
FE-SKViT: A Feature-Enhanced ViT Model with Skip Attention for Automatic Modulation Recognition


Abstract
1. Introduction
- A comprehensive analysis of feature enhancement (FE) improves the effectiveness of feature extraction from input signals;
- A high-accuracy network based on ViT with FE and skip attention (SKAT), named (FE-SKViT), is proposed for automatic modulation classification;
- Compared to mainstream DL methods, the proposed FE-SKViT can achieve effective and robust modulation classification performance.
2. An Overview of Signal Model
3. Proposed Method
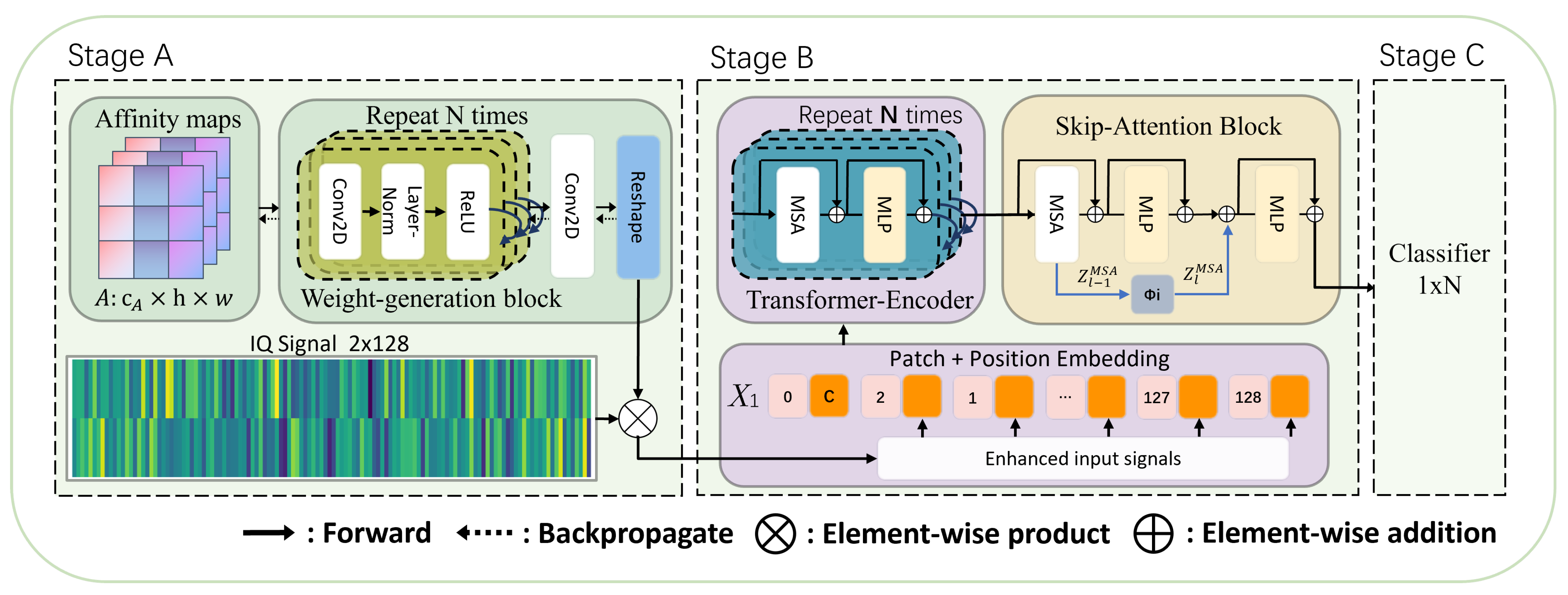
3.1. Overall Architecture
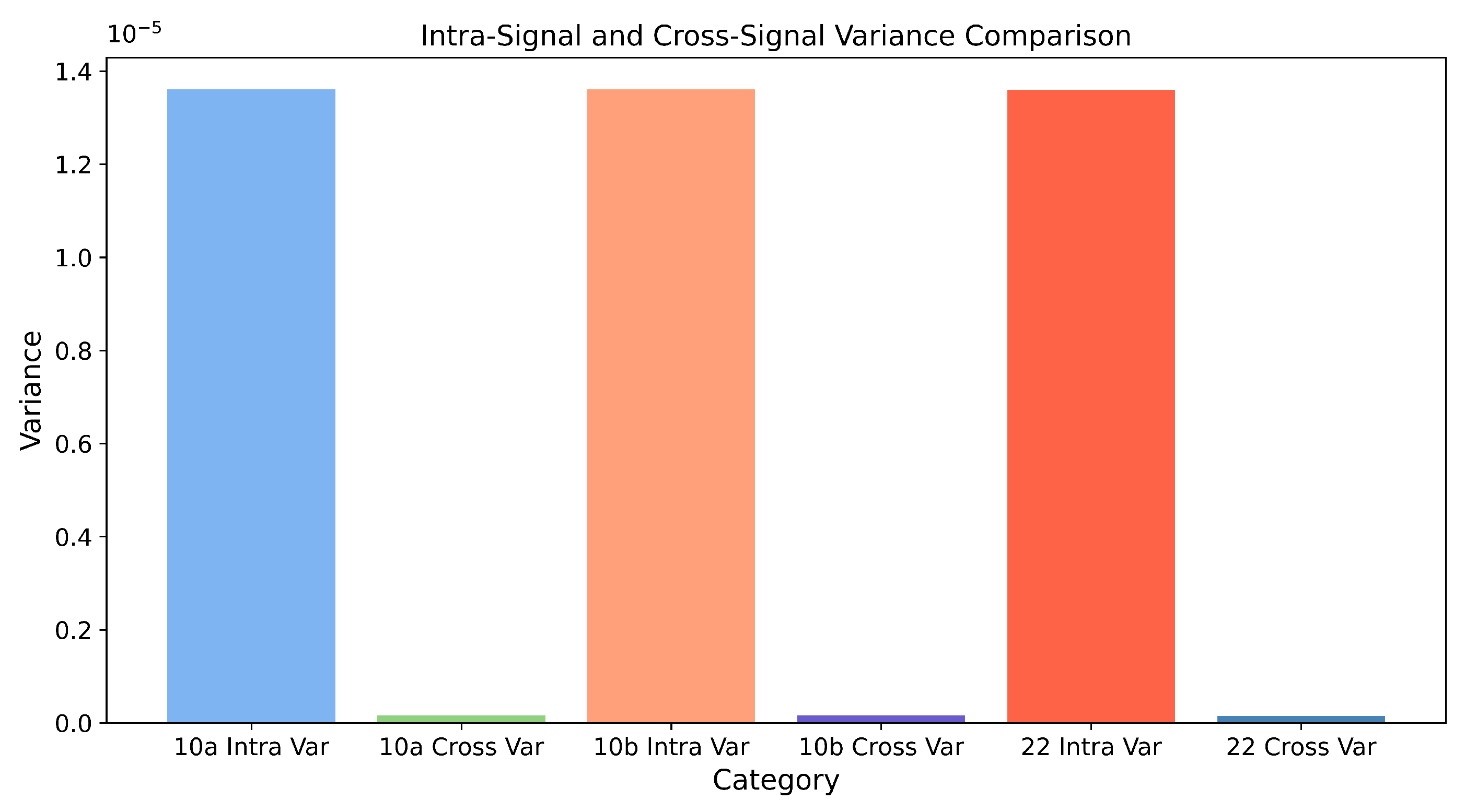
3.2. Investigation on the AMC with Distribution of Cross-Signal and Intra-Signal Variance
3.3. Feature Enhancement Block (FE)
3.3.1. Affinity Map Unit (AMU)
- Learnable Affinity Maps: These maps are trained to highlight the connections between various samples in the IQ signal. Similar to attention mechanisms used in transformers, these affinity maps reduce the computational overhead while capturing essential spatial relationships.
