1. Introduction
A hyperspectral image contains a wealth of spectral information about different materials by collecting the reflectance of hundreds of contiguous narrow spectral bands from the visible to infrared electromagnetic spectrum [
1,
2,
3]. However, the redundant information in a hyperspectral image not only increases computational complexity but also degrades classification performance when training samples are limited. Some research has demonstrated that the redundancy can be reduced without a significant loss of useful information [
4,
5,
6,
7]. As such, reducing the dimensionality of hyperspectral images is a reasonable and important preprocessing step for subsequent analysis and practical applications.
Dimensionality reduction (DR) aims to reduce the redundancy among features and simultaneously preserve the discriminative information. In general, existing DR methods may belong to one of three categories: unsupervised, supervised, and semisupervised. The unsupervised methods do not take the class label information of training samples into consideration. The most commonly used unsupervised DR algorithm is principal component analysis (PCA) [
8], which is to find a linear transformation by maximizing the variance in the projected subspace. Linear discriminant analysis (LDA) [
9], as a simple supervised DR method, is proposed to maximize the trace ratio of between-class and within-class scatter matrices. To address the application limitation in data distribution of LDA, local Fisher’s discriminant analysis (LFDA) [
10] is developed. In order to overcome the difficulty that the number of training samples is usually limited, some semisupervised DR methods in [
11,
12] are proposed.
The graph, as a mathematical data representation, has been successfully embedded in the framework of DR, resulting in the development of many effective DR methods. Recently, a general graph embedding (GE) framework [
13] has been proposed to formulate most of the existing DR methods, in which an undirected graph is constructed to characterize the geometric information of the data.
k-nearest neighbors and
-radius ball [
14] are two traditional methods to construct adjacency graphs. However, these two methods are sensitive to the noise and may lead to incorrect data representation. To construct an appropriate graph, a graph-based discriminant analysis with spectral similarity (GDA-SS) measurement was recently proposed by considering curves changing description among spectral bands in [
15]. Sparse representation (SR) [
16,
17] has attracted much attention because of its benefits of data-adaptive neighborhoods and noise robustness. Based on this work, a sparse graph embedding (SGE) model [
18] was developed by exploring the sparsity structure of the data. In [
19], a sparse graph-based discriminant analysis (SGDA) model was developed for hyperspectral image dimensionality reduction and classification by exploiting the class label information, improving the performance of SGE. In [
20], a weighted SGDA integrated both the locality and sparsity structure of the data. To reduce the computational cost, collaborative graph-based discriminant analysis (CGDA) [
21] was introduced by imposing an
regularization on sparse coefficient vector. In [
22], Laplacian regularization was imposed on CGDA, resulting in the LapCGDA algorithm. SR is able to reveal the local structure but fails in capturing the global structure. To solve this problem, a sparse and low-rank graph-based discriminant analysis (SLGDA) [
23] was proposed to simultaneously preserve the local and global structure of hyperspectral data.
However, the aforementioned graph-based DR methods only deal with spectral vector-based (first-order) representations, which do not take the spatial information of hyperspectral data into consideration. Aiming to overcome this shortcoming, simultaneous sparse graph embedding (SSGE) was proposed to improve the classification performance in [
24]. Although SSGE has obtained enhanced performance, it still puts the spectral-spatial feature into first-order data for analysis and ignores the cubic nature of hyperspectral data that can be taken as a third-order tensor. Some researchers have verified the advantage of tensor representation when processing the hyperspectral data. For example, multilinear principal component analysis (MPCA) [
25] was integrated with support vector machines (SVM) for tensor-based classification in [
26]. A group based tensor model [
27] by exploiting clustering technique was developed for DR and classification. In addition, a tensor discriminative locality alignment (TDLA) [
28] algorithm was proposed for hyperspectral image spectral-spatial feature representation and DR, which has been extended in [
29] by combining with well-known spectral-spatial feature extraction methods (such as extended morphological profiles (EMPs) [
30], extended attribute profiles (EAPs) [
31], and Gabors [
32]) for classification. Though the previous tensor-based DR methods have achieved great improvement on performance, they do not consider the structure property from other perspectives, such as representation-based and graph-based points.
In this context, we propose a novel DR method, i.e., tensor sparse and low-rank graph-based discriminant analysis (TSLGDA), for hyperspectral data, in which the information from three perspectives (tensor representation, sparse and low-rank representation, and graph theory) is exploited to present the data structure for hyperspectral image. It is noteworthy that the proposed method aims to exploit the spatial information through tensor representation, which is different from the work in [
23] only considering the spectral information. Furthermore, tensor locality preserving projection (TLPP) [
33] is exploited to obtain three projection matrices for three dimensions (one spectral dimension and two spatial dimensions) in TSLGDA, while SLGDA [
23] only considers one spectral projection matrix by locality preserving projection. The contributions of our work lie in the following aspects: (1) tensor representation is utilized in the framework of sparse and low-rank graph-based discriminant analysis for DR of hyperspectral image. To the best of our knowledge, this is the first time that tensor theory, sparsity, and low-rankness are combined in graph embedding framework; (2) Tensorial structure contains the spectral-spatial information, sparse and low-rank representation reveals both local and global structure and a graph preserves manifold structure. The integration of these three techniques remarkably promotes discriminative ability of reduced features in low-dimensional subspaces; (3) The proposed method can effectively deal with small training size problem, even for the class with only two labeled samples.
The rest of this paper is organized as follows.
Section 2 briefly describes the tensor basics and some existing DR methods. The proposed TSLGDA algorithm for DR of hyperspectral imagery is provided in detail in
Section 3. Parameters discussions and experimental results compared with some state-of-the-art methods are given in
Section 4. Finally,
Section 5 concludes this paper with some remarks.
2. Related Work
In this paper, if not specified otherwise, lowercase italic letters denote scalars, e.g., , bold lowercase letters denote vectors, e.g., , , bold uppercase letters denote matrices, e.g., , , and bold uppercase letters with underline denote tensors, e.g., , .
2.1. Tensor Basics
A multidimensional array is defined as a tensor, which is represented as
. We regard
as an N-order tensor, corresponding to an N-dimensional data array, with its element denoted as
, where
, and
. Some basic definitions related to tensor operation are provided as follows [
28,
33,
34].
Definition 1. (Frobenius norm): The Frobenius norm of a tensor is defined as .
