Knowledge-Guided Multi-Task Network for Remote Sensing Imagery


Abstract
:1. Introduction
- We propose a novel multi-scale knowledge-guided multi-task learning architecture for remote sensing imagery, which can be applied to various primary tasks (semantic segmentation, height estimation) and also allows for the incorporation of different auxiliary tasks (edge detection, semantic edge detection).
- We introduce the MKF module, which builds a multi-scale multi-task knowledge bank using task-specific feature maps and leverages the CKP module to transfer complementary information from this bank through cross-knowledge affinity, enhancing final predictions.
- We demonstrate our proposed method improves the performance of both semantic segmentation and height estimation against several state-of-the-art approaches on two classical datasets, namely, Potsdam and Vaihingen.
2. Related Work
2.1. Semantic Segmentation
2.2. Height Estimation
2.3. Multi-Task Learning
3. Methodology
3.1. Front-End Network Structure
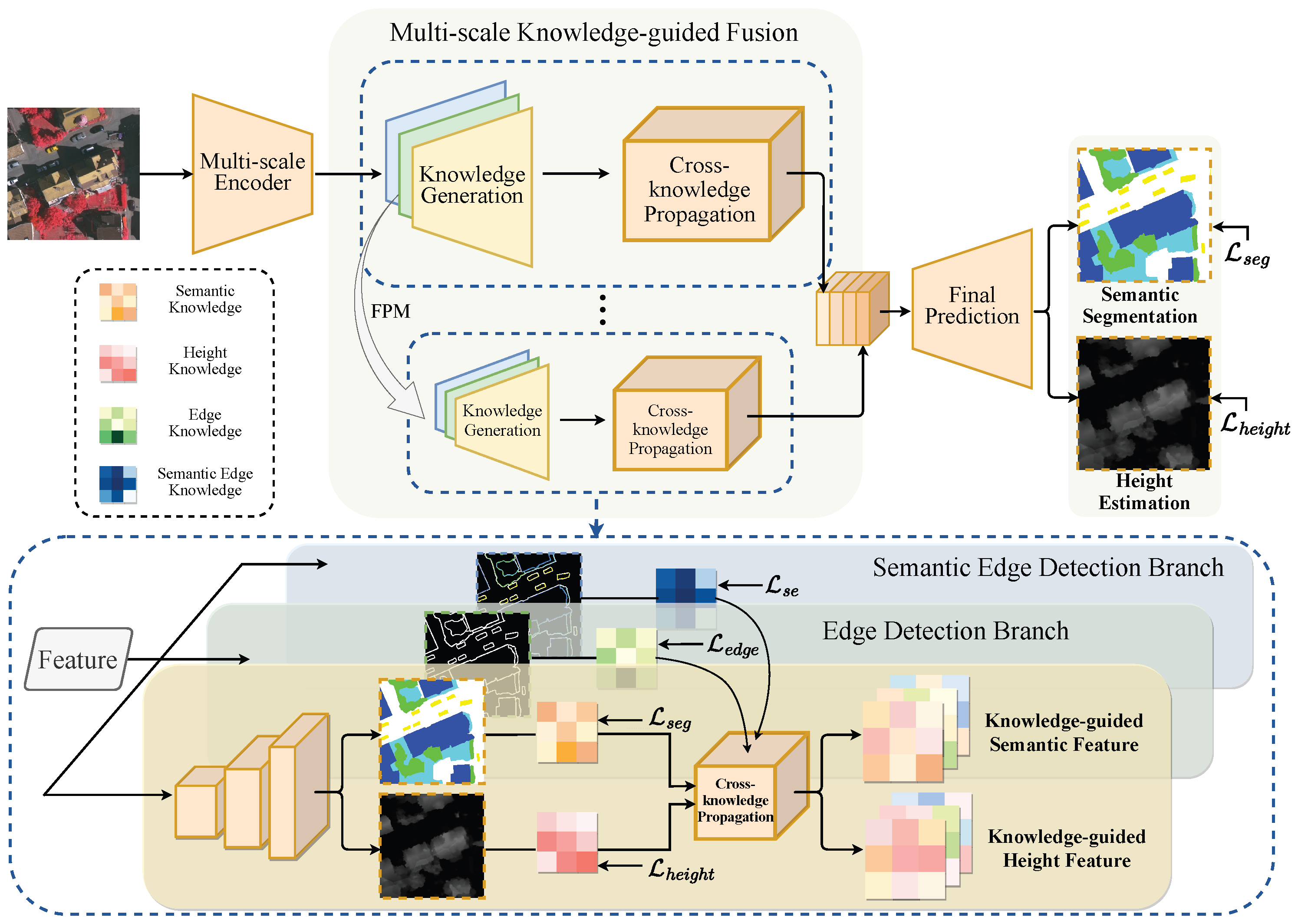
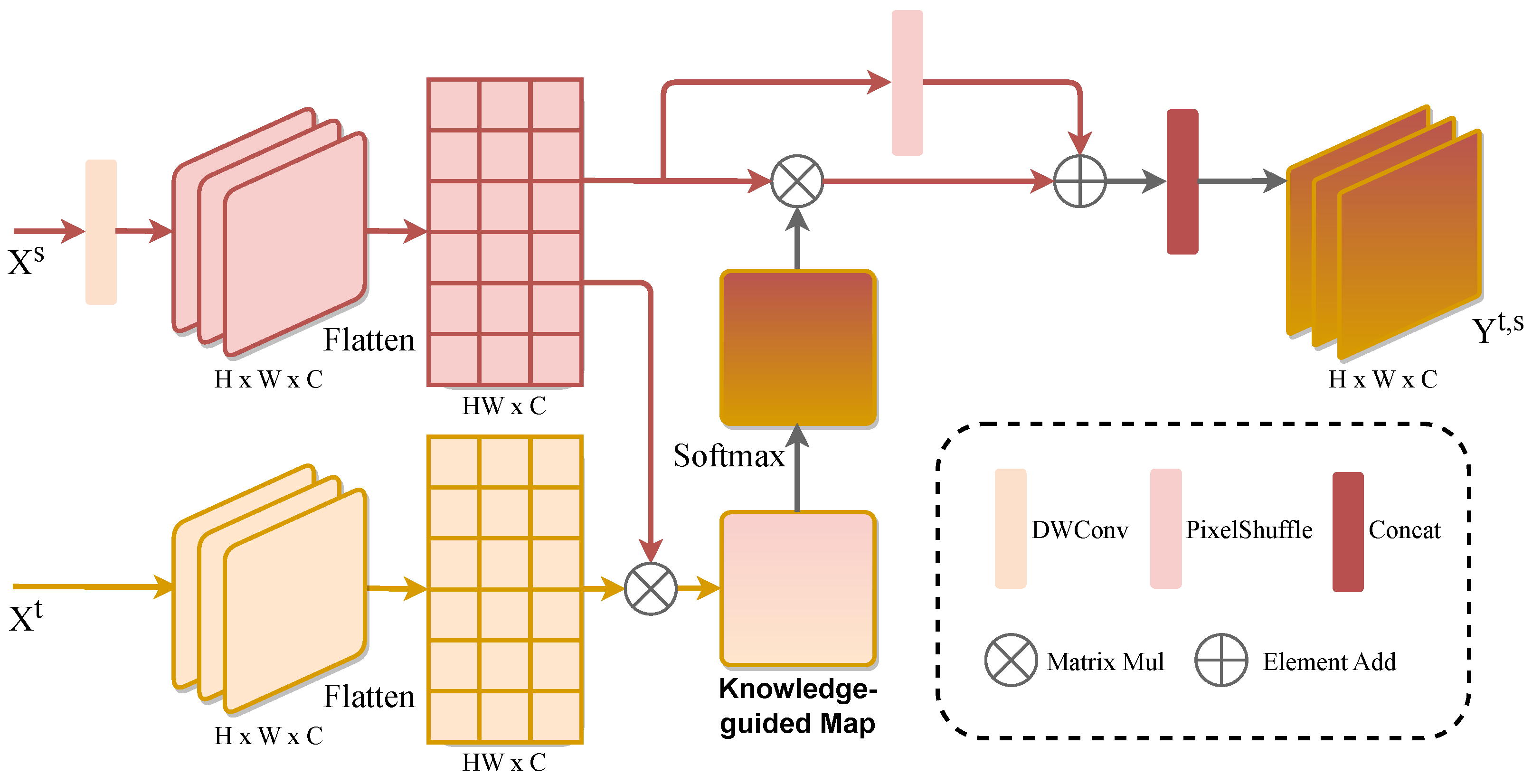
3.2. Multi-Scale Knowledge-Guided Fusion
3.3. Final Predictions
3.4. Optimization Method
4. Experiments Results and Analysis
4.1. Dataset Description
4.2. Implementation Details and Evaluation Metrics
- (i)
- Random rotation;
- (ii)
- Resize with a random scale selected from the interval [0.75, 1.5];
- (iii)
- Color jitter for brightness, contrast, saturation, and hue with a adjust factor of 0.25, for data augmentation.
