
Object-Enhanced YOLO Networks for Synthetic Aperture Radar Ship Detection


Abstract
:1. Introduction
- An improved CFAR algorithm is proposed to simply identify ship objects in the original input images and handle background noise and sea surface clutter in SAR images. Additionally, the network’s object localization capability is strengthened through the additional channel dimensions.
- The coordinated attention mechanism is introduced into the backbone network of YOLOv7-tiny to capture directional and positional awareness information between channels. This addresses the precision loss in lightweight models and enhances the accuracy of the network.
- To address false positives and false negatives caused by multi-scale variations in ship objects in SAR images, Asymptotic Feature Fusion is introduced to optimize the model neck and improve the feature extraction capabilities of the network at different scales.
- Results from experiments conducted on the SAR-Ship-Dataset and HRSID datasets demonstrate that the proposed method surpasses baseline methods and surpasses most other detection approaches based on deep learning.
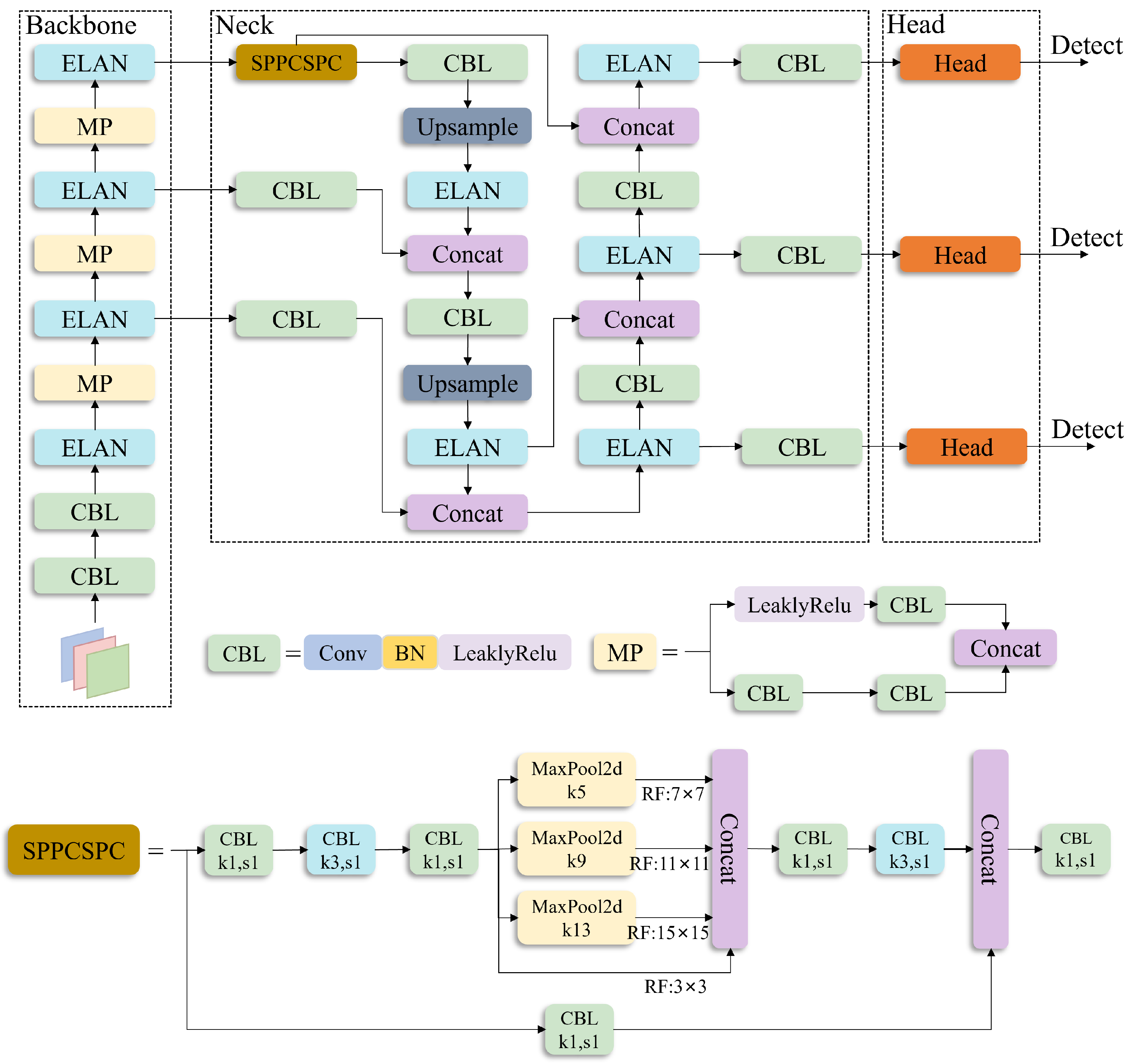
2. Overall Structure and Application Analysis of YOLOv7-Tiny
3. Materials and Methods
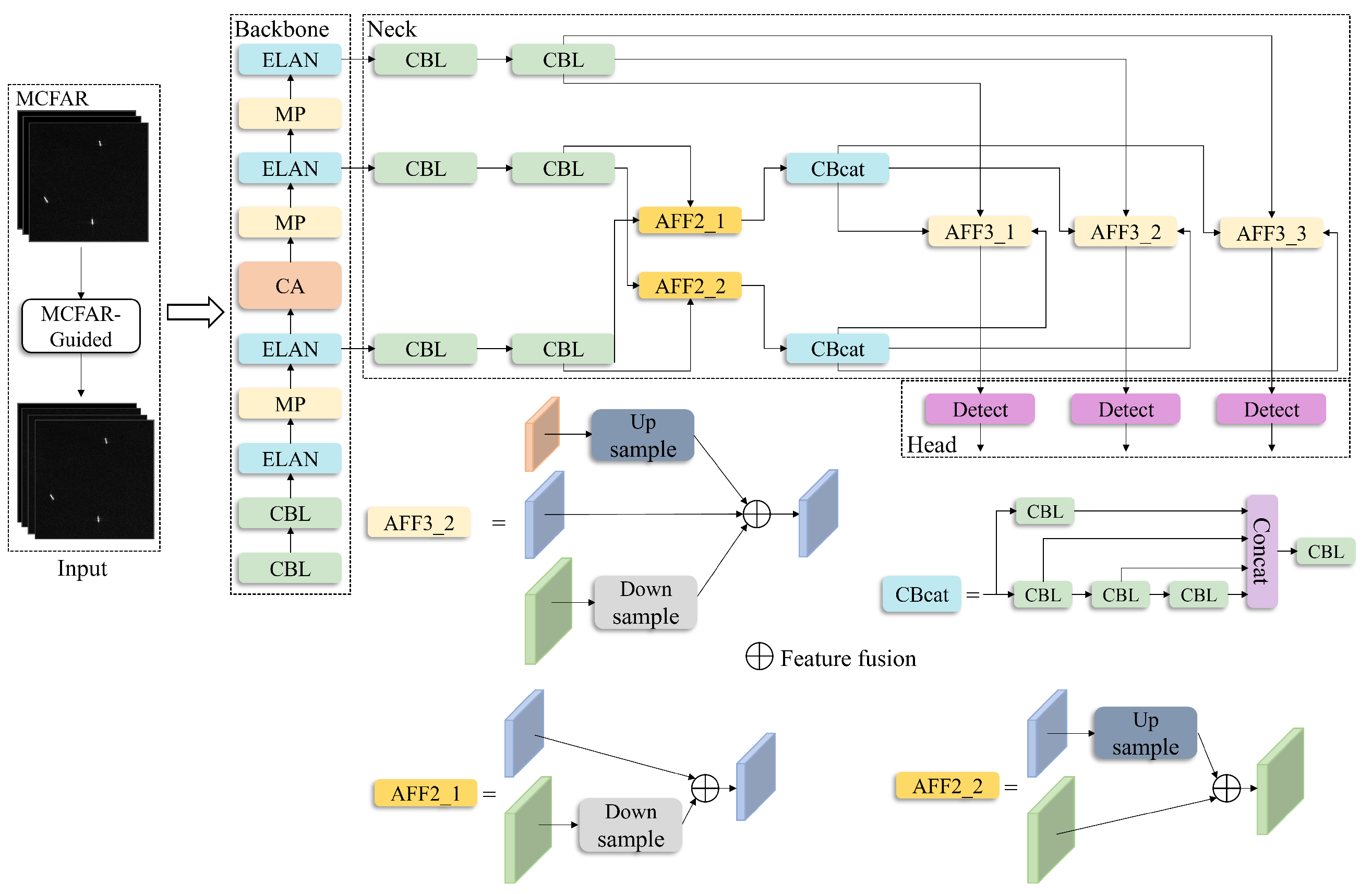
3.1. Overall Network Structure
3.2. Image Processing Module Based on Improved CFAR Detection Algorithm
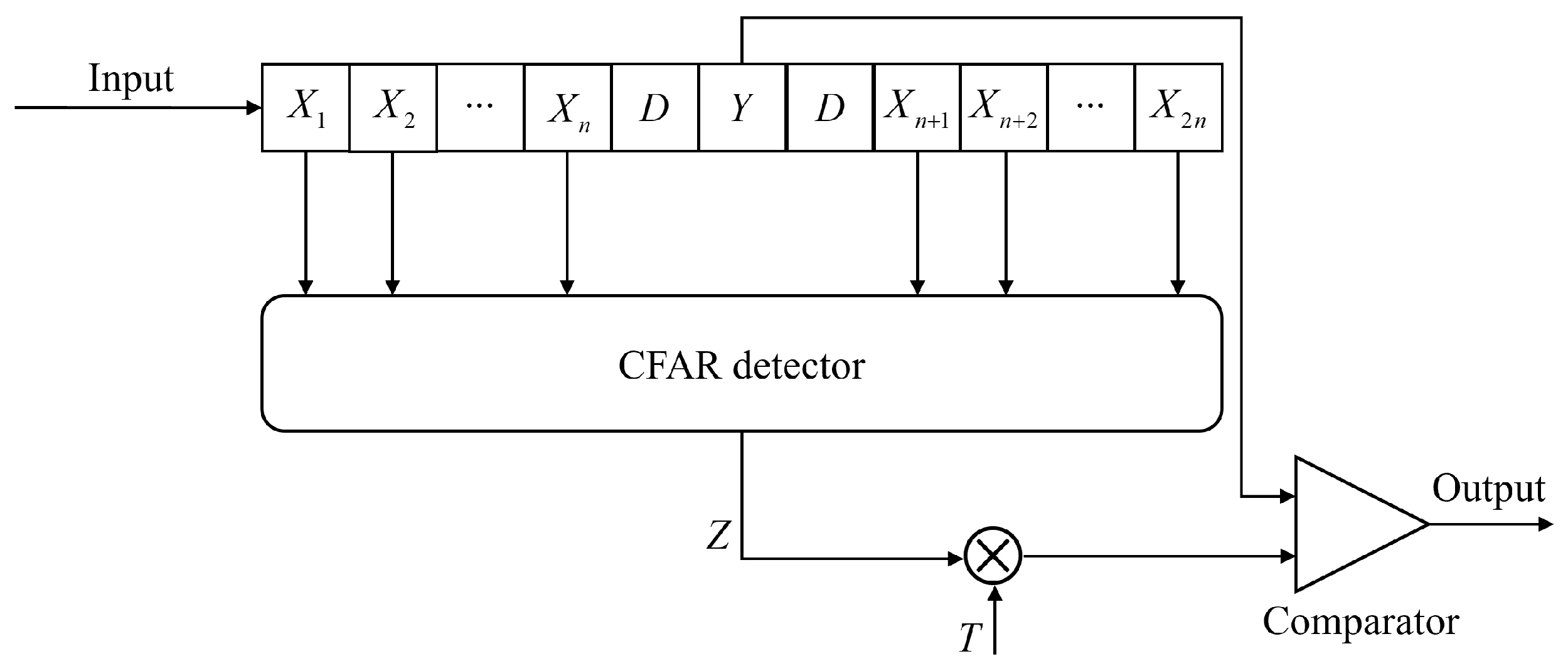
3.2.1. Traditional CFAR Algorithm
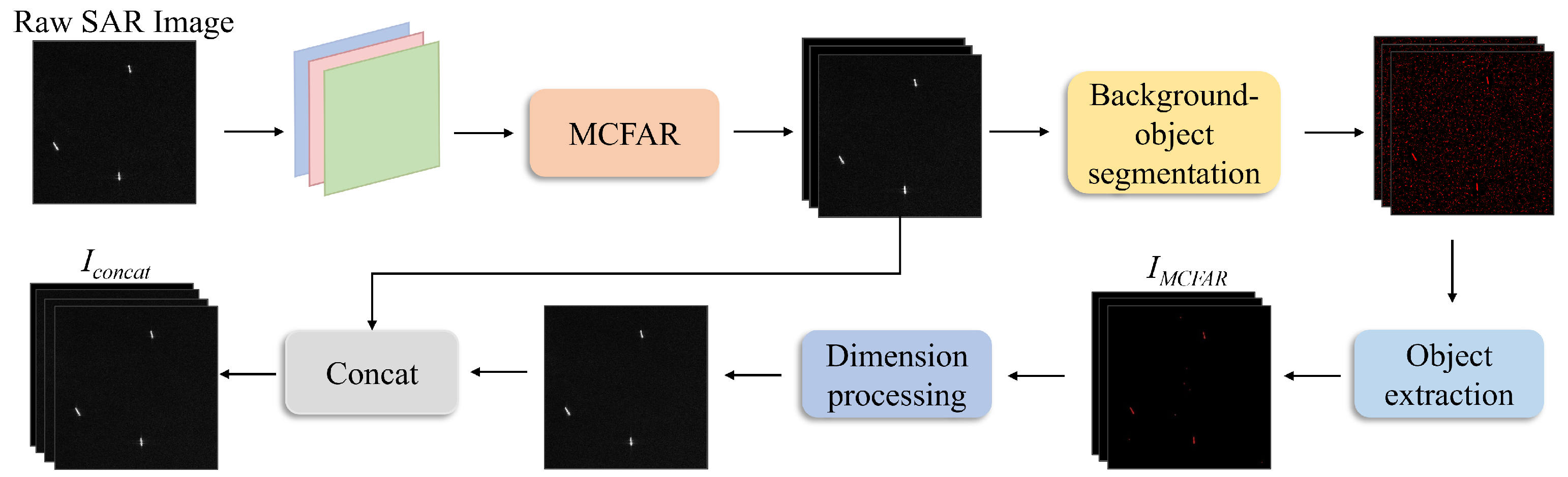
3.2.2. MCFAR: Improvement to the CFAR Algorithm