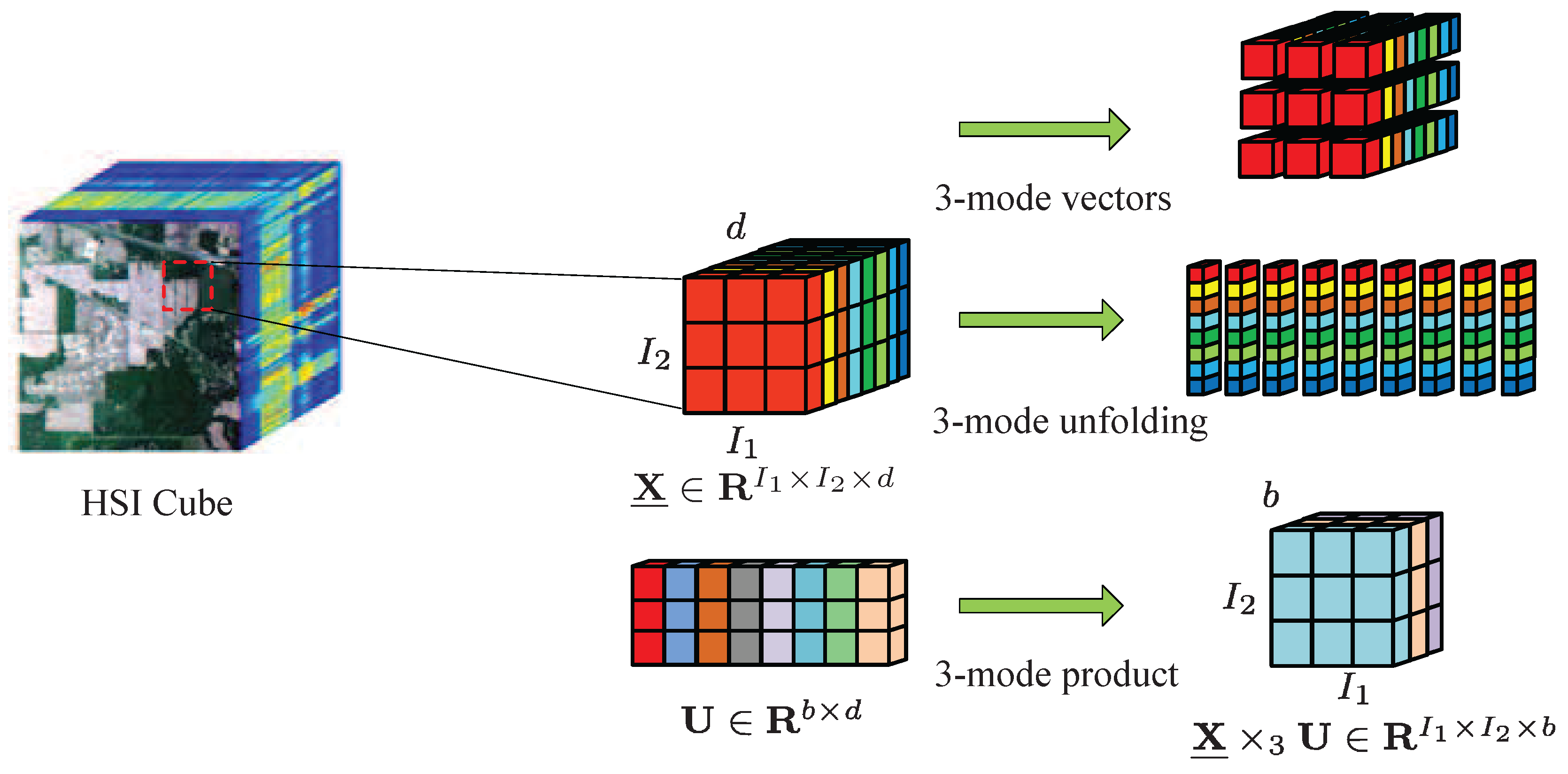
Definition 2. (Mode-n matricizing): The n-mode vector of an N-order tensor is defined as an n-dimensional vector by fixing all indices except . The n-mode matrix is composed of all the n-mode vectors in column form, denoted as . The obtained n-mode matrix is also known as n-mode unfolding of a tensor .
Definition 3. (Mode-n product): The mode-n product of a tensor with a matrix yields , and , whose entries are computed bywhere and . Note that the n-mode product can also be expressed in terms of unfolding tensorwhere denotes mode-n product between a tensor and a matrix.
Definition 4. (Tensor contraction): The contraction of tensors and is defined asThe condition for tensor contraction is that both two tensors should have the same size at the specific mode. For example, when the contraction is conducted on all indices except for the index n on tensors , this operation can be denoted as . According to the property of tensor contraction, we have 2.2. Sparse and Low-Rank Graph-Based Discriminant Analysis
In [
19], sparse graph-based discriminant analysis (SGDA), as a supervised DR method, was proposed to extract important features for hyperspectral data. Although SGDA can successfully reveal the local structure of the data, it fails to capture the global information. To address this problem, sparse and low-rank graph-based discriminant analysis (SLGDA) [
23] was developed to preserve local neighborhood structure and global geometrical structure simultaneously by combining the sparse and low-rank constraints. The objective function of SLGDA can be formulated as
where
and
are two regularization parameters to control the effect of low-rank term and sparse term, respectively,
represents samples from the
lth class in a vector-based way, and
, in which
c is the number of total classes. After obtaining the complete graph weight matrix
, the projection operator can be solved as
where
is defined as the Laplacian matrix,
is a diagonal matrix with the
ith diagonal entry being
, and
may be a simple scale normalization constraint [
13].
The projection can be further formulated as
which can be solved as a generalized eigendecomposition problem
The bth projection vector is the eigenvector corresponding to the bth smallest nonzero eigenvalue. The projection matrix can be formed as , . Finally, the reduced features are denoted as .
2.3. Multilinear Principal Component Analysis
In order to obtain a set of multilinear projections that will map the original high-order tensor data into a low-order tensor space, MPCA performs to directly maximize the total scatter matrix on the subspace
where
and
is the
n-mode unfolding matrix of tensor
.
The optimal projections of MPCA can be obtained from the eigendecomposition
where
is the eigenvector matrix and
is the eigenvalue matrix of
, in which the eigenvalues are ranked in descending order, and
is the eigenvalue corresponding to the eigenvector
. The optimal projection matrix for mode-
n is composed of the eigenvectors corresponding to the first
largest eigenvalues, e.g.,
. After obtained the projection matrix for each mode, the reduced features can be formulated as
where
.