4.3. Comparisons with State-of-the-Art Methods
4.4. Ablation Studies
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ding, P.; Zhang, Y.; Deng, W.J.; Jia, P.; Kuijper, A. A light and faster regional convolutional neural network for object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 141, 208–218. [Google Scholar] [CrossRef]
- Kramer, H.J.; Cracknell, A.P. An overview of small satellites in remote sensing. Int. J. Remote Sens. 2008, 29, 4285–4337. [Google Scholar] [CrossRef]
- Schowengerdt, R.A. Remote Sensing: Models and Methods for Image Processing; Elsevier: Amsterdam, The Netherlands, 2006. [Google Scholar]
- Li, L.; Song, N.; Sun, F.; Liu, X.; Wang, R.; Yao, J.; Cao, S. Point2Roof: End-to-end 3D building roof modeling from airborne LiDAR point clouds. ISPRS J. Photogramm. Remote Sens. 2022, 193, 17–28. [Google Scholar] [CrossRef]
- Beumier, C.; Idrissa, M. Digital terrain models derived from digital surface model uniform regions in urban areas. Int. J. Remote Sens. 2016, 37, 3477–3493. [Google Scholar] [CrossRef]
- Volpi, M.; Tuia, D. Dense semantic labeling of sub-decimeter resolution images with convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 55, 1–13. [Google Scholar]
- Qin, R.; Tian, J.; Reinartz, P. 3D change detection–approaches and applications. ISPRS J. Photogramm. Remote Sens. 2016, 122, 41–56. [Google Scholar] [CrossRef]
- Vega, P.J.S.; da Costa, G.A.O.P.; Feitosa, R.Q.; Adarme, M.X.O.; de Almeida, C.A.; Heipke, C.; Rottensteiner, F. An unsupervised domain adaptation approach for change detection and its application to deforestation mapping in tropical biomes. ISPRS J. Photogramm. Remote Sens. 2021, 181, 113–128. [Google Scholar] [CrossRef]
- Tu, J.; Sui, H.; Feng, W.; Song, Z. Automatic building damage detection method using high-resolution remote sensing images and 3D GIS Model. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 43–50. [Google Scholar]
- Vetrivel, A.; Gerke, M.; Kerle, N.; Nex, F.; Vosselman, G. Disaster damage detection through synergistic use of deep learning and 3D point cloud features derived from very high resolution oblique aerial images, and multiple-kernel-learning. ISPRS J. Photogramm. Remote Sens. 2018, 140, 45–59. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Peters, T.; Brenner, C.; Schindler, K. Semantic segmentation of mobile mapping point clouds via multi-view label transfer. ISPRS J. Photogramm. Remote Sens. 2023, 202, 30–39. [Google Scholar] [CrossRef]
- Carvalho, M.; Le Saux, B.; Trouvé-Peloux, P.; Almansa, A.; Champagnat, F. On regression losses for deep depth estimation. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2915–2919. [Google Scholar]
- Ghamisi, P.; Yokoya, N. IMG2DSM: Height simulation from single imagery using conditional generative adversarial net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 794–798. [Google Scholar] [CrossRef]
- Carvalho, M.; Le Saux, B.; Trouvé-Peloux, P.; Champagnat, F.; Almansa, A. Multi-task learning of height and semantics from aerial images. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1391–1395. [Google Scholar] [CrossRef]
- Standley, T.; Zamir, A.; Chen, D.; Guibas, L.; Malik, J.; Savarese, S. Which tasks should be learned together in multi-task learning? In Proceedings of the International Conference on Machine Learning, Online, 13–18 July 2020; pp. 9120–9132. [Google Scholar]
- Misra, I.; Shrivastava, A.; Gupta, A.; Hebert, M. Cross-Stitch networks for multi-task learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3994–4003. [Google Scholar]
- Xu, D.; Ouyang, W.; Wang, X.; Sebe, N. PAD-Net: Multi-tasks guided prediction-and-distillation network for simultaneous depth estimation and scene parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 675–684. [Google Scholar]
- Gao, Y.; Ma, J.; Zhao, M.; Liu, W.; Yuille, A.L. NDDR-CNN: Layerwise feature fusing in multi-task CNNs by neural discriminative dimensionality reduction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3205–3214. [Google Scholar]
- Vandenhende, S.; Georgoulis, S.; Van Gool, L. MTI-Net: Multi-scale task interaction networks for multi-task learning. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part IV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 527–543. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. GLUE: A multi-task benchmark and analysis platform for natural language understanding. arXiv 2018, arXiv:1804.07461. [Google Scholar]