3.2.3. MCFAR-Guided Image Feature Extraction
3.3. Combined with Coordinated Attention Mechanism (CA)
3.4. Asymptotic Feature Fusion Module
3.5. Loss Function
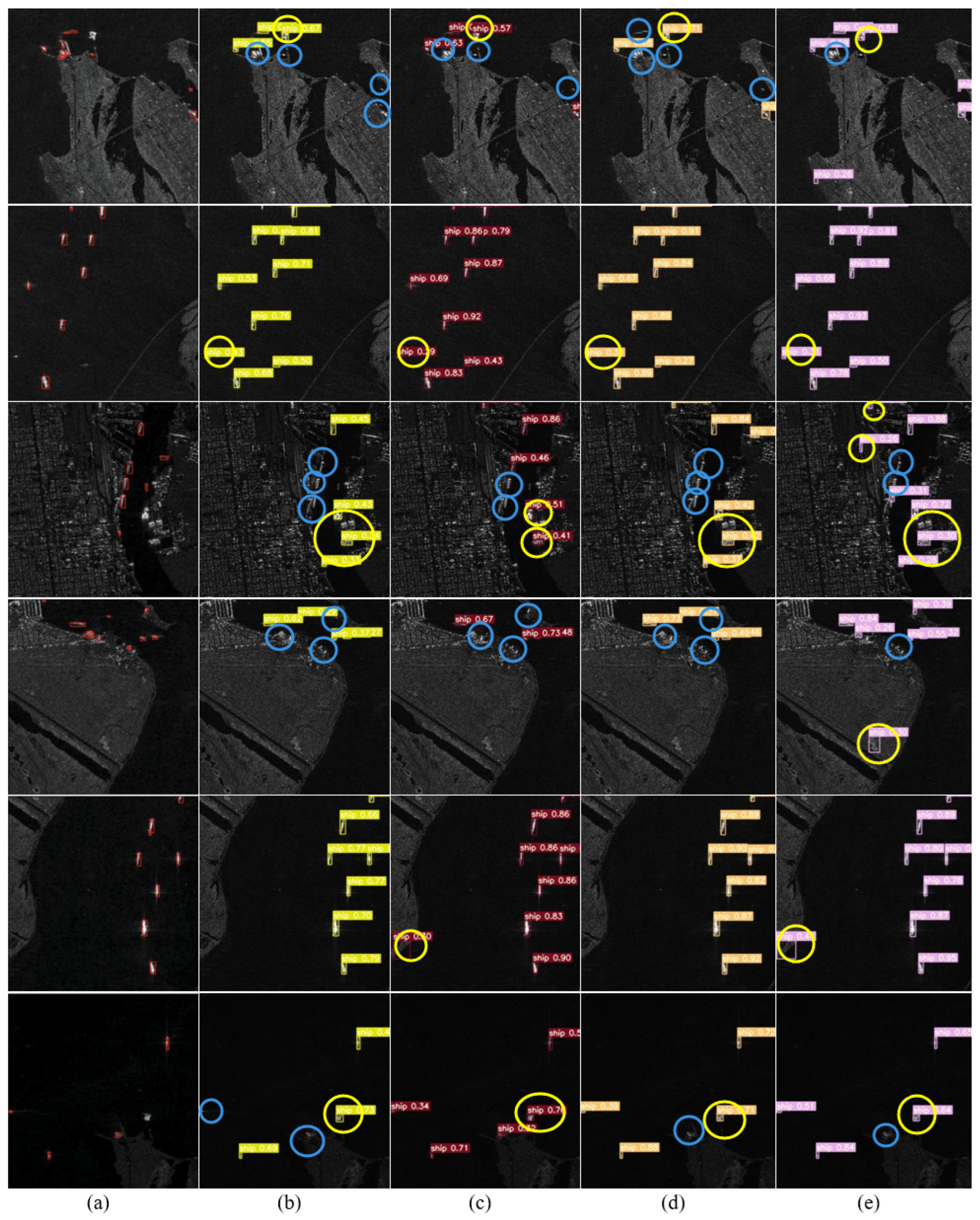
4. Results
4.1. Datasets and Settings
4.1.1. SAR-Ship-Dataset
4.1.2. HRSID
4.1.3. Training Settings
4.2. Evaluation Metric
4.3. Experiments on SAR-Ship-Dataset
4.4. Experiments on HRSID Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Renga, A.; Graziano, M.D.; Moccia, A. Segmentation of marine SAR images by sublook analysis and application to sea traffic monitoring. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1463–1477. [Google Scholar] [CrossRef]
- Tello, M.; López-Martínez, C.; Mallorqui, J.J. A novel algorithm for ship detection in SAR imagery based on the wavelet transform. IEEE Geosci. Remote Sens. Lett. 2005, 2, 201–205. [Google Scholar] [CrossRef]
- Manninen, A.T.; Ulander, L.M.H. Forestry parameter retrieval from texture in CARABAS VHF-band SAR images. IEEE Trans. Geosci. Remote Sens. 2001, 39, 2262–2633. [Google Scholar] [CrossRef]
- Mishra, V.; Malik, K.; Agarwal, V. Impact assessment of unsustainable airport development in the Himalayas using remote sensing: A case study of Pakyong Airport, Sikkim, India. Quat. Sci. Adv. 2024, 13, 100144. [Google Scholar] [CrossRef]
- Zhai, L.; Li, Y.; Su, Y. Inshore ship detection via saliency and context information in high-resolution SAR images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1870–1874. [Google Scholar] [CrossRef]
