1. Introduction
In multi-modal imaging, achievement of multi-modality image fusion which aims to effectively combine complementary information from different types of sensors remains a significant challenge [
1]. Specifically, the integration of infrared and visible image information faces difficulties in simultaneously preserving thermal radiation details and rich textural information due to the inherent differences between these modalities [
2]. Infrared images captured by sensors reflect the thermal radiation intensity of objects, providing benefits for monitoring under low-light and unfavorable weather conditions. Despite this, infrared images lack scene detail information. On the other hand, visible images generally provide higher resolution and more intricate textural details [
3]. As shown in
Figure 1, the fusion process combines the distinct and overlapping information from both types of images to create fused images with enhanced textures and salient targets. This fusion result has various uses in subsequent tasks like multi-modal saliency detection [
4], target detection [
5], and semantic segmentation [
6].
Techniques for fusing infrared and visible images generally fall into two board categories: traditional approaches and deep-learning-based approaches. Traditional approaches often entail measuring activity levels in either the spatial or transform domains, followed by manual fusion using predefined fusion rules [
7]. Representative traditional approaches include Multi-scale Transform (MST) [
8,
9,
10], Sparse Representation (SR) [
11,
12,
13], and subspace-based fusion methods [
14,
15]. While these approaches have been effective in certain situations, their effectiveness may be hindered when dealing with more complex scenes due to their reliance on manually designed rules and limitations in shallow feature learning.
