
Multi-Stage Harmonization for Robust AI across Breast MR Databases


Abstract
:Simple Summary
Abstract
1. Introduction
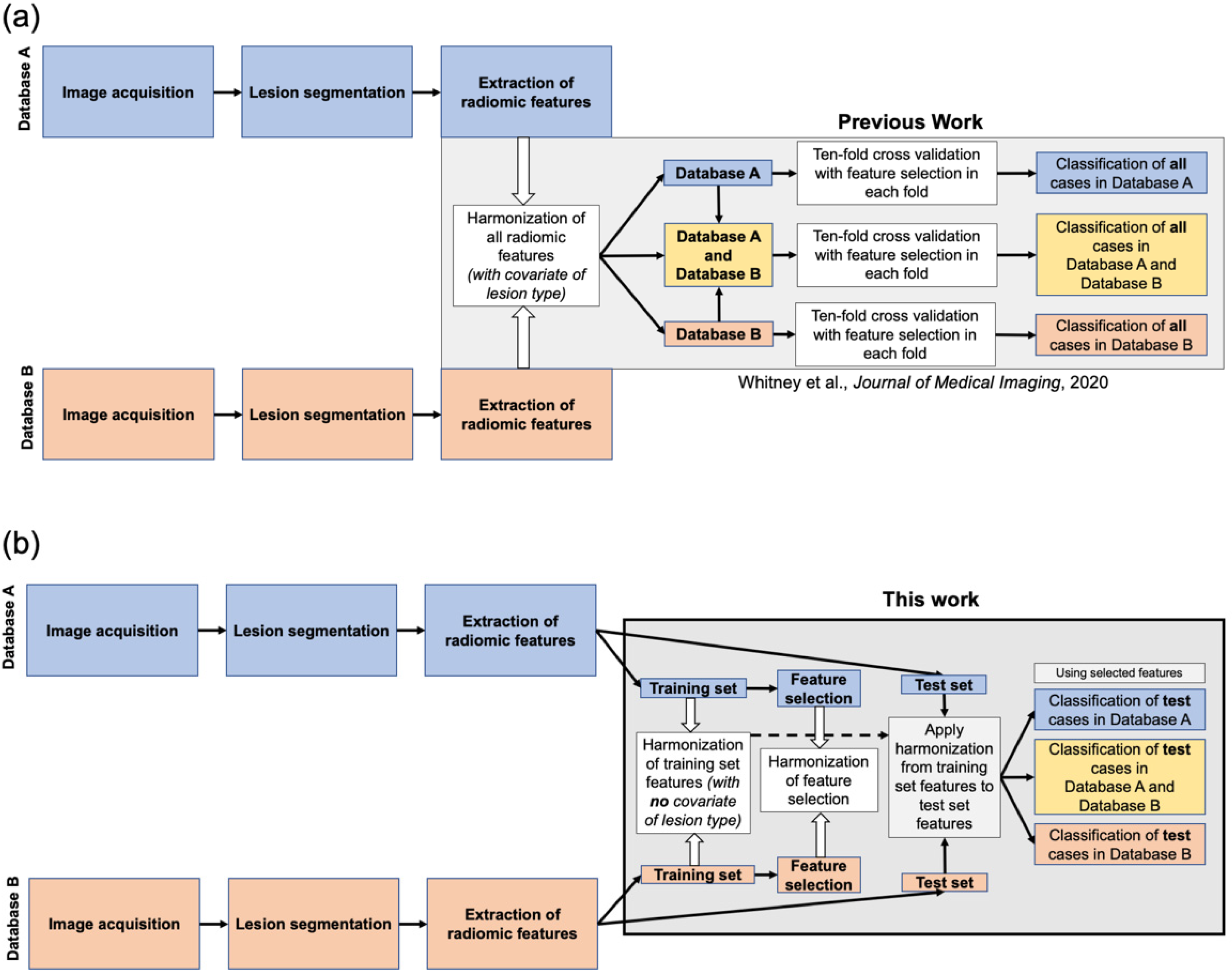
2. Materials and Methods
2.1. Database
2.2. Lesion Segmentation and Feature Extraction
2.3. Harmonization
2.4. Feature Selection
2.5. Lesion Classification
2.6. Classification Performance Comparison on the Test Sets
3. Results
3.1. Visualization of Feature Value Harmonization
3.2. Feature Selection
3.3. Lesion Classification Performance and Comparison
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Clarke, L.P.; Nordstrom, R.J.; Zhang, H.; Tandon, P.; Zhang, Y.; Redmond, G.; Farahani, K.; Kelloff, G.; Henderson, L.; Shankar, L.; et al. The Quantitative Imaging Network: NCI’s Historical Perspective and Planned Goals. Transl. Oncol. 2014, 7, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Johnson, W.; Li, C.; Rabinovic, A. Adjusting batch effects in microarray expression data using empirical Bayes methods. Biostatistics 2006, 8, 118–127. [Google Scholar] [CrossRef]
- Robinson, K.; Li, H.; Lan, L.; Schacht, D.; Giger, M. Radiomics robustness assessment and classification evaluation: A two-stage method demonstrated on multivendor FFDM. Med. Phys. 2019, 46, 2145–2156. [Google Scholar] [CrossRef]
- Orlhac, F.; Boughdad, S.; Philippe, C.; Stalla-Bourdillon, H.; Nioche, C.; Champion, L.; Soussan, M.; Frouin, F.; Frouin, V.; Buvat, I. A Postreconstruction Harmonization Method for Multicenter Radiomic Studies in PET. J. Nucl. Med. 2018, 59, 1321–1328. [Google Scholar] [CrossRef]
- Whitney, H.M.; Li, H.; Ji, Y.; Liu, P.; Giger, M.L. Harmonization of radiomic features of breast lesions across interna-tional DCE-MRI datasets. J. Med. Imaging 2020, 7, 012707. [Google Scholar] [CrossRef]
- Orlhac, F.; Frouin, F.; Nioche, C.; Ayache, N.; Buvat, I. Validation of A Method to Compensate Multicenter Effects Affecting CT Radiomics. Radiology 2019, 291, 53–59. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mahon, R.N.; Ghita, M.; Hugo, G.D.; Weiss, E. ComBat harmonization for radiomic features in independent phantom and lung cancer patient computed tomography datasets. Phys. Med. Biol. 2019, 65, 015010. [Google Scholar] [CrossRef]
- Peeken, J.C.; Spraker, M.B.; Knebel, C.; Dapper, H.; Pfeiffer, D.; Devecka, M.; Thamer, A.; Shouman, M.A.; Ott, A.; von Eisenhart-Rothe, R.; et al. Tumor grading of soft tissue sarcomas using MRI-based radiomics. EBioMedicine 2019, 48, 332–340. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fortin, J.-P.; Parker, D.; Tunç, B.; Watanabe, T.; Elliott, M.A.; Ruparel, K.; Roalf, D.R.; Satterthwaite, T.D.; Gur, R.C.; Gur, R.E.; et al. Harmonization of multi-site diffusion tensor imaging data. NeuroImage 2017, 161, 149–170. [Google Scholar] [CrossRef] [PubMed]