- Yang, M.; Guo, C.; Zhong, H. A curvature-based saliency method for ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1590–1594. [Google Scholar] [CrossRef]
- Sun, Q.; Liu, M.; Chen, S. Ship Detection in SAR Images Based on Multi-Level Superpixel Segmentation and Fuzzy Fusion. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5206215. [Google Scholar]
- Lin, H.; Chen, H.; Jin, K. Ship detection with superpixel-level Fisher vector in high-resolution SAR images. IEEE Geosci. Remote Sens. Lett. 2019, 17, 247–251. [Google Scholar] [CrossRef]
- An, W.; Xie, C.; Yuan, X. An improved iterative censoring scheme for CFAR ship detection with SAR imagery. IEEE Trans. Geosci. Remote Sens. 2013, 52, 4285–4295. [Google Scholar]
- Liu, T.; Zhang, J.; Gao, G. CFAR ship detection in polarimetric synthetic aperture radar images based on whitening filter. IEEE Trans. Geosci. Remote Sens. 2019, 58, 58–81. [Google Scholar] [CrossRef]
- Hong, D.F.; Zhang, B.; Li, H. Cross-city matters: A multimodal remote sensing benchmark dataset for cross-city semantic segmentation using high-resolution domain adaptation networks. Remote Sens. Environ. 2023, 299, 1138–1156. [Google Scholar] [CrossRef]
- Li, C.Y.; Zhang, B.; Hong, D.F. LRR-Net: An Interpretable Deep Unfolding Network for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5513412. [Google Scholar] [CrossRef]
- Hong, D.F.; Zhang, B.; Li, X.Y. SpectralGPT: Spectral Foundation Model. arXiv 2024, arXiv:2311.07113. [Google Scholar] [CrossRef]