3. Tensor Sparse and Low-Rank Graph-Based Discriminant Analysis
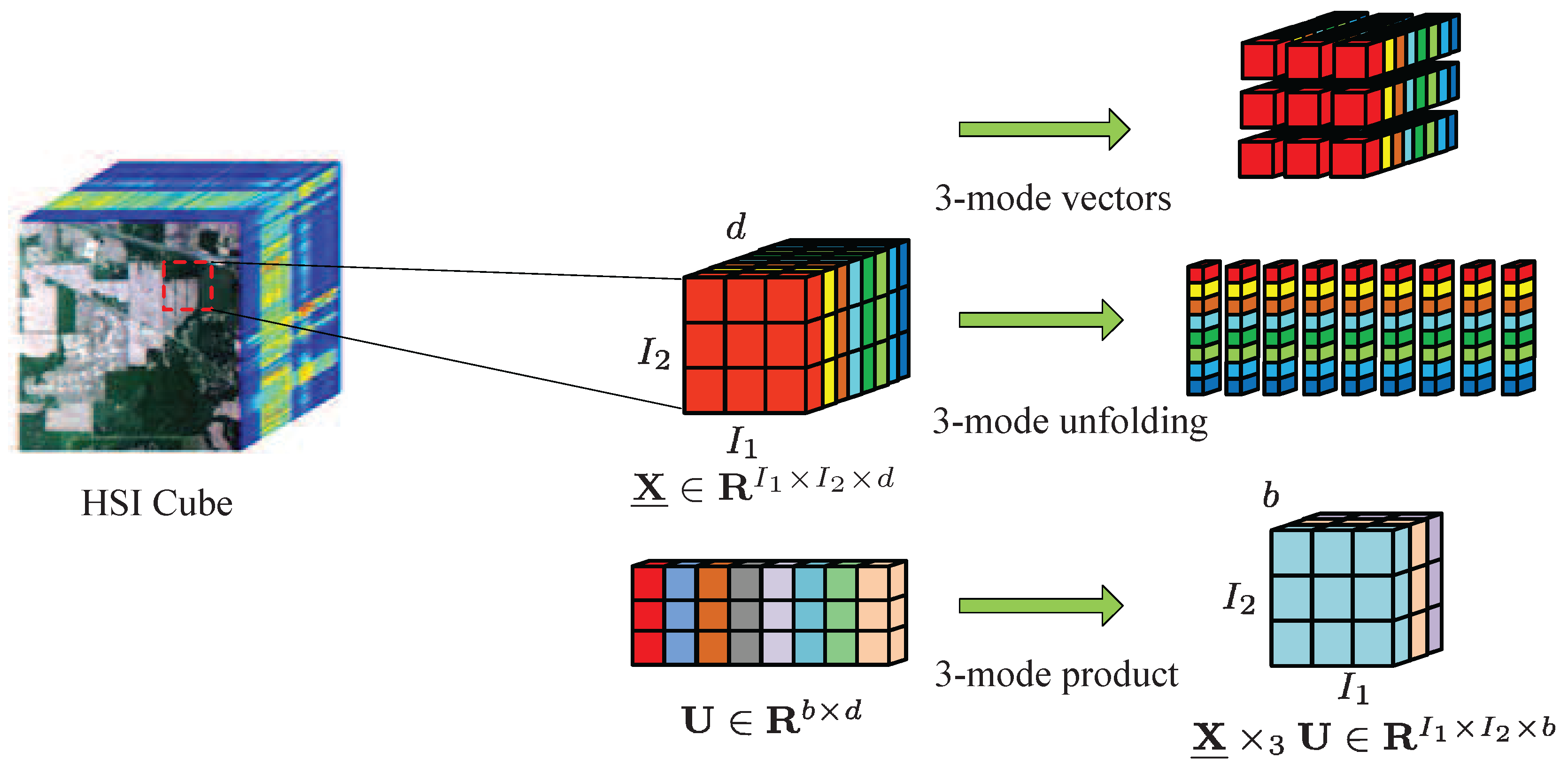
Consider a hyperspectral image as a third-order tensor
, in which
and
refer to the width and height of the data cube, respectively, and
represents the number of spectral bands,
. Assume that the
kth small patch is composed of the
kth training sample and its
neighbors, which is denoted as
.
M patches construct the training set
. The training patches belonging to the
lth class are expressed as
, where
represents the number of patches belonging to the
lth class and
. For the purpose of convenient expression, a fourth-order tensor
is defined to represent these
patches, and
denotes all training patches for
c classes, where
. A visual illustration of 3-mode vectors, 3-mode unfolding, and 3-mode product is shown in
Figure 1.
3.1. Tensor Sparse and Low-Rank Graph
The previous SLGDA framework can capture the local and global structure of hyperspectral data simultaneously by imposing both sparse and low-rank constraints. However, it may lose some important structural information of hyperspectral data, which presents an intrinsic tensor-based data structure. To overcome this drawback, a tensor sparse and low-rank graph is constructed with the objective function
where
denotes the graph weigh matrix using labeled patches from the
lth class only. As such, with the help of class-specific labeled training patches, the global graph weigh matrix
can be designed as a block-diagonal structure
To obtain the
lth class graph weight matrix
, the alternating direction method of multipliers (ADMM) [
35] is adopted to solve problem (
12). Two auxiliary variables
and
are first introduced to make the objective function separable
The augmented Lagrangian function of problem (
14) is given as
where
and
are Lagrangian multipliers, and
is a penalty parameter.
By minimizing the function
, each variable is alternately updated with other variables being fixed. The updating rules are expressed as
where
denotes the learning rate,
is the singular value thresholding operator (SVT), in which
is the soft thresholding operator [
36]. By fixing
and
, the formulation of
can be written as
where
,
, and
is an identity matrix.
The global similarity matrix
will be obtained depending on Equation (
13) when each sub-similarity matrix corresponding to each class is calculated from problem (
12). Until now, a tensor sparse and low-rank graph
is completely constructed with vertex set
and similarity matrix
. How to obtain a set of projection matrices
is the following task.
3.2. Tensor Locality Preserving Projection
The aim of tensor LPP is to find transformation matrices to project high-dimensional data into low-dimensional representation , where .
The optimization problem for tensor LPP can be expressed as
where
. It can be seen that the corresponding tensors
and
in the embedded tensor space are expected to be close to each other if original tensors
and
are greatly similar.
To solve the optimization problem (
19), an iterative scheme is employed [
33]. First, we assume that
are known, then, let
. With properties of tensor and trace, the objective function (
19) is rewritten as
where
denotes the
n-mode unfolding of tensor
. Finally, the optimal solution of problem (
20) is the eigenvectors corresponding to the first
smallest nonzero eigenvalues of the following generalized eigenvalue problem
Assume
,
, then, problem (
21) can be transformed into
To solve this problem, the function embedded in the MATLAB software (R2013a, The MathWorks, Natick, Massachusetts, USA) is adopted, i.e., , and the eigenvectors in corresponding to the first smallest nonzero eigenvalues in are chosen to form the projection matrix. The other projection matrices can be obtained in a similar manner. The complete TSLGDA algorithm is outlined in Algorithm 1.
