1. Introduction
Cancer is the leading cause of death in Taiwan. According to the Cancer Registration Report of Taiwan’s Ministry of Health and Welfare, a total of 13,488 people suffered from lung cancer in 2016, making it the second-most common cancer and the most common cancer in men.
Cancer is usually curable by surgery and adjunctive therapy when it is diagnosed in the early stages [
1]. An early diagnosis is important in the elderly, even if the patient has other diseases. Surgery can improve a patient’s quality of life, even if the goal is not to extend the life of the patient [
2]. The radiation and medical treatment provided after surgery can reduce the risk of the cancer spreading, but these adjuvant treatments can cause temporary harm. For patients over 65 years of age, chemotherapy should be avoided, and if radiation therapy is adopted smaller dosages than usual should be used [
3]. Recent clinical research has shown that patients no longer have an upper age limit, but that they are selected according to their general condition (excluding other diseases). Cancer treatments, such as chemotherapy and radiation therapy, often cause more damage and are more severe in older people than in younger people. However, if the patient has no other diseases, a treatment plan can sometimes be prepared in the same way as for a young patient. Regardless of their age, both drug therapy and radiation therapy may have the same effect. Other diseases of the elderly, such as diabetes, vascular disease, and impaired kidney function, may increase the risk of infection, anemia, nausea, depression, and exhaustion [
4]. Elderly patients tend to recover more slowly from treatment.
Therefore, early diagnosis has been receiving increased attention, and more and more research is focusing on disease prediction and detection. Through artificial intelligence calculations and programming, disease prediction models that are based on big data can be constructed.
2. Literature Review
Previous research has developed a prediction model for lung cancer. Cassidy et al. [
5] employed the LLP(Liverpool Lung Project) risk model to estimate the probability of lung cancer development with a specific combination of risk factors within a five-year period. These risk factors include the age and sex of the patient, previous malignant tumors, smoking duration, the age of onset of lung cancer, asbestos exposure, cases of lung cancer, and pneumonia history. The area under the Receiver Operating Characteristic curve (ROC) of the model was 0.71. Bach et al. [
6] built two models, namely, one for the one-year risk of developing an incidence of lung cancer, and one for computing the risk of dying from lung cancer without a positive diagnosis. The prediction factors of both models include the age and sex of the patient, smoking duration, smoking intensity, the length of time since quitting smoking, and asbestos exposure. The model was built using the Cox proportional hazard regression, and the area under the ROC of the prediction model was 0.72. Many different target disease models have been established by different algorithms, such as the Artificial Neural Network (ANN), Cox regression, logistic regression, and the Support Vector Machine (SVM), for other diseases [
7,
8,
9,
10,
11]. The results of past related studies, including the number of factors, factors and model performance, and the comparison table is shown in
Table 1.
This study developed a 10-year lung cancer risk prediction model based on the Taiwan National Health Insurance Research Database (NHIRD). Potential diseases related to lung cancer were used as the predictive risk factors and were identified by using big data analysis methods, and the prediction model for lung cancer was established by using the Deep Neural Network (DNN) method. From an objective perspective, the model could be used in conjunction with the patients’ health management as a reference for early lung cancer prediction. Patients could also use this model for early screening, based on the risk factors that may be related to lung cancer and, if the results showed an increased possibility of the risk of developing lung cancer, earlier attention could be applied. The model is expected to reduce the risk of lung cancer for patients with advanced related diagnoses through early screening, and furthermore, to reduce the burden on medical services.
3. Method
3.1. Data Resource and Processing
This study sourced the data from the NHIRD, which dataset covers more than 99% of the national health insurance data of the Taiwanese population [
12], including their medical records, diagnosis records, medication records, surgical records, treatment records, and other detailed clinical information. The dataset that was used in this study is published by the NHI in Taiwan and contains all the above-mentioned information on 2,000,000 randomly-sampled individuals from the NHIRD. There is no significant difference between the subset samples and the original NHIRD samples regarding the distribution of gender and age.
Patients who developed lung cancer between 1 January 2000 and 31 December 2009 were eligible for inclusion in this study, and all outpatient records before diagnosis were tracked in order to identify the potential impacts or comorbidities of the disease, and to assist patients with early screening. The target population was lung cancer patients. We identified patients with lung cancer as case groups between 2000–2009, tracked their past diagnostic records, and excluded individuals with other cancer histories. The quadruple number of subjects as control groups were identified by their gender and age distribution [
13].
The patients who were recorded in the Cancer Registration Form, and who had a diagnosis code of ICD-O-3, including C340, C341, C342, C343, C348, C349, were identified as the case group, and patients with any other cancer diagnosis were excluded, to make sure that the participants were not undergoing cancer metastasis. The control group was selected by their distribution of gender and age, based on the quadruple number of the case group. Each patient record included the visit date, the patient’s de-identified pseudo ID, gender, age, and diagnosis. All records with errors, such as miscoded diagnoses, typos, or missing data, were excluded.
