Abstract
Conventional neural network-based approaches for single remote sensing image super-resolution (SRSISR) have made remarkable progress. However, the super-resolution outputs produced by these methods often fall short in terms of visual quality. Recent advances in diffusion models for image generation have demonstrated remarkable potential for enhancing the visual content of super-resolved images. Despite this promise, existing large diffusion models are predominantly trained on natural images, which have huge differences in data distribution, making them hard to apply in remote sensing images (RSIs). This disparity poses challenges for directly applying these models to RSIs. Moreover, while diffusion models possess powerful generative capabilities, their output must be carefully controlled to generate accurate details as the objects in RSIs are small and blurry. In this paper, we introduce RSDiffSR, a novel SRSISR method based on a conditional diffusion model. This framework ensures the high-quality super-resolution of RSIs through three key contributions. First, it leverages a large diffusion model as a generative prior, which substantially enhances the visual quality of super-resolved RSIs. Second, it incorporates low-rank adaptation into the diffusion UNet and multi-stage training process to address the domain gap caused by differences in data distributions. Third, an enhanced control mechanism is designed to process the content and edge information of RSIs, providing effective guidance during the diffusion process. Experimental results demonstrate that the proposed RSDiffSR achieves state-of-the-art performance in both quantitative and qualitative evaluations across multiple benchmarks.
1. Introduction
Remote sensing images (RSIs) captured by aircraft and remote sensing satellites record detailed information about the Earth’s surface and have diverse applications, including environmental monitoring [1], military target recognition, and land resource exploration [2]. Accurate predictions and analyses of remote sensing data necessitate high-resolution images that are rich in detail; however, constraints in imaging equipment and transmission bandwidth frequently result in remote sensing images (RSIs) being compromised by issues, such as blurring, downsampling, noise, and compression artifacts. Given the prohibitive cost of upgrading satellite imaging equipment, single remote sensing image super-resolution (SRSISR) methods, which refer to the technique of enhancing the spatial resolution of a single image using computational methods [3,4], as well as provide a convenient, efficient, and cost-effective approach to improving RSI quality.
Over the past decade, convolutional neural networks (CNNs) [3,5] have been widely utilized in image super-resolution and achieved significant progress. Lim et al. [5] propose an enhanced deep residual network (EDSR) by increasing the depth and reducing batch normalization layers. Lei et al. [3] proposed local-global combined network (LGCNet), which is specially designed for remote sensing image super-resolution. In addition, to obtain visually better results with rich textures, the use of some GAN-based methods [4,6] have also made important contributions, e.g., such as those inspired by SRGAN [6]. Li et al. [4] proposed the SRAGAN model for remote sensing image super-resolution by introducing local and global attention mechanisms to a generative adversarial network. More recently, transformer-based approaches [7,8,9] have been applied to SISR, yielding impressive results. Despite their advancements, these methods often struggle with visual quality, producing reconstructed images with blurry details. The majority of these methods improve the quality of images according to the peak signal-to-noise ratio (PSNR), but this results in images with blurry details [10,11,12,13]. Moreover, their reliance on predefined degradations, such as bicubic downsampling, limits their generalizability to real-world, low-resolution images with complex and diverse degradations.
Recently, diffusion-based algorithms [14,15] have recently achieved remarkable progress in image generation. And a series of SISR methods [16,17,18] have benefited from the impressive content generation capabilities of diffusion models. Saharia et al. [16] proposed a method for natural image SR through iterative refinement (SR3). An LDM [19] conduct diffusion model in latent space with a pre-trained autoencoder largely reduces computational costs. To address the fidelity and arbitrary resolution of restoration, StableSR [17] uses a time-aware encoder, controllable feature wrapping module, and progressive aggregation sampling strategy. While these methods show promise, applying existing large diffusion models to RSIs remains challenging. These models are typically trained on natural images, creating a significant domain gap when applied to RSIs. The differences in the data distribution, scene types, object characteristics, imaging angles, and imaging distances between RSIs and natural images exacerbate this gap, leading to degradation in model performance. Additionally, due to the greater imaging distance in RSIs, the objects in RSIs are usually small and blurry, which may not provide clear guidance in the diffusion process. These issues require proper handling to ensure accurate results.
In response to the issues, we propose RSDiffSR, a SRSISR method based on a conditional diffusion model incorporating low-rank adaptation (LoRA) and content-edge joint guidance (CEJG). To significantly enhance the visual quality of super-resolved RSIs, RSDiffSR utilizes Stable Diffusion XL (SDXL) [20] as the generative prior, a diffusion model that is known for its robust generative capabilities and is pre-trained on billions of natural images. For comparison, existing diffusion-based SRSISR methods [21,22] are trained on tens of thousands RSIs, a dataset size that is insufficient to fully support the generative capacity of diffusion models. As mentioned, the performance of existing diffusion models declines when applied to RSIs, primarily due to the significant differences in data distribution, scene types, object characteristics, imaging angles, and imaging distances between RSIs and natural images, as these models are trained on the latter. To address this, we introduce the low-rank adaptation (LoRA) [23] technique and a multi-stage training process. First, we trained RSDiffSR on natural images where the diversity, quantity, and quality of the data ensure superior SR performance. Then, we involved the LoRA technique and fine tuned the model on a RSI dataset to eliminate the negative effects caused by differences in training data distribution. LoRA is an alternative method for replacing full-parameter training, and it greatly reduces the required computing consumption and the quantity of datasets. Through this approach, we can successfully transfer the generative capacity of SDXL to remote sensing images. In addition, SRSISR is quite different from natural image SR as the objects in RSIs are usually small and blurry, which may cause the wrong information to be generated by diffusion. To this end, we designed a lightweight counterpart crop of UNet as the encoder to extract and process the content information from the input RSIs, and we then introduced the Canny [24] algorithm to extract the edge information. The content and edge information is then processed and fused with diffusion features through the proposed content-edge joint guidance (CEJG) module. This design improves control over the model’s generative capabilities, yielding more accurate reconstructions. Quantitative and qualitative evaluations demonstrate that the proposed model performs favorably against state-of-the-art methods across multiple benchmarks.
The main contributions of this paper are summarized as follows.
- We propose RSDiffSR, a conditional, diffusion-based framework for single remote sensing image super-resolution (SRSISR) that leverages a large natural image generation diffusion model as a generative prior, benefiting from its strong generative capability.
- To address the domain gap between natural images and RSIs that are caused by differences in data distribution, we apply the low-rank adaptation technique and a multi-stage training process, enabling efficient fine tuning with reduced computational and data requirements.
- Given the challenges posed by small and blurry objects in RSIs, we introduce an enhanced control mechanism. This mechanism separately processes edge and content information from input images and combines them with diffusion features using the proposed content-edge joint guidance (CEJG) module, ensuring accurate and realistic reconstructions.
- Quantitative and qualitative evaluations demonstrate that our model performs favorably against state-of-the-art methods across multiple benchmarks. The adoption of a generative prior significantly enhances visual perception, enabling the super-resolved results of RSDiffSR to exhibit superior visual quality with rich details, which positively impacts downstream tasks.
2. Related Works
2.1. Natural Image Super-Resolution
(1) CNN-based Models: Since Dong et al. [25] firstly employed convolutional neural networks (CNNs) into single image super-resolution, CNNs have gradually attracted people’s attention on SISR due to their powerful nonlinear fitting capabilities, and numerous elaborate CNN architectures have also been proposed, e.g., deep [26] and wide [5] architecture, attention mechanism [27], and transformer [9]. While these CNN-based methods achieve strong performance in terms of the peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM) by minimizing the mean squared error (MSE) or mean absolute error (MAE) loss, they often produce smooth super-resolution results that lack fine texture and detail. This limitation arises because the regression functions tend to encourage the network to average regions, leading to undesirable over-smoothing. On the contrary, our RSDiffSR benefits from the exceptional generative capacity of generative prior to recover realistic details, significantly enhancing the visual quality of super-resolved results.
(2) GAN-based Models: To improve the visual quality of super-resolved (SR) images, numerous researchers have contributed significantly to GAN-based SR methods following the introduction of generative adversarial networks (GANs) by Goodfellow [28]. Ledig et al. [6] successfully restored realistic details on natural images using an adversarial training framework (SRGAN). Wang et al. [29] proposed ESRGAN, which incorporates modified discriminative constraints and removes batch normalization (BN) to mitigate artifacts. Based on ESRGAN [29], Wang et al. [30] introduced Real-ESRGAN, which addresses the limitations of traditional super-resolution methods by producing more realistic and artifact-free results, especially for real-world images. Although GANs can bring improvement in visual quality, their generative capabilities are still inferior to those of diffusion models, and they often encounter challenging optimization issues.
(3) Diffusion-based Models: Diffusion models utilize a fixed Markov chain to optimize the boundaries of the likelihood function and have recently garnered increasing attention due to their exceptional performance in generative tasks [19]. The powerful generative capabilities of diffusion models make them highly promising for super-resolution (SR) tasks, and several valuable methods have been proposed. Saharia et al. [16] proposed a new method to image SR through repeated refinement, and this approah achieves stronger photorealistic outputs than GAN-based methods. To address the fidelity and arbitrary resolution of restoration, StableSR [17] has been proposed, which utilizes a time-aware encoder, controllable feature wrapping module, and a progressive aggregation sampling strategy. Diffbir [18] employs a two-stage inference approach, which uses a pre-trained SwinIR network to remove part of the image degradation and then applies a diffusion net to obtain restored images. Similarly, PASD [31] adopts lightweight multi-scale modules to remove degradation, and it includes pixel-aware cross attention to ensure pixel-level alignment in the feature fusion. Yue et al. [32] introduced ResShift, which utilizes an iterative sampling approach from LR to HR images by shifting residuals. CoSeR [33] employed an extra diffusion model to generate high-fidelity images, which are utilized as reference images in the second diffusion process to restore LR images, but such an approach is computationally intensive.
