
Geodesic Flow Kernel Support Vector Machine for Hyperspectral Image Classification by Unsupervised Subspace Feature Transfer



Abstract
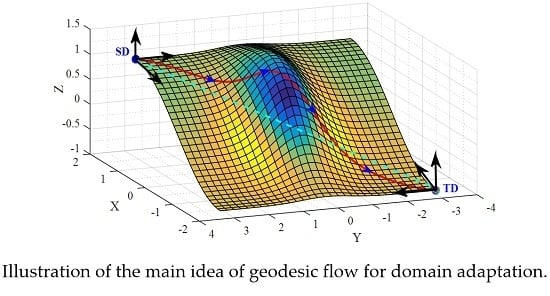
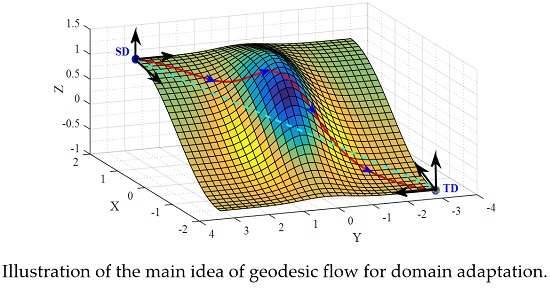
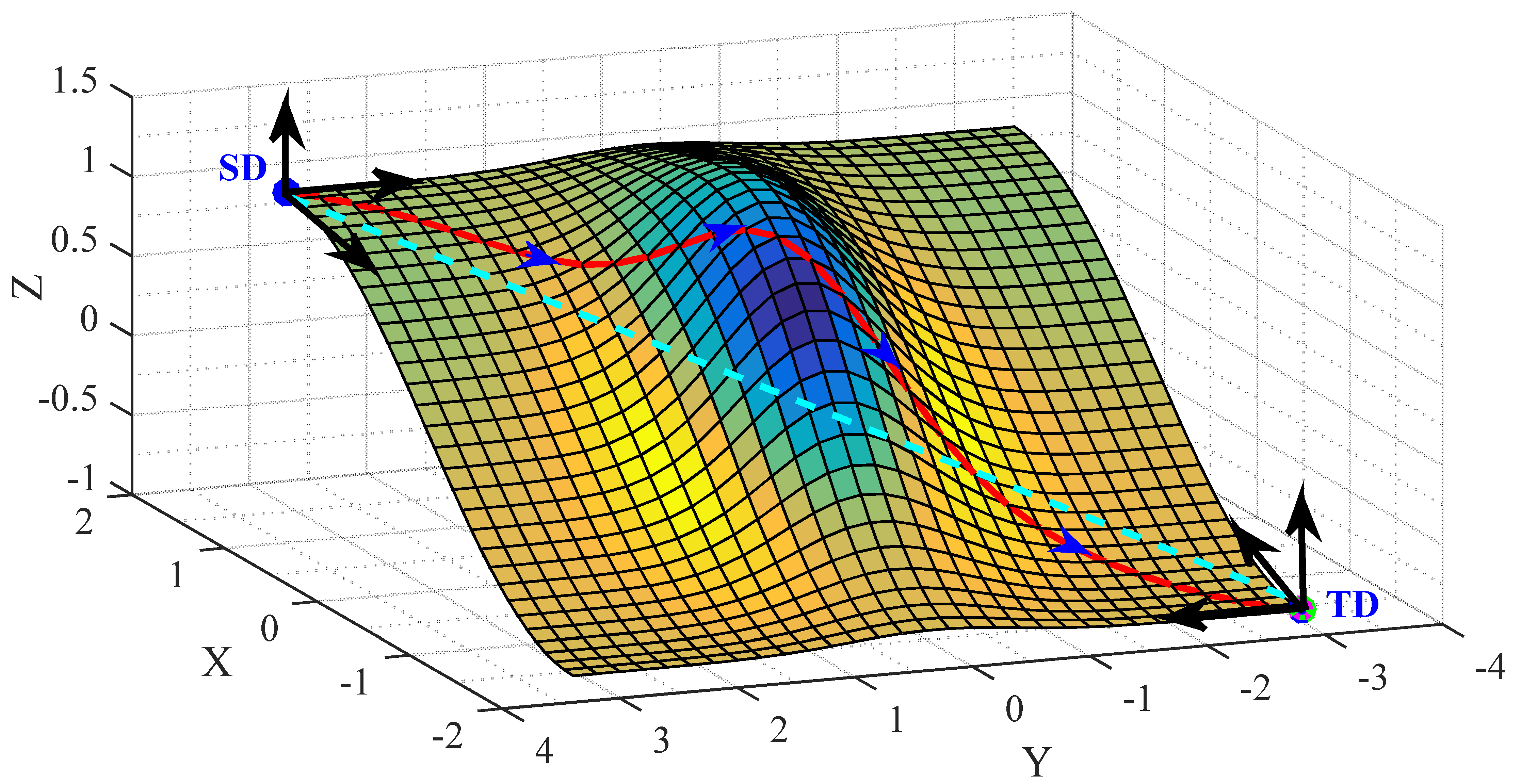
:
1. Introduction
- (1)
- to propose and investigate geodesic Gaussian flow kernel SVM when hyperspectral image classification requires domain adaptation;
- (2)
- (3)
- to compare the proposed methodology with conventional support vector machines (SVMs) and state-of-the-art DA algorithms, such as the information-theoretical learning of discriminative cluster for domain adaptation (ITLDC) [44], the joint distribution adaptation (JDA) [45], and the joint transfer matching (JTM) [46].
2. GFKSVM
2.1. Related Works
2.2. Geodesic Flow for DA
2.3. Geodesic Flow Kernel SVM
| Algorithm 1: GFKSVM |
Inputs:
|
Train:
|
Classify:
|
3. Datasets and Setup
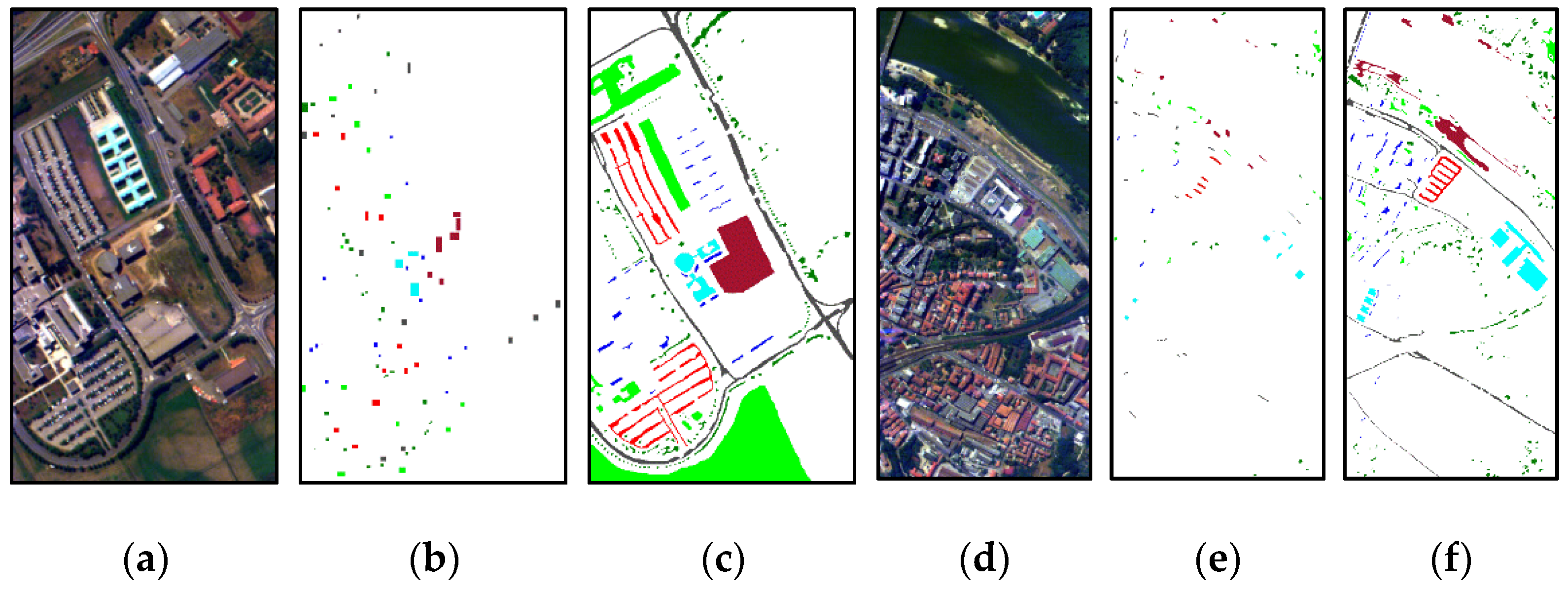
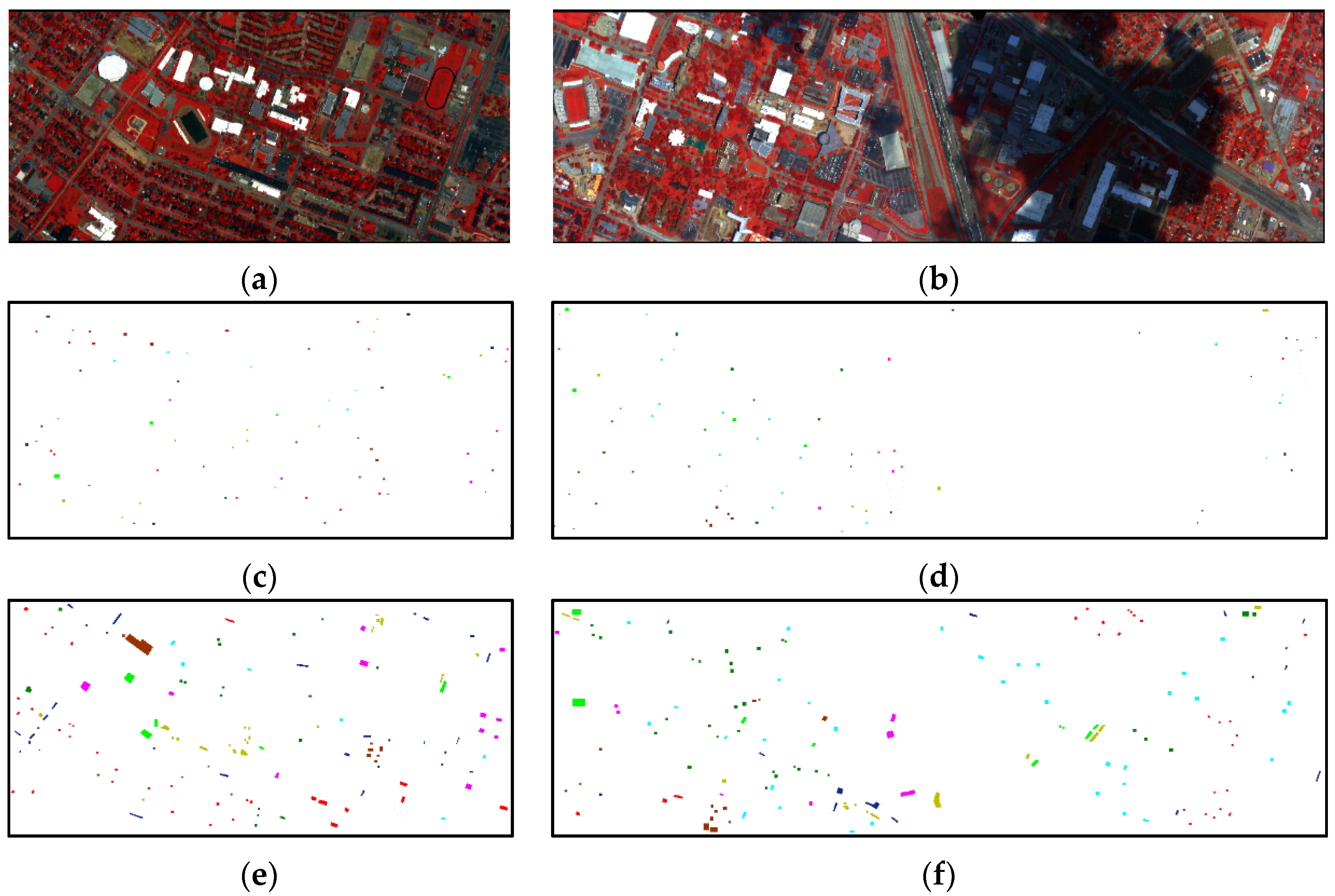
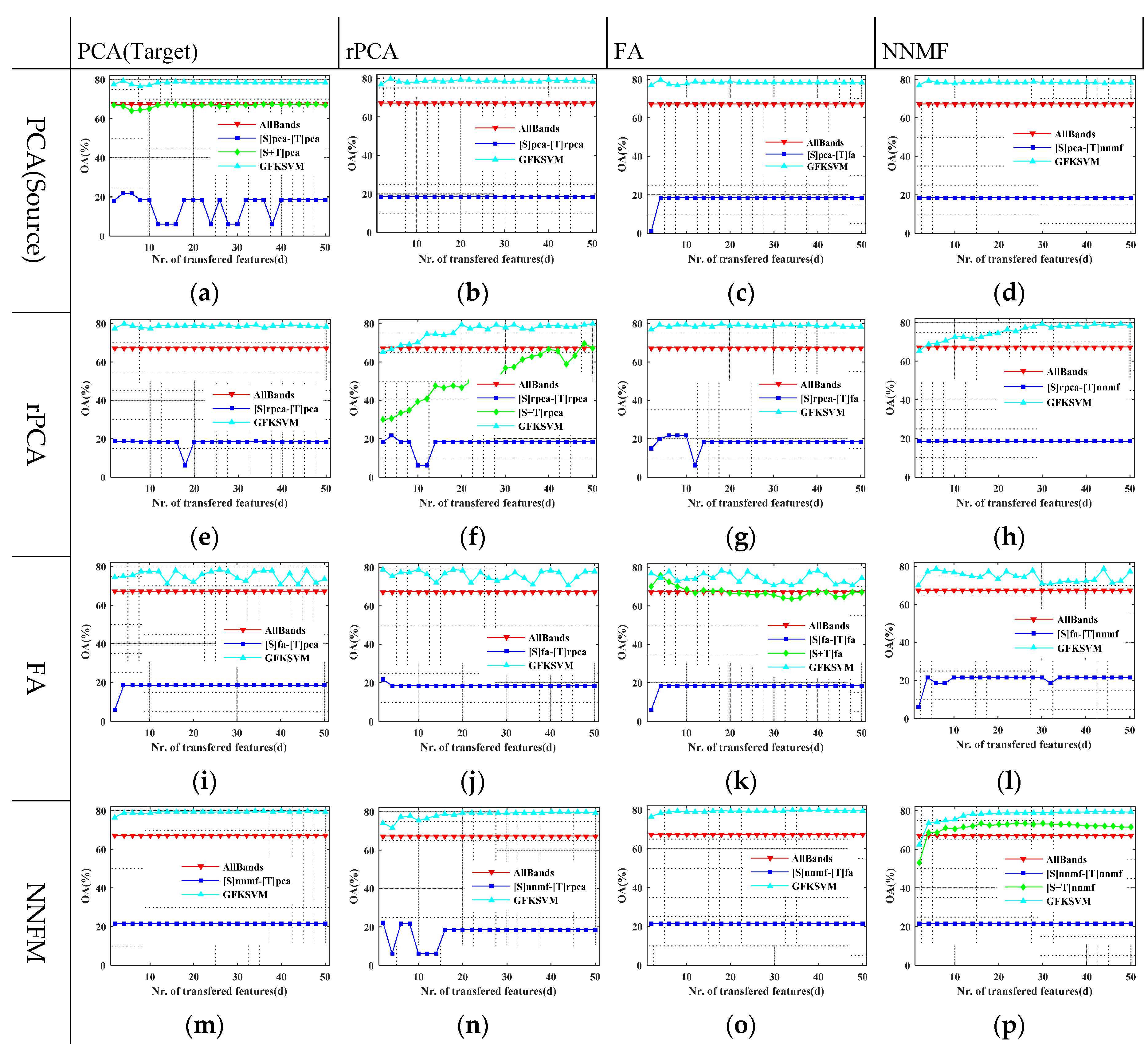
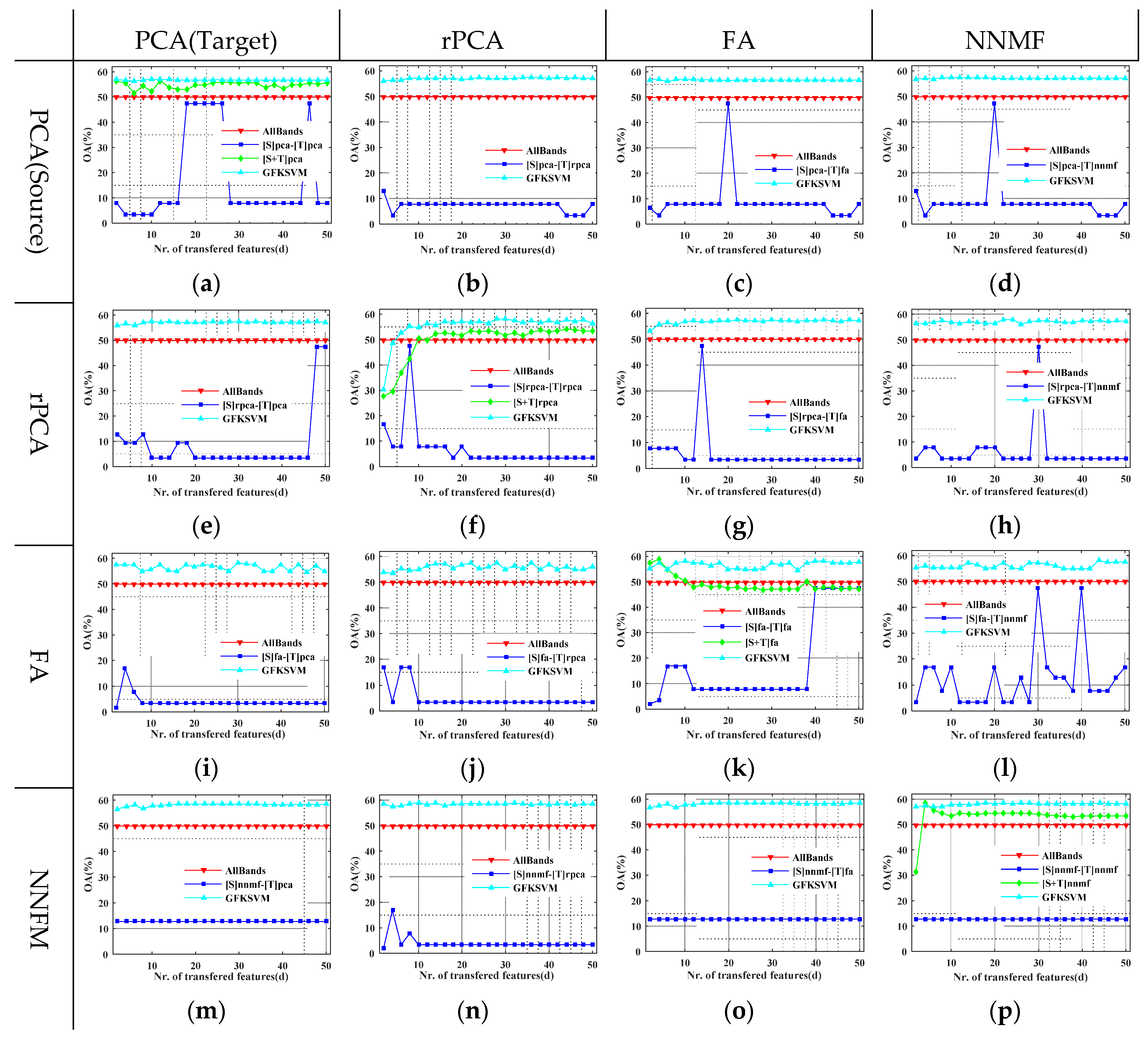
3.1. Datasets Descriptions
3.2. Experimental Setup
4. Experimental Results
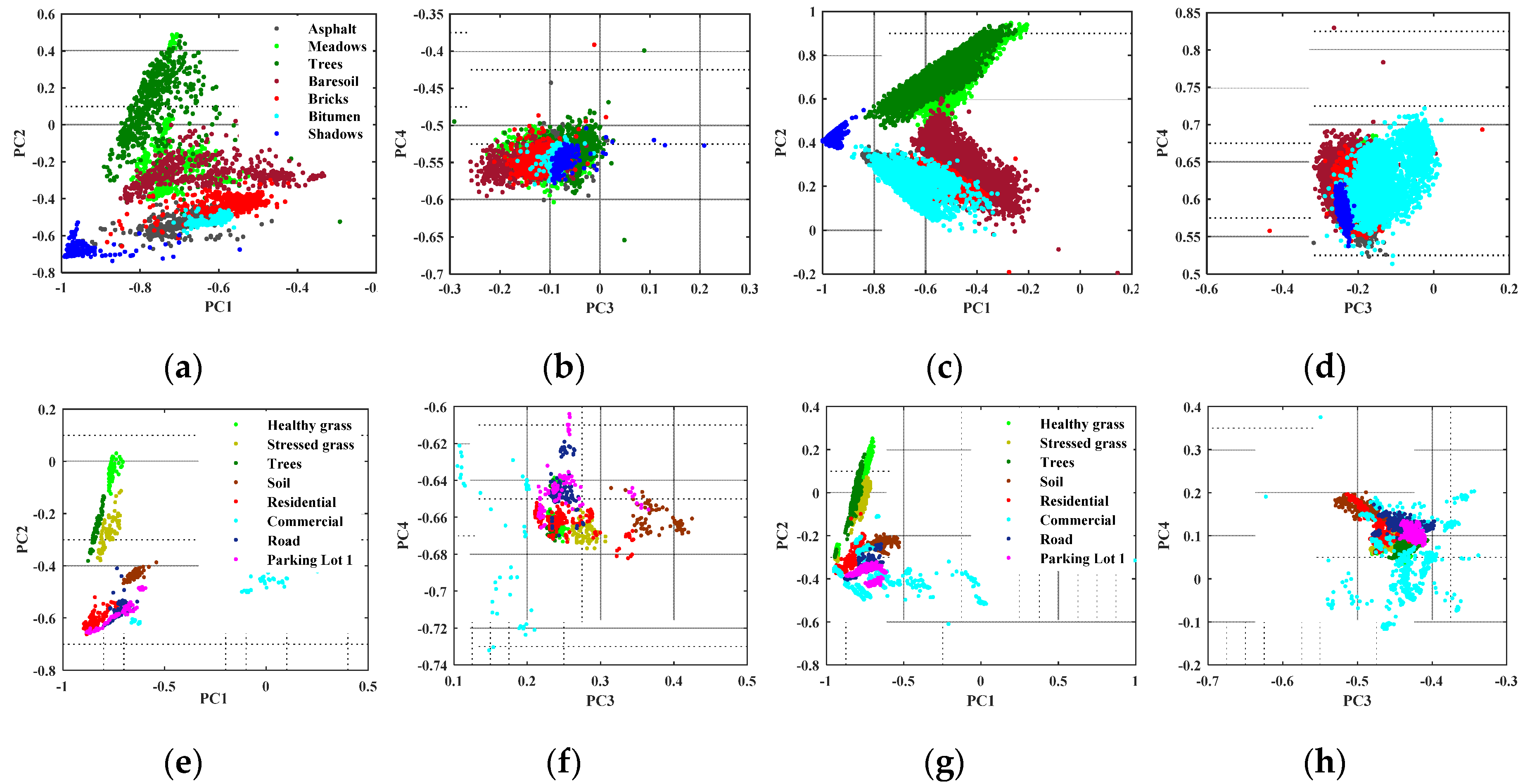
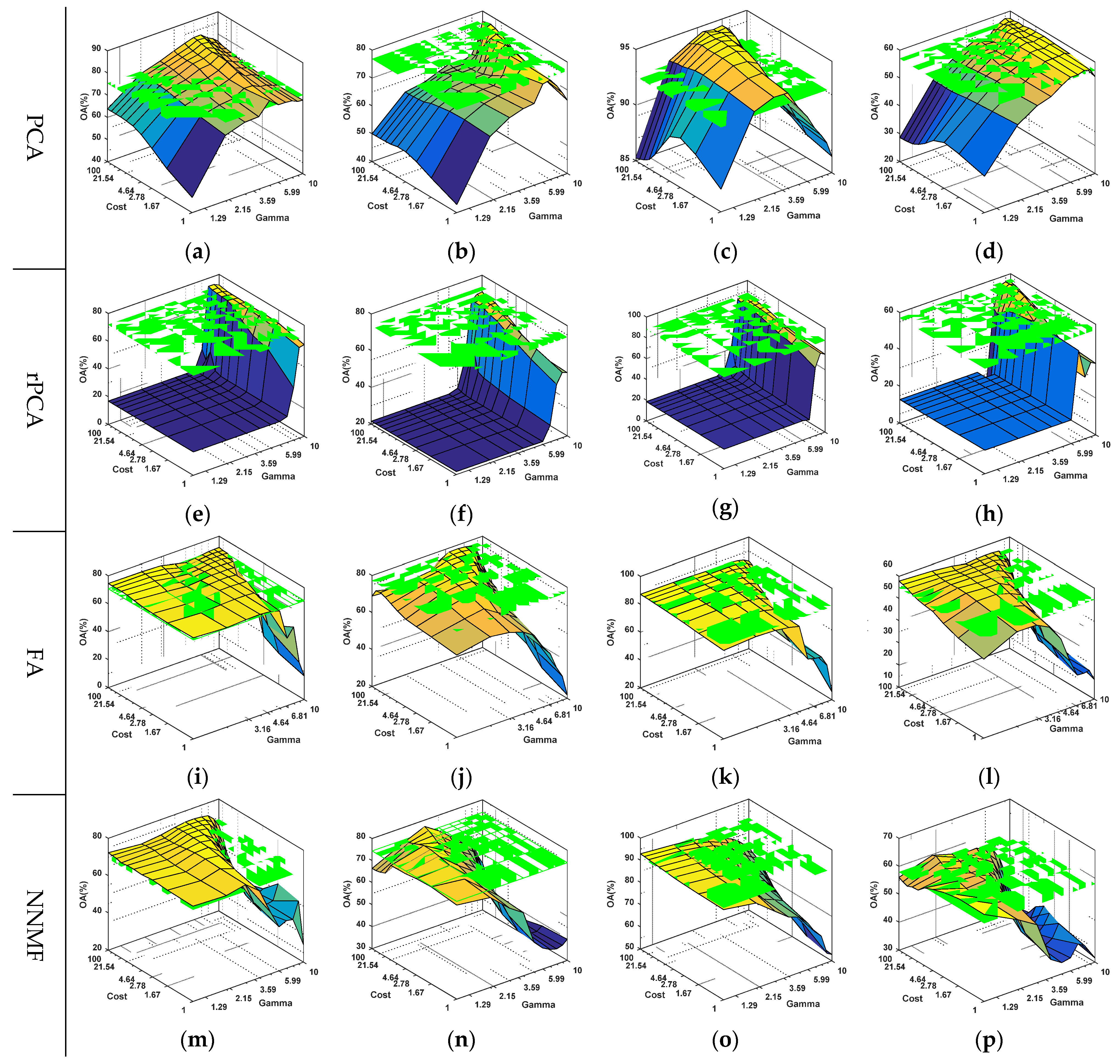
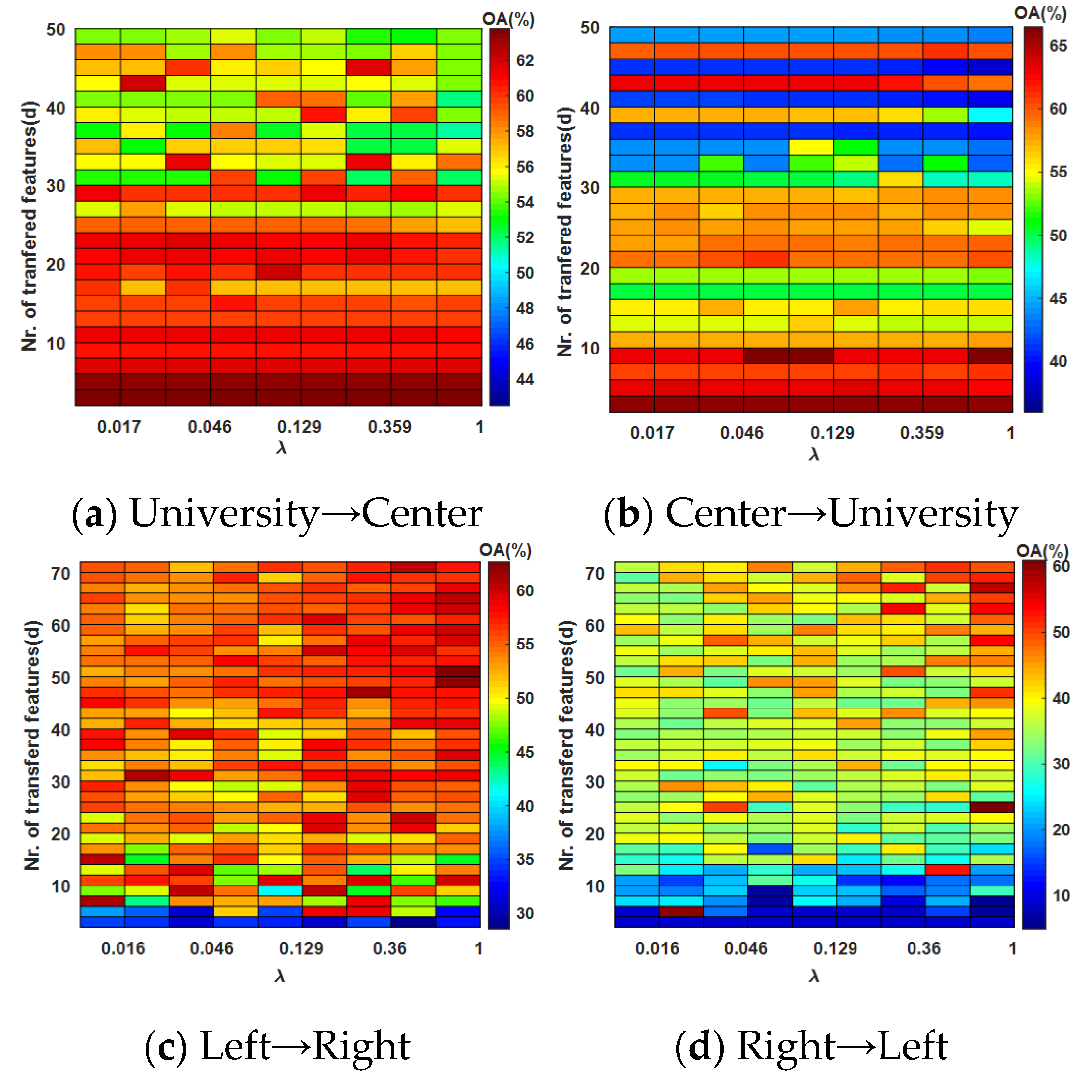
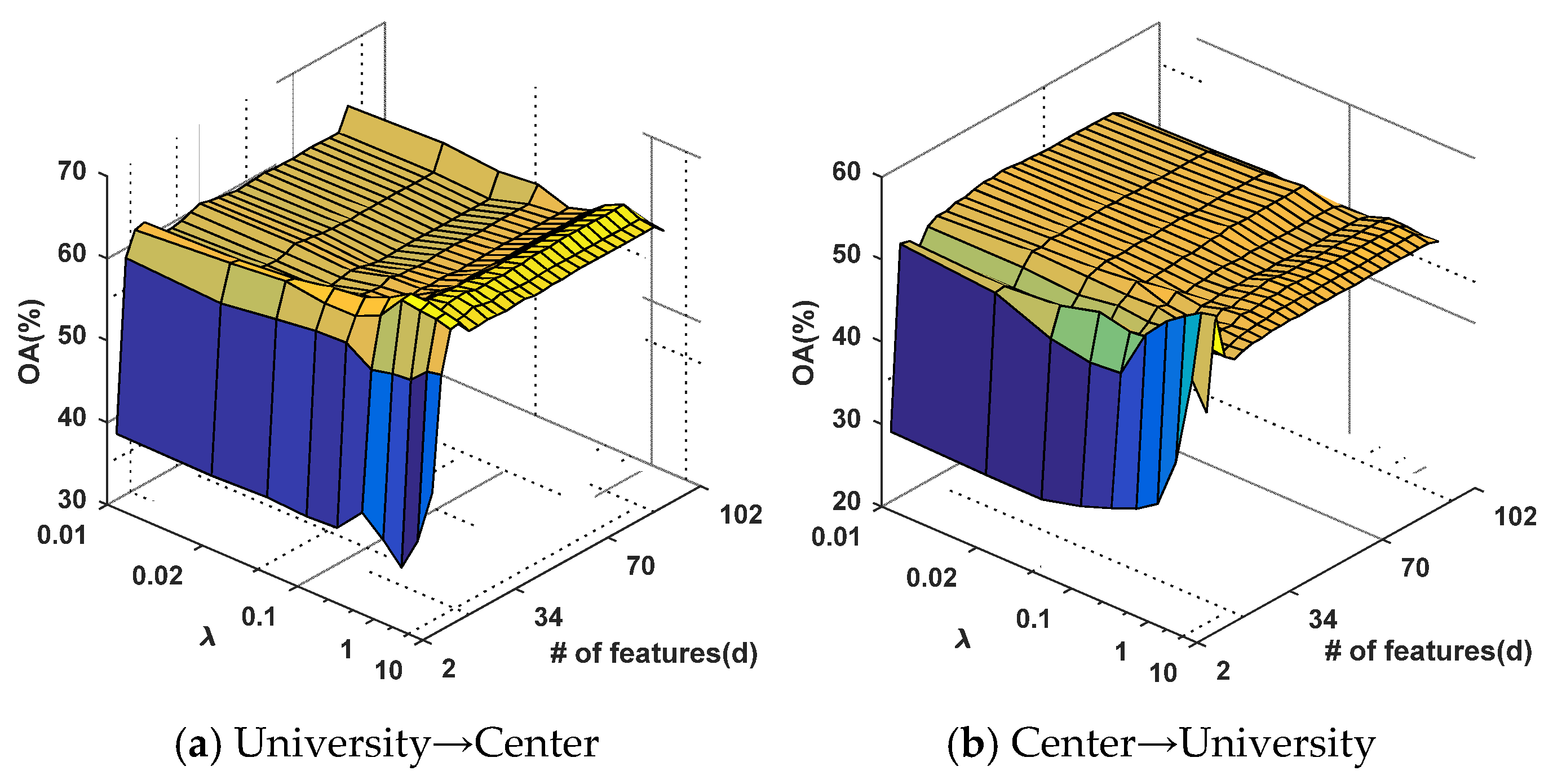
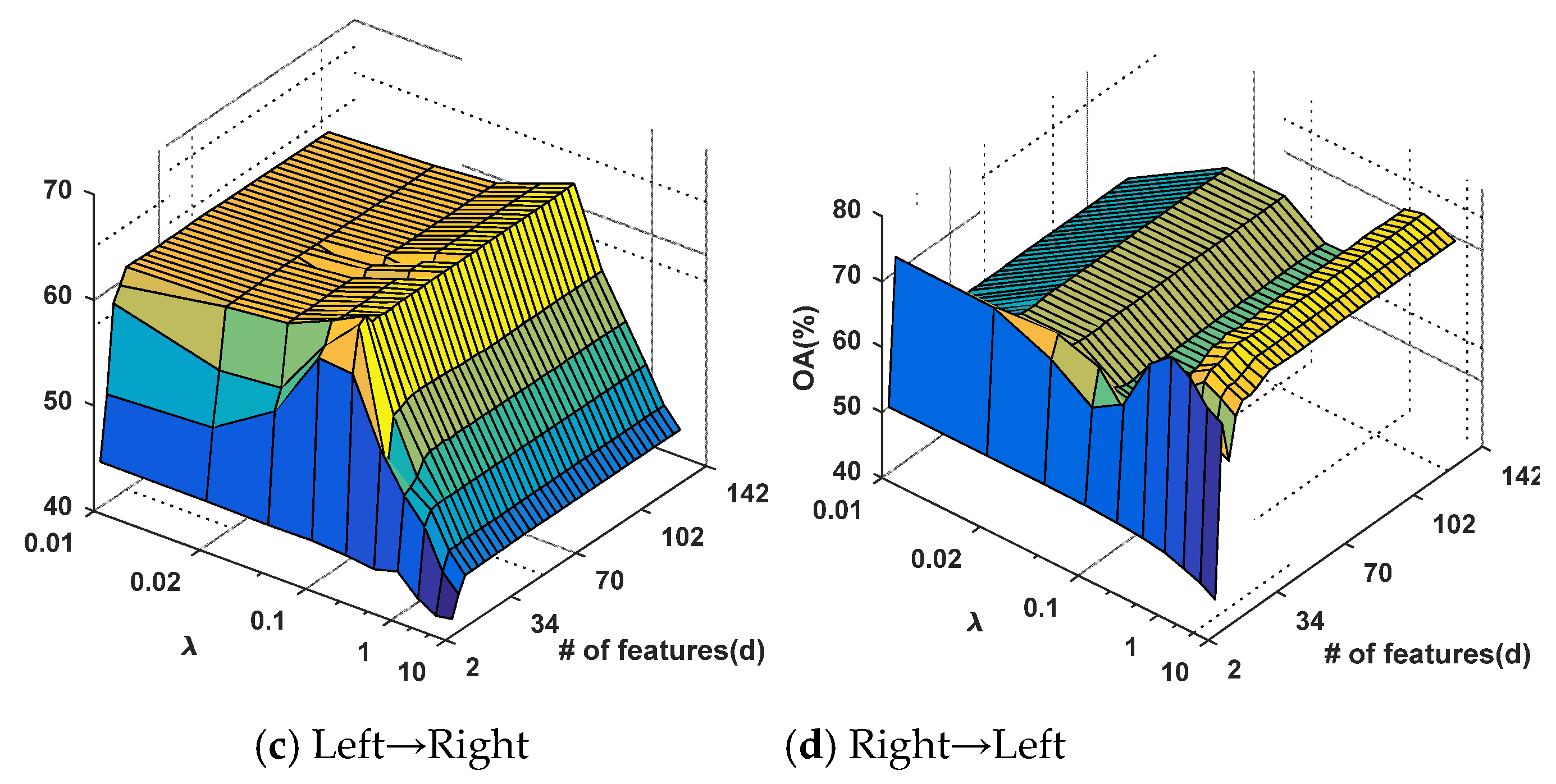
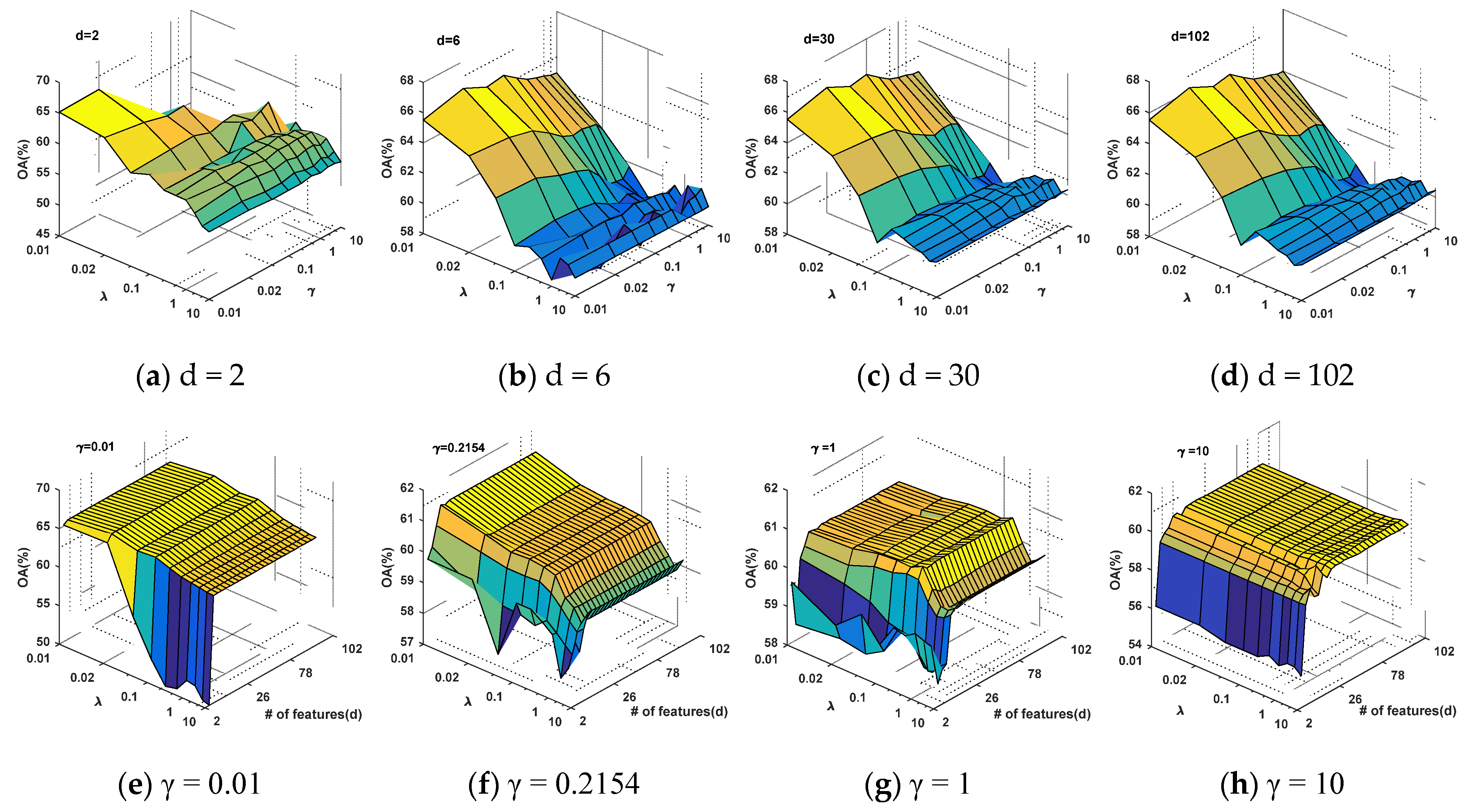
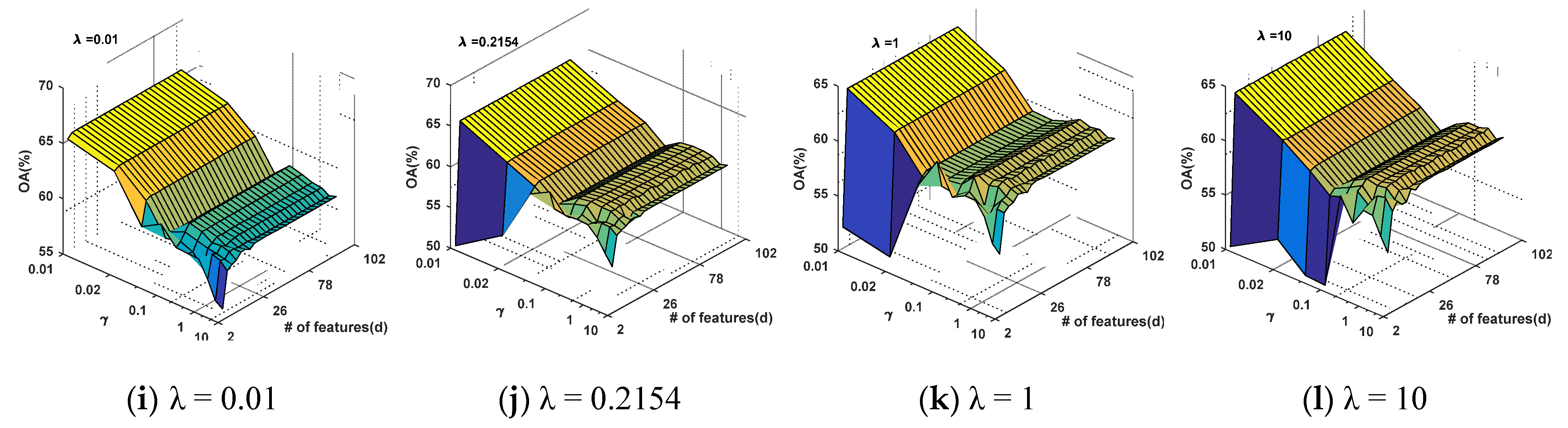
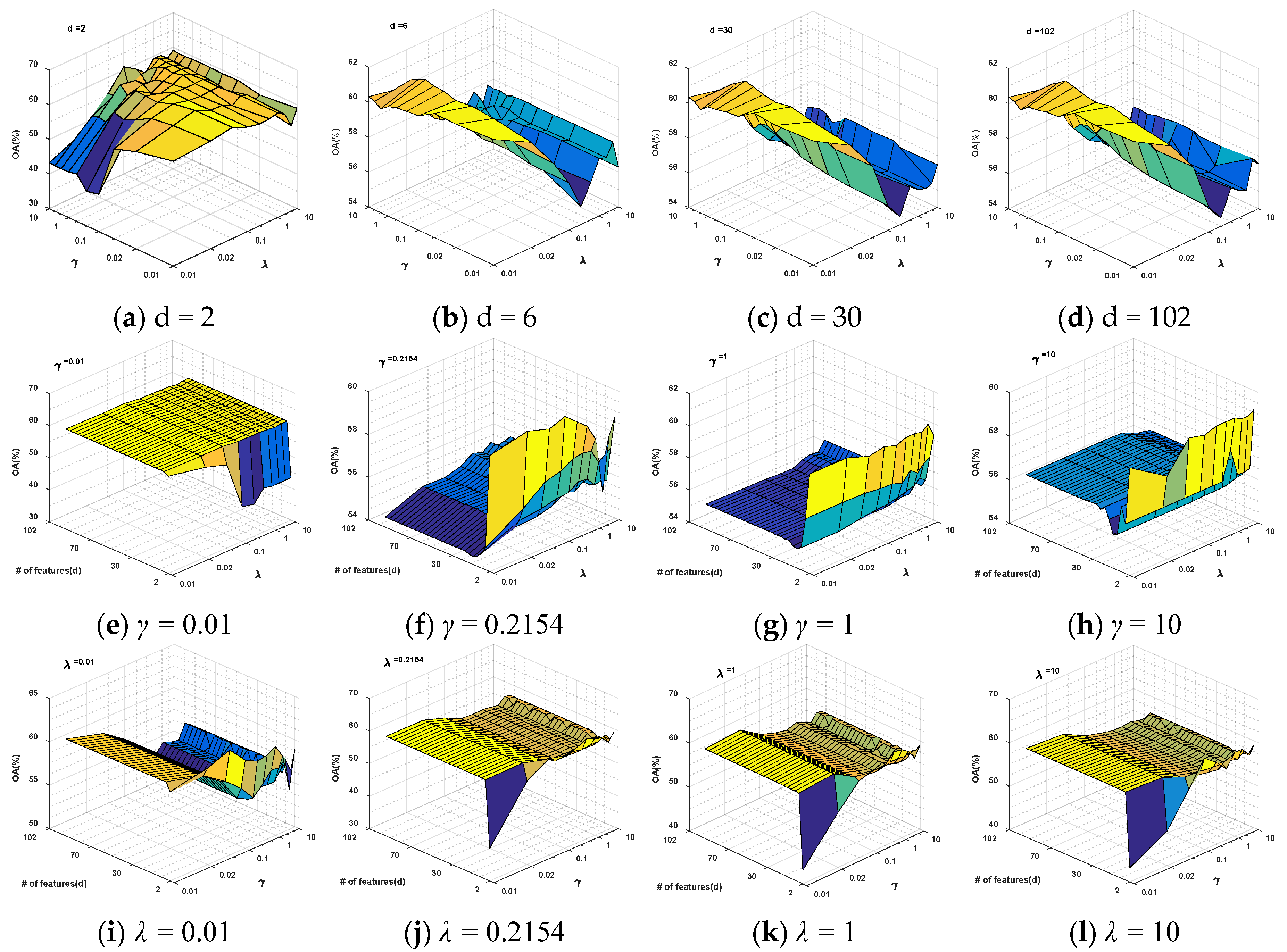
