
Data Uncertainty of Flood Susceptibility Using Non-Flood Samples




Abstract

1. Introduction
2. Data and Research Framework
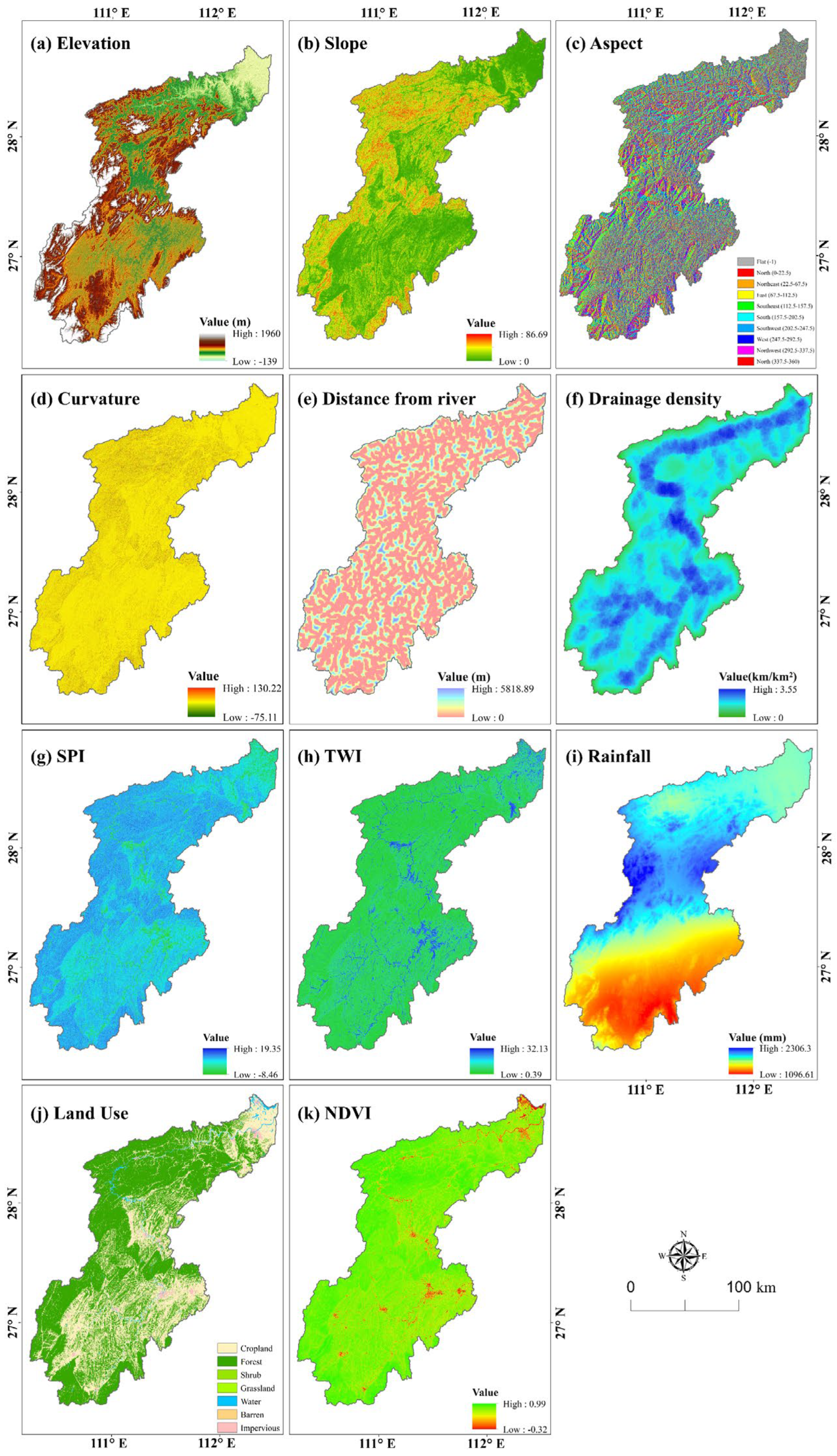
2.1. Data
2.2. Research Framework
3. Methods
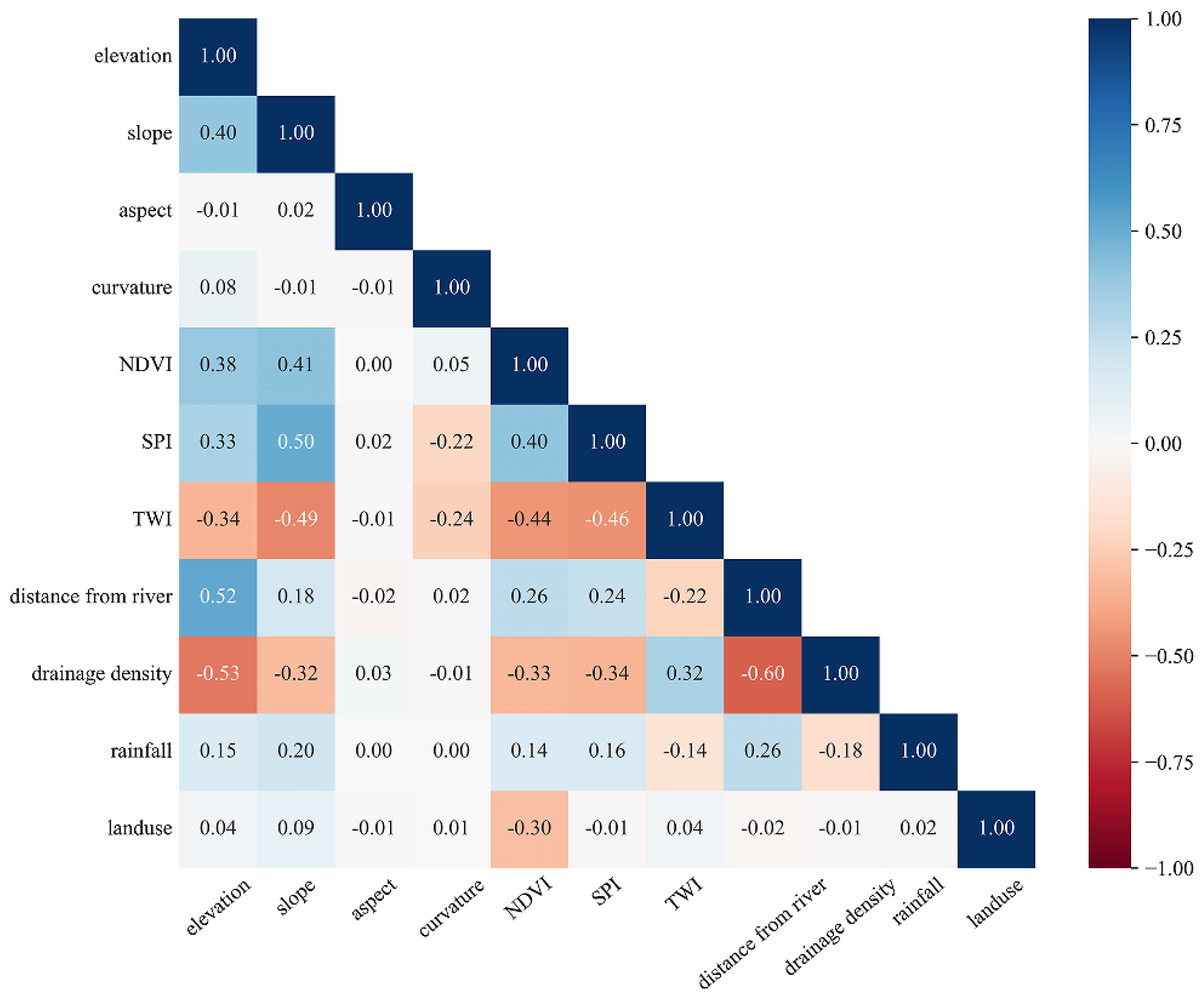
3.1. Multicollinearity Analysis
3.2. One-Class SVM
3.3. Flood Susceptibility Modeling
3.3.1. FR
3.3.2. RF
3.3.3. Adaptive Boosting
3.3.4. Gradient Boosting
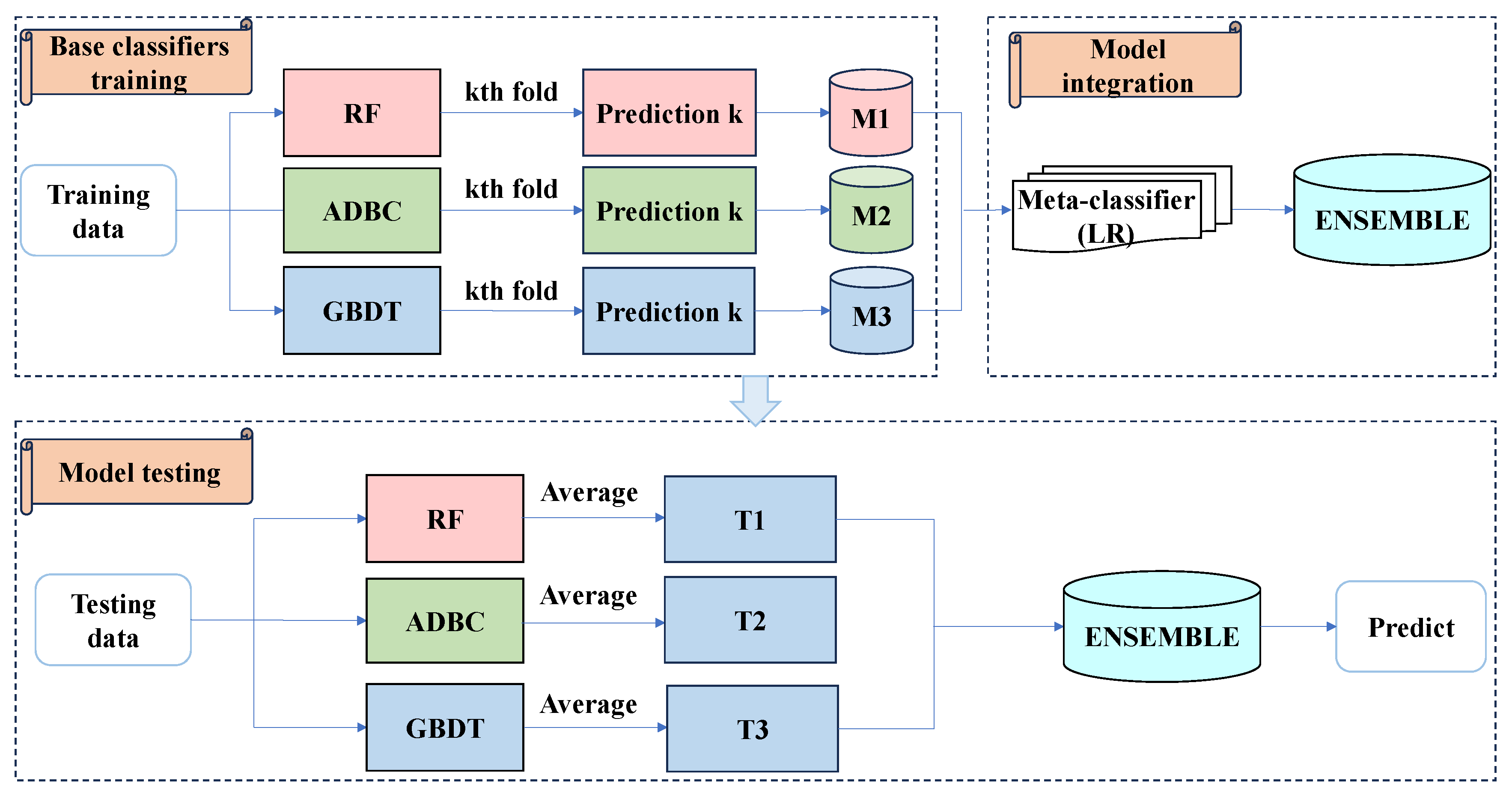
3.3.5. Ensemble Modeling
3.4. Model Evaluation Metrics
3.5. Interpretability Analysis
3.6. Model Validation
4. Result
4.1. Influence Factor Correlation Analysis
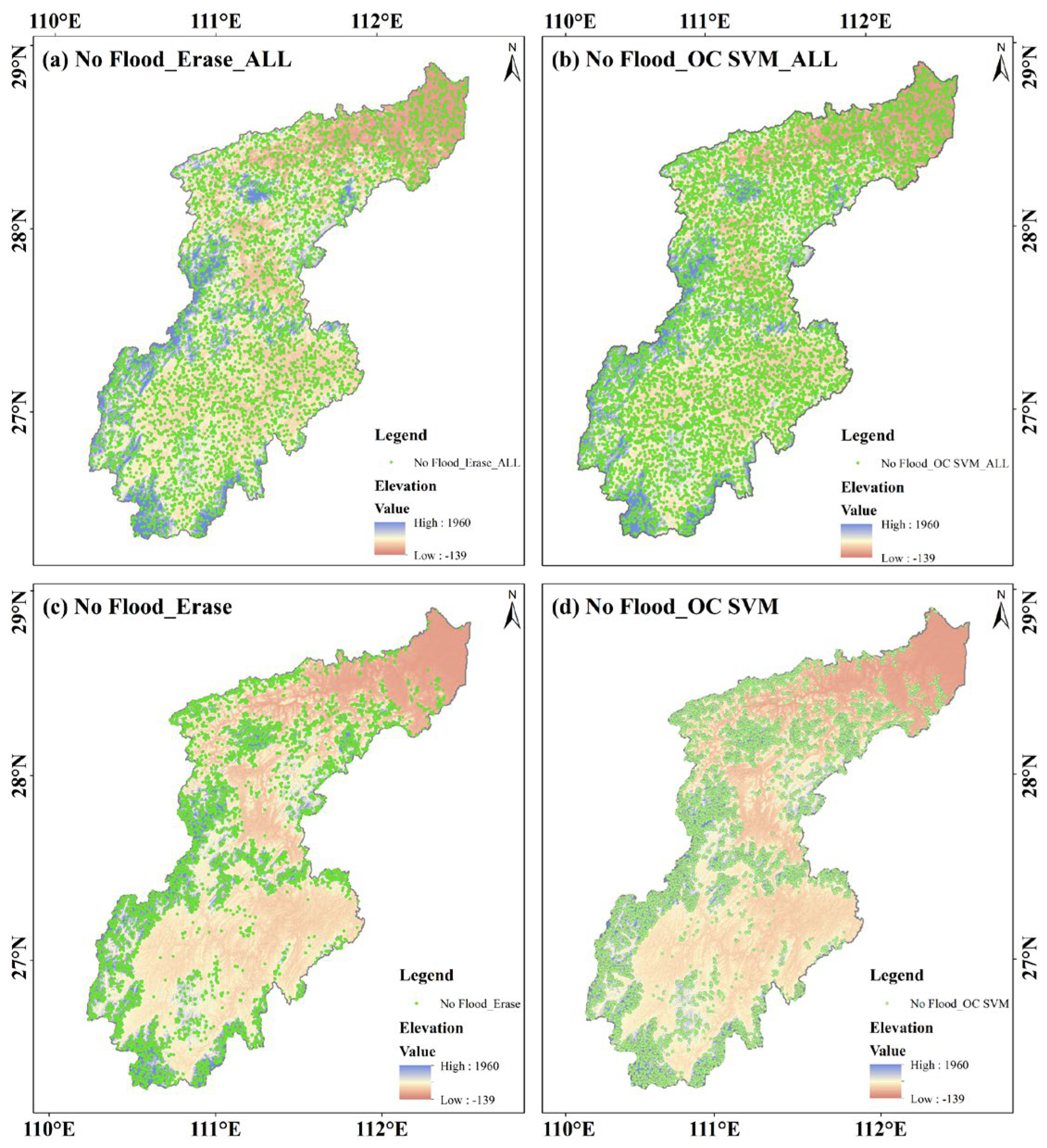
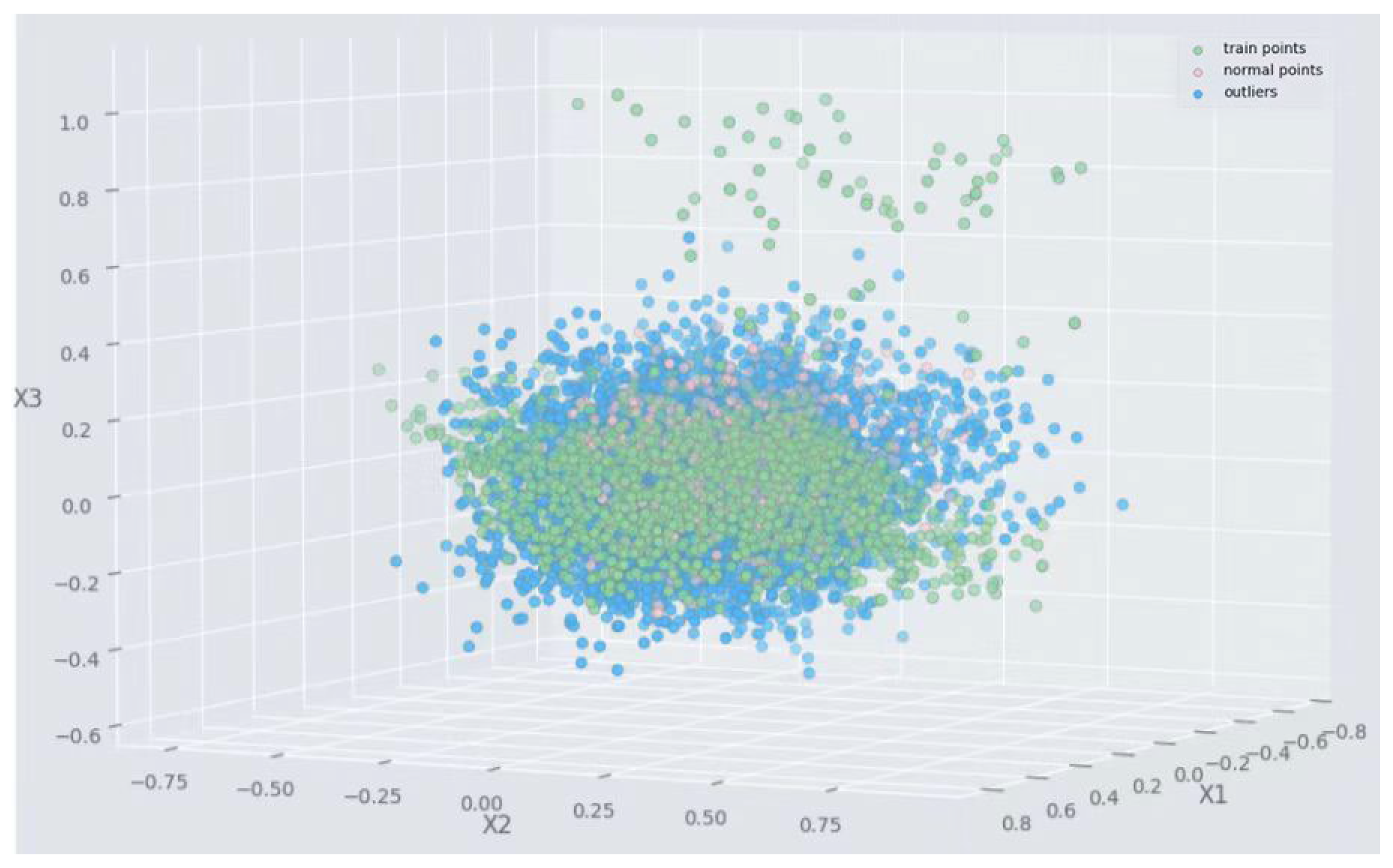
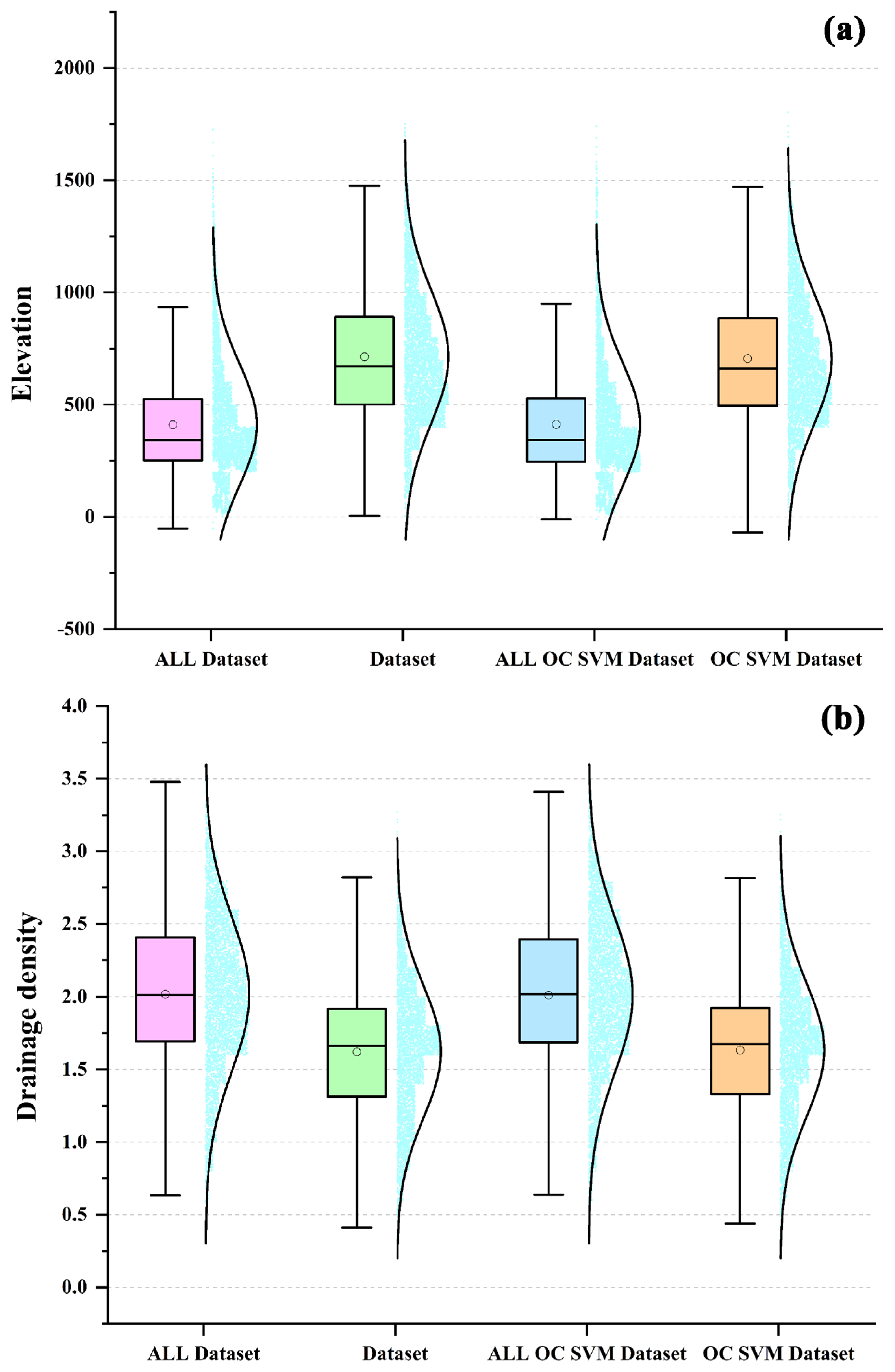
4.2. Non-Flood Point Dataset Extraction
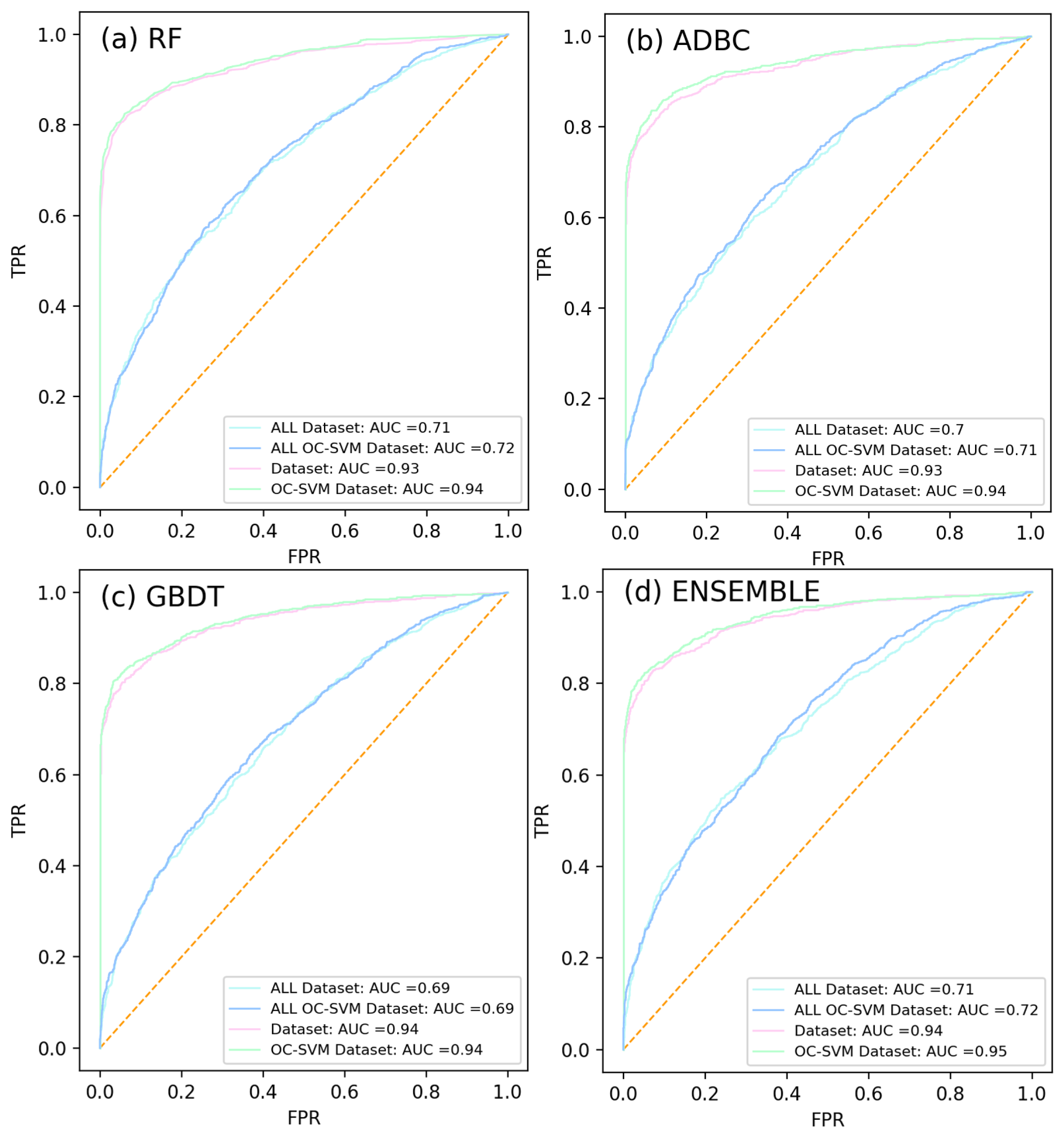
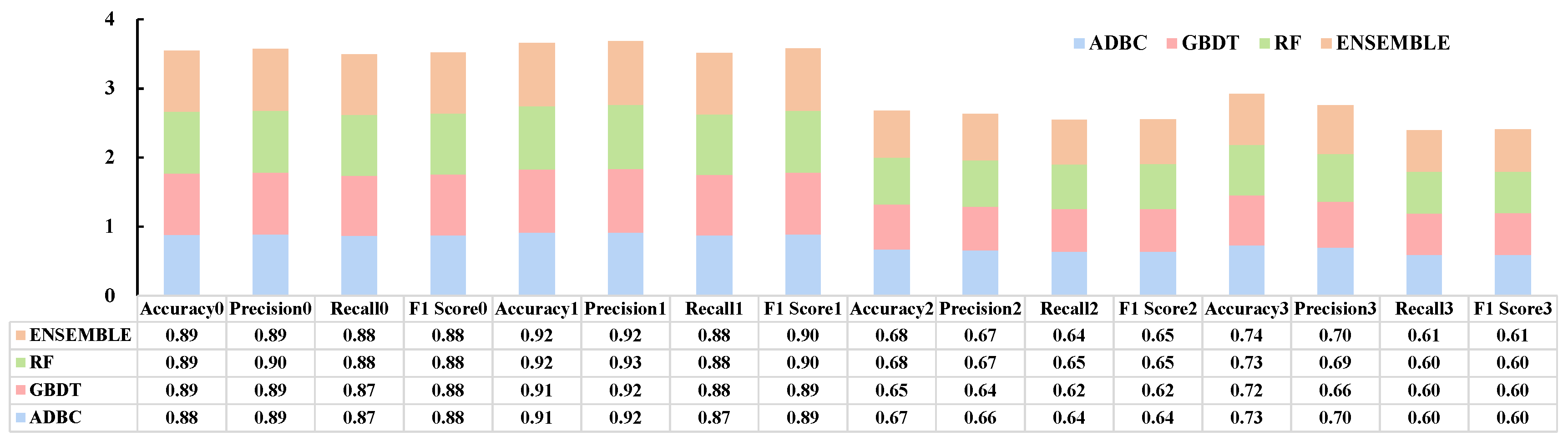
4.3. Accuracy Evaluation of the Model Based on Non-Flood Point Dataset
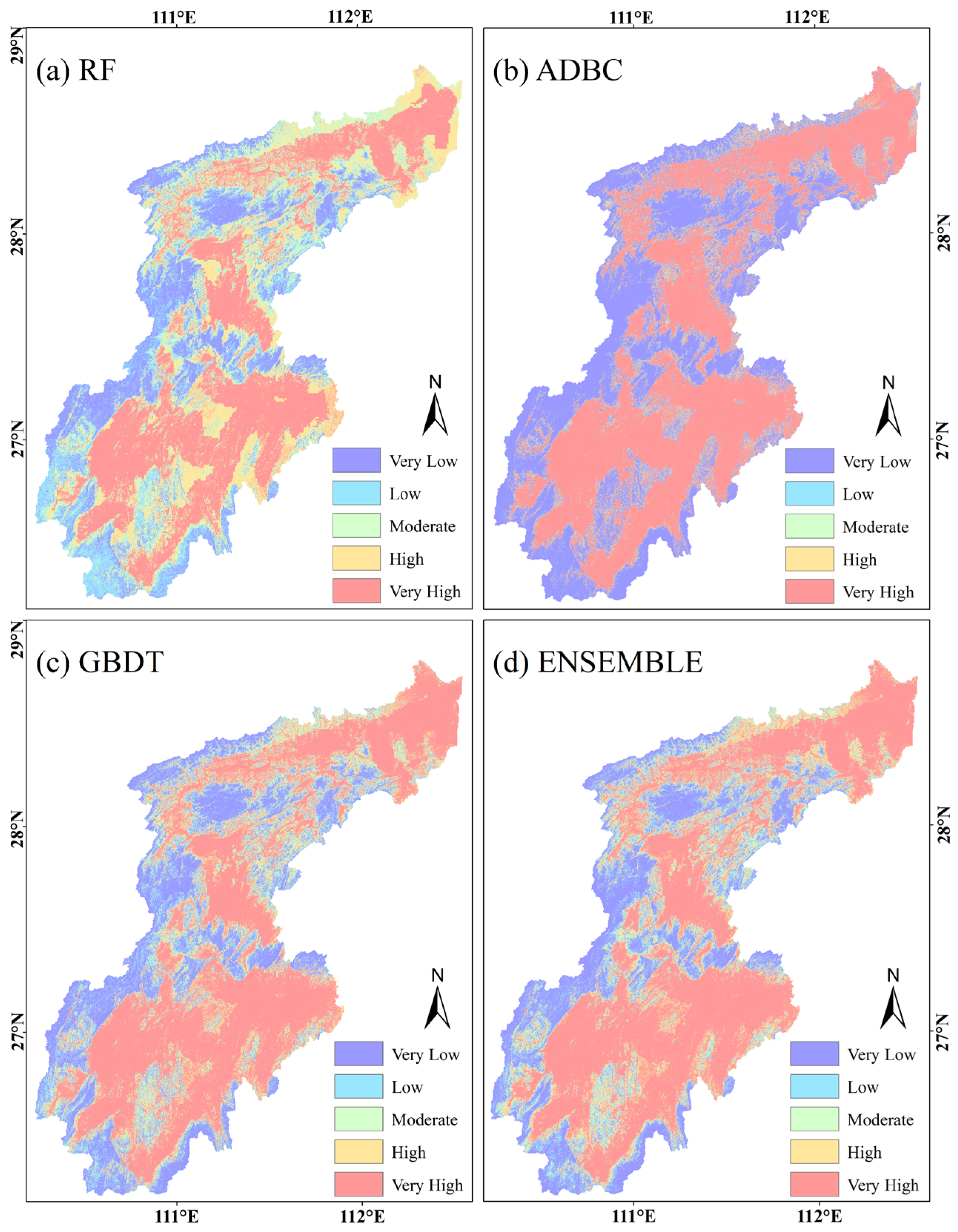
4.4. The Flood Susceptibility Map
4.5. Model Interpretability
5. Discussion
5.1. Uncertainty Analysis of Non-Flood Sample Selection
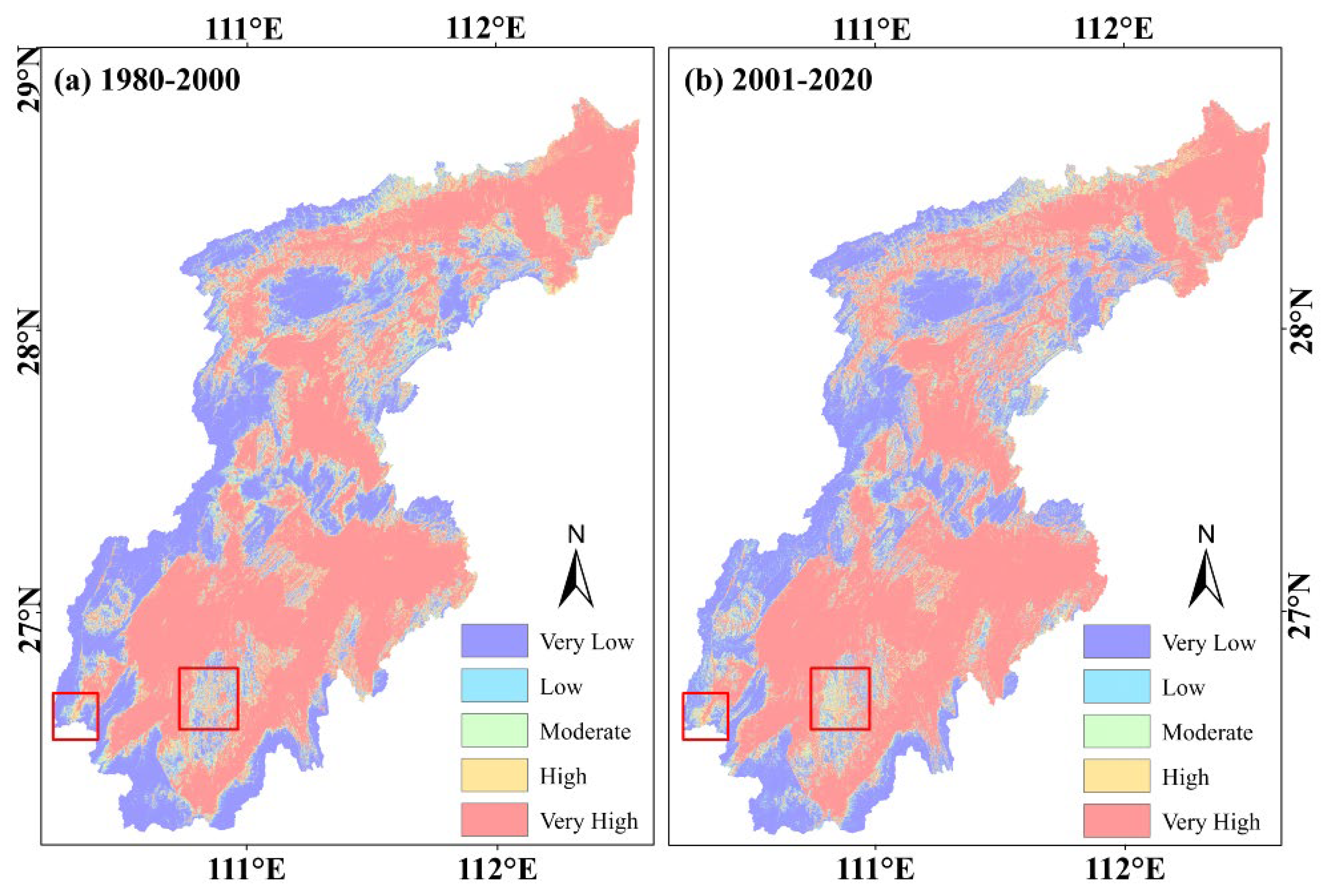
5.2. Dynamic Analysis of Flood Susceptibility
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shahiri Tabarestani, E.; Afzalimehr, H. A comparative assessment of multi-criteria decision analysis for flood susceptibility modelling. Geocarto Int. 2022, 37, 5851–5874. [Google Scholar] [CrossRef]
- Chen, J.; Shi, X.; Gu, L.; Wu, G.; Su, T.; Wang, H.-M.; Kim, J.-S.; Zhang, L.; Xiong, L. Impacts of climate warming on global floods and their implication to current flood defense standards. J. Hydrol. 2023, 618, 129236. [Google Scholar] [CrossRef]
- Shah, S.A.; Ai, S. Flood susceptibility mapping contributes to disaster risk reduction: A case study in Sindh, Pakistan. Int. J. Disaster Risk Reduct. 2024, 108, 104503. [Google Scholar] [CrossRef]
- Islam, A.R.M.T.; Talukdar, S.; Mahato, S.; Kundu, S.; Eibek, K.U.; Pham, Q.B.; Kuriqi, A.; Linh, N.T.T. Flood susceptibility modelling using advanced ensemble machine learning models. Geosci. Front. 2021, 12, 101075. [Google Scholar] [CrossRef]
- Zennaro, F.; Furlan, E.; Simeoni, C.; Torresan, S.; Aslan, S.; Critto, A.; Marcomini, A. Exploring machine learning potential for climate change risk assessment. Earth-Sci. Rev. 2021, 220, 103752. [Google Scholar] [CrossRef]
- Gharbi, M.; Soualmia, A.; Dartus, D.; Masbernat, L. Comparison of 1D and 2D hydraulic models for floods simulation on the Medjerda Riverin Tunisia. J. Mater. Environ. Sci. 2016, 7, 3017–3026. [Google Scholar]
