
Lightweight Design for Infrared Dim and Small Target Detection in Complex Environments



Abstract
:1. Introduction
- (1)
- Deep learning networks currently used for object detection perform well in general scenes where objects are dispersed and do not exhibit overlap or occlusion. However, for infrared small targets, which are excessively small and lack texture and structural features, the average detection accuracy is poor.
- (2)
- To obtain a larger receptive field, downsampling operations are often employed in neural networks; however, excessive downsampling operations are prone to causing information loss of small targets in deep-level features, thereby making it difficult for the detector to extract effective features.
- (3)
- As the number of layers and parameters in neural networks increases, deep learning detection algorithms generally suffer from issues of high computational complexity and large model sizes, posing challenges for deployment on resource-constrained mobile platforms.
- (1)
- A lightweight infrared target detection algorithm, YOLOv5-IR, specifically designed for detecting infrared dim and small targets, is proposed in this paper. By optimizing the network structure, the backbone network’s ability to recognize dim and small targets is enhanced, making it suitable for extracting features from infrared dim and small targets. This optimization effectively reduces the model parameters and computational cost.
- (2)
- A loss function and a detection head in the head layer are designed, altering the bounding box regression loss function to balance positive and negative samples. This improves the detection accuracy of bounding boxes and enhances the network focus on the infrared characteristics of targets.
- (3)
- A pruning architecture for the backbone network is designed, integrating pruning algorithms with network optimization. This improvement removes redundant channel weight parameters and further results in the lightweight version of the algorithm, named YOLOv5-IRL in this paper.
- (4)
- The detection performance of the proposed algorithm is validated on the dim-small aircraft dataset, featuring a diverse range of target quantities, poses, and complex scenes. Further comparisons with other advanced algorithms under varying signal-to-noise ratio conditions are conducted. Comparison experimental results demonstrate that the algorithm proposed in this paper achieves higher detection accuracy and faster detection speed on the dataset.
2. Related Works
2.1. Deep Learning Algorithms for Infrared Dim and Small Target Detection
2.2. Model Lightweighting Methods Based on Deep Learning Networks
3. The Proposed Lightweight Infrared Small Target Detection Algorithm
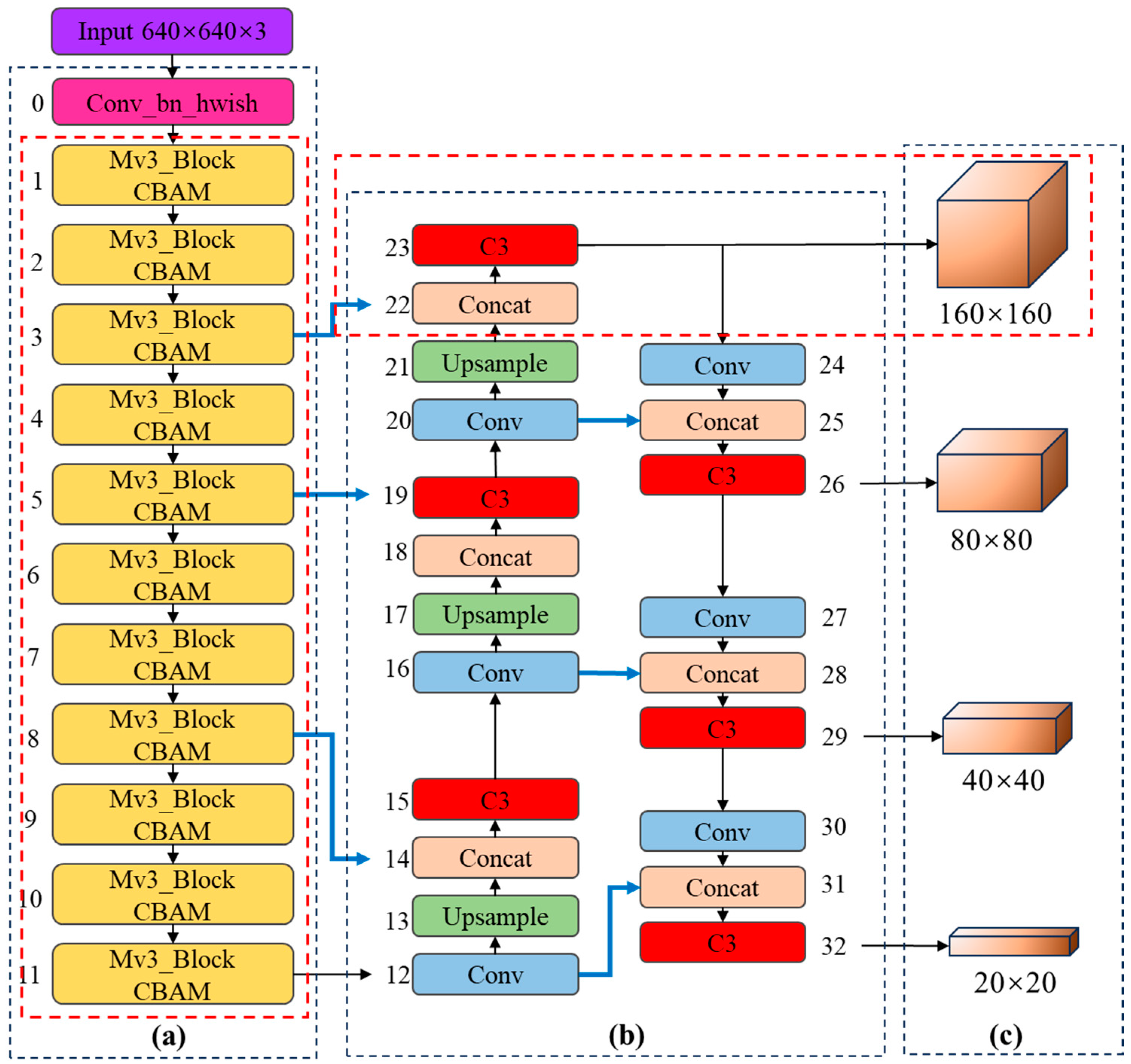
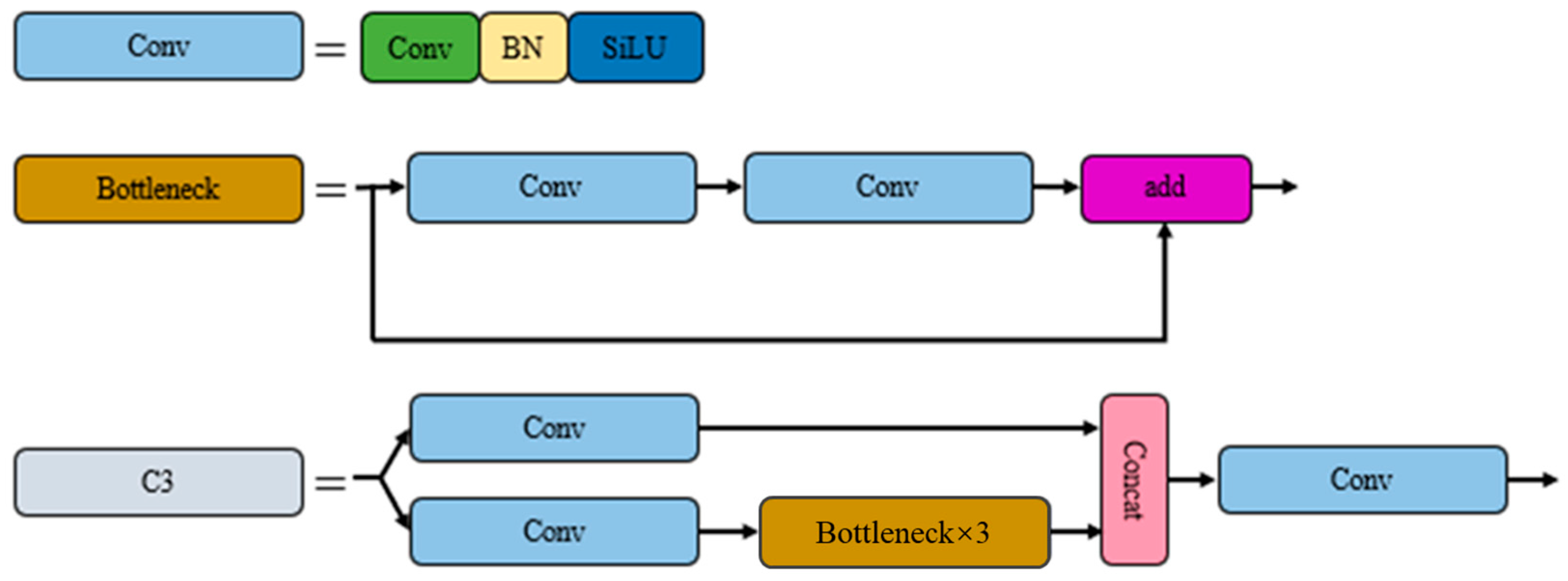
3.1. Network Architecture Design and Optimization
- (1)
- The proposed model incorporates an overall structure with one upsampling and one downsampling process in the feature fusion network. Specifically, three upsampling modules and three downsampling modules are designed.
