
Explainable Automatic Detection of Fiber–Cement Roofs in Aerial RGB Images

 , , , and
, , , and
Abstract
:1. Introduction
2. Related Work
2.1. Remote Sensing in Urbanized Areas
2.2. Explainability
3. Materials and Methods
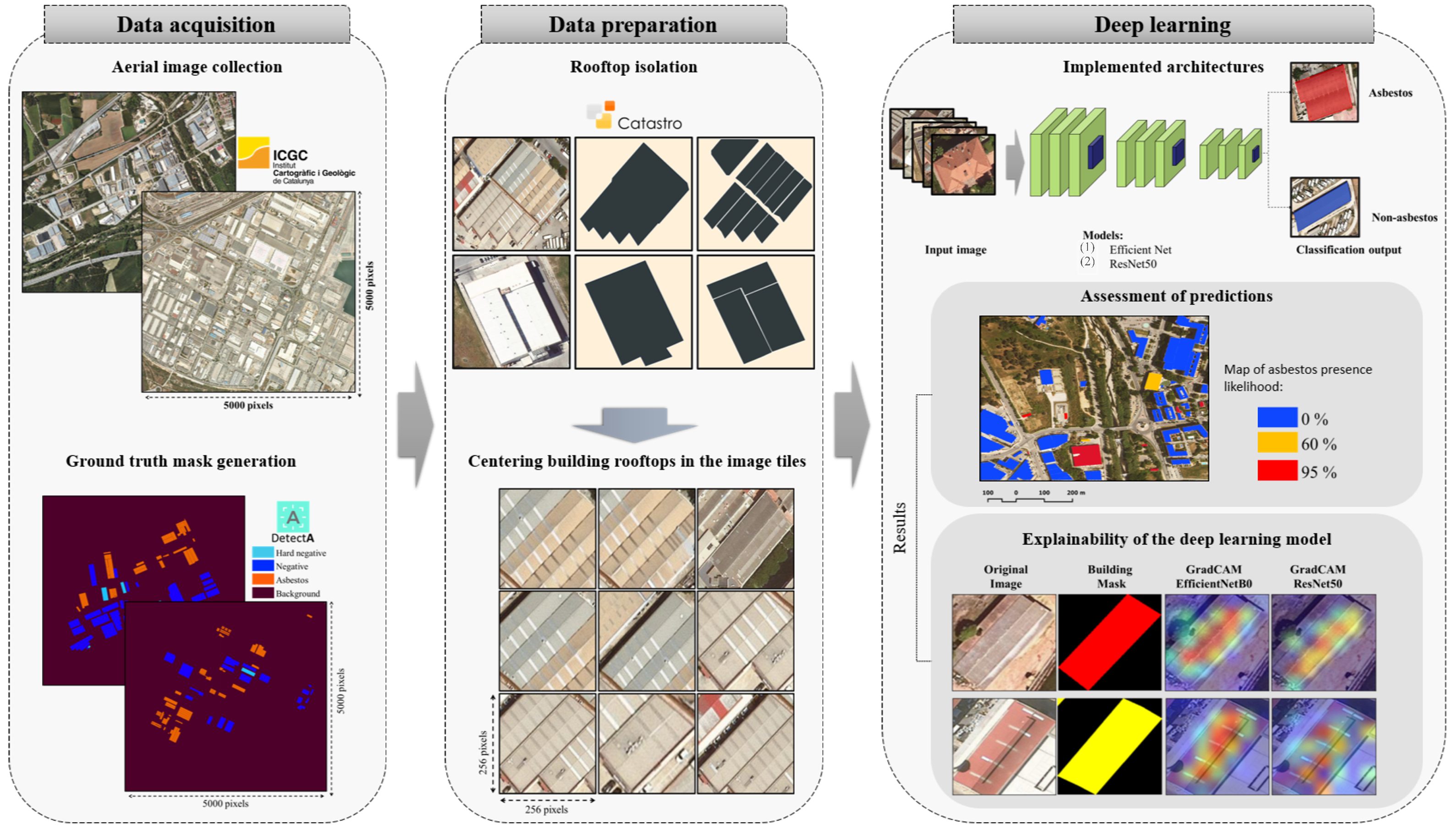
3.1. Aerial Imagery and Asbestos Localization
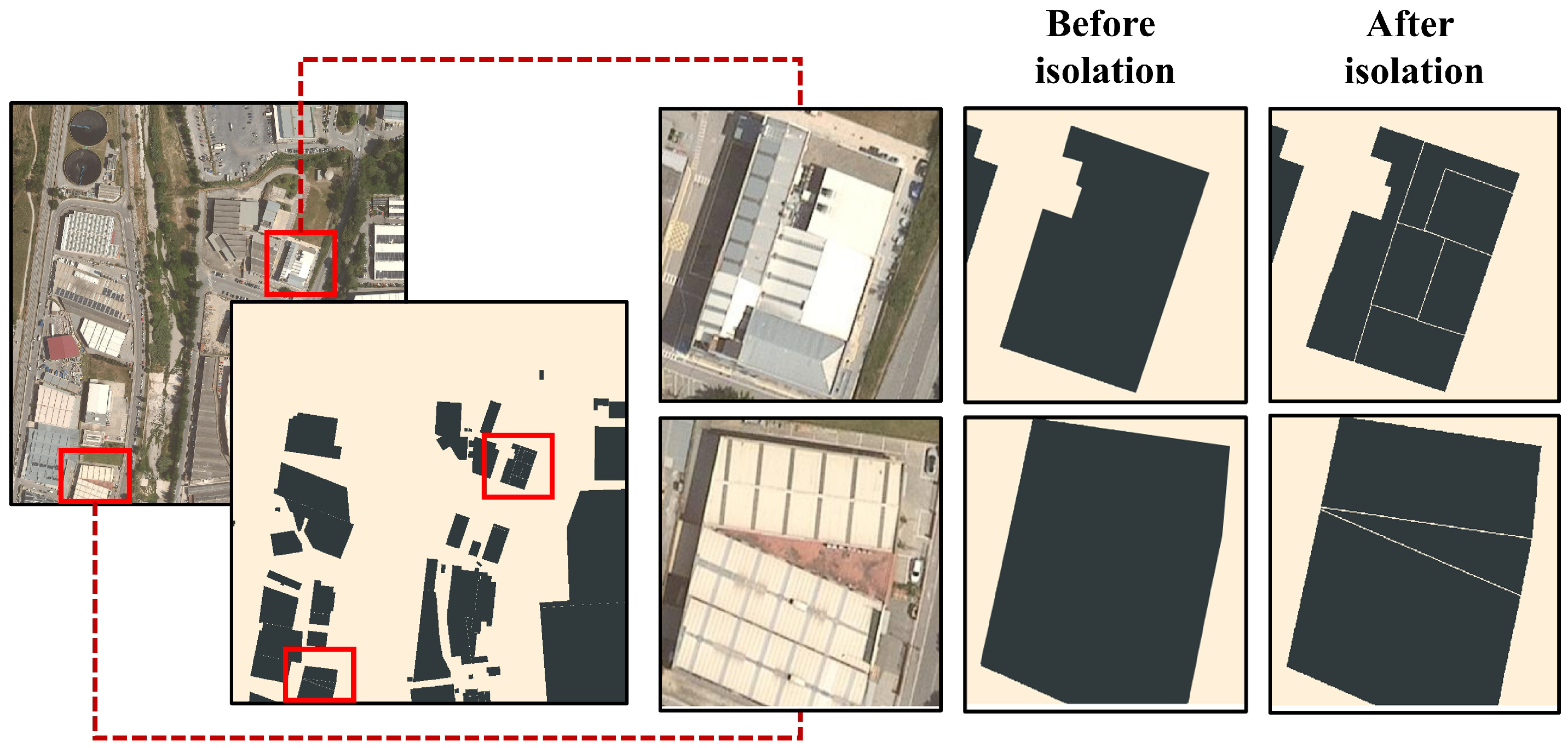
3.1.1. Aerial Imagery GIS Pre-Processing
3.1.2. Ground-Truth Training Dataset Construction
3.2. Classification with Convolutional Neural Networks
3.2.1. CNN Architectures
3.2.2. Training Details
3.2.3. Explainability of CNNs with Class Activation Maps
4. Results
4.1. Random Test Set
4.2. k-Fold Cross Validation
4.3. Explainability Results
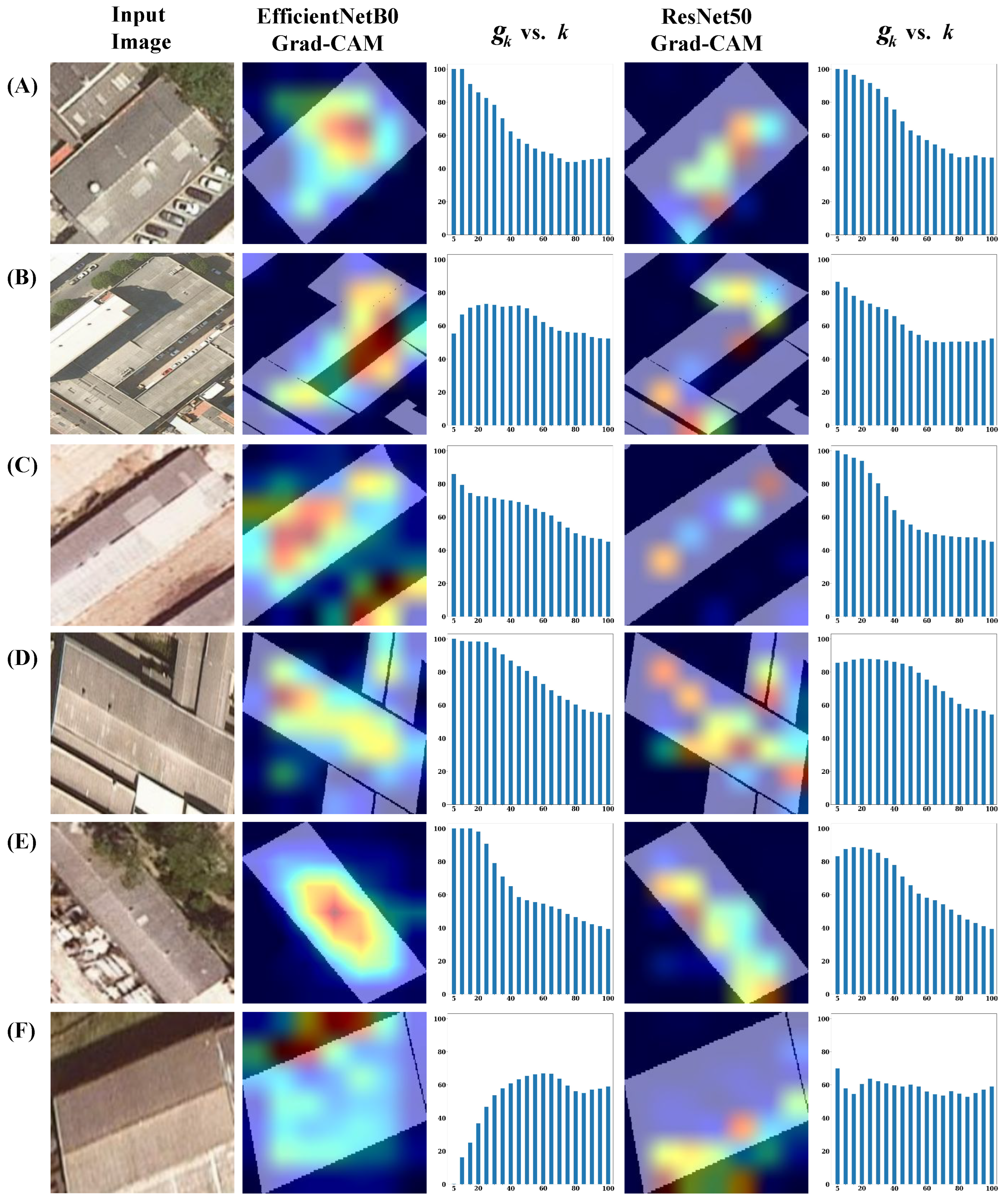
4.3.1. Qualitative insights
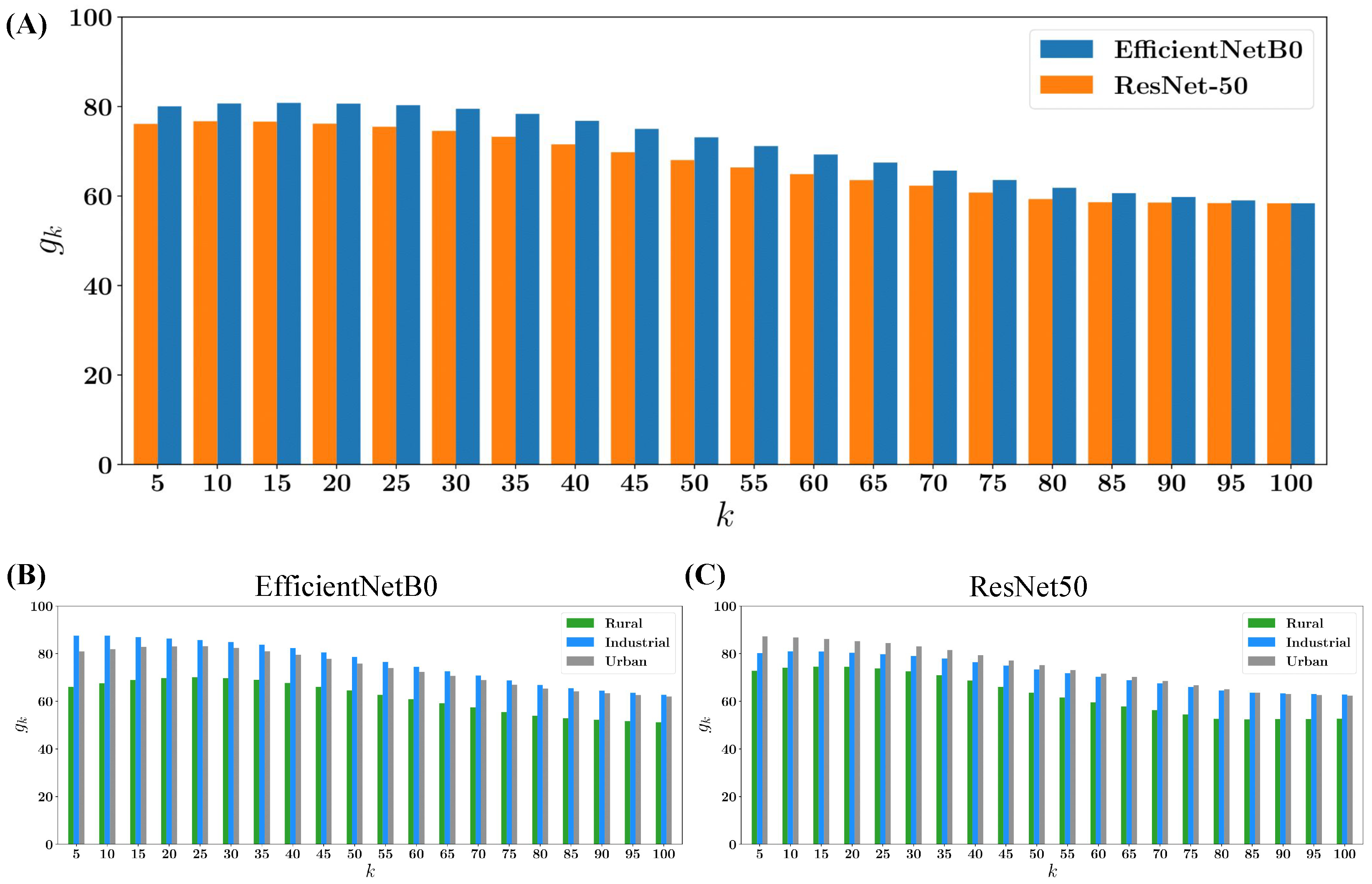
4.3.2. Quantitative Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| EU | European Union |
| DL | Deep Learning |
| CAM | Class Activation Mapping |
| Grad-CAM | Gradient-weighted Class Activation Mapping |
| CNN | Convolutional Neural Networks |
| HSI | HyperSpectral Imagery |
| ICGC | Catalan Cartographic and Geologic Institute |
References
- Nielsen, L.S.; Baelum, J.; Rasmussen, J.; Dahl, S.; Olsen, K.E.; Albin, M.; Hansen, N.C.; Sherson, D. Occupational asbestos exposure and lung cancer—A systematic review of the literature. Arch. Environ. Occup. Health 2014, 69, 191–206. [Google Scholar] [CrossRef]
- Abbasi, M.; Mostafa, S.; Vieira, A.S.; Patorniti, N.; Stewart, R.A. Mapping Roofing with Asbestos-Containing Material by Using Remote Sensing Imagery and Machine Learning-Based Image Classification: A State-of-the-Art Review. Sustainability 2022, 14, 8068. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Geirhos, R.; Jacobsen, J.H.; Michaelis, C.; Zemel, R.; Brendel, W.; Bethge, M.; Wichmann, F.A. Shortcut learning in deep neural networks. Nat. Mach. Intell. 