
Deep Learning Predicts the Malignant-Transformation-Free Survival of Oral Potentially Malignant Disorders

 , ,
, ,
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Patients and Dataset
2.2. Data Cleaning and Feature Engineering
2.3. Machine Learning Algorithms
2.4. Model Training and Internal Validation
2.5. Model Performance Measures
2.6. External Validation and Algorithm Deployment
2.7. Computation
3. Results
3.1. Patient Characteristics
3.2. Performance of Time-to-Event Machine-Learning Models
3.2.1. Cox-PH
3.2.2. Cox-Time
3.2.3. DeepHit
3.2.4. DeepSurv
3.2.5. RSF
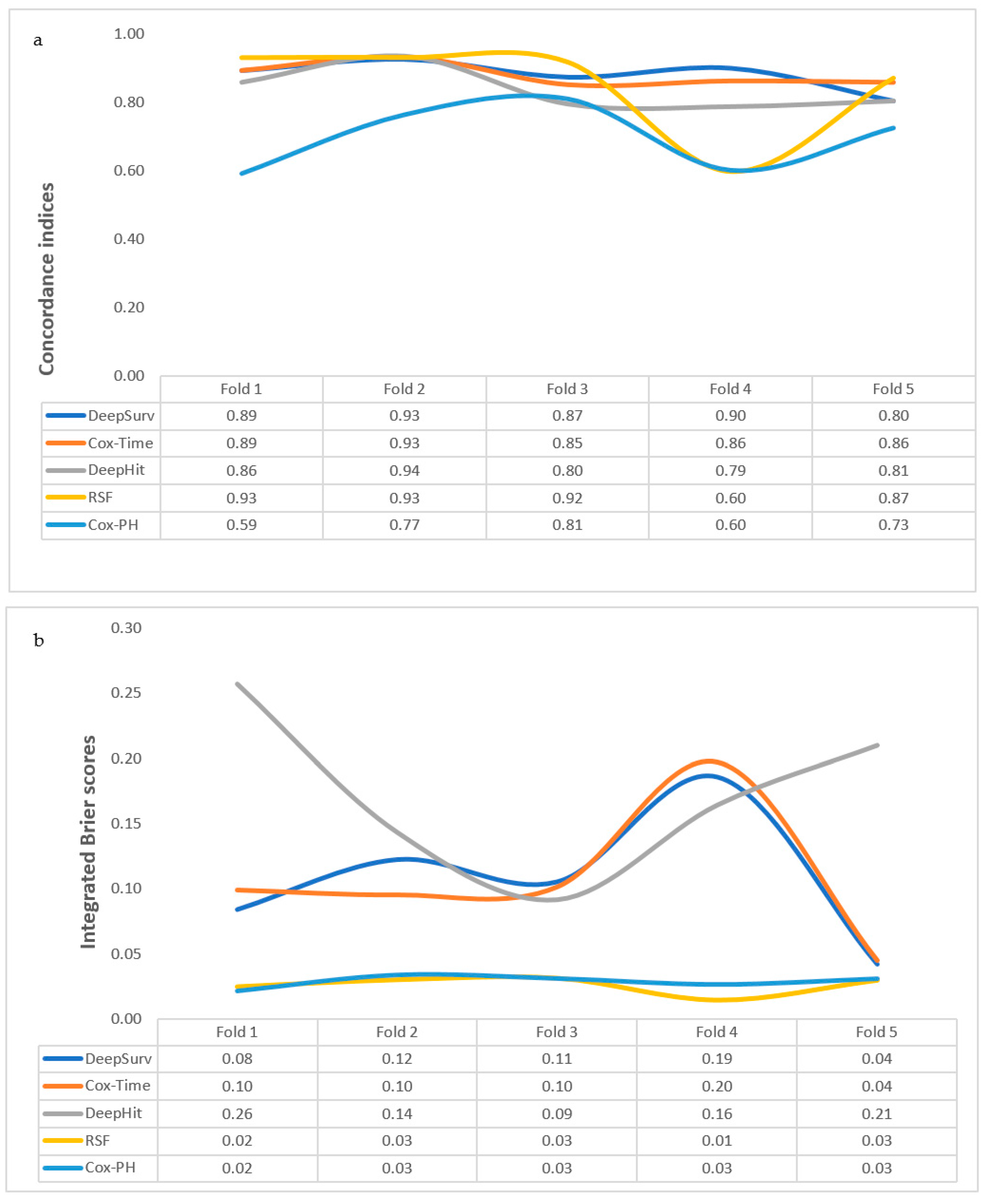
3.3. Comparing the Performance Measures of the Algorithms
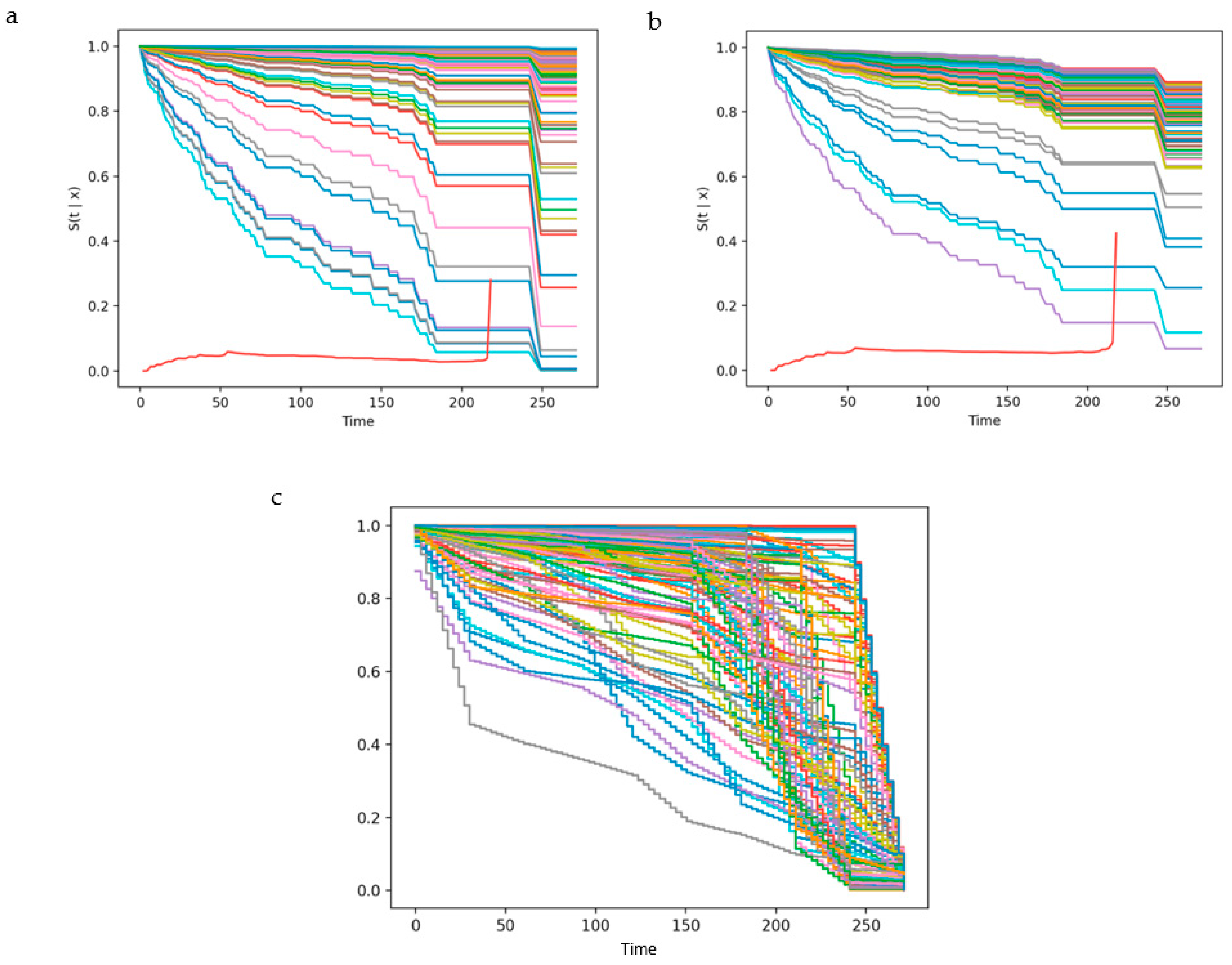
3.4. External Validation and Effect of Missing Variables on Trained Models
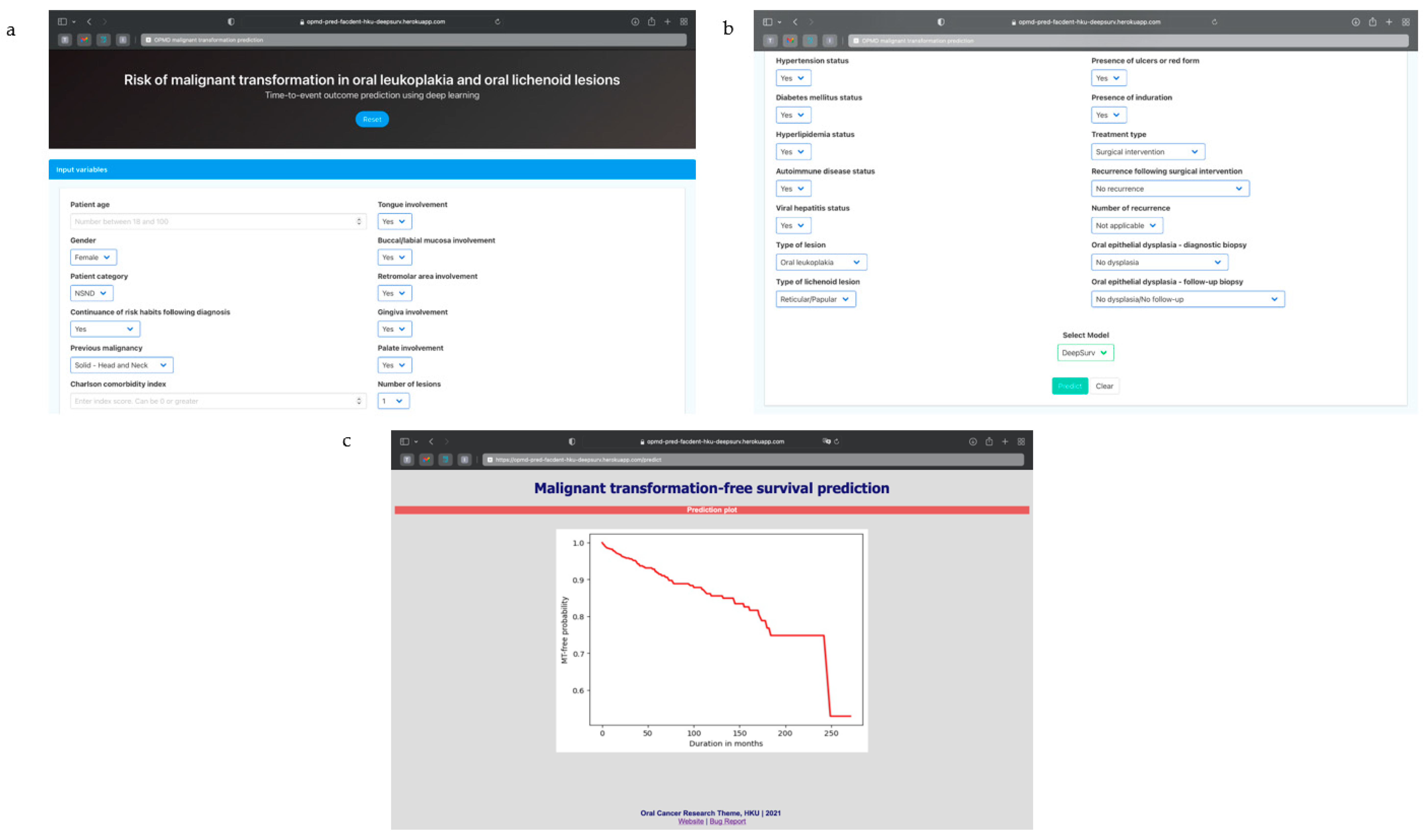
3.5. Algorithm Deployment
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global cancer statistics 2020: Globocan estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Awan, K.H. Oral cancer: Early detection is crucial. J. Int. Oral Health 2014, 6, i–ii. [Google Scholar] [PubMed]
- Baykul, T.; Yilmaz, H.H.; Aydin, U.; Aydin, M.A.; Aksoy, M.; Yildirim, D. Early diagnosis of oral cancer. J. Int. Med. Res. 2010, 38, 737–749. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Warnakulasuriya, S.; Johnson, N.W.; van der Waal, I. Nomenclature and classification of potentially malignant disorders of the oral mucosa. J. Oral Pathol. Med. 2007, 36, 575–580. [Google Scholar] [CrossRef]
- Silverman, S., Jr.; Gorsky, M.; Lozada, F. Oral leukoplakia and malignant transformation. A follow-up study of 257 patients. Cancer 1984, 53, 563–568. [Google Scholar]
- Yardimci, G.; Kutlubay, Z.; Engin, B.; Tuzun, Y. Precancerous lesions of oral mucosa. World J. Clin. Cases 2014, 2, 866–872. [Google Scholar] [CrossRef]
- van der Waal, I. Oral potentially malignant disorders: Is malignant transformation predictable and preventable? Med. Oral Patol. Oral Cir. Bucal. 2014, 19, e386–e390. [Google Scholar] [CrossRef] [PubMed]
