
Identification of Rare Wildlife in the Field Environment Based on the Improved YOLOv5 Model

 ,
,  ,
, 
Abstract
1. Introduction
2. Materials and Methods
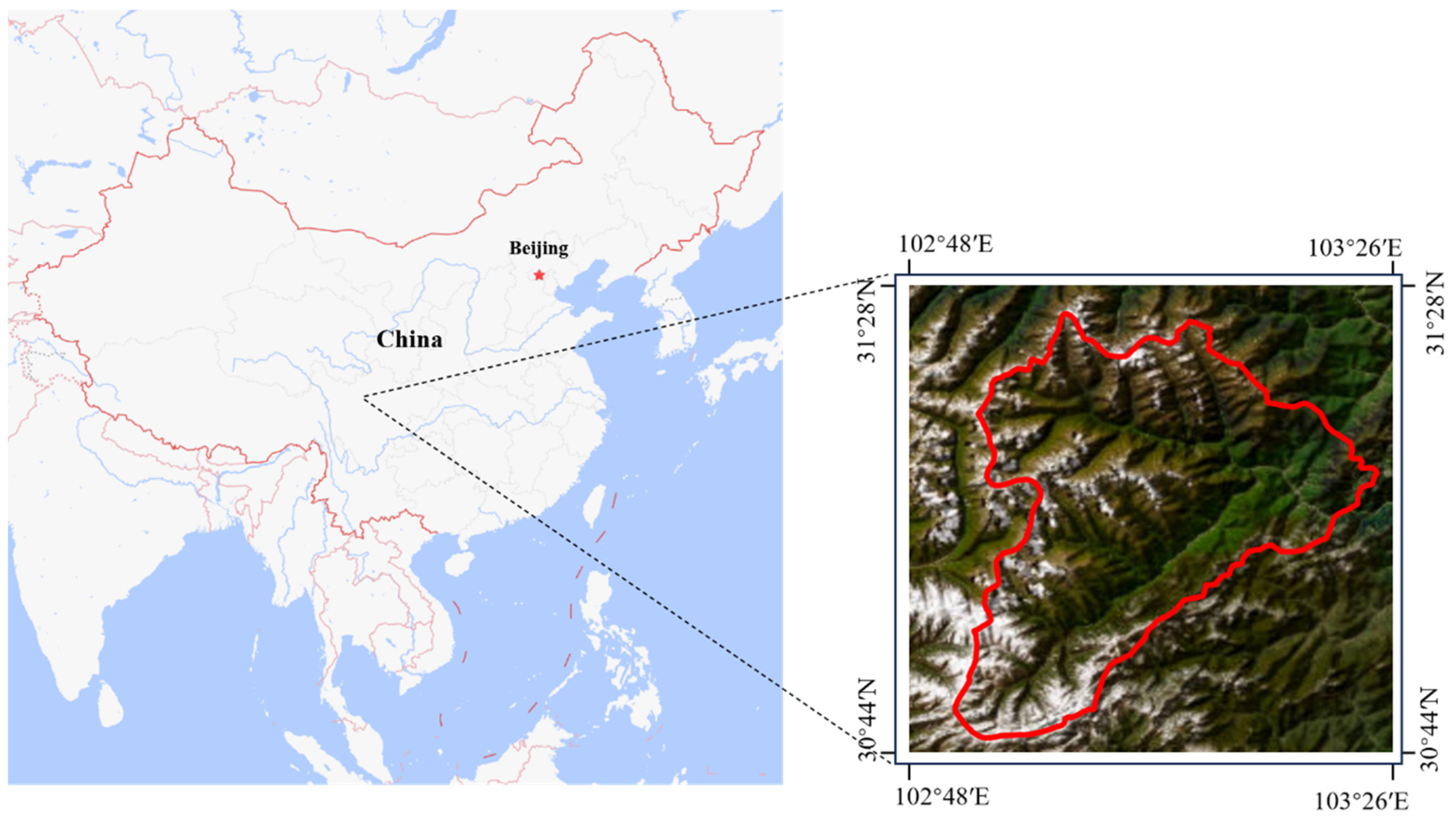
2.1. Dataset
2.2. Models and Methods
2.2.1. YOLOv5
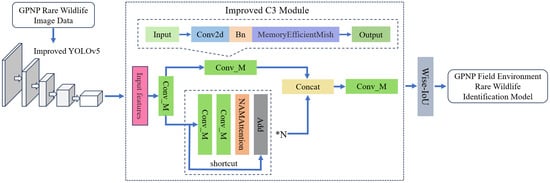
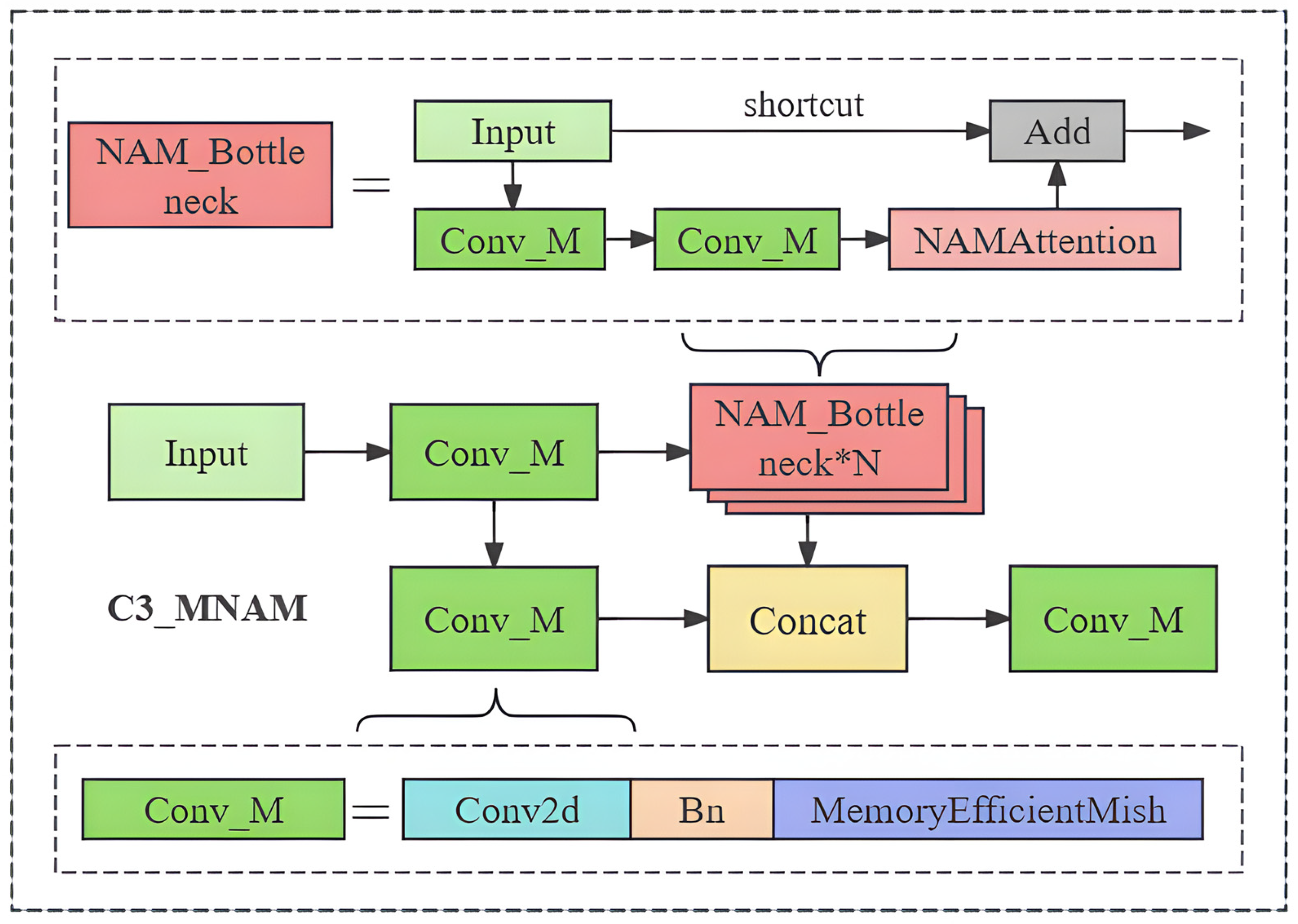
2.2.2. Model Improvement Methods
- No upper bounds with lower bounds: no upper bounds prevent the sharp decrease in training speed caused by gradient saturation, while having lower bounds helps to provide a strong regularization effect similar to the properties of ReLU and SiLU;
- Non-monotonic function: this property helps to maintain small negative values, stabilizing the network’s gradient flow. Some commonly used activation functions, such as Leaky ReLU, do not update for most neurons because of their inability to maintain negative values;
- Infinite order continuity and smoothness: MemoryEfficientMish is a smooth function that avoids singularities, offering better generalization and model optimization abilities. It effectively enhances the quality of experimental results.
