
Prediction of Large-Scale Regional Evapotranspiration Based on Multi-Scale Feature Extraction and Multi-Headed Self-Attention
 , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
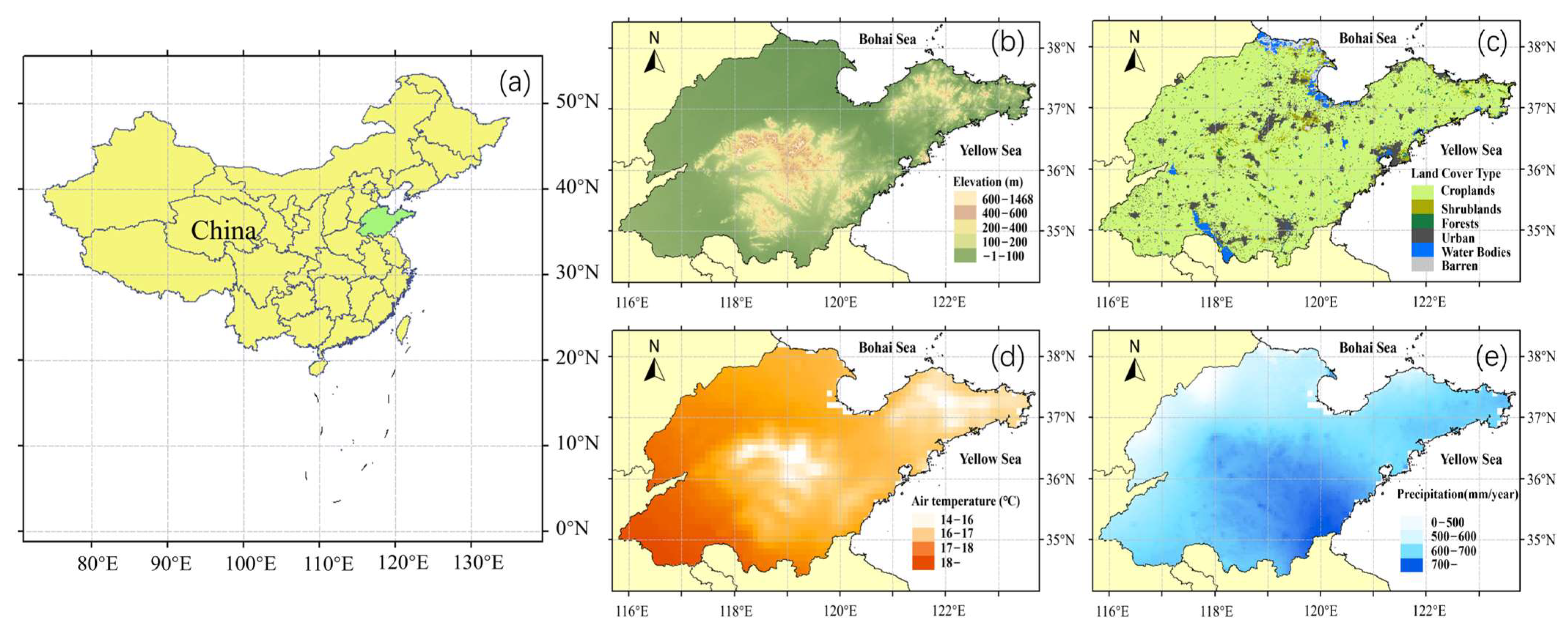
2.1. Study Area
2.2. Data and Preprocessing
2.3. Method
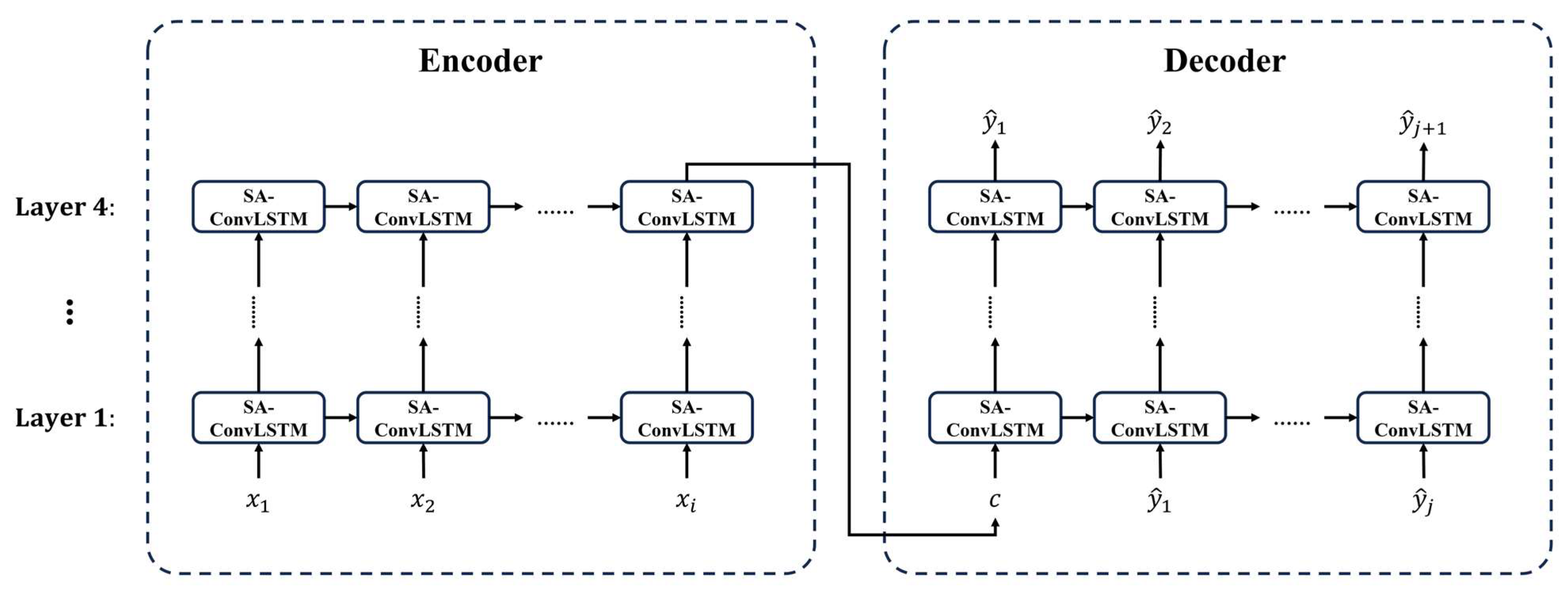
2.3.1. Flowchart
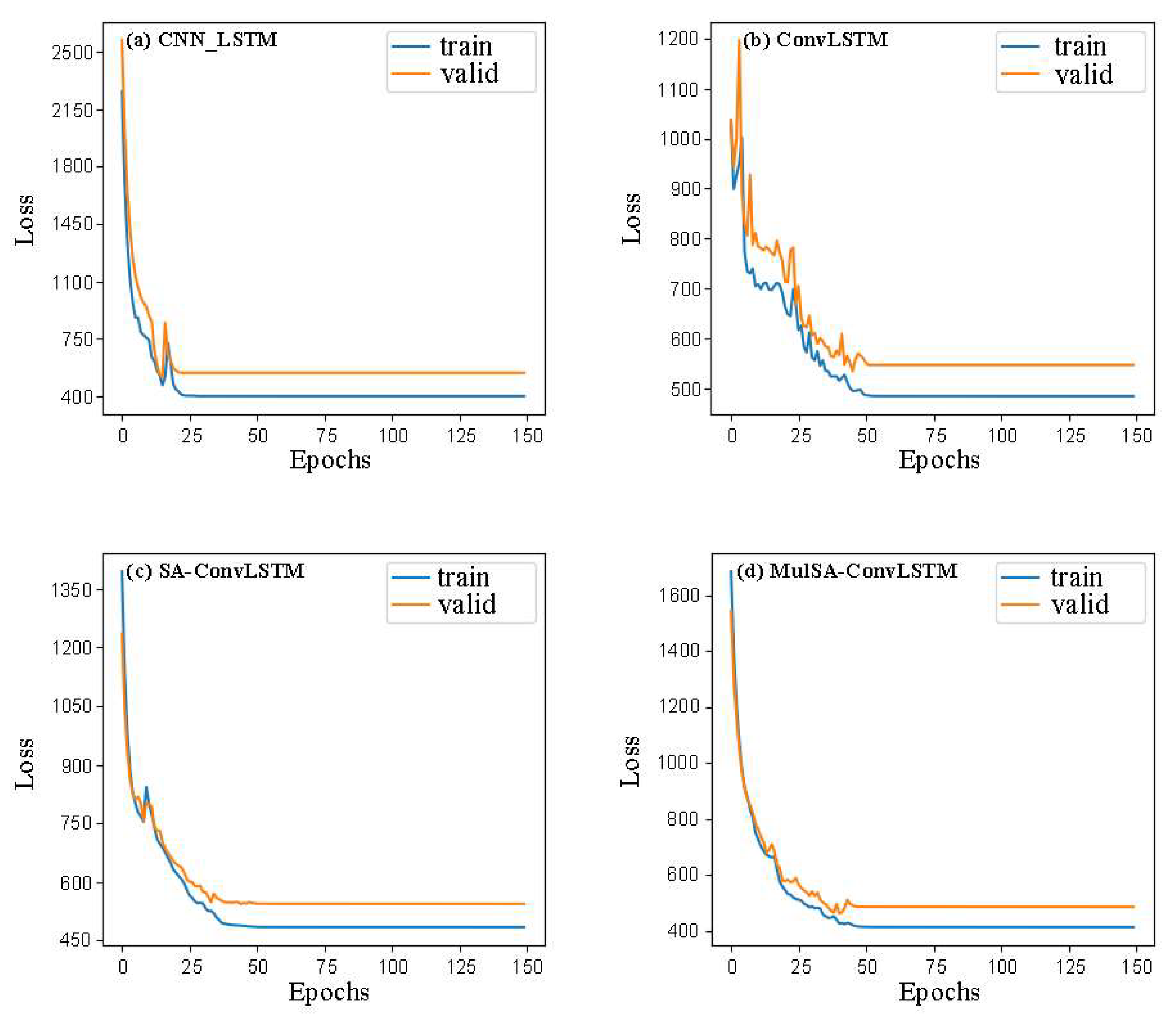
