
Pineapple Detection with YOLOv7-Tiny Network Model Improved via Pruning and a Lightweight Backbone Sub-Network


Abstract
:1. Introduction
- To enhance the flexibility and generalization of the visual model, we collected and constructed a dataset containing images of pineapples in various environments at the pineapple plantation base in Xuwen County, Zhanjiang City, Guangdong Province.
- By replacing the main trunk network, introducing the lightweight GSConv module, and incorporating the decoupled head structure, improvements were made to the YOLOv7-tiny model, enhancing its detection accuracy and efficiency.
- By applying the group-level pruning method based on the analysis of the dependency graph, the model was pruned. This effectively reduced the model’s complexity, maintained detection accuracy, and improved the model’s deployment efficiency on resource-constrained devices.
2. Materials and Methods
2.1. Building the Pineapple Dataset
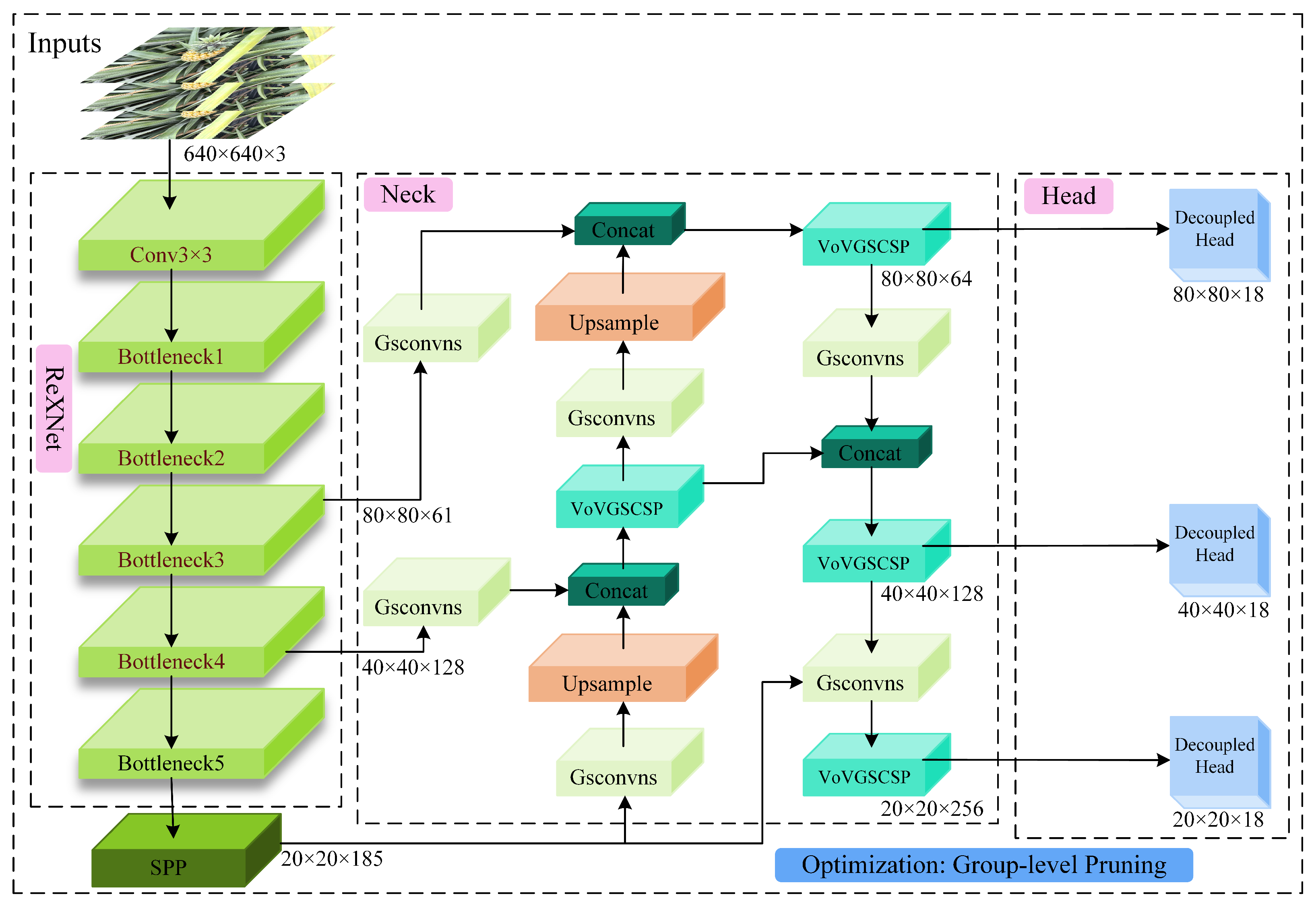
2.2. Improved YOLOv7-Tiny Network Framework
2.2.1. YOLOv7-Tiny Network Framework
2.2.2. Trunk Replacement
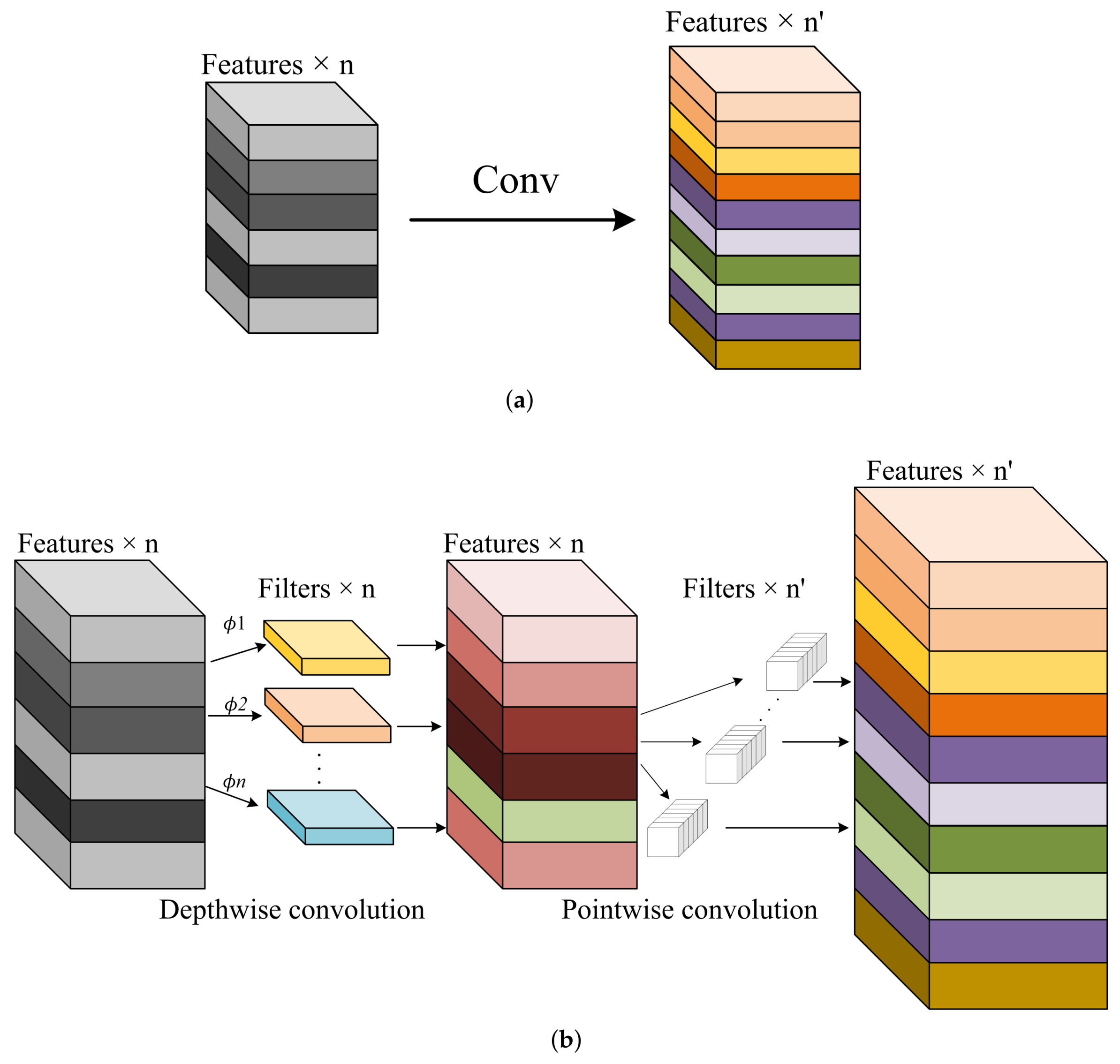
2.2.3. Neck Network Introduces the GSConv Lightweight Module
2.2.4. Detection Network Introduces Decouped Head
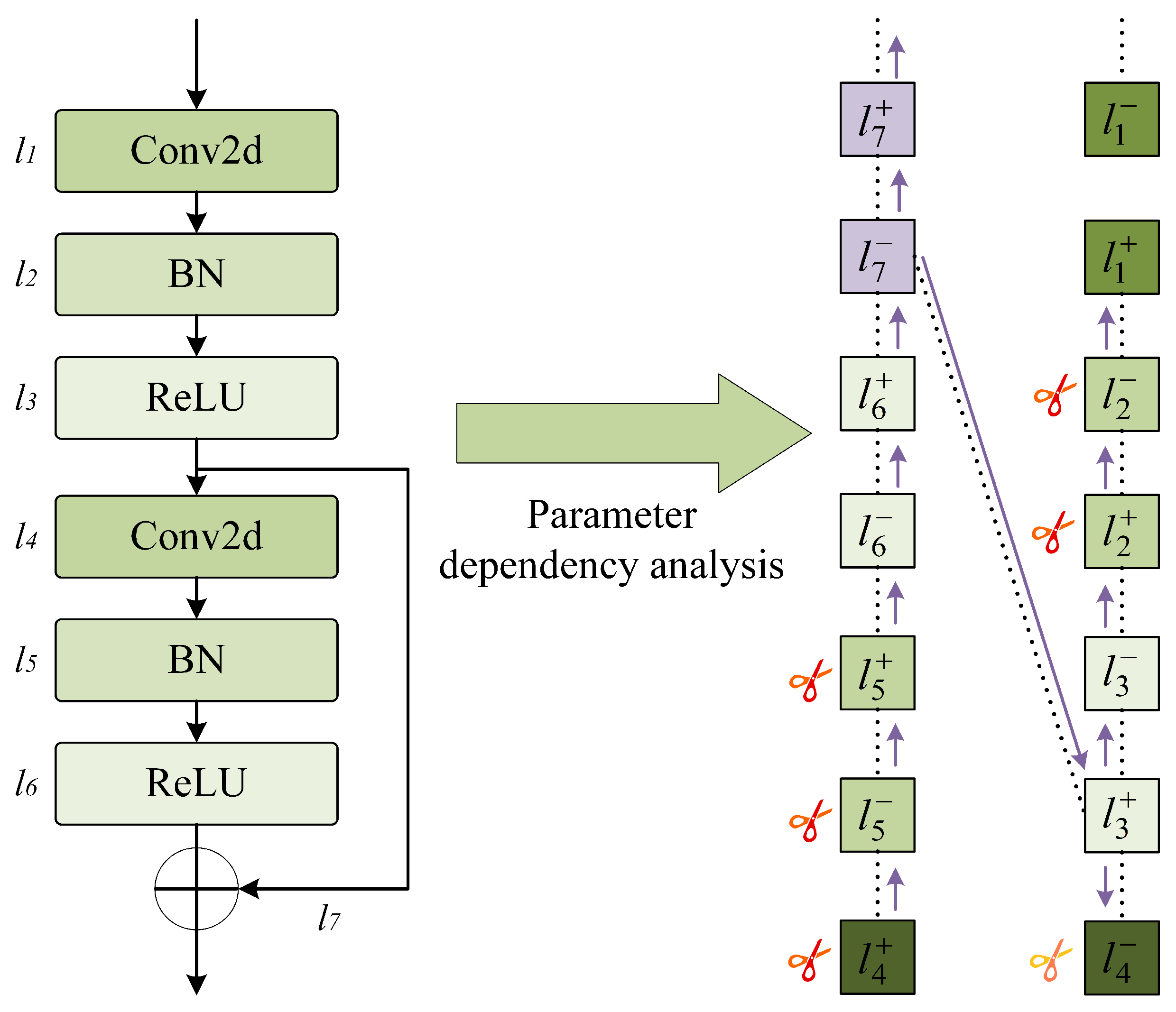
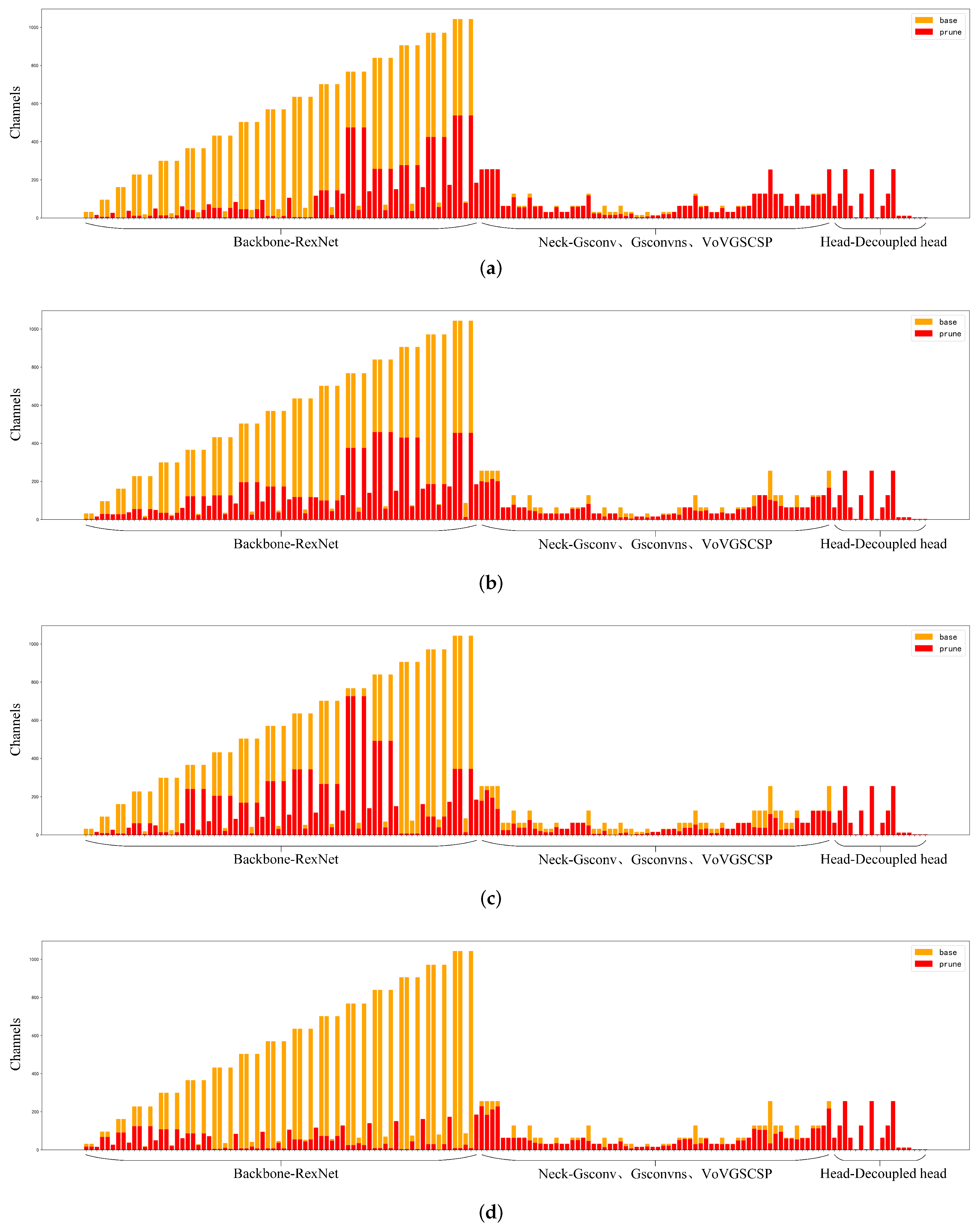
2.3. Model Compression
2.3.1. Model Pruning
2.3.2. Sparse Training
2.4. Model Evaluation Metrics
3. Experiments and Analysis
3.1. Lightweight Backbone Comparative Experiment
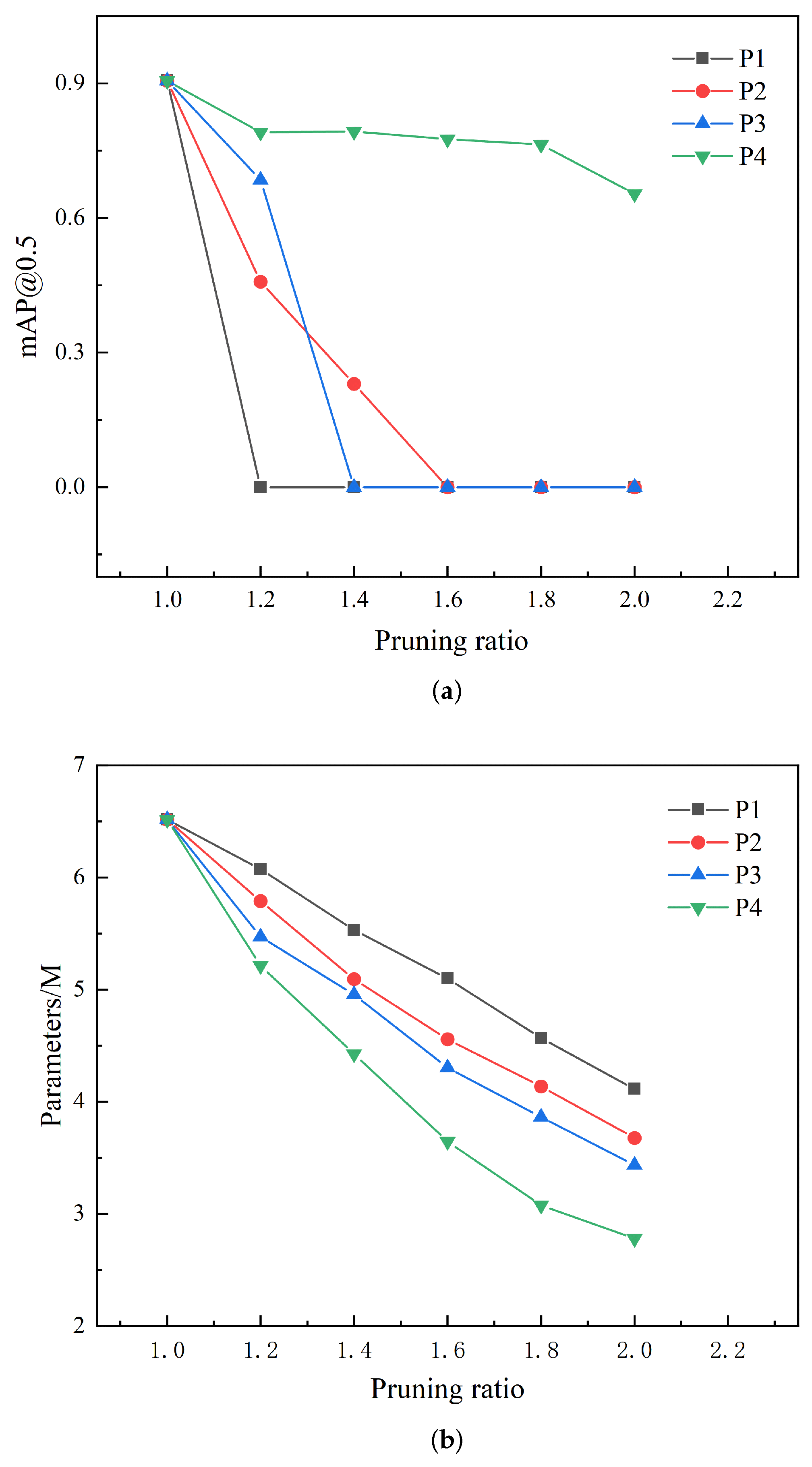
3.2. The Impact of Different Pruning Methods on Model Performance
