4.1. Description of Data Sets
In this section, the experimental results are discussed to demonstrate the effectiveness of the proposed method for HSI classification. Three HSI benchmarks are given for evaluation. The first data set, Indian Pines Site (IPS) image, was generated from AVIRIS (Airborne Visible/Infrared Imaging Spectrometer), which was captured by the Jet Propulsion Laboratory and NASA/Ames in 1992. The IPS image was captured from six miles in the western area of Northwest Tippecanoe County (NTC). A false color IR image of dataset IPS is shown in
Figure 1a. The IPS dataset contained 16 land-cover classes with 220 bands, e.g., Alfalfa(46), Corn-notill(1428), Corn-mintill(830), Corn(237), Grass-pasture(483), Grass-trees(730), Grass-pasture-mowed(28), Hay-windrowed(478), Oats(20), Soybeans-notill(972), Soybeans-mintill(2455), Soybeans-cleantill(593), Wheat(205), Woods(1265), and Bldg-Grass-Tree-Drives(386), and Stone-Steel-Towers(93). The numbers in parentheses were the collected pixel numbers in the dataset. The ground truths in dataset IPS of 10,249 pixels were manually labeled for training and testing. In order to analyze the performance of various algorithms, 10 classes of more than 300 samples were adopted in the experiments, e.g., a subset IPS-10 of 9620 pixels. Nine hundred training samples of 10 classes in subset IPS-10 were randomly chosen from 9,620 pixels, and the remaining samples were used for testing.
Figure 1.
False color of IR images for datasets (a) Indian Pines Site (IPS); (b) Pavia University; and (c) Pavia City Center.
Figure 1.
False color of IR images for datasets (a) Indian Pines Site (IPS); (b) Pavia University; and (c) Pavia City Center.
The other two HSI data sets adopted in the experiments were obtained from the Reflective Optics System Imaging Spectrometer (ROSIS) instrument covering the City of Pavia, Italy. Two scenes, the university area and the Pavia city center, contained 103 and 102 data bands, both with a spectral coverage from 0.43 to 0.86 um and a spatial resolution of 1.3 m. The image sizes of these two areas were 610 × 340 and 1096 × 715 pixels, respectively.
Figure 1b,c show the false color IR image of these two data sets. Nine land-cover classes were available in each data set, and the samples in each data set were separated into two subsets,
i.e., one training and one testing set. Given the Pavia University data set, 90 training samples per class were randomly collected for training, and the 8046 remaining samples were tested for performance evaluation. Similarly, the numbers of training and testing samples used for the Pavia City Center data set were 810 and 9529, respectively.