- Chen, R.; Han, B.; Zhao, L.; Zhang, Y.; Cao, Y. Study on water disaster risk of Majiahe River Watershed in Puyang City under extreme rainfall. Water Resour. Hydropower Eng. 2022, 53, 34–43. [Google Scholar]
- Abbott, M.B.; Bathurst, J.C.; Cunge, J.A.; O’Connell, P.E.; Rasmussen, J. An introduction to the European Hydrological System—Systeme Hydrologique Europeen,“SHE”, 1: History and philosophy of a physically-based, distributed modelling system. J. Hydrol. 1986, 87, 45–59. [Google Scholar] [CrossRef]
- Buahin, C.A.; Horsburgh, J.S. Evaluating the simulation times and mass balance errors of component-based models: An application of OpenMI 2.0 to an urban stormwater system. Environ. Model. Softw. 2015, 72, 92–109. [Google Scholar] [CrossRef]
- Shrestha, N.K.; Leta, O.T.; De Fraine, B.; Van Griensven, A.; Bauwens, W. OpenMI-based integrated sediment transport modelling of the river Zenne, Belgium. Environ. Model. Softw. 2013, 47, 193–206. [Google Scholar] [CrossRef]
- Youssef, A.M.; Mahdi, A.M.; Pourghasemi, H.R. Optimal flood susceptibility model based on performance comparisons of LR, EGB, and RF algorithms. Nat. Hazards 2023, 115, 1071–1096. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood susceptibility mapping using a novel ensemble weights-of-evidence and support vector machine models in GIS. J. Hydrol. 2014, 512, 332–343. [Google Scholar] [CrossRef]
- Seydi, S.T.; Kanani-Sadat, Y.; Hasanlou, M.; Sahraei, R.; Chanussot, J.; Amani, M. Comparison of machine learning algorithms for flood susceptibility mapping. Remote Sens. 2022, 15, 192. [Google Scholar] [CrossRef]
- Lyu, H.M.; Yin, Z.Y. Flood susceptibility prediction using tree-based machine learning models in the GBA. Sustain. Cities Soc. 2023, 97, 104744. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Hong, H.; Peng, L. Flood susceptibility mapping using convolutional neural network frameworks. J. Hydrol. 2020, 582, 124482. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Wang, M.; Peng, L.; Hong, H. Comparative study of landslide susceptibility mapping with different recurrent neural networks. Comput. Geosci. 2020, 138, 104445. [Google Scholar] [CrossRef]
- Bui, Q.T.; Nguyen, Q.H.; Nguyen, X.L.; Pham, V.D.; Nguyen, H.D.; Pham, V.M. Verification of novel integrations of swarm intelligence algorithms into deep learning neural network for flood susceptibility mapping. J. Hydrol. 2020, 581, 124379. [Google Scholar] [CrossRef]
