
A Small-Object Detection Model Based on Improved YOLOv8s for UAV Image Scenarios



Abstract
:1. Introduction
2. Related Work
2.1. Advances in Object Detection
2.2. UAV Object Detection
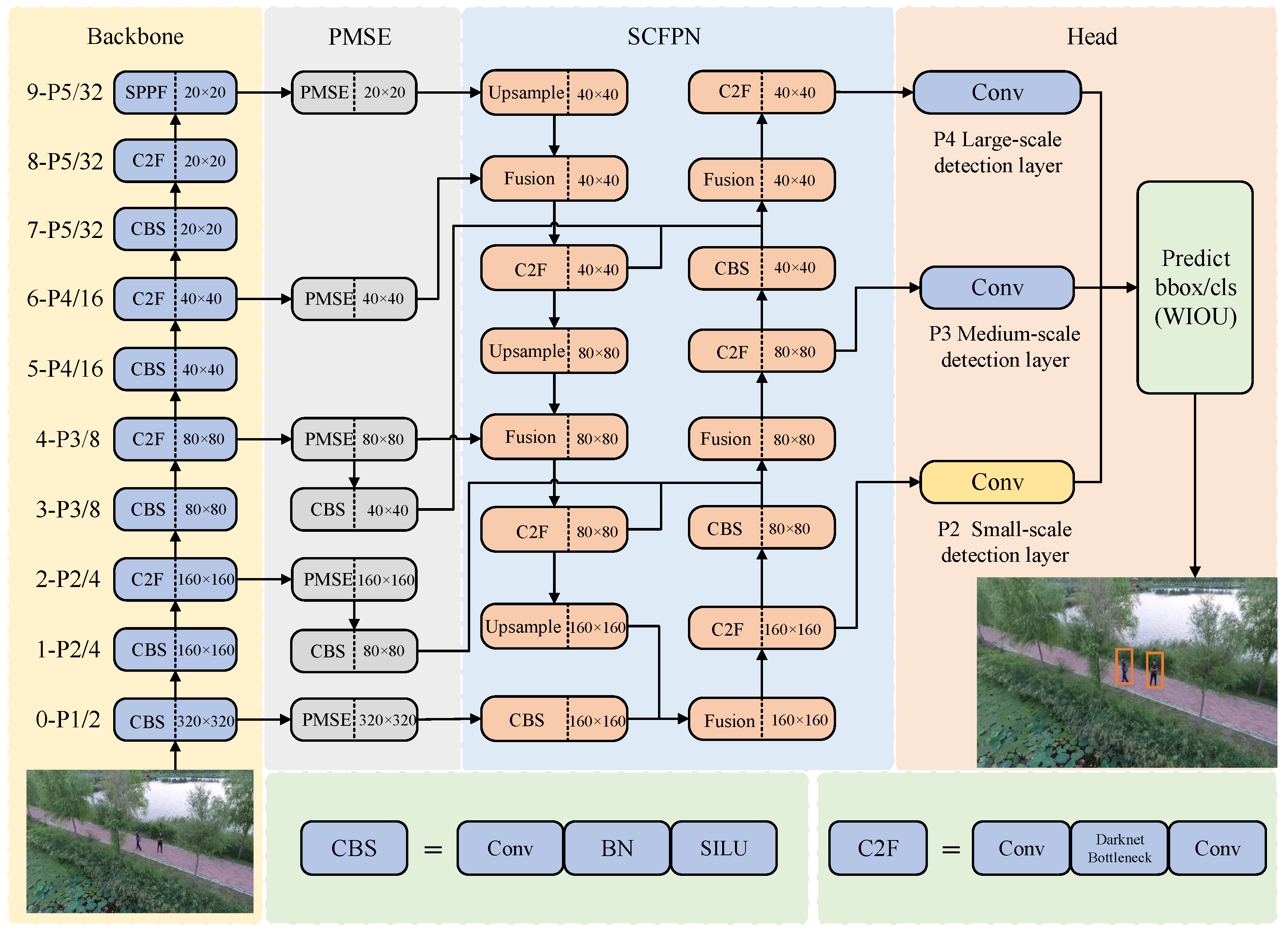
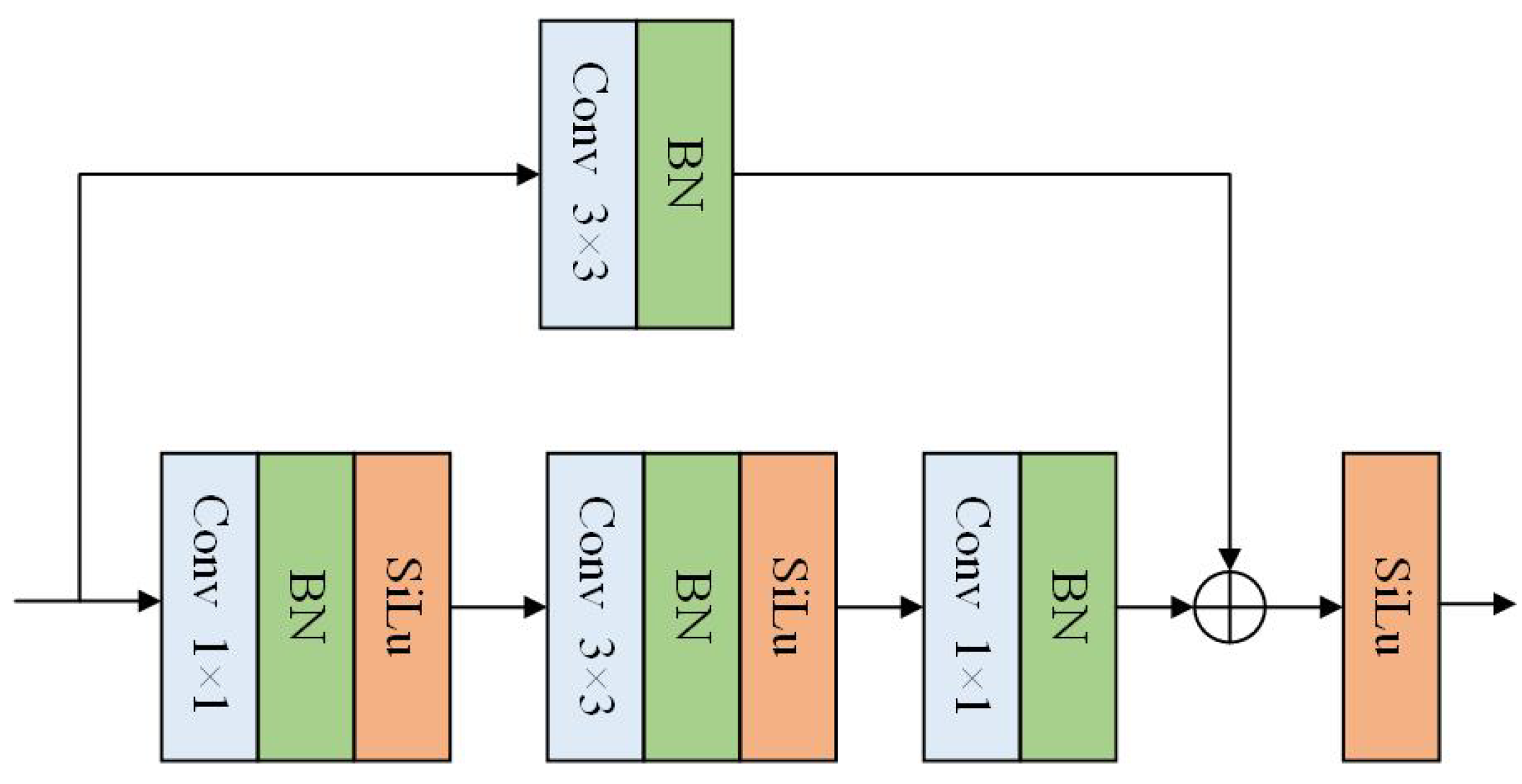
3. Proposed UAV Object Detection Model
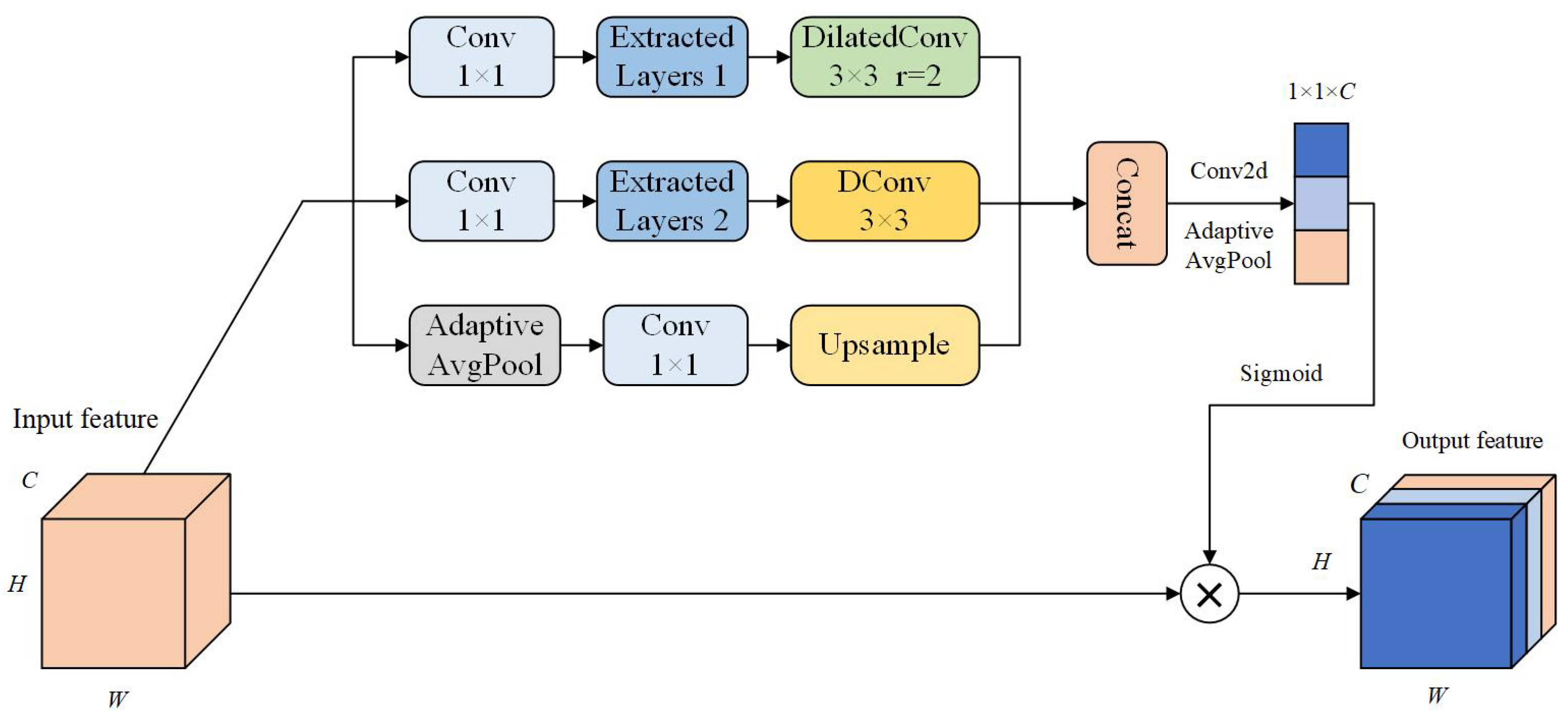
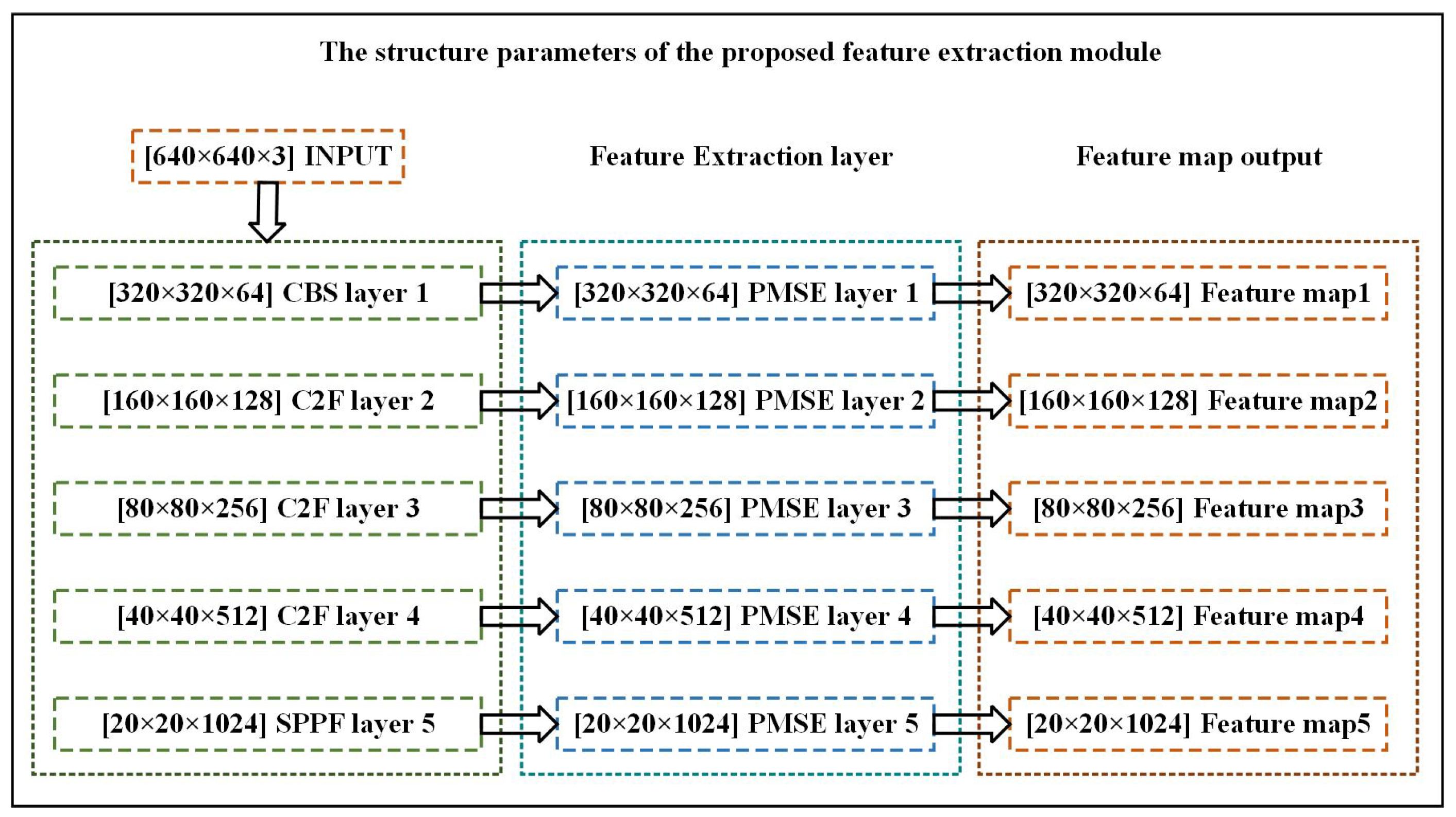
3.1. The Proposed PMSE Module
3.2. The Proposed SCFPN Module
3.3. The Loss Function
4. Experiments
4.1. Datasets and Metrics
4.2. Experimental Settings and Implementation Details
4.3. Comparison Experiments
5. Discussion
5.1. About the SCFPN Structure
5.2. About Different Detection Layers
5.3. Ablation Experiments for the Proposed Modules
5.4. Qualitative Result Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tang, G.; Ni, J.; Zhao, Y.; Gu, Y.; Cao, W. A Survey of Object Detection for UAVs Based on Deep Learning. Remote Sens. 2024, 16, 149. [Google Scholar] [CrossRef]
- Bouguettaya, A.; Zarzour, H.; Kechida, A.; Taberkit, A.M. Vehicle Detection From UAV Imagery With Deep Learning: A Review. IEEE Trans. Neural Networks Learn. Syst. 2022, 33, 6047–6067. [Google Scholar] [CrossRef]
- Ni, J.; Chen, Y.; Tang, G.; Shi, J.; Cao, W.C.; Shi, P. Deep learning-based scene understanding for autonomous robots: A survey. Intell. Robot. 2023, 3, 374–401. [Google Scholar] [CrossRef]
- Bo, W.; Liu, J.; Fan, X.; Tjahjadi, T.; Ye, Q.; Fu, L. BASNet: Burned Area Segmentation Network for Real-Time Detection of Damage Maps in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5627913. [Google Scholar] [CrossRef]
- Zhu, J.; Yang, G.; Feng, X.; Li, X.; Fang, H.; Zhang, J.; Bai, X.; Tao, M.; He, Y. Detecting Wheat Heads from UAV Low-Altitude Remote Sensing Images Using Deep Learning Based on Transformer. Remote Sens. 2022, 14, 5141. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, C.; Guo, W.; Zhang, T.; Li, W. CFANet: Efficient Detection of UAV Image Based on Cross-Layer Feature Aggregation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5608911. [Google Scholar] [CrossRef]
