


MSPV3D: Multi-Scale Point-Voxels 3D Object Detection Net



Abstract
:
1. Introduction
- We propose a partial ground removal algorithm. Leveraging the Z-axis characteristics and reflectivity properties of the ground in the point cloud, this algorithm first separates a portion of the point cloud based on the Z-axis coordinates. Subsequently, it further extracts ground points based on the reflectivity differences between the ground and the objects of interest. Finally, a certain ratio of the extracted ground points is randomly filtered out, thereby increasing the proportion of foreground points.
- This paper introduces the utilization of features from voxels of different sizes. Given the significant size differences among various targets, voxelization using a single scale may result in a significant loss of detailed information. Therefore, we propose a two-stage detection network that introduces voxel features of different scales in the second detection stage. The voxel abstraction set module is employed to extract features from each scale separately and to highlight the features of key points. Additionally, the method of key point feature aggregation has been improved. Finally, the extracted features are utilized to assist in the refinement of candidate bounding boxes for targets of different sizes in the second stage, minimizing information loss during the voxelization process of the point cloud.
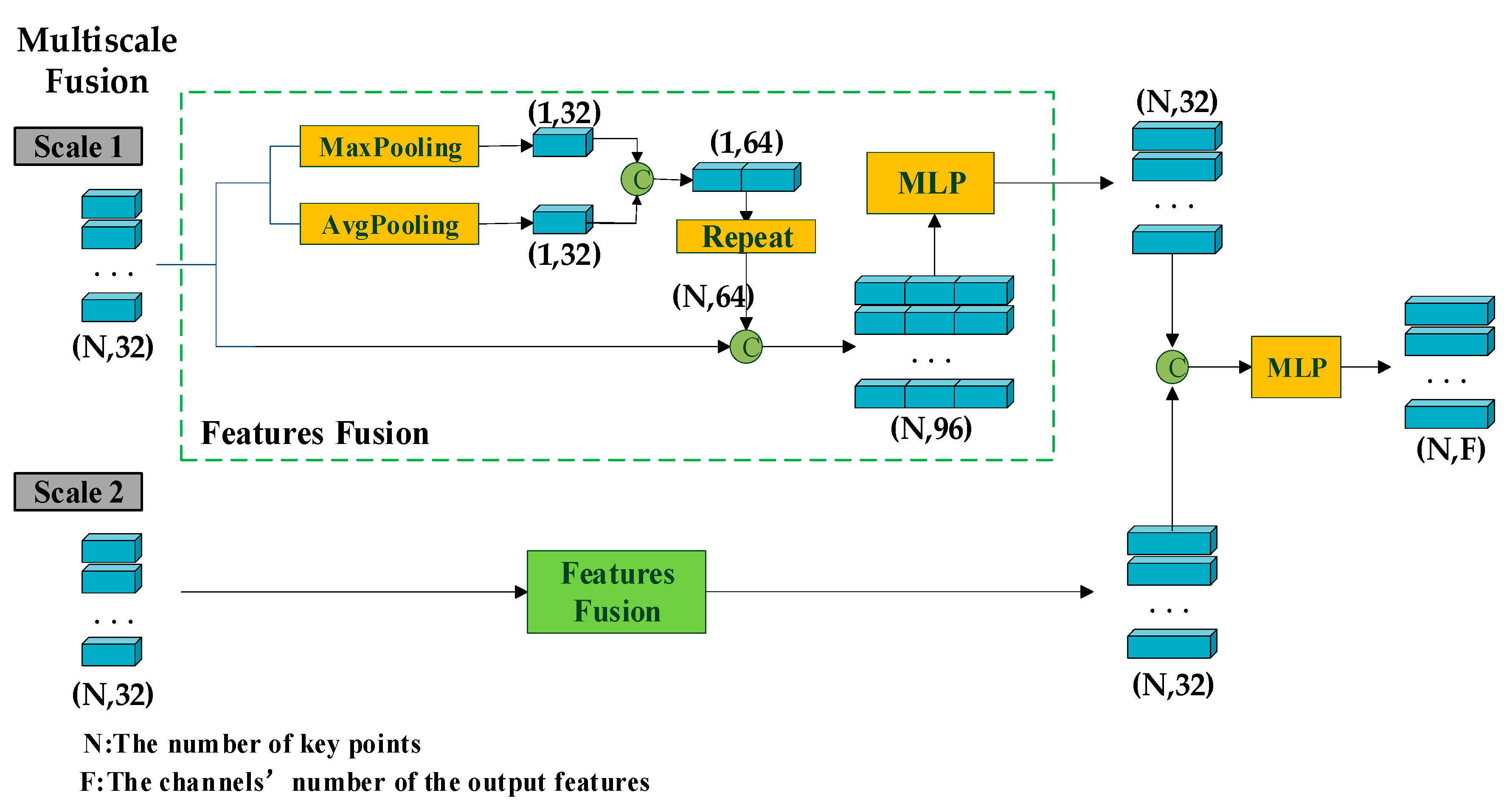