- Thomson, P.J.; Goodson, M.L.; Smith, D.R. Potentially malignant disorders revisited-the lichenoid lesion/proliferative verrucous leukoplakia conundrum. J. Oral Pathol. Med. 2018, 47, 557–565. [Google Scholar] [CrossRef]
- Warnakulasuriya, S.; Ariyawardana, A. Malignant transformation of oral leukoplakia: A systematic review of observational studies. J. Oral Pathol. Med. 2016, 45, 155–166. [Google Scholar] [CrossRef]
- Giuliani, M.; Troiano, G.; Cordaro, M.; Corsalini, M.; Gioco, G.; Lo Muzio, L.; Pignatelli, P.; Lajolo, C. Rate of malignant transformation of oral lichen planus: A systematic review. Oral Dis. 2019, 25, 693–709. [Google Scholar] [CrossRef] [PubMed]
- Fitzpatrick, S.G.; Hirsch, S.A.; Gordon, S.C. The malignant transformation of oral lichen planus and oral lichenoid lesions: A systematic review. J. Am. Dent. Assoc. 2014, 145, 45–56. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alabi, R.O.; Youssef, O.; Pirinen, M.; Elmusrati, M.; Mäkitie, A.A.; Leivo, I.; Almangush, A. Machine learning in oral squamous cell carcinoma: Current status, clinical concerns and prospects for future—A systematic review. Artif. Intell. Med. 2021, 115, 102060. [Google Scholar] [CrossRef] [PubMed]
- Cutillo, C.M.; Sharma, K.R.; Foschini, L.; Kundu, S.; Mackintosh, M.; Mandl, K.D.; Beck, T.; Collier, E.; Colvis, C.; Gersing, K.; et al. Machine intelligence in healthcare—Perspectives on trustworthiness, explainability, usability, and transparency. NPJ Digit. Med. 2020, 3, 47. [Google Scholar] [CrossRef] [Green Version]
- Davenport, T.; Kalakota, R. The potential for artificial intelligence in healthcare. Future Healthc. J. 2019, 6, 94–98. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adeoye, J.; Tan, J.Y.; Choi, S.-W.; Thomson, P. Prediction models applying machine learning to oral cavity cancer outcomes: A systematic review. Int. J. Med. Inform. 2021, 154, 104557. [Google Scholar] [CrossRef]
- Wang, X.; Yang, J.; Wei, C.; Zhou, G.; Wu, L.; Gao, Q.; He, X.; Shi, J.; Mei, Y.; Liu, Y.; et al. A personalized computational model predicts cancer risk level of oral potentially malignant disorders and its web application for promotion of non-invasive screening. J. Oral Pathol. Med. 2020, 49, 417–426. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Y.; Fu, Y.; Liu, T.; Liu, X.; Zhang, X.; Fu, J.; Guan, X.; Chen, T.; Chen, X.; et al. Quantitative prediction of oral cancer risk in patients with oral leukoplakia. Oncotarget 2017, 8, 46057–46064. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Wang, L.; Yang, H.; Lu, H.; Zhang, J.; Li, N.; Guo, C.B. Development and validation of nomogram for prediction of malignant transformation in oral leukoplakia: A large-scale cohort study. J. Oral Pathol. Med. 2019, 48, 491–498. [Google Scholar] [CrossRef]
- Idrees, M.; Kujan, O.; Shearston, K.; Farah, C.S. Oral lichen planus has a very low malignant transformation rate: A systematic review and meta-analysis using strict diagnostic and inclusion criteria. J. Oral Pathol. Med. 2021, 50, 287–298. [Google Scholar] [CrossRef]
- Almangush, A.; Mäkitie, A.A.; Triantafyllou, A.; de Bree, R.; Strojan, P.; Rinaldo, A.; Hernandez-Prera, J.C.; Suárez, C.; Kowalski, L.P.; Ferlito, A.; et al. Staging and grading of oral squamous cell carcinoma: An update. Oral Oncol. 2020, 107, 104799. [Google Scholar] [CrossRef]
- Adeoye, J.; Hui, L.; Tan, J.Y.; Koohi-Moghadam, M.; Choi, S.-W.; Thomson, P. Prognostic value of non-smoking, non-alcohol drinking status in oral cavity cancer. Clin. Oral Investig. 2021, 25, 6909–6918. [Google Scholar] [CrossRef] [PubMed]
- Adeoye, J.; Tan, J.Y.; Ip, C.M.; Choi, S.-W.; Thomson, P.J. Fact or fiction?: Oral cavity cancer in nonsmoking, nonalcohol Drinking patients as a distinct entity—Scoping review. Head Neck 2021, 43, 3662–3680. [Google Scholar] [CrossRef] [PubMed]
- Adeoye, J.; Hui, L.; Koohi-Moghadam, M.; Tan, J.Y.; Choi, S.-W.; Thomson, P. Comparison of time-to-event machine learning models in predicting oral cavity cancer prognosis. Int. J. Med. Inform. 2021, 157, 104635. [Google Scholar] [CrossRef] [PubMed]
- Katzman, J.L.; Shaham, U.; Cloninger, A.; Bates, J.; Jiang, T.; Kluger, Y. Deepsurv: Personalized treatment recommender system using a cox proportional hazards deep neural network. BMC Med. Res. Methodol. 2018, 18, 24. [Google Scholar] [CrossRef] [PubMed]