4.1. Parameter Evaluation
4.1.1. Kernel Parameter Evaluation for GFKSVM
4.1.2. Parameter Evaluation for rPCA
4.1.3. Parameter Evaluation for ITLDC
4.1.4. Parameter Evaluation for JDA
4.1.5. Parameter Evaluation for JTM
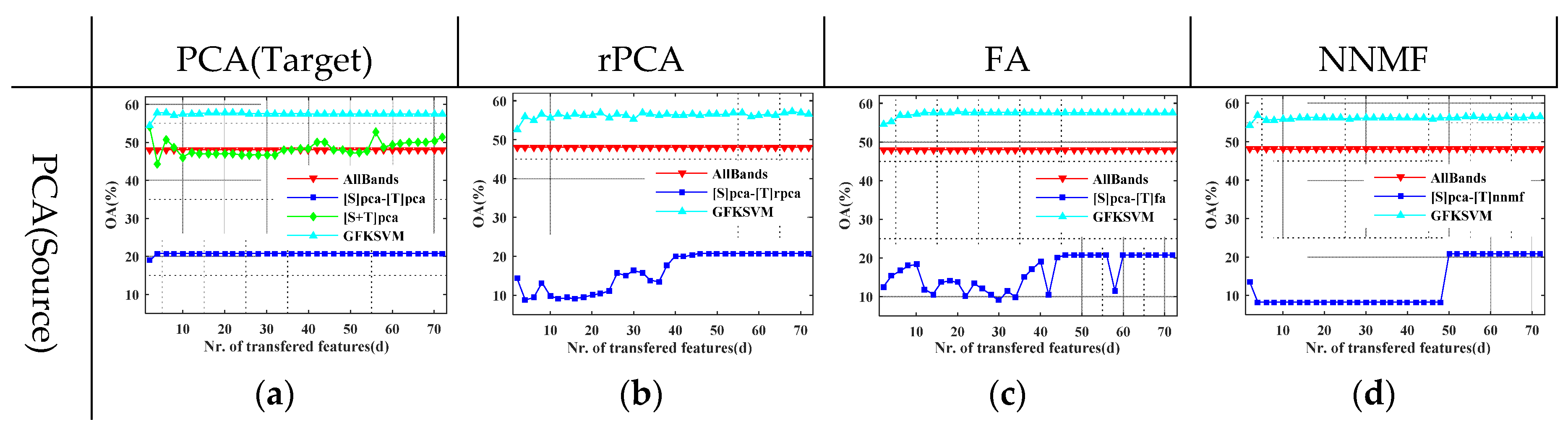
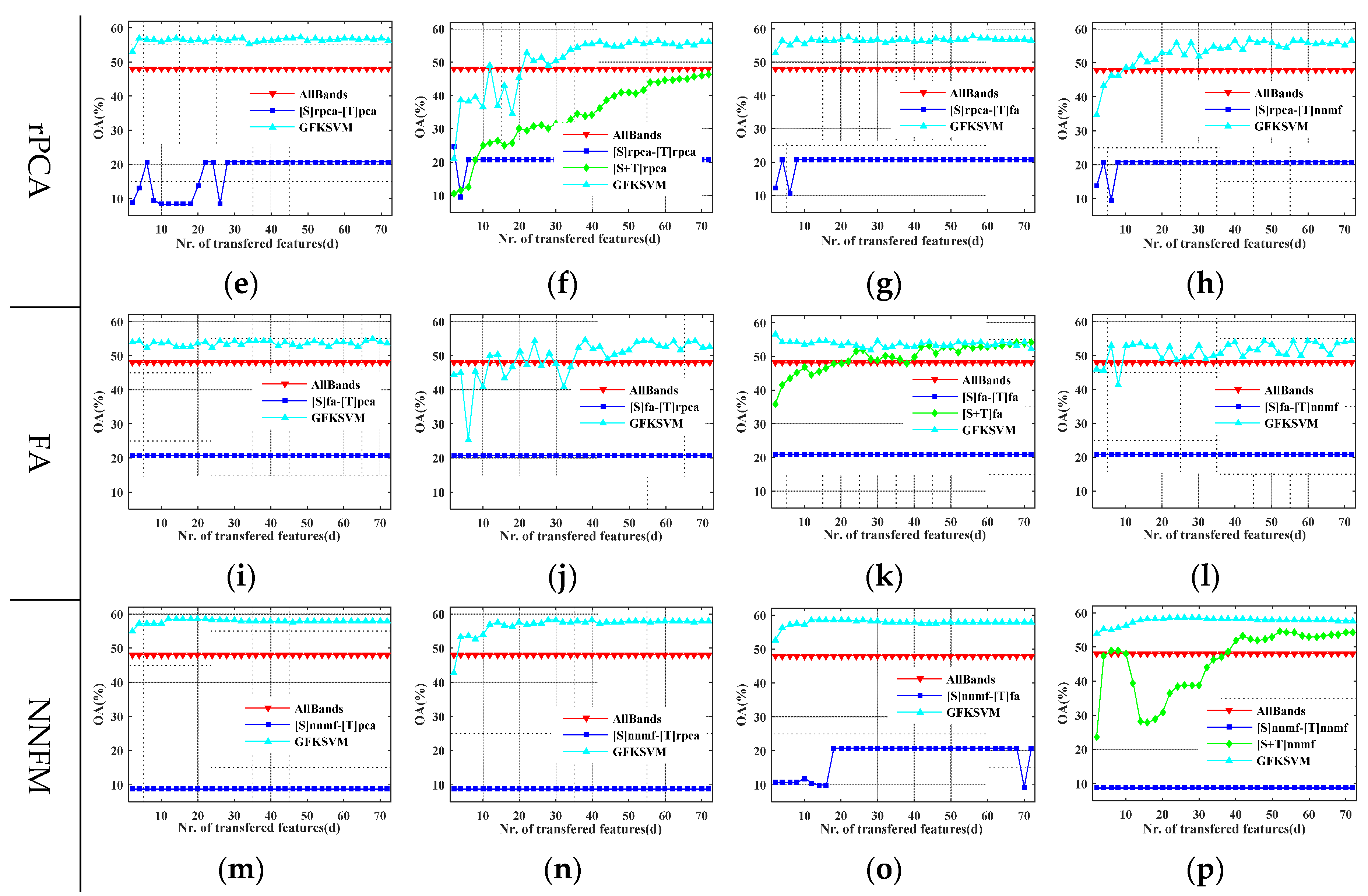
4.2. Evaluation of GFKSVM with Different Feature Transfer Approaches
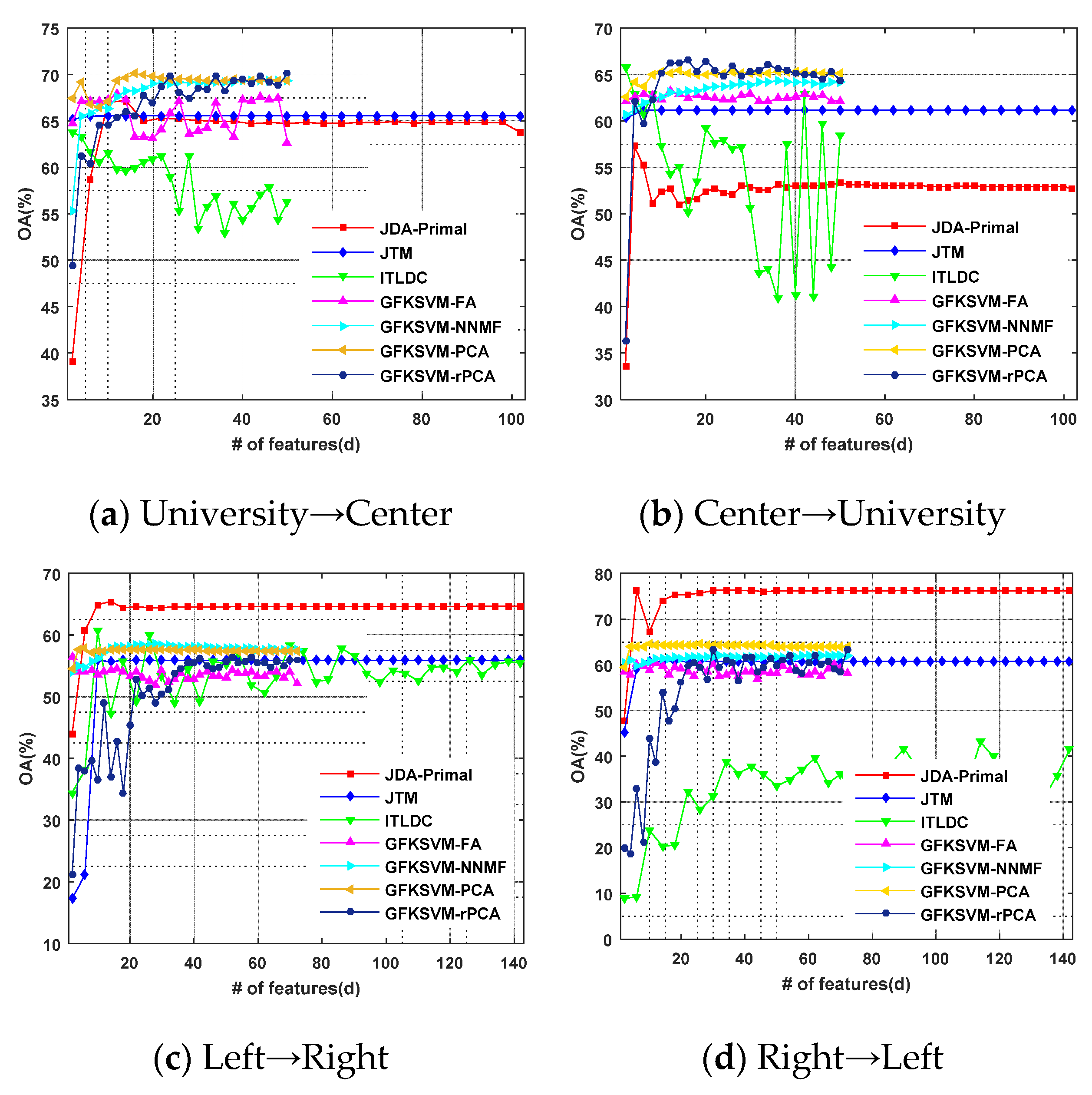
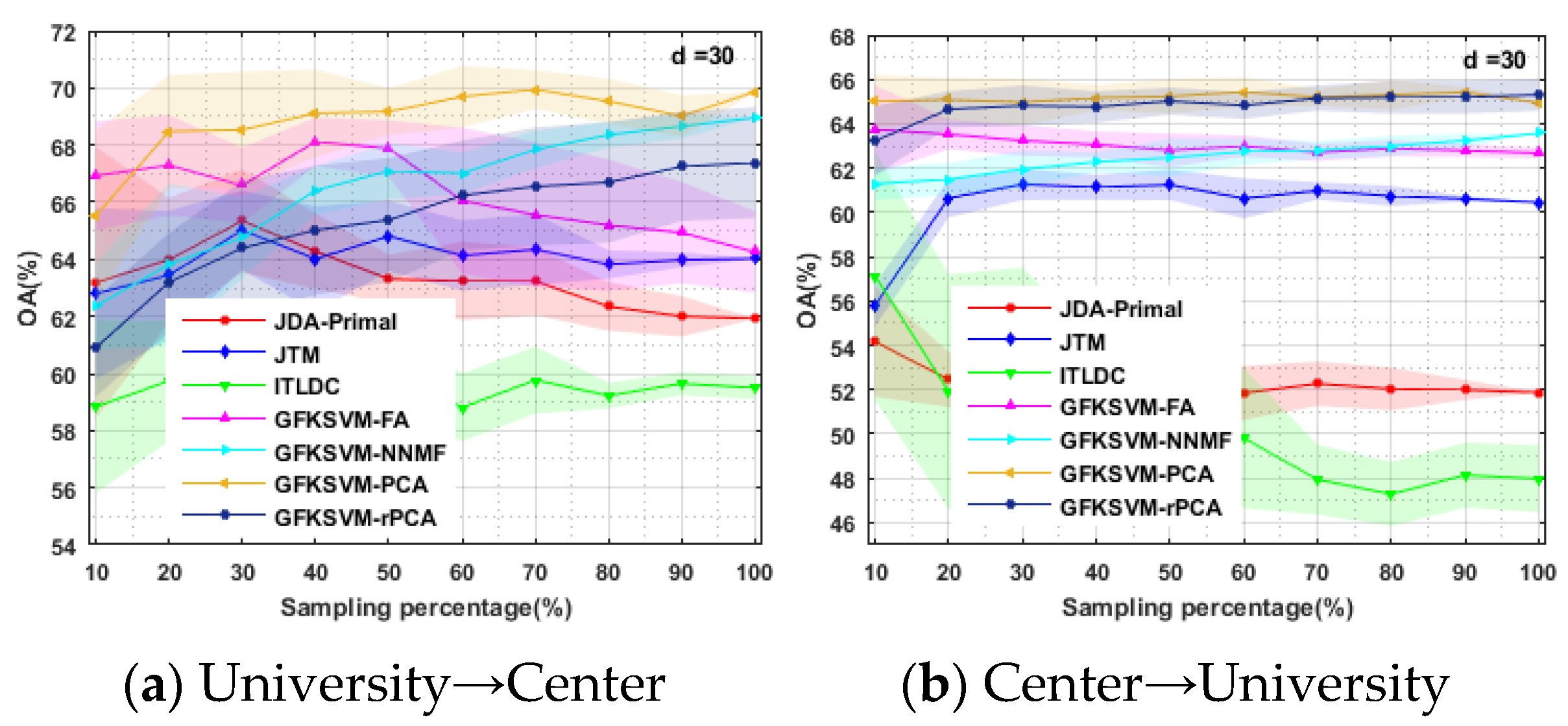
4.3. GFKSVM vs. State-of-the-Art DA Algorithms
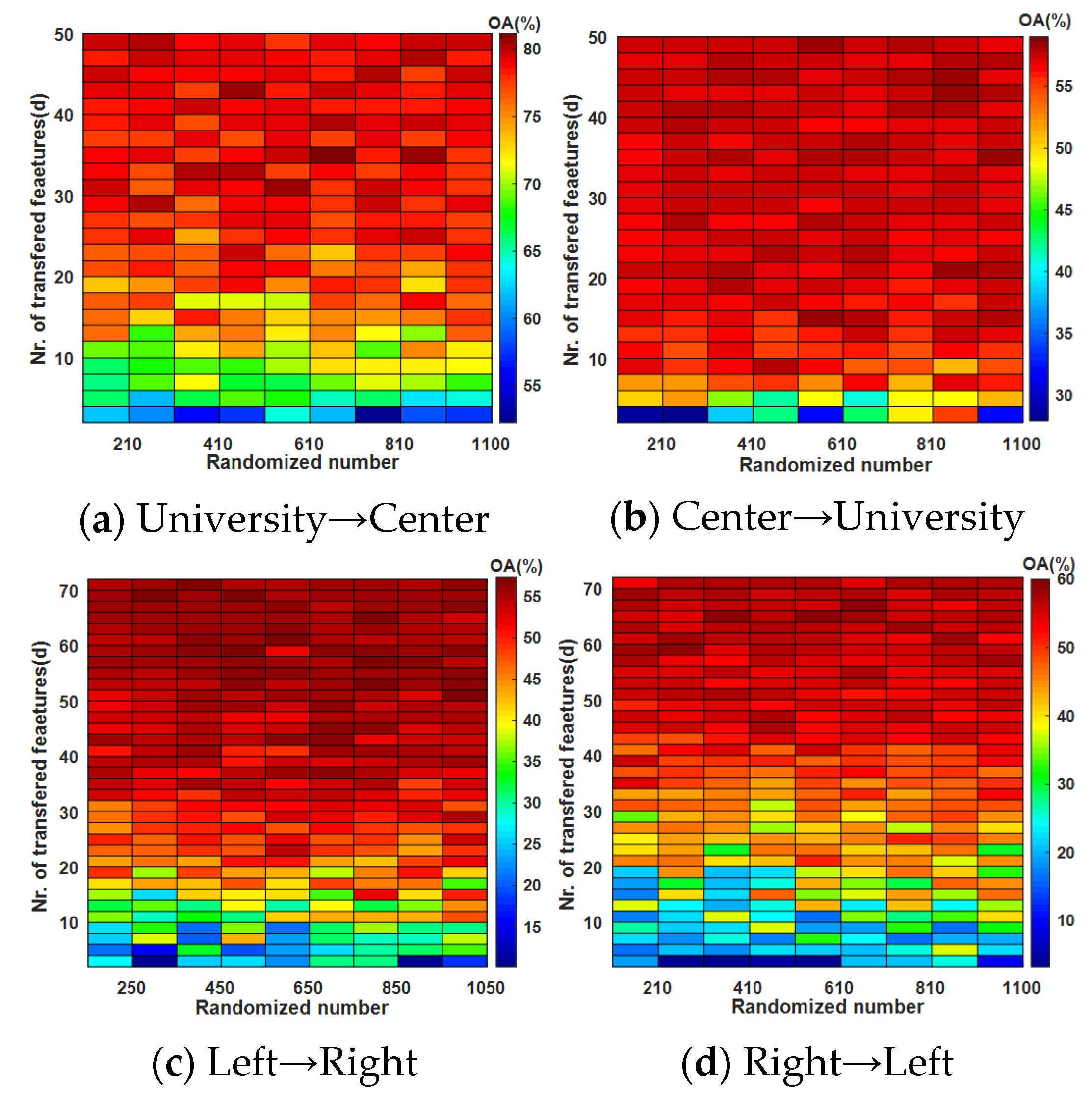
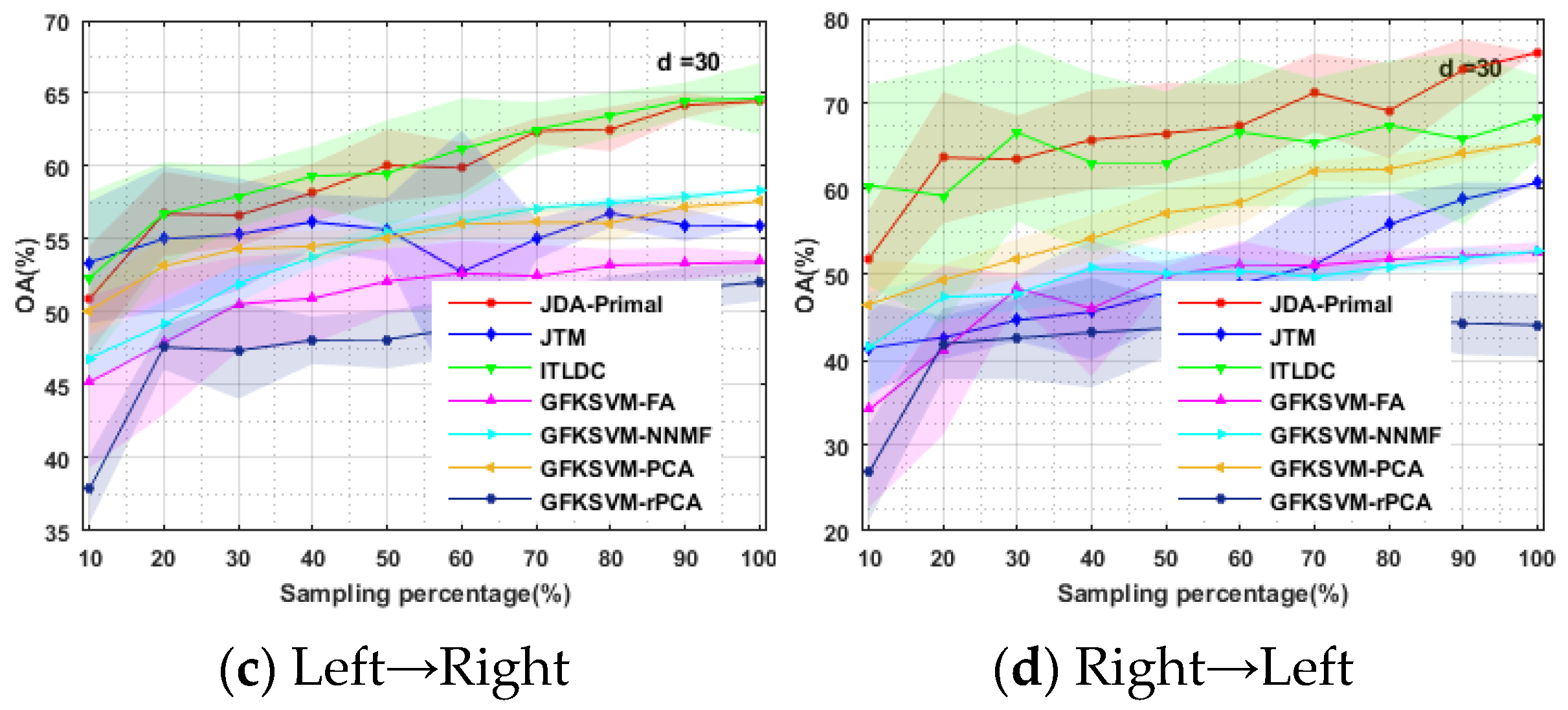
4.4. Influence of the Source Domain Sample Size
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Camps-Valls, G.; Bruzzone, L. Kernel-based methods for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1351–1362. [Google Scholar] [CrossRef]
- Chi, M.; Bruzzone, L. Semisupervised classification of hyperspectral images by SVMs optimized in the primal. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1870–1880. [Google Scholar] [CrossRef]
- Samat, A.; Du, P.; Liu, S.; Li, J.; Cheng, L. E2LM: Ensemble Extreme Learning Machines for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. 2014, 7, 1060–1069. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Bruzzone, L.; Cossu, R. A multiple-cascade-classifier system for a robust and partially unsupervised updating of land-cover maps. IEEE Trans. Geosci. Remote Sens. 2002, 40, 1984–1996. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Gómez-Chova, L.; Muñoz-Marí, J.; Rojo-Álvarez, J.L.; Martínez-Ramón, M. Kernel-based framework for multitemporal and multisource remote sensing data classification and change detection. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1822–1835. [Google Scholar] [CrossRef]
- Bruzzone, L.; Prieto, D.F. Unsupervised retraining of a maximum likelihood classifier for the analysis of multitemporal remote sensing images. IEEE Trans. Geosci. Remote Sens. 2001, 39, 456–460. [Google Scholar] [CrossRef]
- Samat, A.; Li, J.; Liu, S.; Du, P.; Miao, Z.; Luo, J. Improved hyperspectral image classification by active learning using pre-designed mixed pixels. Pattern Recognit. 2016, 51, 43–58. [Google Scholar] [CrossRef]
- Izquierdo-Verdiguier, E.; Gómez-Chova, L.; Bruzzone, L.; Camps-Valls, G. Semisupervised kernel feature extraction for remote sensing image analysis. IEEE Trans. Geosci. Remote Sens. 2014, 52, 5567–5578. [Google Scholar] [CrossRef]
- Curlander, J.C. Location of spaceborne SAR imagery. IEEE Trans. Geosci. Remote Sens. 1982, 2, 359–364. [Google Scholar] [CrossRef]
- Sugiyama, M.; Storkey, A.J. Mixture regression for covariate shift. In Advances in Neural Information Processing Systems; NIPS proceedings: Vancouver, CO, Canada, 2006; pp. 1337–1344. [Google Scholar]
- Huang, J.; Gretton, A.; Borgwardt, K.M.; Schölkopf, B.; Smola, A.J. Correcting sample selection bias by unlabeled data. In Advances in Neural Information Processing Systems; NIPS proceedings: Vancouver, CO, Canada, 2006; pp. 601–608. [Google Scholar]