- We have designed a fusion module for multi-scale voxel features. Since voxelization using different scales leads to the selection of different key voxels during subsequent feature extraction, thus resulting in different aggregated features, it is crucial to highlight the uniqueness of key voxel features extracted from different scales and enhance their representativeness. This module first extracts the global features of voxels from each scale separately and then combines these global features with the voxel-specific features. Finally, the fused features from different scale voxels are further integrated to enrich the final features used for bounding box refinement.
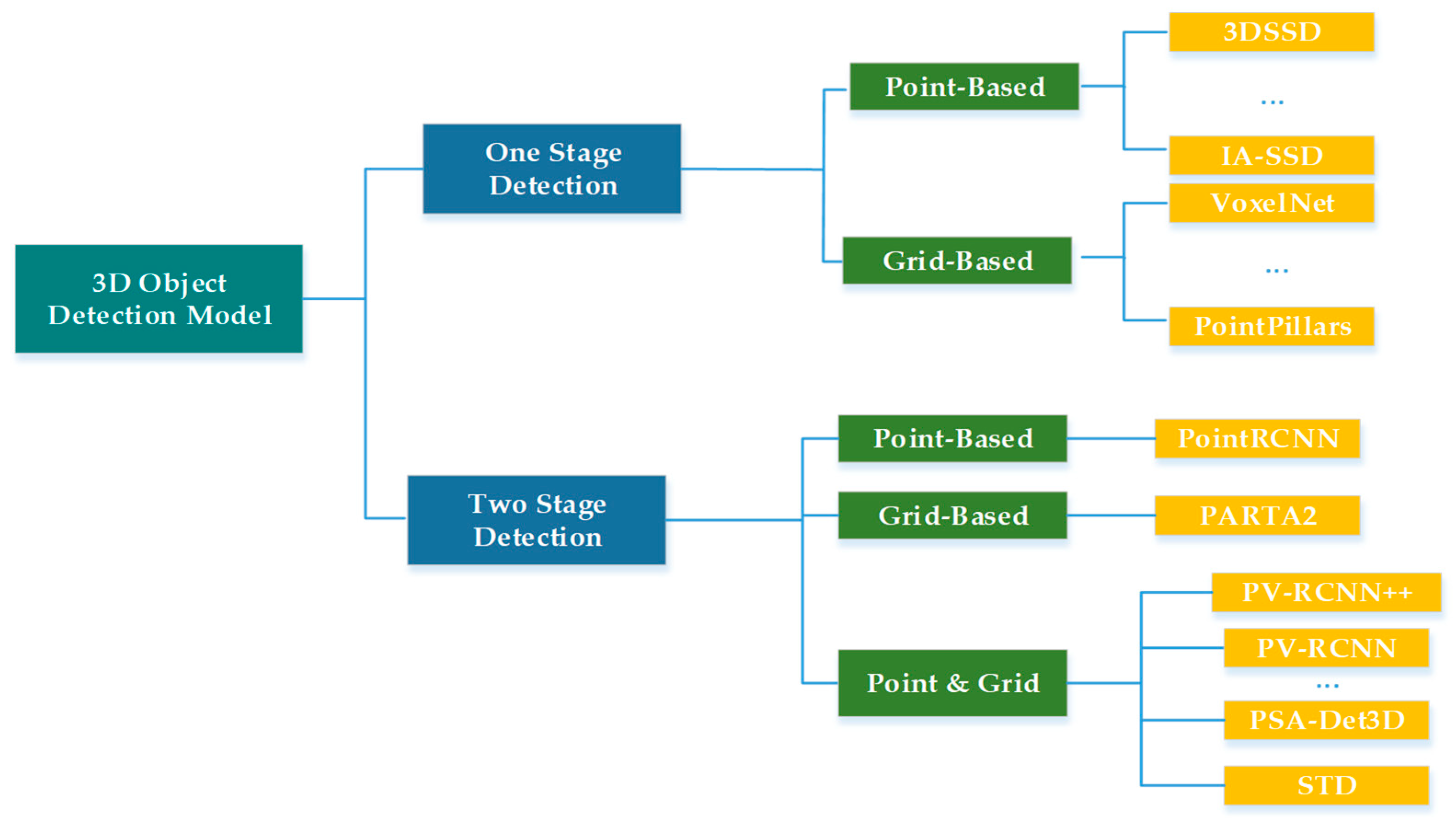
2. Related Works
2.1. One-Stage Detection
2.2. Two-Stage Detection
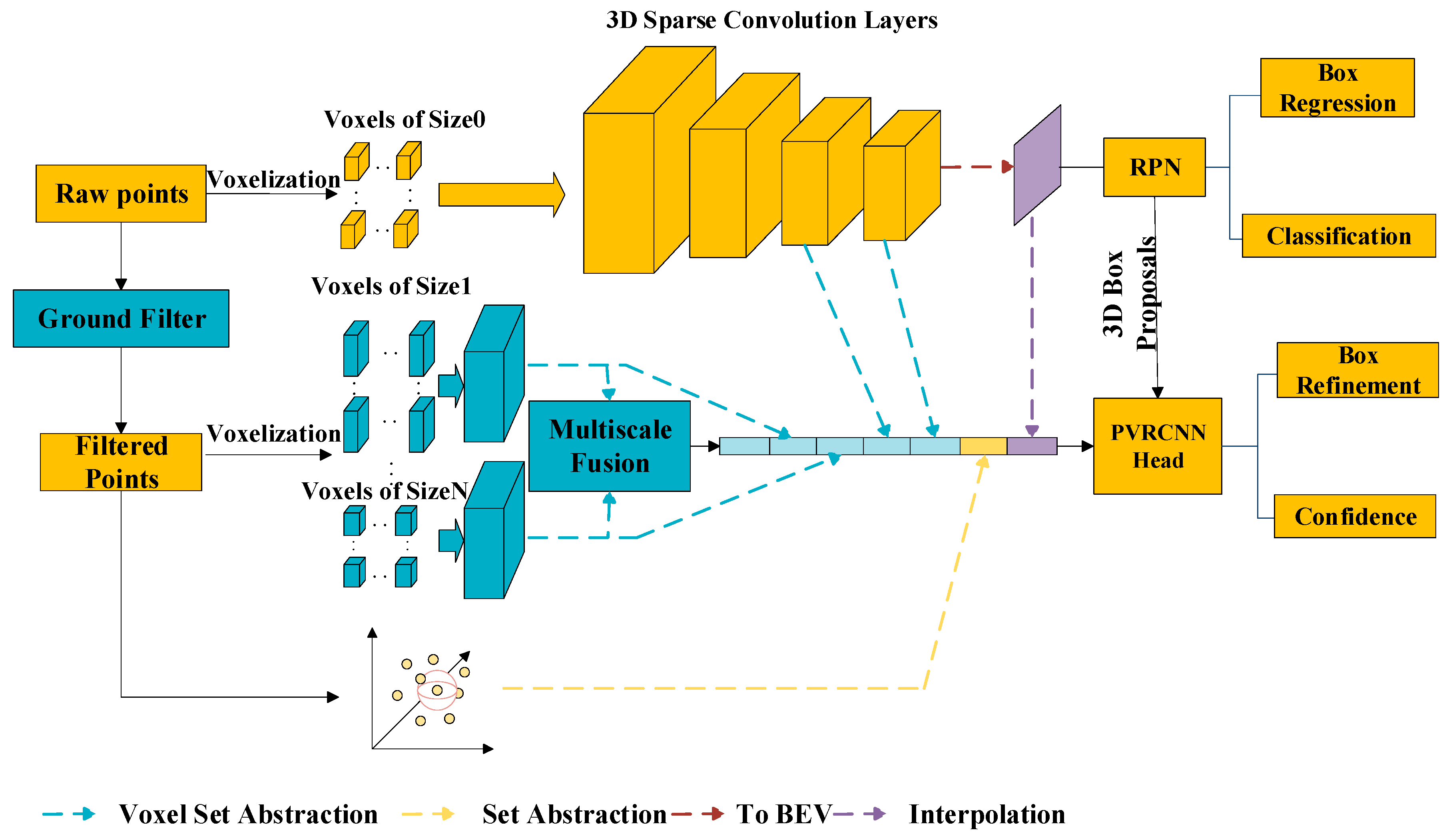
3. Proposed Methods
3.1. Ground Partly Filtering Algorithm
| Algorithm 1: Ground Partly Filter |
| Input: the raw points: ; the size of raw points: N; the Z-axis threshold: Zt; the Z-axis coordinates of points: ; the random sample rate a; Data: the set of points close to the ground: Pg; the point set after filter: Pa Initialize Pg with zero; for i = 0 to N − 1 do if zi ≤ Zt then; Pg.append(pi); end if end m = mean(Pg.f); sd = std(Pg.f); for i in range(len(Pg) do: if m − 3sd ≤ Pg[i]. f ≤ m + 3sd then; Pt.append(Pg[i]); end if end Random sample Pt1 in Pt with random sample rate a; Remove Pt1 from P; return P |
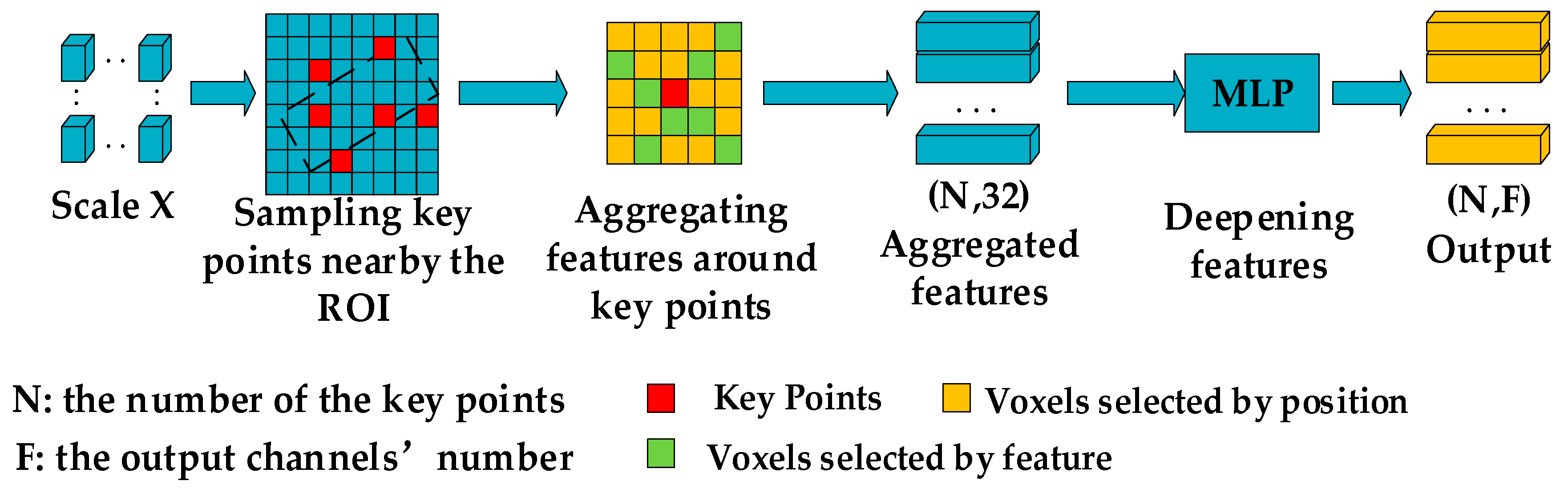
3.2. Multi-Scale Voxels Feature Extraction
3.3. Multi-Scale Voxel Features Fusion
4. Experiment
4.1. Dataset
4.1.1. KITTI Dataset [38]
4.1.2. nuScenes Dataset [39]
