
Operational High Resolution Land Cover Map Production at the Country Scale Using Satellite Image Time Series


Abstract
:
1. Introduction
- how the full image time series is used without the need for date selection;
- how classification consistency is ensured across adjacent orbit tracks;
- the impact of scarcity and spatial inhomogeneity of the reference data used for training and validation;
2. Existing Approaches and Their Drawbacks
2.1. Global Products
2.2. Continental and National Products
2.3. Towards Efficient Large Scale Land Cover Mapping
- automation for efficiency and timeliness;
- spatial continuity of the maps;
- temporal coherence between updates of the product;
- reproducibility of the results;
- support of changes of nomenclature without changing the system.
- all available images acquired during the reference period are used regardless of the amount of cloud cover;
- no manual reference sample collection (either by field surveys or photo-interpretation) is performed, but rather existing databases are used for training supervised classifiers;
- the procedure is fully automatic without need for manual operations;
- the processing chain is implemented using a massively parallel work-flow which achieves a reduced computation time allowing timely map production and data reprocessing for ensuring continuity across reference years in the case of updating the product specifications.
3. Data and Study Site
3.1. Reference Data
3.1.1. Artificial Areas
- CUF Continuous urban fabric (CLC 111): Most of the land is covered by structures and the transport network. Building, roads and artificially surfaced areas cover more than 80% of the total surface. Non-linear areas of vegetation and bare soil are exceptional.
- DUF Discontinuous urban fabric (CLC 112): Most of the land is covered by structures. Building, roads and artificially surfaced areas associated with vegetated areas and bare soil, which occupy discontinuous but significant surfaces.
- ICU Industrial or commercial units (CLC 121): Artificially surfaced areas (with concrete, asphalt, tarmacadam, or stabilised, e.g., beaten earth) without vegetation occupy most of the area, which also contain buildings and/or vegetation.
- RSF Road surfaces (BD Topo): motorway rest areas, parking areas, motorway networks, larger than 50 m.
3.1.2. Agricultural Areas
- Arable land
- ASC Annual summer crops (RPG): annual crops which are seeded from March to mid June and harvested at the end of the summer (mid August to mid September); these are mainly corn and sunflower.
- AWC Annual winter crops (RPG): annual crops which are seeded between November and February and harvested at the beginning of the summer (mid June to the end of July); these are mainly wheat, barley and rapeseed.
