
Mapping Fruit-Tree Plantation Using Sentinel-1/2 Time Series Images with Multi-Index Entropy Weighting Dynamic Time Warping Method


 , ,
, , 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area and Datasets
2.2. Sentinel-1/2 Time Series Images Pre-Processing
2.3. Field Survey Data
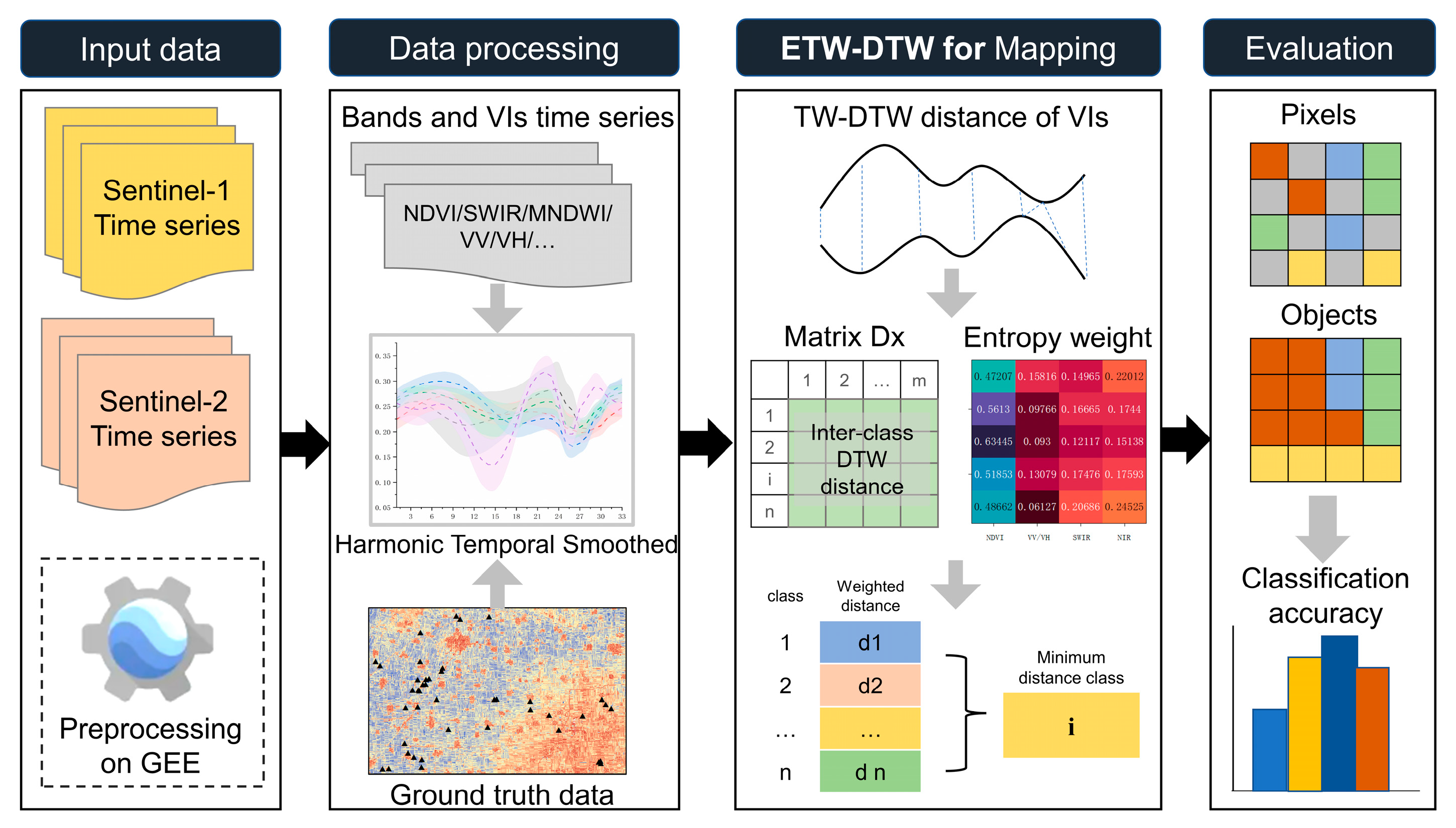
3. Methods
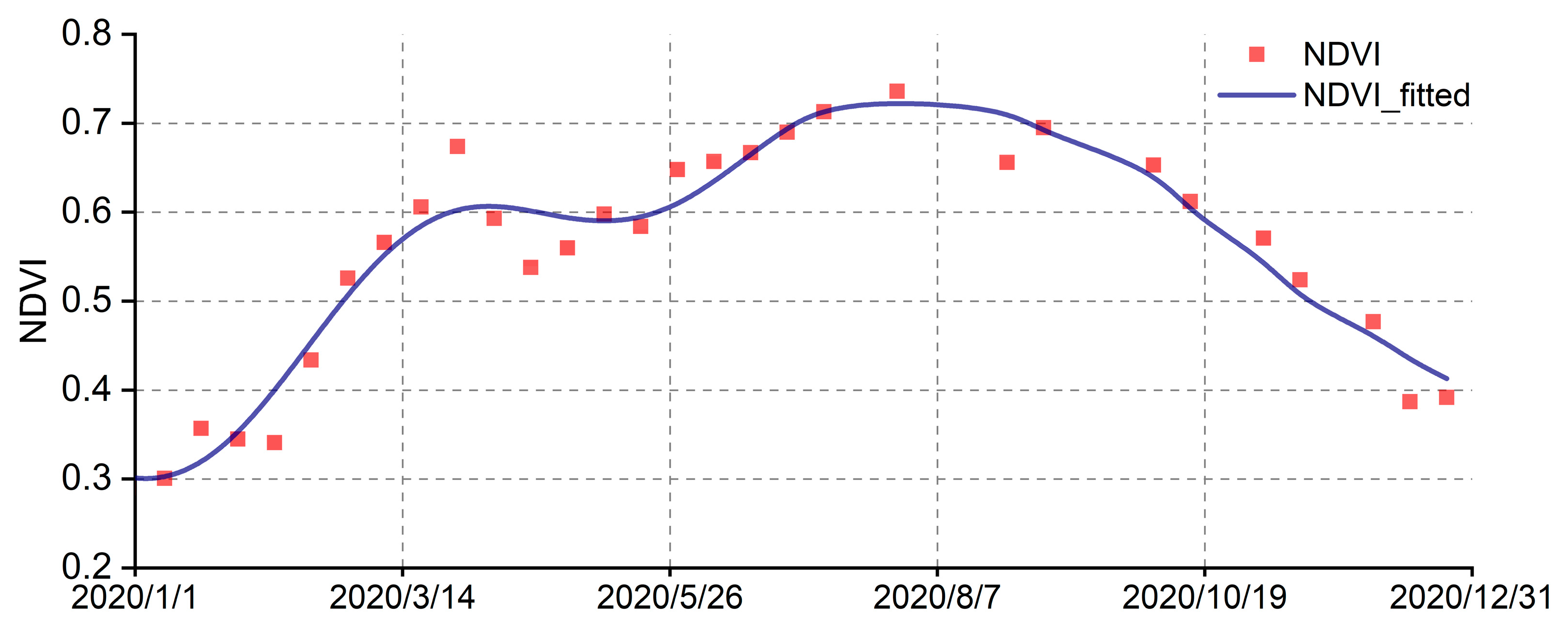
3.1. Sentinel-1/2 Time Series Images Pre-Processing Using HANTS
3.2. Reduction of the Feactures
3.3. Classification Method
3.3.1. Theoretical Background of Time Weighted Dynamic Time Warping
3.3.2. Entropy Weight of Index Feature
- Sample TWDTW distance calculation. Based on the j average timing curve of class i, the TWDTW distances, , between the j and all samples including class i are calculated by the following equation:where h is the total number of samples, which represents all TWDTW distances (mentioned in Section 3.3.1) between all classes on the j curve when the reference is class i. The more discrete is, the greater the distance between each class, which means greater divisibility. A wider means a smaller distance between classes and weaker differentiability.
- Sample size equalization is crucial. The sample size of different classes directly influences the gain of information entropy based on each class. To prevent uncertainty in entropy values due to sample number imbalances, we normalized and equalized the TWDTW distance data obtained for each class. First, assuming follows a normal distribution, distance data beyond the 95% confidence interval were treated as outliers and discarded. Secondly, to mitigate the impact of sample imbalance on entropy gain, we constrained the overall sample size using the minimum number of samples, ensuring an equal number of samples for each class.
- TWDTW distance set reorganization. The TWDTW distance results for each index by column were recombined into the TWDTW distance matrix D, and each column represents the TWDTW distance set of the j index based on various standard curves:
- Data standardization. Given that the TWDTW distance reflects the curve similarity and that it exhibits the characteristic that smaller values indicate higher similarity, in the calculation of entropy weight, the elements in the D matrix are treated as negative indicators. The elements of D are standardized as follows:where is obtained by normalization of D, and represents the elements of the i class and j time series curve of the i class after standardization.
- Calculate the TWDTW distance information entropy , based on the j-exponential time series curve of class i under the action of j:
- The final weight can be expressed as follows:
3.3.3. Mapping Fruit-Tree Plantation Using ETW-DTW Method
3.4. Classification Based on Parcel
3.5. Accuracy Evaluation
4. Results
4.1. Results of Preprocessing
4.1.1. HANTS Simulation of the Time Series Images
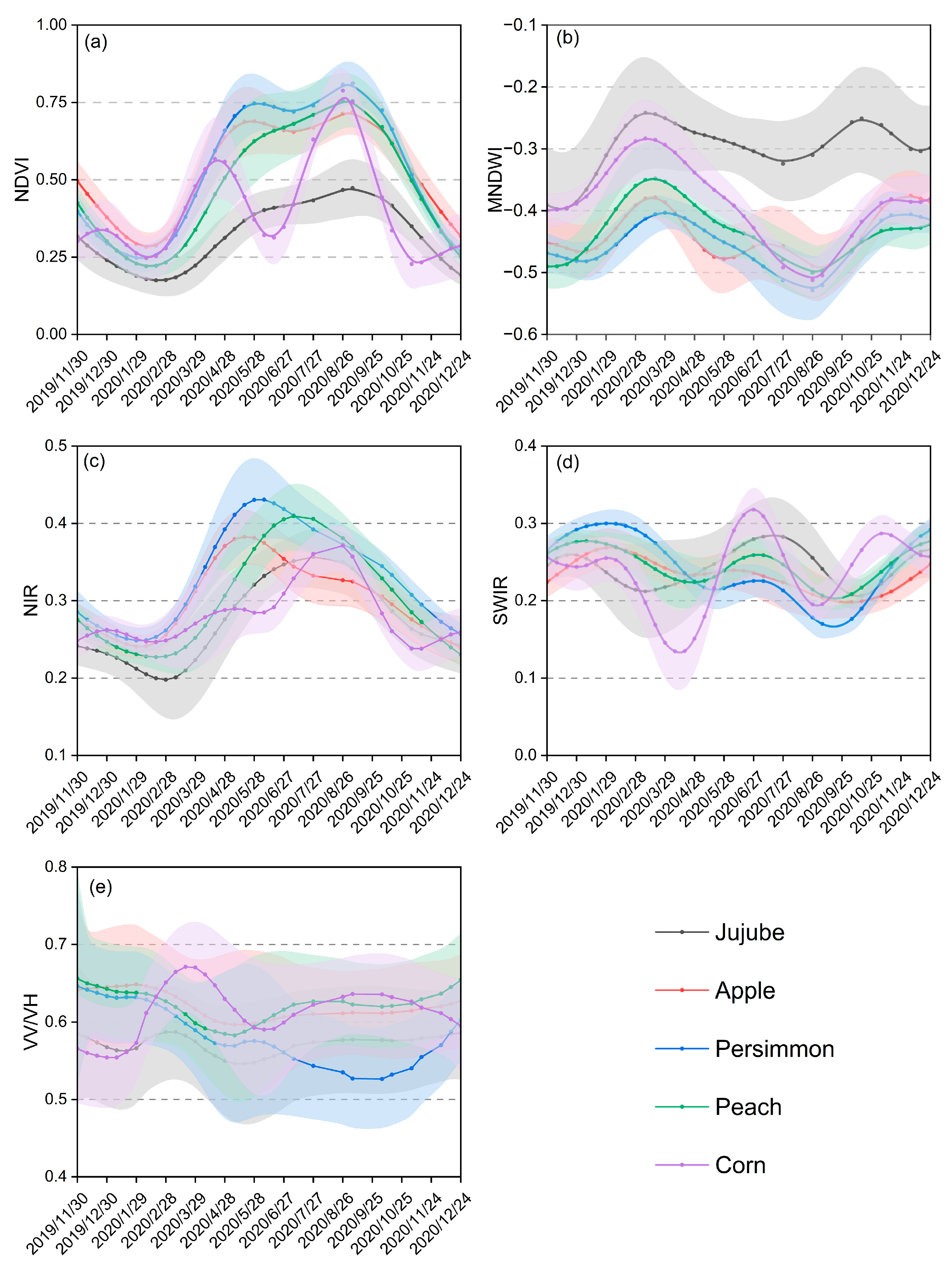
4.1.2. Feature Reduction
4.2. The Results of Classification
4.2.1. Entropy Weight Matrix
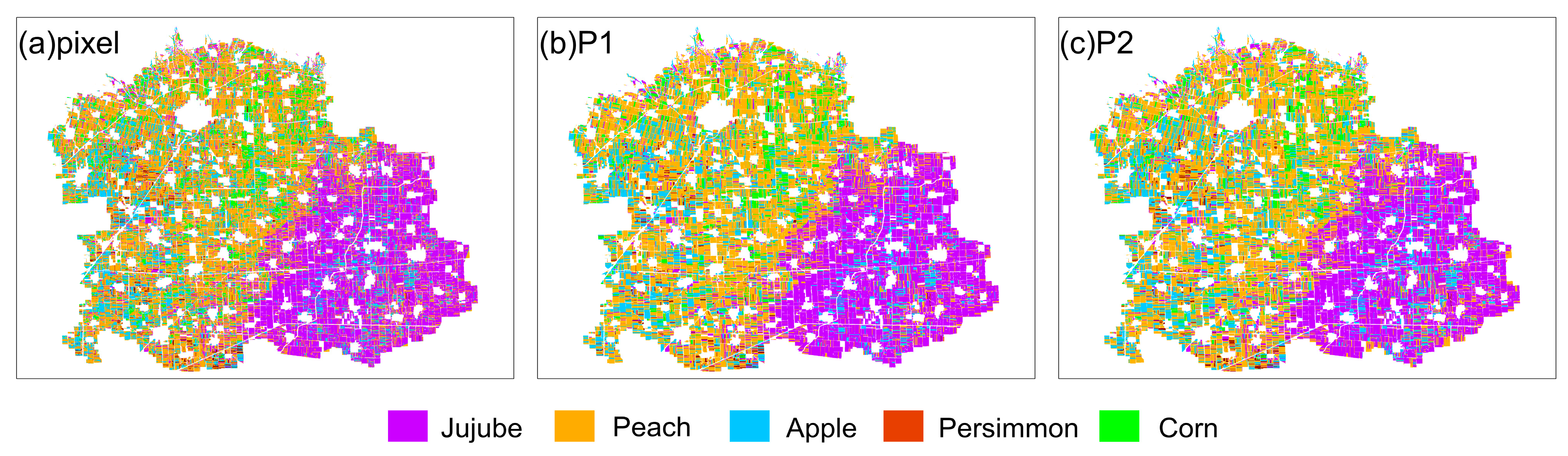
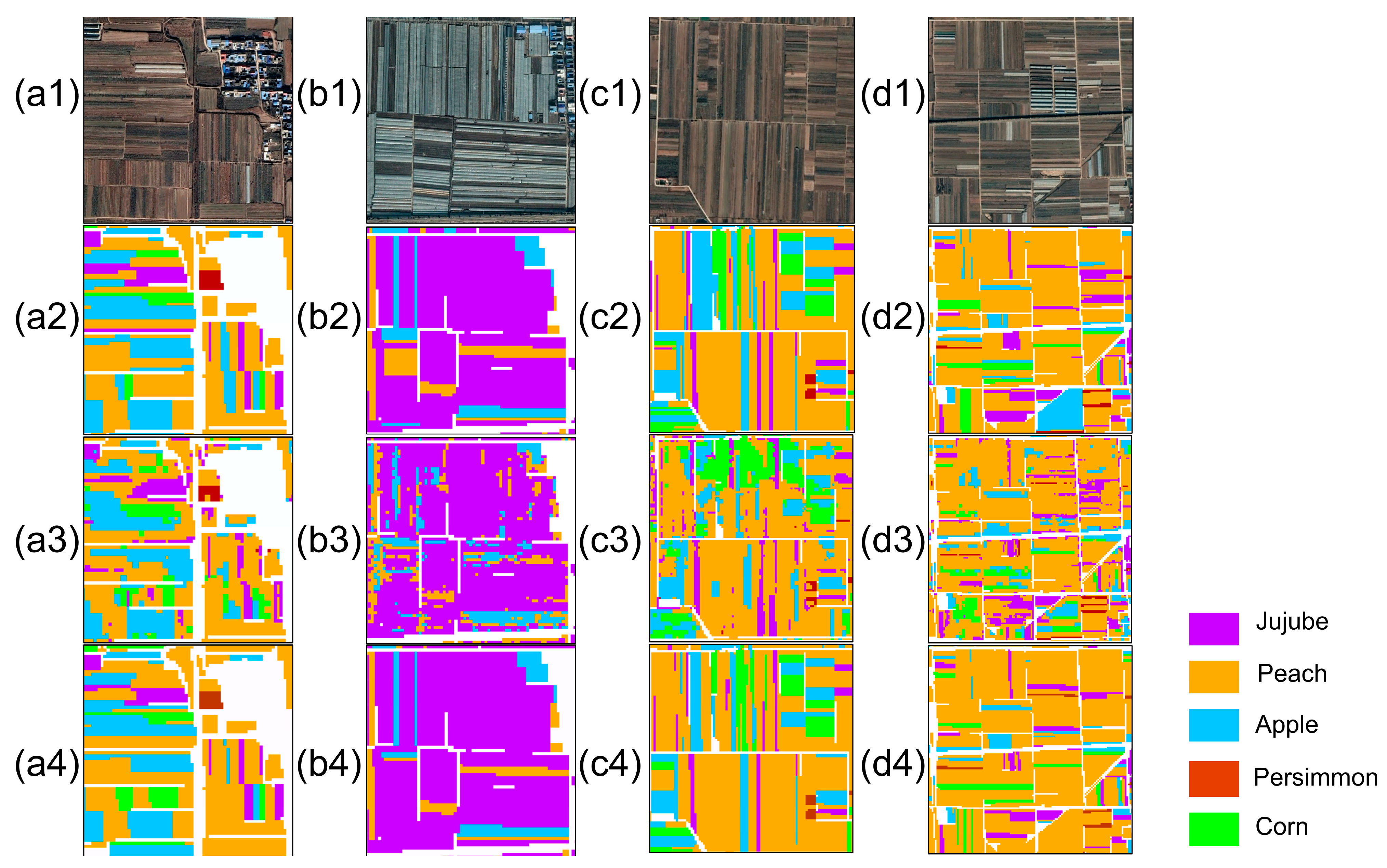
4.2.2. Mapping Orchard Distribution
4.2.3. Comparison of the Results of the Pixel Scale and Parcel Scale with Two Strategies
5. Discussion
5.1. Advantages of the ETW-DTW Method
5.1.1. Integration of SAR Data
5.1.2. Individual Contributions of ETW-DTW Model