- Kvamme, H.; Borgan, Ø.; Scheel, I. Time-to-event prediction with neural networks and cox regression. arXiv 2019, arXiv:1907.00825. [Google Scholar]
- Lee, C.; Zame, W.R.; Yoon, J.; van der Schaar, M. Deephit: A deep learning approach to survival analysis with competing risks. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Ishwaran, H.; Kogalur, U.B.; Blackstone, E.H.; Lauer, M.S. Random survival forests. Ann. Appl. Stat. 2008, 2, 841–860. [Google Scholar] [CrossRef]
- Thomson, P.J.; Goodson, M.L.; Smith, D.R. Profiling cancer risk in oral potentially malignant disorders—A patient cohort study. J. Oral Pathol. Med. 2017, 46, 888–895. [Google Scholar] [CrossRef] [PubMed]
- Thomson, P.J.; Goodson, M.L.; Cocks, K.; Turner, J.E. Interventional laser surgery for oral potentially malignant disorders: A longitudinal patient cohort study. Int. J. Oral Maxillofac. Surg. 2017, 46, 337–342. [Google Scholar] [CrossRef] [Green Version]
- Almangush, A.; Alabi, R.O.; Mäkitie, A.A.; Leivo, I. Machine learning in head and neck cancer: Importance of a web-based prognostic tool for improved decision making. Oral Oncol. 2021, 105452. [Google Scholar] [CrossRef]
- Wild, D.; Weber, M.; Egger, J. Client/server based online environment for manual segmentation of medical images. arXiv 2019, arXiv:1904.08610. [Google Scholar]
- Kim, D.W.; Lee, S.; Kwon, S.; Nam, W.; Cha, I.-H.; Kim, H.J. Deep learning-based survival prediction of oral cancer patients. Sci. Rep. 2019, 9, 6994. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goodson, M.L.; Smith, D.R.; Thomson, P.J. The Newcastle nomogram—Statistical modelling Predicts malignant transformation in potentially malignant disorders. J. Oral Pathol. Med. 2019, 48, 662–668. [Google Scholar] [CrossRef] [PubMed]
- Ipsen, N.; Mattei, P.-A.; Frellsen, J. How to deal with missing data in supervised deep learning? In Proceedings of the ICML Workshop on the Art of Learning with Missing Values (Artemiss), Vienne, Austria, 17–18 July 2020. [Google Scholar]
- Köse, T.; Özgür, S.; Coşgun, E.; Keskinoğlu, A.; Keskinoğlu, P. Effect of missing data imputation on deep learning prediction performance for vesicoureteral reflux and recurrent urinary tract infection clinical study. BioMed Res. Int. 2020, 2020, 1895076. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Input Feature | Type | Missing Instance | Handling Technique |
