1. Introduction
With the existence of clouds, solar radiation cannot or can hardly arrive at the land surface, which not only leads to the missing information and spectral distortion, but also hinders the further image application [
1,
2]. Therefore, cloud detection plays an indispensable role in image pre-processing. However, accurate cloud detection is quite challenging. On the one hand, there are various clouds with different spectral characteristics. On the other hand, some objects with high reflectance (such as snow, ice, etc.) are always confused with clouds. In particular, optical thin clouds are difficult to detect as their spectral signal includes both clouds and the surface underneath [
3].
In recent years, many researchers have studied these issues and a series of cloud detection methods have been proposed. Generally speaking, these methods can be divided into two categories: single-image-based method and multiple-image-based method [
4,
5,
6]. In [
7], cloud and shadow areas are detected using spectral information from the blue, shortwave infrared and thermal infrared bands of Landsat Thematic Mapper (TM) or Enhanced Thematic Mapper Plus (ETM+) imagery from two dates. Goodwin proposes a new automated method to screen cloud and cloud shadow from time series of Landsat TM/ETM+, and the results suggest that temporal information can improve the detection of cloud and cloud shadow [
8]. Zhu also designs an automated cloud, cloud shadow, and snow detection algorithm using multi-temporal Landsat data [
9]. However, imagery without temporal characteristics is much more common and the emergence of single-image-based methods can be helpful for multiple-image-based cloud detection. In this paper, we mainly focus on the cloud detection with single image.
For single-image-based cloud detection, threshold-based methods are widely used [
10,
11,
12,
13]. Irish [
14] proposes an automated cloud cover assessment method to extract clouds from Landsat data by setting a series of thresholds using different indexes. However, it does not provide sufficient precise locations and boundaries of clouds. Zhu and Woodcock acquire the cloud mask by computing a probability mask and a scene-based threshold, while due to the relatively lower threshold settings, the clouds are always overestimated [