2020, 2, 665–673. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. (CSUR) 2018, 51, 93. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Fukui, H.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Attention branch network: Learning of attention mechanism for visual explanation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10705–10714. [Google Scholar]
- Wagner, J.; Kohler, J.M.; Gindele, T.; Hetzel, L.; Wiedemer, J.T.; Behnke, S. Interpretable and fine-grained visual explanations for convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9097–9107. [Google Scholar]
- Desai, S.; Ramaswamy, H.G. Ablation-CAM: Visual Explanations for Deep Convolutional Network via Gradient-free Localization. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 972–980. [Google Scholar]
- Patro, B.N.; Lunayach, M.; Patel, S.; Namboodiri, V.P. U-cam: Visual explanation using uncertainty based class activation maps. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7444–7453. [Google Scholar]
- Bustos, C.; Rhoads, D.; Solé-Ribalta, A.; Masip, D.; Arenas, A.; Lapedriza, A.; Borge-Holthoefer, J. Explainable, automated urban interventions to improve pedestrian and vehicle safety. Transp. Res. Part Emerg. Technol. 2021, 125, 103018. [Google Scholar] [CrossRef]
- Charuchinda, P.; Kasetkasem, T.; Kumazawa, I.; Chanwimaluang, T. On the use of class activation map for land cover mapping. In Proceedings of the 2019 16th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Pattaya, Thailand, 10–13 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 653–656. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.S. Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Kumari, M.; Kaul, A. Deep learning techniques for remote sensing image scene classification: A comprehensive review, current challenges, and future directions. Concurr. Comput. Pract. Exp. 2023, 35, e7733. [Google Scholar] [CrossRef]
