
Wet-ConViT: A Hybrid Convolutional–Transformer Model for Efficient Wetland Classification Using Satellite Data



Abstract

1. Introduction
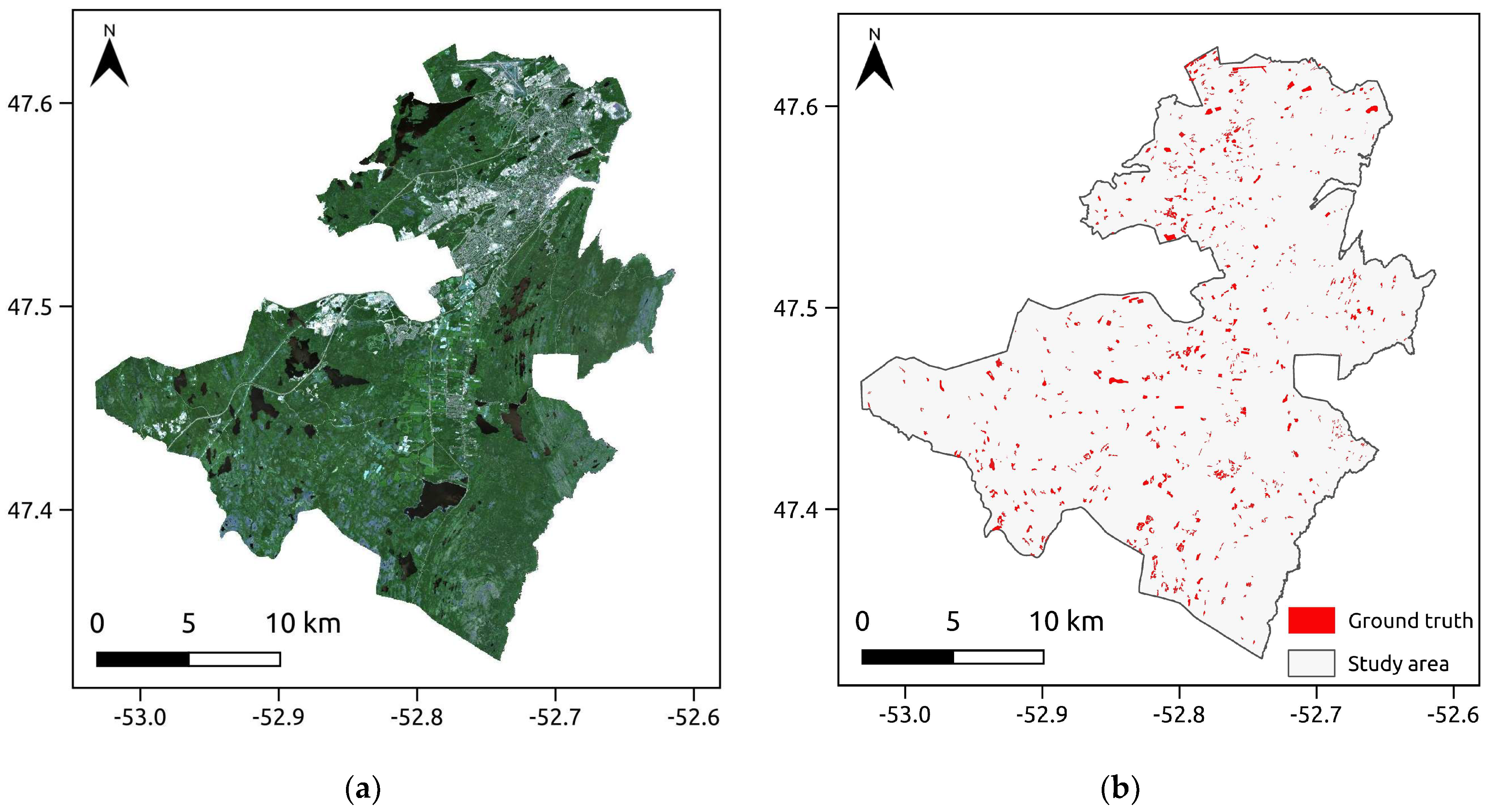
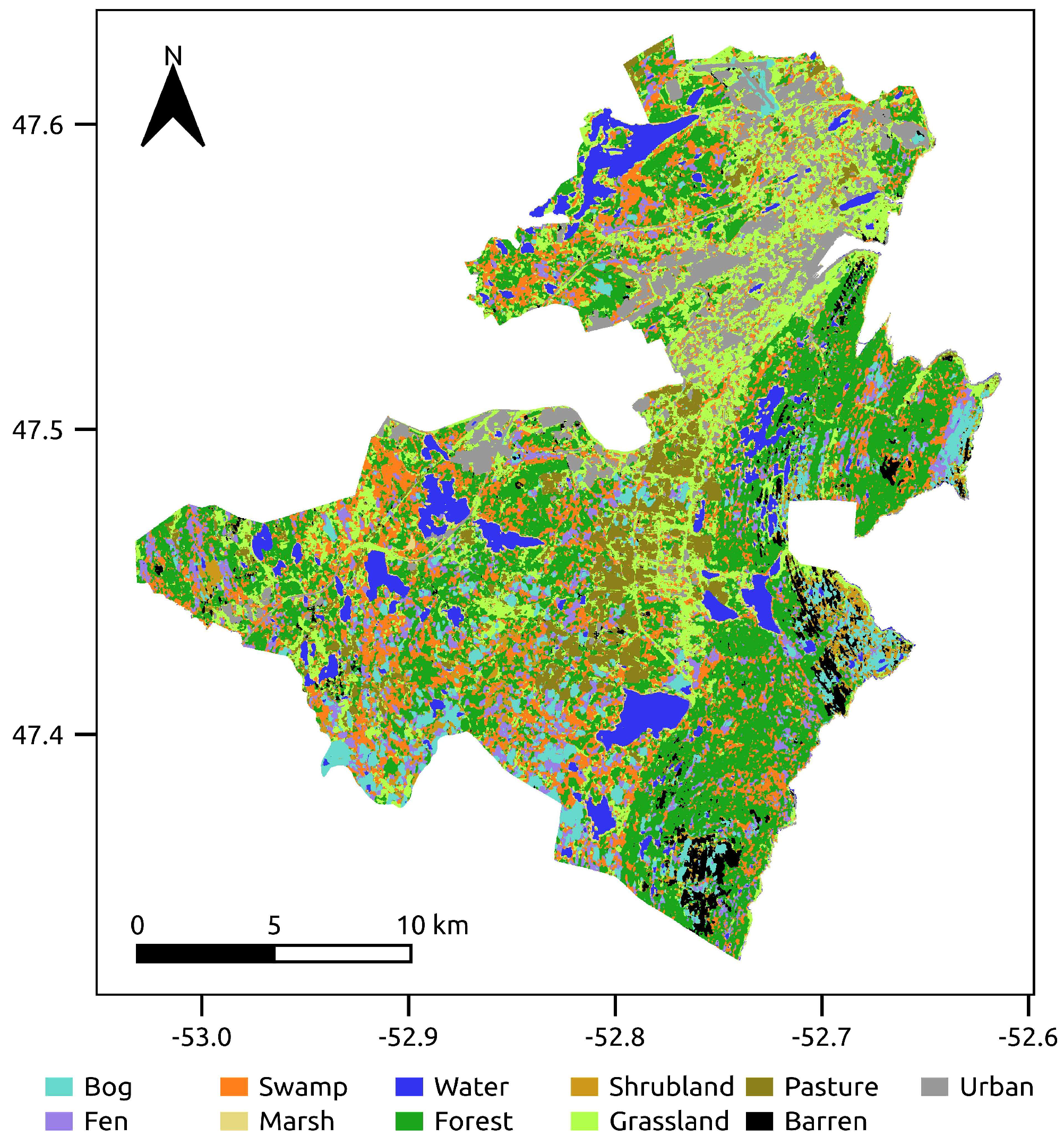
2. Study Area and Dataset
Reference Data
3. Methodology
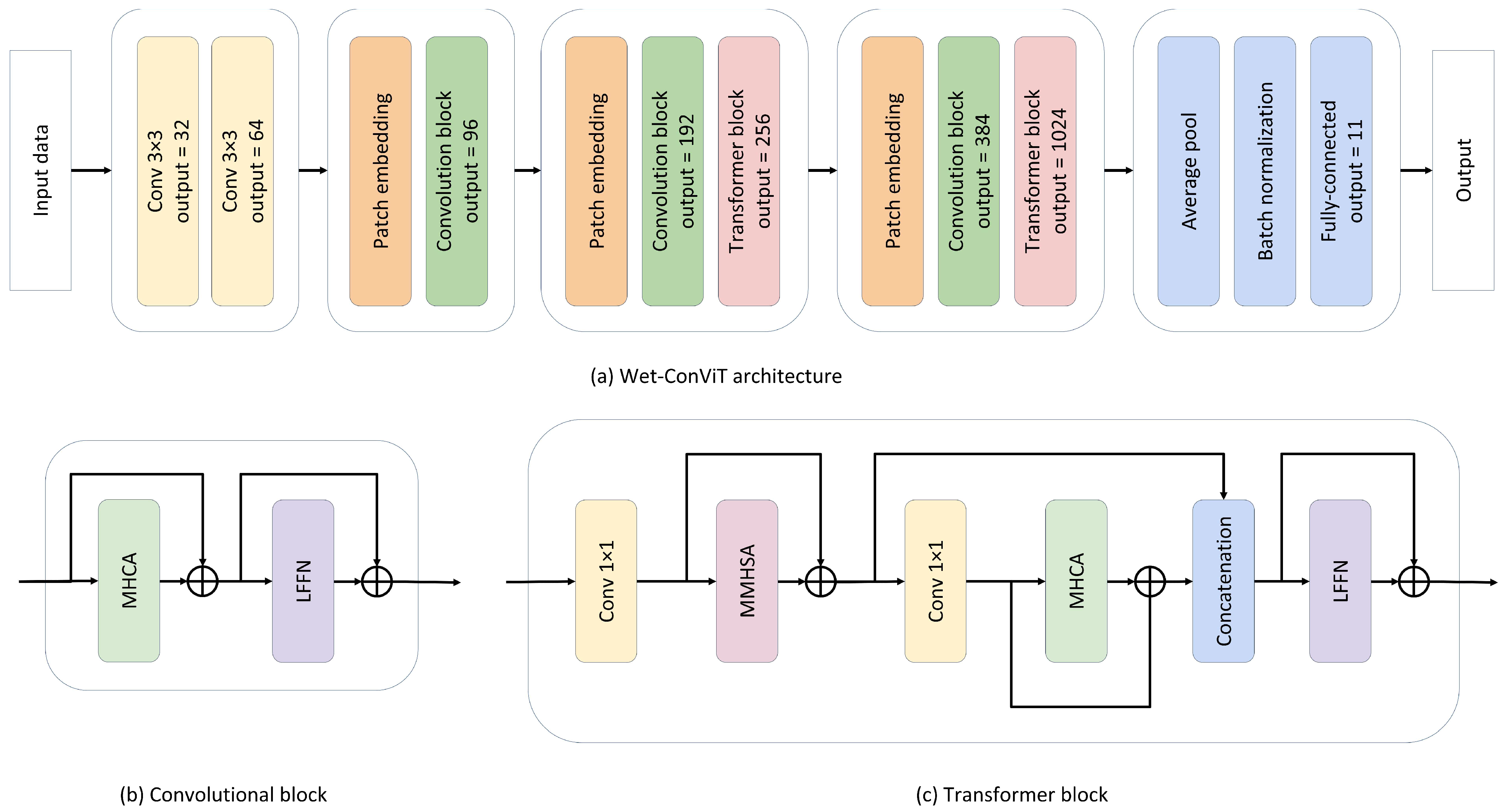
3.1. Proposed Framework
3.1.1. Modified Multi-Head Self-Attention (MMHSA)
3.1.2. Multi-Head Convolutional Attention (MHCA)
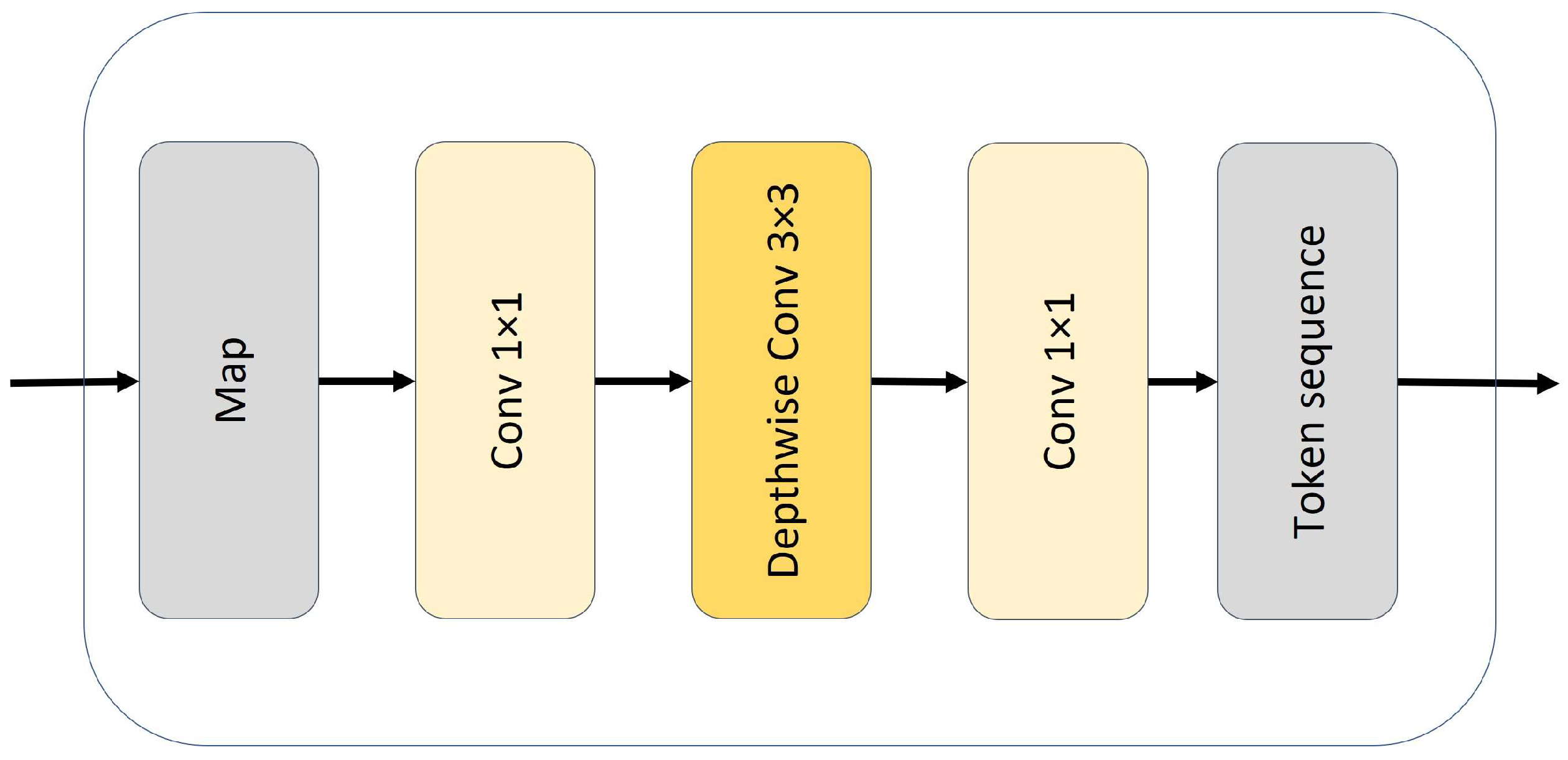
3.1.3. Local Feed-Forward Network (LFFN)
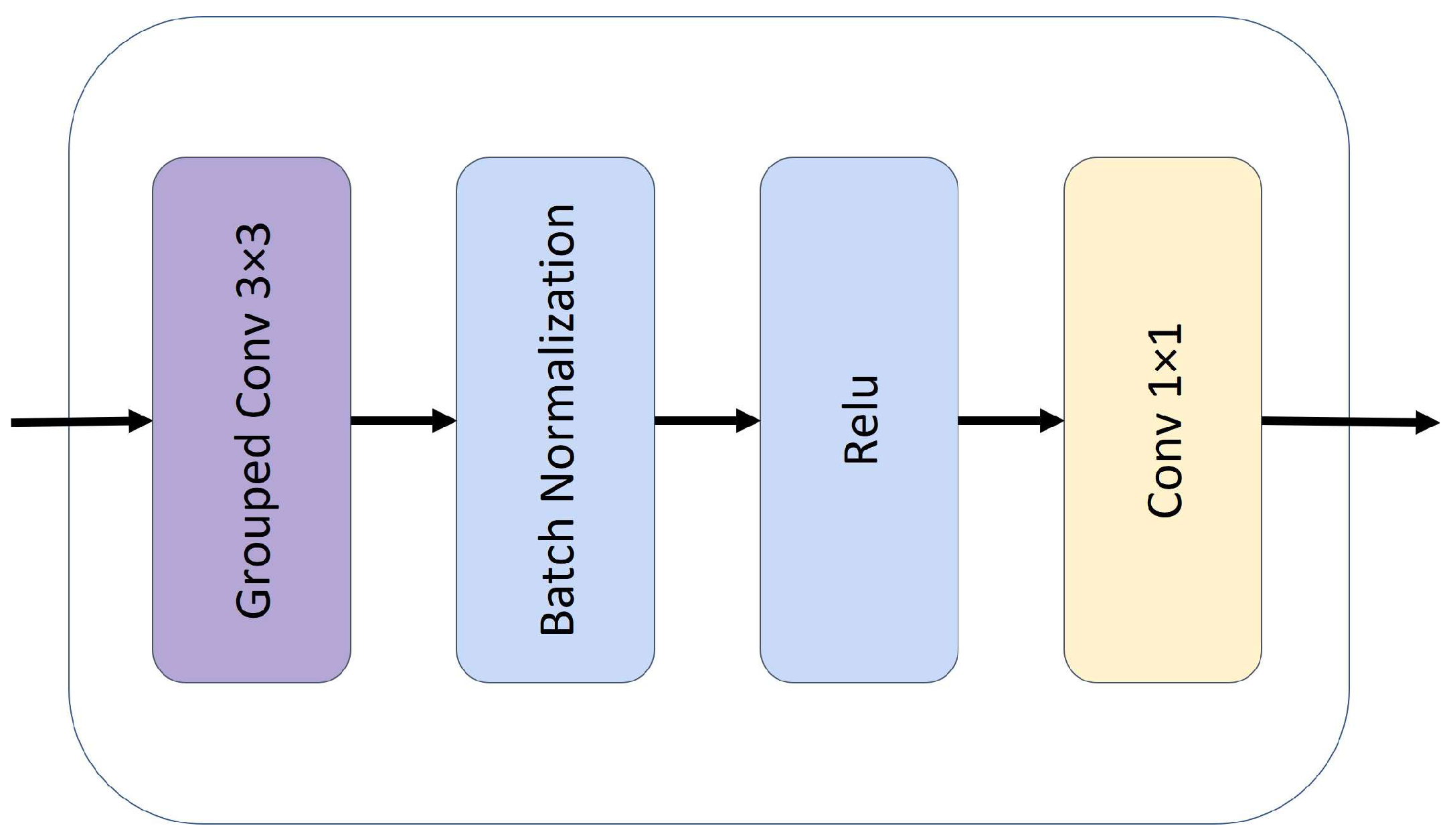
3.1.4. Convolutional and Local Transformer Blocks
3.2. Evaluation Models and Metrics
4. Experiments and Results
4.1. Implementation Details
4.2. Classification Maps
4.3. UMAP Feature Distribution
4.4. Statistical Results
4.5. Result Analysis and Discussion
4.6. Impact of Multi-Source Satellite Data
4.7. Efficiency Analysis
4.8. Patch Size Effect
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jamali, A.; Mahdianpari, M.; Mohammadimanesh, F.; Homayouni, S. A Deep Learning Framework Based on Generative Adversarial Networks and Vision Transformer for Complex Wetland Classification Using Limited Training Samples. Int. J. Appl. Earth Obs. Geoinf. 2022, 115, 103095. [Google Scholar] [CrossRef]
- Jamali, A.; Mahdianpari, M. Swin Transformer and Deep Convolutional Neural Networks for Coastal Wetland Classification Using Sentinel-1, Sentinel-2, and LiDAR Data. Remote Sens. 2022, 14, 359. [Google Scholar] [CrossRef]
- Jaramillo, F.; Brown, I.; Castellazzi, P.; Espinosa, L.; Guittard, A.; Hong, S.-H.; Rivera-Monroy, V.H.; Wdowinski, S. Assessment of Hydrologic Connectivity in an Ungauged Wetland with InSAR Observations. Environ. Res. Lett. 2018, 13, 024003. [Google Scholar] [CrossRef]
- Adeli, S.; Salehi, B.; Mahdianpari, M.; Quackenbush, L.J.; Brisco, B.; Tamiminia, H.; Shaw, S. Wetland Monitoring Using SAR Data: A Meta-Analysis and Comprehensive Review. Remote Sens. 2020, 12, 2190. [Google Scholar] [CrossRef]
- Hosseiny, B.; Mahdianpari, M.; Brisco, B.; Mohammadimanesh, F.; Salehi, B. WetNet: A Spatial–Temporal Ensemble Deep Learning Model for Wetland Classification Using Sentinel-1 and Sentinel-2. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4406014. [Google Scholar] [CrossRef]
- Mitsch, W.J.; Bernal, B.; Hernandez, M.E. Ecosystem Services of Wetlands. Int. J. Biodivers. Sci. Ecosyst. Serv. Manag. 2015, 11, 1–4. [Google Scholar] [CrossRef]