- Sun, Y.; Shao, Z.; Cheng, G.; Huang, X.; Wang, Z. Road and Car Extraction Using UAV Images via Efficient Dual Contextual Parsing Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5632113. [Google Scholar] [CrossRef]
- Zhao, M.; Li, W.; Li, L.; Wang, A.; Hu, J.; Tao, R. Infrared Small UAV Target Detection via Isolation Forest. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5004316. [Google Scholar] [CrossRef]
- Yang, Y.; Yang, F.; Sun, L.; Xiang, T.; Lv, P. Echoformer: Transformer Architecture Based on Radar Echo Characteristics for UAV Detection. IEEE Sens. J. 2023, 23, 8639–8653. [Google Scholar] [CrossRef]
- Deng, A.; Han, G.; Chen, D.; Ma, T.; Liu, Z. Slight Aware Enhancement Transformer and Multiple Matching Network for Real-Time UAV Tracking. Remote Sens. 2023, 15, 2857. [Google Scholar] [CrossRef]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards balanced learning for object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; Volume 2019, pp. 821–830. [Google Scholar]
- Wang, X.; Wang, A.; Yi, J.; Song, Y.; Chehri, A. Small Object Detection Based on Deep Learning for Remote Sensing: A Comprehensive Review. Remote Sens. 2023, 15, 3265. [Google Scholar] [CrossRef]
- Chen, Y.; Ni, J.; Tang, G.; Cao, W.; Yang, S.X. An improved dense-to-sparse cross-modal fusion network for 3D object detection in RGB-D images. Multimed. Tools Appl. 2023, in press. [CrossRef]
- Liu, H.; Sun, F.; Gu, J.; Deng, L. SF-YOLOv5: A Lightweight Small Object Detection Algorithm Based on Improved Feature Fusion Mode. Sensors 2022, 22, 5817. [Google Scholar] [CrossRef] [PubMed]
- Qiu, Z.; Ma, Y.; Fan, F.; Huang, J.; Wu, L.; Du, Y. Improved DBSCAN for Infrared Cluster Small Target Detection. IEEE Geosci. Remote Sens. Lett. 2023, 20, 5511905. [Google Scholar] [CrossRef]
