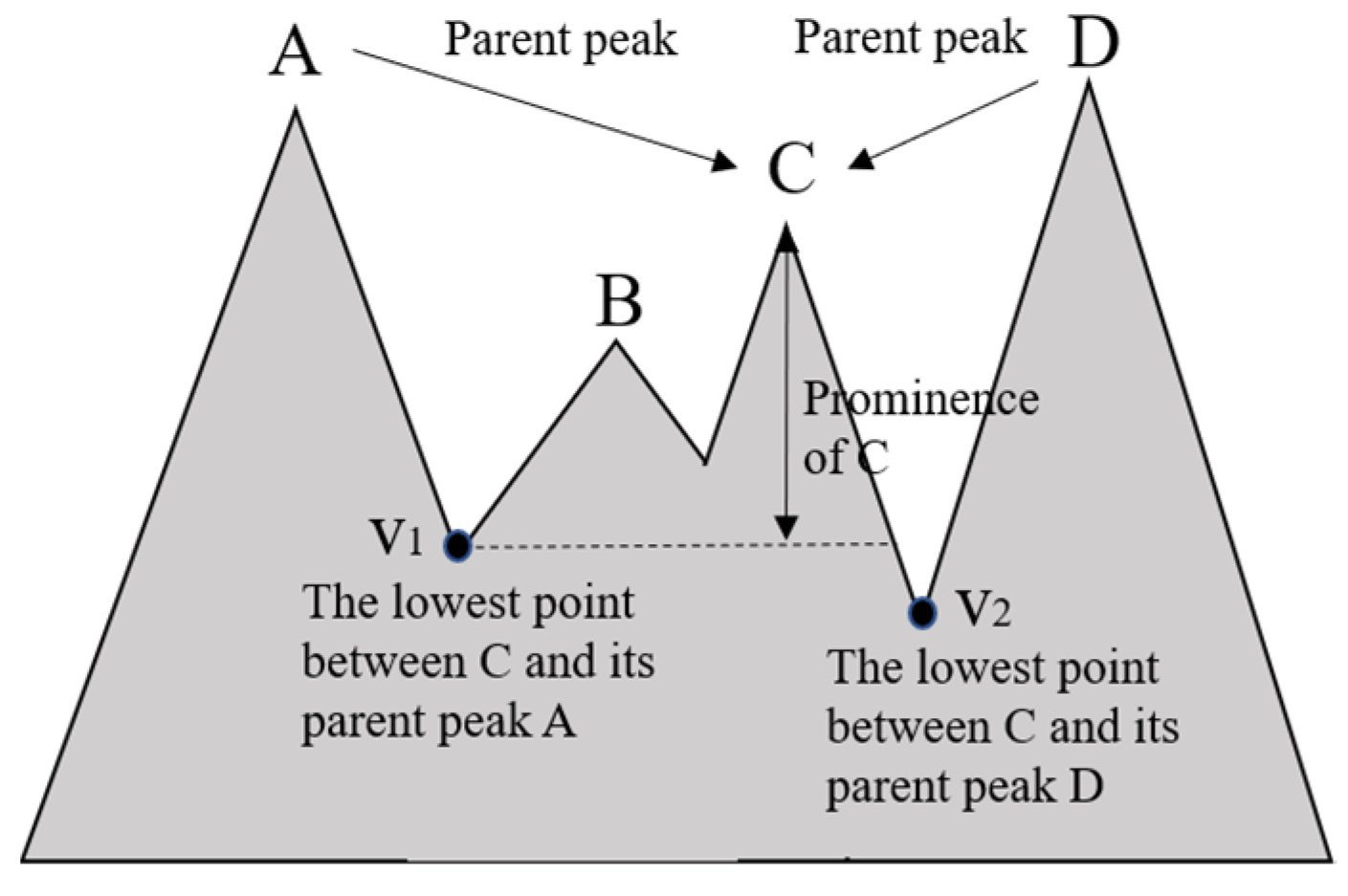
Figure 1.
The vertical line represents the prominence of peak C, which is the difference between the height of C and the height of v1.
Figure 1.
The vertical line represents the prominence of peak C, which is the difference between the height of C and the height of v1.
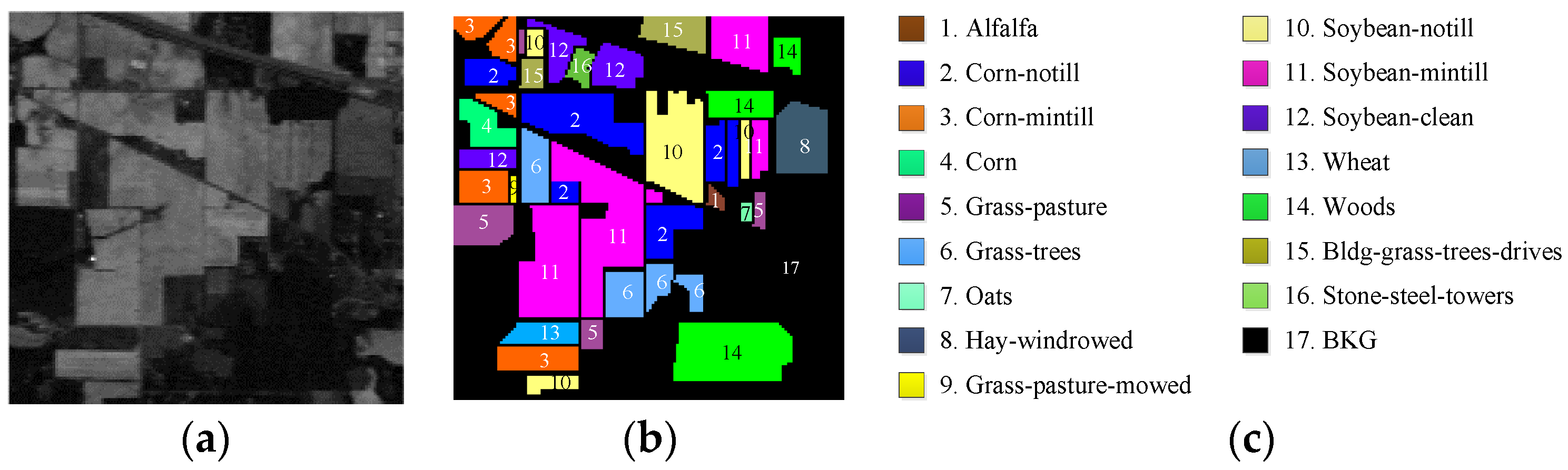
Figure 2.
AVIRIS image scene: Purdue Indiana Indian Pines test site. (a) Band 186 (2162.56 nm). (b) Ground truth map. (c) Classes by colors.
Figure 2.
AVIRIS image scene: Purdue Indiana Indian Pines test site. (a) Band 186 (2162.56 nm). (b) Ground truth map. (c) Classes by colors.
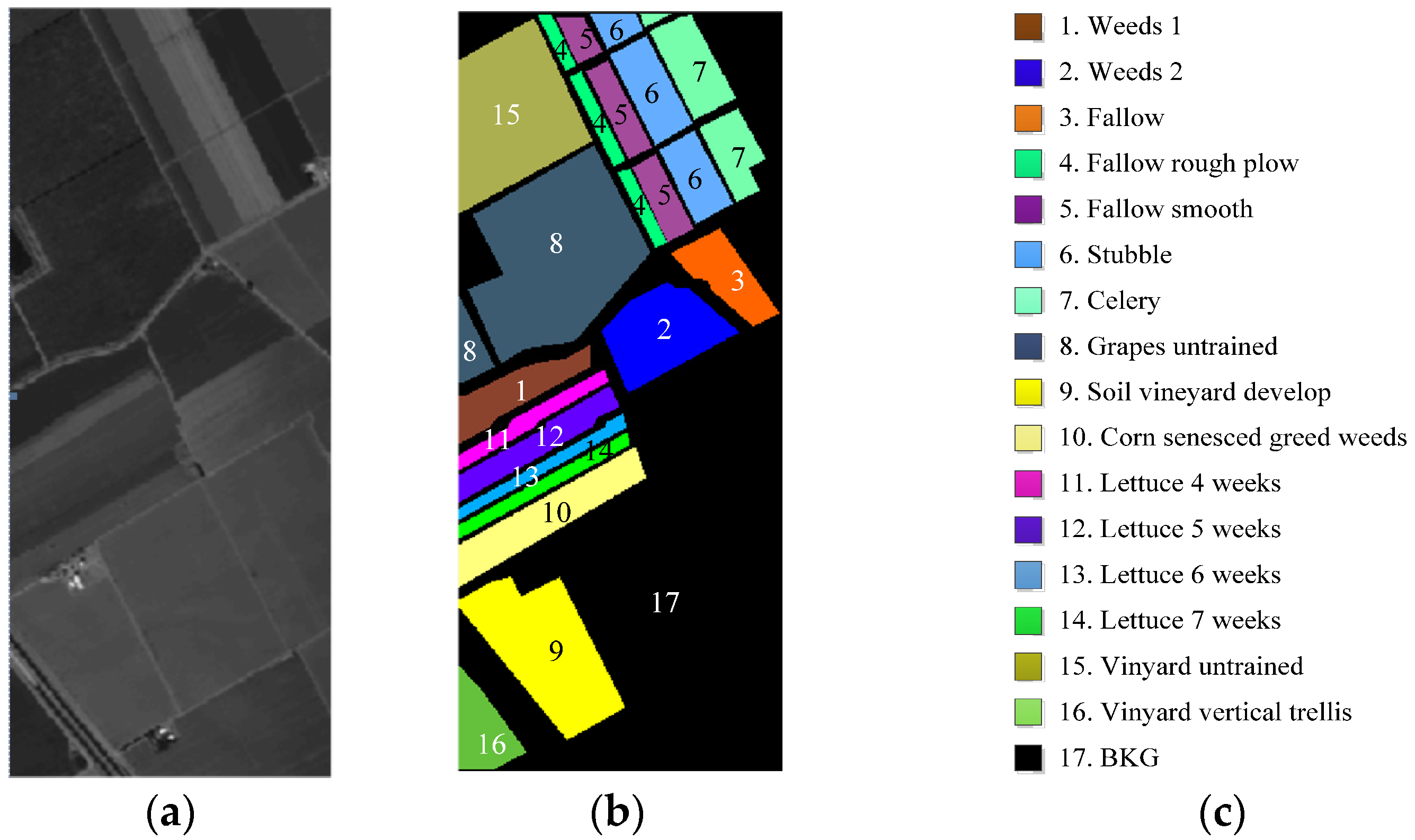
Figure 3.
