Abstract
Instance segmentation of remote sensing images can not only provide object-level positioning information but also provide pixel-level positioning information. This pixel-level information annotation has a wide range of uses in the field of remote sensing, and it is of great value for environmental detection and resource management. Because optical images generally have complex terrain environments and changeable object shapes, SAR images are affected by complex scattering phenomena, and the mask quality obtained by the traditional instance segmentation method used in remote sensing images is not high. Therefore, it is a challenging task to improve the mask quality of instance segmentation in remote sensing images. Since the traditional two-stage instance segmentation method consists of backbone, neck, bbox head, and mask head, the final mask quality depends on the product of all front-end work quality. Therefore, we consider the difficulty of optical and SAR images to bring instance segmentation to the targeted improvement of the neck, bbox head, and mask head, and we propose the Context-Aggregated and SAM-Guided Network (CSNet). In this network, the plain feature fusion pyramid network (PFFPN) can generate a pyramid for the plain feature and provide a feature map of the appropriate instance scale for detection and segmentation. The network also includes a context aggregation bbox head (CABH), which uses the context information and instance information around the instance to solve the problem of missed detection and false detection in detection. The network also has a SAM-Guided mask head (SGMH), which learns by using SAM as a teacher, and uses the knowledge learned to improve the edge of the mask. Experimental results show that CSNet significantly improves the quality of masks generated under optical and SAR images, and CSNet achieves 5.1% and 3.2% AP increments compared with other SOTA models.
1. Introduction
In the field of remote sensing, the instance segmentation task is becoming one of the important and basic research directions, which aims to realize category recognition, fine positioning, and shape determination of each instance object in the image. Specifically, instance segmentation can not only achieve accurate identification of instance categories but also complete the accurate segmentation of pixels in the image region where the instance is located. Academically, remote sensing instance segmentation has become a very important research topic. It has been widely used to obtain object pixel-level information in remote sensing images, especially from optical images and synthetic aperture radar (SAR) images. It also has good results in specific tasks such as building extraction [1,2,3], ship extraction [4,5,6], and aircraft extraction [7]. In practical applications, the study of instance segmentation will provide important help for environmental detection [8,9], ocean management [10,11], disaster detection [12], urban planning [13], and other affairs.
The existing instance segmentation methods can be divided into two methods: top-down (first detection and then segmentation) and bottom-up (first segmentation and then detection). The main idea of the top-down method is to detect the object in the image first, find the horizontal bounding box where the object is located, and then predict the pixel-level mask in this bounding box. The main idea of the bottom-up method is to complete the pixel-level semantic segmentation first and then pull the same instance into different instances through local similarity to segment the instance. At present, the top-down method represented by Mask R-CNN [14] has a good effect and a wide range of applications in instance segmentation. The main framework of this paper will also use the top-down method to detect the location of the instance first and then distinguish the foreground and background in the rectangular area of the instance.
The instance segmentation model is usually composed of a backbone feature extractor unrelated to the detection task and a set of necks and heads containing specific detection prior knowledge. For a long time, the convolutional neural network (CNN) has been used as the backbone of the instance segmentation model. In recent years, Vision Transformers (ViT) [15] has gradually replaced CNN as a backbone for tasks in the visual field and has achieved better performance than CNN. However, unlike CNN, ViT is a plain, non-hierarchical structure. The neck of traditional feature pyramid networks (FPN) [16] design cannot be applied to ViT. It is urgent to explore new neck designs so that ViT can be better applied in detection and segmentation tasks. Especially for remote sensing instance segmentation, the object in the remote sensing image presents the characteristics of uneven distribution and different sizes. The new neck can construct a feature pyramid to facilitate the downstream task of searching the instance from different scales and obtaining the deep features of the instance.
In the instance segmentation framework, the head is divided into a bbox head and a mask head. The bbox head is used to determine the instance category and determine the rectangular position of the instance; the mask head is used to achieve pixel-level segmentation in the rectangular region after the rectangular position is determined. However, the optical image is complex, and the SAR image has complex scattering and noise characteristics. These factors make the bbox head prone to missed and false detection when detecting instances and lead to inaccurate positioning of rectangular boxes. Detection is the premise of segmentation. If missed or false detection, the segmentation result is meaningless; if the rectangular area is not accurate, the segmentation result will lose part of the instance. The mask head can provide instance pixel-level information, but the segmentation effect of traditional methods in remote sensing images is not good, and the mask is not continuous and complete. Most methods only achieve the improvement of indicators, and the actual effect is not satisfactory. Therefore, when the instance segmentation method designed for daily scenes is applied to the field of remote sensing, there will inevitably be a problem of performance degradation. Therefore, it is necessary to improve the traditional instance segmentation model to be more in line with the characteristics of remote sensing.
In this paper, we propose a Context-Aggregated and SAM-Guided network (CSNet) to realize instance segmentation of remote sensing images and improve mask accuracy. Our model uses the encoder of the Segment Anything Model (SAM) [17] as the backbone. SAM is a prompt-based model proposed by the Meta AI team, trained on the Segment Anything 1-Billion mask dataset (SA-1B), the largest segmentation dataset at present, to achieve powerful zero-shot generalization. The SAM model is designed and trained to be promptable so it can be migrated to new image distributions and tasks with zero shots. Due to the powerful image segmentation capabilities of SAM, it was immediately used in the fields of natural scenes, medicine, and remote sensing. SAM is a new visual model, and it is a new attempt to use the encoder of SAM as the backbone.
The SAM architecture consists of three main parts: the image encoder, the prompt encoder, and the mask decoder. The image encoder of SAM is designed based on the ViT structure. In order to enable the ViT structure to be used in the detection and segmentation framework, we designed the plain feature fusion pyramid network (PFFPN). PFFPN can extract and fuse the multi-scale information of the middle layer features of the SAM decoder to generate a feature pyramid suitable for detection and segmentation frameworks. Due to the phenomenon of missed detection and false detection in traditional detection tasks in remote sensing images, we use the context aggregation bbox head (CABH) instead of the traditional bbox head, which detects and backpropagates instances through context features and adds the context information of instances to the prediction of categories and boxes. The model also includes the SAM-Guided Mask head (SGMH), which is designed to learn the knowledge of SAM because the SAM can segment the object of interest with appropriate prompts and leverage the knowledge of SAM to optimize the boundaries of the mask and obtain a more accurate instance mask. By analyzing the shortcomings of the current remote sensing instance segmentation, improvements are proposed in the neck, bbox head, and mask head, which improve the mask accuracy of the final output from the three aspects of feature, detection, and segmentation.
The main contributions of this article are as follows:
- (1)
- The novelty of using the SAM encoder as the backbone and designing a plain feature fusion pyramid network to solve the neck design problem of the ViT structure in the detection and segmentation network. The original plain features in the ViT structure are changed into multi-scale features, and the features of different scales are fully fused and aligned to improve the accuracy of subsequent detection and segmentation;
- (2)
- The context aggregation bbox head is proposed. By introducing the object feature and the object surrounding environment feature at the same time, the context information is integrated into the traditional bbox head to improve the accuracy of object category recognition and the accuracy of the bounding box;
- (3)
- The SAM-Guided Mask Head is proposed to fully learn the segmentation results of SAM under the prompt, and the learned features are integrated into the traditional mask prediction branch to improve the accuracy of object pixel segmentation.
The organizational structure of this paper is as follows: Section 2 summarizes the related works of backbone, instance segmentation, and instance segmentation in the field of remote sensing. Section 3 describes the details of the proposed method, including PFFPN, CABH, and SGMH. Section 4 describes the experiment, including dataset description, evaluation index, experimental analysis, and experimental results. Section 5 analyzes the strengths and weaknesses of the model. Section 6 summarizes this article.
2. Related Works
2.1. Foundation Model
At present, the task of instance segmentation generally adopts the pre-training + fine-tuning paradigm: a general, task-unknown backbone is pre-trained by supervised or self-supervised training, and its structure is subsequently modified and adapted to downstream tasks by the neck. In this framework, the backbone and neck are paired. A type of backbone must have a corresponding neck to fuse and align the features.
At present, the main backbone is various forms of convolutional neural networks, among which the widely used backbones are VGGNet [18], ResNet [19], ResNeXt [20], DarkNet [21], and DenseNet [22]. These networks were originally trained on the classification dataset of ImageNet, which was not related to the segmentation task, but the deep features of the images at different scales were obtained as the network deepened. These networks are multi-level, and the features of each level are also of different scales, and the last feature of different levels is extracted to construct a set of multi-scale feature groups. However, it is not enough to obtain multi-scale feature sets, and the instance features of different scale features are not the same at different relative positions. The purpose of the design neck is to integrate information about the characteristics of different scales into each scale. In this way, the same head can be used to predict instances of different sizes during subsequent detection and segmentation. At present, the necks that are widely used with CNN as the backbone are FPN [16], PAFPN [23], DyFPN [24], HRFPN [25], BiFPN [26], and NASFPN [27]. The commonality of these necks is to fuse multi-scale feature groups to generate feature pyramids that fuse high-level semantics.
ViT is a model that applies Transformer to image classification. When the training data set is large enough, ViT usually performs better than CNN. Due to the excellent performance of ViT, people have begun to use ViT as a new backbone in the field of vision. However, the initially proposed ViT is a non-multi-scale and non-multi-level structure, so the neck and head suitable for CNN design cannot give full play to the performance of ViT as a backbone. Subsequently, many new multi-scale and multi-level Transformers structures have been proposed, such as Swin [28], MViT [29,30], and PVT [31]. These structures introduce the design idea of CNN into the Transformers structure, including hierarchical structure, convolution, pooling, sliding window, and other prior knowledge. Therefore, it is relatively simple to use these backbone replacement CNNs for object detection and instance segmentation. However, for traditional ViT, there are relatively few existing neck designs, and FPN [32] and Simple FPN [33] are more commonly used. The key to these neck designs lies in the choice of features, and the scaling of scales and other parts can be borrowed from traditional neck designs.
