Abstract
Three-dimensional (3D) single-object tracking (3D SOT) is a fundamental yet not well-solved problem in 3D vision, where the complexity of feature matching and the sparsity of point clouds pose significant challenges. To handle abrupt changes in appearance features and sparse point clouds, we propose a novel 3D SOT network, dubbed CDTracker. It leverages both cosine similarity and an attention mechanism to enhance the robustness of feature matching. By combining similarity embedding and attention assignment, CDTracker performs template and search area feature matching in a coarse-to-fine manner. Additionally, CDTracker addresses the problem of sparse point clouds, which commonly leads to inaccurate tracking. It incorporates relatively dense sampling based on the concept of point cloud segmentation to retain more target points, leading to improved localization accuracy. Extensive experiments on both the KITTI and Waymo datasets demonstrate clear improvements in CDTracker over its competitors.
1. Introduction
Single-object tracking (SOT) is a fundamental visual perception task with wide-ranging applications in fields such as autonomous driving, indoor robotics, and UAVs [1,2,3,4]. Three-dimensional (3D) SOT aims to seamlessly and consistently track a specified target across each frame of the input sequence, given the initial 3D state of the target.
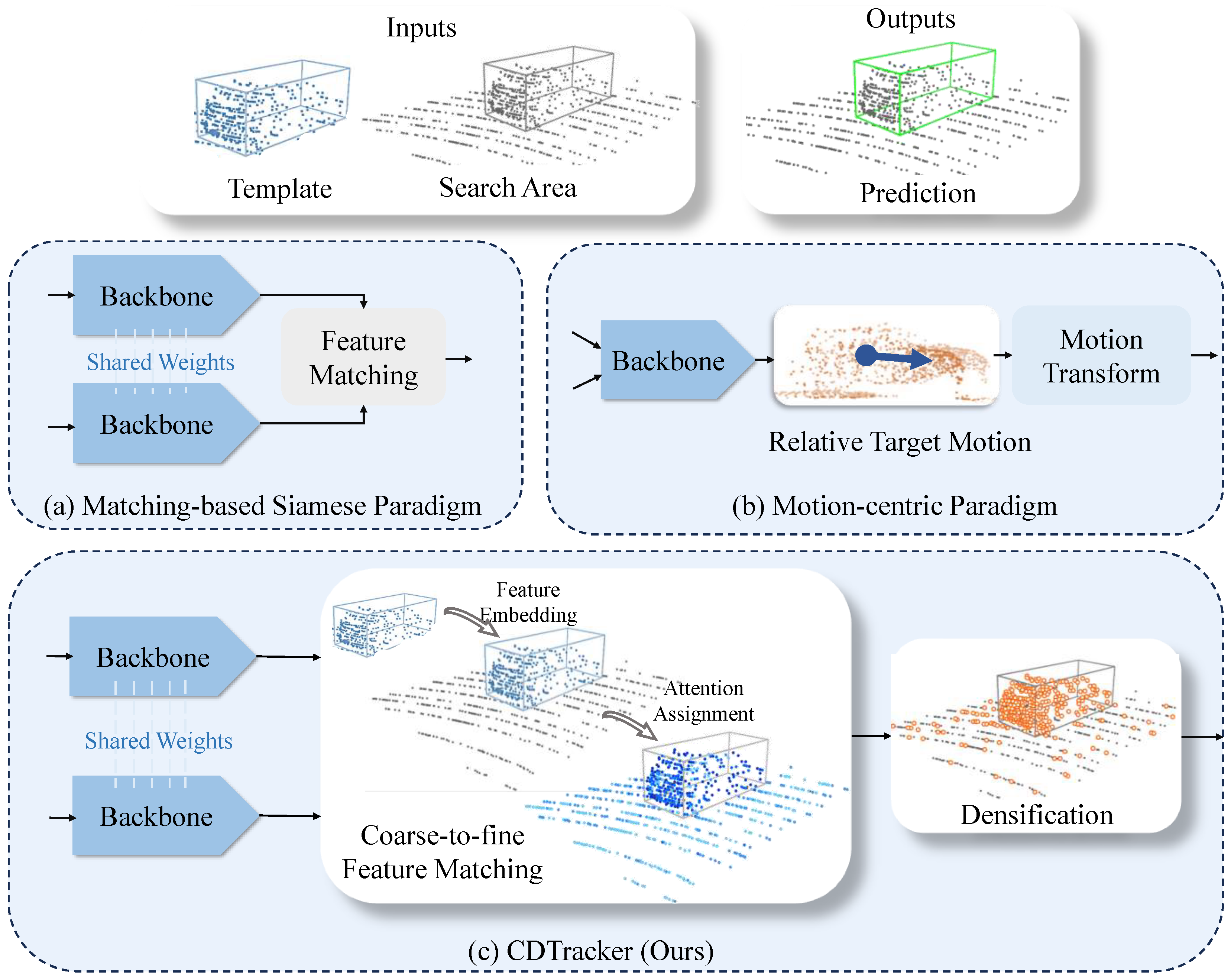
Existing 3D SOT methods (see Figure 1) can be categorized into two paradigms: the matching-based Siamese paradigm [3,5,6,7,8,9] and the motion-centric paradigm [1]. The matching-based Siamese paradigm typically involves the use of Siamese networks to extract point cloud appearance features from both the template and search regions. Subsequently, cosine similarity [3,4] and an attention mechanism [5,8] are performed to match features from these two regions, followed by target recognition and localization. The motion-centric paradigm simply leverages motion features to efficiently track the specified target by estimating the motion state between consecutive pairs of point clouds.
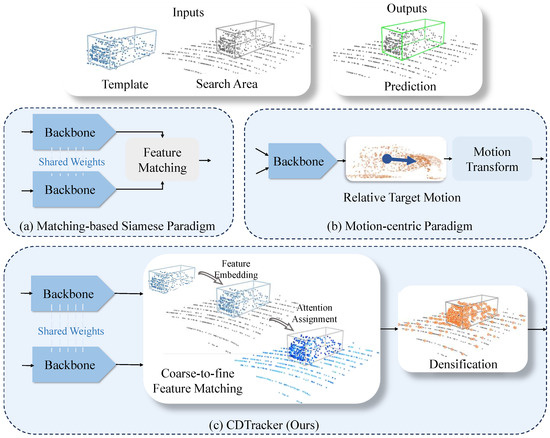
Figure 1.
Comparison of 3D SOT methods. (a) Matching-based Siamese paradigm. It typically uses two identical networks with shared weights to extract the appearance features of the target, matches the features based on appearance similarity, and then performs target localization. (b) Motion-centric paradigm. It predicts the relative motion of the target between two consecutive frames and locates the target in the current frame using motion transformations. (c) Our CDTracker consists of two key modules: the coarse-to-fine feature matching module, which incorporates cosine similarity and an attention mechanism to enhance the robustness of feature matching, and the relatively dense sampling module, which retains more points of interest to achieve more stable tracking results.
