
Estimation and Spatiotemporal Analysis of Surface Evaporation in the Yangtze River Basin from 2010 to 2019

Abstract
:1. Introduction
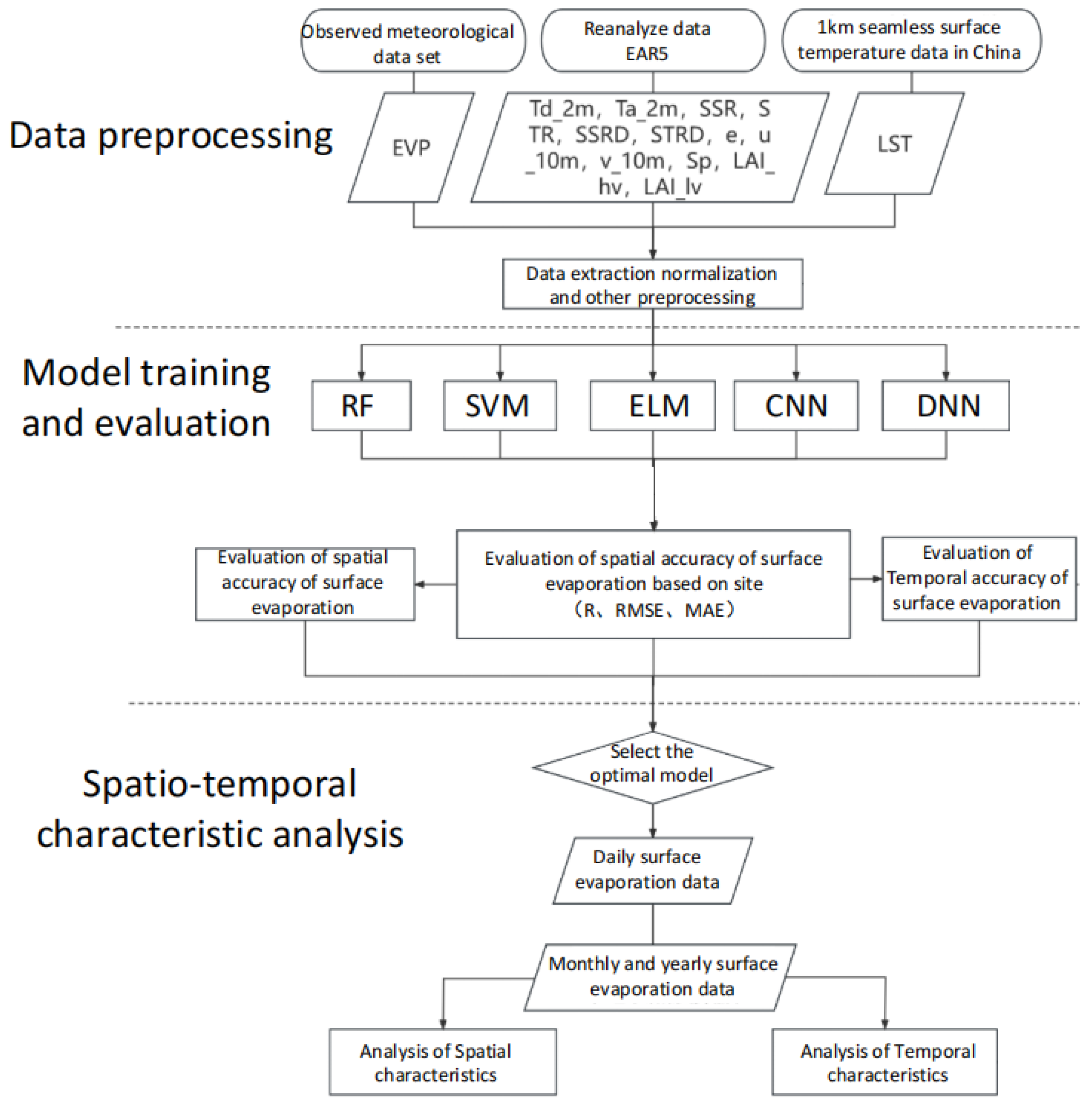
2. Materials and Methods
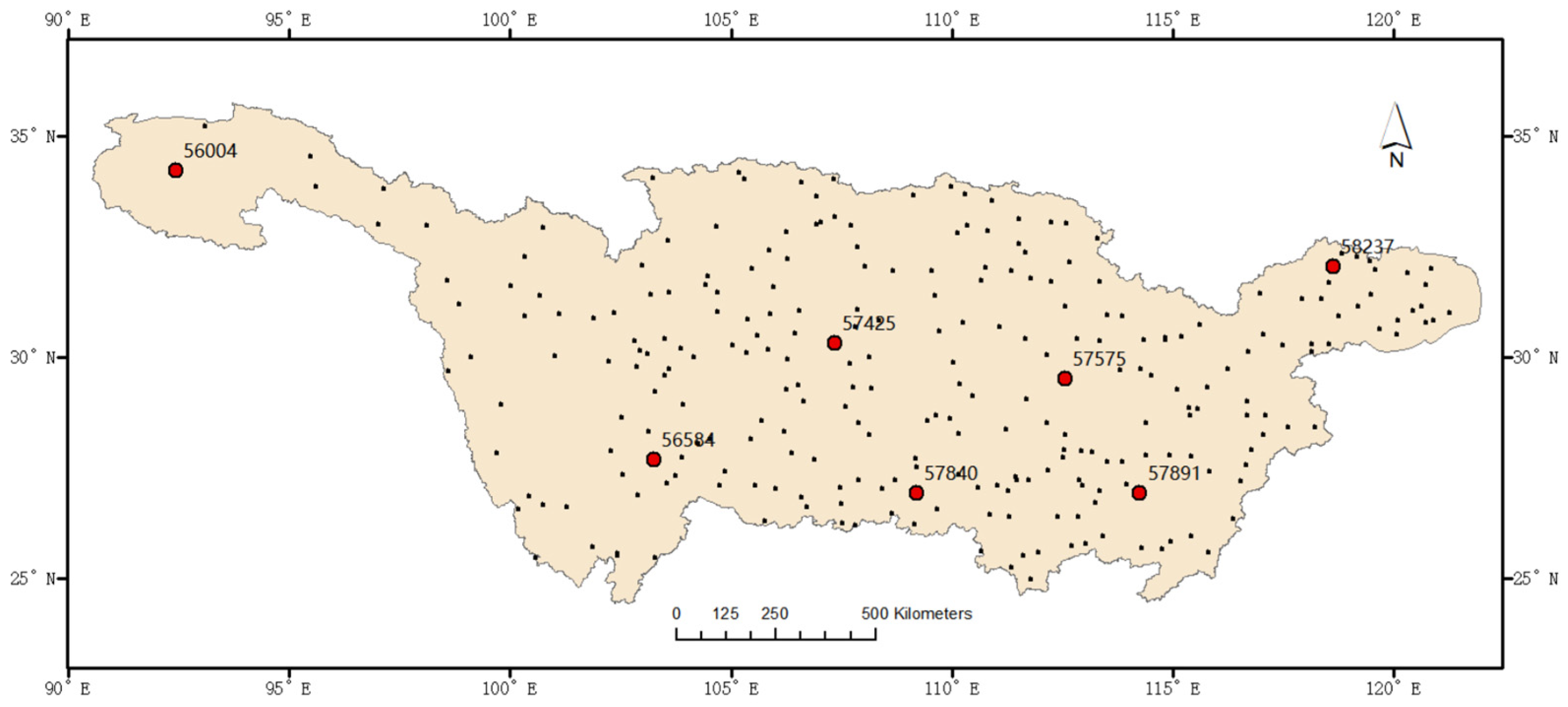
2.1. Study Area and Data
