3.1. Forest Survey Data
The measured data of FSV used in this study are the second-class survey data of forest resources in Baishanzu Forest Park in 2016. According to the survey results, the forest area of Baishanzu Forest Park is 63,339.84 ha, the living forest stock volume is 5.58 million cubic meters, and the forest coverage rate is 89.45%. Mixed forest is the main forest type, including coniferous forest such as Cunninghamia lanceolata, Pinus massoniana, and Pinus taiwanensis, evergreen broad-leaved forest, coniferous and broad-leaved mixed forest, and bamboo forest. The main tree species and their planting area in the study area obtained from the survey data are shown in
Table 1.
In this study, a total of 7563 samples were extracted from the second-class survey data. Each sample point contains the main information of tree species, number of plants, tree age, average tree height, average DBH, plot area, and stand volume. After excluding some samples from non-forest areas, a total of 7306 samples were retained. In total, 80% of the data were randomly selected as the training dataset, 10% as the validation dataset, and 10% as the test dataset.
3.4. Characteristic Variable Extraction
Based on Landsat 8 remote sensing image, SRTM global digital elevation data, and survey data, this study extracted 81 characteristic variables in six categories: spectrum, vegetation index, texture, PCA, topography, and soil, which were used to estimate and model FSV in the study area.
3.4.1. Spectrum and Vegetation index Factor
Based on the Landsat 8 surface reflectance data obtained after radiometric calibration and atmospheric correction preprocessing, seven band reflectance (B1~B7) data, six commonly used vegetation indexes, and three Tasseled Cap Trasform (TCT) vegetation indexes were extracted.
Six of the vegetation indexes are: (1) Ratio vegetation index (RVI): RVI is highly correlated with the biomass and chlorophyll content of green plants, and can be used to estimate the biomass of leaf stems. When the vegetation coverage is high, RVI is very sensitive to vegetation. When the vegetation coverage is less than 50%, this sensitivity is significantly reduced; (2) Normalized vegetation index (NDVI): NDVI can enhance the difference between the radiation reflection of vegetation leaves in the near infrared band and the radiation absorption in the red band, and is positively correlated with the vegetation coverage, which can reflect the vegetation growth status and has a strong correlation with the stock amount; (3) Differential vegetation index (DVI): Also known as the agricultural vegetation index, it is sensitive to soil background changes, can better identify vegetation and water, and can effectively reflect the change in vegetation cover; (4) Enhanced vegetation index (EVI): EVI can reduce the influence of atmosphere and soil on vegetation reflectance at the same time, and can stably reflect the vegetation situation in the test area. The range of red and near-infrared bands is set narrower, which can improve the detection ability of sparse vegetation; (5) Perpendicular vegetation index (PVI): PVI represents the vertical distance between the vegetation pixel and soil brightness line in the two-dimensional coordinate system of the red band and near infrared band, which can effectively eliminate the influence of the soil background, but has low sensitivity to atmosphere; (6) Transformed vegetation index (TVI): Correct the error of NDVI in different terrain.
TCT transforms the original image projection into the three-dimensional feature space of three eigenvectors, Brightness, Greenness, and Wetness, by a fixed transformation matrix. It can reflect the information of vegetation cover, bare soil rock classification, and water content.
These vegetation indices and tasseled cap transformation characteristics are highly correlated with vegetation growth status and are widely used in forest growth assessment. The calculation method is shown in
Table 3 [
37]. The nine normalized vegetation index images obtained through band operation are shown in
Figure 2.
3.4.2. Principal Component Factor
Principal Component Analysis is a statistical method that filters out important variables by reducing the dimension of multiple variables after linear transformation. The transformed variables are called principal components. For remote sensing images, the single-band image of each band corresponds to an input variable of PCA. For multi-spectral data, principal component analysis is very useful for extracting effective information. In this paper, the principal component analysis tool of ENVI 5.3 software is used to screen the principal components through the characteristic contribution rate. The calculation formula is as follows:
Among them, is the contribution rate of the i th principal component eigenvalue, is the i th principal component eigenvalue, and n is the total number of eigenvalues.