3.3. The Impact of Different Pruning Ratios on Model Performance
3.4. Performance Comparison of Different Object-Detection Algorithms
3.5. Pineapple Detection Visualization
3.6. Performance of RGDP-YOLOv7-Tiny in Complex Scenarios
4. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, C.; Liu, Y. Current status of pineapple production and research in China. Guangdong Agric. Sci. 2010, 10, 65–68. [Google Scholar]
- Li, D.; Jing, M.; Dai, X.; Chen, Z.; Ma, C.; Chen, J. Current status of pineapple breeding, industrial development, and genetics in China. Euphytica 2022, 218, 85. [Google Scholar] [CrossRef]
- He, F.; Zhang, Q.; Deng, G.; Li, G.; Yan, B.; Pan, D.; Luo, X.; Li, J. Research Status and Development Trend of Key Technologies for Pineapple Harvesting Equipment: A Review. Agriculture 2024, 14, 975. [Google Scholar] [CrossRef]
- Shu, H.; Sun, W.; Xu, G.; Zhan, R.; Chang, S. The Situation and Challenges of Pineapple Industry in China. Agric. Sci. 2019, 10, 683. [Google Scholar] [CrossRef]
- Jiang, T.; Guo, A.; Cheng, X.; Zhang, D.; Jin, L. Structural design and analysis of pineapple automatic picking-collecting machine. Chin. J. Eng. Des. 2019, 26, 577–586. [Google Scholar]
- Li, J.; Dai, Y.; Su, X.; Wu, W. Efficient Dual-Branch Bottleneck Networks of Semantic Segmentation Based on CCD Camera. Remote Sens. 2022, 14, 3925. [Google Scholar] [CrossRef]
- Zhao, D.H.; Zhang, H.; Hou, J.X. Design of Fruit Picking Device Based on the Automatic Control Technology. Key Eng. Mater. 2014, 620, 471–477. [Google Scholar] [CrossRef]