2.2. Estimation of Surface Evaporation in the Yangtze River Basin within Machine Learning
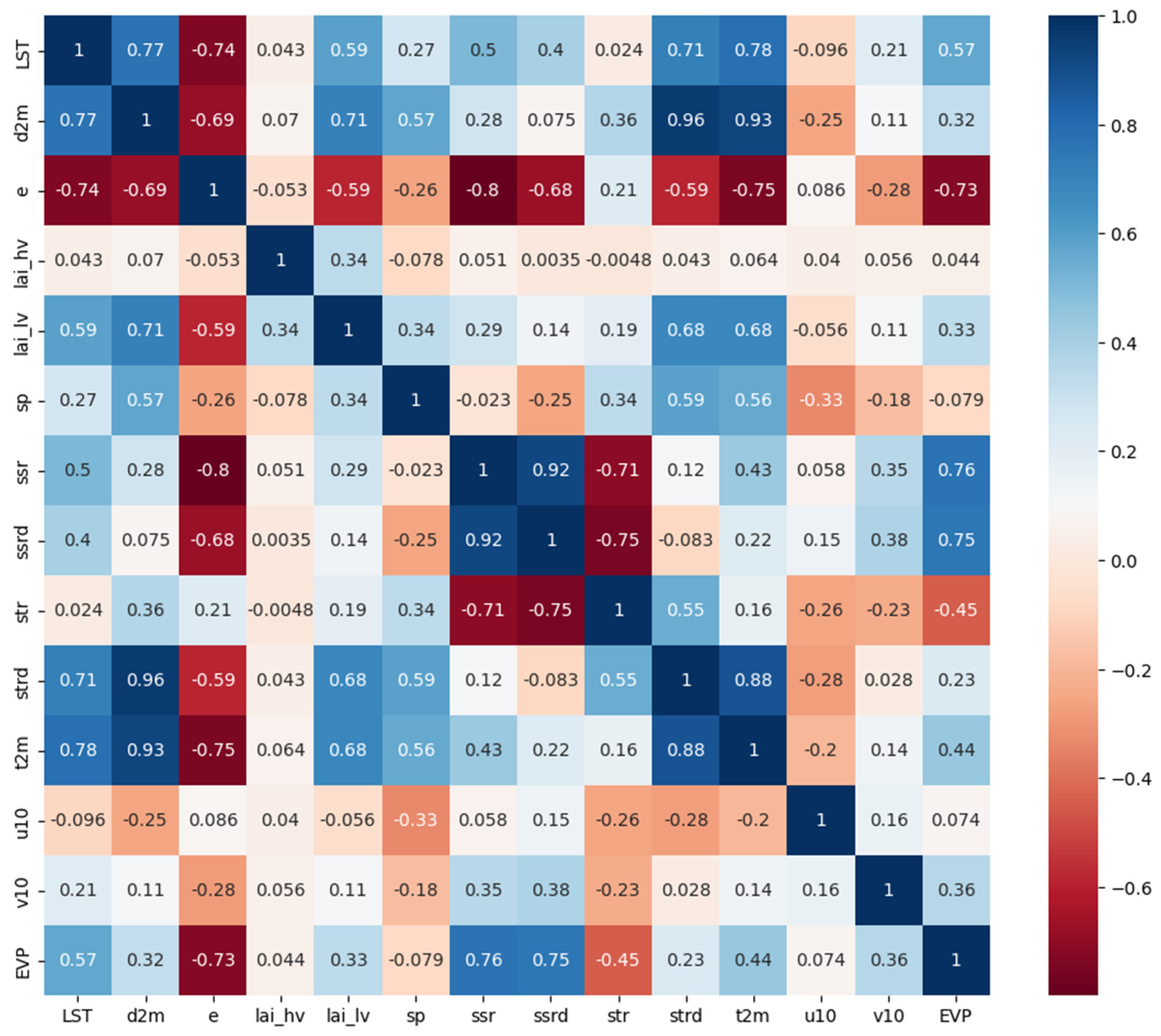
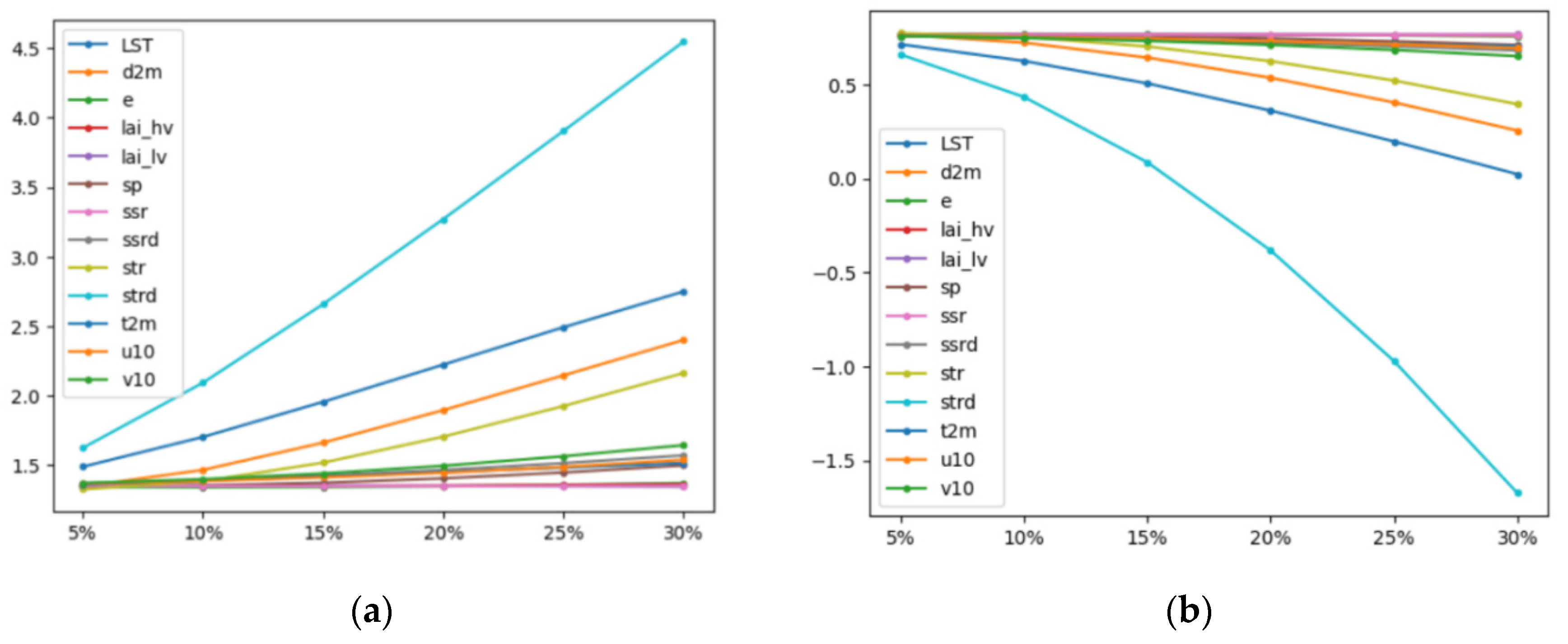
2.2.1. Variable Selection
2.2.2. Machine Learning Model
- Random Forest
- 2.
- Support Vector Machines
- 3.
- Extreme Learning Machine
- 4.
- Deep-Learning Neural Network
- 5.