- IGL Intensive grassland (RPG): dense grass cover, of floral composition, not under a rotation system.
- Perennial crops
- ORC Orchards (RPG): parcels planted with fruit trees or shrubs.
- VIN Vineyards (RPG): areas planted with vines.
3.1.3. Forest and Semi-Natural Areas
- Forests
- BLF Broad-leaved forest (BD Topo).
- COF Coniferous forest (BD Topo).
- Shrubs and herbaceous vegetation
- NGL Natural grasslands (CLC 321): low productivity grassland; often situated in areas of rough, uneven ground and frequently includes rocky areas, briars and heathland.
- WOM Woody moorlands (BD Topo): spontaneous vegetation dominated by woody plants (heather, briar, broom, etc.) and semi-woody plants (fern, phragmites, etc.) shorter than 5 m.
- Open spaces with little or no vegetation
- BDS Beaches, dunes and sand plains (CLC 331): beaches, dunes and expanses of sand or pebbles in coastal or continental locations, including beds of stream channels with torrential regime.
- BRO Bare rock (CLC 332): Scree, cliffs, rock outcrops, including active erosion, rocks and reef flats situated above the high-water mark.
- GPS Glaciers and perpetual snow (Randolph): land covered by glaciers or permanent snowfields.
- WAT Water bodies (CLC 523 and BD Topo): all water bodies longer than 20 m and all water courses larger than 7.5 m.
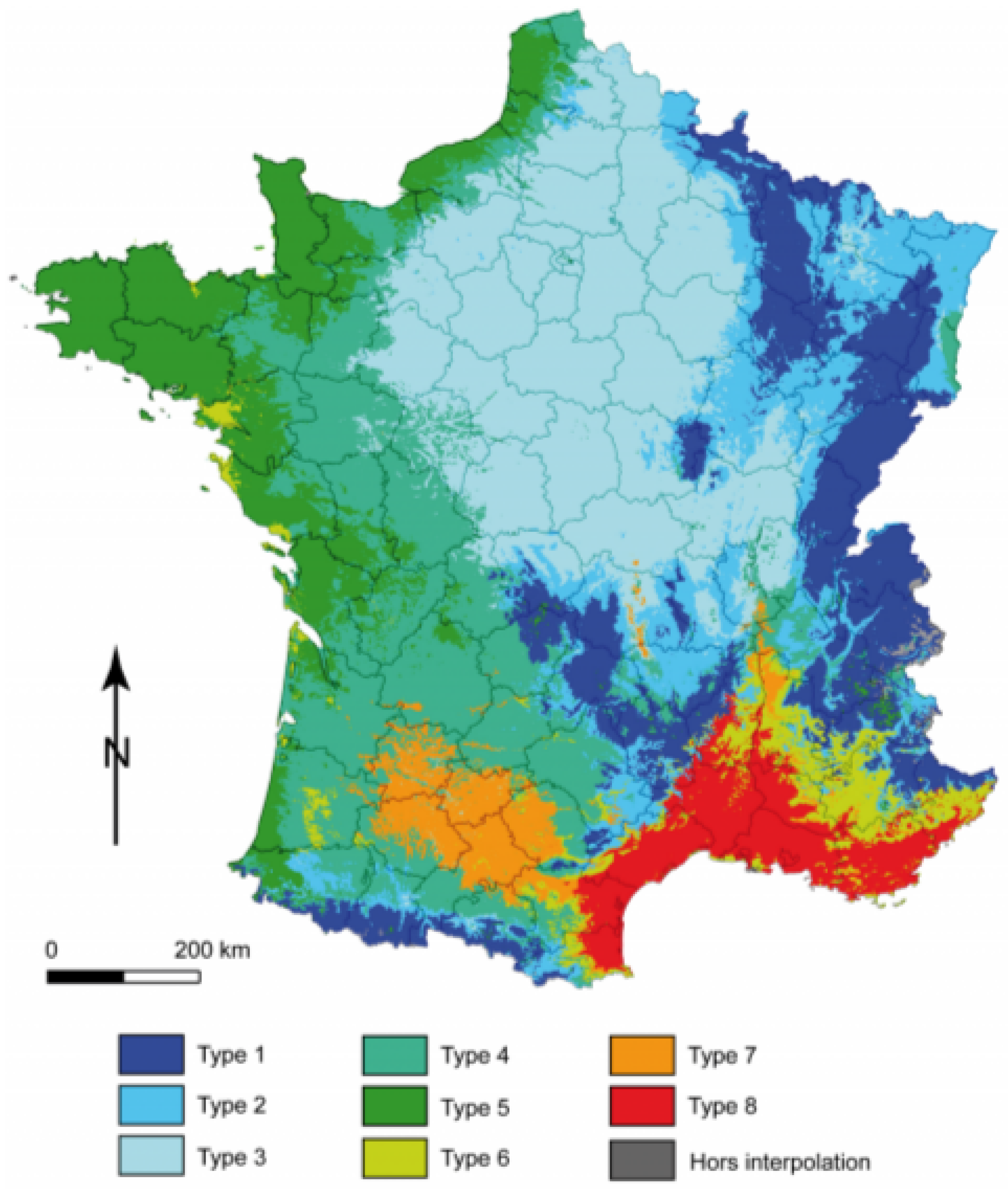
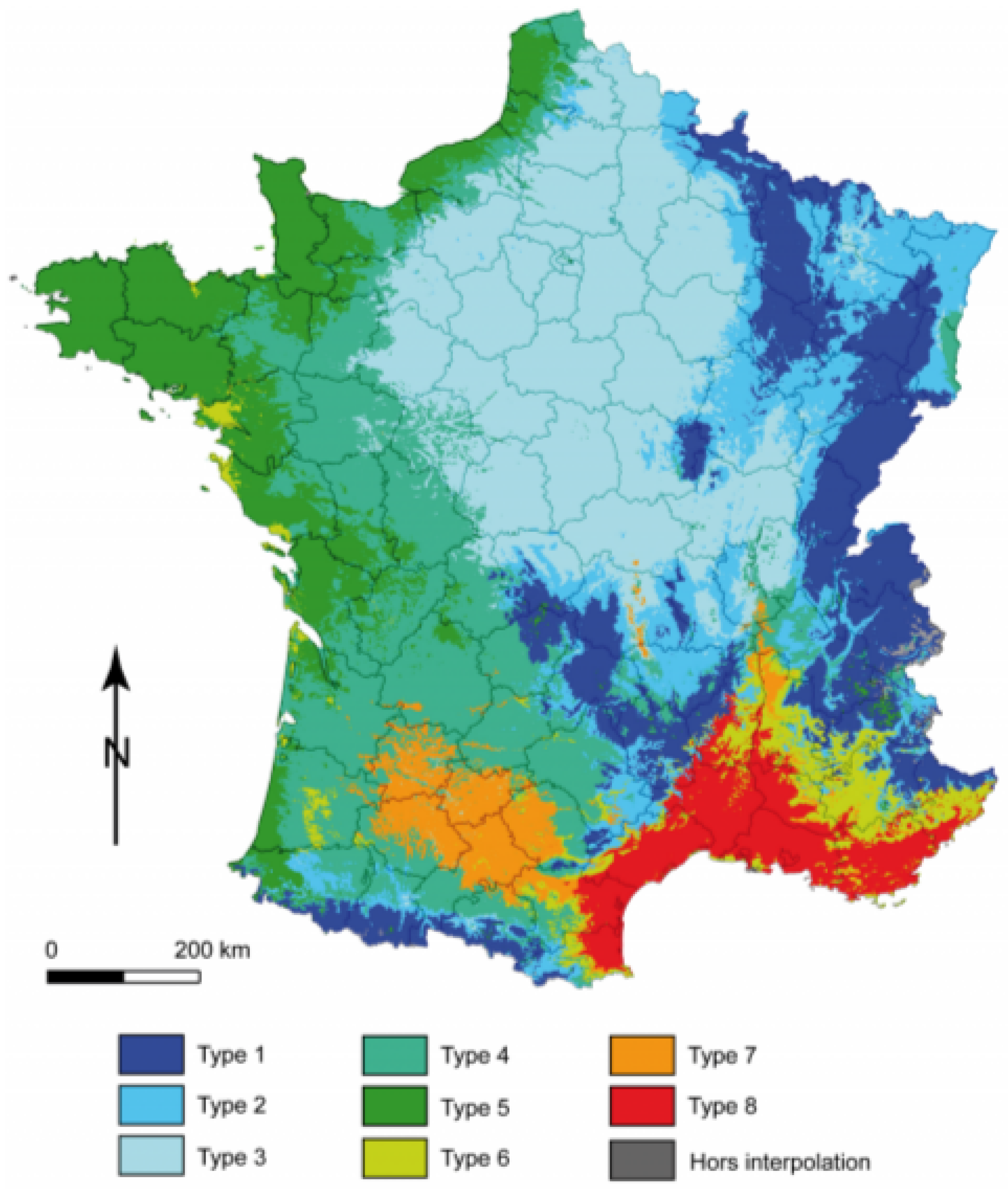
3.2. Climatic Stratification
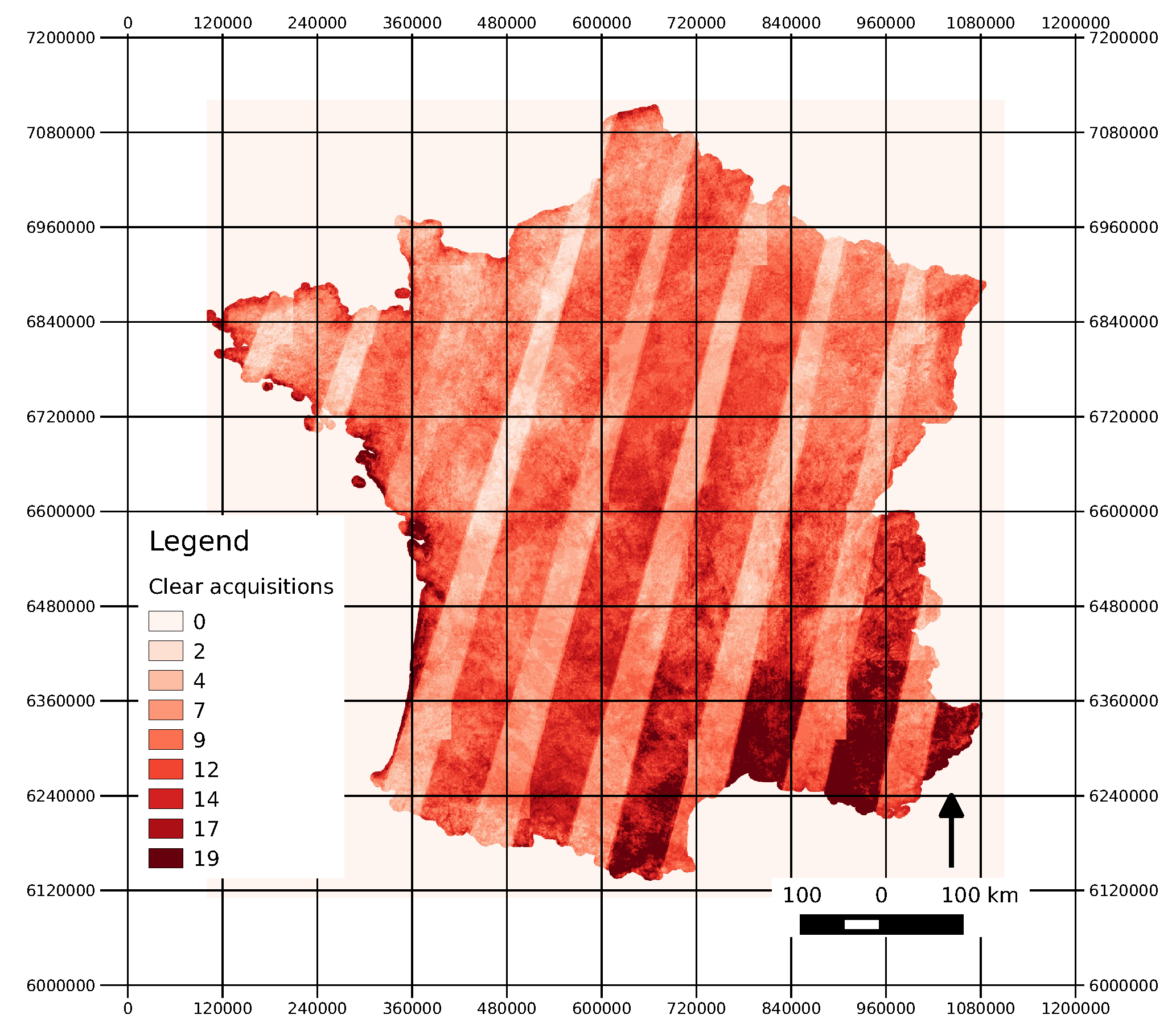
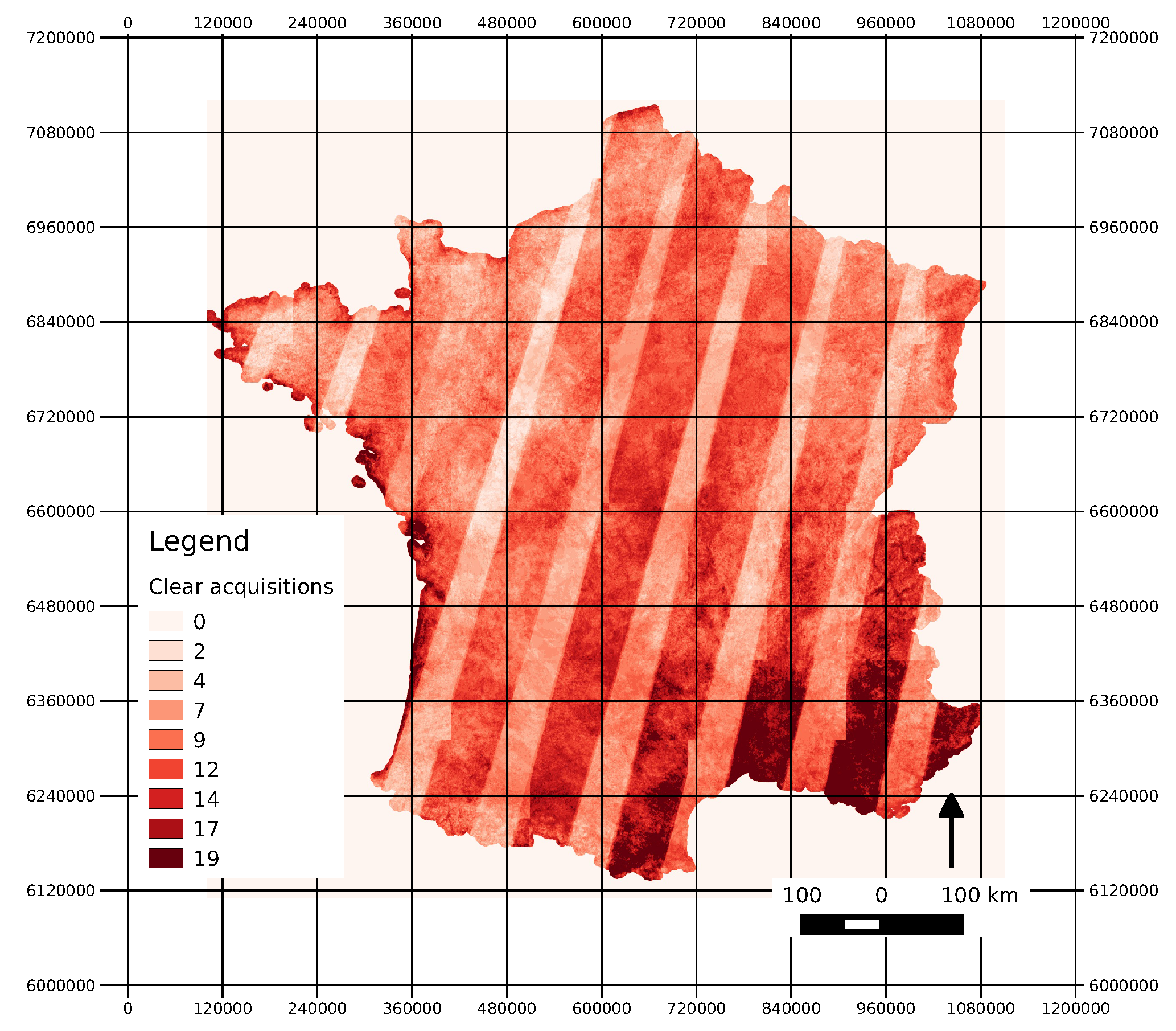
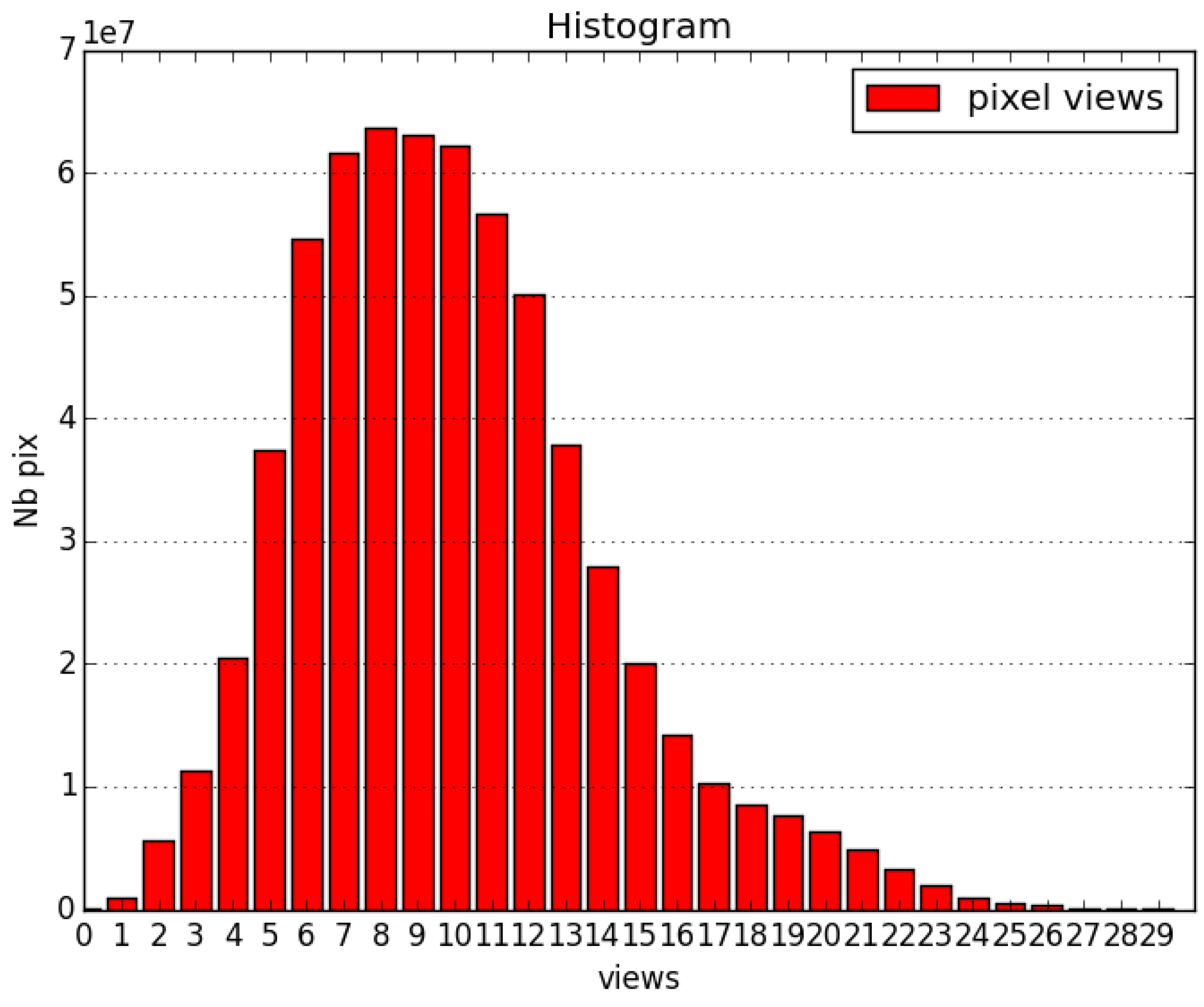
3.3. Satellite Imagery
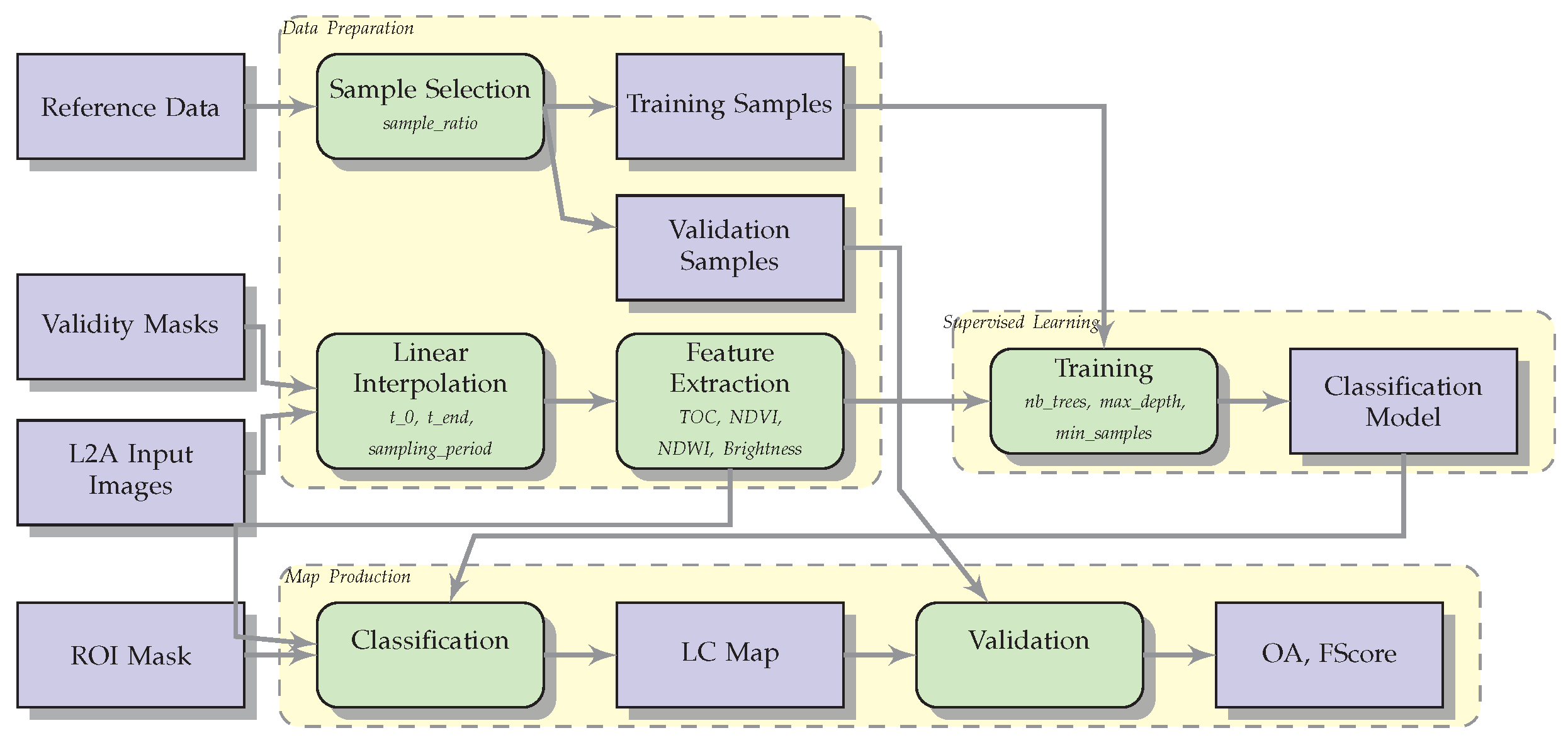
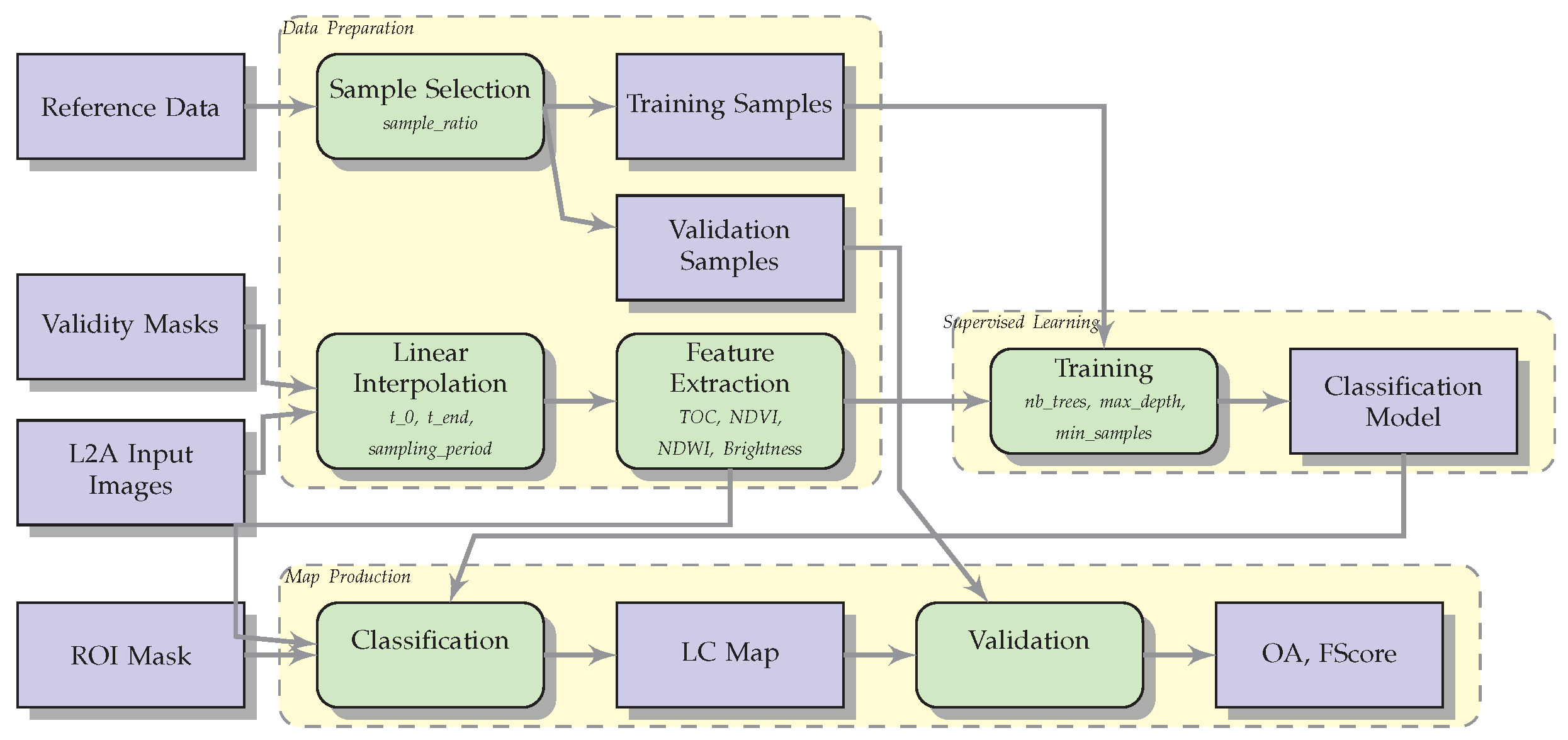
4. Methodology
4.1. Introduction
- A reference data with labelled samples (geographical positions for which the land cover class is known).
- Image time series processed to level 2A (ortho-rectified, surface reflectances).
- Validity masks for the image time series: for each date in the time series every pixel is flagged valid (surface reflectance) or invalid (cloud, cloud shadow, saturation, out of satellite swath).
- As optional input, a region of interest (ROI) mask can be provided to eliminate areas where the map generation is not wanted.
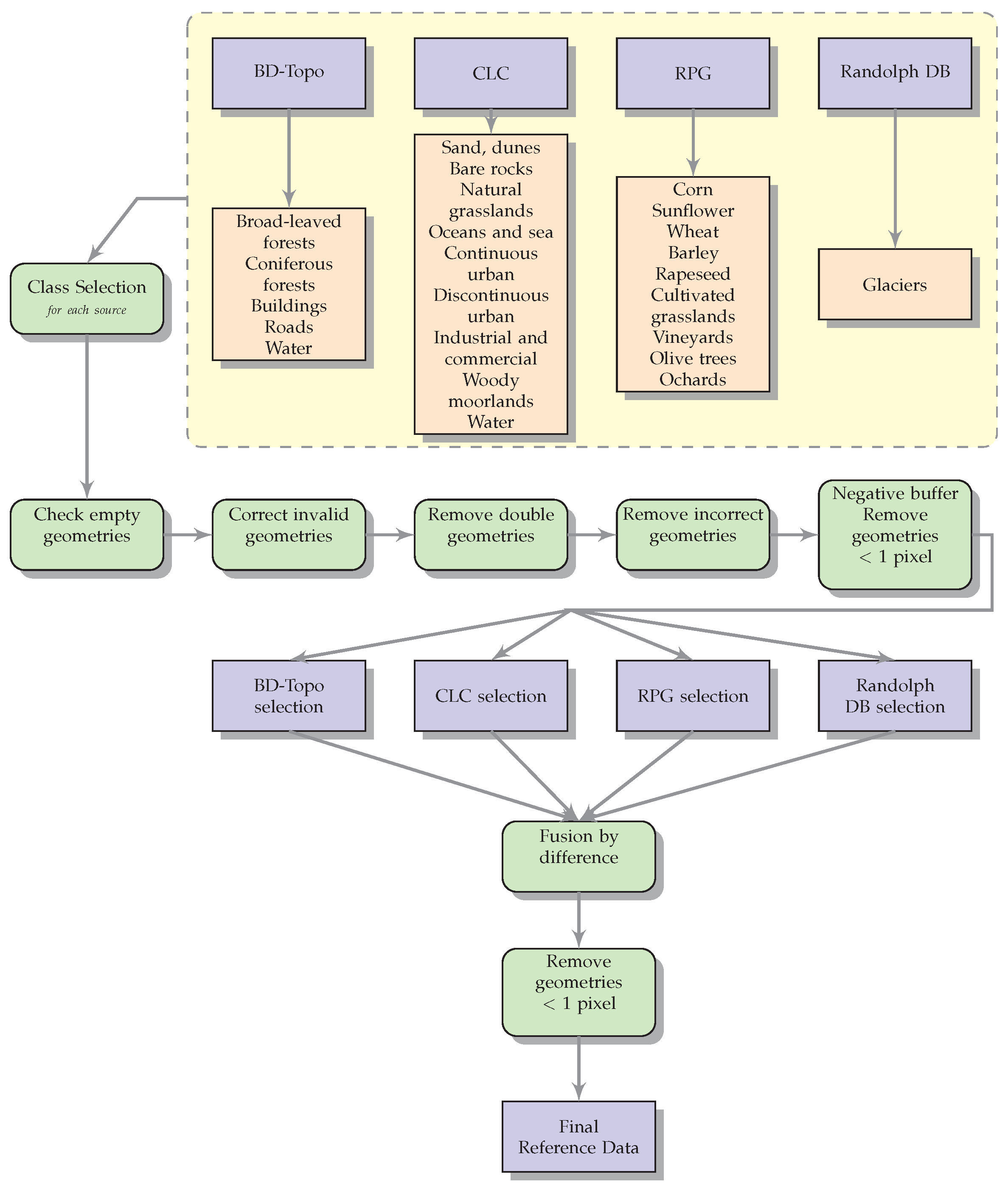
4.2. Reference Data Preparation
- elimination of empty entities;
- correction of invalid geometries, as for instance closing polygons;
- elimination of duplicated entities;
- elimination of invalid geometries which can not be corrected;
- optional negative buffering (erosion of polygons to eliminate object boundaries which often correspond to mixed pixels);
- elimination of polygons smaller than a minimum area (typically, the size of a pixel).