- Pengcheng, B.; Jianxin, L.; Weiwei, C. Research on lightweight convolutional neural network technology. Comput. Eng. Appl. 2019, 16, 25–35. [Google Scholar]
- Li, J.; Li, J.; Zhao, X.; Su, X.; Wu, W. Lightweight detection networks for tea bud on complex agricultural environment via improved YOLO v4. Comput. Electron. Agric. 2023, 211, 107955. [Google Scholar] [CrossRef]
- Liu, X.; Wang, J.; Li, J. URTSegNet: A real-time segmentation network of unstructured road at night based on thermal infrared images for autonomous robot system. Control Eng. Pract. 2023, 137, 105560. [Google Scholar] [CrossRef]
- Li, B.; Ning, W.; Wang, M.; Li, L. In-field pineapple recognition based on monocular vision. Trans. Chin. Soc. Agric. Eng. 2010, 26, 345–349. [Google Scholar]
- Li, X. Design of automatic pineapple harvesting machine based on binocular machine vision. J. Anhui Agric. Sci. 2019, 47, 207–210. [Google Scholar]
- Yang, W.; Rui, Z.; ChenMing, W.; Meng, W.; XiuJie, W.; YongJin, L. A survey on deep-learning-based plant phenotype research in agriculture. Sci. Sin. Vitae 2019, 49, 698–716. [Google Scholar]
- Zheng, Y.; Li, G.; Li, Y. Survey of application of deep learning in image recognition. Comput. Eng. Appl. 2019, 55, 20–36. [Google Scholar]
- Sun, D.; Zhang, K.; Zhong, H.; Xie, J.; Xue, X.; Yan, M.; Wu, W.; Li, J. Efficient Tobacco Pest Detection in Complex Environments Using an Enhanced YOLOv8 Model. Agriculture 2024, 14, 353. [Google Scholar] [CrossRef]
- Chunman, Y.; Cheng, W. Development and application of convolutional neural network model. J. Front. Comput. Sci. Technol. 2021, 15, 27. [Google Scholar]
