
FireNet: A Lightweight and Efficient Multi-Scenario Fire Object Detector



Abstract
:1. Introduction
- In complex environments, shape and color are significant features, which are also the most important factors in feature fusion in traditional detection methods [28]. For example, in the perspective of drone-collected images, the features of smoke and clouds have a high degree of similarity.
- Flames and smoke, due to their strong shape variability, have irregular shapes, leading to the loss of edges in detection. The edges of smoke from a drone’s perspective can easily blend with the air, resulting in incomplete recognition without global correlation.
- In this paper’s pursuit of high accuracy, the network depth increases, which may lead to reduced detection speed.
- In existing samples, there is an imbalance of positive and negative samples. Since the ratio of flame and smoke pixels in the whole sample image is too small compared to the background, the background (negative samples) usually far exceeds the foreground targets (positive samples). This causes the model to be overly sensitive to frequently occurring categories, concentrating too much attention on the background.
- Traditional ViT structures can globally access information, helping the model to capture long-range dependencies of fire targets and edges of smoke. However, they usually have a large number of parameters. We created a lightweight feature extraction backbone, which independently completes the feature extraction work in the backbone through Revisiting Mobile CNN From ViT Perspective (RepViT), showing superior performance and lower latency compared to lightweight CNNs. This improvement is generally attributed to the multi-head self-attention module, which enables the model to learn global representations.
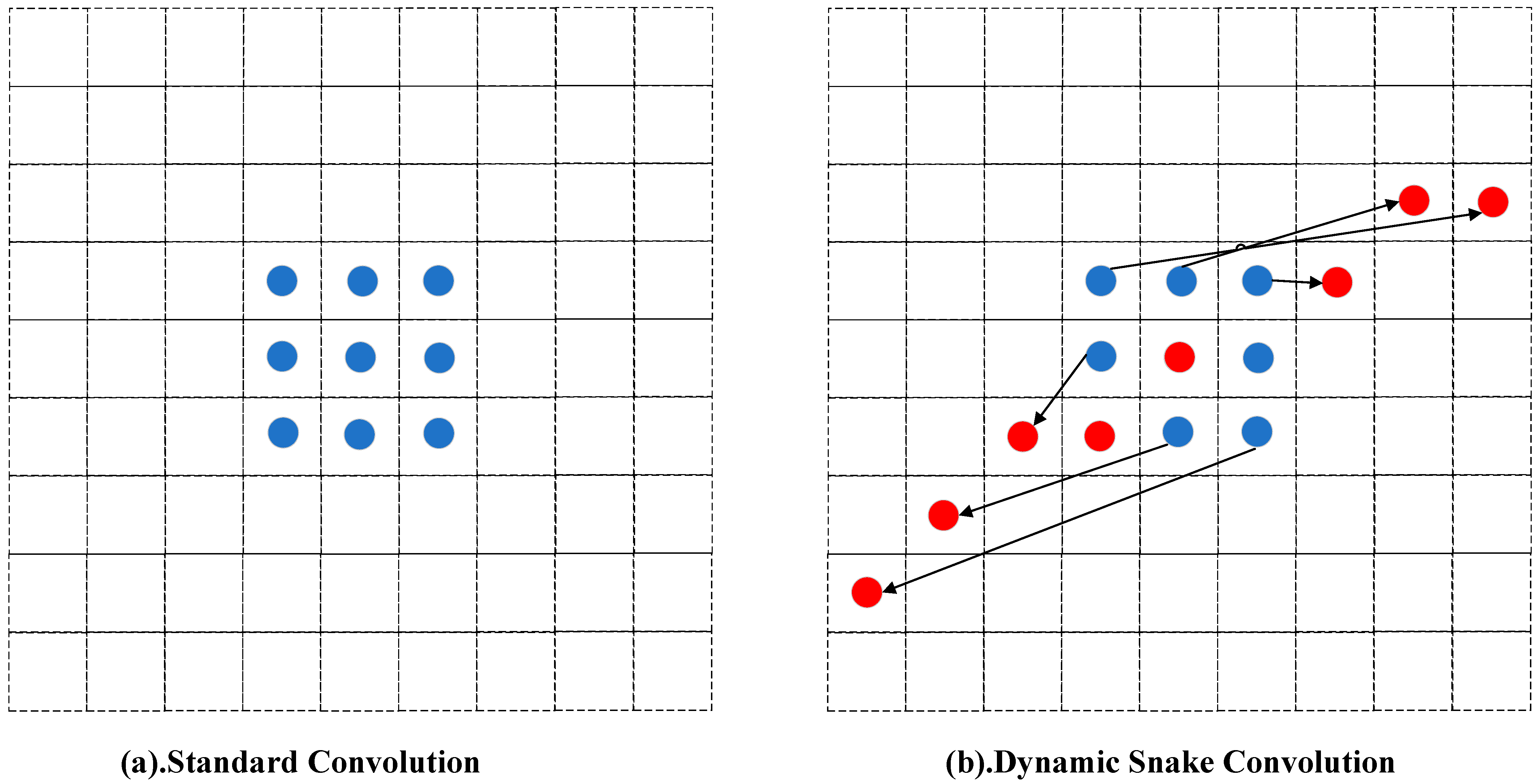
- In response to the irregular boundary features of flames and smoke and their variable contours, Tao et al. [29] addressed the fragile and variable boundaries of smoke by breaking the fixed geometric structure of standard convolutions, considering both representative features and local weak features for feature complementarity. However, the proposed variable convolution allows the network to freely learn geometric variations, leading to perceptual region drift, especially on some thinner smoke structures. We have designed a dynamic snake-like convolutional structure for the neck of the network, considering the features of partial fine structures and supplementing the free learning process with constraints, specifically enhancing the perception of fine structures based on the existing variable convolution.