- Spatial Awareness: By focusing on relationships between pairs of time steps within the IQ sequence, the AMU can distinguish between different characteristics of the IQ signal, such as phase shifts, frequency changes, and amplitude variations, ensuring a nuanced understanding of the signal’s structure.
- Implementation Details: The AMU employs a learnable function f to compute the affinity between each pair of time steps within the IQ signal. This function takes into account the temporal position and signal characteristics, such as amplitude and phase, producing a matrix of affinities. A.
3.3.2. Weight-Generating Unit (WGU)
- Weight Generation: The WGU produces convolutional weights tailored to each spatial location, using the affinity maps to ensure these weights are contextually relevant. The process involves a learnable function g that maps the affinities to convolutional weights.
- Efficiency: To maintain computational efficiency, the weights can be precomputed and stored, allowing for fast retrieval during the inference phase.
- Implementation Details: The function g used in the WGU is designed to take the affinity maps and generate the appropriate weights for each convolutional filter. This function can be implemented using a neural network that outputs a set of weights for each time step based on the affinity values.
3.4. Transformer Encoder with SKAT Framework
3.4.1. Multi-Head Self-Attention
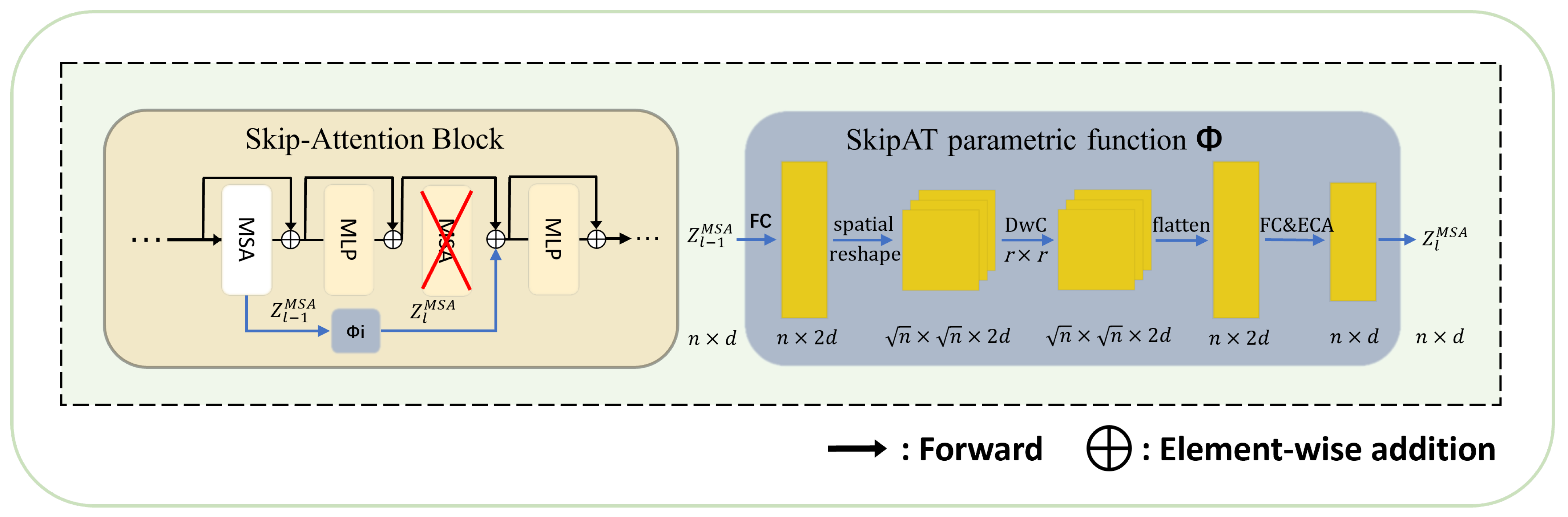
3.4.2. SKAT Framework
3.4.3. Transformer Encoder with SKAT
4. Experimental Results and Discussion
4.1. Datasets
4.2. Analysis of Feature Enhance Module
4.2.1. Performance Comparisons with Different Parameters in the Weight-Generating Block
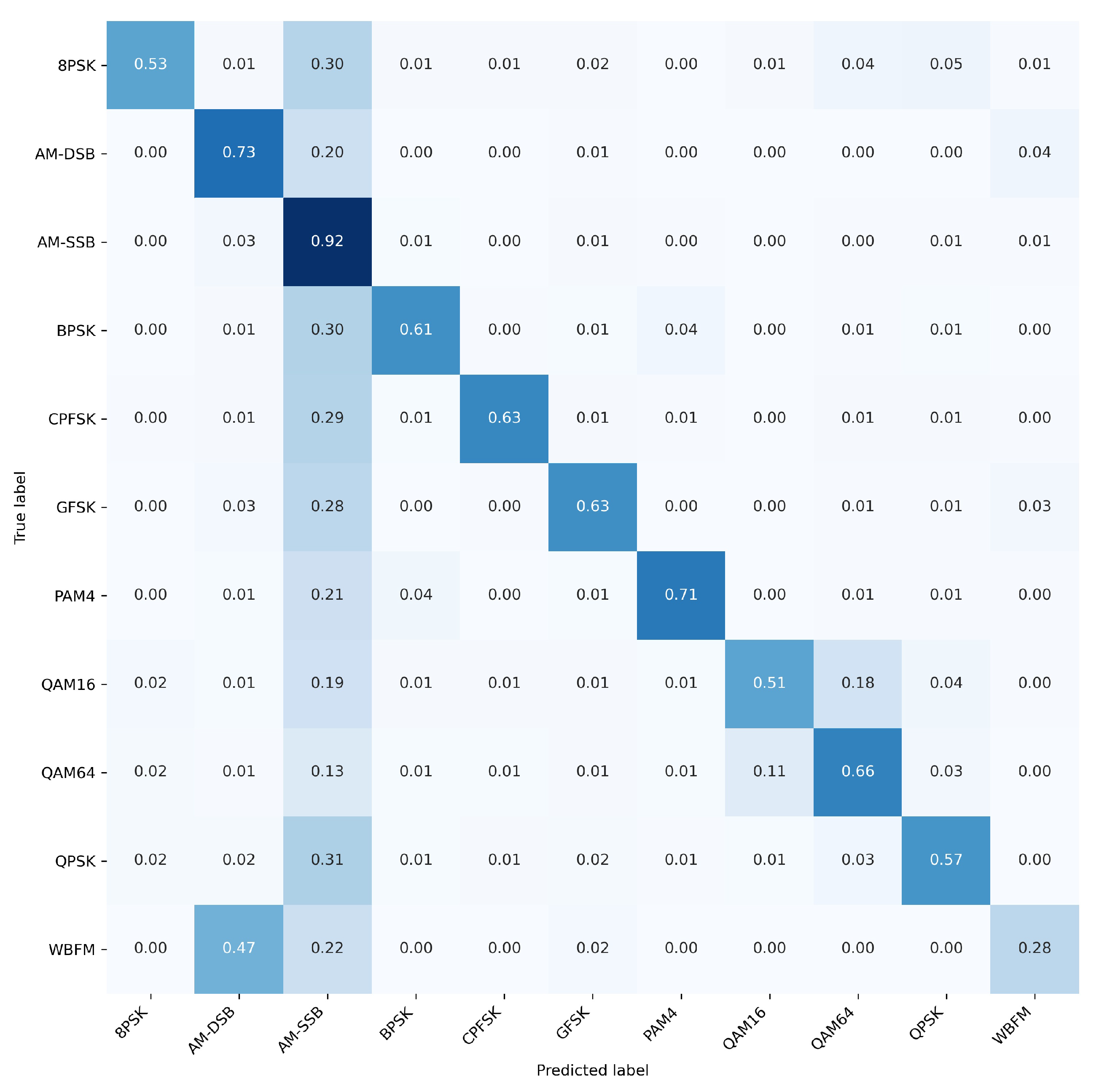
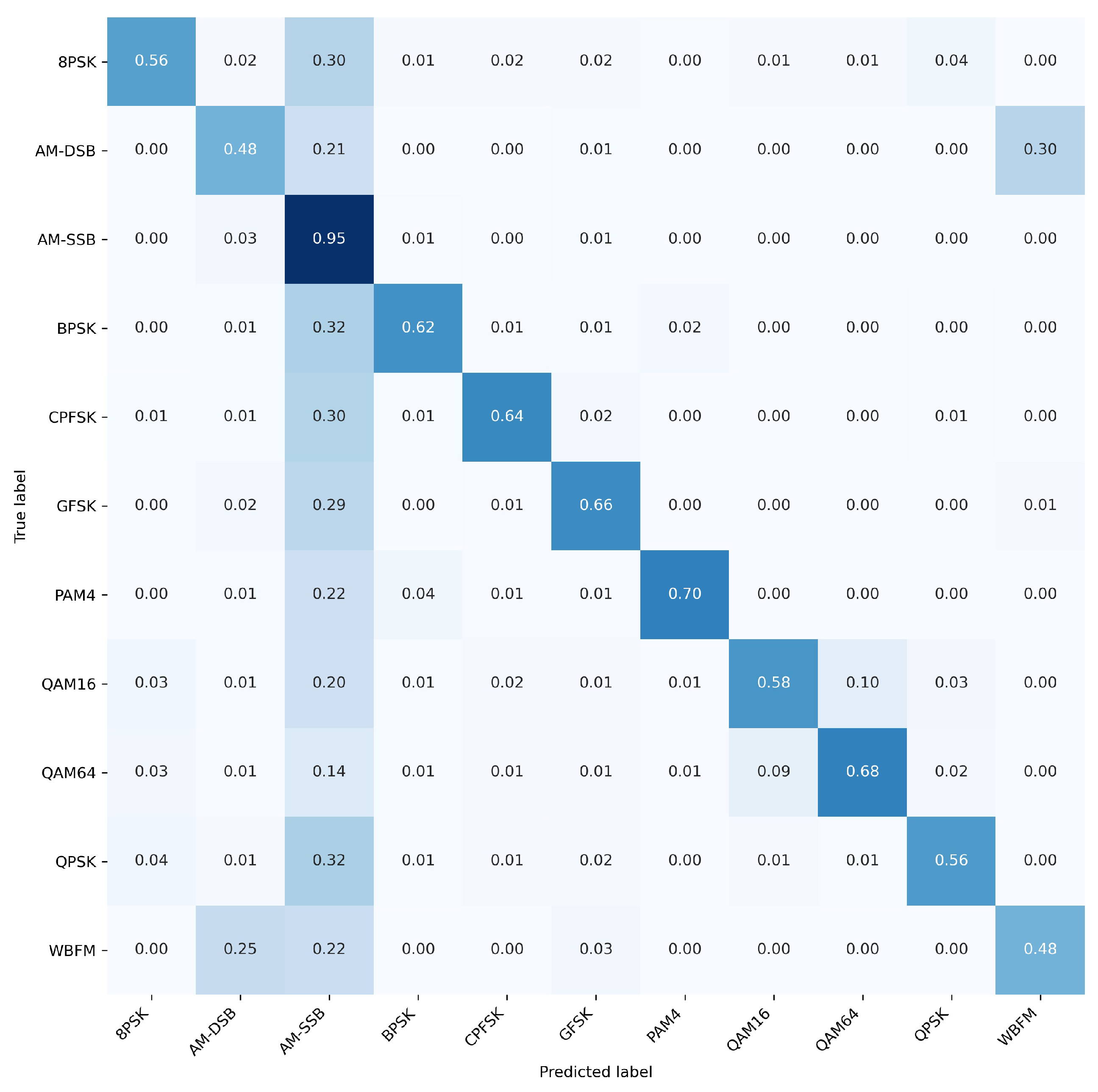
4.2.2. Recognition Performance by SNR and Modulation Type
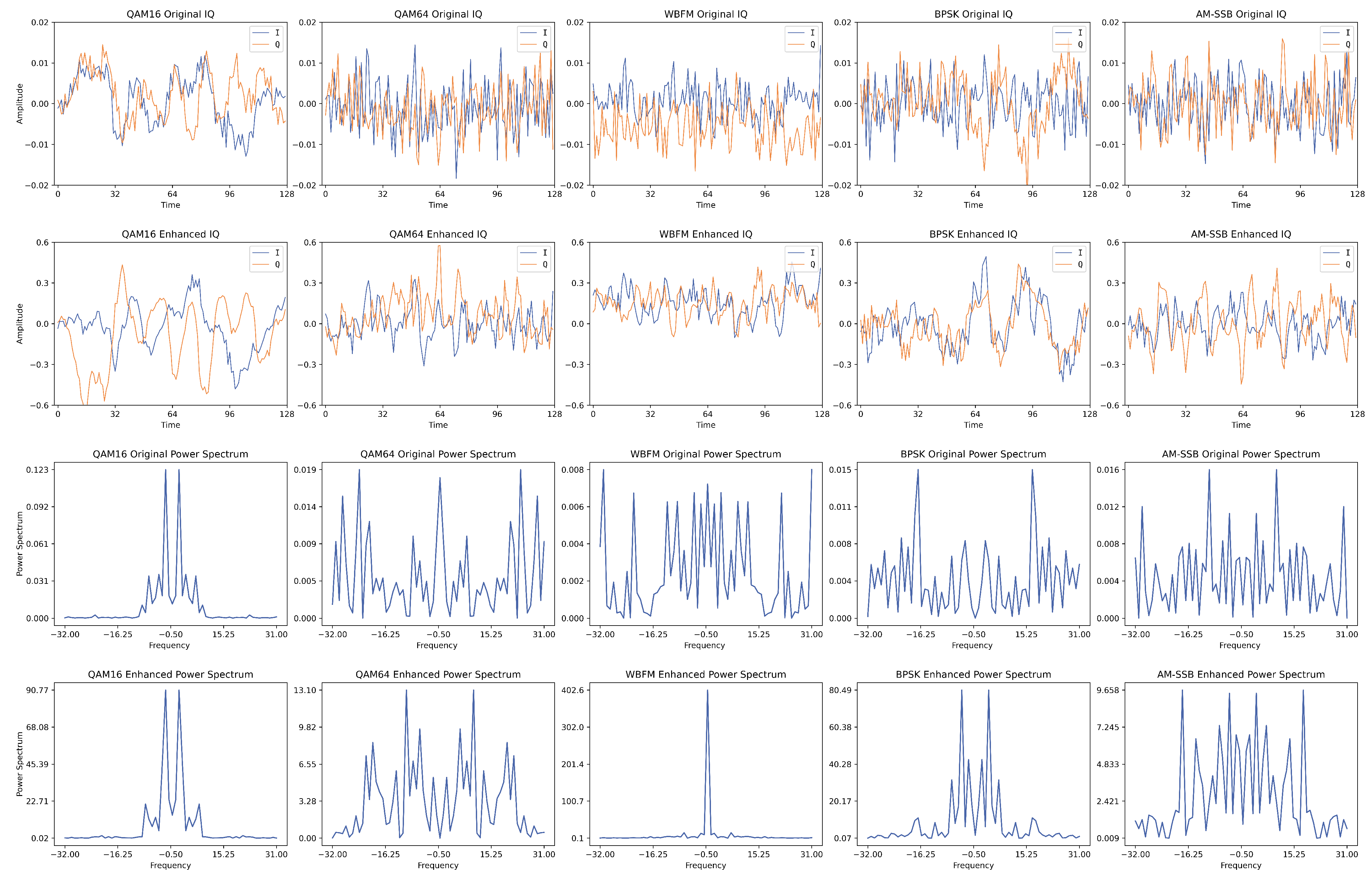
4.2.3. Feature Visualization
4.3. Ablation Study
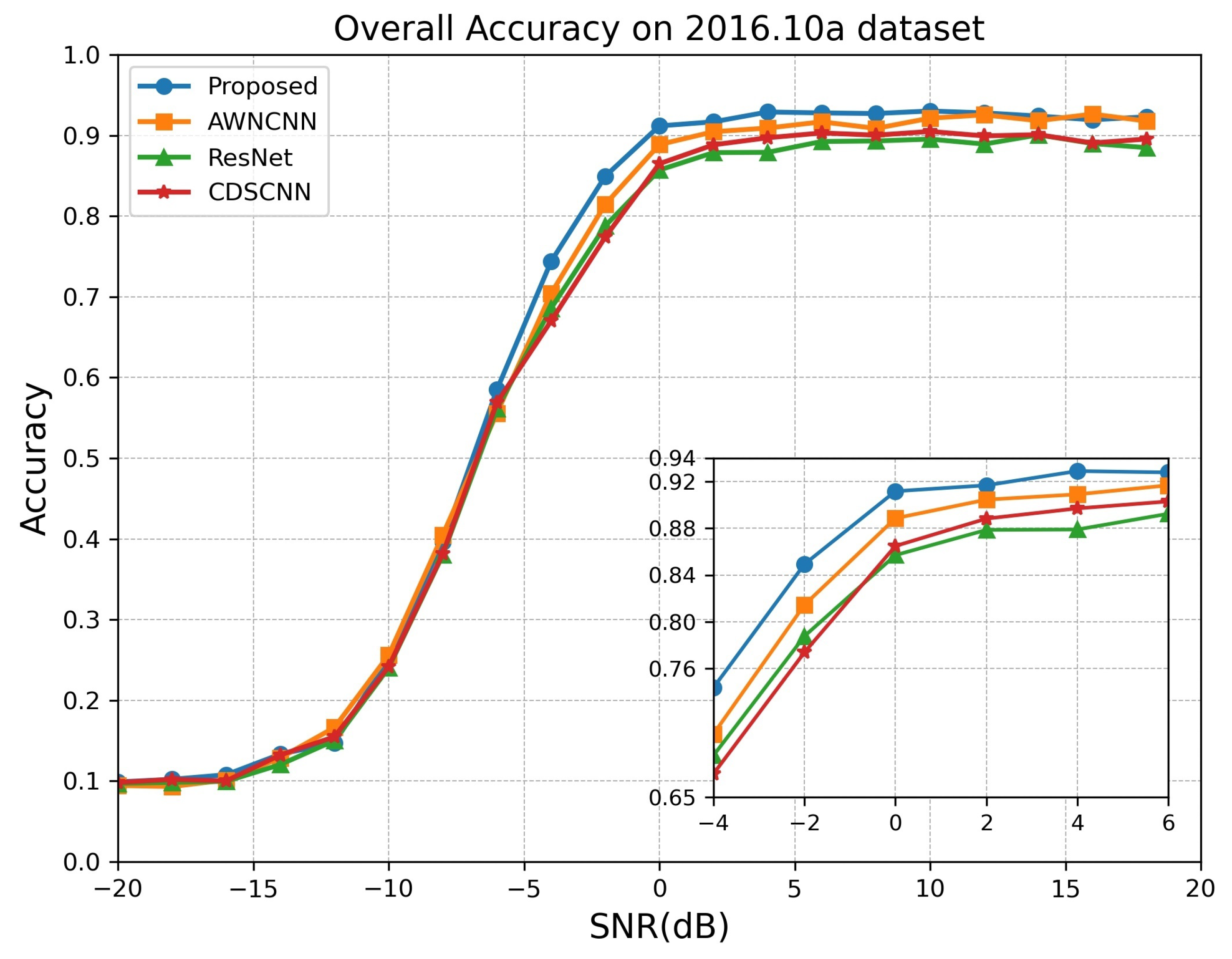
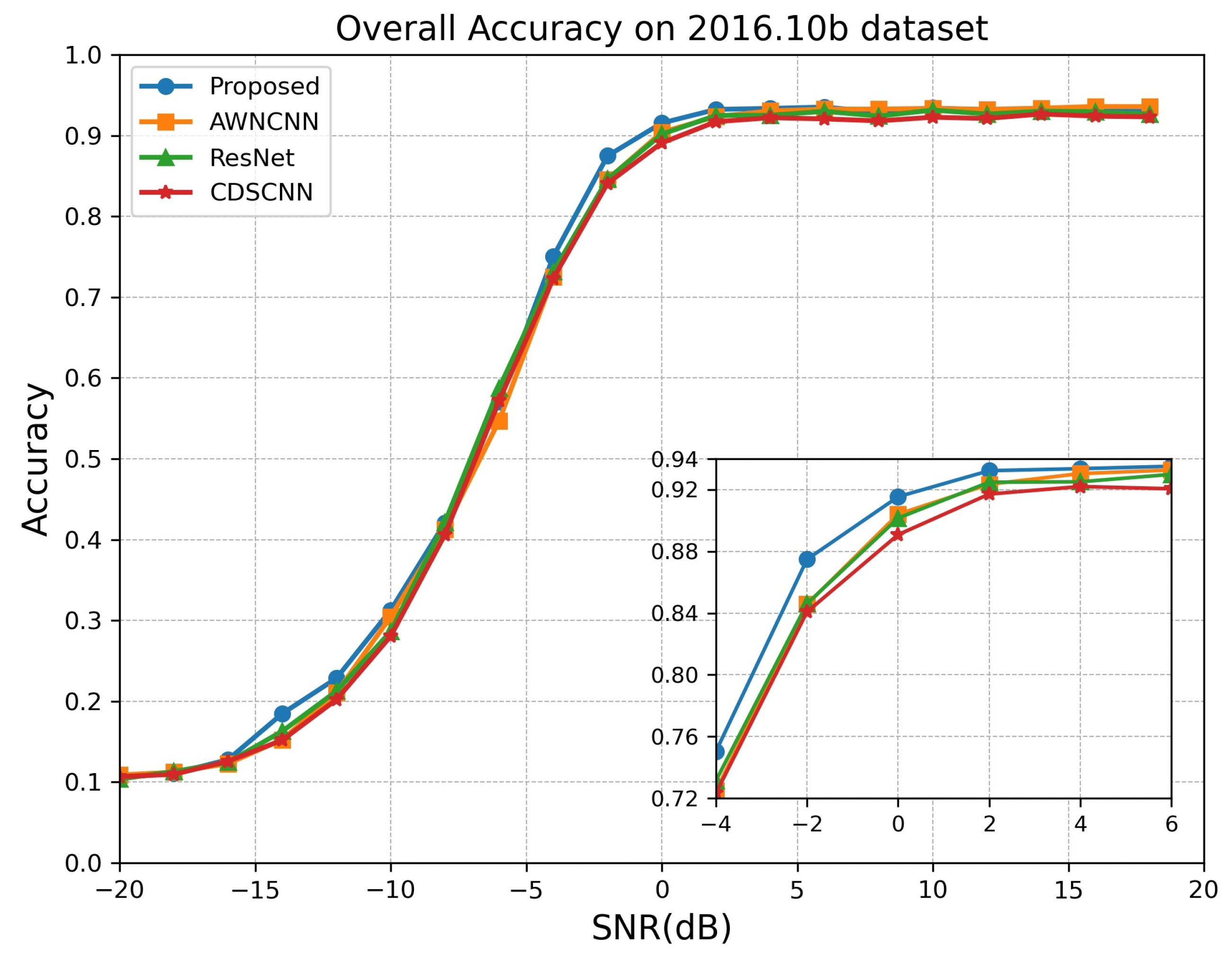
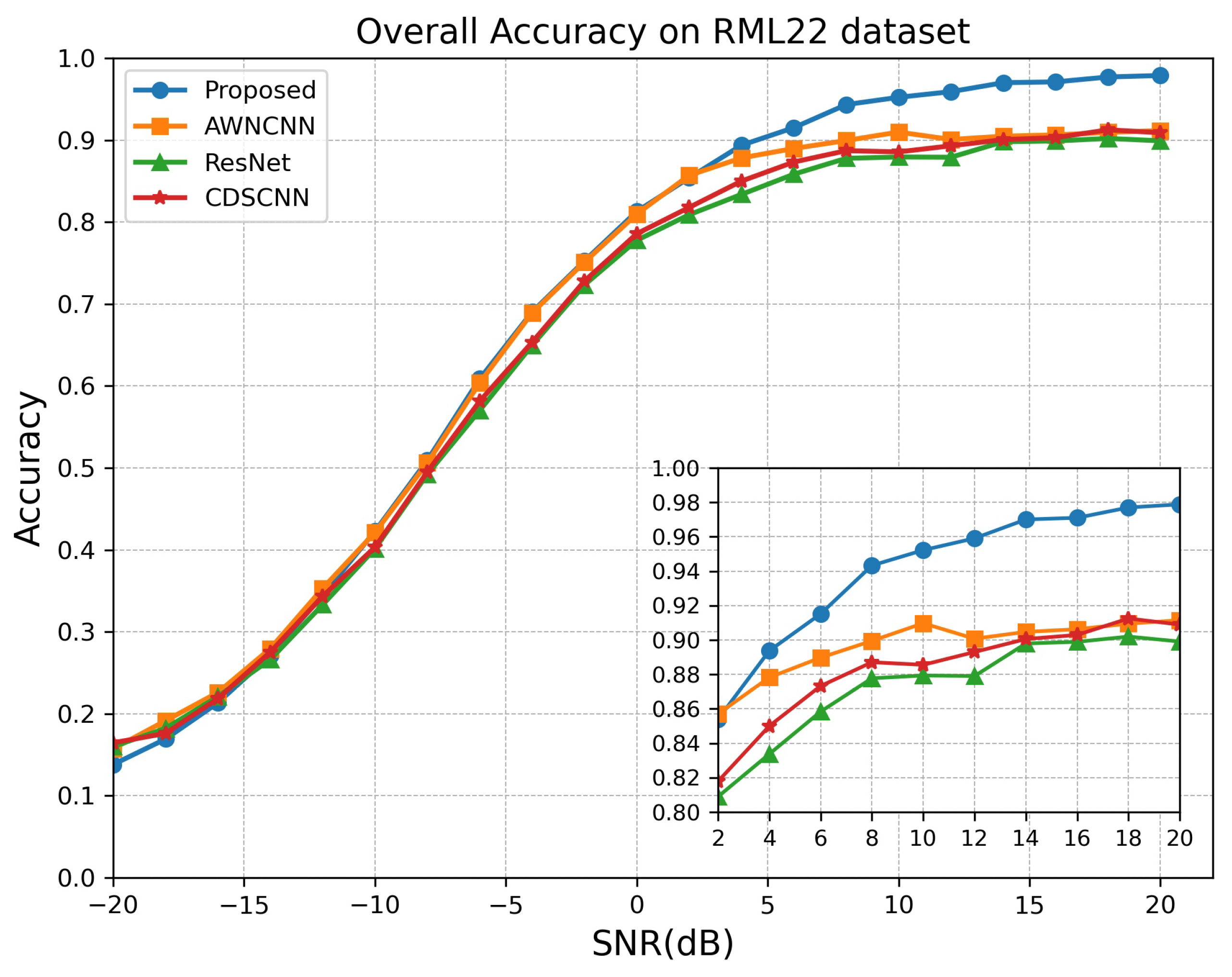
4.4. Performance Comparisons to the State-of-the-Art
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, J.; Liu, X.; Zhang, Y.; Chen, H. Deep Learning Based Automatic Modulation Recognition: Models, Datasets, and Challenges. arXiv 2022, arXiv:2207.09647. [Google Scholar]