2.2. Remote Sensing Image Super-Resolution
(1) CNN-based Models: Early single remote sensing image super-resolution (SRSISR) methods [8,34,35,36] were primarily CNN-based, focusing on achieving high PSNR performance. At that stage, more effort was dedicated to improving the network structure, enabling the convolutional network to capture more of the characteristics of remote sensing images. To better adapt to specific remote sensing images, Zhang et al. [34] proposed a scene-adaptive network. Pan et al. [35] proposed a residual dense back projection network (RDBPN), which is made from the up projection modules and the down projection modules, and these modules are then densely connected into one block. Xiao et al. [36] proposed a multi-scale deformable convolution alignment to alleviate the alignment challenges posed by limited motion and varying scales of moving objects in remote sensing images. Lei et al. [8] introduced a transformer-based multi-stage enhancement method, which can be integrated with traditional SR frameworks to fuse multi-scale high- and low-dimensional features. Nevertheless, since PSNR tends to penalize the reconstruction of high-frequency details, these methods often fail to align well with human preferences in remote sensing images (RSIs).
(2) GAN-based Models: To recover rich, detailed information in remote sensing images (RSI), various GAN-based methods have been proposed. Inspired by SRGAN, Li et al. [4] introduced local and global attention mechanisms to a generative adversarial network and generated sharp results on remote sensing images. Xu et al. [37] proposed a texture enhancement generative adversarial network (TE-SRGAN) to solve blurry object edges and artifacts. Tu et al. [38] proposed Swcgan, a method that employs the long-range modeling capability of the Swin transformer [39] in GANs, achieving favorable visual quality in super-resolved results.
(3) Diffusion-based Models: Research on remote sensing image super-resolution combined with diffusion is still in its infancy. Liu et al. [21] firstly applied diffusion to a remote sensing image super-resolution task. EHC-DMSR [40] adopts an efficient hybrid conditional diffusion model, where the conditions for guiding image generation are extracted through the CNN and transformer. Like Diffbir [18], Ali et al. [41] also sequentially used two stages of restoration and generation to ensure realism and fidelity. EDiffSR [22] contains a conditional prior enhancement module (CPEM) and an efficient activation network (EANet), which help to extract enriched conditions and reduce the computational cost. HSR-Diff [42] is a conditional diffusion model that is specially designed for hyperspectral image SR. However, the diffusion models mentioned above have generative abilities that are not comparable to those of existing mainstream natural image diffusion models [19,20]. There are primarily two reasons for this discrepancy. First, the generative ability of diffusion models is positively correlated with the number of model parameters. However, the RSI diffusion models have relatively fewer parameters compared to mainstream natural image diffusion models. Second, the generative ability of a diffusion model also depends on the training dataset, but the diversity, quantity, and quality of remote sensing image datasets are not comparable to those of natural image datasets. As a result, these RSI diffusion models are trained on tens of thousands of RSIs, which is far fewer than the billions of images used to train natural image diffusion models, leading to limited generative abilities. To address these issues, the proposed RSDiffSR adapts SDXL as the generative prior, leveraging its powerful generative capacity due to its large model parameters and extensive training datasets. Benefiting from this, RSDiffSR demonstrates excellent SR performance, effectively restoring realistic details and visual qualities that closely resemble ground truth images.
3. Methodology
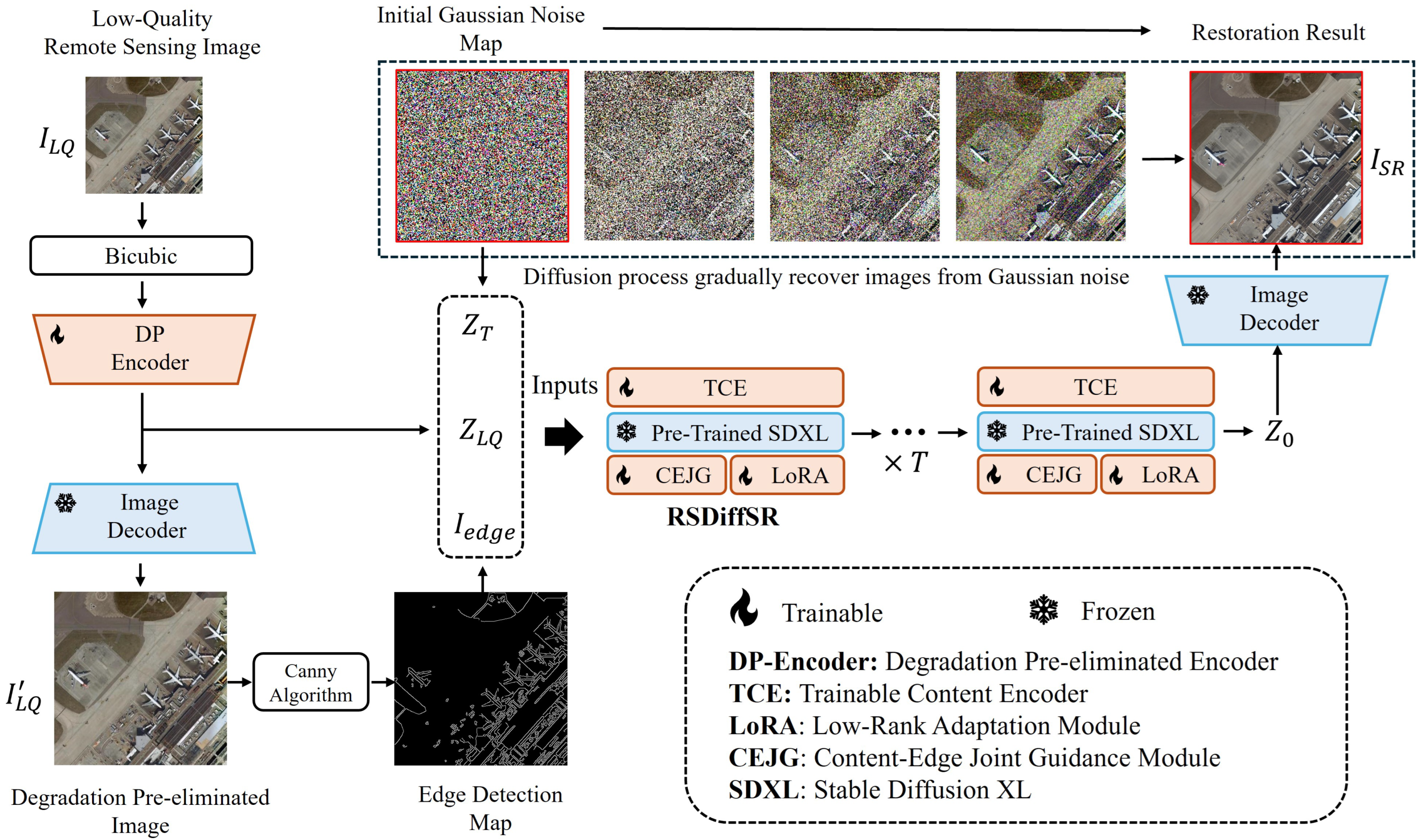
The overall workflow of the proposed RSDiffSR algorithm is illustrated in Figure 1. It consists of five key components: the Degradation Pre-eliminated Encoder (DP-Encoder); the DP-Encoder’s corresponding decoder, the Trainable Content Encoder (TCE); the adopted generative prior (pre-trained Stable Diffusion XL [20]); the proposed content-edge joint guidance (CEJG) module; and the additional low-rank adaptation (LoRA) module [23]. In the process, the low-quality RSI () is first bicubic-downsampled to the required resolution, then encoded into latent space (), with the DP-Encoder eliminating the degradations present in the input image. A copy of the latent is then decoded back into the image space, where the Canny algorithm [24] is applied to extract edge information (). The inputs of RSDiffSR include , , and , which are derived from Gaussian noise. After T iterations of the diffusion reverse process, the latent space representation is obtained, which is then decoded to the image space as to yielding the super-resolved result.
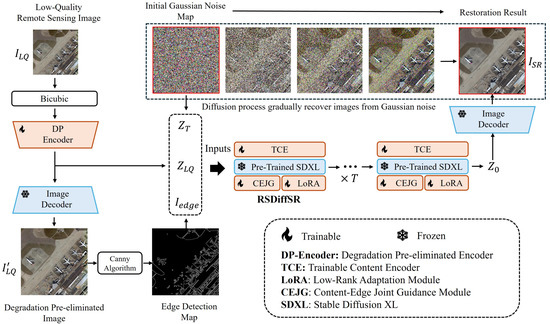
Figure 1.
The overall workflow of the proposed RSDiffSR algorithm.
The motivations of the proposed RSDiffSR can be summed up in two parts. First, existing methods’ SR performance is not satisfactory in visual qualities as they trend to generate relatively blurry results with less detail, showing poor visual perception. Second, although the generative abilities of diffusion models are promising in solving this problem, existing diffusion-based SRSISR methods show inferior SR performance compared with existing diffusion-based natural image SR methods. For diffusion models, the number of training sets and the number of model parameters are positively correlated with their generative abilities. Limited by the quantity of the training RSI dataset, existing diffusion-based SRSISR methods adopt a diffusion model with a relatively smaller model parameter, which further impairs their generative ability as training a large diffusion model requires at least hundreds of millions of images.
In view of the above motivations, we propose corresponding solutions and contributions. To enhance the visual quality of super-resolved RSIs, we employ the pretrained Stable Diffusion XL(SDXL) [20] as the generative prior, which is a diffusion model known for its robust generative capabilities and is pre-trained on billions of natural images. Essentially, we utilize the generative ability of SDXL, which has learned from billions of natural images, and then shift this ability onto RSIs. Clearly, it is impracticable to direct apply SDXL onto RSIs as the differences in data distribution, scene types, object characteristics, imaging angles, and imaging distances between RSIs and natural images result in performance degradation. Meanwhile, as the objects in RSIs are usually blurry and small compared with natural images, this may cause the wrong information to be generated by diffusion with robust generative ability. To solve these two arising issues, we propose the Degradation Pre-eliminated Encoder, the Trainable Content Encoder, and the proposed content-edge joint guidance module. Detailed information of these proposed modules can be found in the following sections.