4.2. A Toy Example
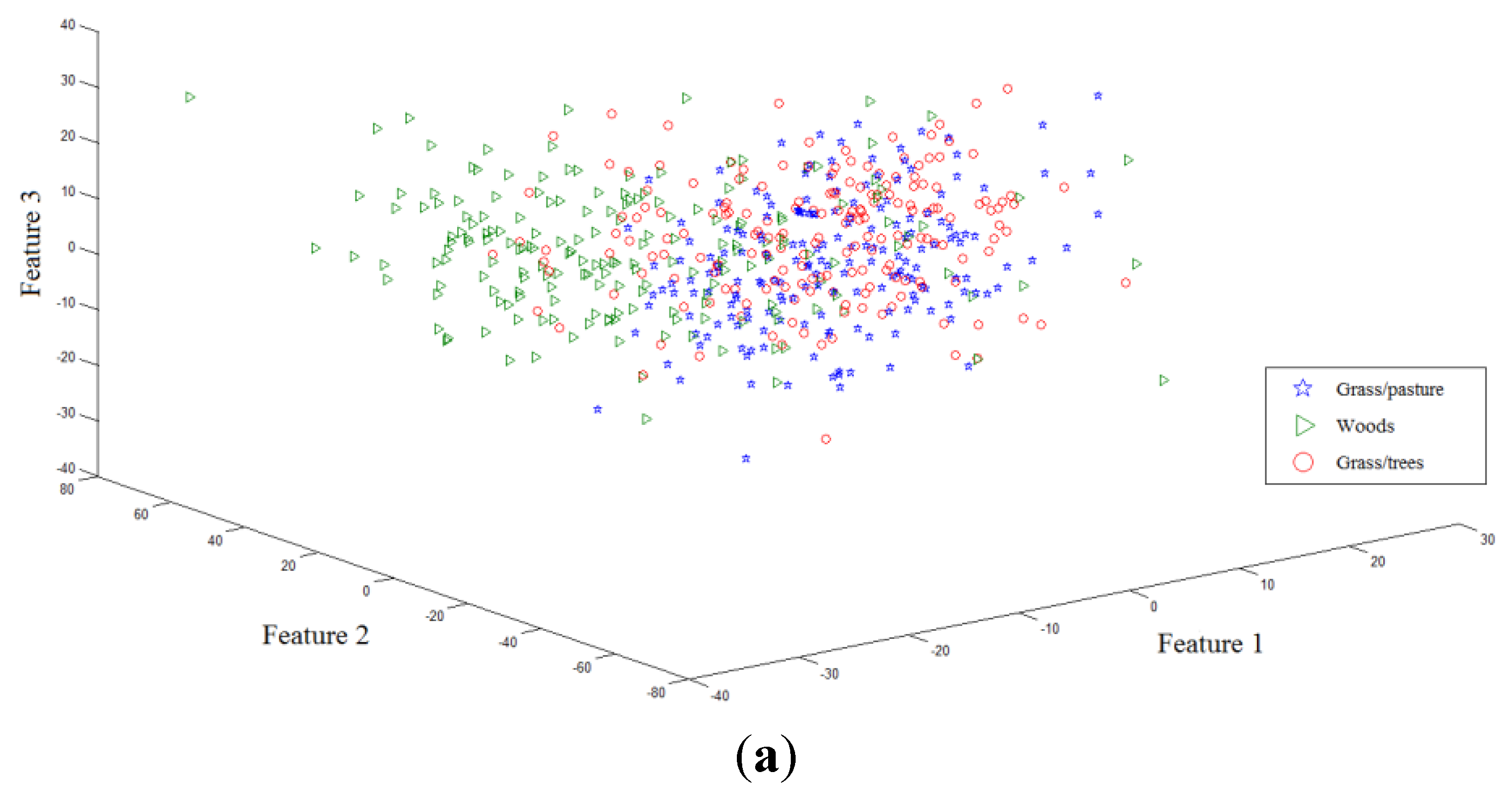
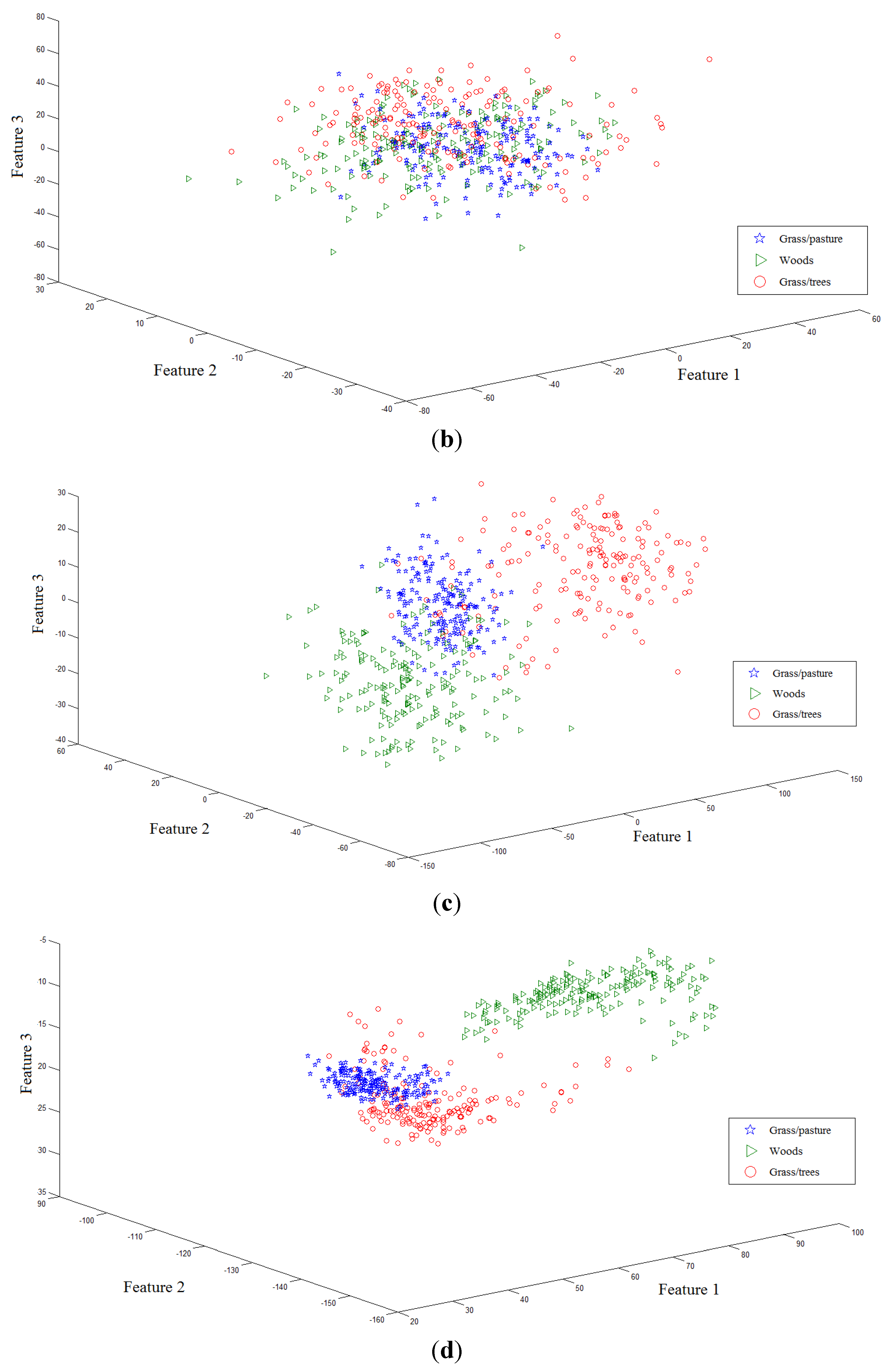
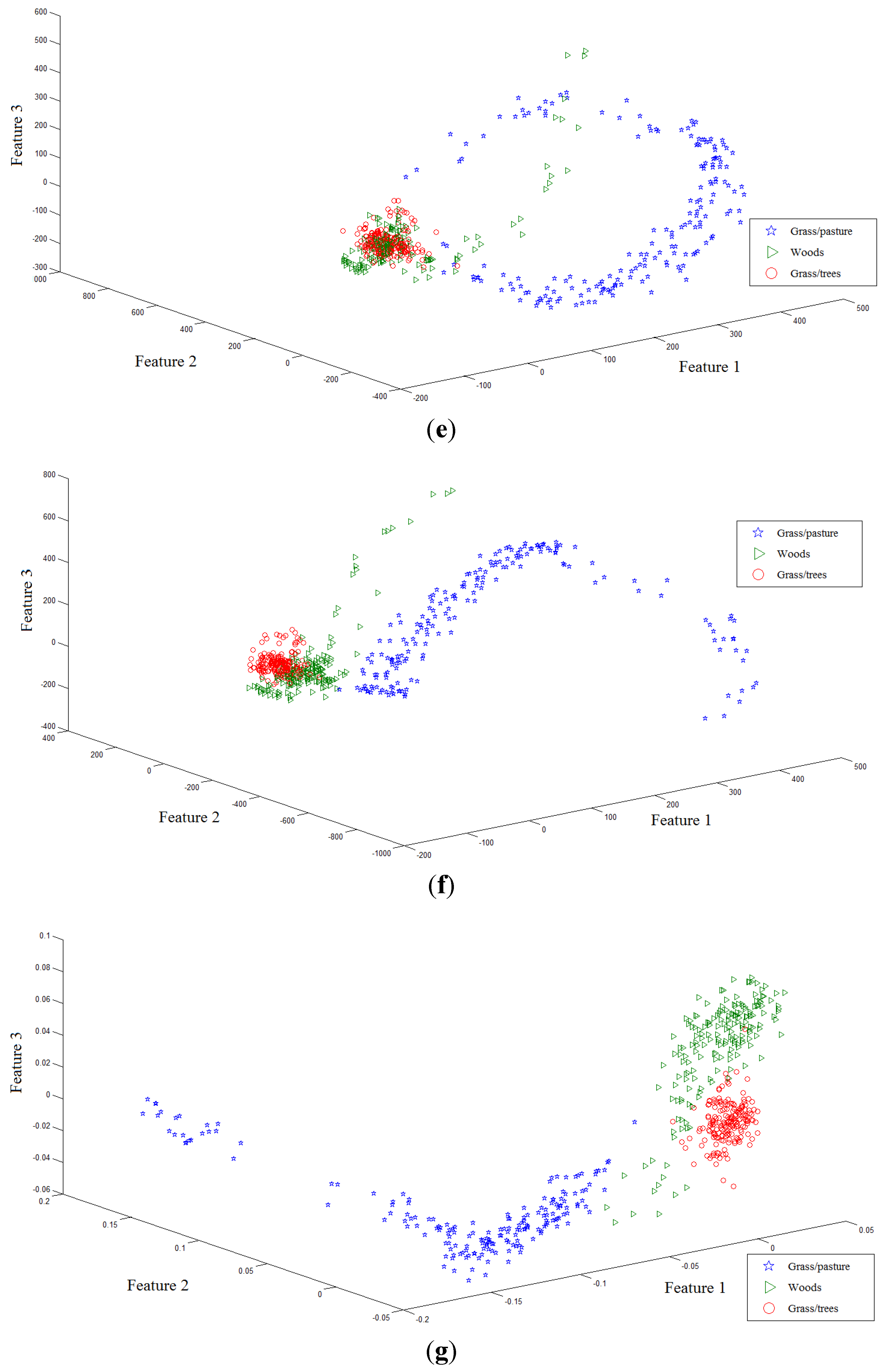
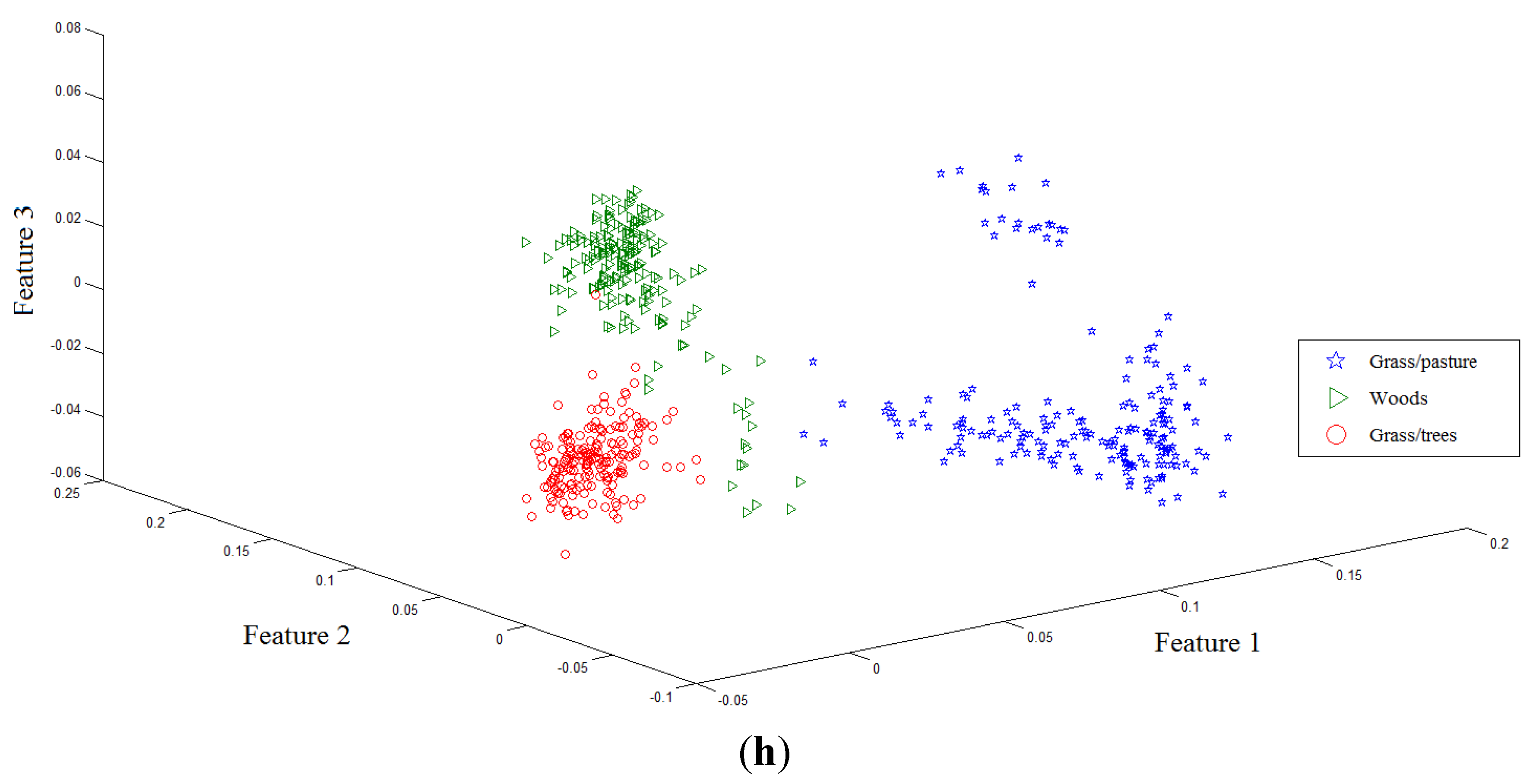
Two toy examples are given to illustrate the discriminative power of FKNFLE in the following. Firstly, 561 samples with 220 dimensions of the three classes (Grass/pasture, Woods, and Grass/trees) were collected from a hyperspectral image. The samples were projected onto the first three axes using eight algorithms: PCA, LDA, supervised LPP, LFDA [
28], NFLE, FNFLE, KNFLE, and FKNFLE, as shown in
Figure 2. These class samples are represented by green triangles (class G), blue stars (class B), and red circles (class R). A simple analysis was done by observing the sample distributions in the reduced spaces. Since the global Euclidean structure criterion was considered during the PCA and LDA training phases, the samples from three classes in the reduced spaces were mixed after the PCA and LDA projections as shown in
Figure 2a,b. Since the samples were distributed in a manifold structure in the original space, the manifold learning algorithms, e.g., supervised LPP, LFDA, and NFLE, were executed to preserve the local structure of the samples. The sample distributions projected by supervised LPP, LFDA, and NFLE are displayed in
Figure 2c–e, respectively. Three classes were efficiently separated and contrasted with those in
Figure 2a,b. The class boundaries, however, were unclear due to the non-linear and non-Euclidean sample distributions in the original space. Kernelization and fuzzification were pre-performed to extend the original non-Euclidean and non-linear space to a higher linear space. Consider the sample distributions in
Figure 2e,h, the boundaries of classes G and R in
Figure 2e being still unclear using the NFLE transformation. The sample distributions of FNFLE and KNFLE as shown in
Figure 2f,g were the results when the kernelization and fuzzification strategies were used, respectively. Obviously, classes G and R were more effectively separated than those in
Figure 2e. The local structures of the samples from the observed sample distribution were preserved, and the class separability improved. Several points located at the boundaries were misclassified in these cases. When both strategies were further adopted in FKNFLE, only one red point was mis-located at class G, and classes G and R were clearly separated. From the analysis, both fuzzification and kernelization strategies enhanced the discriminative power of manifold learning methods.