- Fortin, J.-P.; Cullen, N.; Sheline, Y.I.; Taylor, W.D.; Aselcioglu, I.; Cook, P.A.; Adams, P.; Cooper, C.; Fava, M.; McGrath, P.J.; et al. Harmonization of cortical thickness measurements across scanners and sites. NeuroImage 2018, 167, 104–120. [Google Scholar] [CrossRef] [PubMed]
- Orlhac, F.; Lecler, A.; Savatovski, J.; Goya-Outi, J.; Nioche, C.; Charbonneau, F.; Ayache, N.; Frouin, F.; Duron, L.; Buvat, I. How can we combat multicenter variability in MR radiomics? Validation of a correction procedure. Eur. Radiol. 2021, 31, 2272–2280. [Google Scholar] [CrossRef]
- Da-Ano, R.; Visvikis, D.; Hatt, M. Harmonization strategies for multicenter radiomics investigations. Phys. Med. Biol. 2020, 65, 24TR02. [Google Scholar] [CrossRef]
- Whitney, H.M.; Li, H.; Ji, Y.; Liu, P.; Giger, M.L. Comparison of Breast MRI Tumor Classification Using Human-Engineered Radiomics, Transfer Learning From Deep Convolutional Neural Networks, and Fusion Methods. Proc. IEEE 2020, 108, 163–177. [Google Scholar] [CrossRef]
- Hu, Q.; Whitney, H.M.; Li, H.; Ji, Y.; Liu, P.; Giger, M.L. Improved Classification of Benign and Malignant Breast Lesions Using Deep Feature Maximum Intensity Projection MRI in Breast Cancer Diagnosis Using Dynamic Contrast-enhanced MRI. Radiol. Artif. Intell. 2021, 3, e200159. [Google Scholar] [CrossRef] [PubMed]
- Ji, Y.; Li, H.; Edwards, A.V.; Papaioannou, J.; Ma, W.; Liu, P.; Giger, M.L. Independent validation of machine learning in diagnosing breast Cancer on magnetic resonance imaging within a single institution. Cancer Imaging 2019, 19, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Giger, M.; Bick, U. A Fuzzy C-Means (FCM)-Based Approach for Computerized Segmentation of Breast Lesions in Dynamic Contrast-Enhanced MR Images1. Acad. Radiol. 2006, 13, 63–72. [Google Scholar] [CrossRef] [PubMed]
- Gilhuijs, K.G.A.; Giger, M.L.; Bick, U. Computerized analysis of breast lesions in three dimensions using dynamic magnetic-resonance imaging. Med. Phys. 1998, 25, 1647–1654. [Google Scholar] [CrossRef]
- Chen, W.; Giger, M.; Li, H.; Bick, U.; Newstead, G.M. Volumetric texture analysis of breast lesions on contrast-enhanced magnetic resonance images. Magn. Reson. Med. 2007, 58, 562–571. [Google Scholar] [CrossRef]
- Chen, W.; Giger, M.; Lan, L.; Bick, U. Computerized interpretation of breast MRI: Investigation of enhancement-variance dynamics. Med. Phys. 2004, 31, 1076–1082. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Resour. 2008, 9, 2579–2605. [Google Scholar]
- Jamieson, A.R.; Giger, M.; Drukker, K.; Li, H.; Yuan, Y.; Bhooshan, N. Exploring nonlinear feature space dimension reduction and data representation in breast CADx with Laplacian eigenmaps and -SNE. Med. Phys. 2010, 37, 339–351. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Metz, C.E. Basic principles of ROC analysis. Semin. Nucl. Med. 1978, 8, 283–298. [Google Scholar] [CrossRef]