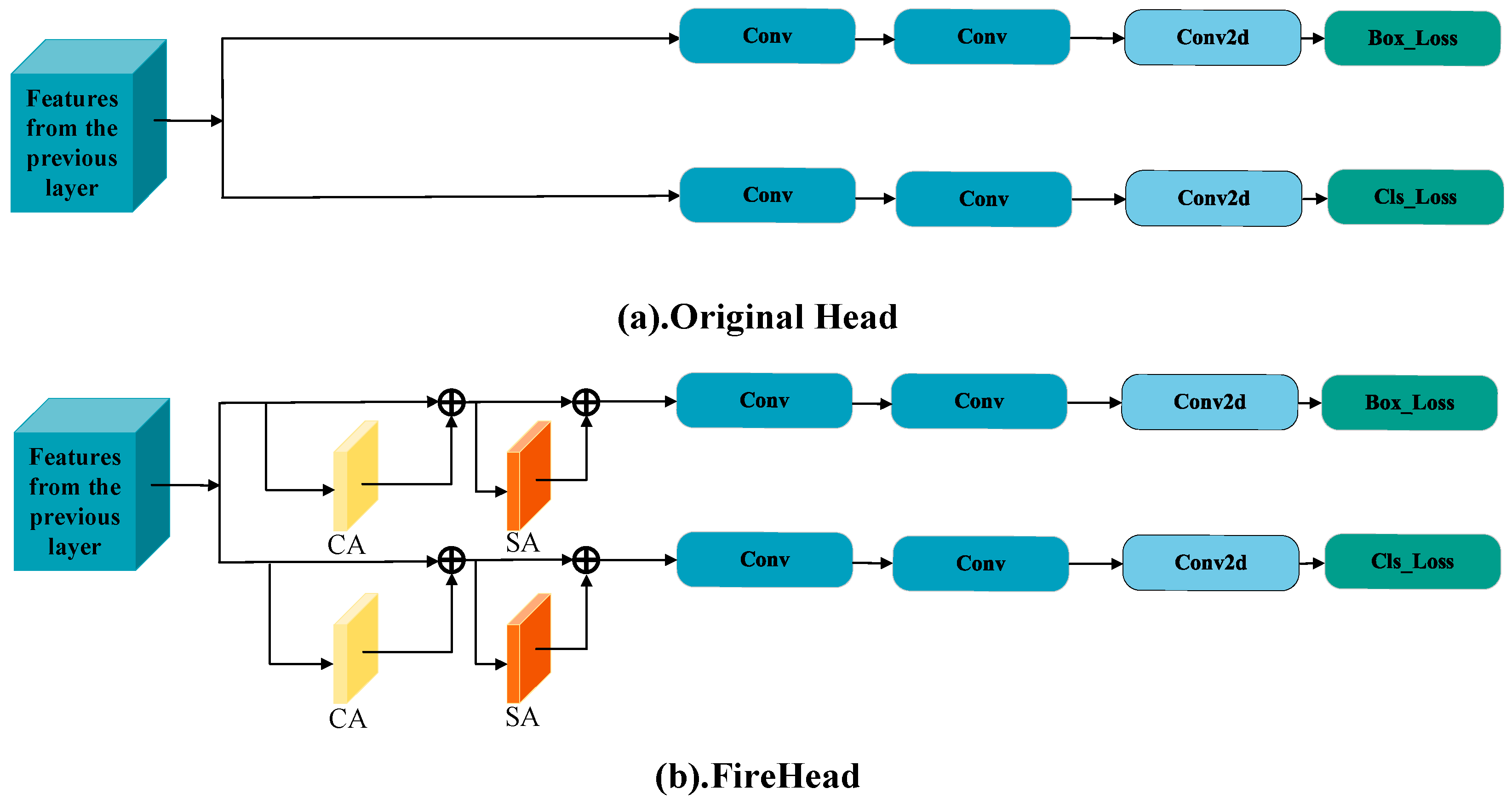
- To address challenges such as the high similarity of small targets under and background noise interference, we designed a lightweight detection head by integrating channel and spatial attention mechanisms. It adaptively selects the most representative image features and concentrates them, thereby improving the network’s classification accuracy. At the same time, a multi-scale feature extraction strategy effectively extracts features of different scales and levels, helping the detector achieve stronger positioning and classification performance while avoiding an increase in model computational complexity.