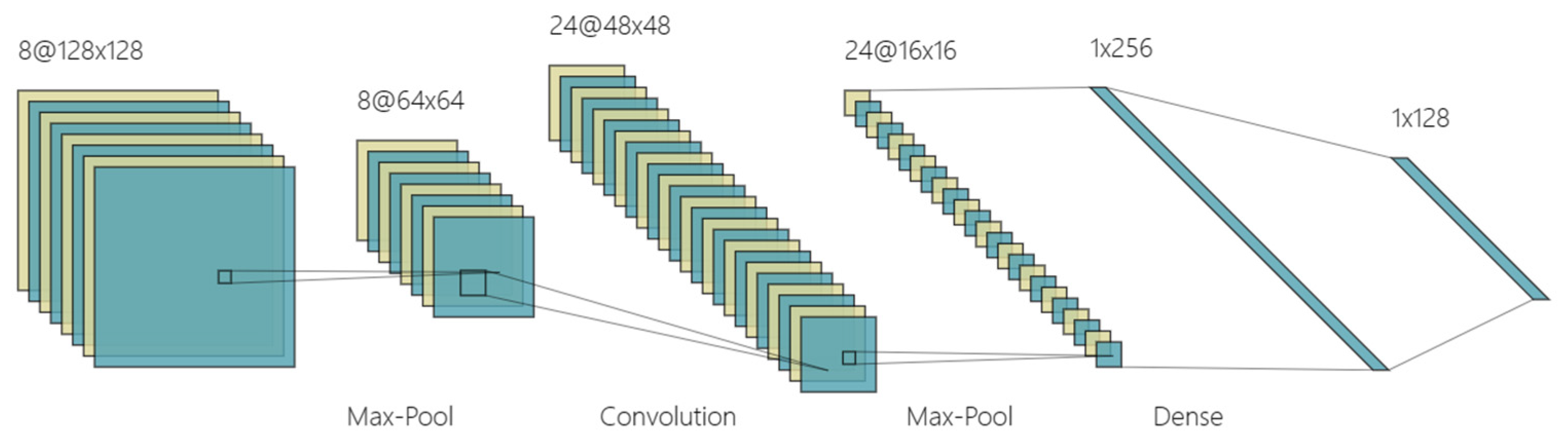
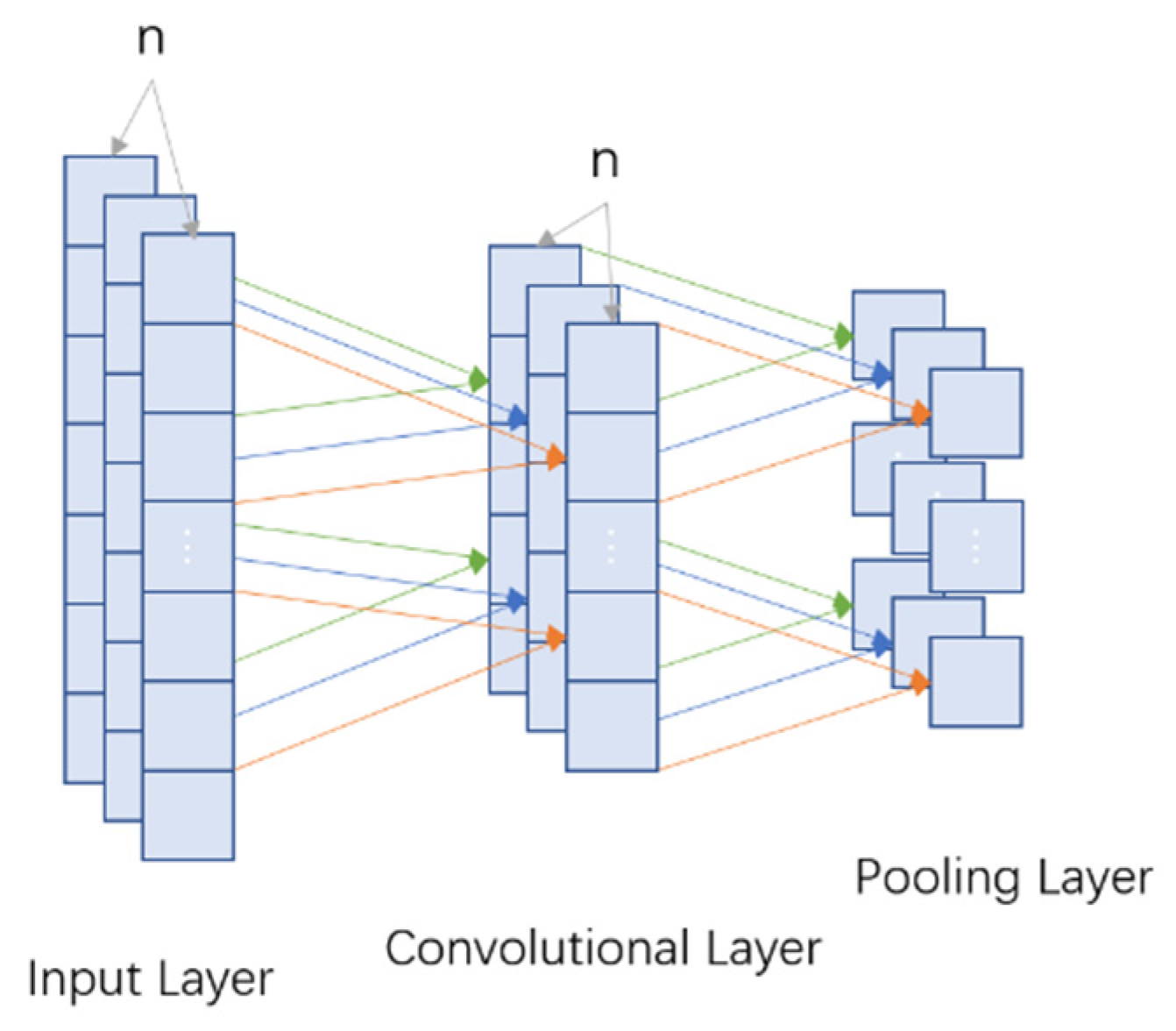
- Convolutional Neural Network
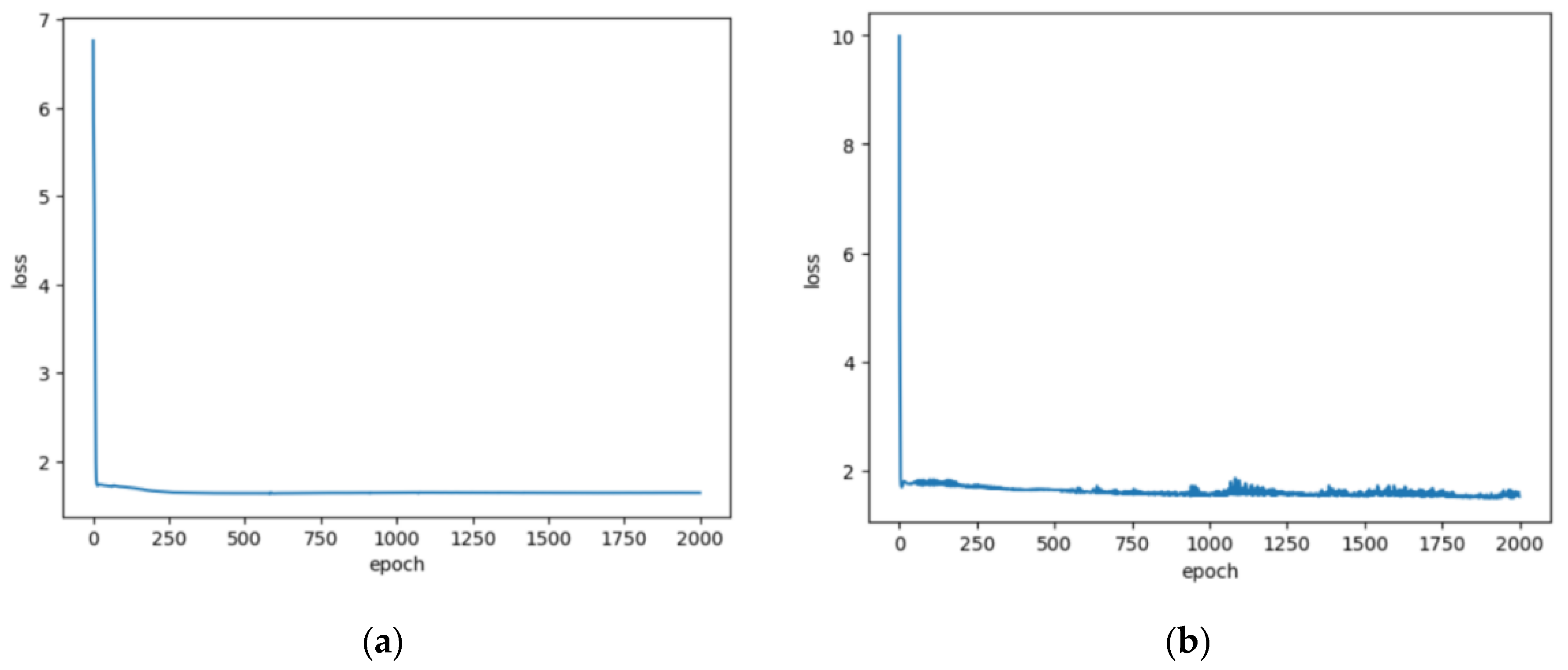
2.2.3. Model Training
2.2.4. Methods for Spatial Analysis of Surface Evaporation
- Analysis of the spatial distribution characteristics of evaporation in the Yangtze River Basin based on ten-year average evaporation data and annual evaporation data.
- Conducting spatial autocorrelation analysis by calculating global and local Moran indices to determine the presence of spatial autocorrelation and identify clustering types and regions.