3. Results
3.1. Experimental Environment
3.2. Evaluation Metrics
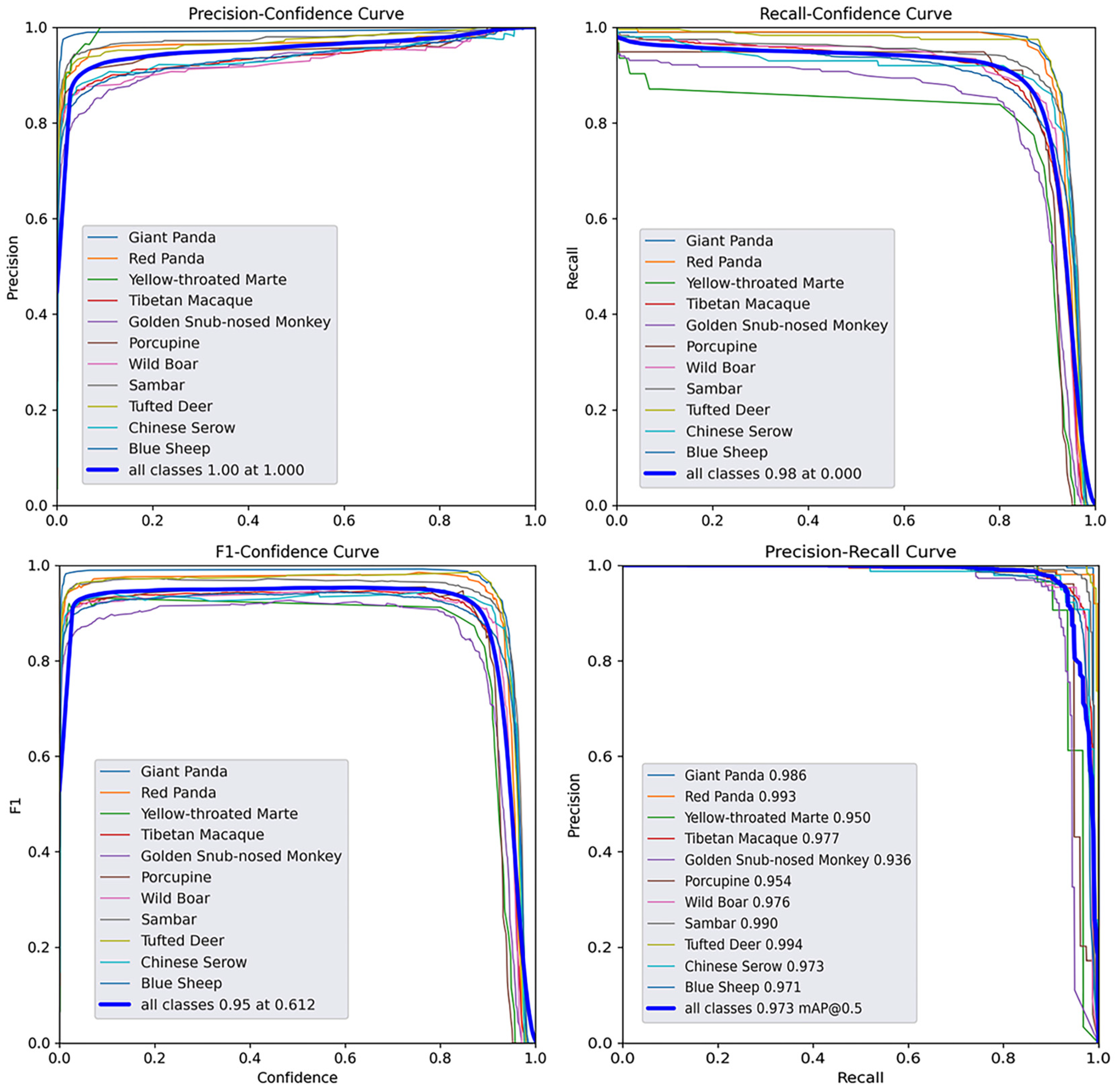
3.3. Model Performance
3.4. Modular Ablation
3.5. Model Comparisons
3.6. Model Generalization
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Song, X.; Jiang, Y.; Zhao, L.; Xi, L.; Yan, C.; Liao, W. Predicting the Potential Distribution of the Szechwan Rat Snake (Euprepiophis perlacea) and Its Response to Climate Change in the Yingjing Area of the Giant Panda National Park. Animals 2023, 13, 3828. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.; Ping, X.; Xu, W.; Hu, Y.; Chang, J.; Swaisgood, R.R.; Zhou, J.; Zhan, X.; Zhang, Z.; Nie, Y.; et al. Wildlife Conservation and Management in China: Achievements, Challenges and Perspectives. Natl. Sci. Rev. 2021, 8, nwab042. [Google Scholar] [CrossRef] [PubMed]
- Berger-Tal, O.; Lahoz-Monfort, J.J. Conservation Technology: The next Generation. Conserv. Lett. 2018, 11, e12458. [Google Scholar] [CrossRef]
- Hill, A.P.; Prince, P.; Piña Covarrubias, E.; Doncaster, C.P.; Snaddon, J.L.; Rogers, A. AudioMoth: Evaluation of a Smart Open Acoustic Device for Monitoring Biodiversity and the Environment. Methods Ecol. Evol. 2018, 9, 1199–1211. [Google Scholar] [CrossRef]
- Sugai, L.S.M.; Silva, T.S.F.; Ribeiro, J.W.; Llusia, D. Terrestrial Passive Acoustic Monitoring: Review and Perspectives. BioScience 2019, 69, 15–25. [Google Scholar] [CrossRef]
- McCallum, J. Changing Use of Camera Traps in Mammalian Field Research: Habitats, Taxa and Study Types. Mammal. Rev. 2013, 43, 196–206. [Google Scholar] [CrossRef]
- Chen, R.; Little, R.; Mihaylova, L.; Delahay, R.; Cox, R. Wildlife Surveillance Using Deep Learning Methods. Ecol. Evol. 2019, 9, 9453–9466. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, H.; Maclagan, S.J.; Nguyen, T.D.; Nguyen, T.; Flemons, P.; Andrews, K.; Ritchie, E.G.; Phung, D. Animal Recognition and Identification with Deep Convolutional Neural Networks for Automated Wildlife Monitoring. In Proceedings of the 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Tokyo, Japan, 19–21 October 2017; pp. 40–49. [Google Scholar]
- Verma, A.; Van Der Wal, R.; Fischer, A. Microscope and Spectacle: On the Complexities of Using New Visual Technologies to Communicate about Wildlife Conservation. Ambio 2015, 44, 648–660. [Google Scholar] [CrossRef] [PubMed]