For clinical characteristics, we screened the patients’ disease history from the NHIRD. The ICD-9-CM (International Classification of Disease-9-Clinical Modification) code was used as the diagnosis code in the NHIRD, and it included the category number (three codes) and the sub-category number (two codes). To avoid including too many disease sub-categories, only the category numbers were used in this study.
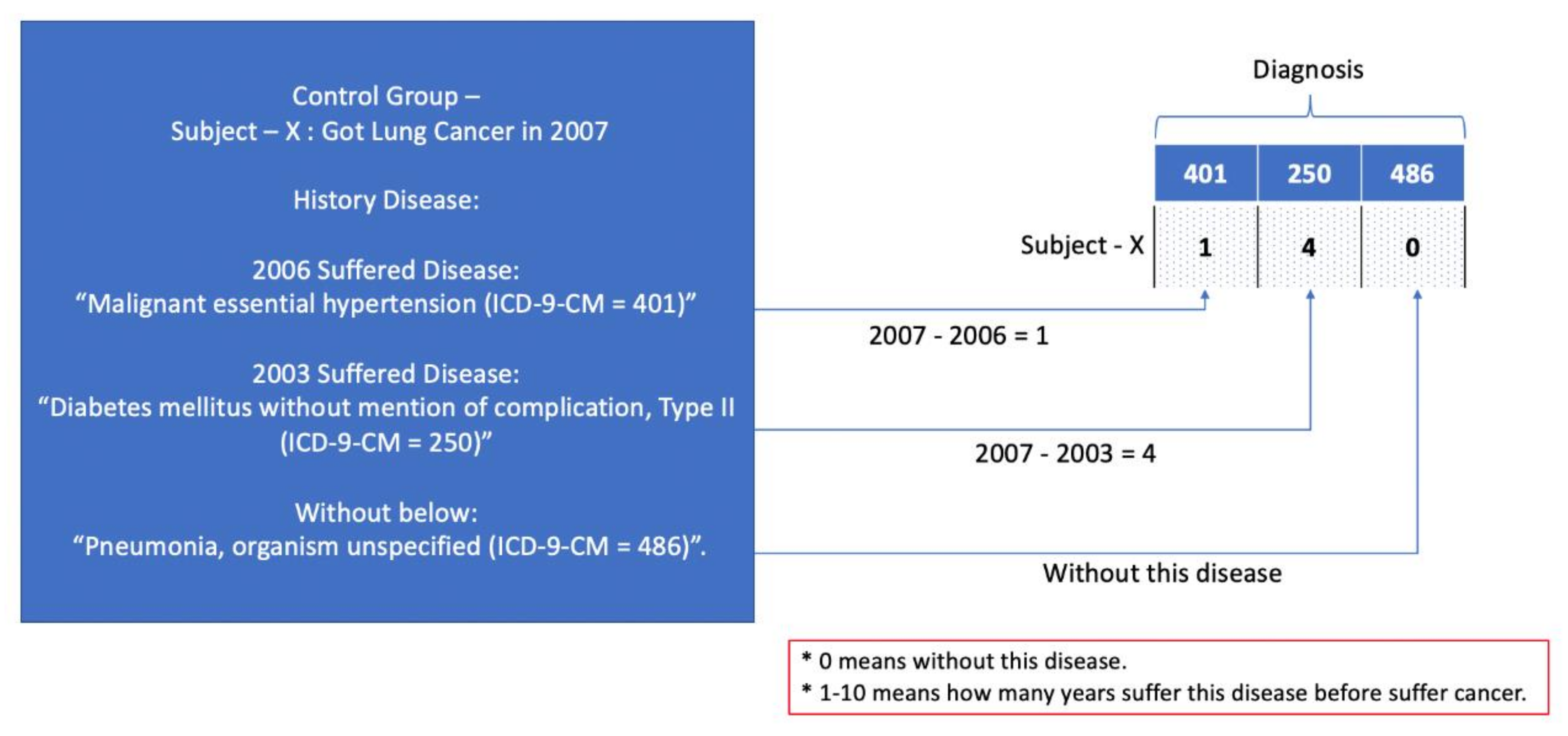
For the data coding process, the data were transferred, depending on the time lapse between the other diseases and the diagnosis of lung cancer. For example, for a subject who was diagnosed with lung cancer in 2007, to code the history disease before the diagnosis, the data were coded from 0–10, where 0 means that the person was without this disease and 1–10 denotes how many years the person has suffered from this disease before suffering from cancer (the control group subject will be based on mapping the subject to the case group). In this example, the data would be coded as 401 = 1, 250 = 4, and 486 = 0. An example is shown in
Figure 1.