- Liu, X.; He, P.; Chen, W.; Gao, J. Improving multi-task deep neural networks via knowledge distillation for natural language understanding. arXiv 2019, arXiv:1904.09482. [Google Scholar]
- Worsham, J.; Kalita, J. Multi-task learning for natural language processing in the 2020s: Where are we going? Pattern Recognit. Lett. 2020, 136, 120–126. [Google Scholar] [CrossRef]
- Kargar, E.; Kyrki, V. Efficient latent representations using multiple tasks for autonomous driving. arXiv 2020, arXiv:2003.00695. [Google Scholar]
- Phillips, J.; Martinez, J.; Bârsan, I.A.; Casas, S.; Sadat, A.; Urtasun, R. Deep multi-task learning for joint localization, perception, and prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4679–4689. [Google Scholar]
- Casas, S.; Sadat, A.; Urtasun, R. MP3: A unified model to map, perceive, predict and plan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14403–14412. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A remote sensing land-cover dataset for domain adaptive semantic segmentation. arXiv 2021, arXiv:2110.08733. [Google Scholar]
- Zheng, Z.; Zhong, Y.; Wang, J. Pop-Net: Encoder-dual decoder for semantic segmentation and single-view height estimation. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 4963–4966. [Google Scholar]
- Wang, Y.; Ding, W.; Zhang, R.; Li, H. Boundary-aware multitask learning for remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 951–963. [Google Scholar] [CrossRef]
- 2D Semantic Labeling Contest. 2014. Available online: https://www.isprs.org/documents/si/SI-2014/ISPRS_SI_report-website_WGIII4_Gerke_2014.pdf (accessed on 1 July 2020).
- Ciresan, D.; Giusti, A.; Gambardella, L.; Schmidhuber, J. Deep neural networks segment neuronal membranes in electron microscopy images. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Xu, Y.; He, F.; Du, B.; Tao, D.; Zhang, L. Self-ensembling GAN for cross-domain semantic segmentation. IEEE Trans. Multimed. 2022, 25, 7837–7850. [Google Scholar] [CrossRef]
- Ma, L.; Xie, H.; Liu, C.; Zhang, Y. Learning cross-channel representations for semantic segmentation. IEEE Trans. Multimed. 2022, 25, 2774–2787. [Google Scholar] [CrossRef]
- Yin, C.; Tang, J.; Yuan, T.; Xu, Z.; Wang, Y. Bridging the gap between semantic segmentation and instance segmentation. IEEE Trans. Multimed. 2021, 24, 4183–4196. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. IEEE Comput. Soc. 2016. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Xu, R.; Wang, C.; Zhang, J.; Xu, S.; Meng, W.; Zhang, X. RSSFormer: Foreground saliency enhancement for remote sensing land-cover segmentation. IEEE Trans. Image Process. 2023, 32, 1052–1064. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef]
- Watson, J.; Mac Aodha, O.; Prisacariu, V.; Brostow, G.; Firman, M. The temporal opportunist: Self-supervised multi-frame monocular depth. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1164–1174. [Google Scholar]
- Wang, L.; Zhang, J.; Wang, O.; Lin, Z.; Lu, H. SDC-Depth: Semantic divide-and-conquer network for monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 541–550. [Google Scholar]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2002–2011. [Google Scholar]
- Li, R.; Xue, D.; Zhu, Y.; Wu, H.; Sun, J.; Zhang, Y. Self-supervised monocular depth estimation with frequency-based recurrent refinement. IEEE Trans. Multimed. 2022, 25, 5626–5637. [Google Scholar] [CrossRef]
- Shao, S.; Li, R.; Pei, Z.; Liu, Z.; Chen, W.; Zhu, W.; Wu, X.; Zhang, B. Towards comprehensive monocular depth estimation: Multiple heads are better than one. IEEE Trans. Multimed. 2022, 25, 7660–7671. [Google Scholar] [CrossRef]
- dos Santos Rosa, N.; Guizilini, V.; Grassi, V. Sparse-to-continuous: Enhancing monocular depth estimation using occupancy maps. In Proceedings of the 2019 19th International Conference on Advanced Robotics (ICAR), Belo Horizonte, Brazil, 2–6 December 2019; pp. 793–800. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Zhang, Z.; Xu, C.; Yang, J.; Gao, J.; Cui, Z. Progressive hard-mining network for monocular depth estimation. IEEE Trans. Image Process. 2018, 27, 3691–3702. [Google Scholar] [CrossRef] [PubMed]