|---|---|---|---|
| Age | Continuous | 0 | NA |
| Sex | Binary | 0 | NA |
| Tobacco smoking | Binary | 2 | One-hot transformation |
| Alcohol drinking | Categorical (nominal) | 33 | |
| Patient category | Categorical (nominal) | 0 | NA |
| Risk-habit indulgence following diagnosis | Categorical (nominal) | 0 | NA |
| Previous malignancy | Categorical (nominal) | 0 | NA |
| Charlson Comorbidity Index (CCI) | Continuous | 0 | NA |
| Hypertension status | Binary | 0 | NA |
| Diabetes Mellitus status | Binary | 0 | NA |
| Hyperlipidemia status | Binary | 0 | NA |
| Autoimmune disease status | Binary | 0 | NA |
| Viral hepatitis status | Binary | 0 | NA |
| Family history of malignancy | Binary | 592 | Variable elimination |
| Type of lesion | Binary | 0 | NA |
| Clinical subtype of lichenoid lesion | Categorical (nominal) | 0 | NA |
| Tongue/FOM involved | Binary | 0 | NA |
| Labial/buccal mucosa involved | Binary | 0 | NA |
| Retromolar area involved | Binary | 0 | NA |
| Gingiva involved | Binary | 0 | NA |
| Palate involved | Binary | 0 | NA |
| Number of lesions | Categorical (ordinal) | 0 | NA |
| Lesion size | Continuous | 464 | Variable elimination |
| Presence of ulcers or erosions | Binary | 0 | NA |
| Lesion border status | Binary | 679 | Variable elimination |
| Presence of induration | Binary | 0 | NA |
| Treatment at diagnosis | Categorical (nominal) | 0 | NA |
| Recurrence after surgical excision | Binary | 0 | NA |
| Number of recurrences | Categorical (ordinal) | 0 | NA |
| Oral epithelial dysplasia at diagnosis | Categorical (nominal) | 0 | NA |
| Oral epithelial dysplasia detected during follow-up | Categorical (nominal) | 0 | NA |
| Variables | N = 716 | |
|---|---|---|
| N (%) | ||
| Median age (IQR) | 58 (49–67) | |
| Gender | Female | 401 (56.0) |
| Male | 315 (44.0) | |
| Patient category | NSND | 469 (65.5) |
| SD | 247 (34.5) | |
| Continued risk habits following diagnosis | Yes | 14 (2.0) |
| No | 167 (23.3) | |
| Not applicable | 535 (74.7) | |
