



Automatic Water Body Extraction from SAR Images Based on MADF-Net

Abstract
1. Introduction
- (1)
- MADF-Net is proposed, which can perform automatic detection for different scales of water regions with high precision.
- (2)
- A feature extraction module, namely DAPP, is proposed based on depth-separable convolution, which can obtain rich semantic information of water bodies and enhance the network’s learning of the detailed features of water from SAR images.
- (3)
- The detailed edge feature extraction module, CSAM, is presented inspired by spatial attention and channel attention, and it carries out the effective distribution of information weights among channels and improves the feature expression and edge information extraction ability in the edge region of the water regions.
2. Materials
3. Methods
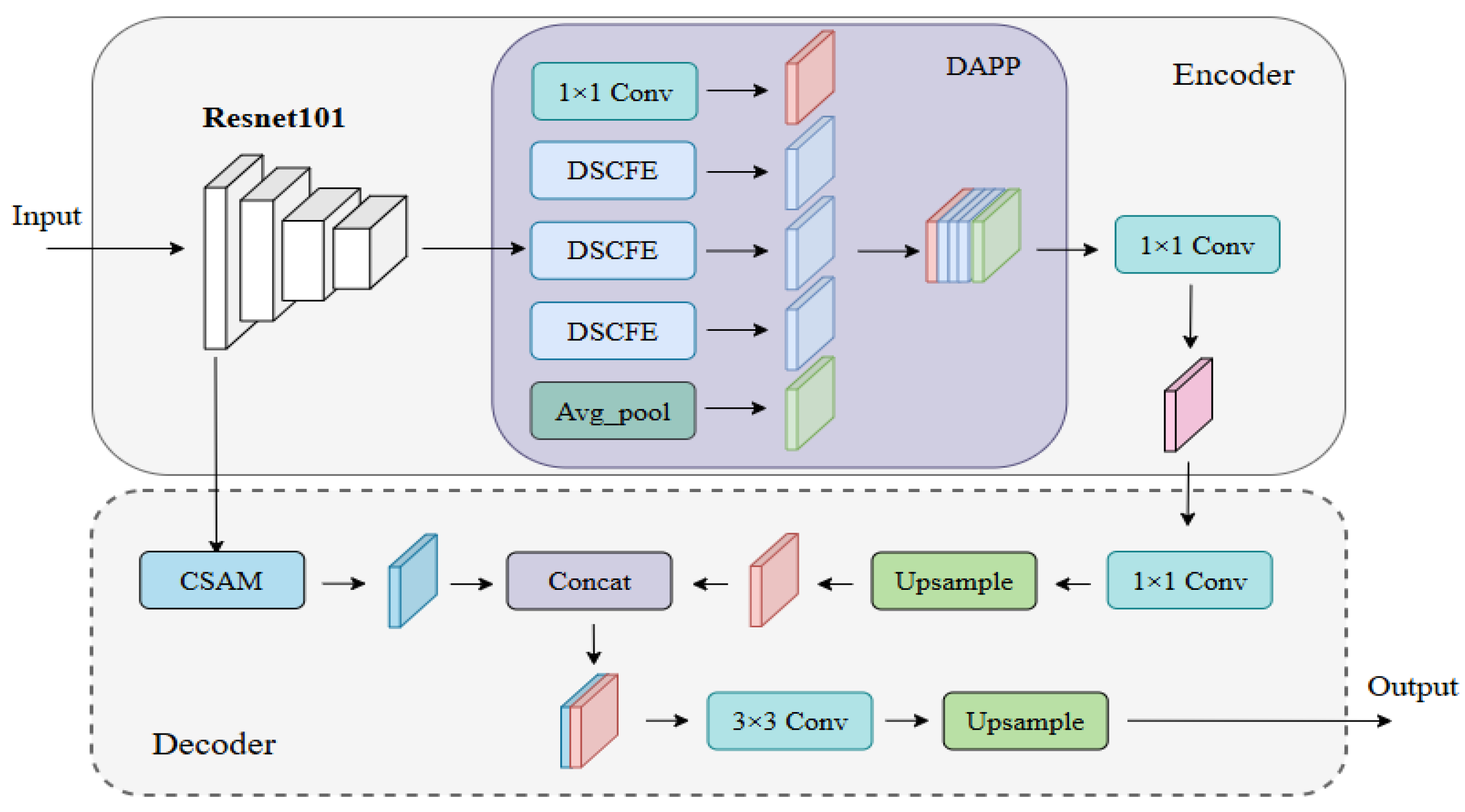
3.1. The Overall Framework
3.2. Residual Neural Network
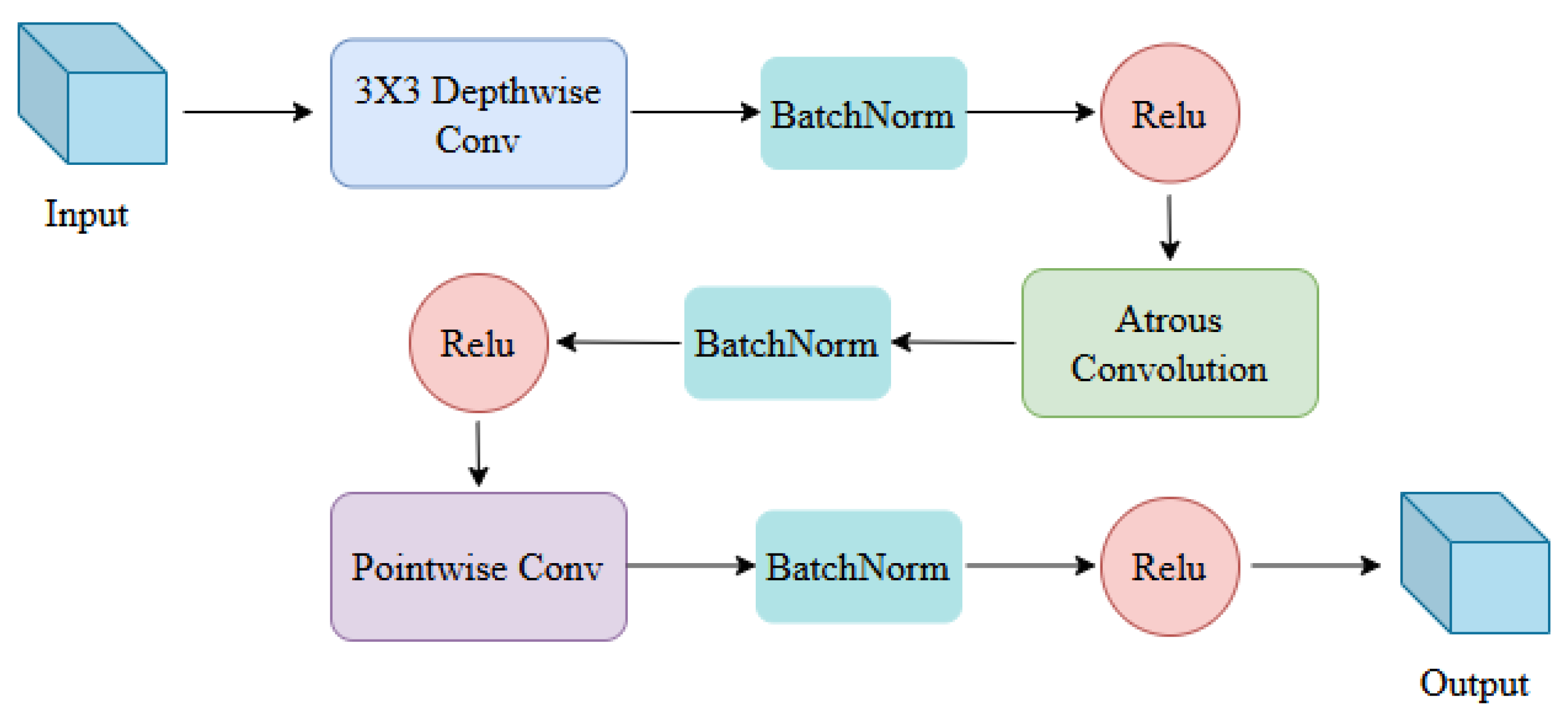
3.3. Deep Atrous Pyramid Pooling (DAPP)
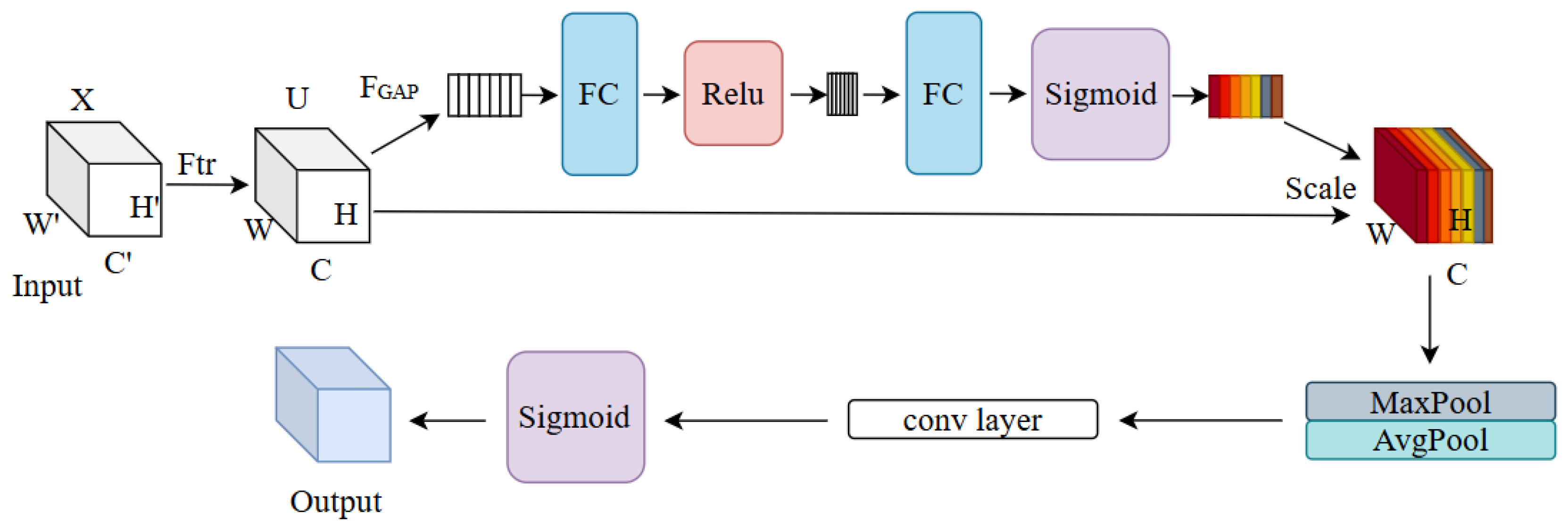
3.4. Channel Space Attention Module (CSAM)
3.5. Evaluation Metrics
4. Results
4.1. Training Parameter Settings
4.2. Comparison Experiments
4.2.1. Scene I
4.2.2. Scene II
4.2.3. Scene III
4.3. Analysis of Experimental Results
4.4. Ablation Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, L.; Cai, X.; Li, Z.; Xing, J.; Ai, J. Where is my attention? An explainable AI exploration in water detection from SAR imagery. Int. J. Appl. Earth Obs. Geoinf. 2024, 130, 103878. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, Y.; Kong, C. Application of inter-spectral relationship method in water body feature extraction. Min. Surv. 2004, 30–32. [Google Scholar]
- Li, J.; Huang, S.; Li, J. Water body extraction from ENVISAT advanced synthetic aperture radar data: An improved maximum inter-class variance thresholding method. J. Nat. Hazards 2010, 19, 139–145. [Google Scholar]
