







A U-Shaped Convolution-Aided Transformer with Double Attention for Hyperspectral Image Classification


Abstract
:1. Introduction
- (1)
- CNNs are good at local perception and extracting low-level features. However, they treat all features equally without considering different significances. Moreover, capturing global contextual information and establishing long-range dependencies can be inefficiently limited by their inherent structure [36].
- (2)
- Transformers are good at global interaction and capturing salient features. However, they often manifest difficulty in local perception [37,38], which is nevertheless critical to the collection of refined information. Furthermore, transformers usually have a considerable demand for training data [39], yet annotated HSI data are mostly inadequate. Moreover, the internal spectral–spatial data structure can be damaged in the transformer architecture, which deteriorates the classification performance.
- (3)
- Most of these CNN- and transformer-based networks follow a patch-wise classification framework; that is, each pixel with its adjacent pixels can form a coherent whole that is labeled as the category of the center pixel [40,41]. This framework is grounded on the spatial homogeneity assumption that the adjacent pixels will share the same land cover category with their center pixel. However, the assumption is not always tenable because the cropped patch is too complicated in spatial distribution to be roughly represented by its center pixel.
- (1)
- A UCaT network, which incorporates group convolutions into a novel transformer architecture, is proposed. The group convolution extracts detailed features locally, and then the MSA recalibrates the obtained features with a global field of vision in consistent groups. This combination takes full account of the characteristics of HSI data, emphasizing informative features while maintaining the inherent spectral–spatial data structure.
- (2)
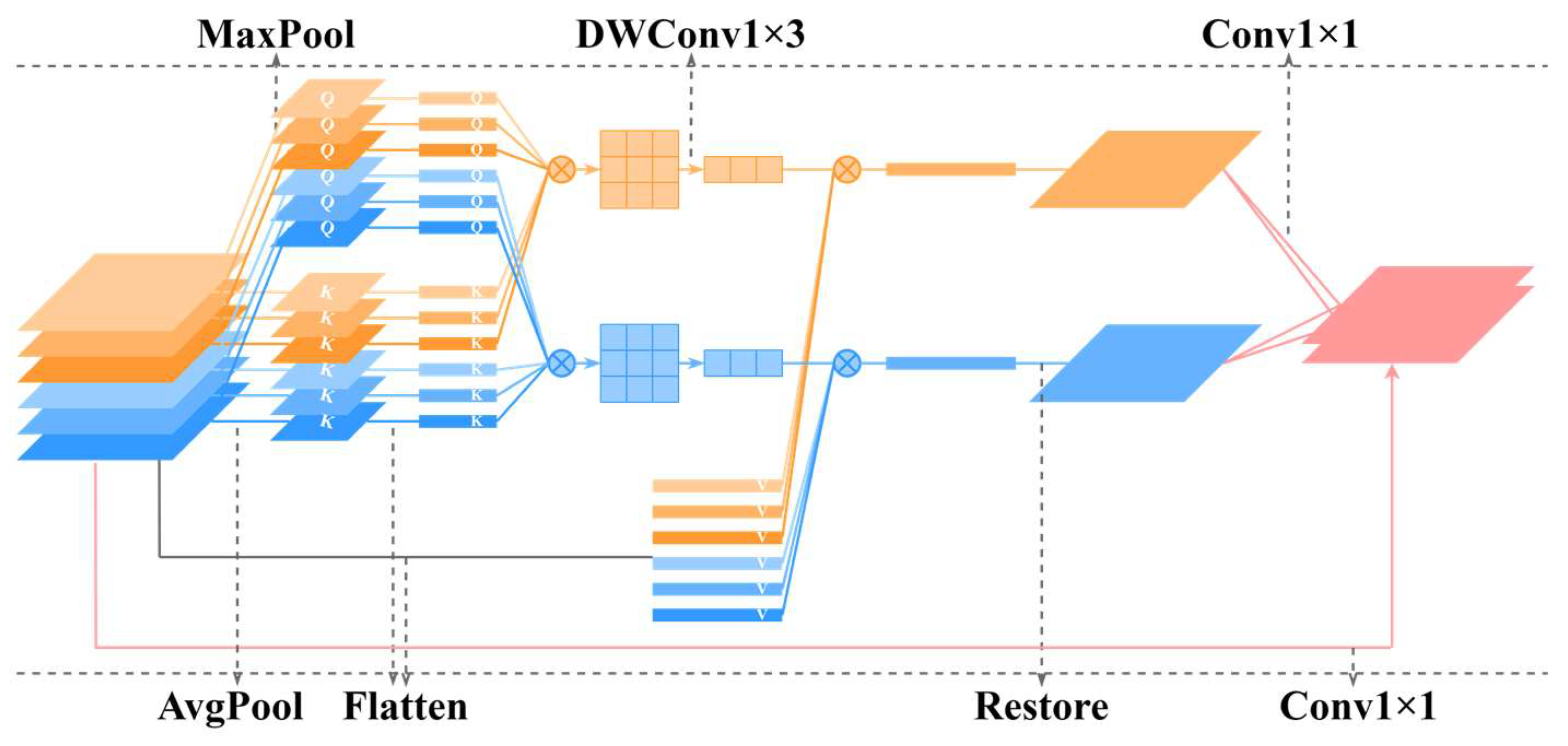
- The spectral-GSA builds spectral attention and provides a new way of dimensionality reduction. It divides the spectral bands into small groups and builds spectral attention in groups, which possesses the ability to capture subtle spectral discrepancies. And a convolutional attention weight adjustment is constructed, which efficiently reduces the spectral dimension.