- Yuan, X.; Shi, J.; Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2021, 169, 114417. [Google Scholar] [CrossRef]
- Shi, W.; Zhang, M.; Zhang, R.; Chen, S.; Zhan, Z. Change detection based on artificial intelligence: State-of-the-art and challenges. Remote. Sens. 2020, 12, 1688. [Google Scholar] [CrossRef]
- Men, G.; He, G.; Wang, G. Concatenated Residual Attention UNet for Semantic Segmentation of Urban Green Space. Forests 2021, 12, 1441. [Google Scholar] [CrossRef]
- Kabisch, N.; Strohbach, M.; Haase, D.; Kronenberg, J. Urban green space availability in European cities. Ecol. Indic. 2016, 70, 586–596. [Google Scholar] [CrossRef]
- Wolch, J.R.; Byrne, J.; Newell, J.P. Urban green space, public health, and environmental justice: The challenge of making cities ‘just green enough’. Landsc. Urban Plan. 2014, 125, 234–244. [Google Scholar] [CrossRef]
- Ramoelo, A.; Cho, M.A.; Mathieu, R.; Madonsela, S.; Van De Kerchove, R.; Kaszta, Z.; Wolff, E. Monitoring grass nutrients and biomass as indicators of rangeland quality and quantity using random forest modelling and WorldView-2 data. Int. J. Appl. Earth Obs. Geoinf. 2015, 43, 43–54. [Google Scholar] [CrossRef]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered object detection in aerial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8311–8320. [Google Scholar]
- Omarzadeh, D.; Karimzadeh, S.; Matsuoka, M.; Feizizadeh, B. Earthquake Aftermath from Very High-Resolution WorldView-2 Image and Semi-Automated Object-Based Image Analysis (Case Study: Kermanshah, Sarpol-e Zahab, Iran). Remote. Sens. 2021, 13, 4272. [Google Scholar] [CrossRef]