Due to the success of the language large model Chat-GPT [34] and GPT-4 [35], the large model has become the most popular research direction in the field of deep learning, and the visual large model has also become the focus of research. At present, SAM, DINO [36], DINOv2 [37], and CLIP [38] have become the representatives of visual large models. After training on large datasets, these models can have good performance on unknown datasets without fine-tuning. Among them, the encoder of SAM is designed based on the ViT structure. In particular, the encoder of SAM does not calculate the global attention of each block but first calculates the 14 × 14 window attention and then calculates the global attention. While reducing the amount of calculation, the local features are enhanced. Similar to the ViT structure, the SAM encoder is still a plain architecture, so it cannot directly replace the backbone of object detection and instance segmentation. With the emergence of large visual models, ViT-based models will also be more widely used, and necks for ViT need to be designed urgently so that the models can be directly used in mature instance segmentation frameworks.
2.2. Instance Segmentation
Instance segmentation is an important research direction in the field of computer vision. Instance segmentation can be considered as a combination of object detection and semantic segmentation tasks. The purpose of instance segmentation is to segment the accurate mask of the object while detecting the object of interest. The most classic work of instance segmentation is that He et al. [14] added a fully convolutional mask head based on Faster R-CNN [39] to obtain Mask R-CNN and expanded the object detection algorithm to make it have the ability of instance segmentation. At the same time, it also opened up the precedent of the top-down instance segmentation algorithm. Firstly, the region of interest of the object is generated by the region proposal network (RPN) [39] and RoIAlign [14], and then the segmentation is carried out on this basis. Based on Mask R-CNN, Huang et al. [40] added a MaskIoU head to take the instance feature and the corresponding predicted mask together to regress the mask IoU. Cai et al. [41] proposed Cascade Mask R-CNN by extending a mask head at each level on the Cascade R-CNN [42]. Due to the cascade structure of Cascade Mask R-CNN, the mask head does not have the same information interaction as the detection branch. Chen et al. [43] proposed the Hybrid Task Cascade (HTC) structure to interleave the detection branch and the mask branch. In view of the inconsistency of training test samples caused by only taking the last level of the mask branch in HTC network testing, Vu et al. [44] proposed SCNet, which retains the cascade detection structure and uses the deep residual structure to make mask prediction to ensure the consistency of sampling in the cascade network training and testing process. In order to solve the problem of low segmentation accuracy of Mask RCNN, Kirillov et al. [45] used a subdivision strategy to adaptively select a non-uniform and low-precision point set to calculate the label. The above method is a derivative method based on Mask R-CNN.
Many scholars have proposed many novel methods in the field of instance segmentation. Fang et al. [46] proposed a data augmentation method, for instance, segmentation tasks. Experiments show that this method can significantly improve the performance of instance segmentation methods. The previous methods are based on the CNN as the backbone. Based on the Mask RCNN structure, Li et al. [33] explored the ordinary, non-hierarchical visual transformer (ViT) as a backbone network for object detection and instance segmentation. Bolya et al. [47] jumped out of the framework of Mask RCNN and decomposed the instance segmentation into two parallel subtasks: generating a set of prototype masks and predicting the mask coefficients of each instance. Then, they generate the instance mask by linearly combining the prototype with the mask coefficient. Wang et al. [48] proposed SOLO, which defines the instance segmentation problem as a predictive semantic category and generates instance masks for each pixel in the feature map. Based on this, an efficient and overall instance mask representation scheme is used to dynamically segment each instance in the image [49]. Based on the FCOS [50], Tian et al. [51] did not use the instance feature as the input of the bbox head and mask head but used the dynamic instance-aware network to dynamically control the mask head to generate the mask. Fang et al. [52] proposed QueryInst, which is a query-based instance segmentation method.
The above methods are based on full supervision, and the method of instance segmentation based on weak supervision has also been explored by many scholars. SDI proposed by Khoreva et al. [53] is the first instance segmentation framework with box annotations. Similar to the semantic segmentation method, SDI also relies on the region proposal generated by MCG [54]. Then the iterative training process is used to further refine the segmentation results. BBTP proposed by Hao et al. [55] defined a box-supervised instance partition as a multi-instance learning (MIL) problem. BBTP is built on Mask R-CNN, and the positive and negative bags are sampled according to the region of interest (RoI) on the CNN feature map. Based on the Condlnst structure, Tian et al. [56] achieved a nearly fully supervised method on the coco dataset by designing the projection loss term and the pairwise affinity loss term, which was only supervised by the box. At present, Boxlnst [56] is the best weakly supervised learning method in the field of best instance segmentation.
2.3. Instance Segmentation in Remote Sensing
Many scholars have applied the instance segmentation method in computer vision to the field of remote sensing. Su et al. [57] proposed HQ-ISNet by combining HRFPN [25] and HTC [43] and first applied the network to instance segmentation of remote sensing images. Liu et al. [3] improved the instance segmentation performance by inputting multi-scale images and obtaining edges through the Sobel operator, and used them for building extraction. Liu et al. [58] applied the self-attention mechanism to the unanchored segmentation architecture to improve the segmentation accuracy of objects in high-resolution remote sensing images. Shi and Zhang [59] designed a saliency supplement module to obtain accurate remote sensing instance-level masks by embedding saliency maps into rough masks. Based on the boxlnst method, Jiang et al. [7] proposed that background restriction loss and foreground restriction loss improved the accuracy of instance segmentation of aircraft in remote sensing images. Liu et al. [60] improved the segmentation accuracy of remote sensing objects by aggregating global visual context on the feature domain, spatial domain, and instance domain. Wei et al. [5] improves the segmentation performance of ship instances in SAR images by enhancing low-level features. Fang et al. [61] introduced instance segmentation into hyperspectral image interpretation for the first time. Chen et al. [62] deal with complex objects in high-resolution remote sensing images through scale balance and category balance. Chen et al. [63] used the prompt function of SAM to apply the image segmentation ability of SAM to remote sensing instance segmentation and achieved good results.
3. Methods
In this section, we will introduce our CSNet. The framework of our model is designed based on Cascade Mask R-CNN [41]. The two-stage instance segmentation model consists of backbone, neck, bbox head, and mask head and is passed forward in this order. The backbone of our model is the image encoder of SAM, and the parameters are not updated. Therefore, if we improve the neck, bbox head, and mask head to be suitable for remote sensing image segmentation, then we will end up with better segmentation results. As shown in Figure 1 the whole framework has three important sub-modules: PFFPN, CABH, and SGMH.
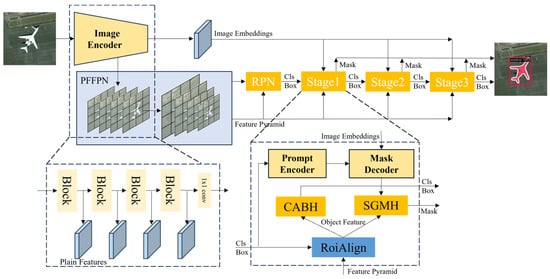
Figure 1.
Overview of the network architecture of CSNet.
The calculation process of the whole model is as follows. The image first passes through the SAM encoder. The encoder of SAM is divided into four stages by global attention. Each stage will undergo n times of sliding window self-attention and one time of global self-attention calculation. Finally, the feature after the last global attention calculation is subjected to 1 × 1 convolution to obtain image embedding. In the process of generating image embedding, the final feature of each stage is extracted to obtain plain feature groups . The plain feature groups are different from the feature pyramid obtained from the CNN structure, which has multi-scale features, and the feature scale of the SAM encoder is consistent. Considering the different sizes and shapes of remote sensing image objects, multi-scale feature groups can significantly enhance the performance of downstream tasks, and there is no suitable instance segmentation framework for single-scale feature groups. Therefore, we input plain feature groups into the Plain Feature Fusion Pyramid Network (PFFPN) to obtain a feature pyramid , which is suitable for traditional object detection and instance segmentation frameworks. Then, the region proposal (cls and box) is obtained through the RPN.
Our model has three stages, and each stage has the same processing flow. The region proposal and the feature pyramid are input into each stage to obtain the prediction mask and the next stage of the region proposal. The calculation process for each stage is as follows: In order to solve the problem of false detection that often occurs in object detection in remote sensing images, the object feature obtained through RoiAlign is input into context aggregation bbox head (CABH) to realize the classification and the prediction of the bounding box. Then, in order to solve the problem of broken discontinuity of the edge of the mask obtained by the traditional method, the object feature and the prediction mask obtained by the SAM decoder are input into the SAM-Guided Mask Head (SGMH) to predict the object mask. In this way, the task of detection and segmentation is realized. Because the framework of our model is designed based on Cascade Mask R-CNN [41], the cls and box predicted in the previous stage are used as the region proposal in the next stage, and thecls and box are adjusted in the new CABH.
3.1. Plain Feature Fusion Pyramid Network
Due to the strong generalization ability of the large model, Vision Transformer (ViT) based on Transformer structure began to be used in the field of instance segmentation. However, since the ViT structure does not have multi-scale features, early studies often learn the experience of the language model and use the mutual attention decoder to obtain a fixed number of results after the image is processed by the ViT self-attention encoder. Until the emergence of VitDet, it brings another possibility for the model with ViT as the backbone to achieve instance segmentation. It obtains multi-scale features by designing Simple FPN [33], and then applies the framework of Mask R-CNN to achieve a good instance segmentation effect on the coco dataset.
Objects in remote sensing images often vary in size, even objects with particularly large scale differences within the same image. In the process of realizing instance segmentation, the construction of feature pyramids can greatly help to detect objects with different scales. As shown in Figure 2, the Plain Feature Fusion Pyramid Network (PFFPN) we designed draws on the idea of Simple FPN to generate multi-scale features from single-scale features.
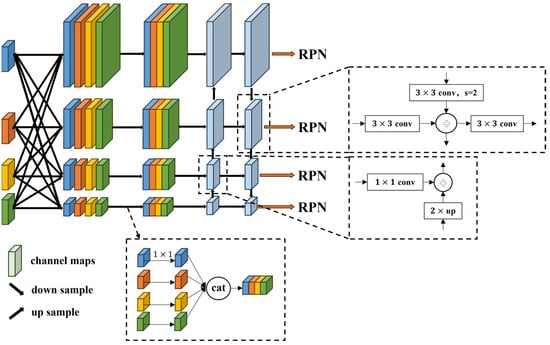
Figure 2.