- Zhou, Y.; Chen, S.; Zhao, J.; Yao, R.; Xue, Y.; Saddik, A.E. CLT-Det: Correlation Learning Based on Transformer for Detecting Dense Objects in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4708915. [Google Scholar] [CrossRef]
- Fang, H.; Xia, M.; Zhou, G.; Chang, Y.; Yan, L. Infrared Small UAV Target Detection Based on Residual Image Prediction via Global and Local Dilated Residual Networks. IEEE Geosci. Remote Sens. Lett. 2023, 19, 733–738. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; Volume 2015, pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Ni, J.; Chen, Y.; Chen, Y.; Zhu, J.; Ali, D.; Cao, W. A Survey on Theories and Applications for Self-Driving Cars Based on Deep Learning Methods. Appl. Sci. 2020, 10, 2749. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the Proceedings—30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; Voume 2017, pp. 936–944. [Google Scholar]
- Ni, J.; Shen, K.; Chen, Y.; Yang, S.X. An Improved SSD-Like Deep Network-Based Object Detection Method for Indoor Scenes. IEEE Trans. Instrum. Meas. 2023, 72, 5006915. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; Volume 2017, pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 2016, pp. 779–788. [Google Scholar]
- Ni, J.; Shen, K.; Chen, Y.; Cao, W.; Yang, S.X. An Improved Deep Network-Based Scene Classification Method for Self-Driving Cars. IEEE Trans. Instrum. Meas. 2022, 71, 5001614. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Chen, L.; Shi, W.; Deng, D. Improved yolov3 based on attention mechanism for fast and accurate ship detection in optical remote sensing images. Remote Sens. 2021, 13, 660. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16X16 words: Transformers for image recognition at scale. In Proceedings of the ICLR 2021—9th International Conference on Learning Representations, Virtual Online, 3–7 May 2021. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 548–558. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Volume 12346 LNCS, pp. 213–229. [Google Scholar]