- Advantages of TWDTW algorithm in orchard classification The choice of classifier determines the accuracy of the classification result [80]. In this study, the TWDTW algorithm was deliberately chosen due to its demonstrated efficacy in handling crop classification tasks utilizing time series imagery: (1) when employing vegetation phenological characteristics as the basis for classification, variations in weather conditions and agricultural practices can introduce disparities in the time series curve characteristics for the same crop. The TWDTW algorithm adeptly mitigates such differences by distorting and aligning the two curves [41]; and (2) the classifier’s performance is directly influenced by the number of samples available for training [33]. The TWDTW algorithm stands out as one of the few algorithms that do not demand a high number of samples [81]. As long as the standard curve adheres to the temporal pattern characteristics of the target category, ideal accuracy can be achieved [44]. Belgiu and Csillik [40] compared the accuracy of the DTW algorithm and the random forest algorithm under small samples to confirm this view.
- The strengths of the entropy weight matrix In this experiment, we attempted to employ the entropy weight method to assign weights to multiple indices, aiming to enable the input of the TWDTW algorithm for multi-dimensional curves and enhance the accuracy of the results. As shown in Table 2, compared to the traditional single-band TWDTW method, the ETW-DTW method, which integrates multi-band information, demonstrates significant advantages. According to the principle of entropy weighting, the level of information entropy depends on the probability distribution of the data, making it highly robust to outliers. In contrast, the variance weighting method also assigns weights based on data dispersion but is highly sensitive to outliers and performs poorly when the indices have different scales or the data characteristics are not distinct. Using the same approach, we replaced the entropy weights with variance weights to obtain the classification accuracy for orchard classification. The overall accuracy (OA) was 0.627, the Kappa coefficient was 0.494, and the F1-score was 0.593, all of which are lower than the classification accuracy based on entropy weights. Overall, entropy weighting better reflects the relative information content of each index, reduces the impact of outliers and extreme values, and is more suitable for handling complex ecological analysis problems involving multiple indices, scales, and distributions.
5.1.3. The Generalizability of ETW-DTW
5.2. Limitations of the ETW-DTW Method
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yuan, B.; Yue, F.; Cui, Y.; Chen, C. The role of fine management techniques in relation to agricultural pollution and farmer income: The case of the fruit industry. Environ. Res. Lett. 2022, 17, 034001. [Google Scholar] [CrossRef]
- Massey, R.; Sankey, T.T.; Congalton, R.G.; Yadav, K.; Thenkabail, P.S.; Ozdogan, M.; Meador, A.J.S. MODIS phenology-derived, multi-year distribution of conterminous US crop types. Remote Sens. Environ. 2017, 198, 490–503. [Google Scholar] [CrossRef]
- Abbasi, N.; Nouri, H.; Didan, K.; Barreto-Muñoz, A.; Chavoshi Borujeni, S.; Salemi, H.; Opp, C.; Siebert, S.; Nagler, P.J.R.S. Estimating actual evapotranspiration over croplands using vegetation index methods and dynamic harvested area. Remote Sens. 2021, 13, 5167. [Google Scholar] [CrossRef]