4.3. Image Pre-Processing
4.3.1. Temporal Gapfilling and Resampling
4.3.2. Feature Extraction
4.4. Classification
4.4.1. Classifier Choice and General Work-Flow
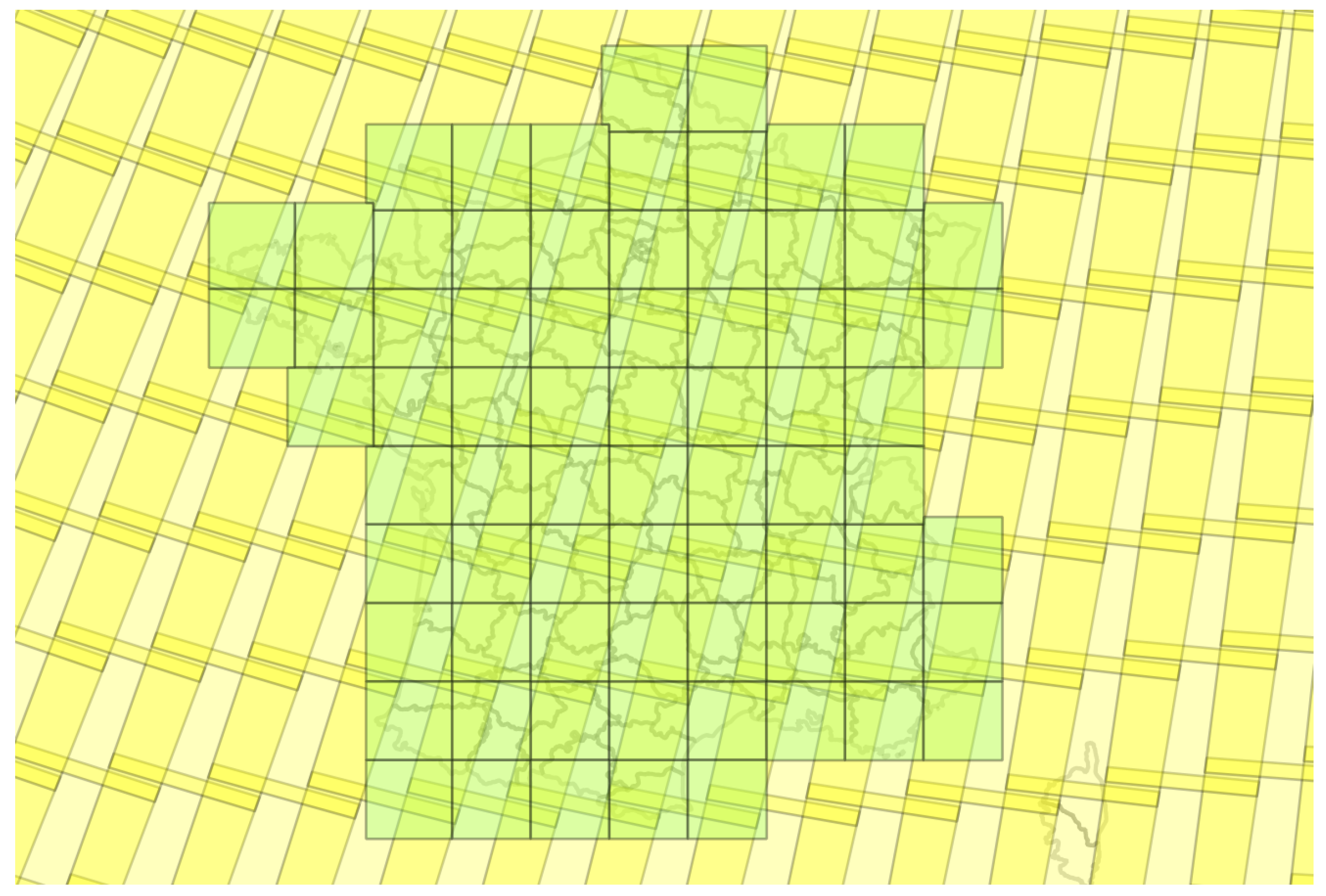
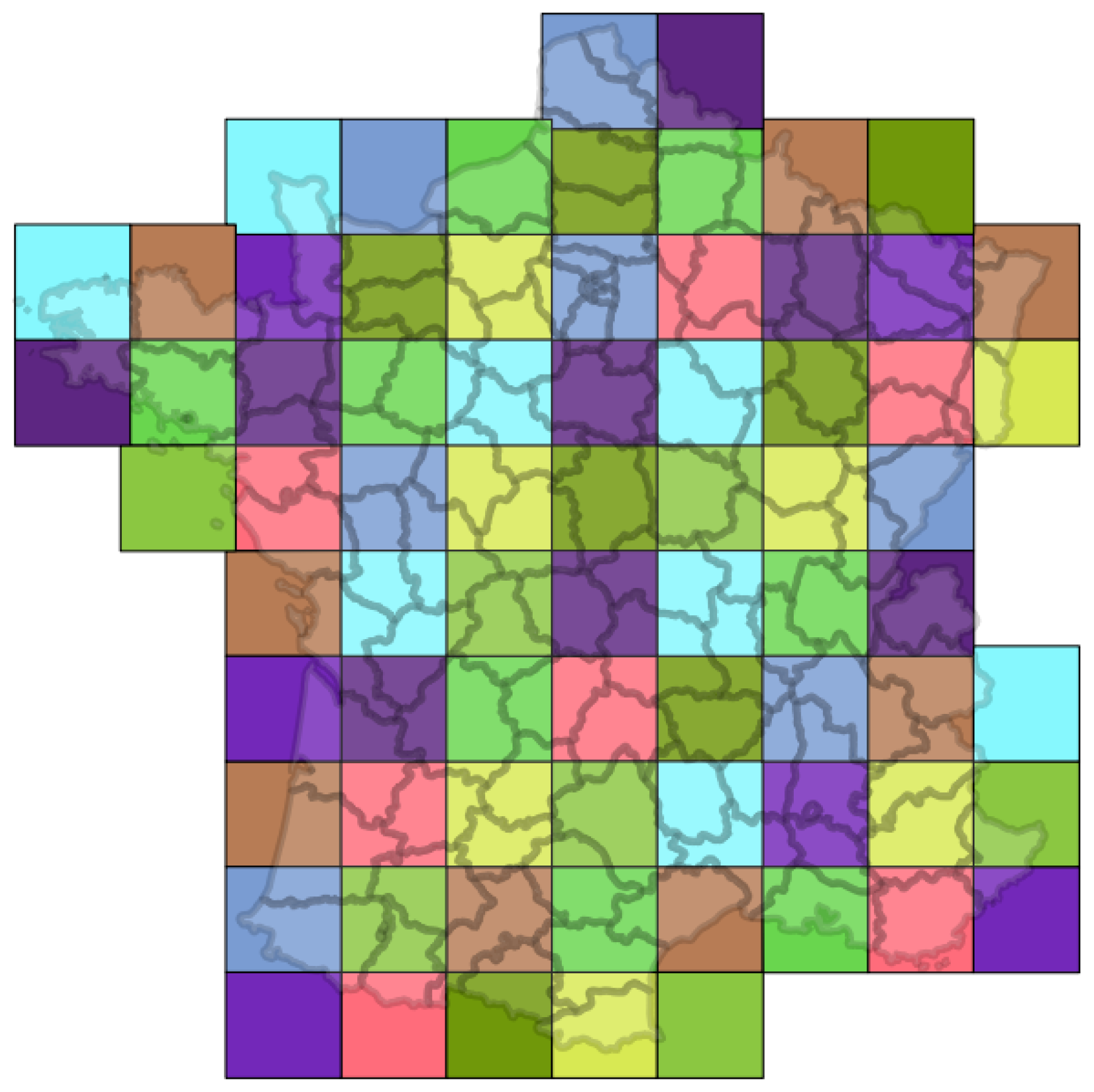
4.4.2. Tile-Based Approach
- each tile is classified using the classifier trained with the same tile;
- each tile is classified using all the classifiers and a majority vote used for the final decision.
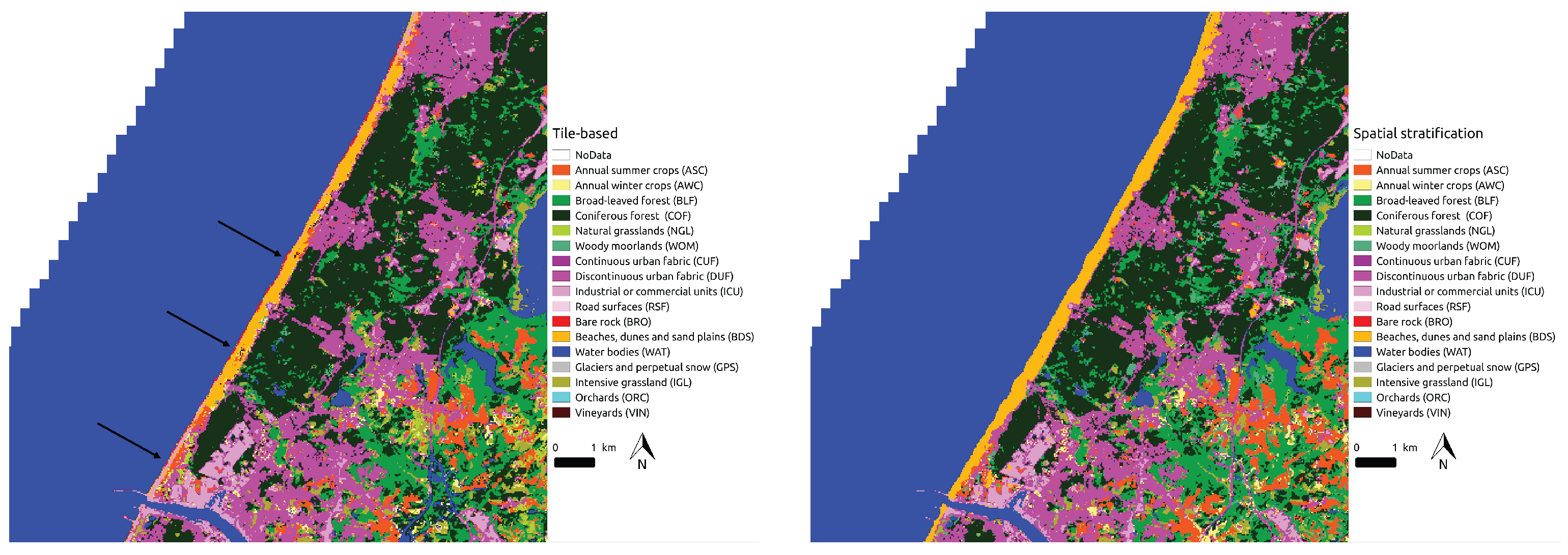
4.4.3. Spatial Stratification
4.5. Land Cover Map Validation
4.5.1. Confusion Matrix and Derived Indices
Producer’s Accuracy
User’s Accuracy
FScore
Kappa Coefficient
| Agreement | κ |
| Excellent | >0.81 |
| Good | 0.80–0.61 |
| Moderate | 0.60–0.41 |
| Weak | 0.40–0.21 |
| Bad | 0.20–0.0 |
| Very bad | < 0 |
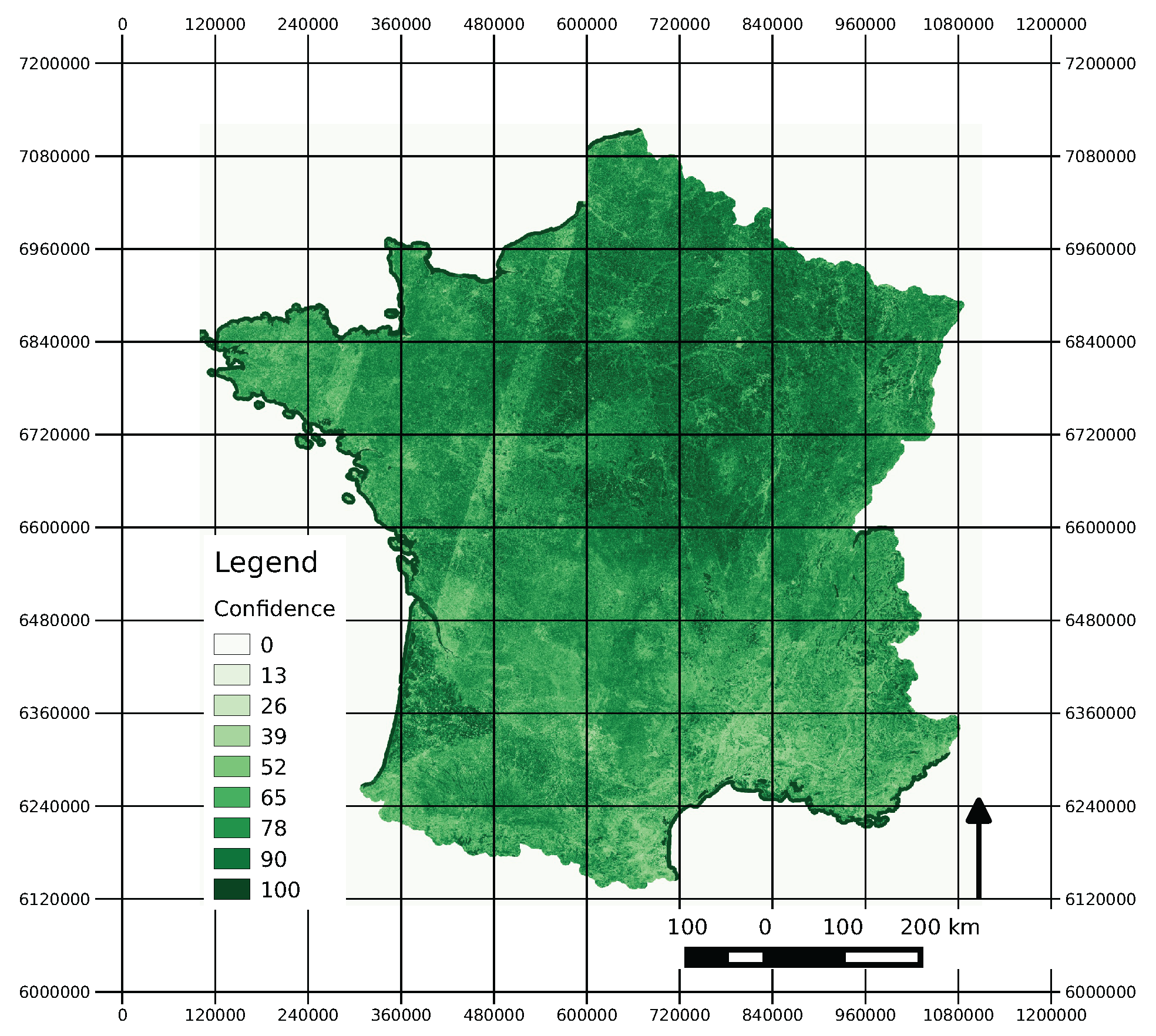
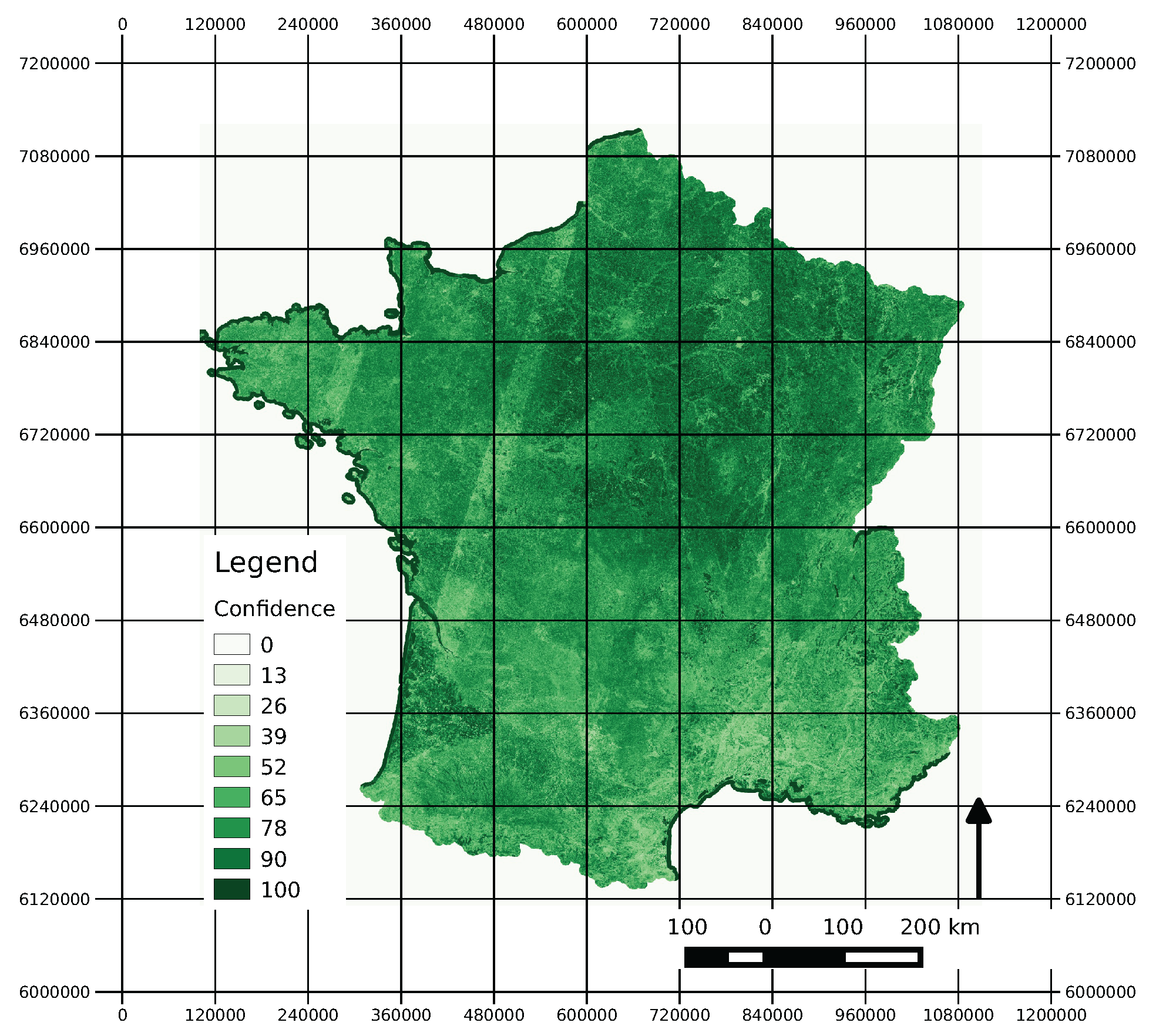
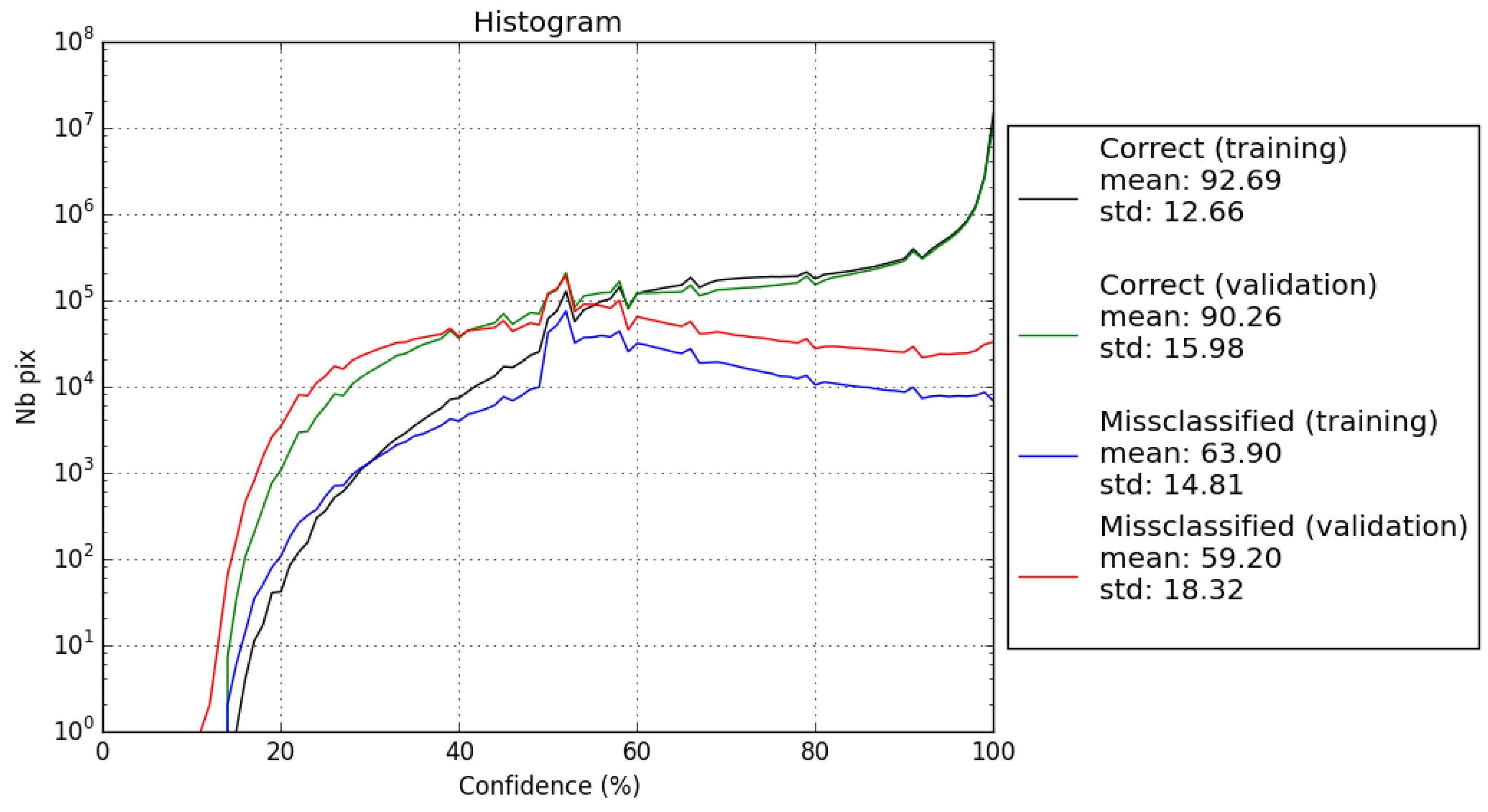
4.5.2. Confidence Map
5. Results
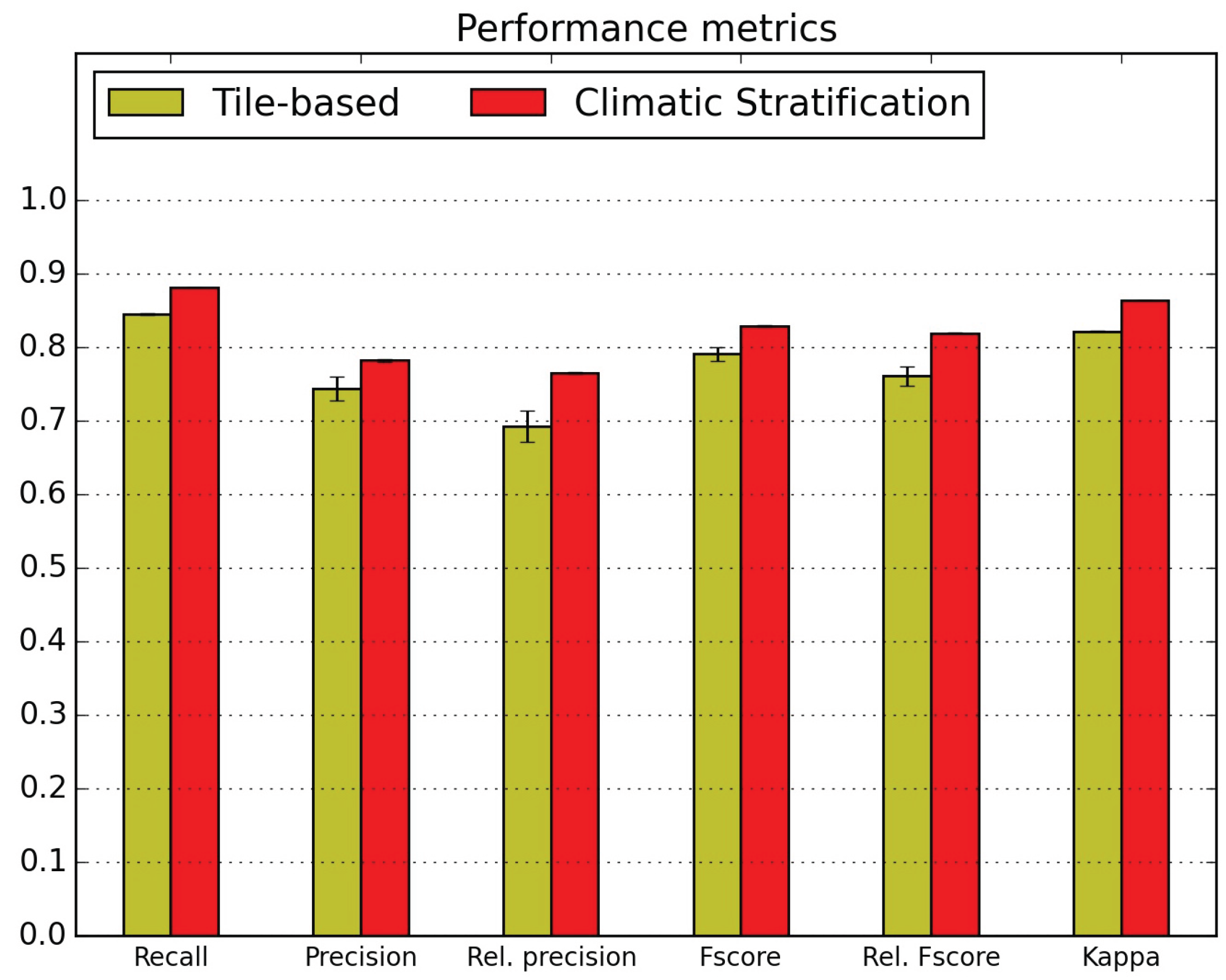
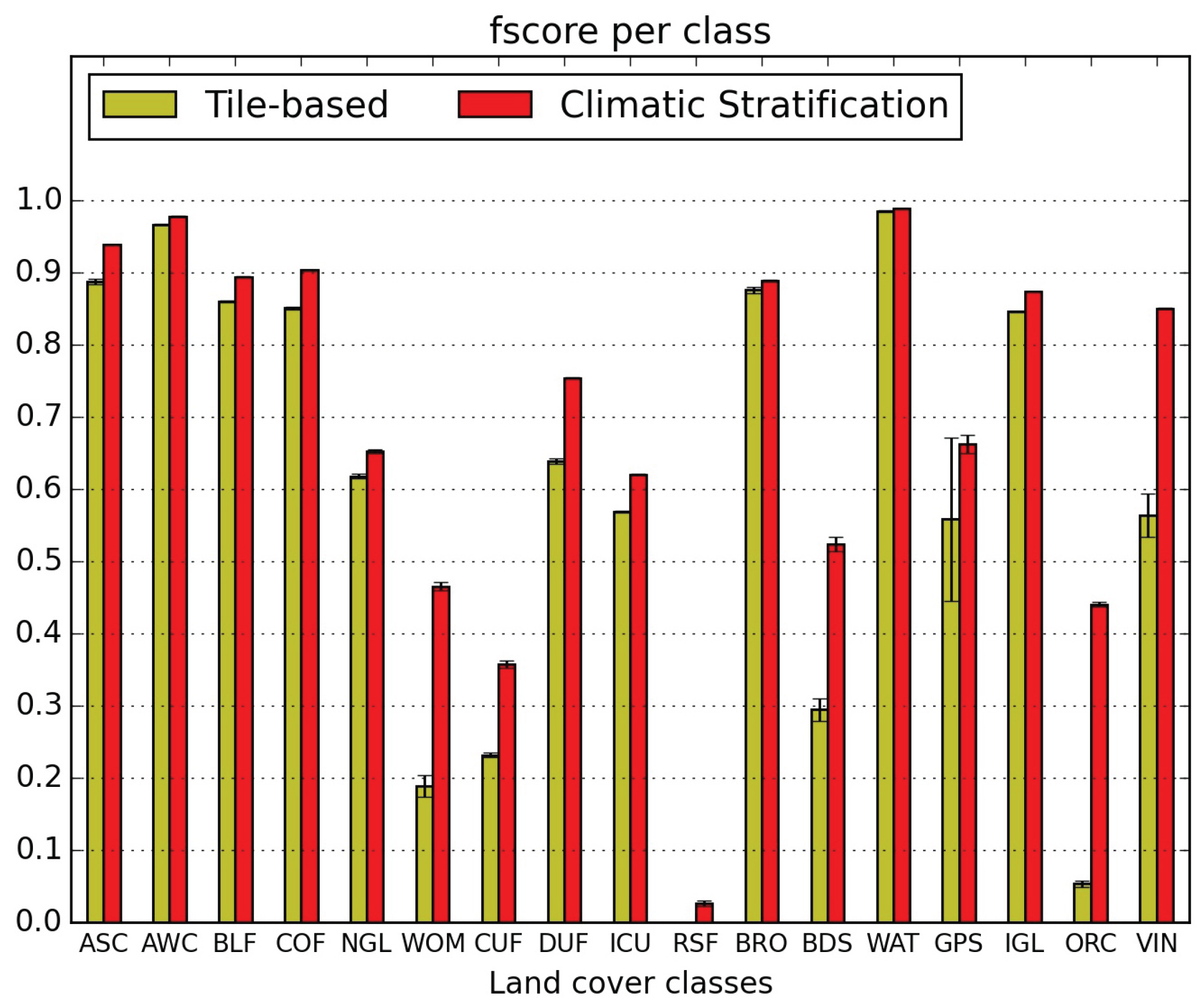
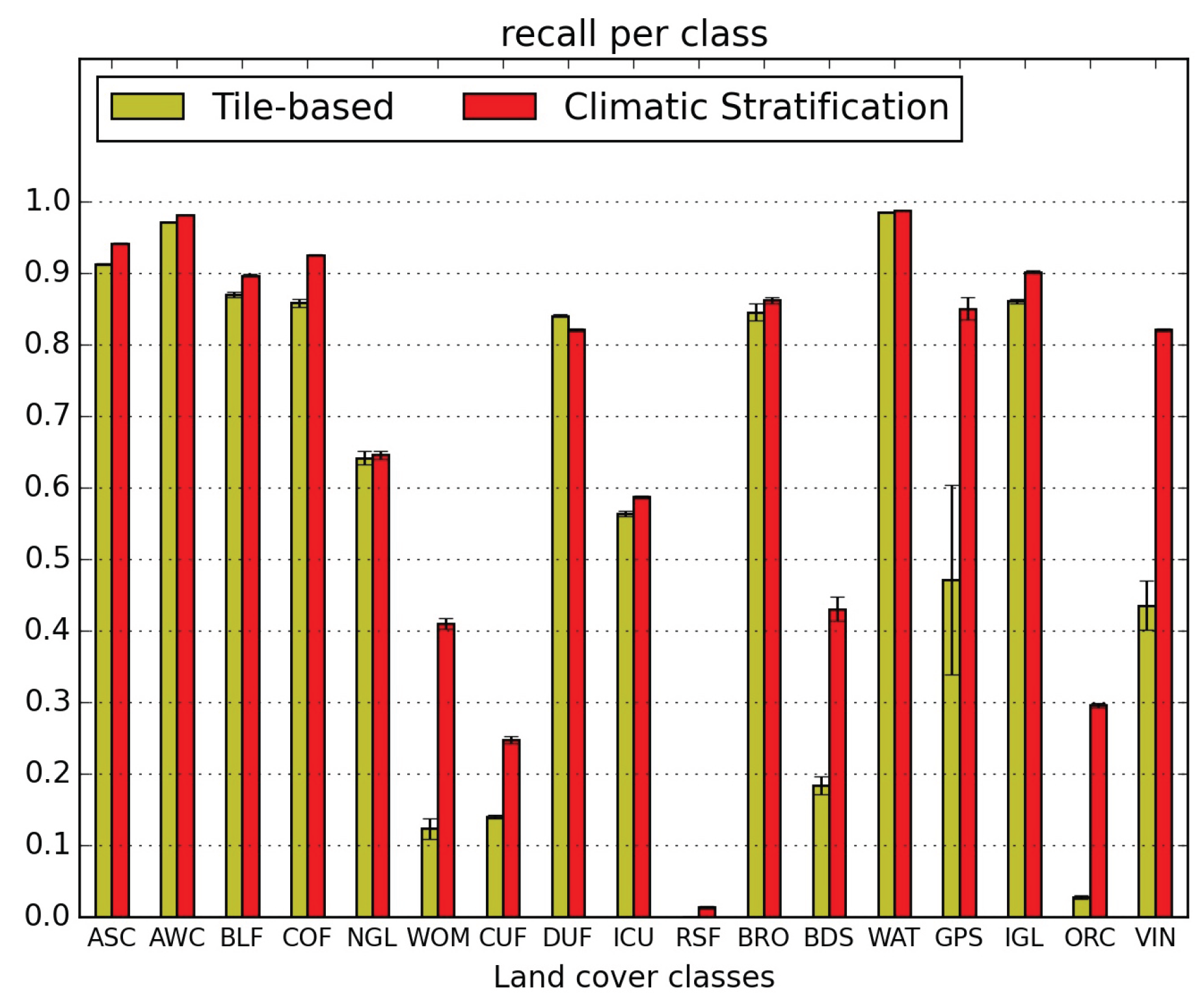
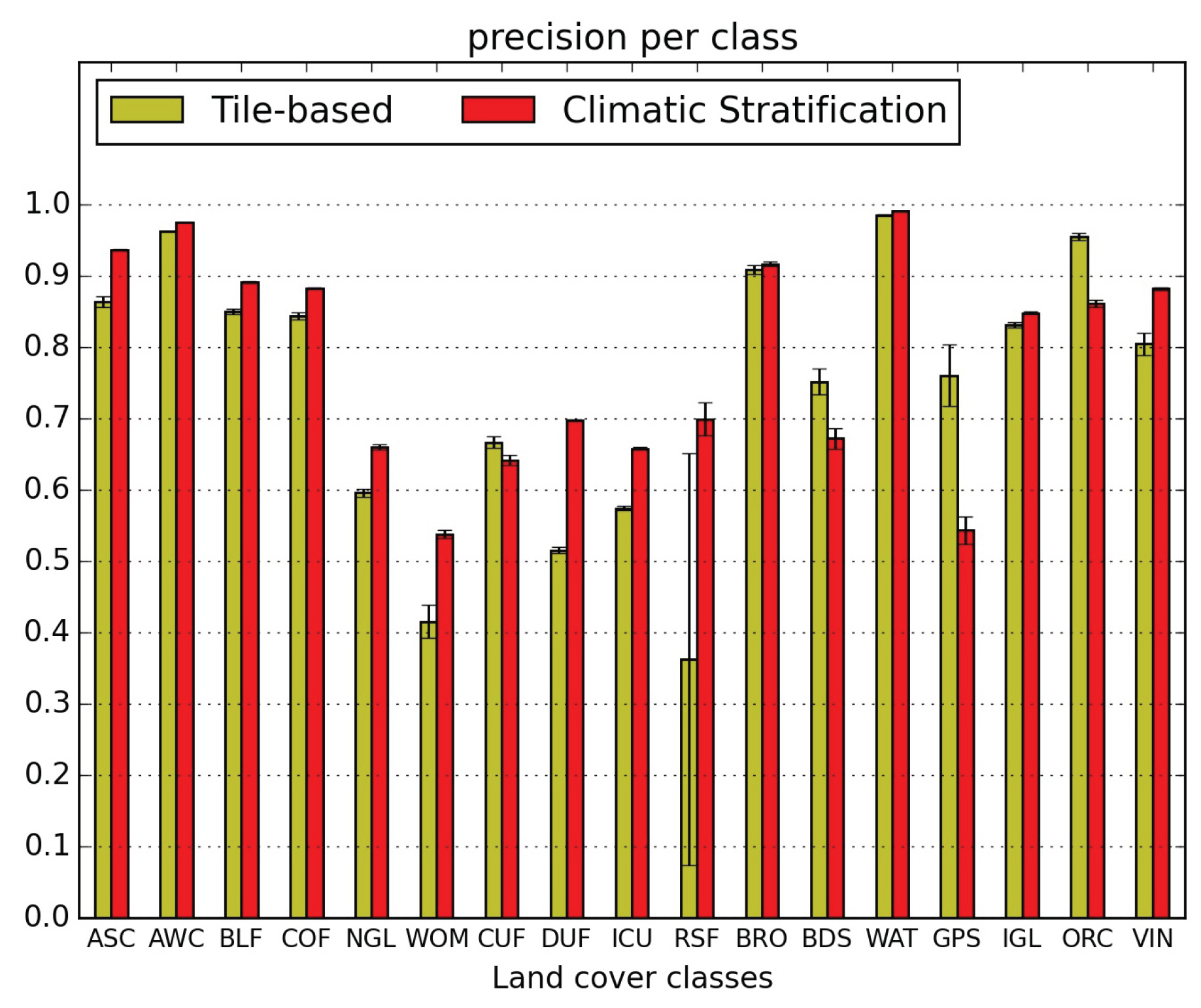