- Zhou, M.; Huang, J.; Yan, K. A General Spatial-Frequency Learning Framework for Multimodal Image Fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Hong, D.F.; Yao, J.; Li, C.Y. Decoupled-and-coupled networks: Self-supervised hyperspectral image super-resolution with subpixel fusion. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5527812. [Google Scholar] [CrossRef]
- Li, C.Y.; Zhang, B.; Hong, D.F. Low-Rank Representations Meets Deep Unfolding: A Generalized and Interpretable Network for Hyperspectral Anomaly Detection. arXiv 2024, arXiv:2402.15335. [Google Scholar]
- Li, Y.X.; Hong, D.F.; Li, C. HD-Net: High-resolution decoupled network for building footprint extraction via deeply supervised body and boundary decomposition. ISPRS J. Photogramm. Remote Sens. 2024, 209, 51–65. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.F.; Chanussot, J. UIU-Net: U-Net in U-Net for infrared small object detection. IEEE Trans. Image Process. 2022, 32, 364–376. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Ke, X.; Zhang, X.; Zhang, T.; Shi, J.; Wei, S. SAR ship detection based on an improved Faster R-CNN using deformable convolution. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium, Brussels, Belgium, 11–16 July 2021; pp. 3565–3568. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. Automatic ship detection based on RetinaNet using multi-resolution Gaofen-3 imagery. Remote Sens. 2019, 11, 531. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Yao, J.; Qi, J.; Zhang, J.; Shao, H.; Yang, J. A real-time detection algorithm for Kiwifruit defects based on YOLOv5. Electronics 2021, 10, 1711. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y. MYOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1590–1594. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Du, L.; Li, L.; Wei, D. Saliency-guided single shot multibox detector for target detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3366–3376. [Google Scholar] [CrossRef]
- Li, Y.; Huang, Q.; Pei, X.; Jiao, L.; Shang, R. RADet: Refine feature pyramid network and multi-layer attention network for arbitrary-oriented object detection of remote sensing images. Remote Sens. 2020, 12, 389. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, C.; Filaretov, V.F. Multi-Scale Ship Detection Algorithm Based on YOLOv7 for Complex Scene SAR Images. Remote Sens. 2023, 15, 2071. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Lee, Y.; Hwang, J.W.; Lee, S.; Bae, Y.; Park, J. An energy and GPU-computation efficient backbone network for real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Kundu, D.; Raqab, M.Z. Generalized Rayleigh distribution: Different methods of estimations. Comput. Stat. Data Anal. 2005, 49, 187–200. [Google Scholar] [CrossRef]
- Rinne, H. The Weibull Distribution: A Handbook; CRC: Boca Raton, FL, USA, 2008. [Google Scholar]
- Yi, W.; Jiang, H.; Kirubarajan, T.; Kong, L.; Yang, X. Track-before-detect strategies for radar detection in G0-distributed clutter. IEEE Trans. Aerosp. Electron. Syst. 2017, 53, 2516–2533. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. Afpn: Asymptotic feature pyramid network for object detection. arXiv 2023, arXiv:2306.15988. [Google Scholar]