2.2.5. Methods for Temporal Analysis of Surface Evaporation
3. Results and Discussion
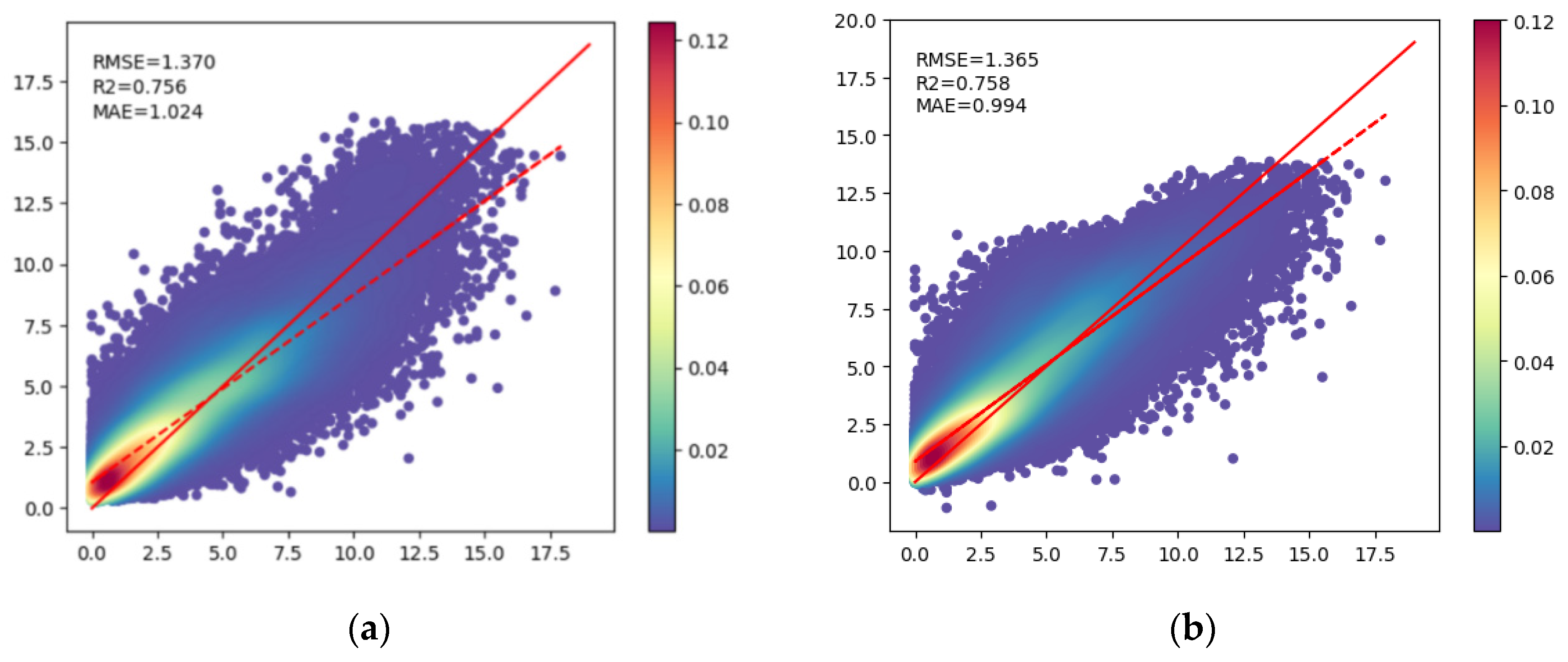
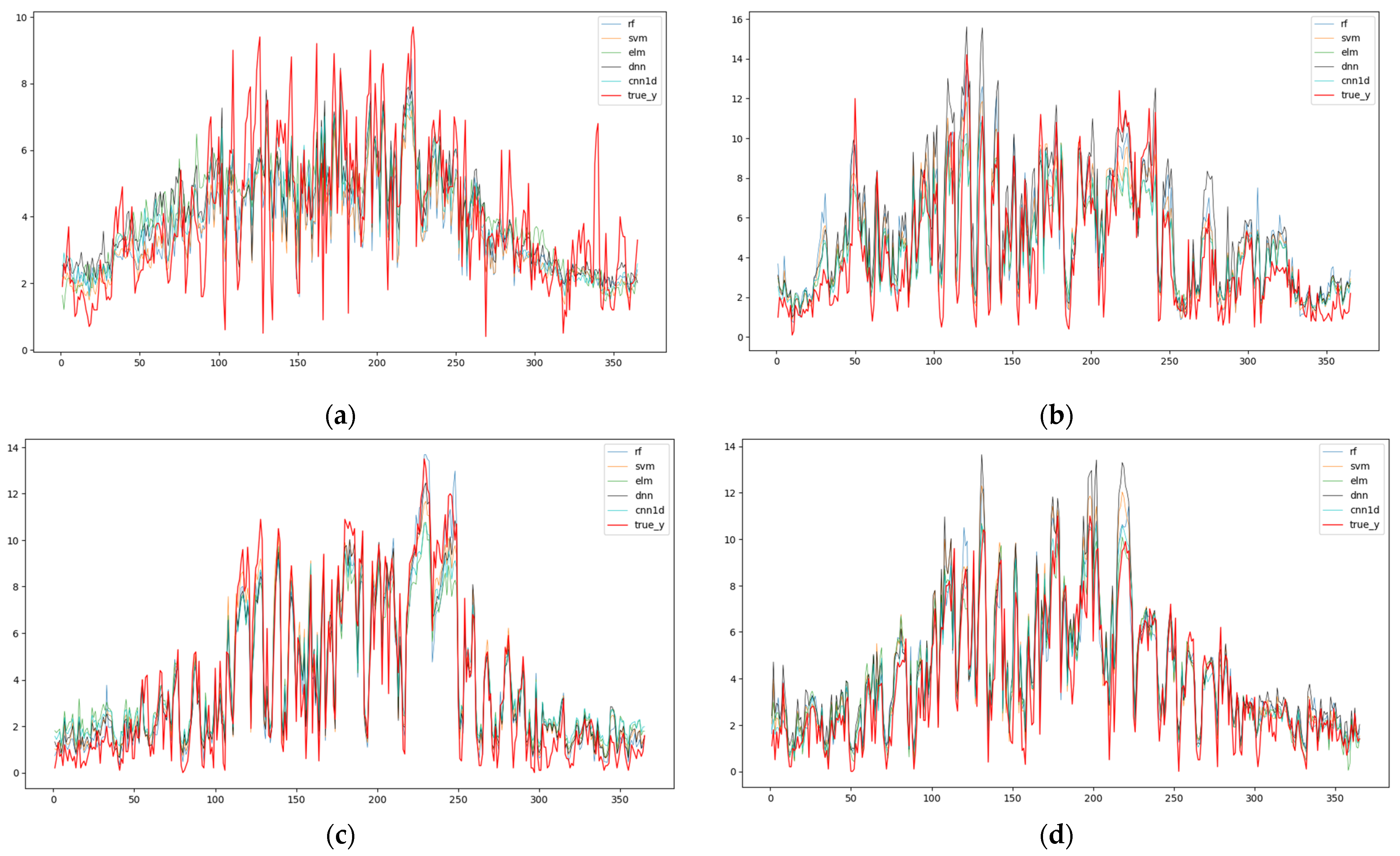
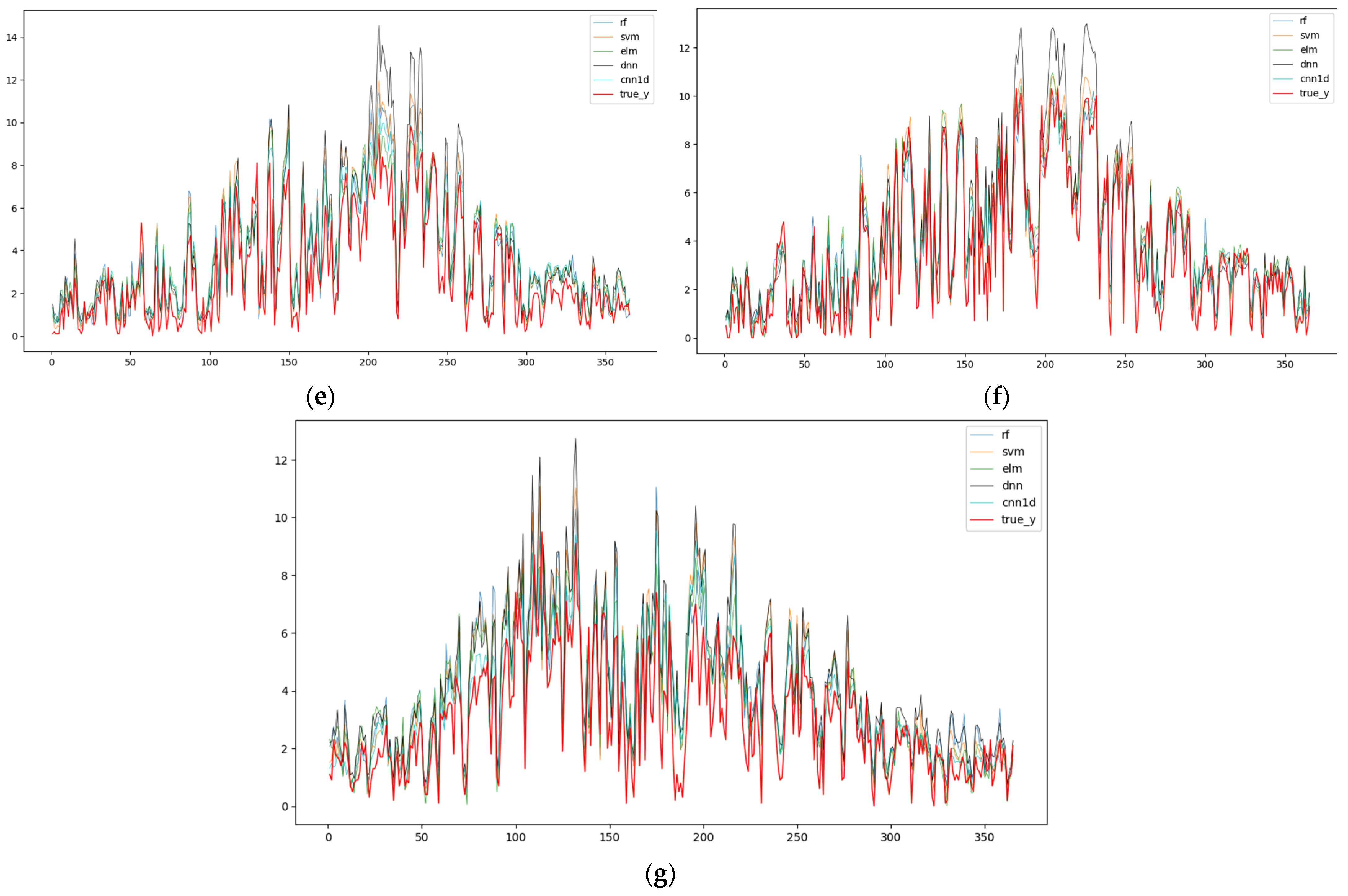
3.1. Evaluation of Spatial Accuracy
3.2. Evaluation of Temporal Accuracy
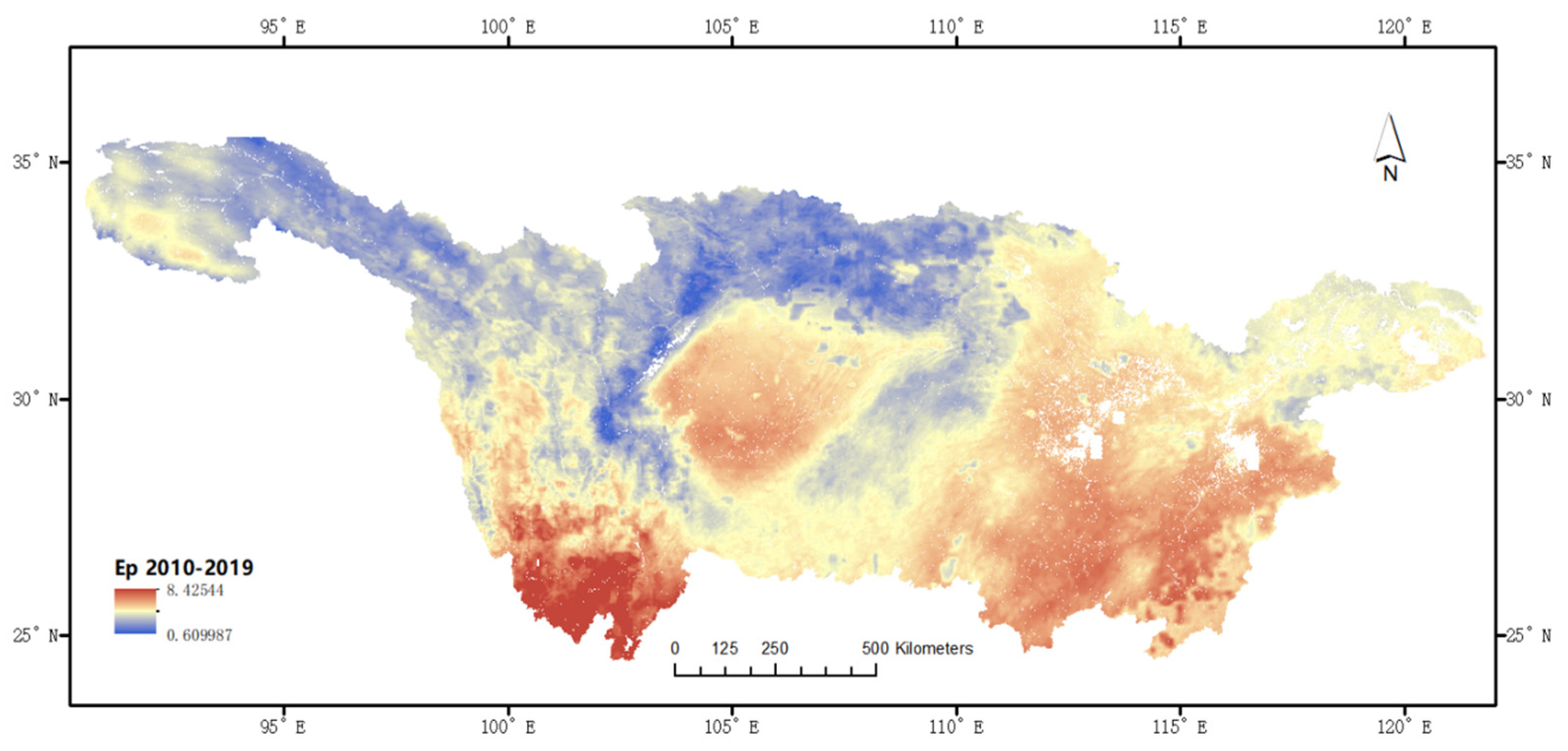
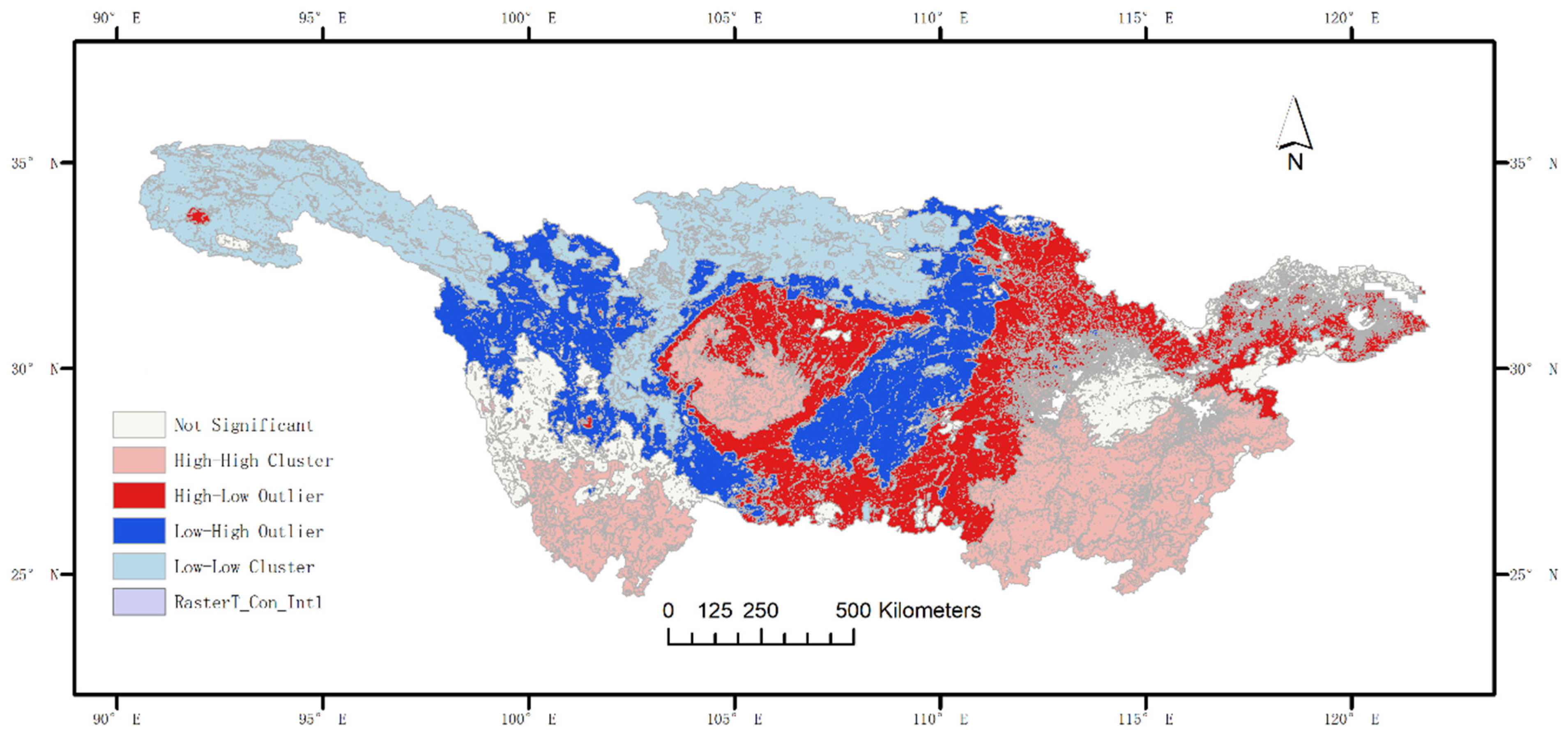
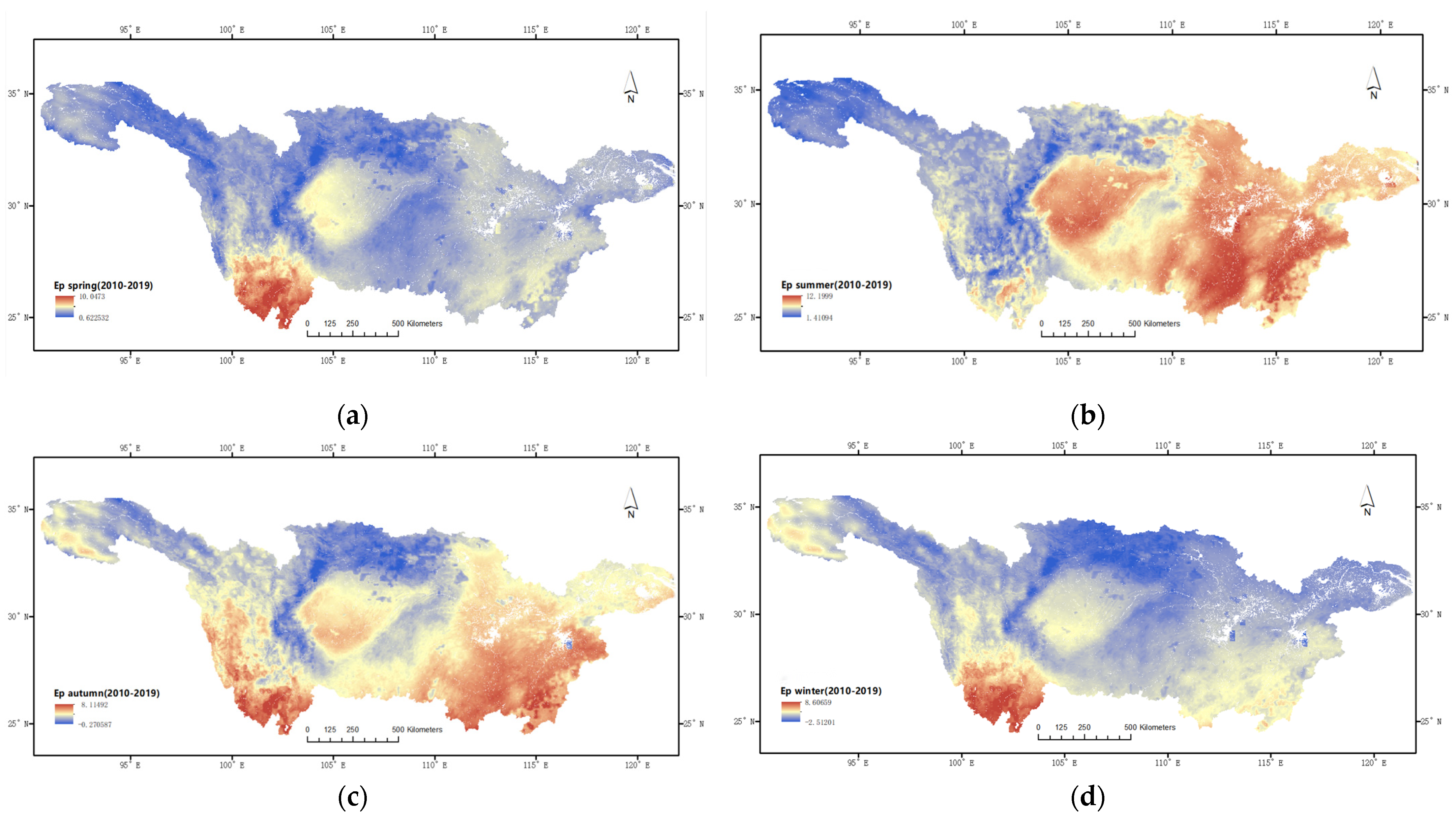
3.3. Analysis of Spatial Characteristics
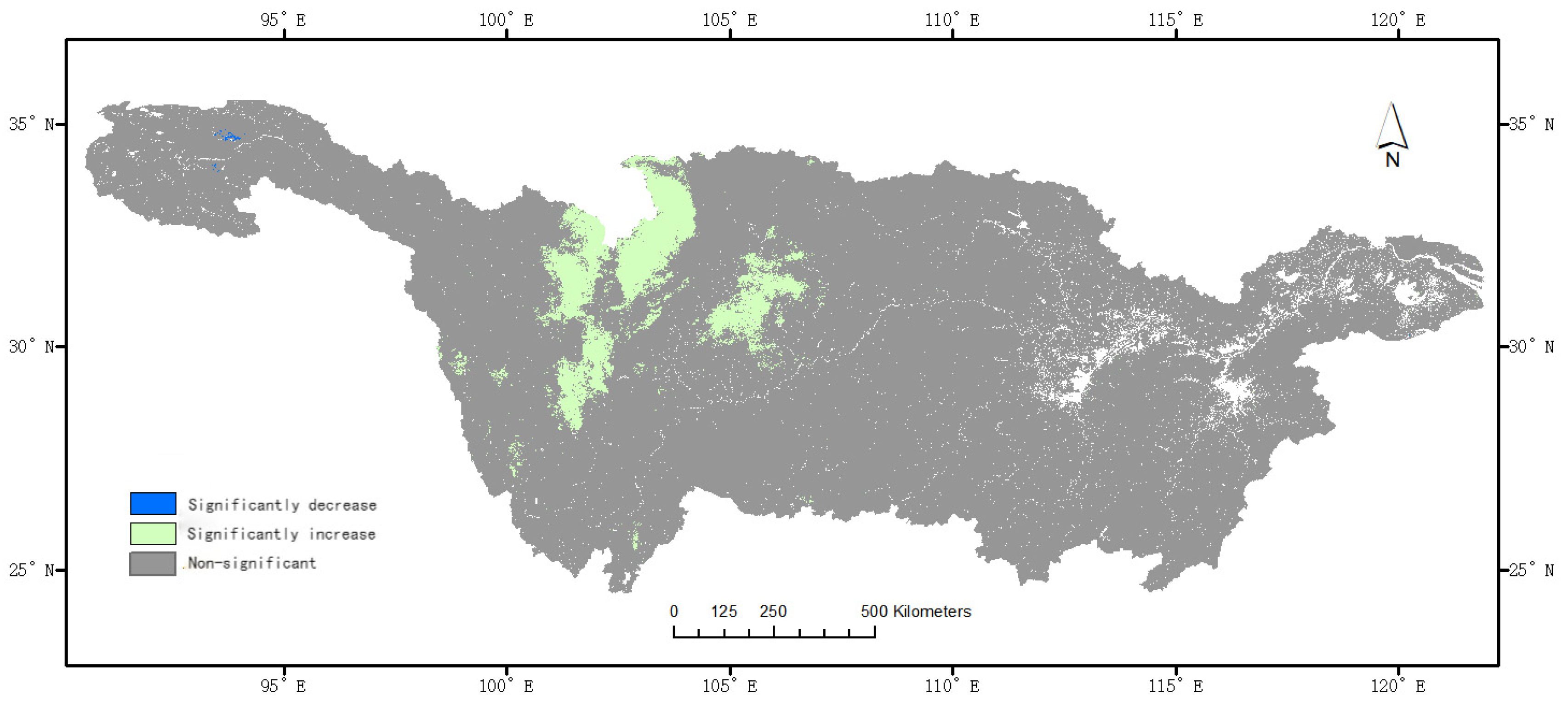
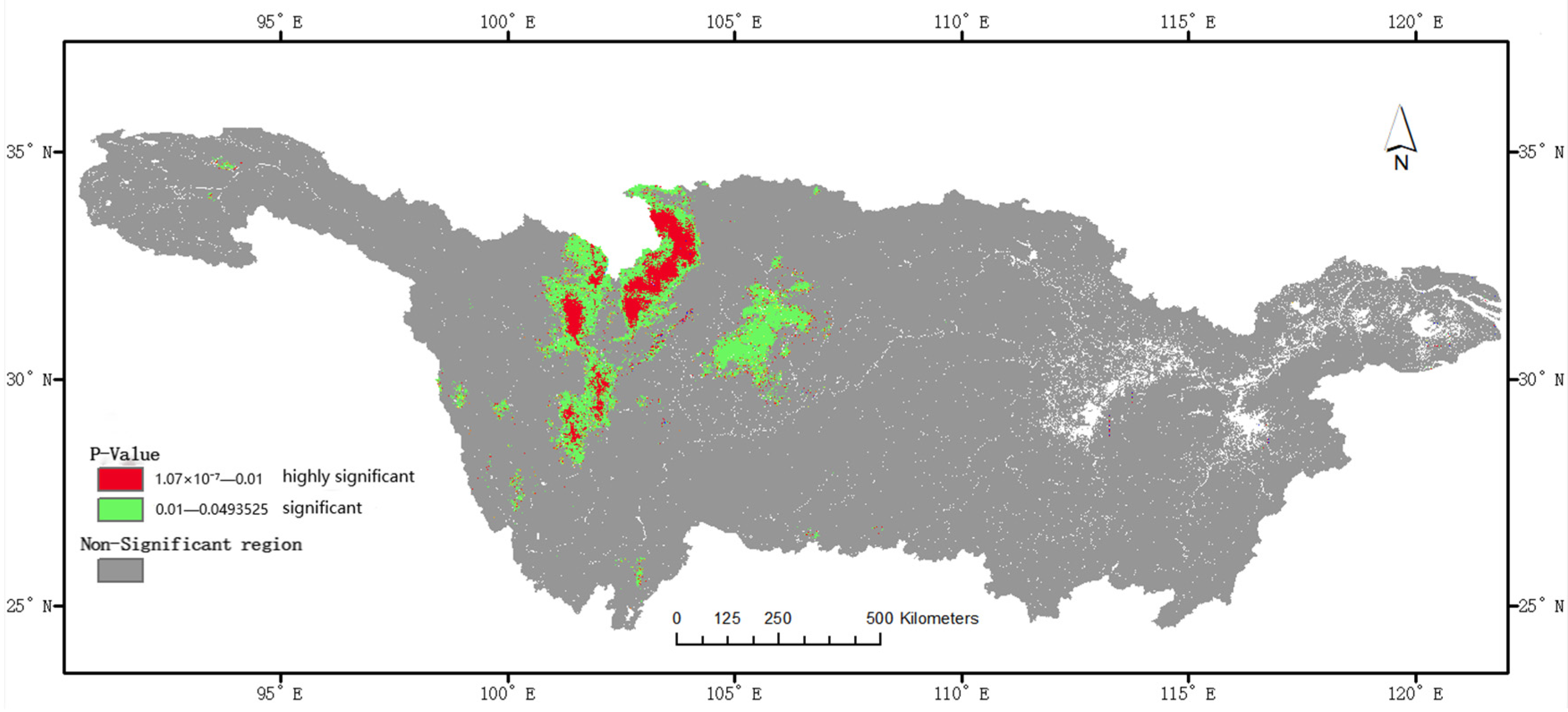
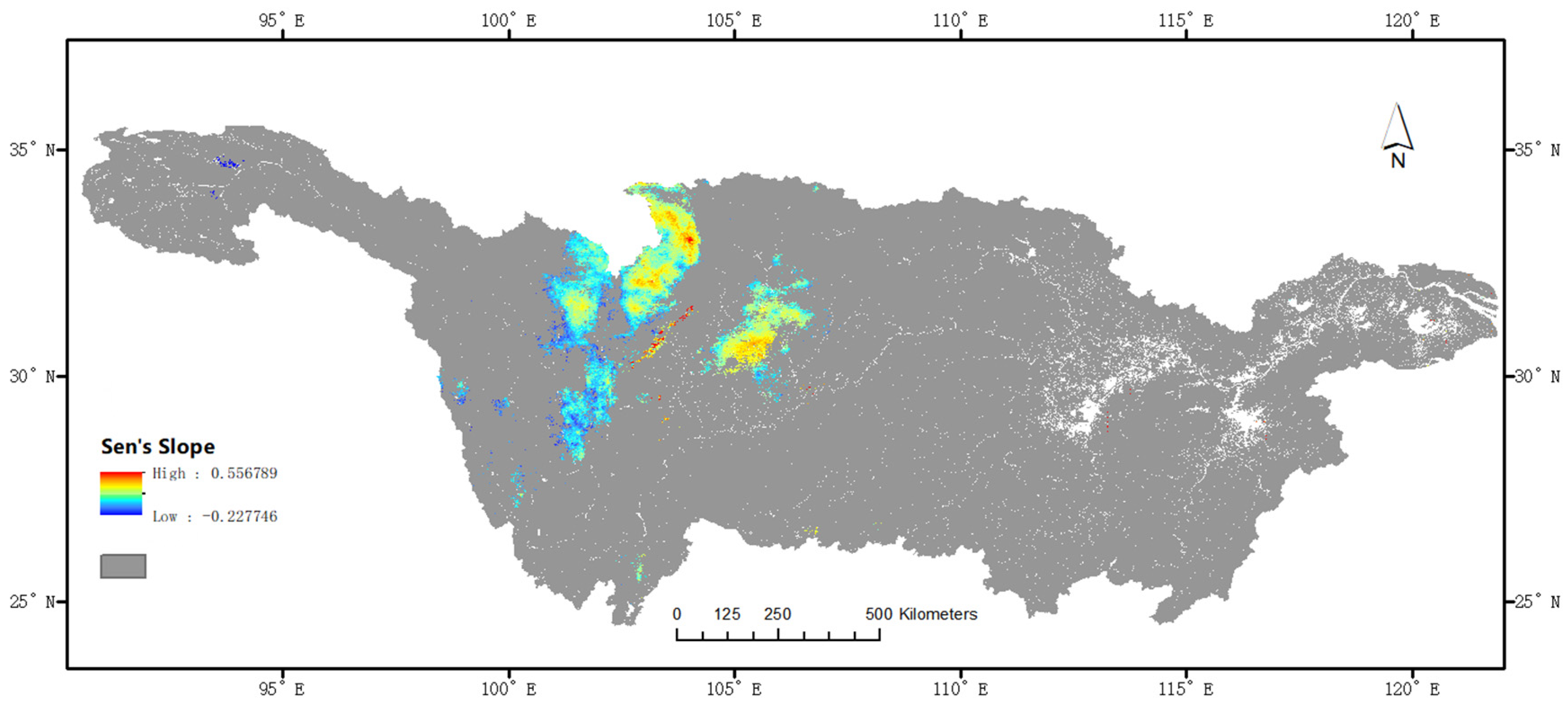
3.4. Analysis of Temporal Characteristics
4. Conclusions
- ■
- Comparative analysis of five machine learning methods for estimating surface evaporation in the Yangtze River Basin:
- ■
- Generation of daily, 1 km surface evaporation data for the Yangtze River Basin using a convolutional neural network:
- In the spatial distribution analysis, the surface evaporation displayed notable spatial variations in the basin, indicating higher evaporation in the southwestern and southeastern regions compared with the western and northern areas.
- Spatial autocorrelation analysis using the Global Moran’s I index suggested significant spatial dependencies, revealing multiple high and low aggregation areas within the basin.
- A time series analysis of seasonal and monthly evaporation data revealed a general trend of higher evaporation in summer compared with other seasons, with certain areas showing a significant increase or decrease in evaporation over ten years. These changes varied spatially, with a notable increase in specific parts of the basin, mainly in the Jialing River Basin.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, B.; Xu, M.; Henderson, M.; Gong, W. A spatial analysis of pan evaporation trends in China, 1955–2000. J. Geophys. Res. Atmos. 2004, 109, D15. [Google Scholar] [CrossRef]
- Ye, L.; Lu, H.; Qin, S.; Zhang, L.; Xiong, L.; Liu, P.; Xia, J.; Cheng, L. Changes in pan evaporation and actual evapotranspiration of the Yangtze River basin during 1960—2019. Adv. Water Sci. 2022, 33, 718–729. [Google Scholar] [CrossRef]