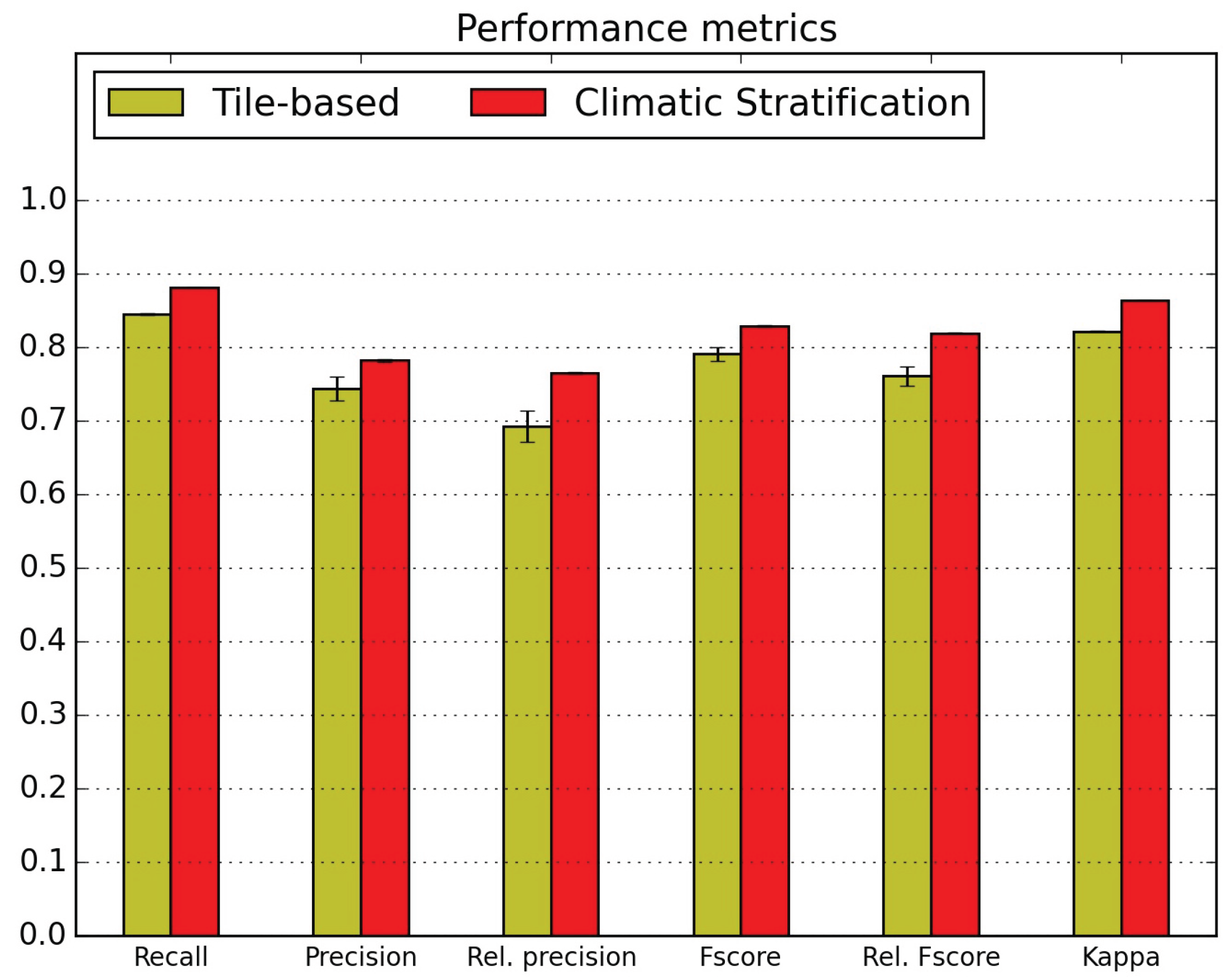
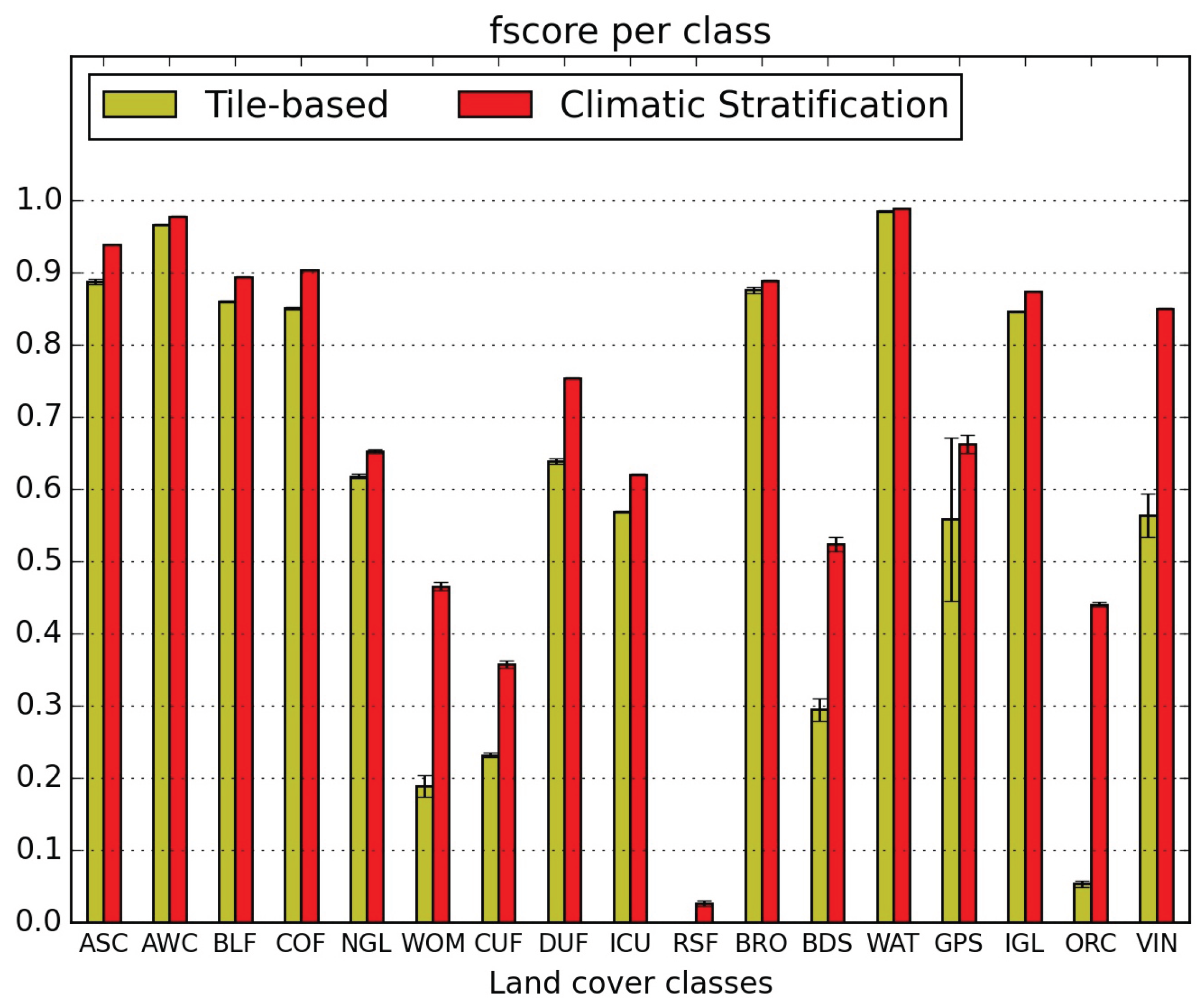
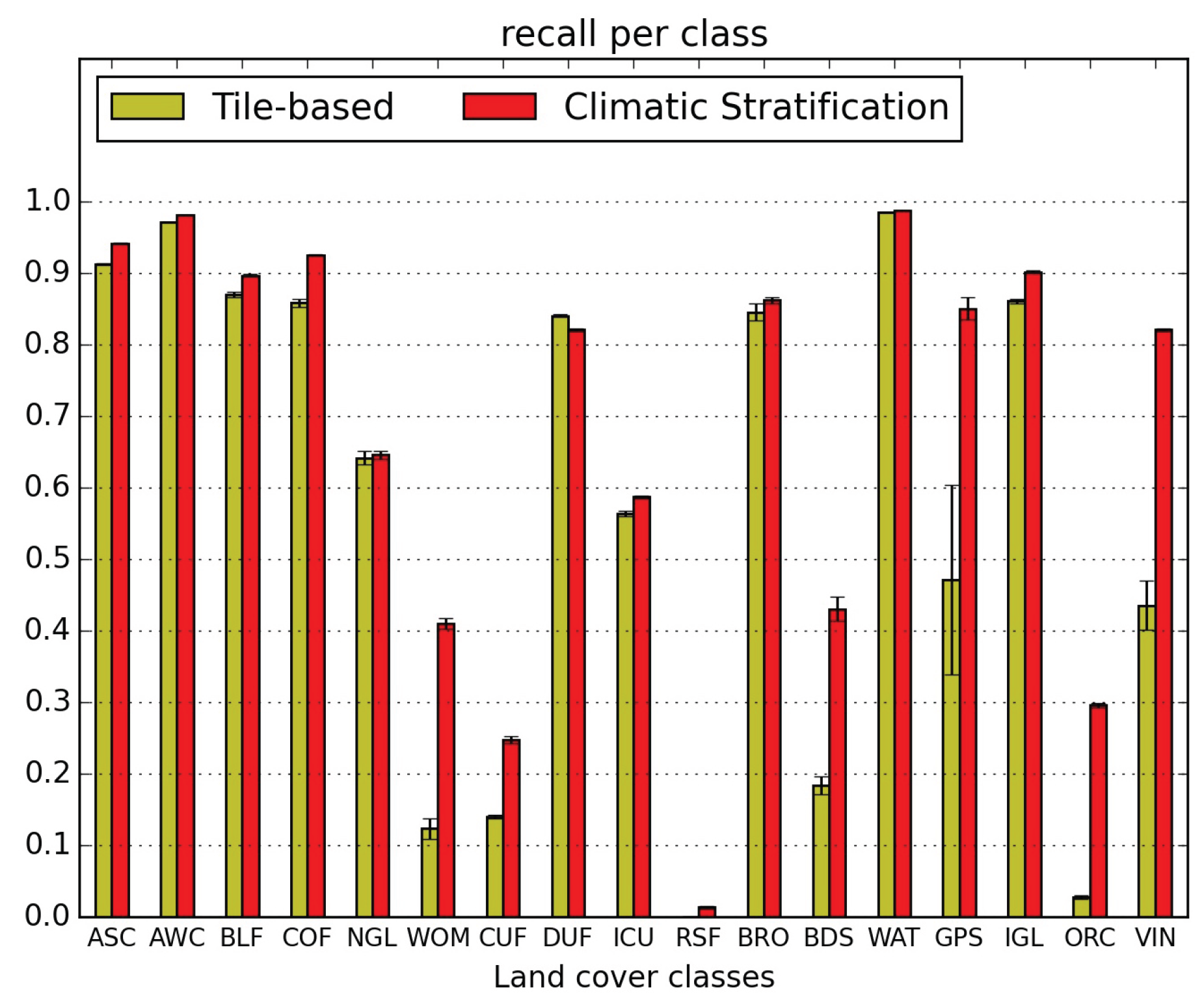
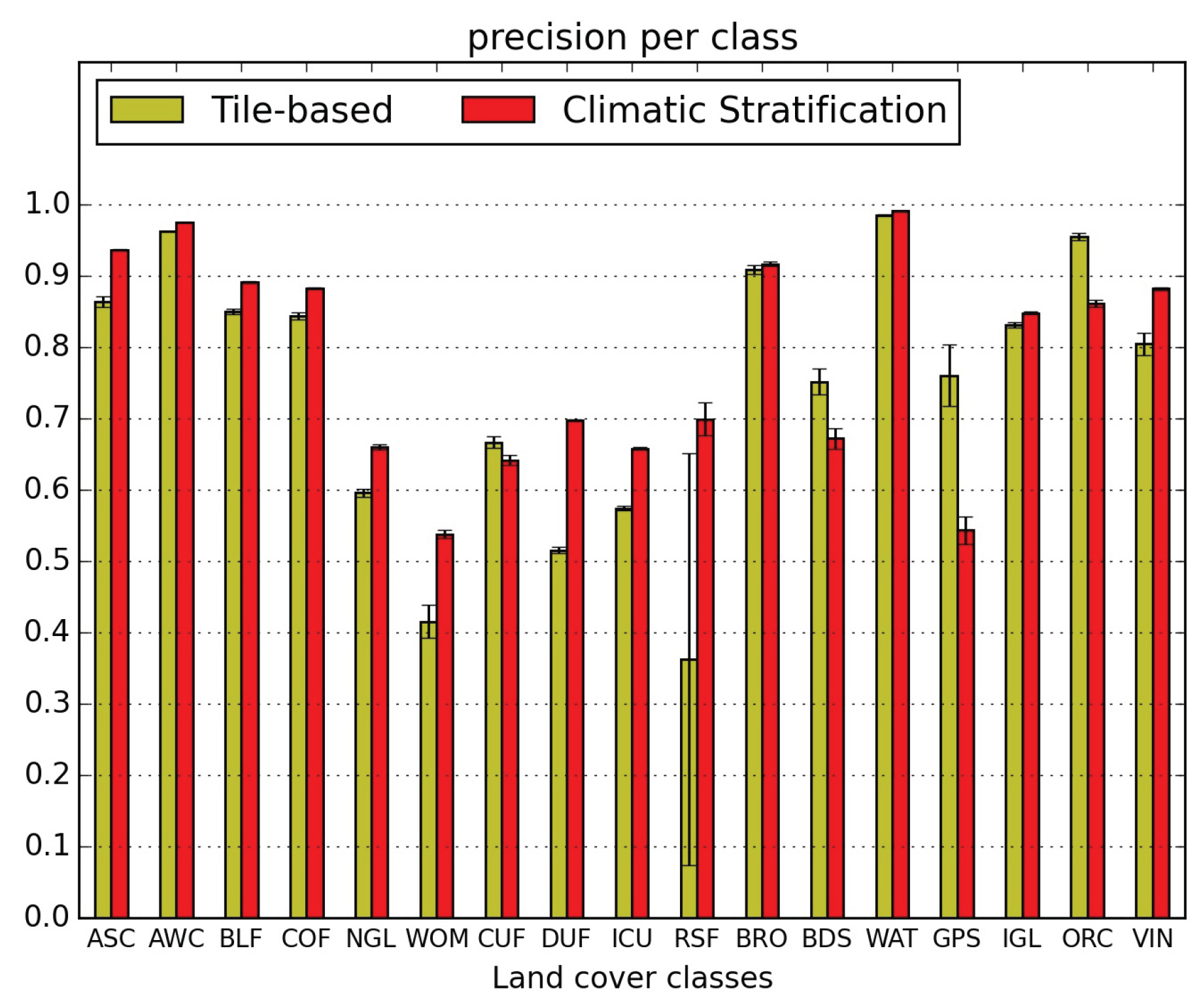
5.1. Quantitative Map Evaluation
- the confusions between natural grasslands (NGL) and woody moorlands (WOM) are reduced in both directions, as well as the WOM classified as discontinuous urban fabric (DUF);
- orchards (ORC) classification is very much improved (they were nearly not detected without stratification) but they are still confused with intensive grasslands (IGL); however the two other main confusions, with broad leaved forests (BLF) and DUF, are very much reduced;
- similarly, vineyards (VIN) which were mainly mis-classified as annual summer crops (ASC) and DUF are reduced to less than 5%;
- the confusion of glaciers and perpetual snow (GPS) with bare rock (BRO) is divided by 3;
- the confusion of beaches dunes and sand (BDS) with industrial and commercial units (ICU) is reduced from 33% to 8%, but the confusion with water (WAT) increases from 17% to 21%.
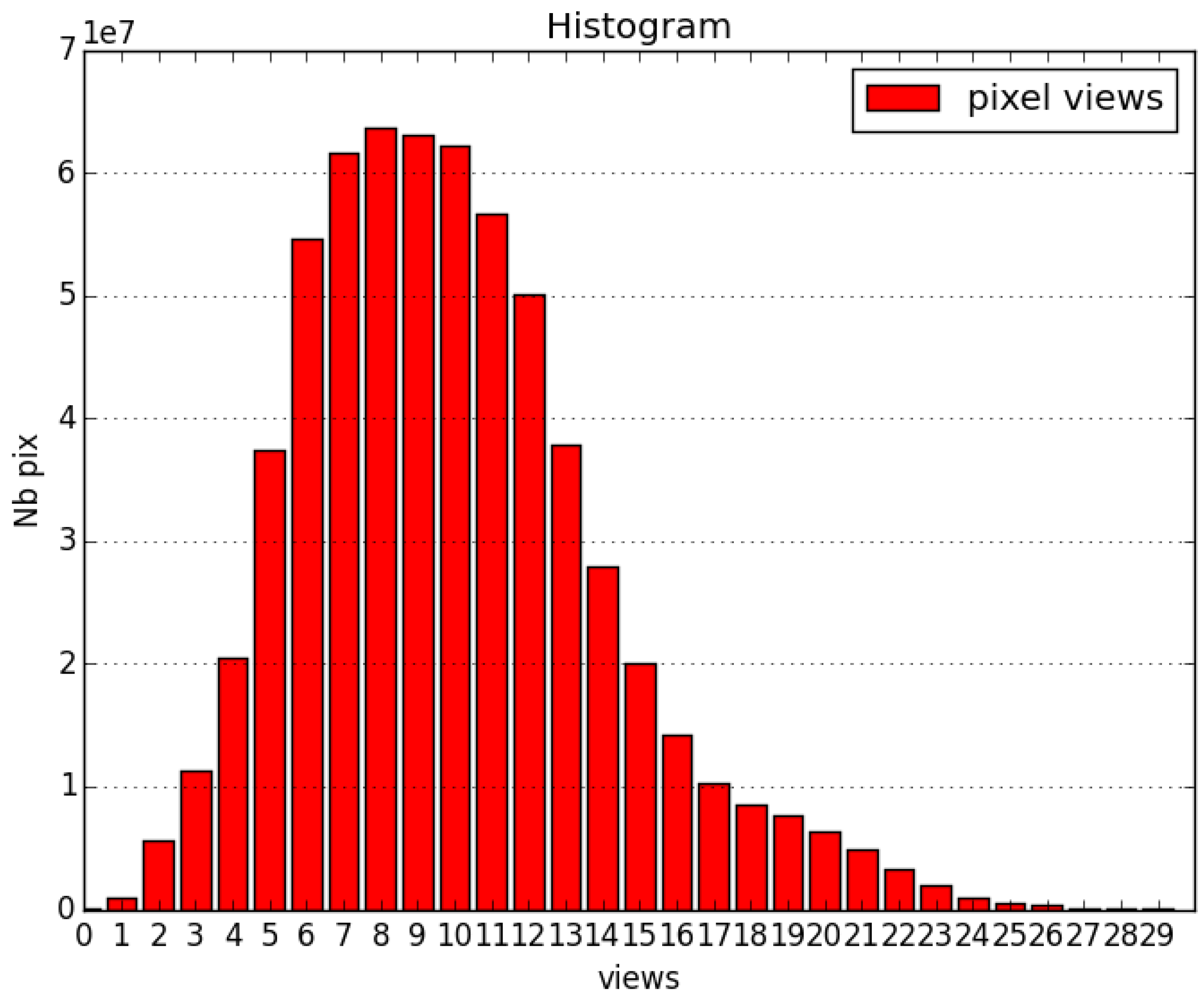
5.2. Use of the Confidence Map