- Mou, L.; Zhu, X.X. IM2HEIGHT: Height estimation from single monocular imagery via fully residual convolutional-deconvolutional network. arXiv 2018, arXiv:1802.10249. [Google Scholar]
- Amirkolaee, H.A.; Arefi, H. Height estimation from single aerial images using a deep convolutional encoder-decoder network. ISPRS J. Photogramm. Remote Sens. 2019, 149, 50–66. [Google Scholar] [CrossRef]
- Liu, C.J.; Krylov, V.A.; Kane, P.; Kavanagh, G.; Dahyot, R. IM2ELEVATION: Building height estimation from single-view aerial imagery. Remote Sens. 2020, 12, 2719. [Google Scholar] [CrossRef]
- Mo, D.; Fan, C.; Shi, Y.; Zhang, Y.; Lu, R. Soft-aligned gradient-chaining network for height estimation from single aerial images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 538–542. [Google Scholar] [CrossRef]
- Xing, S.; Dong, Q.; Hu, Z. Gated feature aggregation for height estimation from single aerial images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Ruder, S.; Bingel, J.; Augenstein, I.; Søgaard, A. Latent multi-task architecture learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Long Beach, CA, USA, 16–17 June 2019; Volume 33, pp. 4822–4829. [Google Scholar]
- Zhang, Z.; Cui, Z.; Xu, C.; Yan, Y.; Sebe, N.; Yang, J. Pattern-affinitive propagation across depth, surface normal and semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4106–4115. [Google Scholar]
- Ye, H.; Xu, D. Inverted pyramid multi-task transformer for dense scene understanding. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 514–530. [Google Scholar]
- Ye, H. Taskexpert: Dynamically assembling multi-task representations with memorial mixture-of-experts. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 21828–21837. [Google Scholar]
- Cheng, D.; Meng, G.; Xiang, S.; Pan, C. FusionNet: Edge aware deep convolutional networks for semantic segmentation of remote sensing harbor images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 5769–5783. [Google Scholar] [CrossRef]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- Li, X.; Wen, C.; Wang, L.; Fang, Y. Geometry-aware segmentation of remote sensing images via joint height estimation. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Feng, Y.; Sun, X.; Diao, W.; Li, J.; Niu, R.; Gao, X.; Fu, K. Height aware understanding of remote sensing images based on cross-task interaction. ISPRS J. Photogramm. Remote Sens. 2023, 195, 233–249. [Google Scholar] [CrossRef]
- Cheng, D.; Meng, G.; Cheng, G.; Pan, C. SeNet: Structured edge network for sea-land segmentation. IEEE Geosci. Remote Sens. Lett. 2016, 14, 247–251. [Google Scholar] [CrossRef]
- Volpi, M.; Tuia, D. Deep multi-task learning for a geographically-regularized semantic segmentation of aerial images. ISPRS J. Photogramm. Remote Sens. 2018, 144, 48–60. [Google Scholar] [CrossRef]
- Hu, Y.; Chen, Y.; Li, X.; Feng, J. Dynamic feature fusion for semantic edge detection. arXiv 2019, arXiv:1902.09104. [Google Scholar]
- Xia, L.; Zhang, X.; Zhang, J.; Yang, H.; Chen, T. Building extraction from very-high-resolution remote sensing images using semi-supervised semantic edge detection. Remote Sens. 2021, 13, 2187. [Google Scholar] [CrossRef]
- Liu, Y.; Cheng, M.M.; Fan, D.P.; Zhang, L.; Bian, J.W.; Tao, D. Semantic edge detection with diverse deep supervision. Int. J. Comput. Vis. 2022, 130, 179–198. [Google Scholar] [CrossRef]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Hou, J.; Guo, Z.; Wu, Y.; Diao, W.; Xu, T. BSNet: Dynamic hybrid gradient convolution based boundary-sensitive network for remote sensing image segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–22. [Google Scholar] [CrossRef]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. Adv. Neural Inf. Process. Syst. 2011, 24. [Google Scholar]
- Zhu, Y.; Sapra, K.; Reda, F.A.; Shih, K.J.; Newsam, S.; Tao, A.; Catanzaro, B. Improving semantic segmentation via video propagation and label relaxation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8856–8865. [Google Scholar]
- Gerke, M. Use of the Stair Vision Library Within the ISPRS 2D Semantic Labeling Benchmark (Vaihingen). Available online: https://www.researchgate.net/publication/270104226_Use_of_the_Stair_Vision_Library_within_the_ISPRS_2D_Semantic_Labeling_Benchmark_Vaihingen (accessed on 1 January 2015).