- Liu, M.; Tang, R.; Li, Z.; Maofang, G.; Yunjun, Y. Progress of data-driven remotely sensed retrieval methods and products on land surface evapotranspiration. Natl. Remote Sens. Bull. 2021, 25, 1517–1537. [Google Scholar] [CrossRef]
- Fan, J.; Wu, L.; Zhang, F.; Xiang, Y.; Zheng, J. Climate change effects on reference crop evapotranspiration across different climatic zones of China during 1956–2015. J. Hydrol. 2016, 542, 923–937. [Google Scholar] [CrossRef]
- Shiri, J.; Kişi, Ö. Application of Artificial Intelligence to Estimate Daily Pan Evaporation Using Available and Estimated Climatic Data in the Khozestan Province (South Western Iran). J. Irrig. Drain. Eng. 2011, 137, 412–425. [Google Scholar] [CrossRef]
- Dong, L.; Zeng, W.; Wu, L.; Lei, G.; Chen, H.; Srivastava, A.K.; Gaiser, T. Estimating the Pan Evaporation in Northwest China by Coupling CatBoost with Bat Algorithm. Water 2021, 13, 256. [Google Scholar] [CrossRef]
- Ding, R.; Kang, S.; Li, F.; Zhang, Y.; Tong, L.; Sun, Q. Evaluating eddy covariance method by large-scale weighing lysimeter in a maize field of northwest China. Agric. Water Manag. 2010, 98, 87–95. [Google Scholar] [CrossRef]
- Xu, C.-Y.; Gong, L.; Jiang, T.; Chen, D.; Singh, V.P. Analysis of spatial distribution and temporal trend of reference evapotranspiration and pan evaporation in Changjiang (Yangtze River) catchment. J. Hydrol. 2006, 327, 81–93. [Google Scholar] [CrossRef]
- Wang, Y.; Jiang, T.; Bothe, O.; Fraedrich, K. Changes of pan evaporation and reference evapotranspiration in the Yangtze River basin. Theor. Appl. Climatol. 2007, 90, 13–23. [Google Scholar] [CrossRef]
- Rong, Y.S.; Zhang, X.N.; Jiang, H.Y.; Bai, L.Y. Pan Evaporation Change and Its Impact on Water Cycle over the Upper Reach of Yangtze River. Chin. J. Geophys. 2012, 55, 488–497. [Google Scholar]
- Lu, X.; Ju, Y.; Wu, L.; Fan, J.; Zhang, F.; Li, Z. Daily pan evaporation modeling from local and cross-station data using three tree-basedmachine learning models. J. Hydrol. 2018, 566, 668–684. [Google Scholar] [CrossRef]
- Chen, J.L.; Yang, H.; Lv, M.Q.; Xiao, Z.L.; Wu, S.J. Estimation of monthly pan evaporation using support vector machine in Three Gorges Reservoir Area, China. Theor. Appl. Climatol. 2019, 138, 1095–1107. [Google Scholar] [CrossRef]