- (3)
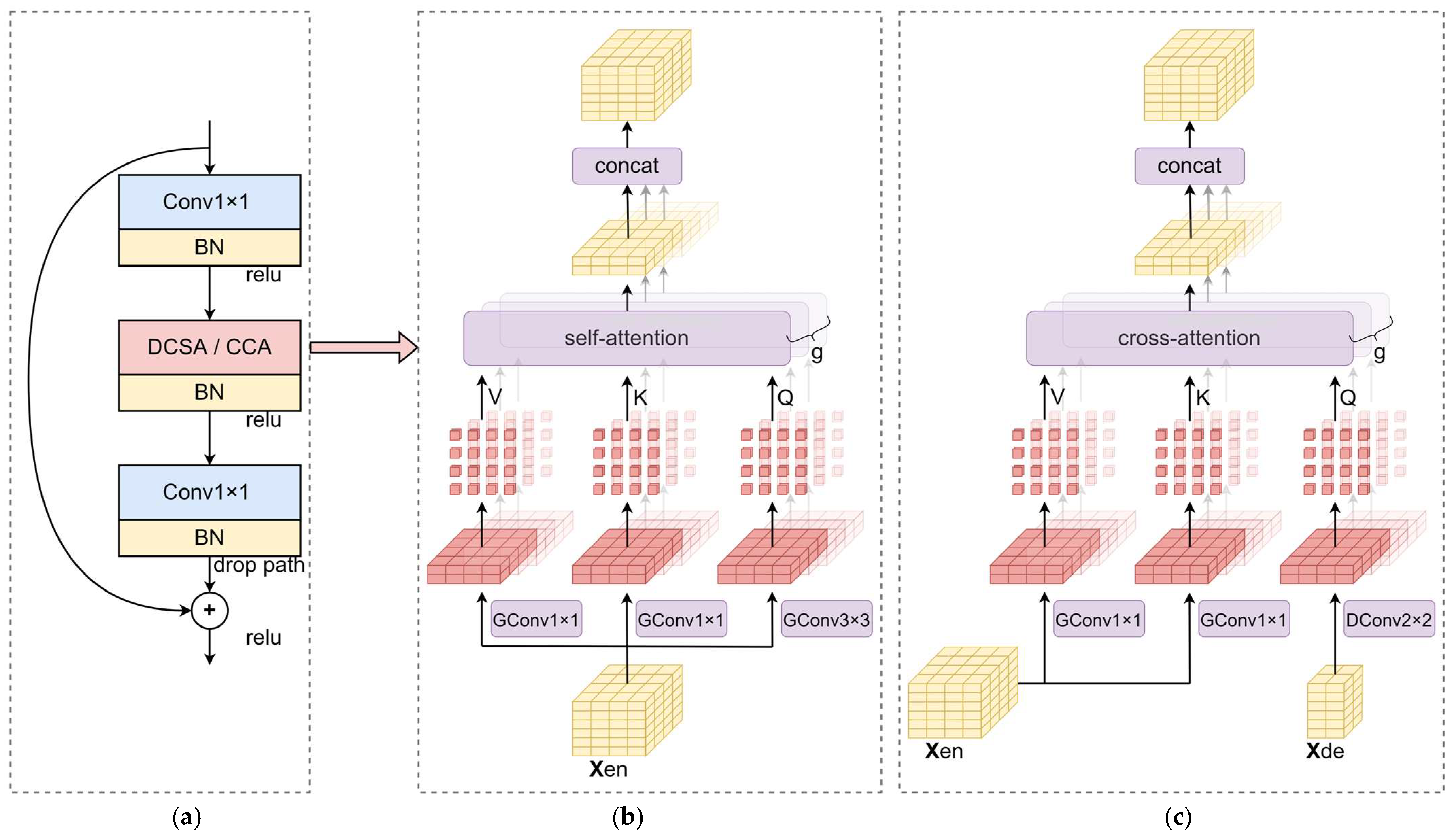
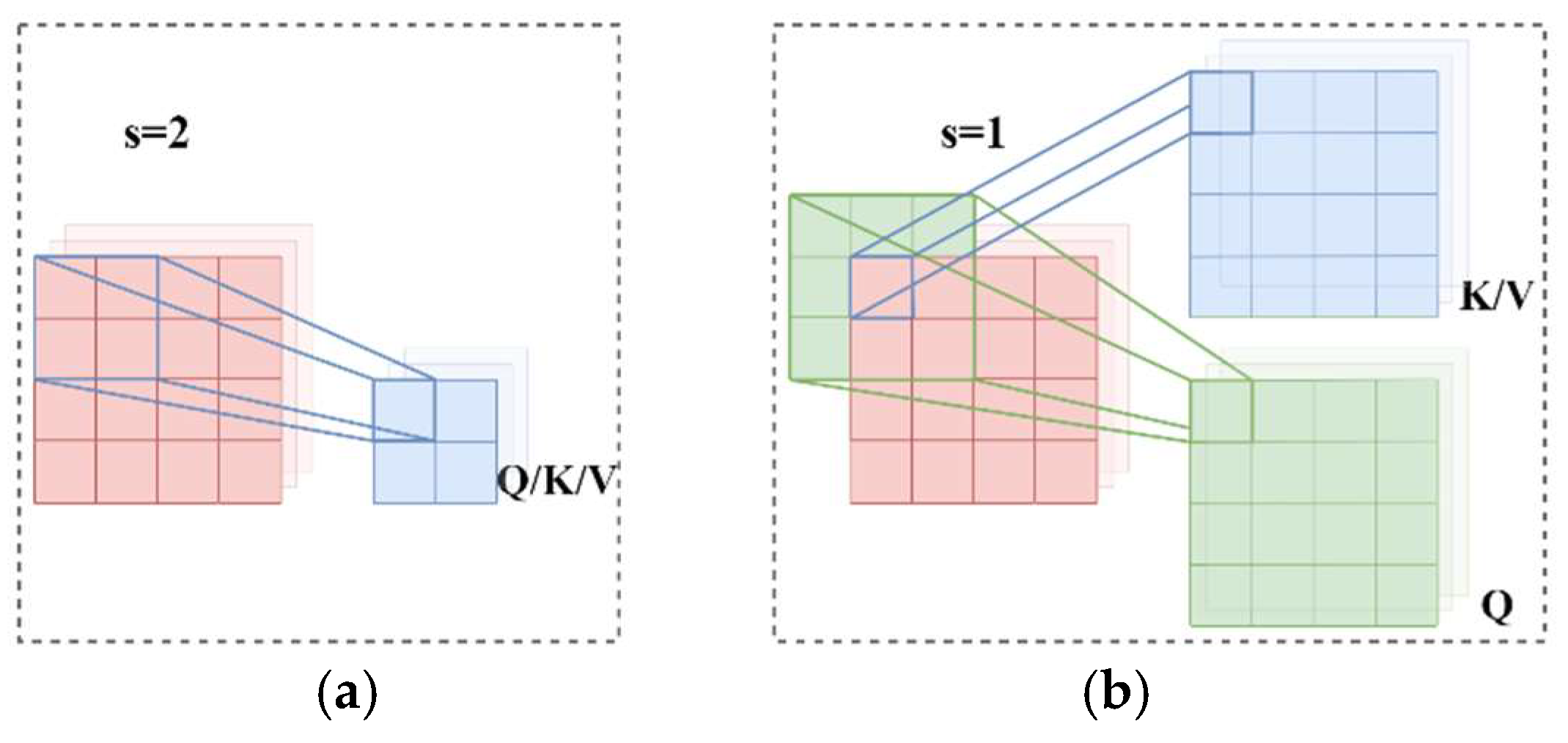
- The spatial-DCSA encoder and the spatial-CCA decoder form a U-shaped architecture to assemble local-global spatial information, where a dual-scale strategy is employed to exploit information in different scales, and the cross-attention strategy is adopted to compensate high-level information with low-level information, which contributes to spatial feature representation.
- (4)
- The UCaT achieves better classification results and better interpretability. Extensive experiments demonstrate that the UCaT outperforms the CNN- and transformer-based state-of-the-art networks. A visual explanation shows that the UCaT can not only distinguish homogeneous areas to eliminate semantic ambiguity but also capture pixel-level spatial dependencies.
2. Related Works
2.1. Transformer-Based Networks
2.2. Segmentation Networks
3. Methodology
3.1. Overview
3.2. Spectral Groupwise Self-Attention Component
3.3. Spatial Dual-Scale Convolution-Aided Self-Attention Encoder
3.4. Spatial Convolution-Aided Cross-Attention Decoder
4. Experiment
4.1. Data Description
- (1)
- IP dataset: The first dataset was acquired by the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) sensor over the Indian Pines field in Northwestern Indiana. After discarding some spectral bands that are affected by the water absorption, the remaining 200 bands in a spatial size of 145 × 145 pixels are used for experiments. The dataset has 10,249 labeled pixels that can be partitioned into 16 land cover types.
- (2)
- PU dataset: The second dataset was gathered by the Reflective Optics System Imaging Spectrometer (ROSIS) sensor at Pavia University, Northern Italy. The image consists of 610 × 340 pixels; among them, 42,776 pixels were labeled. The dataset has 9 types of land cover classes and 103 spectral bands.
- (3)
- SV dataset: The third dataset was also collected by the AVIRIS sensor over Salinas Valley, California. After removing the water absorption bands, the remaining 204 bands with a spatial size of 512 × 217 pixels are used for experiments. The dataset has 16 land cover classes, and a total of 54,129 pixels were labeled.
4.2. Experimental Setup
- (1)
- Metrics: Three evaluation metrics, i.e., overall accuracy (OA), average accuracy (AA), and kappa coefficient (K), are used to measure the classification performance quantitatively. To ensure the reliability of the experiment results, all subsequent experiments are repeated ten times, and each is conducted on randomly selected training and testing sets.
