1. Introduction
Polarimetric synthetic aperture radar (PolSAR) exhibits the potential to capture back-scattering information of land covers, which enables richer feature extraction and better image interpretation beyond the limitations of single-channel SAR. As a result, PolSAR has found broader applications, including topographic mapping, resource exploration, disaster monitoring, change detection, and land cover classification [
1,
2,
3,
4,
5,
6,
7]. Meanwhile, the rapid advancement of deep learning has significantly expanded the possibilities for discoveries and advancements in PolSAR image classification.
Traditional approaches to PolSAR image classification primarily exploit the polarimetric scattering characteristics [
8,
9,
10,
11,
12,
13,
14] and statistical distributions [
15,
16,
17,
18] of PolSAR data. These methods include the Complex Wishart classifier [
19,
20,
21,
22,
23,
24,
25], statistical techniques such as
k-nearest neighbors [
26], and kernel methods, like support vector machine (SVM) [
27,
28,
29]. By incorporating additional feature information, such as regional information [
30,
31], anisotropy, and total polarimetric power (SPAN) [
23], these approaches achieve enhanced performance in characterizing land covers from various perspectives. Moreover, iterative Bayesian approaches based on matrix variate distribution assumptions [
15,
16,
18,
20,
21,
32], such as Markov random field (MRF) [
20,
21] and expectation maximization (EM), can accurately model PolSAR scattering characteristics, while addressing the duplication and degradation of feature representations due to polarimetric decomposition.
Over the last decade, there has been a significant increase in literature published on PolSAR image classification with deep learning approaches. Early works include deep belief networks (DBN) [
33,
34] and restricted Boltzmann machines (RBM) [
35]. For instance, Liu et al. [
33] suggest stacking Wishart–Bernoulli RBM among the hidden layers of DBN. Guo et al. [
35] propose a Wishart Restricted Boltzmann Machine (WRBM), demonstrating superior performance compared to the Gaussian RBM. Moreover, autoencoders (AEs) [
36,
37,
38] have shown remarkable effectiveness in PolSAR image classification. The performance of convolutional neural networks (CNNs) in PolSAR image classification tasks was first verified in [
39,
40,
41]. Additionally, generative adversarial networks (GANs) [
42] and long short-term memory (LSTM) [
43] have also found applications in PolSAR image classification tasks.
For pixel-level image segmentation, U-Net [
44,
45,
46,
47] is an architecture that makes it possible to encode and decode high-level features while preserving local spatial information via a contracting path with pooling layers and an expansive path with unpooling layers. Traditional U-Nets utilize skip connections between encoders and decoders at the same semantic level to construct an image in the decoder part with fine-grained details learned in the encoder part. However, their potential is heavily constrained due to the inability to fuse latent features from multiple resolutions.
Nevertheless, the convolution layers in CNNs often exhibit a limited receptive field, which hinders their capability to model the global relationships within an image, especially in deeper architectures. Furthermore, CNNs are designed for Euclidean data, such as regular images in a grid structure, where each pixel undergoes the same convolutional operation, which may fail to fully capture the intricate relationships between pixels in complex scenes. To overcome these limitations, there have been several attempts reported in the literature to perform PolSAR image classification in the graph domain.
Early research includes spectral graph partitioning and fuzzy clustering techniques that work on undirected symmetric graphs and construct the graph topology with numerous similarity metrics [
7,
48,
49,
50,
51,
52,
53]. For instance, Wei et al. [
51] propose representing the complex relationship among land covers with hypergraphs. Shi et al. [
52] propose a supervised graph embedding (SGE) to learn a low-dimensional manifold and map the PolSAR data into the graph domain. Yang et al. [
54] present a kernel low-rank representation graph for SAR image classification, which projects samples onto a feature space using a kernel function and constructs the graph with a low-rank encoding sparse matrix. Hou et al. [
55] enhance the classification performance of multilayer autoencoders through a novel probabilistic metric in
k-nearest neighbors, which fully utilizes the spatial relations between pixels and superpixels.
Recently, graph neural networks have exhibited considerable potential in the realm of PolSAR image classification tasks [
56,
57,
58]. Using a sparse reconstruction function, Liu et al. [
56] propose the processing of PolSAR data with spatial-anchor graphs. This method clusters the PolSAR image with weighted feature vectors and defines the representative centers as anchors. Later work [
57] utilizes neighboring relations within superpixels to introduce feature weighting and mitigates the limitations of large-scale matrix decomposition. By preselecting cluster centers as anchors, this approach facilitates refined segmentation and rapid graph construction through border reassignment. Bi et al. [
58] propose a pixel-wise graph CNN that employs a label smoothness term, a CNN for feature extraction, and a semi-supervision term to enforce label constraints in its energy function. These studies use the Euclidean distance to model the dissimilarity of pair-wise nodes; thus, the graph structure is not accurate enough. Ren et al. [
7] propose a graph convolutional network (GCN) that applies Wishart similarity to model the weighted graph edges in multiple scales, thus obtaining better performance. However, the graph nodes are the superpixels presegmented by spectral clustering, so pixel-wise PolSAR image segmentation with GCNs remains to be exploited.
The above literature shows that graph methods must focus on constructing an accurate graph structure and deriving appropriate similarity measures for PolSAR data. Kersten et al. [
50] use EM clustering and fuzzy clustering for PolSAR image classification with five distance measures, where the distance measures derived from the Wishart distribution outperform the others. To make the non-symmetric Wishart distance work on undirected graphs, Anfinsen et al. [
59] derive the symmetric revised Wishart distance to initialize the Wishart classifier for classification. Previous work on PolSAR image classification with GCNs [
7,
53] proposed building adjacency matrices by pre-segmenting Pauli RGB images into superpixels (SP) with simple linear iterative clustering (SLIC), and refining the inaccurate graph structure via graph evolving modules, which associate learnable hidden representation with kernel diffusion. However, the shallow networks together with the first-order approximation of Chebyshev polynomials make it hard to incorporate information from higher-order neighbors with the constant adjacency relationship throughout the training process. Another problem is that previous GCN approaches reduce the computational burden brought by spectral convolution by operating on superpixels with mean feature vectors, which also makes it impossible to conduct training with batch-wise processing and to fully utilize the features across different PolSAR images.