- Yao, J.; Zhang, X.; Luo, W.; Liu, C.; Ren, L. Applications of Stacking/Blending ensemble learning approaches for evaluating flash flood susceptibility. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102932. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Merghadi, A.; Sahana, M.; Zhu, Z.; Chen, C.W.; Han, Z.; Pham, B.T. Improved landslide assessment using support vector machine with bagging, boosting, and stacking ensemble machine learning framework in a mountainous watershed, Japan. Landslides 2020, 17, 641–658. [Google Scholar] [CrossRef]
- Chen, W.; Panahi, M.; Tsangaratos, P.; Shahabi, H.; Ilia, I.; Panahi, S.; Li, S.; Jaafari, A.; Ahmad, B.B. Applying population-based evolutionary algorithms and a neuro-fuzzy system for modeling landslide susceptibility. Catena 2019, 172, 212–231. [Google Scholar] [CrossRef]
- Chen, W.; Hong, H.; Li, S.; Shahabi, H.; Wang, Y.; Wang, X.; Ahmad, B.B. Flood susceptibility modelling using novel hybrid approach of reduced-error pruning trees with bagging and random subspace ensembles. J. Hydrol. 2019, 575, 864–873. [Google Scholar] [CrossRef]
- Kanani-Sadat, Y.; Arabsheibani, R.; Karimipour, F.; Nasseri, M. A new approach to flood susceptibility assessment in data-scarce and ungauged regions based on GIS-based hybrid multi criteria decision-making method. J. Hydrol. 2019, 572, 17–31. [Google Scholar] [CrossRef]
- Al-Aizari, A.R.; Alzahrani, H.; AlThuwaynee, O.F.; Al-Masnay, Y.A.; Ullah, K.; Park, H.J.; Al-Areeq, N.M.; Rahman, M.; Hazaea, B.Y.; Liu, X. Uncertainty Reduction in Flood Susceptibility Mapping Using Random Forest and eXtreme Gradient Boosting Algorithms in Two Tropical Desert Cities, Shibam and Marib, Yemen. Remote Sens. 2024, 16, 336. [Google Scholar] [CrossRef]
- Ekmekcioğlu, Ö.; Koc, K.; Özger, M.; Işık, Z. Exploring the additional value of class imbalance distributions on interpretable flash flood susceptibility prediction in the Black Warrior River basin, Alabama, United States. J. Hydrol. 2022, 610, 127877. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Merghadi, A.; Shirzadi, A.; Nguyen, H.; Hussain, Y.; Avtar, R.; Chen, Y.; Pham, B.T.; Yamagishi, H. Different sampling strategies for predicting landslide susceptibilities are deemed less consequential with deep learning. Sci. Total Environ. 2020, 720, 137320. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Mansor, S.; Ahmad, N. Flood susceptibility assessment using GIS-based support vector machine model with different kernel types. Catena 2015, 125, 91–101. [Google Scholar] [CrossRef]