- Nogueira, K.; Dalla Mura, M.; Chanussot, J.; Schwartz, W.R.; Dos Santos, J.A. Dynamic multi-context segmentation of remote sensing images based on convolutional networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7503–7520. [Google Scholar] [CrossRef]
- Mou, L.; Hua, Y.; Zhu, X.X. Relation matters: Relational context-aware fully convolutional network for semantic segmentation of high-resolution aerial images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7557–7569. [Google Scholar] [CrossRef]
- Liu, Y.; Minh Nguyen, D.; Deligiannis, N.; Ding, W.; Munteanu, A. Hourglass-ShapeNetwork based semantic segmentation for high resolution aerial imagery. Remote Sens. 2017, 9, 522. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, X. Multi-path fusion network for high-resolution height estimation from a single orthophoto. In Proceedings of the 2019 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Shanghai, China, 8–12 July 2019; pp. 186–191. [Google Scholar]
- Srivastava, S.; Volpi, M.; Tuia, D. Joint height estimation and semantic labeling of monocular aerial images with CNNs. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 5173–5176. [Google Scholar]
- Liu, S.; Ding, W.; Liu, C.; Liu, Y.; Wang, Y.; Li, H. ERN: Edge loss reinforced semantic segmentation network for remote sensing images. Remote Sens. 2018, 10, 1339. [Google Scholar] [CrossRef]
- Shen, Y.; Liu, D.; Zhang, F.; Zhang, Q. Fast and accurate multi-class geospatial object detection with large-size remote sensing imagery using CNN and Truncated NMS. ISPRS J. Photogramm. Remote Sens. 2022, 191, 235–249. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Segmentation | Height | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Name | Task | pixAcc ↑ | clsAcc ↑ | mF1 ↑ | absRel ↓ | MAE ↓ | RMSE ↓ | ↑ | ↑ | ↑ |
| SVL_V1 [77] | Seg | 77.8 | - | 79.9 | - | - | - | - | - | - |
| UFMG4 [78] | Seg | 87.9 | - | 89.5 | - | - | - | - | - | - |
| S-RA-FCN [79] | Seg | 88.6 | - | 90.2 | - | - | - | - | - | - |
| HSN [80] | Seg | 89.4 | - | 87.9 | - | - | - | - | - | - |
| UZ_1 [6] | Seg | 89.9 | 88.8 | 88.0 | - | - | - | - | - | - |
| HRNet V2 [73] | Seg | 90.8 | 90.6 | 90.6 | - | - | - | - | - | - |
| IMG2DSM [14] | Height | - | - | - | - | - | 3.890 | - | - | - |
| Zhang et al. [81] | Height | - | - | - | - | - | 3.870 | - | - | - |
| Amirkolaee et al. [54] | Height | - | - | - | 0.571 | - | 3.468 | 0.342 | 0.601 | 0.782 |
| D3Net [13] | Height | - | - | - | 0.391 | 1.681 | 3.055 | 0.601 | 0.742 | 0.830 |