Despite the success achieved by both paradigms in 3D SOT, there are still some challenges that remain unresolved. Due to the presence of the feature matching module, the matching-based Siamese paradigm is suitable for targets with little appearance variation, but it often fails in complex and dynamic scenes. Huge appearance variations can cause failures in feature matching and, thus, affect the quality of the features [8,10]. Furthermore, commonly used methods in feature matching, such as cosine similarity and an attention mechanism, were not integrated into previous approaches. This resulted in a lack of embedding important information in the template or not assigning weights to different features appropriately [3,4,6,7]. For the motion-centric paradigm, it eliminates the need for feature matching, enhancing the network’s adaptability to complex and dynamic scenes. However, it demands an extensive dataset with diverse motion patterns for training to achieve robust tracking performance and generalization, which can be resource-intensive [1]. The sparsity of point clouds poses a considerable challenge to tracking performance. The incomplete shapes resulting from this sparsity can cause the network to shift its focus to nearby distractions, thereby substantially affecting tracking results [3,10]. Unfortunately, addressing the issue of sparsity remains unresolved in both paradigms.
We propose a novel robust 3D single-object tracking network, dubbed CDTracker. It first adopts the “coarse-to-fine” concept to enhance the robustness of feature matching to alleviate tracking failures from abrupt appearance changes and further stabilizes tracking by densifying the point cloud. CDTracker consists of two key modules: the coarse-to-fine feature matching module and the relatively dense sampling module. The first module combines cosine similarity and an attention mechanism to grasp point cloud similarity. Our method entails embedding cosine similarity and the corresponding template features into the search region. Thereafter, varying feature weights are assigned, producing a more discriminative feature set. This approach enhances the robustness of feature matching. Moreover, the second module leverages a segmentation-based strategy to preserve a higher density of target points within the search area, which mitigates the sparsity problem and further stabilizes tracking.
We evaluate the performance of CDTracker through a comparative analysis of the KITTI [11] and Waymo [12] datasets. Remarkably, CDTracker outperforms most of its competitors, showcasing its superior performance. Moreover, comprehensive ablation studies demonstrate the effectiveness of our CDTracker. The contributions are mainly three-fold:
- We propose a novel 3D SOT network, dubbed CDTracker, to handle abrupt changes in appearance features and sparse point clouds.
- We introduce a novel coarse-to-fine feature matching module based on the hybrid similarity learning mechanism, which combines cosine embedding and attention assignment in the feature matching of 3D SOT.
- We introduce a relatively dense sampling module that segments and retains more points of interest, thereby further improving the tracking performance.
2. Related Work
3D Single-Object Tracking. Existing 3D SOT methods can be categorized into two paradigms: the matching-based Siamese paradigm and the motion-centric paradigm. A majority of existing methods adhere to the matching-based Siamese paradigm. SC3D [2] is a pioneering work in 3D SOT. It utilizes the Kalman filter to generate suggested target frames, compares them with the target template based on feature similarity, and selects the frame with the highest similarity as the tracking result. However, SC3D has limitations, such as the inability to detect object relationships in the search area, slow inference speed, and the incapability of being trained in an end-to-end manner. P2B [3], the first end-to-end network, employs PointNet++ [13] for feature extraction from point cloud data. It uses cosine similarity for feature matching between the search area and template, enhancing search area features with template information based on similarity. This is followed by employing the Hough vote [14] to regress the target center from the search area. While P2B greatly improves tracking accuracy and speed, it does not consider object size information in point cloud features. To incorporate the object size information, BAT [4] integrates the provided bounding box details from the first frame into the feature representation of each point, enhancing the target features. However, these methods overlook the varying importance of points at different geometric positions in representing the target. For instance, foreground points should receive more attention compared to background points.
PTT [6] is the first to introduce the Transformer [15] into 3D SOT. It replaces cosine similarity with a Transformer-based method, utilizing self-attention to independently weigh template and search area features, and then employing cross-attention for feature matching, thereby obtaining precise attention features and enhancing tracking accuracy. Since then, the Transformer has been widely used in 3D SOT. PTTR [5] introduces a relation-aware sampling module, which retains more points relevant to the template. Furthermore, the prediction refinement module further refines the prediction results, effectively predicting high-quality 3D tracking results in a coarse-to-fine manner.
Recently, there has been a growing interest in motion feature modeling methods based on Bird’s Eye View (BEV). Both V2B [7] and PTTR++ [16] focus on object tracking based on BEV. V2B first obtains a 3D voxel feature map by voxelizing the search area, then performs max-pooling along the Z-axis to obtain dense Bird’s Eye View (BEV) feature maps, and finally conducts object tracking on these BEV feature maps. Unlike V2B, PTTR++ introduces a BEV branch to extract BEV feature maps directly from the raw point cloud and then fuse with the point branch features to obtain the final feature maps for the subsequent tracking. Both methods have achieved satisfactory improvements.
There are many methods, including the 3D proposal generation process, and the quality of the 3D proposal has a great impact on the tracking results. GLT-T [17] focuses on the 3D region proposal network and mentions that using a single seed point feature as the cue for offset learning in VoteNet [14] prevents high-quality 3D proposals from being generated, so it proposes a novel voting scheme to produce higher-quality 3D proposals, and at the same time designs a simple and effective training strategy to train the module. CXTrack [10] uses contextual information across two consecutive frames to improve the tracking results. OSP2B [18] and DMT [19] involve some limitations in two-stage networks, such as tedious hyperparameter tuning, task misalignment, and inaccurate target-specific detection, which limits tracking performance. Toward these concerns, they propose simple yet effective one-stage methods that strike a new balance between efficiency and accuracy.
The motion-centric paradigm, first proposed by [1], simply leverages the motion feature to efficiently track the specified target by estimating the motion between consecutive pairs of point clouds. Although avoiding the commonly used twin network paradigm, it shows superior performance. However, it requires an extensive dataset of varied motion patterns to train the network for robust tracking performance and generalization, which is naturally costly.
Our CDTracker follows the matching-based Siamese paradigm, but in the feature matching module, we collaborate cosine similarity and an attention mechanism to induce more discriminative features, and then achieve the goal of robust feature matching. We introduce a relatively dense sampling module that retains more points of interest, thereby further stabilizing the tracking performance.