Ground-truth of Salinas scene with 16 classes. (a) Salinas scene. (b) Ground-truth image. (c) Classes by colors.
Figure 3.
Ground-truth of Salinas scene with 16 classes. (a) Salinas scene. (b) Ground-truth image. (c) Classes by colors.
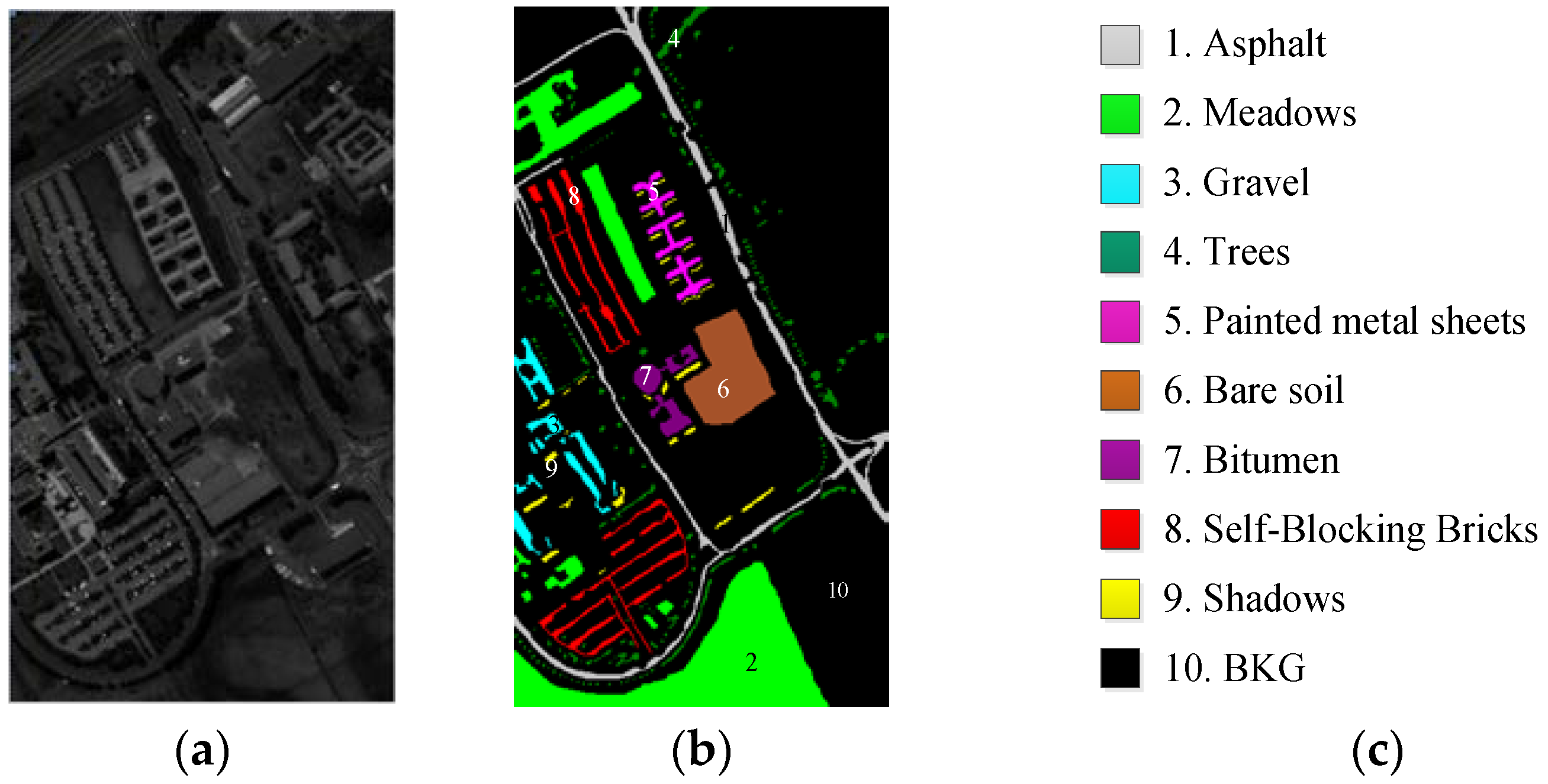
Figure 4.
Ground-truth of University of Pavia scene with nine classes. (a) University of Pavia scene. (b) Ground-truth map. (c) Classes by colors.
Figure 4.
Ground-truth of University of Pavia scene with nine classes. (a) University of Pavia scene. (b) Ground-truth map. (c) Classes by colors.
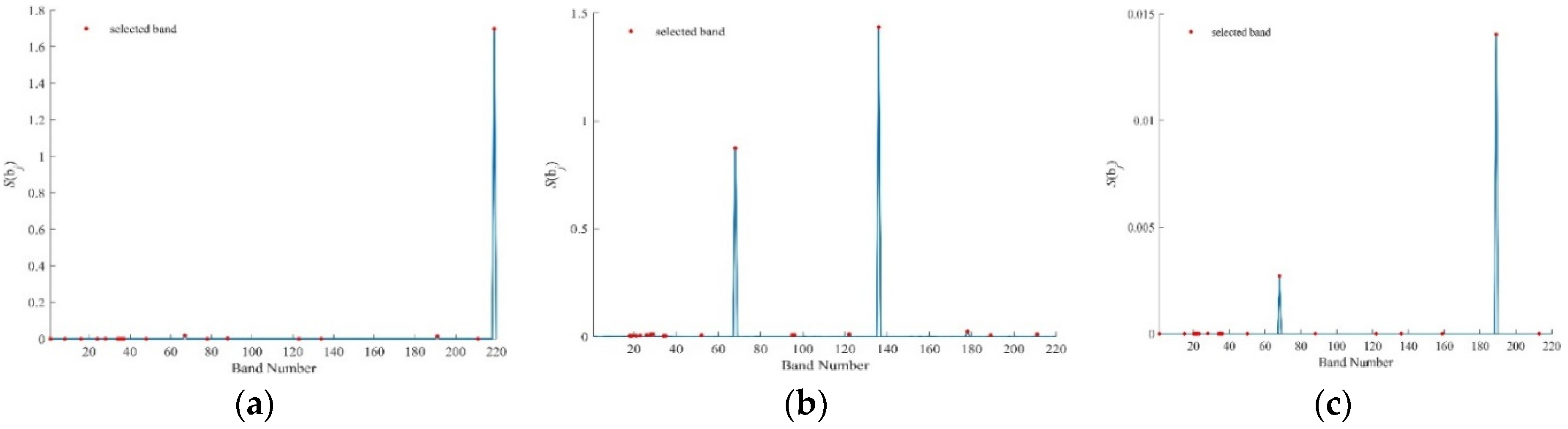
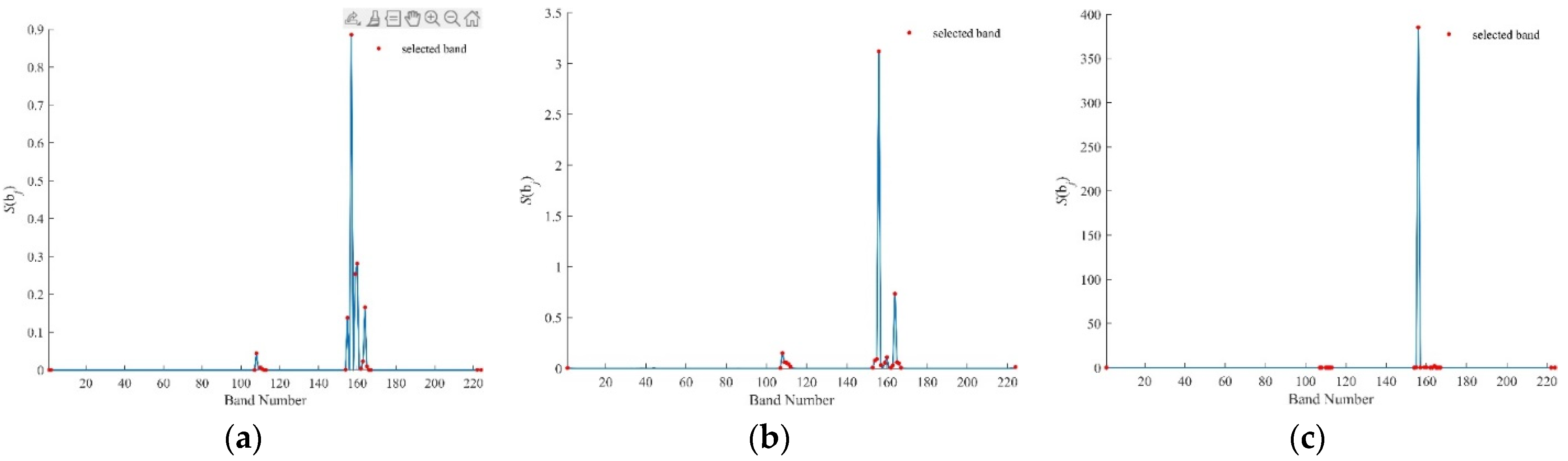
Figure 5.
values by bc-BDPC for the Purdue data using (a) SID, (b) SAM, (c) SIDAM.
Figure 5.
values by bc-BDPC for the Purdue data using (a) SID, (b) SAM, (c) SIDAM.
Figure 6.
values by k-BDPC for the Purdue data using (a) SID, (b) SAM, (c) SIDAM.
Figure 6.
values by k-BDPC for the Purdue data using (a) SID, (b) SAM, (c) SIDAM.