- Bastani, F.; He, S.; Abbar, S.; Alizadeh, M.; Balakrishnan, H.; Chawla, S.; Madden, S.; DeWitt, D. Roadtracer: Automatic extraction of road networks from aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4720–4728. [Google Scholar]
- Hosseini, M.; Sevtsuk, A.; Miranda, F.; Cesar, R.M., Jr.; Silva, C.T. Mapping the walk: A scalable computer vision approach for generating sidewalk network datasets from aerial imagery. Comput. Environ. Urban Syst. 2023, 101, 101950. [Google Scholar] [CrossRef]
- Izquierdo, S.; Rodrigues, M.; Fueyo, N. A method for estimating the geographical distribution of the available roof surface area for large-scale photovoltaic energy-potential evaluations. Sol. Energy 2008, 82, 929–939. [Google Scholar] [CrossRef]
- Mainzer, K.; Fath, K.; McKenna, R.; Stengel, J.; Fichtner, W.; Schultmann, F. A high-resolution determination of the technical potential for residential-roof-mounted photovoltaic systems in Germany. Sol. Energy 2014, 105, 715–731. [Google Scholar] [CrossRef]
- Schallenberg-Rodríguez, J. Photovoltaic techno-economical potential on roofs in regions and islands: The case of the Canary Islands. Methodological review and methodology proposal. Renew. Sustain. Energy Rev. 2013, 20, 219–239. [Google Scholar] [CrossRef]
- Szabó, S.; Burai, P.; Kovács, Z.; Szabó, G.; Kerényi, A.; Fazekas, I.; Paládi, M.; Buday, T.; Szabó, G. Testing algorithms for the identification of asbestos roofing based on hyperspectral data. Environ. Eng. Manag. J. 2014, 143, 2875–2880. [Google Scholar] [CrossRef]
- Cilia, C.; Panigada, C.; Rossini, M.; Candiani, G.; Pepe, M.; Colombo, R. Mapping of asbestos cement roofs and their weathering status using hyperspectral aerial images. ISPRS Int. J. Geo-Inf. 2015, 4, 928–941. [Google Scholar] [CrossRef]