3.1. Diffusion Framework
3.1.1. Generative Prior
Existing diffusion-based SRSISR methods typically employ diffusion models with relatively small parameters and limited training datasets, which constrain their generative capabilities. To enhance the visual quality of super-resolved results, we adopted Stable Diffusion XL [20] (SDXL) as the generative prior for the proposed RSDiffSR algorithm. SDXL is a powerful diffusion model with large parameters, and it is pre-trained on billions of natural images. It employs the Latent Diffusion Model (LDM) framework [19], which uses the autoencoder [43] to transform images () into latents (). In the diffusion process of SDXL, noise is progressively added to the data in the forward process, while the reverse process denoises the data to generate the target distribution. Specifically, the forward process is to iteratively add Gaussian noise to the input .
where is a scalar function, and, by setting close to zero, converges to . The reverse process progressively denoises the data from the Gaussian noise distribution to the target distribution via using a standard Gaussian prior. For a learned inference model , the data can be generated by sequential denoise, i.e., :
where is the average value and refers to the variance.
3.1.2. Degradation Pre-Eliminated Encoder
The diffusion generation process in SDXL [20] operates in the latent space using a pre-trained image encoder and decoder. Consequently, low-quality remote sensing images must also be mapped into latent space in this work. However, the original encoder is trained on clear natural images, which differ significantly in data distribution from low-quality RSIs. This creates a domain gap between the training data and the input RSIs, which can negatively affect the mapping process when low-quality RSIs are encoded into the latent space. To address this issue, we fine tuned the encoder to enable it to effectively mitigate the degradation in low-quality input images. The fine tune process can be simplified as
where is the fine-tuned encoder, refers to the decoder, and and are the low-quality images and ground truth, respectively.
3.1.3. Trainable Content Encoder and Content-Edge Joint Guidance
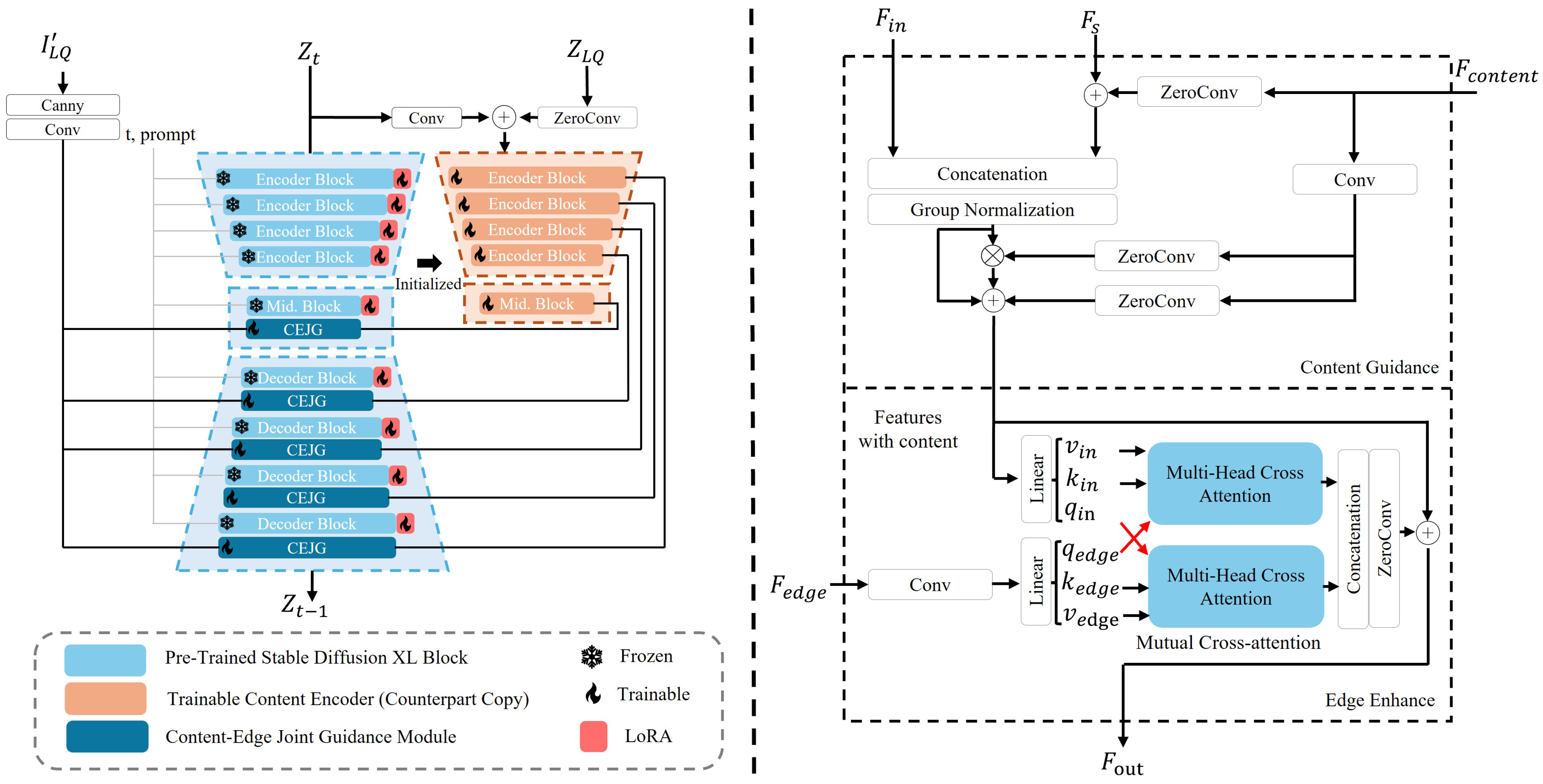
We utilized the diffusion model (SDXL), which is a class of generative models learning a data distribution, as the key component in our algorithm. Following ControlNet [44], the proposed RSDiffSR algorithm was developed by integrating a counterpart crop of the diffusion UNet to establish the ControlNet-like component (Trainable Content Encoder), which primarily processes the content information from low-quality input images. Our model is built upon the SDXL framework and its cropped variant, with a core architecture comprising multi-scale ResNet and multi-head transformer modules. The encoder adopts a hierarchical multi-scale design, enabling the effective extraction of image features across different frequency bands. Specifically, the multi-scale ResNet encodes image information at varying resolutions through a pyramidal structure. Large-scale features primarily capture high-frequency details, such as textures and edges, while small-scale features emphasize low-frequency structural information, including overall contours and shapes. Meanwhile, the multi-head transformer module enhances global information interaction via a self-attention mechanism. Its multi-head attention mechanism dynamically assigns weights, optimizing the joint representation of high- and low-frequency features. By integrating the local inductive bias of ResNet with the global modeling capabilities of transformers, our model effectively processes multi-resolution features, leading to a more robust and expressive feature representation.
On the other hand, the inherent stochasticity of diffusion models poses a challenge. When employing a UNet-based cropped variant to extract conditional information (i.e., the low-resolution input) and guide the diffusion process, the low resolution and blurriness of the input image can result in inaccurate edge reconstruction or the introduction of artifacts, particularly in semantically ambiguous regions. Moreover, objects in remote sensing images are typically small and blurry, further exacerbating this issue. To address this, we propose a specially designed enhanced control mechanism to guide the generative prior, ensuring the generation of more accurate and visually coherent details. Specifically, we use the Canny [24] algorithm to extract the edge information as the extra guidance, and we then fuse it with content features and diffusion features through the proposed content-edge joint guidance module. Such a design can enhance the capability of controlling models generative capacity, leading to more accurate reconstructions of remote sensing images. As shown in Figure 2, the content features from the Trainable Content Encoder are initially fused with diffusion features (including features from the diffusion encoder and decoder shortcuts) to gradually guide the diffusion process toward generating super-resolved features that maintain content consistency with the input image. Since both edge information and content information (i.e., low-resolution features) play equally important roles in the guidance process, we subsequently introduced a Mutual Cross-Attention mechanism. In this mechanism, the query (Q) of edge information is interchanged with the query (Q) of content information during the attention operation, enabling content features to be refined based on edge features while simultaneously adapting edge features according to the content information. Finally, the processed features are fused through concatenation and convolution, generating guidance features at the current scale to effectively steer the diffusion process.
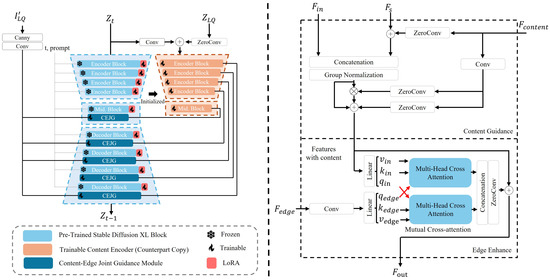
Figure 2.
Detailed architecture of the proposed RSDiffSR algorithm (left side) and the CEJG module (right side). We use the Trainable Content Encoder and the Canny algorithm to process the content and edge information of input images separately, and these two types of information are then processed and fused with diffusion UNet features through the proposed CEJG module, which is shown at the right side of this figure. and represent features from the Trainable Content Encoder and Canny algorithm, respectively, and and refer to the features from diffusion decoder and encoder shortcuts, respectively. The Crossed red arrows denotes interchanged queries (Q) of Cross-Attention.