- Xu, S.; Cheng, J. A new land surface temperature fusion strategy based on cumulative distribution function matching and multiresolution Kalman filtering. Remote Sens. Environ. 2021, 254, 112256. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, N.; Cheng, J.; Xu, S. A Stepwise Downscaling Method for Generating High-Resolution Land Surface Temperature From AMSR-E Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5669–5681. [Google Scholar] [CrossRef]
- Zhang, Q.; Cheng, J. An Empirical Algorithm for Retrieving Land Surface Temperature From AMSR-E Data Considering the Comprehensive Effects of Environmental Variables. Earth Space Sci. 2020, 7, e2019EA001006. [Google Scholar] [CrossRef]
- Cheng, J.; Dong, S.; Shi, J. 1 km Seamless Land Surface Temperature Dataset of China (2002–2020); National Tibetan Plateau/Third Pole Environment Data Center: Beijing, China, 2021. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Svetnik, V.; Liaw, A.; Tong, C.; Culberson, J.C.; Sheridan, R.P.; Feuston, B.P. Random Forest: A Classification and Regression Tool for Compound Classification and QSAR Modeling. J. Chem. Inf. Comput. Sci. 2003, 43, 1947–1958. [Google Scholar] [CrossRef] [PubMed]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Guang-Bin, H.; Qin-Yu, Z.; Chee-Kheong, S. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat No04CH37541), Budapest, Hungary, 25–29 July 2004. [Google Scholar]
- Abed, M.; Imteaz, M.A.; Ahmed, A.N.; Huang, Y.F. Modelling monthly pan evaporation utilising Random Forest and deep learning algorithms. Sci. Rep. 2022, 12, 13132. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Keskin, M.E.; Terzi, Ö. Artificial Neural Network Models of Daily Pan Evaporation. J. Hydrol. Eng. 2006, 11, 65–70. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| For Short | Variable | Implication | Unit |
|---|---|---|---|
| d_2m | 2 m dewpoint temperature | 2 m dew point temperature | K |
| t_2m | 2 m temperature | 2 m air temperature | K |
| ssr | Surface net solar radiation | Net surface solar radiation | J/m2 |
| str | Surface net thermal radiation | Net surface heat radiation | J/m2 |
| ssrd | Surface solar radiation downwards | Solar radiation descending from the surface | J/m2 |