- Kruse, F.A.; Lefkoff, A.; Boardman, J.; Heidebrecht, K.; Shapiro, A.; Barloon, P.; Goetz, A. The spectral image processing system (SIPS)—interactive visualization and analysis of imaging spectrometer data. Remote. Sens. Environ. 1993, 44, 145–163. [Google Scholar] [CrossRef]
- Krówczyńska, M.; Raczko, E.; Staniszewska, N.; Wilk, E. Asbestos—cement roofing identification using remote sensing and convolutional neural networks (CNNs). Remote. Sens. 2020, 12, 408. [Google Scholar] [CrossRef]
- Raczko, E.; Krówczyńska, M.; Wilk, E. Asbestos roofing recognition by use of convolutional neural networks and high-resolution aerial imagery. Testing different scenarios. Build. Environ. 2022, 217, 109092. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Kaplan, G.; Gašparović, M.; Kaplan, O.; Adjiski, V.; Comert, R.; Mobariz, M.A. Machine learning-based classification of asbestos-containing roofs using airborne RGB and thermal imagery. Sustainability 2023, 15, 6067. [Google Scholar] [CrossRef]
- Baek, S.C.; Lee, K.H.; Kim, I.H.; Seo, D.M.; Park, K. Construction of Asbestos Slate Deep-Learning Training-Data Model Based on Drone Images. Sensors 2023, 23, 8021. [Google Scholar] [CrossRef] [PubMed]
- Hikuwai, M.V.; Patorniti, N.; Vieira, A.S.; Frangioudakis Khatib, G.; Stewart, R.A. Artificial Intelligence for the Detection of Asbestos Cement Roofing: An Investigation of Multi-Spectral Satellite Imagery and High-Resolution Aerial Imagery. Sustainability 2023, 15, 4276. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote. Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote. Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Shangguan, B.; Wang, M.; Wu, Z. A multi-level context-guided classification method with object-based convolutional neural network for land cover classification using very high resolution remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2020, 88, 102086. [Google Scholar] [CrossRef]
