
Stepwise Attention-Guided Multiscale Fusion Network for Lightweight and High-Accurate SAR Ship Detection


Abstract
:1. Introduction
- According to the characters of different feature levels, this study presents a stepwise attention mechanism, which robustly detects multiscale objects against complex backgrounds by extracting their discriminative features and then fusing them step by step.
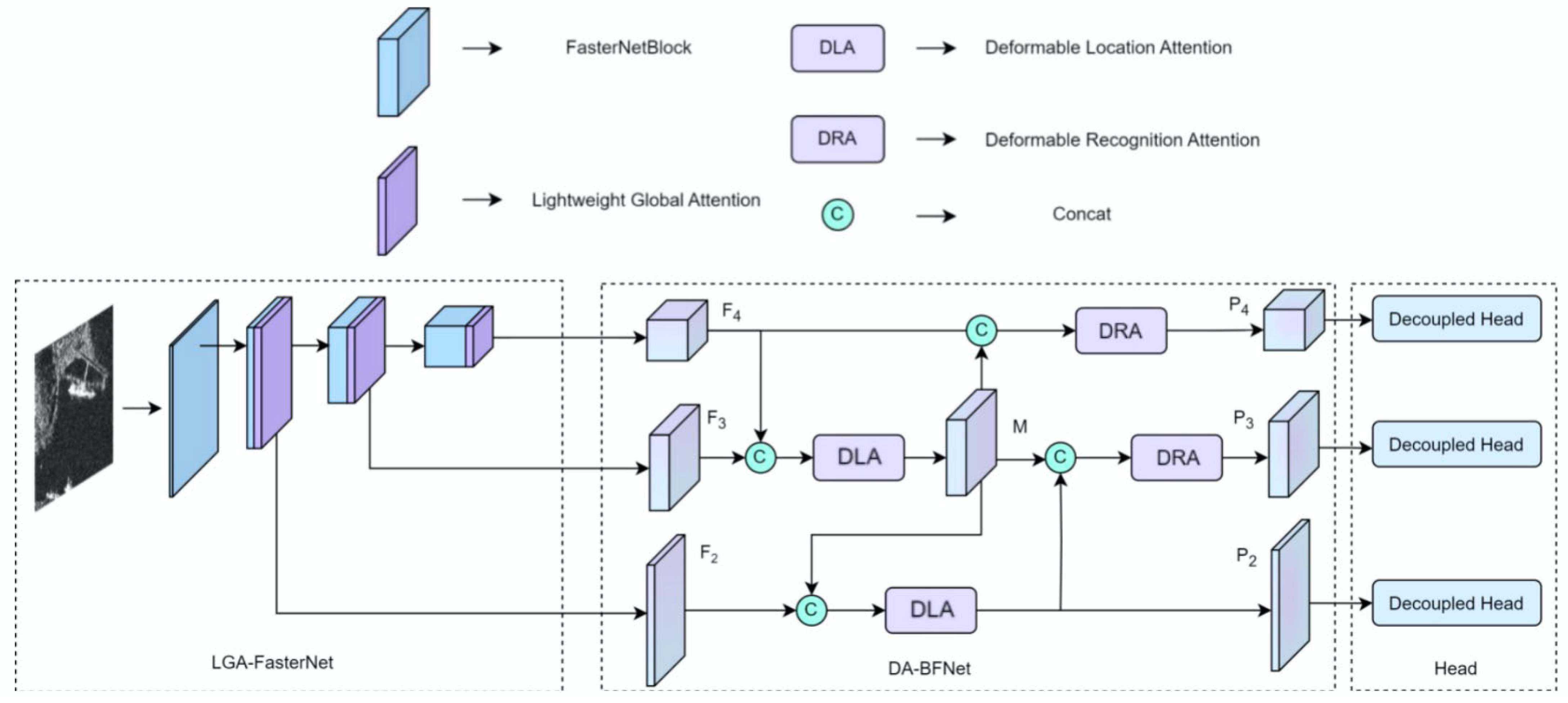
- The incorporation of LGA-FasterNet facilitates both expressive feature extraction and a reduction in model parameters. Moreover, DA-BFNet innovatively integrates the DLA block with the DRA block through bidirectional connections, achieving an enhanced feature fusion.
