
Exploring Reinforced Class Separability and Discriminative Representations for SAR Target Open Set Recognition



Abstract
:1. Introduction
- (1)
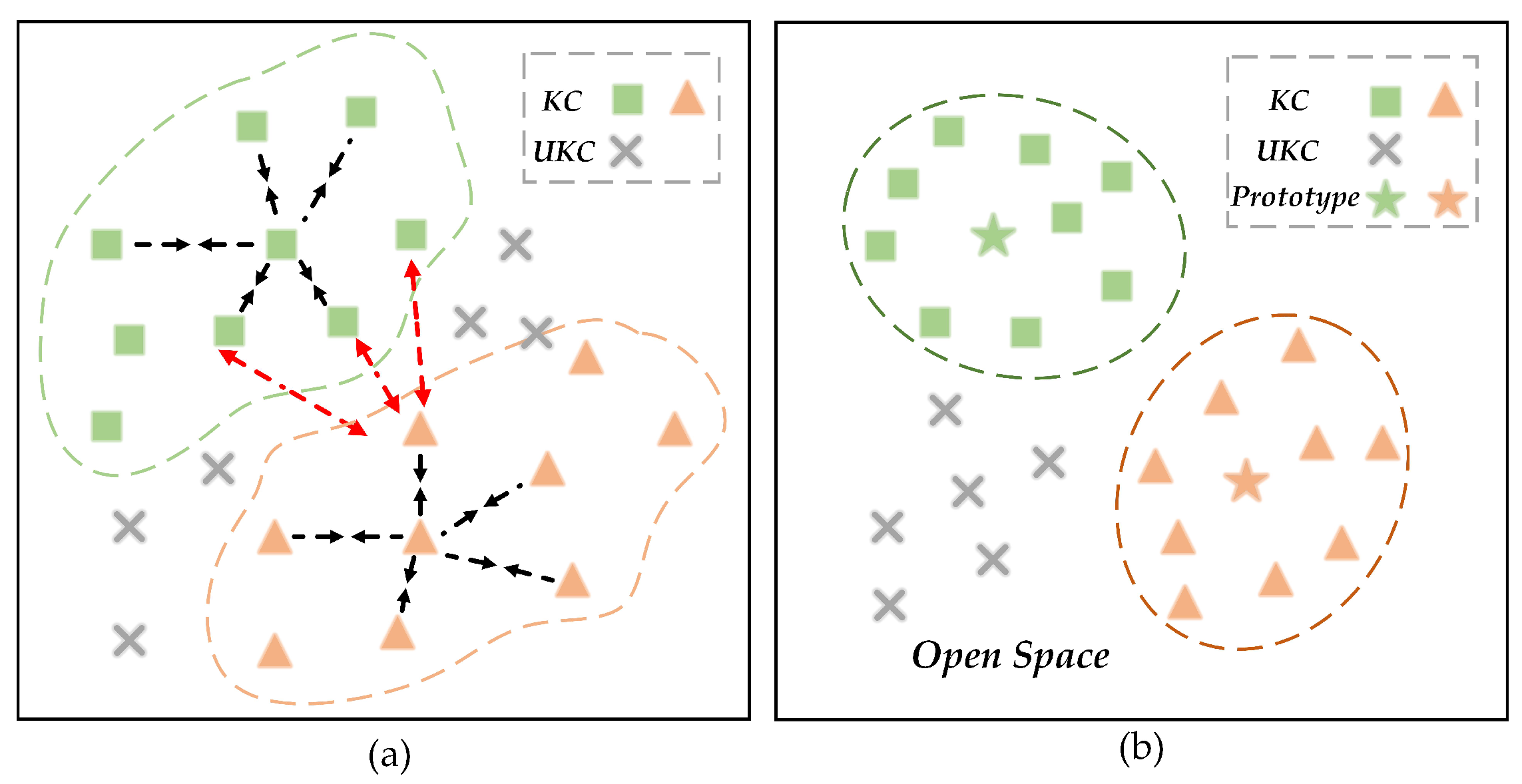
- A novel RCS-OSR framework is proposed for classifying known classes and identifying unknown classes in open scenarios. By emphasizing reinforced class separability, this framework can effectively distinguish between known and unknown classes that are prone to confusion in open scenarios. By designing regularized intra-class compactness loss (RIC-Loss) and intra-class relationship aware consistency loss (IRC-Loss), along with joint supervised training that utilizes cross-entropy loss, it enhances the discriminability of the extracted features, balancing open space risk and empirical classification risk.