The structure of the Plain Feature Fusion Pyramid Network (PFFPN).
In order to construct a feature pyramid, Simple FPN performs deconvolution and pooling operations on features to generate multi-scale feature groups. However, when constructing the feature pyramid, Simple FPN only uses the features of the last layer and abandons the calculation results of the previous features. Although the feature pyramid constructed in this way has multiple scales, the visual information provided is limited. Only by making full use of the visual features of different stages can we provide more information for multiple downstream tasks. Therefore, our method takes into account that the SAM encoder has four global self-attention calculations and extracts the features of each global self-attention calculation to form plain feature groups . The scale of each feature in the plain feature groups is 1/16 of the size of the original image. It is a good method to increase the feature scale by deconvolution, but when the number of features to be calculated increases, the deconvolution of each feature increases the parameters that the network needs to train. Therefore, we interpolate each feature in the plain feature groups into four features of different scales.
contains four groups of feature pyramids, a total of 16 feature maps. represents the interpolation operation of the original feature at four scales. Considering the amount of computation and accuracy, the interpolation here uses bilinear interpolation. For each , a 1 × 1 convolution dimension reduction is performed to obtain , so that each plain feature builds a separate feature pyramid (i = 1, 2, 3, 4).
represents a dimensionality reduction operation for features of different i and j. In the case of not introducing many training parameters, the features are first changed into multiple scales. However, each feature pyramid is only established by the corresponding plain feature. In order to provide more visual information for downstream tasks, multiple feature pyramids need to be merged into one. We combine the same scale features of different feature pyramids to obtain preliminary feature pyramids .
are the preliminary feature pyramids. However, the dimension of the preliminary feature pyramid is too large, the information is redundant, and further dimension reduction is needed, but the features after dimension reduction are not aligned. In order to achieve dimensionality reduction and alignment at the same time, considering that the current has been consistent with the feature pyramid extracted by the convolutional network, the classical FPN can be used to achieve feature dimensionality reduction, alignment, and fusion. Here, we use the PAFPN [23] method to calculate the feature pyramid from top to bottom and then from bottom to top.
are the final feature pyramids. Such a structure can make the low-level features and high-level semantic features fully integrated under the propagation of two directions. At the same time, it can further enhance the positioning ability of the entire feature hierarchy and can make features of different depths have shortcuts to reach each scale.
3.2. Context Aggregation BBox Head
Instance segmentation in ocean scenes has always been a very important research topic, but this task is seriously affected by the interference of complex backgrounds and similar objects. Especially in the case segmentation task of near-shore scenes under SAR images, due to the unique scattering characteristics of SAR, the background and object features in the near-shore are very similar, resulting in false detection. The optical image has a complex clutter situation, and for objects with no special shape, such as vehicles, it is easy to detect some square clutters as vehicles. In order to solve this problem, we propose the method of using the object background information. Once we include the area around the object in the scope of observation, we can easily distinguish between the object and false alarms. Considering that the traditional instance segmentation method does not consider the role of context, but the context information can improve the effect of object detection in remote sensing images, we integrate the context information into the model’s classification of objects and the prediction of regression boxes to obtain the Context-Aggregation BBox Head (CABH), as shown in Figure 3.
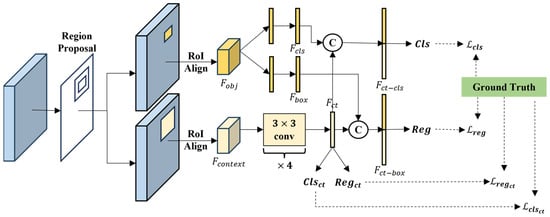
Figure 3.
The structure of the Context-Aggregation BBox Head (CABH).
In the classical bbox head, after the RPN obtains the proposed region, the proposed region in the feature pyramid is interpolated by RoIAlign to obtain the object feature of the object region.
is a feature of the appropriate scale selected from the feature pyramid based on the size of the proposed region. In order to use the context information, we expand the length and width of the proposed region by twice and then use RoiAlign with twice the proposed region to obtain the context feature .
CABH is divided into an object branch and a context branch by processing object feature and context feature . The object branch passes the object feature through different two-layer fully connected layers to obtain the prediction vectors and for the category and the bounding box.
stands for the fully connected layer, the superscript is the number of layers of the fully connected layer, and the subscript is the predicted object. This step does not use the traditional same two-layer fully connected layer to decouple the prediction of class and box to obtain a more accurate prediction. Considering the length and width of the proposed region are doubled, the area of context becomes four times the original. Therefore, the ratio of background information to object information is 3:1. Using good background information can improve the accuracy of category discrimination. Twice the length and width can ensure that the object is included, and adjusting the center position and range of the object will be more accurate. The context branch calculates the context feature through four convolutional layers and a fully connected layer to obtain the feature , which is an intermediate feature for prediction.
stands for the convolution layer, and the superscript is the number of layers of the convolution layer. Using convolutional network processing, can process background and object information spatially and make better use of the structural relationship between the object and background. Class and box are predicted by using the feature through two different fully connected layers.
and are predictions for category and bounding box in the context branch. The context branch prediction results and ground truth are used to calculate the loss, and the weights of the convolution layer and the fully connected layer are updated by back propagation, so that the feature has effective information for distinguishing categories and adjusting the box. In order to add context information to object branch, is combined with and to obtain and , respectively.
and predict class and box through a fully connected network, respectively.
and are predictions for category and bounding box in the object branch, and and are the output of CABH. The loss between the object branch prediction results and ground truth are used for back propagation.
The overall loss in CABH can be expressed as follows:
In this module, two losses are calculated for class and box, respectively. The first is to calculate the loss of the prediction results using the context features in the context branch, and the second is to calculate the loss of the prediction results of the object features combined with the context features in the object branch. The loss in CABH can be expressed, respectively, as follows:
and are the category and bounding box from the ground truth. We use L1 loss to calculate the loss.
3.3. SAM-Guided Mask Head
The usual mask head uses RoiAlign to extract the feature information of the location of the object in the feature pyramid and then uses the semantic segmentation method [64] to obtain the mask. This method uses deep features to achieve binary discrimination of the foreground. However, because the scale of deep features is much smaller than that of the original image, the mask obtained based on deep features is not clear at the edge of the object. SAM responds very well to texture and edge information, and the output is a full-size image, so the obtained by SAM is generally accurate, and the edges are sharp. We can use the mask and edge information obtained by SAM without training to make up for the deficiency of deep features. Therefore, in order to make good use of the deep features and the mask provided by the SAM, we inject the mask information generated by the SAM into the mask head to improve the mask prediction accuracy, and we propose SAM-Guided Mask Head (SGMH), as shown in Figure 4. In order to obtain a mask generated by SAM, we input the results of the boxes in the detection module as a prompt to the SAM. With the box prompt, the SAM generates a mask for the object in the box region. In order to make full use of the mask generated by SAM , we designed a teacher–student network [65]. The student network backbone uses a compact, fully convolutional network (FCN) [64] to predict the .
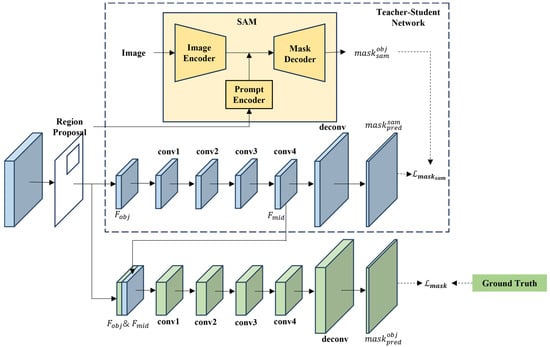
Figure 4.
The structure of the SAM-Guided Mask Head.
stands for the deconvolution layer, and the superscript is the number of layers of the convolution layer. The purpose of a student network is to learn the knowledge of through traditional mask prediction methods, in which SAM acts as a teacher network. Since the is full-picture, and the prediction of the mask under the Mask R-CNN framework is only for the proposed region, it is necessary to process the by RoIAlign to obtain in the proposed region.
is the goal that the student network needs to learn. After full training, the intermediate feature contains the mask information. The intermediate feature and the object feature are combined to obtain , and the predicted mask is obtained by FCN.
is the output of SGMH. The overall loss in SGMH can be expressed as follows:
The loss in SGMH consists of two parts, one is the loss of the mask generated by the FCN and mask generated by the SAM in the teacher–student network, and the other part is the loss of the prediction of SGMH and the ground truth. The two parts loss can be expressed as follows:
is the mask from the ground truth. We use cross-entropy loss to calculate the loss.
4. Experimental Results and Analyses
4.1. Experimental Dataset
In the experimental part, we prepared two remote sensing instance segmentation datasets for the experiment. Our model and the compared model will be trained and validated on the same training set and test set to ensure the credibility of the experimental results. The datasets used in the experiment are the NWPU VHR-10 dataset [66,67] and SSDD dataset [57,68,69]. These two datasets have been used in a large number of literature, so the experimental results of the datasets are highly reliable.
The NWPU VHR-10 dataset [66] is an optical remote sensing image instance segmentation dataset including ten classes: airplane(AI), ship(SH), storage tank(ST), baseball diamond(BD), tennis court(TC), basketball court(BC), ground track field(GTF), harbor(HB), bridge(BR), and vehicle(VC). It includes 715 optical remote sensing images from Google Earth, with a spatial resolution of 0.8–2 m, and 85 pan-sharpened color infrared images from the Vaihingen dataset, with a spatial resolution of 0.08 m. The dataset contains 650 images with instances and 150 background images. In the experiment, we only used 650 images with examples to participate in the training. Among them, 80% of the data were allocated for training and 20% for testing. The NWPU dataset was originally an object detection dataset. Reference [67] provided pixel-level labels for the dataset so that the dataset can be used for instance segmentation tasks.