| strd | Surface thermal radiation downwards | Descending surface heat radiation | J/m2 |
| e | Total evaporation | Total evaporation | m/d |
| u_10m | 10 m u-component of wind | Wind speed in the U direction at 10 m | m/s |
| v_10m | 10 m v-component of wind | Wind speed in the V direction at 10 m | m/s |
| sp | Surface pressure | Surface pressure | Pa |
| lai_hv | Leaf area index, high vegetation | High vegetation leaf area index | / |
| lai_lv | Leaf area index, low vegetation | Low vegetation leaf area index | / |
| Data Type | Product | Variable | Spatial Resolution | Time Resolution | Data Source |
|---|---|---|---|---|---|
| Measured data | Daily value data set of surface climatological data for China | Evaporation (EVP) measured in small evaporating dish (E20) | / | 1 day | National Meteorological Science Data Center |
| Reanalysis data | ERA5 | d_2m, t_2m, ssr, str, ssrd, strd, e, u_10m, v_10m, sp, lai_hv, lai_lv | 0.1° | 1 h | https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-land?tab=overview (accessed on 10 November 2022) |
| Other data | China region 1 km seamless surface temperature dataset (2002–2020) | LST | 1 km | 1 day | National Tibetan Plateau Data Center |
| Variable Name | Variable Meaning | Minimum | 25% Value | 50% Value | 75% Value | Maximum | Mean | Standard Deviation |
|---|---|---|---|---|---|---|---|---|
| LST | Surface temperature (K) | 270.1144 | 290.8603 | 297.7726 | 305.3267 | 344.592 | 298.1359 | 9.833419 |
| d2m | 2 m dew point temperature (K) | 234.5368 | 273.9738 | 282.3932 | 290.1296 | 301.3116 | 281.0068 | 11.45174 |
| e | Total evaporation (m/d) | −0.00582 | −0.00247 | −0.00131 | −0.00066 | 3.19 × 10−5 | −0.00163 | 0.001187 |
| lai_hv | High vegetation leaf area index | −4.44 × 10−16 | 0.930162 | 2.160215 | 2.497014 | 5.878531 | 1.942995 | 1.250639 |
| lai_lv | Low vegetation leaf area index | 0.165024 | 1.25906 | 1.731728 | 2.336332 | 3.566517 | 1.802465 | 0.680875 |
| sp | Surface pressure (Pa) | 55,729.63 | 86,067.28 | 93,759.58 | 98,021.01 | 103,896.8 | 89,369.74 | 12,341.6 |
| ssr | Surface Net Solar Radiation (J/m2) | 436,639.9 | 4,867,988 | 8,848,731 | 12,848,888 | 21,770,216 | 8,990,494 | 4,729,407 |
