
Development of a Multiprotein Classifier for the Detection of Early Stage Ovarian Cancer

 ,
,  ,
,  , , ,
, , , 

Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Serum Samples
2.2. Olink Proseek Oncology II Assay
2.3. Identification of Unstable Proteins
2.4. Data Normalization for Cohort #2
2.5. Statistical Analysis
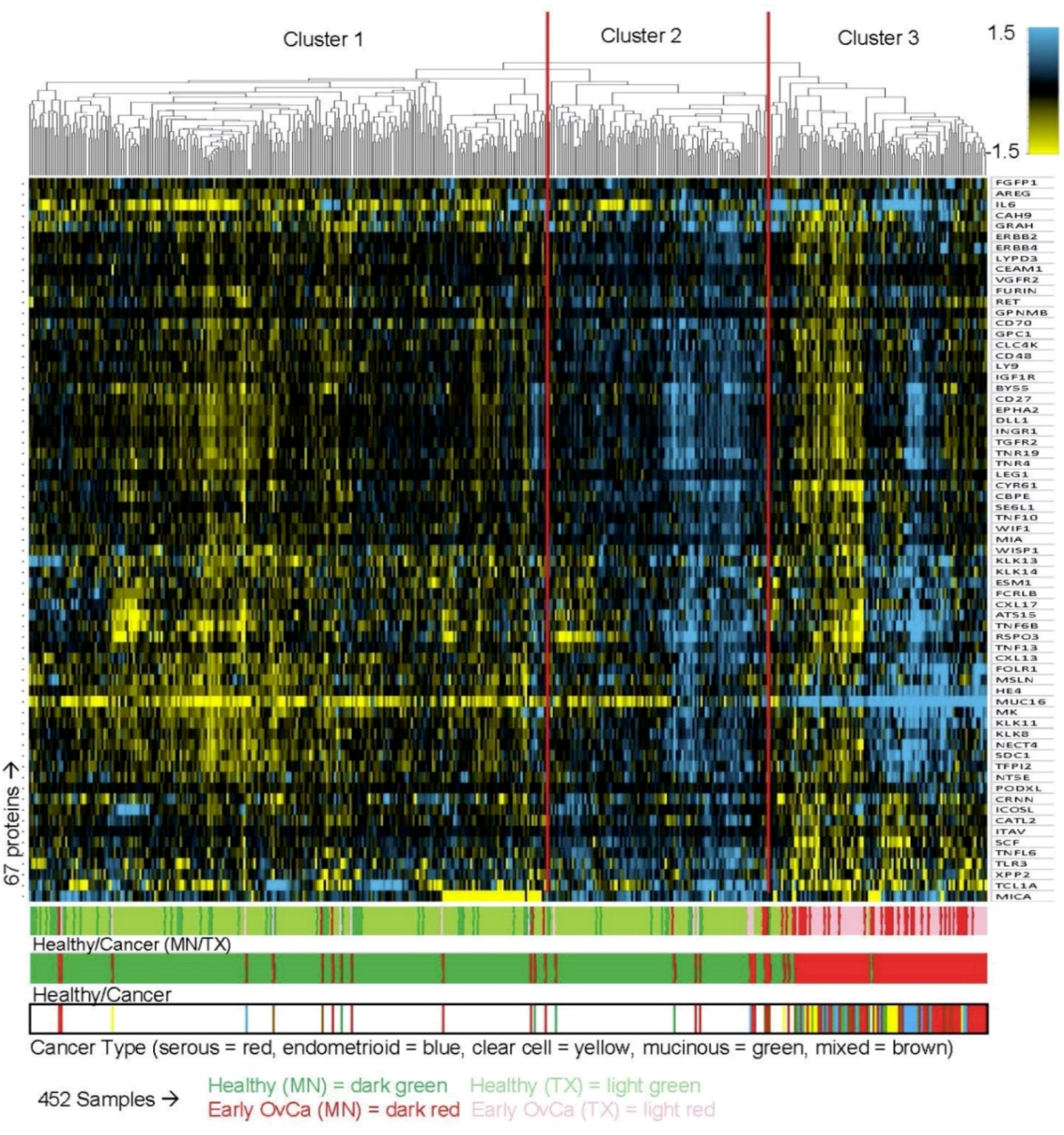
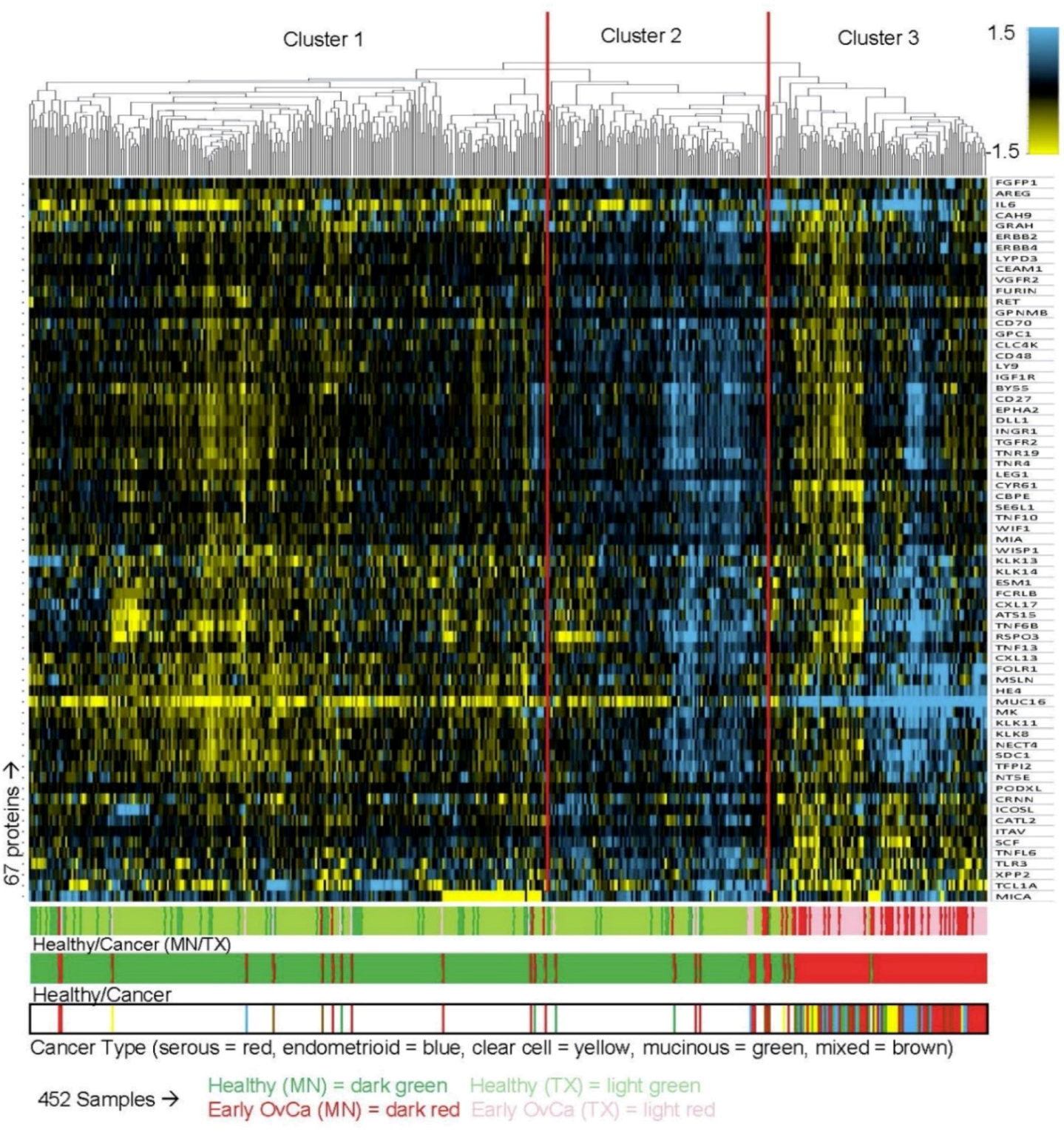