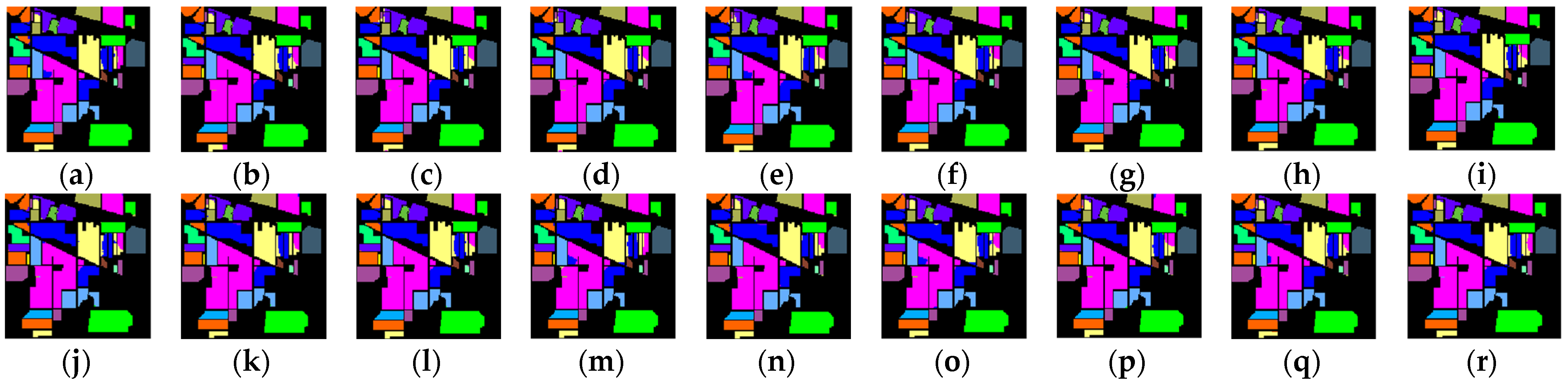
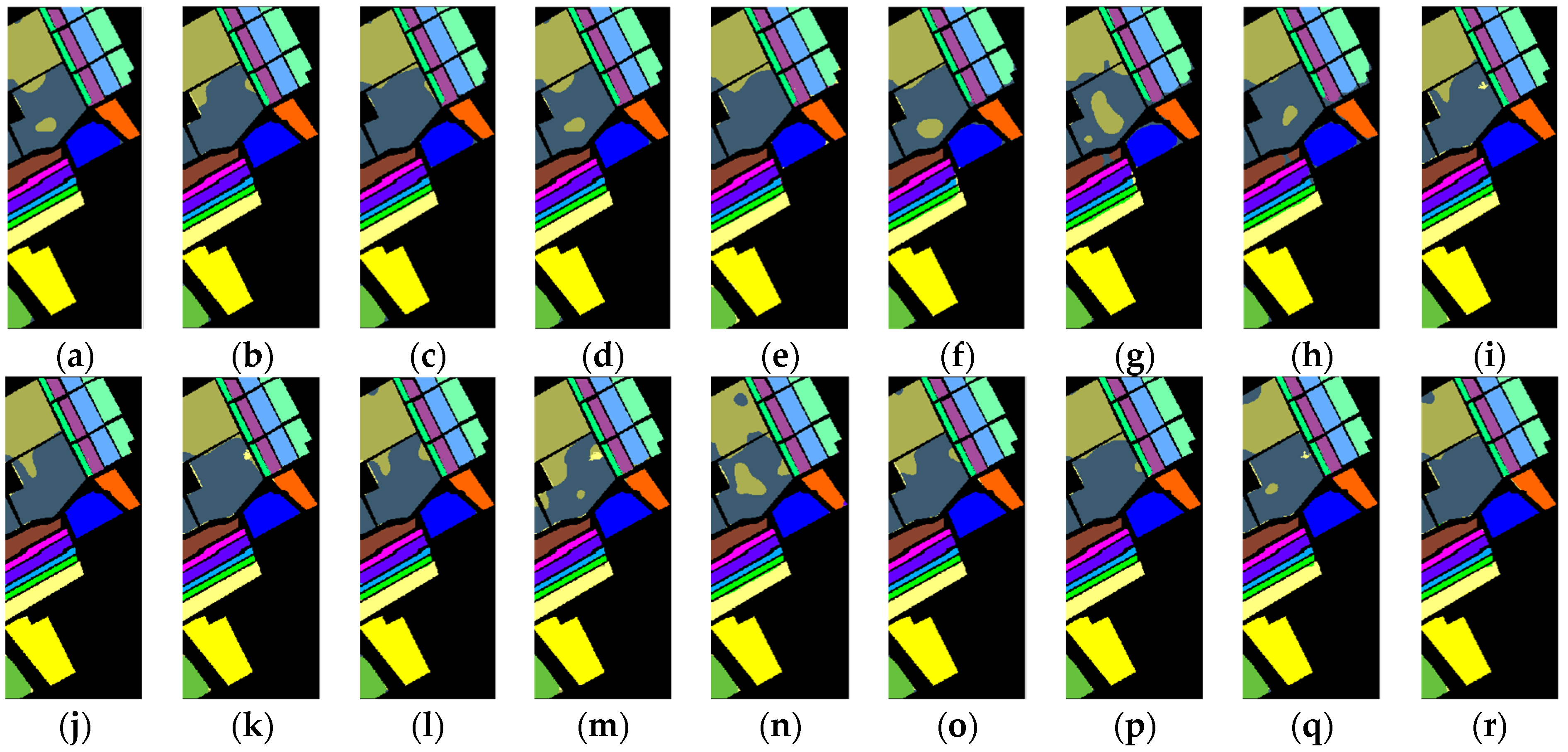
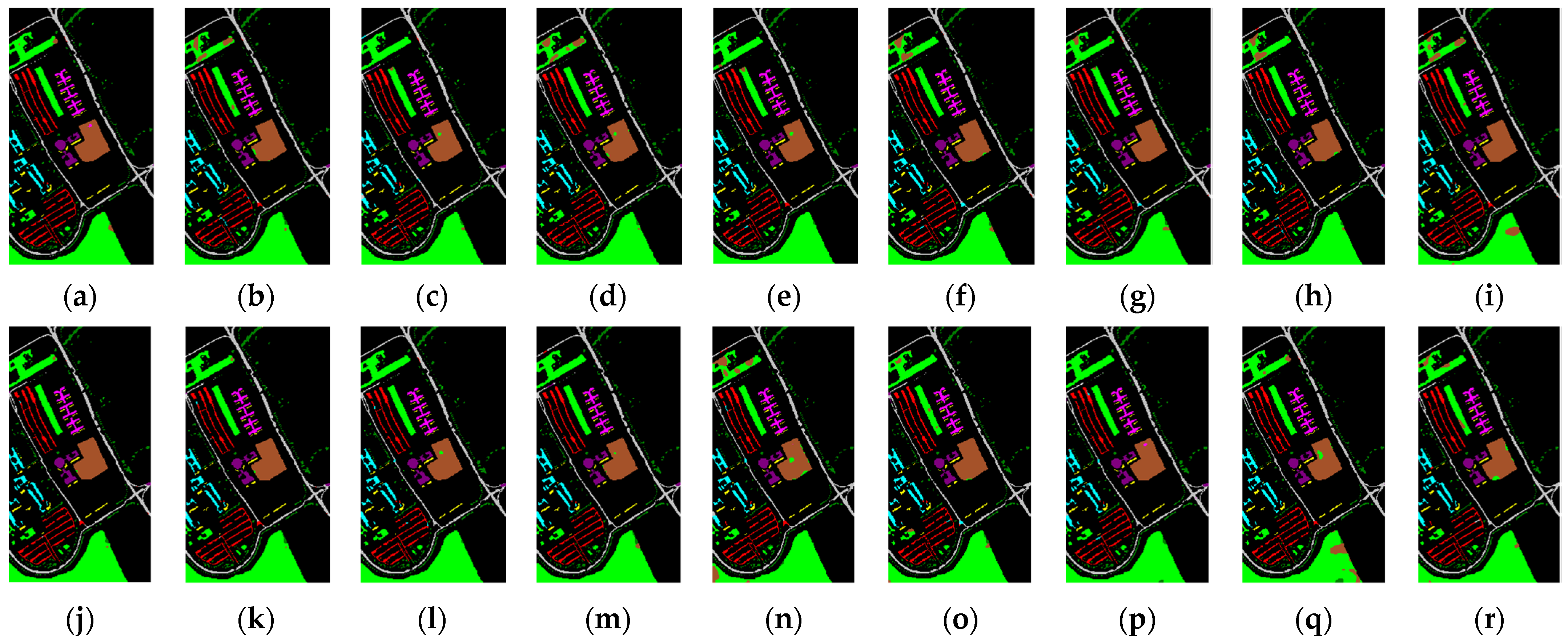
Figure 7.
IEPF-G-g classification maps produced by different BS methods for Purdue data. (a) Full bands (OA = 95.71%), (b) UBS (OA = 96.81%), (c) bc-BDPC-SID (OA = 98.08%),(d) bc-BDPC-SAM (OA = 98.12%), (e) bc-BDPC-SIDAM (OA =97.70%), (f) k-BDPC-SID (OA = 97.53%), (g) k -BDPC-SAM (OA = 97.91%), (h) k-BDPC-SIDA (OA = 97.78%), (i) SMI-BS (OA = 97.57%), (j) ECA (OA = 96.87%), (k) E-FDPC (OA = 97.80%), (l) IaDPI (OA = 97.59%), (m) DPC-KNN (kBS) (OA = 91.77%), (n) DPC-KNN (k = 2%L) (OA = 98.05%), (o) G-DPC-KNN (kBS) (OA = 89.33%), (p) G-DPC-KNN (k = 10) (OA = 97.65%), (q) SNNC (kBS) (OA = 97.14%), (r) SNNC (k = 3) (OA = 97.66%).
Figure 7.
IEPF-G-g classification maps produced by different BS methods for Purdue data. (a) Full bands (OA = 95.71%), (b) UBS (OA = 96.81%), (c) bc-BDPC-SID (OA = 98.08%),(d) bc-BDPC-SAM (OA = 98.12%), (e) bc-BDPC-SIDAM (OA =97.70%), (f) k-BDPC-SID (OA = 97.53%), (g) k -BDPC-SAM (OA = 97.91%), (h) k-BDPC-SIDA (OA = 97.78%), (i) SMI-BS (OA = 97.57%), (j) ECA (OA = 96.87%), (k) E-FDPC (OA = 97.80%), (l) IaDPI (OA = 97.59%), (m) DPC-KNN (kBS) (OA = 91.77%), (n) DPC-KNN (k = 2%L) (OA = 98.05%), (o) G-DPC-KNN (kBS) (OA = 89.33%), (p) G-DPC-KNN (k = 10) (OA = 97.65%), (q) SNNC (kBS) (OA = 97.14%), (r) SNNC (k = 3) (OA = 97.66%).