4.1.3. Evaluating Indicator
4.2. Experiment Setting
4.2.1. KITTI Dataset
4.2.2. nuScenes Dataset
4.3. Network Evaluation
4.4. Ablation Experiment
4.5. Ground Filter Rate Test
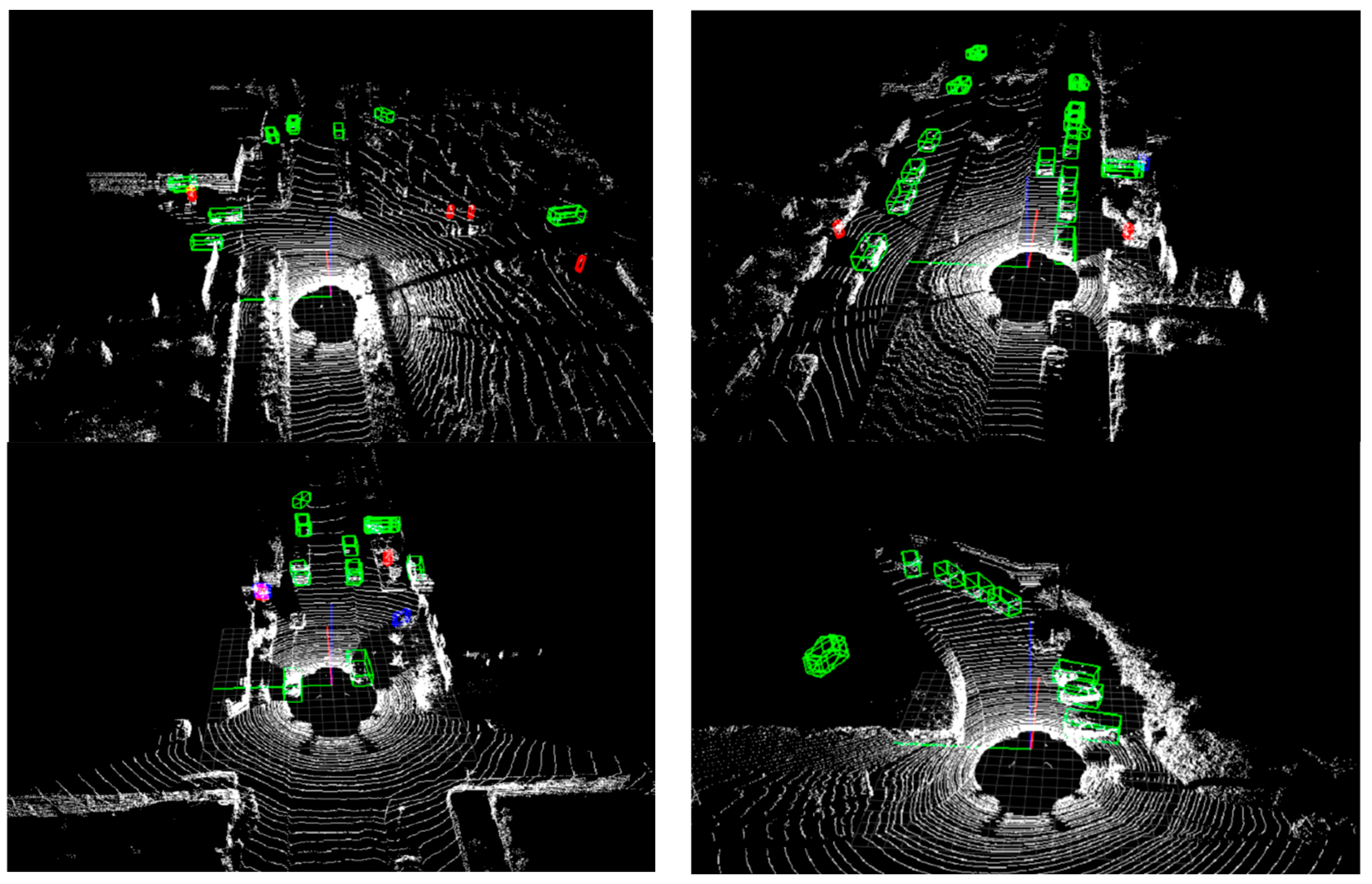
4.6. Detection Effect
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-end learning for point cloud based 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Mao, J.; Xue, Y.; Niu, M.; Bai, H.; Feng, J.; Liang, X.; Xu, H.; Xu, C. Voxel transformer for 3D object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3164–3173. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Zheng, W.; Tang, W.; Jiang, L.; Fu, C.W. SE-SSD: Self-ensembling single-stage object detector from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14494–14503. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3DSSD: Point-based 3D single stage object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11040–11048. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Ye, M.; Xu, S.; Cao, T. HvNet: HYBRID voxel network for lidar based 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1631–1640. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. PV-RCNN: Point-voxel feature set abstraction for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]
- Shi, S.; Jiang, L.; Deng, J.; Wang, Z.; Guo, C.; Shi, J.; Wang, X.; Li, H. PV-RCNN++: Point-voxel feature set abstraction with local vector representation for 3D object detection. Int. J. Comput. Vis. 2023, 131, 531–551. [Google Scholar] [CrossRef]