2.6. Unsupervised Hierarchical Clustering Analysis
3. Results
3.1. Cohort #1 Demographics
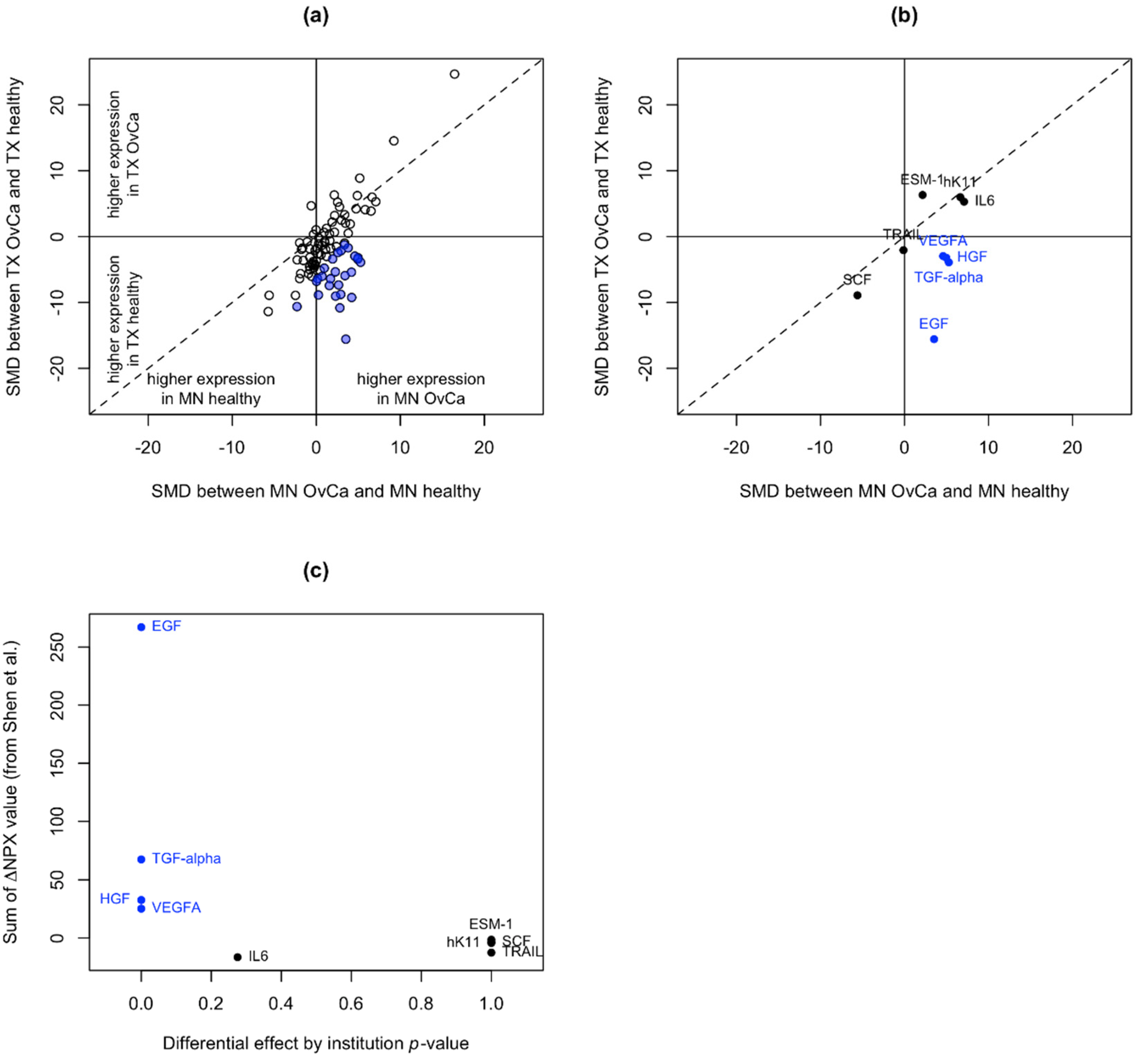
3.2. Identification of Unstable Proteins