- Schott, J.R.; Salvaggio, C.; Volchok, W.J. Radiometric scene normalization using pseudoinvariant features. Remote Sen. Environ. 1988, 26, 1–16. [Google Scholar] [CrossRef]
- Woodcock, C.E.; Macomber, S.A.; Pax-Lenney, M.; Cohen, W.B. Monitoring large areas for forest change using Landsat: Generalization across space, time and Landsat sensors. Remote Sens. Environ. 2011, 78, 194–203. [Google Scholar] [CrossRef]
- Olthof, I.; Butson, C.; Fraser, R. Signature extension through space for northern landcover classification: A comparison of radiometric correction methods. Remote Sens. Environ. 2005, 95, 290–302. [Google Scholar] [CrossRef]
- Rakwatin, P.; Takeuchi, W.; Yasuoka, Y. Stripe noise reduction in MODIS data by combining histogram matching with facet filter. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1844–1856. [Google Scholar] [CrossRef]
- Inamdar, S.; Bovolo, F.; Bruzzone, L.; Chaudhuri, S. Multidimensional probability density function matching for preprocessing of multitemporal remote sensing images. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1243–1252. [Google Scholar] [CrossRef]
- Bruzzone, L.; Marconcini, M. Domain adaptation problems: A DASVM classification technique and a circular validation strategy. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 770–787. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Li, X. Domain adaptation for land use classification: A spatio-temporal knowledge reusing method. ISPRS J. Photogramm. Remote Sens. 2014, 98, 133–144. [Google Scholar] [CrossRef]