3.2. Research Process
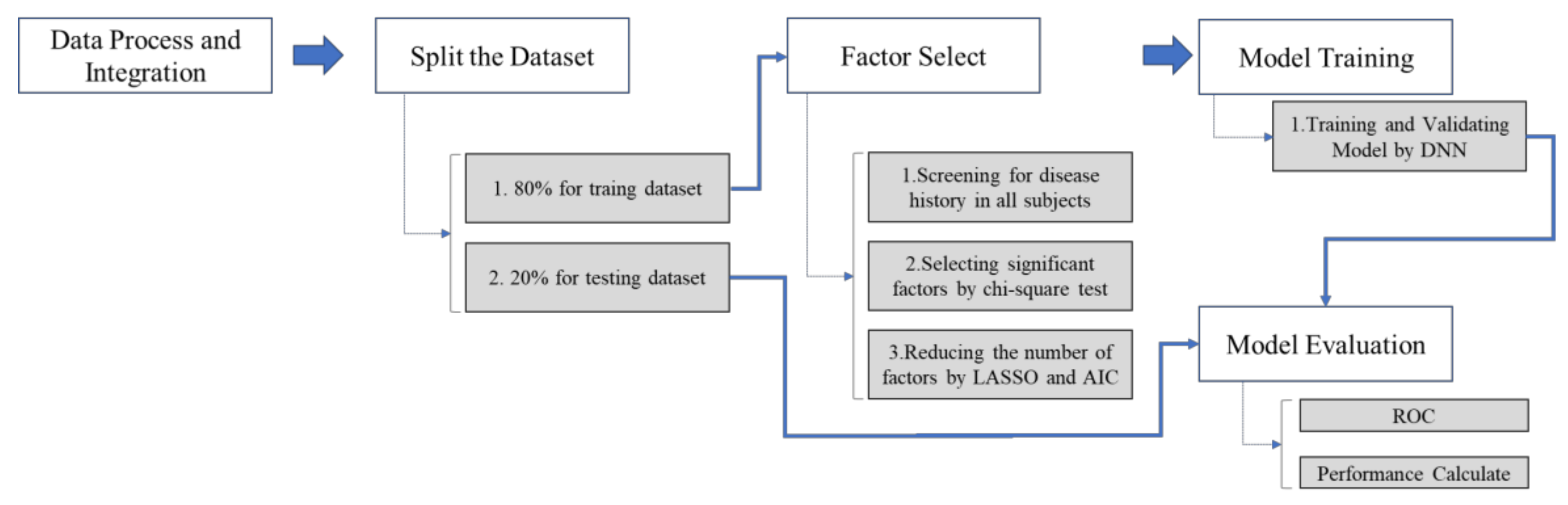
Figure 2 shows the research process. Based on NHIRD, the outpatient records of both the case group and the control group were reviewed retrospectively. After data processing and integration, the research process followed the next three steps.
Step 1. The full dataset was separated into training (80%) and testing (20%) datasets.
Step 2. Select significant factors (predictors) by using the Least Absolute Shrinkage and Selection Operator (LASSO) and Akaike Information Criterion (AIC) from the whole dataset.
Step 3. The model was built using the training dataset by DNN.
Step 4. The model was evaluated by the testing dataset.
Step 5. The performance of the model is presented by accuracy, AUROC, sensitivity, and specificity.
3.3. Factor Selection
For the selection of the influencing factors, all previous disease data were included, and the case group was compared with the control group to find the significant correlation factors. During the comparison process, the factors that had been confirmed by the literature review were also included such as asthma, chronic obstructive pulmonary disease, tuberculosis, emphysema, chronic bronchitis, silicosis, lung trauma, fibrosis, and pleural thickening. The number of selection factors was reduced before finding the best factors for the design of the prediction model.
The factors were reduced by adopting stepwise regression and by using the AIC and the LASSO. LASSO is a regression analysis method that performs both feature selection and regularization, in order to enhance a model’s predictive accuracy and interpretability. It forces the sum of the absolute values of the regression coefficients to be less than a fixed value (e.g., forcing some regression coefficients to become 0), which results in effectively selecting a simpler model that unites the covariates that correspond to these regression coefficients. This method is similar to ridge regression, in which the sum of the squares of the regression coefficients is forced to be less than a certain value. The difference is that ridge regression only changes the value of the coefficient, without setting any values to zero.
LASSO is designed by the least squares method and assumes that a sample includes N events, with each event consisting of p covariates and an output value of
y. Let
yi be the output value of the
ith case, and
the covariate vector of the
ith case; the target equation to be calculated by LASSO is:
where
t is a pre-specified free parameter that determines the amount of regularization. Suppose
=
; when
,
means
will be calculated by an ordinary least squares’ statistical analysis, and the parameter coefficient estimator of the LASSO regression will be equivalent to the least squares difference parameter coefficient estimator. When
, part of the parameter coefficient of the LASSO regression will be reduced to zero, thus completing the dimensionality reduction (feature extraction).
3.4. Model Training
After the factor selection, the prediction model was designed by using an ANN. An ANN simulates a biological neural network by using information systems and hardware [
14]. The neural network is composed of many artificial neurons, which can be divided into the feedforward neural network and the recurrent neural network, with the feedforward type being the most widely used.
The feedforward neural network includes input nodes, as well as neurons, in the hidden layer, and it results in the output layer. In general, the multiple hidden layers, and neurons in the same layer are not connected to each other, but are rather connected to neurons in different layers, and signal transmissions occur in one direction only.