- Xia, H. Cellular signal identification using convolutional neural networks: AWGN and Rayleigh fading channels. In Proceedings of the 2019 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Newark, NJ, USA, 11–14 November 2019. [Google Scholar]
- Peng, S.; Sun, S.; Yao, Y.D. A survey of modulation classification using deep learning: Signal representation and data preprocessing. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 7020–7038. [Google Scholar] [CrossRef] [PubMed]
- Jiang, X.R.; Chen, H.; Zhao, Y.D.; Wang, W.Q. Automatic modulation recognition based on mixed-type features. Int. J. Electron. 2021, 108, 105–114. [Google Scholar] [CrossRef]
- Zhang, D.; Lu, Y.; Li, Y.; Ding, W.; Zhang, B.; Xiao, J. Frequency Learning Attention Networks based on Deep Learning for Automatic Modulation Classification in Wireless Communication. Pattern Recognit. 2023, 137, 109345. [Google Scholar] [CrossRef]
- Xu, J.L.; Su, W.; Zhou, M. Likelihood-ratio approaches to automatic modulation classification. IEEE Trans. Syst., Man, Cybern. C Appl. Rev. 2011, 41, 455–469. [Google Scholar] [CrossRef]
- Al-Sa’d, M.; Boashash, B.; Gabbouj, M. Design of an optimal piece-wise spline wigner-ville distribution for TFD performance 365 evaluation and comparison. IEEE Trans. Signal Process 2021, 69, 3963–3976. [Google Scholar] [CrossRef]
- Abd-Elaziz, O.F.; Abdalla, M.; Elsayed, R.A. Deep learning-based automatic modulation classification using robust CNN architecture for cognitive radio networks. Sensors 2023, 23, 9467. [Google Scholar] [CrossRef]
- Wang, X.; Li, Y.; Zhang, P.; Wang, Z. RNN-based melody generation using sequence-to-sequence learning. IEEE Access 2019, 7, 165346–165356. [Google Scholar]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, long short-term memory, fully connected deep neural networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 4580–4584. [Google Scholar]
- Tu, Y.; Lin, Y. Deep neural network compression technique towards efficient digital signal modulation recognition in edge device. IEEE Access 2019, 7, 58113–58119. [Google Scholar] [CrossRef]