- (2)
- As the network deepens and learns deeper-level features continuously, it is prone to losing shallow-level information. To retain the features from the backbone feature extraction network, the output values of the 3rd layer from the backbone are fused with the output values of the 22nd layer from the upsampling structure in the feature fusion network. Similarly, the 5th layer is fused with the 19th layer and the 8th layer is fused with the 14th layer. To prevent feature loss during upsampling and downsampling operations in the feature fusion network, the output values of the 20th layer from the upsampling structure are fused with the output values of the 25th layer from the downsampling process, the 16th layer is fused with the 28th layer, and the 12th layer is fused with the 31st layer. This approach aims to fuse shallow and deep features.
- (3)
- Aiming at the challenges posed by the dim and insensitive target representation characteristics of infrared small targets, an additional detection head suitable for small targets is introduced in this improvement. Four detection heads are connected to the 23rd, 26th, 29th, and 32nd layers of the feature fusion network, respectively. The sizes of their output feature maps are 20 × 20, 40 × 40, 80 × 80, and 160 × 160, respectively. A preset anchor box specifically designed for detecting small and dim targets is also added. The sizes of the anchor boxes, from large to small, are [(116, 90), (156, 198), (373, 326)], [(30, 61), (62, 45), (59, 119)], [(10, 13), (16, 30), (33, 23)], and [(5, 6), (8, 14), (15, 11)], respectively.
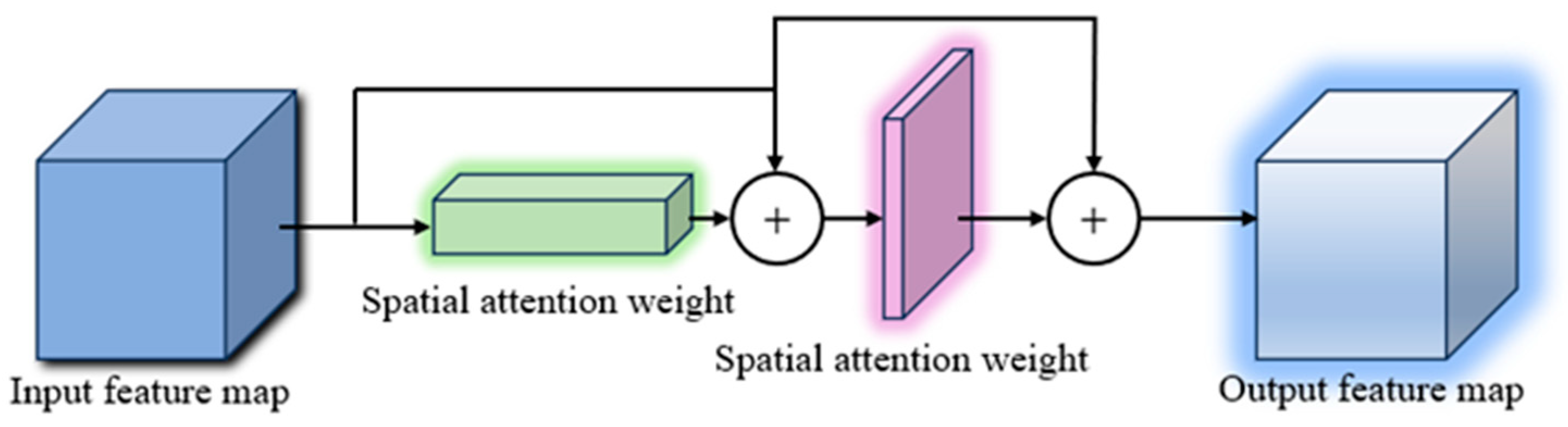
3.2. Design of a Detection Head Oriented towards Infrared Characteristics
3.3. Design of an Adaptive Weighting Loss Function
3.4. Lightweight Design of the Proposed YOLOv5-IR
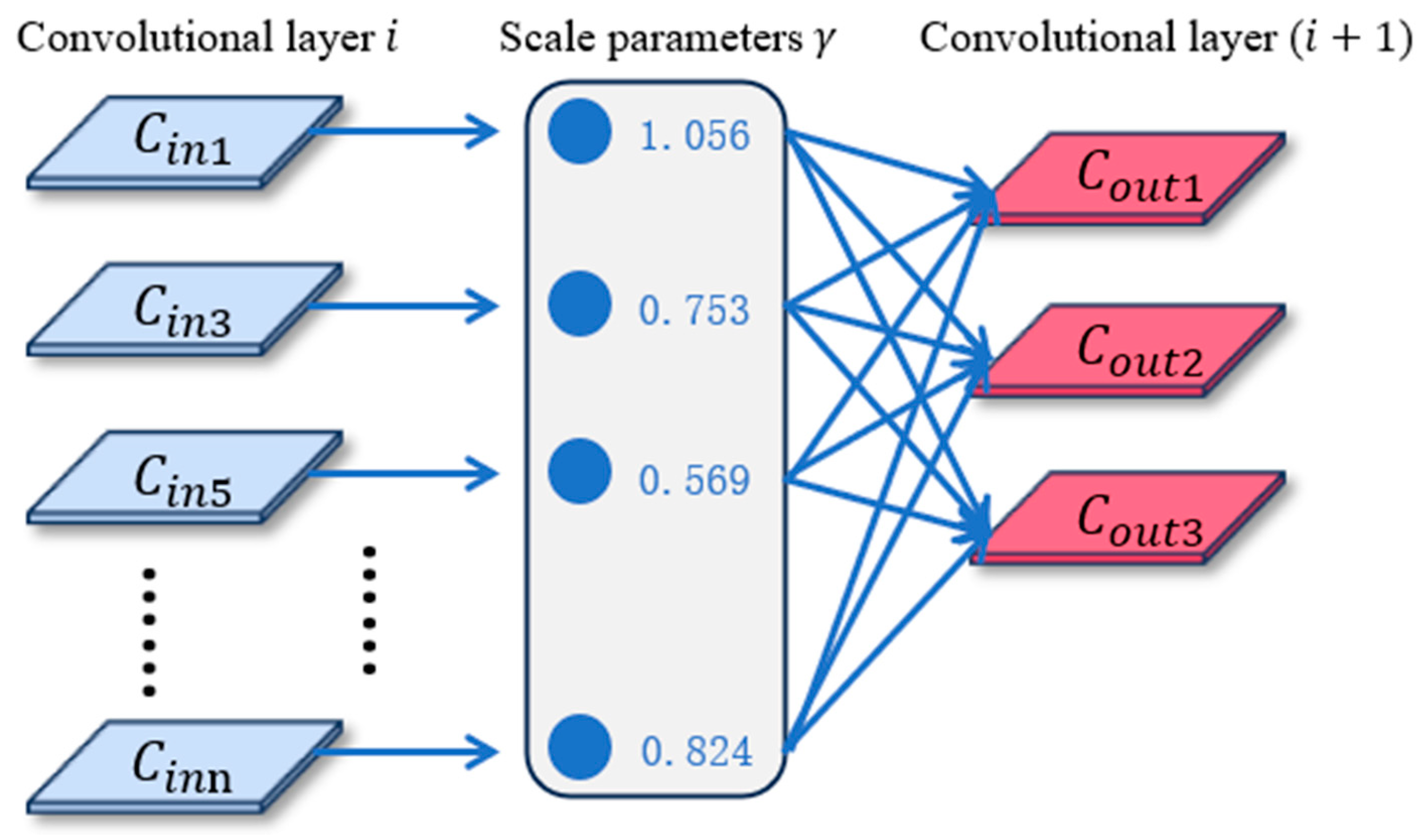
- (1)
- Analysis of BN Layer Algorithm
- (2)
- Sparse Training Method
- (3)
- Pruning and Fine-tuning
4. Experimental Verification
4.1. Dataset
4.2. Training Design
4.3. Evaluation Metrics
- (1)
- Model Parameters
- (2)
- Time taken to detect each image (ms/img)
- (3)
- Mean Average Precision (mAP)