Deep Learning on Point Clouds. With the introduction of PointNet [20] and PointNet++ [13], deep learning on point clouds has been rapidly developed. Existing methods can be mainly divided into graph-based [21,22], voxel-based [23,24], and point-based [3,20,25,26]. Graph-based methods are not suitable for sparse point clouds because few points do not provide enough local geometric information to construct a graph. Voxel-based methods divide the point cloud into regular voxels and then use 3D CNNs to extract voxel features. Compared to voxel-based methods, point-based methods take the whole raw point cloud as input and extract a small number of key points and their features via some SA layers, making them more efficient. As a result, in 3D SOT, point-based networks are typically used as the backbone for feature extraction. In addition, to compare the similarities or differences between features extracted from the template and search regions, 3D SOT often employs a Siamese network architecture, consisting of two identical point-based networks that share weights. For the same purpose mentioned above, we utilize the Siamese Point Transformer to generate discriminative point features in the feature extraction stage, which has demonstrated the significant advantage of capturing long-range contextual information for discriminative learning.
Attention Mechanism. The attention mechanism in deep learning models encourages the network to focus on information that is more important for the current task while paying less attention to non-critical information. Self-attention is a variation of the attention mechanism that excels at capturing internal relationships within data or features. Cross-attention involves two different sequences, and the elements of each sequence are associated with all the elements of the other sequence to capture the dependency between the two sequences. Transformer [15] is the first to utilize self-attention mechanisms to capture long-range dependencies in language sequences. Subsequently, the Transformer architecture has gradually been adapted for various visual tasks, including semantic segmentation [27,28], object detection [29,30,31], and object tracking [32,33]. In the realm of point cloud processing, Point Transformer [34,35] is the first to utilize the self-attention mechanism within the local neighborhoods of point clouds, enabling the extraction of local features for 3D semantic segmentation. Drawing inspiration from Point Transformer, various 3D vision tasks have incorporated the Transformer architecture to achieve impressive results, including 3D object detection [36,37] and 3D object tracking [8]. Taking inspiration from these works, we also incorporate the attention mechanism into the feature matching process. This allows us to assign weights to point features, thereby enhancing internal associations. Together with cosine similarity, our coarse-to-fine feature matching module could alleviate tracking failures from abrupt appearance changes, enhancing the robustness of feature matching.
3. Method
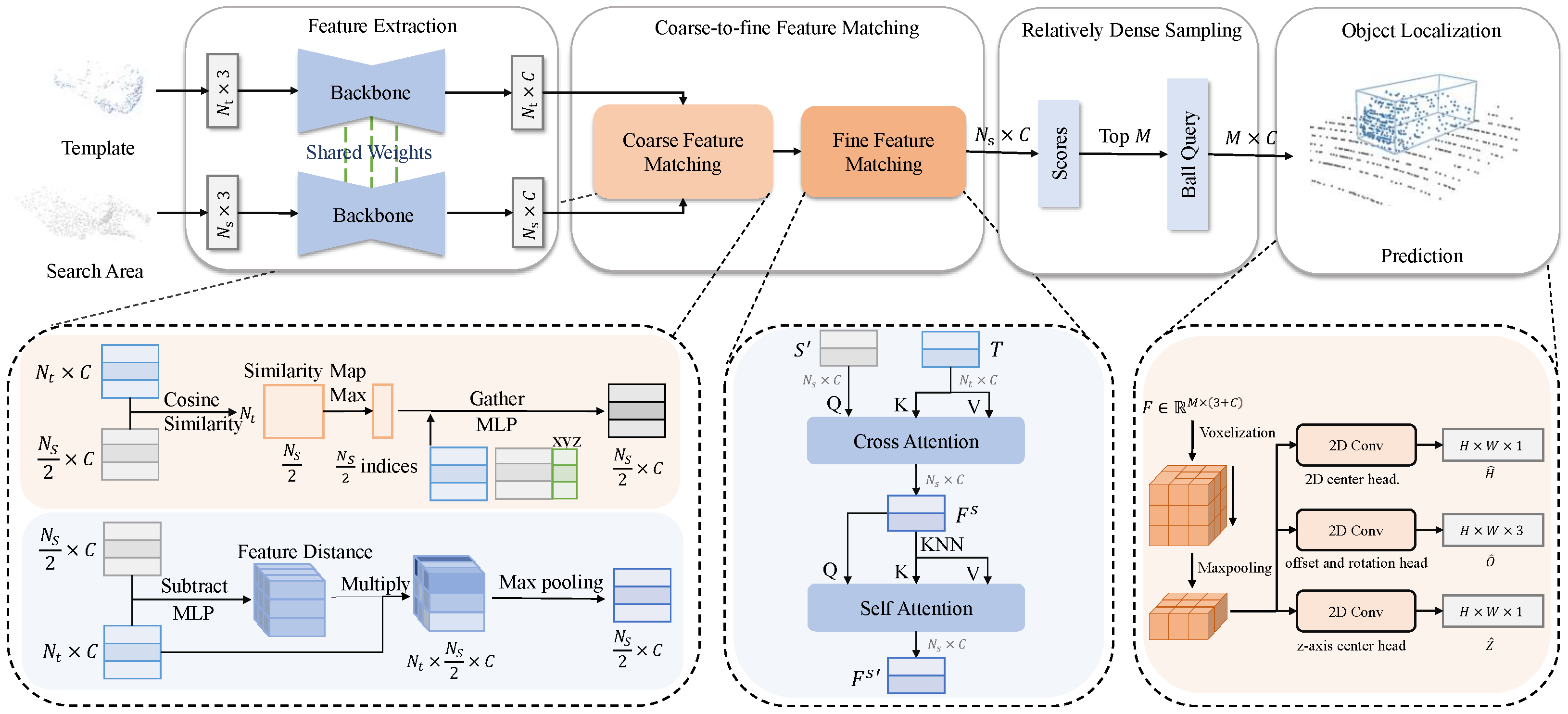
Our CDTracker consists of four main modules: feature extraction, coarse-to-fine feature matching, relatively dense sampling, and object localization, as shown in Figure 2. The feature extraction module follows the Siamese Point Transformer network to extract features from the template and search area. The coarse-to-fine feature matching module collaborates cosine similarity and an attention mechanism to grasp point cloud similarity and then generate discriminative features. The relatively dense sampling module utilizes the idea of segmentation to retain more target points in the search area. The object localization module employs the bird’s eye view (BEV) in capturing motion features to predict the tracking results.
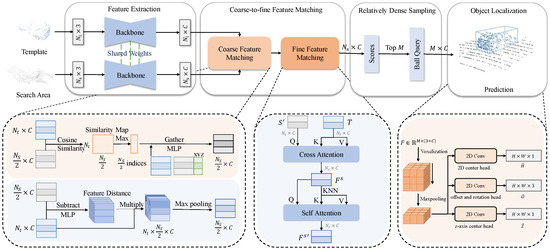
Figure 2.