3.2. Model Training and Low-Rank Adaptation
Applying existing large diffusion models [19,20] to remote sensing image super-resolution still remains with challenges. First, these models are trained on natural image datasets, but the data distributions between natural and remote sensing images differ significantly. For example, when a diffusion prior model is trained on natural images and used for information generation, such as generating images of grass or trees guided by ControlNet or prompts, it typically produces outputs like close-up grass fields or trees viewed at eye level. In contrast, a diffusion model trained on remote sensing images is more likely to generate overhead views of grass or tree canopies. This substantial difference limits the cross-domain applicability of pretrained diffusion models. This lack of coverage and feature distribution bias in training datasets limits the performance of these diffusion models on RSIs. Second, the diversity, quantity, and quality of remote sensing image datasets are not comparable to those of natural image datasets. These datasets are often insufficient for training large diffusion models from scratch, such as SDXL [20], as this requires hundreds of NVIDIA A100-80G GPUs and billions of images. Therefore, a more effective is to shift diffusion models from general image generation to RSI generation through fine tuning the pre-trained diffusion model on RSI datasets.
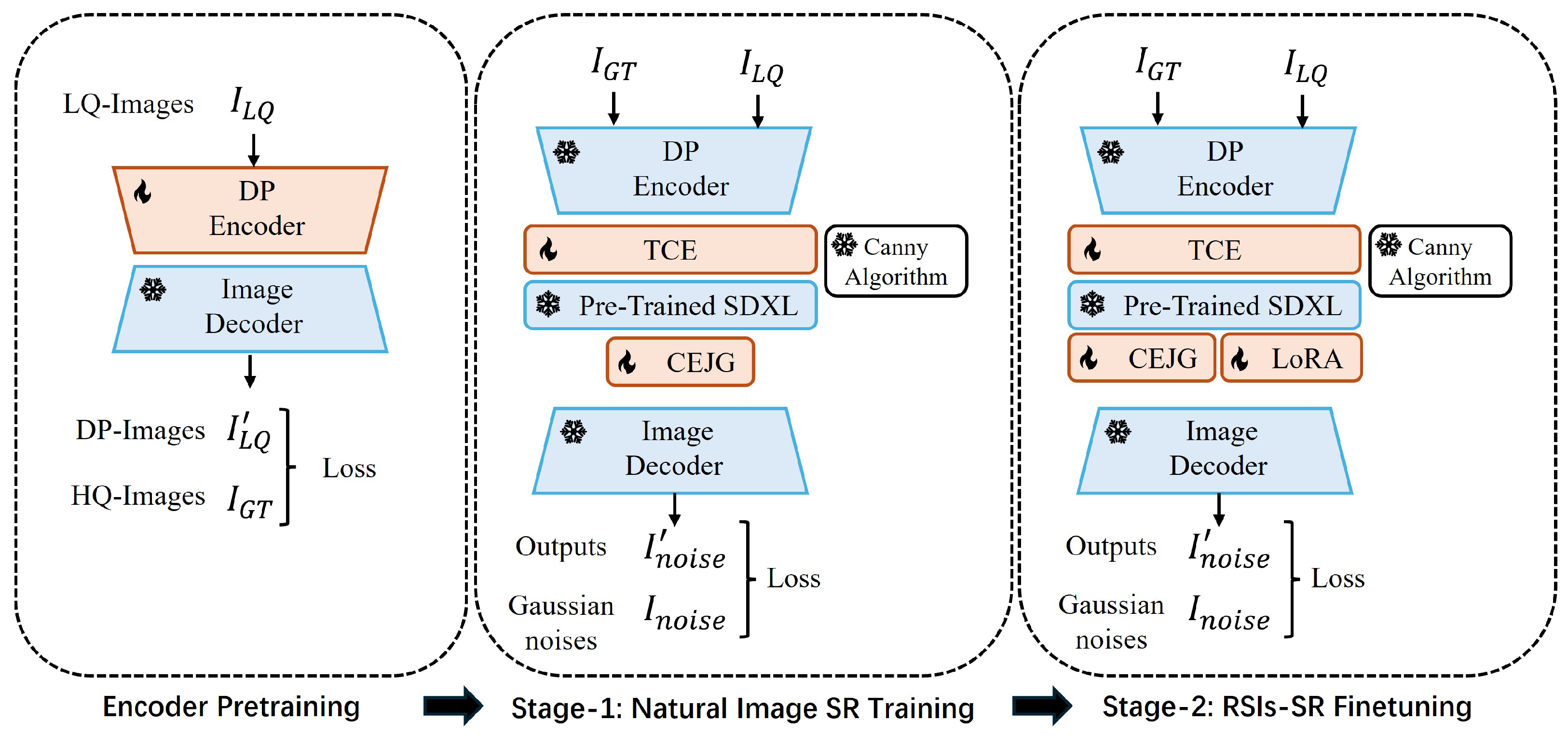
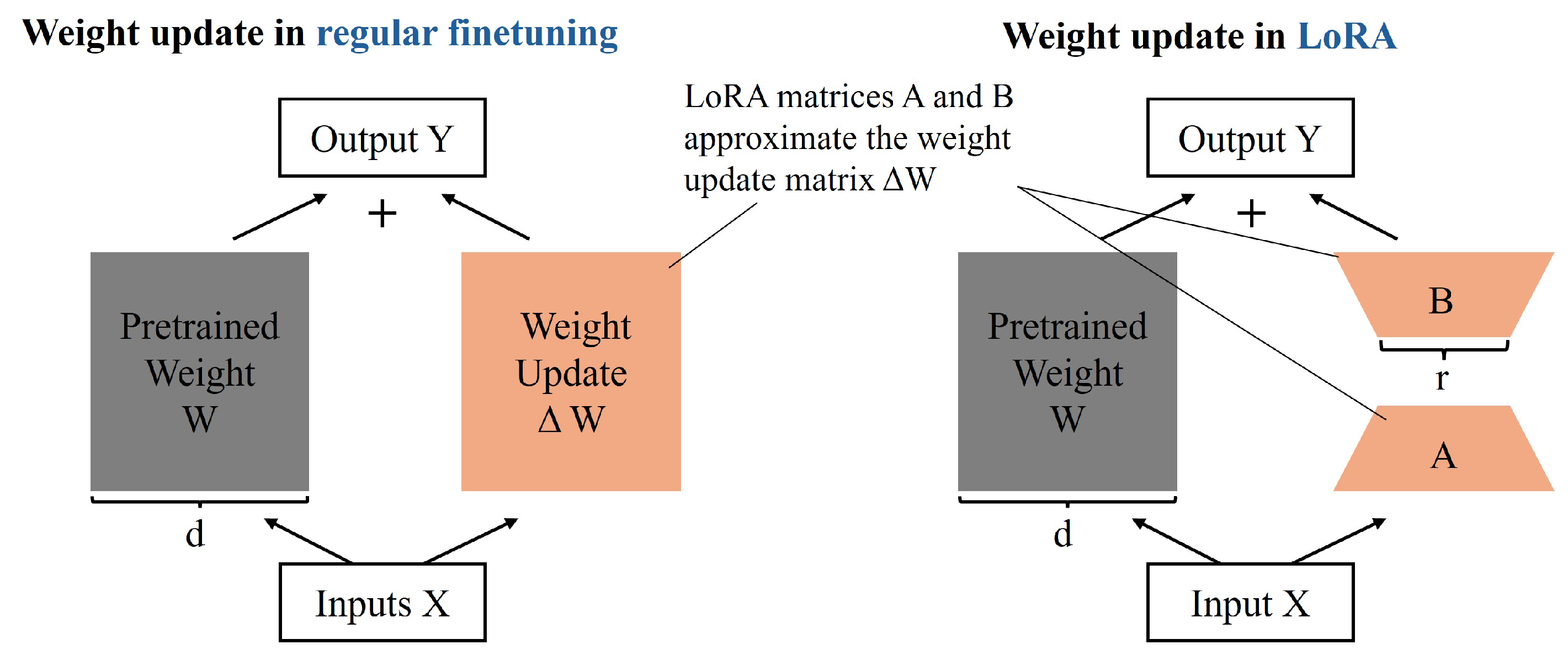
Based on the discussion above, we adopted a two-stage training process (as shown in Figure 3). In the first stage, we trained the proposed algorithm on natural image datasets, where the diversity, quantity, and quality of the data ensured superior SR performance. During this phase, only the TEC and CEJG modules were trained. As shown in Figure 2, the weights of diffusion UNet were frozen, and the weights of the proposed Trainable Content Encoder and content-edge joint guidance module were updated during training. The primary purpose of this first stage of training is to form an outstanding diffusion-based SR algorithm on natural images. In the second stage, we fine tuned the model (including the diffusion UNet) on remote sensing image datasets to shift the learned data distribution from natural to remote sensing images. However, the full-parameter training of a large diffusion model is difficult and computationally expensive, and it also requires vast amounts of data. Therefore, we employed the low-rank adaptation (LoRA) [23] technique to the diffusion UNet during fine tuning. As shown in Figure 4, LoRA serves as an alternative to full-parameter training, significantly reducing computational costs and dataset requirements. The specific process of low-rank adaptation can be summarized as follows:
where the pre-trained matrix is , , and B and A are the low-rank decomposition matrix of , , , and . Therefore, when updating parameters, only the two matrices B and A need to be updated. Since , , the computational costs of fine tuning can be greatly reduced.
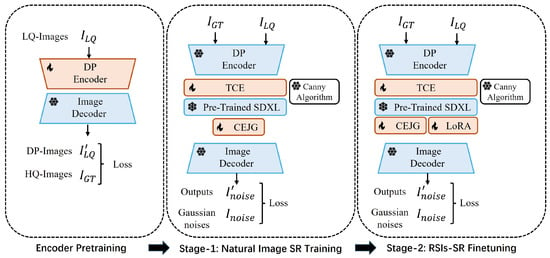
Figure 3.
A workflow diagram of a multi-stage training pipeline. The leftmost part of the figure depicts encoder pretraining, which enhances the encoder’s ability to process low-quality inputs. The middle illustrates Stage-1 training for super-resolution on natural images, while the rightmost part shows Stage-2 training, where the learned capability is transferred to remote sensing images.
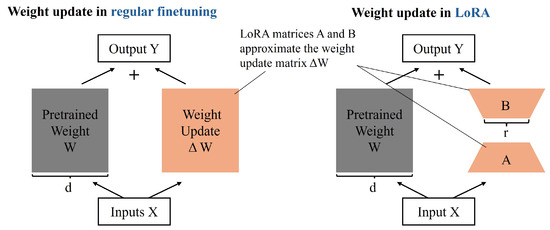
Figure 4.