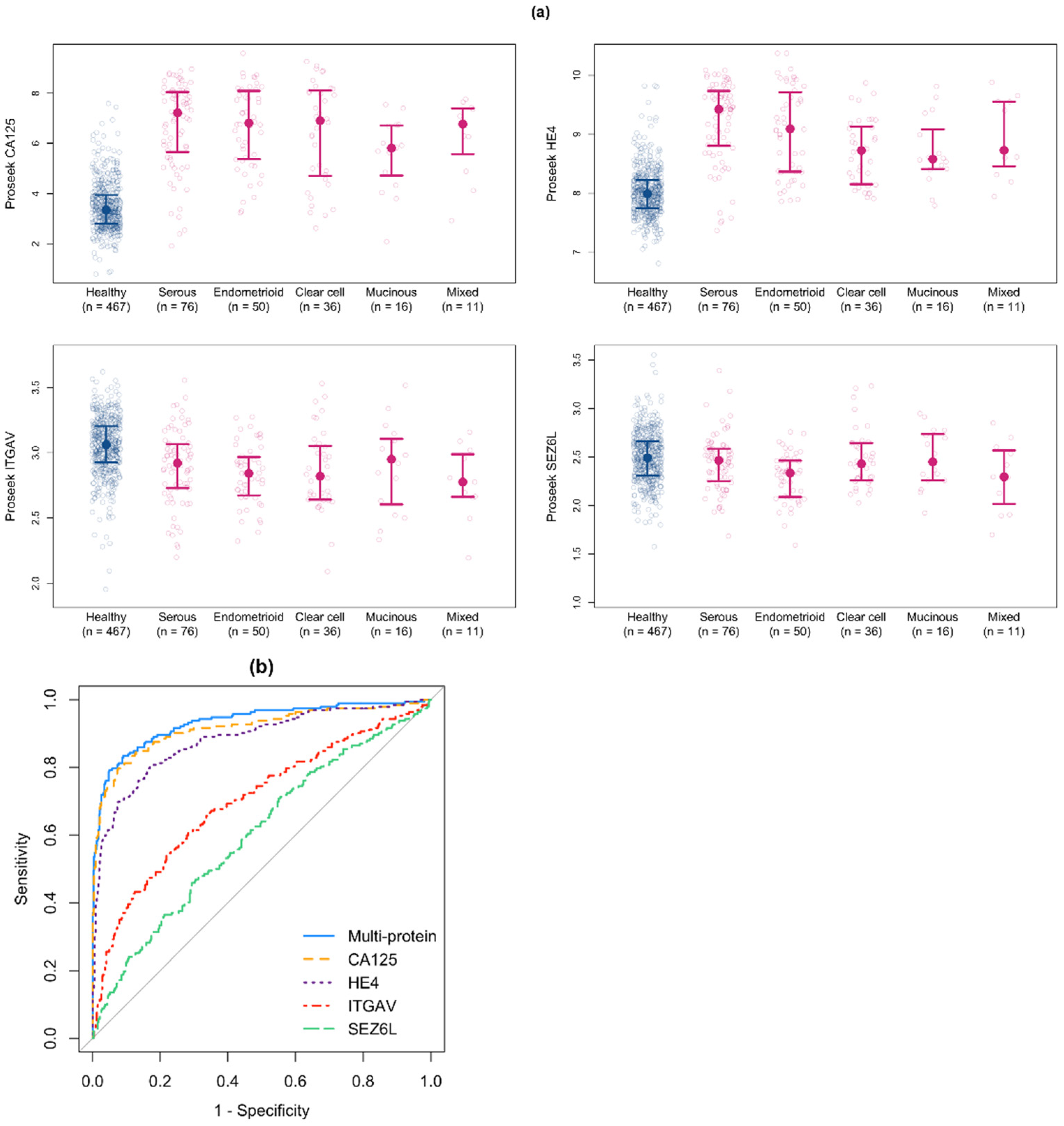
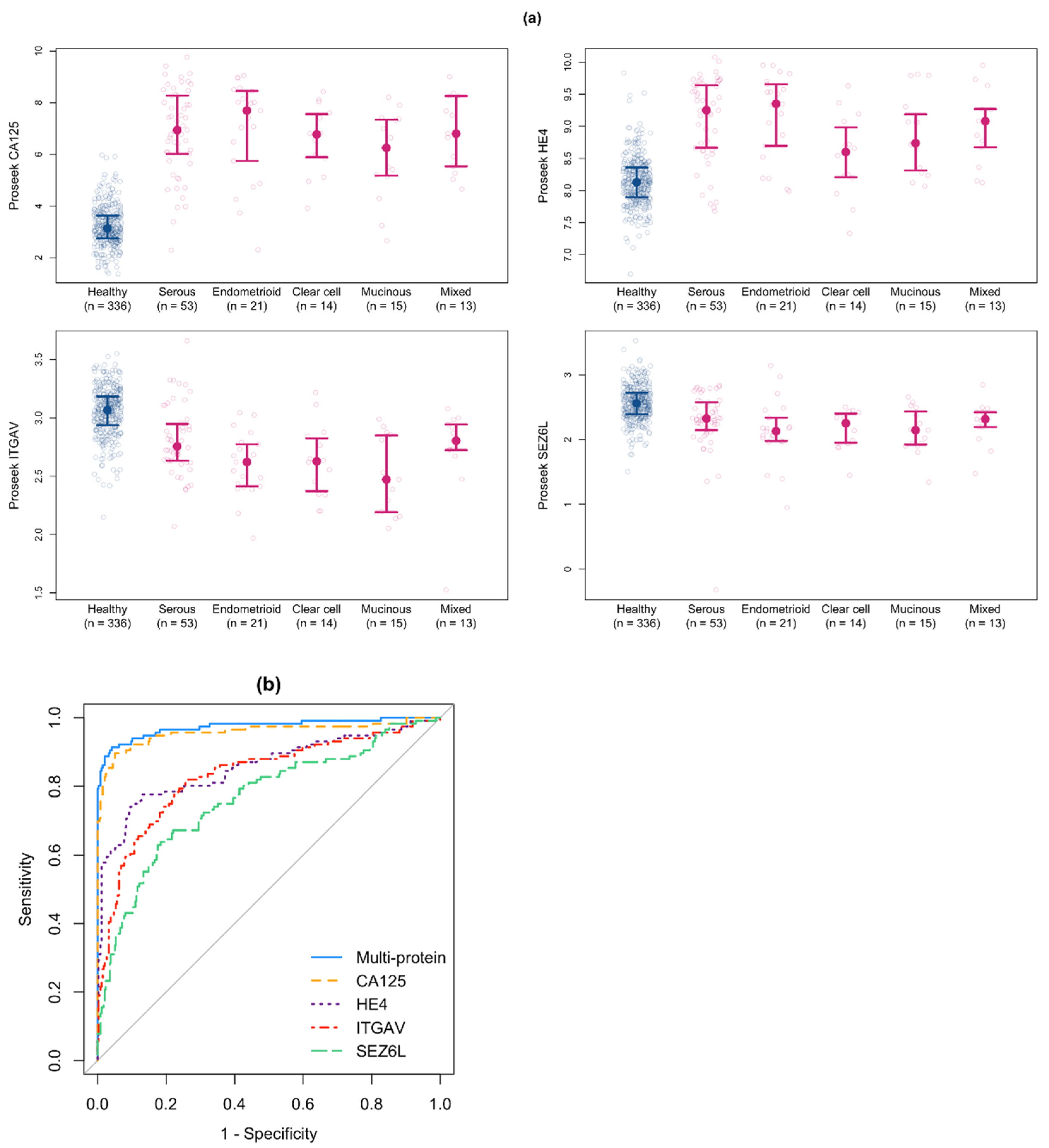
3.3. Identification of Candidate Biomarkers for