



Shadow-Aware Point-Based Neural Radiance Fields for High-Resolution Remote Sensing Novel View Synthesis

 , , ,
, , ,
Abstract
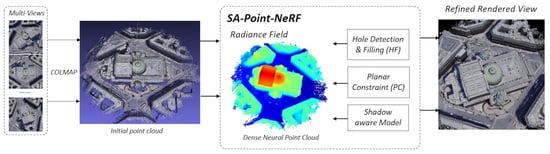
1. Introduction
- To the best of our knowledge, we are the first to apply Point-NeRF to the novel view synthesis of remote sensing images.
- We propose a new neural point-growing method, which detects holes in the rendered image and calculates some alternative 3D points through inverse projection. This method can effectively make up for the plane points being pruned by mistake.
- We design a shadow model based on point cloud geometric consistency to deal with the holes in the shadow areas, which is useful for the perception of shadows.
- Our method was tested on the LEVIR_NVS data set and performed better than state-of-the-art methods.
2. Method
2.1. Preliminary
2.1.1. Neural Radiance Field
2.1.2. Point-Based Neural Radiance Field
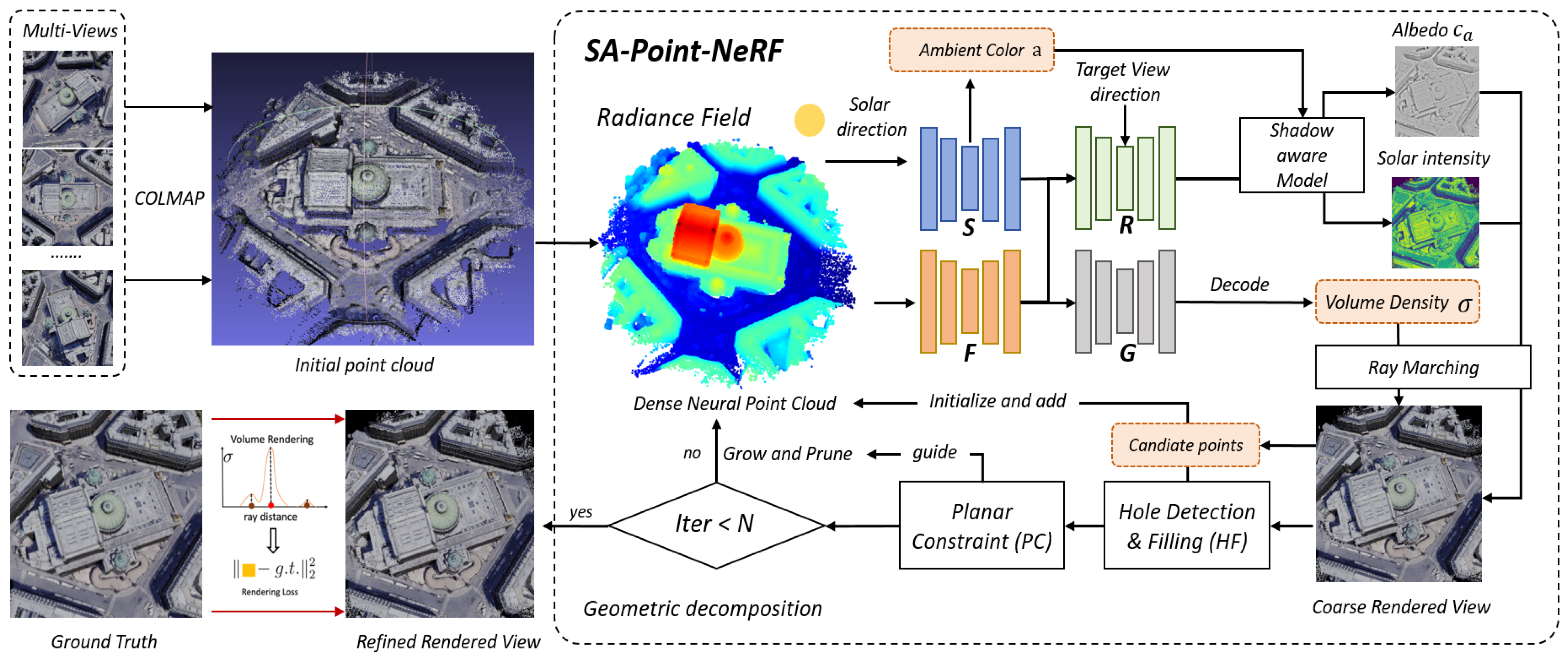
2.2. Overview
2.2.1. Main Workflow
2.2.2. Module Function
2.3. Problem Definition
- : Volume density at location ;
- : Albedo RGB vector, only related to the spatial coordinate, ;
- : Ambient color of the sky according to the solar direction, ;
- : Confidence of whether the point is near the surface;
- : Confidence of whether the point belongs to a plane.