- Zhang, Z.; Bao, Z.; Tian, Q.; Lyu, Z. SAE3D: Set Abstraction Enhancement Network for 3D Object Detection Based Distance Features. Sensors 2023, 24, 26. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Chen, Z.; Zhang, J.; Tao, D. SASA: Semantics-augmented set abstraction for point-based 3D object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2022; Volume 36, pp. 221–229. [Google Scholar]
- Zhu, L.; Chen, Z.; Wang, B.; Tian, G.; Ji, L. SFSS-Net: Shape-awared filter and sematic-ranked sampler for voxel-based 3D object detection. Neural Comput. Appl. 2023, 35, 13417–13431. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, J.; Zhang, X.; Qi, X.; Jia, J. Voxelnext: Fully sparse voxelnet for 3D object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 21674–21683. [Google Scholar]
- Xiong, S.; Li, B.; Zhu, S. DCGNN: A single-stage 3D object detection network based on density clustering and graph neural network. Complex Intell. Syst. 2023, 9, 3399–3408. [Google Scholar] [CrossRef]
- Zhang, Z.; Xu, R.; Tian, Q. PIDFusion: Fusing Dense LiDAR Points and Camera Images at Pixel-Instance Level for 3D Object Detection. Mathematics 2023, 11, 4277. [Google Scholar] [CrossRef]
- Wang, S.; Lu, K.; Xue, J.; Zhao, Y. Da-Net: Density-aware 3D object detection network for point clouds. IEEE Trans. Multimed. 2023, 1–14. [Google Scholar] [CrossRef]
- Pu, Y.; Liang, W.; Hao, Y.; Yuan, Y.; Yang, Y.; Zhang, C.; Hu, H.; Huang, G. Rank-DETR for high quality object detection. Adv. Neural Inf. Process. Syst. 2024, 36, 16100–16113. [Google Scholar]