- Extensive experiments were conducted on the SAR image datasets HRSID and SSDD. Our proposed SAFN exhibits state-of-the-art performance, with detection accuracies reaching 91.33% and 98.18%, respectively.
2. Related Work
3. Methodology
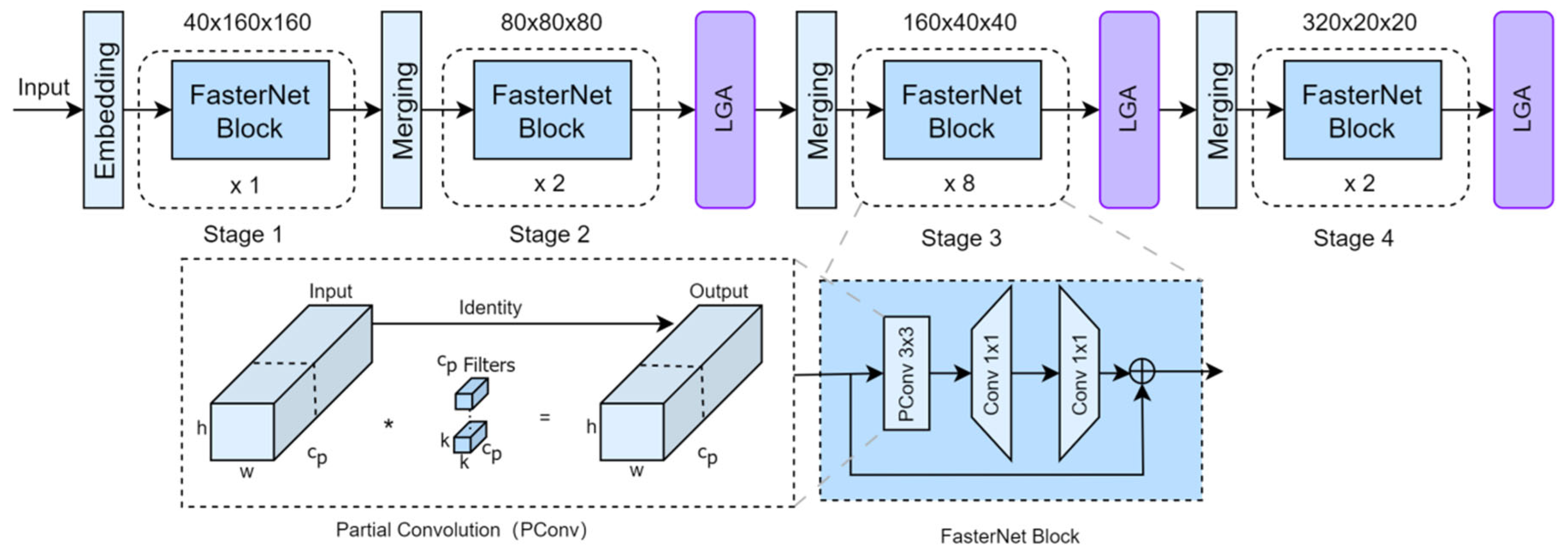
3.1. Feature Extraction Module
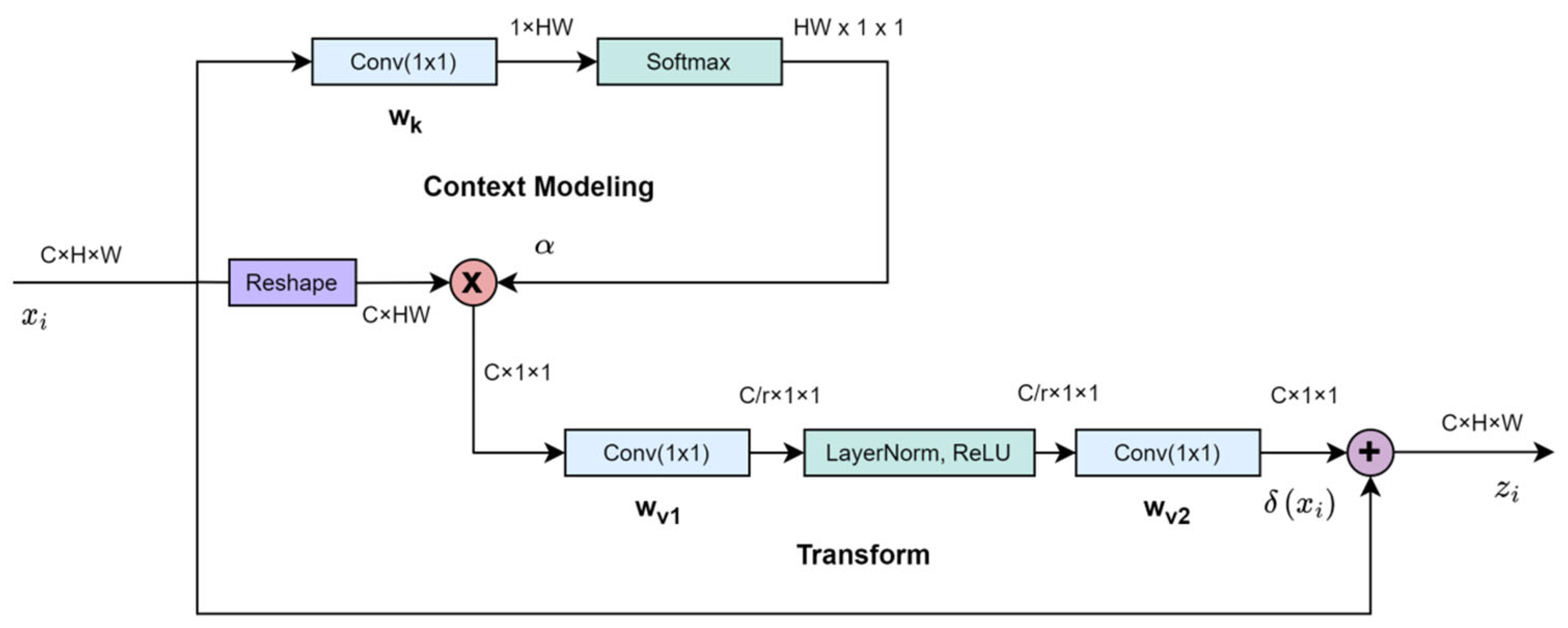
3.1.1. Lightweight Global Attention
3.1.2. FasterNet with Lightweight Global Attention
3.2. Feature Fusion Module
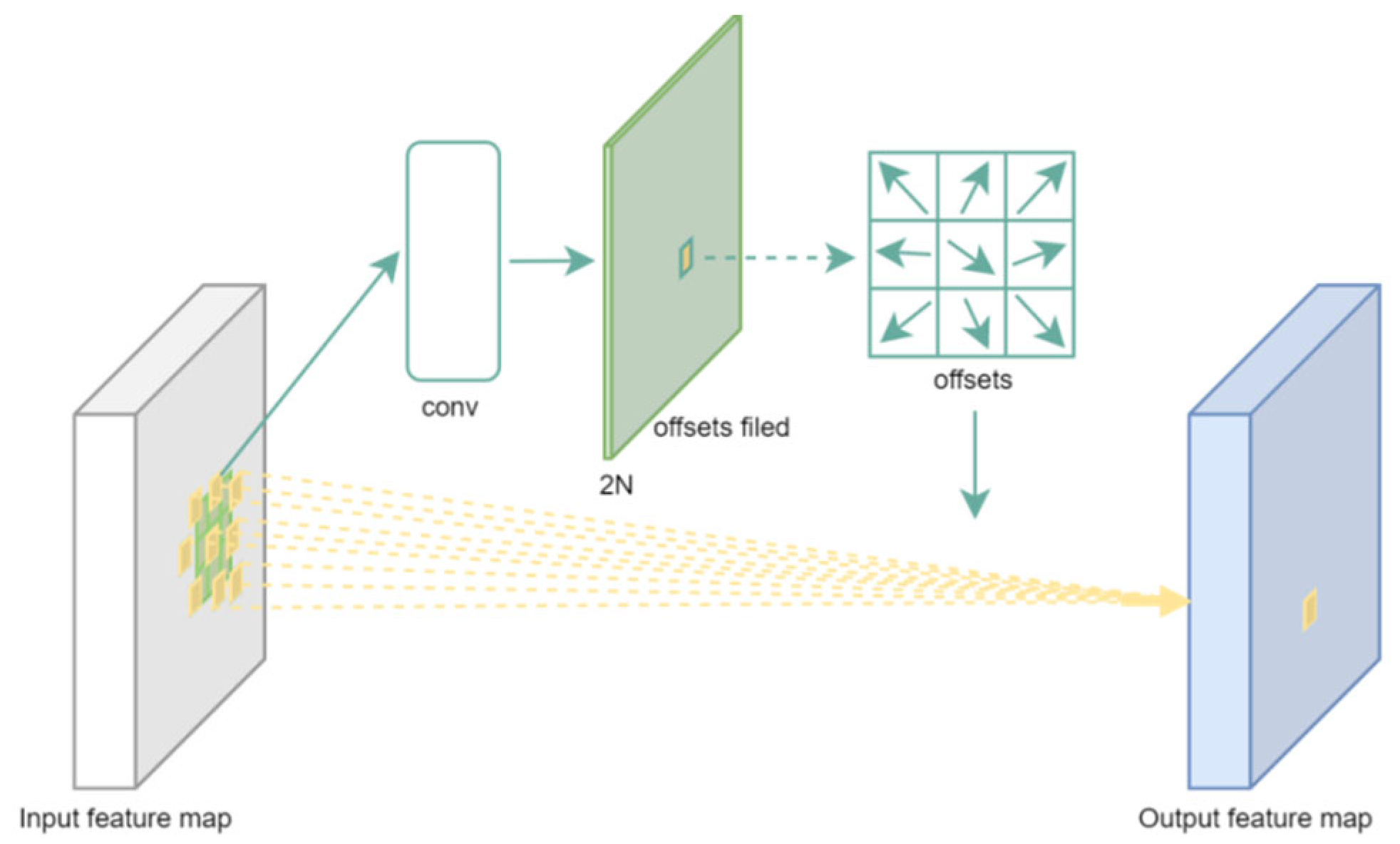
3.2.1. Deformable Convolution Network
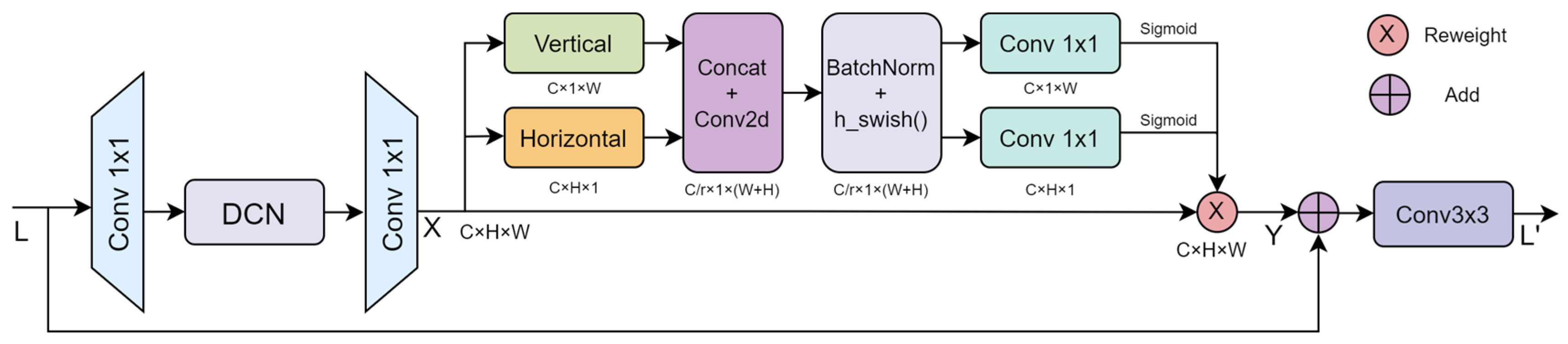
3.2.2. Deformable Location Attention Block
Y = SA(X)
L′ = Conv3×3(L + Y)
gw = σ (Conv1×1 (f w))
yc(i,j) = xc(i,j) × gch(i) × gcw(j)
3.2.3. Deformable Channel Attention Block
Y = CA(X)
L’ = Conv3 × 3(L + Y)
3.2.4. Deformable Attention Bidirectional Fusion Network
P2 = DLA(Concat(F2,Upsampling(M)))
P3 = DRA(Concat(Downsampling(P2),M))
P4 = DRA(Concat(P4,Downsampling(M)))
4. Experimental Results and Analysis
4.1. Datasets and Training Settings
4.2. Evaluation Criteria
4.3. Comparison Experiment
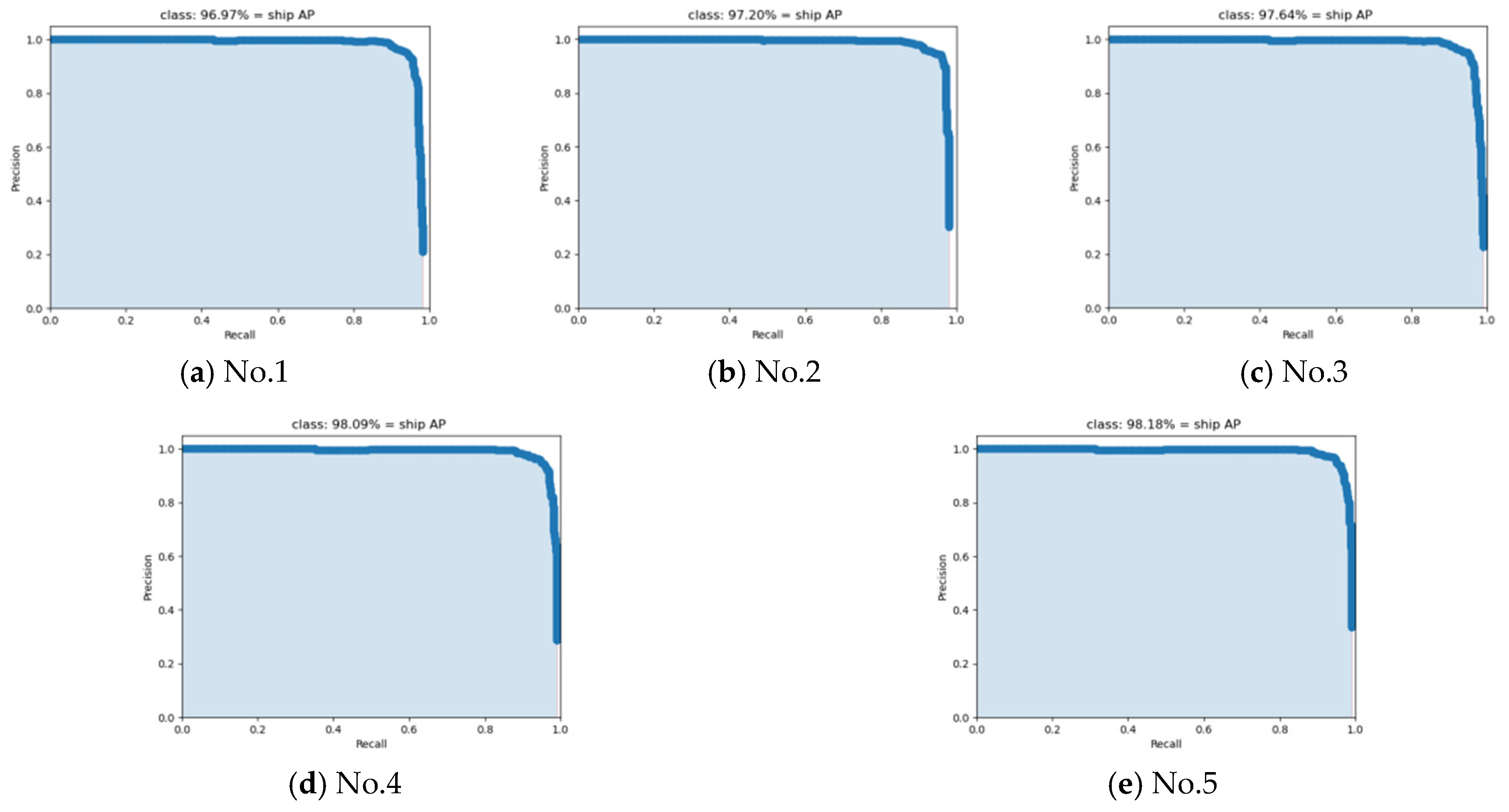
4.4. Ablation Experiment
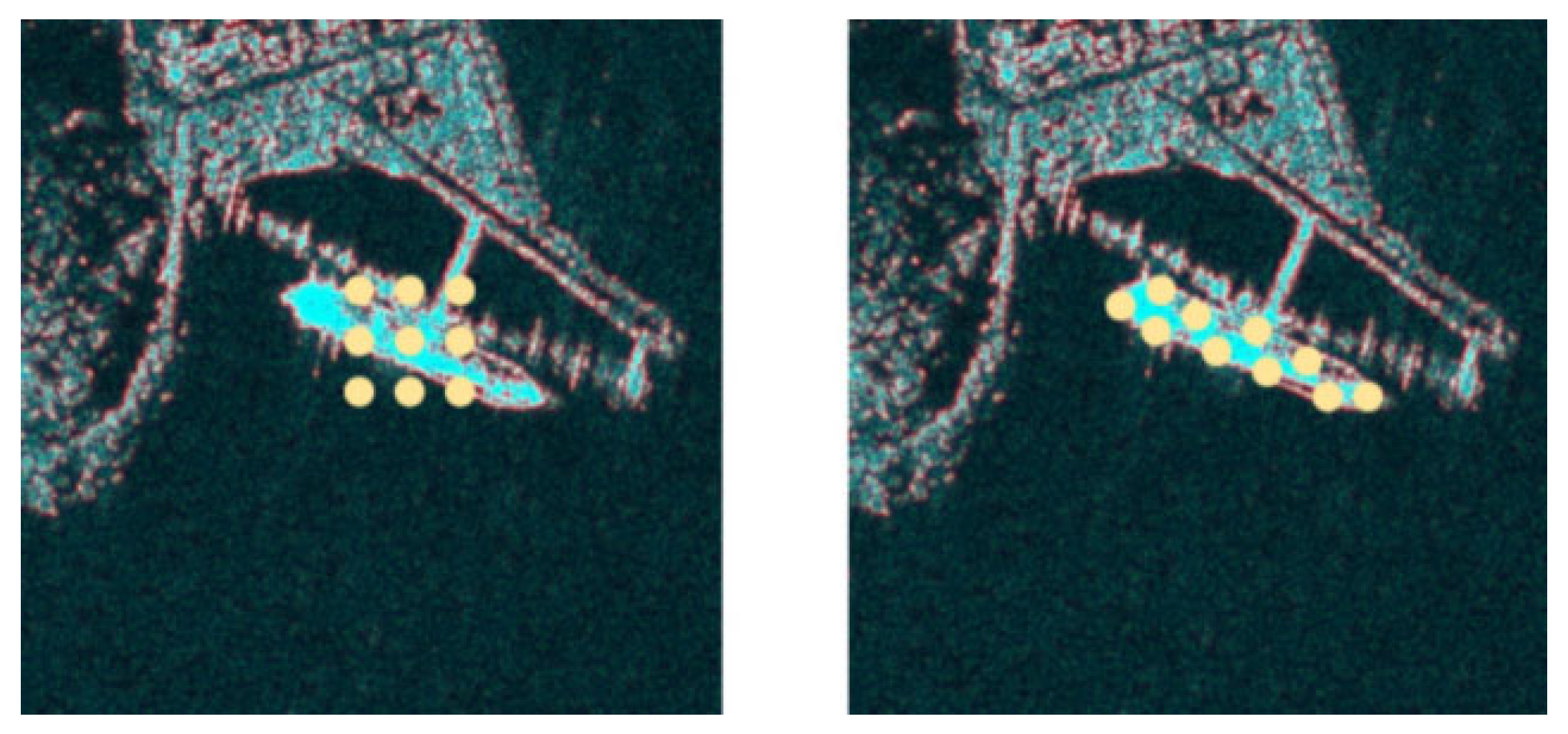
