
Relieving Compression-Induced Local Wear on Non-Volatile Memory Block via Sliding Writes

Abstract
1. Introduction
- We propose a new metric, local bit flips, to describe the effect of compression on local areas of one NVM memory block. From the preliminary study based on this metric, we find that severe local wear is caused by existing compression algorithms, which would sacrifice the NVM lifetime.
- To address the local wear problem, we propose an intra-block wear leveling method called SlidW, which places the compressed data into different areas inside one block. We design the data placement policy under five cases by considering the differences between the size of new data and old data.
- We evaluate our proposed SlidW method using gem5 and NVMain simulators. Experimental results verify that SlidW is able to reduce the local wear effect and extend the NVM lifetime.
2. Background and Motivation
2.1. Introduction of Phase Change Memory
2.2. Memory Compression
2.2.1. Frequent Pattern Compression
2.2.2. Base-Delta-Immediate Compression
2.2.3. Frequent Value Compression
2.3. The Preliminary Study
3. The Local Bit Flips
3.1. The Definition of Local Bit Flips
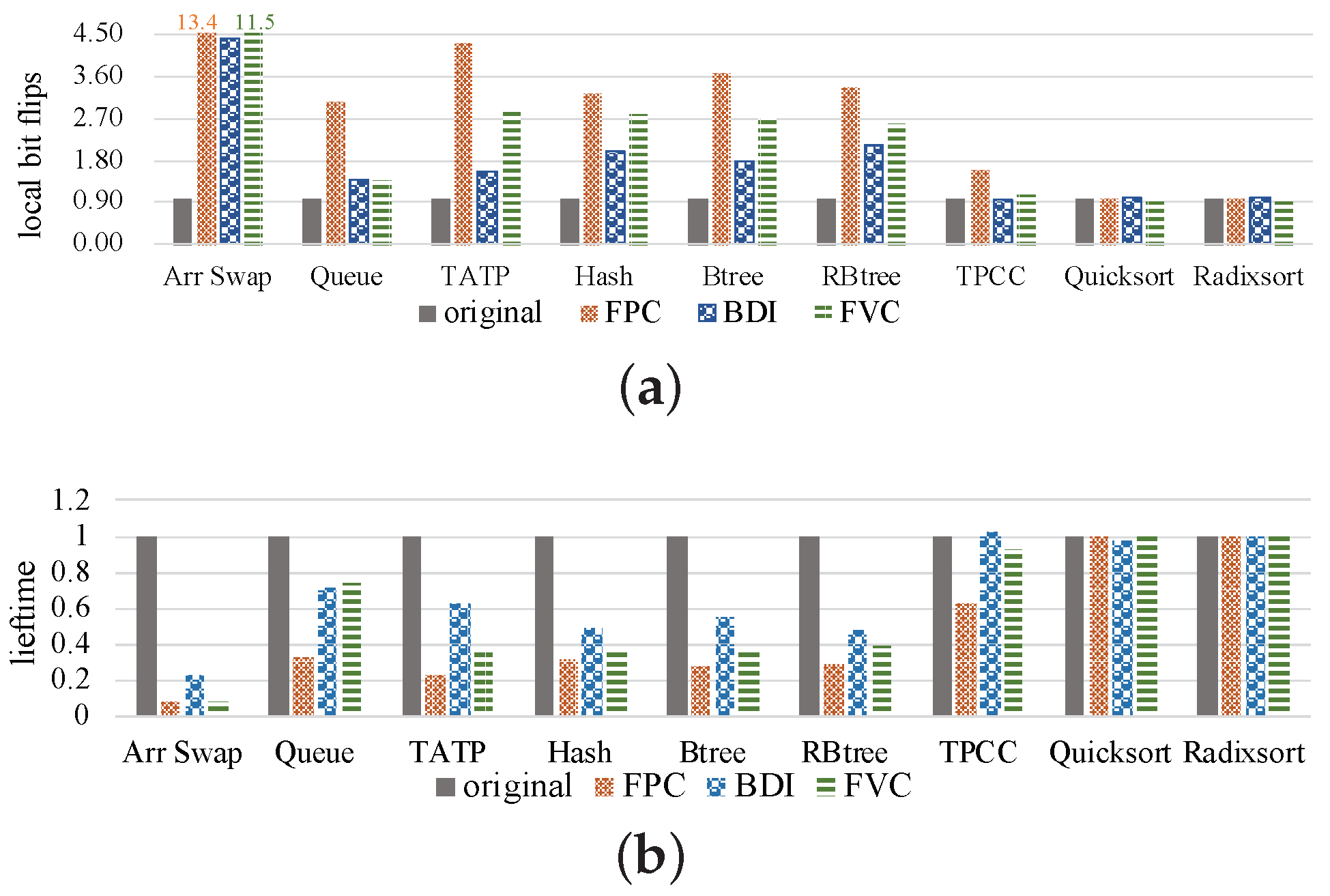
3.2. Results of Local Bit Flips
4. The Sliding Write Method
4.1. Overview
4.2. Memory Block Division
4.3. Case Judgment

4.4. Tag Management

4.5. Data Placement
4.6. Overhead Analysis
5. Evaluation
5.1. Experimental Setup
5.1.1. Compared Methods
- FPC is the baseline method to directly use the FPC algorithm in NVM. The FPC algorithm is a frequently used compression algorithm. The specific compression process is described in Section 2.2.1.