- Jamali, A.; Mahdianpari, M. Swin Transformer for Complex Coastal Wetland Classification Using the Integration of Sentinel-1 and Sentinel-2 Imagery. Water 2022, 14, 178. [Google Scholar] [CrossRef]
- Costanza, R.; De Groot, R.; Sutton, P.; Van Der Ploeg, S.; Anderson, S.J.; Kubiszewski, I.; Farber, S.; Turner, R.K. Changes in the Global Value of Ecosystem Services. Glob. Environ. Change 2014, 26, 152–158. [Google Scholar] [CrossRef]
- Serran, J.N.; Creed, I.F.; Ameli, A.A.; Aldred, D.A. Estimating Rates of Wetland Loss Using Power-Law Functions. Wetlands 2018, 38, 109–120. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Granger, J.E.; Mohammadimanesh, F.; Salehi, B.; Brisco, B.; Homayouni, S.; Gill, E.; Huberty, B.; Lang, M. Meta-Analysis of Wetland Classification Using Remote Sensing: A Systematic Review of a 40-Year Trend in North America. Remote Sens. 2020, 12, 1882. [Google Scholar] [CrossRef]
- Holland, R.A.; Darwall, W.R.T.; Smith, K.G. Conservation Priorities for Freshwater Biodiversity: The Key Biodiversity Area Approach Refined and Tested for Continental Africa. Biol. Conserv. 2012, 148, 167–179. [Google Scholar] [CrossRef]
- Onojeghuo, A.O.; Onojeghuo, A.R. Wetlands Mapping with Deep ResU-Net CNN and Open-Access Multisensor and Multitemporal Satellite Data in Alberta’s Parkland and Grassland Region. Remote Sens Earth Syst Sci 2023, 6, 22–37. [Google Scholar] [CrossRef]
- Cho, M.S.; Qi, J. Characterization of the Impacts of Hydro-Dams on Wetland Inundations in Southeast Asia. Sci. Total Environ. 2023, 864, 160941. [Google Scholar] [CrossRef]
- Fu, B.; Zuo, P.; Liu, M.; Lan, G.; He, H.; Lao, Z.; Zhang, Y.; Fan, D.; Gao, E. Classifying Vegetation Communities Karst Wetland Synergistic Use of Image Fusion and Object-Based Machine Learning Algorithm with Jilin-1 and UAV Multispectral Images. Ecol. Indic. 2022, 140, 108989. [Google Scholar] [CrossRef]
- Singh, M.; Allaka, S.; Gupta, P.K.; Patel, J.G.; Sinha, R. Deriving Wetland-Cover Types (WCTs) from Integration of Multispectral Indices Based on Earth Observation Data. Environ. Monit. Assess. 2022, 194, 878. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Motagh, M.; Akbari, V.; Mohammadimanesh, F.; Salehi, B. A Gaussian Random Field Model for De-Speckling of Multi-Polarized Synthetic Aperture Radar Data. Adv. Space Res. 2019, 64, 64–78. [Google Scholar] [CrossRef]