2.3.2. CNN-LSTM
2.3.3. ConvLSTM
2.3.4. SA-ConvLSTM
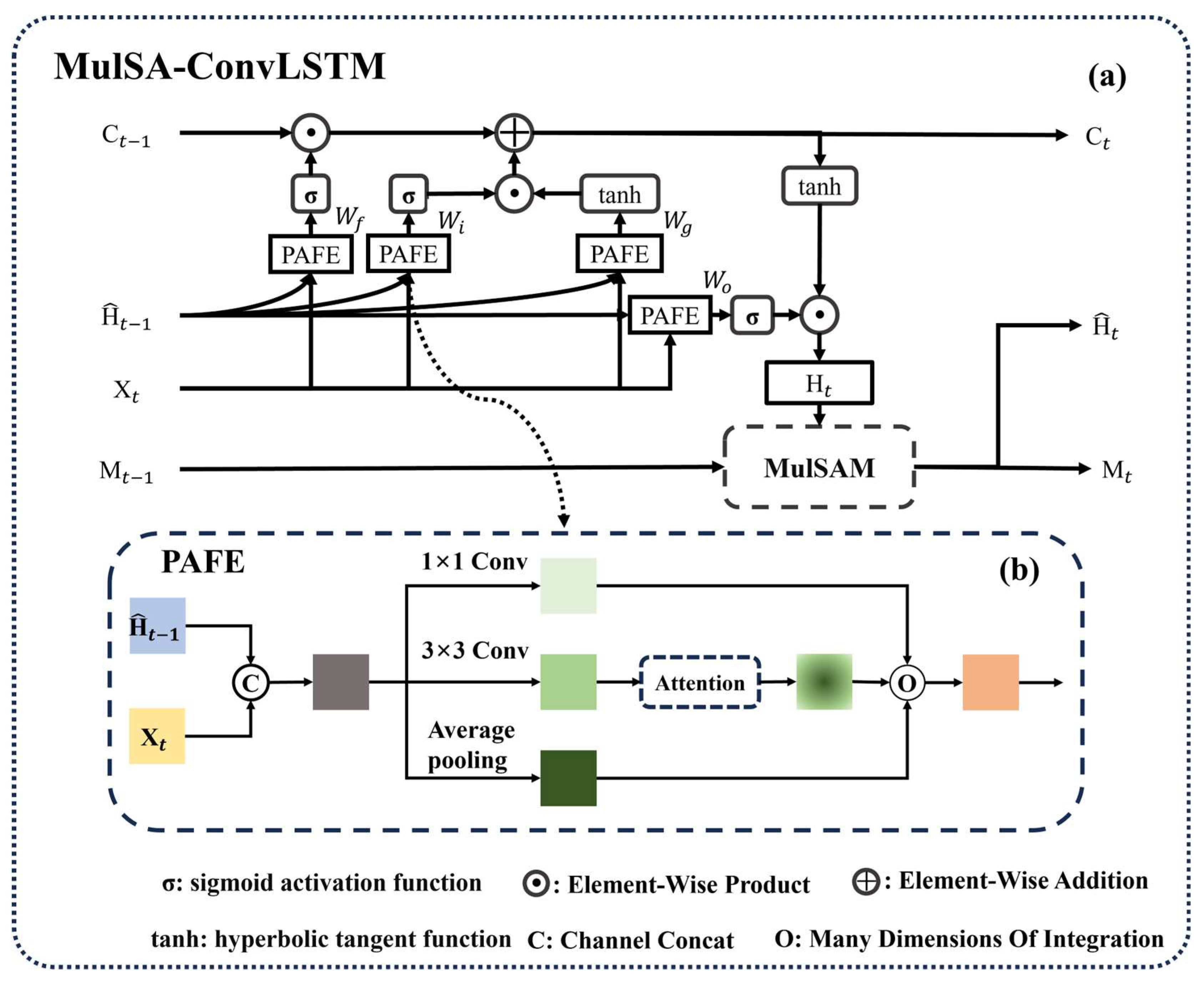
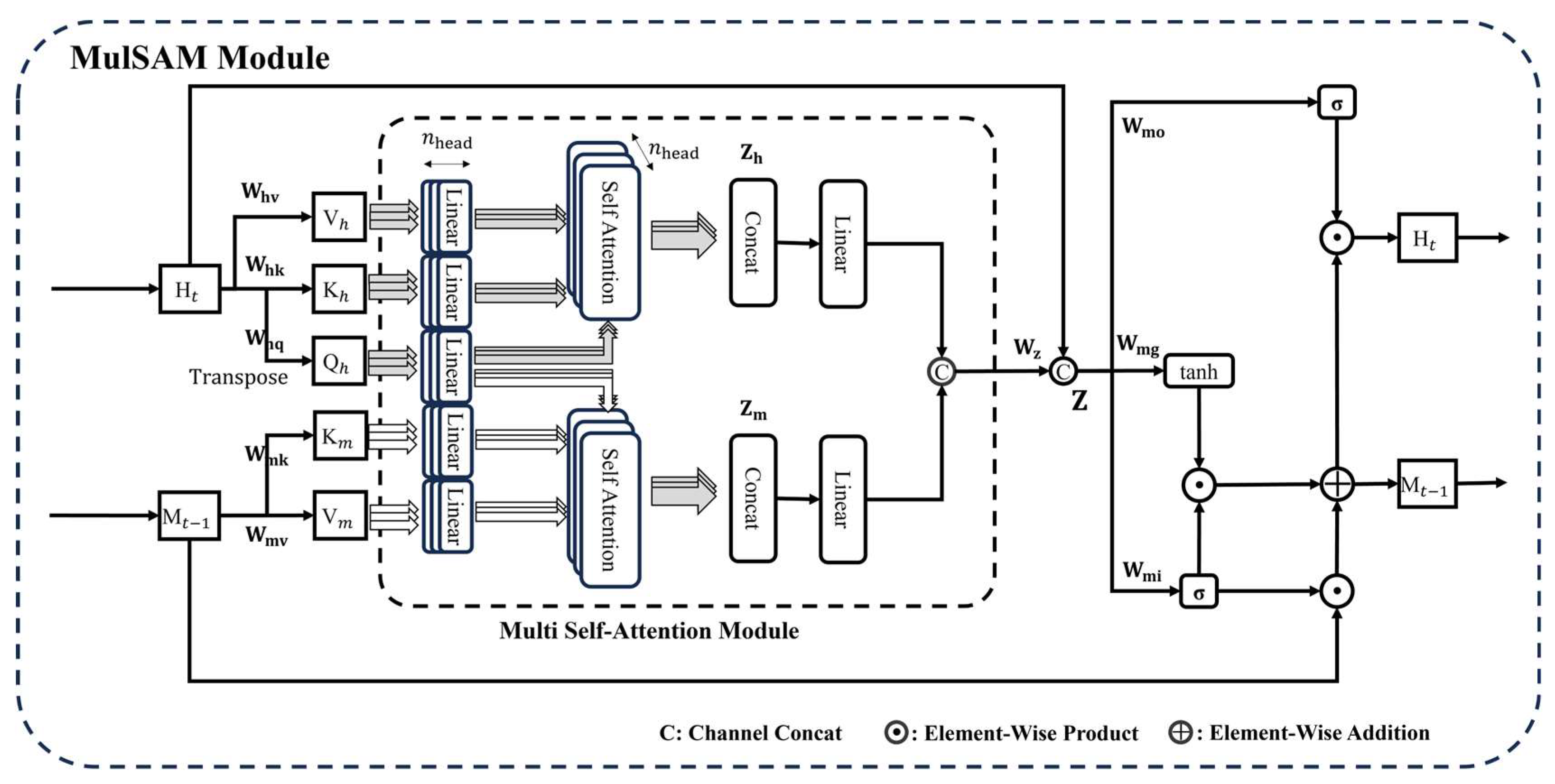
2.3.5. MulSA-ConvLSTM
- Pyramidally Attended Feature Extraction (PAFE)
- b.
- MulSAM module
2.3.6. Model Performance Metrics
3. Results
3.1. Spatiotemporal Evaluation of Regional-Scale Prediction Models
3.2. Performance Evaluation of Regional-Scale Prediction Models
4. Discussion
4.1. Impact of Environmental Factors on Prediction Accuracy
4.2. Impact of Pixels’ Location on Prediction Accuracy
4.3. Sensitivity Analysis of Features
5. Conclusions
- The introduction of PAFE proves to be more efficient in extracting local features and the spatial information of feature variables. Additionally, the results indicate that incorporating a multi-headed self-attention module in the MulSAM module enhances the model’s ability to comprehensively understand the input data features. This improvement allows the model to better adapt to feature relationships at different scales and angles, thereby enhancing its representational capacity and effectively adapting to complex environmental changes.