In recent years, deep learning has proven its robust capability in extracting image features and has gained widespread adoption in image fusion. Among these techniques, Convolutional Neural Networks (CNNs) [
16,
17,
18,
19] are particularly popular. These approaches efficiently preserve the intricate details of the original images through feature extraction carried out by the convolutional layers. However, CNNs can only extract local information within a relatively small receptive field and struggle to retain the overall semantic information of the scene [
20]. To address this, Transformers [
21], adept at extracting global features and capturing long-range dependencies between features, have been introduced into the image fusion domain [
22,
23,
24], delivering more pronounced fusion effects. However, fusion methods based on Transformers are not as effective as CNNs in preserving the textural details of the scene. Therefore, fusion frameworks that combine CNNs and Transformers [
25,
26,
27] have been further proposed. These methods not only preserve the detailed features of the scene but also highlight salient targets. Despite the good performance of the aforementioned methods, they still lack effective control over the importance of different features during the fusion process. In fact, there will be feature redundancy in this process, which would limit the further improvement for fusion performance. Moreover, the unique complementary semantic information learning from different modalities would appear at different feature learning stages using same network structure. However, this is rarely discussed in available studies [
28]. In addition, the aforementioned methods all overlook the importance of informative input features besides raw image forms in mining local information and their impact on the fusion results [