- Duan, Q.; Meng, L.; Fan, Z. Study on the applicability of water body information extraction methods from GF-1 satellite imagery. Remote Sens. Land Resour. 2015, 27, 79–84. [Google Scholar]
- Aung, E.M.M.; Tint, T. Ayeyarwady river regions detection and extraction system from Google Earth imagery. In Proceedings of the 2018 IEEE International Conference on Information Communication and Signal Processing (ICICSP), Singapore, 28–30 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 74–78. [Google Scholar]
- Singh, S.; Girase, S. Semantic Segmentation of Satellite Images for Water Body Detection. In Data Intelligence and Cognitive Informatics, Proceedings of ICDICI 2021, Tirunelveli, India, 16–17 July 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 831–840. [Google Scholar]
- Liu, M.; Liu, J.; Hu, H. A Novel Deep Learning Network Model for Extracting Lake Water Bodies from Remote Sensing Images. Appl. Sci. 2024, 14, 1344. [Google Scholar] [CrossRef]
- Hou, Z.; Meng, M.; Zhou, G. A noise-robust water segmentation method based on synthetic aperture radar images combined with automatic sample collection. Remote Sens. Lett. 2024, 15, 614–623. [Google Scholar] [CrossRef]
- Chen, S.; Liu, Y.; Zhang, C. Water-Body Segmentation for Multi-Spectral Remote Sensing Images by Feature Pyramid Enhancement and Pixel Pair Matching. Int. J. Remote Sens. 2021, 42, 5025–5043. [Google Scholar] [CrossRef]
- Xu, X.; Zhang, T.; Liu, H. An Information-expanding Network for Water Body Extraction based on U-net. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1502205. [Google Scholar] [CrossRef]
- Chen, B.; Zou, X.; Zhang, Y. A Hybrid CNN-Transformer Architecture for Accurate Lake Extraction from Remote Sensing Imagery. In Proceedings of the ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 5710–5714. [Google Scholar]