The overall architecture of CDTracker. Following the matching-based Siamese paradigm, our network consists of four main modules. The feature extraction module extracts point cloud features from the template and search area, respectively. The coarse-to-fine feature matching module combines cosine similarity and an attention mechanism to grasp point cloud similarity. The relatively dense sampling retains more target points in the search area. Finally, we predict the tracking results accurately in the object localization module.
3.1. Feature Extraction
Most of the current methods follow the Siamese paradigm based on appearance matching and use PointNet [20] or PointNet++ [13] as feature extraction backbones. These backbones cannot learn discriminative features that should be assigned different weights based on the points’ locations. Additionally, the Siamese Point Transformer in STNet [8] has demonstrated a significant advantage in capturing long-range contextual information for discriminative learning. Therefore, we follow this approach to generate discriminative point features through the Siamese Point Transformer.
Specifically, the template point cloud is represented as , and the search area point cloud is represented as , where and denote the numbers of template points and search area points, respectively, and 3 denotes the dimension of the point coordinates. The template features after the feature extraction module are denoted as , and the search area features are denoted as , where C denotes the feature dimension.
3.2. Coarse-to-Fine Feature Matching
Regarding feature matching for the single-object tracking task, previous methods [3,4,7] employed cosine similarity to compute the similarity between template features and search area features. With the proposal of the Transformer, Refs. [5,8] integrated the attention mechanism into feature matching, assigning different attention weights to different features, which significantly improved performance compared to cosine similarity. Intuitively, embedding cosine similarity into the search area features first and then assigning different feature weights can induce more discriminative features. Therefore, we have designed a hybrid similarity learning mechanism that combines cosine embedding and attention assignment for coarse-to-fine feature matching.
3.2.1. Coarse Feature Matching
Here we follow V2B [7] in utilizing cosine similarity and feature distance to learn similarity and discrepancy, respectively. Before the feature matching module, we input the point cloud features of the search area into two independent MLPs (multi-layer perceptrons, types of artificial neural networks consisting of multiple layers of interconnected nodes where each node uses a nonlinear activation function) to obtain two feature subsets, and .
To obtain the similarity between the template and the search area, the cosine similarity between the template point cloud and the subset of the search area is first calculated to obtain the similarity map. The similarity map is defined as follows:
where denotes the cosine similarity between two features. and represent the number of point features in T and , respectively. denotes an by similarity map, where each entity represents the cosine similarity between and . Each point in the search region subset with the maximum cosine similarity value is the most similar to a point in the template. We then gather the features and coordinates of the corresponding template points along with the maximum cosine similarity and the features of the search area. These are provided to an MLP, which embeds the template features into the search area features. We formulate this as follows:
where k is the subscript of the point features in T with the maximum cosine similarity related to the feature in . denotes the corresponding maximum similarity value. denotes the coordinates of the corresponding template points. Finally, we obtain the similarity feature set .
Apart from the similar features, the discrepancy features between the template and the search area are important and have important contributions to the subsequent object localization. The discrepancy features are given by the following:
where is the max-pooling operation (max-pooling is a downsampling technique that reduces the dimensions of the input by dividing it into non-overlapping regions and taking the maximum value from each region) and represents the weights between the corresponding feature vectors in T and , respectively. The discrepancy feature set is obtained by assigning weights to the corresponding template features. Finally, we concatenate the similarity feature set and discrepancy feature set to obtain the coarse feature map .
3.2.2. Fine Feature Matching
Due to the large appearance variation between the template and the search area, learning the similarity between the template and the search area by just calculating cosine similarity and discrepancy is not a very effective way. Hence, we apply the attention mechanism in [8] to obtain higher-quality fusion features and mitigate the impact caused by the appearance variation between the template and the search area.
Cross-attention. Given the template features and the search area features after the initial similarity learning, cross-attention is applied to further learn the similarity between them and fuse them. For the template feature and the search area feature , the following cross-attention is used:
where denotes the position embedding of the template, and denote the query, key, and value in the attention mechanism, respectively.
Self-attention. The template information is further enhanced by using self-attention. First, for each point in the search area, we find the K closest neighboring points in the feature space constructed on the cross-attention output , denoted as . We further update the search area point features using the self-attention mechanism:
where and denote the location embedding of the corresponding point and its K-NN neighborhood, respectively. The final feature map is denoted as .
3.3. Relatively Dense Sampling
Sparsity is still one of the main reasons for inaccurate tracking results. We attempt to improve the relative density of the target points to mitigate the sparsity. Inspired by [9], we introduce the sampling module and apply the idea of segmentation to retain more of the target points. This improves the relative density of the target points and provides favorable conditions for stable object localization.
After obtaining the fused search area feature set , we feed it into an MLP to predict a score for each point, which represents the probability that each point is a target point. Meanwhile, the ground truth bounding box can be used to generate smooth one-hot labels for supervision, which can be formulated as follows:
where when point i is in the ground truth bounding box; otherwise . is the hyperparameter, which is set to in the experiment. Considering the imbalance in the number of foreground and background points, focal loss [38] is applied for supervision, which can be expressed by the following equation:
where is the predicted score and is the hyperparameter, which is set to 2 in the experiment.
Finally, points with the highest M scores are retained and grouped as the center of the ball query, and then aggregated with the k neighboring features, which denote . Then after aggregation, we obtain the fusion features , where 3 denotes the dimension of retained point coordinates.
Based on the fusion feature, we use object localization in [7] to regress the target center and yaw angle (see Figure 2).
4. Experiment
4.1. Experiment Setting
Datasets. In the experiment, we use the KITTI [11] and Waymo [12] datasets for evaluation. KITTI is a commonly used challenging real-world computer vision benchmark in autonomous driving scenarios and is often used to evaluate tasks such as stereo, 3D object detection, and tracking. The 3D object tracking task contains 21 training LiDAR sequences and 29 test LiDAR sequences. Waymo is one of the most important and large-scale datasets in the field of autonomous driving, containing 798 training sequences and 202 validation sequences, 12.6 million 3D bounding box tags with tracking IDs. Specifically, we train and test on KITTI and test only on Waymo to verify the generalization ability of our network. For the KITTI dataset, due to the labels of test data not being open, we follow the settings of [3] and divide the training set of KITTI into three parts: sequences 0~16 for training, 17~18 for validation, and 19~20 for testing. The Waymo dataset is classified as easy, medium, and hard, according to the number of points in the first frame. Due to the limitation of our experimental conditions, only 150 scenes are randomly selected in the validation set for testing on the Waymo dataset.