Figure 8.
values by bc-BDPC for Salinas using (a) SID, (b) SAM, (c) SIDAM.
Figure 8.
values by bc-BDPC for Salinas using (a) SID, (b) SAM, (c) SIDAM.
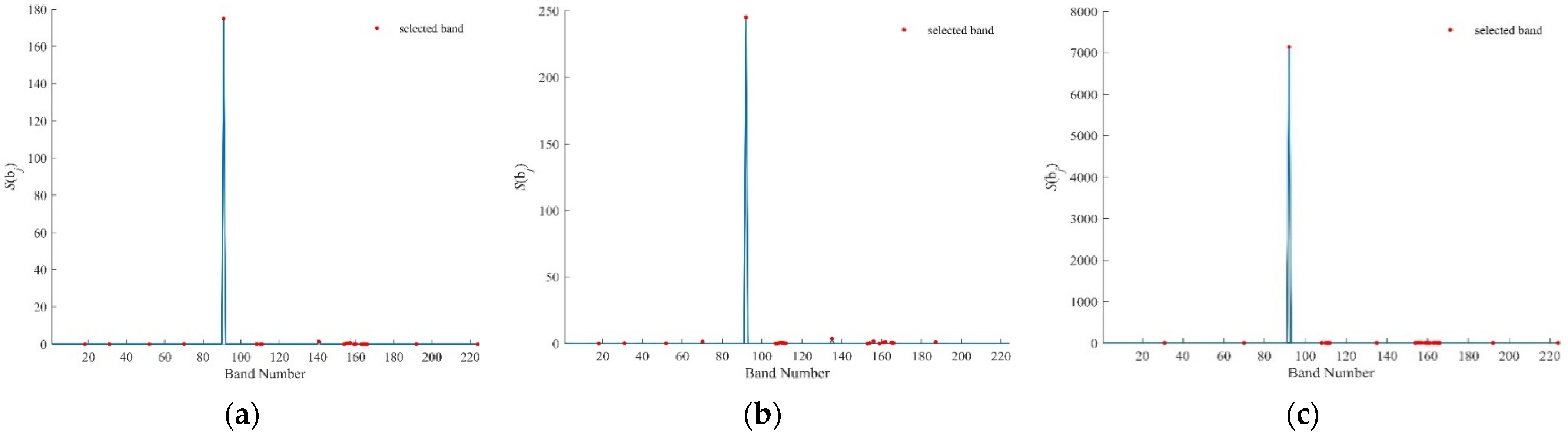
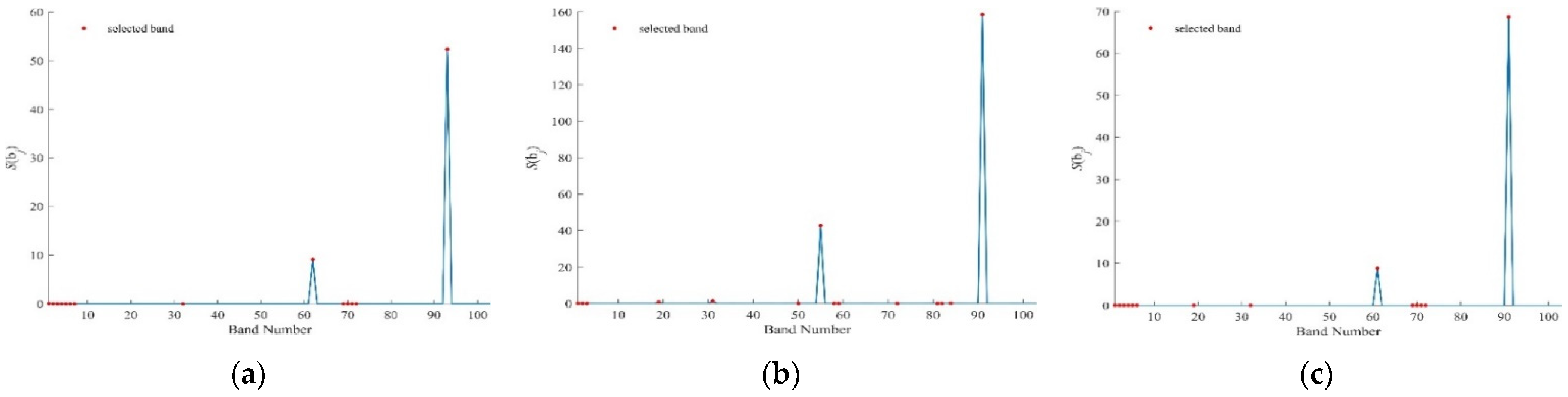
Figure 9.
values by k-BDPC for Salinas using (a) SID, (b) SAM, (c) SIDAM.
Figure 9.
values by k-BDPC for Salinas using (a) SID, (b) SAM, (c) SIDAM.
Figure 10.
Classification maps produced by IEPF-G-g using different BS criterion for Salinas data. (a) Full bands (OA = 96.24%), (b) UBS (OA = 95.69%), (c) bc-BDPC-SID (OA = 95.28%), (d) bc-BDPC-SAM (OA = 96.32%), (e) bc-BDPC-SIDAM (OA = 96.09%), (f) k-BDPC-SID (OA = 91.89%), (g) k -BDPC-SAM (OA = 90.09%), (h) k-BDPC-SIDAM (OA = 90.50%), (i) SMI-BS (OA = 95.32%), (j) ECA (OA = 96.32%), (k) E-FDPC (OA =96.47%), (l) IaDPI (OA = 95.86%), (m) DPC-KNN (kBS) (OA =96.86%), (n) DPC-KNN (k = 2%L) (OA = 95.16%), (o) G-DPC-KNN (kBS) (OA = 95.05%), (p) G-DPC-KNN (k = 10) (OA = 95.81%), (q) SNNC (kBS) (OA = 95.29%), (r) SNNC (k = 3) (OA = 96.91%).
Figure 10.
Classification maps produced by IEPF-G-g using different BS criterion for Salinas data. (a) Full bands (OA = 96.24%), (b) UBS (OA = 95.69%), (c) bc-BDPC-SID (OA = 95.28%), (d) bc-BDPC-SAM (OA = 96.32%), (e) bc-BDPC-SIDAM (OA = 96.09%), (f) k-BDPC-SID (OA = 91.89%), (g) k -BDPC-SAM (OA = 90.09%), (h) k-BDPC-SIDAM (OA = 90.50%), (i) SMI-BS (OA = 95.32%), (j) ECA (OA = 96.32%), (k) E-FDPC (OA =96.47%), (l) IaDPI (OA = 95.86%), (m) DPC-KNN (kBS) (OA =96.86%), (n) DPC-KNN (k = 2%L) (OA = 95.16%), (o) G-DPC-KNN (kBS) (OA = 95.05%), (p) G-DPC-KNN (k = 10) (OA = 95.81%), (q) SNNC (kBS) (OA = 95.29%), (r) SNNC (k = 3) (OA = 96.91%).
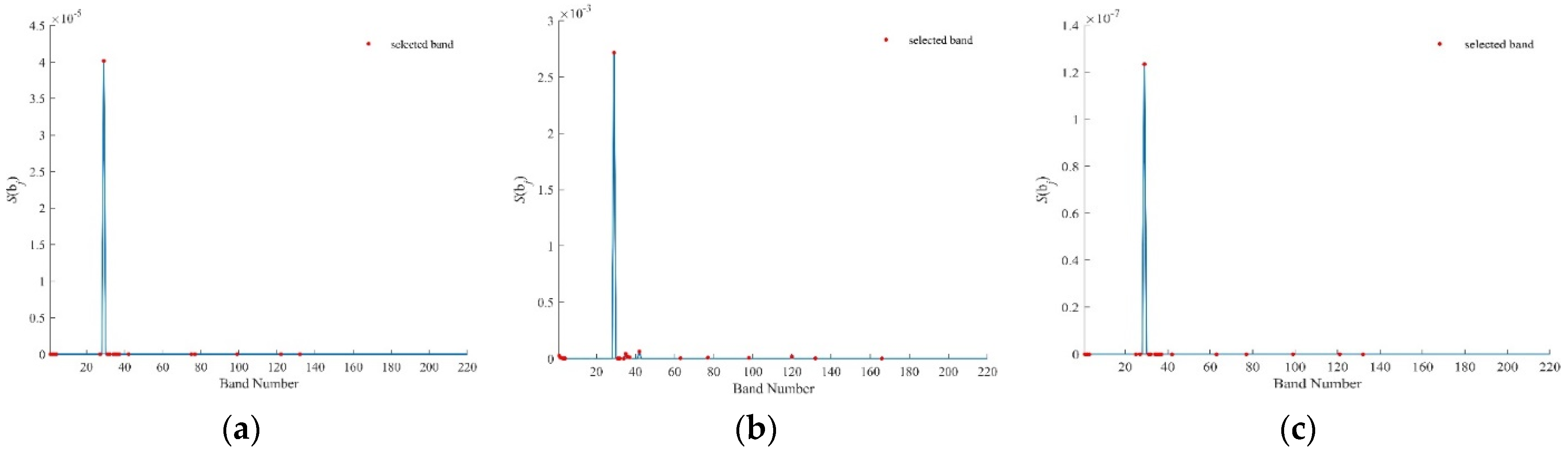
Figure 11.
values by bc-BDPC for U. of Pavia using (a) SID, (b) SAM, (c) SIDAM.
Figure 11.
values by bc-BDPC for U. of Pavia using (a) SID, (b) SAM, (c) SIDAM.