- Berni, J.; Zarco-Tejada, P.; Sepulcre-Cantó, G.; Fereres, E.; Villalobos, F. Mapping canopy conductance and CWSI in olive orchards using high resolution thermal remote sensing imagery. Remote Sens. Environ. 2009, 113, 2380–2388. [Google Scholar] [CrossRef]
- French, A.N.; Hunsaker, D.J.; Sanchez, C.A.; Saber, M.; Gonzalez, J.R.; Anderson, R.J.A.W.M. Satellite-based NDVI crop coefficients and evapotranspiration with eddy covariance validation for multiple durum wheat fields in the US Southwest. Agric. Water Manag. 2020, 239, 106266. [Google Scholar] [CrossRef]
- Lhermitte, S.; Verbesselt, J.; Verstraeten, W.W.; Coppin, P. A comparison of time series similarity measures for classification and change detection of ecosystem dynamics. Remote Sens. Environ. 2011, 115, 3129–3152. [Google Scholar] [CrossRef]
- Jin, S.; Sader, S.A. MODIS time-series imagery for forest disturbance detection and quantification of patch size effects. Remote Sens. Environ. 2005, 99, 462–470. [Google Scholar] [CrossRef]
- Linderman, M.; Rowhani, P.; Benz, D.; Serneels, S.; Lambin, E.F. Land-cover change and vegetation dynamics across Africa. J. Geophys. Res. Atmos. 2005, 110, 12104. [Google Scholar] [CrossRef]
- Zhang, X.; Friedl, M.A.; Schaaf, C.B. Global vegetation phenology from Moderate Resolution Imaging Spectroradiometer (MODIS): Evaluation of global patterns and comparison with in situ measurements. J. Geophys. Res. Biogeosci. 2006, 111, 367–375. [Google Scholar] [CrossRef]
- Weiss, M.; Jacob, F.; Duveiller, G. Remote sensing for agricultural applications: A meta-review. Remote Sens. Environ. 2020, 236, 111402. [Google Scholar] [CrossRef]
- Waldner, F.; Fritz, S.; Di Gregorio, A.; Defourny, P. Mapping priorities to focus cropland mapping activities: Fitness assessment of existing global, regional and national cropland maps. Remote Sens. 2015, 7, 7959–7986. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Peng, J.; Wang, S.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- Fu, G.; Liu, C.; Zhou, R.; Sun, T.; Zhang, Q. Classification for high resolution remote sensing imagery using a fully convolutional network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef]
- Delrue, J.; Bydekerke, L.; Eerens, H.; Gilliams, S.; Piccard, I.; Swinnen, E. Crop mapping in countries with small-scale farming: A case study for West Shewa, Ethiopia. Int. J. Remote Sens. 2013, 34, 2566–2582. [Google Scholar] [CrossRef]
- Gella, G.W. Mapping Crop Types in Smallholder Farming Areas using SAR Imagery with Dynamic Time Warping. Master’s Thesis, University of Twente, Enschede, The Netherlands, 2020. [Google Scholar]
- Xu, D.; Guo, X. Compare NDVI extracted from Landsat 8 imagery with that from Landsat 7 imagery. Am. J. Remote Sens. 2014, 2, 10–14. [Google Scholar] [CrossRef]
- Pan, Z.; Huang, J.; Zhou, Q.; Wang, L.; Cheng, Y.; Zhang, H.; Blackburn, G.A.; Yan, J.; Liu, J. Mapping crop phenology using NDVI time-series derived from HJ-1 A/B data. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 188–197. [Google Scholar] [CrossRef]
- El Hajj, M.; Bégué, A.; Guillaume, S.; Martiné, J.-F. Integrating SPOT-5 time series, crop growth modeling and expert knowledge for monitoring agricultural practices—The case of sugarcane harvest on Reunion Island. Remote Sens. Environ. 2009, 113, 2052–2061. [Google Scholar] [CrossRef]