- Metz, C.E.; Pan, X. “Proper” Binormal ROC Curves: Theory and Maximum-Likelihood Estimation. J. Math. Psychol. 1999, 43, 1–33. [Google Scholar] [CrossRef] [PubMed]
- Bonferroni, C. Teoria statistica delle classi e calcolo delle probabilità. Pubbl. R Ist. Super. Sci. Econ. Commer. Firenze 1936, 89, 3–62. [Google Scholar]
- Ahn, S.; Park, S.H.; Lee, K.H. How to Demonstrate Similarity by Using Noninferiority and Equivalence Statistical Testing in Radiology Research. Radiology 2013, 267, 328–338. [Google Scholar] [CrossRef]
- Luo, R.; Wang, J.; Zhong, H.; Gan, J.; Hu, P.; Shen, L.; Hu, W.; Zhang, Z. OC-0160: Radiomics Features Harmonization for CT and CBCT in Rectal Cancer. Radiother. Oncol. 2017, 123, S81–S82. [Google Scholar] [CrossRef]
- Huynh, K.M.; Chen, G.; Wu, Y.; Shen, D.; Yap, P.-T. Multi-Site Harmonization of Diffusion MRI Data via Method of Moments. IEEE Trans. Med. Imaging 2019, 38, 1599–1609. [Google Scholar] [CrossRef]
- Reuzé, S.; Dirand, A.; Sun, R.; Orlhac, F.; Louvel, G.; Ammari, S.; Deutsch, E.; Robert, C. PV-0528: An innovative MRI harmonization method allowing large scale radiomics analysis in glioblastoma. Radiother. Oncol. 2018, 127, S280–S281. [Google Scholar] [CrossRef]
- Ibrahim, A.; Refaee, T.; Primakov, S.; Barufaldi, B.; Acciavatti, R.; Granzier, R.; Hustinx, R.; Mottaghy, F.; Woodruff, H.; Wildberger, J.; et al. The Effects of In-Plane Spatial Resolution on CT-Based Radiomic Features’ Stability with and without ComBat Harmonization. Cancers 2021, 13, 1848. [Google Scholar] [CrossRef]
- Masson, I.; Da-Ano, R.; Lucia, F.; Doré, M.; Castelli, J.; de Monsabert, C.G.; Ramée, J.; Sellami, S.; Visvikis, D.; Hatt, M.; et al. Statistical harmonization can improve the development of a multicenter CT-based radiomic model predictive of nonresponse to induction chemotherapy in laryngeal cancers. Med. Phys. 2021, 48, 4099–4109. [Google Scholar] [CrossRef]
- Stein, C.K.; Qu, P.; Epstein, J.; Buros, A.; Rosenthal, A.; Crowley, J.; Morgan, G.; Barlogie, B. Removing batch effects from purified plasma cell gene expression microarrays with modified ComBat. BMC Bioinform. 2015, 16, 63. [Google Scholar] [CrossRef] [Green Version]
- Da-Ano, R.; Masson, I.; Lucia, F.; Doré, M.; Robin, P.; Alfieri, J.; Rousseau, C.; Mervoyer, A.; Reinhold, C.; Castelli, J.; et al. Performance comparison of modified ComBat for harmonization of radiomic features for multicenter studies. Sci. Rep. 2020, 10, 1–12. [Google Scholar] [CrossRef]
- Luo, J.; Schumacher, M.; Scherer, A.; Sanoudou, D.; Megherbi, D.B.; Davison, T.S.; Shi, T.; Tong, W.; Shi, L.; Hong, H.; et al. A comparison of batch effect removal methods for enhancement of prediction performance using MAQC-II microarray gene expression data. Pharm. J. 2010, 10, 278–291. [Google Scholar] [CrossRef] [Green Version]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Pszczolkowski, S.; Manzano-Patrón, J.P.; Law, Z.K.; Krishnan, K.; Ali, A.; Bath, P.M.; Sprigg, N.; Dineen, R.A. Quantitative CT radiomics-based models for prediction of haematoma expansion and poor functional outcome in primary intracerebral haemorrhage. Eur. Radiol. 