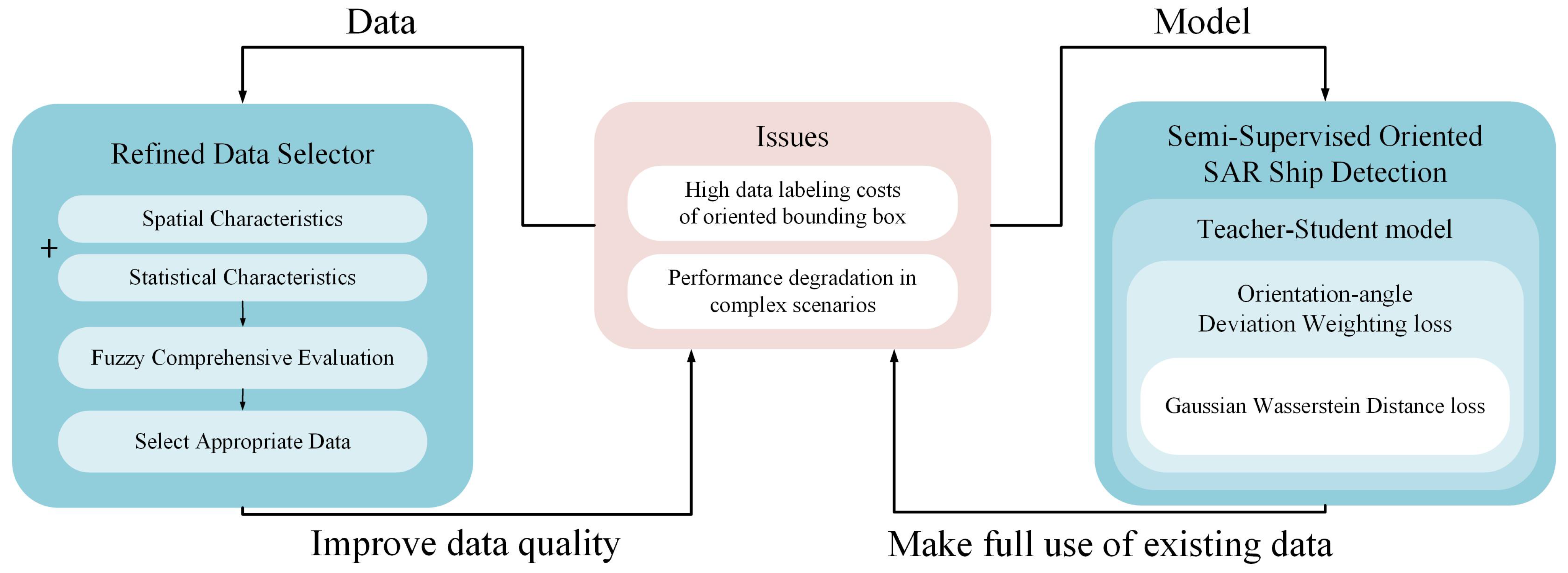
On the data side, a certain percentage of training data is selected as labeled data through the RDS, which has a good representation and includes as many scenarios as possible, to enhance the model’s training performance. First, we obtain the spatial and statistical features of SAR images as evaluation indicators, then use fuzzy comprehensive evaluation to score the images comprehensively, and finally, select the appropriate data based on the comprehensive scores.
On the model side, we designed a semi-supervised oriented SAR ship-detection framework that can fully utilize the existing labeled data and a large amount of unlabeled data. The specific process is shown in
Figure 2. For the first few iterations, known as the “burn-in” stage, supervised training of the student model is performed using only labeled data, and the teacher model is updated by the exponential moving average (EMA). In the unsupervised training stage, the unsupervised loss is calculated between pseudo-label prediction pairs.
The function of each component is shown in
Table 1. In practical applications, if a new SAR ship detection dataset needs to be established, the required amount of data is first selected using the refined data selector (RDS), ensuring that the scenes are highly representative. These selected images are then labeled. Subsequently, the proposed semi-supervised learning model is trained using this small amount of labeled data along with the remaining large amount of unlabeled data. This approach ensures the model’s detection performance while minimizing the labeling burden.