29,
30]. To address these challenges, it is essential to develop a fusion framework that not only integrates global and local features from different modalities but also effectively controls the importance of these features during the fusion process.
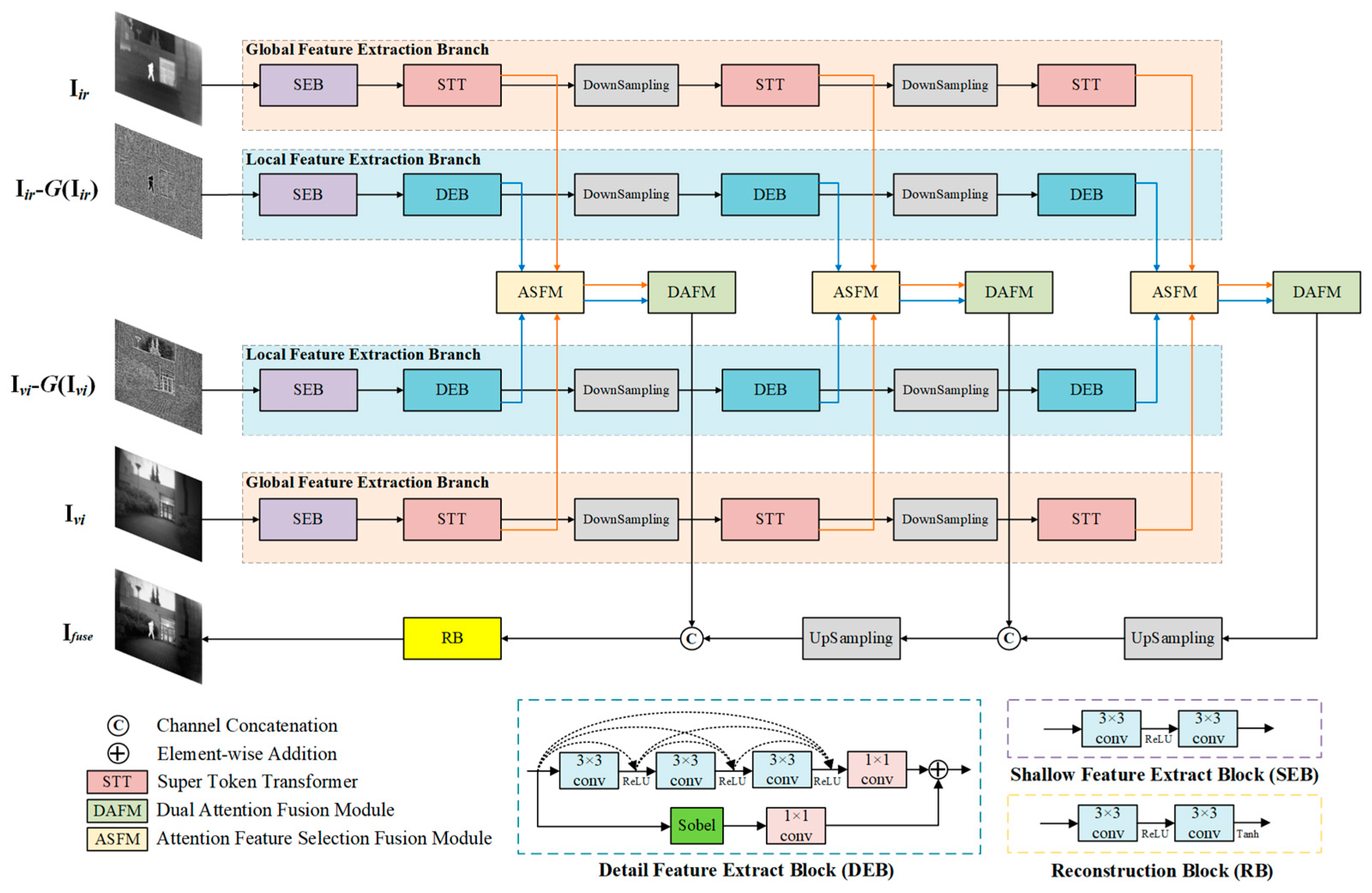
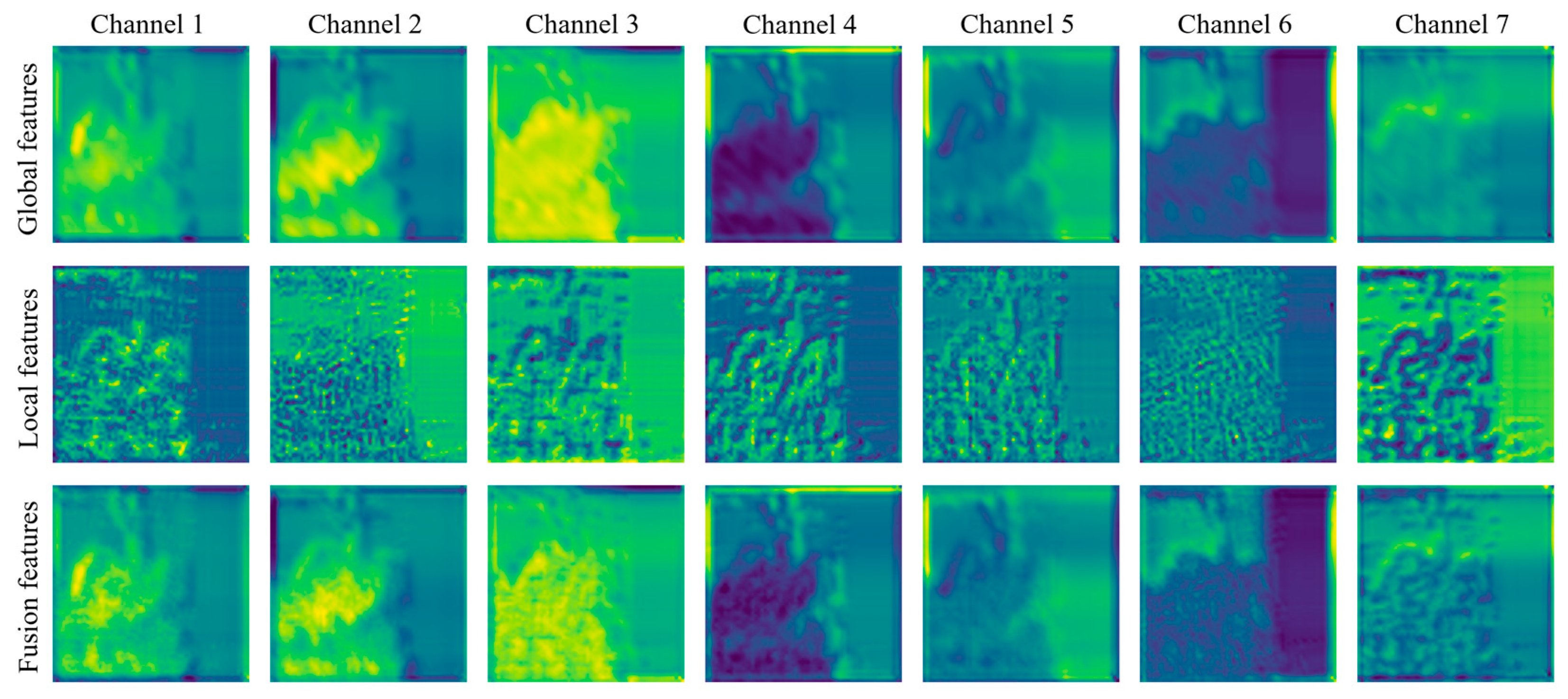
In concern of the aforementioned problems, a novel network architecture for infrared and visible image fusion is designed in this study to improve fusion quality. By incorporating the Transformer-based global feature extraction branches alongside the CNN-based local detail extraction branches, this architecture effectively captures both global and local feature information. Moreover, the Attention-based Feature Selection and Fusion Module (ASFM) and Dual Attention Fusion Module (DAFM) are specifically designed to tackle the issues of feature redundancy and selective feature fusion. These innovations contribute to the creation of more informative and visually coherent fusion images. To summarize, the key contributions of this study are as follows:
A four-branch Transformer-CNN network architecture is constructed for infrared and visible image fusion by utilizing multiple types of image inputs. The network is able to achieve end-to-end training and testing. Its architecture takes both original infrared and visible images and their preprocessed feature maps as input to go through global and local feature extraction and fusion to enhance the fusion quality of infrared and visible images.
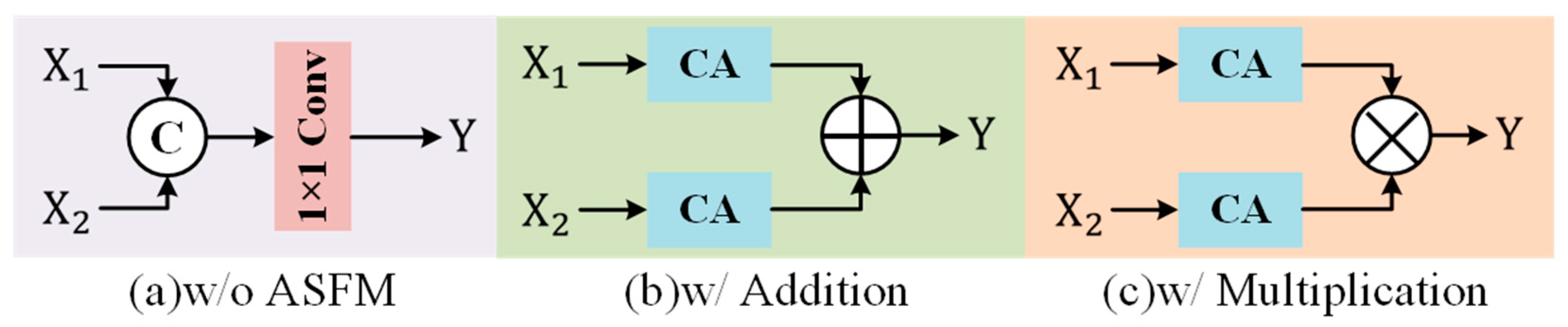
An Attention-based Feature Selection and Fusion Module (ASFM) is developed so that both unique and common features from different modalities can be integrated through an addition–multiplication strategy. This approach increases the richness of information in the fused image.