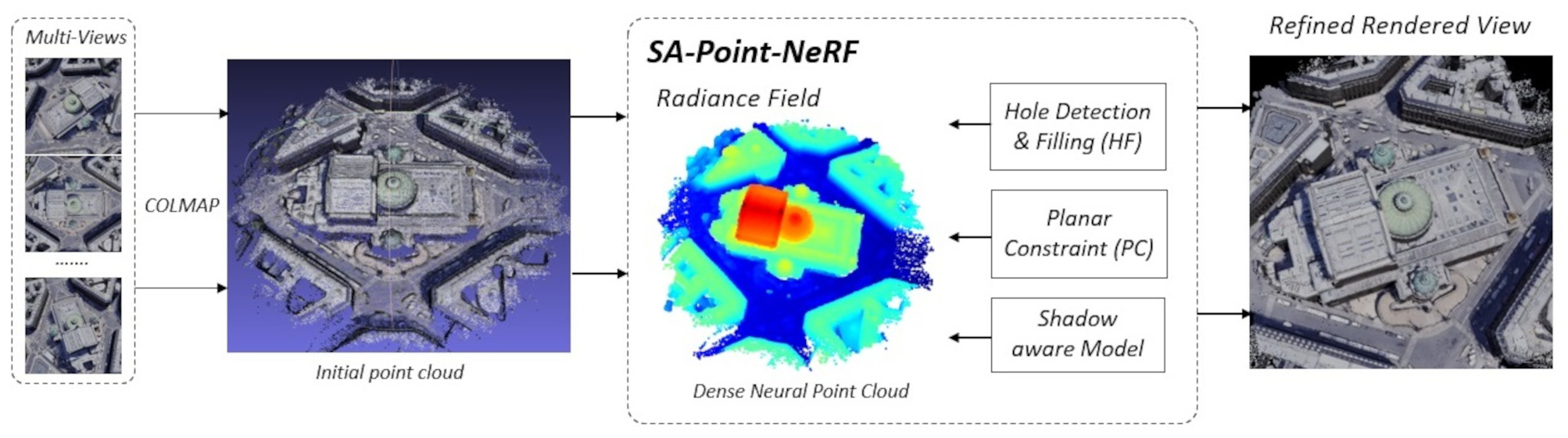
2.4. Hole Detection and Filling
2.5. Incremental Weight of Planar Information
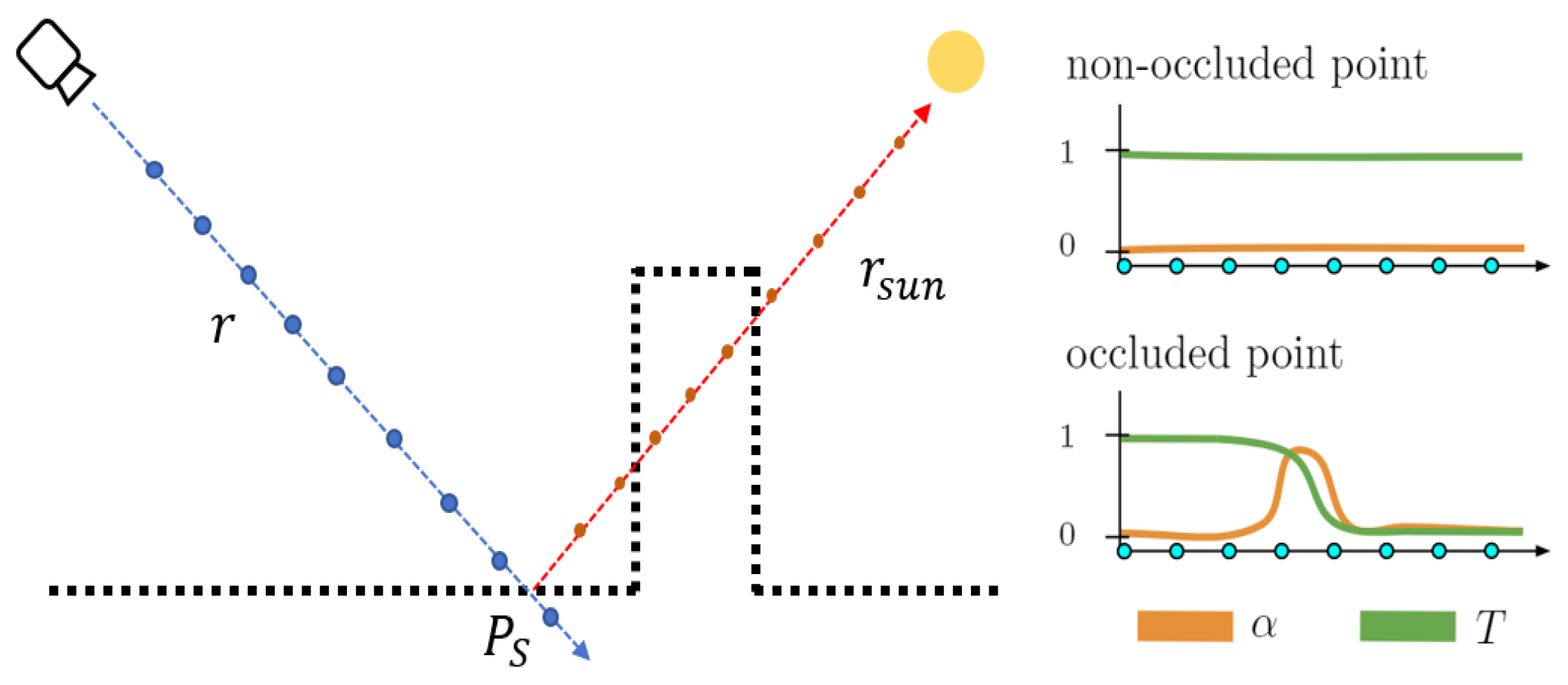
2.6. Structural Consistency Shadow Model
2.7. Loss Function
3. Results
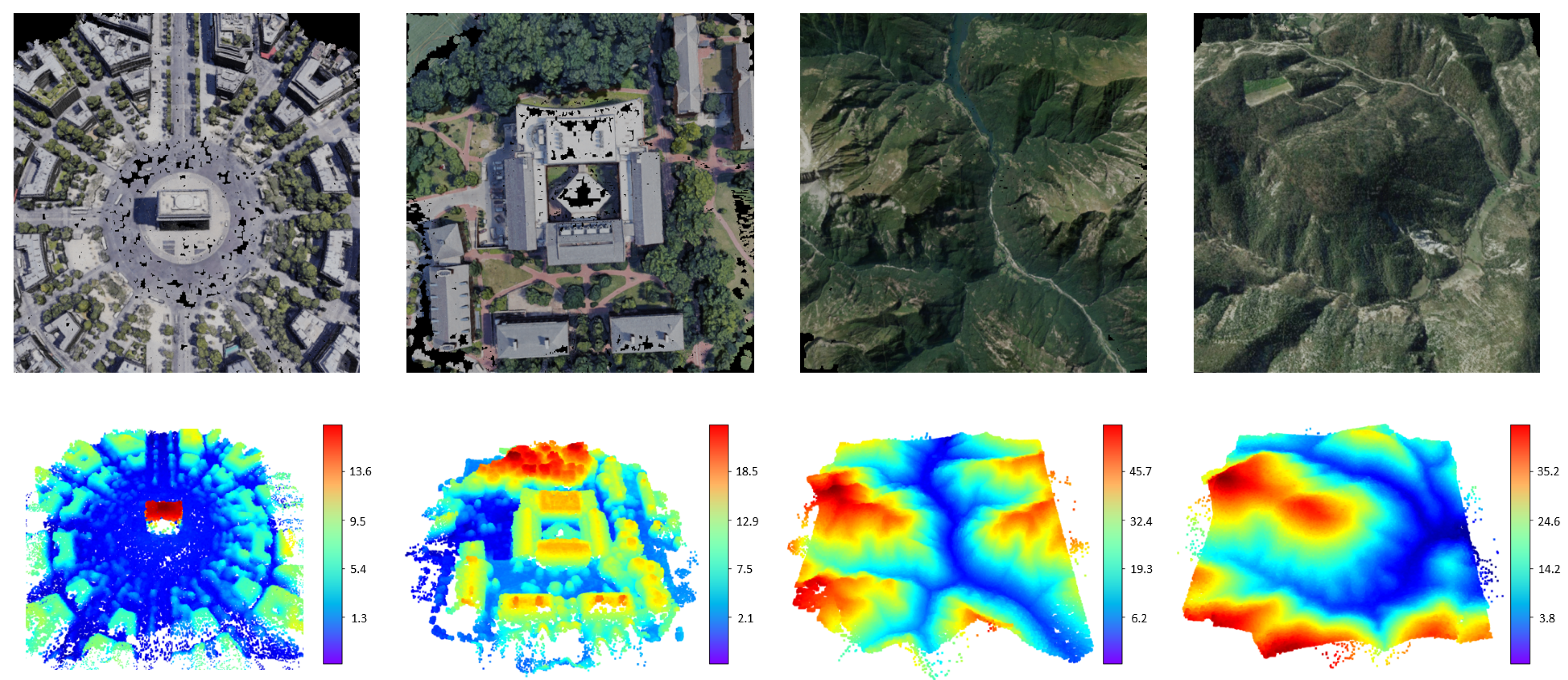
3.1. Datasets
3.2. Quality Assessment Metrics
3.3. Implementation Details
3.4. Performance Comparison
4. Discussion
4.1. Ablation Study
4.2. Efficiency in Optimization and Rendering
4.3. Effectiveness of Structural Consistency Shadow Model
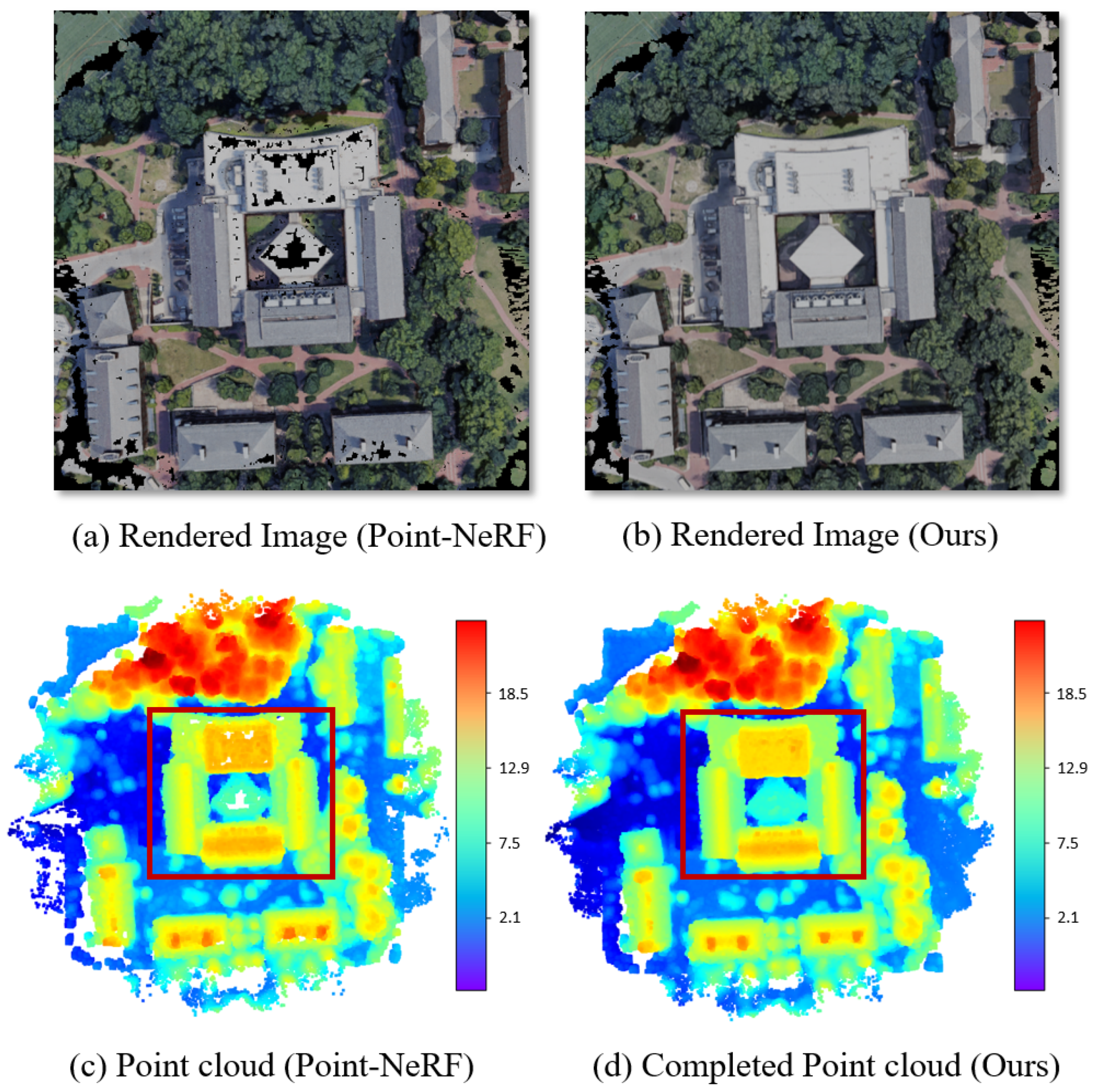
4.4. Effectiveness of Planar Constraint and Hole-Filling


5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, W.; Yang, N.; Zhang, Y.; Wang, F.; Cao, T.; Eklund, P. A review of road extraction from remote sensing images. J. Traffic Transp. Eng. (Engl. Ed.) 2016, 3, 271–282. [Google Scholar] [CrossRef]
- Chen, Z.; Deng, L.; Luo, Y.; Li, D.; Junior, J.M.; Gonçalves, W.N.; Nurunnabi, A.A.M.; Li, J.; Wang, C.; Li, D. Road extraction in remote sensing data: A survey. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102833. [Google Scholar] [CrossRef]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road extraction from high-resolution remote sensing imagery using deep learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef]
- Zhang, L.; Lan, M.; Zhang, J.; Tao, D. Stagewise unsupervised domain adaptation with adversarial self-training for road segmentation of remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Wellmann, T.; Lausch, A.; Andersson, E.; Knapp, S.; Cortinovis, C.; Jache, J.; Scheuer, S.; Kremer, P.; Mascarenhas, A.; Kraemer, R.; et al. Remote sensing in urban planning: Contributions towards ecologically sound policies? Landsc. Urban Plan. 2020, 204, 103921. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Achlioptas, P.; Diamanti, O.; Mitliagkas, I.; Guibas, L. Learning representations and generative models for 3d point clouds. In Proceedings of the International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, 10–15 July 2018; pp. 40–49. [Google Scholar]
- Qi, C.R.; Su, H.; Nießner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and multi-view cnns for object classification on 3d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5648–5656. [Google Scholar]
- Liu, L.; Gu, J.; Zaw Lin, K.; Chua, T.S.; Theobalt, C. Neural sparse voxel fields. Adv. Neural Inf. Process. Syst. 2020, 33, 15651–15663. [Google Scholar]
- Kazhdan, M.; Bolitho, M.; Hoppe, H. Poisson surface reconstruction. In Proceedings of the Fourth Eurographics Symposium on Geometry Processing, Cagliari, Italy, 26–28 June 2006; Volume 7, p. 4. [Google Scholar]
- Chen, Z.; Zhang, H. Learning implicit fields for generative shape modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5939–5948. [Google Scholar]
- Levoy, M.; Hanrahan, P. Light field rendering. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2; Association for Computing Machinery: New York, NY, USA, 2023; pp. 441–452. [Google Scholar]
- Neff, T.; Stadlbauer, P.; Parger, M.; Kurz, A.; Mueller, J.H.; Chaitanya, C.R.A.; Kaplanyan, A.; Steinberger, M. DONeRF: Towards Real-Time Rendering of Compact Neural Radiance Fields using Depth Oracle Networks. Comput. Graph. Forum 2021, 40, 45–59. [Google Scholar] [CrossRef]