- He, L.; Liao, K.; Li, Y.; Li, B.; Zhang, J.; Wang, Y.; Lu, L.; Jian, S.; Qin, R.; Fu, X. Extraction of Tobacco Planting Information Based on UAV High-Resolution Remote Sensing Images. Remote Sens. 2024, 16, 359. [Google Scholar] [CrossRef]
- Yi, H.; Liu, B.; Zhao, B.; Liu, E. Small Object Detection Algorithm Based on Improved YOLOv8 for Remote Sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 1734–1747. [Google Scholar] [CrossRef]
- Ye, T.; Qin, W.; Zhao, Z.; Gao, X.; Deng, X.; Ouyang, Y. Real-Time Object Detection Network in UAV-Vision Based on CNN and Transformer. IEEE Trans. Instrum. Meas. 2023, 72, 2505713. [Google Scholar] [CrossRef]
- Xu, S.; Ji, Y.; Wang, G.; Jin, L.; Wang, H. GFSPP-YOLO: A Light YOLO Model Based on Group Fast Spatial Pyramid Pooling. In Proceedings of the ICICN 2023–2023 IEEE 11th International Conference on Information, Communication and Networks, Xi’an, China, 11–17 August 2023; pp. 733–738. [Google Scholar]
- Yang, Y.; Gao, X.; Wang, Y.; Song, S. VAMYOLOX: An Accurate and Efficient Object Detection Algorithm Based on Visual Attention Mechanism for UAV Optical Sensors. IEEE Sens. J. 2023, 23, 11139–11155. [Google Scholar] [CrossRef]
- Liu, W.; Quijano, K.; Crawford, M.M. YOLOv5-Tassel: Detecting Tassels in RGB UAV Imagery With Improved YOLOv5 Based on Transfer Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8085–8094. [Google Scholar] [CrossRef]
- Ye, T.; Zhang, J.; Li, Y.; Zhang, X.; Zhao, Z.; Li, Z. CT-Net: An Efficient Network for Low-Altitude Object Detection Based on Convolution and Transformer. IEEE Trans. Instrum. Meas. 2022, 71, 2507412. [Google Scholar] [CrossRef]
- Shen, L.; Lang, B.; Song, Z. CA-YOLO: Model Optimization for Remote Sensing Image Object Detection. IEEE Access 2023, 11, 64769–64781. [Google Scholar] [CrossRef]