- (2)
- A CMCFE module with causal region-aware capability is proposed, which can enhance feature discriminability by strengthening the representation of causal regions through attention mechanisms. Furthermore, a multi-scale abstract features aggregation branch and an auxiliary handcrafted feature injection branch are employed to enhance the model’s capability in extracting information from local regions of diverse scales.
- (3)
- A class-aware OSR classifier with adaptive thresholding is proposed, which effectively leverages the differences between different classes. By calculating the distances between correctly classified samples and their corresponding prototypes during training, the similarity distribution matrix can be generated, with the queried maximum value serving as the adaptive threshold for this class of targets.
2. Related Works
2.1. Open Set Recognition
2.2. Prototype Learning
3. Methodology
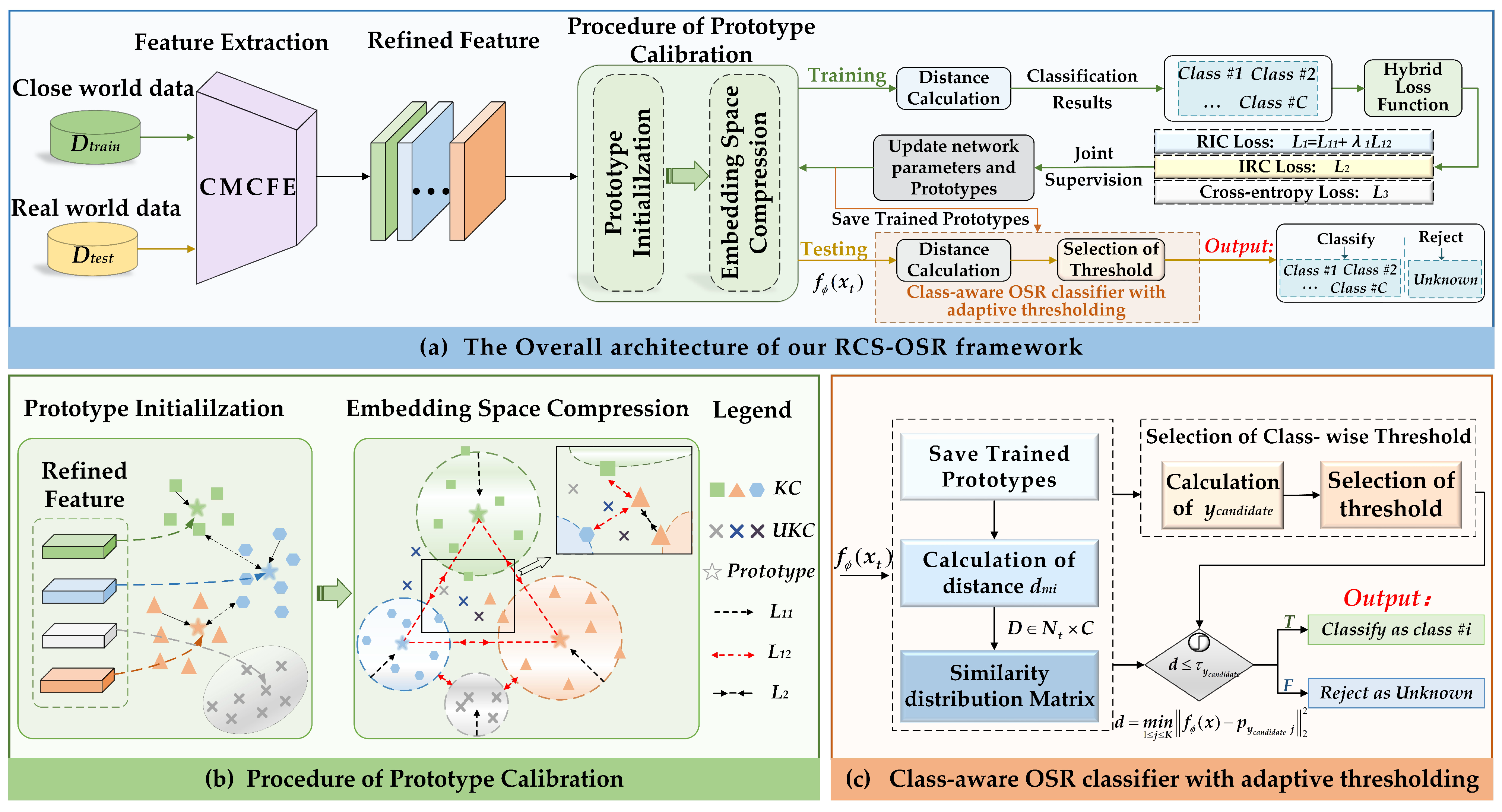
3.1. Overview of RCS-OSR
3.2. Cross-Modal Causal Features Enhancement Module
3.2.1. Multi-Scale Abstract Features Aggregation Branch
3.2.2. Auxiliary Features Injection Branch
3.2.3. Cross-Modal Hybrid Feature Fusion Block
3.3. Hybrid Loss for Discriminative Prototype Learning
| Algorithm 1 Pseudo-code of the Proposed RCS-OSR Algorithm |
| Input: Known class targets for training, hyperparameters: , , , , , initialized learning rate , and the number of training iterations . Output: The set of parameters for the CMCFE module , and all saved prototypes .
|
3.4. Class-Aware OSR Classifier with Adaptive Thresholding
4. Experiments and Results
4.1. Experimental Setup
4.1.1. Dataset Description and Implementation Details
4.1.2. Evaluation Protocols
4.2. Comparison with Other OSR Methods
- (1)
- SoftMax compares the highest probability with a threshold for open set recognition.
- (2)
- OpenMax substitutes the SoftMax layer with the OpenMax layer to generate probabilities for unknown classes and converts the OSR task into a CSR task with classes [27].
- (3)
- GCPL calculates the distances among prototypes for classification. Additionally, GCPL combines discriminative and generative losses to reduce open space risk [17].
- (4)