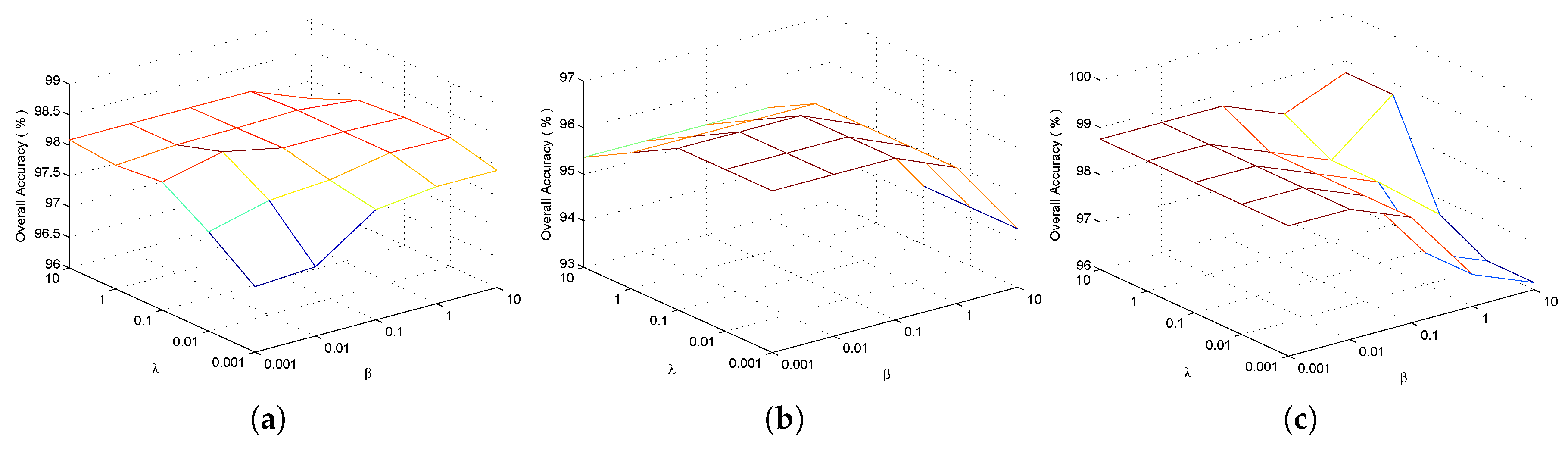
| Algorithm 1: Tensor Sparse and Low-Rank Graph-Based Discriminant Analysis for Classification. |
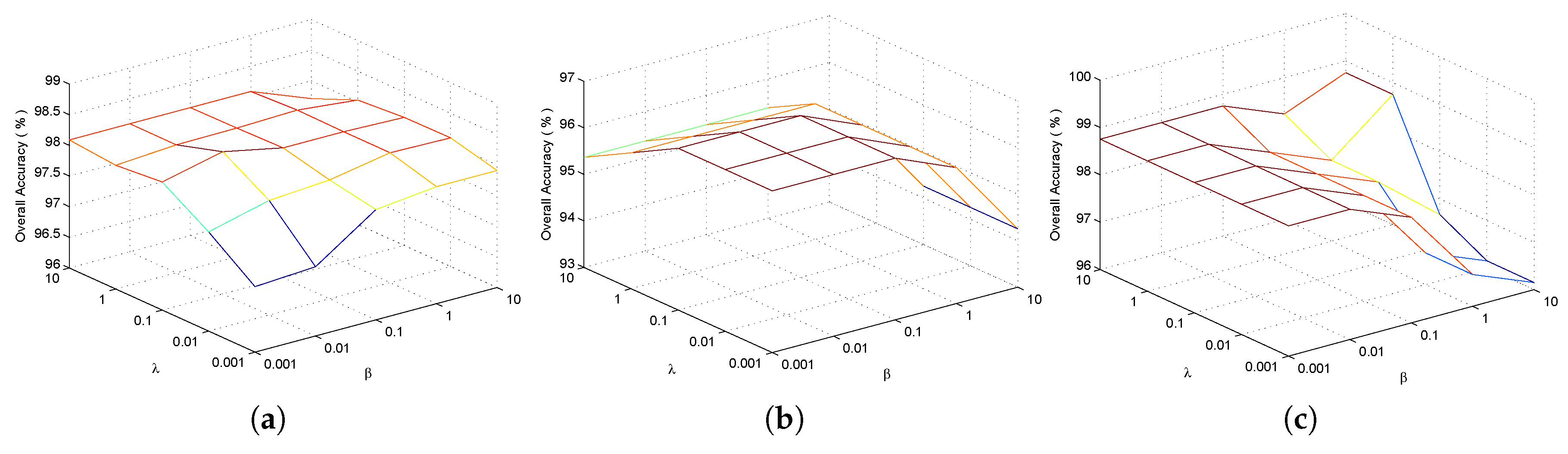
| Input: Training patches , testing patches , regularization parameters and , |
| reduced dimensionality . |
| Initialize: , , , , , , , |
| maxIter = 100, . |
| 1. for do |
| 2. repeat |
| 3. Compute , , and according to (16)–(18). |
| 4. Update the Lagrangian multipliers: |
| , . |
| 5. Update : , where |
|
| 6. Check convergence conditions: . |