| IM2ELEVATION [55] | Height | - | - | - | 0.429 | 1.744 | 3.516 | 0.638 | 0.767 | 0.839 |
| PLNet [57] | Height | - | - | - | 0.318 | 1.201 | 2.354 | 0.639 | 0.833 | 0.912 |
| Srivastava et al. [82] | MTL | 80.1 | 79.2 | 79.9 | 0.624 | 2.224 | 3.740 | 0.412 | 0.597 | 0.720 |
| Carvalho et al. [15] | MTL | 83.2 | 80.9 | 82.2 | 0.441 | 1.838 | 3.281 | 0.575 | 0.720 | 0.808 |
| MTI-Net [20] | MTL | 90.3 | 89.8 | 89.9 | 0.296 | 1.173 | 2.367 | 0.691 | 0.836 | 0.905 |
| BAMTL [30] | MTL | 91.3 | 90.4 | 90.9 | 0.291 | 1.223 | 2.407 | 0.685 | 0.819 | 0.897 |
| InvPT [61] | MTL | 91.1 | 90.3 | 90.6 | 0.253 | 1.210 | 2.402 | 0.673 | 0.829 | 0.904 |
| TaskExpert [62] | MTL | 90.7 | 89.9 | 90.2 | 0.273 | 1.292 | 2.513 | 0.650 | 0.818 | 0.898 |
| Ours | MTL | 91.6 | 91.6 | 91.4 | 0.242 | 1.027 | 2.107 | 0.728 | 0.863 | 0.922 |
| Method | Segmentation | Height | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Name | Task | pixAcc ↑ | clsAcc ↑ | mF1 ↑ | absRel ↓ | MAE ↓ | RMSE ↓ | ↑ | ↑ | ↑ |
| FCN [33] | Seg | 83.2 | - | 79.2 | - | - | - | - | - | - |
| FPL [6] | Seg | 83.8 | 76.5 | 78.8 | - | - | - | - | - | - |
| SegNet [38] | Seg | 84.1 | - | 81.4 | - | - | - | - | - | - |
| ERN [83] | Seg | 85.6 | - | 84.8 | - | - | - | - | - | - |
| UZ_1 [6] | Seg | 87.8 | 81.4 | 83.6 | - | - | - | - | - | - |
| Deeplab V3+ [42] | Seg | 88.2 | 85.4 | 86.3 | - | - | - | - | - | - |
| HRNet V2 [73] | Seg | 88.7 | 88.0 | 87.2 | - | - | - | - | - | - |
| Zhang et al. [81] | Height | - | - | - | - | 2.420 | 3.900 | - | - | - |
| Amirkolaee et al. [54] | Height | - | - | - | 1.163 | - | 2.871 | 0.330 | 0.572 | 0.741 |
| IMG2DSM [14] | Height | - | - | - | - | - | 2.580 | - | - | - |
| D3Net [13] | Height | - | - | - | 2.016 | 1.314 | 2.123 | 0.369 | 0.533 | 0.644 |
| IM2ELEVATION [55] | Height | - | - | - | 0.956 | 1.226 | 1.882 | 0.399 | 0.587 | 0.671 |
| PLNet [57] | Height | - | - | - | 0.833 | 1.178 | 1.775 | 0.386 | 0.599 | 0.702 |
| Srivastava et al. [82] | MTL | 79.3 | 70.4 | 72.6 | 4.415 | 1.861 | 2.729 | 0.217 | 0.385 | 0.517 |
| Carvalho et al. [15] | MTL | 86.1 | 80.4 | 82.3 | 1.882 | 1.262 | 2.089 | 0.405 | 0.562 | 0.663 |
| MTI-Net [20] | MTL | 87.6 | 85.5 | 85.7 | 1.549 | 1.571 | 2.306 | 0.356 | 0.580 | 0.707 |
| BAMTL [30] | MTL | 88.4 | 85.9 | 86.9 | 1.064 | 1.078 | 1.762 | 0.451 | 0.617 | 0.714 |
| InvPT [61] | MTL | 88.7 | 86.5 | 86.0 | 0.830 | 1.334 | 2.009 | 0.379 | 0.638 | 0.768 |
| TaskExpert [62] | MTL | 88.8 | 87.0 | 86.3 | 1.037 | 1.338 | 1.989 | 0.428 | 0.647 | 0.760 |
| Ours | MTL | 89.1 | 88.7 | 87.9 | 0.695 | 1.230 | 1.927 | 0.470 | 0.696 | 0.806 |