- Banerjee, B.; Bovolo, F.; Bhattacharya, A.; Bruzzone, L.; Chaudhuri, S.; Buddhiraju, K.M. A Novel Graph-Matching-Based Approach for Domain Adaptation in Classification of Remote Sensing Image Pair. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4045–4062. [Google Scholar] [CrossRef]
- Matasci, G.; Volpi, M.; Kanevski, M.; Bruzzone, L.; Tuia, D. Semisupervised Transfer Component Analysis for Domain Adaptation in Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3550–3564. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Evgeniou, T.; Pontil, M. Regularized multi-task learning. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2014; pp. 109–117.
- Daume, H., III; Marcu, D. Domain adaptation for statistical classifiers. J. Artificial Intell. Res. 2006, 26, 101–126. [Google Scholar]
- Foster, G.; Goutte, C.; Kuhn, R. Discriminative instance weighting for domain adaptation in statistical machine translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Cambridge, MA, USA, 9–11 October 2010; pp. 451–459.
- Jiang, J.; Zhai, C. Instance weighting for domain adaptation in NLP. In Proceedings of the ACL Conference, Prague, Czech Republic, 23–30 June 2007; pp. 264–271.
- Sugiyama, M.; Nakajima, S.; Kashima, H.; Buenau, P.V.; Kawanabe, M. Direct importance estimation with model selection and its application to covariate shift adaptation. In Advances in Neural Information Processing Systems; NIPS Proceedings: Whistler, BC, Canada, 2007; pp. 1433–1440. [Google Scholar]