- Chang, S.; Deng, Y.; Zhang, Y.; Zhao, Q.; Wang, R.; Zhang, K. An Advanced Scheme for Range Ambiguity Suppression of Spaceborne SAR Based on Blind Source Separation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5230112. [Google Scholar] [CrossRef]
- Slagter, B.; Tsendbazar, N.-E.; Vollrath, A.; Reiche, J. Mapping Wetland Characteristics Using Temporally Dense Sentinel-1 and Sentinel-2 Data: A Case Study in the St. Lucia Wetlands, South Africa. Int. J. Appl. Earth Obs. Geoinf. 2020, 86, 102009. [Google Scholar] [CrossRef]
- Jamali, A.; Roy, S.K.; Ghamisi, P. WetMapFormer: A Unified Deep CNN and Vision Transformer for Complex Wetland Mapping. Int. J. Appl. Earth Obs. Geoinf. 2023, 120, 103333. [Google Scholar] [CrossRef]
- Franklin, S.E.; Skeries, E.M.; Stefanuk, M.A.; Ahmed, O.S. Wetland Classification Using Radarsat-2 SAR Quad-Polarization and Landsat-8 OLI Spectral Response Data: A Case Study in the Hudson Bay Lowlands Ecoregion. Int. J. Remote Sens. 2018, 39, 1615–1627. [Google Scholar] [CrossRef]
- Wang, C.; Pavelsky, T.M.; Kyzivat, E.D.; Garcia-Tigreros, F.; Podest, E.; Yao, F.; Yang, X.; Zhang, S.; Song, C.; Langhorst, T.; et al. Quantification of Wetland Vegetation Communities Features with Airborne AVIRIS-NG, UAVSAR, and UAV LiDAR Data in Peace-Athabasca Delta. Remote Sens. Environ. 2023, 294, 113646. [Google Scholar] [CrossRef]
- Xiang, H.; Xi, Y.; Mao, D.; Mahdianpari, M.; Zhang, J.; Wang, M.; Jia, M.; Yu, F.; Wang, Z. Mapping Potential Wetlands by a New Framework Method Using Random Forest Algorithm and Big Earth Data: A Case Study in China’s Yangtze River Basin. Glob. Ecol. Conserv. 2023, 42, e02397. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Mohammadimanesh, F. Applying GeoAI for Effective Large-Scale Wetland Monitoring. In Advances in Machine Learning and Image Analysis for GeoAI; Elsevier: Amsterdam, The Netherlands, 2024; pp. 281–313. ISBN 978-0-443-19077-3. [Google Scholar]
- Mohammadimanesh, F.; Salehi, B.; Mahdianpari, M.; Gill, E.; Molinier, M. A New Fully Convolutional Neural Network for Semantic Segmentation of Polarimetric SAR Imagery in Complex Land Cover Ecosystem. ISPRS J. Photogramm. Remote Sens. 2019, 151, 223–236. [Google Scholar] [CrossRef]
- Wang, X.; Jiang, W.; Deng, Y.; Yin, X.; Peng, K.; Rao, P.; Li, Z. Contribution of Land Cover Classification Results Based on Sentinel-1 and 2 to the Accreditation of Wetland Cities. Remote Sens. 2023, 15, 1275. [Google Scholar] [CrossRef]