- Wu, Y.; Zou, Z.; Shi, Z. Remote sensing novel view synthesis with implicit multiplane representations. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Lv, J.; Guo, J.; Zhang, Y.; Zhao, X.; Lei, B. Neural Radiance Fields for High-Resolution Remote Sensing Novel View Synthesis. Remote Sens. 2023, 15, 3920. [Google Scholar] [CrossRef]
- Li, X.; Li, C.; Tong, Z.; Lim, A.; Yuan, J.; Wu, Y.; Tang, J.; Huang, R. Campus3d: A photogrammetry point cloud benchmark for hierarchical understanding of outdoor scene. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 238–246. [Google Scholar]
- Iman Zolanvari, S.; Ruano, S.; Rana, A.; Cummins, A.; da Silva, R.E.; Rahbar, M.; Smolic, A. DublinCity: Annotated LiDAR point cloud and its applications. arXiv 2019, arXiv:1909.03613. [Google Scholar]
- Yang, G.; Xue, F.; Zhang, Q.; Xie, K.; Fu, C.W.; Huang, H. UrbanBIS: A Large-Scale Benchmark for Fine-Grained Urban Building Instance Segmentation. In ACM SIGGRAPH 2023 Conference Proceedings; Association for Computing Machinery: New York, NY, USA, 2023; pp. 1–11. [Google Scholar]
- Xu, Q.; Xu, Z.; Philip, J.; Bi, S.; Shu, Z.; Sunkavalli, K.; Neumann, U. Point-nerf: Point-based neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5438–5448. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. Mvsnet: Depth inference for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 767–783. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Schonberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Derksen, D.; Izzo, D. Shadow Neural Radiance Fields for Multi-View Satellite Photogrammetry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Nashville, TN, USA, 19–25 June 2021; pp. 1152–1161. [Google Scholar]