3.1. Refined Data Selector
Selecting an appropriate dataset is crucial in semi-supervised object detection. When using a semi-supervised object-detection method, selecting a suitable dataset can reduce the workload and cost of annotation, on the one hand, and also improve the performance of the model, on the other hand. In general, a SAR image with strong interference, strong clutter, and various scattering points must be more complex than the scene of a calm sea. Since the evaluation of the complexity of SAR images from multiple aspects is fuzzy and subjective, fuzzy comprehensive evaluation (FCE) will make the results as objective as possible and conform to humans’ subjective feelings.
FCE is a decision analysis method used to handle the uncertainty and fuzziness of information. It is commonly applied to solve complex multi-criteria decision-making problems, where there may be cross-impact and fuzziness among various indicators. FCE quantifies uncertainty and fuzziness, synthesizing information from multiple indicators to derive a comprehensive evaluation result. After the comprehensive scores (
s) of all SAR image data are obtained, the data with a certain score distribution are selected as the subsequent semi-supervised learning. The process of the refined data selector (RDS) is shown in
Figure 4.
3.1.1. Construction of Evaluation Indicators
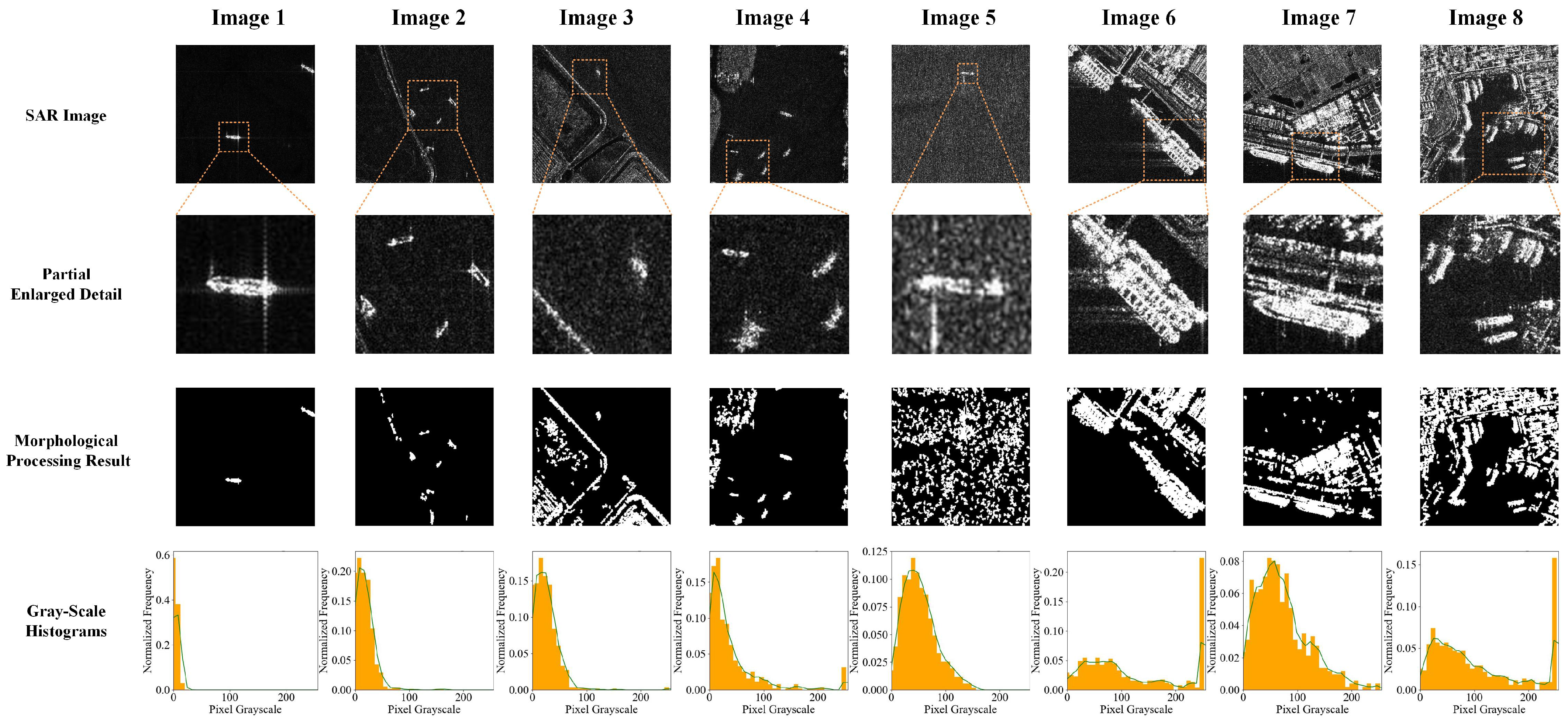
Selecting appropriate evaluation indicators in FCE is the most fundamental step. Two SAR images and their gray-scale histograms are shown in
Figure 5; one is a complex scene A with strong interference, and the other is an offshore scene B with a calm sea. Obviously, the mean value and variance of
Figure 5a will be significantly higher than that of
Figure 5b, and it is more complex spatially. Therefore, the appropriate statistical characteristics of the gray-scale values and the spatial characteristics can be selected as the indicators of FCE. We selected 7 indicators: mean
, variance
, spatial factor
, number of peaks
, position of highest peak
, width and position of the widest peak
w, and
in the histogram. Their calculation methods are as follows.
Mean and Variance
The mean and variance reflect the overall intensity level of SAR images and the fluctuation level of the gray-scale values, respectively. A higher mean value means that there are more strong scattering points or a large area of strong clutter in the image, and a larger the variance means that the gray-scale value distribution in the picture is more disperse. For an image of
:
where
represents the gray-scale value of the pixel in row
i and column
j.
Number of Peaks , Position of Highest Peak , Width of Widest Peak w, and Position of Widest Peak