- Stephenson, P. Technological Advances in Biodiversity Monitoring: Applicability, Opportunities and Challenges. Curr. Opin. Environ. Sustain. 2020, 45, 36–41. [Google Scholar] [CrossRef]
- Zhang, R.; Xu, L.; Yu, Z.; Shi, Y.; Mu, C.; Xu, M. Deep-IRTarget: An Automatic Target Detector in Infrared Imagery Using Dual-Domain Feature Extraction and Allocation. IEEE Trans. Multimed. 2022, 24, 1735–1749. [Google Scholar] [CrossRef]
- Zhang, R.; Cao, Z.; Yang, S.; Si, L.; Sun, H.; Xu, L.; Sun, F. Cognition-Driven Structural Prior for Instance-Dependent Label Transition Matrix Estimation. IEEE Trans. Neural Netw. Learn. Syst. 2024, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Lahoz-Monfort, J.J.; Magrath, M.J.L. A Comprehensive Overview of Technologies for Species and Habitat Monitoring and Conservation. BioScience 2021, 71, 1038–1062. [Google Scholar] [CrossRef] [PubMed]
- Petso, T.; Jamisola, R.S.; Mpoeleng, D. Review on Methods Used for Wildlife Species and Individual Identification. Eur. J. Wildl. Res. 2022, 68, 3. [Google Scholar] [CrossRef]
- Adams, W.M. Geographies of Conservation II: Technology, Surveillance and Conservation by Algorithm. Prog. Hum. Geogr. 2019, 43, 337–350. [Google Scholar] [CrossRef]
- Zhang, W.; Li, H.; Li, Y.; Liu, H.; Chen, Y.; Ding, X. Application of Deep Learning Algorithms in Geotechnical Engineering: A Short Critical Review. Artif. Intell. Rev. 2021, 54, 5633–5673. [Google Scholar] [CrossRef]
- Willi, M.; Pitman, R.T.; Cardoso, A.W.; Locke, C.; Swanson, A.; Boyer, A.; Veldthuis, M.; Fortson, L. Identifying Animal Species in Camera Trap Images Using Deep Learning and Citizen Science. Methods Ecol. Evol. 2019, 10, 80–91. [Google Scholar] [CrossRef]
- Ding, B.; Zhang, R.; Xu, L.; Liu, G.; Yang, S.; Liu, Y.; Zhang, Q. U2D2Net: Unsupervised Unified Image Dehazing and Denoising Network for Single Hazy Image Enhancement. IEEE Trans. Multimed. 2024, 26, 202–217. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Yin, Z.; Zhao, Y.; Xu, Z.; Yu, Q. Automatic Detection of Stereotypical Behaviors of Captive Wild Animals Based on Surveillance Videos of Zoos and Animal Reserves. Ecol. Inform. 2024, 79, 102450. [Google Scholar] [CrossRef]