| 7. . |
| 8. until convergence conditions are satisfied or maxIter. |
| 9. end for |
| 10. Construct the block-diagonal weight matrix according to (13). |
| 11. Compute the projection matrices according to (21). |
| 12. Compute the reduced features: |
| , . |
| 13. Determine the class label of by NN classifier. |
| 14. Output: The class labels of test patches. |
5. Conclusions
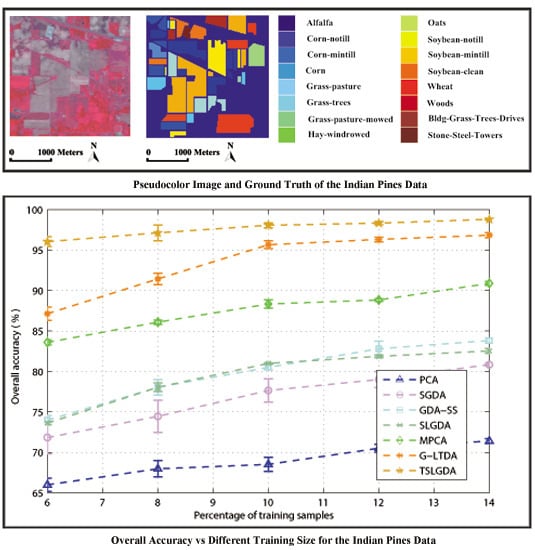
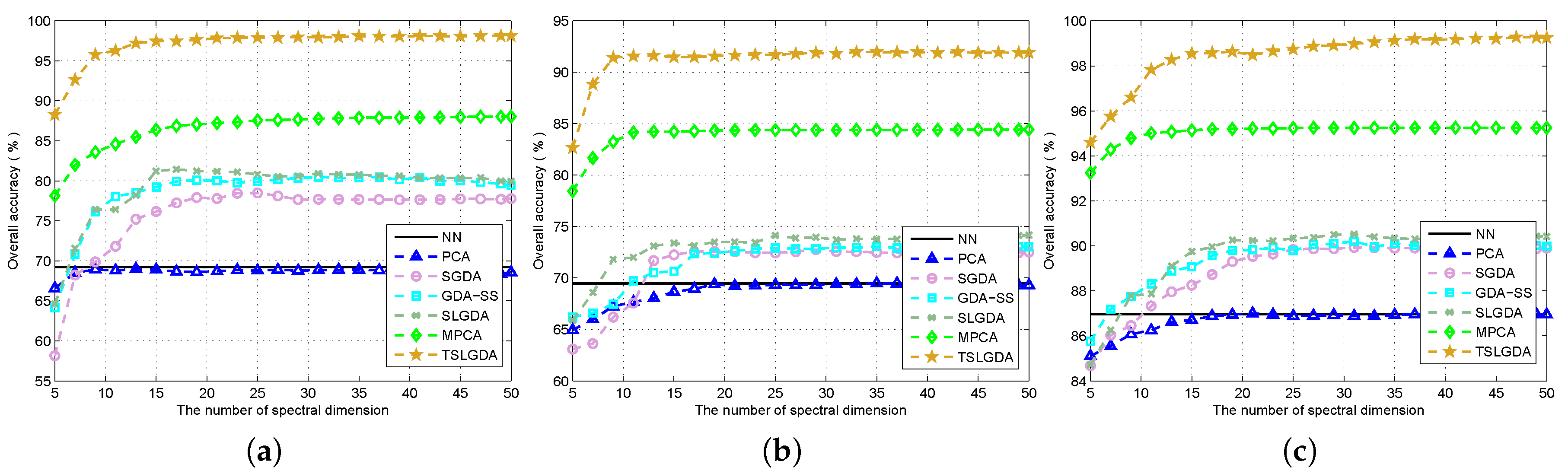
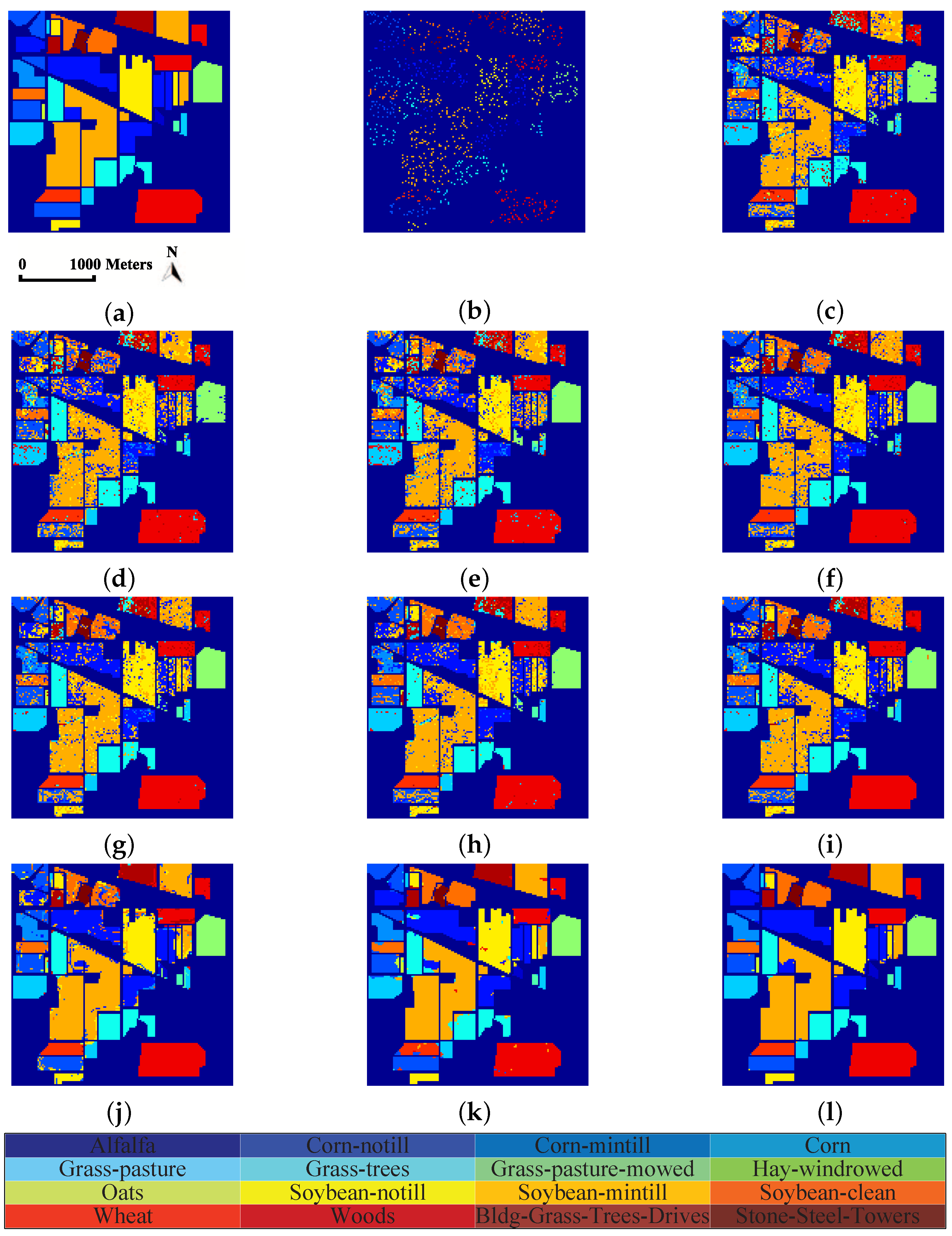