- Khosravi, K.; Shahabi, H.; Pham, B.T.; Adamowski, J.; Shirzadi, A.; Pradhan, B.; Dou, J.; Ly, H.B.; Gróf, G.; Ho, H.L.; et al. A comparative assessment of flood susceptibility modeling using multi-criteria decision-making analysis and machine learning methods. J. Hydrol. 2019, 573, 311–323. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Hong, H.; Costache, R.; Tang, X. Flood susceptibility mapping by integrating frequency ratio and index of entropy with multilayer perceptron and classification and regression tree. J. Environ. Manag. 2021, 289, 112449. [Google Scholar] [CrossRef]
- MacInnes, J.; Santosa, S.; Wright, W. Visual classification: Expert knowledge guides machine learning. IEEE Comput. Graph. Appl. 2009, 30, 8–14. [Google Scholar] [CrossRef]
- Guo, Z.; Tian, B.; Zhu, Y.; He, J.; Zhang, T. How do the landslide and non-landslide sampling strategies impact landslide susceptibility assessment?—A catchment-scale case study from China. J. Rock Mech. Geotech. Eng. 2024, 16, 877–894. [Google Scholar] [CrossRef]
- Ye, C.; Tang, R.; Wei, R.; Guo, Z.; Zhang, H. Generating accurate negative samples for landslide susceptibility mapping: A combined self-organizing-map and one-class SVM method. Front. Earth Sci. 2023, 10, 1054027. [Google Scholar] [CrossRef]
- Yang, J.; Huang, X. 30 m annual land cover and its dynamics in China from 1990 to 2019. Earth Syst. Sci. Data Discuss. 2021, 2021, 1–29. [Google Scholar]
- Yang, H.; Yao, R.; Dong, L.; Sun, P.; Zhang, Q.; Wei, Y.; Sun, S.; Aghakouchak, A. Advancing flood susceptibility modeling using stacking ensemble machine learning: A multi-model approach. J. Geogr. Sci. 2024, 34, 1513–1536. [Google Scholar] [CrossRef]
- Torcivia, C.G.; López, N.R. Preliminary Morphometric Analysis: Río Talacasto Basin, Central Precordillera of San Juan, Argentina Advances in Geomorphology and Quaternary Studies in Argentina; Springer: Cham, Switzerland, 2020; pp. 158–168. [Google Scholar]
- Rau, P.; Bourrel, L.; Labat, D.; Ruelland, D.; Frappart, F.; Lavado, W.; Dewitte, B.; Felipe, O. Assessing multidecadal runoff (1970–2010) using regional hydrological modelling under data and water scarcity conditions in Peruvian Pacific catchments. Hydrol. Process. 2019, 33, 20–35. [Google Scholar] [CrossRef]
- Giovannettone, J.; Copenhaver, T.; Burns, M.; Choquette, S. A statistical approach to mapping flood susceptibility in the Lower Connecticut River Valley Region. Water Resour. Res. 2018, 54, 7603–7618. [Google Scholar] [CrossRef]
