded Population and GDP Scenarios with Spatially Explicit Statistical Downscaling. Sustainability 2019, 11, 2106. [Google Scholar] [CrossRef] [Green Version]
- Dobson, J.E.; Bright, E.A.; Coleman, P.R.; Durfee, R.C.; Worley, B.A. LandScan: A Global Population Database for Estimating Populations at Risk. Photogramm. Eng. Remote Sens. 2000, 66, 849–857. [Google Scholar]
- Zhao, X.; Xia, N.; Xu, Y.; Huang, X.; Li, M. Mapping Population Distribution Based on XGBoost Using Multisource Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11567–11580. [Google Scholar] [CrossRef]
- Yin, C.; Shi, Y.; Wang, H.; Wu, J. Disaggregation of an Urban Population with M_IDW Interpolation and Building Information. J. Urban Plan. Dev. 2015, 141, 04014012. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Anselin, L.; Deichmann, U. A Framework for the Areal Interpolation of Socioeconomic Data. Environ. Plan. Econ. Space 1993, 25, 383–397. [Google Scholar] [CrossRef]
- Cai, Q.; Rushton, G.; Bhaduri, B.; Bright, E.; Coleman, P. Estimating Small-area Populations By Age and Sex Using Spatial Interpolation and Statistical Inference Methods. Trans. GIS 2006, 10, 577–598. [Google Scholar] [CrossRef]
- Zandbergen, P.A.; Ignizio, D.A. Comparison Of Dasymetric Mapping Techniques For Small-Area Population Estimates. Cartogr. Geogr. Inf. Sci. 2010, 37, 199–214. [Google Scholar] [CrossRef]
- Doxsey-Whitfield, E.; MacManus, K.; Adamo, S.B.; Pistolesi, L.; Squires, J.; Borkovska, O.; Baptista, S.R. Taking Advantage of the Improved Availability of Census Data: A First Look at the Gridded Population of the World, Version 4. Pap. Appl. Geogr. 2015, 1, 226–234. [Google Scholar] [CrossRef]
- Zhang, C.; Qiu, F. A Point-Based Intelligent Approach to Areal Interpolation. Prof. Geogr. 2011, 63, 262–276. [Google Scholar] [CrossRef]
- Su, M.-D.; Lin, M.-C.; Hsieh, H.-I.; Tsai, B.-W.; Lin, C.-H. Multi-Layer Multi-Class Dasymetric Mapping to Estimate Population Distribution. Sci. Total Environ. 2010, 408, 4807–4816. [Google Scholar] [CrossRef] [PubMed]
- Bao, W.; Gong, A.; Zhao, Y.; Chen, S.; Ba, W.; He, Y. High-Precision Population Spatialization in Metropolises Based on Ensemble Learning: A Case Study of Beijing, China. Remote Sens. 2022, 14, 3654. [Google Scholar] [CrossRef]
- Ma, T.; Zhou, C.; Pei, T.; Haynie, S.; Fan, J. Quantitative estimation of urbanization dynamics using time series of DMSP/OLS nighttime light data: A comparative case study from China’s cities. Remote Sens. Environ. 2012, 124, 99–107. [Google Scholar] [CrossRef]
- Zeng, C.; Zhou, Y.; Wang, S.; Yan, F.; Zhao, Q. Population spatialization in China based on night-time imagery and land use data. Int. J. Remote Sens. 2011, 32, 9599–9620. [Google Scholar] [CrossRef]
