1. Introduction
As an important means of water resource management, flood prevention, and disaster mitigation, water body detection is of vital significance for maintaining the ecological environment and safeguarding people’s lives and properties. Currently, the global climate changes largely, extreme weather events occur frequently, and natural disasters such as heavy rainfall and floods bring great challenges to human society. Therefore, strengthening the real-time monitoring and early warning of water bodies, as well as improving the accuracy and timeliness of water information, are of vital importance for effectively responding to natural disasters and mitigating disaster losses. Synthetic aperture radar (SAR) is one of the most important technical means for water monitoring in floods [
1]. SAR is not affected by weather, which can be used for all-day and all-weather imaging. The backward scattering coefficient of SAR images for water is very low (due to the mirror reflection), which allows them to be used to perform continuous observation of the spatial distribution of rivers, lakes, and reservoirs, and of the dynamic changes in the areas of timely and effective flood prevention and mitigation.
Traditional water detection methods mainly include the threshold method and classifier method. The threshold method is more often used in medium- and high-resolution images, and is mainly based on the spectral features of the features, using spectral knowledge to construct various classification models and water indices for water extraction. Through an experiment on water detection in Tangshan, Wang et al. [
2] constructed a spectral interrelationship and a ratio model and concluded that the water characteristics of the ratio of TM4 to TM2 were less than 0.9. Li et al. [
3] designed an improved maximum interclass variance thresholding method for water extraction, which integrated the spectral, textural, and spatial features of the images to extract water information. The experiments in the Dongting Lake region during the dry and flooding periods were performed, respectively, and good results were produced. Duan et al. [
4] extracted water bodies by the SVM method, object-oriented method, and water body index method, respectively, and the results showed that the SVM method had the highest extraction accuracy. Aung et al. [
5] utilized the Google Earth RGB image and combined Sobel’s rule, the wavelet transform, and the SVM method for the classification of the river area and sandbar area, and the overall accuracy of detection reached 94%. In recent decades, deep learning techniques have exhibited remarkable achievements in diverse image analysis applications spanning various fields. Convolutional Neural Networks (CNNs) have gained popularity in semantic segmentation tasks due to their proficiency in implementing nonlinear decision mechanisms and their capacity to learn features directly from raw image data through the integration of convolutional and pooling layers. CNNs allow the automatic learning of features in an image, making them more accurate and robust than manually designed features.
CNNs can obtain better accuracy and efficiency when dealing with large image datasets. So, more and more researchers have applied deep learning methods in water detection. Singh et al. [
6] used the predefined architecture U-Net as a segmentation model for detecting and segmenting water in satellite images, which successfully achieved good results with less data. Liu et al. [
7] presented a water extraction network, R50A3-LWBENet, based on ResNet50 and three attention mechanisms. Experiments demonstrated that the network excelled in integrating both global and local information, leading to the sharper refinement of lake water body edges. Hou et al. [
8] proposed an automatic and robust water identification architecture without manual labeling, and the experimental results showed that morphological processing was much more effective for the feature extraction of water. Chen et al. [
9] introduced a novel technique that leverages feature pyramid enhancement and pixel pair matching as its foundation, which could retain more spatial information and transmit it to the backbone network. By utilizing this approach, Chen et al. [
9] effectively addressed the common issue of detail loss that often occurs in deep networks. Xu et al. [
10] built an enhanced version of the traditional U-Net, known as the Information-Extended network, which incorporated rotated isovariant convolution, a rotation-based channel-attention mechanism, and an optimized Batch Normalization layer. It could improve the IoU value of water extraction by 7%. Chen et al. [
11] introduced a hybrid CNN–Transformer architecture, demonstrating through experimental results its superior performance and efficiency, achieving state-of-the-art results on datasets pertaining to surface water and Tibetan Plateau lakes. Bahrami et al. [
12] investigated the utilization of advanced deep learning models, including SegNet, U-Net, and FCN32, for the automated segmentation of flood-affected zones. Their experiments underscored the promising potential of deep learning techniques in augmenting flood detection accuracy and enhancing overall response capabilities, making flood prediction systems more efficient and reliable. Lu et al. [
13] introduced a regionalized approach for coastline extraction from high-resolution images, integrating Simple Linear Iterative Clustering (SLIC), Bayes’ Theorem, and the Metropolis–Hastings (M-H) algorithm. Their experimental findings indicated that the proposed methodology achieved a precise and complete extraction of coastlines. Pech-May et al. [
14] presented a strategy for the classification of flooded areas using satellite images obtained from synthetic aperture radar, as well as the U-Net neural network and ArcGIS platform. Experiments showed that the results were good. Jonnala et al. [
15] proposed a spatial attention residual U-Net architecture to improve the effectiveness of water segmentation. The proposed method used U-Net as the base network to reweight the feature representation spatially to obtain the water element data, which acquired better performance than the existing networks.