- Peng, K.; Jiang, W.; Hou, P.; Wu, Z.; Ling, Z.; Wang, X.; Niu, Z.; Mao, D. Continental-Scale Wetland Mapping: A Novel Algorithm for Detailed Wetland Types Classification Based on Time Series Sentinel-1/2 Images. Ecol. Indic. 2023, 148, 110113. [Google Scholar] [CrossRef]
- Mahdavi, S.; Salehi, B.; Granger, J.; Amani, M.; Brisco, B.; Huang, W. Remote Sensing for Wetland Classification: A Comprehensive Review. GIScience Remote Sens. 2018, 55, 623–658. [Google Scholar] [CrossRef]
- Amani, M.; Salehi, B.; Mahdavi, S.; Granger, J. Spectral analysis of wetlands in newfoundland using sentinel 2a and landsat 8 imagery. In Proceedings of the IGTF, Baltimore, MD, USA, 12–16 March 2017. [Google Scholar]
- Jamali, A.; Mahdianpari, M.; Brisco, B.; Granger, J.; Mohammadimanesh, F.; Salehi, B. Deep Forest Classifier for Wetland Mapping Using the Combination of Sentinel-1 and Sentinel-2 Data. GIScience Remote Sens. 2021, 58, 1072–1089. [Google Scholar] [CrossRef]
- Wang, M.; Mao, D.; Wang, Y.; Xiao, X.; Xiang, H.; Feng, K.; Luo, L.; Jia, M.; Song, K.; Wang, Z. Wetland Mapping in East Asia by Two-Stage Object-Based Random Forest and Hierarchical Decision Tree Algorithms on Sentinel-1/2 Images. Remote Sens. Environ. 2023, 297, 113793. [Google Scholar] [CrossRef]
- Jafarzadeh, H.; Mahdianpari, M.; Gill, E.W.; Mohammadimanesh, F. Enhancing Wetland Mapping: Integrating Sentinel-1/2, GEDI Data, and Google Earth Engine. Sensors 2024, 24, 1651. [Google Scholar] [CrossRef]
- Munizaga, J.; García, M.; Ureta, F.; Novoa, V.; Rojas, O.; Rojas, C. Mapping Coastal Wetlands Using Satellite Imagery and Machine Learning in a Highly Urbanized Landscape. Sustainability 2022, 14, 5700. [Google Scholar] [CrossRef]
- Islam, M.K.; Simic Milas, A.; Abeysinghe, T.; Tian, Q. Integrating UAV-Derived Information and WorldView-3 Imagery for Mapping Wetland Plants in the Old Woman Creek Estuary, USA. Remote Sens. 2023, 15, 1090. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Salehi, B.; Mohammadimanesh, F.; Brisco, B.; Homayouni, S.; Gill, E.; DeLancey, E.R.; Bourgeau-Chavez, L. Big Data for a Big Country: The First Generation of Canadian Wetland Inventory Map at a Spatial Resolution of 10-m Using Sentinel-1 and Sentinel-2 Data on the Google Earth Engine Cloud Computing Platform. Can. J. Remote Sens. 2020, 46, 15–33. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Brisco, B.; Granger, J.E.; Mohammadimanesh, F.; Salehi, B.; Banks, S.; Homayouni, S.; Bourgeau-Chavez, L.; Weng, Q. The Second Generation Canadian Wetland Inventory Map at 10 Meters Resolution Using Google Earth Engine. Can. J. Remote Sens. 2020, 46, 360–375. [Google Scholar] [CrossRef]