- Tu, W.; Liu, Z.; Du, Y.; Yi, J.; Liang, F.; Wang, N.; Qian, J.; Huang, S.; Wang, H. An Ensemble Method to Generate High-Resolution Gridded Population Data for China from Digital Footprint and Ancillary Geospatial Data. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102709. [Google Scholar] [CrossRef]
- Cheng, L.; Wang, L.; Feng, R.; Yan, J. Remote Sensing and Social Sensing Data Fusion for Fine-Resolution Population Mapping With a Multimodel Neural Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5973–5987. [Google Scholar] [CrossRef]
- Wang, L.; Fan, H.; Wang, Y. Fine-Resolution Population Mapping from International Space Station Nighttime Photography and Multisource Social Sensing Data Based on Similarity Matching. Remote Sens. 2019, 11, 1900. [Google Scholar] [CrossRef] [Green Version]
- Chu, H.-J.; Yang, C.-H.; Chou, C.C. Adaptive Non-Negative Geographically Weighted Regression for Population Density Estimation Based on Nighttime Light. ISPRS Int. J. Geo-Inf. 2019, 8, 26. [Google Scholar] [CrossRef] [Green Version]
- He, M.; Xu, Y.; Li, N. Population Spatialization in Beijing City Based on Machine Learning and Multisource Remote Sensing Data. Remote Sens. 2020, 12, 1910. [Google Scholar] [CrossRef]
- Zhao, S.; Liu, Y.; Zhang, R.; Fu, B. China’s Population Spatialization Based on Three Machine Learning Models. J. Clean. Prod. 2020, 256, 120644. [Google Scholar] [CrossRef]
- Zhou, Y.; Ma, M.; Shi, K.; Peng, Z. Estimating and Interpreting Fine-Scale Gridded Population Using Random Forest Regression and Multisource Data. ISPRS Int. J. Geo-Inf. 2020, 9, 369. [Google Scholar] [CrossRef]
- Stevens, F.R.; Gaughan, A.E.; Linard, C.; Tatem, A.J. Disaggregating Census Data for Population Mapping Using Random Forests with Remotely-Sensed and Ancillary Data. PLoS ONE 2015, 10, e0107042. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, H.; Yao, X. Pycnophylactic interpolation revisited: Integration with the dasymetric-mapping method. Int. J. Remote Sens. 2010, 31, 5657–5671. [Google Scholar] [CrossRef]
- Zoraghein, H.; Leyk, S. Enhancing areal interpolation frameworks through dasymetric refinement to create consistent population estimates across censuses. Int. J. GIS 2018, 32, 1948–1976. [Google Scholar] [CrossRef]
- Cockx, K.; Canters, F. Incorporating spatial non-stationarity to improve dasymetric mapping of population. Appl. Geogr. 2015, 63, 220–230. [Google Scholar] [CrossRef]