- This paper collected flame and smoke images from multiple scenarios to construct the Fire and Smoke (FAS) dataset. In addition to common fire-prone scenarios, the dataset also includes non-fire scenes, such as burning cigarettes and open fires during picnics. Notably, this paper incorporated a large number of drone-collected images into the dataset to test small target fire scenes. Furthermore, this paper compared FireNet with state-of-the-art (SOTA) algorithms on the FAS dataset and additionally conducted comparisons on the public fire smoke dataset. The results demonstrate that the proposed model performs exceptionally well in multi-scenario fire detection. (We will upload this paper’s source code1) 1 [Online]. Available: https://github.com/DC9874/FireNet, accessed on 22 October 2024.
2. Related Work
2.1. Dataset
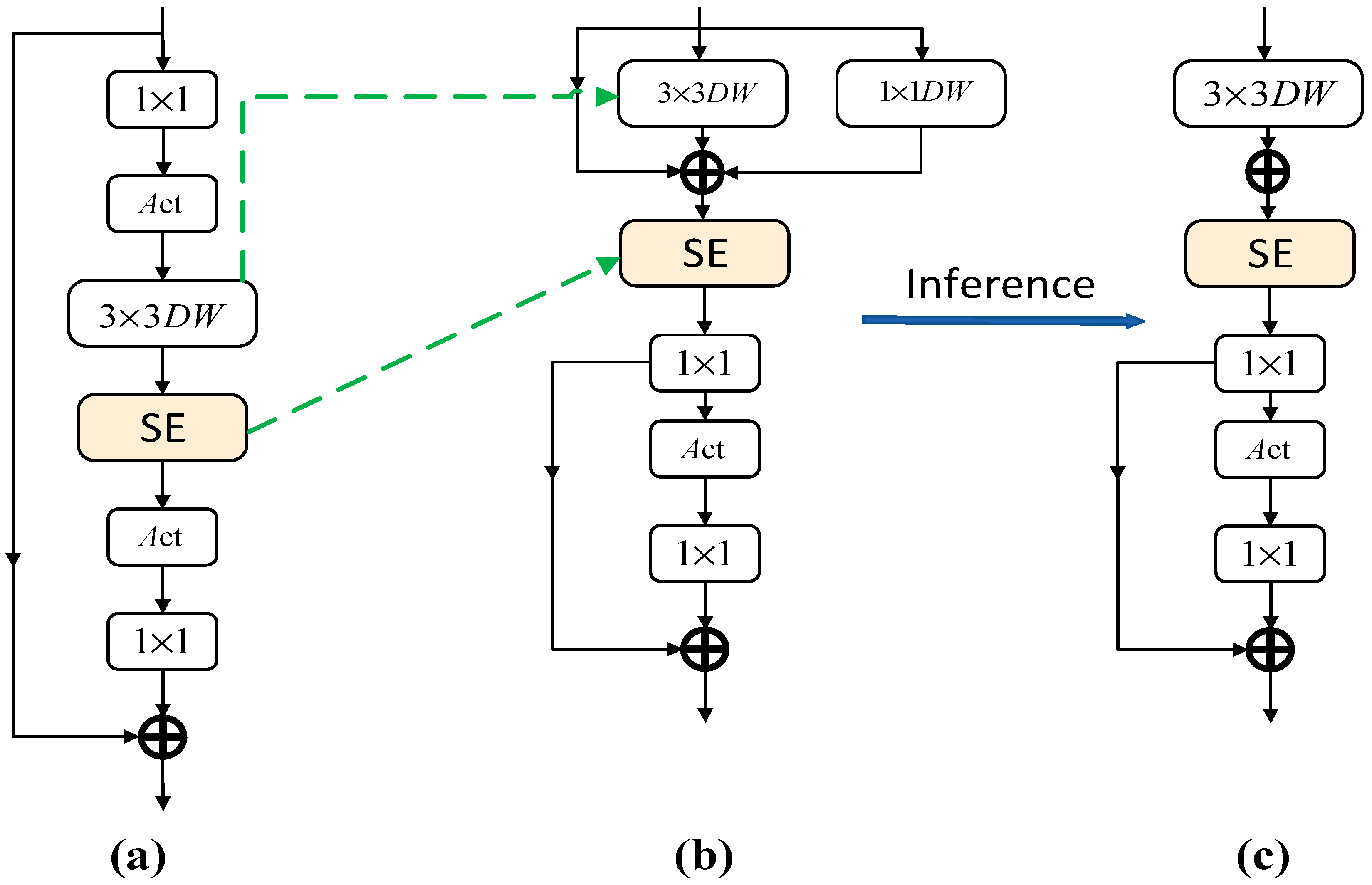
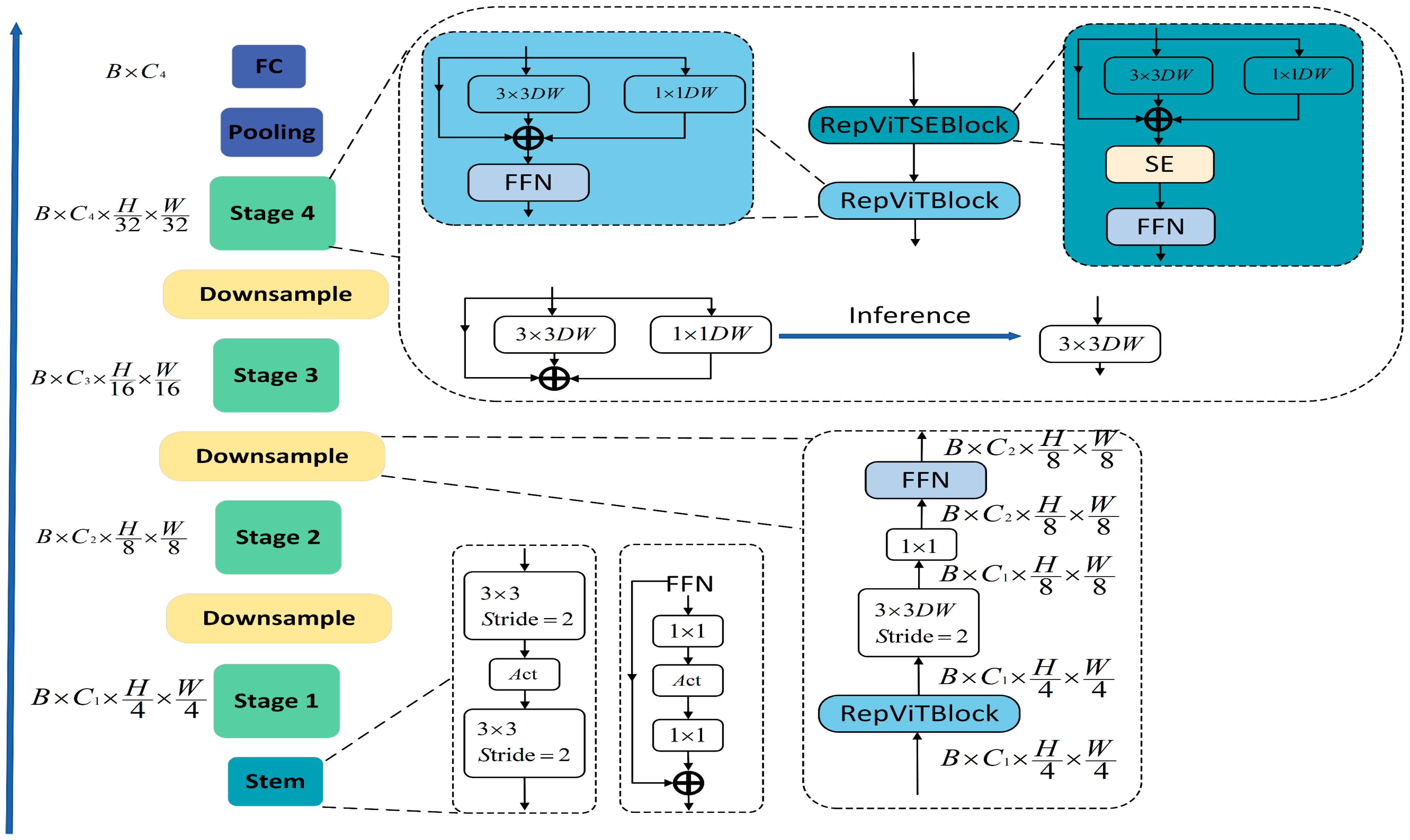
2.2. Reparameterization Vision Transformer Block (RepViTBlock)
- ViTs segment the input image into non-overlapping small patches, which is equivalent to using non-overlapping convolution operations with large kernel sizes and large strides. However, research in [34] has found that this approach might cause ViTs to fall short in terms of optimization performance and sensitivity to training strategies. The study suggests using a small number of stacked convolution layers with a stride of 2 as the stem, a method known as “early convolutions”. This approach has also been widely used in lightweight models subsequently.