The SAR Ship Detection Dataset (SSDD) [68,69] includes 1160 SAR images obtained from RadarSat-2, TerraSAR-X, and Sentinel-1, with a resolution range spanning from 1 to 15 m, and includes 2540 ship instances; 80% of the data were allocated for training and 20% for testing. Reference [57] provided pixel-level labels for the dataset, so that the dataset can be used for instance segmentation tasks.
4.2. Evaluation Protocol and Metrics
Akin to the object detection, instance segmentation selects the mask IoU as the basic criterion of evaluation
where is the mask prediction and is the counterpart ground truth. Given a certain IoU threshold, the predictions can be categorized into true positive (TP), true negative (TN), false positive (FP), and false negative (FN). Thus, we can define precision (P) and recall (R) via
Meanwhile, the threshold is calculated by
In order to evaluate the performance of the proposed method, we use the widely used COCO mean average precision (mAP) index. This index is often used to objectively evaluate the effectiveness of object detection or instance segmentation methods. When the intersection over union (IoU) between the prediction box or mask of an instance and its corresponding ground truth value is greater than the threshold T, and its prediction category matches, the prediction is considered to be true positive.
In this paper, , , , , , , , , , , and are used for evaluation. The term AP refers to the average measure across all 10 IoU thresholds (0.50: 0.05: 0.95) and across all categories. A larger AP value indicates a more accurate prediction of the instance mask, thereby better instance segmentation performance. The represents the calculation at the IoU threshold of 0.50, while the represents a more rigorous metric corresponding to the calculation at the IoU threshold of 0.75. Therefore, is superior to in evaluating the mask accuracy. The larger the value is, the more accurate the instance mask is. The prediction ability of , , to represent the three types of small (area < ), medium ( < area < ), and large (area > ) size instances, respectively. If is significantly smaller than the other two indicators, it shows that the algorithm has weak ability to detect and segment small objects. The subscript box and mask represent the prediction accuracy of the regression box for object detection and the prediction accuracy for the segmentation instance.
4.3. Implementation Details
SAM has three models of different sizes: ViT-B, ViT-L, and ViT-H. The ViT-H model is used by default in the experiment. Since the default input image size of SAM is 1024 × 1024, the original image is selected to be adjusted to 1024 × 1024 for calculation in the training and verification stages. The algorithm is written on the python platform and is developed based on the PyTorch framework. Our code is based on the MMDetection [70] project. During the training process, the parameters of the SAM are not involved in the training, and all additional modules are trained from scratch.
The platform used for training is NVIDIA A100 Tensor Core GPUs, memory 40 G. In order to accelerate the convergence of the training model, we use the SGD optimizer with an initial learning rate of to train our model, and the batch size is set to 4. The total training rounds of the NWPU and SSDD datasets are 36 epochs, that is, 3 schedules. In terms of the adjustment of the learning rate, the linear learning rate (LinearLR) is used to warm up in the training, and then the multi-stage learning rate (MultiStepLR) is used to adjust the learning rate from to and at the 24th and 33rd epoch.
4.4. Comparison with the State-of-the-Art
In this part, we compare the proposed method with several other state-of-the-art (SOTA) instance segmentation methods. Including Mask R-CNN [14], Mask Scoring R-CNN [40], Cascade Mask R-CNN [41], HTC [43], SCNet [44], PointRend [45], VitAE [32], VitDet [33], Yolact [47], Condlnst [51], Boxlnst [56], Querylnst [52], HQ-ISNet [57], CATNet [60], LFGNet [5], RSPrompter [63], and YOLO v8. In the method of comparison, except for the pre-training model of VitDet and VitAE with Transformer structure, the other methods use ResNet101 [19] as the pre-training model. We compare the quantitative results of CSNet with other SOTA methods on the NWPU dataset and SSDD dataset in threshold AP (including , and ) and scale AP (including , and ) defined in Section 4.2.
In order to further improve the performance of the model, we conducted additional multi-scale training on CSNet. The quantitative results on the NWPU dataset are shown in the Table 1. Without multi-scale training, CSNet achieves 71.6%, 95.0%, 84.2%, 67.9%, 94.8%, and 74.2% value. Compared with Mask R-CNN, CSNet receives 7.3% and 7.6% increments; compared with VitDet, CSNet receives 5.9% and 3.7% increments; compared with Cascade Mask R-CNN, CSNet receives 4.9% and 5.0% increments. Among the 12 test indicators, CSNet achieves the best performance. We use Standard Scale Jittering (SSJ) [71], which resizes and crops an image with a resize range of 0.8 to 1.25 of the original image size to achieve multi-scale training of CSNet. When the multi-scale training technique is simultaneously adopted in training CSNet, termed CSNet*, it receives 73.1%, 95.2%, 86.2%, 70.5%, 95.1%, and 78.4% value, which is the highest quantitative result among the state-of-the-art methods. Compared with VitDet, CSNet* receives 7.4% and 6.3% increments; compared with HQ-ISNet, CSNet* receives 3.9% and 6.4% increments. This shows that CSNet has a very good performance in the instance segmentation task of optical remote sensing images. Due to the small size of the NWPU dataset, it shows that with the help of the generalization ability of SAM, the accurate segmentation ability of the object can be enhanced.

Table 1.
Comparative analysis of the proposed methods and state-of-the-art methods on the NWPU dataset, demonstrating AP(%) for boxes and masks at various IoU thresholds.
The quantitative results on the SSDD dataset are shown in the Table 2. The SSDD dataset is different from the NWPU dataset. The NWPU dataset has many different instances, while the SSDD dataset only detects and segments the ship objects in the image. In addition, the number of images in the SSDD dataset is more than the NWPU dataset. Without multi-scale training, CSNet achieves 73.4%, 97.4%, 90.0%, 70.5%, 96.6%, and 96.7% value. Compared with Mask R-CNN, CSNet receives 3.3% and 2.7% increments; compared with VitDet, CSNet receives 4.9% and 3.4% increments; compared with Cascade Mask R-CNN, CSNet receives 1.0% and 1.6% increments. When a multi-scale training technique is simultaneously adopted in training CSNet, termed CSNet*, it receives 75.3%, 98.0%, 93.1%, 72.7%, 98.0%, and 92.0% value, which is the highest quantitative result among the state-of-the-art methods. Compared with VitDet, CSNet* receives 6.8% and 5.6% increments; compared with HQ-ISNet, CSNet* receives 2.3% and 4.0% increments. CSNet and CSNet * achieve the best in all indicators, indicating that our model has a very good performance in SAR image ship instance segmentation.
Table 2.
Comparative analysis of the proposed methods and state-of-the-art methods on the SSDD dataset, demonstrating AP(%) for boxes and masks at various IoU thresholds.
In order to visually compare our model with SOTA, we chose Mask R-CNN, SCNet, Condlnst, VitDet, and HQ-ISNet as the representative of SOTA for qualitative comparison with CSNet. Figure 5 and Figure 6 illustrate sample segmentation instances from the NWPU dataset and SSDD dataset. In the qualitative results of the NWPU dataset, in the scene of the car park, CSNet has the best precision and recall rate, and the segmentation of the vehicle contour is accurate; in the airport scene, CSNet has the best processing of the edge of the aircraft mask; in the playground scene, CSNet can achieve smooth, continuous and angular segmentation edges of large and small objects. In the port scene, CSNet accurately segments each port. In the qualitative results of the SSDD dataset, CSNet can also accurately detect and segment images with complex backgrounds and dense ship arrangements. These visualization results validate the superiority of our CSNet in the task of instance segmentation.

Figure 5.
Qualitative results of CSNet∗ and SOTA methods on NWPU dataset. Row 1 is the ground truth; rows 2–7 are the visualized instance segmentation results of Mask R-CNN, SCNet, CondInst, ViTDet, HQ-ISNet, and CSNet∗, respectively.

Figure 6.
Qualitative results of CSNet∗ and SOTA methods on SSDD dataset. Row 1 is the ground truth; rows 2–7 are the visualized instance segmentation results of Mask R-CNN, SCNet, CondInst, ViTDet, HQ-ISNet, and CSNet∗, respectively.4.5. Ablation Study.
In summary, with the help of SAM’s zero-shot segmentation ability, the model segmentation accuracy has been significantly improved. The introduction of context information makes the recall accuracy and recall rate of CSNet higher. CSNet has better instance segmentation ability than the SOTA method and has better performance on optical images and SAR images.
In this section, we undertake a series of experiments on the NWPU dataset to investigate the significance of each component and parameter setting within our proposed methodology.
The impacts of the main component are as follows: We designed module experiments to verify the impact of each module on the performance of the model and added PFFPN, CABH, and SGMH to the baseline model in turn (the baseline model uses SAM’s image encoder as the backbone, simple FPN as the neck, and the head design uses Cascade Mask R-CNN’s bbox head and mask head). In order to fully prove the effectiveness of each module, we conducted experiments on NWPU and SSDD datasets, and the results are shown in Table 3. On the NWPU dataset, with the addition of PFFPN, CABH, and SGMH, the and of the model increased by 0.9%/2.2%, 0.7%/0.7%, and 1.1%/1.1%, respectively, with a total increase of 2.9%/4.0%. On the SSDD dataset, with the addition of PFFPN, CABH, and SGMH, the and of the model increase by 1.2%/2.0%, 1.0%/1.0%, and 1.4%/1.4%, respectively, and the total increase is 3.6%/4.4%. On other evaluation indicators, PFFPN, CABH, and SGMH all have a positive impact on the model, indicating that our designed PFFPN, CABH, and SGMH is a method that can effectively improve the accuracy of instance segmentation. At the same time, in order to show the performance of the module more intuitively, we visualize the experimental results, as shown in Figure 7 and Figure 8. It can be seen from the feature map that PFFPN can enhance the response of the object and highlight the location of the object. It can be seen from the segmentation results that after highlighting the object response, the mask of the instance is more complete and can reduce the aliasing of the mask. CABH further makes the overall area of the object in a high response state, reducing false detection in the results. SGMH has restrictions on the edge, and the response on the feature is more in line with the object shape. In the experimental results, the mask edge of SGMH is very flat, and the edge angle is more obvious. The visualization experiment shows that our module is obviously helpful for instance segmentation.
Table 3.