The histogram analysis of SAR images reveals key characteristics for identifying ship targets and clutter. In the same SAR image, the gray-scale value of the ship target is relatively strong and uniform, and the proportion of pixels is small, so it should be displayed as a peak with a higher gray-scale value, narrower width, and lower height on the histogram. Therefore, the more peaks there are, the wider the width of the widest peak, indicating that there may be strong sea clutter, interference, or land clutter in the SAR image. Conversely, the highest peak and widest peak of SAR images with calm sea are more likely to have a lower gray-scale value, and the width is narrower, as shown in
Figure 5b. The histogram of SAR image gray-scale values is drawn and smoothed. The gradient is used to identify peak values. When the gradient of the signal exceeds a certain threshold, it is considered as a peak, and the full-width at half-maximum is used to calculate the width of the peak, as shown in the middle image of
Figure 5a.
Spatial Factor
Spatial factors reflect the spatial characteristics of SAR images and can explain the complexity of the scene to some extent. First, Otsu’s method is used to binarize SAR images and convert them to black and white. Next, we used the connected components labeling algorithm to label the connected regions in the image and obtain some statistics about each connected region, such as the area and centroid position. Then, according to the default threshold, we removed the small connected regions, which may be noise or unimportant parts. Next, we processed the binary image using the dilation operation so that adjacent white areas can be connected together, and regions remain. We then used a KD tree to find the nearest neighbor regions between the connected regions in the image and calculated the distance between them.
We believe that the more connected regions there are, the larger their area, and the closer the distance between adjacent regions, the larger the spatial factor is. Finally, we calculated the initial density of each pair of adjacent regions based on the distance
d and the area
S of connected regions, shown in
Figure 5a, and obtained the final spatial factor by:
where
,
, and
denote the weights of the number, area, and distance of the connection regions, which were empirically set as 0.3, 0.05, and 0.1, respectively.
3.1.2. Fuzzy Comprehensive Evaluation
The basic process of FCE is as follows: first, determine the evaluation set and the weights of the evaluation indicators for the SAR images, ranging from simple to complex. Next, conduct corresponding fuzzy evaluations for each indicator, and determine the membership function. Then, form the fuzzy judgment matrix. Finally, perform fuzzy operations with the weight matrix to obtain a quantitative comprehensive evaluation result.