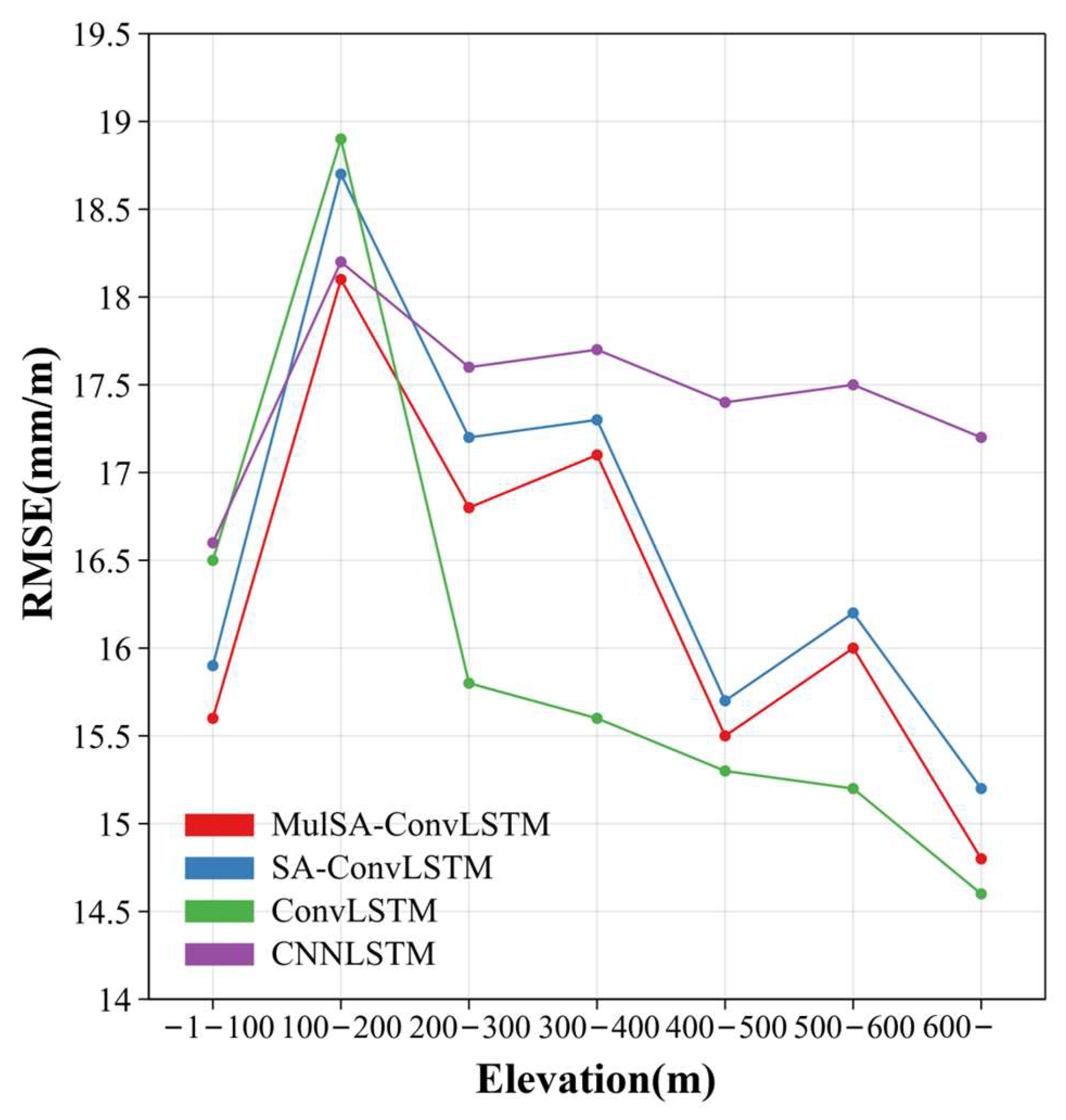
- Among the four models, the MulSA-ConvLSTM model exhibited superior predictive performance for , with SA-ConvLSTM slightly outperforming CNN-LSTM and ConvLSTM. Specifically, the experimental results of MulSA-ConvLSTM (R = 0.908) showed a 2% improvement compared to SA-ConvLSTM (R = 0.882). As the elevation difference of the study area increases, the prediction accuracy of all four models generally exhibits a declining trend.
- MulSA-ConvLSTM demonstrates higher precision in predicting than the three other models in regions with high elevation differences. Moreover, MulSA-ConvLSTM and SA-ConvLSTM show heightened sensitivity to characteristic changes in coastal areas, showcasing superior performance in prediction experiments.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bharati, L.; Rodgers, C.; Erdenberger, T.; Plotnikova, M.; Shumilov, S.; Vlek, P.; Martin, N. Integration of economic and hydrologic models: Exploring conjunctive irrigation water use strategies in the Volta Basin. Agric. Water Manag. 2008, 95, 925–936. [Google Scholar] [CrossRef]
- Yang, Y.; Yang, Y.; Liu, D.L.; Nordblom, T.; Wu, B.; Yan, N. Regional water balance based on remotely sensed evapotranspiration and irrigation: An assessment of the Haihe Plain, China. Remote Sens. 2014, 6, 2514–2533. [Google Scholar] [CrossRef]
- Paul, M.; Rajib, A.; Negahban-Azar, M.; Shirmohammadi, A.; Srivastava, P. Improved agricultural Water management in data-scarce semi-arid watersheds: Value of integrating remotely sensed leaf area index in hydrological modeling. Sci. Total Environ. 2021, 791, 148177. [Google Scholar] [CrossRef] [PubMed]
- Wanniarachchi, S.; Sarukkalige, R. A review on evapotranspiration estimation in agricultural water management: Past, present, and future. Hydrology 2022, 9, 123. [Google Scholar] [CrossRef]
- Jackson, R.B.; Carpenter, S.R.; Dahm, C.N.; McKnight, D.M.; Naiman, R.J.; Postel, S.L.; Running, S.W. Water in a changing world. Ecol. Appl. 2001, 11, 1027–1045. [Google Scholar] [CrossRef]
- Devia, G.K.; Ganasri, B.P.; Dwarakish, G.S. A review on hydrological models. Aquat. Procedia 2015, 4, 1001–1007. [Google Scholar] [CrossRef]
- Herman, M.R.; Nejadhashemi, A.P.; Abouali, M.; Hernandez-Suarez, J.S.; Daneshvar, F.; Zhang, Z.; Anderson, M.C.; Sadeghi, A.M.; Hain, C.R.; Sharifi, A. Evaluating the role of evapotranspiration remote sensing data in improving hydrological modeling predictability. J. Hydrol. 2018, 556, 39–49. [Google Scholar] [CrossRef]
- Calera, A.; Campos, I.; Osann, A.; D’Urso, G.; Menenti, M. Remote sensing for crop water management: From ET modelling to services for the end users. Sensors 2017, 17, 1104. [Google Scholar] [CrossRef] [PubMed]
- Anapalli, S.S.; Fisher, D.K.; Reddy, K.N.; Rajan, N.; Pinnamaneni, S.R. Modeling evapotranspiration for irrigation water management in a humid climate. Agric. Water Manag. 2019, 225, 105731. [Google Scholar] [CrossRef]
- Gorguner, M.; Kavvas, M.L. Modeling impacts of future climate change on reservoir storages and irrigation water demands in a Mediterranean basin. Sci. Total Environ. 2020, 748, 141246. [Google Scholar] [CrossRef] [PubMed]
- Bastiaanssen, W.G.M.; Noordman, E.J.M.; Pelgrum, H.; Davids, G.; Thoreson, B.P.; Allen, R.G. SEBAL model with remotely sensed data to improve water-resources management under actual field conditions. J. Irrig. Drain. Eng. 2005, 131, 85–93. [Google Scholar] [CrossRef]
- Cao, G.; Han, D.; Song, X. Evaluating actual evapotranspiration and impacts of groundwater storage change in the North China Plain. Hydrol. Process. 2014, 28, 1797–1808. [Google Scholar] [CrossRef]
- Sang, J.; Hou, B.; Wang, H.; Ding, X. Prediction of water resources change trend in the Three Gorges Reservoir Area under future climate change. J. Hydrol. 2023, 617, 128881. [Google Scholar] [CrossRef]
- Farooque, A.A.; Afzaal, H.; Abbas, F.; Bos, M.; Maqsood, J.; Wang, X.; Hussain, N. Forecasting daily evapotranspiration using artificial neural networks for sustainable irrigation scheduling. Irrig. Sci. 2022, 40, 55–69. [Google Scholar] [CrossRef]