Effects of PFFPN, CABH, and SGMH. All the results are evaluated on the NWPU and SSDD test set.

Figure 7.
Qualitative results of effects of PFFPN, CABH, and SGMH on NWPU dataset. Column (a) is the ground truth; columns (b–e) are the visualized results and feature maps of baseline, baseline with PFFPN, baseline with PFFPN and CABH, and CSNet, respectively.
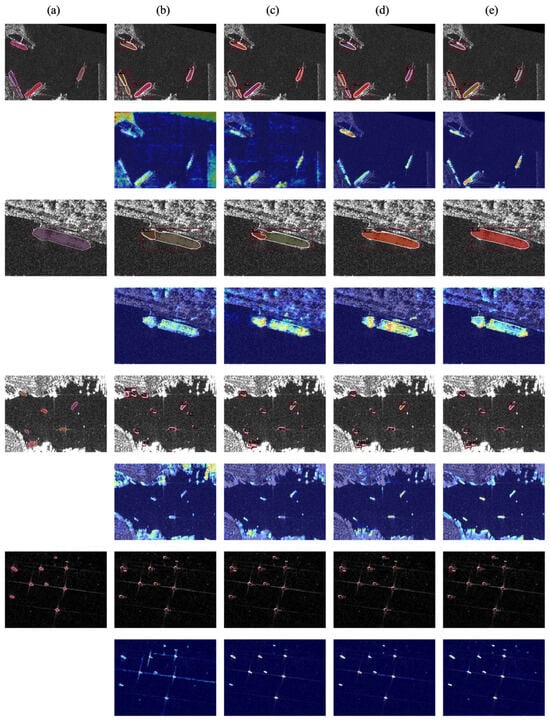
Figure 8.
Qualitative results of effects of PFFPN, CABH, and SGMH on SSDD dataset. Column (a) is the ground truth; columns (b–e) are the visualized results and feature maps of baseline, baseline with PFFPN, baseline with PFFPN and CABH, and CSNet, respectively.
The impacts of various image encoders as backbones are as follows: Backbone is a very important part of tasks such as instance segmentation. A good backbone can achieve better performance under the same model. For our model, we use the SAM image encoder as the backbone. There are three versions of the image encoder: ViT-B, ViT-L, and ViT-H. We designed different versions of the image encoder as the backbone to explore the influence of the image encoder on the model. The experimental results are shown in Table 4. It can be seen from the table that the performance of the model increases as the parameter size of the image encoder becomes larger. When the model wants to achieve the best performance, the and of ViT-H reach 71.6% and 67.9%. When the model has the fastest running speed, the and of ViT-B can also reach 68.8% and 65.4%. When trying to balance performance and speed, the and of ViT-L can reach 69.7% and 66.2%, respectively.
Table 4.
Effects of various image encoders as the backbone. All the results are evaluated on the NWPU test set.
The impacts of the schedule in training are as follows: We hope that the training epochs are as few as possible without affecting the accuracy, so as to reduce the training time. Therefore, we designed experiments to explore the influence of training rounds on the experimental results. The experimental results are shown in Table 5. Under the training schedule of 1x and 2x, and are significantly smaller than those under the training schedule of 3x and 6x. The training schedule set to 3x and 6x have basically the same performance. Considering the factors that reduce the training time, the model chooses 3x for the training schedule.
Table 5.
Effects of schedule in training. All the results are evaluated on the NWPU test set.
The impacts of various hierarchical features and feature dimensions are as follows: The instance segmentation method based on ViT structure is still less explored for FPN. Which features should be selected to construct FPN in various hierarchical features in ViT needs further exploration. Due to the large feature dimension in ViT, the dimension should be appropriately reduced, and the loss of performance should be reduced as much as possible while reducing the amount of calculation. Therefore, for our proposed PFFPN structure, we designed experiments to explore the effects of various hierarchical features and feature dimensions on FPN performance. The experimental structure is shown in Table 6. It can be seen from the experimental results that when a feature is extracted every 8 layers, and a total of 4 layers of features are extracted for the construction of FPN, the performance of the model is better than that of extracting 1, 2, and 8 layers of features. When the number of feature layers is 4, the performance difference between 256,128, and 64 is not significant. However, when the dimension is 64, the optimal performance can be obtained on five indicators, and the and of the model can reach 71.6% and 67.9%. PFFPN takes [7,15,23,31] as input, and the dimension reduction to 64 after interpolation can maximize the performance improvement of the model.
Table 6.
Effects of various hierarchical features and feature dimensions in the PFFPN. [start: end: step] denotes the index of the kept feature maps, ranging from the start to the end with a specified step interval. All the results are evaluated on the NWPU test set.
The impacts of various fpns in different vit structures are as follows: The proposed PFFPN achieves the best level of the structure after optimizing the parameters. In order to test whether PFFPN performs well in the model with ViT as the backbone, we compare PFFPN with FPN in VitAE and Simple FPN in ViTDet. The experimental results are shown in Table 7. From the table, it can be seen that by replacing the FPN of VitAE with PFFPN, the and increased from 65.4% and 63.3% to 68.4% and 65.4%, with an increase of 3.0% and 2.1%, respectively. By replacing the Simple FPN of ViTDet with PFFPN, the and increased from 65.7% and 64.2% to 68.3% and 64.7%, with an increase of 2.6% and 0.5%, respectively. For CSNet without PFFPN, and decrease by 1.3% and 1.8%, respectively. Experiments show that in the network with VitAE, ViTDet and SAM as backbones, PFFPN has stronger feature extraction and fusion capabilities, which can significantly improve the performance of the network.
Table 7.
Comparison with various fpns in different vit structures. All the results are evaluated on the NWPU test set.
The impacts of the object branch and context branch are as follows: In CABH, we design the object branch and context branch to assist object recognition and localization with context information. However, for the object branch and context branch, further experiments are still needed to explore how to design to maximize performance. At present, the most common bbox head is the two-layer fully connected layer set in Fast R-CNN. In addition, there are four layers of convolution in ViTDet and one layer of fully connected layer. In these settings of the bbox head, object recognition and positioning are through the same network. In order to remove the coupling relationship between object recognition and positioning tasks, we designed a bbox head to predict cls and box through different two-layer fully connected layers. We designed experiments to explore what kind of network is the most effective for the object branch and context branch, respectively. The experimental results are shown in Table 8. It can be seen from the experiment that the object branch uses Separated 2fc, and the context branch uses Shared 4conv1fc to make the CABH detection performance the best. Separated 2fc can remove the coupling relationship between object recognition and positioning tasks and improve the detection performance. Shared 4conv1fc first captures context information through convolution and then transforms context information into useful information for object recognition and localization tasks through a fully connected layer.
Table 8.
Effects of different sets of object branches and context branches in CABH. All the results are evaluated on the NWPU test set.
The impacts of CABH as the bbox head are as follows: We hope that our designed CABH can not only improve the detection performance of our model but also improve the detection performance when applied to other models (based on Mask R-CNN). Therefore, we design to replace the bbox head of Mask R-CNN, Cascade Mask R-CNN, and ViTDet with CABH and judge the effect of CABH on the performance of the model by the index of the . The experimental results are shown in Table 9. CABH improved the of Mask R-CNN from 64.3% to 66.4%. The of Cascade Mask R-CNN increased from 66.7% to 68.5%. The of ViTDet increased from 65.7% to 67.1%. The introduction of CABH improves the six indicators of detection in all three models. Replacing the CABH in CSNet with a general bbox head, the decreased by 1.1%, and the other five indicators also decreased. The above experiments show that CABH can effectively improve the detection performance.
Table 9.
Effects of CABH in different methods. All the results are evaluated on the NWPU test set.
The impacts of SAM, FCN, and SGMH used in mask head are as follows: Because SAM has the ability to zero-shot, masks can be generated for untrained images without fine-tuning. Therefore, SAM has the ability to act as a mask head alone. We designed experiments to replace SGMH in CSNet with SAM and FCN to evaluate which mask head has the best performance. The experimental results are shown in Table 10. Among SAM, FCN, and SGMH, SGMH has the best performance, and SAM has the worst performance. This shows that although SAM can generate masks without training, the mask accuracy is not as good as the model trained under the pixel-level label. Compared with FCN, SGMH has improved performance on NWPU and SSDD datasets, indicating that learning SAM masks through student networks can capture more information to enrich deep features, thereby improving mask quality.
Table 10.
Effects of SAM, FCN, and SGMH used in mask head. All the results are evaluated on the NWPU and SSDD test set.
The impacts of mask size are as follows: In SGMH, FCN is used as the structure of the prediction instance mask. The larger the size of the mask, the greater the amount of calculation consumed. However, in order to learn the knowledge of SAM in SGMH, the larger the mask size, the more details can be retained. Therefore, the mask size should be the appropriate size, and we designed to experiment with the performance of CSNet under different mask sizes. The experimental results are shown in Table 11. From the table, when the mask size is , CSNet has the best performance on the five mask-related indicators, reaches 67.9%. Considering the performance and computation time, the mask size in SGMH should be set to .
Table 11.
Effects of different mask sizes in SGMH. All the results are evaluated on the NWPU test set.
The impacts of SGMH as the mask head are as follows: Similar to CABH, we hope that SGMH can improve the segmentation performance of other models (based on Mask R-CNN). Therefore, we designed to replace the mask head of Mask R-CNN, Cascade Mask R-CNN, and ViTDet with SGMH(ViT-B), SGMH(ViT-L), and SGMH(ViT-H) and judge the effect of SGMH on the performance of the model by the index of the . The experimental results are shown in Table 12. SGMH(ViT-L) improved the of Mask R-CNN from 60.3% to 64.7%. The of Cascade Mask R-CNN increased from 62.9% to 65.0%. The of ViTDet increased from 66.2% to 69.5%. SGMH(ViT-B) and SGMH(ViT-L) also improved the . The introduction of SGMH improves the six indicators of segmentation in all three models. Replacing the SGMH in CSNet with a general mask head, decreased by 1.0%, and the other five indicators also decreased. The above experiments show that SGMH can effectively improve the segmentation performance.
Table 12.
Effects of SGMH in different methods. All the results are evaluated on the NWPU test set.