Figure 2.
The first toy sample distributions projected on the first three axes using algorithms (a) PCA (principal component analysis); (b) LDA (linear discriminant analysis); (c) supervised LPP (locality preserving projection); (d) LFDA (local Fisher discriminant analysis); (e) NFLE (nearest feature line (NFL) embedding); (f) FNFLE (fuzzy nearest feature line embedding); (g) KNFLE (kernel nearest feature line embedding); and (h) FKNFLE (fuzzy-kernel nearest feature line).
Figure 2.
The first toy sample distributions projected on the first three axes using algorithms (a) PCA (principal component analysis); (b) LDA (linear discriminant analysis); (c) supervised LPP (locality preserving projection); (d) LFDA (local Fisher discriminant analysis); (e) NFLE (nearest feature line (NFL) embedding); (f) FNFLE (fuzzy nearest feature line embedding); (g) KNFLE (kernel nearest feature line embedding); and (h) FKNFLE (fuzzy-kernel nearest feature line).
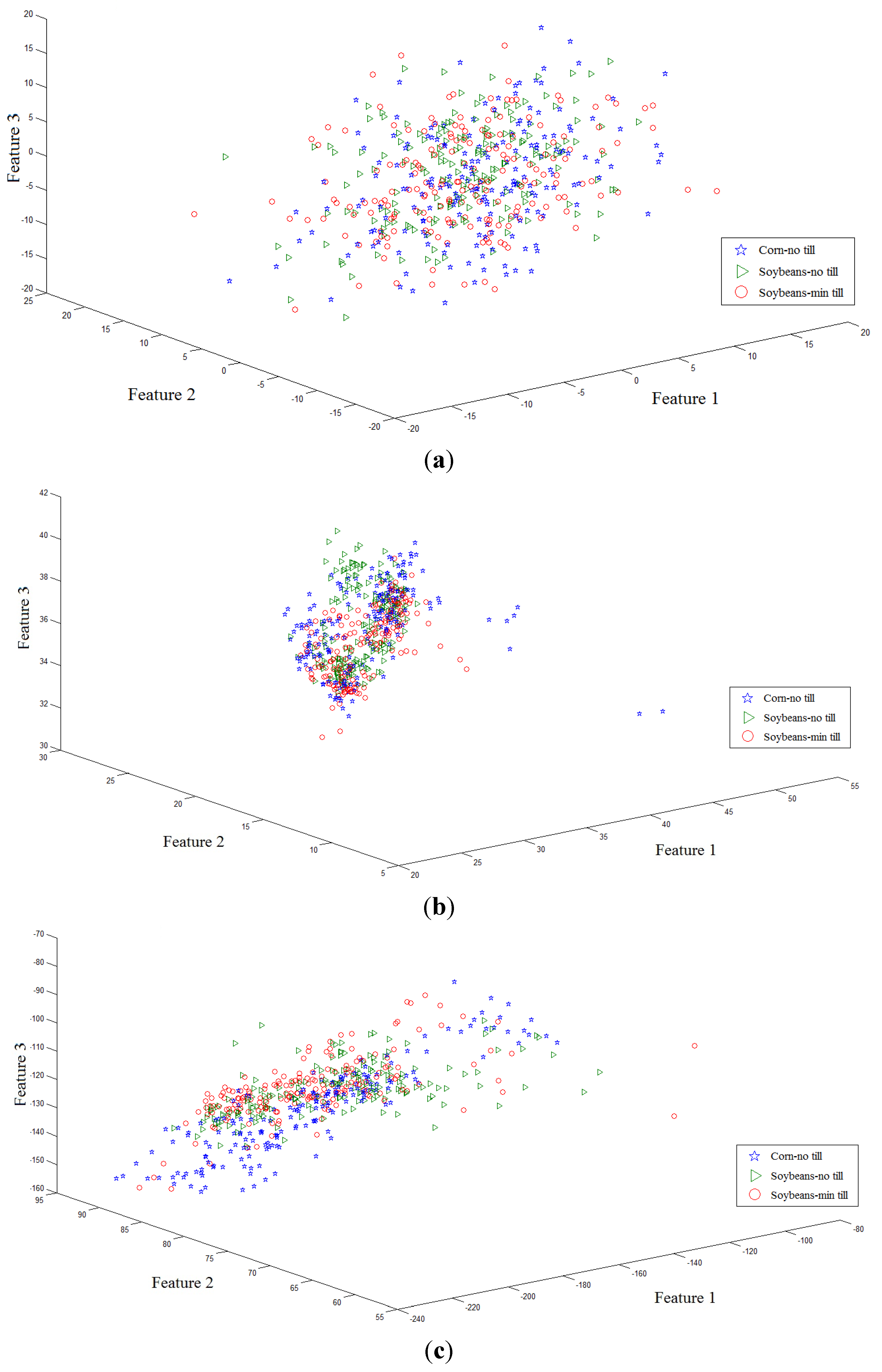
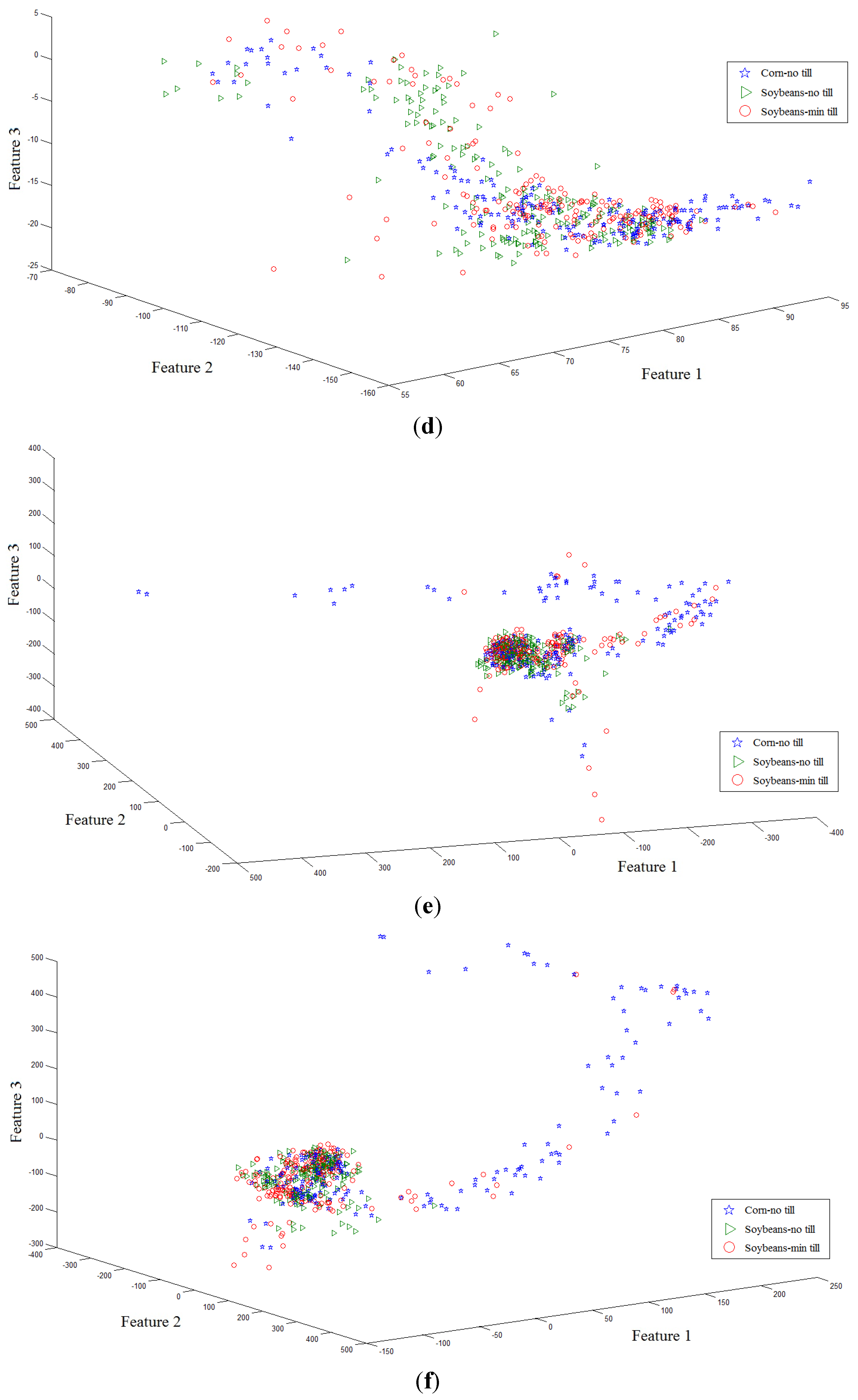
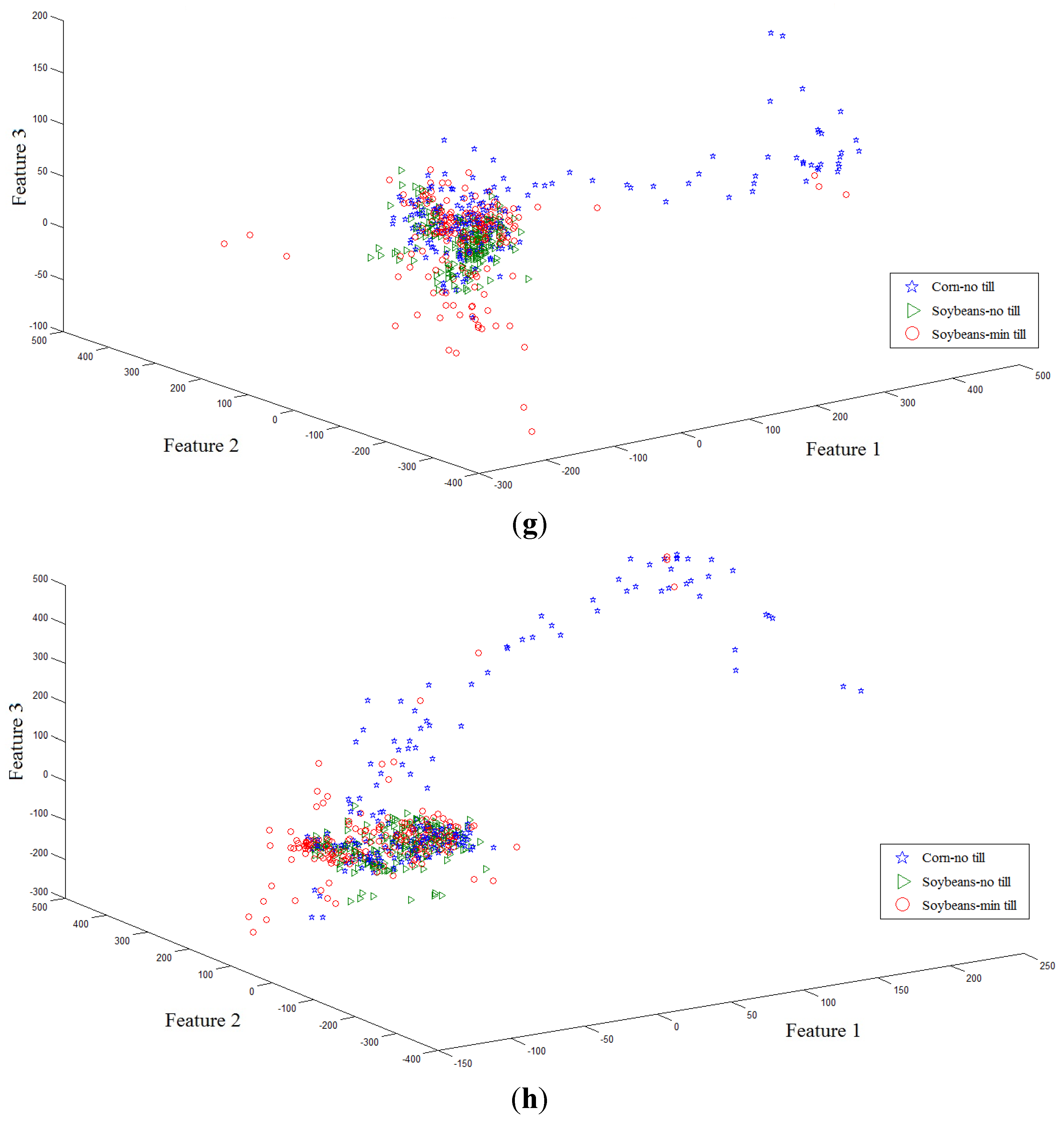
Secondly, 561 samples with 220 dimensions of the three classes (Corn-no till, Soybeans-min till, Soybeans-no till) were collected from a hyperspectral image. The samples were projected onto the first three axes by eight algorithms: PCA, LDA, supervised LPP, LFDA, NFLE, FNFLE, KNFLE, and FKNFLE, as shown in
Figure 3. These class samples are also represented by green triangles (class G), blue stars (class B), and red circles (class R). A simple analysis was also done by observing the sample distributions in the reduced spaces. Since the global Euclidean structure criterion was considered during the PCA and LDA training phases, the samples of three classes in the reduced spaces were mixed after the PCA and LDA projections as shown in
Figure 3a,b. Since the samples were distributed in a manifold structure in the original space, the manifold learning algorithms, e.g., supervised LPP, LFDA, and NFLE, were executed to preserve the local structure of the samples. The sample distributions projected by supervised LPP, LFDA, and NFLE are displayed in
Figure 3c–e, respectively. Due to the strong overlapping in classes G, R, and B, they were mixed, and the separation was relatively low compared with those in
Figure 2c–e. However, when the kernelization and fuzzification strategies were used, class B was more effectively separated than those shown in