- Flip-N-Write (FNW) [15] is a method to reduce bit flips by selectively flipping data according to the bit flip number between old data and new data. In detail, it first divides the data in the block into several same-size segments. In this experiment, data are divided into eight segments because n segments require n additional flag bits and using compression will reduce the data size by at least 8 bits. The eight flag bits generated by setting eight segments can be stored in the memory block without taking up additional storage space. The size can be changed according to the requirements. Then, it needs to count the number of bit flips in each segment. If the number of bit flips is greater than half the size of the segment (in bits), it flips the entire segment and sets the corresponding flag bit indicating that the segment is flipped, so that the number of flips per segment is less than half the size. If the number of bit flips is less than half the size of the segment, no flips are performed and the corresponding flag bits are reset. FPC+FNW is to use the FPC algorithm in FNW. In order to facilitate data reading, we place the flag bits in the last byte of the memory block. FPC+FNW is to use FPC algorithm in FNW.
- Space [7] is a method to implement intra-block wear leveling by moving data into different segments. It needs to divide a block into four segments of the same size. Write from the first block for the first time, and then write from the next segment of the last written segment each time. If the data can not write starting from the next segment, it loops forward to the position where it can be written. It will also be skipped if zero lines are written. This algorithm does not consider the size of the old data, resulting in a large amount of data overlap. The writing of the second half and the writing of the first half of the four segments will also be unbalanced. Using the loop algorithm to go forward in turn until finding a location where data can be written, will also increase the time complexity, although, at most, three comparisons. FPC+Space is to use FPC algorithm in the Space method.
5.1.2. Calculation of Local Bit Flips
5.2. Experimental Results and Analysis
5.2.1. Local Bit Flips
5.2.2. NVM Lifetime
5.2.3. Sensitivity Study on Block Division Granularity
5.2.4. Sensitivity Study on Compression Algorithms
5.2.5. Sensitivity Study on Block Size and Cache Level
5.2.6. Results of Read and Write Latency
5.2.7. Results of Energy Consumption
6. Related Works
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rashidi, S.; Jalili, M.; Sarbazi-Azad, H. A survey on pcm lifetime enhancement schemes. ACM Comput. Surv. 2019, 52, 1–38. [Google Scholar] [CrossRef]
- Xia, F.; Jiang, D.J.; Xiong, J.; Sun, N.H. A survey of phase change memory systems. J. Comput. Sci. Technol. 2015, 30, 121–144. [Google Scholar] [CrossRef]
- Boukhobza, J.; Rubini, S.; Chen, R.; Shao, Z. Emerging NVM: A survey on architectural integration and research challenges. ACM Trans. Des. Autom. Electron. Syst. 2017, 23, 1–32. [Google Scholar] [CrossRef]
- Kültürsay, E.; Kandemir, M.; Sivasubramaniam, A.; Mutlu, O. Evaluating STT-RAM as an energy-efficient main memory alternative. In Proceedings of the 2013 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Austin, TX, USA, 21–23 April 2013; pp. 256–267. [Google Scholar]