4.5. Visualization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yasir, M.; Wan, J.; Xu, M.; Sheng, H.; Zeng, Z.; Liu, S.; Colak, A.T.I.; Hossain, M.S. Ship detection based on deep learning using SAR imagery: A systematic literature review. Soft Comput. 2023, 27, 63–84. [Google Scholar] [CrossRef]
- Zheng, X.; Wang, B.; Du, X.; Lu, X. Mutual attention inception network for remote sensing visual question answering. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Chen, Y.; Zhou, L.; Pei, S.; Yu, Z.; Chen, Y.; Liu, X.; Du, J.; Xiong, N. KNN-BLOCK DBSCAN: Fast clustering for large scale data. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 3939–3953. [Google Scholar] [CrossRef]
- Jin, K.; Chen, Y.; Xu, B.; Yin, J.; Wang, X.; Yang, J. A patch to-pixel convolutional neural network for small ship detection with PolSAR images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6623–6638. [Google Scholar] [CrossRef]
- Robey, F.C.; Fuhrmann, D.R.; Kelly, E.J. A CFAR adaptive matched filter detector. IEEE Trans. Aerosp. Electron. Syst. 1992, 28, 208–216. [Google Scholar] [CrossRef]
- Li, J.; Xu, C.; Su, H.; Gao, L.; Wang, T. Deep learning for SAR ship detection: Past, present and future. Remote Sens. 2022, 14, 2712. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Y.; Wu, Y.; Zhang, K.; Wang, Q. FRPNet: A feature reflflowing pyramid network for object detection of remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Guo, H.; Gu, D. Closely arranged inshore ship detection using a bi-directional attention feature pyramid network. Int. J. Remote Sens. 2023, 44, 7106–7125. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, realtime object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4:Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S. Depthwise separable convolution neural network for high-speed SAR ship detection. Remote Sens. 2019, 11, 2483. [Google Scholar] [CrossRef]
- Pang, L.; Li, B.; Zhang, F.; Meng, X.; Zhang, L. A lightweight YOLOv5-MNE algorithm for SAR ship detection. Sensors 2022, 22, 7088. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. ShipDeNet-20: An only 20 convolution layers and <1-MB lightweight SAR ship detector. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1234–1238. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, S.; Duan, S.; Yang, W. An effective and lightweight hybrid network for object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 62, 1–11. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, J.; Chen, C.; Yang, D. An efficient and lightweight CNN model with soft quantification for ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Xiao, M.; He, Z.; Li, X.; Lou, A. Power transformations and feature alignment guided network for SAR ship detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Yao, C.; Xie, P.; Zhang, L.; Fang, Y. ATSD: Anchor-Free Two-Stage Ship Detection Based on Feature Enhancement in SAR Images. Remote Sens. 2022, 14, 6058. [Google Scholar] [CrossRef]
- Bai, L.; Yao, C.; Ye, Z.; Xue, D.; Lin, X.; Hui, M. A novel anchor-free detector using global context-guide feature balance pyramid and united attention for SAR ship detection. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Feng, Y.; Chen, J.; Huang, Z.; Wan, H.; Xia, R.; Wu, B.; Sun, L.; Xing, M. A lightweight position-enhanced anchor-free algorithm for SAR ship detection. Remote Sens. 2022, 14, 1908. [Google Scholar] [CrossRef]
- Yu, C.; Shin, Y. SAR ship detection based on improved YOLOv5 and BiFPN. ICT Express 2023, 10, 28–33. [Google Scholar] [CrossRef]
- Wang, H.; Han, D.; Cui, M.; Chen, C. NAS-YOLOX: A SAR ship detection using neural architecture search and multi-scale attention. Connect. Sci. 2023, 35, 1–32. [Google Scholar] [CrossRef]
- Tang, G.; Zhao, H.; Claramunt, C.; Zhu, W.; Wang, S.; Wang, Y.; Ding, Y. PPA-Net: Pyramid Pooling Attention Network for Multi-Scale Ship Detection in SAR Images. Remote Sens. 2023, 15, 2855. [Google Scholar] [CrossRef]