4.4. Detection Results and Quality Evaluation
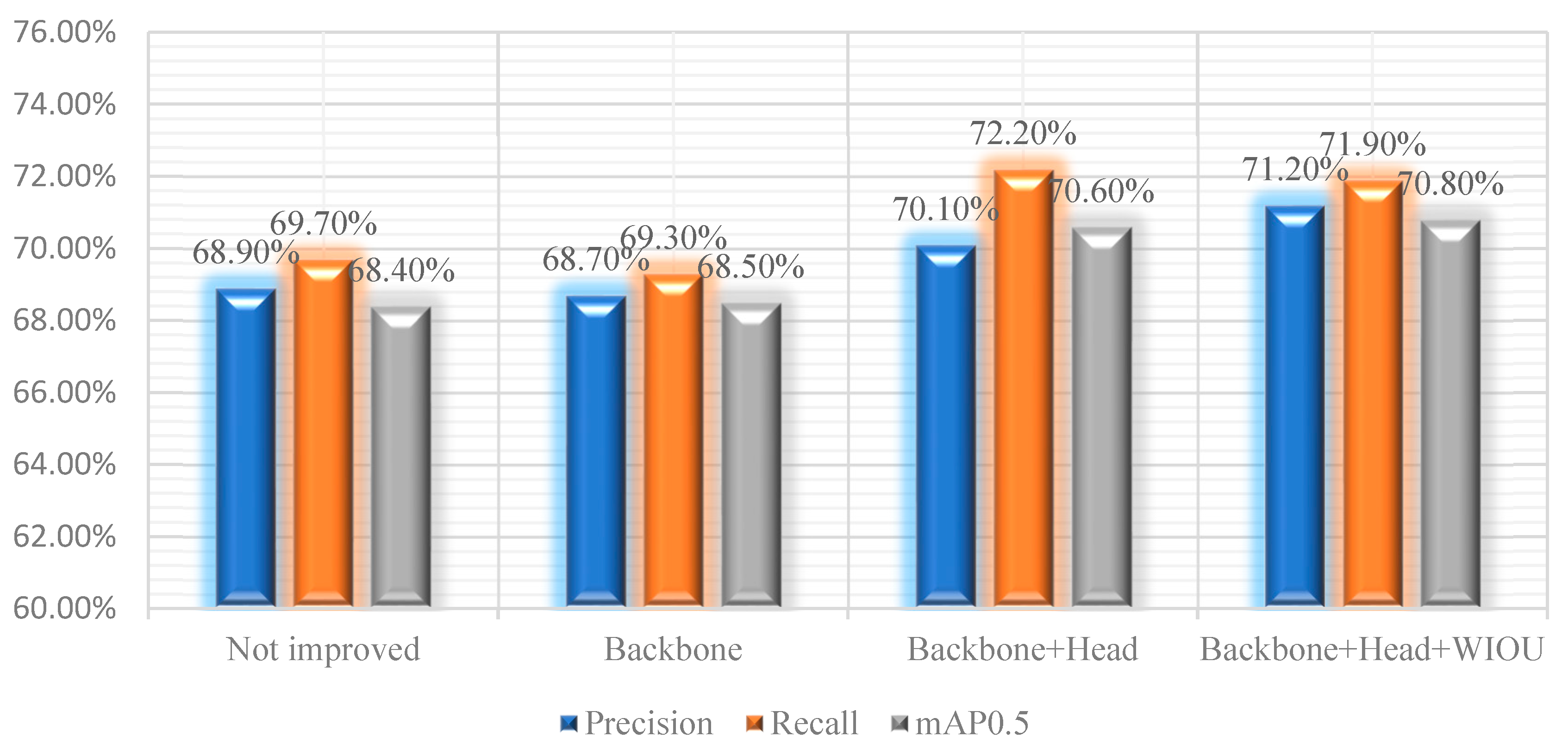
4.5. Ablation Experiment
5. Discussion
6. Conclusions
- (1)
- Network structure optimization: YOLOv5-IR outperforms the original YOLOv5s model in key evaluation metrics such as mean Average Precision (mAP), Precision, and Recall. This demonstrates that despite fewer parameters, the rational design of spatial attention and channel management mechanisms effectively extracts infrared target features. The addition of an enhanced head layer, sensitive to small targets, significantly enhances the focus on infrared small and dim targets. As a result, the proposed model effectively improves the detection of such targets in complex environments.
- (2)
- Loss function optimization: By introducing an adaptive weighting loss function, the model has intensified its focus on targets within low-quality samples, resulting in enhanced detection performance. This demonstrates the paramount importance of loss function design in improving the model adaptability and generalization capabilities in complex scenarios.