- Gao, J.; Zhang, Y.; Geng, X.; Tang, H.; Bhatti, U.A. PE-Transformer: Path enhanced transformer for improving underwater object detection. Expert Syst. Appl. 2024, 246, 123253. [Google Scholar] [CrossRef]
- Shi, S.; Wang, Z.; Wang, X.; Li, H. Part-A2 Net: 3D Part-aware and aggregation neural network for object detection from point cloud. arXiv 2019, arXiv:1907.03670. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Wu, D.; Liao, M.-W.; Zhang, W.-T.; Wang, X.-G.; Bai, X.; Cheng, W.-Q.; Liu, W.-Y. YOLOP: You only look once for panoptic driving perception. Mach. Intell. Res. 2022, 19, 550–562. [Google Scholar] [CrossRef]
- Yang, Y.; Deng, H. GC-YOLOv3: You only look once with global context block. Electronics 2020, 9, 1235. [Google Scholar] [CrossRef]
- Wong, A.; Famuori, M.; Shafiee, M.J.; Li, F.; Chwyl, B.; Chung, J. YOLO nano: A highly compact you only look once convolutional neural network for object detection. In Proceedings of the 2019 Fifth Workshop on Energy Efficient Machine Learning and Cognitive Computing-NeurIPS Edition (EMC2-NIPS), Vancouver, BC, Canada, 13 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 22–25. [Google Scholar]
- Shafiee, M.J.; Chywl, B.; Li, F.; Wong, A. Fast YOLO: A fast you only look once system for real-time embedded object detection in video. arXiv 2017, arXiv:1709.05943. [Google Scholar] [CrossRef]
- Li, J.; Luo, C.; Yang, X. PillarNeXt: Rethinking network designs for 3D object detection in LiDAR point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17567–17576. [Google Scholar]