- Marí, R.; Facciolo, G.; Ehret, T. Sat-NeRF: Learning Multi-View Satellite Photogrammetry with Transient Objects and Shadow Modeling Using RPC Cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, New Orleans, LA, USA, 19–20 June 2022; pp. 1311–1321. [Google Scholar]
- Marí, R.; Facciolo, G.; Ehret, T. Multi-Date Earth Observation NeRF: The Detail Is in the Shadows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Vancouver, BC, Canada, 18–22 June 2023; pp. 2035–2045. [Google Scholar]
- Zhang, K.; Riegler, G.; Snavely, N.; Koltun, V. NeRF++: Analyzing and Improving Neural Radiance Fields. Clin. Orthop. Relat. Res. 2020. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of | PSNR | SSIM | LPIPS | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Scene | ImMPI | Point-NeRF | Ours | ImMPI | Point-NeRF | Ours | ImMPI | Point-NeRF | Ours |
| Building #1 | 24.92/24.77 | 14.49/14.42 | 25.89/25.43 | 0.867/0.865 | 0.709/0.702 | 0.889/0.883 | 0.150/0.151 | 0.354/0.359 | 0.147/0.152 |
| Building #2 | 23.31/22.73 | 19.12/18.57 | 24.97/24.88 | 0.783/0.776 | 0.866/0.862 | 0.867/0.864 | 0.217/0.218 | 0.233/0.237 | 0.211/0.216 |
| College | 26.17/25.71 | 17.57/17.52 | 24.92/23.84 | 0.820/0.817 | 0.813/0.806 | 0.825/0.818 | 0.201/0.203 | 0.272/0.274 | 0.198/0.205 |
| Mountain #1 | 30.23/29.88 | 23.21/23.18 | 30.57/30.23 | 0.854/0.854 | 0.891/0.888 | 0.896/0.896 | 0.187/0.185 | 0.228/0.228 | 0.193/0.197 |
| Mountain #2 | 29.56/29.37 | 22.82/22.82 | 29.47/29.33 | 0.844/0.843 | 0.913/0.911 | 0.916/0.915 | 0.172/0.173 | 0.189/0.192 | 0.169/0.173 |