- Blitzer, J.; McDonald, R.; Pereira, F. Domain adaptation with structural correspondence learning. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Sydney, Australia, 22–23 July 2006; pp. 120–128.
- Gao, J.; Fan, W.; Jiang, J.; Han, J. Knowledge transfer via multiple model local structure mapping. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 283–291.
- Mihalkova, L.; Huynh, T.; Mooney, R.J. Mapping and revising Markov logic networks for transfer learning. In Proceedings of the Twenty-Second AAAI Conference on Artificial Intelligence, Vancouver, BC, USA, 22–23 July 2007; Volume 7, pp. 608–614.
- Nielsen, A.A.; Conradsen, K.; Simpson, J.J. Multivariate alteration detection (MAD) and MAF postprocessing in multispectral, bitemporal image data: New approaches to change detection studies. Remote Sens. Environ. 1998, 64, 1–19. [Google Scholar] [CrossRef]
- Bruzzone, L.; Persello, C. A novel approach to the selection of spatially invariant features for the classification of hyperspectral images with improved generalization capability. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3180–3191. [Google Scholar] [CrossRef]
- Tuia, D.; Munoz-Mari, J.; Gomez-Chova, L.; Malo, J. Graph matching for adaptation in remote sensing. IEEE Trans. Geosci. Remote Sens. 2013, 51, 329–341. [Google Scholar] [CrossRef]