Factor Set and Evaluation Set
The seven indicators mentioned in
Section 3.1.1 were set as the factor set by:
Four levels were set as the evaluation set, which were used to describe the complexity of the picture:
In FCE, the weights of different evaluation indicators are crucial as they reflect the importance or role of each factor in the comprehensive decision-making process, directly affecting the outcome. is the only spatial feature that can adequately reflect the spatial distribution of pixels in SAR images, thereby indicating the complexity of the scene. Therefore, we assigned it the highest weight. , , and w can fully reflect the overall intensity distribution of SAR images, so they are given moderate weights. For histograms with a single peak, , , and cannot independently reflect the scene complexity of SAR images; hence, they are assigned lower weights. Based on this, by fine-tuning these weights, we found that the final evaluation aligns better with our intuitive understanding of SAR image scene complexity when the weight vector is . In addition, the entropy weight method and the analytic hierarchy process can be used to determine the weights. Although the empirically assigned weights used in this paper are somewhat subjective, they reflect the actual situation to a certain extent, and the final evaluation results are relatively accurate.
Comprehensive Evaluation Matrix
Construct the comprehensive evaluation matrix
R and perform the comprehensive evaluation in conjunction with the weights
A.
where
is the normalized fuzzy evaluation set. ∘ denotes the weighted average fuzzy product of a row vector and a matrix, expressed as:
The weighted average principle is used to draw a comprehensive conclusion and assign scores to each level:
, resulting in the final score:
The results of each single factor evaluation
can be obtained by setting the membership function with different factors. The form of the membership function is shown in
Figure 6, and the parameters
are determined according to the distribution of each factor. Then, we can obtain the comprehensive evaluation matrix.
3.1.3. Choice of Appropriate Data
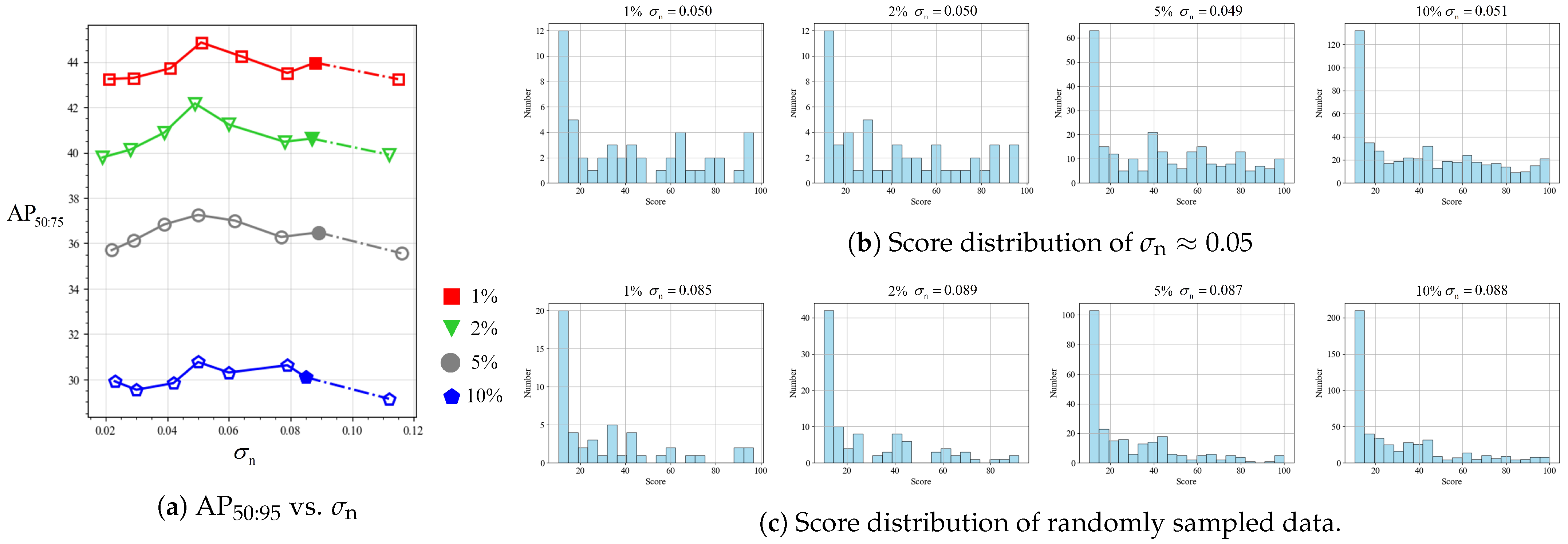
Appropriate training data were selected by interval sampling according to a certain distribution. According to the distribution of all data, the gray-scale values were manually divided into several intervals, and a certain amount of data was randomly sampled in different intervals to obtain labeled training data with different distributions.