Due to the limitations of constant graph topology and edge weights, the generalization capacity of traditional GCNs [
7,
53,
60] is greatly hindered since they only aggregate node embeddings within the same neighborhood at each training step. To address this deficiency, dynamic graph convolution [
61,
62,
63] has recently been proposed to allow graph structure refinement in each layer, thus enabling better graph representations compared to traditional GCNs. More notably, dynamic neighbors can effectively enlarge the receptive field and greatly help alleviate the over-smoothing problem of deep GCNs. On the other hand, most GCNs conduct node classification tasks with binary adjacency matrices, which means that each neighboring node plays the same role in propagation. Recent studies [
7,
53] have witnessed the improvement in classification performance brought by weighted graphs, where the edge weights are more competitive in exploring effective feature representations than binary adjacency matrices.
Combining the advantages of the methods above, the proposed CLIGUNet leverages a
k-NN (
k-nearest neighbors) approach [
64] to find the nearest neighbors for each node in the latent feature space of each layer, where each patch is a unique graph with pixel-wise features. Afterwards, our CLIGUNet encodes the symmetric revised Wishart distance in weighted adjacency matrices, capturing essential polarimetric scattering information in multiple resolutions. Compared to spectral GCNs [
7,
53], our CLIGUNet performs weighted max-relative spatial graph convolution in multiple scales and across dynamic graph patches, which greatly enhances its capacity to generalize across PolSAR images. To address the weakness of U-Nets, this paper proposes cross-level interactions to enhance feature discrimination by integrating multi-scale latent features with the help of residual transformers. Moreover, it utilizes a deep supervision strategy to refine the feature maps at higher resolutions and address the vanishing gradient problem. Compared with the graph self-attention integration module in [
7,
53], the cross-level interactions presented in this paper can better utilize graph representations across multiple resolutions and various PolSAR image patches through the residual transformers with multi-head attention. Finally, by leveraging the benefits of the U-Net architecture, residual transformers, weighted spatial graph convolution, and dynamic graphs, this paper develops a cross-level interaction graph U-Net (CLIGUNet) to achieve robust pixel-wise PolSAR image segmentation within and across PolSAR image datasets. To the best of our knowledge, application of spatial GCNs in PolSAR image classification has not been fully explored, making our proposed CLIGUNet a pioneering effort in this field. In contrast to existing deep learning methodologies for PolSAR image classification, our paper introduces several key innovations, including the following:
(1) Compared with U-Net [
47,
65], which applies skip connections between encoders and decoders only on the same level, our cross-level interactions take into account both the inter-connections between encoder and decoder blocks and the intra-connections among the stacked feature maps within the decoder at each scale. Moreover, our cross-level interactions utilize trainable residual transformers with multi-head attention to integrate multi-scale graph feature representations and select effective features from various scales. Afterwards, the refined latent features in previous layers of different resolutions serve as the input to their next graph convolution module to achieve multi-scale graph representation learning.
(2) To bridge the gap between GCNs and multi-graph inputs, we propose a weighted max-relative spatial convolution, which makes it possible to learn the latent feature maps of different graphs at the same time. Moreover, traditional GCNs operate on undirected graphs where all neighboring nodes have equal importance. However, the contribution of each neighbor can vary significantly in the graph learning progress. Therefore, weighted adjacency matrices derived from the revised Wishart distance are incorporated to encode polarimetric similarity in the graph topology. Compared to previous GCN approaches that operate on superpixels, our weighted max-relative spatial convolution also enables more accurate pixel-wise image segmentation and better generalization capability across PolSAR image datasets.
(3) Given that most GCNs have not considered the interaction between the feature representation and graph structure, their adjacency matrices remain constant throughout the training process. To address this deficiency, multi-scale dynamic graphs are defined to make appropriate adjacency matrix refinements on the connectivity relationships and edge weights within the neighborhoods of each resolution, which also enlarge the receptive field of each node by reaching out for higher-order neighbors when each scale updates its latent feature maps, thus providing significant boosts in classification performance and generalization capacity with limited training samples.
The rest of this paper is organized as follows:
Section 2 provides a comprehensive overview of the methodologies employed in our proposed cross-level interaction graph U-Net (CLIGUNet).