- Shi, G.; Li, R.; Ma, C. PillarNet: Real-time and high-performance pillar-based 3D object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 35–52. [Google Scholar]
- Guo, D.; Yang, G.; Wang, C. PillarNet++: Pillar-based 3D object detection with multi-attention. IEEE Sens. J. 2023, 23, 27733–27743. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Zhang, Y.; Hu, Q.; Xu, G.; Ma, Y.; Wan, J.; Guo, Y. Not all points are equal: Learning highly efficient point-based detectors for 3D lidar point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18953–18962. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Li, Z.; Wang, F.; Wang, N. Lidar R-CNN: An efficient and universal 3D object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7546–7555. [Google Scholar]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3D object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11784–11793. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. STD: Sparse-to-dense 3D object detector for point cloud. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1951–1960. [Google Scholar]
- Huang, Z.; Zheng, Z.; Zhao, J.; Hu, H.; Wang, Z.; Chen, D. PSA-Det3D: Pillar set abstraction for 3D object detection. Pattern Recognit. Lett. 2023, 168, 138–145. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Salton, G.; McGill, M.J. Introduction to Modern Information Retrieval; McGraw-Hill, Inc.: New York, NY, USA, 1986. [Google Scholar]
- OD Team. OpenPCDet: An Open-Source Toolbox for 3D Object Detection from Point Clouds; GitHub: San Francisco, CA, USA, 2020. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Car 3D AP (%) | Ped. 3D AP (%) | Cyc. 3D AP (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | |
| SECOND [2] | 85.44 | 77.96 | 73.94 | 48.63 | 41.08 | 39.48 | 44.25 | 36.14 | 34.23 |
| SE-SSD [7] | 87.05 | 76.43 | 75.12 | 52.78 | 44.79 | 42.42 | 48.59 | 41.28 | 39.24 |
| PointPillars [4] | 82.57 | 74.13 | 67.89 | 50.49 | 41.89 | 38.96 | 74.10 | 56.65 | 49.92 |
| PointRCNN [9] | 85.96 | 74.64 | 69.70 | 47.98 | 39.37 | 36.01 | 72.96 | 56.62 | 50.73 |
| IA-SSD [32] | 88.34 | 80.13 | 75.04 | 45.51 | 38.03 | 34.61 | 75.35 | 61.94 | 55.70 |
| PSA-Det3D [37] | 87.46 | 78.80 | 74.47 | 49.72 | 42.81 | 39.58 | 75.82 | 61.79 | 55.12 |
| PVRCNN++ [12] | 88.94 | 78.54 | 77.50 | 58.68 | 52.88 | 48.33 | 76.30 | 66.98 | 62.81 |
| Ours | 88.64 | 78.12 | 77.32 | 62.05 | 55.51 | 51.05 | 83.09 | 68.24 | 64.13 |
| Methods | NDS | mAP | Car | Tru. | Bus | Tra. | C.V. | Ped. | Mo. | Bic. | T.C. | Bar. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pointpillar [4] | 45.2 | 25.8 | 70.3 | 32.9 | 44.9 | 18.5 | 4.2 | 46.8 | 14.8 | 0.6 | 7.5 | 21.3 |
| 3DSSD [8] | 51.7 | 34.5 | 75.9 | 34.7 | 60.7 | 21.4 | 10.6 | 59.2 | 25.5 | 7.4 | 14.8 | 25.5 |
| SASA [14] | 55.3 | 36.1 | 71.7 | 42.2 | 63.5 | 29.6 | 12.5 | 62.6 | 27.5 | 9.1 | 12.2 | 30.4 |
| PVRCNN++ [12] | 58.9 | 44.6 | 79.3 | 45.6 | 59.4 | 32.4 | 11.3 | 71.2 | 25.3 | 10.2 | 16.3 | 32.6 |
| MSPV3D | 61.3 | 48.2 | 76.1 | 40.2 | 62.8 | 31.3 | 14.2 | 75.3 | 28.4 | 13.8 | 18.4 | 31.2 |
| Muti | Fusion | Car 3D AP (%) | Ped. 3D AP (%) | Cyc. 3D AP (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | ||