| Mountain #3 | 33.02/32.81 | 29.52/29.11 | 33.81/33.77 | 0.880/0.878 | 0.966/0.963 | 0.988/0.982 | 0.156/0.157 | 0.087/0.084 | 0.155/0.159 |
| Observation | 23.04/22.54 | 18.32/18.18 | 24.48/24.10 | 0.728/0.718 | 0.673/0.669 | 0.794/0.789 | 0.267/0.272 | 0.325/0.338 | 0.243/0.250 |
| Church | 21.60/21.04 | 18.87/18.82 | 22.62/22.57 | 0.729/0.720 | 0.838/0.834 | 0.849/0.843 | 0.254/0.258 | 0.262/0.265 | 0.236/0.245 |
| Town #1 | 26.34/25.88 | 21.63/21.59 | 27.62/27.35 | 0.849/0.844 | 0.907/0.901 | 0.922/0.914 | 0.163/0.167 | 0.191/0.191 | 0.161/0.164 |
| Town #2 | 25.89/25.31 | 20.11/20.05 | 26.81/26.58 | 0.855/0.850 | 0.896/0.892 | 0.915/0.914 | 0.156/0.158 | 0.179/0.176 | 0.147/0.151 |
| Town #3 | 26.23/25.68 | 26.44/26.13 | 27.19/26.93 | 0.840/0.834 | 0.965/0.964 | 0.963/0.960 | 0.187/0.190 | 0.088/0.092 | 0.091/0.096 |
| Stadium | 26.69/26.50 | 21.38/21.12 | 26.31/26.12 | 0.878/0.876 | 0.873/0.869 | 0.888/0.887 | 0.123/0.125 | 0.168/0.173 | 0.145/0.164 |
| Factory | 28.15/28.08 | 19.22/19.22 | 27.65/27.53 | 0.908/0.907 | 0.891/0.889 | 0.910/0.902 | 0.109/0.109 | 0.191/0.193 | 0.129/0.131 |
| Park | 27.87/27.81 | 19.34/19.32 | 27.93/27.62 | 0.896/0.896 | 0.901/0.901 | 0.925/0.923 | 0.123/0.124 | 0.176/0.177 | 0.126/0.128 |
| School | 25.74/25.33 | 20.61/20.58 | 25.84/25.82 | 0.830/0.825 | 0.796/0.788 | 0.856/0.852 | 0.163/0.165 | 0.209/0.207 | 0.183/0.185 |
| Downtown | 24.99/24.24 | 20.58/20.56 | 25.12/25.08 | 0.825/0.816 | 0.898/0.898 | 0.903/0.901 | 0.201/0.205 | 0.212/0.211 | 0.199/0.204 |
| mean | 26.34/25.95 | 20.83/20.70 | 26.95/26.69 | 0.835/0.831 | 0.862/0.858 | 0.894/0.890 | 0.172/0.173 | 0.210/0.212 | 0.170/0.176 |