- (2)
- Data partition: For the IP, PU, and SV datasets, 10% (1024 pixels), 5% (2138 pixels), and 3% (1623 pixels), respectively, of the labeled samples, are randomly selected for training. The random seeds for the ten times repeated experiments are set to 0~9 for reducing random error.
- (3)
- Implementation details: All experiments are implemented with the Python 3.7 compiler and the PyTorch platform, running on a desktop PC with an Intel Core i7-9700 CPU and an NVIDIA GeForce RTX 3080 graphics card. Before training, the original HSI datasets are normalized to the range [0, 1] using the min-max scaling. Then, the cross-entropy loss and the AdamW optimizer (the weight decay is set to 0.03) are used to supervise training. Specifically, we train the network for 105 epochs with a mini-batch size of 128. The learning rate is initialized to 0.03, and then the CosineAnnealingWarmRestarts learning rate scheduler is employed to adjust it, where the number of iterations for the first restart T_0 is set to 5, and the increase factor after each restart T_mult is set to 4.
4.3. Parameter Analysis
4.3.1. Influence of Patch Size
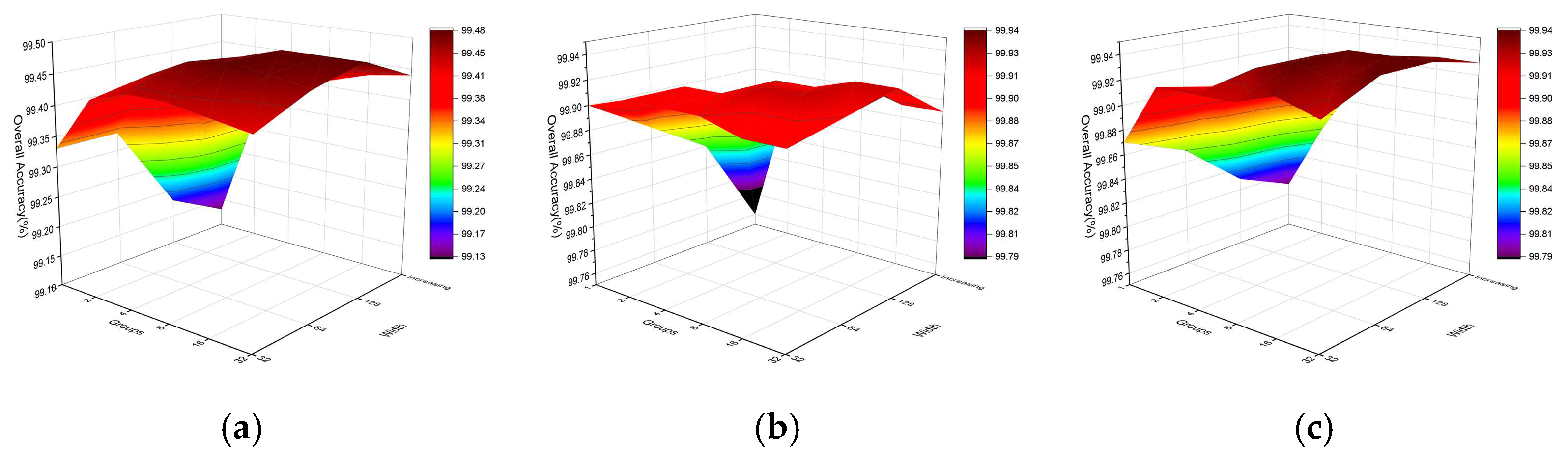
4.3.2. Influence of Network Width and the Number of Groups
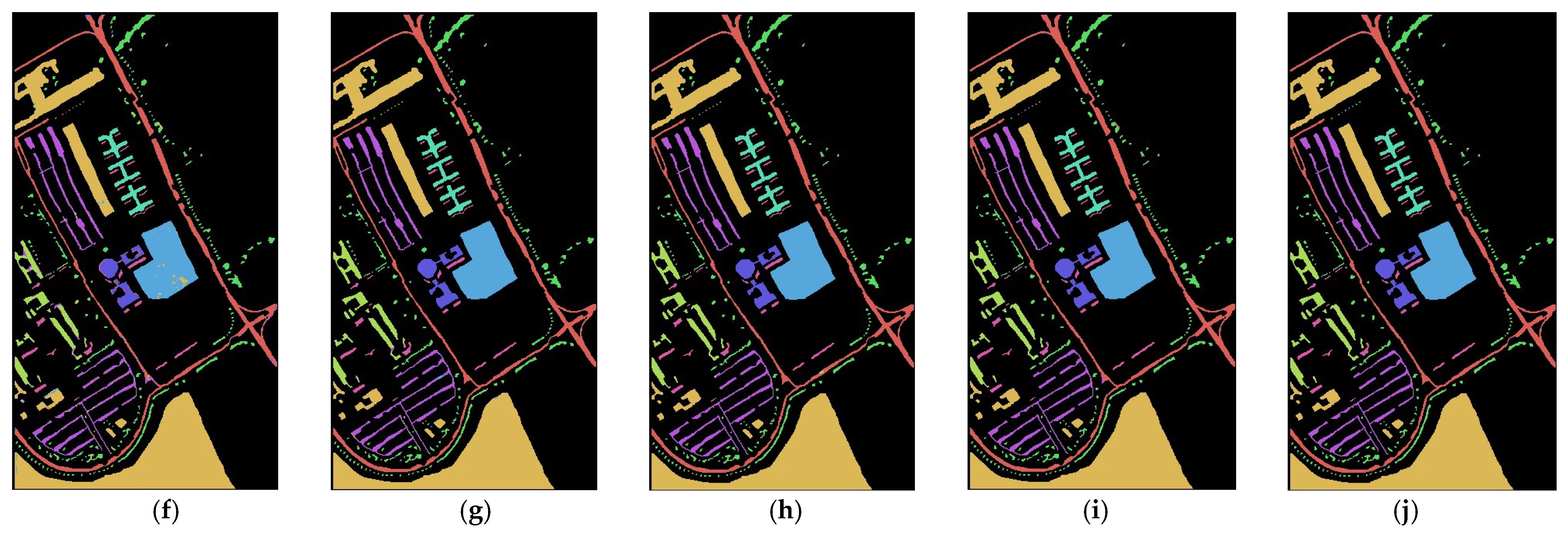
4.4. Classification Results
4.5. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, L.; Zhao, G.; Zheng, Y.; Wu, Z. Spectral–Spatial Feature Tokenization Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5522214. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, L. Beyond the Patchwise Classification: Spectral–Spatial Fully Convolutional Networks for Hyperspectral Image Classification. IEEE Trans. Big Data 2020, 6, 492–506. [Google Scholar] [CrossRef]
- Xue, X.; Zhang, H.; Fang, B.; Bai, Z.; Li, Y. Grafting Transformer on Automatically Designed Convolutional Neural Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5531116. [Google Scholar] [CrossRef]
- Zhou, Q.; Zhou, S.; Shen, F.; Yin, J.; Xu, D. Hyperspectral Image Classification Based on 3-D Multihead Self-Attention Spectral–Spatial Feature Fusion Network. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2023, 16, 1072–1084. [Google Scholar] [CrossRef]
- Zhang, H.; Yao, J.; Ni, L.; Gao, L.; Huang, M. Multimodal Attention-Aware Convolutional Neural Networks for Classification of Hyperspectral and LiDAR Data. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2023, 16, 3635–3644. [Google Scholar] [CrossRef]
- Yu, H.; Xu, Z.; Zheng, K.; Hong, D.; Yang, H.; Song, M. MSTNet: A Multilevel Spectral–Spatial Transformer Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5532513. [Google Scholar] [CrossRef]
- Cai, Y.; Liu, X.; Cai, Z. BS-Nets: An End-to-End Framework for Band Selection of Hyperspectral Image. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1969–1984. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, T.; Tang, X.; Hu, X.; Peng, Y. CAEVT: Convolutional Autoencoder Meets Lightweight Vision Transformer for Hyperspectral Image Classification. Sensors 2022, 22, 3902. [Google Scholar] [CrossRef]
- Qiao, X.; Roy, S.K.; Huang, W. Rotation Is All You Need: Cross Dimensional Residual Interaction for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2023, 16, 5387–5404. [Google Scholar] [CrossRef]