In brief, output
Yi can be calculated as
, where Σ is the summation and
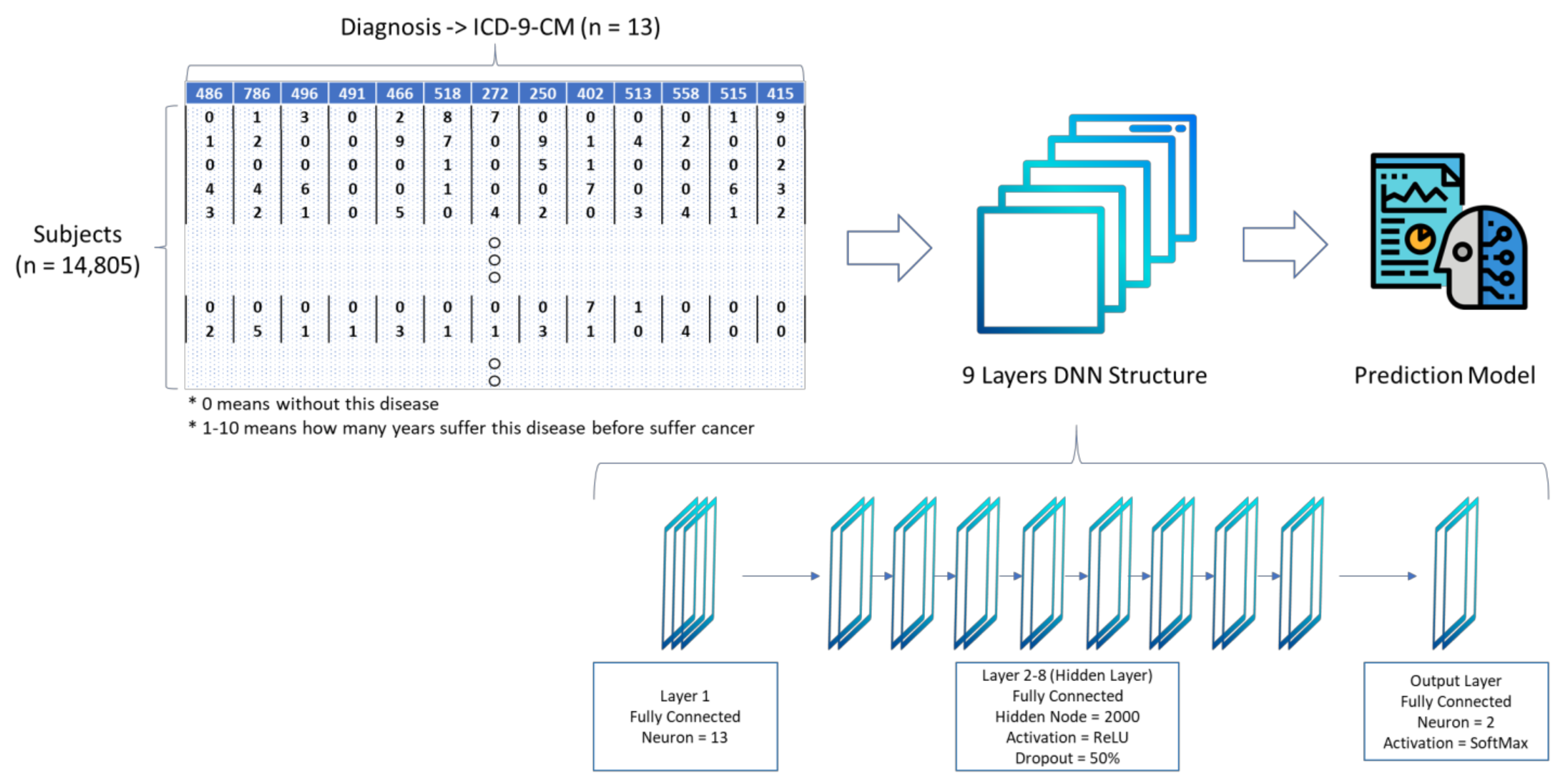
Hijk is the neuron value to be learned. Back propagation is most representative in the feedforward learning method, which first calculates the output error term and then feeds the output error term from the output layer to the hidden layer through the neural link. Backpropagation calculates the loss function relative to the network weight gradient for a single input-output value. Through repeated iterations, the neural network is trained to make the output value close to the actual value. In this study, a nine-layer deep ANN was used for model training. Each layer included 2000 neurons, and the ReLu (Rectified Linear Unit) activation function was used. To avoid model over fitting, the dropout layer, which was a dropout of 50% neurons, was used randomly between Layers One and Two. The model structure is shown in
Figure 3.
3.5. Model Evaluation
The Area Under the Receiver Operating Characteristic curve (AUROC) was used to evaluate the performance of the model in this study. When the area is large, it means that the prediction of the model is more significant. In other words, when AUROC is close to 1, the prediction precision of the diagnosis is higher, and when it is close to 0.5, the precision rate of the model is lower [
15].