- Mikolajick, T.; Dehm, C.; Hartner, W.; Kasko, I.; Kastner, M.; Nagel, N.; Moert, M.; Mazure, C. FeRAM technology for high density applications. Microelectron. Reliab. 2001, 41, 947–950. [Google Scholar] [CrossRef]
- Akinaga, H.; Shima, H. Resistive random access memory (ReRAM) based on metal oxides. Proc. IEEE 2010, 98, 2237–2251. [Google Scholar] [CrossRef]
- Liu, H.; Ye, Y.; Liao, X.; Jin, H.; Zhang, Y.; Jiang, W.; He, B. Space-oblivious compression and wear leveling for non-volatile main memories. In Proceedings of the 36th International Conference on Massive Storage Systems and Technology, Santa Clara, CA, USA, 29–30 October 2020. [Google Scholar]
- Huang, K.; Mei, Y.; Huang, L. Quail: Using nvm write monitor to enable transparent wear-leveling. J. Syst. Archit. 2020, 102, 101658. [Google Scholar] [CrossRef]
- Hakert, C.; Chen, K.H.; Genssler, P.R.; von der Brüggen, G.; Bauer, L.; Amrouch, H.; Chen, J.J.; Henkel, J. Softwear: Software-only in-memory wear-leveling for non-volatile main memory. arXiv 2020, arXiv:2004.03244. [Google Scholar]
- Xiao, C.; Cheng, L.; Zhang, L.; Liu, D.; Liu, W. Wear-aware Memory Management Scheme for Balancing Lifetime and Performance of Multiple NVM Slots. In Proceedings of the 2019 35th Symposium on Mass Storage Systems and Technologies (MSST), Santa Clara, CA, USA, 20–24 May 2019; pp. 148–160. [Google Scholar]
- Ni, Y.; Zhao, J.; Bittman, D.; Miller, E. Reducing NVM Writes with Optimized Shadow Paging. In Proceedings of the 10th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 18), Boston, MA, USA, 9–10 July 2018. [Google Scholar]
- García, A.A.; de Jong, R.; Wang, W.; Diestelhorst, S. Composing lifetime enhancing techniques for non-volatile main memories. In Proceedings of the International Symposium on Memory Systems, Alexandria, VA, USA, 2–5 October 2017; pp. 363–373. [Google Scholar]
- Bittman, D.; Long, D.D.; Alvaro, P.; Miller, E.L. Optimizing Systems for Byte-Addressable NVM by Reducing Bit Flipping. In Proceedings of the 17th USENIX Conference on File and Storage Technologies (FAST 19), Boston, MA, USA, 25–28 February 2019; pp. 17–30. [Google Scholar]
- Chen, Y.S.; Wu, C.F.; Chang, Y.H.; Kuo, T.W. A Write-friendly Arithmetic Coding Scheme for Achieving Energy-Efficient Non-Volatile Memory Systems. In Proceedings of the 2021 26th Asia and South Pacific Design Automation Conference (ASP-DAC), Tokyo, Japan, 18–21 January 2021; pp. 633–638. [Google Scholar]
- Cho, S.; Lee, H. Flip-N-Write: A simple deterministic technique to improve PRAM write performance, energy and endurance. In Proceedings of the 42nd Annual IEEE/ACM International Symposium on Microarchitecture, New York, NY, USA, 12–16 December 2009; pp. 347–357. [Google Scholar]
- Feng, D.; Xu, J.; Hua, Y.; Tong, W.; Liu, J.; Li, C.; Chen, Y. A low-overhead encoding scheme to extend the lifetime of nonvolatile memories. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2019, 39, 2516–2529. [Google Scholar] [CrossRef]
- Xu, J.; Feng, D.; Hua, Y.; Tong, W.; Liu, J.; Li, C. Extending the lifetime of NVMs with compression. In Proceedings of the 2018 Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 1604–1609. [Google Scholar] [CrossRef]