15]. Zhang et al. obtain a coarse cloud detection result relying on the significance map and the proposed optimal threshold setting [
16]. The threshold-based method is a simple and practical approach for cloud detection, while it is impractical for general use because of its sensitivity to the background and the range of cloud cover [
17].
Subsequently, more sophisticated methods are used to identify cloud from remote sensing imagery [
18,
19,
20,
21]. In [
22], decision trees based on empirical studies and simulations are designed for cloud detection and acquire relatively satisfactory performance. As cloud and cloud shadow always occur in pairs, the relationship between cloud and cloud shadow as well as the sensor parameters can also be used for cloud detection [
23,
24]. Nevertheless, it is a tough job for acquiring sensor parameters, which to some extent increases the difficulty of cloud identification. According to the unique characteristics of clouds, which are brighter and colder than most of the earth surface, spectral features can always be used for cloud pixel detection. In addition, some existing methods add other information of images, such as texture information, shape information, spatial information, and so on [
25,
26,
27,
28].
In essence, cloud detection is a classification problem, and the recent developments of machine learning provide more available approaches for cloud detection [
29,
30]. Therefore, some classifier-based methods (such as Support Vector Machine (SVM), Random Forest (RF), etc.) have increasing popularity. Latry classifies the cloud picture using radiances and geometrical characteristics based on SVM [
31]. In [
32], researchers adopt a visual attention technique in computer-vision based RF to automatically identify images with a significant cloud cover. Ma et al. [