- Roni, R.; Jia, P. An Optimal Population Modeling Approach Using Geographically Weighted Regression Based on High-Resolution Remote Sensing Data: A Case Study in Dhaka City, Bangladesh. Remote Sens. 2020, 12, 1184. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Wang, Y.; Li, B.; Cai, Z.; Kang, M. A Population Spatialization Model at the Building Scale Using Random Forest. Remote Sens. 2022, 14, 1811. [Google Scholar] [CrossRef]
- Ge, Y.; Jin, Y.; Stein, A.; Chen, Y.; Wang, J.; Wang, J.; Cheng, Q.; Bai, H.; Liu, M.; Atkinson, P.M. Principles and Methods of Scaling Geospatial Earth Science Data. Earth-Sci. Rev. 2019, 197, 102897. [Google Scholar] [CrossRef]
- Mei, Y.; Gui, Z.; Wu, J.; Peng, D.; Li, R.; Wu, H.; Wei, Z. Population spatialization with pixel-level attribute grading by considering scale mismatch issue in regression modeling. Geo-Spatial Inf. Sci. 2022, 25, 365–382. [Google Scholar] [CrossRef]
- Qiu, G.; Bao, Y.; Yang, X.; Wang, C.; Ye, T.; Stein, A.; Jia, P. Local Population Mapping Using a Random Forest Model Based on Remote and Social Sensing Data: A Case Study in Zhengzhou, China. Remote Sens. 2020, 12, 1618. [Google Scholar] [CrossRef]
- Yin, X.; Li, P.; Feng, Z.; Yang, Y.; You, Z.; Xiao, C. Which Gridded Population Data Product Is Better? Evidences from Mainland Southeast Asia (MSEA). ISPRS Int. J. Geo-Inf. 2021, 10, 681. [Google Scholar] [CrossRef]
- Jin, Y.; Hao, Z.; Chen, J.; He, D.; Tian, Q.; Mao, Z.; Pan, D. Retrieval of Urban Aerosol Optical Depth from Landsat 8 OLI in Nanjing, China. Remote Sens. 2021, 13, 415. [Google Scholar] [CrossRef]
- Xiang, Y.; Tang, Y.; Wang, Z.; Peng, C.; Huang, C.; Dian, Y.; Teng, M.; Zhou, Z. Seasonal Variations of the Relationship between Spectral Indexes and Land Surface Temperature Based on Local Climate Zones: A Study in Three Yangtze River Megacities. Remote Sens. 2023, 15, 870. [Google Scholar] [CrossRef]
- Chen, Z.; Yu, B.; Yang, C.; Zhou, Y.; Yao, S.; Qian, X.; Wang, C.; Wu, B.; Wu, J. An Extended Time Series (2000–2018) of Global NPP-VIIRS-like Nighttime Light Data from a Cross-Sensor Calibration. Earth Syst. Sci. Data 2021, 13, 889–906. [Google Scholar] [CrossRef]
- Gao, B.; Huang, Q.; He, C.; Ma, Q. Dynamics of Urbanization Levels in China from 1992 to 2012: Perspective from DMSP/OLS Nighttime Light Data. Remote Sens. 2015, 7, 1721–1735. [Google Scholar] [CrossRef] [Green Version]
- Ye, T.; Zhao, N.; Yang, X.; Ouyang, Z.; Liu, X.; Chen, Q.; Hu, K.; Yue, W.; Qi, J.; Li, Z.; et al. Improved population mapping for China using remotely sensed and points-of-interest data within a random forests model. Sci. Total Environ. 2019, 658, 936–946. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random Forest in Remote Sensing: A Review of Applications and Future Directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Pouladi, N.; Møller, A.B.; Tabatabai, S.; Greve, M.H. Mapping Soil Organic Matter Contents at Field Level with Cubist, Random Forest and Kriging. Geoderma 2019, 342, 85–92. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Randomforest: Breiman and Cutler’s Random Forests for Classification and Regression; RpackageVersion 4.7-1.1; 2022. Available online: https://cran.r-project.org/web/packages/randomForest/ (accessed on 7 July 2022).