- Borsoi, R.A.; Imbiriba, T.; Bermudez, J.C.M.; Richard, C.; Chanussot, J.; Drumetz, L.; Tourneret, J.Y.; Zare, A.; Jutten, C. Spectral Variability in Hyperspectral Data Unmixing: A Comprehensive Review. IEEE Geosci. Remote Sens. Mag. 2021, 9, 223–270. [Google Scholar] [CrossRef]
- Alkhatib, M.Q.Q.; Al-Saad, M.; Aburaed, N.; Almansoori, S.; Zabalza, J.; Marshall, S.; Al-Ahmad, H. Tri-CNN: A Three Branch Model for Hyperspectral Image Classification. Remote Sens. 2023, 15, 316. [Google Scholar] [CrossRef]
- Zhou, P.; Han, J.; Cheng, G.; Zhang, B. Learning Compact and Discriminative Stacked Autoencoder for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4823–4833. [Google Scholar] [CrossRef]
- Ma, X.; Wang, H.; Geng, J. Spectral–Spatial Classification of Hyperspectral Image Based on Deep Auto-Encoder. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2016, 9, 4073–4085. [Google Scholar] [CrossRef]
- Hang, R.; Liu, Q.; Hong, D.; Ghamisi, P. Cascaded Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5384–5394. [Google Scholar] [CrossRef]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef]
- Wu, H.; Prasad, S. Semi-Supervised Deep Learning Using Pseudo Labels for Hyperspectral Image Classification. IEEE Trans. Image Process. 2018, 27, 1259–1270. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep Learning for Hyperspectral Image Classification: An Overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Haut, J.M.; Paoletti, M.E.; Plaza, J.; Li, J.; Plaza, A. Active Learning with Convolutional Neural Networks for Hyperspectral Image Classification Using a New Bayesian Approach. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6440–6461. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral Image Classification with Deep Feature Fusion Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Lu, Z.; Xu, B.; Sun, L.; Zhan, T.; Tang, S. 3-D Channel and Spatial Attention Based Multiscale Spatial–Spectral Residual Network for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2020, 13, 4311–4324. [Google Scholar] [CrossRef]
- Xue, Z.; Xu, Q.; Zhang, M. Local Transformer with Spatial Partition Restore for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2022, 15, 4307–4325. [Google Scholar] [CrossRef]
- Shu, Z.; Liu, Z.; Zhou, J.; Tang, S.; Yu, Z.; Wu, X.J. Spatial–Spectral Split Attention Residual Network for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2023, 16, 419–430. [Google Scholar] [CrossRef]
- Li, X.; Ding, M.; Pižurica, A. Deep Feature Fusion via Two-Stream Convolutional Neural Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2615–2629. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–Spatial Residual Network for Hyperspectral Image Classification: A 3-D Deep Learning Framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]
- Zhao, H.; Wang, C.; Chen, H.; Chen, T.; Deng, W. A Hybrid Classification Method with Dual-Channel CNN and KELM for Hyperspectral Remote Sensing Images. Int. J. Remote Sens. 2023, 44, 289–310. [Google Scholar] [CrossRef]
- Zhang, H.; Li, Y.; Zhang, Y.; Shen, Q. Spectral–Spatial Classification of Hyperspectral Imagery Using a Dual-Channel Convolutional Neural Network. Remote Sens. Lett. 2017, 8, 438–447. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef]