33] successfully applies the cascaded adaboost classifier to solve the cloud detection problem. In existing methods, a larger number of features are artificially designed and extracted as the classifier input. These artificially designed features rely on prior knowledge and they are difficult to accurately represent the cloud characteristics under complex environment. Thus, we adopt a model integrating deep discriminative feature learning and fuzzy function strategies to detect clouds, which could not only extract implicit information, but also attain good performance.
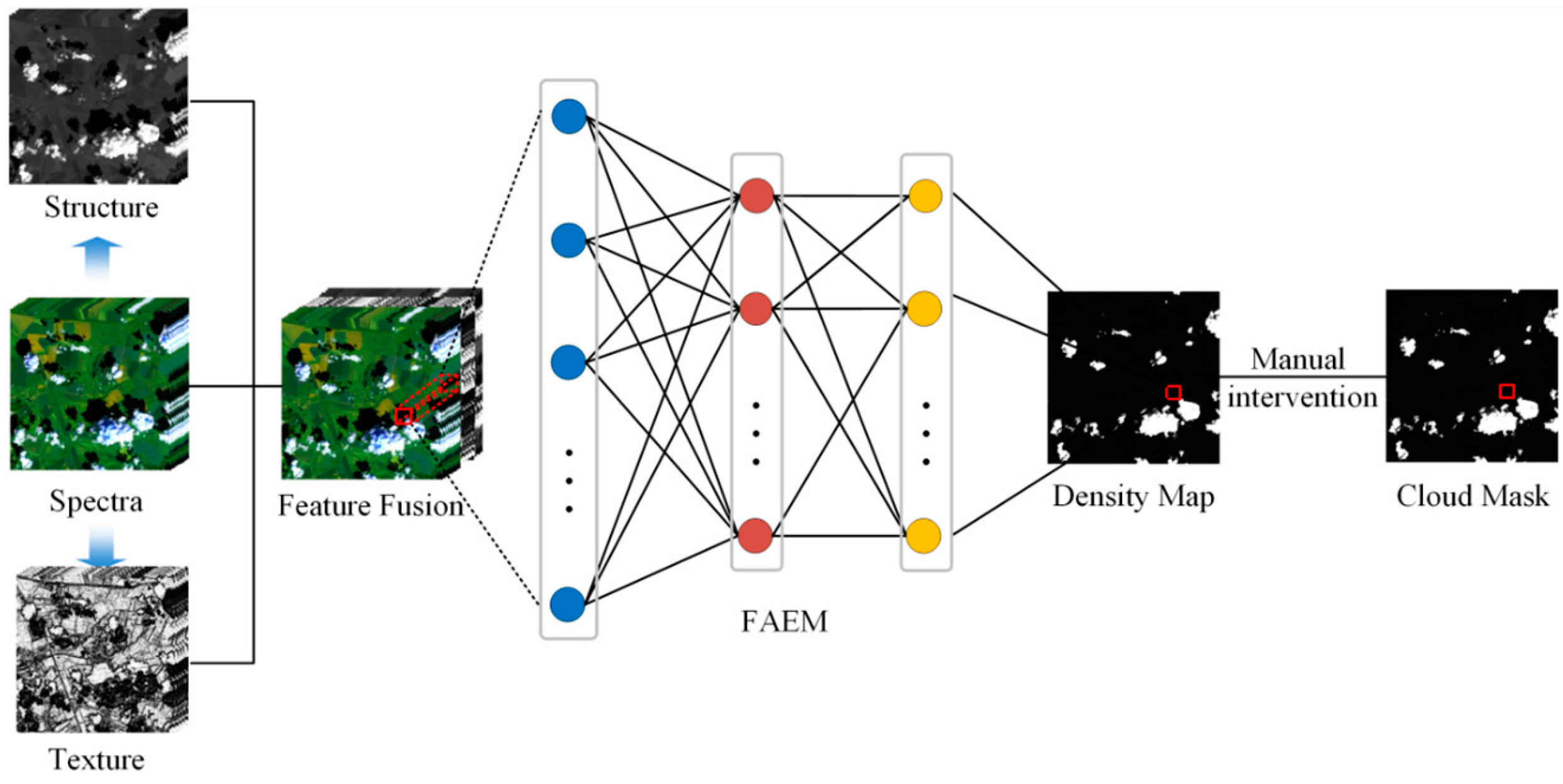
In this paper, we establish a model named FAEM for discriminative feature learning instead of artificial feature designing. The proposed FAEM mainly consists of two parts: stacked autoencode networks are introduced to learn the deep discriminative features from a great deal of samples, and then a fuzzy function is combined to obtain the accurate cloud detection results. The remainder of this manuscript is organized as follows.
Section 2 describes datasets and preprocessing. The proposed methodology for cloud detection is introduced in
Section 3, followed by the cloud extraction experiments and result in
Section 4. Further discussions are arranged in
Section 5 and in
Section 6 we give a brief summary of our works.
4. Experiments and Results
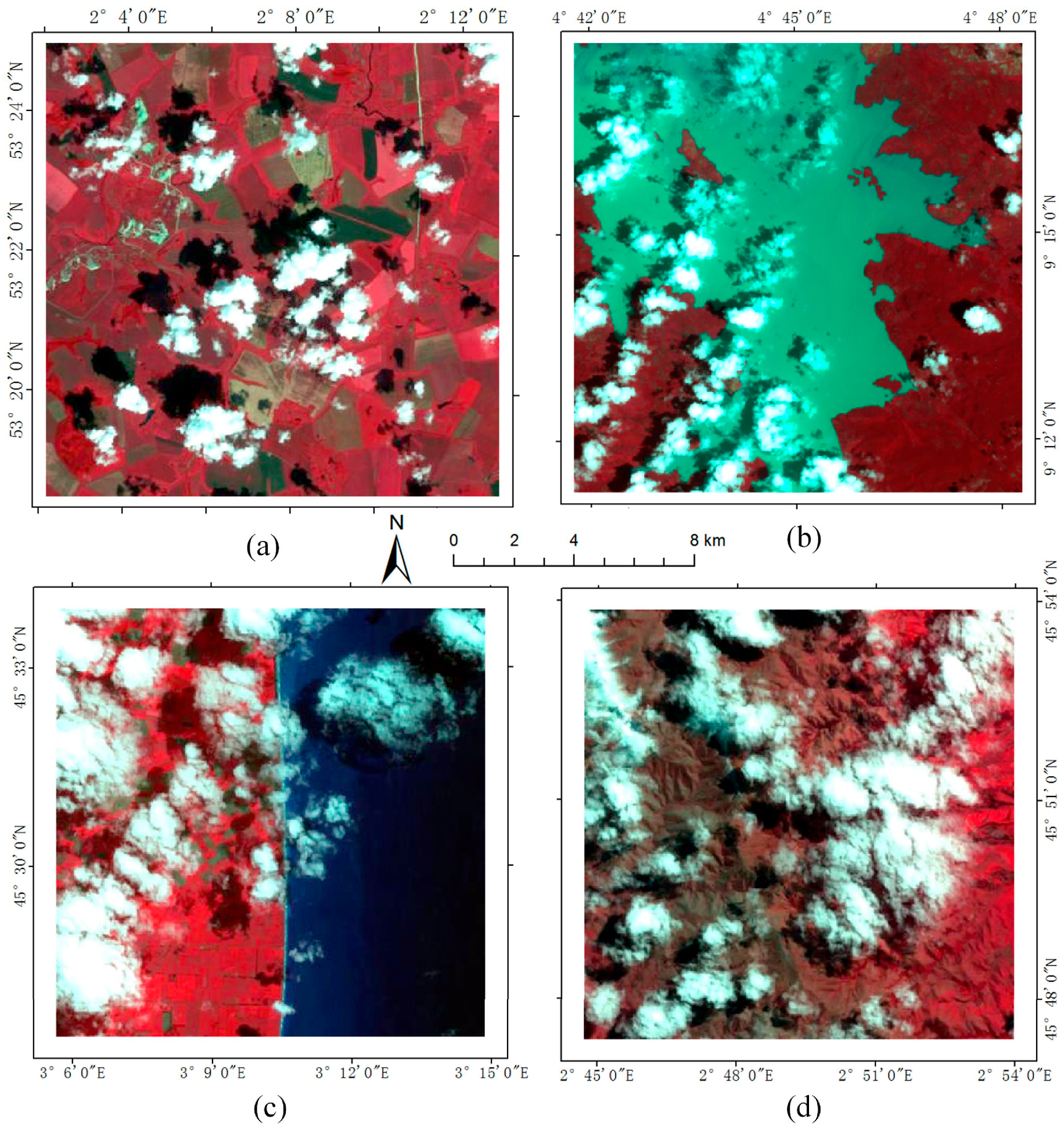
As there are some adjustable parameters in our FAEM model, we first analysis and determine the best parameter combination for accurate detection result. In this experiments, 16,698 cloud pixels and 50,253 non-cloud pixels which contain as many objects as possible are selected as samples for the Landsat ETM+ imagery. The numbers of cloud and non-cloud samples for 25 GF-1 images are 13,197 and 17,462 respectively. In addition, the samples should belong to the pure objects such as thick cloud, water, building, vegetation and so on, the thin cloud which is actually the mixture of cloud and ground objects is not selected as samples.