- Murakami, T.; Ogawa, S.; Ishitsuka, N.; Kumagai, K.; Saito, G. Crop discrimination with multitemporal SPOT/HRV data in the Saga Plains, Japan. Int. J. Remote Sens. 2001, 22, 1335–1348. [Google Scholar] [CrossRef]
- McNairn, H.; Brisco, B. The application of C-band polarimetric SAR for agriculture: A review. Can. J. Remote Sens. 2004, 30, 525–542. [Google Scholar] [CrossRef]
- Khabbazan, S.; Vermunt, P.; Steele-Dunne, S.; Ratering Arntz, L.; Marinetti, C.; van der Valk, D.; Iannini, L.; Molijn, R.; Westerdijk, K.; van der Sande, C. Crop monitoring using Sentinel-1 data: A case study from The Netherlands. Remote Sens. 2019, 11, 1887. [Google Scholar] [CrossRef]
- Xie, G.; Niculescu, S.J.R.S. Mapping crop types using sentinel-2 data machine learning and monitoring crop phenology with sentinel-1 backscatter time series in pays de Brest, Brittany, France. Remote Sens. 2022, 14, 4437. [Google Scholar] [CrossRef]
- Danilla, C.; Persello, C.; Tolpekin, V.; Bergado, J.R. Classification of multitemporal SAR images using convolutional neural networks and Markov random fields. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 2231–2234. [Google Scholar]
- Niculescu Sr, S.; Billey, A.; Talab-Ou-Ali, H., Jr. Random forest classification using Sentinel-1 and Sentinel-2 series for vegetation monitoring in the Pays de Brest (France). In Proceedings of the Remote Sensing for Agriculture, Ecosystems, and Hydrology XX, Berlin, Germany, 10–13 September 2018; p. 1078305. [Google Scholar]
- Betbeder, J.; Laslier, M.; Corpetti, T.; Pottier, E.; Corgne, S.; Hubert-Moy, L. Multi-temporal optical and radar data fusion for crop monitoring: Application to an intensive agricultural area in Brittany (France). In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 1493–1496. [Google Scholar]
- Dusseux, P.; Corpetti, T.; Hubert-Moy, L.; Corgne, S. Combined use of multi-temporal optical and radar satellite images for grassland monitoring. Remote Sens. 2014, 6, 6163–6182. [Google Scholar] [CrossRef]
- Colson, D.; Petropoulos, G.P.; Ferentinos, K.P. Exploring the potential of Sentinels-1 & 2 of the Copernicus Mission in support of rapid and cost-effective wildfire assessment. Int. J. Appl. Earth Obs. Geoinf. 2018, 73, 262–276. [Google Scholar]
- Rajah, P.; Odindi, J.; Mutanga, O. Feature level image fusion of optical imagery and Synthetic Aperture Radar (SAR) for invasive alien plant species detection and mapping. Remote Sens. Appl. Soc. Environ. 2018, 10, 198–208. [Google Scholar] [CrossRef]
- Skriver, H. Crop classification by multitemporal C-and L-band single-and dual-polarization and fully polarimetric SAR. IEEE Trans. Geosci. Remote Sens. 2011, 50, 2138–2149. [Google Scholar] [CrossRef]
- Huang, X.; Wang, J.; Shang, J.; Liao, C.; Liu, J. Application of polarization signature to land cover scattering mechanism analysis and classification using multi-temporal C-band polarimetric RADARSAT-2 imagery. Remote Sens. Environ. 2017, 193, 11–28. [Google Scholar] [CrossRef]
- Waske, B.; Braun, M. Classifier ensembles for land cover mapping using multitemporal SAR imagery. ISPRS J. Photogramm. Remote Sens. 2009, 64, 450–457. [Google Scholar] [CrossRef]
- Sonobe, R.; Tani, H.; Wang, X.; Kobayashi, N.; Shimamura, H. Discrimination of crop types with TerraSAR-X-derived information. Phys. Chem. Earth Parts A/B/C 2015, 83, 2–13. [Google Scholar] [CrossRef]