- Pebesma, E.; Graeler, B. Gstat: Spatial and Spatio-Temporal Geostatistical Modelling, Prediction and Simulation; RpackageVersion 2.1-0; 2022. Available online: https://cran.r-project.org/web/packages/gstat/ (accessed on 12 December 2022).
- Yang, W.; Wan, X.; Liu, M.; Zheng, D.; Liu, H. A two-level random forest model for predicting the population distributions of urban functional zones: A case study in Changsha, China. Sustain. Cities Soc. 2023, 88, 104297. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, R.; Ge, Y.; Jin, Y.; Xia, Z. Downscaling census data for gridded population mapping with geographically weighted area-to-point regression kriging. IEEE Access 2019, 7, 149132–149141. [Google Scholar] [CrossRef]
- Abdullah, A.Y.M.; Masrur, A.; Adnan, M.S.G.; Baky, M.A.A.; Hassan, Q.K.; Dewan, A. Spatio-Temporal Patterns of Land Use/Land Cover Change in the Heterogeneous Coastal Region of Bangladesh between 1990 and 2017. Remote Sens. 2019, 11, 790. [Google Scholar] [CrossRef] [Green Version]
- Georganos, S.; Grippa, T.; Vanhuysse, S.; Lennert, M.; Shimoni, M.; Kalogirou, S.; Wolff, E. Less is more: Optimizing classification performance through feature selection in a very-high-resolution remote sensing object-based urban application. Gisci. Remote Sens. 2018, 55, 221–242. [Google Scholar] [CrossRef]
- Li, X.; Levin, N.; Xie, J.; Li, D. Monitoring Hourly Night-Time Light by an Unmanned Aerial Vehicle and Its Implications to Satellite Remote Sensing. Remote Sens. Environ. 2020, 247, 111942. [Google Scholar] [CrossRef]
- Gao, K.; Yang, X.; Wang, Z.; Zhang, H.; Huang, C.; Zeng, X. Spatial Sustainable Development Assessment Using Fusing Multisource Data from the Perspective of Production-Living-Ecological Space Division: A Case of Greater Bay Area, China. Remote Sens. 2022, 14, 2772. [Google Scholar] [CrossRef]
- Calka, B.; Orych, A.; Bielecka, E.; Mozuriunaite, S. The Ratio of the Land Consumption Rate to the Population Growth Rate: A Framework for the Achievement of the Spatiotemporal Pattern in Poland and Lithuania. Remote Sens. 2022, 14, 1074. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, C.; Feng, Y.; Zhao, M.; Gu, J. Using Earth Observation for Monitoring SDG 11.3.1-Ratio of Land Consumption Rate to Population Growth Rate in Mainland China. Remote Sens. 2020, 12, 357. [Google Scholar] [CrossRef] [Green Version]