After that, the samples are divided into two parts: training set and test set, and the number of training and test set are 2/3 and 1/3 of the total number of samples respectively. During the training procedure, training set is used for model training and after each training epoch, the test sets are used to test the trained model and output the corresponding test accuracy. At the prediction procedure, each pixel’s degree of belonging to cloud is predicted and used to derive the corresponding cloud density map. Moreover, to demonstrate the efficiency of proposed model, both Landsat ETM+ and GF-1 images with different spatial resolution are applied in this experiment.
4.1. Parameter Analysis
The number of layers and hidden nodes can influence the result of cloud detection. In our previous experiments with Landsat ETM+ imagery, the number of the fundamental vector is 13 (including spectral, texture and structural information) and the numbers of the two hidden layers are 12 and 10, respectively, and a cloud density map is outputted as last. For convenience, we denote the model node number as 13-12-10-1. In this section, several experiments are designed to fully explore the relation between different model parameter combinations and cloud detection results.
Based on our model parameters set in
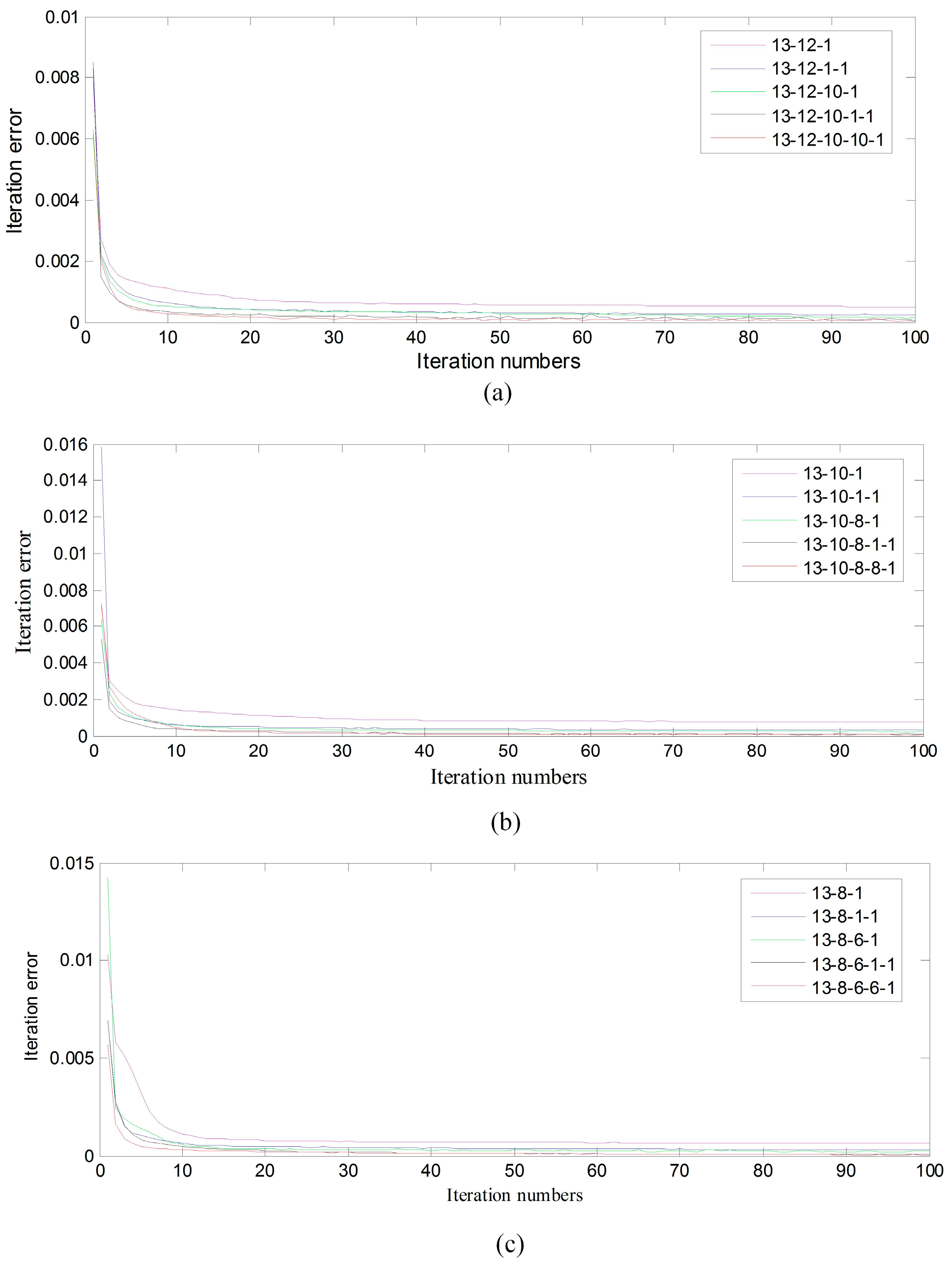
Section 3.2, we conduct four groups of experiments in this section. The trend of iteration error and the iteration number are reported in
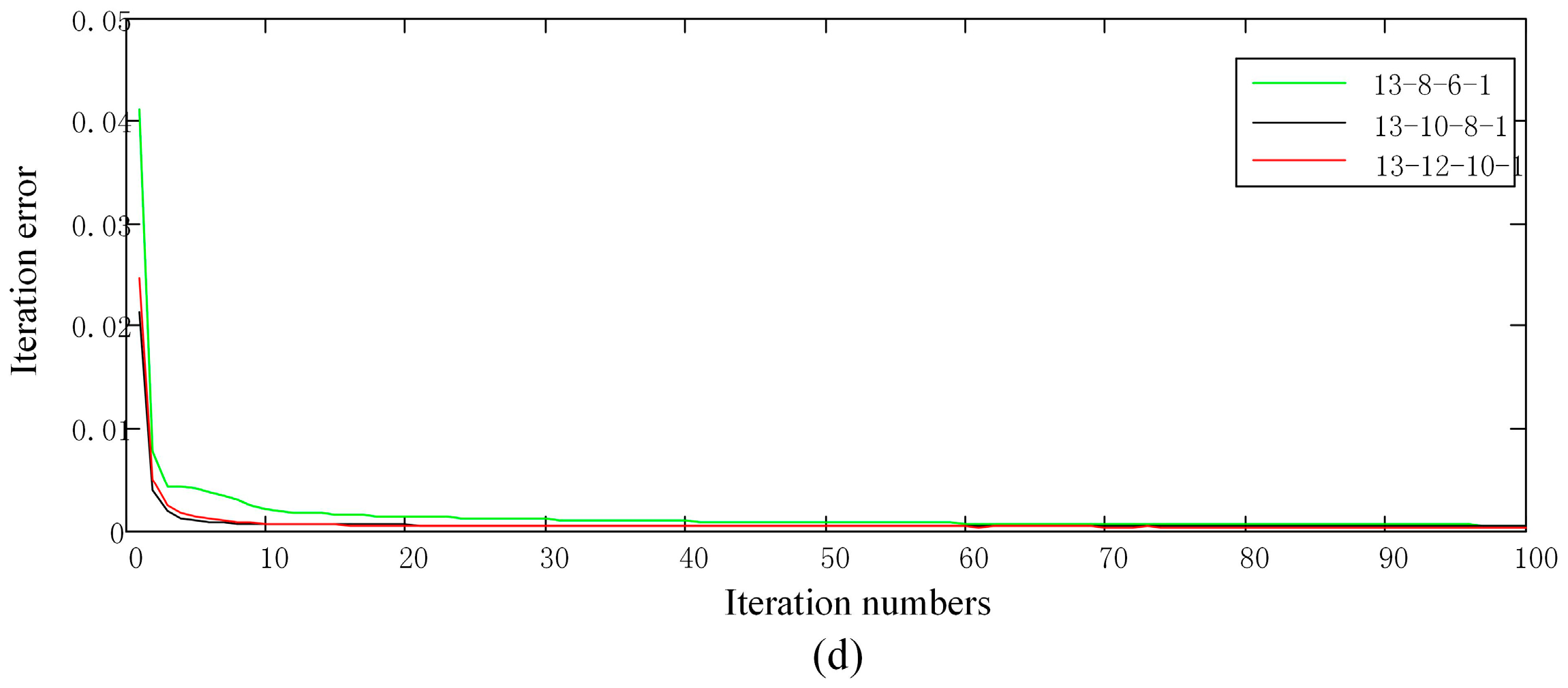
Figure 3. In experiment (a), by comparing experiments with node number 13-12-1, 13-12-10-1 and 13-12-10-10-1, we can see that the convergent rate is getting quicker and the final iteration error is becoming lower with the increase of the model layers. Similarly, experiments (b) and (c) demonstrate the same regular pattern. In addition, it also shows that when the model layers increase from 3 to 4, the final iteration error falls along with it. At the same time, the final iteration error with 4 and 5 model layers are basically equal, while the computational complexity can be raised. Therefore, we focus on the relation of model performance and the number of hidden nodes with 4 model layers.
Figure 3d exhibits the results with different number of hidden nodes, which shows that model 13-12-10-1 has acquired relatively better performance for our cloud detection issue.