Evaluation metrics. We use the success and precision defined in one-pass evaluation [39] as the evaluation metrics for 3D single-object tracking. Specifically, the success is defined as the IoU between the predicted boxes and the ground truth, and the precision measures the AUC (area under the curve) of the distance between the prediction box center and the ground truth box center from 0 to 2 meters.
Implementation details. For the original input point number, we set the template point number and the search area point number . After the feature extraction module, the feature dimension is set to , so the size of the template feature T and search area feature S are and , respectively. We set the reserved points in the relatively dense sampling part, resulting in an output feature map size of . We also try setting the retained points to , and a comparative analysis of the two results will be provided in the ablation experiment in Section 4.3.
4.2. Results
Quantitative results. We test our network on the KITTI [11] dataset and compare it with other 3D single-object tracking networks, including SC3D [2], P2B [3], BAT [4], PTT [6], PTTR [5], V2B [7], STNet [8], DMT [19], OSP2B [18], and GLT-T [17]; the results are shown in Table 1. Note that the STNet results in the table are not the results listed in the paper, but the test results after retraining, and the other network results are taken from the corresponding papers. Compared with the baseline STNet, for the car category, our network improves the success and precision from 70.6% to 71.7% and 82.3% to 83.1% with a gain of about 1.1% and 0.8%, respectively. (Considering the limited number of scenes in the KITTI dataset, we conducted additional cross-validation experiments. We changed the settings for dataset partitioning as follows: 0~14, 17, 18 for training, 15~16 for validation, and 19~20 for testing, yielding a result of 71.3/83.1 for the car category). In the KITTI dataset, the car category has the largest amount of training data, supporting our network to perform best in this category. We achieve a more significant improvement in the cyclist category, with success and precision rates improving from 64.6% to 71.2% and 91.7% to 93.2%, respectively (improvements of 6.6% and 1.5%, respectively). We manually reviewed the KITTI dataset and found that the cyclist category has fewer distractors, which has less impact on the tracking results. However, the Pedestrian category contains many distractors (pedestrians usually appear in groups) around the target object, which causes our method to perform poorly on Pedestrians compared to other methods. Our design does not handle this difficult distraction scenario very well. Our results are down in the van category compared to the baseline. We consider the possible reason for this to be that there is less training data on the van category, which limits the performance of our network in this category.

Table 1.
Performance comparison on the KITTI dataset. Success/precision are used for evaluation. The results are produced based on the official implementation.
In order to verify the generalization ability of our network, we also test on the Waymo [12]. Table 2 shows the results for the vehicle and pedestrian categories in the Waymo dataset. It can be observed that our method outperforms the baseline in the easy and hard scenarios within the vehicle category, and in the medium and hard scenarios within the pedestrian category. But our method falls below the baseline on the Mean metric in the vehicle category. We attribute this to having conducted experiments on only 150 validation scenes due to limitations in our experimental conditions, whereas the baseline uses a full validation set. The results on the Waymo dataset demonstrate the effectiveness of the method for unencountered scenarios.