5. Discussion
Based on the logic of the two-stage instance segmentation method, this paper decomposes the instance segmentation task into three stages: feature generation, object detection, and object segmentation. Based on these three stages, the problems faced in remote sensing images are solved one by one so as to comprehensively improve the final segmentation performance of the model. Specifically, we propose CSNet to implement instance segmentation tasks for optical and SAR images. The model integrates the three modules of PFFPN, CABH, and SGMH, enhances the semantic information of deep features, improves the problem of missed detection and false detection, and improves the edge details of the mask. Our model outperforms all fully supervised methods on public datasets and shows strong segmentation ability. This work can provide new ideas for subsequent optical and SAR image instance segmentation methods, starting from large models to solve problems in the field of remote sensing.
Although our model shows good instance segmentation performance, there are still some limitations that need to be improved. First of all, because SAM is a large model in the field of images, the process of using SAM’s encoder and decoder to train the network takes up more video memory. This puts forward requirements for the hardware of the experimenter, and the model cannot be trained without a graphics card with sufficient memory. Secondly, since the two-stage instance segmentation method must first use RoIAlign to obtain the object feature when obtaining the mask, the mask generated by SAM also needs RoIAlign when calculating the loss of the student network prediction result and the mask generated by SAM. It wastes the higher mask accuracy of the original full-image mask.
In future work, we plan to explore the lightweight of visual large models, hoping to achieve similar results with fewer parameters. The lightweight large model is applied to the field of remote sensing image segmentation. In the case of reducing the burden of graphics cards, we will continue to improve the quality of segmentation. In addition, we will combine the single-stage instance segmentation method with SAM in the future and use the full-image prediction of the single-stage instance segmentation method and the full-image mask of SAM to obtain a better object mask.
6. Conclusions
In this article, the generalization ability of the visual large model is used to assist the instance segmentation of remote sensing images and CSNet is proposed. This is a novel method, which not only takes the ViT structure as the backbone, but also integrates the context information and the zero-shot ability of SAM into the model. Our model solves the problem of lack of FPN design with ViT structure as the backbone and proposes PFFPN to align the plain features of different blocks to generate a feature pyramid, and the network using PFFPN has obvious performance improvement. By injecting context information into the prediction branch, CSNet also solves the problem of missed detection and false detection in remote sensing image object recognition. Qualitative experimental results show that CSNet performs well in both object-intensive scenes and scenes with similar objects and backgrounds. In order to solve the problem of mask edge fragmentation predicted by traditional algorithms, we propose that SGMH inherits the zero-shot ability of SAM through the teacher–student network. Qualitative experiments show that the edge of the mask obtained by CSNet is continuous and flat, and it can remain sharp at the corner points. The above parts have been confirmed by ablation experiments. At the same time, the ablation experiment also shows that the above modules also have very good effects on other models. The results on two remote sensing public instance segmentation datasets show that our model is due to other state-of-the-art instance segmentation methods on each index.
Author Contributions
Conceptualization, S.L.; methodology, S.L.; software, S.L.; validation, S.L.; formal analysis, S.L.; investigation, S.L.; resources, S.L.; data curation, S.L.; writing—original draft preparation, S.L.; writing—review and editing, S.L., F.W. and H.Y.; visualization, S.L.; supervision, S.L.; project administration, F.W., H.Y., N.J., G.Z. and T.Z.; funding acquisition, F.W., H.Y., N.J., G.Z. and T.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The NWPU and SSDD datasets we use for our research are available at the following URLs: https://github.com/LiuShuangZhou/CSNet (accessed on 24 June 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Gao, J.; Zhang, B.; Wu, Y.; Guo, C. Building Extraction from High Resolution Remote Sensing Images Based on Improved Mask R-CNN. In Proceedings of the 2022 4th International Conference on Robotics and Computer Vision (ICRCV), Wuhan, China, 25 September 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, S.; Cao, Y.; Sui, B. DF-Mask R-CNN: Direction Field-Based Optimized Instance Segmentation Network for Building Instance Extraction. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, D.; Ma, A.; Zhong, Y.; Fang, F.; Xu, K. Multiscale U-Shaped CNN Building Instance Extraction Framework with Edge Constraint for High-Spatial-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6106–6120. [Google Scholar] [CrossRef]
- Tian, T.; Gao, P.; Pan, Z.; Li, H.; Wang, L. Inshore Ship Detection Based on Multi-Information Fusion Network and Instance Segmentation. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September 2020; pp. 972–975. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Zhang, H.; Zhou, Z.; Shi, J.; Zhang, X. LFG-Net: Low-Level Feature Guided Network for Precise Ship Instance Segmentation in SAR Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Feng, Y.; Diao, W.; Zhang, Y.; Li, H.; Chang, Z.; Yan, M.; Sun, X.; Gao, X. Ship Instance Segmentation from Remote Sensing Images Using Sequence Local Context Module. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1025–1028. [Google Scholar] [CrossRef]
- Jiang, S.; Jia, Q.; Luo, F.; Yang, T. An Improved BoxInst Model for Plane Instance Segmentation in Remote Sensing Images. In Proceedings of the 2021 IEEE 4th Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 18 June 2021; pp. 1694–1699. [Google Scholar] [CrossRef]
- Amitrano, D.; Di Martino, G.; Guida, R.; Iervolino, P.; Iodice, A.; Papa, M.N.; Riccio, D.; Ruello, G. Earth Environmental Monitoring Using Multi-Temporal Synthetic Aperture Radar: A Critical Review of Selected Applications. Remote Sens. 2021, 13, 604. [Google Scholar] [CrossRef]
- Liu, C.; Xing, C.; Hu, Q.; Wang, S.; Zhao, S.; Gao, M. Stereoscopic Hyperspectral Remote Sensing of the Atmospheric Environment: Innovation and Prospects. Earth-Sci. Rev. 2022, 226, 103958. [Google Scholar] [CrossRef]
- Wu, Z.; Hou, B.; Ren, B.; Ren, Z.; Wang, S.; Jiao, L. A Deep Detection Network Based on Interaction of Instance Segmentation and Object Detection for SAR Images. Remote Sens. 2021, 13, 2582. [Google Scholar] [CrossRef]
- Zhu, M.; Hu, G.; Li, S.; Zhou, H.; Wang, S.; Feng, Z. A Novel Anchor-Free Method Based on FCOS + ATSS for Ship Detection in SAR Images. Remote Sens. 2022, 14, 2034. [Google Scholar] [CrossRef]
- Yu, D.; Ji, S.; Li, X.; Yuan, Z.; Shen, C. Earthquake Crack Detection From Aerial Images Using a Deformable Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Bühler, M.M.; Sebald, C.; Rechid, D.; Baier, E.; Michalski, A.; Rothstein, B.; Nübel, K.; Metzner, M.; Schwieger, V.; Harrs, J.-A.; et al. Application of Copernicus Data for Climate-Relevant Urban Planning Using the Example of Water, Heat, and Vegetation. Remote Sens. 2021, 13, 3634. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN 2018. arXiv 2018. Available online: http://arxiv.org/abs/1703.06870 (accessed on 23 April 2024).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale 2021. arXiv 2021. Available online: https://arxiv.org/abs/2010.11929 (accessed on 23 April 2024).
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. Segment Anything 2023. arXiv 2023. Available online: https://arxiv.org/abs/2103.14030 (accessed on 11 August 2023).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition 2015. arXiv 2015. Available online: http://arxiv.org/abs/1409.1556 (accessed on 23 April 2024).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Lan, J.; Liu, X.; Li, B.; Li, Y.; Geng, T. DarknetSec: A Novel Self-Attentive Deep Learning Method for Darknet Traffic Classification and Application Identification. Comput. Secur. 2022, 116, 102663. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks 2018. arXiv 2018. Available online: http://arxiv.org/abs/1608.06993 (accessed on 23 April 2024).
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhu, M.; Han, K.; Yu, C.; Wang, Y. Dynamic Feature Pyramid Networks for Object Detection 2021. arXiv 2021. Available online: http://arxiv.org/abs/2012.00779 (accessed on 23 April 2024).
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5686–5696. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Ghiasi, G.; Lin, T.-Y.; Pang, R.; Le, Q.V. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7029–7038. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows 2021. Available online: http://arxiv.org/abs/1904.07392 (accessed on 23 April 2024).
- Fan, H.; Xiong, B.; Mangalam, K.; Li, Y.; Yan, Z.; Malik, J.; Feichtenhofer, C. Multiscale Vision Transformers 2021. arXiv 2021. Available online: http://arxiv.org/abs/2104.11227 (accessed on 23 April 2024).
- Li, Y.; Wu, C.-Y.; Fan, H.; Mangalam, K.; Xiong, B.; Malik, J.; Feichtenhofer, C. MViTv2: Improved Multiscale Vision Transformers for Classification and Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 4794–4804. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Xu, Y.; Zhang, Q.; Zhang, J.; Tao, D. ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias. Adv. Neural Inf. Process. Syst. 2021, 34, 28522–28535. [Google Scholar]
- Li, Y.; Mao, H.; Girshick, R.; He, K. Exploring Plain Vision Transformer Backbones for Object Detection. In Computer Vision—ECCV 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Lecture Notes in Computer Science; Springer Nature Switzerland: Cham, Switzerland, 2022; Volume 13669, pp. 280–296. ISBN 978-3-031-20076-2. [Google Scholar] [CrossRef]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.L.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training Language Models to Follow Instructions with Human Feedback 2022. arXiv 2022. Available online: http://arxiv.org/abs/2203.02155 (accessed on 23 April 2024).
- OpenAI; Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; et al. GPT-4 Technical Report 2024. arXiv 2024. Available online: http://arxiv.org/abs/2303.08774 (accessed on 23 April 2024).
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.-Y. DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection 2022. arXiv 2024. Available online: http://arxiv.org/abs/2203.03605 (accessed on 23 April 2024).
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. DINOv2: Learning Robust Visual Features without Supervision 2024. arXiv 2024. Available online: http://arxiv.org/abs/2304.07193 (accessed on 23 April 2024).