The comparison between full-scale fine tuning and low-rank adaptation.
The rationale for using LoRA can be summarized into two key aspects. First, it significantly reduces the GPU memory required for fine tuning. Full-parameter training demands at least 60 GB of GPU memory, restricting it to A100-80 GB multi-GPU servers and resulting in prohibitively high computational costs. Second, LoRA decreases the dataset size required for fine tuning. Estimates indicate that LoRA can reduce the number of images needed for second-stage fine tuning from a minimum of 500 K to approximately 10–30 K, which aligns with the typical scale of most remote sensing datasets. Given the limited availability of large-scale remote sensing datasets, full-parameter training of RSDiffSR is impractical.
The overall learning objective of the proposed RSDiffSR algorithm during training is to keep the same format with existing diffusion-based SISR methods [14,15,19,45,46], which can be formulated as follows:
where is the overall learning objective of the entire diffusion model; is a target image in latent space; t represents the number of times noise is added; denotes the clipped text prompts, which is set to null in this work; is a task-specific condition; refers to the proposed RSDiffSR algorithm; and is a noise that is sampled from Gaussian noise .
The training and inference of the proposed RSDiffSR algorithm are presented in the pseudo-codes Algorithms 1 and 2.
Where denotes the training dataset; x refers to the LR; y is the GT image; and refer to the latent encoder and decoder, respectively; is the Canny algorithm; , ; and .
| Algorithm 1 Training |
repeat Inputs: Network:
Outputs:
Take a gradient descent step on Loss: until converged |
| Algorithm 2 Sampling |
Inputs: x fordo if , else end for Return: |
4. Experiments
4.1. Datasets and Implementation
4.1.1. Training and Testing Datasets
In our experiments, we used two natural image datasets—HQ-50K [47] and LAION [48], which are renowned for their wide variety of objects and scenarios—for stage-1 SR training. For transferring the reconstruction capability of the proposed RSDiffSR to the remote sensing image super-resolution task, we utilized two RSI datasets, the DOTA [49] and AID [50] datasets, for stage-2 training. Specifically, HQ-50K [47] is a large-scale, high-quality dataset for natural image restoration, and it contains 50,000 high-quality images with rich texture details and semantic diversity. LAION [48] is an open large-scale dataset for image-text training, and it contains 5.85 billion image-text pairs. In this work, we used a subset of LAION (1 million images) for training. DOTA [49] contains 2806 aerial images from different sensors and platforms. Each image contains objects exhibiting a wide variety of scales, orientations, and shapes. AID [50] is a large-scale aerial image dataset of images collected from Google Earth, and it contains 10,000 images with 30 aviation scene types.
In terms of dataset selection, we did not impose any thresholds on the contrast of input images; however, the training data naturally encompassed both high-contrast samples (e.g., urban street scenes) and low-contrast samples (e.g., rainy or foggy scenes). The training datasets also incorporated images with varying resolutions (ranging from low-to-high definition) to ensure the model’s capability in capturing multi-scale features. Additionally, since the LAION-5B dataset includes image tags, we ensured diversity by randomly selecting a training subset while manually removing images of indoor objects, as they provide limited benefit to the remote sensing domain.
For the test datasets, we arranged four datasets, including the testset of DOTA [49], RSOD [51], Potsdam [52], and NWPU VHR-10 [53] datasets. RSOD [51] is a dataset used for object detection in remote sensing images, and it includes four types of targets: aircraft, playgrounds, overpasses, and oil drums. Potsdam [52] is an urban remote sensing dataset with 2D semantic segmentation content annotation. NWPU VHR-10 [53] is a challenging dataset with ten categories of geospatial object detection. The dataset contains a total of 800 VHR optical remote sensing images, of which there are 715 color images obtained from Google Earth.
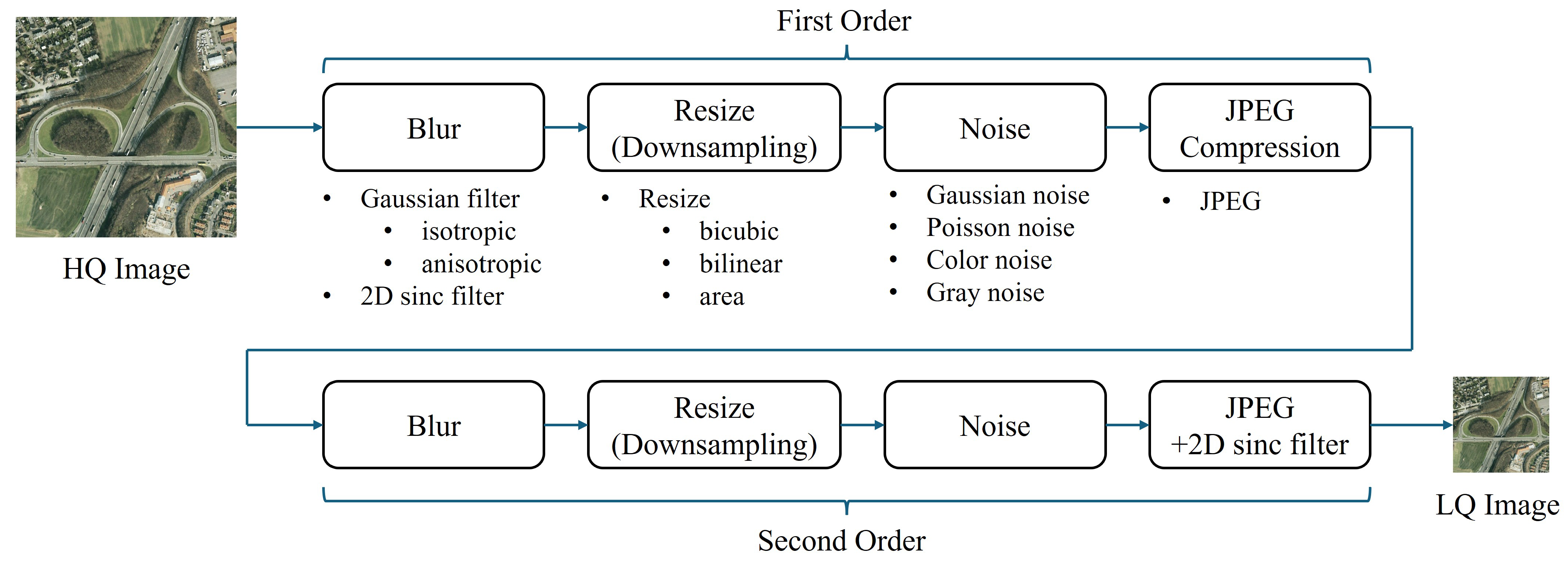
In terms of degradation, existing SRSISR methods usually employ bicubic downsampling to synthesize the LR-HR image pairs of training and testing datasets. However, the limitations in satellite imaging equipment and transmission bandwidth often lead to RSIs suffering from blur, downsampling, noise, and compression artifacts. As such, simple bicubic downsampling does not adequately represent true degradation. Therefore, we employed the Real-ESRGAN [30] degradation pipeline (as shown in Figure 5) to generate synthetic low-resolution (LR) and high-resolution (HR) pairs for the training and testing datasets. The Real-ESRGAN degradation pipeline involves second-order degradation to better simulate the real-world process of image degradation, which often involves not only the first-order degradation (such as blurring, noise, and downsampling), but also more complex, non-linear effects that occur in real-world scenarios. The second-order degradation helps improve the model’s ability to restore images by simulating more realistic degradations. For reference, we also conducted experiments using synthetic datasets that were generated via bicubic downsampling.
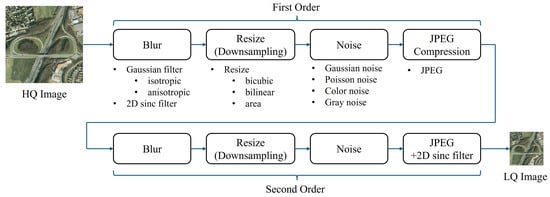
Figure 5.
An illustration of the Real-ESRGAN degradation pipeline. While many works use bicubic downsampling to synthesize LR-HR image pairs for training and testing datasets, this approach fails to represent real-world degradation. As the limitations in satellite imaging equipment and transmission bandwidth often lead to RSIs suffering from blur, downsampling, noise, and compression artifacts, the Real-ESRGAN degradation pipeline employs a second-order degradation process to simulate real-world degradations. Each degradation step follows a classical degradation model, with specific choices for blur, resizing, noise, and JPEG compression, as outlined above.
The ground truth images of DOTA and RSOD are cropped into 1024 × 1024, and the size of corresponding 2× and 4× LR inputs are 512 × 512 and 256 × 256, respectively. Moreover, to further evaluate the SR performance of our proposed model, we conducted inference experiments (2× and 4× SR task) on real-world RSIs (Potsdam [52] and NWPU VHR-10 [53] dataset) without any extra synthetic degradation or downsampling. The size of these images were cropped into 512 × 512, and the size of the 2× and 4× super-resolved images were 1024 × 1024 and 2048 × 2048, respectively.
4.1.2. Implementation Details
We utilized Stable Diffusion XL [20] as the generative prior of the proposed algorithm, owing to its robust content generation capabilities. Following ControlNet [44], the proposed RSDiffSR was formed by making a counterpart crop of UNet to form the Trainable Content Encoder. Meanwhile, we involved the Canny algorithm to generate the edge information to enhance the proposed algorithm, which further enhances the proposed algorithm. The edge and content features were fused with diffusion features by our proposed content-edge joint guidance (CEJG) module. The detailed architecture of the proposed algorithm is shown in Figure 1. Moreover, in order to reduce the domain gap between natural images and remote sensing images, we adopted the LoRA [23] technique to fine tune the pre-trained SISR model with the RSI datasets. Regarding the catastrophic forgetting issue with fine tuning, we used a relatively high rank (64) in LoRA; meanwhile, the training set consisted of a mix of natural and remote sensing images, with the ratio gradually adjusted from 1:1 at the beginning to 1:9 toward the end of training. The overall training process requires 8 days with 6 NVIDIA RTX8000 GPUs (manufactured by NVIDIA Corporation, Santa Clara, CA, USA). The batch size is 24, and the learning rate is set to with an Adam [54] optimizer. For inference, we adopted EDM [55] sampling with 30 timesteps. The text prompts used for both training and testing were set to null.