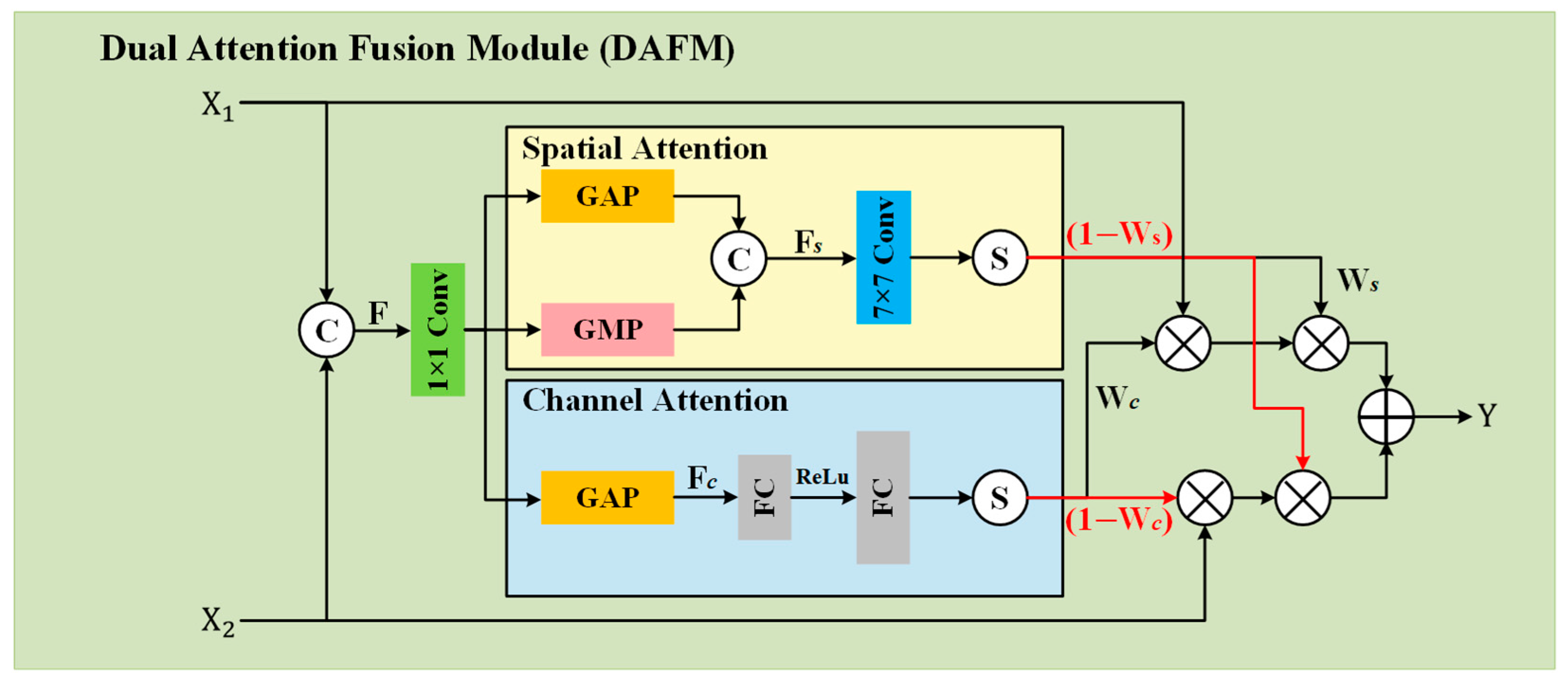
A Dual Attention Fusion Module (DAFM) is proposed that employs a combination of channel and spatial attention mechanisms. It enables selectively filtering and fusing global and local features to reduce feature redundancy in the fused image.
A perception loss function is specifically designed for image fusion based on semantic information at different levels from different modalities. This loss function adds constraints based on feature differences in input images from different modalities, leading to fused images that align more closely with human visual perception.
The following structure is evident throughout this paper:
Section 2 introduces various methods and applications that are related.