- In traditional ViTs, spatial downsampling is typically achieved through a separate merging layer (patch merging layer) using convolutions with a kernel size of 4 and a stride of 2. This design, while mitigating information loss due to reduced resolution, also increases network depth. We, on the other hand, form a feedforward network (FFN) by connecting the input and output of two 1 × 1 convolutions through residual connections. We also added the RepViTBlock module to further deepen the downsampling layers, mitigating information loss in the spatial dimension, not only improving the model’s accuracy but also maintaining lower latency, adapting to this paper’s proposed resource-limited drone detection system.
- We employed a global average pooling layer and a linear layer as the classifier. By using a simple classifier and adjusting the stage ratio and depth of the network, we can effectively balance the performance and latency of lightweight ViTs, making them more suitable for applications on mobile devices while also enhancing the model’s accuracy.
- Overall stage ratio, we found that different numbers of blocks in the four stages of the model have varying impacts on the model’s performance. Hou and others [35] indicate that more aggressive stage ratios and deeper layouts perform better for smaller models. The Conv2Former’s Conv2Former-T and Conv2Former-S adopted series ratios of 1:1:4:1 and 1:1:8:1, respectively. Whereas [35] shows that using an optimized stage ratio of 1:1:7:1 for the network achieves a deeper layout. We have illustrated the framework of RepViT’s four structural components in Figure 4.