- Alameldeen, A.; Wood, D. Frequent Pattern Compression: A Significance-Based Compression Scheme for L2 Caches; Technical Report; Madison Department of Computer Sciences, University of Wisconsin: Madison, WI, USA, 2004. [Google Scholar]
- Pekhimenko, G.; Seshadri, V.; Mutlu, O.; Kozuch, M.A.; Gibbons, P.B.; Mowry, T.C. Base-delta-immediate compression: Practical data compression for on-chip caches. In Proceedings of the 2012 21st International Conference on Parallel Architectures and Compilation Techniques (PACT), Minneapolis, MN, USA, 19–23 September 2012; pp. 377–388. [Google Scholar]
- Angerd, A.; Arelakis, A.; Spiliopoulos, V.; Sintorn, E.; Stenström, P. GBDI: Going beyond base-delta-immediate compression with global bases. In Proceedings of the 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Seoul, Republic of Korea, 2–6 April 2022; pp. 1115–1127. [Google Scholar]
- Yang, J.; Zhang, Y.; Gupta, R. Frequent value compression in data caches. In Proceedings of the 33rd Annual ACM/IEEE International Symposium on Microarchitecture, Monterey, CA, USA, 10–13 December 2000; pp. 258–265. [Google Scholar]
- Song, S.; Das, A.; Mutlu, O.; Kandasamy, N. Improving phase change memory performance with data content aware access. In Proceedings of the 2020 ACM SIGPLAN International Symposium on Memory Management, London, UK, 16 June 2020; pp. 30–47. [Google Scholar]
- Jadidi, A.; Arjomand, M.; Tavana, M.K.; Kaeli, D.R.; Kandemir, M.T.; Das, C.R. Exploring the potential for collaborative data compression and hard-error tolerance in PCM memories. In Proceedings of the 2017 47th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Denver, CO, USA, 26–29 June 2017; pp. 85–96. [Google Scholar]
- Jadidi, A.; Kandemir, M.; Das, C. Tolerating write disturbance errors in PCM: Experimental characterization, analysis, and mechanisms. In Proceedings of the 2018 IEEE 26th International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS), Milwaukee, WI, USA, 25–28 September 2018; pp. 53–65. [Google Scholar]
- Lowe-Power, J.; Ahmad, A.M.; Akram, A.; Alian, M.; Amslinger, R.; Andreozzi, M.; Zulian, E.F. The gem5 Simulator: Version 20.0+. arXiv 2020, arXiv:2007.03152. [Google Scholar]
- Poremba, M.; Zhang, T.; Xie, Y. Nvmain 2.0: A user-friendly memory simulator to model (non-) volatile memory systems. IEEE Comput. Archit. Lett. 2015, 14, 140–143. [Google Scholar] [CrossRef]
- Benchmark Usando Gem5. Available online: https://github.com/ernestovaz/gem5benchmarkcodes (accessed on 20 December 2021).
- Liu, S.; Seemakhupt, K.; Pekhimenko, G.; Kolli, A.; Khan, S. Janus: Optimizing memory and storage support for non-volatile memory systems. In Proceedings of the 2019 ACM/IEEE 46th Annual International Symposium on Computer Architecture (ISCA), Phoenix, AZ, USA, 22–26 June 2019; pp. 143–156. [Google Scholar]
- Neuvonen, S.; Wolski, A.; Manner, M.; Raatikka, V. Telecom Application Transaction Processing Benchmark. 2011. Available online: https://tatpbenchmark.sourceforge.net/ (accessed on 19 December 2021).
- Council, T.P.P. Transaction Processing Performance Council. 2005. Available online: https://www.tpc.org/tpcc (accessed on 19 December 2021).