- Mahmoud, S.H.; Gan, T.Y. Multi-criteria approach to develop flood susceptibility maps in arid regions of Middle East. J. Clean. Prod. 2018, 196, 216–229. [Google Scholar] [CrossRef]
- Moore, I.D.; Grayson, R.B. Terrain-based catchment partitioning and runoff prediction using vector elevation data. Water Resour. Res. 1991, 27, 1177–1191. [Google Scholar] [CrossRef]
- Ogden, F.L.; Raj Pradhan, N.; Downer, C.W.; Zahner, J.A. Relative importance of impervious area, drainage density, width function, and subsurface storm drainage on flood runoff from an urbanized catchment. Water Resour. Res. 2011, 47. [Google Scholar] [CrossRef]
- Wilson, J.P.; Gallant, J.C. (Eds.) Terrain Analysis: Principles and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2000. [Google Scholar]
- Merz, R.; Blöschl, G. A process typology of regional floods. Water Resour. Res. 2003, 39. [Google Scholar] [CrossRef]
- Lin, L.; Wu, Z.; Liang, Q. Urban flood susceptibility analysis using a GIS-based multi-criteria analysis framework. Nat. Hazards 2019, 97, 455–475. [Google Scholar] [CrossRef]
- Yariyan, P.; Avand, M.; Abbaspour, R.A.; Torabi Haghighi, A.; Costache, R.; Ghorbanzadeh, O.; Janizadeh, S.; Blaschke, T. Flood susceptibility mapping using an improved analytic network process with statistical models. Geomat. Nat. Hazards Risk 2020, 11, 2282–2314. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Jones, S.; Shabani, F. Identifying the essential flood conditioning factors for flood prone area mapping using machine learning techniques. Catena 2019, 175, 174–192. [Google Scholar] [CrossRef]
- Shin, H.J.; Eom, D.H.; Kim, S.S. One-class support vector machines—An application in machine fault detection and classification. Comput. Ind. Eng. 2005, 48, 395–408. [Google Scholar] [CrossRef]
- He, X.; Mourot, G.; Maquin, D.; Ragot, J.; Beauseroy, P.; Smolarz, A.; Grall-Maës, E. Multi-task learning with one-class SVM. Neurocomputing 2014, 133, 416–426. [Google Scholar] [CrossRef]
- Liuzzo, L.; Sammartano, V.; Freni, G. Comparison between different distributed methods for flood susceptibility mapping. Water Resour. Manag. 2019, 33, 3155–3173. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Du, P.; Samat, A.; Waske, B.; Liu, S.; Li, Z. Random forest and rotation forest for fully polarized SAR image classification using polarimetric and spatial features. ISPRS J. Photogramm. Remote Sens. 2015, 105, 38–53. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A desicion-theoretic generalization of on-line learning and an application to boosting. In European Conference on Computational Learning Theory; Springer: Berlin/Heidelberg, Germany, 1995; pp. 23–37. [Google Scholar]