| SC | PC | HF | PSNR↑ | SSIM↑ | LPIPS↓ | |
|---|---|---|---|---|---|---|
| Init (Point-NeRF) | - | 20.83 | 0.862 | 0.210 | ||
| Configuration | ✓ | 23.64 | 0.877 | 0.192 | ||
| ✓ | 23.58 | 0.875 | 0.209 | |||
| ✓ | 22.49 | 0.870 | 0.205 | |||
| ✓ | ✓ | 24.89 | 0.884 | 0.197 | ||
| ✓ | ✓ | 25.06 | 0.892 | 0.184 | ||
| ✓ | ✓ | 25.42 | 0.903 | 0.188 | ||
| ✓ | ✓ | ✓ | 26.95 | 0.984 | 0.170 | |
| Method | Image Size | Pre-Training | Optimization | Rendering |
|---|---|---|---|---|
| NeRF [7] | 512 × 512 | - | >90 min | >20 s |
| NeRF++ [27] | 512 × 512 | - | >60 min | >20 s |
| ImMPI [15] | 512 × 512 | 21 h | <30 min | <1 s |
| Point-NeRF [20] | 512 × 512 | - | <60 min | 12–14 s |
| Ours | 512 × 512 | - | <60 min | 9–12 s |
| Test | Area #1 | Area #2 | Area #3 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | Iteration | num_p | z_mean | z_var | num_p | z_mean | z_var | num_p | z_mean | z_var |
| Point-NeRF [20] | 10 k | 101,795 | −22.48 | 15.69 | 153,496 | −40.63 | 18.60 | 203,548 | −55.83 | 16.58 |
| 50 k | 194,486 | −21.75 | 12.81 | 203,694 | −35.64 | 15.66 | 434,848 | −53.61 | 13.52 | |
| 150 k | 256,478 | −20.78 | 8.64 | 289,492 | −36.77 | 12.93 | 643,518 | −51.84 | 10.96 | |
| w/PC | 10 k | 122,767 | −20.28 | 13.85 | 183,647 | −42.53 | 16.30 | 233,648 | −53.64 | 13.64 |
| 50 k | 245,862 | −19.36 | 10.11 | 262,148 | −38.68 | 14.28 | 468,319 | −51.62 | 13.25 | |
| 150 k | 294,518 | −19.27 | 8.36 | 331,496 | −35.96 | 11.89 | 723,971 | −49.36 | 11.30 | |
| w/HF | 10 k | 153,976 | −23.44 | 14.23 | 203,546 | −40.01 | 17.31 | 264,726 | −58.16 | 16.17 |