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision 2021. arXiv 2021. Available online: http://arxiv.org/abs/2103.00020 (accessed on 23 April 2024).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; Volume 28, pp. 91–99. [Google Scholar]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask Scoring R-CNN 2019. arXiv 2019. Available online: http://arxiv.org/abs/1903.00241 (accessed on 23 April 2024).
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High Quality Object Detection and Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. Available online: http://arxiv.org/abs/1906.09756 (accessed on 23 April 2024). [CrossRef] [PubMed]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2017; pp. 6154–6162. [Google Scholar]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid Task Cascade for Instance Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Vu, T.; Kang, H.; Yoo, C.D. SCNet: Training Inference Sample Consistency for Instance Segmentation. Proc. AAAI Conf. Artif. Intell. 2021, 35, 2701–2709. [Google Scholar] [CrossRef]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. PointRend: Image Segmentation as Rendering. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Fang, H.-S.; Sun, J.; Wang, R.; Gou, M.; Li, Y.-L.; Lu, C. InstaBoost: Boosting Instance Segmentation via Probability Map Guided Copy-Pasting. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-Time Instance Segmentation. In Proceedings of the 2019 IEEE/CVF In-ternational Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9156–9165. [Google Scholar]
- Wang, X.; Kong, T.; Shen, C.; Jiang, Y.; Li, L. SOLO: Segmenting Objects by Locations 2020. arXiv 2020. Available online: http://arxiv.org/abs/1912.04488 (accessed on 25 August 2023).
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. SOLOv2: Dynamic and Fast Instance Segmentation 2020. arXiv 2020. Available online: http://arxiv.org/abs/2003.10152 (accessed on 25 August 2023).
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H. Conditional Convolutions for Instance Segmentation 2020. arXiv 2020. Available online: http://arxiv.org/abs/2003.05664 (accessed on 14 December 2023).
- Fang, Y.; Yang, S.; Wang, X.; Li, Y.; Fang, C.; Shan, Y.; Feng, B.; Liu, W. Instances as Queries 2021. arXiv 2021. Available online: http://arxiv.org/abs/2105.01928 (accessed on 14 December 2023).
- Khoreva, A.; Benenson, R.; Hosang, J.; Hein, M.; Schiele, B. Simple Does It: Weakly Supervised Instance and Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1665–1674. [Google Scholar] [CrossRef]
- Pont-Tuset, J.; Arbelaez, P.T.; Barron, J.; Marques, F.; Malik, J. Multiscale Combinatorial Grouping for Image Segmentation and Object Proposal Generation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 128–140. [Google Scholar] [CrossRef]
- Hao, S.; Wang, G.; Gu, R. Weakly Supervised Instance Segmentation Using Multi-Prior Fusion. Comput. Vis. Image Underst. 2021, 211, 103261. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Wang, X.; Chen, H. BoxInst: High-Performance Instance Segmentation with Box Annotations 2020. arXiv 2020. Available online: http://arxiv.org/abs/2012.02310 (accessed on 14 December 2023).