- (3)
- Lightweight design: Through the integration of lightweight modules and model pruning techniques, the proposed YOLOv5-IR and YOLOv5-IRL have faster detection speeds while maintaining high accuracy in detecting infrared small and dim targets. This supports the deployment and real-time application of the algorithms on mobile devices.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, W.; Cong, M.; Wang, L. Algorithms for optical weak small targets detection and tracking: Review. Int. Conf. Neural Netw. Signal Process. 2003, 1, 643–647. [Google Scholar]
- Zhang, R.; Zhang, J.; Qi, X.; Zuo, H.; Xu, Z. Infrared target detection and recognition in complex scene. Opto-Electron. Eng. 2020, 47, 2003–2014. [Google Scholar]
- Yang, Y.; Xu, C.; Ma, Y.; Huang, C. Review of research on infrared weak and small target detection algorithms under low signal-to-noise ratio. Laser Infrared 2019, 49, 643–649. [Google Scholar]
- Huang, N.; Li, Z. A new method of infrared small target recognition. In Proceedings of the 2021 7th International Symposium on Mechatronics and Industrial Informatics (ISMII), Zhuhai, China, 22–24 January 2021; pp. 206–210. [Google Scholar]
- Gu, Y.; Wang, C.; Liu, B.; Zhang, Y. A kernel-based nonparametric regression method for clutter removal in infrared small-target detection applications. IEEE Geosci. Remote Sens. Lett. 2010, 7, 469–473. [Google Scholar] [CrossRef]
- Wang, X.; Peng, Z.; Kong, D.; Zhang, P.; He, Y. Infrared dim target detection based on total variation regularization and principal component pursuit. Image Vis. Comput. 2017, 63, 1–9. [Google Scholar] [CrossRef]
- Dong, X.; Huang, X.; Zheng, Y.; Shen, L.; Bai, S. Infrared dim and small target detecting and tracking method inspired by human visual system. Infrared Phys. Technol. 2014, 62, 100–109. [Google Scholar] [CrossRef]
- Wang, X.; LÜ, G.F.; Xu, L. Infrared dim target detection based on visual attention. Infrared Phys. Technol. 2012, 55, 513–521. [Google Scholar] [CrossRef]
- Chen, C.; Li, H.; Wei, Y.; Xia, T.; Tang, Y. A local contrast method for small infrared target detection. IEEE Trans. Geosci. Remote Sens. 2013, 52, 574–581. [Google Scholar] [CrossRef]
- Zhang, K.; Yang, K.; Li, S.; Chen, H. A difference-based local contrast method for infrared small target detection under complex background. IEEE Access 2019, 7, 105503–105513. [Google Scholar] [CrossRef]
- Wei, Y.; You, X.; Li, H. Multiscale patch-based contrast measure for small infrared target detection. Pattern Recognit. 2016, 58, 216–226. [Google Scholar] [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A. Infrared patch-image model for small target detection in a single image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef] [PubMed]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image transformer. In Proceedings of the International Conference on Machine Learning, PM-LR 2018, Stockholm, Sweden, 10–15 July 2018; pp. 4055–4064. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Han, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2014, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision(ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Diwala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Mao, H. Yolov4: Optimal speed and accuracy of object detection. In Proceedings of the ArXiv Computer Vision and Pattern Recognition 2020, Cornell University, Ithaca, NY, USA, 15–17 March 2020; pp. 10923–10934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Liu, X.; Gong, W.; Shang, L.; Li, X.; Gong, Z. Remote Sensing Image Target Detection and Recognition Based on YOLOv5. Remote Sens. 2023, 15, 4459. [Google Scholar] [CrossRef]