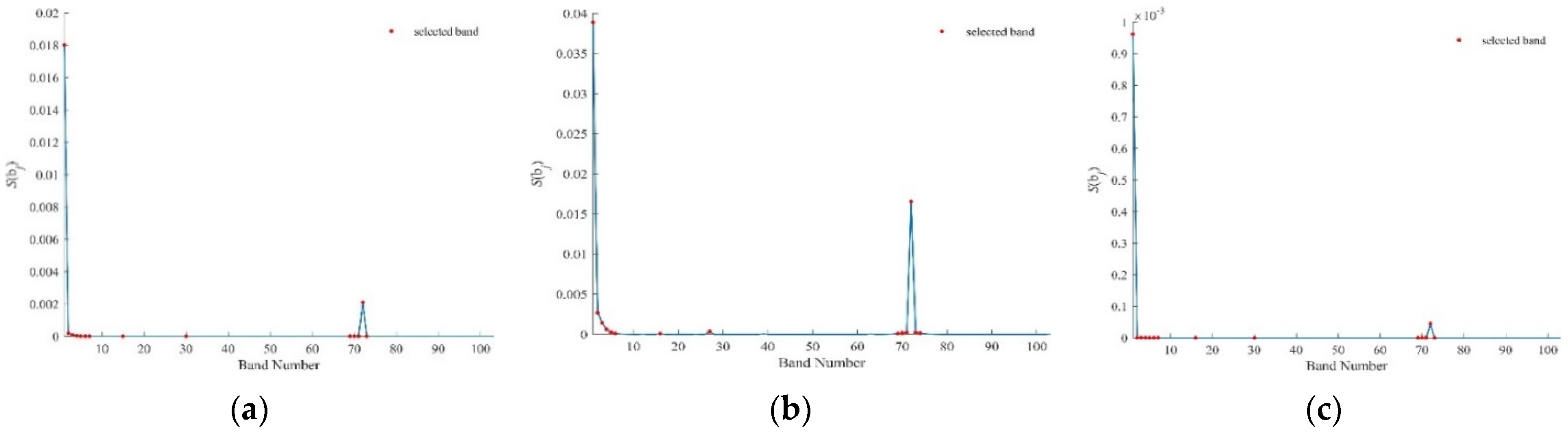
Figure 12.
values by k-BDPC for U. of Pavia using (a) SID, (b) SAM, (c) SIDAM.
Figure 12.
values by k-BDPC for U. of Pavia using (a) SID, (b) SAM, (c) SIDAM.
Figure 13.
Classification maps produced by IEPF-G-g using different BS criterion for University of Pavia data. (a) Full bands (OA = 98.23%), (b) UBS (OA = 96.87%), (c) bc-BDPC-SID (OA = 97.82%), (d) bc-BDPC-SAM (OA = 97.83%), (e) bc-BDPC-SIDAM (OA = 98.13%), (f) k-BDPC-SID (OA = 89.12%), (g) k -BDPC-SAM (OA = 9707%), (h) k-BDPC-SIDA (OA = 96.63%), (i) SMI-BS (OA = 97.46%), (j) ECA (OA = 95.76%), (k) E-FDPC (OA =97.95%), (l) IaDPI (OA = 97.00%), (m) DPC-KNN (kBS) (OA = 97.79%), (n) DPC-KNN (k = 2%L) (OA = 96.07%), (o) G-DPC-KNN (kBS) (OA = 96.93%), (p) G-DPC-KNN (k = 10) (OA = 96.79%), (q) SNNC (kBS) (OA = 97.39%), (r) SNNC (k = 3) (OA = 96.30%).
Figure 13.
Classification maps produced by IEPF-G-g using different BS criterion for University of Pavia data. (a) Full bands (OA = 98.23%), (b) UBS (OA = 96.87%), (c) bc-BDPC-SID (OA = 97.82%), (d) bc-BDPC-SAM (OA = 97.83%), (e) bc-BDPC-SIDAM (OA = 98.13%), (f) k-BDPC-SID (OA = 89.12%), (g) k -BDPC-SAM (OA = 9707%), (h) k-BDPC-SIDA (OA = 96.63%), (i) SMI-BS (OA = 97.46%), (j) ECA (OA = 95.76%), (k) E-FDPC (OA =97.95%), (l) IaDPI (OA = 97.00%), (m) DPC-KNN (kBS) (OA = 97.79%), (n) DPC-KNN (k = 2%L) (OA = 96.07%), (o) G-DPC-KNN (kBS) (OA = 96.93%), (p) G-DPC-KNN (k = 10) (OA = 96.79%), (q) SNNC (kBS) (OA = 97.39%), (r) SNNC (k = 3) (OA = 96.30%).
Table 1.
Class labels of Purdue Indiana Indian Pines with number of data samples in each class.
Table 1.
Class labels of Purdue Indiana Indian Pines with number of data samples in each class.
| class 1 (46) | Alfalfa | class 7 (28) | grass/pasture-mowed | class 13 (205) | wheat |
| class 2 (1428) | corn-notill | class 8 (478) | hay-windrowed | class 14 (1265) | woods |
| class 3 (830) | corn-min | class 9 (20) | oats | class 15 (386) | bldg-grass green-drives |
| class 4 (237) | corn | class 10 (972) | soybeans-notill | class 16 (93) | stone-steel towers |
| class 5 (483) | grass/pasture | class 11 (2455) | soybeans-min | class 17 (10,249) | BKG |
| class 6 (730) | grass/trees | class 12 (593) | soybeans-clean |
Table 2.
Class labels of Salinas with number of data samples in each class.
Table 2.
Class labels of Salinas with number of data samples in each class.
| class 1 (2009) | Brocoli_green_weeds_1 | class 10 (3278) | Corn_senesced_green_weeds |
| class 2 (3726) | Brocoli_green_weeds_2 | class 11 (1068) | Lettuce_romaine_4wk |
| class 3 (1976) | Fallow | class 12 (1927) | Lettuce_romaine_5wk |
| class 4 (1394) | Fallow_rough_plow | class 13 (916) | Lettuce_romaine_6wk |
| class 5 (2678) | Fallow_smooth | class 14 (1070) | Lettuce_romaine_7wk |
| class 6 (3959) | Stubble | Class 15 (7268) | Vinyard_untrained |
| class 7 (3579) | Celery | class 16 (1807) | Vinyard_vertical_trellis |
| class 8 (11,271) | Grapes_untrained | class 17 (56,975) | BKG |
| class 9 (6203) | Soil_vinyard_develop | | |
Table 3.
Class labels of University of Pavia with number of data samples in each class.
Table 3.
Class labels of University of Pavia with number of data samples in each class.
| class 1 (6631) | Asphalt | class 5 (1345) | Painted metal sheets | Class 9 (947) | Shadows |
| class 2 (18,649) | Meadows | class 6 (5029) | Bare Soil | Class 10 (164,624) | BKG |
| class 3 (2099) | Gravel | class 7 (1330) | Bitumen | | |
| class 4 (3064) | Trees | class 8 (3682) | Self-Blocking Bricks | | |
Table 4.
Number of training samples of each class for three datasets.
Table 4.
Number of training samples of each class for three datasets.
| Class | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | Total |
|---|
| Purdue | 25 | 91 | 80 | 65 | 68 | 73 | 14 | 70 | 11 | 81 | 111 | 70 | 66 | 84 | 69 | 47 | 1025 |
| Salinas | 67 | 67 | 67 | 67 | 68 | 67 | 69 | 69 | 67 | 69 | 67 | 67 | 67 | 68 | 68 | 69 | 1083 |
| U. of Pavia | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | | | | | | | | 900 |
Table 5.
Parameter setting for compared DPC-BS methods.
Table 5.
Parameter setting for compared DPC-BS methods.
| DPC Methods | k | bc |
|---|
| bc-BDPC | | nclusters |
| IaDPI | | 2% × L × (L − 1)/exp(nBS/L) |
| k-BDPC | | |
| DPC-kNN | | |
| G-DPC-kNN | emperical selection | Gini coefficient |
| SNNC | k = 3 | |
Table 6.
18 bands selected for the Purdue data.
Table 6.
18 bands selected for the Purdue data.
| | Selected Bands (nVD = 18) |
|---|
| bc-BDPC-SID | 219 | 67 | 191 | 88 | 28 | 134 | 48 | 211 | 16 | 24 | 1 | 35 | 123 | 34 | 36 | 78 | 37 | 8 |
| bc-BDPC-SAM | 136 | 68 | 178 | 29 | 122 | 211 | 28 | 96 | 95 | 26 | 189 | 52 | 23 | 21 | 35 | 18 | 19 | 34 |
| bc-BDPC-SIDAM | 189 | 68 | 28 | 88 | 136 | 159 | 15 | 50 | 21 | 213 | 22 | 122 | 1 | 20 | 35 | 34 | 23 | 36 |
| k-BDPC-SID | 29 | 35 | 42 | 1 | 36 | 122 | 37 | 77 | 99 | 2 | 32 | 75 | 34 | 132 | 3 | 31 | 27 | 4 |
| k -BDPC-SAM | 29 | 42 | 35 | 1 | 36 | 120 | 37 | 77 | 98 | 2 | 63 | 132 | 3 | 32 | 166 | 4 | 31 | 34 |
| k-BDPC-SIDAM | 29 | 35 | 42 | 1 | 36 | 121 | 37 | 77 | 99 | 34 | 2 | 32 | 63 | 31 | 3 | 132 | 27 | 25 |
| SMI-BS | 59 | 117 | 125 | 38 | 40 | 180 | 173 | 20 | 168 | 31 | 34 | 12 | 114 | 192 | 160 | 108 | 95 | 92 |
| ECA | 164 | 129 | 67 | 83 | 193 | 52 | 14 | 197 | 28 | 110 | 147 | 103 | 112 | 111 | 149 | 208 | 165 | 107 |
| E-FDPC | 194 | 32 | 2 | 100 | 98 | 61 | 1 | 36 | 35 | 99 | 60 | 31 | 101 | 76 | 62 | 13 | 58 | 59 |
| IaDPI | 171 | 115 | 8 | 208 | 87 | 58 | 142 | 46 | 77 | 135 | 31 | 176 | 97 | 190 | 15 | 92 | 54 | 160 |
| DPC-KNN (kBS) | 150 | 136 | 187 | 146 | 147 | 119 | 145 | 116 | 103 | 110 | 114 | 101 | 112 | 115 | 125 | 111 | 205 | 208 |
| DPC-KNN (k = 2%L) | 37 | 36 | 2 | 75 | 46 | 1 | 57 | 61 | 42 | 4 | 7 | 100 | 32 | 3 | 47 | 35 | 62 | 183 |
| G-DPC-KNN (kBS) | 204 | 206 | 203 | 205 | 148 | 202 | 112 | 207 | 209 | 167 | 201 | 65 | 69 | 70 | 126 | 129 | 132 | 133 |
| G-DPC-KNN (k = 10) | 1 | 101 | 81 | 100 | 37 | 117 | 61 | 145 | 46 | 76 | 60 | 36 | 58 | 75 | 78 | 3 | 4 | 79 |
| SNNC (kBS) | 104 | 3 | 1 | 37 | 77 | 58 | 38 | 2 | 61 | 119 | 60 | 5 | 6 | 100 | 82 | 76 | 40 | 36 |
| SNNC (k = 3) | 180 | 49 | 84 | 65 | 132 | 10 | 6 | 81 | 77 | 142 | 21 | 2 | 1 | 88 | 82 | 207 | 57 | 76 |
| uniform BS | 1 | 14 | 27 | 40 | 53 | 66 | 79 | 92 | 105 | 118 | 131 | 144 | 157 | 170 | 183 | 196 | 209 | 220 |
Table 7.