- Hou, J.; Yang, C.; He, Y.; Hou, B. Detecting Diseases in Apple Tree Leaves Using FPN–ISResNet–Faster RCNN. Eur. J. Remote Sens. 2023, 56, 2186955. [Google Scholar] [CrossRef]
- Wang, Z.; Du, L.; Mao, J.; Liu, B.; Yang, D. SAR Target Detection Based on SSD with Data Augmentation and Transfer Learning. IEEE Geosci. Remote Sens. Lett. 2019, 16, 150–154. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo Algorithm Developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Zhao, T.; Yi, X.; Zeng, Z.; Feng, T. MobileNet-Yolo Based Wildlife Detection Model: A Case Study in Yunnan Tongbiguan Nature Reserve, China. J. Intell. Fuzzy Syst. 2021, 41, 2171–2181. [Google Scholar] [CrossRef]
- Xiong, B.; Li, D.; Zhang, Q.; Desneux, N.; Luo, C.; Hu, Z. Image Detection Model Construction of Apolygus lucorum and Empoasca spp. Based on Improved YOLOv5. Pest Manag. Sci. 2024, ps.7964. [Google Scholar] [CrossRef] [PubMed]
- Roy, A.M.; Bhaduri, J.; Kumar, T.; Raj, K. WilDect-YOLO: An Efficient and Robust Computer Vision-Based Accurate Object Localization Model for Automated Endangered Wildlife Detection. Ecol. Inform. 2023, 75, 101919. [Google Scholar] [CrossRef]
- Liu, D.; Hou, J.; Huang, S.; Liu, J.; He, Y.; Zheng, B.; Ning, J.; Zhang, J. LoTE-Animal: A Long Time-Span Dataset for Endangered Animal Behavior Understanding. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 20007–20018. [Google Scholar]
- Wang, Z.; Jin, L.; Wang, S.; Xu, H. Apple Stem/Calyx Real-Time Recognition Using YOLO-v5 Algorithm for Fruit Automatic Loading System. Postharvest Biol. Technol. 2022, 185, 111808. [Google Scholar] [CrossRef]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-Based Attention Module. arXiv 2021, arXiv:2111.12419. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Yang, Z. Activation Function: Cell Recognition Based on YoLov5s/m. J. Comput. Commun. 2021, 9, 1–16. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. AAAI 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Wu, S.; Li, X.; Wang, X. IoU-Aware Single-Stage Object Detector for Accurate Localization. Image Vis. Comput. 2020, 97, 103911. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Zhang, R.; Yang, S.; Zhang, Q.; Xu, L.; He, Y.; Zhang, F. Graph-Based Few-Shot Learning with Transformed Feature Propagation and Optimal Class Allocation. Neurocomputing 2022, 470, 247–256. [Google Scholar] [CrossRef]