- Xu, L.; Huang, H.; Ding, W.; Fan, Y. Detection of small fruit target based on improved DenseNet. J. Zhejiang Univ. (Eng. Sci.) 2021, 55, 377–385. [Google Scholar]
- Pengfei, Z.; Mengbo, Q.; Kaiqi, Z.; Yijie, S.; Haoyu, W. Improvement of Sweet Pepper Fruit Detection in YOLOv7-Tiny Farming Environment. Comput. Eng. Appl. 2023, 59, 329–340. [Google Scholar]
- Liang, X.; Pang, Q.; Yang, Y.; Wen, C.; Li, Y.; Huang, W.; Zhang, C.; Zhao, C. Online detection of tomato defects based on YOLOv4 model pruning. Trans. Chin. Soc. Agric. Eng 2022, 6, 283–292. [Google Scholar]
- Yinghui, K.; Chengcheng, Z.; LinLin, C. Flower recognition in complex background and model pruning based on MobileNets. Sci. Technol. Eng. 2018, 18, 84–88. [Google Scholar]
- Li, J.Y.; Zhao, Y.K.; Xue, Z.E.; Cai, Z.; Li, Q. A survey of model compression for deep neural networks. Chin. J. Eng. 2019, 41, 1229–1239. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Zhou, J.; Zhang, Y.; Wang, J. RDE-YOLOv7: An improved model based on YOLOv7 for better performance in detecting dragon fruits. Agronomy 2023, 13, 1042. [Google Scholar] [CrossRef]
- Yang, H.; Liu, Y.; Wang, S.; Qu, H.; Li, N.; Wu, J.; Yan, Y.; Zhang, H.; Wang, J.; Qiu, J. Improved apple fruit target recognition method based on YOLOv7 model. Agriculture 2023, 13, 1278. [Google Scholar] [CrossRef]
- Xu, J.; Li, Z.; Du, B.; Zhang, M.; Liu, J. Reluplex made more practical: Leaky ReLU. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar]
- Han, D.; Yun, S.; Heo, B.; Yoo, Y. Rethinking channel dimensions for efficient model design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 732–741. [Google Scholar]