- CGDL proposes a novel method, conditional Gaussian distribution learning, based on the variational auto-encoder, which can classify known classes by forcing different latent features to approximate different Gaussian models [30].
- (5)
- CAC allocates anchored class centers to known classes to increase intra-class compactness, which can reserve extra space for the emergence of unknown classes [33].
- (6)
- ARPL introduces an adversarial margin constraint to confine the open space based on RPL. Additionally, it devised an instantiated adversarial enhancement method to generate diverse unknown classes [20].
4.2.1. Performance Comparison on the MSTAR Dataset
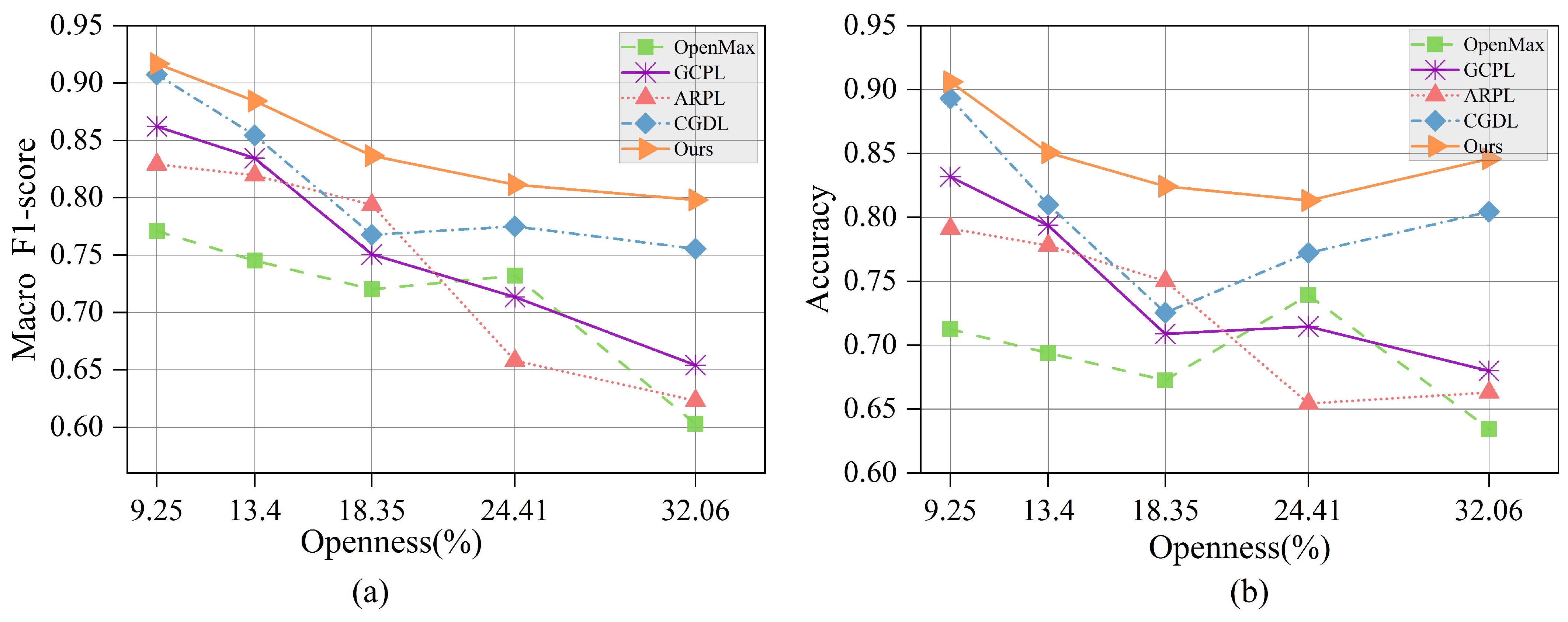
4.2.2. Performance Comparison Against Various Openness and Epochs
5. Discussion
5.1. Ablation Studies
5.2. Performance Comparison with Different Loss Functions
5.3. Effectiveness Evaluation of CMCFE
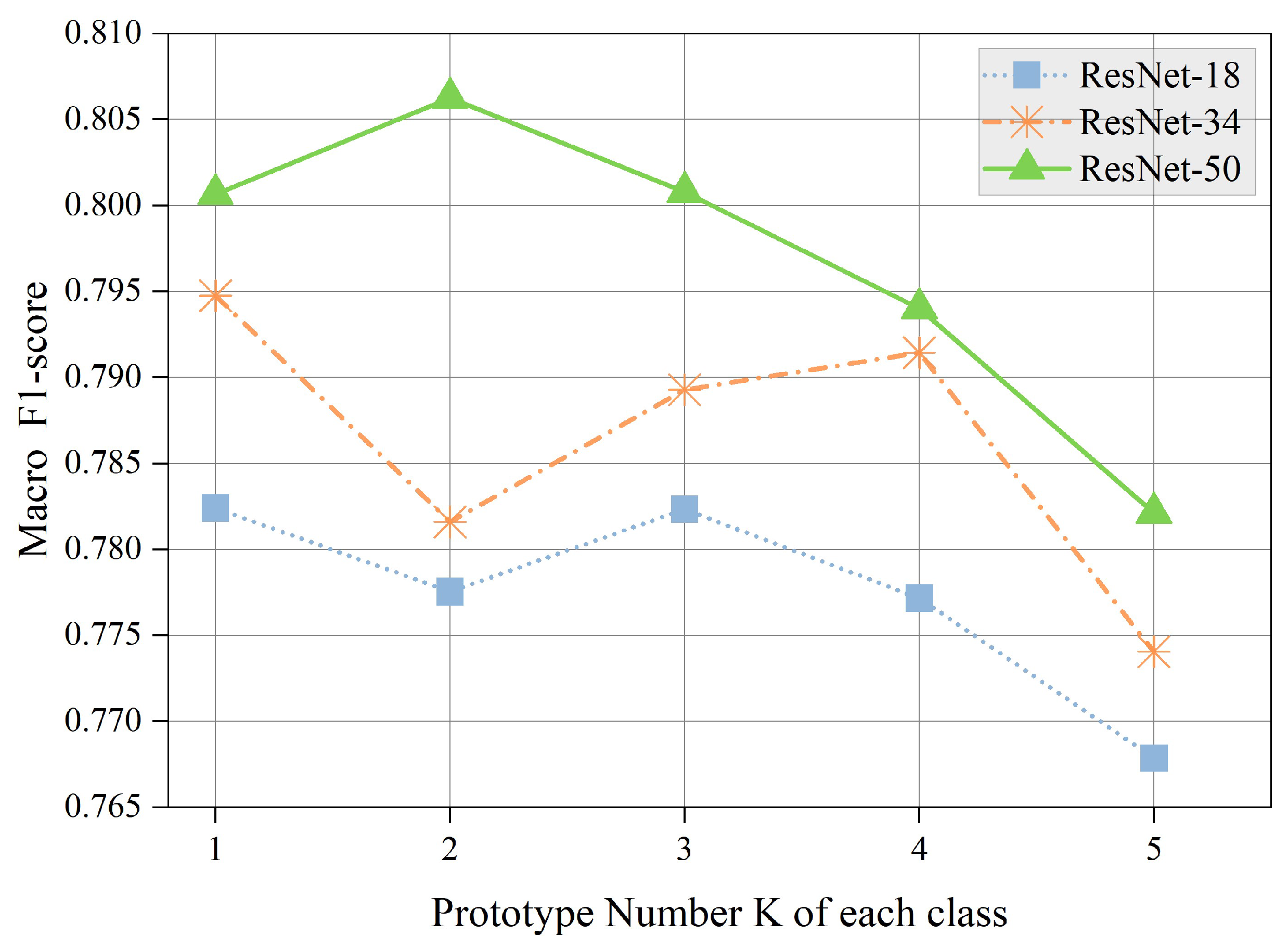
5.4. Influence of Prototype Number K
5.5. Hyperparameters Analysis of the Hybrid Loss Function
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- El-Darymli, K.; Gill, E.W.; Mcguire, P.; Power, D.; Moloney, C. Automatic Target Recognition in Synthetic Aperture Radar Imagery: A State-of-the-Art Review. IEEE Access 2016, 4, 6014–6058. [Google Scholar] [CrossRef]
- Gao, F.; Kong, L.; Lang, R.; Sun, J.; Wang, J.; Hussain, A.; Zhou, H. Sar Target Incremental Recognition Based on Features with Strong Separability. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5202813. [Google Scholar] [CrossRef]
- Wang, C.; Luo, S.; Pei, J.; Huang, Y.; Zhang, Y.; Yang, J. Crucial Feature Capture and Discrimination for Limited Training Data SAR ATR. ISPRS J. Photogramm. Remote Sens. 2023, 204, 291–305. [Google Scholar] [CrossRef]
- Ma, X.; Ji, K.; Feng, S.; Zhang, L.; Xiong, B.; Kuang, G. Open Set Recognition With Incremental Learning for SAR Target Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Yue, Z.; Gao, F.; Xiong, Q.; Wang, J.; Huang, T.; Yang, E.; Zhou, H. A Novel Semi-Supervised Convolutional Neural Network Method for Synthetic Aperture Radar Image Recognition. Cogn. Comput. 2021, 13, 795–806. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, H.; Ma, F.; Pan, Z.; Zhang, F. A Sidelobe-Aware Small Ship Detection Network for Synthetic Aperture Radar Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Zeng, Z.; Sun, J.; Wang, Y.; Gu, D.; Han, Z.; Hong, W. Few-Shot SAR Target Recognition through Meta Adaptive Hyper-parameters Learning for Fast Adaptation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5219517. [Google Scholar] [CrossRef]
- Huang, H.; Gao, F.; Sun, J.; Wang, J.; Hussain, A.; Zhou, H. Novel Category Discovery without Forgetting for Automatic Target Recognition. IEEE J. Selected Topics App. Earth Observ. Remote Sens. 2024, 17, 4408–4420. [Google Scholar] [CrossRef]
- Zhang, F.; Sun, X.; Ma, F.; Yin, Q. Superpixelwise Likelihood Ratio Test Statistic for PolSAR Data and Its Application to Built-up Area Extraction. ISPRS J. Photogramm. Remote Sens. 2024, 209, 233–248. [Google Scholar] [CrossRef]
- Zeng, Z.; Sun, J.; Xu, C.; Wang, H. Unknown SAR target identification method based on feature extraction network and KLD–RPA joint discrimination. Remote Sens. 2021, 13, 2901. [Google Scholar] [CrossRef]
- Liao, N.; Datcu, M.; Zhang, Z.; Guo, W.; Zhao, J.; Yu, W. Analyzing the separability of SAR classification dataset in open set conditions. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7895–7910. [Google Scholar] [CrossRef]
- Geng, C.; Huang, S.j.; Chen, S. Recent Advances in Open Set Recognition: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3614–3631. [Google Scholar] [CrossRef]
- Li, Y.; Ren, H.; Yu, X.; Zhang, C.; Zou, L.; Zhou, Y. Threshold-free Open-set Learning Network for SAR Automatic Target Recognition. IEEE Sens. J. 2024, 24, 6700–6708. [Google Scholar] [CrossRef]
- Fang, L.; Yang, Z.; Ma, T.; Yue, J.; Xie, W.; Ghamisi, P.; Li, J. Open-World Recognition in Remote Sensing: Concepts, challenges, and opportunities. IEEE Geosci. Remote Sens. Mag. 2024, 12, 8–31. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Xie, G.S.; Li, X.; Mei, T.; Liu, C.L. A survey on learning to reject. Proc. IEEE 2023, 111, 185–215. [Google Scholar] [CrossRef]
- Xia, Z.; Wang, P.; Dong, G.; Liu, H. Spatial Location Constraint Prototype Loss for Open Set Recognition. Comput. Vis. Image Underst. 2023, 229, 103651. [Google Scholar] [CrossRef]