Figure 3c–e. According to the analysis, in the case of strong overlapping, both fuzzification and kernelization strategies enhanced the discriminative power of manifold learning methods.
Figure 3.
The second toy sample distributions projected on the first three axes using algorithms (a) PCA; (b) LDA; (c) supervised LPP; (d) LFDA; (e) NFLE; (f) FNFLE; (g) KNFLE; and (h) FKNFLE.
Figure 3.
The second toy sample distributions projected on the first three axes using algorithms (a) PCA; (b) LDA; (c) supervised LPP; (d) LFDA; (e) NFLE; (f) FNFLE; (g) KNFLE; and (h) FKNFLE.
4.3. Classification Results
The proposed methods, NFLE [
20,
21], KNFLE, FNFLE [
26], and FKNFLE, were compared with two state-of-the-art algorithms,
i.e., nearest regularized subspace (NRS) [
25] and NRS-LFDA [
25]. The parameter configurations for both algorithms NRS [
29] and NRS-LFDA were as seen in [
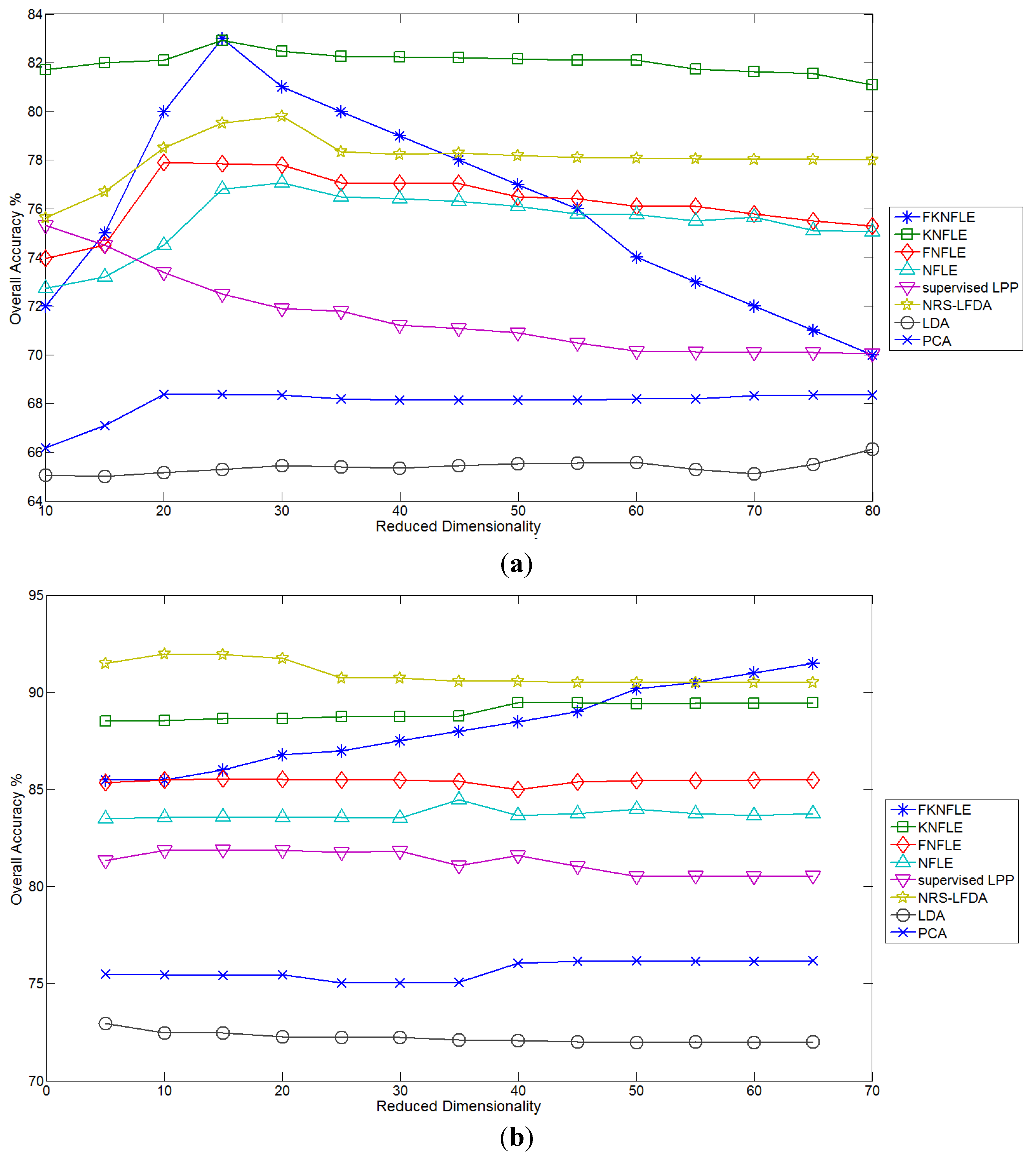
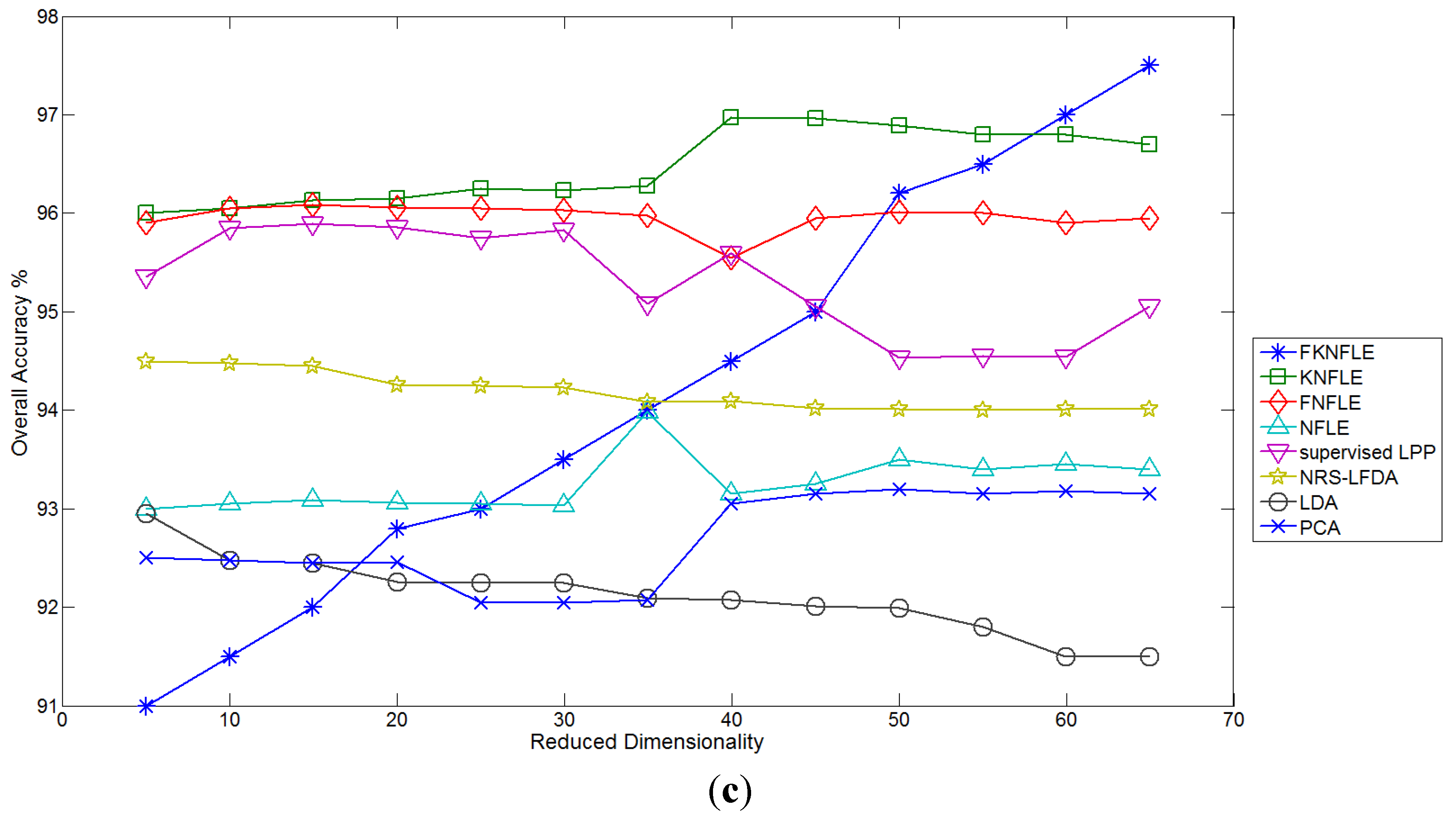
25]. The gallery samples were randomly chosen for training the transformation matrix, and the query samples were matched with the gallery samples using the nearest neighbor (NN) matching rule. Each algorithm was run 30 times to obtain the average rates. To obtain the appropriate reduced dimensions of FKNFLE, the available training samples were used to evaluate the overall accuracy (OA)
versus the reduced dimensions in the benchmark datasets. As shown in
Figure 4, the best dimensions of algorithm FKNFLE for datasets IPS-10, Pavia University, and Pavia City Center were 25, 50, and 50, respectively. The proposed FKNFLE and KNFLE algorithms are both extended from algorithm NFLE. From the classification results as shown in
Figure 4, though FKNFLE achieves the best results at the specific reduced dimensions on three datasets, the high variant OA rates are obtained. Moreover, two additional parameters
and
were needed for training during the fuzzification. On the other hand, the performance of KNFLE is more robust than that of FKNFLE. KNFLE usually achieves a higher performance even at low reduced dimensions, e.g., five or 10. It also outperforms the other algorithms at all reduced dimensions on datasets IPS-10 and Pavia City Center. Compared with NRS-LDA, slightly reduced OA rates were obtained on dataset Pavia University. From this analysis, algorithm KNFLE is more competitive than FKNFLE in HSI classification.
Figure 4.