- Feng, D.C.; Liu, Z.T.; Wang, X.D.; Chen, Y.; Chang, J.Q.; Wei, D.F.; Jiang, Z.M. Machine learning-based compressive strength prediction for concrete: An adaptive boosting approach. Constr. Build. Mater. 2020, 230, 117000. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Asadi, B.; Hajj, R. Prediction of asphalt binder elastic recovery using tree-based ensemble bagging and boosting models. Constr. Build. Mater. 2024, 410, 134154. [Google Scholar] [CrossRef]
- Fang, Z.; Wang, Y.; Peng, L.; Hong, H. A comparative study of heterogeneous ensemble-learning techniques for landslide susceptibility mapping. Int. J. Geogr. Inf. Sci. 2021, 35, 321–347. [Google Scholar]
- Zhang, R.; Chai, Z.; Zhang, T.; Li, J. Research progress of flood forecasting based on machine learning models. Water Resour. Hydropower Eng. 2023, 54, 89–101. [Google Scholar]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar]
- Pradhan, B.; Lee, S.; Dikshit, A.; Kim, H. Spatial flood susceptibility mapping using an explainable artificial intelligence (XAI) model. Geosci. Front. 2023, 14, 101625. [Google Scholar] [CrossRef]
- Wang, N.; Zhang, H.; Dahal, A.; Cheng, W.; Zhao, M.; Lombardo, L. On the use of explainable AI for susceptibility modeling: Examining the spatial pattern of SHAP values. Geosci. Front. 2024, 15, 101800. [Google Scholar] [CrossRef]
- Wan, A.; Dunlap, L.; Ho, D.; Yin, J.; Lee, S.; Jin, H.; Petryk, S.; Bargal, S.A.; Gonzalez, J.E. NBDT: Neural-backed decision trees. arXiv 2020, arXiv:2004.00221. [Google Scholar]
- Shapley, L.S. A value for n-person games. Contrib. Theory Games 1953, 2. [Google Scholar] [CrossRef]
- Sahana, M.; Rehman, S.; Sajjad, H.; Hong, H. Exploring effectiveness of frequency ratio and support vector machine models in storm surge flood susceptibility assessment: A study of Sundarban Biosphere Reserve, India. Catena 2020, 189, 104450. [Google Scholar] [CrossRef]
- Tien Bui, D.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, P.; Wang, W.; Xiao, P.; Wang, Q. Driving force analysis and risk assessment of flash flood disaster based on multi-parameter optimized geographic detector. Water Resour. Hydropower Eng. 2024, 55, 1–15. [Google Scholar]
- Costache, R.; Pal, S.C.; Pande, C.B.; Islam, A.R.M.T.; Alshehri, F.; Abdo, H.G. Flood mapping based on novel ensemble modeling involving the deep learning, Harris Hawk optimization algorithm and stacking based machine learning. Appl. Water Sci. 2024, 14, 78. [Google Scholar] [CrossRef]