- Lee, S.H.; Kim, K.-Y.; Kim, J.H.; Shin, Y. Effective feature-based automatic modulation classification method using DNN algorithm. In Proceedings of the 2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Okinawa, Japan, 11–13 February 2019; pp. 557–559. [Google Scholar]
- Shi, J.; Hong, S.; Cai, C.; Wang, Y.; Huang, H.; Gui, G. Deep learning based automatic modulation recognition method in the presence of phase offset. IEEE Access 2020, 8, 42841–42847. [Google Scholar] [CrossRef]
- Hiremath, S.M.; Behura, S.; Kedia, S.; Deshmukh, S.; Patra, S.K. Deep learning-based modulation classification using time and stockwell domain channeling. In Proceedings of the 2019 National Conference on Communications (NCC), Bangalore, India, 20–23 February 2019; pp. 1–6. [Google Scholar]
- Peng, S.; Jiang, H.; Wang, H.; Alwageed, H.; Zhou, Y.; Sebdani, M.M.; Yao, Y.D. Modulation classification based on signal constellation diagrams and deep learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 718–727. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Zhang, M.; Li, Z.; Li, J.; Fu, M.; Cui, Y.; Chen, X. Modulation format recognition and OSNR estimation using CNN-based deep learning. IEEE Photon. Technol. Lett. 2017, 29, 1667–1670. [Google Scholar] [CrossRef]
- Li, Y.; Shao, G.; Wang, B. Automatic modulation classification based on bispectrum and CNN. In Proceedings of the 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 24–26 May 2019; pp. 311–316. [Google Scholar]
- Mendis, G.J.; Wei, J.; Madanayake, A. Deep learning-based automated modulation classification for cognitive radio. In Proceedings of the 2016 IEEE International Conference on Communication Systems (ICCS), Shenzhen, China, 14–16 December 2016; pp. 1–6. [Google Scholar]
- Huang, S.; Jiang, Y.; Gao, Y.; Feng, Z.; Zhang, P. Automatic modulation classification using contrastive fully convolutional network. IEEE Wireless Commun. Lett. 2019, 8, 1044–1047. [Google Scholar] [CrossRef]
- Hu, S.; Pei, Y.; Liang, P.P.; Liang, Y.-C. Deep neural network for robust modulation classification under uncertain noise conditions. IEEE Trans. Veh. Technol. 2020, 69, 564–577. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, Y.; Wang, Z. A novel deep learning automatic modulation classifier with fusion of multichannel information using GRU. EURASIP J. Wirel. Commun. Netw. 2023, 2023, 66. [Google Scholar]