- Xiong, C.; Zayed, T.; Abdelkader, E.M. A Novel YOLOv8-GAM-Wise-IoU Model for Automated Detection of Bridge Surface Cracks. Constr. Build. Mater. 2024, 414, 135025. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Norouzzadeh, M.S.; Nguyen, A.; Kosmala, M.; Swanson, A.; Palmer, M.S.; Packer, C.; Clune, J. Automatically Identifying, Counting, and Describing Wild Animals in Camera-Trap Images with Deep Learning. Proc. Natl. Acad. Sci. USA 2018, 115, E5716–E5725. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Species | P | R | mAP50 | mAP50:95 |
|---|---|---|---|---|
| Giant Panda | 0.994 | 0.990 | 0.986 | 0.884 |
| Red Panda | 0.970 | 0.990 | 0.993 | 0.875 |
| Yellow-throated Marte | 1.000 | 0.847 | 0.950 | 0.751 |
| Tibetan Macaque | 0.947 | 0.942 | 0.978 | 0.819 |
| Golden Snub-nosed Monkey | 0.954 | 0.894 | 0.939 | 0.738 |
| Porcupine | 0.957 | 0.949 | 0.955 | 0.712 |
| Wild Boar | 0.947 | 0.945 | 0.974 | 0.825 |
| Sambar | 0.982 | 0.956 | 0.990 | 0.912 |
| Tufted Deer | 0.981 | 0.979 | 0.994 | 0.889 |
| Chinese Serow | 0.952 | 0.920 | 0.973 | 0.888 |
| Blue Sheep | 0.955 | 0.931 | 0.971 | 0.867 |
| All | 0.967 | 0.940 | 0.973 | 0.833 |
| Model | P | R | mAP50 | mAP50:95 |
|---|---|---|---|---|
| YOLOv5x | 0.963 | 0.943 | 0.967 | 0.817 |
| C3_NAM | 0.963 | 0.945 | 0.970 | 0.826 |
| C3_M | 0.966 | 0.940 | 0.969 | 0.822 |
| C3_MNAM | 0.966 | 0.945 | 0.972 | 0.824 |
| WIoU | 0.965 | 0.939 | 0.971 | 0.828 |
| NMW-YOLOv5 | 0.967 | 0.940 | 0.973 | 0.833 |
| Species | YOLOv5x | C3_NAM | C3_M | C3_MNAM | WIoU | NMW-YOLOv5 |
|---|---|---|---|---|---|---|
| Giant Panda | 0.878 | 0.880 | 0.877 | 0.878 | 0.879 | 0.884 |
| Red Panda | 0.873 | 0.870 | 0.881 | 0.879 | 0.853 | 0.875 |
| Yellow-throated Marte | 0.684 | 0.724 | 0.740 | 0.729 | 0.742 | 0.751 |
| Tibetan Macaque | 0.817 | 0.817 | 0.824 | 0.819 | 0.817 | 0.819 |
| Golden Snub-nosed Monkey | 0.705 | 0.700 | 0.697 | 0.702 | 0.735 | 0.738 |
| Porcupine | 0.669 | 0.683 | 0.675 | 0.679 | 0.711 | 0.712 |
| Wild Boar | 0.823 | 0.833 | 0.827 | 0.837 | 0.828 | 0.825 |
| Sambar | 0.909 | 0.911 | 0.910 | 0.912 | 0.911 | 0.912 |
| Tufted Deer | 0.884 | 0.889 | 0.886 | 0.884 | 0.887 | 0.889 |
| Chinese Serow | 0.878 | 0.884 | 0.887 | 0.886 | 0.879 | 0.888 |
| Blue Sheep | 0.862 | 0.862 | 0.866 | 0.863 | 0.862 | 0.867 |