- training samples correctly classified (black);
- validation samples correctly classified (green);
- mis-classified training samples (blue);
- mis-classified validation samples (red).
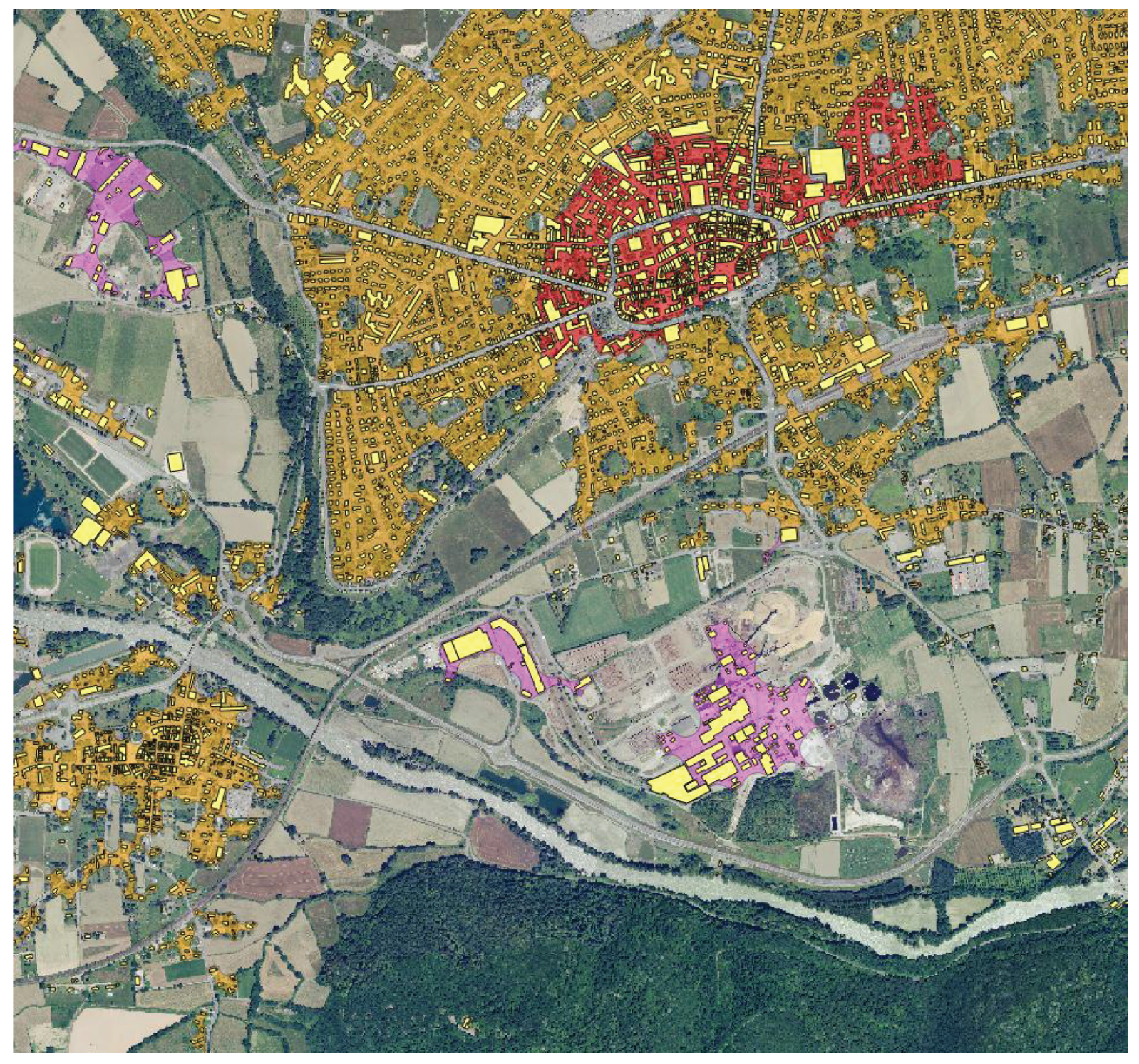
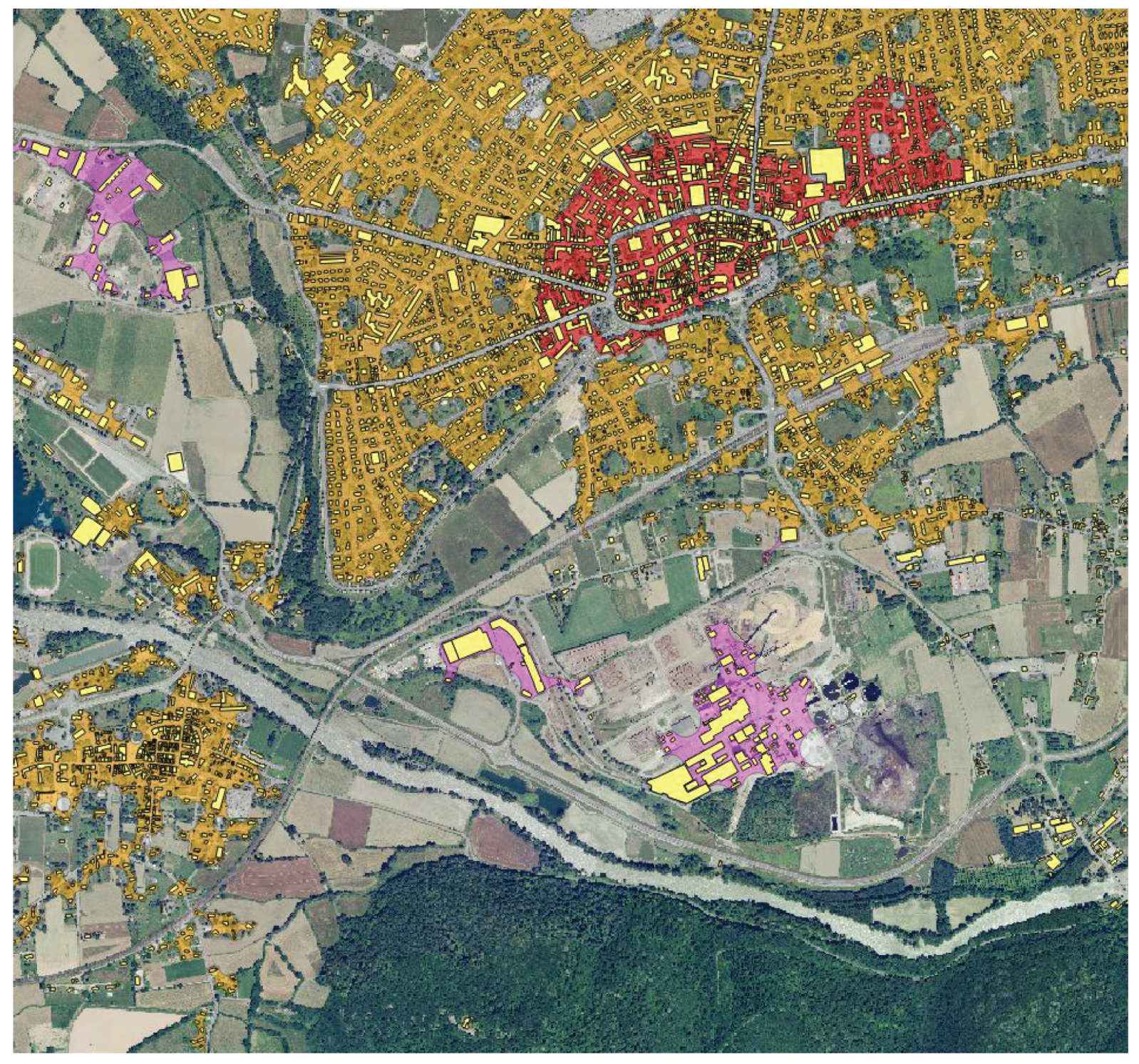
5.3. Visual Inspection
5.3.1. Difficult Landscapes
5.3.2. Small, Local Classes
5.3.3. Artefacts
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bojinski, S.; Verstraete, M.; Peterson, T.C.; Richter, C.; Simmons, A.; Zemp, M. The concept of essential climate variables in support of climate research, applications, and policy. Bull. Am. Meteorol. Soc. 2014, 95, 1431–1443. [Google Scholar] [CrossRef]
- Heymann, Y. CORINE Land Cover: Technical Guide; Office for Official Publications of the European Communities: Luxembourg, 1994. [Google Scholar]
- Drusch, M.; Bello, U.D.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Whitcraft, A.; Becker-Reshef, I.; Justice, C. A framework for defining spatially explicit earth observation requirements for a global agricultural monitoring initiative (GEOGLAM). Remote Sens. 2015, 7, 1461–1481. [Google Scholar] [CrossRef]
- Whitcraft, A.; Becker-Reshef, I.; Killough, B.; Justice, C. Meeting earth observation requirements for global agricultural monitoring: An evaluation of the revisit capabilities of current and planned moderate resolution optical earth observing missions. Remote Sens. 2015, 7, 1482–1503. [Google Scholar] [CrossRef]
- Irons, J.R.; Dwyer, J.L.; Barsi, J.A. The next Landsat satellite: The Landsat data continuity mission. Remote Sens. Environ. 2012, 122, 11–21. [Google Scholar] [CrossRef]
- Inglada, J.; Arias, M.; Tardy, B.; Hagolle, O.; Valero, S.; Morin, D.; Dedieu, G.; Sepulcre, G.; Bontemps, S.; Defourny, P.; et al. Assessment of an operational system for crop type map production using high temporal and spatial resolution satellite optical imagery. Remote Sens. 2015, 7, 12356–12379. [Google Scholar] [CrossRef]
- Arino, O.; Gross, D.; Ranera, F.; Leroy, M.; Bicheron, P.; Brockman, C.; Defourny, P.; Vancutsem, C.; Achard, F.; Durieux, L.; et al. GlobCover: ESA service for global land cover from MERIS. In Proceedings of the 2007 IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–28 July 2007.