- Graves, A.; Fernández, S.; Schmidhuber, J. Bidirectional LSTM networks for improved phoneme classification and recognition. In Proceedings of the 15th International Conference on Artificial Neural Networks (ICANN), Warsaw, Poland, 11–15 September 2005; pp. 799–804. [Google Scholar]
- Chen, Y.; Li, Q.; Zhao, L.; Wang, M. Enhancing Automatic Modulation Recognition for IoT Applications Using Transformers. arXiv 2023, arXiv:2403.15417. [Google Scholar]
- Chen, Y.; Dong, B.; Liu, C.; Xiong, W.; Li, S. Abandon locality: Framewise embedding aided transformer for automatic modulation recognition. IEEE Commun. Lett. 2023, 27, 327–331. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Dao, T.-T.; Noh, D.-I.; Pham, Q.-V.; Hasegawa, M.; Sekiya, H.; Hwang, W.-J. VT-MCNet: High-Accuracy Automatic Modulation Classification Model Based on Vision Transformer. IEEE Commun. Lett. 2024, 28, 98–102. [Google Scholar] [CrossRef]
- Worrall, D.E.; Garbin, S.J.; Turmukhambetov, D.; Brostow, G.J. Harmonic networks: Deep translation and rotation equivariance. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5028–5037. [Google Scholar]
- Li, W.; Deng, W.; Wang, K.; You, L.; Huang, Z. A Complex-Valued Transformer for Automatic Modulation Recognition. IEEE Internet Things J. 2024, 11, 22197–22207. [Google Scholar] [CrossRef]
- Chen, J.; He, T.; Zhuo, W.; Ma, L.; Ha, S.; Chan, S.H.G. Tvconv: Efficient translation variant convolution for layout-aware visual processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12548–12558. [Google Scholar]
- Venkataramanan, S.; Ghodrati, A.; Asano, Y.M.; Porikli, F.; Habibian, A. Skip-attention: Improving vision transformers by paying less attention. arXiv 2023, arXiv:2301.02240. [Google Scholar]
- O’shea, T.J.; West, N. Radio machine learning dataset generation with GNU radio. In Proceedings of the 6th GNU Radio Conference, Boulder, CO, USA, 12–16 September 2016; pp. 1–6. [Google Scholar]
- Sathyanarayanan, V.; Gerstoft, P.; Gamal, A.E. RML22: Realistic Dataset Generation for Wireless Modulation Classification. IEEE Trans. Wirel. Commun. 2023, 22, 7663–7675. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; Volume 22, pp. 11534–11542. [Google Scholar]