- Yang, H.M.; Zhang, X.Y.; Yin, F.; Liu, C.L. Robust Classification with Convolutional Prototype Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3474–3482. [Google Scholar]
- Yang, H.M.; Zhang, X.Y.; Yin, F.; Yang, Q.; Liu, C.L. Convolutional Prototype Network for Open Set Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2358–2370. [Google Scholar] [CrossRef] [PubMed]
- Chen, G.; Qiao, L.; Shi, Y.; Peng, P.; Li, J.; Huang, T.; Pu, S.; Tian, Y. Learning Open Set Network with Discriminative Reciprocal Points. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 507–522. [Google Scholar]
- Chen, G.; Peng, P.; Wang, X.; Tian, Y. Adversarial Reciprocal Points Learning for Open Set Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8065–8081. [Google Scholar] [CrossRef]
- Scheirer, W.J.; de Rezende Rocha, A.; Sapkota, A.; Boult, T.E. Toward Open Set Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1757–1772. [Google Scholar] [CrossRef]
- Scheirer, W.J.; Jain, L.P.; Boult, T.E. Probability Models for Open Set Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2317–2324. [Google Scholar] [CrossRef]
- Scherreik, M.D.; Rigling, B.D. Open Set Recognition for Automatic Target Classification with Rejection. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 632–642. [Google Scholar] [CrossRef]
- Scherreik, M.; Rigling, B. Multi-Class Open Set Recognition for SAR Imagery. In Proceedings of the Automatic Target Recognition XXVI; SPIE: Bellingham, WA, USA, 2016; Volume 9844, pp. 150–158. [Google Scholar]
- Rudd, E.M.; Jain, L.P.; Scheirer, W.J.; Boult, T.E. The extreme value machine. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 762–768. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Patel, V.M. Sparse representation-based open set recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1690–1696. [Google Scholar] [CrossRef] [PubMed]
- Bendale, A.; Boult, T.E. Towards Open Set Deep Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1563–1572. [Google Scholar]
- Yoshihashi, R.; Shao, W.; Kawakami, R.; You, S.; Iida, M.; Naemura, T. Classification-reconstruction learning for open-set recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 4016–4025. [Google Scholar]