The classification accuracy versus the reduced dimension on three benchmark datasets using the various algorithms: (a) IPS-10; (b) Pavia University; (c) Pavia City Center.
Figure 4.
The classification accuracy versus the reduced dimension on three benchmark datasets using the various algorithms: (a) IPS-10; (b) Pavia University; (c) Pavia City Center.
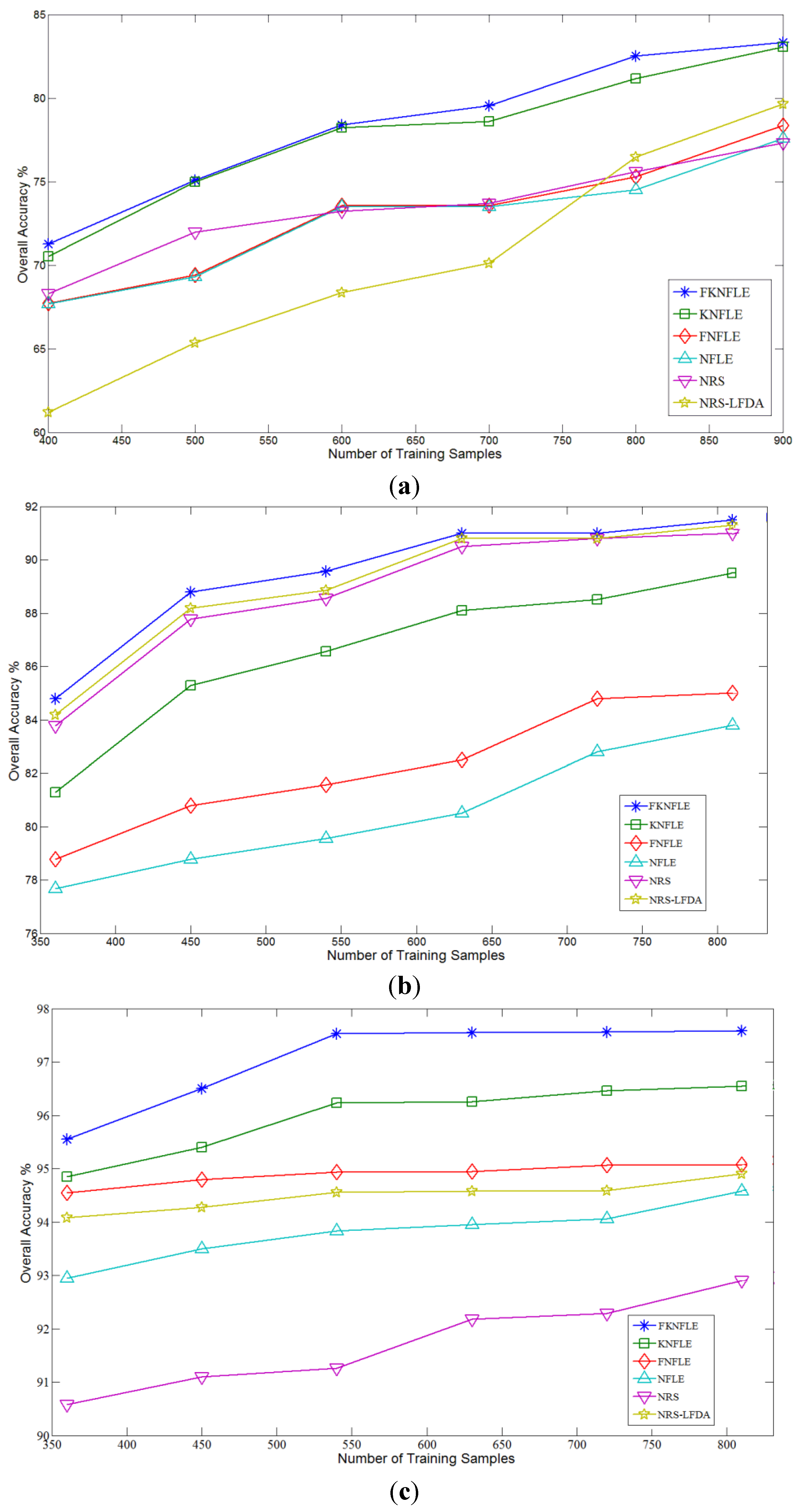
The average classification rates
versus the number of training samples on dataset IPS-10 are shown in
Figure 5a; algorithms FKNFLE and KNFLE outperformed the other methods. The accuracy rate of FKNFLE was 4% higher than that of FNFLE. The kernelization strategy effectively enhanced the discriminative power. The performance of FKNFLE was better than that of KNFLE to a value of 0.8%, and the rate of FNFLE was higher than that of NFLE to a value of 0.7%. This shows that the fuzzification strategy slightly enhanced the performance.
Figure 5b,c also demonstrates the overall accuracy
versus the number of training samples in the benchmark datasets of Pavia University and Pavia City Center, respectively. According to the classification rates in these two datasets, algorithm FKNFLE outperformed the other methods. In addition, the classification results were insensitive to the number of training samples. Next, the maps of the classification results for the dataset IPS-10 are given in
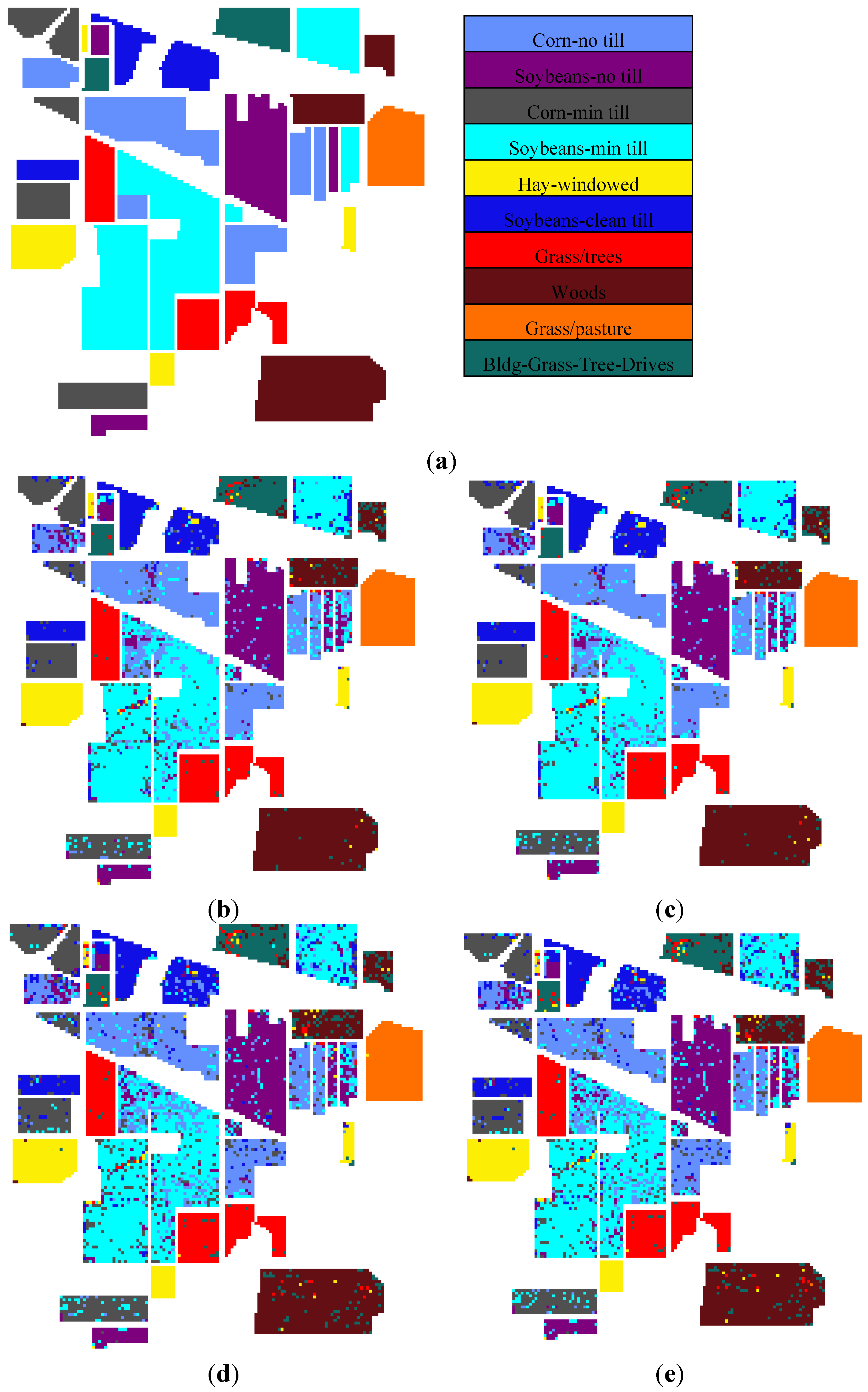
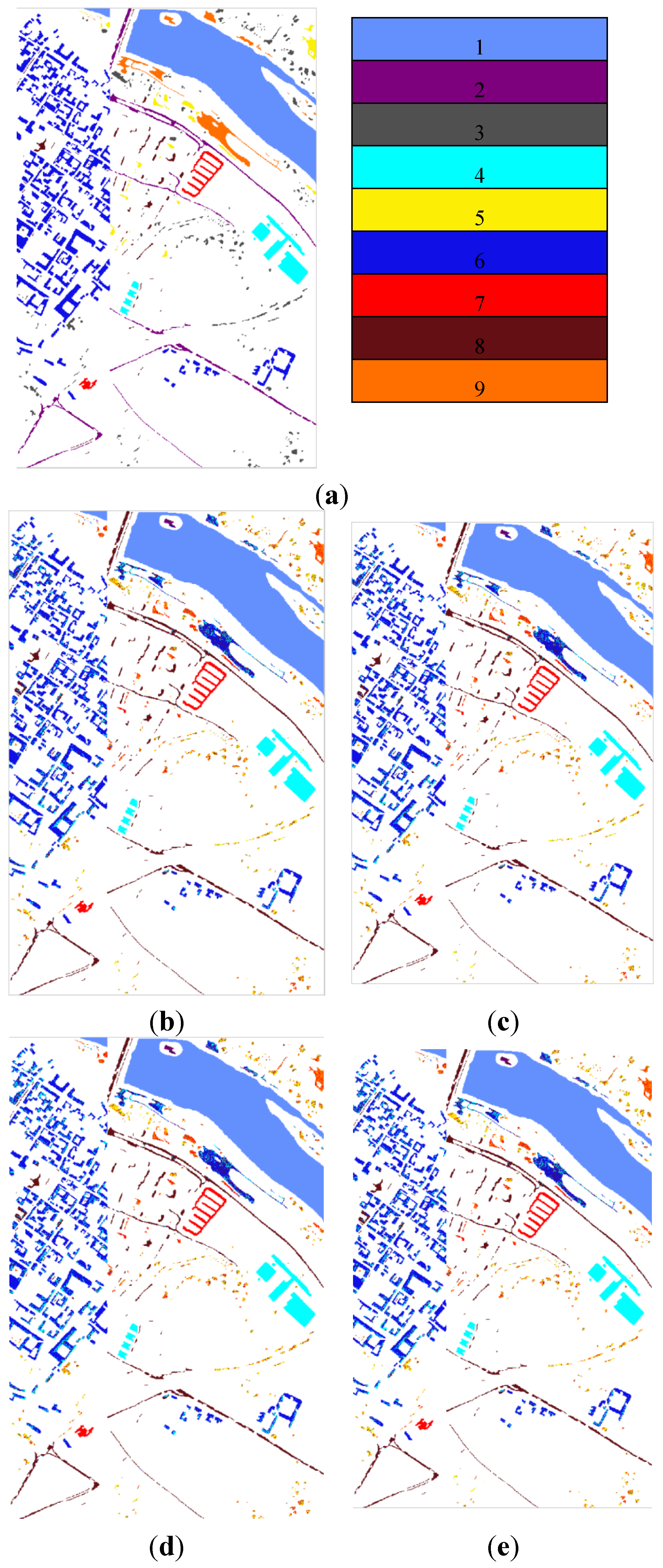
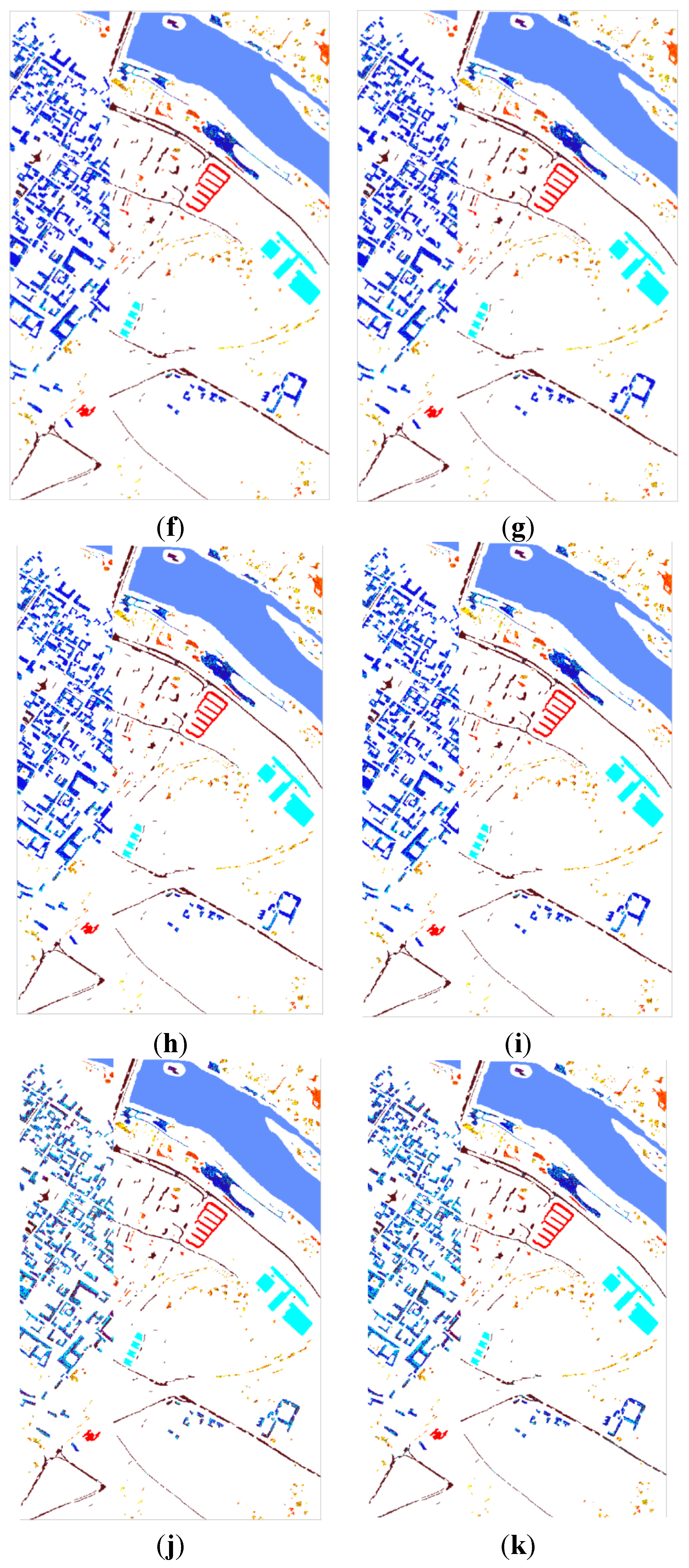
Figure 6. The classification results of algorithms FKNFLE, KNFLE, FNFLE, NFLE, NRS, and NRS-LFDA are given based on the maps of 145 × 145 pixels depicting the ground truth. The speckle-like errors of FKNFLE were fewer than those of the other algorithms.
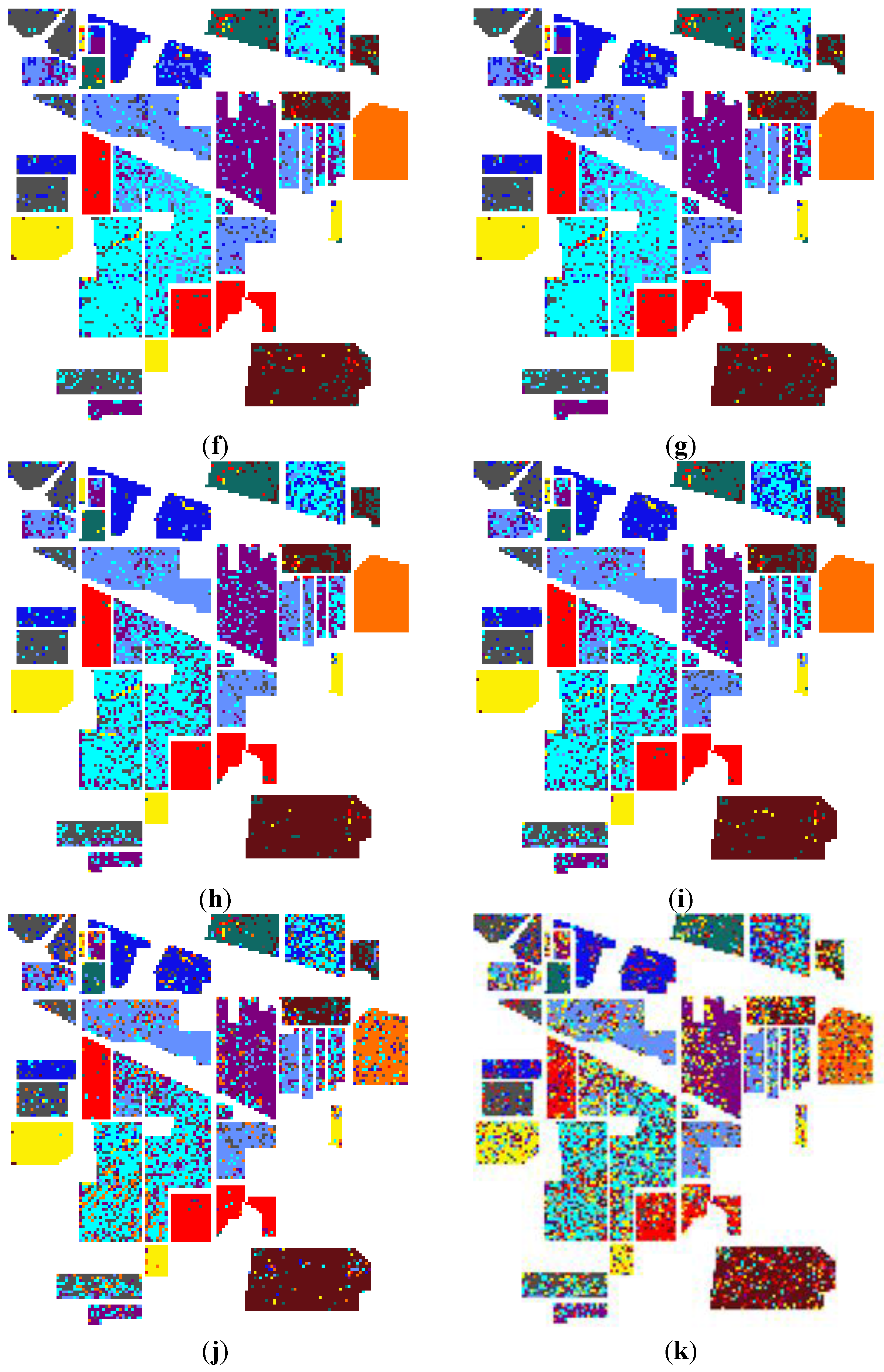
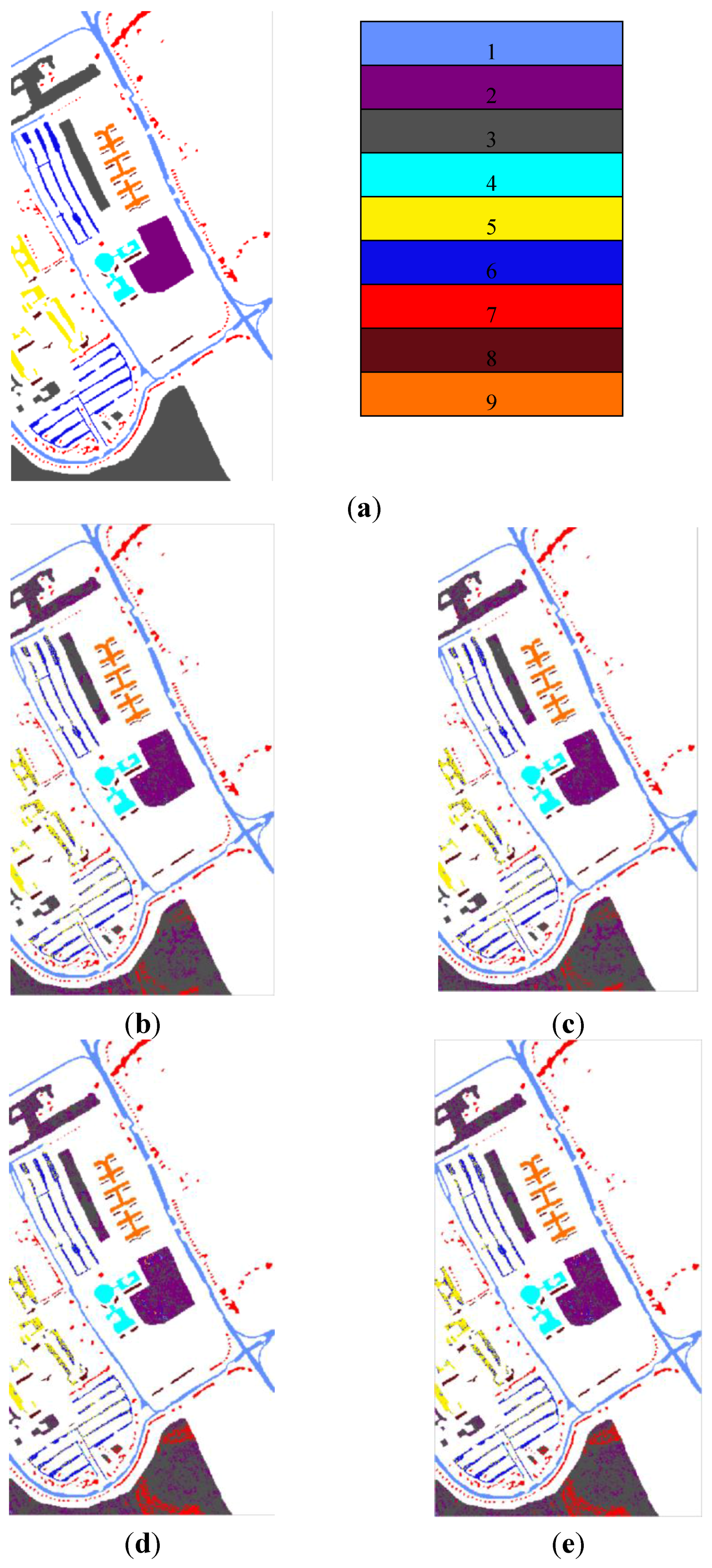
Figure 6,
Figure 7 and
Figure 8 give the maps of the classification results for datasets Pavia University and Pavia City Center, respectively. Once again, the speckle-like errors of FKNFLE were fewer than in the case of the other algorithms. In addition, the thematic maps of Pavia University and Pavia City Center are shown in
Figure 9a,b, respectively, using the proposed FKNFLE method. Observing the results in
Figure 9a, the roads, buildings, and the areas in University were clearly classified even though there was some speckle-like noise in the images. The roads, rivers, buildings, small islands, and the areas in the city were classified in the same way. See
Figure 9b. Algorithm FKNFLE effectively classified the land cover even in the limited training samples.