- Kakogeorgiou, I.; Karantzalos, K. Evaluating explainable artificial intelligence methods for multi-label deep learning classification tasks in remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102520. [Google Scholar] [CrossRef]
- Zhang, Y.; Hong, D.; McClement, D.; Oladosu, O.; Pridham, G.; Slaney, G. Grad-CAM helps interpret the deep learning models trained to classify multiple sclerosis types using clinical brain magnetic resonance imaging. J. Neurosci. Methods 2021, 353, 109098. [Google Scholar] [CrossRef] [PubMed]
- Shi, C.; Zhang, X.; Sun, J.; Wang, L. Remote sensing scene image classification based on dense fusion of multi-level features. Remote. Sens. 2021, 13, 4379. [Google Scholar] [CrossRef]
- Chen, S.B.; Wei, Q.S.; Wang, W.Z.; Tang, J.; Luo, B.; Wang, Z.Y. Remote sensing scene classification via multi-branch local attention network. IEEE Trans. Image Process. 2021, 31, 99–109. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Shi, D.; Diao, X.; Xu, H. SCL-MLNet: Boosting few-shot remote sensing scene classification via self-supervised contrastive learning. IEEE Trans. Geosci. Remote. Sens. 2021, 60, 5801112. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Huang, X.; Yuille, A.L. Deep networks under scene-level supervision for multi-class geospatial object detection from remote sensing images. ISPRS J. Photogramm. Remote. Sens. 2018, 146, 182–196. [Google Scholar] [CrossRef]
- Huang, X.; Sun, Y.; Feng, S.; Ye, Y.; Li, X. Better visual interpretation for remote sensing scene classification. IEEE Geosci. Remote. Sens. Lett. 2021, 19, 6504305. [Google Scholar] [CrossRef]