- Tuia, D.; Volpi, M.; Trolliet, M.; Camps-Valls, G. Semisupervised Manifold Alignment of Multimodal Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7708–7720. [Google Scholar] [CrossRef]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [PubMed]
- Matasci, G.; Tuia, D.; Kanevski, M. SVM-based boosting of active learning strategies for efficient domain adaptation. IEEE J. Sel. Top. Appl. Earth Obs. 2012, 5, 1335–1343. [Google Scholar] [CrossRef]
- Patel, V.M.; Gopalan, R.; Li, R.; Chellappa, R. Visual Domain Adaptation: A survey of recent advances. IEEE Signal Process. Mag. 2015, 32, 53–69. [Google Scholar] [CrossRef]
- Gong, B.; Shi, Y.; Sha, F.; Grauman, K. Geodesic flow kernel for unsupervised domain adaptation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2066–2073.
- Gopalan, R.; Li, R.; Chellappa, R. Domain adaptation for object recognition: An unsupervised approach. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 999–1006.
- Absil, P.A.; Mahony, R.; Sepulchre, R. Riemannian geometry of Grassmann manifolds with a view on algorithmic computation. Acta Appl. Math. 2004, 80, 199–220. [Google Scholar] [CrossRef]
- Trier, Ø.D.; Jain, A.K.; Taxt, T. Feature extraction methods for character recognition—A survey. Pattern Recognit. 1996, 29, 641–662. [Google Scholar] [CrossRef]
- Lopez-Paz, D.; Sra, S.; Smola, A.; Ghahramani, Z.; Schölkopf, B. Randomized Nonlinear Component Analysis. Available online: http://arxiv.org/abs/1402.0119 (accessed on 9 March 2016).