- Zhang, J.; Wang, T.; Feng, Z.; Yang, S. Toward the Automatic Modulation Classification With Adaptive Wavelet Network. IEEE Trans. Cogn. Commun. Netw. 2023, 9, 549–563. [Google Scholar] [CrossRef]
- Liang, Z.; Tao, M.; Wang, L.; Su, J.; Yang, X. Automatic modulation recognition based on adaptive attention mechanism and ResNeXt WSL model. IEEE Commun. Lett. 2021, 25, 2953–2957. [Google Scholar] [CrossRef]
- Xiao, C.; Yang, S.; Feng, Z. Complex-valued Depth-wise Separable Convolutional Neural Network for Automatic Modulation Classification. IEEE Trans. Instrum. Meas. 2023, 72, 1–10. [Google Scholar]
- Hao, X.; Feng, Z.; Yang, S.; Wang, M.; Jiao, L. Automatic Modulation Classification via Meta-Learning. IEEE Internet Things J. 2023, 10, 12276–12292. [Google Scholar] [CrossRef]
- Wang, S.; Xing, H.; Wang, C.; Zhou, H.; Hou, B.; Jiao, L. SigDA: A Superimposed Domain Adaptation Framework for Automatic Modulation Classification. IEEE Trans. Wirel. Commun. 2024, 23, 13159–13172. [Google Scholar] [CrossRef]
- Chen, Y.; Shao, W.; Liu, J.; Yu, L.; Qian, Z. Automatic modulation classification scheme based on LSTM With random erasing and attention mechanism. IEEE Access 2020, 8, 154290–154300. [Google Scholar] [CrossRef]
- Huynh-The, T.; Pham, Q.-V.; Nguyen, T.-V.; Nguyen, T.T.; Costa, D.B.D.; Kim, D.-S. RanNet: Learning residual-attention structure in CNNsfor automatic modulation classification. IEEE Wirel. Commun. Lett. 2022, 11, 1243–1247. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | RML2016.10a | RML2016.10b | RML22 |
|---|---|---|---|
| Modulations | BPSK, QPSK, 8PSK, 16QAM, 64QAM, GFSK, CPFSK, PAM4, AM-DSB, AMSSB, WBFM | BPSK, QPSK, 8PSK, 16QAM, 64QAM, PAM4, WBFM, CPFSK, GFSK, AM-DSB | BPSK, QPSK, 8PSK, 16QAM, 64QAM, PAM4, WBFM, CPFSK, GFSK, AM-DSB |
| Signal dimension | 2 × 128(I/Q) | 2 × 128(I/Q) | 2 × 128(I/Q) |
| SNR range | −20 dB:2 dB:18 dB | −20 dB:2 dB:20 dB | −20 dB:2 dB:20 dB |
| Distortion | Sample rate offset, Symbol rate offset, Selective fading, Center frequency offset, AWGN noise | Thermal Noise, Sample rate offset, Center frequency offset, Channel effects, Doppler frequency | Thermal Noise, Sample rate offset, Center frequency offset, Channel effects, Doppler frequency |