2.3. Introduction to the Neck Module of Dynamic Snake Convolution (DSConv)
2.4. Decoupled Detection Head with Attention
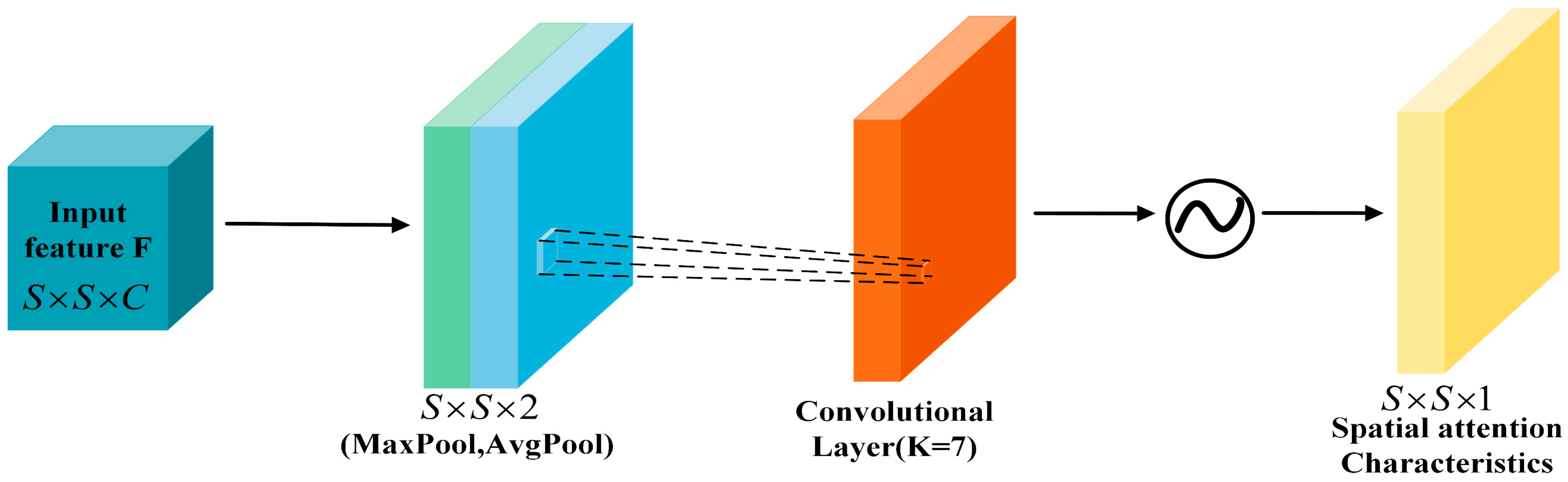
2.4.1. CBAM Attention Mechanism
2.4.2. Firehead
3. Experiments and Results
3.1. Experimental Configuration
3.2. Evaluation Criteria
3.3. Performance Evaluation and Study of FireNet Modelt
3.3.1. Global Experiment
3.3.2. ViT Structure Experiment (Backbone)
3.3.3. Neck ‘Number and Position’ Study
3.3.4. Experiment with Decoupled Detection Heads Carrying Attention Mechanisms
3.4. Comparison Experiments and Visualization
4. Discussion
- More lightweight
- Module position study
5. Conclusions
6. Impact Statement
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jain, A.; Srivastava, A. Privacy-Preserving Efficient Fire Detection System for Indoor Surveillance. IEEE Trans. Ind. Inform. 2022, 18, 3043–3054. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, R.; Li, Y.; Pan, F. Passenger Evacuation Path Planning in Subway Station Under Multiple Fires Based on Multiobjective Robust Optimization. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21915–21931. [Google Scholar] [CrossRef]
- John, J.; Harikumar, K.; Senthilnath, J.; Sundaram, S. An Efficient Approach with Dynamic Multiswarm of UAVs for Forest Firefighting. IEEE Trans. Syst. Man Cybern. Syst. 2024, 54, 2860–2871. [Google Scholar] [CrossRef]
- Çelik, T.; Özkaramanlı, H.; Demirel, H. Fire and smoke detection without sensors: Image processing based approach. In Proceedings of the 2007 15th European Signal Processing Conference, Poznan, Poland, 3–7 September 2007; pp. 1794–1798. [Google Scholar]
- Almeida, J.S.; Huang, C.; Nogueira, F.G.; Bhatia, S.; de Albuquerque, V.H.C. EdgeFireSmoke: A Novel Lightweight CNN Model for Real-Time Video Fire–Smoke Detection. IEEE Trans. Ind. Inform. 2022, 18, 7889–7898. [Google Scholar] [CrossRef]
- Xie, J.; Zhao, H. Forest Fire Ob-ject Detection Analysis Based on Knowledge Distillation. Fire 2023, 6, 446. [Google Scholar] [CrossRef]
- Wang, Z.; Gao, Q.; Xu, J.; Li, D. A Review of UAV Power Line Inspection. Advances in Guidance. Navig. Control. Lect. Notes Electr. Eng. 2022, 644, 3147–3159. [Google Scholar]
- Chiu, Y.-Y.; Omura, H.; Chen, H.-E.; Chen, S.C. Indicators for post-disaster search and rescue efficiency developed using progressive deathtolls. Sustainability 2020, 12, 8262. [Google Scholar] [CrossRef]
- Ye, T.; Qin, W.; Li, Y.; Wang, S.; Zhang, J.; Zhao, Z. Dense and small object detection in UA V-vision based on a global-local feature enhanced network. IEEE Trans. Instrum. Meas. 2022, 71, 1–13. [Google Scholar]
- Jayathunga, S.; Pearse, G.D.; Watt, M.S. Unsupervised Methodology for Large-Scale Tree Seedling Mapping in Di-verse Forestry Settings Using UAV-Based RGB Imagery. Remote Sens. 2023, 15, 5276. [Google Scholar] [CrossRef]
- Dong, Y.; Xie, X.; An, Z.; Qu, Z.; Miao, L.; Zhou, Z. NMS Free Oriented Object Detection Based on Channel Expansion and Dynamic Label Assignment in UAV Aerial Images. Remote Sens. 2023, 15, 5079. [Google Scholar] [CrossRef]
- Chen, X.; An, Q.; Yu, K.; Ban, Y. A Novel Fire Identification Algorithm Based on Improved Color Segmentation and Enhanced Feature Data. IEEE Trans. Instrum. Meas. 2021, 70, 1–15. [Google Scholar] [CrossRef]