4.1.3. Evaluation Metrics
We employed multiple full-reference and non-reference metrics metrics, including PSNR, SSIM, FID [56], LPIPS [13], NIQE [57], MUSIQ [58], CLIP-IQA [59], and MANIQA [11] to assess the quality of super-resolved frames. It should be noted that prior works [10,11,12] have reported that these full-reference metrics do not reliably evaluate generative methods and tend to perform poorly with realistic visuals. Non-reference metrics, i.e., NIQE [57], MUSIQ [57], CLIP-IQA [59], and MANIQA [11] are considered more reliable for visual perception. Specifically, MUSIQ [57] uses a multi-scale image quality transformer to capture image quality at different granularities. CLIP-IQA [59] uses the rich visual language prior encapsulated in the CLIP model for assessing both the abstract perception and quality perception of input images. MANIQA [11] evaluates the quality of images using a multi-dimensional attention network.
4.2. Comparisons with Existing Methods
In this section, we compare our proposed method with leading super-resolution algorithms for both natural images and remote sensing images, including SwinIR [9], RealESRGAN Plus [30], HESNET [60], TransENET [8], TTST [61], EDiffSR [22], FastDiffSR [62], StableSR [17], and DiffBIR [18]. Specifically, SwinIR, Real-ESRGAN Plus, DiffBIR, and StableSR represent milestone approaches in natural image super-resolution, leveraging transformer, GAN, and diffusion architectures, respectively. In contrast, HSENet, TransENet, TTST, EDiffSR, and FastDiffSR are specifically designed for remote sensing image super-resolution, employing diverse architectural paradigms, including CNNs, transformers, and diffusion models. The code for these benchmark methods was obtained from the authors’ GitHub repositories, and the relevant parameters were carefully configured according to the authors’ recommendations. For a fair comparison, all of the methods were trained on DOTA [49] and AID [50] datasets under identical conditions. Both quantitative and qualitative evaluations demonstrate that our proposed RSDiffSR outperforms these methods.
4.2.1. Results of the DOTA and RSOD Datasets
For this experiment, Table 1 presents the results of our proposed method and existing methods with ×2 and ×4 scales on the DOTA [49] and RSOD [51] datasets. The LR images of the test datasets were generated by the Real-ESRGAN degradation pipeline, which better simulates real-world degradation conditions. For both ×2 and ×4 scale tasks, our proposed method achieved the best results of all the non-reference metrics, demonstrating its superior performance. Regarding reference-based metrics, our method also shows strong results in FID and LPIPS. However, it should be noted that our method performs poorly in PSNR and SSIM compared to other methods. Due to the nature of the diffusion process, super-resolved results are generated from random Gaussian noise, which prioritizes visual quality over pixel-wise accuracy (as measured by PSNR and SSIM). As shown in Figure 6, our results exhibit significantly better visual perception but with lower PSNR and SSIM scores. This phenomenon has also been observed in previous studies [10,11,12,13], which have noted that full-reference metrics often fail to reliably assess generative methods and perform poorly with realistic visuals. We argue that, as visual perception quality improves in SR results, there is a need to reconsider existing reference-based metrics and explore more effective ways to evaluate advanced SR methods, particularly those oriented toward visual perception.

Table 1.
Quantitative results of existing methods on the DOTA [49] and RSOD [51] datasets. The LR images were generated by the Real-ESRGAN degradation pipeline. The upward arrow indicates that a higher value corresponds to better performance, whereas the downward arrow indicates the opposite. The best and second best results are highlighted in BOLD and UNDERLINED text.

Figure 6.
The example results show the misalignment between reference-based metrics (blue font) and human perception (red font). While our proposed algorithm effectively removes degradations and generates images with rich textures, it yields lower PSNR and SSIM scores. Zoom in for details.
For reference, we also conducted experiments on LR images that had been degenerated by bicubic downsampling, the results of which are shown in Table 2. Our proposed method also showed excellent performance in all non-reference metrics. Real-ESRGAN plus and Stable also achieve good results in perceptual-oriented metrics due to their generative abilities. Despite SwinIR [9] and Real-ESRGAN Plus [30] performing well on reference-based metrics, they failed to produce visually compelling results.
Table 2.
Quantitative results of existing methods on the DOTA and RSOD datasets. The LR images were generated by bicubic downsampling. The upward arrow indicates that a higher value corresponds to better performance, whereas the downward arrow indicates the opposite. The best and second best results are highlighted in BOLD and UNDERLINED text.
Figure 7 and Figure 8 show a ×2 and ×4 visual comparison of the models on the DOTA and RSOD datasets, where the LR inputs of these tests were generated by the Real-ESRGAN degradation pipeline and bicubic downsampling, respectively. Figure 7 presents an overhead view of a road with a roundabout and a lakeside villa, encompassing various types of surface textures. As shown in the figure, while SwinIR [9], HSENet [60], TTST [61], and TransENet [8] achieve decent reference-based metrics, their outputs fail to effectively remove blur and noise and struggle to generate realistic details for tree canopies and rooftops. Compared to these methods, the GAN-based Real-ESRGAN Plus [30] effectively eliminates blur and noise; however, the results appear overly smooth and lack essential details, such as rooftop textures, the grass in front of the villa, and the texture of the road, which are lost during the restoration process. Diffusion-based methods, such as EDiffSR [22], FastDiffSR [62], StableSR [17], and DiffBIR [18], exhibit slightly better visual perception as they not only remove blur and noise, but also reconstruct some fine details. Nevertheless, our proposed RSDiffSR demonstrates superior performance, successfully eliminating noise and blur while generating more realistic tree canopies, building structures, and driveway details. The upper part of Figure 8 showcases an overhead view of a grass field and a tennis court. This image is relatively simple, and, since bicubic downsampling was used, it was easier to restore compared to Figure 7. In this case, HSENet [60], TTST [61], TransENet [8], and EDiffSR [22] exhibited noticeable artifacts, whereas Real-ESRGAN Plus [30], FastDiffSR [62], StableSR [17], DiffBIR [18], and RSDiffSR all successfully restored the image. The lower part of Figure 8 features an overhead view of airplanes. In this scenario, all non-diffusion-based methods failed to produce a satisfactory restoration, resulting in severe noise and edge distortions. Although Real-ESRGAN Plus [30] successfully removes artifacts, it fails to generate meaningful structural details. Among all diffusion-based approaches, our proposed RSDiffSR produced the most realistic reconstruction.

Figure 7.
Visual comparisons of the models on synthetic datasets for the ×2 and ×4 SR tasks. The LR inputs were generated by the Real-ESRGAN degradation pipeline. Among the tested methods, only our proposed model successfully recovered the details of trees and the roof (zoom in for details).

Figure 8.
Visual comparisons of the models on synthetic datasets for the ×2 and ×4 SR tasks. The LR inputs were generated by bicubic downsampling. Our proposed RSDiffSR generated the most realistic airplane reconstruction (zoom in for details).
4.2.2. Real-World Evaluations
To further evaluate the SR performance of our proposed method, we conducted inference experiments (×2 and ×4 tasks) on real-world remote sensing images without any additional synthetic degradation or downsampling. A total of 1800 images (cropped to 512 × 512) from the Potsdam [52] and NWPU VHR-10 [53] datasets were used as the input data. Table 3 shows the results of our proposed method and existing methods with ×2 and ×4 scales on the NWPU VHR-10 [53] and Potsdam [52] datasets. As there were no ground truth images, we relied solely on non-reference metrics to evaluate the methods. Consistent with previous experimental trends, our method achieved optimal performance across all datasets and scales.
Table 3.
Quantitative results of existing methods on the NWPU VHR-10 and Potsdam datasets. The upward arrow indicates that a higher value corresponds to better performance, whereas the downward arrow indicates the opposite. The best and second best results are highlighted in BOLD and UNDERLINED text.
The visual comparisons are shown in Figure 9 and Figure 10. Figure 9 presents the results on the NWPU VHR-10 dataset for the ×2 and ×4 real-world super-resolution tasks, including overhead views of urban blocks and an airport. As shown in the upper part of Figure 9, the results produced by SwinIR [9], HSENet [60], TTST [61], TransENet [8], and EDiffSR [22] exhibited noise and ghosting artifacts. In contrast, Real-ESRGAN Plus [30], FastDiffSR [62], StableSR [17], DiffBIR [18], and our proposed RSDiffSR successfully restored the high-resolution details. As shown in the lower part of Figure 9, a similar trend could be observed, where SwinIR [9], HSENet [60], TTST [61], TransENet [8], and EDiffSR [22] all failed to remove the inherent blur and noise present in real-world remote sensing images. Although FastDiffSR [62], StableSR [17], and DiffBIR [18] manage to eliminate blur and noise, their generated results lack fine details and do not exhibit a photorealistic texture. In comparison, Real-ESRGAN Plus [30] performs exceptionally well in this case, while our proposed RSDiffSR achieved the most realistic reconstruction of the aircraft, effectively restoring its surface texture with a lifelike appearance.

Figure 9.
Visual comparisons of the models on the NWPU VHR-10 dataset for the ×2 and ×4 real-world SR tasks. In this evaluation, RSDiffSR successfully restored the details of community streets and airplanes (zoom in for details).

Figure 10.
Visual comparisons of the models on the Potsdam dataset for the ×2 and ×4 real-world SR tasks. RSDiffSR successfully restored the texture and details of trees and cars under real-world degradation (zoom in for details).