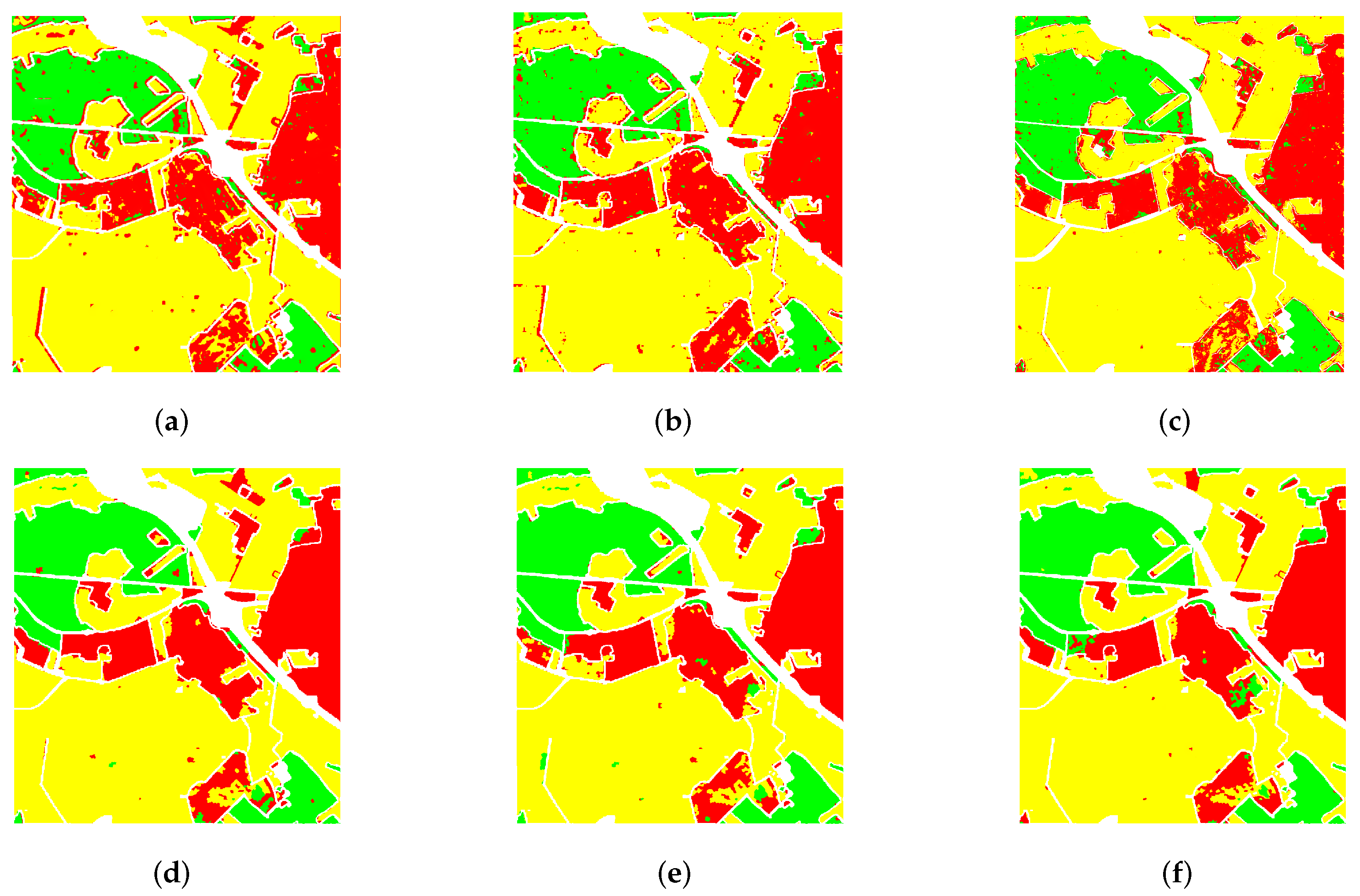
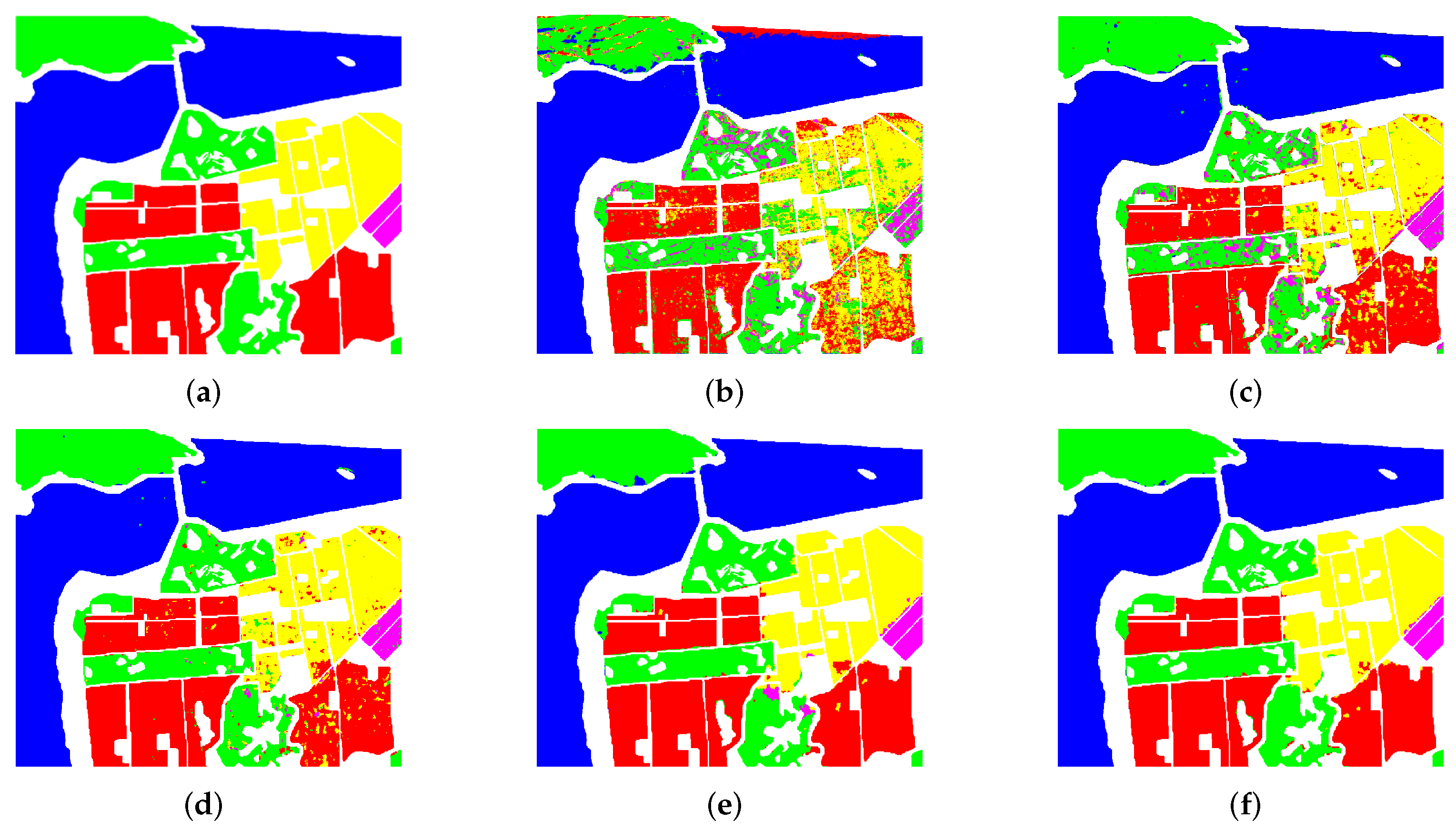
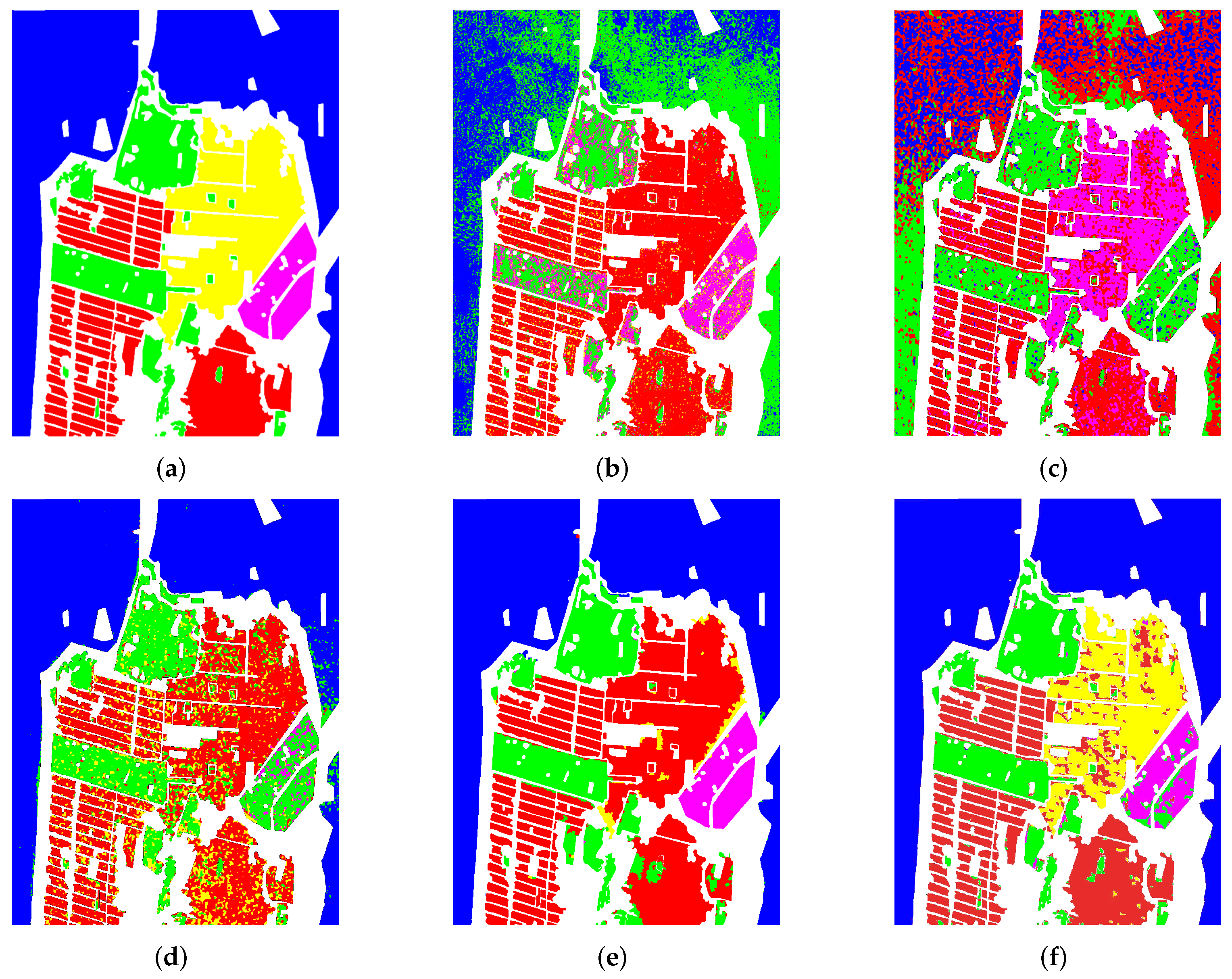
Section 3 presents the experiments and analyses conducted on four real PolSAR datasets. Finally,
Section 4 summarizes the paper and provides insights into our future work.
2. Theory and Methodology
This paper proposes a PolSAR image segmentation model based on the cross-level interaction graph U-Net (CLIGUNet). First,
Section 2.1 introduces PolSAR data preparation, where a coherency matrix is adopted as the input features. Next,
Section 2.2 gives an overview of the network architecture and implementation of CLIGUNet. Then,
Section 2.3 illustrates the motivation to propose the weighted max-relative spatial graph convolution inspired by deep GCNs [
64], which incorporates the advantages of both image features in Euclidean space and polarimetric scattering similarity in the non-Euclidean graph domain, and thus enables the network parameters to generalize well on unseen graphs.
Section 2.4 provides insight into the theoretical derivation of multi-scale dynamic graphs using
k-NN and symmetric revised Wishart similarity, which is performed each iteration to map the image patches into the graph domain. Afterwards, in
Section 2.5, a residual transformer with multi-head attention is proposed to interact between the bottleneck features and the graph structure across multiple resolutions. Finally, in
Section 2.6, a deep supervision strategy is designated to fully utilize multi-scale information from neighbors in various scales, thus obtaining better segmentation results.
2.1. PolSAR Data Preparation
PolSAR platforms, by virtue of their ability to transmit and receive various polarimetric electromagnetic waves, can capture abundant scattering information from observed land covers, with each resolution cell in the fundamental SLC format being represented by a
complex scattering matrix. Here,
H and
V represent the horizontal and vertical polarization modes, respectively. Subsequently, a
complex polarimetric scattering matrix can be expressed as
where the first and second subscripts denote the polarization modes of the received and transmitted electromagnetic waves, respectively.