| Number of samples | 220,000 | 420,000 | 420,000 |
| Split of training, validation, test | 8:1:1 | 8:1:1 | 8:1:1 |
| Parameters | Value |
|---|---|
| Learning rate | 0.0001 |
| Optimizer | AdamW |
| Loss Function | Cross-Entropy Loss |
| Episode | 300 |
| Early stopping | 20 |
| BChans | Convergence Batch | Minimum Verification Loss | Parameter (m) | Overall Acc |
|---|---|---|---|---|
| 128 | 236 | 1.03732 | 4.37 | 62.926 |
| 72 | 247 | 1.03542 | 1.77 | 63.058 |
| 64 | 40 | 1.03231 | 1.48 | 63.326 |
| 32 | 241 | 1.04346 | 0.57 | 62.597 |
| 16 | 236 | 1.04996 | 0.24 | 62.357 |
| 8 | 240 | 1.05810 | 0.11 | 62.076 |
| 4 | 248 | 1.07966 | 0.05 | 60.673 |
| AChans | Convergence Batch | Minimum Verification Loss | Trainable Params | Overall Acc |
|---|---|---|---|---|
| 6 | 238 | 1.04420 | 389,568 | 62.643 |
| 5 | 244 | 1.03688 | 388,992 | 63.071 |
| 4 | 240 | 1.03231 | 388,416 | 63.326 |
| 3 | 236 | 1.03868 | 387,840 | 62.930 |
| 2 | 248 | 1.03897 | 387,264 | 62.874 |
| 1 | 243 | 1.03992 | 386,688 | 62.801 |
| BLayers | Convergence Batch | Minimum Verification Loss | Params Size (MB) | Overall Acc |
|---|---|---|---|---|
| 6 | 238 | 1.03772 | 1.75 | 63.048 |
| 5 | 240 | 1.03231 | 1.48 | 63.326 |
| 4 | 194 | 1.03690 | 1.22 | 63.031 |
| 3 | 236 | 1.03728 | 0.95 | 62.928 |
| 2 | 242 | 1.04006 | 0.68 | 62.693 |
| 1 | 233 | 1.04708 | 0.42 | 62.257 |
| Model | QAM16 | QAM64 | WBFM | BPSK | AM-DSB | AM-SSB | Overall Acc |
|---|---|---|---|---|---|---|---|
| ViT | 74.00 | 80.88 | 31.00 | 94.94 | 88.01 | 93.12 | 80.17 |
| FE-ViT | 84.50 | 90.19 | 54.50 | 94.94 | 64.89 | 95.76 | 83.34 |
| Dataset | Model | OA | MF1 | Kappa |
|---|---|---|---|---|
| RML2016.10a | ViT | 0.6184 | 0.6401 | 0.5801 |
| FE-ViT | 0.6283 | 0.6583 | 0.5913 | |
| FE-SKViT | 0.6333 | 0.6597 | 0.5959 | |
| RML2016.10b | ViT | 0.6405 | 0.6412 | 0.5999 |
| FE-ViT | 0.6445 | 0.6424 | 0.6044 | |
| FE-SKViT | 0.6503 | 0.6479 | 0.6106 | |
| RML2022 | ViT | 0.6483 | 0.6398 | 0.6087 |
| FE-ViT | 0.6613 | 0.6541 | 0.6233 | |
| FE-SKViT | 0.6832 | 0.6788 | 0.6475 |
| Parameters | Value |
|---|---|
| Input channels | 2 |
| Patch size | (16, 2) |
| Embed dimensions | 45 |
| Layers | 8 |
| SKipped layers | 3–6 |
| Heads | 9 |