- Ferreira, L.B.; da Cunha, F.F.; Fernandes Filho, E.I. Exploring machine learning and multi-task learning to estimate meteorological data and reference evapotranspiration across Brazil. Agric. Water Manag. 2022, 259, 107281. [Google Scholar] [CrossRef]
- Hashemi, M.; Sepaskhah, A.R. Evaluation of artificial neural network and Penman–Monteith equation for the prediction of barley standard evapotranspiration in a semi-arid region. Theor. Appl. Climatol. 2020, 139, 275–285. [Google Scholar] [CrossRef]
- Roy, D.K. Long short-term memory networks to predict one-step ahead reference evapotranspiration in a subtropical climatic zone. Environ. Process. 2021, 8, 911–941. [Google Scholar] [CrossRef]
- Chen, R.; Wang, X.; Zhang, W.; Zhu, X.; Li, A.; Yang, C. A hybrid CNN-LSTM model for typhoon formation forecasting. GeoInformatica 2019, 23, 375–396. [Google Scholar] [CrossRef]
- Cai, H.; Shi, H.; Liu, S.; Babovic, V. Impacts of regional characteristics on improving the accuracy of groundwater level prediction using machine learning: The case of central eastern continental United States. J. Hydrol. Reg. Stud. 2021, 37, 100930. [Google Scholar] [CrossRef]
- Granata, F. Evapotranspiration evaluation models based on machine learning algorithms—A comparative study. Agric. Water Manag. 2019, 217, 303–315. [Google Scholar] [CrossRef]
- Ball, J.E.; Anderson, D.T.; Chan, C.S. Comprehensive survey of deep learning in remote sensing: Theories, tools, and challenges for the community. J. Appl. Remote Sens. 2017, 11, 042609. [Google Scholar] [CrossRef]
- Lary, D.J.; Alavi, A.H.; Gandomi, A.H.; Walker, A.L. Machine learning in geosciences and remote sensing. Geosci. Front. 2016, 7, 3–10. [Google Scholar] [CrossRef]
- e Lucas, P.D.O.; Alves, M.A.; e Silva, P.C.D.L.; Guimaraes, F.G. Reference evapotranspiration time series forecasting with ensemble of convolutional neural networks. Comput. Electron. Agric. 2020, 177, 105700. [Google Scholar] [CrossRef]
- Ferreira, L.B.; da Cunha, F.F. New approach to estimate daily reference evapotranspiration based on hourly temperature and relative humidity using machine learning and deep learning. Agric. Water Manag. 2020, 234, 106113. [Google Scholar] [CrossRef]
- Ferreira, L.B.; da Cunha, F.F. Multi-step ahead forecasting of daily reference evapotranspiration using deep learning. Comput. Electron. Agric. 2020, 178, 105728. [Google Scholar] [CrossRef]
- Nagappan, M.; Gopalakrishnan, V.; Alagappan, M. Prediction of reference evapotranspiration for irrigation scheduling using machine learning. Hydrol. Sci. J. 2020, 65, 2669–2677. [Google Scholar] [CrossRef]
- Sharma, G.; Singh, A.; Jain, S. Hybrid deep learning techniques for estimation of daily crop evapotranspiration using limited climate data. Comput. Electron. Agric. 2022, 202, 107338. [Google Scholar] [CrossRef]
- Alibabaei, K.; Gaspar, P.D.; Lima, T.M. Modeling soil water content and reference evapotranspiration from climate data using deep learning method. Appl. Sci. 2021, 11, 5029. [Google Scholar] [CrossRef]
- Dong, J.; Zhu, Y.; Jia, X.; Han, X.; Qiao, J.; Bai, C.; Tang, X. Nation-scale reference evapotranspiration estimation by using deep learning and classical machine learning models in China. J. Hydrol. 2022, 604, 127207. [Google Scholar] [CrossRef]
- Li, Y.; Wang, W.; Wang, G.; Tan, Q. Actual evapotranspiration estimation over the Tuojiang River Basin based on a hybrid CNN-RF model. J. Hydrol. 2022, 610, 127788. [Google Scholar] [CrossRef]
- Babaeian, E.; Paheding, S.; Siddique, N.; Devabhaktuni, V.K.; Tuller, M. Short-and mid-term forecasts of actual evapotranspiration with deep learning. J. Hydrol. 2022, 612, 128078. [Google Scholar] [CrossRef]
- Xiong, T.; He, J.; Wang, H.; Tang, X.; Shi, Z.; Zeng, Q. Contextual Sa-attention convolutional LSTM for precipitation nowcasting: A spatiotemporal sequence forecasting view. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 12479–12491. [Google Scholar] [CrossRef]