- Oza, P.; Patel, V.M. C2ae: Class Conditioned Auto-Encoder for Open-Set Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2307–2316. [Google Scholar]
- Sun, X.; Yang, Z.; Zhang, C.; Ling, K.V.; Peng, G. Conditional Gaussian Distribution Learning for Open Set Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 13480–13489. [Google Scholar]
- Dang, S.; Cao, Z.; Cui, Z.; Pi, Y.; Liu, N. Open Set Incremental Learning for Automatic Target Recognition. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4445–4456. [Google Scholar] [CrossRef]
- Wang, C.; Luo, S.; Pei, J.; Liu, X.; Huang, Y.; Zhang, Y.; Yang, J. An Entropy-Awareness Meta-Learning Method for SAR Open-Set ATR. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar]
- Miller, D.; Sunderhauf, N.; Milford, M.; Dayoub, F. Class Anchor Clustering: A Loss for Distance-Based Open Set Recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3570–3578. [Google Scholar]
- Ge, Z.; Demyanov, S.; Chen, Z.; Garnavi, R. Generative Openmax for Multi-Class Open Set Classification. arXiv 2017, arXiv:1707.07418. [Google Scholar]
- Neal, L.; Olson, M.; Fern, X.; Wong, W.K.; Li, F. Open Set Learning with Counterfactual Images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 613–628. [Google Scholar]
- Geng, X.; Dong, G.; Xia, Z.; Liu, H. SAR Target Recognition via Random Sampling Combination in Open-World Environments. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 16, 331–343. [Google Scholar] [CrossRef]
- Zhang, H.; Li, A.; Guo, J.; Guo, Y. Hybrid Models for Open Set Recognition. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 102–117. [Google Scholar]
- Kuncheva, L.I.; Bezdek, J.C. Nearest Prototype Classification: Clustering, Genetic Algorithms, or Random Search? IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 1998, 28, 160–164. [Google Scholar] [CrossRef]
- Kohonen, T. Improved Versions of Learning Vector Quantization. In Proceedings of the 1990 Ijcnn International Joint Conference on Neural Networks, San Diego, CA, USA, 17–21 June 1990; pp. 545–550. [Google Scholar]
- Bendale, A.; Boult, T. Towards Open World Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1893–1902. [Google Scholar]