A classification model (classifier or diagnosis) is the mapping of instances between certain groups. The classifier or diagnosis result can be a real value (classifier by a threshold) or it can be a discrete class label, indicating one of the classes.
This study designed a two-class prediction problem (binary classification), in which the results were labeled either as positive (p) or negative (n). There were four possible results from the simple problem:
1. True Positive (TP), in which the results from a prediction are positive and the actual value is also positive.
2. False Positive (FP), in which the results from a prediction are positive and the actual value is negative.
3. True Negative (TN), in which the results from a prediction are negative and the actual value is also negative.
4. False Negative (FN), in which the results from a prediction are negative and the actual value is positive.
Based on the False Positive Rate (FPR) as the X axis and the True Positive Rate (TPR) as the Y axis, the ROC curve can be drawn on the coordinate plane.
Given a binary classification model and its threshold, a (X = FPR, Y = TPR) coordinate point can be calculated from the (positive/negative) true and predicted values of all samples.
The diagonal from (0, 0) to (1,1) divides the ROC space into the upper left/lower right areas. The points above this line represent a good classification result (better than random classification), while the points below this line represent a poor classification result (inferior to random classification).
The perfect prediction point is a point in the upper left corner. At the ROC space coordinate (0,1) point, X = 0 means no false positive and Y = 1 means no false negative (all positives are true positive); that is, regardless of whether the classifier output is positive or negative, it is 100% correct. A random prediction will result in a point on the diagonal from (0, 0) to (1, 1) (also called the no-recognition rate line).
When judging the quality of the model, in addition to the AUROC graph, the discriminating power of the ROC can also be determined. The AUC curve ranges from 0 to 1, and a larger value is preferred. The following are the general discriminant rules for AUC values:
AUC = 0.5 (no discrimination or without discrimination)
0.7 ≦ AUC ≦ 0.8 (acceptable discrimination)
0.8 ≦ AUC ≦ 0.9 (excellent discrimination)
0.9 ≦ AUC ≦ 1.0 (outstanding discrimination)
3.6. Tool
The data statistic and model structure were completed by the R program. The LASSO statistics were completed by applying the Glmnet package, and the ANN model was constructed by using the MXNet package. Finally, the ROC curve analysis was accomplished by using the Plotly package (Plotly, CA, USA).
4. Results
4.1. Demography
This study identified 3448 subjects who received a lung cancer diagnosis from 1 December 2000 to 30 December 2009. A total of 132 patients were excluded due to typos or missing data. Finally, a total of 3316 subjects were included in the case group for this study. A total of 13,264 subjects were selected by their gender and age distribution as the control group, of which 1775 subjects were excluded, due to typos or missing data.
The demographic and clinical characteristics of the 3316 subjects in the case group and the 11,489 subjects in the control groups are summarized in
Table 2. In order to prevent the model from being affected by age and gender factors, the control group data screening was completed, based on the gender and age distribution. The gender and age distribution of the two groups were similar. The average age of case group subjects (patients with cancer) was 68.36 ± 12.3 years, while the average age of the control group (no cancer) was 68.08 ± 12.3 years. Males made up 67% of the subjects in both groups.
As can be seen from the basic data, 66% of the subjects were male and 34% of the subjects were female. Regarding the age distribution, 75% of the patients were elderly (60–109 years old).
The distribution of clinical characteristics of the case group are as follows: 12% of the subjects had pneumonia, organism unspecified; 41% of the subjects had respiratory abnormalities, unspecified; 17% of the subjects had NEC (Necrotizing enterocolitis) chronic airway obstruction, not elsewhere classified; 27% of the subjects had simple chronic bronchitis; 55% of the subjects had acute bronchitis; 10% of the subjects had pure hypercholesterolemia; 18% of the subjects had diabetes mellitus without mention of complication, Type II; 20% of the subjects had malignant hypertensive heart disease without congestive heart failure; and 28% of the subjects had other unspecified non-infectious gastroenteritis and colitis.
The distribution of the clinical characteristics of the control group are as follows: 5% of the subjects had pneumonia, organism unspecified; 31% of the subjects had respiratory abnormalities, unspecified; 11% of the subjects had NEC chronic airway obstruction, not elsewhere classified; 21% of the subjects had simple chronic bronchitis; 51% of the subjects had acute bronchitis; 14% of the subjects had pure hypercholesterolemia; 24% of the subjects had diabetes mellitus, without mention of complications, Type II; 26% of the subjects had malignant hypertensive heart disease, without congestive heart failure; and 34% of the subjects had other unspecified non-infectious gastroenteritis and colitis.
The distribution of clinical characteristics indicated that the proportion of lung disease in the case group was higher than that in the control group; however, chronic diseases, such as diabetes and hypertension, were lower in the case group than in the control group.
4.2. Factor Selection
In the case group, a total of 919 disease cases were diagnosed before the diagnosis of lung cancer. The chi-square test was performed on the 919 disease cases, and 132 independent factors were identified as being significantly associated with lung cancer.