- Hemati, M.; Mahdianpari, M.; Shiri, H.; Mohammadimanesh, F. Integrating SAR and Optical Data for Aboveground Biomass Estimation of Coastal Wetlands Using Machine Learning: Multi-Scale Approach. Remote Sens. 2024, 16, 831. [Google Scholar] [CrossRef]
- Dang, K.B.; Nguyen, M.H.; Nguyen, D.A.; Phan, T.T.H.; Giang, T.L.; Pham, H.H.; Nguyen, T.N.; Tran, T.T.V.; Bui, D.T. Coastal Wetland Classification with Deep U-Net Convolutional Networks and Sentinel-2 Imagery: A Case Study at the Tien Yen Estuary of Vietnam. Remote Sens. 2020, 12, 3270. [Google Scholar] [CrossRef]
- Zheng, J.-Y.; Hao, Y.-Y.; Wang, Y.-C.; Zhou, S.-Q.; Wu, W.-B.; Yuan, Q.; Gao, Y.; Guo, H.-Q.; Cai, X.-X.; Zhao, B. Coastal Wetland Vegetation Classification Using Pixel-Based, Object-Based and Deep Learning Methods Based on RGB-UAV. Land 2022, 11, 2039. [Google Scholar] [CrossRef]
- DeLancey, E.R.; Simms, J.F.; Mahdianpari, M.; Brisco, B.; Mahoney, C.; Kariyeva, J. Comparing Deep Learning and Shallow Learning for Large-Scale Wetland Classification in Alberta, Canada. Remote Sens. 2019, 12, 2. [Google Scholar] [CrossRef]
- Yang, R.; Luo, F.; Ren, F.; Huang, W.; Li, Q.; Du, K.; Yuan, D. Identifying Urban Wetlands through Remote Sensing Scene Classification Using Deep Learning: A Case Study of Shenzhen, China. ISPRS Int. J. Geo-Inf. 2022, 11, 131. [Google Scholar] [CrossRef]
- Jafarzadeh, H.; Mahdianpari, M.; Gill, E.W. Wet-GC: A Novel Multimodel Graph Convolutional Approach for Wetland Classification Using Sentinel-1 and 2 Imagery With Limited Training Samples. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5303–5316. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2021, Virtual, 11–17 October 2021. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin Transformer V2: Scaling Up Capacity and Resolution. arXiv 2021, arXiv:2111.09883. [Google Scholar] [CrossRef]
- Qi, W.; Huang, C.; Wang, Y.; Zhang, X.; Sun, W.; Zhang, L. Global–Local 3-D Convolutional Transformer Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5510820. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Mahdianpari, M.; Salehi, B.; Mohammadimanesh, F.; Homayouni, S.; Gill, E. The First Wetland Inventory Map of Newfoundland at a Spatial Resolution of 10 m Using Sentinel-1 and Sentinel-2 Data on the Google Earth Engine Cloud Computing Platform. Remote Sens. 2018, 11, 43. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Salehi, B.; Mohammadimanesh, F.; Brisco, B. An Assessment of Simulated Compact Polarimetric SAR Data for Wetland Classification Using Random Forest Algorithm. Can. J. Remote Sens. 2017, 43, 468–484. [Google Scholar] [CrossRef]