- Su, H.; Wei, S.; Liu, S.; Liang, J.; Wang, C.; Shi, J.; Zhang, X. HQ-ISNet: High-Quality Instance Segmentation for Remote Sensing Imagery. Remote Sens. 2020, 12, 989. [Google Scholar] [CrossRef]
- Liu, X.; Di, X. Global Context Parallel Attention for Anchor-Free Instance Segmentation in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Shi, F.; Zhang, T. An Anchor-Free Network With Box Refinement and Saliency Supplement for Instance Segmentation in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Liu, Y.; Li, H.; Hu, C.; Luo, S.; Luo, Y.; Chen, C.W. Learning to Aggregate Multi-Scale Context for Instance Segmentation in Remote Sensing Images 2022. arXiv 2022. Available online: http://arxiv.org/abs/2111.11057 (accessed on 25 August 2023).
- Fang, L.; Jiang, Y.; Yan, Y.; Yue, J.; Deng, Y. Hyperspectral Image Instance Segmentation Using Spectral–Spatial Feature Pyramid Network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–13. [Google Scholar] [CrossRef]
- Chen, Z.; Shang, Y.; Python, A.; Cai, Y.; Yin, J. DB-BlendMask: Decomposed Attention and Balanced BlendMask for Instance Segmentation of High-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Chen, K.; Liu, C.; Chen, H.; Zhang, H.; Li, W.; Zou, Z.; Shi, Z. RSPrompter: Learning to Prompt for Remote Sensing Instance Segmentation Based on Visual Foundation Model 2023. arXiv 2023. Available online: http://arxiv.org/abs/2306.16269 (accessed on 28 June 2023).
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network 2015. arXiv 2015. Available online: http://arxiv.org/abs/1503.02531 (accessed on 27 April 2024).
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-Class Geospatial Object Detection and Geographic Image Classification Based on Collection of Part Detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Su, H.; Wei, S.; Yan, M.; Wang, C.; Shi, J.; Zhang, X. Object Detection and Instance Segmentation in Remote Sensing Imagery Based on Precise Mask R-CNN. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1454–1457. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. SAR Ship Detection Dataset (SSDD): Official Release and Comprehensive Data Analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Li, J.; Qu, C.; Shao, J. Ship Detection in SAR Images Based on an Improved Faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark 2019. arXiv 2019. Available online: http://arxiv.org/abs/1906.07155 (accessed on 19 June 2023).
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.-Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple Copy-Paste Is a Strong Data Augmentation Method for Instance Segmentation 2021. arXiv 2021. Available online: http://arxiv.org/abs/2012.07177 (accessed on 27 April 2023).
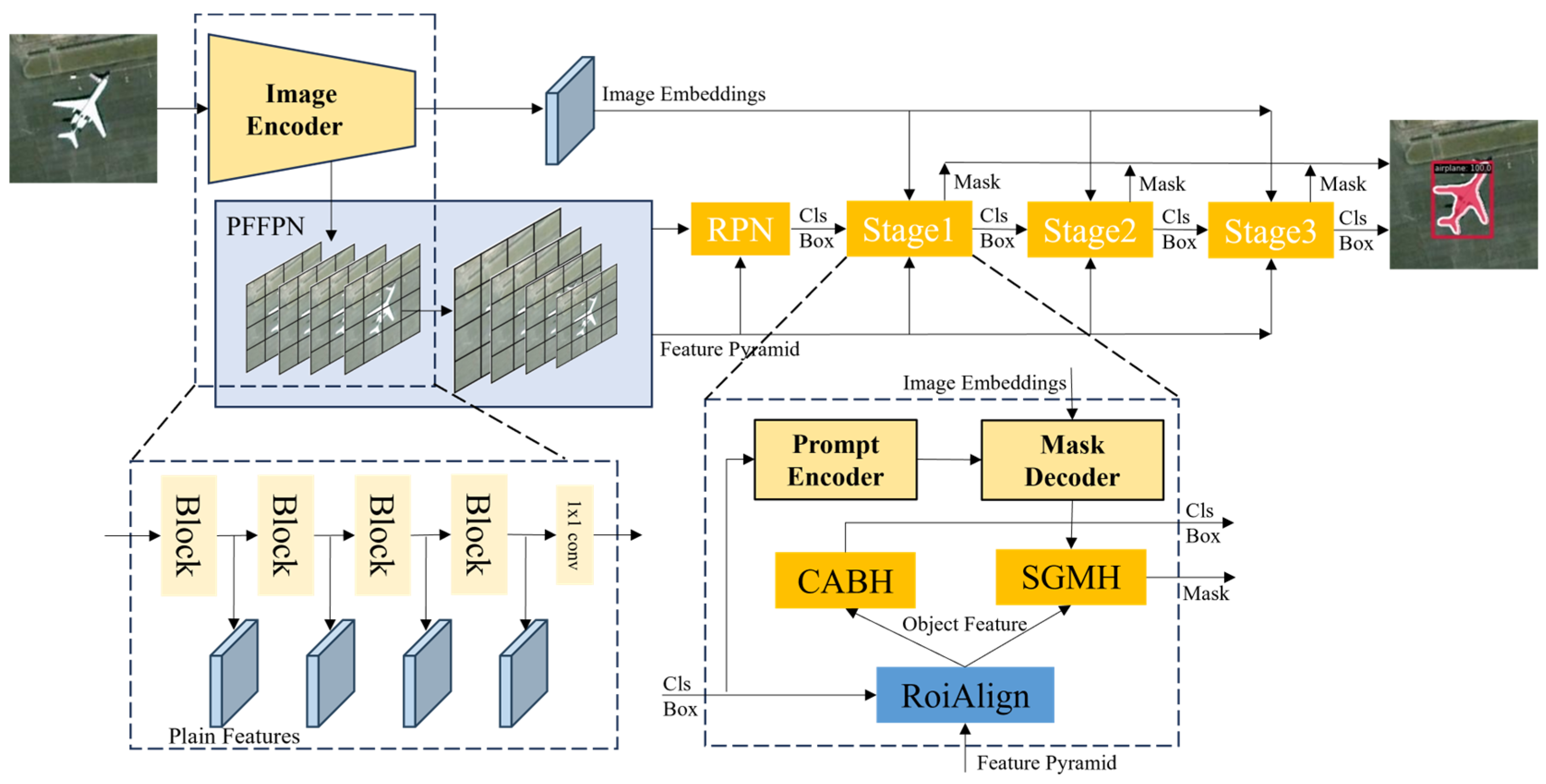
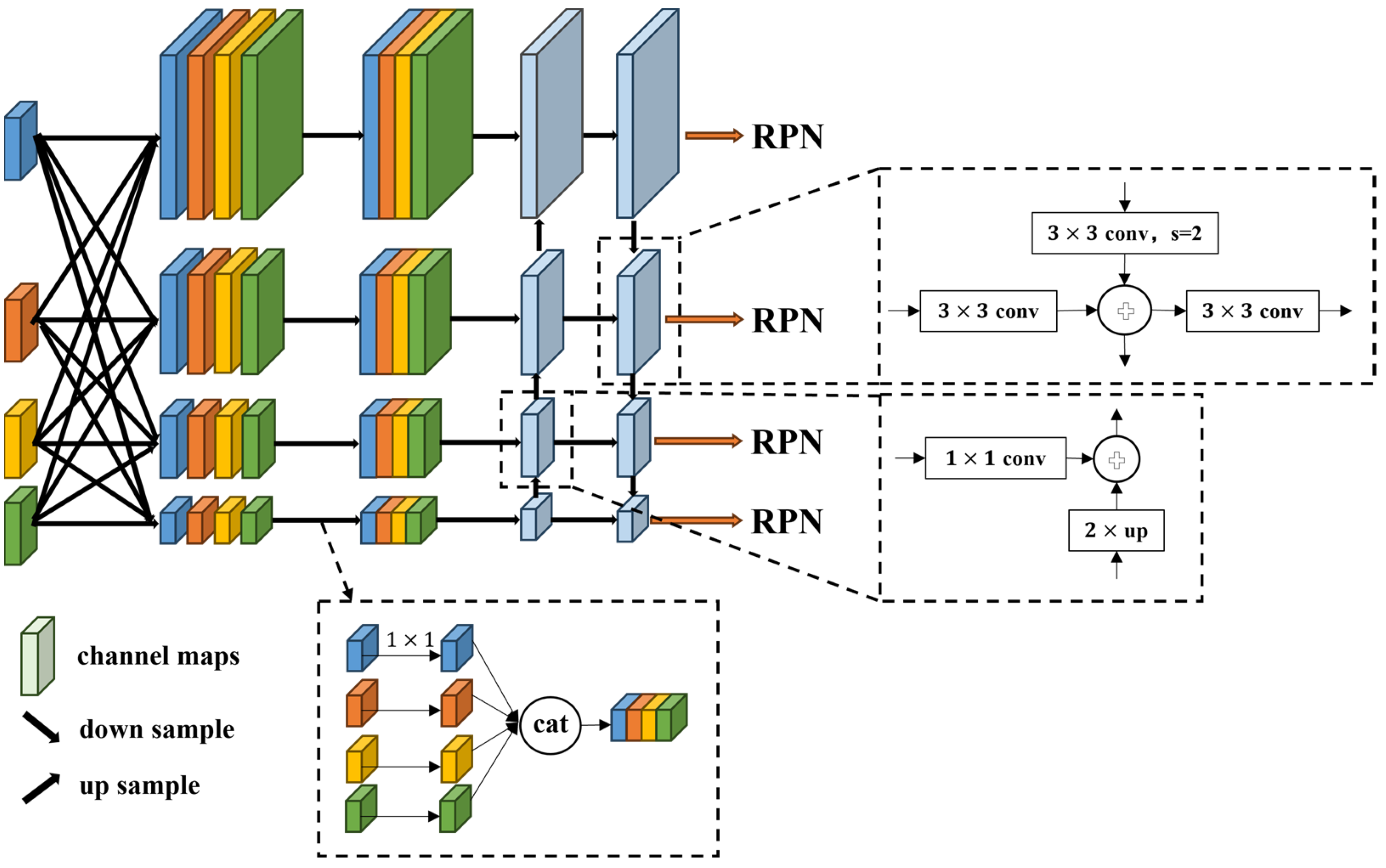
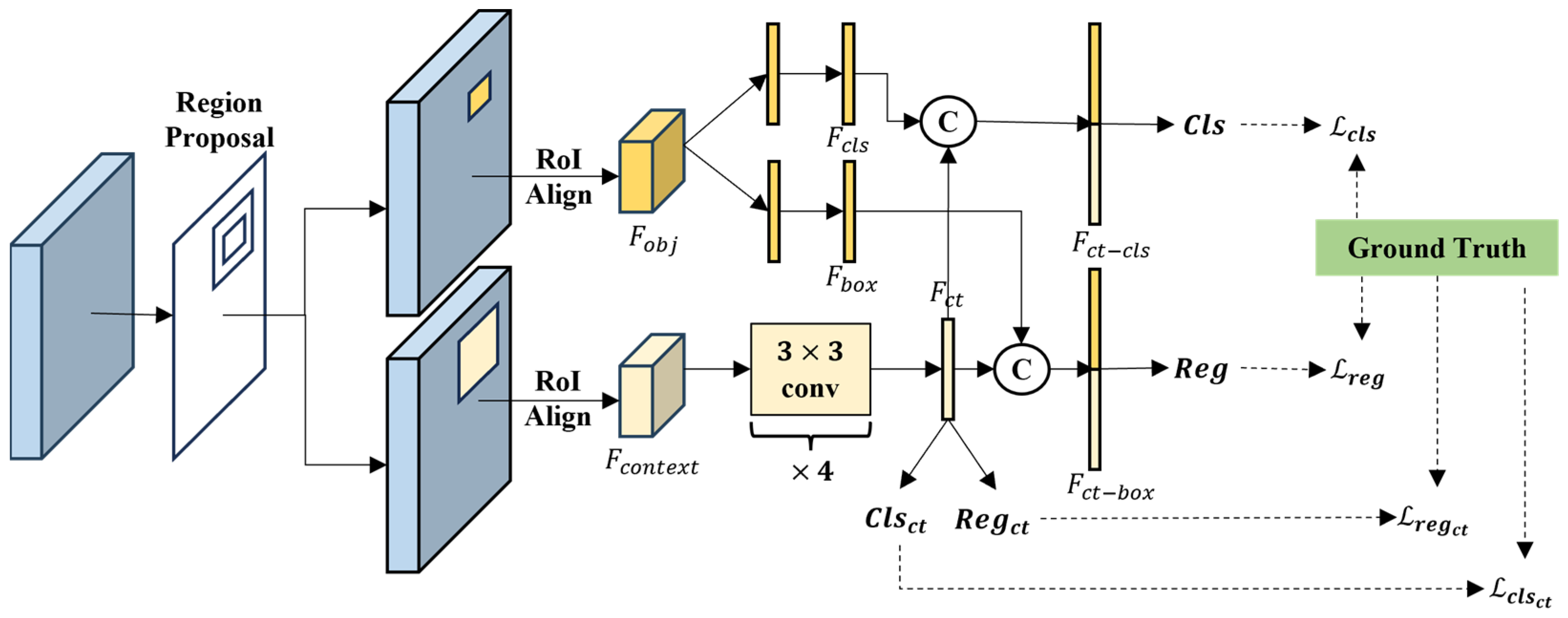
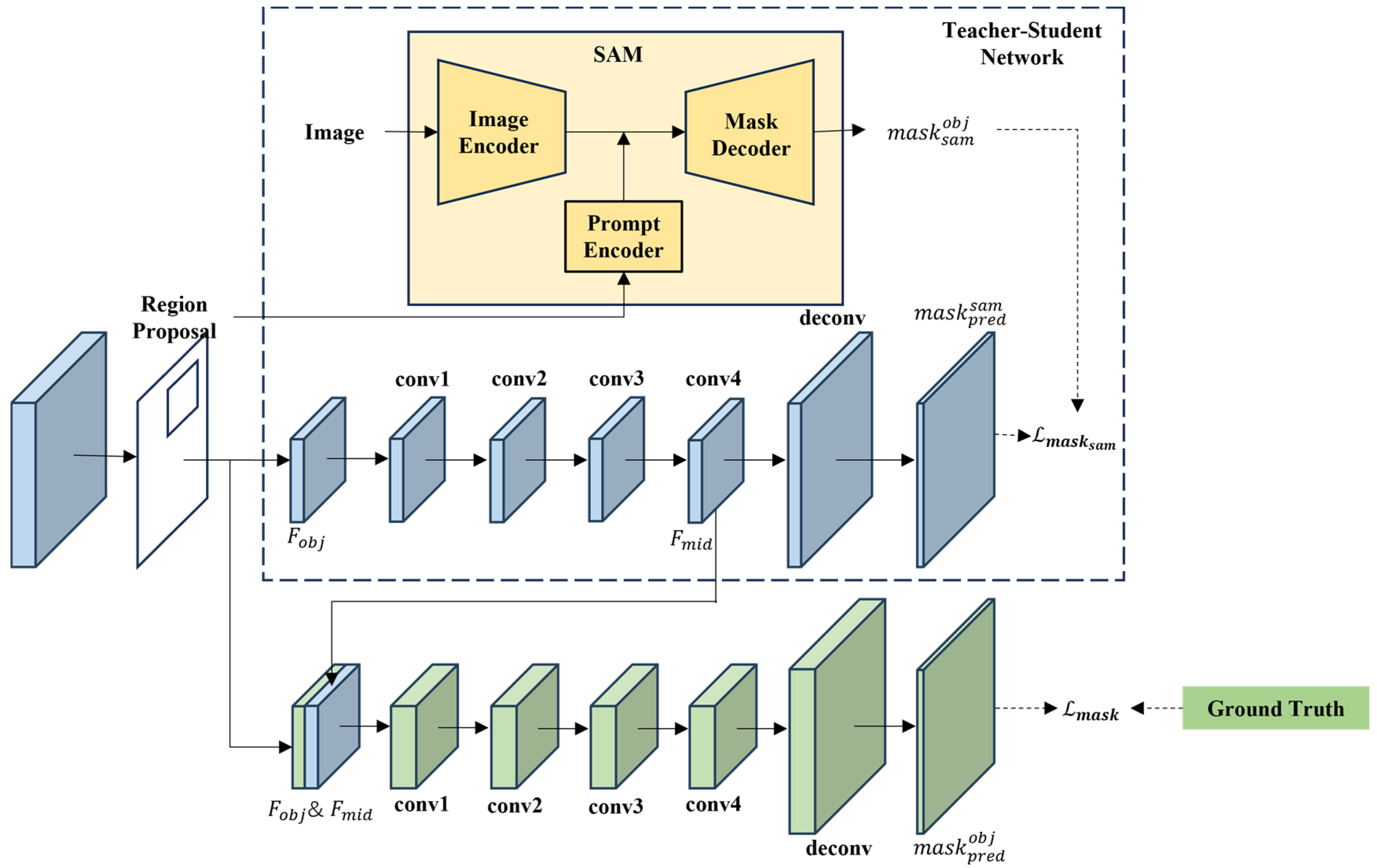



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).