The dataset was randomly divided into 80% for the training dataset and 20% for the external validation dataset, based on the same stratified sample size of 4:1 (Control Group: Case Group).
Finally, 13 factors were selected by executing the LASSO and the Akaike Information Criterion (AIC) from the training dataset. The coefficient and p value of each factor calculated by LASSO and AIC are shown in
Table 3. The Akaike information standard was developed by Japanese statistician Hirotugu Akaike [
16]. It now forms the basis of the basic statistical paradigm and is also widely used for statistical inference. The Akaike Information Criterion (AIC) is an estimate of the out-of-sample prediction error, and therefore the relative quality of the statistical model for a given data set. Given the set of models used for the data, AIC estimates the quality of each model relative to every other model. Therefore, AIC provides a method of model selection. which can estimate the relative amount of information lost by a given model: the less information the model loses, the higher the quality of the model. When estimating the amount of information lost by the model, AIC will weigh the model’s goodness of fit and model simplicity. In other words, AIC deals with the risk of overfitting and the risk of underfitting.
In this study, AIC was employed to select the critical factor for establishing the model. Using AIC’s repeated loss of information and the characteristics of the training model, the factors identified by this process were selected as the main factors for final prediction model analysis.
4.3. Model Establishment and Evaluation
The dataset was randomly divided into 80% for the training dataset and 20% for the external validation dataset, based on the same stratified sample size of 4:1 (Control Group: Case Group).
The training data is used to train the predictive model. The prediction model was established by the nine layers of the DNN model. The input layer included 13 factors, and each factor was given a rating of between 0–10 (in which 0 indicated no disease and 1–10 indicated how many years a person suffered from the disease before suffering from cancer). Each control group subject can be mapped to the case group subject by their gender and age, and the tracking date of control group subjects is the same as that of the case group.