- Gao, H.; Wang, C.; Wang, G.; Fu, H.; Zhu, J. A novel crop classification method based on ppfSVM classifier with time-series alignment kernel from dual-polarization SAR datasets. Remote Sens. Environ. 2021, 264, 112628. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Yu, L.; Gong, P.; Biging, G.S. Automated mapping of soybean and corn using phenology. ISPRS J. Photogramm. Remote Sens. 2016, 119, 151–164. [Google Scholar] [CrossRef]
- Waldner, F.; Canto, G.S.; Defourny, P. Automated annual cropland mapping using knowledge-based temporal features. ISPRS J. Photogramm. Remote Sens. 2015, 110, 1–13. [Google Scholar] [CrossRef]
- Bargiel, D. A new method for crop classification combining time series of radar images and crop phenology information. Remote Sens. Environ. 2017, 198, 369–383. [Google Scholar] [CrossRef]
- Kenduiywo, B.K.; Bargiel, D.; Soergel, U. Higher order dynamic conditional random fields ensemble for crop type classification in radar images. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4638–4654. [Google Scholar] [CrossRef]
- Leite, P.B.C.; Feitosa, R.Q.; Formaggio, A.R.; da Costa, G.A.O.P.; Pakzad, K.; Sanches, I.D.A. Hidden Markov Models for crop recognition in remote sensing image sequences. Pattern Recognit. Lett. 2011, 32, 19–26. [Google Scholar] [CrossRef]
- Csillik, O.; Belgiu, M.; Asner, G.P.; Kelly, M. Object-based time-constrained dynamic time warping classification of crops using Sentinel-2. Remote Sens. 2019, 11, 1257. [Google Scholar] [CrossRef]
- Belgiu, M.; Csillik, O. Sentinel-2 cropland mapping using pixel-based and object-based time-weighted dynamic time warping analysis. Remote Sens. Environ. 2018, 204, 509–523. [Google Scholar] [CrossRef]
- Petitjean, F.; Inglada, J.; Gançarski, P. Satellite image time series analysis under time warping. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3081–3095. [Google Scholar] [CrossRef]
- Maus, V.; Câmara, G.; Cartaxo, R.; Sanchez, A.; Ramos, F.M.; De Queiroz, G.R. A time-weighted dynamic time warping method for land-use and land-cover mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3729–3739. [Google Scholar] [CrossRef]
- Xu, H.; Qi, S.; Gong, P.; Liu, C.; Wang, J. Long-term monitoring of citrus orchard dynamics using time-series Landsat data: A case study in southern China. Int. J. Remote Sens. 2018, 39, 8271–8292. [Google Scholar] [CrossRef]
- Dong, Q.; Chen, X.; Chen, J.; Zhang, C.; Liu, L.; Cao, X.; Zang, Y.; Zhu, X.; Cui, X. Mapping winter wheat in North China using Sentinel 2A/B data: A method based on phenology-time weighted dynamic time warping. Remote Sens. 2020, 12, 1274. [Google Scholar] [CrossRef]
- Gella, G.W.; Bijker, W.; Belgiu, M. Mapping crop types in complex farming areas using SAR imagery with dynamic time warping. ISPRS J. Photogramm. Remote Sens. 2021, 175, 171–183. [Google Scholar] [CrossRef]
- Fagan, M.E.; DeFries, R.S.; Sesnie, S.E.; Arroyo-Mora, J.P.; Soto, C.; Singh, A.; Townsend, P.A.; Chazdon, R.L.J.R.S. Mapping species composition of forests and tree plantations in Northeastern Costa Rica with an integration of hyperspectral and multitemporal Landsat imagery. Remote Sens. 2015, 7, 5660–5696. [Google Scholar] [CrossRef]