| All | 0.817 | 0.824 | 0.825 | 0.824 | 0.828 | 0.833 |
| Model | p | R | mAP50 | mAP50:95 | Layers | Parameters |
|---|---|---|---|---|---|---|
| YOLOv5x | 0.963 | 0.943 | 0.967 | 0.817 | 322 | 86,240,704 |
| YOLOv5s | 0.945 | 0.905 | 0.947 | 0.713 | 157 | 9,039,792 |
| YOLOv5m | 0.944 | 0.923 | 0.954 | 0.775 | 212 | 20,905,467 |
| YOLOv5l | 0.946 | 0.948 | 0.969 | 0.814 | 267 | 46,162,128 |
| YOLOv7 | 0.949 | 0.940 | 0.968 | 0.812 | 415 | 37,250,496 |
| YOLOv7e6 | 0.951 | 0.941 | 0968 | 0.816 | 645 | 110,571,008 |
| YOLOv8s | 0.952 | 0.925 | 0.959 | 0.808 | 168 | 11,129,841 |
| YOLOv8m | 0.952 | 0.927 | 0.965 | 0.815 | 216 | 25,862,689 |
| YOLOv8l | 0.956 | 0.928 | 0.968 | 0.817 | 268 | 43,615,089 |
| NMW-YOLOv5 | 0.967 | 0.940 | 0.973 | 0.833 | 492 | 86,252,224 |
| Species | Actual | Correct Estimate | Correct Rate (%) |
|---|---|---|---|
| Giant Panda | 30 | 30 | 100 |
| Red Panda | 22 | 21 | 95.5 |
| Tibetan Macaque | 21 | 13 | 61.9 |
| Golden Snub-nosed Monkey | 21 | 21 | 100 |
| Porcupine | 24 | 12 | 50 |
| Sambar | 22 | 14 | 63.6 |
| Tufted Deer | 21 | 15 | 71.4 |
| Chinese Serow | 21 | 15 | 71.4 |
| Blue Sheep | 22 | 20 | 90.9 |
| All | 206 | 169 | 82.0 |
| Empty Shot | 30 | 27 | 90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, X.; Zhang, J.; Ma, Z.; Dong, Y.; Zi, J.; Xu, N.; Zhang, H.; Xu, F.; Chen, F. Identification of Rare Wildlife in the Field Environment Based on the Improved YOLOv5 Model. Remote Sens. 2024, 16, 1535. https://doi.org/10.3390/rs16091535
Su X, Zhang J, Ma Z, Dong Y, Zi J, Xu N, Zhang H, Xu F, Chen F. Identification of Rare Wildlife in the Field Environment Based on the Improved YOLOv5 Model. Remote Sensing. 2024; 16(9):1535. https://doi.org/10.3390/rs16091535
Chicago/Turabian StyleSu, Xiaohui, Jiawei Zhang, Zhibin Ma, Yanqi Dong, Jiali Zi, Nuo Xu, Haiyan Zhang, Fu Xu, and Feixiang Chen. 2024. "Identification of Rare Wildlife in the Field Environment Based on the Improved YOLOv5 Model" Remote Sensing 16, no. 9: 1535. https://doi.org/10.3390/rs16091535
APA StyleSu, X., Zhang, J., Ma, Z., Dong, Y., Zi, J., Xu, N., Zhang, H., Xu, F., & Chen, F. (2024). Identification of Rare Wildlife in the Field Environment Based on the Improved YOLOv5 Model. Remote Sensing, 16(9), 1535. https://doi.org/10.3390/rs16091535