| Previous malignancy | Head and neck tumors | 21 (2.9) |
| Other tumors | 46 (6.4) | |
| Hematologic malignancies | 23 (3.2) | |
| No malignancy | 626 (87.4) | |
| Charlson comorbidity index—mean (SD) | 0.64 (1.02) | |
| Hypertension | 211 (29.5) | |
| Diabetes mellitus | 111 (15.5) | |
| Hyperlipidemia | 122 (17.0) | |
| Autoimmune disease | 42 (5.9) | |
| Viral hepatitis infection | 69 (9.6) | |
| Lesion | Oral leukoplakia | 389 (54.3) |
| Oral lichen planus/oral lichenoid lesion | 327 (45.7) | |
| Clinical subtype of lichenoid lesion | Reticular/Papular | 100 (14.0) |
| Erosive/Atrophic | 142 (19.8) | |
| Plaque | 85 (11.9) | |
| Tongue/FOM | 245 (34.2) | |
| Buccal/Labial mucosa | 407 (56.8) | |
| Retromolar area | 26 (3.6) | |
| Gingiva | 88 (12.3) | |
| Palate | 23 (3.2) | |
| Number of lesions | Single | 469 (65.5) |
| Bilateral or double | 210 (29.3) | |
| Multiple | 37 (5.2) | |
| Presence of ulcers or erosions | 228 (31.8) | |
| Induration | 47 (6.6) | |
| Treatment | Surgical excision | 221 (30.9) |
| Medical | 195 (27.2) | |
| No treatment | 300 (41.9) | |
| Post-excision recurrence | 42 (19.0) | |
| Number of recurrences | 1 | 30 (4.2) |
| 2 | 7 (1.0) | |
| 3 | 4 (0.6) | |
| 4 | 1 (0.1) | |
| Oral epithelial dysplasia at diagnosis | Absent | 641 (89.5) |
| Mild | 34 (4.7) | |
| Moderate | 27 (3.8) | |
| Severe | 7 (1.0) | |
| Unknown (defaulted biopsy at diagnosis) | 7 (1.0) | |
| Oral epithelial dysplasia at follow-up | Absent | 658 (91.9) |
| Mild | 11 (1.5) | |
| Moderate | 15 (2.1) | |
| Severe | 24 (3.4) | |
| Unknown (defaulted biopsy during follow-up) | 8 (1.1) | |
| Malignant transformation | 76 (10.6) | |
| AJCC TNM stage | Stage I | 47 (6.6) |
| Stage II | 9 (1.3) | |
| Stage III | 6 (0.8) | |
| Stage IV | 12 (1.7) | |
| Tumor grade | Well differentiated | 23 (3.2) |
| Moderately differentiated | 30 (4.2) | |
| Poorly differentiated | 3 (0.4) | |
| Tumor prognosis | Remission | 58 (8.1) |
| Recurrence | 6 (0.8) | |
| Cancer-related death | 6 (0.8) | |
| Second primary tumor | 6 (0.8) | |