Usually, the DNN architecture consists of many hidden layers in the network, connected to each other. Under normal circumstances, the structure of the best model can only be determined by training with incremental testing. Different data needs to be used with different number of DNN layer structures to find a better performance model. In this study a total of nine layers of DNN structure including one input layer, seven hidden layers, and one output layer is established. The testing result of different DNN structures is shown in
Table 4, in which the prediction model established by the structure has the best performance and is better than other previous studies.
The model is trained 1000 times, the batch size is set to 100, the SGD optimizer is used, the learning rate is set to 0.1, and the momentum is set to 0.1. The parameters of the DNN structure are shown in
Table 5.
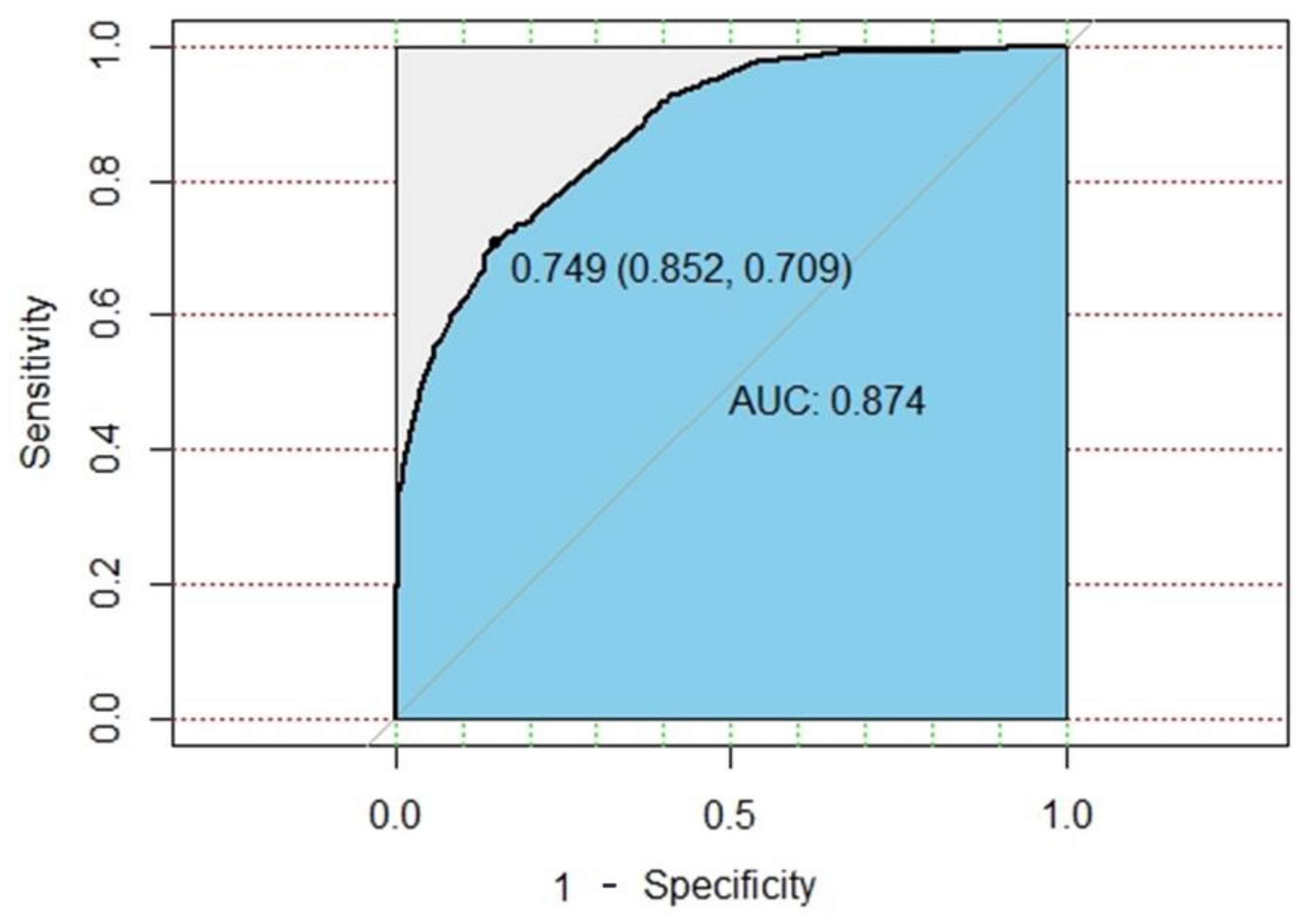
After the model is established, the external validation data is used for external verification of the model. The best threshold of the lung cancer prediction model was 0.749 (95% CI, 0.852 – 0.709), and the performance of the model could attain an accuracy of 85.4% and an AUROC of 0.874 (95% CI, 0.8604–0.8885), with a sensitivity of 72.4% and a specificity of 85%. The ROC plot of the DNN model is shown in
Figure 4.
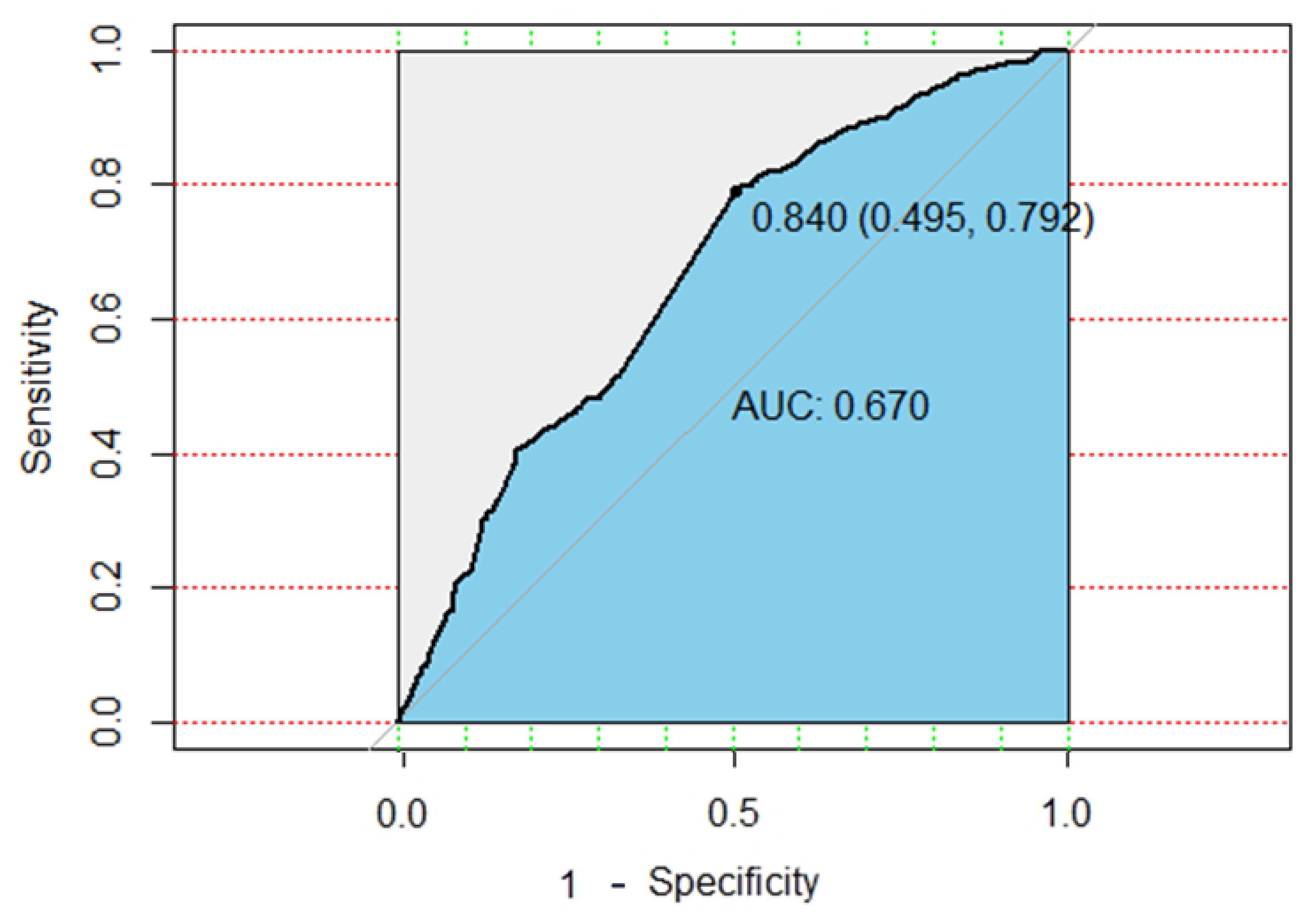
This study also uses traditional machine learning methods to compare baseline performance. We use XGBoost for model development and comparison. When training 3000 times, XGBoost model showed an accuracy of 75%, a sensitivity of 18% and a specificity of 91.5%, as well as a 67.3% area under ROC (AUROC) model precision. The ROC plot of XGBOOST model is shown in
Figure 5. However, the sensitivity of the XGBoost model is quite low. This study aims to establish an early preventive screening model to assist in personal health management and lung cancer prediction. In this study, sensitivity is the key point of model performance evaluation. Therefore, the performance of the DNN model is better than that of traditional machine learning.