- Xue, H.; Ma, J.; Cai, Z.; Fu, J.; Guo, F.; Weng, W.; Dong, Y.; Zhang, Z. NLFA: A Non Local Fusion Alignment Module for Multi-Scale Feature in Object Detection. In Proceedings of the 3rd International Symposium on Automation, Mechanical and Design Engineering, Beijing, China, 16–18 December 2023; Volume 138, pp. 155–173. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Sun, S.; Mo, B.; Xu, J.; Li, D.; Zhao, J.; Han, S. Multi-YOLOv8: An infrared moving small object detection model based on YOLOv8 for air vehicle. Neurocomputing 2024, 588, 127685. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Virtual, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Wang, Y.; Zou, H.; Yin, M.; Zhang, X. SMFF-YOLO: A Scale-Adaptive YOLO Algorithm with Multi-Level Feature Fusion for Object Detection in UAV Scenes. Remote Sens. 2023, 15, 4580. [Google Scholar] [CrossRef]
- Zhao, D.; Shao, F.; Liu, Q.; Yang, L.; Zhang, H.; Zhang, Z. A Small Object Detection Method for Drone-Captured Images Based on Improved YOLOv7. Remote Sens. 2024, 16, 1002. [Google Scholar] [CrossRef]
- Wang, K.; Wei, Z. YOLO V4 with hybrid dilated convolution attention module for object detection in the aerial dataset. Int. J. Remote Sens. 2022, 43, 1323–1344. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the IEEE International Conference on Computer Vision, Cambridge, MA, USA, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Wu, Q.; Li, Y.; Huang, W.; Chen, Q.; Wu, Y. C3TB-YOLOv5: Integrated YOLOv5 with transformer for object detection in high-resolution remote sensing images. Int. J. Remote Sens. 2024, 45, 2622–2650. [Google Scholar] [CrossRef]
- Ni, J.; Zhang, Z.; Shen, K.; Tang, G.; Yang, S.X. An improved deep network-based RGB-D semantic segmentation method for indoor scenes. Int. J. Mach. Learn. Cybern. 2024, 15, 589–604. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A Small-Object-Detection Model Based on Improved YOLOv8 for UAV Aerial Photography Scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Xiong, G.; Qi, J.; Wang, M.; Wu, C.; Sun, H. GCGE-YOLO: Improved YOLOv5s Algorithm for Object Detection in UAV Images. In Proceedings of the Chinese Control Conference, CCC, Tianjin, China, 24–26 July 2023; pp. 7723–7728. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9756–9765. [Google Scholar]
- Wang, J.; Liu, W.; Zhang, W.; Liu, B. LV-YOLOv5: A light-weight object detector of Vit on Drone-captured Scenarios. In Proceedings of the International Conference on Signal Processing Proceedings, ICSP, Beijing, China, 21–24 October 2022; Volume 1, pp. 178–183. [Google Scholar]
- Chen, L.; Liu, C.; Li, W.; Xu, Q.; Deng, H. DTSSNet: Dynamic Training Sample Selection Network for UAV Object Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5902516. [Google Scholar] [CrossRef]
- Liu, J.; Zheng, K.; Liu, X.; Xu, P.; Zhou, Y. SDSDet: A real-time object detector for small, dense, multi-scale remote sensing objects. Image Vis. Comput. 2024, 142, 104898. [Google Scholar] [CrossRef]
- Yang, Q.; Cao, L.; Huang, C.; Song, Q.; Yuan, C. A2Net: An Anchor-free Alignment Network for Oriented Object Detection in Remote Sensing Images. IEEE Access 2024, 12, 42017–42027. [Google Scholar] [CrossRef]
- Wang, G.; Zhuang, Y.; Chen, H.; Liu, X.; Zhang, T.; Li, L.; Dong, S.; Sang, Q. FSoD-Net: Full-Scale Object Detection from Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5602918. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning roi transformer for oriented object detection in aerial images. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; Volume 2019, pp. 2844–2853. [Google Scholar]
- Cao, X.; Zhang, Y.; Lang, S.; Gong, Y. Swin-Transformer-Based YOLOv5 for Small-Object Detection in Remote Sensing Images. Sensors 2023, 23, 3634. [Google Scholar] [CrossRef] [PubMed]