- Xiao, C.; Li, P.; Feng, Z.; Liu, Y.; Zhang, X. Geoinformation, Sentinel-2 red-edge spectral indices (RESI) suitability for mapping rubber boom in Luang Namtha Province, northern Lao PDR. Int. J. Appl. Earth Obs. Geoinf. 2020, 93, 102176. [Google Scholar]
- Abbasi, M.; Verrelst, J.; Mirzaei, M.; Marofi, S.; Riyahi Bakhtiari, H.R. Optimal spectral wavelengths for discriminating orchard species using multivariate statistical techniques. Remote Sens. 2019, 12, 63. [Google Scholar] [CrossRef] [PubMed]
- Peña, M.; Liao, R.; Brenning, A. Using spectrotemporal indices to improve the fruit-tree crop classification accuracy. ISPRS J. Photogramm. Remote Sens. 2017, 128, 158–169. [Google Scholar] [CrossRef]
- Cui, B.; Huang, W.; Ye, H.; Chen, Q. The suitability of PlanetScope imagery for mapping rubber plantations. Remote Sens. 2022, 14, 1061. [Google Scholar] [CrossRef]
- Nagori, R. Discrimination of mango orchards in Malihabad, India using textural features. Geocarto Int. 2021, 36, 1060–1074. [Google Scholar] [CrossRef]
- Li, J.; Yang, G.; Yang, H.; Xu, W.; Feng, H.; Xu, B.; Chen, R.; Zhang, C.; Wang, H. Orchard classification based on super-pixels and deep learning with sparse optical images. Comput. Electron. Agric. 2023, 215, 108379. [Google Scholar] [CrossRef]
- Nabil, M.; Farg, E.; Arafat, S.M.; Aboelghar, M.; Afify, N.M.; Elsharkawy, M.M. Environment, Tree-fruits crop type mapping from Sentinel-1 and Sentinel-2 data integration in Egypt’s New Delta project. Remote Sens.Appl. Soc. Environ. 2022, 27, 100776. [Google Scholar]
- Kordi, F.; Yousefi, H. Environment, Crop classification based on phenology information by using time series of optical and synthetic-aperture radar images. Remote Sens.Appl. Soc. Environ. 2022, 27, 100812. [Google Scholar]
- d’Andrimont, R.; Taymans, M.; Lemoine, G.; Ceglar, A.; Yordanov, M.; van der Velde, M. Detecting flowering phenology in oil seed rape parcels with Sentinel-1 and-2 time series. Remote Sens. Environ. 2020, 239, 111660. [Google Scholar] [CrossRef] [PubMed]
- Griffiths, P.; Nendel, C.; Hostert, P. Intra-annual reflectance composites from Sentinel-2 and Landsat for national-scale crop and land cover mapping. Remote Sens. Environ. 2019, 220, 135–151. [Google Scholar] [CrossRef]
- Xu, L.; Zhang, H.; Wang, C.; Zhang, B.; Liu, M. Crop classification based on temporal information using sentinel-1 SAR time-series data. Remote Sens. 2018, 11, 53. [Google Scholar] [CrossRef]
- Lee, J.-S. Digital image smoothing and the sigma filter. Comput. Vis. Graph. Image Process. 1983, 24, 255–269. [Google Scholar] [CrossRef]
- You, N.; Dong, J.; Huang, J.; Du, G.; Zhang, G.; He, Y.; Yang, T.; Di, Y.; Xiao, X. The 10-m crop type maps in Northeast China during 2017–2019. Sci. Data 2021, 8, 41. [Google Scholar] [CrossRef]
- Yang, G.; Shen, H.; Zhang, L.; He, Z.; Li, X. A moving weighted harmonic analysis method for reconstructing high-quality SPOT VEGETATION NDVI time-series data. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6008–6021. [Google Scholar] [CrossRef]
- Xu, Y.; Shen, Y.; Wu, Z. Development, Spatial and temporal variations of land surface temperature over the Tibetan Plateau based on harmonic analysis. Mt. Res. Dev. 2013, 33, 85–94. [Google Scholar] [CrossRef]
- Peña, M.; Brenning, A. Assessing fruit-tree crop classification from Landsat-8 time series for the Maipo Valley, Chile. Remote Sens. Environ. 2015, 171, 234–244. [Google Scholar] [CrossRef]