- Wang, C.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Kim, J.H.; Hwang, Y. GAN-based synthetic data augmentation for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Gu, Y.; Zhang, H.; Sun, S. Infrared small target detection model with multiscale fractal attention. J. Electron. Inf. Technol. 2023, 45, 3002–3011. [Google Scholar]
- Li, J.; Liang, X.; Wei, Y.; Xu, T.; Feng, J.; Yan, S. Perceptual generative adversarial networks for small object detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Piscataway, NJ, USA, 18–24 June 2017; pp. 1222–1230. [Google Scholar]
- Liu, T.; Yang, D.; Song, J.; Fu, R.; He, J. Air-based down-ward-looking multi-angle infrared target recognition. Appl. Electron. Tech. 2022, 48, 131–139. [Google Scholar]
- Hou, Q.; Zhang, L.; Tan, F.; Xi, Y.; Zheng, H.; Li, N. ISTDU-Net: Infrared small-target detection U-Net. IEEE Geosci. Remote Sens. Lett. 2022, 3, 1–5. [Google Scholar] [CrossRef]
- Fan, X.; Ding, W.; Qin, W.; Xiao, D.; Min, L.; Yan, H. Fusing self-attention and coordconv to improve the YOLOv5s algorithm for infrared weak target detection. Sensors 2023, 23, 6755. [Google Scholar] [CrossRef]
- He, J.; Yang, D.; An, C.; Li, J.; Huang, C. Infrared dim target detection technology based on IRI-CNN. In Proceedings of the Seventh Asia Pacific Conference on Optics Manufacture and 2021 Inter-national Forum of Young Scientists on Advanced Optical Manufacturing (APCOM and YSAOM 2021), Shanghai, China, 28–31 October 2022; pp. 1350–1361. [Google Scholar]
- Mou, X.; Lei, S.; Zhou, X. YOLO-FR: A YOLOv5 infrared small target detection algorithm based on feature reassembly sampling method. Sensors 2023, 23, 2710. [Google Scholar] [CrossRef] [PubMed]
- Yang, R.; Li, W.; Shang, X.; Zhu, D.; Man, X. KPE-YOLOv5:an improved small target detection algorithm based on YOLOv5. Electronics 2023, 12, 817. [Google Scholar] [CrossRef]
- Iandola, F.; Han, S.; Moskewicz, M.; Ashraf, K.; Dally, K.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. Mobilenetv2: Inverted residuals and linear bottlenecks. Proc. IEEE Conf. Comput. Vis. Pattern Recognit. 2018, 3, 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2019, Seoul, South Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Gosaye, K.; Moloo, R. A Mobile Application for Fruit Fly Identification Using Deep Transfer Learning: A Case Study for Mauritius. In Proceedings of the 2022 International Conference for Advancement in Technology, Goa, India, 21–23 January 2022; pp. 1–5. [Google Scholar]
- Murthy, C.; Hashmi, M.; Keskar, A. Optimized MobileNet+ SSD: A real-time pedestrian detection on a low-end edge device. Int. J. Multimed. Inf. Retr 2021, 10, 171–184. [Google Scholar] [CrossRef]
- Vadera, S.; Ameen, S. Methods for Pruning Deep Neural Networks. IEEE Access 2022, 10, 63280–63300. [Google Scholar] [CrossRef]
- Peng, B.; Tan, W.; Li, Z.; Zhang, S.; Xie, D.; Pu, S. Extreme network compression via filter group approximation. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018; pp. 300–316. [Google Scholar]
- Gou, J.; Yu, B.; Maybank, S.; Tao, D. Knowledge Distillation: A Survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Liu, L.; Ke, C.; Lin, H.; Xu, H. Research on pedestrian detection algorithm based on MobileNet-YoLo. Comput. Intell. Neurosci. 2022, 5, 1–12. [Google Scholar] [CrossRef]
- Sha, M.; Zeng, K.; Tao, Z.; Wang, Z.; Liu, Q. Lightweight pedestrian detection based on feature multiplexed residual network. Electronics 2023, 12, 918. [Google Scholar] [CrossRef]
- Li, C.; Wang, Y.; Liu, X. A multi-pedestrian tracking algorithm for dense scenes based on an attention mechanism association. Appl. Sci. 2022, 12, 9597. [Google Scholar] [CrossRef]