According to the reciprocity theorem,
equals
in monostatic SAR systems. Consequently, the scattering vector in the Pauli basis can be written as
Therefore, the polarimetric coherence matrix
T can be obtained by
2.2. Overall Network Architecture
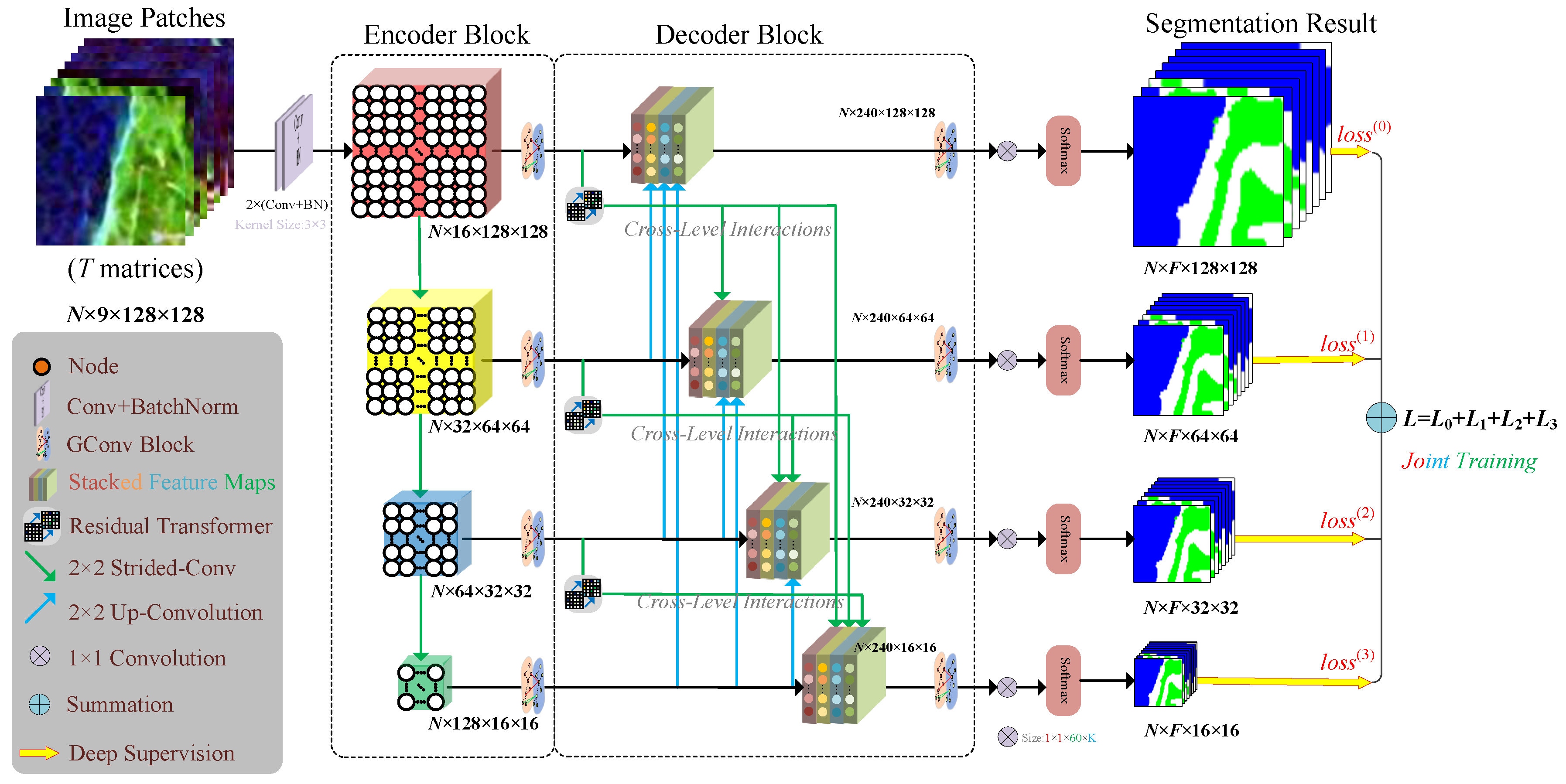
Figure 1 illustrates the hierarchical structure of the proposed CLiGUNet, which starts with an encoder backbone followed by a decoder sub-network. The detailed settings of the encoder block and decoder block are shown in
Table 1 and
Table 2, respectively, where
denotes the batch size,
denotes the input image size,
D denotes the feature dimension, and
L is the latent dimension (set to 16 in the experiments) of the stem component.
E denotes the hidden dimension ratio, which means the convolutional layer number in FFN.
K denotes the number of neighbors in the GC layer. The nine elements of the coherence matrix are used as the initial feature vector of each node in the input graph. Using two convolution layers with batch normalization, the input feature vectors are first mapped into a high-dimensional representation. To bridge the gap between image patches in the Euclidean grid structure and node feature representations in the graph domain, our CLIGUNet uses a
k-NN approach [
62] to recompute and generate the graph topology with learnable features in latent space in each iteration. To fully utilize the polarimetric scattering information of the PolSAR data, the edge weights of each graph are obtained based on the symmetric revised Wishart distance [
50] and the thresholded weighting function.
The encoder section on the left comprises four stacked graph convolution (GC) blocks. Each GC block consists of a multi-layer neural network, including a weighted max-relative spatial graph convolutional layer with batch normalization and ReLU activation, as well as a feed-forward network (FFN) module. The FFN module serves to enhance the feature transformation capacity and alleviate the over-smoothing issue in the deeper graph convolutional layers. Then, a strided convolutional layer is applied to encode higher-level graph representations and reduce the input graph size. Afterwards, residual transformers are integrated to enhance the skip connections among the encoder features and decoder features. With the exception of the last convolution block, the feature representations from the preceding block are sub-sampled by a strided convolutional layer (depicted in green) before being passed to the next block. The input image size is set to , where F denotes the number of land cover types and N represents the batch size.