- Denize, J.; Hubert-Moy, L.; Betbeder, J.; Corgne, S.; Baudry, J.; Pottier, E. Evaluation of using sentinel-1 and-2 time-series to identify winter land use in agricultural landscapes. Remote Sens. 2018, 11, 37. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Kostelich, E.J.; Schreiber, T. Noise reduction in chaotic time-series data: A survey of common methods. Phys. Rev. E 1993, 48, 1752. [Google Scholar] [CrossRef] [PubMed]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Veloso, A.; Mermoz, S.; Bouvet, A.; Le Toan, T.; Planells, M.; Dejoux, J.-F.; Ceschia, E. Understanding the temporal behavior of crops using Sentinel-1 and Sentinel-2-like data for agricultural applications. Remote Sens. Environ. 2017, 199, 415–426. [Google Scholar] [CrossRef]
- Rakszawski, B.; Wright, R.; Cadieux, J.H.; Davidson, L.S.; Brenner, C. The Effects of Preprocessing Strategies for Pediatric Cochlear Implant Recipients. J. Am. Acad. Audiol. 2016, 27, 85–102. [Google Scholar] [CrossRef]
- Zhang, Z.; Tang, P.; Huo, L.; Zhou, Z. MODIS NDVI time series clustering under dynamic time warping. Int. J. Wavelets Multiresolut. Inf. Process. 2014, 12, 1461011. [Google Scholar] [CrossRef]
- Li, F.J.; Ren, J.Q.; Wu, S.R.; Zhao, H.W.; Zhang, N.D. Comparison of Regional Winter Wheat Mapping Results from Different Similarity Measurement Indicators of NDVI Time Series and Their Optimized Thresholds. Remote Sens. 2021, 13, 1162. [Google Scholar] [CrossRef]
- Peña-Barragán, J.M.; Ngugi, M.K.; Plant, R.E.; Six, J. Object-based crop identification using multiple vegetation indices, textural features and crop phenology. Remote Sens. Environ. 2011, 115, 1301–1316. [Google Scholar] [CrossRef]
- Fei, S.; Hassan, M.; Ma, Y.; Shu, M.; Cheng, Q.; Li, Z.; Chen, Z.; Xiao, Y. Entropy Weight Ensemble Framework for Yield Prediction of Winter Wheat Under Different Water Stress Treatments Using Unmanned Aerial Vehicle-Based Multispectral and Thermal Data. Front. Plant Sci. 2021, 12, 730181. [Google Scholar] [CrossRef]
- Farhadinia, B. A multiple criteria decision making model with entropy weight in an interval-transformed hesitant fuzzy environment. Cogn. Comput. 2017, 9, 513–525. [Google Scholar] [CrossRef]
- Kussul, N.; Lemoine, G.; Gallego, F.J.; Skakun, S.V.; Lavreniuk, M.; Shelestov, A.Y. Parcel-based crop classification in Ukraine using Landsat-8 data and Sentinel-1A data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2500–2508. [Google Scholar] [CrossRef]
- McNairn, H.; Champagne, C.; Shang, J.; Holmstrom, D.; Reichert, G. Integration of optical and Synthetic Aperture Radar (SAR) imagery for delivering operational annual crop inventories. ISPRS J. Photogramm. Remote Sens. 2009, 64, 434–449. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Roerink, G.; Menenti, M.; Verhoef, W. Reconstructing cloudfree NDVI composites using Fourier analysis of time series. Int. J. Remote Sens. 2000, 21, 1911–1917. [Google Scholar] [CrossRef]
- Alhammoud, B.; Jackson, J.; Clerc, S.; Arias, M.; Bouzinac, C.; Gascon, F.; Cadau, E.G.; Iannone, R.Q.; Boccia, V. Sentinel-2 Level-1 Radiometry Assessment Using Vicarious Methods From DIMITRI Toolbox and Field Measurements From RadCalNet Database. Ieee J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3470–3479. [Google Scholar] [CrossRef]
- Bayle, A.; Carlson, B.Z.; Thierion, V.; Isenmann, M.; Choler, P. Improved Mapping of Mountain Shrublands Using the Sentinel-2 Red-Edge Band. Remote Sens. 2019, 11, 2807. [Google Scholar] [CrossRef]