Quantitative comparative analysis of classification for the Purdue data among bc-BDPC and k-BDPC using, SID, SAM, and SIDAM along with full bands and uniform BS, with the best and second-best results highlighted and boldfaced in red and black, respectively.
Table 7.
Quantitative comparative analysis of classification for the Purdue data among bc-BDPC and k-BDPC using, SID, SAM, and SIDAM along with full bands and uniform BS, with the best and second-best results highlighted and boldfaced in red and black, respectively.
| IEPF-G-g |
|---|
| Class | bc-BDPC-SID | bc-BDPC-SAM | bc-BDPC-SIDAM | k-BDPC-SID | k-BDPC-SAM | k-BDPC-SIDAM | Uniform BS | Full Bands |
|---|
| 1 | 1.0000 | 0.9957 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.9978 | 0.9957 |
| 2 | 0.9646 | 0.9660 | 0.9644 | 0.9590 | 0.9637 | 0.9568 | 0.9293 | 0.9302 |
| 3 | 0.9886 | 0.9833 | 0.9865 | 0.9857 | 0.9877 | 0.9883 | 0.9839 | 0.9619 |
| 4 | 0.9975 | 0.9987 | 0.9979 | 0.9983 | 0.9992 | 0.9987 | 1.0000 | 0.9899 |
| 5 | 0.9783 | 0.9799 | 0.9783 | 0.9762 | 0.9785 | 0.9756 | 0.9764 | 0.9627 |
| 6 | 0.9996 | 0.9993 | 0.9999 | 0.9996 | 0.9997 | 0.9993 | 0.9986 | 0.9947 |
| 7 | 0.9929 | 0.9893 | 0.9964 | 0.9929 | 0.9929 | 0.9929 | 0.9893 | 0.9893 |
| 8 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 9 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 10 | 0.9697 | 0.9786 | 0.9643 | 0.9770 | 0.9773 | 0.9731 | 0.9551 | 0.9399 |
| 11 | 0.9656 | 0.9654 | 0.9527 | 0.9446 | 0.9559 | 0.9530 | 0.9411 | 0.9224 |
| 12 | 0.9921 | 0.9874 | 0.9892 | 0.9914 | 0.9917 | 0.9921 | 0.9916 | 0.9855 |
| 13 | 0.9976 | 0.9961 | 0.9971 | 0.9976 | 0.9971 | 0.9976 | 0.9966 | 0.9966 |
| 14 | 0.9962 | 0.9975 | 0.9972 | 0.9963 | 0.9972 | 0.9963 | 0.9962 | 0.9837 |
| 15 | 0.9969 | 0.9940 | 0.9982 | 0.9951 | 0.9953 | 0.9953 | 0.9969 | 0.9886 |
| 16 | 0.9968 | 0.9978 | 0.9978 | 0.9989 | 0.9978 | 0.9989 | 0.9989 | 0.9957 |
| POA | 0.9808 | 0.9812 | 0.9770 | 0.9753 | 0.9791 | 0.9768 | 0.9681 | 0.9571 |
| PAA | 0.9898 | 0.9893 | 0.9887 | 0.9883 | 0.9896 | 0.9886 | 0.9845 | 0.9773 |
| Kappa | 0.9779 | 0.9786 | 0.9740 | 0.9721 | 0.9763 | 0.9736 | 0.9638 | 0.9514 |
| time (s) | 27 | 3 | 85 | 42 | 7 | 69 | | |
Table 8.
Quantitative comparative analysis of classification for the Purdue data among SMI-BS, ECA, E-FDPC, IaDPI, DPC-KNN, G-DPC-KNN, and SNNC, with the best and second-best results highlighted and boldfaced in red and black, respectively.
Table 8.
Quantitative comparative analysis of classification for the Purdue data among SMI-BS, ECA, E-FDPC, IaDPI, DPC-KNN, G-DPC-KNN, and SNNC, with the best and second-best results highlighted and boldfaced in red and black, respectively.
| IEPF-G-g |
|---|
| Class | SMI-BS | ECA | E-FDPC | IaDPI | DPC-KNN (kBS) | DPC-KNN
(k = 2%L) | G-DPC-KNN (kBS) | G-DPC-KNN
(k = 10) | SNNC (kBS) | SNNC
(k = 3) |
|---|
| 1 | 1.0000 | 1.0000 | 0.9978 | 0.9978 | 1.0000 | 0.9957 | 0.9609 | 0.9978 | 0.9957 | 0.9957 |
| 2 | 0.9575 | 0.9440 | 0.9629 | 0.9538 | 0.8965 | 0.9723 | 0.8763 | 0.9567 | 0.9502 | 0.9491 |
| 3 | 0.9851 | 0.9800 | 0.9841 | 0.9878 | 0.9167 | 0.9898 | 0.8848 | 0.9837 | 0.9855 | 0.9887 |
| 4 | 0.9987 | 0.9987 | 0.9975 | 0.9975 | 0.9764 | 0.9975 | 0.9435 | 0.9992 | 0.9970 | 0.9970 |
| 5 | 0.9797 | 0.9783 | 0.9762 | 0.9816 | 0.9482 | 0.9723 | 0.8874 | 0.9716 | 0.9712 | 0.9789 |
| 6 | 0.9993 | 0.9981 | 0.9984 | 0.9989 | 0.9296 | 0.9970 | 0.8788 | 0.9964 | 0.9968 | 0.9989 |
| 7 | 0.9929 | 0.9893 | 0.9964 | 0.9929 | 1.0000 | 0.9857 | 0.9750 | 0.9857 | 0.9857 | 0.9964 |
| 8 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.9862 | 0.9998 | 0.9427 | 1.0000 | 1.0000 | 1.0000 |
| 9 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.9650 | 1.0000 | 0.9350 | 1.0000 | 1.0000 | 1.0000 |
| 10 | 0.9679 | 0.9531 | 0.9779 | 0.9723 | 0.9032 | 0.9767 | 0.8606 | 0.9677 | 0.9629 | 0.9660 |
| 11 | 0.9505 | 0.9374 | 0.9545 | 0.9509 | 0.8727 | 0.9604 | 0.9124 | 0.9576 | 0.9431 | 0.9598 |
| 12 | 0.9922 | 0.9921 | 0.9921 | 0.9934 | 0.9290 | 0.9931 | 0.8663 | 0.9944 | 0.9933 | 0.9907 |
| 13 | 0.9951 | 0.9971 | 0.9966 | 0.9961 | 0.9815 | 0.9976 | 0.9444 | 0.9980 | 0.9980 | 0.9980 |
| 14 | 0.9963 | 0.9947 | 0.9968 | 0.9947 | 0.9435 | 0.9957 | 0.8736 | 0.9960 | 0.9942 | 0.9953 |
| 15 | 0.9953 | 0.9974 | 0.9917 | 0.9959 | 0.9733 | 0.9876 | 0.9254 | 0.9899 | 0.9878 | 0.9959 |
| 16 | 0.9989 | 1.0000 | 0.9968 | 0.9978 | 0.9645 | 0.9925 | 0.9570 | 0.9978 | 0.9957 | 0.9978 |
| POA | 0.9757 | 0.9687 | 0.9780 | 0.9759 | 0.9177 | 0.9805 | 0.8933 | 0.9765 | 0.9714 | 0.9766 |
| PAA | 0.9881 | 0.9850 | 0.9887 | 0.9882 | 0.9491 | 0.9883 | 0.9140 | 0.9870 | 0.9848 | 0.9880 |
| Kappa | 0.9723 | 0.9644 | 0.9751 | 0.9724 | 0.9071 | 0.9779 | 0.8798 | 0.9734 | 0.9677 | 0.9734 |
| time (s) | 36 | 0.2 | 0.2 | 0.3 | 0.2 | 0.2 | 0.3 | 0.3 | 0.4 | 0.7 |
Table 9.
21 bands selected for Salinas.
Table 9.