The decoder section on the right consists of four decoder blocks. Each decoder block has a weighted max-relative spatial graph convolutional layer and a deconvolution layer, which aggregate information from neighbors and restore the graph to a higher resolution structure. The intra-connections among the stacked feature maps within the decoder sub-network are designed to facilitate the flow of information across different resolutions, enabling the network to capture both coarse-grained semantics and fine-grained details. Meanwhile, the interconnections between the encoder and decoder blocks help to establish skip connections, allowing the decoder to access and integrate multi-scale feature representations from the encoder, which helps in preserving spatial information and enhancing the performance of feature reconstruction. As a result, the skip connections above integrate feature maps from both lower- and same-scale layers of the encoder, as well as larger-scale feature maps from the decoder. Subsequently, softmax normalization is applied after the last GC block at each resolution to produce the segmentation result for each concatenated feature map, which comes in the form of multi-class probabilities for each image patch. After that, the dice loss and cross-entropy (CE) at each scale are summed up to perform deep supervision. Finally, PolSAR image segmentation is performed by taking the column number with the highest probability value and merging the results of all image patches.
2.3. Weighted Max-Relative Spatial Graph Convolution
Compared with CNNs, GCNs are capable of extracting more extensive features by aggregating node features from their neighborhood. The recent literature has witnessed the application of spectral GCNs in PolSAR image classification tasks [
7,
53]. However, spectral GCNs are often designed to operate on a specific graph structure with a fixed adjacency matrix, which makes it struggle to generalize well on unseen graphs with a different topology. This limitation arises because the feature representation in the spectral domain is closely related to the graph Laplacian [
66]. Thus, any change in the adjacency matrix can substantially impact the spectral characteristics. Spatial GCN exhibits better adaptability to varying graph structures and is exceptionally well-suited to deal with this issue. This is because spatial convolutional operations depend on the local neighborhood, making the model more robust to changes in the graph topology.
Suppose the PolSAR dataset is divided into
N patches, and each patch is flattened into a feature vector. Then, the graph nodes can be described as
. Then, the
k-NN [
64] is utilized to establish connections between nodes. Therefore, the graph representation of each image patch can be denoted as
, where
denotes the graph nodes and
denotes the graph edges.
For the graph representation
and the input features
X, a spatial graph convolutional layer can be applied to aggregate node features from its neighbor nodes, as follows:
where
and
are the learnable weights of the update and aggregation operations, respectively. The Aggregate operator aggregates the neighboring node features, and the Update operator merges the aggregated feature representation as follows:
where
are the neighboring nodes of
.
Inspired by [
64], weighted max-relative graph convolution
is proposed to fully leverage the edge weights derived from the PolSAR scattering characteristics, which can be written as:
where
is the edge weight between node
i and node
j and
b is the bias term.
To enrich the feature diversity of spatial graph convolution, the multi-head update operation is adopted in multiple feature subspaces by splitting the aggregated feature
into
H heads, which is set to 4 by default. Then, these heads are updated with different weights and concatenated to obtain the final representation, as follows:
where
denotes the bias term of the
ith attention head (
).
To alleviate over-fitting and thus enhance the generalization ability, a DropPath layer [
67] has been applied to stochastically deactivate some of the skip connections during training. Thus, the final expression of the graph convolution module can be written as:
where GELU is the Gaussian error linear unit [
68], which is differentiable in all ranges and allows to have gradients in the negative range to prevent vanishing gradients.
X denotes the input features,
is the bias term, and
and
are the fully connected (FC) layer weights for input and output, respectively.
To further boost the feature transformation capability and relieve the over-smoothing in deeper layers, a feed-forward module (FFN) is applied after graph convolution. It consists of a multi-layer structure with two FC layers, i.e.,
where
Z is the output of the graph convolution module,
and
are FC layer weights, and
and
are the bias terms.
2.4. Multi-Scale Dynamic Graphs
After the application of a sliding window to slice the PolSAR dataset into image patches, our CLIGUNet utilizes a
k-NN approach [
64] to generate the graph topology at each scale. This strategy constructs a graph from an image patch by first representing each pixel in the patch as a node in the graph. Then, the k-nearest neighbors of each node in the feature space are selected to form the edges between the central pixel and its k-nearest neighbors. Based on the Euclidean distance, this graph representation captures the local spatial relationships within the image patch, thus facilitating effective feature extraction and contextual information modeling in each iteration.
Afterwards, the k-NN approach encodes connected pixel groups in the ith PolSAR image patch into an adjacency matrix , with N denoting the batch size of CLIGUNet. To evaluate the relative importance of neighboring nodes, the symmetric revised Wishart distance is applied to derive multi-scale weighted adjacency matrices , as described below.
2.4.1. Weighted Adjacency Matrix
Our CLIGUNet focuses on weighted, connected, undirected graphs , which are made up of node sets , edge sets , and a weighted adjacency matrix W. The difference between the binary adjacency matrix A and W lies in their edge weights, which can help the graph convolutional layers to address the neighbors with stronger relevance.
To alleviate the computational cost, sliding windows are utilized to slice the Pauli RGB images into patches, where each pixel serves as a graph node. However, the revised symmetric Wishart distance can take both negative and positive values, which cannot be directly applied for graph construction. To cope with this problem, a thresholded Gaussian kernel weighting function [
69] normalizes the distance to a similarity value between 0 and 1. The pair-wise similarity, which indicates the edge weight of the neighboring node
i and node
j, can be derived as:
where
denotes the connectivity between node
i and node
j (
), which is equal to 1 for neighboring pixels,
represents the Euclidean distance between the neighboring nodes, and
represents the Gaussian kernel standard deviation.
Recent research has validated the effectiveness of the symmetric revised Wishart distance [
7,
49,
53,
59,
70] in assessing the dissimilarity among complex coherency matrices. It is defined as:
where
and
represent the coherence matrices for pixel
i and pixel
j, respectively.
Derived from the weighting function in (
10) and the distance measure in (
11), our paper constructs the weighted adjacency matrix as:
where
indicates the node pair connectivity,
denotes the local scaling parameter [
48] defined as the median distance between the current node
i and its neighborhood, and
denotes the symmetric revised Wishart distance between two mean coherence matrices.
2.4.2. Graph Connectivity Augmentation via Graph Power
The
kth power of graph
is applied to avoid possible isolated nodes and increase graph connectivity, where
k indicates that the neighbors are within
k hops from the current node. To sample the augmented graph with better connectivity, a self-loop is applied to renormalize the adjacency matrix
. Since our proposed network deploys a graph convolutional layer before strided convolution to aggregate the features of first-order neighbors, it is safe to assume the graph order
k as 2, thus obtaining the second power of the graph, as follows:
where
denotes the second power of the adjacency matrix
on layer
ℓ,
ranges from 1 to
N, and
N denotes the batch number in graph
.