Section 3 outlines the architecture and loss function of the method proposed by us.
Section 4 provides a detailed analysis and presentation of extensive experimental results. Ultimately,
Section 5 concludes the paper.
2. Related Work
In unsupervised scenarios, Generative Adversarial Networks (GANs) have emerged as an ideal choice for image fusion. Ma et al. [
31] pioneered the application of GANs in this field with their proposal of FusionGAN. In this approach, the generator is tasked with creating fused images that incorporate detailed information from visible images. Then, through adversarial training, the fused images are given more significant information from infrared images. To enhance fusion performance, Ma et al. [
32] introduced the Dual Discriminator Conditional GAN (DDcGAN) fusion framework. The framework introduced a novel target-emphasized loss function and implemented a dual discriminator structure, thereby further advancing the capabilities of FusionGAN. In addition, Li et al. [
33] introduced AttentionFGAN to respond to the need for perceiving prominent information in source images. This model integrates a multi-scale attention mechanism into GANs, enabling the generator to focus on infrared salient targets and visible background intricacies while ensuring the discriminator concentrates on regions of interest. Although GAN-based fusion models circumvent the limitations associated with manually crafting fusion rules, the absence of explicit ground truth in image fusion tasks poses a challenge. This difficulty hinders the discriminator’s ability to effectively distinguish and learn features from various sources, consequently obstructing the development of GAN-based image fusion models.
Convolutional Neural Networks (CNNs), which are widely utilized in merging infrared and visible images due to their robust feature extraction and adaptability, have been demonstrated to have remarkable performance. Li et al. [
16] introduced the DenseFuse framework, utilizing dense blocks in the encoding process to combine features from both shallow and deep layers, thus extracting richer source image features. Inspired by DenseFuse, Li et al. [
34] later introduced NestFuse, advancing the fusion strategy by incorporating spatial and channel attention mechanisms. These mechanisms underscore the relevance of each spatial position and channel, leveraging deep-learned features. A different approach was proposed by Zhao et al. [
18] with DIDFuse, which aims to separate images into two distinct components including two principal components: one capturing the low-frequency aspects in a background feature map, and the other encapsulating the high-frequency elements in a detail feature map. To facilitate the fusion of images with prominent targets and clear textures, they also introduced a specialized loss function. These prominent fusion techniques are all part of the Autoencoder (AE) connected network family. However, due to the manual fusion strategies required for the extracted multi-modal features in these studies, the fusion performance is constrained.
To alleviate excessive reliance on prior knowledge, researchers have explored alternative fusion network frameworks that implicitly integrate feature extraction, merging, and image synthesis into end-to-end CNN-associated networks with carefully designed loss functions. For instance, Zhang et al. [
35] introduced IFCNN, which first introduced perceptual loss during the training phase of image fusion models, to enable fused images with richer texture information. Zhang et al. [
36] conceptualized the image fusion challenge as one of preserving the texture and intensity ratios inherent in the source images. Thus, they formulated a unified loss function that incorporates both types of information, making it adaptable across various fusion tasks. Xu et al. [
17] introduced the U2Fusion technique, which utilizes an unsupervised unified network for image fusion. They also presented a unique loss function that focuses on preserving adaptive information and incorporates pretrained CNNs for extracting features. In a similar vein, Tang et al. [
37] introduced SeAFusion, a real-time, semantic-aware image fusion network. This network leverages dense blocks with gradient residuals for feature extraction and integrates loss functions inspired by semantic segmentation to guide the fusion network’s training process. It is evident from the aforementioned studies that developing suitable loss functions to enhance semantic information perception has the potential to boost the performance of CNN-related networks for fused infrared and visible images. Additionally, CNN-related fusion methods may have limitations in terms of their ability to learn local features.