- Foody, G.M.; Mathur, A.; Sanchez-Hernandez, C.; Boyd, D.S. Training set size requirements for the classification of a specific class. Remote Sens. Environ. 2006, 104, 1–14. [Google Scholar] [CrossRef]
- Stehman, S.V. Sampling designs for accuracy assessment of land cover. Int. J. Remote Sens. 2009, 30, 5243–5272. [Google Scholar] [CrossRef]
- Bruzzone, L.; Chi, M.; Marconcini, M. A novel transductive SVM for semisupervised classification of remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 3363–3373. [Google Scholar] [CrossRef]
- Bruzzone, L.; Marconcini, M. Domain adaptation problems: A DASVM classification technique and a circular validation strategy. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 770–787. [Google Scholar] [CrossRef] [PubMed]
- Matasci, G.; Volpi, M.; Kanevski, M.; Bruzzone, L.; Tuia, D. Semisupervised transfer component analysis for domain adaptation in remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3550–3564. [Google Scholar] [CrossRef]
- Petitjean, F.; Inglada, J.; Gancarski, P. Satellite image time series analysis under time warping. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3081–3095. [Google Scholar] [CrossRef]
- Defries, R.S.; Townshend, J.R.G. Global land cover characterization from satellite data: From research to operational implementation. GCTE/LUCC research review. Glob. Ecol. Biogeogr. 1999, 8, 367–379. [Google Scholar] [CrossRef]
- Hansen, M.C.; Loveland, T.R. A review of large area monitoring of land cover change using Landsat data. Remote Sens. Environ. 2012, 122, 66–74. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global land cover mapping at 30m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Grekousis, G.; Mountrakis, G.; Kavouras, M. An overview of 21 global and 43 regional land-cover mapping products. Int. J. Remote Sens. 2015, 36, 1–27. [Google Scholar] [CrossRef]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ Data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef]
- Yu, L.; Wang, J.; Gong, P. Improving 30 m global land-cover map from-GLC with time series MODIS and auxiliary data sets: A segmentation-based approach. Int. J. Remote Sens. 2013, 34, 5851–5867. [Google Scholar] [CrossRef]
- Yu, L.; Wang, J.; Li, X.; Li, C.; Zhao, Y.; Gong, P. A multi-resolution global land cover dataset through multisource data aggregation. Sci. China Earth Sci. 2014, 57, 2317–2329. [Google Scholar] [CrossRef]
- Giri, C.; Long, J. Land cover characterization and mapping of South America for the year 2010 using Landsat 30 m satellite data. Remote Sens. 2014, 6, 9494–9510. [Google Scholar] [CrossRef]
- Homer, C.; Dewitz, J.; Fry, J.; Coan, M.; Hossain, N.; Larson, C.; Herold, N.; McKerrow, A.; VanDriel, J.N.; Wickham, J.; et al. Completion of the 2001 national land cover database for the counterminous United States. Photogramm. Eng. Remote Sens. 2007, 73, 337. [Google Scholar]
- Jin, S.; Yang, L.; Danielson, P.; Homer, C.; Fry, J.; Xian, G. A comprehensive change detection method for updating the national land cover database to circa 2011. Remote Sens. Environ. 2013, 132, 159–175. [Google Scholar] [CrossRef]
- Deng, X.; Liu, J. Mapping land cover and land use changes in China. In Remote Sensing of Land Use and Land Cover: Principles and Applications; CRC Press: Boca Raton, FL, USA, 2012; pp. 339–349. [Google Scholar]
- Zhang, Z.; Wang, X.; Zhao, X.; Liu, B.; Yi, L.; Zuo, L.; Wen, Q.; Liu, F.; Xu, J.; Hu, S. A 2010 update of national land use/cover database of China at 1:100000 scale using medium spatial resolution satellite images. Remote Sens. Environ. 2014, 149, 142–154. [Google Scholar] [CrossRef]
- Congalton, R.; Gu, J.; Yadav, K.; Thenkabail, P.; Ozdogan, M. Global land cover mapping: A review and uncertainty analysis. Remote Sens. 2014, 6, 12070–12093. [Google Scholar] [CrossRef]
- Peel, M.C.; Finlayson, B.L.; McMahon, T.A. Updated world map of the Köppen-Geiger climate classification. Hydrol. Earth Syst. Sci. 2007, 11, 1633–1644. [Google Scholar] [CrossRef]
- Bossard, M.; Feranec, J.; Otahel, J. CORINE Land Cover Technical Guide. Addendum 2000; European Environment Agency: Copenhagen, Denmark, 2000. [Google Scholar]
- Maugeais, E.; Lecordix, F.; Halbecq, X.; Braun, A. Dérivation cartographique multi échelles de la BDTopo de l’IGN France: Mise en œuvre du processus de production de la Nouvelle Carte de Base. In Proceedings of the 25th International Cartographic Conference, Paris, France, 3–8 July 2011; pp. 3–8.
- Cantelaube, P.; Carles, M. Le registre parcellaire graphique: Des données géographiques pour décrire la couverture du sol agricole. In Le Cahier des Techniques de l’INRA; INRA: Paris, France, 2014; pp. 58–64. [Google Scholar]
- Pfeffer, W.T.; Arendt, A.A.; Bliss, A.; Bolch, T.; Cogley, J.G.; Gardner, A.S.; Hagen, J.O.; Hock, R.; Kaser, G.; Kienholz, C.; et al. The randolph glacier inventory: A globally complete inventory of glaciers. J. Glaciol. 2014, 60, 537–552. [Google Scholar] [CrossRef] [Green Version]
- Joly, D.; Brossard, T.; Cardot, H.; Cavailhes, J.; Hilal, M.; Wavresky, P. Les types de climats en France, une construction spatiale. Cybergeo 2010. [Google Scholar] [CrossRef]
- Hagolle, O.; Sylvander, S.; Huc, M.; Claverie, M.; Clesse, D.; Dechoz, C.; Lonjou, V.; Poulain, V. SPOT4 (Take5): Simulation of sentinel-2 time series on 45 large sites. Remote Sens. 2015, 7, 12242–12264. [Google Scholar] [CrossRef]
- Inglada, J.; Vincent, A.; Arias, M.; Tardy, B. iota2-a25386. 2016. Available online: http://tully.ups-tlse.fr/jordi/iota2 (assessed on 18 January 2017).
- Inglada, J.; Christophe, E. The Orfeo Toolbox remote sensing image processing software. In Proceedings of the 2009 IEEE International Geoscience and Remote Sensing Symposium, Cape Town, South Africa, 12–17 July 2009; Volume 4, pp. IV-733–IV-736.
- Michel, J.; Grizonnet, M. State of the Orfeo Toolbox. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 1336–1339.
- OTB Development Team. Orfeo Toolbox 5.4. Available online: https://git.orfeo-toolbox.org/otb.git/tag/faf53491eabbd6f30672c0132afb61737e9f47f6 (assessed on 18 January 2017).
- Inglada, J. OTB Gapfilling, a Temporal Gapfilling for Image Time Series Library. 2016. Available online: http://tully.ups-tlse.fr/jordi/temporalgapfilling (assessed on 18 January 2017).
- Arias, M.; Morin, D. Vector-Tools-7ab2125a. 2016. Available online: http://tully.ups-tlse.fr/jordi/vector_tools (assessed on 18 January 2017).
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef]
- Gao, B.C. NDWI. A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Folleco, A.; Khoshgoftaar, T.M.; Hulse, J.V.; Bullard, L. Software quality modeling: The impact of class noise on the random forest classifier. In Proceedings of the 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–6 June 2008.
- Frenay, B.; Verleysen, M. Classification in the presence of label noise: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 845–869. [Google Scholar] [CrossRef] [PubMed]
- Pelletier, C.; Valero, S.; Inglada, J.; Champion, N.; Dedieu, G. Assessing the robustness of random forests to map land cover with high resolution satellite image time series over large areas. Remote Sens. Environ. 2016, 187, 156–168. [Google Scholar] [CrossRef]
- Mellor, A.; Boukir, S.; Haywood, A.; Jones, S. Exploring issues of training data imbalance and mislabelling on random forest performance for large area land cover classification using the ensemble margin. ISPRS J. Photogramm. Remote Sens. 2015, 105, 155–168. [Google Scholar] [CrossRef]
- Inglada, J.; Vincent, A.; Arias, M.; Marais-Sicre, C. Improved early crop type identification by joint use of high temporal resolution SAR and optical image time series. Remote Sens. 2016, 8, 362. [Google Scholar] [CrossRef]
- Sicre, C.M.; Inglada, J.; Fieuzal, R.; Baup, F.; Valero, S.; Cros, J.; Huc, M.; Demarez, V. Early detection of summer crops using high spatial resolution optical image time series. Remote Sens. 2016, 8, 591. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Path | Row | #Dates | Date List |
|---|---|---|---|
| 194 | 29 | 17 | 01-24 02-09 02-25 03-13 03-29 04-14 |
| 05-16 06-01 07-03 07-19 08-04 08-20 | |||
| 09-05 10-23 11-08 12-10 12-26 | |||
| 194 | 30 | 15 | 01-24 02-09 02-25 03-13 04-14 05-16 |
| 06-01 06-17 07-03 08-20 09-05 10-23 | |||
| 11-08 12-10 12-26 | |||
| 195 | 26 | 9 | 01-15 03-04 04-21 05-23 06-08 06-24 |
| 08-11 09-28 10-14 | |||
| 195 | 27 | 9 | 01-15 01-31 03-20 05-23 06-08 09-12 |
| 09-28 10-14 10-30 | |||
| 195 | 28 | 9 | 01-31 03-20 05-23 06-08 08-27 09-12 |
| 09-28 10-14 10-30 | |||
| 195 | 29 | 16 | 01-15 01-31 03-04 03-20 04-05 05-07 |
| 05-23 06-08 06-24 07-10 07-26 08-11 | |||
| 08-27 09-12 09-28 10-30 | |||
| 195 | 30 | 17 | 01-15 01-31 02-16 03-04 03-20 04-05 |
| 05-07 05-23 06-08 06-24 07-10 07-26 | |||
| 08-11 08-27 09-12 09-28 10-30 | |||
| 196 | 26 | 12 | 01-06 02-23 03-11 03-27 04-12 05-14 |
| 06-15 07-01 07-17 09-03 09-19 11-22 | |||
| 196 | 27 | 17 | 01-22 02-23 03-11 03-27 04-12 05-14 |
| 05-30 06-15 07-01 07-17 08-18 09-03 | |||
| 09-19 10-21 11-06 11-22 12-24 | |||
| 196 | 28 | 18 | 01-06 01-22 02-23 03-11 03-27 04-12 |
| 05-14 05-30 06-15 07-01 07-17 08-18 | |||
| 09-03 10-05 10-21 11-06 11-22 12-24 | |||
| 196 | 29 | 19 | 01-06 01-22 02-23 03-11 03-27 04-12 |
| 04-28 05-14 05-30 07-01 07-17 08-02 | |||
| 08-18 09-03 10-21 11-06 11-22 12-08 | |||
| 12-24 | |||
| 196 | 30 | 20 | 01-06 01-22 02-23 03-11 03-27 04-12 |
| 04-28 05-14 05-30 06-15 07-01 07-17 | |||
| 08-02 08-18 09-03 09-19 10-05 10-21 | |||
| 11-06 12-24 | |||
| 197 | 25 | 7 | 01-29 04-03 05-05 06-06 06-22 07-24 |
| 09-26 | |||
| 197 | 26 | 13 | 03-02 03-18 04-03 04-19 05-05 06-06 |
| 06-22 07-24 08-09 09-10 09-26 11-13 | |||
| 12-15 | |||
| 197 | 27 | 16 | 03-02 03-18 04-19 05-05 06-06 06-22 |
| 07-08 07-24 08-09 08-25 09-10 09-26 | |||
| 10-28 11-13 12-15 12-31 | |||
| 197 | 28 | 14 | 03-02 03-18 04-19 05-05 06-06 06-22 |
| 07-24 08-09 08-25 09-10 09-26 10-28 | |||
| 11-13 12-15 | |||
| 197 | 29 | 17 | 03-02 03-18 04-19 05-05 05-21 06-22 |
| 07-08 07-24 08-09 08-25 09-10 09-26 | |||