- Huang, W.; Zhao, Z.; Sun, L.; Ju, M. Dual-Branch Attention-Assisted CNN for Hyperspectral Image Classification. Remote Sens. 2022, 14, 6158. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- He, X.; Chen, Y.; Lin, Z. Spatial–Spectral Transformer for Hyperspectral Image Classification. Remote Sens. 2021, 13, 498. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking Hyperspectral Image Classification with Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5518615. [Google Scholar] [CrossRef]
- He, J.; Zhao, L.; Yang, H.; Zhang, M.; Li, W. HSI-BERT: Hyperspectral Image Classification Using the Bidirectional Encoder Representation from Transformers. IEEE Trans. Geosci. Remote Sens. 2020, 58, 165–178. [Google Scholar] [CrossRef]
- Liang, M.; He, Q.; Yu, X.; Wang, H.; Meng, Z.; Jiao, L. A Dual Multi-Head Contextual Attention Network for Hyperspectral Image Classification. Remote Sens. 2022, 14, 3091. [Google Scholar] [CrossRef]
- Wang, S.; Liu, Z.; Chen, Y.; Hou, C.; Liu, A.; Zhang, Z. Expansion Spectral-Spatial Attention Network for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2023, 16, 6411–6427. [Google Scholar] [CrossRef]
- Peng, Y.; Liu, Y.; Tu, B.; Zhang, Y. Convolutional Transformer-Based Few-Shot Learning for Cross-Domain Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2023, 16, 1335–1349. [Google Scholar] [CrossRef]
- Yuan, K.; Guo, S.; Liu, Z.; Zhou, A.; Yu, F.; Wu, W. Incorporating Convolution Designs into Visual Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 559–568. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training Data-Efficient Image Transformers & Distillation Through Attention. In Proceedings of the International Conference on Machine Learning (ICML), Electr Network, Online, 18–24 July 2021; pp. 7358–7367. [Google Scholar]
- Bai, J.; Wen, Z.; Xiao, Z.; Ye, F.; Zhu, Y.; Alazab, M.; Jiao, L. Hyperspectral Image Classification Based on Multibranch Attention Transformer Networks. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5535317. [Google Scholar] [CrossRef]
- Sun, H.; Zheng, X.; Lu, X.; Wu, S. Spectral–Spatial Attention Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3232–3245. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. CvT: Introducing Convolutions to Vision Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 22–31. [Google Scholar]
- Graham, B.; El-Nouby, A.; Touvron, H.; Stock, P.; Joulin, A.; Jégou, H.; Douze, M. LeViT: A Vision Transformer in ConvNet’s Clothing for Faster Inference. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 12239–12249. [Google Scholar]
- Liu, H.; Li, W.; Xia, X.G.; Zhang, M.; Gao, C.Z.; Tao, R. Central Attention Network for Hyperspectral Imagery Classification. EEE Trans. Neural Netw. Learn. Syst. 2022, 34, 8989–9003. [Google Scholar] [CrossRef]
- Yang, K.; Sun, H.; Zou, C.; Lu, X. Cross-Attention Spectral–Spatial Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5518714. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Audebert, N.; Saux, B.L.; Lefevre, S. Deep Learning for Classification of Hyperspectral Data: A Comparative Review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 159–173. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Petit, O.; Thome, N.; Rambour, C.; Themyr, L.; Collins, T.; Soler, L. U-Net Transformer: Self and Cross Attention for Medical Image Segmentation. In Proceedings of the 12th International Workshop on Machine Learning in Medical Imaging (MLMI 2021), Strasbourg, France, 27 September 2021; pp. 267–276. [Google Scholar]