- Zhang, Z. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. A SAR dataset of ship detection for deep learning under complex backgrounds. Remote Sens. 2019, 11, 765. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A High-Resolution SAR Images Dataset for Ship Detection and Instance Segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Backbone | P (%) | R (%) | mAP0.5 (%) | mAP0.5:0.95 (%) |
|---|---|---|---|---|---|
| YOLOv4 | Darknet53 | 79.48 | 73.94 | 78.33 | 32.89 |
| YOLOv7 | ELANCSP | 83.52 | 82.73 | 85.64 | 39.72 |
| YOLOv7-tiny | ELANCSP | 83.68 | 80.63 | 84.45 | 39.41 |
| RetinaNet | ResNet50 | 83.14 | 79.64 | 82.34 | – |
| Cascade R-CNN | DetNet59 | 81.65 | 75.89 | 82.45 | – |
| SSD | VGG-16 | 82.34 | 81.45 | 84.78 | – |
| OE-YOLO | ELANCSP + CA | 85.38 | 81.49 | 86.04 | 39.62 |
| Image Size | File Size | Processing Time | P (%) | R (%) | mAP0.5 (%) |
|---|---|---|---|---|---|
| 800 × 800 | 582 M | 7.3 s/img | 77.3 | 62.17 | 67.84 |
| 256 × 256 | 36 M | 1.5 s/img | 78.45 | 60.74 | 67.38 |
| Methods | Backbone | P (%) | R (%) | mAP0.5 (%) | mAP0.5:0.95 (%) |
|---|---|---|---|---|---|
| YOLOv4 | Darknet53 | 78.38 | 59.95 | 66.45 | 33.76 |
| YOLOv7 | ELANCSP | 71.78 | 57.05 | 61.91 | 29.92 |
| YOLOv7-tiny | ELANCSP | 75.40 | 58.69 | 64.22 | 30.63 |
| RetinaNet | ResNet50 | 76.56 | 56.34 | 60.87 | – |
| Cascade R-CNN | DetNet59 | 73.43 | 51.34 | 58.53 | – |
| SSD | VGG-16 | 73.06 | 32.29 | 57.42 | – |
| OE-YOLO | ELANCSP + CA | 78.45 | 60.74 | 67.38 | 34.55 |
| Methods | MCFAR | CA | AFF | P (%) | R (%) | mAP0.5 (%) | Params | FLOPs |
|---|---|---|---|---|---|---|---|---|
| Baseline | – | – | – | 83.68 | 80.63 | 84.45 | 6.015 M | 13.2 G |