In SAR image analysis, DeepLabV3+ has demonstrated its powerful segmentation ability, and has been increasingly used in water detection, land cover classification, and disaster monitoring [
16]. Many researchers have improved DeepLabV3+ for water extraction from SAR images. In their latest study, Chen et al. [
1] discussed the water detection method of SAR images based on interpretive artificial intelligence (AI) and focused on the attention mechanism of the model, providing a new perspective for understanding the decision-making process of the model. Wu et al. [
17] proposed to use the spatial pyramid pool module to combine feature maps at different scales in DeepLabV3+. Chen et al. [
18] proposed a multi-level feature attention fusion network (MFAF-Net), which realized the high-precision automatic detection of water from multi-frequency and multi-resolution SAR images. Zhang et al. [
19] proposed a deep neural network for the automatic extraction of water and shadows from SAR images by integrating CNN, ResNet, DenseNet, global convolutional network (GCN), and convolutional long short-term memory (ConvLSTM), which was experimentally proved to be effective for water and shadow extraction. Chen et al. [
20] introduced a pioneering interpretable deep neural network (DNN) architecture for detecting surface water, which seamlessly integrated SAR domain expertise, DNN, and Extensible Artificial Intelligence (XAI). Experimental results demonstrated its ability to provide transparency into the DNN’s decision-making process during water detection, along with corresponding attribution analysis for a specific SAR image input. Cai et al. [