- Mohammadimanesh, F.; Salehi, B.; Mahdianpari, M.; Motagh, M.; Brisco, B. An Efficient Feature Optimization for Wetland Mapping by Synergistic Use of SAR Intensity, Interferometry, and Polarimetry Data. Int. J. Appl. Earth Obs. Geoinf. 2018, 73, 450–462. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Granger, J.E.; Mohammadimanesh, F.; Warren, S.; Puestow, T.; Salehi, B.; Brisco, B. Smart Solutions for Smart Cities: Urban Wetland Mapping Using Very-High Resolution Satellite Imagery and Airborne LiDAR Data in the City of St. John’s, NL, Canada. J. Environ. Manag. 2021, 280, 111676. [Google Scholar] [CrossRef] [PubMed]
- Warner, B.G.; Rubec, C.D. The Canadian Wetland Classification System; Wetlands Research Centre, University of Waterloo: Waterloo, ON, Canada, 1997; ISBN 0-662-25857-6. [Google Scholar]
- Agriculture and Agri-Food Canada. ISO 19131 Annual Crop Inventory–Data Product Specifications; Agriculture and Agri-Food Canada: Ottawa, ON, Canada, 2018; Volume 27. [Google Scholar]
- Manzari, O.N.; Ahmadabadi, H.; Kashiani, H.; Shokouhi, S.B.; Ayatollahi, A. MedViT: A Robust Vision Transformer for Generalized Medical Image Classification. Comput. Biol. Med. 2023, 157, 106791. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012; Volume 25. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 18–24 July 2021. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. CvT: Introducing Convolutions to Vision Transformers. arXiv 2021, arXiv:2103.15808. [Google Scholar] [CrossRef]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. CoAtNet: Marrying Convolution and Attention for All Data Sizes. arXiv 2021, arXiv:2106.04803. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar] [CrossRef]
- Sang, H.; Zhang, J.; Lin, H.; Zhai, L. Multi-Polarization ASAR Backscattering from Herbaceous Wetlands in Poyang Lake Region, China. Remote Sens. 2014, 6, 4621–4646. [Google Scholar] [CrossRef]
- Xing, M.; Chen, L.; Wang, J.; Shang, J.; Huang, X. Soil Moisture Retrieval Using SAR Backscattering Ratio Method during the Crop Growing Season. Remote Sens. 2022, 14, 3210. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Polygons | Samples |
|---|---|---|
| Bog | 98 | 42,148 |
| Fen | 113 | 29,648 |