- Bi, C.; Wang, J.; Duan, Y.; Fu, B.; Kang, J.R.; Shi, Y. MobileNet based apple leaf diseases identification. Mob. Netw. Appl. 2022, 27, 172–180. [Google Scholar] [CrossRef]
- Sun, J.; Tan, W.; Wu, X.; Shen, J.; Lu, B.; Dai, C. Real-time recognition of sugar beet and weeds in complex backgrounds using multi-channel depth-wise separable convolution model. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2019, 35, 184–190. [Google Scholar]
- Zhao, X.; Song, Y. Improved Ship Detection with YOLOv8 Enhanced with MobileViT and GSConv. Electronics 2023, 12, 4666. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Qiu, M.; Huang, L.; Tang, B.H. Bridge detection method for HSRRSIs based on YOLOv5 with a decoupled head. Int. J. Digit. Earth 2023, 16, 113–129. [Google Scholar] [CrossRef]
- Fang, G.; Ma, X.; Song, M.; Mi, M.B.; Wang, X. Depgraph: Towards any structural pruning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 16091–16101. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, DC, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetv2: Enhance cheap operation with long-range attention. Adv. Neural Inf. Process. Syst. 2022, 35, 9969–9982. [Google Scholar]
- Chen, J.; Kao, S.h.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 12021–12031. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Molchanov, P.; Mallya, A.; Tyree, S.; Frosio, I.; Kautz, J. Importance estimation for neural network pruning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11264–11272. [Google Scholar]
- LeCun, Y.; Denker, J.; Solla, S. Optimal brain damage. Adv. Neural Inf. Process. Syst. 1989, 2, 598–605. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequential | Input | Operator | Output | Stride |