- Wang, J.; Dong, X.; Xie, Y.; Jouppi, N.P. i2WAP: Improving non-volatile cache lifetime by reducing inter- and intra-set write variations. In Proceedings of the 2013 IEEE 19th International Symposium on High Performance Computer Architecture (HPCA), Shenzhen, China, 23–27 February 2013; pp. 234–245. [Google Scholar] [CrossRef]
- Jacobvitz, A.N.; Calderbank, R.; Sorin, D.J. Coset coding to extend the lifetime of memory. In Proceedings of the 2013 IEEE 19th International Symposium on High Performance Computer Architecture (HPCA), Shenzhen, China, 23–27 February 2013; pp. 222–233. [Google Scholar]
- Alsuwaiyan, A.; Mohanram, K. MFNW: An MLC/TLC Flip-N-Write Architecture. ACM J. Emerg. Technol. Comput. Syst. 2018, 14, 1–32. [Google Scholar] [CrossRef]
- Kargar, S.; Nawab, F. Hamming Tree: The Case for Memory-Aware Bit Flipping Reduction for NVM Indexing. In Proceedings of the 11th Annual Conference on Innovative Data Systems Research, Vitrual Event, 10–15 January 2021. [Google Scholar]
- Kargar, S.; Litz, H.; Nawab, F. Predict and Write: Using K-Means Clustering to Extend the Lifetime of NVM Storage. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 768–779. [Google Scholar] [CrossRef]
- Ho, C.C.; Wang, W.C.; Hsu, T.H.; Jiang, Z.D.; Li, Y.C. Approximate Programming Design for Enhancing Energy, Endurance and Performance of Neural Network Training on NVM-based Systems. In Proceedings of the 2021 IEEE 10th Non-Volatile Memory Systems and Applications Symposium (NVMSA), Beijing, China, 18–20 August 2021; pp. 1–6. [Google Scholar]
- Bittman, D.; Gray, M.; Raizes, J.; Mukhopadhyay, S.; Bryson, M.; Alvaro, P.; Long, D.D.; Miller, E.L. Designing data structures to minimize bit flips on NVM. In Proceedings of the 2018 IEEE 7th Non-Volatile Memory Systems and Applications Symposium (NVMSA), Hakodate, Japan, 28–31 August 2018; pp. 85–90. [Google Scholar]
- Staudigl, F.; Al Indari, H.; Schön, D.; Sisejkovic, D.; Merchant, F.; Joseph, J.M.; Rana, V.; Menzel, S.; Leupers, R. NeuroHammer: Inducing Bit-Flips in Memristive Crossbar Memories. arXiv 2021, arXiv:2112.01087. [Google Scholar]
- Qureshi, M.K.; Karidis, J.; Franceschini, M.; Srinivasan, V.; Lastras, L.; Abali, B. Enhancing lifetime and security of PCM-based Main Memory with Start-Gap Wear Leveling. In Proceedings of the 2009 42nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), New York, NY, USA, 12–16 December 2009; pp. 14–23. [Google Scholar] [CrossRef]
- Hakert, C.; Kühn, R.; Chen, K.H.; Chen, J.J.; Teubner, J. OCTO+: Optimized Checkpointing of B+ Trees for Non-Volatile Main Memory Wear-Leveling. In Proceedings of the 2021 IEEE 10th Non-Volatile Memory Systems and Applications Symposium (NVMSA), Beijing, China, 18–20 August 2021; pp. 1–6. [Google Scholar]
- Kulandai, A.D.R.; Rose, J.; Schwarz, T. Balanced Gray Codes for Reduction of Bit-Flips in Phase Change Memories. In Proceedings of the Symposium on Modelling, Analysis, and Simulation of Computer and Telecommunication Systems, Nice, France, 17–19 November 2020; pp. 159–171. [Google Scholar]
- Dgien, D.B.; Palangappa, P.M.; Hunter, N.A.; Li, J.; Mohanram, K. Compression architecture for bit-write reduction in non-volatile memory technologies. In Proceedings of the 2014 IEEE/ACM International Symposium on Nanoscale Architectures (NANOARCH), Paris, France, 8–10 July 2014; pp. 51–56. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Word Patterns | Prefix | Compressed Size |
|---|---|---|
| zero run | 000 | 0 bits |
| 4-bit sign-extended | 001 | 4 bits |
| 1-byte sign-extended | 010 | 8 bits |
| half-word sign-extended | 011 | 16 bits |