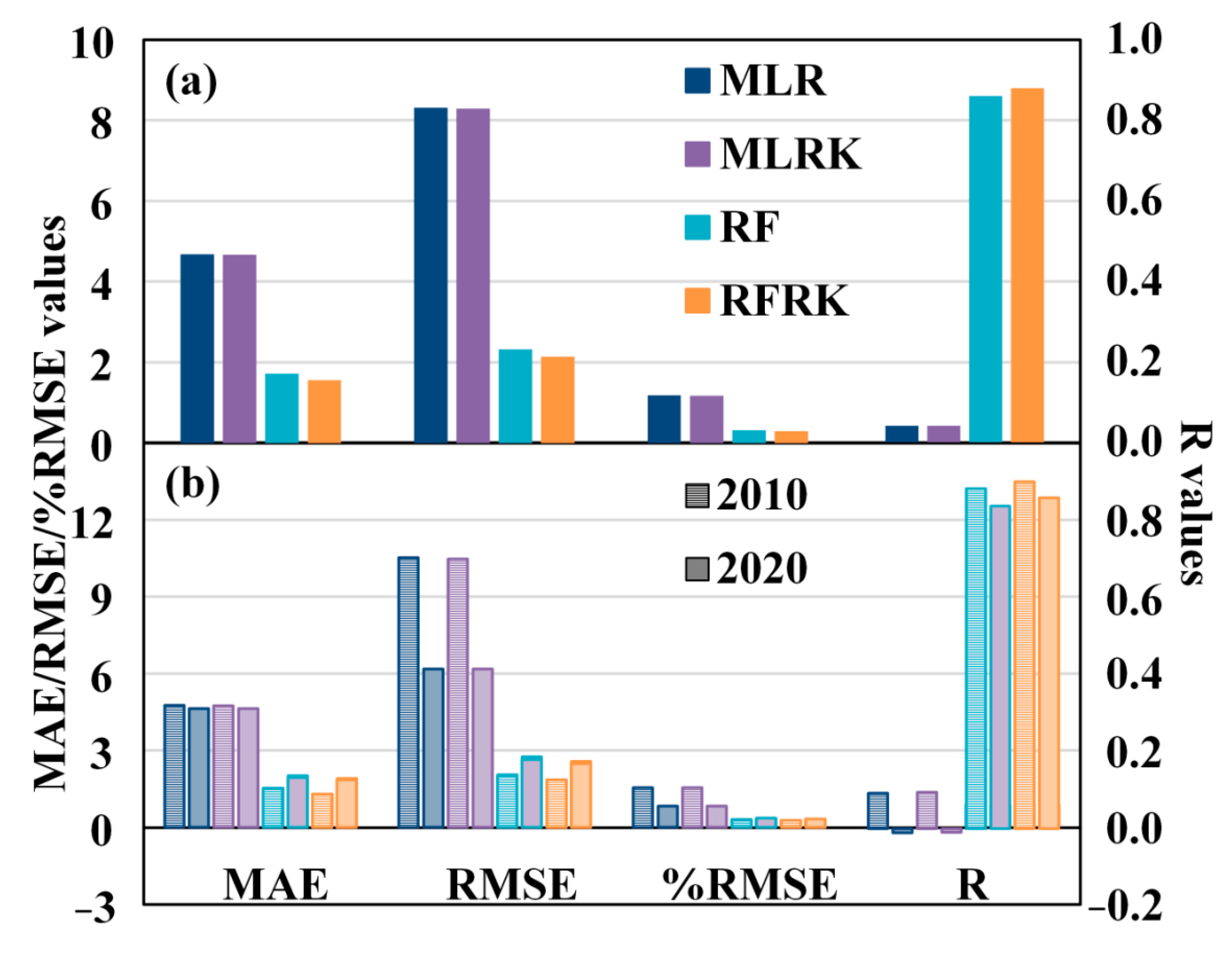

| 2010 | 2020 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | %RMSE | R | MAE | RMSE | %RMSE | R | ||
| 1 km | MLR | 5.020 | 11.259 | 1.656 | 0.085 | 4.709 | 6.320 | 0.842 | −0.031 |
| RF | 1.485 | 2.008 | 0.295 | 0.903 | 1.884 | 2.613 | 0.348 | 0.860 | |
| MLRK | 5.008 | 11.216 | 1.649 | 0.086 | 4.707 | 6.318 | 0.841 | −0.031 | |
| RFRK | 1.271 | 1.815 | 0.267 | 0.922 | 1.790 | 2.452 | 0.327 | 0.880 | |
| 500 m | MLR | 4.748 | 10.441 | 1.535 | 0.095 | 4.696 | 6.207 | 0.827 | 0.008 |
| RF | 1.548 | 2.082 | 0.306 | 0.895 | 2.003 | 2.688 | 0.358 | 0.852 | |
| MLRK | 4.728 | 10.367 | 1.524 | 0.098 | 4.695 | 6.206 | 0.826 | 0.008 | |
| RFRK | 1.329 | 1.903 | 0.280 | 0.913 | 1.898 | 2.516 | 0.335 | 0.873 | |
| 100 m | MLR | 4.744 | 10.378 | 1.526 | 0.100 | 4.724 | 6.278 | 0.836 | −0.009 |
| RF | 1.553 | 2.076 | 0.305 | 0.896 | 2.032 | 2.750 | 0.366 | 0.845 | |
| MLRK | 4.727 | 10.304 | 1.515 | 0.102 | 4.722 | 6.277 | 0.836 | −0.009 | |
| RFRK | 1.333 | 1.884 | 0.277 | 0.915 | 1.919 | 2.562 | 0.341 | 0.868 | |
| WPop 1 km | WPop 100 m | LPop | CPop | Improvements of RFRK | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 2010 | 2020 | 2010 | 2020 | 2010 | 2020 | 2010 | Wpop | LPop | CPop | |
| MAE | 2.231 | 3.753 | 2.238 | 3.124 | 2.953 | 4.661 | 2.768 | ↓ 1.259 | ↓ 2.277 | ↓ 1.435 |
| RMSE | 3.231 | 5.179 | 3.292 | 4.314 | 4.321 | 6.319 | 3.677 | ↓ 1.826 | ↓ 3.186 | ↓ 1.793 |
| %RMSE | 0.475 | 0.690 | 0.484 | 0.575 | 0.635 | 0.841 | 0.541 | ↓ 0.253 | ↓ 0.442 | ↓ 0.264 |
| R | 0.820 | 0.509 | 0.815 | 0.617 | 0.587 | 0.260 | 0.904 | ↑ 0.206 | ↑ 0.478 | ↑ 0.011 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, Y.; Liu, R.; Fan, H.; Li, P.; Liu, Y.; Jia, Y. Multi-Resolution Population Mapping Based on a Stepwise Downscaling Approach Using Multisource Data. Remote Sens. 2023, 15, 1947. https://doi.org/10.3390/rs15071947
Jin Y, Liu R, Fan H, Li P, Liu Y, Jia Y. Multi-Resolution Population Mapping Based on a Stepwise Downscaling Approach Using Multisource Data. Remote Sensing. 2023; 15(7):1947. https://doi.org/10.3390/rs15071947
Chicago/Turabian StyleJin, Yan, Rui Liu, Haoyu Fan, Pengdu Li, Yaojie Liu, and Yan Jia. 2023. "Multi-Resolution Population Mapping Based on a Stepwise Downscaling Approach Using Multisource Data" Remote Sensing 15, no. 7: 1947. https://doi.org/10.3390/rs15071947
APA StyleJin, Y., Liu, R., Fan, H., Li, P., Liu, Y., & Jia, Y. (2023). Multi-Resolution Population Mapping Based on a Stepwise Downscaling Approach Using Multisource Data. Remote Sensing, 15(7), 1947. https://doi.org/10.3390/rs15071947