- Qiu, T.; Yan, Y.; Lu, G. An Autoadaptive Edge-Detection Algorithm for Flame and Fire Image Processing. IEEE Trans. Instrum. Meas. 2012, 61, 1486–1493. [Google Scholar] [CrossRef]
- Xie, Y.; Zhu, J.; Cao, Y.; Zhang, Y.; Feng, D.; Zhang, Y.; Chen, M. Efficient Video Fire Detection Exploiting Motion-Flicker-Based Dynamic Features and Deep Static Features. IEEE Access 2020, 8, 81904–81917. [Google Scholar] [CrossRef]
- Xi, D.; Qin, Y.; Luo, J.; Pu, H.; Wang, Z. Multipath Fusion Mask R-CNN with Double Attention and Its Application Into Gear Pitting Detection. IEEE Trans. Instrum. Meas. 2021, 70, 1–11. [Google Scholar] [CrossRef]
- Fang, F.; Li, L.; Zhu, H.; Lim, J.-H. Combining Faster R-CNN and Model-Driven Clustering for Elongated Object Detection. IEEE Trans. Image Process. 2020, 29, 2052–2065. [Google Scholar] [CrossRef]
- Hnewa, M.; Radha, H. Integrated Multiscale Domain Adaptive YOLO. IEEE Trans. Image Process. 2023, 32, 1857–1867. [Google Scholar] [CrossRef]
- Zhang, H.; Tian, Y.; Wang, K.; Zhang, W.; Wang, F.-Y. Mask SSD: An Effective Single-Stage Approach to Object Instance Segmentation. IEEE Trans. Image Process. 2020, 29, 2078–2093. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Baik, S.W. Early fire detection using convolutional neural networks during surveillance for effective disaster management. Neurocomputing 2018, 288, 30–42. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Dimitropoulos, K.; Kaza, K.; Grammalidis, N. Fire Detection from Images Using Faster R-CNN and Multidimensional Texture Analysis. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8301–8305. [Google Scholar]
- Wu, Z.; Xue, R.; Li, H. Real-Time Video Fire Detection via Modified YOLOv5 Network Model. Fire Technol. 2022, 58, 2377–2403. [Google Scholar] [CrossRef]
- Li, J.; Zhou, G.; Chen, A.; Lu, C.; Li, L. BCMNet: Cross-Layer Extraction Structure and Multiscale Downsampling Network with Bidirectional Transpose FPN for Fast Detection of Wildfire Smoke. IEEE Syst. J. 2023, 17, 1235–1246. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Sun, Z.; Cao, S.; Yang, Y.; Kitani, K.M. Rethinking transformer-based set prediction for object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3611–3620. [Google Scholar]
- Dai, Y.; Liu, W.; Wang, H.; Xie, W.; Long, K. YOLO-Former: Marrying YOLO and Transformer for Foreign Object Detection. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Li, W.; Zhang, L.; Wu, C.; Cui, Z.; Niu, C. A new lightweight deep neural network for surface scratch detection. Int. J. Adv. Manuf. Technol. 2022, 123, 1999–2015. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; He, Z.; Guan, Y.; Zhang, H. Real-Time Forest Fire Detection by Ensemble Lightweight YOLOX-L and Defogging Method. Sensors 2023, 23, 1894. [Google Scholar] [CrossRef]
- Liu, L.; Song, X.; Lyu, X. FCFR-Net: Feature fusion based coarse-to-fine residual learning for depth completion. arXiv 2020, arXiv:2012.08270. [Google Scholar] [CrossRef]
- Tao, H. A label-relevance multi-direction interaction network with enhanced deformable convolution for forest smoke recognition. Expert. Syst. Appl. 2024, 236, 121383. [Google Scholar] [CrossRef]
- Jocher, G.; Stoken, A.; Borovec, J.; Changyu, L.; Hogan, A.; Diaconu, L.; Rai, P. Ultralytics/YOLOv5: Initial Release; Zenodo: 2020. Available online: https://zenodo.org/record/3983579 (accessed on 22 October 2024).