| Methods (1) | ✓ | – | – | 84.90 | 80.15 | 84.96 | 6.015 M | 13.2 G |
| Methods (2) | ✓ | ✓ | – | 85.66 | 81.49 | 85.15 | 6.018 M | 13.2 G |
| Methods (3) | ✓ | – | ✓ | 85.89 | 81.06 | 86.13 | 5.852 M | 13.2 G |
| Methods (4) | ✓ | ✓ | ✓ | 85.38 | 81.49 | 86.04 | 5.855 M | 13.2 G |
| Methods | MCFAR | CA | AFF | P (%) | R (%) | mAP0.5 (%) | Params | FLOPs |
|---|---|---|---|---|---|---|---|---|
| Baseline | – | – | – | 75.40 | 58.69 | 64.22 | 6.015 M | 13.2 G |
| Methods (1) | ✓ | – | – | 76.70 | 60.72 | 66.53 | 6.015 M | 13.2 G |
| Methods (2) | ✓ | ✓ | – | 76.37 | 60.12 | 66.21 | 6.018 M | 13.2 G |
| Methods (3) | ✓ | – | ✓ | 75.86 | 59.36 | 65.35 | 5.852 M | 14.2 G |
| Methods (4) | ✓ | ✓ | ✓ | 78.45 | 60.74 | 67.38 | 5.855 M | 14.2 G |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, K.; Zhang, Z.; Chen, Z.; Liu, G. Object-Enhanced YOLO Networks for Synthetic Aperture Radar Ship Detection. Remote Sens. 2024, 16, 1001. https://doi.org/10.3390/rs16061001
Wu K, Zhang Z, Chen Z, Liu G. Object-Enhanced YOLO Networks for Synthetic Aperture Radar Ship Detection. Remote Sensing. 2024; 16(6):1001. https://doi.org/10.3390/rs16061001
Chicago/Turabian StyleWu, Kun, Zhijian Zhang, Zeyu Chen, and Guohua Liu. 2024. "Object-Enhanced YOLO Networks for Synthetic Aperture Radar Ship Detection" Remote Sensing 16, no. 6: 1001. https://doi.org/10.3390/rs16061001
APA StyleWu, K., Zhang, Z., Chen, Z., & Liu, G. (2024). Object-Enhanced YOLO Networks for Synthetic Aperture Radar Ship Detection. Remote Sensing, 16(6), 1001. https://doi.org/10.3390/rs16061001