The scores of the selected data were divided into 20 intervals, and the data number
of each interval was calculated. Their standard deviation can be used as a reference index to measure whether the data distribution is uniform: the smaller the standard deviation, the more uniform the distribution is. However, the different data amounts are different even if they are based on the same standard deviation, so the normalized standard deviation of these 20 intervals can be obtained by dividing the standard deviation with the amount of data to obtain the evenness index:
where
denotes the mean value of
.
3.2. Orientation-Angle Deviation Weighting Loss
We designed the orientation deviation weighting (ODW) loss as the unsupervised loss to enhance the performance of semi-supervised learning. In supervised learning, the ground truth is used as a reliable reference, and the prediction results will be forced to move closer to it. However, in semi-supervised learning, we cannot simply take the pseudo-labels, generated by the teacher model, as the ground truth, and copying the supervised training will cause the effect of semi-supervised learning to deteriorate in a positive feedback style: the student model learns the wrong information from the unreliable pseudo-labels generated by the teacher model, and the EMA-updated teacher model continuously obtains the wrong “cognition” and generates more unreliable pseudo-labels, eventually leading to the deterioration of the performance of semi-supervised training.
The overall loss is defined as the weighted sum of the supervised and unsupervised losses:
where
and
denote the supervised loss of labeled images and the unsupervised loss of unlabeled images, respectively, and
.
indicates the importance of the unsupervised loss. Both of them are normalized by the respective number of images in the training data batch:
where
and
denote the
i-th labeled and unlabeled image, respectively.
,
, and
are the classification loss, bounding box loss, and centerness loss, respectively.
and
indicate the number of labeled and unlabeled images, respectively. The bounding box loss, i.e., L1 loss, of the pseudo-label prediction pair is replaced by the Gaussian Wasserstein distance (GWD) loss, while the classification loss and centerness loss still adopt the focal loss and binary cross-entropy (BCE) loss.
Considering that the difference in orientation-angle between pseudo-label prediction pairs can reflect the difficulty of the sample to a certain extent, this deviation can be used as a weight to adaptively adjust the unsupervised loss. All the unsupervised losses were dynamically weighted by the orientation-angle deviation of the pseudo-label prediction pairs as the final unsupervised loss. The unsupervised bounding box losses are shown in Equation (
12), and the classification loss and centerness loss have similar forms. The supervised loss is also similar, but without weight
.
where
represents the number of pseudo-label prediction pairs for each image,
denotes the GWD loss of the
j-th pseudo-label prediction pairs, while
and
are the bounding boxes of the student model prediction and pseudo-label generated by the teacher model, respectively. The calculation method for the weight
is shown as follows:
where
and
are the oriented angles of the student model’s prediction and pseudo-label.
and
are hyper-parameters reflecting the importance of the orientation and the smoothness of the Huber loss, which can be empirically set as 50 and 1, respectively.
Sometimes, a small training loss does not mean a better result of detection, due to the inconsistency of the metric and loss function: such as the rotated intersection over union (RIoU) and smooth L1 loss. When using the smooth L1 loss, there are boundary discontinuity and square-like problems whether OpenCV or Long Edge is adopted as the bounding box definition. Therefore, we adopted the Gaussian Wasserstein distance (GWD) loss between the pseudo-labels and the student’s predicting results, instead of the smooth L1 loss.