- Zeng, S.; Yang, W.; Jiao, Y.; Geng, L.; Chen, X. SCA-YOLO: A new small object detection model for UAV images. Vis. Comput. 2024, 40, 1787–1803. [Google Scholar] [CrossRef]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic Feature Pyramid Network for Object Detection. In Proceedings of the Conference Proceedings—IEEE International Conference on Systems, Man and Cybernetics, Banff, AB, Canada, 1–4 October 2023; pp. 2184–2189. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network parameters | Learning rate | 0.0005 |
| Weight decay | 0.0005 | |
| Batch size | 8 | |
| Workers | 8 | |
| Momentum | 0.9 | |
| Image size | ||
| Computer configurations | Operating System | Ubuntu 20.04 |
| Cpu | 2.10GHZ | |
| Gpu | GeForce RTX 3090 | |
| RAM | 24.0 GB |
| Models | Parameters (M) | FLOPs (G) | ||
|---|---|---|---|---|
| SSD [51] | 23.9 | 13.1 | 24.5 | 87.9 |
| RetinaNet [52] | 27.3 | 15.5 | 19.8 | 93.7 |
| ATSS [56] | 31.7 | 18.6 | 10.3 | 57.0 |
| Faster-RCNN [19] | 33.2 | 17.0 | 41.2 | 207.1 |
| GCGE-YOLO [55] | 34.1 | 19.2 | 4.5 | 10.8 |
| YOLOv5s [37] | 35.4 | 20.5 | 9.1 | 23.8 |
| Swin Transformer [29] | 35.6 | 20.6 | 34.2 | 44.5 |
| YOLOv8s [53] | 36.4 | 21.6 | 11.1 | 28.5 |
| C3TB-YOLOv5 [49] | 38.3 | 22.0 | 8.0 | 19.7 |
| TPH-YOLO [48] | 39.3 | 23.6 | 51.5 | 138.1 |
| DTSSNet [58] | 39.9 | 24.2 | 10.1 | 50.4 |
| YOLOv9 [54] | 43.4 | 26.5 | 51.0 | 239.0 |
| LV-YOLOv5 [57] | 41.7 | 25.6 | 36.6 | 38.8 |
| Ours | 47.1 | 28.7 | 10.2 | 64.9 |
| Models | Parameters (M) | FLOPs (G) | ||
|---|---|---|---|---|
| Faster-RCNN [19] | 42.0 | 26.2 | 41.2 | 207.1 |
| SSD [51] | 52.4 | 32.3 | 24.5 | 87.9 |
| RetinaNet [52] | 61.6 | 38.7 | 19.8 | 93.7 |
| SDS-Det [59] | 67.5 | 43.0 | 4.9 | 11.3 |
| A2-Net [60] | 69.5 | / | 9.6 | 50.3 |
| RoI-Transformer [62] | 69.6 | / | / | / |
| YOLOv5s [37] | 70.2 | 46.5 | 9.1 | 23.8 |
| YOLOv8s [53] | 70.7 | 46.7 | 11.1 | 28.5 |
| Swin-YOLOv5 [63] | 74.7 | / | / | / |
| FSoD-Net [61] | 75.3 | / | 232.2 | 165.0 |
| SCA-YOLO [64] | 75.8 | 50.7 | 47.9 | 126.4 |
| Ours | 74.2 | 49.7 | 10.2 | 64.9 |