4.2. Experiment on Landsat ETM+ Imagery
4.2.1. Cloud Density Map Predication
In this section, we give some qualitative prediction results with our model. According to the parameter analysis in
Section 4.1, we set the parameter combination of the FAEM for Landsat ETM+ imagery to be 13-12-10-1. The parameters
and
(in
Section 3.3) in the membership function are set as 3 and 1, respectively.
Figure 4 shows the predicted cloud density map two randomly selected experimental images. The left column represents the original Landsat ETM+ images. The images in the second column are corresponding cloud density map. It can be seen that either thin cloud or thick cloud have been detected very well with our proposed FAEM. In addition, for images that contain many ma-made objects, which have similar spectral characteristics with clouds, the proposed model can still precisely detect the cloud without being affected.
4.2.2. Comparison with Other Methods
As most traditional methods regard the cloud detection as 0–1 classification problem [
43,
44,
45], the classification results only contain cloud and non-cloud. For the convenience of quantitative comparison, we use a threshold 0.5 to cut the pixels whose cloud degrees in density map are smaller than the threshold to be non-cloud and the remains are regard as clouds. In this experiment, Landsat ETM+ images are considered to demonstrate the effectiveness of proposed approach.
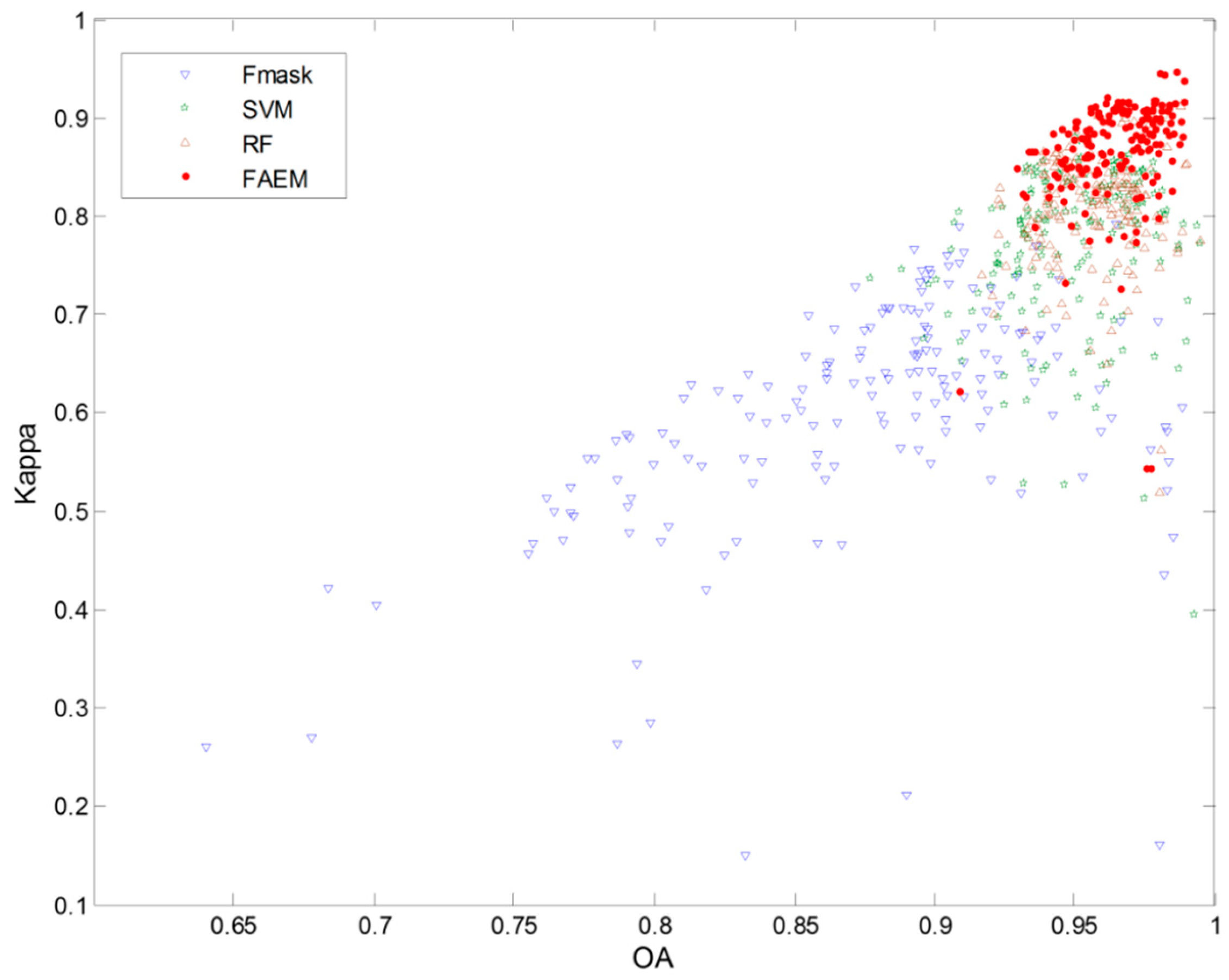
In this experiment, we use 172 Landsat ETM+ images with manual labelled as ground truth and the results are compared with some other cloud detection methods such as Fmask, SVM and RF.
Figure 5 shows the detection results of three images containing different underlying surfaces with different methods. Results show that regardless of images with vegetation (first row), water (second row) or snow (third row), the proposed method has shown stronger stability and better performance than Fmask, SVM and RF for cloud detection. Obviously, Fmask is seriously overestimated in the three images. For images with extensive vegetation in the first row, SVM is much more likely to detect some bright ground objects as cloud. While in the second-row images with water, SVM confuses some cloud as non-cloud. In particular, for the third-row images with snow, which is a challenging case in cloud detection since snow and cloud also have similar characteristics on remote sensing image, both SVM and RF obtain false results in such circumstance, SVM has regarded much more ice as cloud while RF only detects a part of the cloud from the snow.