| Models | Five-Fold Cross-Validation | Internal Validation | Repeat Five-Fold Cross-Validation with Reduced Features | Internal Validation | External Validation | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Concordance Index | Integrated Brier Scores (IBS) | Concordance Index | Integrated Brier Scores (IBS) | Concordance Index | Integrated Brier Scores (IBS) | Concordance Index | Integrated Brier Scores (IBS) | Concordance Index | Integrated Brier Scores (IBS) | |
| Mean (SD) | Mean (SD) | Mean (SD) | Mean (SD) | |||||||
| Cox-PH | 0.70 (0.098) | 0.03 (0.005) | 0.83 | 0.03 | ||||||
| Cox-Time | 0.88 (0.034) | 0.11 (0.055) | 0.86 | 0.06 | ||||||
| DeepHit | 0.84 (0.061) | 0.17 (0.064) | 0.86 | 0.08 | ||||||
| DeepSurv | 0.88 (0.046) | 0.11 (0.053) | 0.95 | 0.04 | 0.78 (0.097) | 0.13 (0.069) | 0.92 | 0.05 | 0.82 | 0.18 |
| RSF | 0.85 (0.142) | 0.03 (0.007) | 0.91 | 0.03 | 0.89 (0.064) | 0.03 (0.006) | 0.92 | 0.03 | 0.73 | 0.03 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adeoye, J.; Koohi-Moghadam, M.; Lo, A.W.I.; Tsang, R.K.-Y.; Chow, V.L.Y.; Zheng, L.-W.; Choi, S.-W.; Thomson, P.; Su, Y.-X. Deep Learning Predicts the Malignant-Transformation-Free Survival of Oral Potentially Malignant Disorders. Cancers 2021, 13, 6054. https://doi.org/10.3390/cancers13236054
Adeoye J, Koohi-Moghadam M, Lo AWI, Tsang RK-Y, Chow VLY, Zheng L-W, Choi S-W, Thomson P, Su Y-X. Deep Learning Predicts the Malignant-Transformation-Free Survival of Oral Potentially Malignant Disorders. Cancers. 2021; 13(23):6054. https://doi.org/10.3390/cancers13236054
Chicago/Turabian StyleAdeoye, John, Mohamad Koohi-Moghadam, Anthony Wing Ip Lo, Raymond King-Yin Tsang, Velda Ling Yu Chow, Li-Wu Zheng, Siu-Wai Choi, Peter Thomson, and Yu-Xiong Su. 2021. "Deep Learning Predicts the Malignant-Transformation-Free Survival of Oral Potentially Malignant Disorders" Cancers 13, no. 23: 6054. https://doi.org/10.3390/cancers13236054
APA StyleAdeoye, J., Koohi-Moghadam, M., Lo, A. W. I., Tsang, R. K. -Y., Chow, V. L. Y., Zheng, L. -W., Choi, S. -W., Thomson, P., & Su, Y. -X. (2021). Deep Learning Predicts the Malignant-Transformation-Free Survival of Oral Potentially Malignant Disorders. Cancers, 13(23), 6054. https://doi.org/10.3390/cancers13236054