- Bahrami, B.; Arbabkhah, H. Enhanced Flood Detection through Precise Water Segmentation Using Advanced Deep Learning Models. Civ. Eng. Res. J. 2024, 6, 1–8. [Google Scholar] [CrossRef]
- Lu, Z.S.; Wang, Y.; Liang, S.Y. Automatic regionalized coastline extraction method based on high-resolution images. IEEE Access 2024, 12, 13537–13552. [Google Scholar] [CrossRef]
- Pech-May, F.; Aquino-Santos, R.; Delgadillo-Partida, J. Sentinel-1 SAR images and deep learning for water body map. Remote Sens. 2023, 15, 3009. [Google Scholar] [CrossRef]
- Jonnala, N.S.; Gupta, N. SAR U-Net: Spatial attention residual U-Net structure for water body segmentation from remote sensing satellite images. Multimed. Tools Appl. 2024, 83, 44425–44454. [Google Scholar] [CrossRef]
- Chen, L.; Li, Z.; Song, C.; Xing, J.; Cai, X.; Fang, Z.; Luo, R.; Li, Z. Automatic detection of earthquake triggered landslides using Sentinel-1 SAR imagery based on deep learning. Int. J. Digit. Earth 2024, 17, 2393261. [Google Scholar] [CrossRef]
- Wu, P.; Fu, J.; Yi, X.; Wang, G.; Mo, L.; Maponde, B.T.; Liang, H.; Tao, C.; Ge, W.; Jiang, T. Research on Water Extraction from High Resolution Remote Sensing Images based on Deep Learning. Front. Remote Sens. 2023, 4, 1283615. [Google Scholar] [CrossRef]
- Chen, L.; Long, F.; Li, Z. Multi-level Feature Attention Fusion Network for Water Extraction from Multi-source SAR Images. Geomat. Inf. Sci. Wuhan Univ. 2023. [Google Scholar] [CrossRef]
- Zhang, P.; Jin, X.; Li, Z.; Xing, X. Water and shadow extraction in SAR image based on a new deep learning network. Sensors 2019, 19, 3576. [Google Scholar] [CrossRef]
- Chen, L.; Xing, J.; Li, Z.; Zhu, W.; Yuan, Z.; Fang, Z. Towards transparent deep learning for surface water detection from SAR imagery. Int. J. Appl. Earth Obs. Geoinf. 2023, 118, 103287. [Google Scholar] [CrossRef]