| Mlp dimensions | 32 |
| Model | FLOPs | Memory | Speed | Params |
|---|---|---|---|---|
| ViT | 0.019 G | 7.99 MB | 0.009 s | 1.118 M |
| FE-ViT | 0.0682 G | 11.76 MB | 0.0130 s | 1.520 M |
| FE-SKViT | 0.0685 G | 35.44 MB | 0.0114 s | 1.507 M |
| ResNet18 | CDSCNN | AWN | FE-SKViT |
|---|---|---|---|
| Conv2d + BN + ReLU | Conv2d + BN + ReLU | Weight Generating | |
| Conv2d + BN + ReLU | MaxPool2D | PatchEmbedding | |
| ResBlock | Conv2d + BN + ReLU | Conv2d + BN + ReLU | MultiHeadAttention |
| ResBlock | Depth-wise Conv2d | Adaptive Wavelet | BlockSkipAt |
| ResBlock | Pointwise Conv2d | Attention Mechanism | MultiHeadAttention |
| Flatten | Flatten | Flatten | Linear |
| Model | FLOPs | Memory | Speed | Params | Average Accuracy (RML16a) | Average Accuracy (RML16b) | Average Accuracy (RML22) |
|---|---|---|---|---|---|---|---|
| ResNet18 | 0.022 G | 15.52 MB | 0.027 s | 3.85 MB | 60.41 | 64.19 | 64.34 |
| ViT | 0.019 G | 7.99 MB | 0.009 s | 1.118 MB | 61.84 | 64.05 | 64.83 |
| FE-ViT | 0.0682 G | 11.76 MB | 0.013 s | 1.52 MB | 62.83 | 64.45 | 66.13 |
| FE-SKViT | 0.0685 G | 35.44 MB | 0.011 s | 1.51 MB | 63.33 | 65.03 | 68.32 |
| CDSCNN | 0.0095 G | 7.52 MB | 0.004 s | 0.33 MB | 60.84 | 63.52 | 65.03 |
| AWN | 0.006 G | 2.33 MB | 0.007 s | 0.12 MB | 62.28 | 64.18 | 66.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, G.; Zang, B.; Yang, P.; Zhang, W.; Li, B. FE-SKViT: A Feature-Enhanced ViT Model with Skip Attention for Automatic Modulation Recognition. Remote Sens. 2024, 16, 4204. https://doi.org/10.3390/rs16224204
Zheng G, Zang B, Yang P, Zhang W, Li B. FE-SKViT: A Feature-Enhanced ViT Model with Skip Attention for Automatic Modulation Recognition. Remote Sensing. 2024; 16(22):4204. https://doi.org/10.3390/rs16224204
Chicago/Turabian StyleZheng, Guangyao, Bo Zang, Penghui Yang, Wenbo Zhang, and Bin Li. 2024. "FE-SKViT: A Feature-Enhanced ViT Model with Skip Attention for Automatic Modulation Recognition" Remote Sensing 16, no. 22: 4204. https://doi.org/10.3390/rs16224204
APA StyleZheng, G., Zang, B., Yang, P., Zhang, W., & Li, B. (2024). FE-SKViT: A Feature-Enhanced ViT Model with Skip Attention for Automatic Modulation Recognition. Remote Sensing, 16(22), 4204. https://doi.org/10.3390/rs16224204