2021, 31, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Radua, J.; Vieta, E.; Shinohara, R.; Kochunov, P.; Quidé, Y.; Green, M.J.; Weickert, C.S.; Weickert, T.; Bruggemann, J.; Kircher, T.; et al. Increased power by harmonizing structural MRI site differences with the ComBat batch adjustment method in ENIGMA. NeuroImage 2020, 218, 116956. [Google Scholar] [CrossRef] [PubMed]
- Da-Ano, R.; Lucia, F.; Masson, I.; Abgral, R.; Alfieri, J.; Rousseau, C.; Mervoyer, A.; Reinhold, C.; Pradier, O.; Schick, U.; et al. A transfer learning approach to facilitate ComBat-based harmonization of multicentre radiomic features in new datasets. PLoS ONE 2021, 16, e0253653. [Google Scholar] [CrossRef] [PubMed]
- Wu, Q.; Markey, M.K. Computer-aided diagnosis of breast cancer on MR imaging. In Recent Advances in Breast Imaging, Mammography, and Computer-Aided Diagnosis of Breast Cancer; Suri, J.S., Rangayyan, R.M., Eds.; SPIE: Bellingham, WA, USA, 2006; pp. 739–762. [Google Scholar]
- Sheth, D.; Giger, M.L. Artificial intelligence in the interpretation of breast cancer on MRI. J. Magn. Reson. Imaging 2020, 51, 1310–1324. [Google Scholar] [CrossRef]
- Wiggins, W.F.; Caton, M.T.; Magudia, K.; Glomski, S.-H.A.; George, E.; Rosenthal, M.H.; Gaviola, G.C.; Andriole, K.P. Preparing Radiologists to Lead in the Era of Artificial Intelligence: Designing and Implementing a Focused Data Science Pathway for Senior Radiology Residents. Radiol. Artif. Intell. 2020, 2, e200057. [Google Scholar] [CrossRef]
- Wood, M.J.; Tenenholtz, N.A.; Geis, J.R.; Michalski, M.H.; Andriole, K.P. The Need for a Machine Learning Curriculum for Radiologists. J. Am. Coll. Radiol. 2019, 16, 740–742. [Google Scholar] [CrossRef]
- Bhooshan, N.; Giger, M.; Jansen, S.A.; Li, H.; Lan, L.; Newstead, G.M. Cancerous Breast Lesions on Dynamic Contrast-enhanced MR Images: Computerized Characterization for Image-based Prognostic Markers. Radiology 2010, 254, 680–690. [Google Scholar] [CrossRef]
- Shimauchi, A.; Giger, M.L.; Bhooshan, N.; Lan, L.; Pesce, L.L.; Lee, J.K.; Abé, H.; Newstead, G.M. Evaluation of Clinical Breast MR Imaging Performed with Prototype Computer-aided Diagnosis Breast MR Imaging Workstation: Reader Study. Radiology 2011, 258, 696–704. [Google Scholar] [CrossRef]
- Monticciolo, D.L.; Newell, M.S.; Moy, L.; Niell, B.; Monsees, B.; Sickles, E.A. Breast Cancer Screening in Women at Higher-Than-Average Risk: Recommendations From the ACR. J. Am. Coll. Radiol. 2018, 15, 408–414. [Google Scholar] [CrossRef]
- U.S. Department of Health and Human Services. Male Breast Cancer Incidence and Mortality, United States—2013–2017; USCS Data Brief, no. 19; Centers for Disease Control and Prevention: Atlanta, GA, USA, 2020.