The Vision Transformer (ViT) [
38] has been demonstrated to have strong effectiveness in handling long-range dependencies and has had widespread application in various machine vision domains in recent years, including visual recognition [
39,
40], object detection [
41,
42], tracking [
43,
44], and segmentation [
45,
46,
47]. Initially introduced by Zhao et al. [
27], the Transformer was integrated into infrared and visible image fusion, using a sequential DenseNet to extract detailed features and a Dual-Transformer (DT) to enhance global information before fusion. Chen et al. [
48] further advanced this by integrating the Transformer into a CNN-based fusion network to capture both global and local features, employing a dual-branch CNN module for shallow feature extraction and a Transformer module for leveraging global channel and spatial relationships. A different fusion strategy was proposed by Yi et al. [
49] with their TCPMFNet, leveraging an autoencoder structure and parallel hybrid fusion strategy using Transformer and a CNN. Tang et al. [
50] developed a network featuring a local feature extraction branch to retain complementary information and a global feature extraction branch with three Transformer blocks to capture long-distance relationships. To address computational costs, Huang et al. [
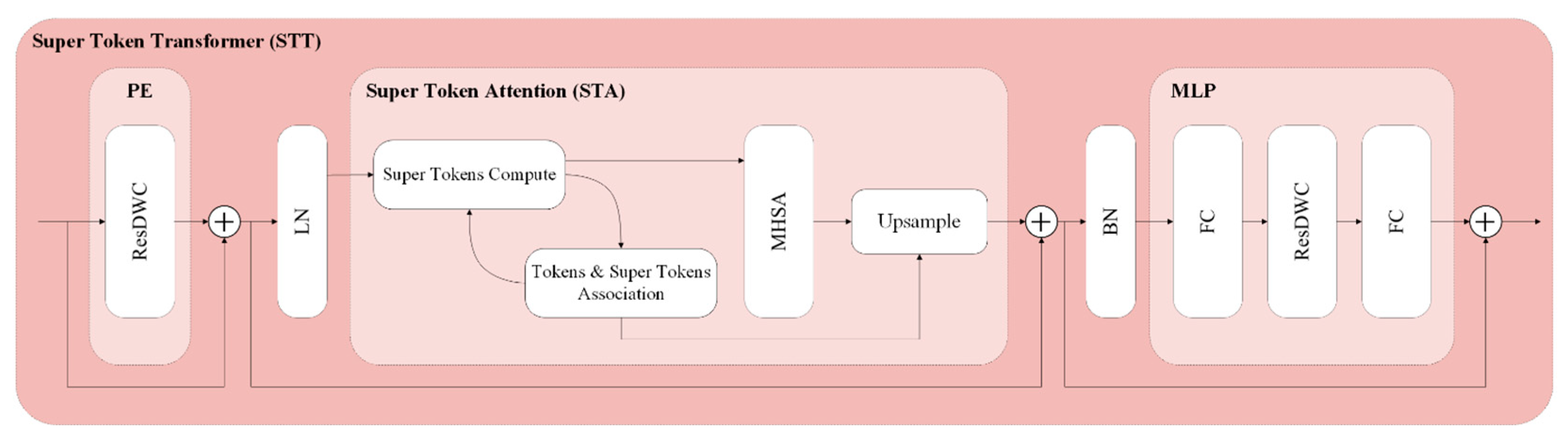
51] introduced the Super Token Transformer (STT) as a more efficient alternative. The Super Token Attention (STA) module within the STT significantly reduces the number of tokens involved in computations by leveraging clustering and sparse association learning concepts, while maintaining model performance. As such, the STA module presents a promising option for feature learning in Transformer-based image fusion.
Along with feature learning regarding the range of perceived information, attention-mechanism-based feature fusion strategies are also an important aspect to empower the model’s capability to enhance informative feature learning through adaptively handling different data characteristics. Yang et al. [
52] proposed a fusion module that combines channel attention and spatial attention mechanisms. They used the channel attention mechanism to analyze the feature responses of different channels, while utilizing the spatial attention mechanism to adaptively focus on key regions in the image. To address potential artifacts and non-consistency issues in fused images, Li et al. [
53] introduced an attention-based fusion strategy that analyzes the differences between input features. Specifically, it highlights thermal targets in infrared images while preserving details in visible light images, which effectively prevents artifacts in fusion image. Furthermore, in concern of the significant correlation and complementarity between features of different modalities, Li et al. [
54] proposed an innovative Cross-Attention Mechanism (CAM). It significantly improves the network’s ability to extract and utilize complementary features through balancing the emphasis on salient targets and detail preservation. In this process, it reduces redundant information from different modalities. In summary, these attention-mechanism-based fusion methods are able to adaptively analyze and integrate the key information. Thus, they enable the deep learning models to achieve more powerful and flexible feature representation capabilities in various visual tasks.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}