Table 2.
Performance comparison on the Waymo dataset. Success/precision are used for evaluation.
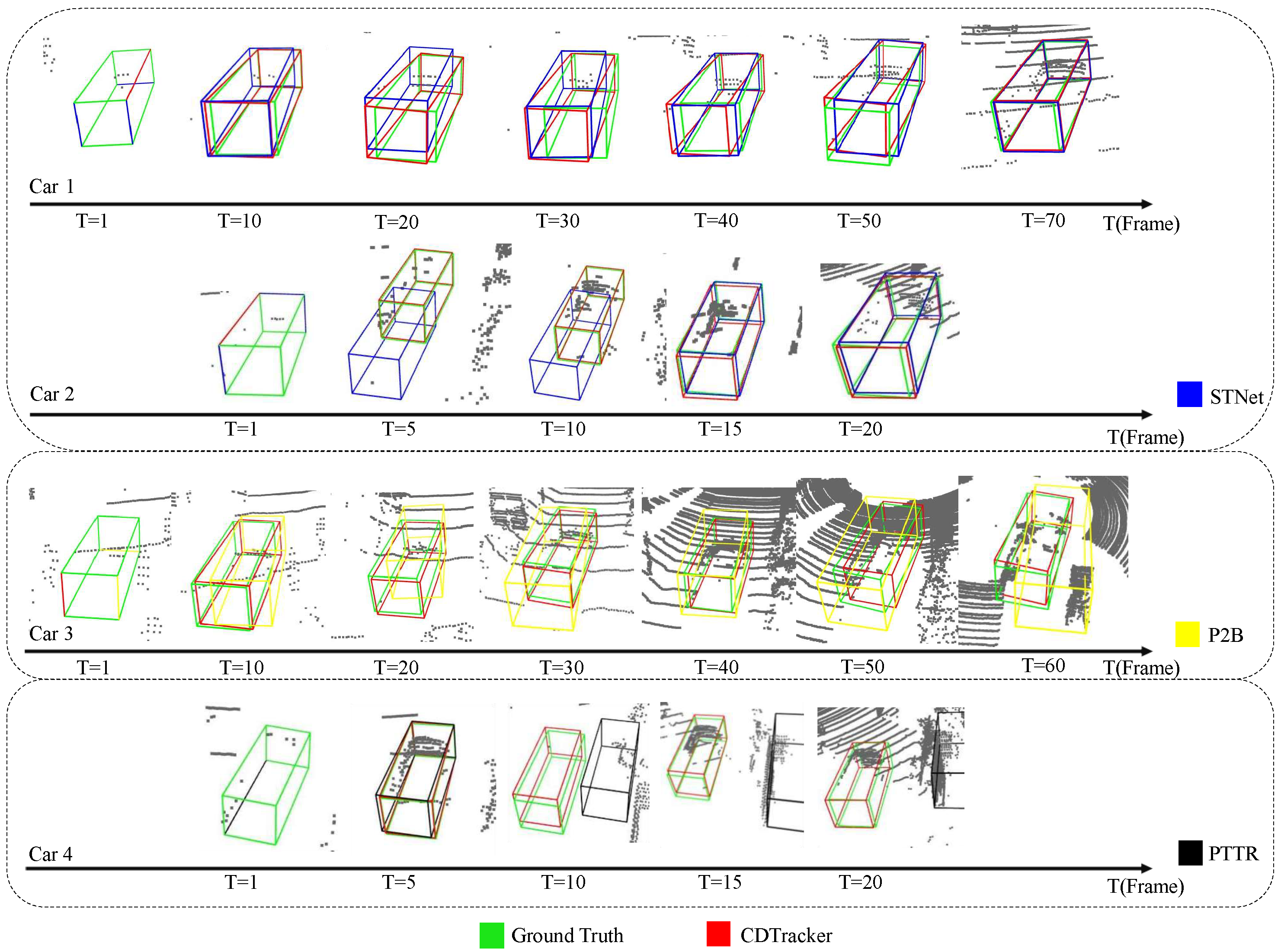
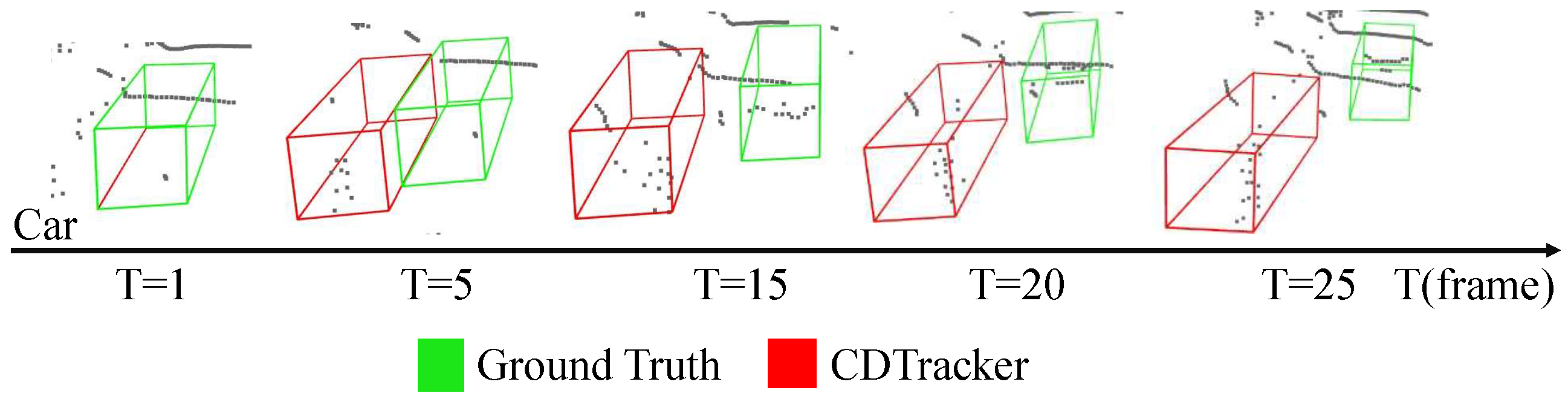
Visualization results. In order to show the tracking effect of the network, some visualization results of our network are shown in this section and some visualization results are shown in Figure 3. The visualization results show that most tracking results are very close to the ground truth bounding box, which is a very intuitive demonstration of the effectiveness of our network for single-object tracking tasks. The tracking results are also visualized and compared with those of STNet. As shown in Figure 3, it is obvious that our network tracks better than the baseline network at T = 20 frames of car 1 and T = 10 frames of car 2. Therefore, when the number of point clouds is small, the tracking effect of this network is better and more robust. When the number of point clouds is larger and the object shape is more complete, the performance of our network is similar to that of the baseline network. To further show the tracking effectiveness of our network, a partial comparison of the tracking results with PTTR and P2B is added, as shown in Figure 3. Compared with PTTR and P2B, our network has better stability in some cases.
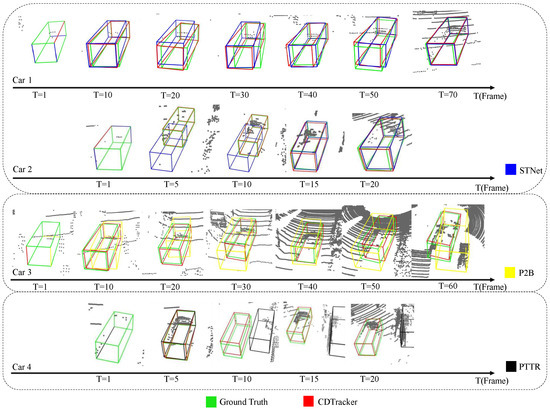
Figure 3.
Partial visualization of comparison results between our CDTracker (red) and STNet (blue), PTTR (black), and P2B (yellow). Our CDTracker is more robust in the case of sparse point clouds.
4.3. Ablation Study
In this section, the effectiveness of two designs (coarse feature matching based on cosine similarity and relatively dense sampling) are ablated separately to verify the boosting of the baseline network, and the results are shown in Table 3. The experimental results show that both the coarse feature matching based on cosine similarity and the relatively dense sampling introduced in this paper improve the tracking performance of the network. The most significant improvement is observed when both modules are added at the same time.
Table 3.
Ablation studies on Design 1 (coarse feature matching), Design 2 (relatively dense sampling), the number of retained points M.
To analyze the impact of the feature dimension on the experimental results, we conducted ablation experiments on different values of C (C = 16, 32, 64). The results are shown in Table 4. The experiments show that the best effect is achieved when the feature dimension is 32, the result is relatively poor when the feature dimension is 16, and while the results with a dimension of 64 are similar to those of 32, the training speed decreases due to the increased number of parameters. Therefore, a feature dimension of 32 is the best choice to balance accuracy and efficiency.
Table 4.
Influence of different feature dimensions, C, after the backbone of the car category for the KITTI dataset.
We also conduct ablation experiments on the number of retained points in relatively dense sampling, using and , respectively. The experimental results for the car category are 66.1%/77.9% and 71.7%/83.1%, respectively. As shown in Table 3, the tracking results improve with a higher number of retained points, as the sparsity of the point cloud remains one of the main issues causing inaccurate tracking. Retaining more points enhances the relative density of the target points and alleviates the point cloud sparsity problem. In addition, retaining some key background points also contributes to ensuring tracking accuracy. When the number of retained points is small, it often results in a scenario where most of these points are foreground points with only a few being background points, leading to suboptimal tracking results.