21] proposed an automatic and fast extraction method for InSAR image stacking based on a multi-layer feature fusion attention mechanism, which effectively improved the accuracy and speed of stacked information extraction. Chen et al. [
22] designed a multi-scale deep neural network to achieve high-precision water recognition under complex terrain conditions for the problem of water detection in mountainous SAR images.
At present, great progress has been made in the research of SAR image water detection. Many researchers have used attention mechanisms, multi-scale feature fusion, super-resolution reconstruction, and other methods to conduct research. However, most of the water detection algorithms have been designed and verified for SAR images in specific areas or under specific conditions, and their generalization ability is limited. For example, Hou et al. [
8] used data from only one area of the Tibetan Plateau lake in their experiment. When applied to other regions or conditions, a large number of parameter adjustments and algorithm optimizations might be required, which would increase the complexity and cost of the algorithm’s application. Most of the research has been conducted on large areas of water; however, for small areas, there are still deficiencies in the accuracy of water detection and edge extraction. For example, Xu et al. [
10] mentioned that the Aug-U-Net model was unsatisfactory for the extraction of small tributaries.
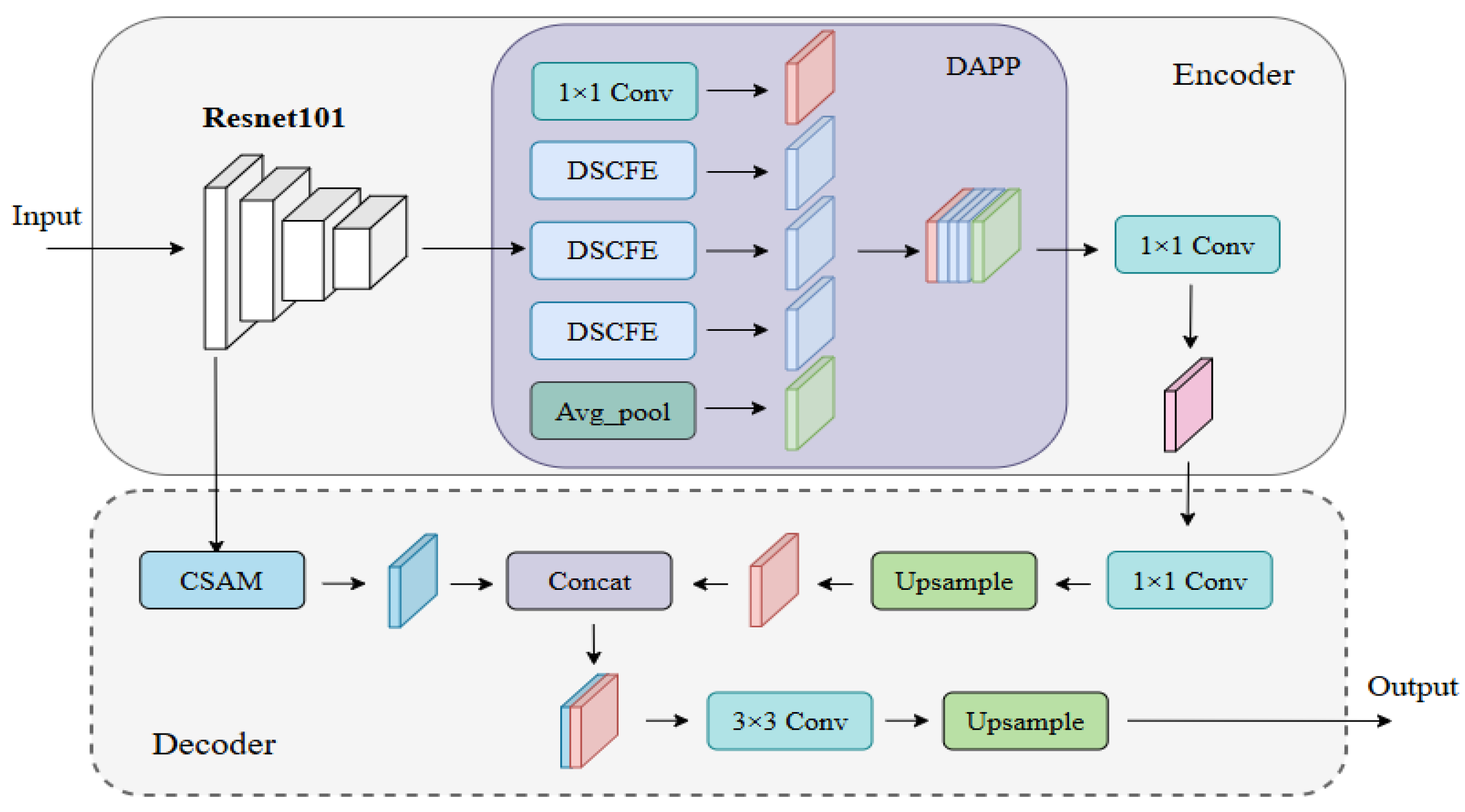
In summary, water detection still faces the problem of low generalization, weak extraction ability of detailed information and multi-scale features for water, and a weak suppression ability for complex background noises. To address this, a Multi-scale Attention Detailed Feature Fusion Network (MADF-Net) is proposed in this paper, which obviously improved the performance of water detection for different types of water from SAR images by constructing a deep multi-scale feature extraction (DAPP) module and a dual-attention mechanism (CSAM) module. The contributions of this paper are as follows:
- (1)
MADF-Net is proposed, which can perform automatic detection for different scales of water regions with high precision.
- (2)
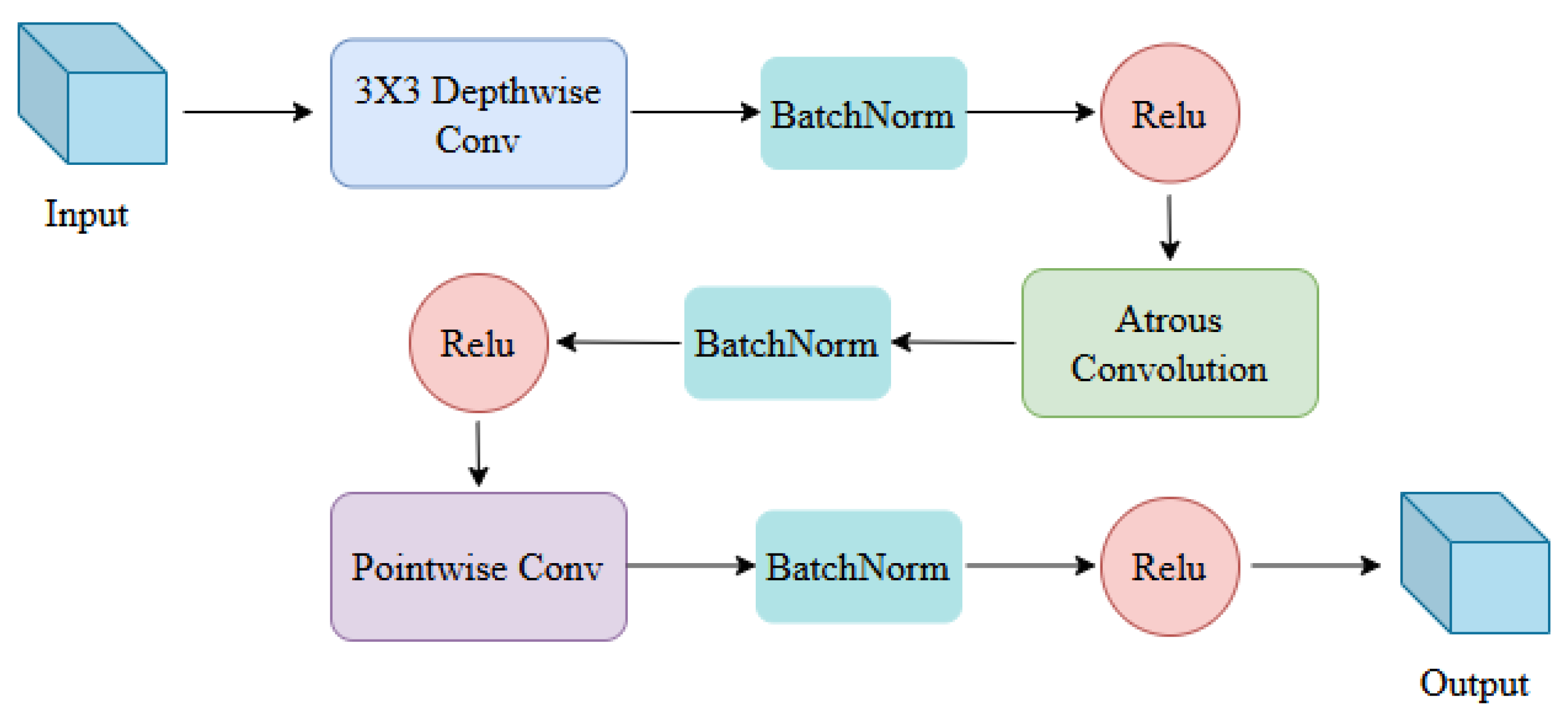
A feature extraction module, namely DAPP, is proposed based on depth-separable convolution, which can obtain rich semantic information of water bodies and enhance the network’s learning of the detailed features of water from SAR images.
- (3)
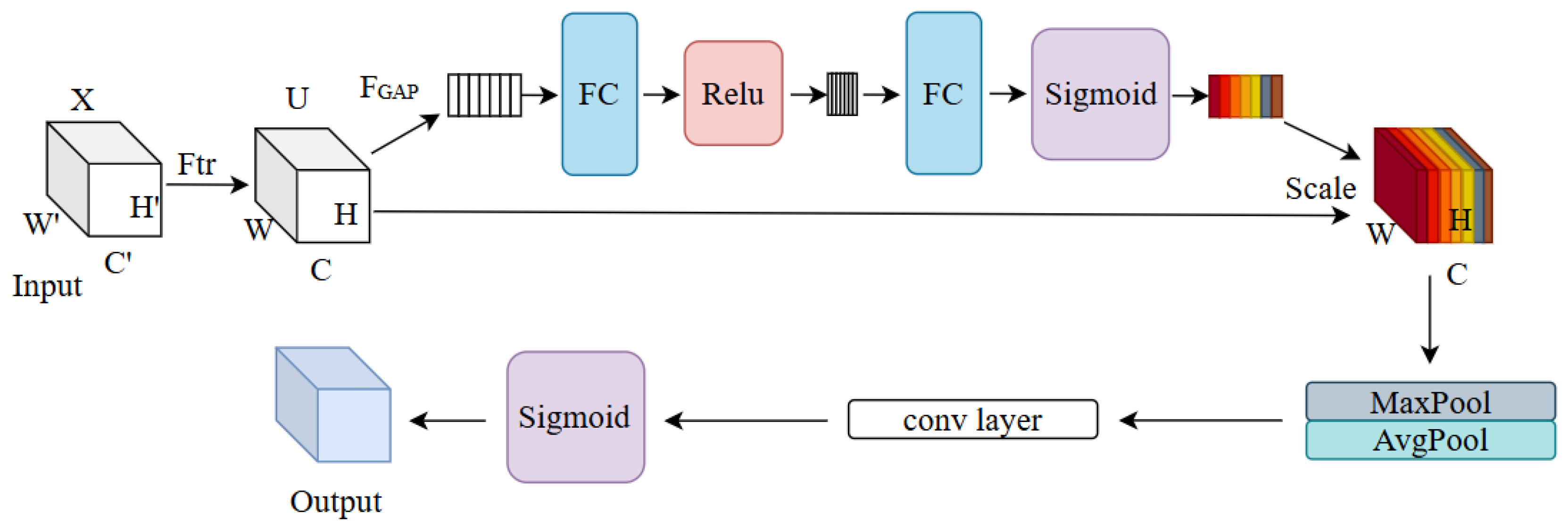
The detailed edge feature extraction module, CSAM, is presented inspired by spatial attention and channel attention, and it carries out the effective distribution of information weights among channels and improves the feature expression and edge information extraction ability in the edge region of the water regions.