- Cai, X.; Xing, J.; Xing, X.; Luo, R.; Tan, S.; Wang, J. Automatic and fast extraction of layover from InSAR imagery based on multi-layer feature fusion attention mechanism. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar]
- Chen, L.; Zhang, P.; Xing, J.; Li, Z.; Xing, X.; Yuan, Z. A Multi-scale Deep Neural Network for Water Detection from SAR Images in the Mountainous Areas. Remote Sens. 2020, 12, 3205. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Pandey, R.; Karmakar, S.; Ramakrishnan, A. Computationally efficient approaches for image style transfer. In Proceedings of the 2018 15th IEEE India Council International Conference (INDICON), Coimbatore, India, 6–18 December 2018; pp. 1–6. [Google Scholar]
- Chen, L.C.; Papandreou, G. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.; Luo, R.; Li, Z.; Cai, X. Geospatial transformer is what you need for aircraft detection in SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5225715. [Google Scholar] [CrossRef]
- Chen, L.; Xing, J.; Li, Z.; Yuan, Z.; Pan, Z.; Tan, S.; Ru, L. Employing deep learning for automatic river bridge detection from SAR images based on adaptively effective feature fusion. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102245. [Google Scholar] [CrossRef]
- Luo, R.; Chen, L.; Xing, J.; Yuan, Z.; Tan, S.; Cai, X.; Wang, J. A Fast Aircraft Detection Method for SAR Images Based on Efficient Bidirectional Path Aggregated Attention Network. Remote Sens. 2021, 13, 2940. [Google Scholar] [CrossRef]
- Chen, L.; Cui, X.; Li, Z.; Xing, J.; Xing, X.; Jia, Z. A new Deep Learning Algorithm for SAR Scenes Classification Based on Space Statistical Modeling and Features Re-calibration. Sensors 2019, 19, 2479. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Ma, H.; Han, G.; Peng, L. Rock thin sections identification based on improved squeeze-and-Excitation Networks model. Comput. Geosci. 2021, 152, 104780. [Google Scholar] [CrossRef]