- Guo, X.; Hou, B.; Wu, Z.; Ren, B.; Wang, S.; Jiao, L. Prob-POS: A Framework for Improving Visual Explanations from Convolutional Neural Networks for Remote Sensing Image Classification. Remote. Sens. 2022, 14, 3042. [Google Scholar] [CrossRef]
- Song, W.; Dai, S.; Wang, J.; Huang, D.; Liotta, A.; Di Fatta, G. Bi-gradient verification for grad-CAM towards accurate visual explanation for remote sensing images. In Proceedings of the 2019 International Conference on Data Mining Workshops (ICDMW), Beijing, China, 8–11 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 473–479. [Google Scholar]
- Dutta, S.; Das, M.; Maulik, U. Towards Causality-Based Explanation of Aerial Scene Classifiers. IEEE Geosci. Remote. Sens. Lett. 2023, 21, 8000405. [Google Scholar] [CrossRef]
- Fu, K.; Dai, W.; Zhang, Y.; Wang, Z.; Yan, M.; Sun, X. Multicam: Multiple class activation mapping for aircraft recognition in remote sensing images. Remote. Sens. 2019, 11, 544. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, X.; Xiao, P.; Zheng, Z. On the effectiveness of weakly supervised semantic segmentation for building extraction from high-resolution remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2021, 14, 3266–3281. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 630–645. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Chai, J.; Zeng, H.; Li, A.; Ngai, E.W. Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Mach. Learn. Appl. 2021, 6, 100134. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Area Name | Number of Images | Covered Area (km2) |
|---|---|---|
| Badalona | 71 | 110.9375 |
| Sant Adrià | 4 | 6.25 |
| Bages | 285 | 445.3125 |
| Zona Franca | 19 | 29.6875 |
| Vilanova i la Geltrú | 20 | 31.25 |
| Vallès | 32 | 50 |
| Castellbisbal | 44 | 68.75 |
| Cubelles | 15 | 23.4375 |
| Gavà-Viladecans | 16 | 25 |
| Ginestar | 6 | 9.375 |
| Hostalric | 9 | 14.0625 |
| La Verneda | 6 | 9.375 |