| 50 k | 279,549 | −21.30 | 11.38 | 364,795 | −34.28 | 15.92 | 412,818 | −52.11 | 13.76 | |
| 150 k | 332,156 | −19.12 | 8.15 | 369,842 | −33.16 | 12.87 | 736,487 | −53.19 | 13.89 | |
| w/PC + HF | 10 k | 235,716 | −21.55 | 12.65 | 294,298 | −35.68 | 15.28 | 301,428 | −54.60 | 14.17 |
| 50 k | 303,674 | −20.10 | 9.20 | 364,792 | −33.14 | 13.64 | 453,972 | −49.73 | 12.98 | |
| 150 k | 401,498 | −19.03 | 7.29 | 423,699 | −32.27 | 12.39 | 782,364 | −48.32 | 9.98 | |
| COLMAP | - | 31,498 | −18.63 | 6.97 | 39,483 | −29.14 | 10.29 | 42,369 | −42.98 | 7.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Zhang, Y.; Wang, Z.; Zhang, Z.; Jiang, Z.; Yu, Y.; Li, L.; Zhang, L. Shadow-Aware Point-Based Neural Radiance Fields for High-Resolution Remote Sensing Novel View Synthesis. Remote Sens. 2024, 16, 1341. https://doi.org/10.3390/rs16081341
Li L, Zhang Y, Wang Z, Zhang Z, Jiang Z, Yu Y, Li L, Zhang L. Shadow-Aware Point-Based Neural Radiance Fields for High-Resolution Remote Sensing Novel View Synthesis. Remote Sensing. 2024; 16(8):1341. https://doi.org/10.3390/rs16081341
Chicago/Turabian StyleLi, Li, Yongsheng Zhang, Ziquan Wang, Zhenchao Zhang, Zhipeng Jiang, Ying Yu, Lei Li, and Lei Zhang. 2024. "Shadow-Aware Point-Based Neural Radiance Fields for High-Resolution Remote Sensing Novel View Synthesis" Remote Sensing 16, no. 8: 1341. https://doi.org/10.3390/rs16081341
APA StyleLi, L., Zhang, Y., Wang, Z., Zhang, Z., Jiang, Z., Yu, Y., Li, L., & Zhang, L. (2024). Shadow-Aware Point-Based Neural Radiance Fields for High-Resolution Remote Sensing Novel View Synthesis. Remote Sensing, 16(8), 1341. https://doi.org/10.3390/rs16081341