| 10-12 10-28 11-13 12-15 12-31 | |||
| 197 | 30 | 19 | 01-29 02-14 03-02 03-18 04-19 05-05 |
| 05-21 06-06 06-22 07-24 08-09 08-25 | |||
| 09-10 09-26 10-12 10-28 11-13 12-15 | |||
| 12-31 | |||
| 197 | 31 | 15 | 01-29 02-14 03-02 03-18 04-19 05-05 |
| 06-06 06-22 07-08 08-09 08-25 09-26 | |||
| 10-12 11-13 12-31 | |||
| 198 | 25 | 14 | 02-05 02-21 03-09 03-25 04-10 06-13 |
| 07-31 08-16 09-01 09-17 10-03 10-19 | |||
| 11-20 12-06 | |||
| 198 | 26 | 11 | 02-21 03-09 03-25 04-10 06-13 07-31 |
| 08-16 09-01 09-17 10-03 10-19 | |||
| 198 | 27 | 13 | 02-21 03-09 04-10 05-28 06-13 07-31 |
| 08-16 09-01 09-17 10-03 10-19 11-20 | |||
| 12-22 | |||
| 198 | 28 | 13 | 03-09 04-10 05-28 06-13 06-29 07-31 |
| 08-16 09-01 09-17 10-03 10-19 11-20 | |||
| 12-22 | |||
| 198 | 29 | 12 | 03-09 04-10 05-28 06-13 07-31 08-16 |
| 09-01 09-17 10-03 10-19 11-20 12-22 | |||
| 198 | 30 | 18 | 01-20 03-09 03-25 04-10 04-26 05-12 |
| 05-28 06-13 06-29 07-31 08-16 09-01 | |||
| 09-17 10-03 10-19 11-20 12-06 12-22 | |||
| 198 | 31 | 17 | 01-04 01-20 03-09 03-25 04-10 05-12 |
| 05-28 06-13 06-29 07-31 08-16 09-01 | |||
| 09-17 10-03 10-19 11-20 12-06 | |||
| 199 | 24 | 11 | 01-11 02-12 03-16 05-03 05-19 06-20 |
| 08-07 08-23 09-08 11-11 12-29 | |||
| 199 | 25 | 11 | 02-12 03-16 04-01 04-17 05-19 08-07 |
| 08-23 09-08 10-10 10-26 11-11 | |||
| 199 | 26 | 16 | 01-11 01-27 02-12 02-28 03-16 04-01 |
| 04-17 05-03 05-19 08-23 09-08 09-24 | |||
| 10-10 10-26 11-11 12-29 | |||
| 199 | 27 | 15 | 01-27 02-12 02-28 03-16 04-01 04-17 |
| 05-03 05-19 06-20 09-08 09-24 10-26 | |||
| 11-11 11-27 12-29 | |||
| 199 | 28 | 16 | 01-27 02-12 02-28 03-16 04-01 04-17 |
| 05-19 06-04 06-20 07-22 09-08 09-24 | |||
| 10-26 11-11 11-27 12-29 | |||
| 199 | 29 | 13 | 02-12 03-16 04-01 04-17 05-19 06-04 |
| 06-20 07-22 09-08 10-26 11-11 11-27 | |||
| 12-29 | |||
| 199 | 30 | 20 | 01-11 01-27 02-12 02-28 03-16 04-01 |
| 04-17 05-03 05-19 06-04 06-20 07-22 | |||
| 08-07 08-23 09-08 09-24 10-26 11-11 | |||
| 11-27 12-29 | |||
| 199 | 31 | 1 | 06-04 |
| 200 | 24 | 7 | 01-02 02-03 03-23 04-08 09-15 11-02 |
| 12-20 | |||
| 200 | 25 | 13 | 01-02 02-03 03-07 03-23 04-08 06-11 |
| 08-14 09-15 10-01 10-17 11-02 11-18 | |||
| 12-20 | |||
| 200 | 26 | 9 | 01-02 01-18 02-03 03-07 04-08 06-11 |
| 06-27 09-15 10-01 | |||
| 200 | 27 | 10 | 01-02 01-18 02-03 03-07 03-23 06-11 |
| 06-27 08-30 09-15 10-01 | |||
| 200 | 28 | 17 | 01-02 01-18 02-03 03-07 03-23 04-08 |
| 06-11 06-27 07-29 08-14 08-30 09-15 | |||
| 10-01 10-17 11-02 11-18 12-20 | |||
| 200 | 29 | 14 | 01-02 02-19 03-07 03-23 04-08 06-11 |
| 06-27 07-29 08-14 08-30 09-15 10-01 | |||
| 10-17 11-18 | |||
| 200 | 30 | 16 | 02-19 03-07 03-23 04-08 05-10 05-26 |
| 06-11 06-27 07-13 07-29 08-14 09-15 | |||
| 10-01 10-17 11-18 12-04 | |||
| 201 | 25 | 13 | 01-09 02-26 04-15 05-17 06-02 06-18 |
| 07-04 08-21 09-22 10-08 11-09 12-11 | |||
| 12-27 | |||
| 201 | 26 | 16 | 01-25 02-26 03-14 03-30 04-15 05-17 |
| 06-18 07-04 08-05 08-21 09-06 09-22 | |||
| 10-08 11-09 12-11 12-27 | |||
| 201 | 27 | 17 | 01-25 02-26 03-14 03-30 04-15 05-17 |
| 06-02 06-18 07-04 08-05 08-21 09-06 | |||
| 09-22 10-08 10-24 11-09 12-27 | |||
| 201 | 28 | 16 | 01-25 02-26 03-14 03-30 04-15 05-17 |
| 06-02 06-18 07-04 08-05 08-21 09-06 | |||
| 09-22 10-08 10-24 11-09 | |||
| 201 | 29 | 8 | 03-14 04-15 06-18 07-20 08-05 08-21 |
| 09-22 10-24 | |||
| 201 | 30 | 11 | 01-25 02-26 03-14 04-15 05-01 05-17 |
| 06-02 06-18 08-21 09-06 10-08 | |||
| 202 | 25 | 10 | 01-16 03-05 03-21 05-24 06-09 06-25 |
| 07-11 08-12 08-28 10-31 | |||
| 202 | 26 | 13 | 01-16 02-01 03-05 03-21 05-24 06-09 |
| 06-25 07-11 08-12 08-28 09-29 10-31 | |||
| 11-16 | |||
| 202 | 27 | 15 | 01-16 02-01 03-05 03-21 04-22 05-24 |
| 06-09 06-25 07-27 08-12 08-28 09-13 | |||
| 09-29 10-31 11-16 | |||
| 203 | 26 | 19 | 01-07 01-23 02-08 02-24 03-12 04-13 |
| 05-15 05-31 06-16 07-02 07-18 08-03 | |||
| 08-19 09-04 09-20 10-06 10-22 11-07 | |||
| 12-25 | |||
| 203 | 27 | 17 | 01-07 02-08 02-24 03-12 05-15 05-31 |
| 06-16 07-02 07-18 08-03 08-19 09-04 | |||
| 10-06 10-22 11-07 12-09 12-25 | |||
| 204 | 26 | 11 | 04-04 05-06 06-07 06-23 07-09 07-25 |
| 08-10 08-26 09-11 09-27 10-13 | |||
| 204 | 27 | 8 | 01-14 04-04 06-07 06-23 08-10 09-11 |
| 09-27 10-13 |
| ASC | AWC | BLF | COF | NGL | WOM | CUF | DUF | ICU | RSF | BRO | BDS | WAT | GPS | IGL | ORC | VIN | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ASC | 91.19 | 2.66 | 0.37 | 0.38 | 0.39 | 0.08 | 0.01 | 2.44 | 0.37 | 0.00 | 0.00 | 0.01 | 0.15 | 0.00 | 1.65 | 0.00 | 0.29 |
| AWC | 0.67 | 97.14 | 0.07 | 0.15 | 0.13 | 0.03 | 0.00 | 0.83 | 0.14 | 0.00 | 0.00 | 0.01 | 0.07 | 0.00 | 0.72 | 0.00 | 0.05 |
| BLF | 0.19 | 0.18 | 86.98 | 6.74 | 1.94 | 0.52 | 0.00 | 0.83 | 0.02 | 0.00 | 0.00 | 0.00 | 0.18 | 0.00 | 2.40 | 0.00 | 0.03 |
| COF | 0.81 | 0.31 | 4.60 | 85.82 | 3.03 | 1.76 | 0.00 | 2.65 | 0.08 | 0.00 | 0.06 | 0.00 | 0.16 | 0.00 | 0.48 | 0.00 | 0.23 |
| NGL | 0.97 | 0.75 | 3.88 | 6.93 | 64.18 | 3.02 | 0.00 | 7.70 | 0.33 | 0.00 | 2.42 | 0.01 | 0.15 | 0.01 | 9.12 | 0.00 | 0.55 |
| WOM | 1.27 | 0.76 | 8.47 | 13.71 | 33.72 | 12.36 | 0.00 | 13.91 | 1.11 | 0.00 | 2.37 | 0.03 | 2.25 | 0.00 | 9.85 | 0.00 | 0.20 |
| CUF | 0.17 | 0.06 | 0.25 | 0.61 | 0.13 | 0.08 | 14.02 | 55.11 | 28.82 | 0.00 | 0.03 | 0.01 | 0.54 | 0.00 | 0.16 | 0.00 | 0.03 |
| DUF | 0.50 | 0.72 | 0.95 | 1.36 | 0.89 | 0.09 | 0.41 | 84.03 | 7.55 | 0.00 | 0.09 | 0.01 | 0.19 | 0.00 | 3.11 | 0.00 | 0.12 |
| ICU | 0.37 | 0.65 | 0.85 | 0.79 | 0.45 | 0.10 | 0.39 | 38.15 | 56.32 | 0.00 | 0.03 | 0.02 | 0.36 | 0.00 | 1.46 | 0.00 | 0.05 |
| RSF | 0.43 | 0.95 | 0.54 | 0.58 | 0.80 | 0.06 | 0.09 | 22.62 | 71.39 | 0.00 | 0.55 | 0.07 | 0.47 | 0.00 | 1.39 | 0.00 | 0.05 |
| BRO | 0.04 | 0.01 | 0.06 | 0.55 | 8.62 | 0.43 | 0.01 | 0.73 | 1.83 | 0.00 | 84.53 | 0.02 | 2.46 | 0.69 | 0.01 | 0.00 | 0.00 |
| BDS | 2.24 | 1.38 | 2.65 | 1.25 | 2.26 | 0.71 | 0.01 | 16.00 | 33.36 | 0.01 | 1.63 | 18.35 | 17.63 | 0.00 | 2.15 | 0.00 | 0.37 |
| WAT | 0.09 | 0.08 | 0.16 | 0.15 | 0.10 | 0.26 | 0.00 | 0.19 | 0.23 | 0.00 | 0.02 | 0.03 | 98.48 | 0.00 | 0.18 | 0.00 | 0.00 |
| GPS | 0.00 | 0.00 | 0.00 | 0.00 | 1.53 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 45.45 | 0.07 | 5.86 | 47.09 | 0.00 | 0.00 | 0.00 |
| IGL | 0.29 | 1.17 | 1.98 | 0.95 | 7.96 | 0.32 | 0.00 | 0.76 | 0.02 | 0.00 | 0.21 | 0.00 | 0.20 | 0.00 | 86.10 | 0.00 | 0.03 |
| ORC | 6.05 | 5.01 | 18.33 | 2.18 | 6.00 | 0.98 | 0.00 | 22.12 | 0.30 | 0.00 | 0.00 | 0.01 | 0.12 | 0.00 | 33.45 | 2.73 | 2.70 |
| VIN | 25.81 | 1.38 | 0.25 | 1.25 | 3.40 | 0.26 | 0.00 | 18.21 | 0.23 | 0.00 | 0.00 | 0.07 | 0.08 | 0.00 | 5.49 | 0.01 | 43.55 |
| ASC | AWC | BLF | COF | NGL | WOM | CUF | DUF | ICU | RSF | BRO | BDS | WAT | GPS | IGL | ORC | VIN | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ASC | 94.19 | 1.96 | 0.26 | 0.49 | 0.18 | 0.11 | 0.02 | 1.00 | 0.16 | 0.00 | 0.00 | 0.02 | 0.05 | 0.00 | 1.15 | 0.01 | 0.41 |
| AWC | 0.66 | 98.16 | 0.06 | 0.08 | 0.11 | 0.04 | 0.00 | 0.28 | 0.05 | 0.00 | 0.00 | 0.01 | 0.02 | 0.00 | 0.49 | 0.01 | 0.06 |
| BLF | 0.15 | 0.16 | 89.65 | 5.06 | 2.02 | 1.17 | 0.00 | 0.33 | 0.02 | 0.00 | 0.00 | 0.00 | 0.11 | 0.00 | 1.25 | 0.01 | 0.05 |
| COF | 0.24 | 0.08 | 3.20 | 92.54 | 1.79 | 1.08 | 0.00 | 0.51 | 0.06 | 0.00 | 0.07 | 0.01 | 0.02 | 0.00 | 0.34 | 0.00 | 0.06 |
| NGL | 0.24 | 0.50 | 2.79 | 5.63 | 64.57 | 8.34 | 0.00 | 1.40 | 0.18 | 0.00 | 2.68 | 0.04 | 0.13 | 0.01 | 13.14 | 0.02 | 0.30 |
| WOM | 0.54 | 0.45 | 5.68 | 9.45 | 29.47 | 41.03 | 0.00 | 1.84 | 0.29 | 0.00 | 2.58 | 0.14 | 2.91 | 0.00 | 5.34 | 0.03 | 0.26 |
| CUF | 0.21 | 0.06 | 0.25 | 0.53 | 0.25 | 0.32 | 24.80 | 46.47 | 26.23 | 0.01 | 0.11 | 0.11 | 0.27 | 0.00 | 0.13 | 0.01 | 0.25 |
| DUF | 0.63 | 0.76 | 0.87 | 1.44 | 1.27 | 0.85 | 0.84 | 82.07 | 7.76 | 0.00 | 0.18 | 0.05 | 0.11 | 0.00 | 2.76 | 0.04 | 0.40 |
| ICU | 0.48 | 0.75 | 0.79 | 0.91 | 0.54 | 0.57 | 0.73 | 34.39 | 58.73 | 0.03 | 0.16 | 0.16 | 0.29 | 0.00 | 1.28 | 0.04 | 0.16 |
| RSF | 0.51 | 0.93 | 0.50 | 0.67 | 0.93 | 0.82 | 0.33 | 19.31 | 71.28 | 1.34 | 0.88 | 0.45 | 0.56 | 0.00 | 1.33 | 0.03 | 0.13 |
| BRO | 0.01 | 0.00 | 0.06 | 0.76 | 6.88 | 1.57 | 0.00 | 0.20 | 0.46 | 0.00 | 86.22 | 0.06 | 0.22 | 3.39 | 0.18 | 0.00 | 0.00 |
| BDS | 1.23 | 0.80 | 2.19 | 1.50 | 3.88 | 5.89 | 0.03 | 9.10 | 8.25 | 0.02 | 1.04 | 43.05 | 21.38 | 0.00 | 1.14 | 0.13 | 0.39 |
| WAT | 0.05 | 0.05 | 0.11 | 0.06 | 0.08 | 0.48 | 0.00 | 0.05 | 0.06 | 0.00 | 0.04 | 0.12 | 98.74 | 0.00 | 0.15 | 0.00 | 0.01 |
| GPS | 0.00 | 0.00 | 0.00 | 0.00 | 0.42 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 14.47 | 0.01 | 0.05 | 85.05 | 0.00 | 0.00 | 0.00 |
| IGL | 0.23 | 0.66 | 1.59 | 0.83 | 4.58 | 0.94 | 0.00 | 0.49 | 0.01 | 0.00 | 0.22 | 0.01 | 0.19 | 0.00 | 90.14 | 0.02 | 0.09 |
| ORC | 3.83 | 2.85 | 9.40 | 2.04 | 7.65 | 6.06 | 0.01 | 8.72 | 0.25 | 0.00 | 0.00 | 0.08 | 0.17 | 0.00 | 21.74 | 29.60 | 7.58 |
| VIN | 5.73 | 1.08 | 0.24 | 1.50 | 1.99 | 0.88 | 0.02 | 3.94 | 0.09 | 0.00 | 0.00 | 0.04 | 0.07 | 0.00 | 2.19 | 0.15 | 82.08 |
© 2017 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Inglada, J.; Vincent, A.; Arias, M.; Tardy, B.; Morin, D.; Rodes, I. Operational High Resolution Land Cover Map Production at the Country Scale Using Satellite Image Time Series. Remote Sens. 2017, 9, 95. https://doi.org/10.3390/rs9010095
Inglada J, Vincent A, Arias M, Tardy B, Morin D, Rodes I. Operational High Resolution Land Cover Map Production at the Country Scale Using Satellite Image Time Series. Remote Sensing. 2017; 9(1):95. https://doi.org/10.3390/rs9010095
Chicago/Turabian StyleInglada, Jordi, Arthur Vincent, Marcela Arias, Benjamin Tardy, David Morin, and Isabel Rodes. 2017. "Operational High Resolution Land Cover Map Production at the Country Scale Using Satellite Image Time Series" Remote Sensing 9, no. 1: 95. https://doi.org/10.3390/rs9010095
APA StyleInglada, J., Vincent, A., Arias, M., Tardy, B., Morin, D., & Rodes, I. (2017). Operational High Resolution Land Cover Map Production at the Country Scale Using Satellite Image Time Series. Remote Sensing, 9(1), 95. https://doi.org/10.3390/rs9010095