|---|---|---|---|---|
| 1 | × 3 | Conv 3 × 3 | 32 | 2 |
| 2 | × 32 | MB-bneck1 | 16 | 1 |
| 3 | × 16 | MB-bneck6 | 27 | 2 |
| 4 | × 27 | MB-bneck6 | 38 | 1 |
| 5 | × 38 | MB-bneck6 | 50 | 2 |
| 6 | × 50 | MB-bneck6 | 61 | 1 |
| 7 | × 61 | MB-bneck6 | 72 | 2 |
| 8 | × 72 | MB-bneck6 | 84 | 1 |
| 9 | × 84 | MB-bneck6 | 95 | 1 |
| 10 | × 95 | MB-bneck6 | 106 | 1 |
| 11 | × 106 | MB-bneck6 | 117 | 1 |
| 12 | × 117 | MB-bneck6 | 128 | 1 |
| 13 | × 128 | MB-bneck6 | 140 | 2 |
| 14 | × 140 | MB-bneck6 | 151 | 1 |
| 15 | × 151 | MB-bneck6 | 162 | 1 |
| 16 | × 162 | MB-bneck6 | 174 | 1 |
| 17 | × 174 | MB-bneck6 | 185 | 1 |
| 18 | × 185 | Conv 1 × 1, pool 7 × 7 | 1280 | 1 |
| 19 | × 1280 | Fc | 1000 | 1 |
| Configuration | Parameters |
|---|---|
| CPU | I5-12600KF |
| GPU | NVIDIA GeForce RTX 4060 Ti |
| Operating system | Windows 10 |
| Accelerated environment | CUDA 12.1.0; CUDNN 8.9.4.25 |
| Library | Pytorch 2.1.1; Torch-Pruning 1.3.6 |
| Model | Pruning Ratio | [email protected] (%) | Precision (%) | Recall (%) | F1 Score (%) | Params (M) | FLOPs () | Model Size (MB) |
|---|---|---|---|---|---|---|---|---|
| 1.0 | 87.1 | 92.9 | 80.2 | 86.1 | 6.01 | 13.2 | 12.3 | |
| YOLOv7-tiny | 2.0 | 88.0 | 93.3 | 81.7 | 87.1 | 3.0 | 6.5 | 6.3 |
| 2.5 | 86.8 | 89.7 | 81.7 | 85.5 | 2.37 | 5.2 | 5.0 | |
| 1.0 | 88.4 | 93.1 | 81.9 | 87.1 | 4.29 | 7.5 | 9.0 | |
| GhostNet-YOLOv7-tiny | 2.0 | 80.0 | 90.3 | 71.8 | 80.0 | 1.76 | 3.7 | 3.9 |
| 2.5 | 79.0 | 89.0 | 71.6 | 79.4 | 1.4 | 3.0 | 3.2 | |
| 1.0 | 89.7 | 95.2 | 82.3 | 88.3 | 4.59 | 7.9 | 9.6 | |