| MKF Module | Edge | SemEdge | Segmentation | Height | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| pixAcc ↑ | clsAcc ↑ | mF1 ↑ | absRel ↓ | MAE ↓ | RMSE ↓ | ↑ | ↑ | ↑ | |||
| 86.9 | 86.4 | 84.7 | 0.946 | 1.362 | 1.988 | 0.384 | 0.617 | 0.742 | |||
| ✓ | 88.7 | 87.3 | 86.9 | 0.914 | 1.245 | 1.912 | 0.409 | 0.641 | 0.764 | ||
| ✓ | ✓ | 88.9 | 88.2 | 87.5 | 0.714 | 1.231 | 1.908 | 0.446 | 0.693 | 0.805 | |
| ✓ | ✓ | ✓ | 89.1 | 88.7 | 87.9 | 0.695 | 1.230 | 1.927 | 0.470 | 0.696 | 0.806 |
| Method | Segmentation | Height | Params | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Name | Backbone | pixAcc ↑ | clsAcc ↑ | mF1 ↑ | absRel ↓ | MAE ↓ | RMSE ↓ | ↑ | ↑ | ↑ | |
| Srivastava et al. [82] | — | 79.3 | 70.4 | 72.6 | 4.415 | 1.861 | 2.729 | 0.217 | 0.385 | 0.517 | — |
| Carvalho et al. [15] | — | 86.1 | 80.4 | 82.3 | 1.882 | 1.262 | 2.089 | 0.405 | 0.562 | 0.663 | — |
| MTI-Net [20] | HRNet18 | 87.6 | 85.5 | 85.7 | 1.549 | 1.571 | 2.306 | 0.356 | 0.580 | 0.707 | 8.6 |
| MTI-Net [20] | HRNet48 | 88.7 | 87.4 | 87.1 | 0.809 | 1.259 | 1.928 | 0.415 | 0.663 | 0.784 | 98.7 |
| BAMTL [30] | ResNet101 | 88.4 | 85.9 | 86.9 | 1.064 | 1.078 | 1.762 | 0.451 | 0.617 | 0.714 | 59.1 |
| BAMTL [30] | HRNet48 | 88.5 | 85.7 | 86.2 | 1.216 | 1.303 | 2.125 | 0.291 | 0.529 | 0.684 | 83.5 |
| InvPT [61] | ViT-L | 88.7 | 86.5 | 86.0 | 0.830 | 1.334 | 2.009 | 0.379 | 0.638 | 0.768 | 358.7 |
| TaskExpert [62] | ViT-L | 88.8 | 87.0 | 86.3 | 1.037 | 1.338 | 1.989 | 0.428 | 0.647 | 0.760 | 372.1 |
| Ours | HRNet18 | 88.7 | 87.9 | 87.2 | 0.802 | 1.321 | 2.058 | 0.414 | 0.660 | 0.785 | 14.8 |
| Ours | HRNet48 | 89.1 | 88.7 | 87.9 | 0.695 | 1.230 | 1.927 | 0.470 | 0.696 | 0.806 | 137.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Wang, G.; Li, T.; Yang, Y.; Li, W.; Liu, X.; Liu, Y. Knowledge-Guided Multi-Task Network for Remote Sensing Imagery. Remote Sens. 2025, 17, 496. https://doi.org/10.3390/rs17030496
Li M, Wang G, Li T, Yang Y, Li W, Liu X, Liu Y. Knowledge-Guided Multi-Task Network for Remote Sensing Imagery. Remote Sensing. 2025; 17(3):496. https://doi.org/10.3390/rs17030496
Chicago/Turabian StyleLi, Meixuan, Guoqing Wang, Tianyu Li, Yang Yang, Wei Li, Xun Liu, and Ying Liu. 2025. "Knowledge-Guided Multi-Task Network for Remote Sensing Imagery" Remote Sensing 17, no. 3: 496. https://doi.org/10.3390/rs17030496
APA StyleLi, M., Wang, G., Li, T., Yang, Y., Li, W., Liu, X., & Liu, Y. (2025). Knowledge-Guided Multi-Task Network for Remote Sensing Imagery. Remote Sensing, 17(3), 496. https://doi.org/10.3390/rs17030496