| Swamp | 116 | 15,424 |
| Marsh | 49 | 3445 |
| Water | 68 | 24,615 |
| Forests | 103 | 35,452 |
| Shrublands | 37 | 6400 |
| Grassland | 126 | 17,624 |
| Pastures | 47 | 19,745 |
| Barren | 24 | 1789 |
| Urban | 48 | 25,308 |
| Total | 829 | 221,598 |
| Models | ||||||||
|---|---|---|---|---|---|---|---|---|
| Convolution | Transformer | Hybrid | ||||||
| Class | ResNet50 | EfficientNet | ViT | Swin | CvT | CoAtNet | WMP | Proposed |
| Bog | 90.14% | 89.07% | 81.94% | 88.87% | 90.71% | 92.15% | 88.15% | 94.79% |
| Fen | 83.29% | 82.61% | 78.14% | 81.19% | 84.63% | 86.85% | 82.45% | 90.57% |
| Swamp | 80.66% | 79.81% | 73.93% | 75.56% | 79.01% | 84.47% | 81.37% | 89.04% |
| Marsh | 75.80% | 79.42% | 79.59% | 76.91% | 84.94% | 89.52% | 82.03% | 89.91% |
| Water | 98.66% | 98.62% | 98.97% | 98.63% | 99.07% | 99.21% | 99.43% | 99.02% |
| Forests | 90.52% | 90.34% | 87.32% | 89.20% | 90.94% | 94.29% | 91.09% | 95.96% |
| Shrublands | 88.35% | 87.61% | 84.46% | 85.56% | 91.29% | 96.66% | 88.18% | 94.88% |
| Grassland | 82.86% | 82.77% | 78.15% | 79.45% | 83.29% | 89.75% | 85.89% | 93.41% |
| Pastures | 93.89% | 94.93% | 92.23% | 91.71% | 93.74% | 95.40% | 96.33% | 98.08% |
| Barren | 92.33% | 89.85% | 92.35% | 86.20% | 82.03% | 98.66% | 94.63% | 94.23% |
| Urban | 98.77% | 98.32% | 98.90% | 97.90% | 98.44% | 99.21% | 99.13% | 99.46% |
| OA | 90.39% | 90.18% | 87.05% | 88.75% | 90.82% | 93.34% | 90.91% | 95.36% |
| AA | 88.66% | 88.49% | 86.00% | 86.47% | 88.92% | 93.29% | 88.84% | 94.49% |
| k | 89.08% | 88.82% | 85.26% | 87.22% | 89.56% | 92.44% | 89.64% | 94.72% |
| S1 | S2 | S1S2 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | CvT | CoAtNet | WMF | Proposed | CvT | CoAtNet | WMF | Proposed | CvT | CoAtNet | WMF | Proposed |
| Bog | 70.41% | 81.89% | 58.56% | 79.79% | 81.60% | 83.22% | 79.86% | 93.78% | 90.71% | 92.15% | 88.15% | 94.79% |
| Fen | 61.47% | 75.63% | 54.44% | 72.88% | 79.99% | 79.26% | 78.46% | 89.19% | 84.63% | 86.85% | 82.45% | 90.57% |
| Swamp | 50.37% | 65.07% | 28.62% | 68.36% | 67.46% | 71.90% | 70.34% | 86.63% | 79.01% | 84.47% | 81.37% | 89.04% |
| Marsh | 64.57% | 73.84% | 48.72% | 79.11% | 48.44% | 59.78% | 51.98% | 87.73% | 84.94% | 89.52% | 82.03% | 89.91% |
| Water | 96.80% | 96.49% | 95.73% | 97.75% | 97.25% | 98.52% | 98.14% | 97.83% | 99.07% | 99.21% | 99.43% | 99.02% |
| Forests | 72.28% | 82.66% | 72.58% | 85.36% | 80.93% | 85.03% | 85.29% | 94.06% | 90.94% | 94.29% | 91.09% | 95.96% |