- Ryu, S.W.; Ho, K.; O’Toole, S.A.; Green, A.; Kim, H.W. Case report of male breast cancer detected on magnetic resonance imaging. J. Med. Imaging Radiat. Oncol. 2016, 61, 369–371. [Google Scholar] [CrossRef] [PubMed]
- Shaw, A.; Smith, B.; Howlett, D. Male breast carcinoma and the use of MRI. Radiol. Case Rep. 2011, 6, 455. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amstutz, P.; Drukker, K.; Li, H.; Abe, H.; Giger, M.L.; Whitney, H.M. Case-based diagnostic classification repeatability using radiomic features extracted from full-field digital mammography images of breast lesions. In Proceedings of the Medical Imaging 2021: Computer-Aided Diagnosis, Online Only, 15 February 2021; p. 115970. [Google Scholar]
- de Oliveira, M.; Drukker, K.; Vieceli, M.; Abe, H.; Giger, M.L.; Whitney, H.M. Comparison of diagnostic performances, case-based repeatability, and operating sensitivity and specificity in classification of breast lesions using DCE-MRI. In Proceedings of the Medical Imaging 2021: Image Perception, Observer Performance, and Technology Assessment, Online Only, 15 February 2021; p. 115990. [Google Scholar]
- Van Dusen, A.; Vieceli, M.; Drukker, K.; Abe, H.; Giger, M.L.; Whitney, H.M. Repeatability profiles towards consistent sensitivity and specificity levels for machine learning on breast DCE-MRI. In Proceedings of the Medical Imaging 2020: Image Perception, Observer Performance, and Technology Assessment, Houston, TX, USA, 16 March 2020; Volume 11316, p. 113160I. [Google Scholar] [CrossRef]
- Vieceli, M.; Van Dusen, A.; Drukker, K.; Abe, H.; Giger, M.L.; Whitney, H.M. Case-based repeatability of machine learning classification performance on breast MRI. In Proceedings of the Medical Imaging 2020: Computer-Aided Diagnosis, Houston, TX, USA, 16 March 2020; Volume 11314, p. 1131421. [Google Scholar] [CrossRef]
- Drukker, K.; Pesce, L.; Giger, M. Repeatability in computer-aided diagnosis: Application to breast cancer diagnosis on sonography. Med. Phys. 2010, 37, 2659–2669. [Google Scholar] [CrossRef] [PubMed] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set | Test Set | |||
|---|---|---|---|---|
| Database | Benign | Cancer | Benign | Cancer |
| A + B | (A + B)tr | (A + B)te | ||
| Number (% of set) | 554 (24%) | 1726 (76%) | 183 (22%) | 660 (78%) |
| Age in years (median, [95% CI]) (min, max) | 44 [23, 70] (16, 86) | 49 [31, 77] (19, 89) | 44 [22, 67] (19, 74) | 50 [30, 73] (23, 84) |
| Size in mm (median, [95% CI]) | 18.1 [5.6, 66.7] | 28.6 [10.6, 98] | 16.5 [5.7, 60.2] | 28.3 [11.0, 95.2] |
| A | Atr (2005–2011) | Ate (2012–2017) | ||
| Number (% of set) | 184 (22%) | 646 (78%) | 72 (23%) | 235 (77%) |
| Age in years (median, [95% CI]) (min, max) | 49 [25, 74] (24, 86) | 56 [34, 82] (23, 89) | 47 [27, 67] (27, 74) | 52 [30, 74] (23, 84) |
| Size in mm (median, [95% CI]) | 12.9 [5.3, 55.8] | 29.5 [8.3, 105.5] | 12.7 [4.7, 55.2] | 35 [9.7, 115.2] |
| B | Btr (2015–2016) | Bte (2017) | ||
| Number (% of set) | 370 (26%) | 1080 (74%) | 111 (21%) | 425 (79%) |
| Age in years (median, [95% CI]) (min, max) | 43 [21.5, 62.5] (16, 76) | 47 [30, 70] (19, 77) | 43 [21, 59.2] (19, 65) | 48 [30, 68] (25, 75) |
| Size in mm (median, [95% CI]) | 20.9 [5.9, 70.1] | 28.2 [12.0, 90.5] | 17.7 [7.2, 63.2] | 27.3 [11.8, 85.5] |
| Radiomic Features Deemed Eligible for Harmonization | ||
| Feature Abbreviation | Feature Name | Feature Description |
| M1 | Margin sharpness | Mean of the image gradient at the lesion margin |
| M2 | Variance of margin sharpness | Variance of the image gradient at the lesion margin |