21 bands selected for Salinas.
| | Selected Bands (nVD = 21) | |
|---|
| bc-BDPC-SID | 91 | 141 | 157 | 156 | 155 | 70 | 159 | 108 | 192 | 164 | 160 | 165 | 31 | 111 | 166 | 110 | 163 | 154 | 224 | 18 | 52 |
| bc-BDPC -SAM | 92 | 135 | 156 | 70 | 162 | 187 | 161 | 109 | 165 | 110 | 111 | 166 | 154 | 31 | 112 | 52 | 18 | 108 | 159 | 107 | 153 |
| bc-BDPC -SIDAM | 92 | 156 | 155 | 157 | 164 | 159 | 163 | 160 | 161 | 165 | 108 | 135 | 111 | 154 | 166 | 192 | 70 | 110 | 112 | 224 | 31 |
| k-BDPC-SID | 157 | 160 | 159 | 164 | 155 | 108 | 163 | 165 | 110 | 162 | 111 | 154 | 166 | 224 | 1 | 112 | 222 | 107 | 167 | 113 | 2 |
| k -BDPC -SAM | 156 | 164 | 108 | 160 | 155 | 154 | 109 | 165 | 159 | 110 | 166 | 111 | 157 | 163 | 112 | 224 | 153 | 162 | 167 | 107 | 1 |
| k-BDPC -SIDAM | 156 | 164 | 159 | 160 | 155 | 157 | 108 | 163 | 165 | 162 | 110 | 111 | 154 | 166 | 224 | 112 | 222 | 107 | 167 | 1 | 113 |
| SMI-BS | 15 | 32 | 34 | 40 | 63 | 117 | 150 | 157 | 184 | 206 | 223 | 22 | 41 | 64 | 71 | 94 | 118 | 151 | 176 | 185 | 202 |
| ECA | 109 | 184 | 88 | 68 | 136 | 211 | 32 | 194 | 218 | 55 | 215 | 96 | 153 | 93 | 118 | 204 | 224 | 160 | 161 | 166 | 180 |
| E-FDPC | 193 | 61 | 104 | 5 | 4 | 103 | 78 | 64 | 81 | 102 | 9 | 39 | 105 | 2 | 36 | 83 | 38 | 3 | 80 | 106 | 84 |
| IaDPI | 154 | 38 | 107 | 194 | 8 | 65 | 140 | 19 | 89 | 167 | 101 | 112 | 159 | 136 | 96 | 33 | 85 | 133 | 175 | 170 | 162 |
| DPC-KNN (kBS) | 111 | 24 | 89 | 73 | 197 | 129 | 104 | 5 | 17 | 105 | 64 | 2 | 63 | 210 | 81 | 3 | 37 | 15 | 36 | 106 | 103 |
| DPC-KNN (k = 6%L) | 159 | 156 | 157 | 158 | 163 | 162 | 164 | 108 | 165 | 110 | 111 | 155 | 154 | 112 | 222 | 212 | 137 | 220 | 92 | 161 | 217 |
| G-DPC-KNN (kBS) | 204 | 205 | 202 | 150 | 209 | 206 | 207 | 119 | 203 | 118 | 117 | 170 | 36 | 22 | 23 | 24 | 27 | 21 | 17 | 15 | 25 |
| G-DPC-KNN (k = 7) | 38 | 64 | 57 | 49 | 6 | 134 | 133 | 63 | 108 | 109 | 5 | 104 | 45 | 43 | 78 | 8 | 87 | 38 | 64 | 57 | 49 |
| SNNC (kBS) | 39 | 121 | 4 | 22 | 3 | 117 | 123 | 41 | 104 | 63 | 85 | 43 | 64 | 1 | 2 | 65 | 8 | 39 | 121 | 4 | 22 |
| SNNC (k = 3) | 183 | 5 | 130 | 14 | 18 | 173 | 24 | 4 | 84 | 3 | 66 | 96 | 82 | 193 | 10 | 2 | 54 | 183 | 5 | 130 | 14 |
| Uniform BS | 1 | 12 | 23 | 34 | 45 | 56 | 67 | 78 | 89 | 100 | 111 | 122 | 133 | 144 | 155 | 166 | 177 | 188 | 199 | 210 | 224 |
Table 10.
Quantitative comparative analysis of classification for Salinas among bc-BDPC and k-BDPC using SID, SAM, and SIDAM, along with full bands and uniform BS, with the best and second-best results highlighted and boldfaced in red and black, respectively.
Table 10.
Quantitative comparative analysis of classification for Salinas among bc-BDPC and k-BDPC using SID, SAM, and SIDAM, along with full bands and uniform BS, with the best and second-best results highlighted and boldfaced in red and black, respectively.
| IEPF-G-g |
|---|
| Class | bc-BDPC-SID | bc-BDPC-SAM | bc-BDPC-SIDAM | k-BDPC-SID | k-BDPC-SAM | k-BDPC-SIDAM | UBS | Full Bands |
|---|
| 1 | 0.9990 | 0.9979 | 0.9983 | 0.9924 | 0.9855 | 0.9795 | 0.9998 | 1.0000 |
| 2 | 0.9909 | 0.9914 | 0.9937 | 0.9837 | 0.9749 | 0.9612 | 0.9964 | 0.9967 |
| 3 | 0.9989 | 0.9978 | 0.9935 | 0.9945 | 0.9907 | 0.9844 | 0.9997 | 0.9986 |
| 4 | 0.9945 | 0.9944 | 0.9963 | 0.9919 | 0.9896 | 0.9851 | 0.9986 | 0.9973 |
| 5 | 0.9872 | 0.9886 | 0.9851 | 0.9757 | 0.9801 | 0.9786 | 0.9916 | 0.9899 |
| 6 | 0.9961 | 0.9962 | 0.9946 | 0.9983 | 0.9997 | 0.9937 | 0.9988 | 0.9978 |
| 7 | 0.9943 | 0.9926 | 0.9920 | 0.9940 | 0.9944 | 0.9806 | 0.9963 | 0.9958 |
| 8 | 0.8876 | 0.9058 | 0.9048 | 0.7649 | 0.7155 | 0.7559 | 0.8886 | 0.8944 |
| 9 | 0.9946 | 0.9929 | 0.9848 | 0.9934 | 0.9903 | 0.9893 | 0.9957 | 0.9964 |
| 10 | 0.9868 | 0.9883 | 0.9739 | 0.9738 | 0.9702 | 0.9612 | 0.9889 | 0.9820 |
| 11 | 0.9934 | 0.9925 | 0.9944 | 0.9949 | 0.9966 | 0.9829 | 0.9982 | 0.9960 |
| 12 | 0.9992 | 0.9977 | 0.9982 | 0.9866 | 0.9955 | 0.9853 | 1.0000 | 1.0000 |
| 13 | 0.9893 | 0.9902 | 0.9880 | 0.9988 | 0.9979 | 0.9848 | 0.9927 | 0.9936 |
| 14 | 0.9874 | 0.9904 | 0.9880 | 0.9931 | 0.9857 | 0.9859 | 0.9932 | 0.9894 |
| 15 | 0.8968 | 0.9084 | 0.9098 | 0.8127 | 0.7621 | 0.7646 | 0.8728 | 0.9098 |
| 16 | 0.9878 | 0.9826 | 0.9776 | 0.9872 | 0.9925 | 0.9877 | 0.9903 | 0.9901 |
| POA | 0.9582 | 0.9632 | 0.9609 | 0.9189 | 0.9009 | 0.9050 | 0.9569 | 0.9624 |
| PAA | 0.9802 | 0.9817 | 0.9796 | 0.9647 | 0.9576 | 0.9538 | 0.9814 | 0.9830 |
| Kappa | 0.9537 | 0.9529 | 0.9567 | 0.9106 | 0.8911 | 0.8955 | 0.9523 | 0.9583 |
| time (s) | 139 | 8 | 275 | 228 | 48 | 278 | | |
Table 11.
Quantitative comparative analysis of classification for Salinas among SMI-BS, ECA, E-FDPC, IaDPI, DPC-KNN, G-DPC-KNN, and SNNC, with the best and second-best results highlighted and boldfaced in red and black, respectively.
Table 11.
Quantitative comparative analysis of classification for Salinas among SMI-BS, ECA, E-FDPC, IaDPI, DPC-KNN, G-DPC-KNN, and SNNC, with the best and second-best results highlighted and boldfaced in red and black, respectively.
| IEPF-G-g |
|---|
| Class | SMI-BS | ECA | E-FDPC | IaDPI | DPC-KNN (kBS) | DPC-KNN (k = 2%L) | G-DPC-KNN (kBS) | G-DPC-KNN (k = 7) | SNNC (kBS) | SNN
(k = 3) |
|---|
| 1 | 0.9998 | 0.9999 | 1.0000 | 1.0000 | 0.9999 | 0.9959 | 0.9940 | 0.9999 | 1.0000 | 0.9999 |
| 2 | 0.9947 | 0.9948 | 0.9979 | 0.9989 | 0.9977 | 0.9857 | 0.9977 | 0.9973 | 0.9979 | 0.9976 |
| 3 | 0.9996 | 0.9991 | 0.9992 | 0.9992 | 0.9999 | 0.9920 | 0.9879 | 0.9990 | 0.9997 | 0.9997 |
| 4 | 0.9979 | 0.9981 | 0.9966 | 0.9985 | 0.9958 | 0.9946 | 0.9951 | 0.9981 | 0.9976 | 0.9961 |
| 5 | 0.9909 | 0.9874 | 0.9896 | 0.9879 | 0.9929 | 0.9825 | 0.9771 | 0.9884 | 0.9882 | 0.9926 |
| 6 | 0.9982 | 0.9978 | 0.9994 | 0.9987 | 0.9990 | 0.9930 | 0.9922 | 0.9990 | 0.9993 | 0.9987 |
| 7 | 0.9955 | 0.9960 | 0.9968 | 0.9963 | 0.9963 | 0.9907 | 0.9928 | 0.9956 | 0.9961 | 0.9963 |
| 8 | 0.8611 | 0.9004 | 0.8997 | 0.8773 | 0.9178 | 0.8784 | 0.9037 | 0.8710 | 0.8652 | 0.9160 |
| 9 | 0.9945 | 0.9950 | 0.9998 | 0.9963 | 0.9960 | 0.9867 | 0.9880 | 0.9977 | 0.9993 | 0.9968 |
| 10 | 0.9822 | 0.9824 | 0.9829 | 0.9884 | 0.9854 | 0.9678 | 0.9803 | 0.9855 | 0.9864 | 0.9882 |
| 11 | 0.9961 | 0.9947 | 0.9963 | 0.9970 | 0.9978 | 0.9898 | 0.9890 | 0.9965 | 0.9971 | 0.9970 |
| 12 | 1.0000 | 0.9996 | 1.0000 | 0.9999 | 1.0000 | 0.9884 | 0.9934 | 1.0000 | 1.0000 | 0.9999 |
| 13 | 0.9936 | 0.9940 | 0.9963 | 0.9976 | 0.9931 | 0.9922 | 0.9956 | 0.9944 | 0.9951 | 0.9942 |
| 14 | 0.9915 | 0.9920 | 0.9951 | 0.9933 | 0.9918 | 0.9841 | 0.9873 | 0.9928 | 0.9917 | 0.9931 |
| 15 | 0.8946 | 0.9091 | 0.9121 | 0.9026 | 0.9154 | 0.8946 | 0.8393 | 0.9095 | 0.8763 | 0.9201 |
| 16 | 0.9912 | 0.9883 | 0.9918 | 0.9888 | 0.9907 | 0.9736 | 0.9869 | 0.9939 | 0.9951 | 0.9900 |
| POA | 0.9532 | 0.9632 | 0.9647 | 0.9586 | 0.9686 | 0.9516 | 0.9515 | 0.9581 | 0.9529 | 0.9691 |
| PAA | 0.9801 | 0.9830 | 0.9846 | 0.9826 | 0.9856 | 0.9744 | 0.9750 | 0.9824 | 0.9803 | 0.9860 |
| Kappa | 0.9483 | 0.9591 | 0.9609 | 0.9541 | 0.9652 | 0.9464 | 0.9462 | 0.9536 | 0.9478 | 0.9657 |
| time (s) | 149 | 1.8 | 1.8 | 2.1 | 1.9 | 1.8 | 1.7 | 1.7 | 1.9 | 1.9 |
Table 12.