- Azad, R.; Asadi-Aghbolaghi, M.; Fathy, M. Attention DeepLabV3++: Multi-level context attention mechanism for skin lesion segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 251–266. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G. Large kernel matters--improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Networks | PA (%) | IoU (%) |
|---|---|---|
| DeepLabV3+ | 79.96 | 71.73 |
| MFAF-Net | 71.05 | 63.15 |
| GCN | 13.64 | 13.59 |
| MADF-Net | 80.88 | 76.16 |
| Networks | PA (%) | IoU (%) |
|---|---|---|
| DeepLabV3+ | 89.35 | 83.13 |
| MFAF-Net | 95.84 | 77.08 |
| GCN | 92.74 | 83.05 |
| MADF-Net | 90.40 | 86.78 |
| Networks | PA (%) | IoU (%) |
|---|---|---|
| DeepLabV3+ | 84.64 | 75.63 |
| MFAF-Net | 53.54 | 50.57 |
| GCN | 51.73 | 50.94 |
| MADF-Net | 86.77 | 81.45 |
| DAPP | CSAM | PA(%) | IoU(%) | |
|---|---|---|---|---|
| × | × | 86.06 | 79.57 | |
| Baseline | √ | × | 88.99 | 82.38 |
| × | √ | 86.43 | 81.38 | |
| √ | √ | 89.71 | 83.37 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Jia, D.; Xue, J.; Wu, Z.; Song, W. Automatic Water Body Extraction from SAR Images Based on MADF-Net. Remote Sens. 2024, 16, 3419. https://doi.org/10.3390/rs16183419
Wang J, Jia D, Xue J, Wu Z, Song W. Automatic Water Body Extraction from SAR Images Based on MADF-Net. Remote Sensing. 2024; 16(18):3419. https://doi.org/10.3390/rs16183419
Chicago/Turabian StyleWang, Jing, Dongmei Jia, Jiaxing Xue, Zhongwu Wu, and Wanying Song. 2024. "Automatic Water Body Extraction from SAR Images Based on MADF-Net" Remote Sensing 16, no. 18: 3419. https://doi.org/10.3390/rs16183419
APA StyleWang, J., Jia, D., Xue, J., Wu, Z., & Song, W. (2024). Automatic Water Body Extraction from SAR Images Based on MADF-Net. Remote Sensing, 16(18), 3419. https://doi.org/10.3390/rs16183419