- Bai, L.; Yao, C.; Ye, Z.; Xue, D.; Lin, X.; Hui, M. Feature enhancement pyramid and shallow feature reconstruction network for SAR ship detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1042–1056. [Google Scholar] [CrossRef]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Global context networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 45, 6881–6895. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9300–9308. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Effificient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Zhang, T.; Zhang, X.; Liu, C.; Shi, J.; Wei, S.; Ahmad, I.; Zhan, X.; Zhou, Y.; Pan, D.; Li, J.; et al. Balance learning for ship detection from synthetic aperture radar remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 182, 190–207. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | APS (%) | APH (%) | FLOPs (G) | Params (M) |
|---|---|---|---|---|
| Faster R-CNN | 95.40 | 82.12 | 91.41 | 41.12 |
| YOLOv3 | 96.20 | 85.20 | 61.62 | 77.54 |
| CenterNet | 95.10 | 86.59 | 20.40 | 14.21 |
| YOLOv5-s | 96.28 | 87.34 | 16.54 | 7.23 |
| YOLOX-s | 96.97 | 87.50 | 26.92 | 8.96 |
| YOLOv7-s | 97.40 | 89.70 | 18.38 | 5.68 |
| Proposed method | 98.18 | 91.33 | 10.98 | 3.70 |