5. Discussion and Conclusions
The amount of healthcare data is increasing constantly. Through machine learning technology, large amounts of medical data can be analyzed quickly [
17]. Therefore, it is possible to implement machine learning and deep learning models for personalized care relating to clinical decision support and health management. By using an appropriate deep learning ANN prediction model, doctors can make clinical decisions by extracting the minimum amount of necessary data [
18]. The model proposed in this study could assist in the early diagnosis of lung cancer, thereby helping to improve the efficiency and quality of clinical diagnoses. The early diagnosis of any disease is essential, as the time of diagnosis is one of the strongest factors in the success rate of any treatment plan. Therefore, the time of diagnosis for each disease was used in our model. Stepwise regression of LASSO and AIC was used cautiously as a feature selection strategy. Data from the NHIRD were used to represent the Taiwanese population, and the predictive model could be integrated easily into the Electronic Medical Record to identify the risk of lung cancer.
This research demonstrated that a neural network model could be used to design a model that recognizes patients who are at risk of lung cancer, especially for those with specific diseases. The model could help physicians to achieve an effective early diagnosis and to minimize potential harm to patients. A number of studies have suggested that several comorbidities are prevalent in patients with lung cancer, including smoking, age [
19,
20], heavy drinking [
20], pneumothorax, COPD, tuberculosis, and hypertension [
21,
22,
23,
24]. Although those studies have shown encouraging results, they have some limitations, as most of them need questionnaire answers to calculate the risk, which may not be available in all clinical and health management environments.
In this study, 13 diseases (factors) were selected, not only by using statistical algorithms, but also by confirming the clinical evidence [
21,
22,
23,
24]. The 13 diseases included lung-, diabetes-, hypertension-, and heart-related diseases, which are closely-related to lung cancer. These 13 diseases were used to calculate the risk of lung cancer. In contrast to previous studies, questionnaires on smoking and tuberculosis were not necessary in the proposed model, thus making it beneficial for rapid clinical screening, as the patients’ personal health records or electronic health records could be used for rapid screening without the need for questionnaires. The developed models could be used for personal health management.
Previous research models for lung cancer prediction have produced various AUROC results. The Bach model, proposed by Bach et al., has a 0.72 AUROC [
6], the Liverpool lung project model, proposed by Cassidy et al., has a 0.71 AUROC [
5], the Spitz model, proposed by Spitz et al., has a 0.57–0.63 AUROC [
8], the African-American model, proposed by Etzel et al., has a 0.75 AUROC [
10], the PLCO
M2012 model, proposed by Tammemagi et al., has a 0.803 AUROC [
7], and the Hoggart model, proposed by Hoggart et al., has a 0.843 AUROC. The results indicated that the proposed model had a higher AUROC. Although the model had a high performance, differences in data resources, datasets, and features could cause differences in the predictive performance.
Based on the data and deep learning analyses, this study identified some features that could be explained by clinical knowledge. For example, there was no evidence that other unspecified non-infectious gastroenteritis and colitis were directly related to lung cancer; however, it had a high weighting factor in our model. Eliminating this factor from the DNN model training would cause the performance of the model to be greatly reduced.
Future work could attempt to extract evidence of special factors through data mining, and to use other data sets to adjust and re-train the model.
Overall, the results of this study demonstrated that lung cancer can be predicted by a person’s disease history. This study tracked a decade of clinical diagnostic records to identify the possible symptoms and comorbidities of lung cancer, to allow for the early prediction of the disease, and to assist more patients by providing an early diagnosis.
Based on the disease diagnostic data that are currently available for this study, the accuracy of the prediction model was close to 86%. In our future study, clinical diagnostic data, blood test data, and physiological data will be integrated and analyzed, which could improve the accuracy of the predictions.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}