- Abatzoglou, J.T.; Dobrowski, S.Z.; Parks, S.A.; Hegewisch, K.C. TerraClimate, a high-resolution global dataset of monthly climate and climatic water balance from 1958–2015. Sci. Data 2018, 5, 170191. [Google Scholar] [CrossRef] [PubMed]
- Muñoz-Sabater, J.; Dutra, E.; Agustí-Panareda, A.; Albergel, C.; Arduini, G.; Balsamo, G.; Boussetta, S.; Choulga, M.; Harrigan, S.; Hersbach, H.; et al. ERA5-Land: A state-of-the-art global reanalysis dataset for land applications. Earth Syst. Sci. Data 2021, 13, 4349–4383. [Google Scholar] [CrossRef]
- Blonquist, J., Jr.; Allen, R.; Bugbee, B. An evaluation of the net radiation sub-model in the ASCE standardized reference evapotranspiration equation: Implications for evapotranspiration prediction. Agric. Water Manag. 2010, 97, 1026–1038. [Google Scholar] [CrossRef]
- Valipour, M. Importance of solar radiation, temperature, relative humidity, and wind speed for calculation of reference evapotranspiration. Arch. Agron. Soil Sci. 2015, 61, 239–255. [Google Scholar] [CrossRef]
- Patro, S.; Sahu, K.K. Normalization: A preprocessing stage. arXiv 2015, arXiv:1503.06462. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Shewalkar, A.; Nyavanandi, D.; Ludwig, S.A. Performance evaluation of deep neural networks applied to speech recognition: RNN, LSTM and GRU. J. Artif. Intell. Soft Comput. Res. 2019, 9, 235–245. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Hong, S.; Joh, M.; Song, S.-k. Deeprain: Convlstm network for precipitation prediction using multichannel radar data. arXiv 2017, arXiv:1711.02316. [Google Scholar]
- Moishin, M.; Deo, R.C.; Prasad, R.; Raj, N.; Abdulla, S. Designing deep-based learning flood forecast model with ConvLSTM hybrid algorithm. IEEE Access 2021, 9, 50982–50993. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-C. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Advances in Neural Information Processing Systems 28 (NIPS 2015); MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Lewkowycz, A. How to decay your learning rate. arXiv 2021, arXiv:2103.12682. [Google Scholar]
- Lin, Z.; Li, M.; Zheng, Z.; Cheng, Y.; Yuan, C. Self-attention convlstm for spatiotemporal prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; AAAI Press: Washington, DC, USA, 2020; Volume 34, pp. 11531–11538. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Zhang, L.; Pang, Y.; Lu, H.; Zhang, L. A Single Stream Network for Robust and Real-Time RGB-D Salient Object Detection. In Computer Vision—ECCV 2020; Springer: Cham, Switzerland, 2020; pp. 646–662. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems 30 (NIPS 2017); MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Voita, E.; Talbot, D.; Moiseev, F.; Sennrich, R.; Titov, I. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. arXiv 2019, arXiv:1905.09418. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 7354–7363. [Google Scholar]
- Cohen, I.; Huang, Y.; Chen, J.; Benesty, J.; Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson Correlation Coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–4. [Google Scholar]
- Asuero, A.G.; Sayago, A.; González, A.G. The correlation coefficient: An overview. Crit. Rev. Anal. Chem. 2006, 36, 41–59. [Google Scholar] [CrossRef]
- Fick, S.E.; Hijmans, R.J. WorldClim 2: New 1-km spatial resolution climate surfaces for global land areas. Int. J. Climatol. 2017, 37, 4302–4315. [Google Scholar] [CrossRef]
- Harris, I.; Jones, P.D.; Osborn, T.J.; Lister, D.H. Updated high-resolution grids of monthly climatic observations–the CRU TS3. 10 Dataset. Int. J. Climatol. 2014, 34, 623–642. [Google Scholar] [CrossRef]
- Neto, A.K.; Ribeiro, R.B.; Pruski, F.F. Assessment Water Balance through Different Sources of Precipitation and Actual Evapotranspiration. 2022. Available online: https://www.researchsquare.com/article/rs-1443692/v1 (accessed on 26 February 2024).