The principal component feature window shown in
Figure 3 is obtained after the principal component analysis of the Landsat 8 image. It can be seen from the figure that the image feature information is mainly distributed in the first, second, and third components, and the noise of the principal component image after the fourth component is larger. Therefore, this study used the first, second, and third principal component components to construct the forest stock volume estimation model of Baishanzu Forest Park.
3.4.3. Texture Transform Factor
In this study, eight kinds of texture features, contrast, correlation, dissimilarity, entropy, homogeneity, mean, second moment, and variance, were extracted by the gray level co-occurrence matrix shown as follows:
where
p(
i,
j) is the value of column
j in row
i of the normalized gray level co-occurrence matrix, and
V(
i,
j) is the value of column
j in row
i of the moving window, and
n is the number of rows and columns of the gray co-occurrence matrix.
The size of the texture feature calculation window will also affect the extracted features. If the window setting is too small, the internal texture features will be misdivided. If the window setting when calculating texture features is too large, the boundary texture features will be misdivided. In this study, the size of the moving window is 3 × 3, and the step size is 1.
The above eight types of texture features were extracted from each band of the preprocessed Landsat 8 remote sensing image in ENVI 5.3 software, and finally 56 texture feature factors were obtained for FSV modeling analysis.
3.4.4. Topographic and Soil Factors
In this study, two topographic factors, altitude, slope, and aspect, were used to estimate the FSV in the study area. The elevation and slope data of the study area were derived from the obtained SRTM elevation data using ARCGIS 10.2 software, as shown in
Figure 4.
In addition to the parameters such as tree height, diameter at breast height, and stand volume that can directly reflect the amount of stock volume, there are many soil parameters in the survey data. Different types of soil and soil microbial content will affect the growth of vegetation, and the soil composition at the same position will not change for a long time. Some parameters can be extracted as characteristic factors for stock volume estimation. Based on this, this paper analyzes the survey data in Arcmap10.8, and extracts four soil parameters: soil texture, soil layer thickness, humus layer thickness, and soil category. Different soil textures and soil categories are distinguished by different digital codes to meet the input conditions of the network.
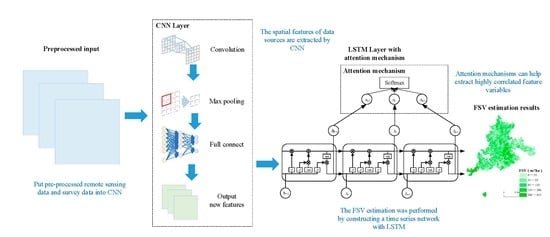
3.6. CNN-LSTM-Attention FSV Prediction Model
The FSV dataset based on multi-source remote sensing and survey data constructed in this study has the following characteristics: a large amount of spatial information and a time series based on survey time. The convolution kernel pooling operation unique to a convolutional neural network can extract the feature information of the data well, while LSTM has a strong memory and has a good effect on serialized data processing. Based on the advantages of the two neural network models, this study combines the two models to construct the FSV prediction model.
Using CNN to extract the potential features of FSV modeling variables can reduce the number of useless feature variables to compress the model training time and improve the prediction accuracy of FSV. The structure of the convolutional neural network is shown in
Figure 5, including a convolution layer, a pooling layer for dimensionality reduction, and a fully connected layer. Firstly, all the feature variables extracted by preprocessing are normalized to ensure that the data scale input into CNN is the same. Then, the first feature fusion and extraction of variables are performed in the convolution layer through a 3 × 3 convolution kernel. Then, the maximum pooling method is used to extract the data twice through the pooling layer to reduce the amount of data required for FSV prediction. At the same time, the ReLU activation function is used after the pooling layer to enhance the ability of model learning. Finally, the secondary feature fusion and extracted data are re-formed into a one-dimensional array. The array is used as the input of the fully connected layer and is connected to the neurons of the upper structure to realize the transformation of the data dimension, while retaining the useful information of the data. Finally, the output of the new FSV prediction features is completed.
The long short-term memory network (LSTM) has great advantages in processing time series data, and it also has an excellent performance in establishing strong sequential and multivariate regression models. Adding an attention mechanism to LSTM can make the output layer of the network have higher discrimination to the output of the hidden layer, increase the weight of the strong correlation output, and improve the prediction accuracy of FSV. Therefore, this study constructs a FSV prediction model based on LSTM-Attention.