- Zou, F.; Li, X.; Xu, Q.; Sun, Z.; Zhu, J. Correlation-and-correction fusion attention network for occluded pedestrian detection. IEEE Sens. J. 2023, 23, 6061–6073. [Google Scholar] [CrossRef]
- Li, M.; Sun, G.; Yu, J. A pedestrian detection network model based on improved YOLOv5. Entropy 2023, 25, 381. [Google Scholar] [CrossRef] [PubMed]
- Hao, S.; Gao, S.; Ma, X.; An, B.; He, T. Anchor-free infrared pedestrian detection based on cross-scale feature fusion and hierarchical attention mechanism. Infrared Phys. Technol. 2023, 131, 104660. [Google Scholar] [CrossRef]
- Hui, B.; Song, Z.; Fan, H.; Zong, P.; Hu, W.; Zhang, X.; Lin, J.; Su, H.; Jin, W.; Zhang, Y. Weak and small aircraft target detection and tracking data set in infrared images under ground/air background. Chin. Sci. Data: Chin. Engl. Online Ed. 2020, 5, 12. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicator Items | Parameter |
|---|---|
| Fuselage length | 2.0 m |
| Wingspan length | 2.6 m |
| Flight speed | Airspeed: 30 km/h |
| Turning radius | 130 m |
| Near and far ends of the flight route | Near end: 500 m, Far end: 5000 m |
| Flight altitude | Near end: 50 m, Far end: 500 m |
| Data Segments | Number of Images | Number of Targets | Training Set | Validation Set | Test Set | Background | State |
|---|---|---|---|---|---|---|---|
| Data1 | 399 | 399 | 240 | 120 | 39 | Noise sky | The target moves in close proximity |
| Data2 | 599 | 1198 | 360 | 180 | 59 | Noise sky | The two targets gradually intersect |
| Data3 | 100 | 100 | 60 | 30 | 10 | The mountain peaks meet the sky | The target moves over long distances |
| Data7 | 399 | 399 | 240 | 120 | 39 | Complex ground | The target is from near to far |
| Data16 | 499 | 499 | 300 | 150 | 49 | Complex ground | The target is from far to near |
| Data20 | 400 | 400 | 240 | 120 | 40 | The mountain peaks meet the sky | The target is from near to far |
| Model | Precision | Recall | mAP0.5 | Parameters/M | ms/img |
|---|---|---|---|---|---|
| YOLOv3 [22] | 0.647 | 0.641 | 0.634 | 61.53 | 10.5 |
| YOLOv5m [35] | 0.702 | 0.709 | 0.699 | 20.95 | 7.6 |
| YOLOv5s [32] | 0.689 | 0.697 | 0.684 | 7.04 | 5.9 |
| SSD(VGG) [19] | 0.652 | 0.645 | 0.657 | 90.6 | 15.5 |
| Xception-SSD [42] | 0.675 | 0.672 | 0.663 | 56.8 | 14.92 |
| MoblieNet-SSD [43] | 0.679 | 0.683 | 0.674 | 43.6 | 11.76 |
| YOLOv7 [26] | 0.658 | 0.664 | 0.652 | 71.3 | 16.8 |
| YOLOv5-IR | 0.712 | 0.719 | 0.708 | 4.02 | 5.1 |
| YOLOv5-IRL | 0.698 | 0.705 | 0.702 | 3.83 | 4.9 |
| Groups | Backbone | Head | WIOU | Precision | Recall | mAP0.5 |
|---|---|---|---|---|---|---|
| 1 | 68.9% | 69.7% | 68.4% | |||
| 2 | √ | 68.7% | 69.3% | 68.5% | ||
| 3 | √ | √ | 70.1% | 72.2% | 70.6% | |
| 4 | √ | √ | √ | 71.2% | 71.9% | 70.8% |
| Model | Pruning Rate | Original Network mAP0.5 | After Fine-Tuning mAP0.5 | Parameters/M | ms |
|---|---|---|---|---|---|
| YOLOv5-IR | 0 | 70.8% | - | 4.02 | 5.1 |
| 0.2 | 68.9% | 70.2% | 3.83 | 4.9 | |
| 0.3 | 67.8% | 68.3% | 3.56 | 4.6 | |
| 0.4 | 64.7% | 65.1% | 3.25 | 4.3 | |
| 0.5 | 59.9% | 61.5% | 3.09 | 3.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, Y.; Ma, D.; Ding, Y.; Chen, K.; Zhou, D. Lightweight Design for Infrared Dim and Small Target Detection in Complex Environments. Remote Sens. 2024, 16, 3761. https://doi.org/10.3390/rs16203761
Chang Y, Ma D, Ding Y, Chen K, Zhou D. Lightweight Design for Infrared Dim and Small Target Detection in Complex Environments. Remote Sensing. 2024; 16(20):3761. https://doi.org/10.3390/rs16203761
Chicago/Turabian StyleChang, Yan, Decao Ma, Yao Ding, Kefu Chen, and Daming Zhou. 2024. "Lightweight Design for Infrared Dim and Small Target Detection in Complex Environments" Remote Sensing 16, no. 20: 3761. https://doi.org/10.3390/rs16203761