Figure 6 exhibits the Kappa and OA of 172 Landsat ETM+ images with Fmask, SVM, RF and proposed approach. The Kappa and OA for our proposed method, which are lying in the upper right corner, are dramatically higher than others. By comparison, the performance of Fmask is slightly unsatisfactory. The result of SVM and RF is very close, and most of their OA and Kappa are higher than 0.9 and 0.8 respectively.
To further compare the detection results, four evaluation indicators RR, ER, FAR and RER are calculated in this experiment. The average results of 172 Landsat ETM+ images are shown in
Table 4. We can see that for Fmask, RR is closer to 1, ER and FAR are 10 times larger than others, and the RER is least among all methods. This shows the performance of Fmask is overestimated: many non-cloud are regarded as cloud pixels. Meanwhile, the RR of our proposed method is high up to 0.86, which is more than SVM and RF, while the ER of the proposed method is much smaller. More importantly, the RER of our method is high, up to 29.50, while it is only 10.984, 21.84 and 23.02 for Fmask, SVM and RF, respectively.
4.3. Experiments on GF-1 Imagery
4.3.1. Cloud Density Map Predication
To demonstrate that the proposed model is available for different imagery with different spatial resolutions, GF-1 imagery with 8 m spatial resolution is also be considered in this section. The fundamental vector dimension of GF-1 imagery is 9 (including spectral, texture and structure information) in this experiment. Similar to the parameter analysis in
Section 4.1, we set the model parameter combination for GF-1 imagery to be 9-8-6-1. The parameters
and
(in
Section 3.3) in the membership function are set as 3 and 1 respectively, which is the same with Landsat ETM+ imagery.
Similar as the experiments on Landsat ETM+ imagery, two randomly selected images and their corresponding detection results are shown in
Figure 7. The left column represents the original GF-1 images and the images in second column are their corresponding cloud density map. It shows that for GF-1 imagery with higher spatial resolution, the proposed model still work well for accurate cloud detection. In
Figure 7, we can see that both thin cloud and thick cloud have been well detected. Larger value represents that the pixels contains more cloud composition. For the value equals to 1, it means that the pixel is pure cloud. Conversely, the smaller the value is, the thinner the cloud is likely to be at the point.
4.3.2. Comparison with Other Methods
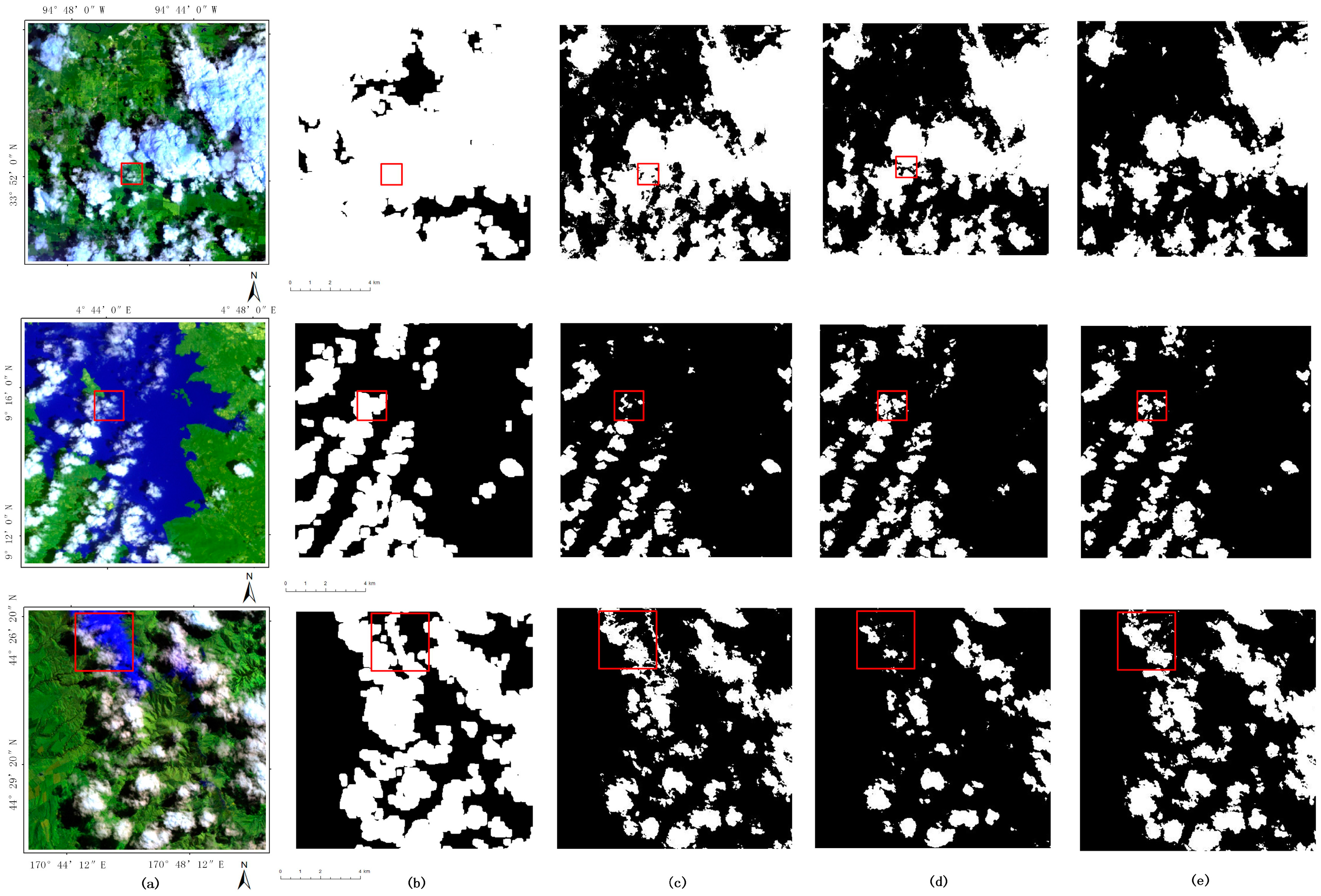
Twenty-five GF-1 images are considered in this experiment. To save space, we display only three groups of detection results with different methods.