14 bands selected for U. of Pavia.
Table 12.
14 bands selected for U. of Pavia.
| | Selected Bands (nVD = 14) |
|---|
| bc-BDPC-SID | 93 | 62 | 1 | 2 | 3 | 71 | 4 | 70 | 32 | 5 | 72 | 69 | 6 | 7 |
| bc-BDP-SAM | 91 | 55 | 31 | 19 | 84 | 1 | 2 | 82 | 58 | 50 | 72 | 59 | 3 | 81 |
| bc-BDPC-SIDAM | 91 | 61 | 1 | 2 | 3 | 71 | 70 | 4 | 32 | 72 | 5 | 69 | 19 | 6 |
| k-BDPC-SID | 1 | 72 | 2 | 3 | 4 | 5 | 30 | 6 | 15 | 71 | 70 | 7 | 73 | 69 |
| k -BDPC-SAM | 1 | 72 | 2 | 3 | 4 | 27 | 5 | 71 | 73 | 70 | 74 | 6 | 69 | 16 |
| k-BDPC-SIDAM | 1 | 72 | 2 | 3 | 4 | 5 | 30 | 16 | 6 | 71 | 70 | 73 | 69 | 7 |
| SMI-BS | 22 | 41 | 91 | 9 | 18 | 21 | 37 | 40 | 48 | 57 | 66 | 82 | 92 | 94 |
| ECA | 61 | 88 | 53 | 46 | 33 | 62 | 56 | 63 | 49 | 60 | 92 | 47 | 57 | 54 |
| E-FDPC | 50 | 93 | 24 | 84 | 82 | 2 | 4 | 3 | 68 | 5 | 67 | 69 | 1 | 6 |
| IaDPI | 74 | 32 | 5 | 98 | 84 | 45 | 51 | 41 | 94 | 76 | 75 | 73 | 77 | 72 |
| DPC-KNN (kBS) | 58 | 93 | 16 | 35 | 1 | 2 | 3 | 4 | 82 | 69 | 84 | 77 | 5 | 52 |
| DPC-KNN (k = 2%L) | 60 | 63 | 61 | 57 | 53 | 47 | 64 | 51 | 49 | 45 | 89 | 32 | 91 | 55 |
| G-DPC-KNN (kBS) | 28 | 27 | 29 | 26 | 30 | 31 | 36 | 35 | 33 | 34 | 32 | 79 | 78 | 77 |
| G-DPC-KNN (k = 7) | 75 | 71 | 72 | 68 | 67 | 76 | 74 | 69 | 73 | 60 | 58 | 56 | 50 | 53 |
| SNNC (kBS) | 82 | 5 | 2 | 49 | 1 | 3 | 4 | 7 | 29 | 9 | 6 | 93 | 11 | 86 |
| SNNC (k = 5) | 92 | 59 | 1 | 7 | 2 | 3 | 4 | 17 | 5 | 100 | 6 | 75 | 8 | 9 |
| Uniform BS | 1 | 9 | 17 | 25 | 33 | 41 | 49 | 57 | 65 | 73 | 81 | 89 | 97 | 103 |
Table 13.
Quantitative comparative analysis of classification for U. of Pavia among bc-BDPC and k-BDPC using SID, SAM, and SIDAM, along with full bands and uniform BS, with the best and second-best results highlighted and boldfaced in red and black, respectively.
Table 13.
Quantitative comparative analysis of classification for U. of Pavia among bc-BDPC and k-BDPC using SID, SAM, and SIDAM, along with full bands and uniform BS, with the best and second-best results highlighted and boldfaced in red and black, respectively.
| IEPF-G-g |
|---|
| Class | bc-BDPC-SID | bc-BDPC-SAM | bc-BDPC-SIDAM | k-BDPC-SID | k-BDPC-SAM | k-BDPC-SIDAM | Uniform BS | Full Bands |
|---|
| 1 | 0.9765 | 0.9811 | 0.9845 | 0.9064 | 0.9861 | 0.9877 | 0.9827 | 0.9816 |
| 2 | 0.9708 | 0.9658 | 0.9751 | 0.8574 | 0.9558 | 0.9452 | 0.9434 | 0.9738 |
| 3 | 0.9784 | 0.9881 | 0.9842 | 0.9041 | 0.9818 | 0.9817 | 0.9874 | 0.9915 |
| 4 | 0.9887 | 0.9874 | 0.9865 | 0.9079 | 0.9803 | 0.9805 | 0.9929 | 0.9870 |
| 5 | 0.9992 | 0.9995 | 0.9996 | 0.9320 | 0.9989 | 0.9988 | 0.9977 | 0.9984 |
| 6 | 0.9919 | 0.9940 | 0.9898 | 0.8931 | 0.9771 | 0.9727 | 0.9832 | 0.9967 |
| 7 | 0.9998 | 0.9996 | 0.9999 | 0.9265 | 1.0000 | 0.9999 | 0.9969 | 0.9997 |
| 8 | 0.9706 | 0.9812 | 0.9712 | 0.9747 | 0.9685 | 0.9734 | 0.9881 | 0.9816 |
| 9 | 0.9982 | 0.9995 | 0.9992 | 0.9235 | 0.9955 | 0.9962 | 0.9960 | 0.9998 |
| POA | 0.9782 | 0.9783 | 0.9813 | 0.8912 | 0.9707 | 0.9663 | 0.9683 | 0.9823 |
| PAA | 0.9860 | 0.9885 | 0.9878 | 0.9140 | 0.9826 | 0.9818 | 0.9854 | 0.9900 |
| Kappa | 0.9713 | 0.9715 | 0.9754 | 0.8602 | 0.9616 | 0.9558 | 0.9584 | 0.9767 |
| time (s) | 85 | 14 | 118 | 165 | 38 | 189 | | |
Table 14.
Quantitative comparative analysis of classification for U. of Pavia among SMI-BS, ECA, E-FDPC, IaDPI, DPC-KNN, G-DPC-KNN, and SNNC, with the best and second-best results highlighted and boldfaced in red and black, respectively.
Table 14.
Quantitative comparative analysis of classification for U. of Pavia among SMI-BS, ECA, E-FDPC, IaDPI, DPC-KNN, G-DPC-KNN, and SNNC, with the best and second-best results highlighted and boldfaced in red and black, respectively.
| IEPF-G-g |
|---|
| Class | SMI-BS | ECA | E-FDPC | IaDPI | DPC-KNN (kBS) | DPC-KNN
(k = 2%L) | G-DPC-KNN (kBS) | G-DPC-KNN
(k = 7) | SNNC (kBS) | SNNC
(k = 5) |
|---|
| 1 | 0.9782 | 0.9701 | 0.9833 | 0.9777 | 0.9844 | 0.9766 | 0.9723 | 0.9703 | 0.9823 | 0.9783 |
| 2 | 0.9613 | 0.9360 | 0.9684 | 0.9508 | 0.9658 | 0.9353 | 0.9559 | 0.9559 | 0.9584 | 0.9403 |
| 3 | 0.9879 | 0.9791 | 0.9884 | 0.9834 | 0.9841 | 0.9860 | 0.9870 | 0.9731 | 0.9871 | 0.9809 |
| 4 | 0.9933 | 0.9901 | 0.9898 | 0.9895 | 0.9898 | 0.9891 | 0.9876 | 0.9883 | 0.9919 | 0.9875 |
| 5 | 0.9967 | 0.9991 | 0.9991 | 0.9984 | 0.9980 | 0.9983 | 0.9984 | 0.9987 | 0.9981 | 0.9949 |
| 6 | 0.9873 | 0.9568 | 0.9922 | 0.9851 | 0.9923 | 0.9687 | 0.9705 | 0.9792 | 0.9847 | 0.9692 |
| 7 | 0.9972 | 0.9937 | 0.9992 | 0.9979 | 0.9987 | 0.9958 | 0.9968 | 0.9981 | 0.9986 | 0.9950 |
| 8 | 0.9733 | 0.9688 | 0.9784 | 0.9807 | 0.9751 | 0.9765 | 0.9769 | 0.9600 | 0.9758 | 0.9802 |
| 9 | 0.9957 | 0.9939 | 0.9987 | 0.9988 | 0.9961 | 0.9931 | 0.9974 | 0.9946 | 0.9971 | 0.9937 |
| POA | 0.9746 | 0.9576 | 0.9795 | 0.9700 | 0.9779 | 0.9607 | 0.9693 | 0.9679 | 0.9739 | 0.9630 |
| PAA | 0.9857 | 0.9764 | 0.9886 | 0.9847 | 0.9871 | 0.9799 | 0.9825 | 0.9798 | 0.9860 | 0.9800 |
| Kappa | 0.9666 | 0.9446 | 0.9730 | 0.9606 | 0.9709 | 0.9486 | 0.9598 | 0.9579 | 0.9656 | 0.9516 |
| time(s) | 92 | 1.1 | 1.1 | 1.8 | 1.0 | 1.1 | 1.0 | 1.1 | 1.4 | 1.4 |


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}