| 🗴 | 🗴 | 88.94 | 78.54 | 77.50 | 58.68 | 52.88 | 48.33 | 76.30 | 66.98 | 62.81 |
| ✓ | 🗴 | 88.42 | 78.37 | 77.65 | 60.43 | 53.04 | 49.98 | 80.86 | 67.75 | 62.15 |
| ✓ | ✓ | 88.64 | 78.12 | 77.32 | 62.05 | 55.51 | 51.05 | 83.09 | 68.24 | 64.13 |
| Filter Rate (a) | Car 3D AP (%) | Ped. 3D AP (%) | Cyc. 3D AP (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | |
| 0 | 88.74 | 78.21 | 77.32 | 59.28 | 52.74 | 48.32 | 79.20 | 66.05 | 61.63 |
| 0.3 | 88.88 | 78.23 | 77.08 | 59.47 | 52.88 | 48.65 | 79.89 | 65.95 | 61.73 |
| 0.5 | 88.96 | 78.25 | 77.42 | 60.80 | 53.75 | 48.65 | 78.26 | 67.21 | 62.06 |
| 0.7 | 88.64 | 78.12 | 77.32 | 62.05 | 55.51 | 51.05 | 83.09 | 68.24 | 64.13 |
| 1 | 88.60 | 78.02 | 76.73 | 60.29 | 54.18 | 49.61 | 80.94 | 66.26 | 63.71 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Bao, Z.; Wei, Y.; Zhou, Y.; Li, M.; Tian, Q. MSPV3D: Multi-Scale Point-Voxels 3D Object Detection Net. Remote Sens. 2024, 16, 3146. https://doi.org/10.3390/rs16173146
Zhang Z, Bao Z, Wei Y, Zhou Y, Li M, Tian Q. MSPV3D: Multi-Scale Point-Voxels 3D Object Detection Net. Remote Sensing. 2024; 16(17):3146. https://doi.org/10.3390/rs16173146
Chicago/Turabian StyleZhang, Zheng, Zhiping Bao, Yun Wei, Yongsheng Zhou, Ming Li, and Qing Tian. 2024. "MSPV3D: Multi-Scale Point-Voxels 3D Object Detection Net" Remote Sensing 16, no. 17: 3146. https://doi.org/10.3390/rs16173146
APA StyleZhang, Z., Bao, Z., Wei, Y., Zhou, Y., Li, M., & Tian, Q. (2024). MSPV3D: Multi-Scale Point-Voxels 3D Object Detection Net. Remote Sensing, 16(17), 3146. https://doi.org/10.3390/rs16173146