Figure 5.
The accuracy rates versus the number of training samples for datasets (a) IPS-10; (b) Pavia University; and (c) Pavia City Center.
Figure 5.
The accuracy rates versus the number of training samples for datasets (a) IPS-10; (b) Pavia University; and (c) Pavia City Center.
Figure 6.
The classification maps of dataset IPS using various algorithms: (a) The ground truth; (b) FKNFLE; (c) KNFLE; (d) FNFLE; (e) NFLE; (f) NRS (nearest regularized subspace); (g) LFDA-NRS (local Fisher discriminant analysis-NRS); (h) LFDA; (i) supervised LPP; (j) LDA; and (k) PCA.
Figure 6.
The classification maps of dataset IPS using various algorithms: (a) The ground truth; (b) FKNFLE; (c) KNFLE; (d) FNFLE; (e) NFLE; (f) NRS (nearest regularized subspace); (g) LFDA-NRS (local Fisher discriminant analysis-NRS); (h) LFDA; (i) supervised LPP; (j) LDA; and (k) PCA.
Figure 7.
The classification maps of dataset Pavia University using various algorithms: (a) The ground truth; (b) FKNFLE; (c) KNFLE; (d) FNFLE; (e) NFLE; (f) NRS; (g) LFDA-NRS; (h) LFDA; (i) supervised LPP; (j) LDA; and (k) PCA.
Figure 7.
The classification maps of dataset Pavia University using various algorithms: (a) The ground truth; (b) FKNFLE; (c) KNFLE; (d) FNFLE; (e) NFLE; (f) NRS; (g) LFDA-NRS; (h) LFDA; (i) supervised LPP; (j) LDA; and (k) PCA.
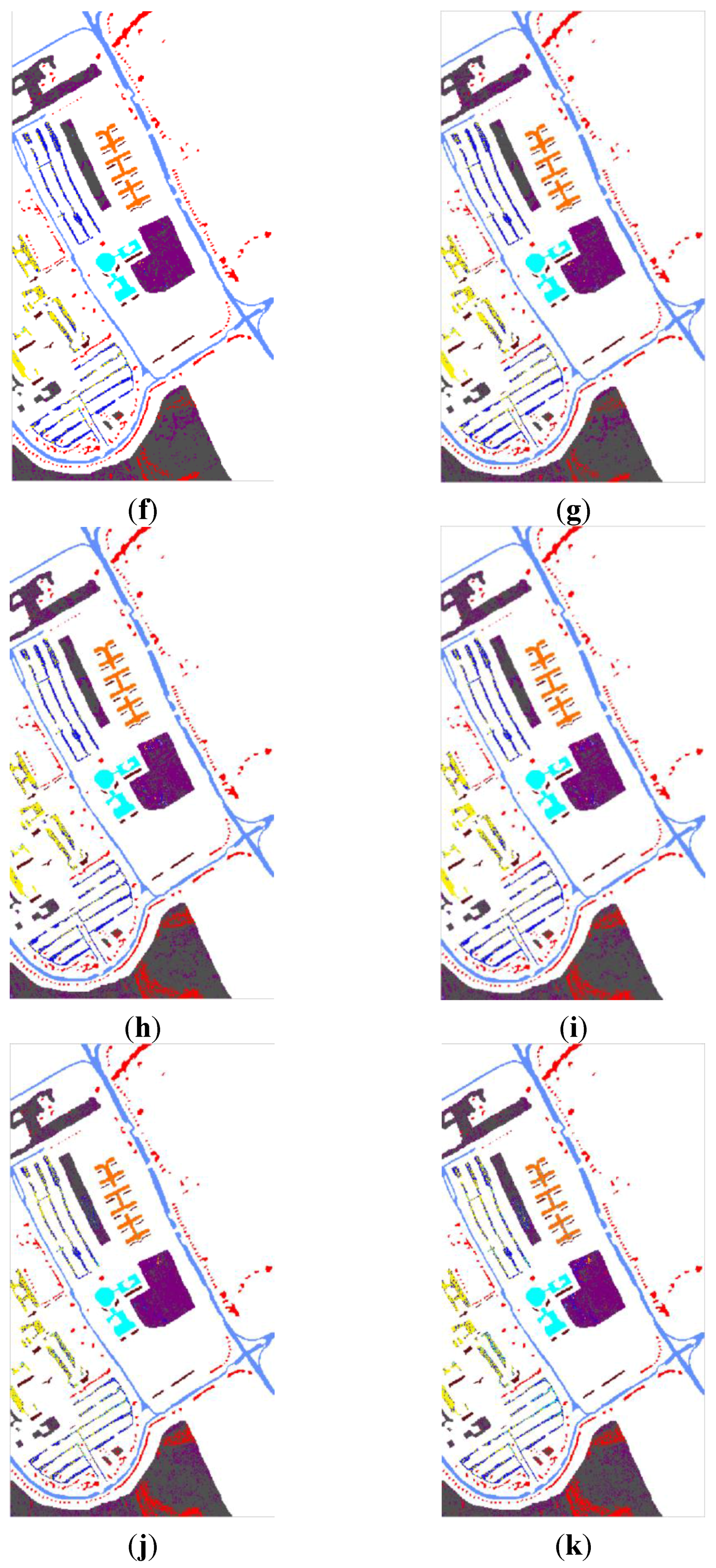
Figure 8.
The classification maps of dataset Pavia City Center using various algorithms: (a) The ground truth, (b) FKNFLE; (c) KNFLE; (d) FNFLE; (e) NFLE; (f) NRS; (g) LFDA-NRS; (h) LFDA; (i) supervised LPP; (j) LDA; and (k) PCA.
Figure 8.
The classification maps of dataset Pavia City Center using various algorithms: (a) The ground truth, (b) FKNFLE; (c) KNFLE; (d) FNFLE; (e) NFLE; (f) NRS; (g) LFDA-NRS; (h) LFDA; (i) supervised LPP; (j) LDA; and (k) PCA.
Figure 9.
The thematic maps of (a) Pavia University, and (b) Pavia City Center using the proposed FKNFLE algorithm.
Figure 9.
The thematic maps of (a) Pavia University, and (b) Pavia City Center using the proposed FKNFLE algorithm.
The proposed method was compared with various classification methods on computational time. All methods were implemented by MATALB codes on a personal computer with an i7 2.93-GHz CPU and 12.0 gigabyte RAM. The comparisons of various algorithms on computational time were tabulated in
Table 2 for the IPS-10, Pavia University, and Pavia City Center datasets. Considering the training time, the proposed FKNFLE algorithm was generally faster than NRS and NRS-LFDA by two times and 15 times, respectively. Due to the fuzzification process, algorithms FKNFLE and FNFLE were slower than KNFLE and NFLE, by 13 times and 15 times, respectively.
Table 2.
The training and testing times of various algorithms for the benchmark datasets (s).
Table 2.
The training and testing times of various algorithms for the benchmark datasets (s).
| Datasets | IPS-10 | Pavia University | Pavia City Center |
|---|
| Algorithms | Training | Testing | Training | Testing | Training | Testing |
|---|
| | 900 | 8720 | 810 | 8046 | 810 | 9529 |
| NFLE-NN | 10 | 18 | 9 | 16 | 9 | 20 |
| KNFLE-NN | 12 | 18 | 11 | 16 | 11 | 20 |
| FNFLE-NN | 155 | 18 | 140 | 16 | 140 | 20 |
| FKNFLE-NN | 156 | 18 | 141 | 16 | 141 | 20 |
| NRS | 326 | 326 | 294 | 300 | 294 | 351 |
| LFDA-NRS | 2331 | 327 | 2098 | 301 | 2098 | 352 |
From
Table 3,
Table 4 and
Table 5, the producer’s accuracy, overall accuracy, kappa coefficients, and user’s accuracy defined by the error matrices (or confusion matrices) [
27] were calculated for performance evaluation. They are briefly defined in the following. The user’s accuracy and the producer’s accuracy are two widely used measures for class accuracy. The user’s accuracy is defined as the ratio of the number of correctly classified pixels in each class by the total pixel number classified in the same class. The user’s accuracy is a measure of commission error, whereas the producer’s accuracy measures the errors of omission and indicates the probability that certain samples of a given class on the ground are actually classified as such. The kappa coefficient, also called the kappa statistic, is defined to be a measure of the difference between the actual agreement and the changed agreement. The overall accuracies of the proposed method were 83.34% in IPS-10, 91.31% in Pavia University, and 97.59% in Pavia City Center with the kappa coefficients of 0.821, 0.910, and 0.971, respectively. Subset IPS-10 of 10 classes is used for fair comparisons with other algorithms. Another alternative classification on the whole IPS dataset of 16 classes was performed. Ten percent training samples of each class were randomly chosen from 10,249 pixels except for class Oats. Three training samples were randomly chosen from class Oats because of few samples in this data set. The remaining samples were used for testing. The classification error matrix is given in
Table 6 in which the overall accuracy and kappa coefficient are 83.85% and 0.826, respectively.
Table 3.
The classification error matrix for data set IPS-10 (in percentage).
Table 3.
The classification error matrix for data set IPS-10 (in percentage).
| Classes | Reference Data | User’s Accuracy |
|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|
| 1 | 79.20 | 3.43 | 0.28 | 0.35 | 0 | 5.46 | 9.73 | 1.54 | 0 | 0 | 79.20 |
| 2 | 5.90 | 81.81 | 0 | 0.12 | 0 | 1.33 | 6.39 | 4.34 | 0 | 0.12 | 81.81 |
| 3 | 0 | 0 | 97.49 | 1.46 | 0.21 | 0.42 | 0 | 0.21 | 0.42 | 0.84 | 97.49 |
| 4 | 0 | 0 | 0.27 | 96.30 | 0 | 0 | 0 | 0 | 0 | 3.42 | 96.30 |
| 5 | 0 | 0 | 0.42 | 0 | 99.58 | 0 | 0 | 0 | 0 | 0 | 99.58 |
| 6 | 5.14 | 0.21 | 0.10 | 0.41 | 0 | 88.89 | 4.42 | 0.72 | 0 | 0.10 | 88.89 |
| 7 | 10.59 | 5.58 | 0.29 | 0.33 | 0.04 | 9.78 | 69.98 | 3.30 | 0 | 0.12 | 69.98 |
| 8 | 1.35 | 4.05 | 1.52 | 0.34 | 0 | 1.69 | 1.85 | 88.53 | 0 | 0.67 | 88.53 |
| 9 | 0 | 0 | 3.32 | 0.16 | 0 | 0 | 0 | 0 | 90.83 | 5.69 | 90.83 |
| 10 | 0 | 0 | 3.89 | 5.70 | 0 | 0 | 0 | 0.26 | 10.88 | 79.27 | 79.27 |
| Producer’s Accuracy | 77.51 | 86.04 | 90.62 | 91.57 | 99.75 | 82.63 | 75.76 | 89.51 | 88.94 | 87.85 | |
| Kappa Coefficient: 0.821 | Overall Accuracy: 83.34% |
Table 4.
The classification error matrix for data set Pavia University (in percentage).
Table 4.