Considering that the feature vector of the current node itself should play a more important role, a self-loop is applied to renormalize the adjacency matrix A, thus obtaining an augmented graph with better connectivity.
2.4.3. Weighted Graphs and Ground Truth in Multiple Scales
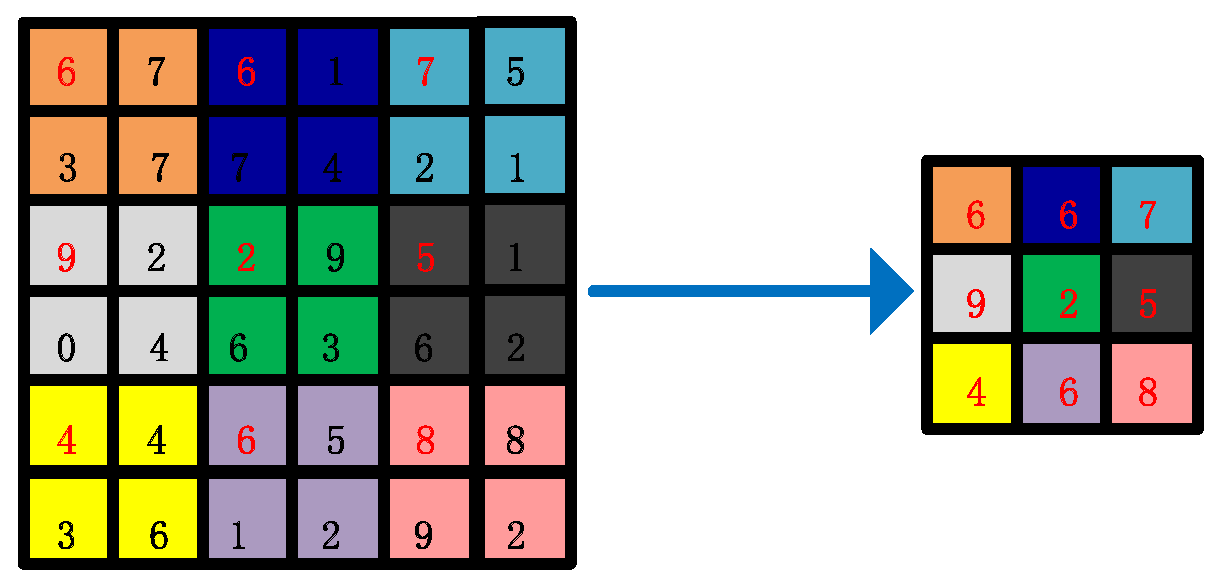
The main advantage of our CLIGUNet lies in its ability to learn node features from multiple scales weighted graphs. In the data preparation stage, the dense weighted adjacency matrices
are saved in advance, assuming that all nodes are interconnected with each other, where
n (
) is the patch number and
l (
) denotes the
lth scale. The multi-scale labels of each image patch are obtained by taking the first value in the upper left corner every
pixels, as shown in
Figure 2, where the label map with 36 pixels is coarsened to 9 pixels. During the training process, the binary adjacency matrices
are obtained by searching the
k-nearest neighbors of each node. Afterwards, the weighted adjacency matrices
can be calculated by taking the dot products of
and
.
2.5. Cross-Level Interactions with Residual Transformer
We introduce a novel approach to the integrated multi-scale features by leveraging the concept of cross-level interactions with residual transformers to address the relative importance of node features at different scales. Drawing inspiration from the graph integration module [
7,
53] and the bottleneck attention module [
71,
72], a weighted max-relative spatial graph convolution module is constructed at each resolution, facilitating the extraction of features at the local scale. Then, pooling and unpooling layers are employed to align feature vectors across scales. Afterwards, node feature representations in the decoder are obtained by concatenating deep features from all scales, utilizing residual connections between encoders and corresponding decoder blocks to transfer spatial information for better performance. Finally, in each resolution, the feature maps from multiple scales are concatenated together and fed into a graph convolution layer to generate the segmentation result for the corresponding scale and calculate the total loss in this batch.