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Adam, H. Efficient convolutional neural networks for mobile vision applications. arXiv 2020, arXiv:1704.04861. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Xiao, T.; Singh, M.; Mintun, E.; Darrell, T.; Dollár, P.; Girshick, R. Early convolutions help transformers see better. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; pp. 30392–30400. [Google Scholar]
- Qi, Y.; He, Y.; Qi, X.; Zhang, Y.; Yang, G. Dynamic Snake Convolution based on Topological Geometric Constraints for Tubular Structure Segmentation. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 6047–6056. [Google Scholar]
- Dai, J. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Karen, S.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Dang, C.; Wang, Z.X. RCYOLO: An Efficient Small Target Detector for Crack Detection in Tubular Topological Road Structures Based on Unmanned Aerial Vehicles. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 12731–12744. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Yazdi, A.; Qin, H.; Jordan, C.B.; Yang, L.; Yan, F. Nemo: An Open-Source Transformer-Supercharged Benchmark for Fine-Grained Wildfire Smoke Detection. Remote Sens. 2022, 14, 3979. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, M.; Chang, Q. Real-Time Helmetless Detection System for Lift Truck Operators Based on Improved YOLOv5s. IEEE Access 2024, 12, 4354–4369. [Google Scholar] [CrossRef]
- Li, X.; Chen, S.; Zhang, S.; Hou, L.; Zhu, Y.; Xiao, Z. Human Activity Recognition Using IR-UWB Radar: A Lightweight Transformer Approach. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Zhang, X.; Li, J.; Hua, Z. MRSE-Net: Multiscale Residuals and SE-Attention Network for Water Body Segmentation From Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5049–5064. [Google Scholar] [CrossRef]
- Sudakow, I.; Asari, V.K.; Liu, R.; Demchev, D. MeltPondNet: A Swin Transformer U-Net for Detection of Melt Ponds on Arctic Sea Ice. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8776–8784. [Google Scholar] [CrossRef]
- Li, G.; Shi, G.; Zhu, C. Dynamic Serpentine Convolution with Attention Mechanism Enhancement for Beef Cattle Behavior Recognition. Animals 2024, 14, 466. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, B.; Cao, Y.; Sun, M.; He, K.; Cao, Z.; Wang, M. Mask Detection Method Based on YOLO-GBC Network. Electronics 2023, 12, 408. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Dang, C.; Wang, Z.; He, Y.; Wang, L.; Cai, Y.; Shi, H.; Jiang, J. The Accelerated Inference of a Novel Optimized YOLOv5-LITE on Low-Power Devices for Railway Track Damage Detection. IEEE Access 2023, 11, 134846–134865. [Google Scholar] [CrossRef]
- Baek, J.-W.; Chung, K. Swin Transformer-Based Object Detection Model Using Explainable Meta-Learning Mining. Appl. Sci. 2023, 13, 3213. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, Z.; Zhou, S.; Qi, W.; Wu, X.; Zhang, T.; Han, L. LS-YOLO: A Novel Model for Detecting Multiscale Landslides with Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 4952–4965. [Google Scholar] [CrossRef]
- Cao, X.; Su, Y.; Geng, X.; Wang, Y. YOLO-SF: YOLO for Fire Segmentation Detection. IEEE Access 2023, 11, 111079–111092. [Google Scholar] [CrossRef]
- Guo, X.; Cao, Y.; Hu, T. An Efficient and Lightweight Detection Model for Forest Smoke Recognition. Forests 2024, 15, 210. [Google Scholar] [CrossRef]
- Zheng, X.; Chen, F.; Lou, L.; Cheng, P.; Huang, Y. Real-Time Detection of Full-Scale Forest Fire Smoke Based on Deep Convolution Neural Network. Remote Sens. 2022, 14, 536. [Google Scholar] [CrossRef]