The rest of this paper is organized as follows.
Section 2 gives detailed information on the SAR images used.
Section 3 elaborates on the principle of MADF-Net proposed in this paper. In
Section 4, an experiment is performed using Sentinel-1 SAR images for water detection, and several excellent networks are compared.
Section 5 discusses several problems in this paper. Finally, the conclusion is given in
Section 6.
2. Materials
In this paper, the single-polarized intensity images in IW mode from Sentinel-1 are used, which work in the C-band and have a resolution of 5 m (azimuth) × 20 m (range) in IW mode. In this study, the Sentinel-1 SAR images was downloaded from Scientific Data Hub of the European Space Agency (ESA), which was located in Paris, France. There were three regions in June, July, September, and October 2018, and the latitude and longitude of the three regions were 96°~119°E, 32°~42°N; 113°41′~115°05′E, 29°58′~31°22′N; and 99°38′~100°45′E, 36°32′~37°12′N, respectively. Firstly, the downloaded data are preprocessed through orbit correction, thermal noise removal, radiometric calibration, filtering, and geometric correction by the Sentinel Application Platform (SNAP). Then, the dataset is produced and manually labeled with reference to the PASCAL VOC 2012 format, and the Labelme v5.3.1 software is used to label the water body areas as water and other areas as background. Firstly, the large-scale SAR images are sliced using the sliding window to generate 512 × 512-pixel images, and 11,000 samples are finally generated, in which the ratio of the training set to the validation set is 8:2. The dataset folder contains two folders, training and testing, and the training folder contains the file name of the ImageSet image, the training validation set image, and the validation set image. JPEGImages stores all the images of training and testing, and SegmentationClass stores all the tags of training and testing. At the same time, the images selected to make the dataset include three cases: the combination of tributaries and small tributaries, the combination of large areas of water and small areas, and the combination of large areas of water and tributaries. And each SAR image corresponds to a red and black label, where red is for water and black is for something other than water. In addition, three water scenes with different characteristics are reserved for independent testing, and are not used in the dataset.
5. Discussion
In this paper, single-polarization intensity images in Interferometric Wide (IW) mode in Sentinel-1 are utilized to construct a dataset, and the proposed MADF-Net is verified for automatic water extraction. DeepLabV3+ extracts low-level features from the middle layer of the backbone network, which contains more image detail information, but this process is still limited. Especially when dealing with images with complex boundaries or fine structures, the model may not be able to recover all the details completely accurately. The GCN model proposes a residual-based boundary-refinement module to refine the object boundary, but this method may still not be able to completely solve the boundary localization problem in blurred boundaries or complex scenes. In some extreme cases, the boundary-refinement module may not be effective at distinguishing between adjacent similar objects or handling occlusion. The MFAF-Net model adopts a multi-level feature extraction and attention fusion mechanism, which improves the accuracy of the model for water extraction from multi-source SAR images, but also increases the complexity and computational cost of the model. Compared to these three networks, the proposed MADF-Net obviously outperforms them in performance for water extraction.