Additionally, Figure 11, Figure 12, Figure 13 and Figure 14 provide visual comparisons at larger display sizes. These images encompass various remote sensing scenes, including trees, vehicles, buildings, grasslands, bare soil, and residential areas. Through these enlarged views, it is evident that our proposed method consistently achieves superior performance across real-world images by effectively mitigating degradation artifacts and generating highly realistic details.
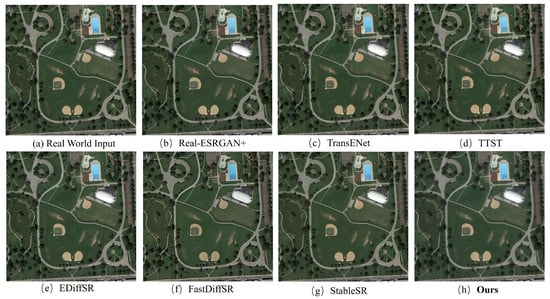
Figure 11.
Visual comparisons of the models on the NWPU VHR-10 dataset for the ×2 SR task (zoom in for details).

Figure 12.
Visual comparisons of the models on the NWPU VHR-10 dataset for the ×4 SR task (zoom in for details).

Figure 13.
Visual comparisons of the models on the Potsdam dataset for the ×2 SR task (zoom in for details).

Figure 14.
Visual comparisons of the models on the Potsdam dataset for the ×4 SR task (zoom in for details).
4.2.3. Inference Time and Model Size Comparison
In terms of inference time and model size, as shown in Table 4, the diffusion models used in remote sensing image super-resolution, such as EDiffSR [22] and FastDiffSR [62], generally have fewer parameters compared to those designed for natural images. This is primarily due to the limited availability of large-scale training datasets. Existing remote sensing datasets are insufficient to support the training of diffusion models at the same scale as StableSR [17] or DiffBIR [18], both of which are based on Stable Diffusion 2.1 [19].
Table 4.
Comparison of the inference time and model parameters across existing methods. For a more detailed comparison, all of the methods were evaluated on the same image size (256 → 1024, 4× SR) and equipment (NVIDIA RTX 8000, manufactured by NVIDIA Corporation, USA).
Since the generative capability of diffusion models is positively correlated with both the model size and the number of training images, current diffusion-based SRSISR methods, despite their relatively small parameter sizes, suffer from long inference times and fail to achieve significant improvements in perceptual quality compared to CNN- and transformer-based approaches. Furthermore, while StableSR, DiffBIR, and RSDiffSR have significantly larger parameter counts than existing diffusion-based remote sensing super-resolution methods, their inference times are actually shorter. This efficiency is primarily attributed to the latent diffusion architecture [19]. Specifically, StableSR and DiffBIR utilize a 4× downsampling autoencoder and a 4× upsampling autodecoder, whereas RSDiffSR employs an 8× scaling strategy, further optimizing computational efficiency. In addition, despite the large number of parameters in RSDiffSR, due to the use of LoRA, it requires only a small dataset and minimal computational resources for training. This enables training and deployment on common hardware, enhancing its practical applicability.
4.3. Ablation Study
As shown in this section, we conducted an ablation study to explore the individual contributions of the proposed Content-Edge Guidance (CEJG) module and low-rank adaptation (LoRA) method. To this end, including the proposed RSDiffSR, we developed five different models and employed four non-reference perceptual metrics to measure their performance. To evaluate the effectiveness of the CEJG module, we set three corresponding models: Model A, where the content part of the CEJG module is replaced by Zero Convolution; Model B, where the edge part of the CEJG module is replaced by Zero Convolution; and Model C, where the entire edge part of the CEJG and the Canny algorithm is removed. All three models showed inferior performance compared with RSDiffSR, demonstrating the effectiveness of the proposed CEJG module. In addition, we also evaluated the effectiveness of LoRA, where removing the LoRA part (Model D) led to worse performance, which demonstrates the effectiveness of the learned data distribution shift through LoRA and fine tuning. For a fair comparison, all of the models mentioned above were trained on the same train datasets with the same settings and iterations. The experiments were performed by real-world evaluation in the NWPU VHR-10 [53] datasets (×4 scales, 512 → 2048), and the results are shown in Table 5.
Table 5.
The ablation study of the proposed RSDiffSR algorithm. The performances were reported on NWPU VHR-10. The upward arrow indicates that a higher value corresponds to better performance, whereas the downward arrow indicates the opposite. The best results are highlighted in BOLD text.
4.4. Failure Cases
Although our proposed method achieved outstanding results, there are still some scenarios where it fails to perform effectively. RSDiffSR has certain limitations when processing highly uniform images, such as calm ocean surfaces. The threshold for Canny edge detection cannot be set too low as this would introduce excessive noise into the extracted edge information. When processing images of calm ocean surfaces that lack high-contrast elements such as islands or ships, the Canny algorithm may fail to detect any meaningful boundary information. In such cases, the image restoration process relies entirely on the TCE module. Additionally, images of this nature are relatively uncommon in the training dataset, leading to insufficient model exposure and suboptimal performance in such scenarios. Moreover, due to the inherent randomness of the diffusion model, test results in these cases may exhibit slight color shifts or minor displacements in wave patterns. A visual example of this phenomenon is presented in Figure 15.

Figure 15.
Analysis of an unconventional low-contrast scene (zoom in for details).
5. Discussion
In this paper, we propose RSDiffSR, a conditional diffusion model that incorporates low-rank adaptation and content-edge joint guidance for remote sensing image super-resolution (RSISR). This work was motivated by two observations. First, traditional non-diffusion SR methods often produce overly smooth results and struggle to recover fine, realistic details. The generative capabilities of large diffusion models offer a promising solution to this challenge. Second, while existing large diffusion models have demonstrated excellent performance on natural images, they face difficulties in remote sensing image (RSI) SR tasks due to the domain gap between natural images and RSIs. To this end, we adapted SDXL as the generative prior of the proposed model and introduced LoRA and fine tuning to reduce the negative effectiveness of the domain gap between natural images and RSIs. Moreover, given the strong generative abilities of SDXL, it must be carefully controlled to generate the desired information as objects in RSIs are typically small and blurry. To overcome this challenge, we introduced content-edge joint guidance, where the guidance process during diffusion is enhanced by edge information from the Canny algorithm. Extensive experiments show that the proposed model performs favorably against state-of-the-art methods.
Compared to existing methods, our model benefits from the integration of generative priors, enabling it to produce super-resolved images with superior visual quality and rich details. While some CNN- or transformer-based approaches achieve high numerical scores on reference metrics, their performance on non-reference metrics and perceptual quality remains significantly inferior to ours. Similarly, compared to existing diffusion-based super-resolution methods, our approach demonstrates superior perceptual fidelity. Moreover, due to the limited size of available datasets, current diffusion-based single remote sensing super-resolution (SRSISR) methods, despite having relatively small parameter sizes, suffer from long inference times and fail to achieve substantial improvements in perceptual quality over CNN- and transformer-based approaches. In contrast, our method not only enhances perceptual quality, but it also achieves faster inference, offering a more effective solution.
Despite the superior performance of the proposed RSDiffSR algorithm, several limitations remain. First, as a diffusion-based approach leveraging Stable Diffusion XL as the generative prior, RSDiffSR requires iterative inference, resulting in longer processing times and higher GPU memory consumption compared to one-step methods. This makes it less practical for efficiency-critical applications. Second, due to the inherent design limitations, the algorithm struggles with processing highly uniform images. In addition, the absence of paired text and remote sensing images prevents the integration of text prompts during training and inference. To address these challenges, several future research directions could help mitigate these limitations. Although RSDiffSR prioritizes performance, applying techniques such as knowledge distillation or model pruning could reduce parameter size and improve efficiency. Moreover, given that existing remote sensing datasets are relatively small and lack paired text annotations, constructing a large-scale remote sensing dataset tailored for diffusion models would be highly beneficial.
In terms of application, the RSDiffSR algorithm exhibits significant advantages in reconstructing complex surface textures, particularly in enhancing details of irregular natural boundaries, such as trees, grass, and exposed soil. By effectively enhancing edge information, the restored edges become clearer and more distinct, which greatly benefits downstream tasks. For instance, in vegetation dynamics monitoring, the algorithm’s ability to refine textures of trees and grass—such as leaf shapes and canopy shadows—enhances the identification of phenological features in low-resolution images, leading to improved monitoring accuracy. Similarly, in disaster response scenarios, such as earthquakes or landslides, the algorithm’s enhancement of exposed surfaces (e.g., mud) and residual vegetation details, along with its refined edge delineation, facilitates more accurate disaster assessment.
6. Conclusions
In this paper, we propose RSDiffSR, a conditional diffusion-based framework for single remote sensing image super-resolution (SRSISR). Our approach leverages a pre-trained large-scale natural image diffusion model as a generative prior, capitalizing on its strong generative capabilities to enhance reconstruction quality. To bridge the domain gap between natural images and remote sensing images (RSIs) that are caused by distributional differences, we employ low-rank adaptation (LoRA) and a multi-stage training strategy, enabling efficient fine tuning with minimal computational and data overhead. Addressing the challenges of small and blurry objects in RSIs, we introduce an enhanced control mechanism that decouples edge and content information from inputs. These features are adaptively fused with diffusion features via our novel content-edge joint guidance (CEJG) module, ensuring both accurate and realistic reconstructions. Extensive quantitative and qualitative evaluations demonstrate that RSDiffSR outperforms state-of-the-art methods across multiple benchmarks.
Author Contributions
Conceptualization, C.Z.; methodology, C.Z.; software, C.Z.; validation, C.Z. and Y.L.; formal analysis, C.Z.; investigation, C.Z.; resources, S.H.; data curation, C.Z.; writing—original draft preparation, C.Z.; writing—review and editing, Y.L. and F.W.; visualization, C.Z.; supervision, F.W.; project administration, F.W.; funding acquisition, F.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Major Science and Technology Projects of China under Grant 2009XJTU0016.