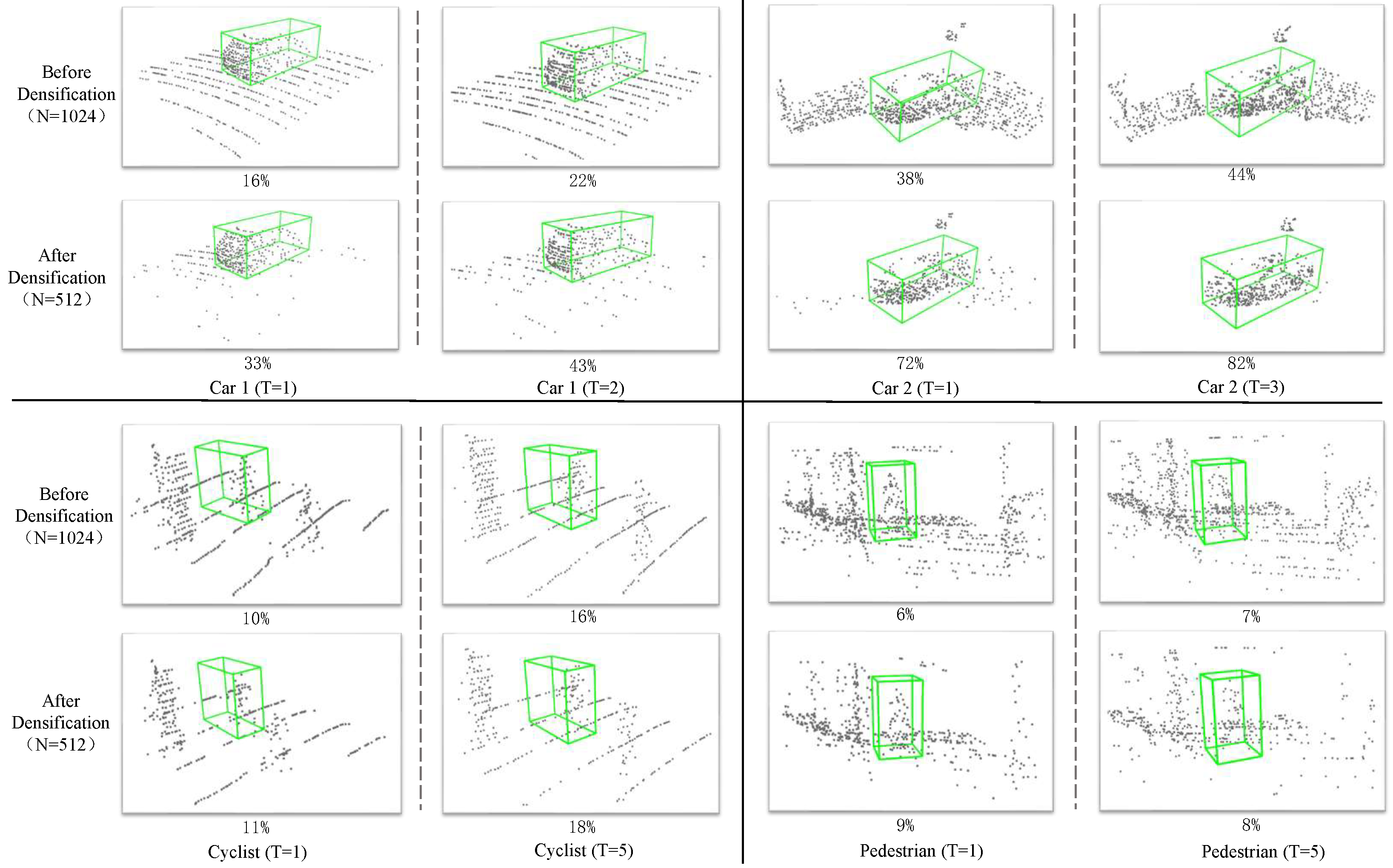
In the following, we also visualize the retained points before and after sampling for some objects with the number of retained points . Visual observations and calculations of the occupation ratio reveal that relatively dense sampling can retain more target points, thus increasing the relative density of these points and providing more favorable information for subsequent target localization. Specifically, as shown in Figure 4, when the target object is a car, there is a more obvious target point retention (the ratios of positive points increase from 38% and 22% to 72% and 43%, respectively). When the target objects are cyclists and pedestrians, the ratios of positive points increase from 10% and 6% to 11% and 9%, respectively. Even though there are more interfering objects nearby, there is still a slight increase, which visually verifies the effectiveness of this module.
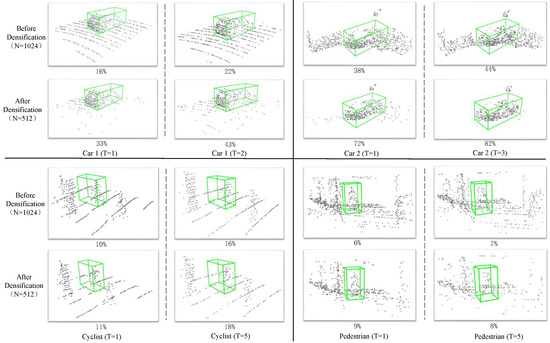
Figure 4.
Visualization of the retained points before and after densification. We show the retained points before and after densification with and , respectively. The relatively dense sampling allows the target points to become relatively dense. The green bounding box represents the ground truth. The percentage in the figure represents the ratio of retained points to all sampled points. T represents the corresponding frame.
4.4. Limitations
Our network has some shortcomings. When the number of point clouds is too small, our network often fails to track the correct object, tending instead to incorrectly latch onto objects very close to the target or to surrounding noise points. As shown in Figure 5, the point cloud in the real surround frame of the first frame is very sparse, and our network incorrectly tracks to the next area where there are more point clouds. To the best of our knowledge, other models have encountered the same problem; they mentioned some failure cases in cases of extremely sparse point clouds [3,10,40], where the tracking tends to drift to background points. To address this problem, we considered some potential solutions. First, making the point cloud denser through point cloud upsampling is an intuitive approach. Additionally, using other modal information, such as 2D images, can serve as an enhancement to obtain more robust initial features.
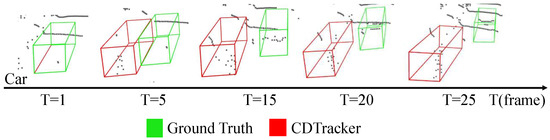
Figure 5.
Examples of failure cases. Our tracking failures mainly occur when the point clouds are extremely sparse.
5. Conclusions
In this paper, we design a coarse-to-fine feature matching module to match the features of the template and the search area. Unlike previous methods that only used cosine similarity or an attention mechanism, we apply both methods to perform feature matching in a coarse-to-fine way, which enhances the robustness of feature matching and alleviates tracking failures from abrupt appearance changes. In addition, to address the problem of inaccurate tracking results caused by sparse point clouds, we introduce the relatively dense sampling module based on point cloud segmentation, which densifies the target points by segmenting the foreground points and background points. Experiments on KITTI and Waymo verify the effectiveness of our CDTracker and each design. But when the point cloud is too sparse, the network may mislocate the nearby interfering objects and fail to track the target correctly. In the future, we will continue to study related problems and explore more effective solutions.
Author Contributions
Methodology, Y.Z.; Software, C.P. and Y.Q.; Formal analysis, Y.Z.; Investigation, C.P.; Data curation, C.P.; Writing—original draft, M.N.; Writing—review & editing, Y.Q.; Visualization, X.W.; Supervision, J.Y.; Funding acquisition, M.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China, grant number 92367301, 92267201, 52275493.