| Methods | APS (%) | APH (%) | FLOPs (G) | Params (M) |
|---|---|---|---|---|
| BL-Net [40] | 95.25 | 88.67 | 41.17 | 47.81 |
| YOLOv5 + BiFPN [28] | 95.02 | 85.11 | - | - |
| ATSD [25] | 96.88 | 88.19 | 7.25 | 61.5 |
| FBUA-Net [26] | 96.20 | 90.30 | 71.11 | 36.54 |
| LPEDet [27] | 97.40 | 89.70 | 18.38 | 5.68 |
| NAS-YOLOX [29] | 97.2 | 91.10 | - | 44.4 |
| PPA-Net [30] | 95.19 | 89.27 | - | - |
| FEPS-Net [31] | 96.00 | 90.70 | - | 37.31 |
| Proposed method | 98.18 | 91.33 | 10.98 | 3.70 |
| Experiment | APS (%) | APH (%) | FLOPs (GMac) | Params (M) |
|---|---|---|---|---|
| YOLOX(CSPDarknet + FPN) | 96.97 | 87.50 | 26.92 | 8.96 |
| LGA-FasterNet + FPN | 97.64 | 89.06 | 10.70 | 4.50 |
| SE-FasterNet + FPN | 97.54 | 88.94 | 10.60 | 4.50 |
| CBMA-FasterNet + FPN | 97.68 | 89.12 | 11.00 | 4.70 |
| FasterNet + FPN | 97.20 | 88.14 | 10.40 | 4.30 |
| MobilenetV3 + FPN | 95.79 | 86.36 | 15.60 | 6.25 |
| GhostNet+FPN | 96.12 | 86.94 | 10.40 | 4.25 |
| LGA-FasterNet + DCN-BFNet | 97.82 | 89.93 | 10.80 | 3.65 |
| LGA-FasterNet + DLA-BFNet | 98.01 | 90.57 | 10.80 | 3.65 |
| LGA-FasterNet + DRA-BFNet | 97.98 | 90.41 | 10.80 | 3.65 |
| SAFN(LGA-FasterNet + DA-BFNet) | 98.18 | 91.33 | 10.98 | 3.70 |
| Experiment | APS (%) | APH (%) | FLOPs (GMac) | Params (M) |
|---|---|---|---|---|