| Total | 527 | 823.4375 |
| Models | Accuracy | F1-Score | Asbestos Samples | Non-Asbestos Samples |
|---|---|---|---|---|
| EfficientNetB0 | 0.92 | 0.92 | 291 | 268 |
| ResNet50 | 0.81 | 0.80 | 291 | 268 |
| Pred | |||
| Asbestos | Non-asbestos | ||
| GT | Asbestos | 275 | 16 |
| Non-asbestos | 31 | 237 | |
| Pred | |||
| Asbestos | Non-asbestos | ||
| GT | Asbestos | 242 | 49 |
| Non-asbestos | 60 | 208 | |
| Networks | -Fold | -Fold | -Fold | -Fold | -Fold | Avg Accuracy |
|---|---|---|---|---|---|---|
| EfficientNetB0 | 0.81 | 0.88 | 0.89 | 0.86 | 0.85 | 0.86 |
| ResNet50 | 0.78 | 0.81 | 0.81 | 0.83 | 0.75 | 0.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Omarzadeh, D.; González-Godoy, A.; Bustos, C.; Martín-Fernández, K.; Scotto, C.; Sánchez, C.; Lapedriza, A.; Borge-Holthoefer, J. Explainable Automatic Detection of Fiber–Cement Roofs in Aerial RGB Images. Remote Sens. 2024, 16, 1342. https://doi.org/10.3390/rs16081342
Omarzadeh D, González-Godoy A, Bustos C, Martín-Fernández K, Scotto C, Sánchez C, Lapedriza A, Borge-Holthoefer J. Explainable Automatic Detection of Fiber–Cement Roofs in Aerial RGB Images. Remote Sensing. 2024; 16(8):1342. https://doi.org/10.3390/rs16081342
Chicago/Turabian StyleOmarzadeh, Davoud, Adonis González-Godoy, Cristina Bustos, Kevin Martín-Fernández, Carles Scotto, César Sánchez, Agata Lapedriza, and Javier Borge-Holthoefer. 2024. "Explainable Automatic Detection of Fiber–Cement Roofs in Aerial RGB Images" Remote Sensing 16, no. 8: 1342. https://doi.org/10.3390/rs16081342
APA StyleOmarzadeh, D., González-Godoy, A., Bustos, C., Martín-Fernández, K., Scotto, C., Sánchez, C., Lapedriza, A., & Borge-Holthoefer, J. (2024). Explainable Automatic Detection of Fiber–Cement Roofs in Aerial RGB Images. Remote Sensing, 16(8), 1342. https://doi.org/10.3390/rs16081342