LSTM has a chain structure, which stores the state of neurons through the gate structure. The chain structure is shown in
Figure 6. Each yellow box represents a neural network layer, which is composed of weight, bias, and the activation function; each green circle represents a pointwise operation; the arrows indicate the direction of the vector; the intersecting arrows represent the concatenation of vectors; and the bifurcated arrows represent the copy of the vector. LSTM has three inputs: cell state
Ct−1 (blue circle), hidden layer state of the last moment
ht−1 (purple circle), and
t time input vector
xt (blue circle), and the output has two: cell state at
t time
Ct and hidden layer state
ht. The information of the cell state
Ct−1 is always transmitted on the line above. The hidden layer state
ht at time
t and the input
xt will modify
Ct appropriately and then pass it to the next moment.
Ct−1 will participate in the calculation of the output
ht at time
t. The information of the hidden layer state
ht−1 modifies the cell state through the gate structure of LSTM and participates in the calculation of the output. In general, the information of the cell state has been transmitted on the upper line, and the hidden layer state has been transmitted on the lower line. They interact with each other through the gate structure. In the three-gate structures, the results of 0~1 are calculated by the activation function
σ to affect the proportion of the information access and abandonment of the previous neuron.
The gate structure increases the number of network iterations, and the error of the activation function can still be transmitted in reverse to avoid long-term dependence. At the same time, the output of the upper layer neurons is accepted by the three-gate structures of the forgetting gate, input gate, and output gate, and the effective information of the historical moment is selectively retained.
The forgetting gate calculation formula is as follows:
where
wf is the forgetting gate weight matrix and
bf is the forgetting gate bias.
The input gate calculation formula is as follows:
where
wg is the input gate weight matrix,
bg is the input gate bias,
is the input gate short-term state vector,
wp is the tanh layer weight matrix,
bp is the tanh layer bias, and
Pt is the updated neuron state.
The output gate calculation formula is as follows:
where
yt is the information to be output retained by the activation function
σ,
wy is the output gate weight matrix, and
by is the output gate bias.
For the FSV prediction model, the variables with a high correlation with FSV are found in many characteristic variables, and more weights are assigned to high correlation variables, which can improve the performance of model prediction. Therefore, the attention mechanism is introduced between the LSTM hidden layer and the output layer in this study.
Let the output data of the hidden layer be
hi, the weight value of the input data be
ai, and the final result calculated by the Attention mechanism be
h*. The attention mechanism calculation formula is as follows:
The correlation weight
ai of
hi and
h* is calculated by the vector dot product scoring function. The greater the correlation is, the greater the result value of the scoring function is. The calculation formula is as follows:
After that, the weight value
ai is calculated by the weighted average of the Softmax function, and the sum of the weight values of all
hi is 1. The calculation formula is as follows:
The structure between the hidden layer and the output layer of LSTM with an attention mechanism is shown in
Figure 7.
Where
x0,
x1,
x2,…,
xt denotes the input characteristics of FSV;
h0,
h1,
h2,…,
ht represents the output value of the LSTM hidden layer; and
a0,
a1,
a2…,
at represents the attention weight value of the attention mechanism to the output of the LSTM hidden layer. Calculate the weight
ai of the hidden layer output
hi to
h* at each time. Then the weighted average calculation is carried out to obtain
and pass it to the softmax layer. The full connection calculation is carried out to obtain the output value of the output layer, that is, the FSV prediction value. The calculation formula is as follows:
where
Wv is the weight matrix and
bv is the bias.
Finally, the model input of this study is the normalized data after Pearson correlation analysis and one-dimensional CNN preprocessing, which is input into the LSTM-Attention model [
38]. The attention mechanism is introduced into the hidden layer to obtain the weighted average weight coefficient of the hidden layer output, and then the weight coefficient is multiplied by the output of the LSTM hidden layer to sum, and the result is input into the output layer of the LSTM for a full connection calculation. Finally, the output result is inversely normalized to obtain the prediction result of FSV [
39]. The workflow of the entire model is shown in
Figure 8.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}