| YOLOX(CSPDarknet + FPN) | 96.97 | 87.50 | 26.92 | 8.96 |
| FasterNet + FPN | 97.20 | 88.14 | 10.40 | 4.30 |
| LGA-FasterNet + FPN | 97.64 | 89.06 | 10.70 | 4.50 |
| CSPDarknet + DA-BFNet | 98.09 | 89.36 | 26.98 | 8.70 |
| SAFN(LGA-FasterNet + DA-BFNet) | 98.18 | 91.33 | 10.98 | 3.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Cai, X.; Wu, F.; Cui, P.; Wu, Y.; Zhang, Y. Stepwise Attention-Guided Multiscale Fusion Network for Lightweight and High-Accurate SAR Ship Detection. Remote Sens. 2024, 16, 3137. https://doi.org/10.3390/rs16173137
Wang C, Cai X, Wu F, Cui P, Wu Y, Zhang Y. Stepwise Attention-Guided Multiscale Fusion Network for Lightweight and High-Accurate SAR Ship Detection. Remote Sensing. 2024; 16(17):3137. https://doi.org/10.3390/rs16173137
Chicago/Turabian StyleWang, Chunyuan, Xianjun Cai, Fei Wu, Peng Cui, Yang Wu, and Ye Zhang. 2024. "Stepwise Attention-Guided Multiscale Fusion Network for Lightweight and High-Accurate SAR Ship Detection" Remote Sensing 16, no. 17: 3137. https://doi.org/10.3390/rs16173137
APA StyleWang, C., Cai, X., Wu, F., Cui, P., Wu, Y., & Zhang, Y. (2024). Stepwise Attention-Guided Multiscale Fusion Network for Lightweight and High-Accurate SAR Ship Detection. Remote Sensing, 16(17), 3137. https://doi.org/10.3390/rs16173137