- Heydari, S.S.; Mountrakis, G. Effect of classifier selection, reference sample size, reference class distribution and scene heterogeneity in per-pixel classification accuracy using 26 Landsat sites. Remote Sens. Environ. 2018, 204, 648–658. [Google Scholar] [CrossRef]
- Zhao, F.; Yang, G.; Yang, H.; Zhu, Y.; Meng, Y.; Han, S.; Bu, X. Short and medium-term prediction of winter wheat NDVI based on the DTW–LSTM combination method and MODIS time series data. Remote Sens. 2021, 13, 4660. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Ref. | Valid. |
|---|---|---|
| Jujube | 3 | 25 |
| Corn | 3 | 18 |
| Persimmon | 3 | 12 |
| Apple | 3 | 22 |
| Peach | 3 | 14 |
| Total | 15 | 91 |
| Method | ETW-DTW | NDVI | MNDWI | NIR | SWIR | VV/VH | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | PA | UA | PA | UA | PA | UA | PA | UA | PA | UA | PA | UA |
| Jujube | 0.932 | 0.854 | 0.852 | 0.937 | 0.921 | 0.916 | 0.763 | 0.767 | 0.843 | 0.495 | 0.832 | 0.796 |
| Persimmon | 0.509 | 0.549 | 0.088 | 0.212 | 0.075 | 0.425 | 0.137 | 0.176 | 0.363 | 0.436 | 0.064 | 0.221 |
| Apple | 0.820 | 0.626 | 0.743 | 0.454 | 0.553 | 0.377 | 0.628 | 0.621 | 0.712 | 0.472 | 0.495 | 0.112 |
| Peach | 0.467 | 0.710 | 0.428 | 0.505 | 0.514 | 0.202 | 0.511 | 0.475 | 0.376 | 0.757 | 0.316 | 0.539 |
| OA | 0.721 | 0.643 | 0.557 | 0.609 | 0.544 | 0.453 | ||||||
| KAPPA | 0.654 | 0.580 | 0.486 | 0.505 | 0.403 | 0.364 | ||||||
| F1-score | 0.673 | 0.511 | 0.446 | 0.509 | 0.523 | 0.374 | ||||||
| Methods | ETW-DTW-Pixel | ETW-DTW-P1 | ETW-DTW-P2 | |||
|---|---|---|---|---|---|---|
| Class | UA | PA | UA | PA | UA | PA |
| Jujube | 0.897 | 0.841 | 0.924 | 0.879 | 0.932 | 0.854 |
| Persimmon | 0.354 | 0.399 | 0.444 | 0.457 | 0.509 | 0.549 |
| Apple | 0.752 | 0.489 | 0.799 | 0.518 | 0.820 | 0.626 |
| Peach | 0.399 | 0.667 | 0.443 | 0.746 | 0.467 | 0.710 |
| OA | 0.648 | 0.692 | 0.721 | |||
| KAPPA | 0.567 | 0.621 | 0.654 | |||
| F1-score | 0.584 | 0.634 | 0.673 | |||
| Methods | ETW-DTW-S2 | ETW-DTW-S1/2 | ||
|---|---|---|---|---|
| Class | UA | PA | UA | PA |
| Jujube | 0.933 | 0.845 | 0.932 | 0.854 |
| Persimmon | 0.213 | 0.263 | 0.509 | 0.549 |
| Apple | 0.793 | 0.551 | 0.820 | 0.626 |
| Peach | 0.419 | 0.674 | 0.467 | 0.710 |
| OA | 0.665 | 0.721 | ||
| KAPPA | 0.586 | 0.654 | ||
| F1-score | 0.572 | 0.673 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, W.; Li, Z.; Lin, H.; Shao, G.; Zhao, F.; Wang, H.; Cheng, J.; Lei, L.; Chen, R.; Han, S.; et al. Mapping Fruit-Tree Plantation Using Sentinel-1/2 Time Series Images with Multi-Index Entropy Weighting Dynamic Time Warping Method. Remote Sens. 2024, 16, 3390. https://doi.org/10.3390/rs16183390
Xu W, Li Z, Lin H, Shao G, Zhao F, Wang H, Cheng J, Lei L, Chen R, Han S, et al. Mapping Fruit-Tree Plantation Using Sentinel-1/2 Time Series Images with Multi-Index Entropy Weighting Dynamic Time Warping Method. Remote Sensing. 2024; 16(18):3390. https://doi.org/10.3390/rs16183390
Chicago/Turabian StyleXu, Weimeng, Zhenhong Li, Hate Lin, Guowen Shao, Fa Zhao, Han Wang, Jinpeng Cheng, Lei Lei, Riqiang Chen, Shaoyu Han, and et al. 2024. "Mapping Fruit-Tree Plantation Using Sentinel-1/2 Time Series Images with Multi-Index Entropy Weighting Dynamic Time Warping Method" Remote Sensing 16, no. 18: 3390. https://doi.org/10.3390/rs16183390