- Kundu, S.; Maulik, U.; Sheshanarayana, R.; Ghosh, S. Vehicle Smoke Synthesis and Attention-Based Deep Approach for Vehicle Smoke Detection. IEEE Trans. Ind. Appl. 2023, 59, 2581–2589. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Valid | Test | Sum |
|---|---|---|---|---|
| Quantity | 6028 | 753 | 753 | 7534 |
| Hardware environment | CPU | Inte(R) Xeon(R) Silver 4210R CPU @ 2.40 GHz |
| GPU | NVIDIA GeForce RTX 3080 | |
| RAM | 64 G | |
| Software Environment | OS | Windows 10 |
| CUDA Toolkit | 12.2 | |
| Python | 3.8.18 | |
| Training information | Optimizer | SGD |
| Epoch | 300 | |
| Batch size | 8 | |
| Learning range | 0.01 |
| RepVit | C2f_DSConv | FireHead | mAP@0.5% | mParam (M) | GFLOPs | Time (ms) |
|---|---|---|---|---|---|---|
| - | - | - | 0.743 | 5.18 | 10.3 | 25.3 |
| √ | - | - | 0.766 | 5.20 | 10.3 | 25.8 |
| - | √ | - | 0.753 | 5.19 | 10.3 | 25.5 |
| - | - | √ | 0.769 | 5.21 | 10.3 | 25.9 |
| √ | √ | - | 0.767 | 5.21 | 10.4 | 26.3 |
| √ | - | √ | 0.788 | 5.25 | 10.5 | 26.4 |
| - | √ | √ | 0.796 | 5.24 | 10.4 | 26.2 |
| √ | √ | √ | 0.802 | 5.33 | 10.6 | 26.7 |
| mAP@0.5/% | Params/M | GFLOPs | Time (ms) | |
|---|---|---|---|---|
| A | 78.24 | 5.34 | 10.5 | 28.3 |
| B | 78.59 | 5.29 | 10.5 | 26.4 |
| C | 79.11 | 5.34 | 10.5 | 28.3 |
| D | 77.02 | 5.53 | 10.5 | 28.0 |
| AB | 78.65 | 5.33 | 10.6 | 27.8 |
| AC | 78.47 | 5.41 | 10.6 | 27.1 |
| AD | 79.44 | 5.60 | 10.6 | 29.2 |
| BC | 80.28 | 5.33 | 10.6 | 26.7 |
| BD | 78.98 | 5.33 | 10.6 | 26.8 |
| CD | 76.33 | 5.60 | 10.6 | 29.3 |
| ABC | 79.22 | 5.42 | 10.7 | 27.1 |
| ABD | 78.57 | 5.45 | 10.7 | 27.3 |
| ACD | 79.29 | 5.49 | 10.7 | 27.4 |
| BCD | 78.64 | 5.48 | 10.7 | 27.4 |
| ABCD | 80.11 | 5.69 | 10.8 | 30.1 |
| mAP@0.5% | Recall% | Precision% | Param (M) | GFLOPs | Time (ms) | |
|---|---|---|---|---|---|---|
| None | 76.7 | 74.2 | 77.3 | 5.21 | 10.4 | 25.9 |
| SE [47] | 76.8 | 75.5 | 78.0 | 5.33 | 10.7 | 27.1 |
| EMA [44] | 80.1 | 79.8 | 81.1 | 6.10 | 11.4 | 26.9 |
| GAM [45] | 79.4 | 74.4 | 79.9 | 7.46 | 19.9 | 29.6 |
| CBAM | 80.2 | 78.4 | 82.6 | 5.33 | 10.6 | 26.7 |
| mAP@0.5/% | Recall/% | Precision/% | Param (M) | GFLOPs | Time (ms) | |
|---|---|---|---|---|---|---|
| Fast R-CNN | 69.4 | 72 | 75.7 | 5.18 | 10.2 | 25.2 |
| RetinaNet | 70.4 | 69.6 | 68.7 | 6.91 | 16.2 | 31.8 |
| YOLOv7 | 73.6 | 72.2 | 74.2 | 5.53 | 10.8 | 27.2 |
| YOLOv7x | 74.1 | 73.1 | 75.9 | 6.11 | 12.8 | 28.8 |
| YOLOv8 | 74.3 | 72.1 | 76.8 | 5.18 | 10.3 | 25.3 |
| BF_MB-YOLOv5 | 79.3 | 78.2 | 76.8 | 5.46 | 11.5 | 26.5 |
| YOLOv11 | 80.3 | 78.5 | 82.7 | 5.30 | 11.2 | 27.0 |
| (Ours) | 80.2 | 78.4 | 82.6 | 5.33 | 10.6 | 26.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Y.; Sahma, A.; He, X.; Wu, R.; Zhang, R. FireNet: A Lightweight and Efficient Multi-Scenario Fire Object Detector. Remote Sens. 2024, 16, 4112. https://doi.org/10.3390/rs16214112
He Y, Sahma A, He X, Wu R, Zhang R. FireNet: A Lightweight and Efficient Multi-Scenario Fire Object Detector. Remote Sensing. 2024; 16(21):4112. https://doi.org/10.3390/rs16214112
Chicago/Turabian StyleHe, Yonghuan, Age Sahma, Xu He, Rong Wu, and Rui Zhang. 2024. "FireNet: A Lightweight and Efficient Multi-Scenario Fire Object Detector" Remote Sensing 16, no. 21: 4112. https://doi.org/10.3390/rs16214112
APA StyleHe, Y., Sahma, A., He, X., Wu, R., & Zhang, R. (2024). FireNet: A Lightweight and Efficient Multi-Scenario Fire Object Detector. Remote Sensing, 16(21), 4112. https://doi.org/10.3390/rs16214112