In terms of the structure, the proposed network (MADF-Net) has a low-level feature extraction layer and a high-level feature extraction layer. Its low-level feature extraction layers contain a small number of convolutional and pooling layers that capture the basic features of the image. Convolutional layers use small convolutional kernels to extract local features, while pooled layers are used to reduce the size of feature maps while preserving important information. As the depth of the network increases, the convolutional layer uses more convolutional kernels and more complex feature combinations to extract higher-level features. These features are more abstract and capable of representing complex objects or scene structures. Methodologically, the depth separable convolution significantly reduces the number of parameters of the model. This makes the network lighter, reducing the complexity and storage requirements of the model. And through the point-by-point convolutional layer, the features of different channels are fused to maintain good feature extraction and representation capabilities. Multi-scale pooling can capture more diverse feature information, which helps to enhance the invariance of the model to scale changes in input data and improve the robustness of the model. The attention mechanism helps the model to capture the key features of the input data more accurately, improving the performance of the model. Therefore, MADF-Net not only enhances extraction accuracy but also demonstrates significant advantages in capturing finer detailed information.
In addition, our network achieved an IoU of 86.78% on the test set, a 3% improvement over other benchmark networks, demonstrating superior performance. However, it is worth noting that our network has also increased in computational complexity and storage requirements to achieve this increase in accuracy. Specifically, our network reaches 262 GFLOPs and the number of Params reaches 59 million, which is indeed slightly higher than some efficient networks, and the improvement in accuracy may be attributed to the deeper and richer feature extraction and more complex connection patterns used in our network architecture. Although this leads to slightly higher computational complexity and storage requirements, we also believe that such a design leads to stronger feature representation capabilities and better generalization performance, which may be of great value in practical application scenarios. In order to address this problem, we are actively exploring model compression and optimization techniques, such as pruning, quantization, and model distillation, to reduce FLOPs and Params while maintaining higher accuracy. We believe that through these efforts, a more efficient and high-performance network model can be achieved in the near future.
Furthermore, the data currently used are all single-band, single-resolution, and single-source SAR images, which may limit the application of water detection from SAR images of different frequencies and resolutions. In addition, in shallow waters, the penetrating ability of a long-wave radar may cause scattered signals from the water body and the land surface to interfere with each other, affecting the accuracy of water withdrawal. Therefore, in our further research, we will collect many water scenes with different backgrounds and SAR images with different water depth and radar parameters, and fuse data from different sources to find problems in water detection and improve the network for better performance. Finally, the network can be used to automatically detect large areas of water against different backgrounds with high accuracy.
6. Conclusions
In this paper, a multi-scale detailed feature attention fusion network is proposed, namely, MADF-Net, which is used to solve the problem of the poor detection accuracy of fine tributaries and small water areas in SAR images. In the MADF-Net, a deep multi-scale feature extraction module is constructed (DAPP), which not only improves the overall accuracy for water detection but also reduces the number of parameters. It further enhances the network’s ability to capture key water features in complex scenes by performing multi-scale pooling operations on input features. The constructed DAPP module can extract information at different scales, increasing sensitivity to small targets such as small water streams, lake edges, etc.
Furthermore, an edge feature extraction module (CSAM) is also proposed based on the channel attention module and the spatial attention module. By fusing the attention weights of the channel and spatial dimensions, the module enables the network to automatically focus on the feature areas that are critical for identifying the edge of the water body. This attention mechanism greatly improves the network’s ability to distinguish between small objects and backgrounds in complex backgrounds, ensuring that the extracted water body information is both accurate and detailed. In the decoding stage, we fuse the high-level semantic information extracted by the encoder with the low-level edge features generated by the decoder to achieve a comprehensive feature description from coarse to fine, and from the whole to the parts. This multi-level feature fusion strategy not only improves the adaptability of the model to specific scenarios (i.e., improves the accuracy of small target extraction), but also enhances the generalization ability of the model. Because the low-level edge features provide a direct description of the shape and contour of an object, while the high-level semantic information provides an in-depth understanding of the object’s classes and attributes, the combination of the two allows the model to maintain stable performance in different scenarios.
From the selection of ResNet101 to the introduction of DAPP and CSAM to the design of feature fusion strategy, our method has always been optimized around the goal of improving the accuracy of small target extraction. Together, these design elements work across the network, making our approach excellent for small targets in complex scenarios. Experiments are conducted using three water scenes with different features, scales and backgrounds from Sentinel-1 images. The results show that MADF-Net has an obvious performance improvement over DeepLabV3+, GCN, and MFAF-Net in terms of extraction ability for detailed water information, with an average precision and IoU for water extraction up to 92.77% and 89.03% for the three scenes. Therefore, MADF-Net can perform water extraction with high precision from SAR images for different types of water, which could also be extended to perform segmentation tasks of other typical targets from SAR images. If a flood occurs, MADF-Net could be used to detect water so that the disaster caused by water could be evaluated precisely.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}