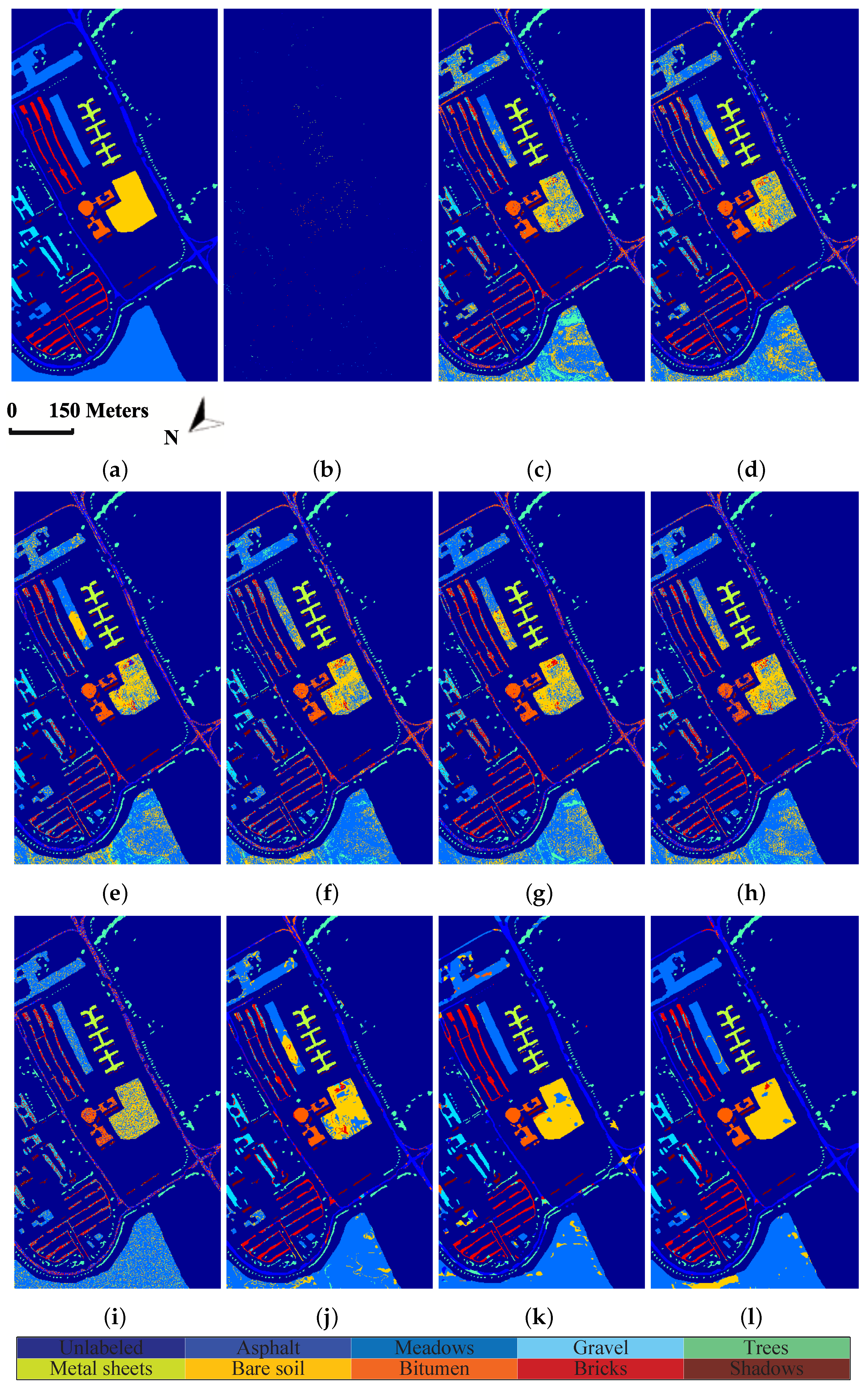
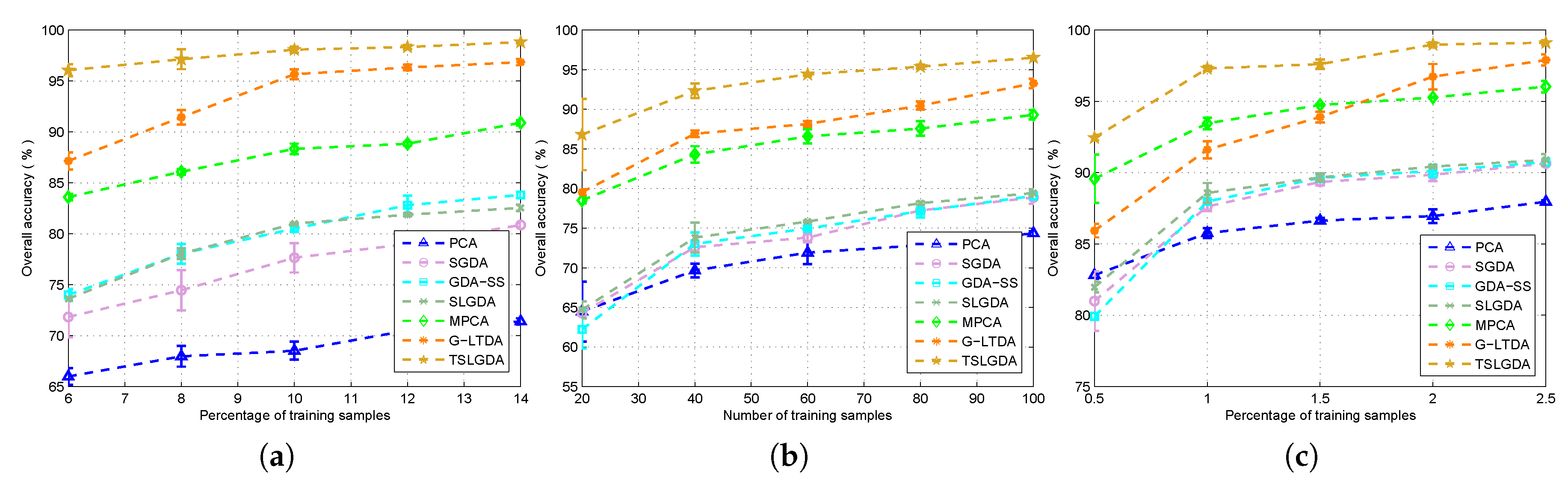
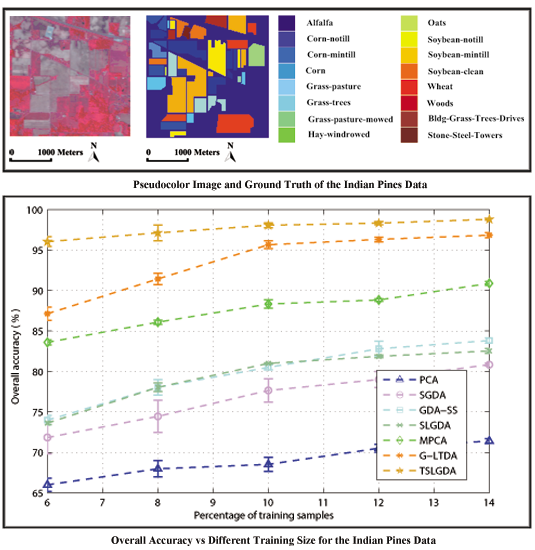
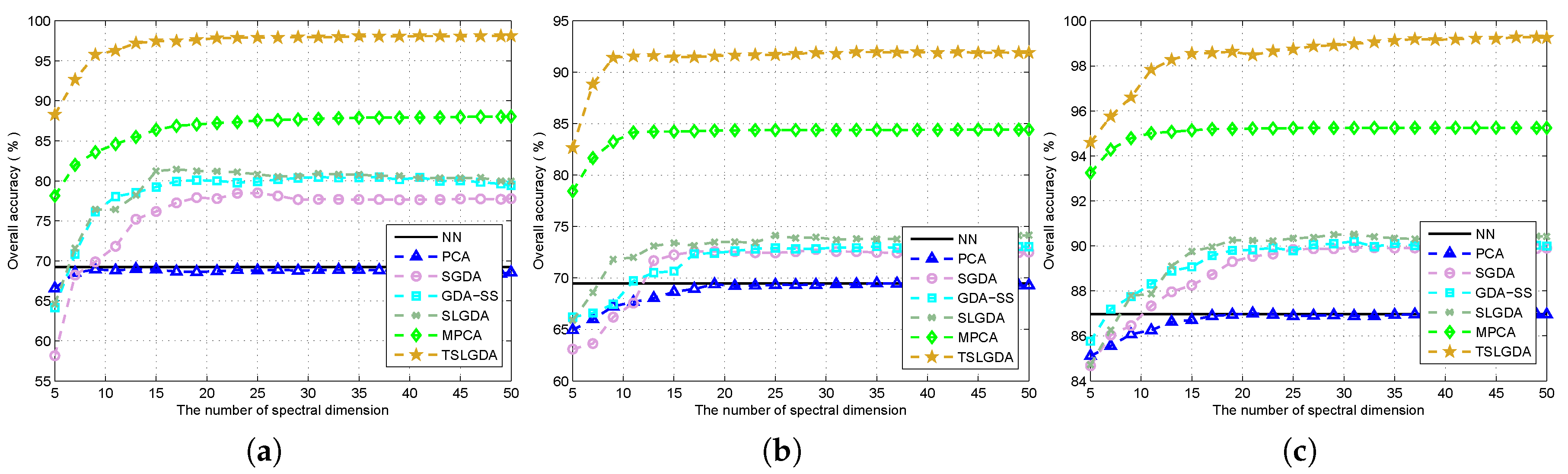
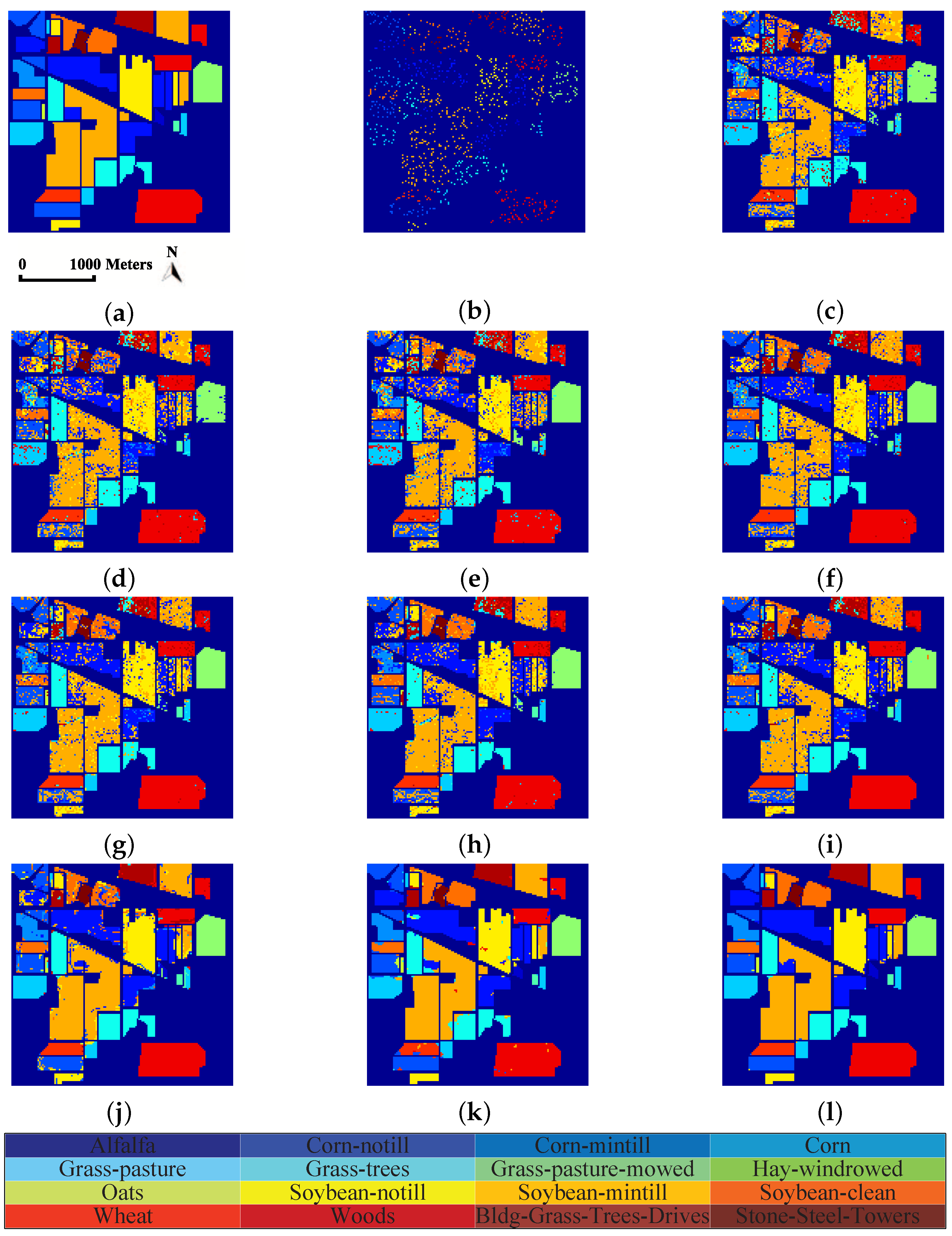
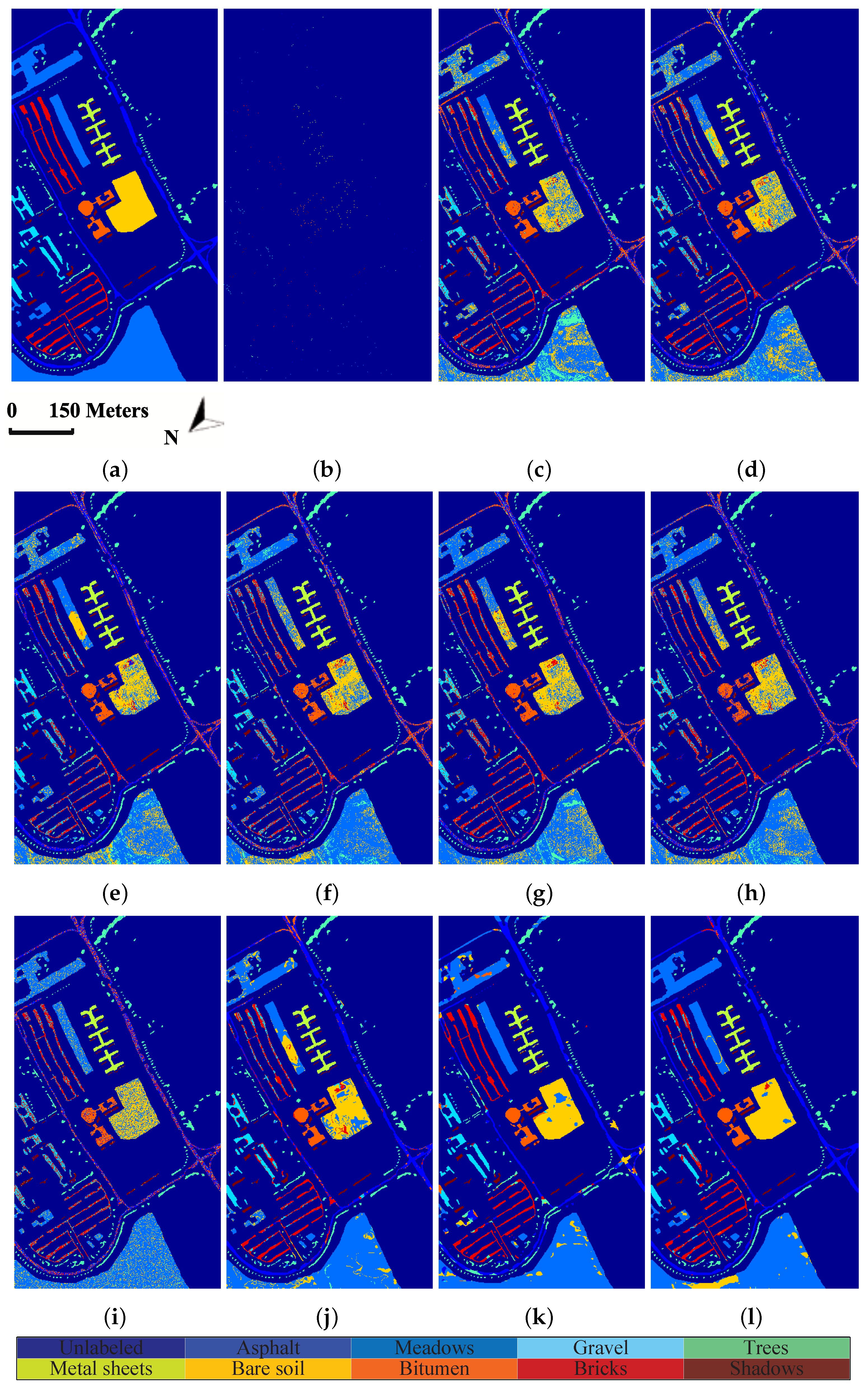
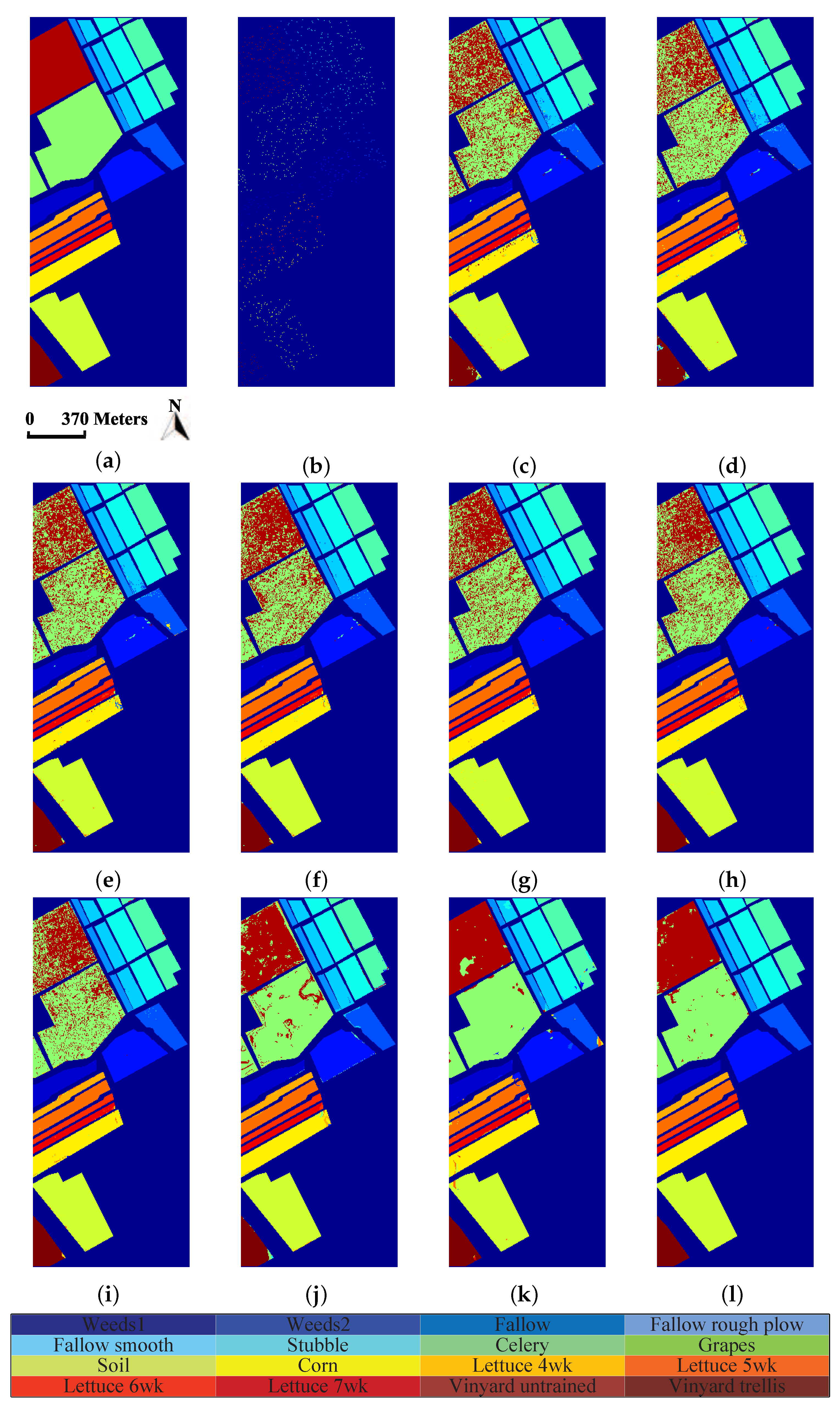
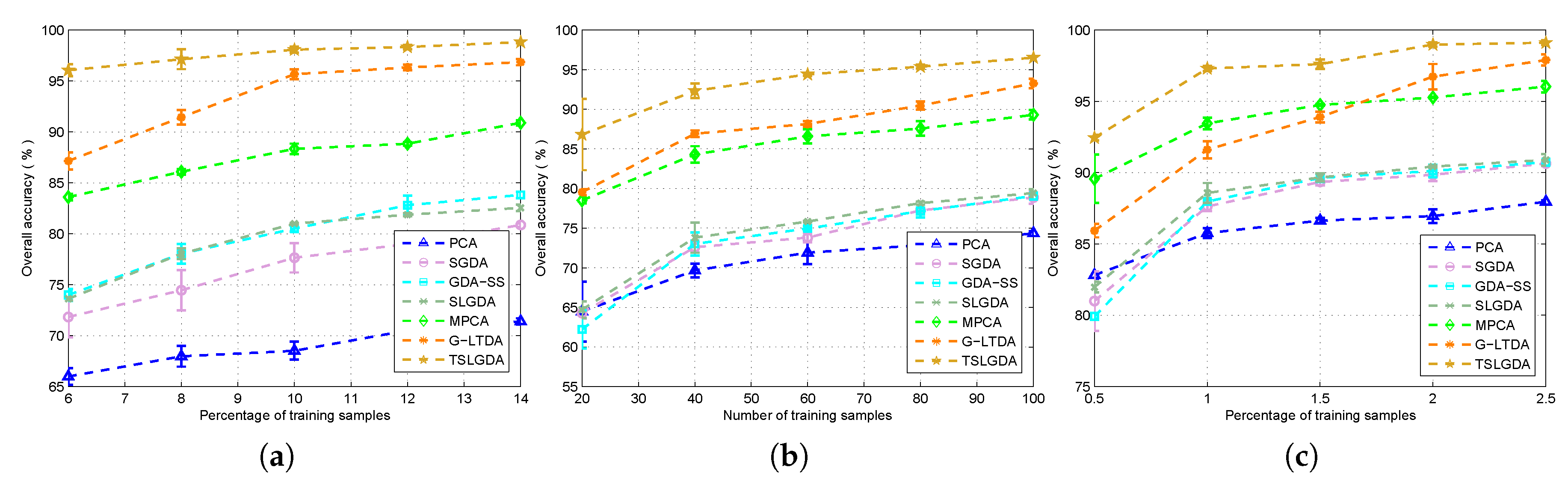
In this paper, we have proposed a tensor sparse and low-rank graph-based discriminant analysis method (i.e., TSLGDA) for dimensionality reduction of hyperspectral imagery. The hyperspectral data cube is taken as a third-order tensor, from which sub-tensors (local patches) centered at the training samples are extracted to construct the sparse and low-rank graph. On the one hand, by imposing both the sparse and low-rank constraints on the objective function, the proposed method is capable of capturing the local and global structure simultaneously. On the other hand, due to the spatial structure information introduced by tensor data, the proposed method can improve the graph structure and enhance the discriminative ability of reduced features. Experiments conducted on three hyperspectral datasets have consistently confirmed the effectiveness of our proposed TSLGDA algorithm, even for small training size. Compared to some state-of-the-art methods, the overall classification accuracy of TSLGDA in the low-dimensional space improves about 2% to 30%, 5% to 20%, and 2% to 12% for three experimental datasets, respectively, with increased computational complexity.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}