The classification error matrix for data set Pavia University (in percentage).
| Classes | Reference Data | User’s Accuracy |
|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|
| 1 | 90.18 | 3.15 | 0 | 0 | 0 | 3.24 | 1.35 | 1.26 | 0.81 | 90.18 |
| 2 | 2.31 | 92.50 | 0 | 2.31 | 0 | 1.85 | 0 | 1.01 | 0 | 92.50 |
| 3 | 0 | 0 | 90.07 | 2.38 | 1.58 | 0.99 | 2.97 | 0.99 | 0.99 | 90.07 |
| 4 | 0 | 1.23 | 2.84 | 90.24 | 1.42 | 1.42 | 1.51 | 1.32 | 0 | 90.24 |
| 5 | 0.63 | 1.13 | 0.75 | 1.26 | 91.91 | 0.63 | 1.64 | 0.88 | 1.13 | 91.91 |
| 6 | 1.10 | 1.19 | 1.38 | 1.56 | 1.19 | 92.54 | 0.55 | 0.46 | 0 | 92.54 |
| 7 | 0 | 1.12 | 0.51 | 0.61 | 2.24 | 0 | 93.25 | 1.22 | 1.02 | 93.25 |
| 8 | 0.47 | 1.42 | 0.95 | 1.42 | 2.38 | 1.90 | 0 | 90.76 | 0.66 | 90.76 |
| 9 | 1.14 | 0 | 2.15 | 2.01 | 0 | 2.29 | 0 | 2.15 | 90.22 | 90.22 |
| Producer’s Accuracy | 94.10 | 90.92 | 91.30 | 88.65 | 91.25 | 88.25 | 92.08 | 90.71 | 95.14 | |
| Kappa Coefficient: 0.910 | Overall Accuracy: 91.31% |
Table 5.
The classification error matrix for data set Pavia City Center (in percentage).
Table 5.
The classification error matrix for data set Pavia City Center (in percentage).
| Classes | Reference Data | User’sAccuracy |
|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|
| 1 | 98.61 | 0.17 | 0.51 | 0.34 | 0.34 | 0 | 0 | 0 | 0 | 98.61 |
| 2 | 1.04 | 97.47 | 0.43 | 0 | 0 | 0.34 | 0.17 | 0.52 | 0 | 97.47 |
| 3 | 0.59 | 0.82 | 96.23 | 0.69 | 0.99 | 0 | 0 | 0 | 0.69 | 96.23 |
| 4 | 0 | 0.56 | 0.66 | 96.68 | 0.37 | 0.47 | 0.66 | 0.56 | 0 | 96.68 |
| 5 | 0 | 0 | 0.43 | 0.34 | 97.73 | 0.26 | 0.34 | 0.34 | 0.52 | 97.73 |
| 6 | 0.35 | 0.26 | 0.61 | 0 | 0 | 98.15 | 0 | 0.26 | 0.35 | 98.15 |
| 7 | 0.35 | 0.26 | 0 | 0.35 | 0 | 0.44 | 98.23 | 0.35 | 0 | 98.23 |
| 8 | 0 | 0 | 0.37 | 0.30 | 0.37 | 0.52 | 0.45 | 97.43 | 0.52 | 97.43 |
| 9 | 0.39 | 0.59 | 0.79 | 0.29 | 0.29 | 0 | 0 | 0 | 97.60 | 97.60 |
| Producer’s Accuracy | 97.32 | 97.34 | 96.20 | 97.67 | 97.64 | 97.97 | 98.38 | 97.96 | 97.91 | |
| Kappa Coefficient: 0.971 | Overall Accuracy: 97.59% |
Table 6.
The classification error matrix for data set IPS of 16 classes (in percentage).
Table 6.
The classification error matrix for data set IPS of 16 classes (in percentage).
| | Reference Data | UA |
|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
|---|
| 1 | 78.22 | 0 | 0 | 0 | 4.35 | 0 | 0 | 17.43 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 78.22 |
| 2 | 0 | 77.15 | 2.22 | 0.69 | 0 | 0.18 | 0 | 0 | 0.07 | 5.17 | 13.26 | 1.19 | 0 | 0 | 0.07 | 0 | 77.15 |
| 3 | 0 | 3.32 | 73.03 | 3.04 | 0 | 0 | 0 | 0 | 0 | 0.71 | 15.15 | 4.75 | 0 | 0 | 0 | 0 | 73.03 |
| 4 | 0 | 13.91 | 8.84 | 65.83 | 0.42 | 0 | 0 | 0.82 | 0 | 1.29 | 7.59 | 1.29 | 0 | 0 | 0 | 0 | 65.83 |
| 5 | 0 | 0.21 | 0.23 | 0.24 | 94.61 | 0.22 | 0 | 0 | 0 | 0.80 | 0.81 | 1.04 | 0 | 1.85 | 0 | 0 | 94.61 |
| 6 | 0 | 0.12 | 0.14 | 0 | 0.19 | 97.11 | 0 | 0 | 0 | 0 | 0.68 | 0 | 0 | 0.58 | 1.18 | 0 | 97.11 |
| 7 | 0 | 0 | 0 | 0 | 3.61 | 0 | 92.81 | 3.58 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 92.81 |
| 8 | 1.81 | 0 | 0 | 0 | 0 | 0 | 0 | 98.19 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 98.19 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 94.99 | 0 | 0 | 0 | 5.01 | 0 | 0 | 0 | 94.99 |
| 10 | 0 | 3.83 | 0.31 | 0 | 0.32 | 0.31 | 0 | 0 | 0.11 | 81.74 | 12.95 | 0.43 | 0 | 0 | 0 | 0 | 81.74 |
| 11 | 0 | 4.62 | 3.52 | 0.22 | 0.32 | 0.31 | 0 | 0 | 0.08 | 5.45 | 83.95 | 1.37 | 0 | 0 | 0.16 | 0 | 83.95 |
| 12 | 0 | 4.93 | 7.93 | 0.61 | 0.12 | 0.14 | 0 | 0 | 0 | 2.05 | 9.79 | 74.25 | 0 | 0 | 0.17 | 0 | 74.25 |
| 13 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.49 | 99.51 | 0 | 0 | 0 | 99.51 |
| 14 | 0 | 0 | 0 | 0 | 0.47 | 0.08 | 0 | 0 | 0 | 0 | 0 | 0 | 0.08 | 96.03 | 3.34 | 0 | 96.03 |
| 15 | 0 | 0 | 0.54 | 0.54 | 7.25 | 15.02 | 0 | 0 | 0.20 | 1.85 | 2.59 | 0.25 | 0.25 | 16.85 | 54.66 | 0 | 54.66 |
| 16 | 0 | 1.03 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.06 | 3.28 | 0 | 0 | 0 | 0 | 94.63 | 94.63 |
| PA | 97.73 | 70.70 | 75.47 | 92.49 | 84.73 | 85.65 | 1 | 81.81 | 99.51 | 81.64 | 56.21 | 87.29 | 94.90 | 83.27 | 91.74 | 1 | |
| Kappa Coefficient: 0.826 | Overall Accuracy: 83.85% |
In this study, since we focused on the performance of kernelization and fuzzification, the
k-NN classifier was adopted rather than the complex support vector machine (SVM) classifier. An analysis of various
k values is given to demonstrate the performance of the
k-NN classifier as shown in
Table 7. Here, value
k was set as values 1, 3, and 4, and the voting strategy was used in this analysis. Obviously, an adaptive higher value of the
k-NN classifier can achieve more competitive performances. Next, the empirical parameters
and
were properly determined by a cross-validation technique. Training samples were separated into two groups: the training and validation subsets, where, for example, 50% of the samples for training and the other for validation. The validation results were generated under various parameters, and the proper setting was determined by selecting the best results. From the cross-validation experiment, the proper parameters
,
,
, and
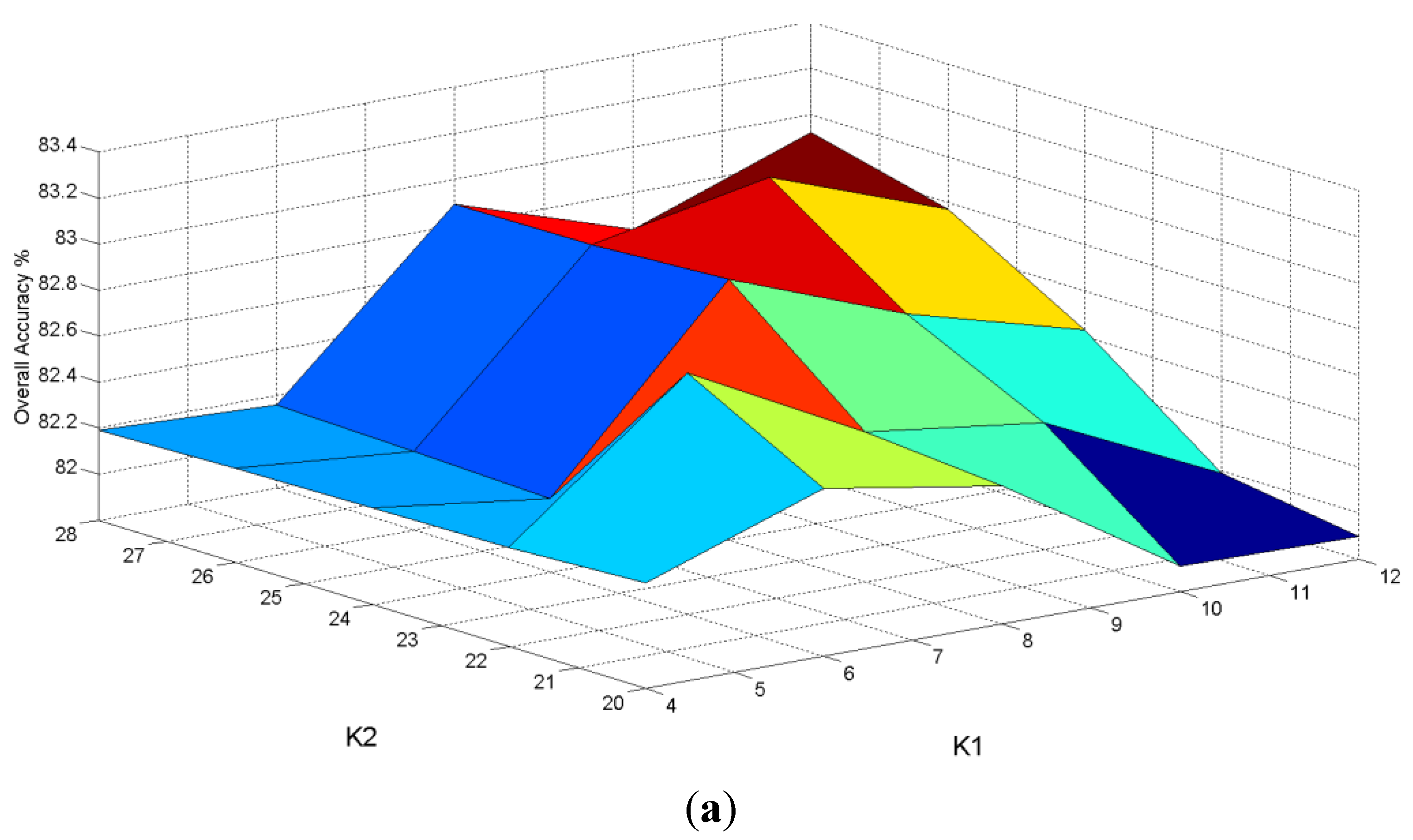
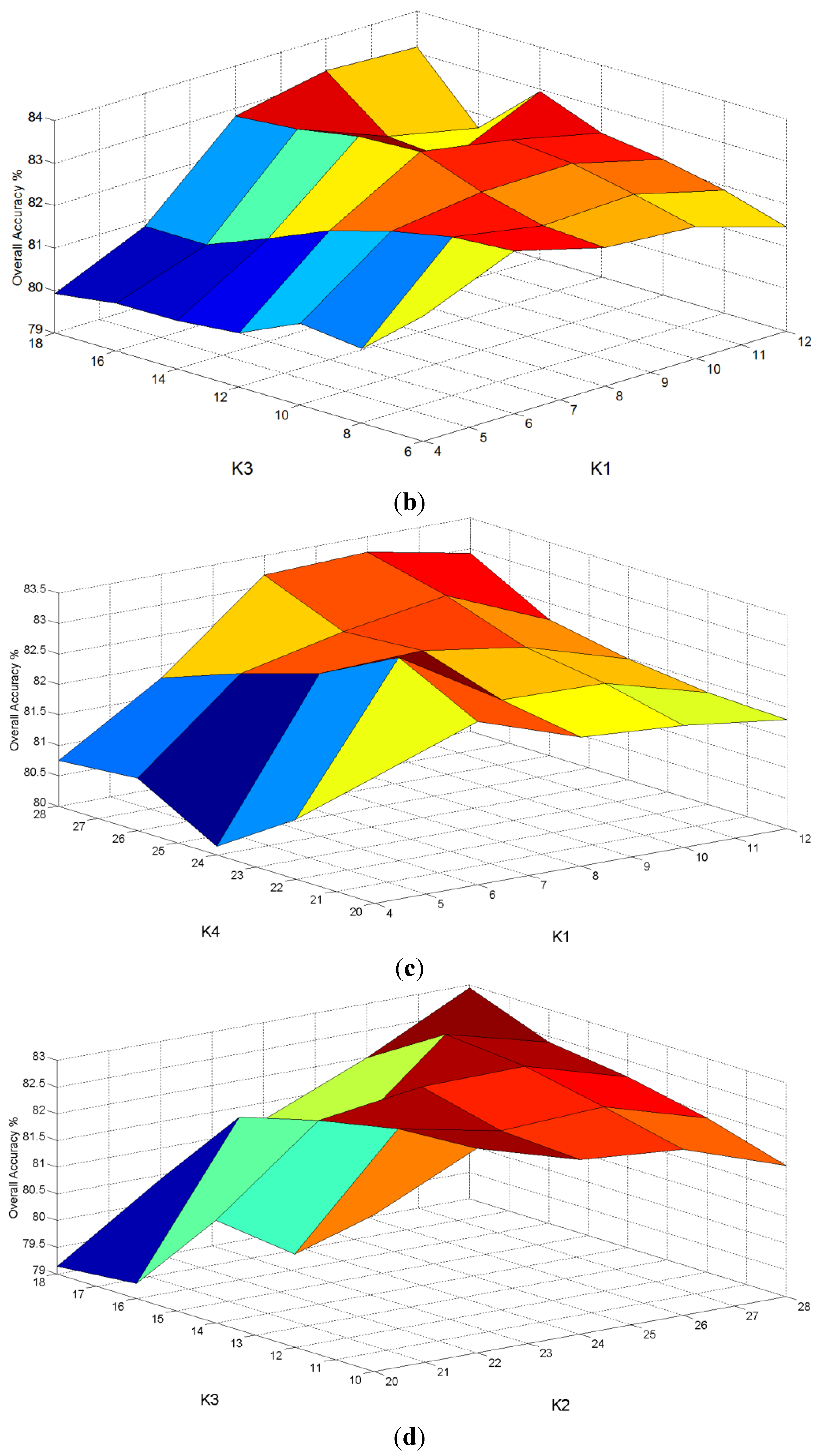
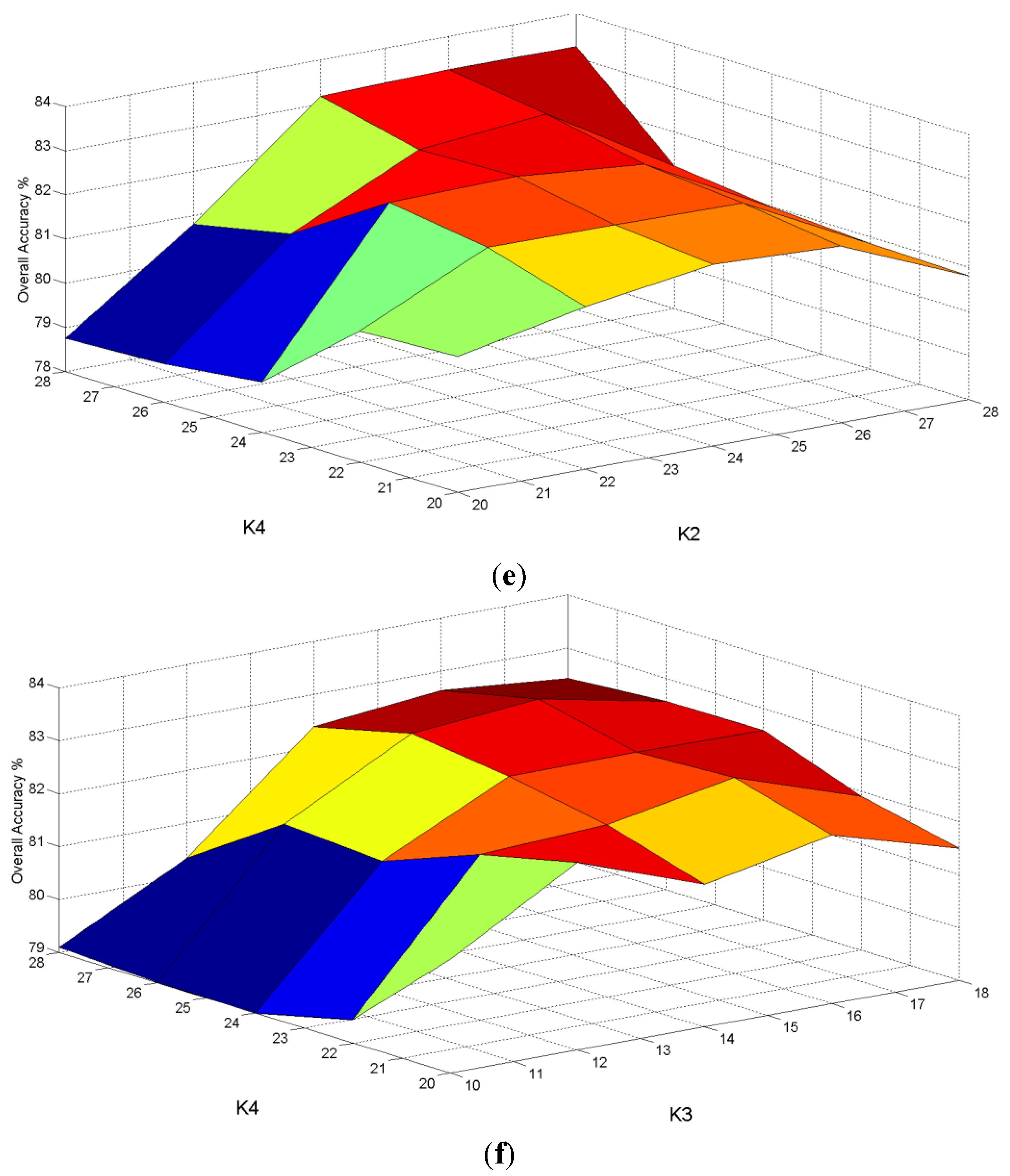
were chosen. After that, the transformation was obtained from the whole training set. A sensitivity analysis on four parameters
and
was done as shown in
Figure 10. In
Figure 10a, the variances of classification rates were relatively low for parameters
versus . In contrast, from