| ssrd | Surface Net Solar Radiation (J/m2) | 490,030.3 | 6,515,555 | 11,113,285 | 15,512,798 | 26,533,810 | 11,105,916 | 5,583,336 |
| str | Surface Net Heat Radiation (J/m2) | −8,013,409 | −3,582,834 | −2,407,841 | −1,420,580 | 275,050.2 | −2,551,303 | 1,384,084 |
| strd | Surface Net Heat Radiation (J/m2) | 4,556,421 | 13,004,630 | 15,291,245 | 17,438,143 | 21,136,594 | 14,965,575 | 3,137,576 |
| t2m | 2 m air temperature (K) | 249.2020 | 278.6251 | 286.8802 | 294.3579 | 309.7132 | 285.7649 | 11.46349 |
| u10 | 10 m meridional wind speed (m/s) | −9.45987 | −0.82943 | −0.2765 | 0.256194 | 9.524438 | −0.27517 | 0.997803 |
| v10 | 10 m zonal wind speed (m/s) | −8.60936 | −0.83048 | −0.06951 | 0.597828 | 7.586802 | −0.09855 | 1.378779 |
| Model | RMSE | R2 | MAE |
|---|---|---|---|
| RF | 1.370 | 0.756 | 1.024 |
| SVM | 1.365 | 0.758 | 0.994 |
| ELM | 1.407 | 0.743 | 1.048 |
| CNN | 1.355 | 0.762 | 1.013 |
| DNN | 1.462 | 0.723 | 1.072 |
| RF | SVM | ELM | CNN | DNN | |
|---|---|---|---|---|---|
| Station.56004 | 0.593 | 0.596 | 0.514 | 0.630 | 0.602 |
| Station.56584 | 0.708 | 0.724 | 0.736 | 0.747 | 0.582 |
| Station.57425 | 0.911 | 0.913 | 0.858 | 0.874 | 0.910 |
| Station.57575 | 0.829 | 0.810 | 0.851 | 0.868 | 0.735 |
| Station.57840 | 0.688 | 0.642 | 0.709 | 0.719 | 0.460 |
| Station.57891 | 0.851 | 0.852 | 0.846 | 0.873 | 0.757 |
| Station.58237 | 0.491 | 0.431 | 0.586 | 0.597 | 0.265 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Liu, D.; Wan, K.; Huang, W.; Chen, N. Estimation and Spatiotemporal Analysis of Surface Evaporation in the Yangtze River Basin from 2010 to 2019. Remote Sens. 2024, 16, 57. https://doi.org/10.3390/rs16010057
Chen Z, Liu D, Wan K, Huang W, Chen N. Estimation and Spatiotemporal Analysis of Surface Evaporation in the Yangtze River Basin from 2010 to 2019. Remote Sensing. 2024; 16(1):57. https://doi.org/10.3390/rs16010057
Chicago/Turabian StyleChen, Zeqiang, Dongyang Liu, Ke Wan, Wenzhe Huang, and Nengcheng Chen. 2024. "Estimation and Spatiotemporal Analysis of Surface Evaporation in the Yangtze River Basin from 2010 to 2019" Remote Sensing 16, no. 1: 57. https://doi.org/10.3390/rs16010057