Data Availability Statement
The datasets presented in this study are available public datasets.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Bandara, W.G.C.; Nair, N.G.; Patel, V.M. Ddpm-cd: Remote sensing change detection using denoising diffusion probabilistic models. arXiv 2022, arXiv:2206.11892. [Google Scholar]
- Wang, X.; Yi, J.; Guo, J.; Song, Y.; Lyu, J.; Xu, J.; Yan, W.; Zhao, J.; Cai, Q.; Min, H. A review of image super-resolution approaches based on deep learning and applications in remote sensing. Remote Sens. 2022, 14, 5423. [Google Scholar] [CrossRef]
- Lei, S.; Shi, Z.; Zou, Z. Super-resolution for remote sensing images via local–global combined network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]
- Li, Y.; Mavromatis, S.; Zhang, F.; Du, Z.; Sequeira, J.; Wang, Z.; Zhao, X.; Liu, R. Single-image super-resolution for remote sensing images using a deep generative adversarial network with local and global attention mechanisms. IEEE Trans. Geosci. Remote Sens. 2021, 60, 3000224. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 4681–4690. [Google Scholar]
- Chen, X.; Wang, X.; Zhou, J.; Qiao, Y.; Dong, C. Activating more pixels in image super-resolution transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22367–22377. [Google Scholar]
- Lei, S.; Shi, Z.; Mo, W. Transformer-based multistage enhancement for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5615611. [Google Scholar] [CrossRef]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Shi, S.; Bai, Q.; Cao, M.; Xia, W.; Wang, J.; Chen, Y.; Yang, Y. Region-adaptive deformable network for image quality assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 324–333. [Google Scholar]
- Yang, S.; Wu, T.; Shi, S.; Lao, S.; Gong, Y.; Cao, M.; Wang, J.; Yang, Y. Maniqa: Multi-dimension attention network for no-reference image quality assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1191–1200. [Google Scholar]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning texture transformer network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5791–5800. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Yang, L.; Liu, J.; Hong, S.; Zhang, Z.; Huang, Z.; Cai, Z.; Zhang, W.; Cui, B. Improving diffusion-based image synthesis with context prediction. Adv. Neural Inf. Process. Syst. 2024, 36. [Google Scholar]
- Saharia, C.; Ho, J.; Chan, W.; Salimans, T.; Fleet, D.J.; Norouzi, M. Image super-resolution via iterative refinement. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4713–4726. [Google Scholar] [CrossRef]
- Wang, J.; Yue, Z.; Zhou, S.; Chan, K.C.; Loy, C.C. Exploiting diffusion prior for real-world image super-resolution. Int. J. Comput. Vis. 2024, 132, 5929–5949. [Google Scholar] [CrossRef]
- Lin, X.; He, J.; Chen, Z.; Lyu, Z.; Dai, B.; Yu, F.; Qiao, Y.; Ouyang, W.; Dong, C. Diffbir: Toward blind image restoration with generative diffusion prior. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 430–448. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Podell, D.; English, Z.; Lacey, K.; Blattmann, A.; Dockhorn, T.; Müller, J.; Penna, J.; Rombach, R. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv 2023, arXiv:2307.01952. [Google Scholar]
- Liu, J.; Yuan, Z.; Pan, Z.; Fu, Y.; Liu, L.; Lu, B. Diffusion model with detail complement for super-resolution of remote sensing. Remote Sens. 2022, 14, 4834. [Google Scholar] [CrossRef]
- Xiao, Y.; Yuan, Q.; Jiang, K.; He, J.; Jin, X.; Zhang, L. EDiffSR: An Efficient Diffusion Probabilistic Model for Remote Sensing Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5601514. [Google Scholar] [CrossRef]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Xu, Z.; Baojie, X.; Guoxin, W. Canny edge detection based on Open CV. In Proceedings of the 2017 13th IEEE International Conference on Electronic Measurement & Instruments (ICEMI), Yangzhou, China, 20–22 October 2017; pp. 53–56. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part IV 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 184–199. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, X.; Xie, L.; Dong, C.; Shan, Y. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1905–1914. [Google Scholar]
- Yang, T.; Wu, R.; Ren, P.; Xie, X.; Zhang, L. Pixel-aware stable diffusion for realistic image super-resolution and personalized stylization. In Proceedings of the European Conference on Computer Vision, Paris, France, 26–27 March 2025; pp. 74–91. [Google Scholar]
- Yue, Z.; Wang, J.; Loy, C.C. Resshift: Efficient diffusion model for image super-resolution by residual shifting. Adv. Neural Inf. Process. Syst. 2024, 36, 13294–13307. [Google Scholar]
- Sun, H.; Li, W.; Liu, J.; Chen, H.; Pei, R.; Zou, X.; Yan, Y.; Yang, Y. CoSeR: Bridging Image and Language for Cognitive Super-Resolution. arXiv 2023, arXiv:2311.16512. [Google Scholar]
- Zhang, S.; Yuan, Q.; Li, J.; Sun, J.; Zhang, X. Scene-adaptive remote sensing image super-resolution using a multiscale attention network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4764–4779. [Google Scholar] [CrossRef]
- Pan, Z.; Ma, W.; Guo, J.; Lei, B. Super-resolution of single remote sensing image based on residual dense backprojection networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7918–7933. [Google Scholar] [CrossRef]
- Xiao, Y.; Su, X.; Yuan, Q.; Liu, D.; Shen, H.; Zhang, L. Satellite video super-resolution via multiscale deformable convolution alignment and temporal grouping projection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5610819. [Google Scholar] [CrossRef]
- Guo, J.; Lv, F.; Shen, J.; Liu, J.; Wang, M. An improved generative adversarial network for remote sensing image super-resolution. IET Image Process. 2023, 17, 1852–1863. [Google Scholar] [CrossRef]
- Tu, J.; Mei, G.; Ma, Z.; Piccialli, F. SWCGAN: Generative adversarial network combining swin transformer and CNN for remote sensing image super-resolution. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5662–5673. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Han, L.; Zhao, Y.; Lv, H.; Zhang, Y.; Liu, H.; Bi, G.; Han, Q. Enhancing remote sensing image super-resolution with efficient hybrid conditional diffusion model. Remote Sens. 2023, 15, 3452. [Google Scholar] [CrossRef]
- Ali, A.M.; Benjdira, B.; Koubaa, A.; Boulila, W.; El-Shafai, W. TESR: Two-stage approach for enhancement and super-resolution of remote sensing images. Remote Sens. 2023, 15, 2346. [Google Scholar] [CrossRef]
- Wu, C.; Wang, D.; Bai, Y.; Mao, H.; Li, Y.; Shen, Q. HSR-Diff: Hyperspectral image super-resolution via conditional diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 7083–7093. [Google Scholar]
- Pinaya, W.H.L.; Vieira, S.; Garcia-Dias, R.; Mechelli, A. Autoencoders. In Machine Learning; Elsevier: Amsterdam, The Netherlands, 2020; pp. 193–208. [Google Scholar]
- Zhang, L.; Rao, A.; Agrawala, M. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 3836–3847. [Google Scholar]
- Brooks, T.; Holynski, A.; Efros, A.A. Instructpix2pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18392–18402. [Google Scholar]
- Yang, F.; Yang, S.; Butt, M.A.; van de Weijer, J. Dynamic prompt learning: Addressing cross-attention leakage for text-based image editing. Adv. Neural Inf. Process. Syst. 2024, 36, 26291–26303. [Google Scholar]
- Yang, Q.; Chen, D.; Tan, Z.; Liu, Q.; Chu, Q.; Bao, J.; Yuan, L.; Hua, G.; Yu, N. HQ-50K: A Large-scale, High-quality Dataset for Image Restoration. arXiv 2023, arXiv:2306.05390. [Google Scholar]
- Schuhmann, C.; Beaumont, R.; Vencu, R.; Gordon, C.; Wightman, R.; Cherti, M.; Coombes, T.; Katta, A.; Mullis, C.; Wortsman, M.; et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Adv. Neural Inf. Process. Syst. 2022, 35, 25278–25294. [Google Scholar]
- Ding, J.; Xue, N.; Xia, G.S.; Bai, X.; Yang, W.; Yang, M.Y.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; et al. Object detection in aerial images: A large-scale benchmark and challenges. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7778–7796. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate object localization in remote sensing images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Rottensteiner, F.; Sohn, G.; Gerke, M.; Wegner, J.D.; Breitkopf, U.; Jung, J. Results of the ISPRS benchmark on urban object detection and 3D building reconstruction. ISPRS J. Photogramm. Remote Sens. 2014, 93, 256–271. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Kingma, D.P. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Karras, T.; Aittala, M.; Aila, T.; Laine, S. Elucidating the design space of diffusion-based generative models. Adv. Neural Inf. Process. Syst. 2022, 35, 26565–26577. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30, 6626–6637. [Google Scholar]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Ke, J.; Wang, Q.; Wang, Y.; Milanfar, P.; Yang, F. Musiq: Multi-scale image quality transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5148–5157. [Google Scholar]
- Wang, J.; Chan, K.C.; Loy, C.C. Exploring clip for assessing the look and feel of images. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 2555–2563. [Google Scholar]
- Lei, S.; Shi, Z. Hybrid-scale self-similarity exploitation for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5401410. [Google Scholar] [CrossRef]
- Xiao, Y.; Yuan, Q.; Jiang, K.; He, J.; Lin, C.W.; Zhang, L. TTST: A top-k token selective transformer for remote sensing image super-resolution. IEEE Trans. Image Process. 2024, 33, 738–752. [Google Scholar] [CrossRef]
- Meng, F.; Chen, Y.; Jing, H.; Zhang, L.; Yan, Y.; Ren, Y.; Wu, S.; Feng, T.; Liu, R.; Du, Z. A conditional diffusion model with fast sampling strategy for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5408616. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).