| half-word padding with zero half-word | 100 | 16 bits |
| two half-words with 1 Byte sign-extended in each | 101 | 16 bits |
| repeated bytes | 110 | 8 bits |
| uncompressed word | 111 | 32 bits |
| Patterns | Encode | Base Size (#Byte) | Delta | Compressed Size (#Byte) |
|---|---|---|---|---|
| Zeros | 0000 | 1 | 0 | 1 |
| repeated values | 0001 | 8 | 0 | 8 |
| Base8-Delta1 | 0010 | 8 | 1 | 16 |
| Base8-Delta2 | 0011 | 8 | 2 | 24 |
| Base8-Delta4 | 0100 | 8 | 4 | 40 |
| Base4-Delta1 | 0101 | 4 | 1 | 20 |
| Base4-Delta2 | 0110 | 4 | 2 | 36 |
| Base2-Delta1 | 0111 | 2 | 1 | 34 |
| Uncompressed | 1111 | N/A | N/A | 64 |
| encode_tag | addr_tag | end_tag | |
|---|---|---|---|
| Case1 | 01 | last written | + NSize |
| Case2 | 11 | granularity-NSize | 00 |
| Case3 | 10 | last written | last written |
| Case4 | 11 | granularity-NSize | 00 |
| Case5 | 00(uncompressed) or 01(compressed) | 00 | 00 |
| Processor and Cache | |
|---|---|
| CPU | single-core x86-64 processor, 1 GHZ |
| private L1/shared L2 caches | 32 KB/2 MB |
| Memory (PCM-Based Memory) | |
| Capacity | 8 GB, 1 channel, 1 rank, 8 banks |
| memory controller | first-ready-first-come-first-serve (FRFCFS) |
| set/reset lat. | 60 cycles/20 cycles |
| read latency | 54 cycles |
| Parameters of SlidW | |
| FNW en/decoding lat. | 4 cycles/2 cycles |
| FPC compression/decompression lat. | 8 cycles/5 cycles |
| Threshold | 48 Bytes |
| Threshold | 3 |
| Benchmark | Description | Ops (#) | Writes |
|---|---|---|---|
| Array Swap | Swap items in an array | 1,040,691 | 76.4% |
| Hash Table | Insert values to a hash table | 2,870,832 | 18.6% |
| Queue | En/dequeue item to/from a queue | 1,596,168 | 64.8% |
| TATP | Update records in TATP benchmark | 6,360,544 | 54.4% |
| RBtree | Insert and delete nodes to a red-black tree | 1,280,056 | 35.2% |
| Btree | Insert and delete nodes to a b-tree | 4,378,578 | 33.6% |
| TPCC | Add new orders to the benchmark | 1,532,425 | 50.2% |
| Quicksort | Sort numbers using key value | 901,539 | 48.1% |
| Radixsort | Sort numbers using the DAC algorithm | 1,046,992 | 44.3% |
| Benchmarks | Address Change Times | Coverage Size | ||
|---|---|---|---|---|
| FPC+Space | FPC+SlidW | FPC+Space | FPC+SlidW | |
| Array Swap | 143,275 | 505,578 | 3591 | 1283 |
| Queue | 233,886 | 608,865 | 3,735,788 | 932,333 |
| TATP | 50,566 | 375,543 | 1,103,508 | 601,245 |
| Hash Table | 171,335 | 167,383 | 787,772 | 369,626 |
| Btree | 400,678 | 822,446 | 899,457 | 65,736 |
| RBtree | 38,082 | 37,746 | 187,636 | 648 |
| TPCC | 2910 | 17,510 | 57,491 | 30,986 |
| Quicksort | 182 | 179 | 1431 | 565 |
| Radixsort | 183 | 195 | 1637 | 894 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, K.; Du, Y.; Zhang, M.; Yin, Z.; Ausavarungnirun, R. Relieving Compression-Induced Local Wear on Non-Volatile Memory Block via Sliding Writes. Micromachines 2023, 14, 568. https://doi.org/10.3390/mi14030568
Jin K, Du Y, Zhang M, Yin Z, Ausavarungnirun R. Relieving Compression-Induced Local Wear on Non-Volatile Memory Block via Sliding Writes. Micromachines. 2023; 14(3):568. https://doi.org/10.3390/mi14030568
Chicago/Turabian StyleJin, Kailun, Yajuan Du, Mingzhe Zhang, Zhenghao Yin, and Rachata Ausavarungnirun. 2023. "Relieving Compression-Induced Local Wear on Non-Volatile Memory Block via Sliding Writes" Micromachines 14, no. 3: 568. https://doi.org/10.3390/mi14030568
APA StyleJin, K., Du, Y., Zhang, M., Yin, Z., & Ausavarungnirun, R. (2023). Relieving Compression-Induced Local Wear on Non-Volatile Memory Block via Sliding Writes. Micromachines, 14(3), 568. https://doi.org/10.3390/mi14030568