- Yang, Z.; Yue, J.; Ghamisi, P.; Zhang, S.; Ma, J.; Fang, L. Open Set Recognition in Real World. Int. J. Comput. Vis. 2024, 132, 3208–3231. [Google Scholar] [CrossRef]
- Li, W.; Yang, W.; Liu, L.; Zhang, W.; Liu, Y. Discovering and explaining the noncausality of deep learning in SAR ATR. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19.
- Ma, F.; Sun, X.; Zhang, F.; Zhou, Y.; Li, H.C. What Catch Your Attention in SAR Images: Saliency Detection Based on Soft-Superpixel Lacunarity Cue. IEEE Trans. Geosci. Remote Sens. 2022, 61, 1–17. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. Injection of Traditional Hand-Crafted Features into Modern CNN-based Models for SAR Ship Classification: What, Why, Where, and How. Remote Sens. 2021, 13, 2091. [Google Scholar] [CrossRef]
- Ghannadi, M.A.; Saadaseresht, M. A modified local binary pattern descriptor for SAR image matching. IEEE Geosci. Remote Sens. Lett. 2018, 16, 568–572. [Google Scholar] [CrossRef]
- Nehary, E.A.; Dey, A.; Rajan, S.; Balaji, B.; Damini, A.; Chanchlani, R. Synthetic Aperture Radar-Based Ship Classification Using CNN and Traditional Handcrafted Features. In Proceedings of the 2023 IEEE Sensors Applications Symposium (SAS), Ottawa, ON, Canada, 18–20 July 2023; pp. 01–06. [Google Scholar]
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image Matching from Handcrafted to Deep Features: A Survey. Int. J. Comput. Vis. 2021, 129, 23–79. [Google Scholar] [CrossRef]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A Discriminative Feature Learning Approach for Deep Face Recognition. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 499–515. [Google Scholar]
- Ma, X.; Ji, K.; Zhang, L.; Feng, S.; Xiong, B.; Kuang, G. SAR Target Open-Set Recognition Based on Joint Training of Class-Specific Sub-Dictionary Learning. IEEE Geosci. Remote Sens. Lett. 2024, 21, 3342904. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Train | Number | Test | Number |
|---|---|---|---|---|
| 1-2S1 | 17 | 299 | 15 | 274 |
| 2-ZSU234 | 17 | 299 | 15 | 274 |
| 3-BRDM2 | 17 | 298 | 15 | 274 |
| 4-BTR60 | 17 | 256 | 15 | 195 |
| 5-BMP2 | 17 | 233 | 15 | 195 |
| 6-BTR70 | 17 | 233 | 15 | 196 |
| 7-D7 | 17 | 299 | 15 | 274 |
| 8-ZIL131 | 17 | 299 | 15 | 274 |
| 9-T62 | 17 | 299 | 15 | 273 |
| 10-T72 | 17 | 232 | 15 | 196 |