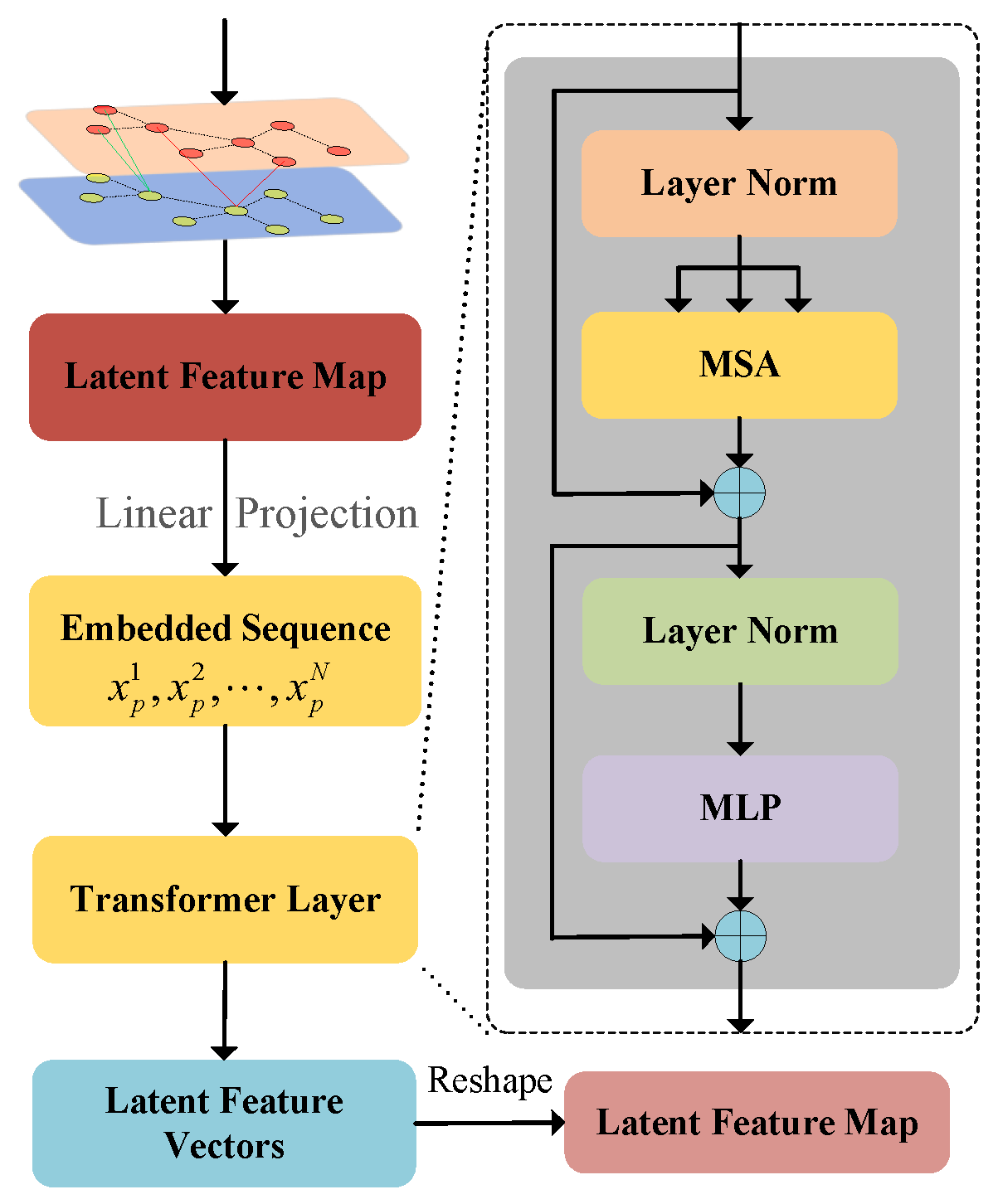
The residual transformer module is a key component in our architecture, leveraging self-attention to capture the global relationships between the encoder and decoder, as shown in
Figure 3. This mechanism, crucial for learning the relative importance of each channel, is enhanced by residual connections across resolutions. Similar to other transformer modules, our residual transformer incorporates multi-head self-attention (MSA), multi-layer perceptron (MLP), and layer normalization (LN). Compared with CNNs, which rely on convolutional and pooling layers for feature extraction from local information, the transformer excels in extracting global features. By employing the attention mechanism, the model learns long-range dependencies, enabling the encoding of patches with global contextual information. This capability enables to capture relationships between ordered patches, ultimately enhancing the segmentation performance at each resolution.
To preserve spatial location information among input patches, the latent feature map
X is flattened into a patch sequence
, where
is the input sequence length, which equals the number of image patches in a single batch,
P is the patch size,
C is the number of channels, and
H and
W are the height and width of the input image patch, respectively. Using a trainable linear projection, these vectorized patches
are then projected into a latent feature embedding subspace, which can be written as:
where
represents the position embedding and
E denotes the patch embedding projection.
Let us assume that each residual transformer module consists of
L layers of MSA and MLP. The output of the
ℓ-th layer can be obtained as:
where the MLP in (
16) consists of two FC layers and a GELU activation function, and
denotes the latent feature representation in the
ℓ-th layer.
Then, the three learnable weight matrices composed of query , key , and value , are introduced to perform multiplication with the input image representation sequence , written as , where , , , and denote the feature dimension of query, key, and value, respectively.
The relative importance of each patch in the input image representation sequence
can be obtained by computing the dot product between the
Q-vector and the
K-vectors. After that, a softmax function is applied to calculate the
V values. Finally, each patch embedding vector is multiplied by the
V values to address the effective representations with a higher attention score, as
During the MSA phase, multiple dot-product attention is performed by iterating (
17)
h times. Afterwards, each parallel attention map
is concatenated as follows:
where
denotes the relative importance of each attention head, and
are the three learnable attention weights for the
ith head.
As illustrated in
Figure 3, both MSA and MLP utilize LN layers for normalization and skip-connections for better gradient flow and alleviate the vanishing gradient problem in the transformer module. The MSA block extracts rich semantic features from a patch sequence by capturing data correlations and establishing dependencies among various features. Then, the weights derived from MSA are directed to the MLP layer. Layer normalization [
73] is applied before the MLP layer to accelerate training and mitigate the challenges posed by a vanishing gradient. The MLP layer consists of two FC layers, with the nonlinearity between the layers being activated by the GELU function.
2.6. Joint Training of Multi-Scale Graphs
Taking inspiration from deeply supervised networks (DeepSup) [
74], this paper leverages multi-scale side outputs, multi-scale labels, and deep supervision to enhance the discriminative capability of feature maps across multiple resolutions and alleviate potential issues with gradient vanishing.
In contrast to conventional U-Nets and graph U-Nets, our CLIGUNet not only incorporates feature maps from different hierarchical levels via strided convolution and transposed convolution, but also produces the segmentation map at each resolution.
Figure 1 depicts the process of collecting effective representations at all resolutions using a deep supervision training strategy, employing side outputs across multiple scales. This technique facilitates model pruning and yields improved or comparable performance, as opposed to relying solely on the top layer’s output to calculate the loss function.
By integrating multi-scale residual connections in the decoder, our CLIGUNet produces feature maps and segmentation results across each semantic level, which are the foundational conditions for implementing deep supervision.
The total loss function is composed of four parts, where each part is a combination of both the dice loss and CE loss, as follows:
where
represents the loss value of the
lth side output,
indicates the batch size, and
and
denote the flattened ground truth (class labels) and probability output (predictions) of the
ith image patch at the
lth scale, respectively.
denotes the
-norm regularization term, with the regularization strength
being a hyperparameter that adjusts the tradeoff between having a low training loss and having low weights.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}