- Posthumus, H.; Hewett, C.J.M.; Morris, J.; Quinn, P.F. Agricultural land use and flood risk management: Engaging with stakeholders in North Yorkshire. Agric. Water Manag. 2008, 95, 787–798. [Google Scholar] [CrossRef]
- Zope, P.E.; Eldho, T.I.; Jothiprakash, V. Impacts of land use–land cover change and urbanization on flooding: A case study of Oshiwara River Basin in Mumbai, India. Catena 2016, 145, 142–154. [Google Scholar] [CrossRef]
- Özay, B.; Orhan, O. Flood susceptibility mapping by best–worst and logistic regression methods in Mersin, Turkey. Environ. Sci. Pollut. Res. 2023, 30, 45151–45170. [Google Scholar] [CrossRef]
- Miao, Y.M.; Zhu, A.X.; Yang, L.; Bai, S.B.; Liu, J.Z.; Deng, Y. Sensitivity of BCS for sampling landslide absence data in landslide susceptibility assessment. Mt. Res. Dev. 2016, 34, 432–441. [Google Scholar]
- Lucchese, L.V.; de Oliveira, G.G.; Pedrollo, O.C. Investigation of the influence of nonoccurrence sampling on landslide susceptibility assessment using Artificial Neural Networks. Catena 2021, 198, 105067. [Google Scholar] [CrossRef]
- Miao, Y.M.; Zhu, A.X.; Yang, L.; Bai, S.B.; Zeng, C. A new method of pseudo absence data generation in landslide susceptibility mapping. Geogr. Geo-Inf. Sci. 2016, 32, 61–67. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factor Types | Data | Data Types in GIS | Scale | Source |
|---|---|---|---|---|
| Topographic factors | Elevation | Grid | 30 × 30 m | https://www.gscloud.cn/ (accessed on 10 October 2023) |
| Slope | Grid | 30 × 30 m | https://www.gscloud.cn/ (accessed on 10 October 2023) | |
| Aspect | Grid | 30 × 30 m | https://www.gscloud.cn/ (accessed on 10 October 2023) | |
| Curvature | Grid | 30 × 30 m | https://www.gscloud.cn/ (accessed on 10 October 2023) | |
| Hydrological factors | SPI | Grid | 30 × 30 m | https://www.gscloud.cn/ (accessed on 10 October 2023) |
| TWI | Grid | 30 × 30 m | https://www.gscloud.cn/ (accessed on 10 October 2023) | |
| Distance from river | Polygon | - | https://www.gscloud.cn/ (accessed on 10 October 2023) | |
| Drainage density | Grid | 30 × 30 m | https://www.gscloud.cn/ (accessed on 10 October 2023) | |
| Complementary factors | NDVI | Grid | 30 × 30 m | https://www.gscloud.cn/ (accessed on 10 October 2023) |
| Land use | Grid | 30 × 30 m | land cover dataset in China [32] | |
| Rainfall | Grid | 30 × 30 m | https://www.resdc.cn/ (accessed on 21 October 2023) |
| Flood Conditioning Factor | TOL | VIF |
|---|---|---|
| elevation | 0.567 | 1.763 |