| Total | 2747 | 2425 |
| Methods | OSR Performance (%) | |||
|---|---|---|---|---|
| Recall | Precision | Accuracy | ||
| SoftMax | 65.7 | 65.4 | 64.2 | - |
| OpenMax | 76.0 | 67.8 | 67.5 | 78.2 |
| OSmIL | 93.4 | 87.0 | 89.9 | 93.7 |
| CGDL | 90.7 | 85.1 | 87.6 | 92.5 |
| CAC | 84.8 | 88.4 | 86.2 | 92.4 |
| EVM | 90.5 | 81.0 | 85.0 | 91.8 |
| GCPL | 86.3 | 73.1 | 78.3 | 85.6 |
| ARPL | 68.8 | 55.6 | 59.4 | 71.9 |
| GvRSC | 73.2 | 67.8 | 69.2 | - |
| Ours | 94.1 | 87.8 | 90.7 | 94.2 |
| Methods | Classifying Known: TPR | Identifying Unknown: 1-FPR |
|---|---|---|
| OSmIL | 93.4 | 93.1 |
| EVM | 91.8 | 92.3 |
| OpenMax | 74.9 | 79.3 |
| CAC | 81.09 | 96.34 |
| CGDL | 90.09 | 93.36 |
| GCPL | 86.69 | 85.36 |
| ARPL | 68.21 | 73.31 |
| Ours | 94.38 | 94.23 |
| MSFE | Auxiliary Features | CMHF2 | Hybrid Loss | OSR Performance | |
|---|---|---|---|---|---|
| Accuracy | |||||
| - | - | - | - | 74.26 | 73.03 |
| ✓ | - | - | - | 77.10 | 75.75 |
| ✓ | ✓ | - | - | 77.66 | 76.37 |
| ✓ | ✓ | ✓ | - | 78.63 | 77.44 |
| ✓ | ✓ | ✓ | ✓ | 81.50 | 81.60 |
| Loss Function | Accuracy | |
|---|---|---|
| Cross Entropy | 67.25 | 66.27 |
| Center Loss | 74.52 | 74.02 |
| Center Loss + | 78.11 | 77.67 |
| Center Loss + + | 79.24 | 79.51 |
| Ours | 81.50 | 81.60 |
| Fusion Strategy | Accuracy | |
|---|---|---|
| Baseline | 78.33 | 77.39 |
| Method 1 | 78.36 | 77.32 |
| Method 2 | 79.52 | 78.36 |
| Ours | 80.93 | 81.14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, F.; Luo, X.; Lang, R.; Wang, J.; Sun, J.; Hussain, A. Exploring Reinforced Class Separability and Discriminative Representations for SAR Target Open Set Recognition. Remote Sens. 2024, 16, 3277. https://doi.org/10.3390/rs16173277
Gao F, Luo X, Lang R, Wang J, Sun J, Hussain A. Exploring Reinforced Class Separability and Discriminative Representations for SAR Target Open Set Recognition. Remote Sensing. 2024; 16(17):3277. https://doi.org/10.3390/rs16173277
Chicago/Turabian StyleGao, Fei, Xin Luo, Rongling Lang, Jun Wang, Jinping Sun, and Amir Hussain. 2024. "Exploring Reinforced Class Separability and Discriminative Representations for SAR Target Open Set Recognition" Remote Sensing 16, no. 17: 3277. https://doi.org/10.3390/rs16173277