- Langville, A.N.; Meyer, C.D.; Albright, R.; Cox, J.; Duling, D. Algorithms, Initializations, and Convergence for the Nonnegative Matrix Factorization. Available online: http://arxiv.org/abs/1407.7299 (accessed on 9 March 2016).
- Shi, Y.; Sha, F. Information-Theoretical Learning of Discriminative Clusters for Unsupervised Domain Adaptation. Available online: http://arxiv.org/abs/1206.6438 (accessed on 9 March 2016).
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer feature learning with joint distribution adaptation. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 2200–2207.
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer Joint Matching for Unsupervised Domain Adaptation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1410–1417.
- Lee, S.I.; Chatalbashev, V.; Vickrey, D.; Koller, D. Learning a meta-level prior for feature relevance from multiple related tasks. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007; pp. 489–496.
- Pan, S.J.; Kwok, J.T.; Yang, Q. Transfer Learning via Dimensionality Reduction. In Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence, Chicago, IL, USA, 13–17 July 2008; Volume 8, pp. 677–682.
- Hamm, J.; Lee, D.D. Grassmann discriminant analysis: A unifying view on subspace-based learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 376–383.
- Turaga, P.; Veeraraghavan, A.; Srivastava, A.; Chellappa, R. Statistical computations on Grassmann and Stiefel manifolds for image and video-based recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2273–2286. [Google Scholar] [CrossRef] [PubMed]
- Ruiz, A.; López-de-Teruel, P.E. Nonlinear kernel-based statistical pattern analysis. IEEE Trans. Neural Netw. 2001, 12, 16–32. [Google Scholar] [CrossRef] [PubMed]
- Jayasumana, S.; Hartley, R.; Salzmann, M.; Li, H.; Harandi, M. Kernel methods on the riemannian manifold of symmetric positive definite matrices. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 73–80.
- Borgwardt, K.M.; Gretton, A.; Rasch, M.J.; Kriegel, H.P.; Schölkopf, B.; Smola, A.J. Integrating structured biological data by kernel maximum mean discrepancy. Bioinformatics 2006, 22, 49–57. [Google Scholar] [CrossRef] [PubMed]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Class | Code | University | Center | ||
|---|---|---|---|---|---|---|
| Train | Test | Train | Test | |||
| 1 | Asphalt | 548 | 6631 | 678 | 7585 | |
| 2 | Meadows | 540 | 18649 | 797 | 2905 | |
| 3 | Trees | 524 | 3064 | 785 | 6508 | |
| 4 | Bare soil | 532 | 5029 | 820 | 6549 | |
| 5 | Bricks | 514 | 3682 | 485 | 2140 | |
| 6 | Bitumen | 375 | 1330 | 808 | 7287 | |
| 7 | Shadows | 231 | 947 | 195 | 2165 | |
| No. | Class | Code | Left | Right | ||
|---|---|---|---|---|---|---|
| Train | Test | Train | Test | |||
| 1 | Healthy grass | 98 | 449 | 100 | 604 | |
| 2 | Stressed grass | 87 | 482 | 103 | 582 | |
| 3 | Trees | 78 | 373 | 110 | 683 | |
| 4 | Soil | 72 | 688 | 114 | 368 | |
| 5 | Residential | 173 | 687 | 23 | 385 | |
| 6 | Commercial | 47 | 132 | 144 | 921 | |
| 7 | Road | 108 | 589 | 85 | 470 | |
| 8 | Parking Lot 1 | 88 | 625 | 104 | 416 | |
| Class | GFKSVM | JDA | ITLDC | JTM | |||
|---|---|---|---|---|---|---|---|
| PCA | rPCA | FA | NNMF | ||||
| Asphalt | 97.73 | 98.05 | 97.82 | 98.04 | 90.27 | 95.87 | 85.55 |
| Meadows | 21.45 | 25.13 | 7.37 | 19.72 | 47.30 | 17.31 | 9.54 |
| Trees | 97.51 | 97.66 | 99.08 | 99.15 | 96.69 | 92.74 | 99.49 |
| Bare soil | 76.62 | 81.68 | 75.08 | 79.84 | 85.00 | 88.29 | 74.51 |
| Bricks | 75.65 | 75.98 | 75.65 | 75.14 | 56.49 | 63.92 | 61.03 |
| Bitumen | 65.02 | 60.85 | 64.43 | 61.30 | 71.04 | 36.51 | 62.75 |
| Shadows | 99.91 | 99.91 | 99.86 | 99.91 | 64.10 | 100.00 | 82.05 |
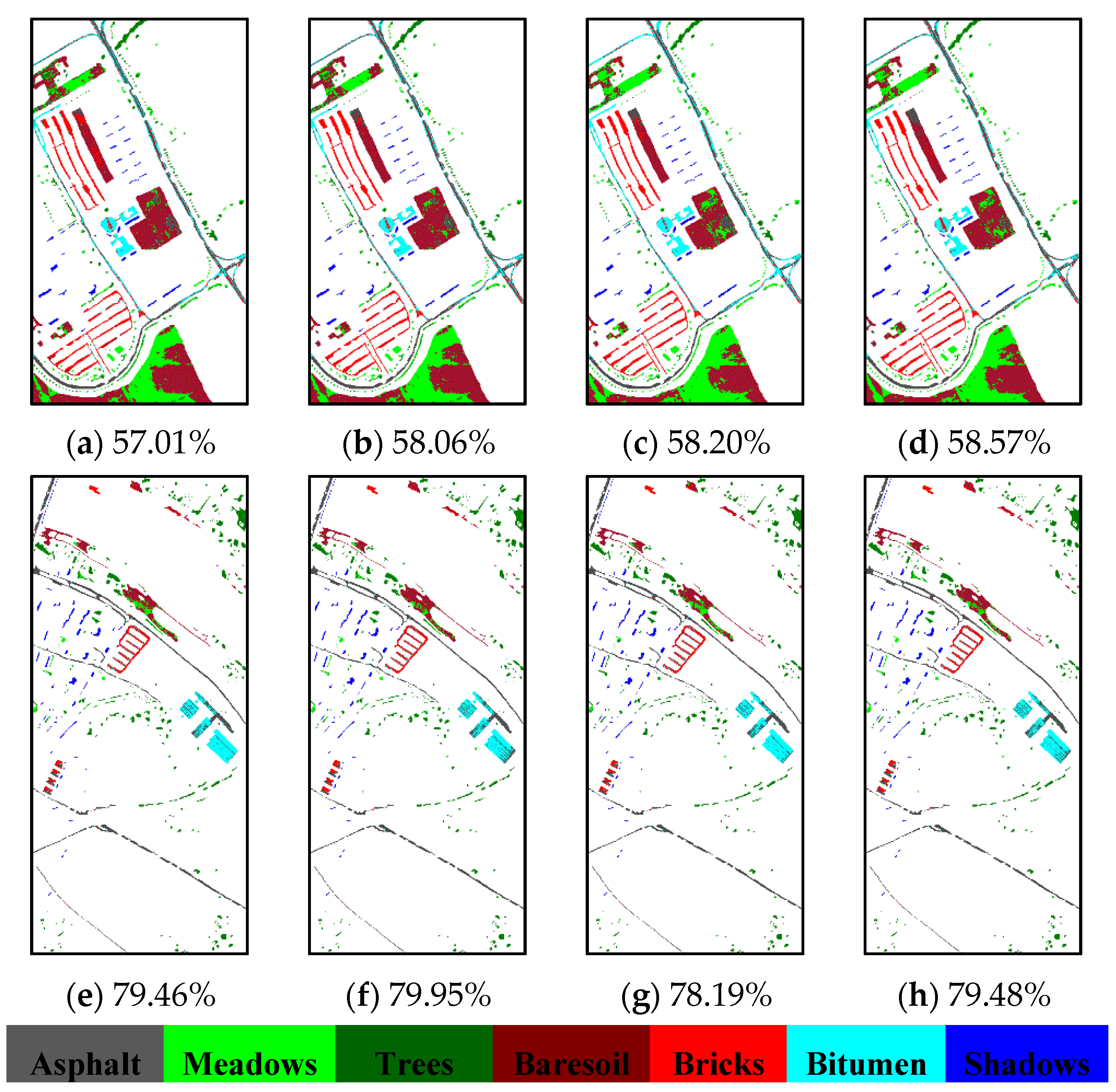
| AA | 76.27 | 77.04 | 74.18 | 76.16 | 72.98 | 70.66 | 67.85 |
| OA | 79.46 | 79.95 | 78.19 | 79.48 | 74.82 | 66.55 | 65.92 |
| κ | 0.75 | 0.76 | 0.74 | 0.75 | 0.70 | 0.60 | 0.60 |
| Class | GFKSVM | JDA | ITLDC | JTM | |||
|---|---|---|---|---|---|---|---|
| PCA | rPCA | FA | NNMF | ||||
| Healthy grass | 55.00 | 62.00 | 51.00 | 76.00 | 100.00 | 83.07 | 99.55 |
| Stressed grass | 100.00 | 100.00 | 100.00 | 100.00 | 89.83 | 62.66 | 93.15 |
| Trees | 100.00 | 99.09 | 96.36 | 100.00 | 99.73 | 93.57 | 0.54 |
| Soil | 70.18 | 72.81 | 71.05 | 71.93 | 99.71 | 77.33 | 98.98 |
| Residential | 100.00 | 100.00 | 100.00 | 100.00 | 76.86 | 53.13 | 39.01 |
| Commercial | 27.78 | 27.08 | 27.78 | 22.22 | 83.33 | 99.24 | 74.24 |
| Road | 81.18 | 80.00 | 78.82 | 69.41 | 81.49 | 78.10 | 84.89 |
| Parking Lot 1 | 24.04 | 7.69 | 0.00 | 0.00 | 0.00 | 32.48 | 0.00 |
| AA | 69.77 | 68.58 | 65.63 | 67.45 | 78.87 | 72.45 | 61.30 |
| OA | 64.50 | 63.22 | 60.15 | 61.94 | 75.98 | 67.45 | 60.75 |
| κ | 0.59 | 0.58 | 0.55 | 0.57 | 0.72 | 0.63 | 0.54 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samat, A.; Gamba, P.; Abuduwaili, J.; Liu, S.; Miao, Z. Geodesic Flow Kernel Support Vector Machine for Hyperspectral Image Classification by Unsupervised Subspace Feature Transfer. Remote Sens. 2016, 8, 234. https://doi.org/10.3390/rs8030234
Samat A, Gamba P, Abuduwaili J, Liu S, Miao Z. Geodesic Flow Kernel Support Vector Machine for Hyperspectral Image Classification by Unsupervised Subspace Feature Transfer. Remote Sensing. 2016; 8(3):234. https://doi.org/10.3390/rs8030234
Chicago/Turabian StyleSamat, Alim, Paolo Gamba, Jilili Abuduwaili, Sicong Liu, and Zelang Miao. 2016. "Geodesic Flow Kernel Support Vector Machine for Hyperspectral Image Classification by Unsupervised Subspace Feature Transfer" Remote Sensing 8, no. 3: 234. https://doi.org/10.3390/rs8030234
APA StyleSamat, A., Gamba, P., Abuduwaili, J., Liu, S., & Miao, Z. (2016). Geodesic Flow Kernel Support Vector Machine for Hyperspectral Image Classification by Unsupervised Subspace Feature Transfer. Remote Sensing, 8(3), 234. https://doi.org/10.3390/rs8030234