- Li, R.; Zheng, S.; Duan, C.; Yang, Y.; Wang, X. Classification of Hyperspectral Image Based on Double-Branch Dual-Attention Mechanism Network. Remote Sens. 2020, 12, 582. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D.; IEEE. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | CNN-Based | Transformer-Based | Segmentation Network | Proposed | |||||
|---|---|---|---|---|---|---|---|---|---|
| SSRN | HybridSN | DBDA | ViT | SF | SSFTT | UNet | UT | UCaT | |
| 1 | 87.81 | 86.10 | 91.95 | 62.68 | 39.02 | 94.39 | 95.85 | 96.34 | 98.05 |
| 2 | 97.99 | 94.20 | 98.10 | 89.35 | 89.25 | 98.48 | 98.91 | 98.86 | 99.25 |
| 3 | 98.05 | 96.20 | 97.87 | 88.73 | 88.70 | 97.95 | 98.85 | 98.38 | 99.22 |
| 4 | 97.23 | 93.24 | 96.34 | 88.26 | 78.12 | 96.71 | 97.28 | 98.73 | 99.20 |
| 5 | 96.60 | 95.59 | 95.45 | 91.68 | 93.56 | 96.05 | 96.58 | 96.94 | 97.68 |
| 6 | 99.59 | 98.19 | 98.90 | 98.01 | 97.84 | 98.33 | 99.56 | 99.36 | 99.88 |
| 7 | 99.20 | 88.00 | 98.00 | 80.40 | 56.80 | 99.60 | 92.40 | 90.00 | 96.80 |
| 8 | 99.79 | 99.70 | 99.86 | 98.79 | 99.56 | 99.98 | 99.98 | 99.91 | 100 |
| 9 | 80.00 | 62.22 | 90.00 | 81.67 | 75.00 | 85.00 | 93.89 | 93.33 | 100 |
| 10 | 96.83 | 95.46 | 96.79 | 87.89 | 87.21 | 96.99 | 98.66 | 98.37 | 99.29 |
| 11 | 98.47 | 98.36 | 98.26 | 96.03 | 90.95 | 99.05 | 99.72 | 99.65 | 99.86 |
| 12 | 96.52 | 91.85 | 96.76 | 79.59 | 80.82 | 96.91 | 98.15 | 98.28 | 99.03 |
| 13 | 99.78 | 98.76 | 99.03 | 99.51 | 98.00 | 99.73 | 99.68 | 99.41 | 99.95 |
| 14 | 99.37 | 98.89 | 99.51 | 98.16 | 96.69 | 99.80 | 99.92 | 99.76 | 99.99 |
| 15 | 97.90 | 94.41 | 97.23 | 85.53 | 89.05 | 98.42 | 92.48 | 99.42 | 99.54 |
| 16 | 99.05 | 86.91 | 95.60 | 99.76 | 97.14 | 92.74 | 96.31 | 98.69 | 97.74 |
| OA (%) | 98.17 | 96.42 | 97.99 | 92.42 | 90.79 | 98.34 | 98.81 | 99.02 | 99.48 |
| AA (%) | 96.51 | 92.38 | 96.85 | 89.13 | 84.86 | 96.88 | 97.39 | 97.84 | 99.09 |
| K (%) | 97.91 | 95.91 | 97.70 | 91.34 | 89.50 | 98.10 | 98.65 | 98.88 | 99.41 |
| Class | CNN-Based | Transformer-Based | Segmentation Network | Proposed | |||||
|---|---|---|---|---|---|---|---|---|---|
| SSRN | HybridSN | DBDA | ViT | SF | SSFTT | UNet | UT | UCaT | |
| 1 | 99.75 | 99.82 | 99.72 | 94.91 | 96.19 | 99.93 | 99.74 | 99.79 | 99.95 |
| 2 | 99.82 | 99.99 | 99.94 | 98.02 | 99.38 | 99.96 | 100 | 100 | 100 |
| 3 | 97.17 | 98.33 | 98.55 | 82.69 | 90.92 | 98.04 | 99.76 | 99.97 | 99.96 |
| 4 | 98.93 | 96.96 | 98.52 | 97.52 | 96.19 | 98.16 | 99.06 | 99.08 | 99.23 |
| 5 | 100 | 99.70 | 99.88 | 99.91 | 100 | 99.85 | 100 | 100 | 100 |
| 6 | 99.74 | 99.87 | 98.81 | 76.47 | 97.60 | 99.93 | 100 | 100 | 100 |
| 7 | 99.81 | 99.76 | 99.87 | 83.86 | 87.55 | 99.95 | 99.26 | 100 | 100 |
| 8 | 98.15 | 98.35 | 98.84 | 92.00 | 91.83 | 98.74 | 99.59 | 99.76 | 99.96 |
| 9 | 99.80 | 97.30 | 98.82 | 99.28 | 97.64 | 97.03 | 99.80 | 99.89 | 99.61 |
| OA (%) | 99.47 | 99.43 | 99.48 | 93.34 | 97.00 | 99.56 | 99.82 | 99.88 | 99.92 |
| AA (%) | 99.24 | 98.90 | 99.22 | 91.63 | 95.26 | 99.07 | 99.69 | 99.83 | 99.86 |
| K (%) | 99.29 | 99.25 | 99.31 | 91.10 | 96.02 | 99.41 | 99.76 | 99.83 | 99.90 |