| M3 | Variance of radial gradient histogram | Degree to which the enhancement structure extends in a radial pattern originating from the center of the lesion |
| T1 | Contrast | Location image variations |
| T2 | Correlation | Image linearity |
| T3 | Difference entropy | Randomness of the difference of neighboring voxels’ gray-levels |
| T4 | Difference variance | Variations of difference of gray-levels between voxel-pairs |
| T5 | Energy | Image homogeneity |
| T6 | Entropy | Randomness of the gray-levels |
| T7 | Inverse difference moment (homogeneity) | Image homogeneity |
| T8 | Information measure of correlation 1 | Nonlinear gray-level dependence |
| T9 | Information measure of correlation 2 | Nonlinear gray-level dependence |
| T10 | Maximum correlation coefficient | Nonlinear gray-level dependence |
| T11 | Sum average | Overall brightness |
| T12 | Sum entropy | Randomness of the sum of gray-levels of neighboring voxels |
| T13 | Sum variance | Spread in the sum of the gray-levels of voxel-pairs distribution |
| T14 | Sum of squares (variance) | Spread in the gray-level distribution |
| K1 | Maximum enhancement | Maximum contrast enhancement |
| K2 | Time to peak (s) | Time at which the maximum enhancement occurs |
| K3 | Uptake rate (1/s) | Uptake speed of the contrast enhancement |
| K6 | Enhancement at first postcontrast time point | Enhancement at first post-contrast time point |
| K7 | Signal enhancement ratio | Ratio of initial enhancement to overall enhancement |
| Radiomic Features Deemed not Eligible for Harmonization | ||
| Feature Abbreviation | Feature Name | Feature Description |
| S1 | Volume (mm3) | Volume of lesion |
| S2 | Effective diameter (mm) | Greatest dimension of a sphere with the same volume as the lesion |
| S3 | Surface area (mm2) | Lesion surface area |
| S4 | Maximum linear size (mm) | Maximum distance between any 2 voxels in the lesion |
| G1 | Sphericity | Similarity of the lesion shape to a sphere |
| G2 | Irregularity | Deviation of the lesion surface from the surface of a sphere |
| G3 | Surface area/volume (1/mm) | Ratio of surface area to volume |
| K4 | Washout rate (1/s) | Washout speed of the contrast enhancement |
| K5 | Curve shape index | Difference between late and early enhancement |
| K8 | Volume of most enhancing voxels (mm3) | Volume of the most enhancing voxels |
| Training Set | Independent Test Set | p-Value for ΔAUC [95% CI of ΔAUC] | Equivalence Margin (ΔAUC) for Equivalence |
|---|---|---|---|
| Using Features Selected from Database-Specific Training Set | |||
| Atr | Bte | <0.0001 * [0.034, 0.063] | n/a |
| Btr | Ate | 0.5 [−0.028, 0.058] | 0.058 |
| Using Features Selected from Combined Training Set | |||
| (A + B)tr | Ate | 0.9 [−0.019, 0.017] | 0.019 |
| (A + B)tr | Bte | 0.17 [−0.003, 0.020] | 0.020 |
| (A + B)tr | (A + B)te | 0.4 [−0.005, 0.014] | 0.014 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Whitney, H.M.; Li, H.; Ji, Y.; Liu, P.; Giger, M.L. Multi-Stage Harmonization for Robust AI across Breast MR Databases. Cancers 2021, 13, 4809. https://doi.org/10.3390/cancers13194809
Whitney HM, Li H, Ji Y, Liu P, Giger ML. Multi-Stage Harmonization for Robust AI across Breast MR Databases. Cancers. 2021; 13(19):4809. https://doi.org/10.3390/cancers13194809
Chicago/Turabian StyleWhitney, Heather M., Hui Li, Yu Ji, Peifang Liu, and Maryellen L. Giger. 2021. "Multi-Stage Harmonization for Robust AI across Breast MR Databases" Cancers 13, no. 19: 4809. https://doi.org/10.3390/cancers13194809