| Models | Parameters (M) | ||
|---|---|---|---|
| PA-FPN [41] | 36.4 | 21.6 | 11.1 |
| BiFPN [43] | 36.7 | 21.9 | 7.4 |
| AFPN [65] | 34.6 | 20.3 | 7.1 |
| SCFPN (Ours) | 41.9 | 25.3 | 7.6 |
| Baseline | P2 | P3 | P4 | P5 | Parameters (M) | FLOPs (G) | ||
|---|---|---|---|---|---|---|---|---|
| ✓ | ✓ | 36.5 | 21.6 | 9.4 | 25.6 | |||
| ✓ | ✓ | ✓ | 36.5 | 21.7 | 10.0 | 27.6 | ||
| ✓ | ✓ | ✓ | ✓ | 36.4 | 21.6 | 11.1 | 28.5 | |
| ✓ | ✓ | ✓ | 41.1 | 24.6 | 9.5 | 34.9 | ||
| ✓ | ✓ | ✓ | ✓ | 41.3 | 24.8 | 9.7 | 36.5 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 41.3 | 24.8 | 10.6 | 37.0 |
| Baseline | PMSE | SCFPN | WIOU | Parameters (M) | FLOPs (G) | ||
|---|---|---|---|---|---|---|---|
| ✓ | 36.4 | 21.6 | 11.1 | 28.5 | |||
| ✓ | ✓ | 37.6 | 22.4 | 11.9 | 31.7 | ||
| ✓ | ✓ | 45.6 | 27.8 | 7.4 | 59.1 | ||
| ✓ | ✓ | 38.2 | 22.4 | 11.1 | 28.5 | ||
| ✓ | ✓ | ✓ | ✓ | 39.1 | 23.2 | 11.9 | 31.7 |
| ✓ | ✓ | ✓ | 46.4 | 28.3 | 10.2 | 64.9 | |
| ✓ | ✓ | ✓ | 46.6 | 28.4 | 7.4 | 59.1 | |
| ✓ | ✓ | ✓ | ✓ | 47.1 | 28.7 | 10.2 | 64.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ni, J.; Zhu, S.; Tang, G.; Ke, C.; Wang, T. A Small-Object Detection Model Based on Improved YOLOv8s for UAV Image Scenarios. Remote Sens. 2024, 16, 2465. https://doi.org/10.3390/rs16132465
Ni J, Zhu S, Tang G, Ke C, Wang T. A Small-Object Detection Model Based on Improved YOLOv8s for UAV Image Scenarios. Remote Sensing. 2024; 16(13):2465. https://doi.org/10.3390/rs16132465
Chicago/Turabian StyleNi, Jianjun, Shengjie Zhu, Guangyi Tang, Chunyan Ke, and Tingting Wang. 2024. "A Small-Object Detection Model Based on Improved YOLOv8s for UAV Image Scenarios" Remote Sensing 16, no. 13: 2465. https://doi.org/10.3390/rs16132465
APA StyleNi, J., Zhu, S., Tang, G., Ke, C., & Wang, T. (2024). A Small-Object Detection Model Based on Improved YOLOv8s for UAV Image Scenarios. Remote Sensing, 16(13), 2465. https://doi.org/10.3390/rs16132465