| Class | CNN-Based | Transformer-Based | Segmentation Network | Proposed | |||||
|---|---|---|---|---|---|---|---|---|---|
| SSRN | HybridSN | DBDA | ViT | SF | SSFTT | UNet | UT | UCaT | |
| 1 | 99.75 | 99.96 | 99.79 | 99.80 | 99.15 | 100 | 99.94 | 99.95 | 100 |
| 2 | 97.94 | 100 | 100 | 98.89 | 99.72 | 100 | 99.91 | 99.96 | 100 |
| 3 | 99.09 | 100 | 99.97 | 99.54 | 99.00 | 100 | 99.91 | 100 | 99.99 |
| 4 | 99.60 | 99.10 | 99.16 | 97.96 | 99.03 | 99.94 | 99.57 | 99.59 | 99.93 |
| 5 | 93.58 | 99.43 | 98.18 | 99.24 | 99.12 | 99.37 | 99.55 | 99.69 | 99.51 |
| 6 | 100 | 99.85 | 99.89 | 99.74 | 99.56 | 99.99 | 100 | 100 | 100 |
| 7 | 99.97 | 99.92 | 99.88 | 98.89 | 99.23 | 99.92 | 99.91 | 99.96 | 100 |
| 8 | 95.99 | 99.58 | 97.83 | 91.15 | 88.15 | 99.42 | 99.76 | 99.98 | 100 |
| 9 | 99.99 | 100 | 99.94 | 99.66 | 99.60 | 100 | 99.95 | 99.96 | 100 |
| 10 | 99.43 | 99.27 | 98.92 | 93.54 | 94.28 | 99.80 | 99.25 | 99.48 | 99.83 |
| 11 | 98.49 | 99.69 | 99.49 | 95.55 | 93.77 | 99.87 | 99.62 | 99.32 | 99.86 |
| 12 | 99.93 | 99.85 | 99.96 | 99.51 | 99.02 | 99.96 | 100 | 100 | 100 |
| 13 | 99.62 | 99.48 | 98.67 | 99.11 | 98.20 | 99.78 | 99.74 | 99.78 | 99.91 |
| 14 | 99.01 | 98.98 | 97.94 | 99.02 | 97.04 | 99.86 | 99.31 | 99.06 | 99.48 |
| 15 | 89.49 | 99.64 | 96.92 | 83.33 | 87.01 | 99.46 | 99.86 | 99.85 | 99.95 |
| 16 | 99.42 | 99.94 | 99.39 | 97.29 | 97.66 | 99.65 | 98.45 | 99.19 | 99.99 |
| OA (%) | 97.13 | 99.71 | 98.83 | 94.98 | 94.83 | 99.73 | 99.75 | 99.84 | 99.94 |
| AA (%) | 98.21 | 99.67 | 99.12 | 97.01 | 96.85 | 99.81 | 99.67 | 99.74 | 99.90 |
| K (%) | 96.80 | 99.68 | 98.70 | 94.40 | 94.25 | 99.70 | 99.72 | 99.82 | 99.93 |
| Spectral-GSA | Spatial-DCSA | Spatial-CCA | OA (%) | AA (%) | K (%) |
|---|---|---|---|---|---|
| √ | √ | √ | 99.48 | 99.09 | 99.41 |
| √ | √ | 99.39 | 98.78 | 99.31 | |
| √ | √ | 99.38 | 98.94 | 99.29 | |
| √ | 98.97 | 97.74 | 98.82 | ||
| √ | √ | 99.42 | 99.02 | 99.34 |
| Q | K/V | OA (%) | AA (%) | K (%) | Params |
|---|---|---|---|---|---|
| 1 | 1 | 99.36 | 98.88 | 99.27 | 175k |
| 3 | 1 | 99.48 | 99.09 | 99.41 | 187k |
| 3 | 3 | 99.46 | 98.92 | 99.39 | 212k |
| OA (%) | AA (%) | K (%) | Params | |
|---|---|---|---|---|
| Cross-Attention | 99.48 | 99.09 | 99.41 | 187k |
| Concatenate | 99.39 | 98.94 | 99.30 | 207k |
| Add | 99.41 | 98.98 | 99.33 | 190k |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, R.; Wang, C.; Wu, Y.; Du, H.; Lv, M. A U-Shaped Convolution-Aided Transformer with Double Attention for Hyperspectral Image Classification. Remote Sens. 2024, 16, 288. https://doi.org/10.3390/rs16020288
Qin R, Wang C, Wu Y, Du H, Lv M. A U-Shaped Convolution-Aided Transformer with Double Attention for Hyperspectral Image Classification. Remote Sensing. 2024; 16(2):288. https://doi.org/10.3390/rs16020288
Chicago/Turabian StyleQin, Ruiru, Chuanzhi Wang, Yongmei Wu, Huafei Du, and Mingyun Lv. 2024. "A U-Shaped Convolution-Aided Transformer with Double Attention for Hyperspectral Image Classification" Remote Sensing 16, no. 2: 288. https://doi.org/10.3390/rs16020288
APA StyleQin, R., Wang, C., Wu, Y., Du, H., & Lv, M. (2024). A U-Shaped Convolution-Aided Transformer with Double Attention for Hyperspectral Image Classification. Remote Sensing, 16(2), 288. https://doi.org/10.3390/rs16020288