| slope | 0.583 | 1.715 |
| aspect | 0.998 | 1.002 |
| curvature | 0.803 | 1.246 |
| NDVI | 0.601 | 1.665 |
| SPI | 0.570 | 1.755 |
| TWI | 0.570 | 1.755 |
| distance from river | 0.550 | 1.819 |
| drainage density | 0.541 | 1.850 |
| rainfall | 0.901 | 1.109 |
| land use | 0.844 | 1.185 |
| Flood Susceptibility Model | Susceptibility Class | Pixels in Each Susceptibility Class | Flood Points in Each Susceptibility Class | SCAI | ||
|---|---|---|---|---|---|---|
| Number of Pixels | Percentage of Pixels | Number of Flood Points | Percentage of Flood Points | |||
| RF | Very Low | 4,967,412 | 0.161 | 1732 | 0.052 | 3.099 |
| Low | 4,652,028 | 0.151 | 720 | 0.098 | 1.544 | |
| Moderate | 4,375,537 | 0.142 | 408 | 0.121 | 1.171 | |
| High | 5,735,496 | 0.186 | 329 | 0.214 | 0.870 | |
| Very High | 11,081,626 | 0.360 | 175 | 0.515 | 0.699 | |
| ADBC | Very Low | 11,074,785 | 0.359 | 2438 | 0.176 | 2.046 |
| Low | 1,274,367 | 0.041 | 126 | 0.035 | 1.169 | |
| Moderate | 917,565 | 0.030 | 90 | 0.027 | 1.113 | |
| High | 1,120,421 | 0.036 | 119 | 0.037 | 0.971 | |
| Very High | 16,424,961 | 0.533 | 591 | 0.725 | 0.736 | |
| GBDT | Very Low | 6,396,066 | 0.208 | 2232 | 0.070 | 2.946 |
| Low | 3,242,960 | 0.105 | 356 | 0.076 | 1.394 | |
| Moderate | 2,751,002 | 0.089 | 285 | 0.085 | 1.054 | |
| High | 3,334,045 | 0.108 | 254 | 0.106 | 1.022 | |
| Very High | 15,088,026 | 0.490 | 237 | 0.663 | 0.738 | |
| ENSEMBLE | Very Low | 6,222,257 | 0.202 | 2297 | 0.065 | 3.088 |
| Low | 3,080,312 | 0.100 | 360 | 0.068 | 1.462 | |
| Moderate | 2,445,763 | 0.079 | 257 | 0.076 | 1.039 | |
| High | 3,487,977 | 0.113 | 230 | 0.107 | 1.058 | |
| Very High | 15,575,790 | 0.51 | 220 | 0.683 | 0.740 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Wei, Y.; Yao, R.; Sun, P.; Zhen, N.; Xia, X. Data Uncertainty of Flood Susceptibility Using Non-Flood Samples. Remote Sens. 2025, 17, 375. https://doi.org/10.3390/rs17030375
Zhang Y, Wei Y, Yao R, Sun P, Zhen N, Xia X. Data Uncertainty of Flood Susceptibility Using Non-Flood Samples. Remote Sensing. 2025; 17(3):375. https://doi.org/10.3390/rs17030375
Chicago/Turabian StyleZhang, Yayi, Yongqiang Wei, Rui Yao, Peng Sun, Na Zhen, and Xue Xia. 2025. "Data Uncertainty of Flood Susceptibility Using Non-Flood Samples" Remote Sensing 17, no. 3: 375. https://doi.org/10.3390/rs17030375
APA StyleZhang, Y., Wei, Y., Yao, R., Sun, P., Zhen, N., & Xia, X. (2025). Data Uncertainty of Flood Susceptibility Using Non-Flood Samples. Remote Sensing, 17(3), 375. https://doi.org/10.3390/rs17030375