As shown in
Figure 7, the GWD converts an oriented bounding box
into a 2D Gaussian distribution
. The detailed calculation process is expressed as follows:
where
and
represent the rotation matrix and the diagonal matrix of the eigenvalues, respectively.
The GWD between two probability distribution measures
and
can be expressed as:
The final form of the GWD loss is:
where
represents a nonlinear function to make the loss smoother and more expressive. In this paper, we set
as the nonlinear function and
.








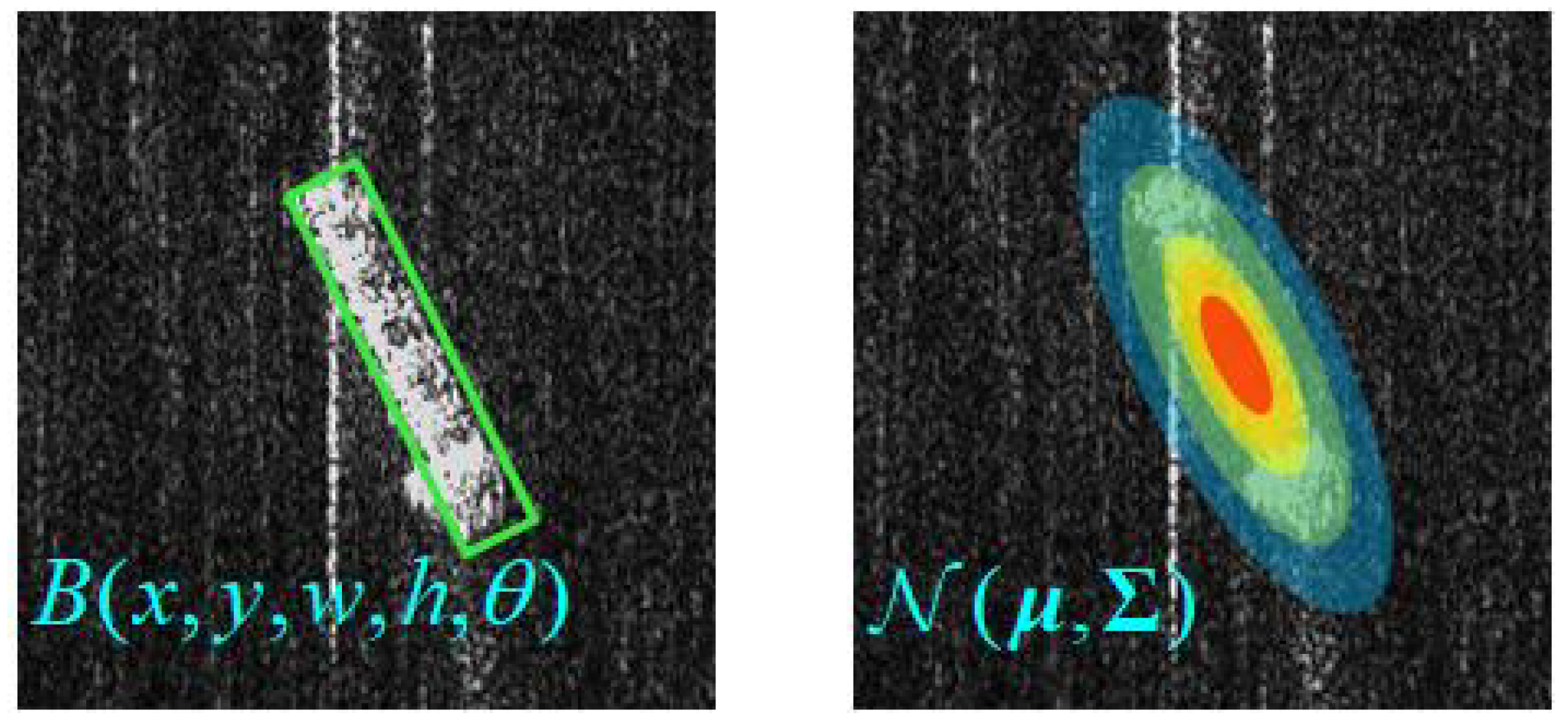



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}