Figure 8 shows the pseudo color images combined with band 4, 3, and 2. Clouds in these images have quite different shapes and thicknesses. From the left to right of
Figure 8, it shows original image and the detection results with SVM, RF and the proposed method, respectively. For images with extensive mountainous area, all three methods have acquired relatively satisfactory detection results. However, when there are many buildings and roads in the image, SVM and RF, which simply use artificially designed primary features, have difficulty. The advantage of our proposed method is well shown in this case.
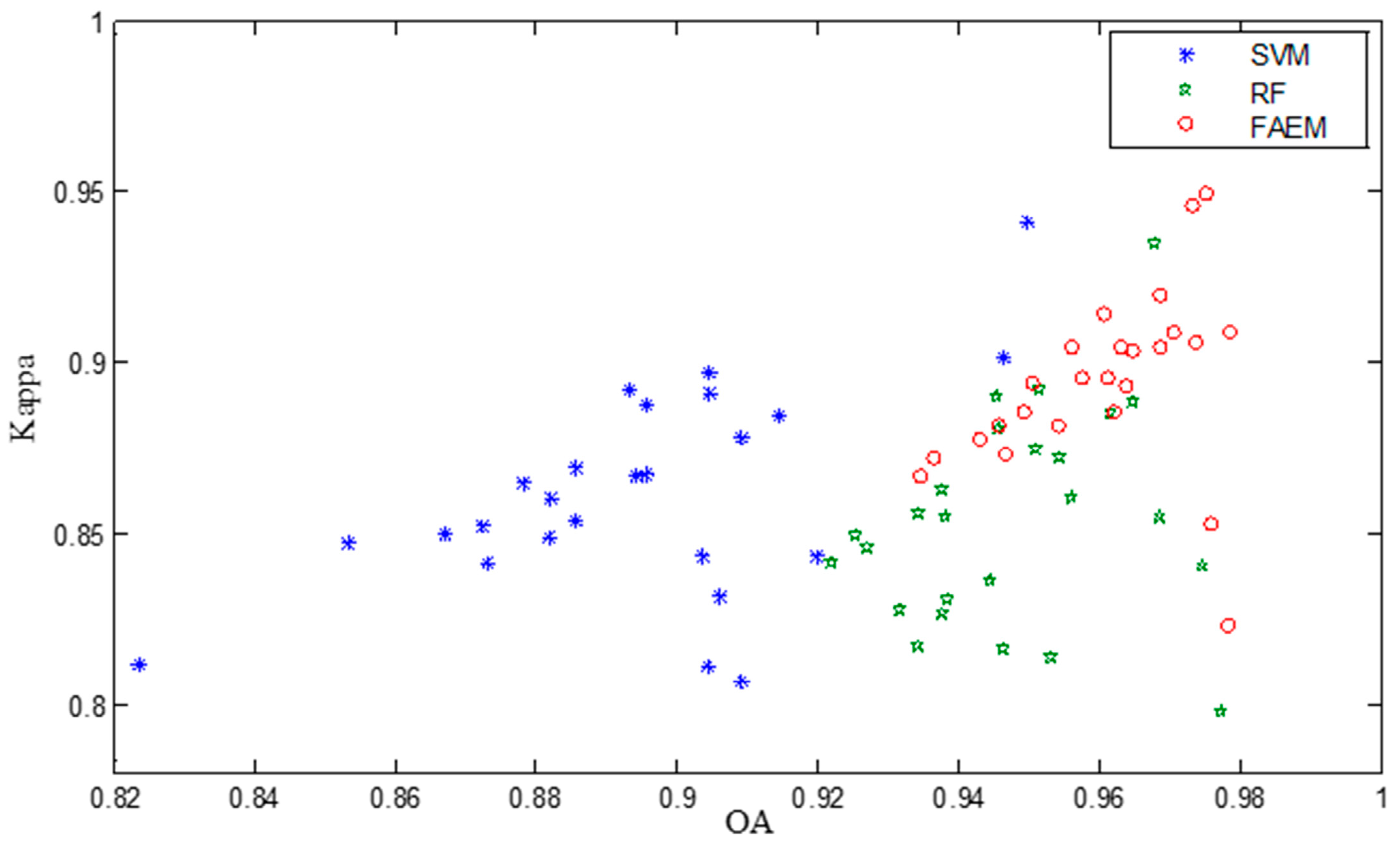
In
Figure 9, we can see the Kappa and OA of cloud detection results on GF-1 images. Most of our results appear in the upper right corner. It shows that higher accuracy can be achieved in our method.