| GhostNetv2-YOLOv7-tiny | 2.0 | 80.4 | 89.0 | 73.2 | 80.3 | 1.9 | 3.8 | 4.2 |
| 2.5 | 80.2 | 88.8 | 74.3 | 80.9 | 1.5 | 3.1 | 3.4 | |
| 1.0 | 85.5 | 89.7 | 79.1 | 84.1 | 5.65 | 11.4 | 11.6 | |
| FasterNet-YOLOv7-tiny | 2.0 | 86.0 | 92.5 | 79.3 | 85.4 | 3.09 | 5.6 | 6.5 |
| 2.5 | 85.4 | 91.7 | 78.8 | 84.8 | 2.43 | 4.5 | 5.1 | |
| 1.0 | 88.6 | 93.4 | 81.7 | 87.2 | 6.64 | 12.0 | 13.7 | |
| ReXNet-YOLOv7-tiny | 2.0 | 89.5 | 94.8 | 81.7 | 87.8 | 3.09 | 6.0 | 6.6 |
| 2.5 | 86.5 | 92.8 | 80.7 | 86.3 | 2.57 | 4.7 | 5.5 | |
| 1.0 | 85.9 | 93.5 | 77.6 | 84.8 | 4.48 | 6.7 | 9.3 | |
| MobileNetv3-YOLOv7-tiny | 2.0 | 82.5 | 89.0 | 76.2 | 82.1 | 1.86 | 3.3 | 4.0 |
| 2.5 | 83.3 | 94.7 | 73.9 | 83.0 | 1.72 | 2.6 | 3.8 |
| Pruning Methods | Pruning Ratio | [email protected] (%) | Precision (%) | Recall (%) | F1 Score (%) | Params (M) | FLOPs () | Model Size (MB) |
|---|---|---|---|---|---|---|---|---|
| P1 | 2.0 | 74.2 | 87.5 | 64.5 | 74.3 | 4.11 | 5.7 | 8.7 |
| P2 | 83.9 | 92.1 | 75.1 | 82.7 | 3.64 | 5.6 | 7.8 | |
| P3 | 76.9 | 88.2 | 67.8 | 76.7 | 3.43 | 5.6 | 7.4 | |
| P4 | 87.9 | 92.5 | 81.7 | 86.8 | 2.77 | 5.7 | 6.0 |
| Pruning Ratio | [email protected] (%) | Precision (%) | Recall (%) | F1 Score (%) | Params (M) | FLOPs () | Model Size (MB) |
|---|---|---|---|---|---|---|---|
| 1.0 | 90.1 | 91.6 | 85.3 | 88.3 | 6.52 | 11.4 | 13.6 |
| 2.0 | 87.9 | 92.5 | 81.7 | 86.8 | 2.77 | 5.7 | 6.0 |
| 2.1 | 87.4 | 91.4 | 81.0 | 85.9 | 2.60 | 5.3 | 5.7 |
| 2.2 | 87.8 | 93.1 | 80.3 | 86.2 | 2.49 | 5.1 | 5.5 |
| 2.3 | 87.0 | 92.6 | 80.2 | 86.0 | 2.39 | 4.9 | 5.3 |
| 2.4 | 87.7 | 91.3 | 82.3 | 86.6 | 2.33 | 4.7 | 5.1 |