| Shrublands | 56.78% | 67.09% | 46.79% | 67.56% | 85.72% | 83.40% | 87.33% | 90.98% | 91.29% | 96.66% | 88.18% | 94.88% |
| Grassland | 52.39% | 65.76% | 16.41% | 70.36% | 77.26% | 79.86% | 79.35% | 90.14% | 83.29% | 89.75% | 85.89% | 93.41% |
| Pastures | 85.89% | 91.33% | 84.11% | 91.46% | 85.29% | 90.79% | 90.89% | 96.51% | 93.74% | 95.40% | 96.33% | 98.08% |
| Barren | 60.53% | 73.73% | 30.16% | 72.39% | 39.24% | 45.81% | 72.22% | 92.31% | 82.03% | 98.66% | 94.63% | 94.23% |
| Urban | 84.97% | 93.37% | 86.08% | 90.47% | 94.85% | 94.78% | 94.49% | 98.74% | 98.44% | 99.21% | 99.13% | 99.46% |
| OA | 72.43% | 82.36% | 67.52% | 82.56% | 82.23% | 84.42% | 83.89% | 93.73% | 90.82% | 93.34% | 90.91% | 95.36% |
| AA | 69.51% | 78.79% | 56.62% | 80.78% | 77.37% | 81.93% | 79.43% | 92.75% | 88.92% | 93.29% | 88.84% | 94.49% |
| k | 68.77% | 79.95% | 62.77% | 80.18% | 79.75% | 82.23% | 81.59% | 92.87% | 89.56% | 92.44% | 89.64% | 94.72% |
| ResNet50 | EfficientNet | ViT | Swin | CvT | CoAtNet | WMF | Proposed | |
|---|---|---|---|---|---|---|---|---|
| Params (millions) | 23.57 | 20.19 | 87.72 | 27.61 | 19.66 | 17.37 | 0.7 | 9.44 |
| Memory size (MB) | 90.2 | 77.9 | 335.1 | 105.8 | 75.3 | 66.4 | 8.3 | 36.3 |
| Training time (s) | 63 | 122 | 122 | 276 | 116 | 75 | 37 | 77 |
| Inference time (s) | 5.99 | 13.64 | 13.08 | 32.99 | 19.73 | 15.55 | 3.07 | 9.16 |
| OA (%) | 90.39 | 90.18 | 87.05 | 88.75 | 90.82 | 93.34 | 90.91 | 95.36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Radman, A.; Mohammadimanesh, F.; Mahdianpari, M. Wet-ConViT: A Hybrid Convolutional–Transformer Model for Efficient Wetland Classification Using Satellite Data. Remote Sens. 2024, 16, 2673. https://doi.org/10.3390/rs16142673
Radman A, Mohammadimanesh F, Mahdianpari M. Wet-ConViT: A Hybrid Convolutional–Transformer Model for Efficient Wetland Classification Using Satellite Data. Remote Sensing. 2024; 16(14):2673. https://doi.org/10.3390/rs16142673
Chicago/Turabian StyleRadman, Ali, Fariba Mohammadimanesh, and Masoud Mahdianpari. 2024. "Wet-ConViT: A Hybrid Convolutional–Transformer Model for Efficient Wetland Classification Using Satellite Data" Remote Sensing 16, no. 14: 2673. https://doi.org/10.3390/rs16142673
APA StyleRadman, A., Mohammadimanesh, F., & Mahdianpari, M. (2024). Wet-ConViT: A Hybrid Convolutional–Transformer Model for Efficient Wetland Classification Using Satellite Data. Remote Sensing, 16(14), 2673. https://doi.org/10.3390/rs16142673