- Zhao, W.L.; Gentine, P.; Reichstein, M.; Zhang, Y.; Zhou, S.; Wen, Y.; Lin, C.; Li, X.; Qiu, G.Y. Physics-constrained machine learning of evapotranspiration. Geophys. Res. Lett. 2019, 46, 14496–14507. [Google Scholar] [CrossRef]
- Mai, M.; Wang, T.; Han, Q.; Jing, W.; Bai, Q. Comparison of environmental controls on daily actual evapotranspiration dynamics among different terrestrial ecosystems in China. Sci. Total Environ. 2023, 871, 162124. [Google Scholar] [CrossRef] [PubMed]
- Anderson, D.B. Relative humidity or vapor pressure deficit. Ecology 1936, 17, 277–282. [Google Scholar] [CrossRef]
- McVicar, T.R.; Roderick, M.L.; Donohue, R.J.; Van Niel, T.G. Less bluster ahead? Ecohydrological implications of global trends of terrestrial near-surface wind speeds. Ecohydrology 2012, 5, 381–388. [Google Scholar] [CrossRef]
- Zou, M.; Zhong, L.; Ma, Y.; Hu, Y.; Feng, L. Estimation of actual evapotranspiration in the Nagqu river basin of the Tibetan Plateau. Theor. Appl. Climatol. 2018, 132, 1039–1047. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | Unit | Spatial Resolution | Temporal Resolution | Data Source |
|---|---|---|---|---|---|
| Actual evapotranspiration | 4 km × 4 km | Monthly | TerraClimate | ||
| VPD | Vapor pressure deficit | 4 km × 4 km | Monthly | TerraClimate | |
| WS | Wind speed | 4 km × 4 km | Monthly | TerraClimate | |
| P | Precipitation | 4 km × 4 km | Monthly | TerraClimate | |
| TA | Air temperature | °C | 0.1° × 0.1° (~11 × ~11 km) | Monthly | ERA5-land |
| RN | Net radiation | 0.1° × 0.1° (~11 × ~11 km) | Monthly | ERA5-land |
| Croplands | Shrublands | Forests | Urban | Barren | |
|---|---|---|---|---|---|
| CNN-LSTM | 17.1 | 16.8 | 16.9 | 18.1 | 16.1 |
| ConvLSTM | 16.9 | 16.6 | 16.8 | 17.8 | 15.6 |
| SA-ConvLSTM | 16.4 | 16.1 | 16.3 | 17.6 | 15.3 |
| MulSA-ConvLSTM | 16.2 | 15.9 | 16.1 | 17.2 | 15.0 |
| Model | R | RMSE (mm/m) | MAE (mm/m) | Bias (mm/m) |
|---|---|---|---|---|
| CNN-LSTM | 0.861 | 17.4 (23.8%) | 9.7 | −10.3 |
| ConvLSTM | 0.869 | 17.1 (22.5%) | 9.3 | −8.53 |
| SA-ConvLSTM | 0.882 | 16.9 (20.2%) | 9.1 | 8.42 |
| MulSA-ConvLSTM | 0.908 | 16.6 (15.6%) | 8.9 | 6.26 |
| CNN-LSTM | ConvLSTM | SA-ConvLSTM | MulSA-ConvLSTM | |
|---|---|---|---|---|
| Number of parameters (M) | 430.2 | 1.1 | 1.8 | 2.6 |
| Time/epoch (s) | 9 | 13 | 16 | 19 |
| Feature | ALL | RN | TA | P | VPD | WS |
|---|---|---|---|---|---|---|
| R | 0.908 | 0.645 | 0.611 | 0.739 | 0.652 | 0.769 |
| Dropped Feature | ALL | RN | TA | P | VPD | WS |
|---|---|---|---|---|---|---|
| R | 0.908 | 0.733 | 0.831 | 0.839 | 0.815 | 0.744 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, X.; Zhang, S.; Zhang, J.; Yang, S.; Huang, J.; Meng, X.; Bai, Y. Prediction of Large-Scale Regional Evapotranspiration Based on Multi-Scale Feature Extraction and Multi-Headed Self-Attention. Remote Sens. 2024, 16, 1235. https://doi.org/10.3390/rs16071235
Zheng X, Zhang S, Zhang J, Yang S, Huang J, Meng X, Bai Y. Prediction of Large-Scale Regional Evapotranspiration Based on Multi-Scale Feature Extraction and Multi-Headed Self-Attention. Remote Sensing. 2024; 16(7):1235. https://doi.org/10.3390/rs16071235
Chicago/Turabian StyleZheng, Xin, Sha Zhang, Jiahua Zhang, Shanshan Yang, Jiaojiao Huang, Xianye Meng, and Yun Bai. 2024. "Prediction of Large-Scale Regional Evapotranspiration Based on Multi-Scale Feature Extraction and Multi-Headed Self-Attention" Remote Sensing 16, no. 7: 1235. https://doi.org/10.3390/rs16071235