| 2.5 | 87.9 | 94.9 | 81.0 | 87.4 | 2.27 | 4.5 | 5.0 |
| 2.6 | 85.2 | 89.3 | 79.7 | 84.2 | 2.21 | 4.3 | 4.9 |
| 2.7 | 74.4 | 84.3 | 68.5 | 75.6 | 2.16 | 4.2 | 4.8 |
| 2.8 | 74.5 | 89.6 | 66.3 | 76.2 | 2.09 | 4.0 | 4.7 |
| 2.9 | 74.1 | 88.6 | 65.2 | 75.1 | 2.04 | 3.9 | 4.6 |
| 3.0 | 74.3 | 85.7 | 65.9 | 74.5 | 1.95 | 3.8 | 4.4 |
| Pruning Ratio | [email protected] (%) | Precision (%) | Recall (%) | F1 Score (%) | Params (M) | FLOPs () | Model Size (MB) |
|---|---|---|---|---|---|---|---|
| YOLOv5s | 85.8 | 91.5 | 77.0 | 83.6 | 7.02 | 15.9 | 14.4 |
| YOLOv7 | 90.0 | 93.2 | 83.3 | 88.0 | 37.20 | 105.1 | 74.8 |
| YOLOv7-tiny | 87.1 | 92.9 | 80.2 | 86.1 | 6.01 | 13.2 | 12.3 |
| YOLOv8n | 87.6 | 92.9 | 80.2 | 86.1 | 3.01 | 8.2 | 6.3 |
| YOLOv8s | 87.2 | 90.4 | 81.1 | 85.5 | 11.14 | 28.6 | 22.5 |
| RGDP-YOLOv7-tiny | 87.9 | 94.9 | 81.0 | 87.4 | 2.27 | 4.5 | 5.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Liu, Y.; Li, C.; Luo, Q.; Lu, J. Pineapple Detection with YOLOv7-Tiny Network Model Improved via Pruning and a Lightweight Backbone Sub-Network. Remote Sens. 2024, 16, 2805. https://doi.org/10.3390/rs16152805
Li J, Liu Y, Li C, Luo Q, Lu J. Pineapple Detection with YOLOv7-Tiny Network Model Improved via Pruning and a Lightweight Backbone Sub-Network. Remote Sensing. 2024; 16(15):2805. https://doi.org/10.3390/rs16152805
Chicago/Turabian StyleLi, Jiehao, Yaowen Liu, Chenglin Li, Qunfei Luo, and Jiahuan Lu. 2024. "Pineapple Detection with YOLOv7-Tiny Network Model Improved via Pruning and a Lightweight Backbone Sub-Network" Remote Sensing 16, no. 15: 2805. https://doi.org/10.3390/rs16152805