After the previous qualitative comparison, we now focus on a quantitative comparison of our method as shown in
Table 5. Similar with the analyses of Landsat ETM+ images, the four same evaluation indicators RR, ER, FAR and RER are used for GF-1 assessment. It can be seen from
Table 5 that our proposed method has acquired much higher right rate than SVM and RF, while the error rate of the proposed method is much smaller. In particular, The RER with our method is high, up to 25.94, while for SVM and RF it is only 19.15 and 17.75, respectively.
6. Conclusions
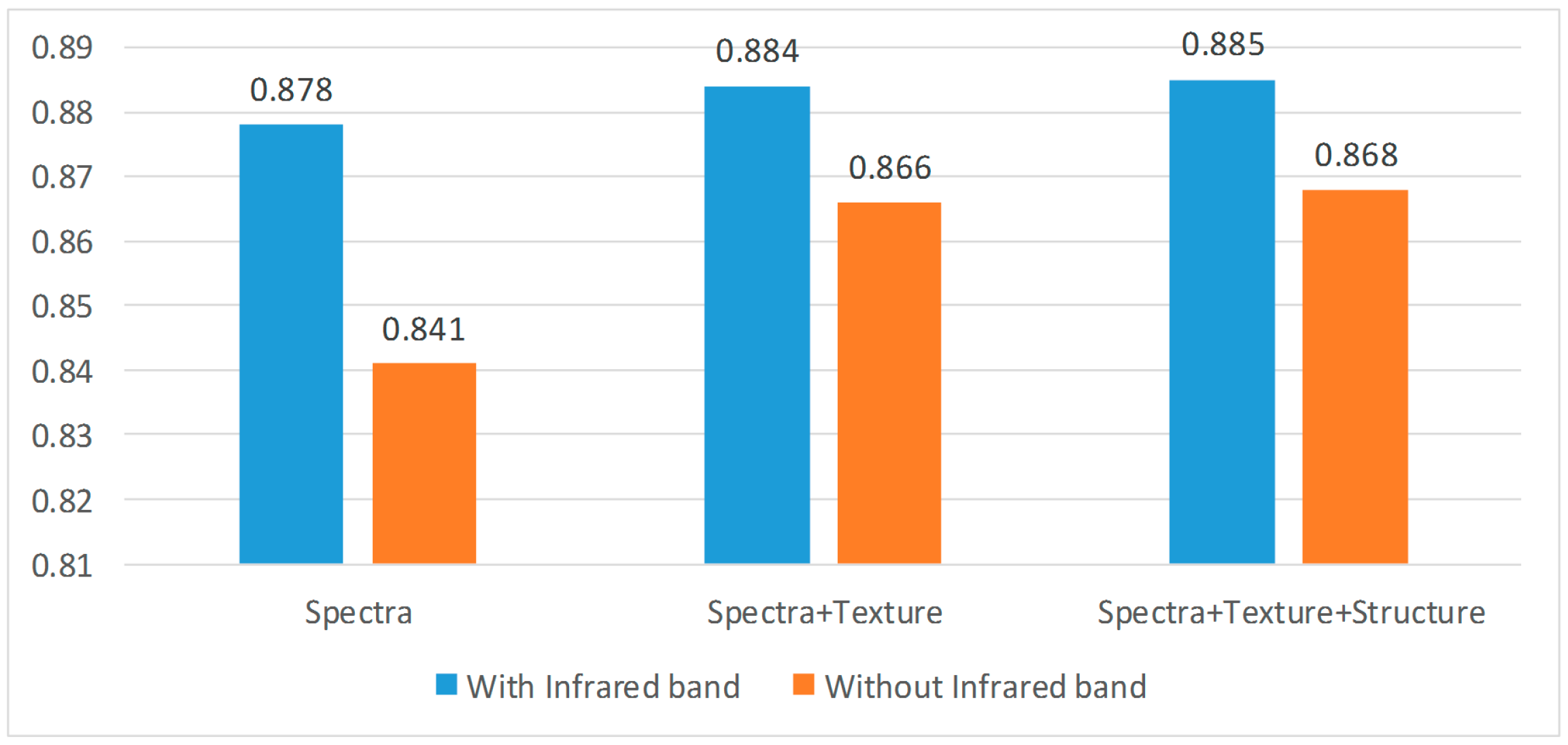
This study has presented a new cloud detection method. The advantages of the proposed method are integrating the feature learning ability of stacked autoencode networks and the detection ability of fuzzy function to acquire good performance on cloud detection. To validate the effectiveness of our method, 172 Landsat ETM+ images and 25 GF-1 images are used in this paper. Experimental results demonstrate that the proposed approach has achieved relatively higher detection accuracy compared with several state-of-the-art cloud detection methods (Fmask, SVM, and RF). Furthermore, we experimentally demonstrate that feature combination of spectral + texture + structure has attained better performance than single feature. Our proposed method is applicable in a variety of scenarios and is reliable in different resolution images. Generally, the proposed approach can potentially yield better results in terms of detection accuracy compared with related approaches, and is not limited by image resolution.
To fully consider the spatial and spectral information for a better cloud detection result, three fundamental features, spectral, texture and structure features, are applied in this work as the basic information to learn a deep discriminative feature. However, these texture and structure features are still manually selected and may not contain enough information. In future study, we will consider applying convolutional network for cloud detection. In addition, as convolutional network extracts feature with convolution kernel by integrating the local spatial information, the global constraint information will also be combined for accurate cloud detection.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}