Figure 10b–f, parameters
and
resulted in a higher variance of classification rates. In other words, the NFLE parameters
and
were not sensitive to the classification rates, and the parameters
and
of fuzzy
k nearest neighbor were sensitive to the classification rates. According to the results of the sensitivity analysis of the four parameters, the parameters selected in the proposed algorithm were
,
,
, and
, which are consistent with the parameters in the cross-validation test.
Table 7.
The classification performance using various k-NN for data set IPS-10 (in percentage).
Table 7.
The classification performance using various k-NN for data set IPS-10 (in percentage).
| | FKNFLE | KNFLE | FNFLE | NFLE |
|---|
| k-Value | k-Value | k-Value | k-Value |
|---|
| 1 | 3 | 4 | 1 | 3 | 4 | 1 | 3 | 4 | 1 | 3 | 4 |
|---|
| IPS-10 | 83.34 | 84.19 | 85.11 | 83.07 | 83.55 | 84.19 | 78.37 | 78.98 | 79.10 | 77.59 | 78.89 | 78.93 |
| Pavia City Center | 97.59 | 98.18 | 98.24 | 96.55 | 96.84 | 96.88 | 95.08 | 95.32 | 95.51 | 94.58 | 95.26 | 95.41 |
| Pavia University | 91.31 | 92.13 | 92.36 | 89.50 | 90.04 | 90.19 | 85.10 | 86.05 | 86.57 | 83.80 | 84.63 | 85.05 |
Figure 10.
The sensitivity analysis of four parameters , , , . (a) vs. ; (b) vs. ; (c) vs. ; (d) vs. ; (e) vs. ; (f) vs. .
Figure 10.
The sensitivity analysis of four parameters , , , . (a) vs. ; (b) vs. ; (c) vs. ; (d) vs. ; (e) vs. ; (f) vs. .
Furthermore, due to the proposed algorithm being based on kernelization and fuzzification, the performance comparison between the proposed algorithms and the well-known kernelization-based algorithm GCK-MLR (Generalized composite kernel-multinomial logistic regression) [
17,
30] is illustrated in
Table 8 and
Table 9. Basically, algorithm GCK-MLR is a multinomial logistic regression (MLR)-based classifier of composite kernels in which four kernels, spectral, spatial, spectral-spatial cross information, and spatial-spectral cross information kernels, deeply impact the classification results. The training configurations in [
17] were quite different from ours. Besides, it is unfair for comparing the results of a single kernel (KNFLE) method with those of multi-kernels (GCK-MLR). In the experiment, we re-trained the classifier using the same configurations of [
17]. The training configurations and classification results have directly been referred from [
17]. Moreover, only the results using a single spectral kernel
were used for the fair comparison. Datasets IPS of 16 classes and Pavia University were evaluated as shown in
Table 8 and
Table 9, respectively. Considering the IPS dataset of 16 classes in
Table 8, algorithm GCK-MLR outperforms the proposed method at the overall accuracy index, while the average accuracy rate is lower than those of algorithms FKNFLE and KNFLE. In
Table 9, the overall accuracy and average accuracy rates of the proposed method are both higher than those of algorithm GCK-MLR.
Table 8.
The comparison between algorithm GCK-MLR () and the proposed method for dataset IPS of 16 classes (in percent).
Table 8.
The comparison between algorithm GCK-MLR () and the proposed method for dataset IPS of 16 classes (in percent).
| Class | Number of Samples | GCK-MLR () | FKNFLE | KNFLE |
|---|
| Train | Test |
|---|
| Alfalfa | 3 | 51 | 47.06 ± 15.41 | 65.22 ± 15.32 | 56.52 ± 16.42 |
| Corn-no till | 71 | 1363 | 78.24 ± 3.01 | 70.66 ± 3.05 | 67.44 ± 3.03 |
| Corn-min till | 41 | 793 | 64.17 ± 3.01 | 67.71 ± 3.04 | 71.08 ± 3.05 |
| Corn | 11 | 223 | 48.211 ± 1.76 | 43.88 ± 11.54 | 47.68 ± 12.14 |
| Grass/pasture | 24 | 473 | 87.76 ± 2.27 | 84.47 ± 2.18 | 87.16 ± 2.58 |
| Grass/tree | 37 | 710 | 95.13 ± 1.40 | 96.58 ± 1.42 | 94.79 ± 1.32 |
| Grass/pasture-mowed | 3 | 23 | 53.04 ± 11.74 | 92.86 ± 11.88 | 92.82 ± 10.68 |
| Hay-windrowed | 24 | 465 | 98.84 ± 0.61 | 97.28 ± 0.59 | 98.12 ± 0.62 |
| Oats | 3 | 17 | 68.82 ± 17.33 | 65.10 ± 16.31 | 70.12 ± 15.35 |
| Soybeans-no till | 48 | 920 | 68.42 ± 5.22 | 70.27 ± 5.12 | 66.87 ± 5.42 |
| Soybeans-min till | 123 | 2245 | 82.56 ± 1.26 | 77.43 ± 1.31 | 73.93 ± 1.25 |
| Soybeans-clean till | 30 | 584 | 74.52 ± 5.35 | 62.56 ± 5.32 | 61.89 ± 5.52 |
| Wheat | 10 | 202 | 99.36 ± 0.52 | 91.71 ± 0.54 | 94.63 ± 0.51 |
| Woods | 64 | 1230 | 95.46 ± 1.53 | 96.60 ± 1.49 | 97.15 ± 1.54 |
| Bldg-grass-tree-drives | 19 | 361 | 50.75 ± 3.49 | 38.34 ± 3.18 | 48.19 ± 3.38 |
| Stone-steel towers | 4 | 91 | 62.09 ± 6.95 | 82.80 ± 6.89 | 83.87 ± 6.59 |
| Overall accuracy | 80.16 ± 0.73 | 77.19 ± 0.71 | 76.43 ± 0.73 |
| Average accuracy | 73.40 ± 1.26 | 75.22 ± 1.21 | 75.76 ± 1.25 |
Table 9.
The comparison between algorithm GCK-MLR () and the proposed method for dataset Pavia University of nine classes (in percent).
Table 9.
The comparison between algorithm GCK-MLR () and the proposed method for dataset Pavia University of nine classes (in percent).
| Class | Number of Samples | GCK-MLR () | FKNFLE | KNFLE |
|---|
| Train | Test |
|---|
| Asphalt | 548 | 6631 | 82.64 | 83.14 | 82.64 |
| Bare soil | 540 | 18,649 | 68.62 | 82.89 | 82.07 |
| Bitumen | 392 | 2099 | 75.04 | 81.75 | 79.32 |
| Bricks | 524 | 3064 | 97.00 | 93.21 | 92.95 |
| Gravel | 265 | 1345 | 99.41 | 99.93 | 99.93 |
| Meadows | 532 | 5029 | 93.88 | 80.47 | 79.48 |
| Metal Sheets | 375 | 1330 | 90.08 | 92.26 | 92.41 |
| Shadows | 514 | 3682 | 91.36 | 85.61 | 85.17 |
| Trees | 231 | 947 | 97.57 | 99.89 | 99.89 |
| Overall accuracy | 80.34 | 85.76 | 84.04 |
| Average accuracy | 88.40 | 88.79 | 88.20 |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




