Data Availability Statement
Data available on request due to restrictions. The data presented in this study are available on request from the corresponding author due to the commercial confidentiality involved.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Zheng, C.; Yan, X.; Zhang, H.; Wang, B.; Cheng, S.; Cui, S.; Li, Z. Beyond 3d siamese tracking: A motion-centric paradigm for 3d single object tracking in point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8111–8120. [Google Scholar]
- Giancola, S.; Zarzar, J.; Ghanem, B. Leveraging shape completion for 3d siamese tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1359–1368. [Google Scholar]
- Qi, H.; Feng, C.; Cao, Z.; Zhao, F.; Xiao, Y. P2b: Point-to-box network for 3d object tracking in point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6329–6338. [Google Scholar]
- Zheng, C.; Yan, X.; Gao, J.; Zhao, W.; Zhang, W.; Li, Z.; Cui, S. Box-aware feature enhancement for single object tracking on point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 13199–13208. [Google Scholar]
- Zhou, C.; Luo, Z.; Luo, Y.; Liu, T.; Pan, L.; Cai, Z.; Zhao, H.; Lu, S. Pttr: Relational 3d point cloud object tracking with transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8531–8540. [Google Scholar]
- Shan, J.; Zhou, S.; Fang, Z.; Cui, Y. Ptt: Point-track-transformer module for 3d single object tracking in point clouds. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 1310–1316. [Google Scholar]
- Hui, L.; Wang, L.; Cheng, M.; Xie, J.; Yang, J. 3D Siamese voxel-to-BEV tracker for sparse point clouds. Adv. Neural Inf. Process. Syst. 2021, 34, 28714–28727. [Google Scholar]
- Hui, L.; Wang, L.; Tang, L.; Lan, K.; Xie, J.; Yang, J. 3d siamese transformer network for single object tracking on point clouds. In Computer Vision–ECCV 2022, Proceedings of the 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part II; Springer: Cham, Switzerland, 2022; pp. 293–310. [Google Scholar]
- Zhao, K.; Zhao, H.; Wang, Z.; Peng, J.; Hu, Z. Object Preserving Siamese Network for Single Object Tracking on Point Clouds. arXiv 2023, arXiv:2301.12057. [Google Scholar] [CrossRef]
- Xu, T.X.; Guo, Y.C.; Lai, Y.K.; Zhang, S.H. CXTrack: Improving 3D point cloud tracking with contextual information. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1084–1093. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in Neural Information Processing Systems; MIT: Cambridge, MA, USA, 2017; Volume 30. [Google Scholar]
- Qi, C.R.; Litany, O.; He, K.; Guibas, L.J. Deep hough voting for 3d object detection in point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9277–9286. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30.
- Luo, Z.; Zhou, C.; Pan, L.; Zhang, G.; Liu, T.; Luo, Y.; Zhao, H.; Liu, Z.; Lu, S. Exploring Point-BEV Fusion for 3D Point Cloud Object Tracking with Transformer. arXiv 2022, arXiv:2208.05216. [Google Scholar] [CrossRef] [PubMed]
- Nie, J.; He, Z.; Yang, Y.; Gao, M.; Zhang, J. Glt-t: Global-local transformer voting for 3d single object tracking in point clouds. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 1957–1965. [Google Scholar]
- Nie, J.; He, Z.; Yang, Y.; Bao, Z.; Gao, M.; Zhang, J. OSP2B: One-Stage Point-to-Box Network for 3D Siamese Tracking. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI 2023, Macao, China, 19–25 August 2023; pp. 1285–1293. [Google Scholar]
- Xia, Y.; Wu, Q.; Li, W.; Chan, A.B.; Stilla, U. A lightweight and detector-free 3d single object tracker on point clouds. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5543–5554. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Natali, M.; Biasotti, S.; Patanè, G.; Falcidieno, B. Graph-based representations of point clouds. Graph. Model. 2011, 73, 151–164. [Google Scholar] [CrossRef]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Chen, R.; Wu, J.; Luo, Y.; Xu, G. PointMM: Point Cloud Semantic Segmentation CNN under Multi-Spatial Feature Encoding and Multi-Head Attention Pooling. Remote Sens. 2024, 16, 1246. [Google Scholar] [CrossRef]
- Shi, M.; Zhang, F.; Chen, L.; Liu, S.; Yang, L.; Zhang, C. Position-Feature Attention Network-Based Approach for Semantic Segmentation of Urban Building Point Clouds from Airborne Array Interferometric SAR. Remote Sens. 2024, 16, 1141. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Chen, X.; Li, D.; Liu, M.; Jia, J. CNN and Transformer Fusion for Remote Sensing Image Semantic Segmentation. Remote Sens. 2023, 15, 4455. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Quan, H.; Lai, H.; Gao, G.; Ma, J.; Li, J.; Chen, D. Pairwise CNN-Transformer Features for Human–Object Interaction Detection. Entropy 2024, 26, 205. [Google Scholar] [CrossRef] [PubMed]
- Gong, H.; Mu, T.; Li, Q.; Dai, H.; Li, C.; He, Z.; Wang, W.; Han, F.; Tuniyazi, A.; Li, H.; et al. Swin-transformer-enabled YOLOv5 with attention mechanism for small object detection on satellite images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8126–8135. [Google Scholar]
- Yang, J.; Pan, Z.; Liu, Y.; Niu, B.; Lei, B. Single object tracking in satellite videos based on feature enhancement and multi-level matching strategy. Remote Sens. 2023, 15, 4351. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16259–16268. [Google Scholar]
- Estrella-Ibarra, L.F.; León-Cuevas, A.d.; Tovar-Arriaga, S. Nested Contrastive Boundary Learning: Point Transformer Self-Attention Regularization for 3D Intracranial Aneurysm Segmentation. Technologies 2024, 12, 28. [Google Scholar] [CrossRef]
- Mao, J.; Xue, Y.; Niu, M.; Bai, H.; Feng, J.; Liang, X.; Xu, H.; Xu, C. Voxel transformer for 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3164–3173. [Google Scholar]
- Pan, X.; Xia, Z.; Song, S.; Li, L.E.; Huang, G. 3d object detection with pointformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7463–7472. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Kristan, M.; Matas, J.; Leonardis, A.; Vojíř, T.; Pflugfelder, R.; Fernandez, G.; Nebehay, G.; Porikli, F.; Čehovin, L. A novel performance evaluation methodology for single-target trackers. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2137–2155. [Google Scholar] [CrossRef]
- Yang, Y.; Deng, Y.; Nie, J.; Zhang, J. BEVTrack: A Simple Baseline for Point Cloud Tracking in Bird’s-Eye-View. arXiv 2023, arXiv:2309.02185. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).