Early Stage Ovarian Cancer
3.4. Development of a Multiprotein Classifier for Early Stage Ovarian Cancer
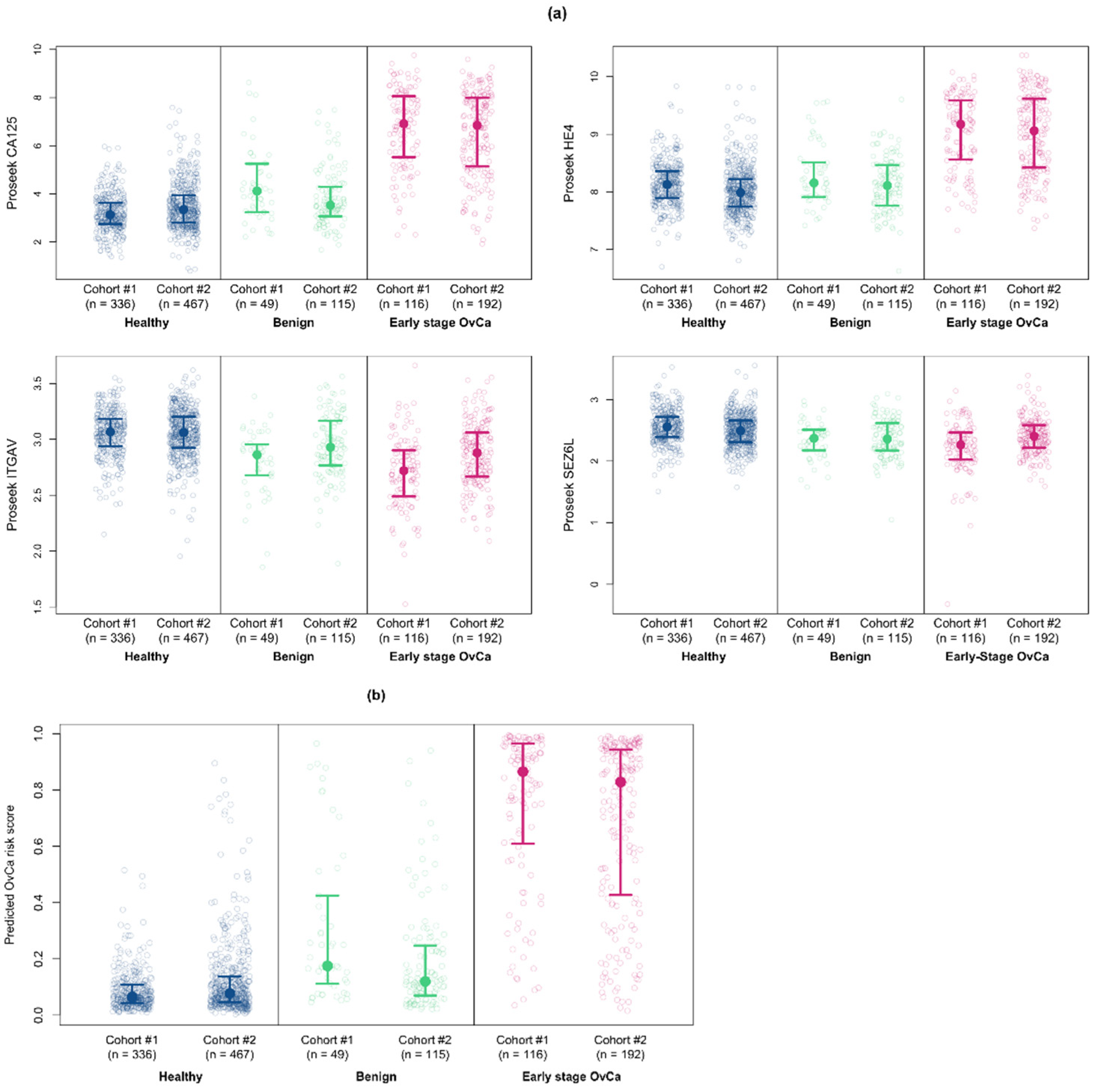
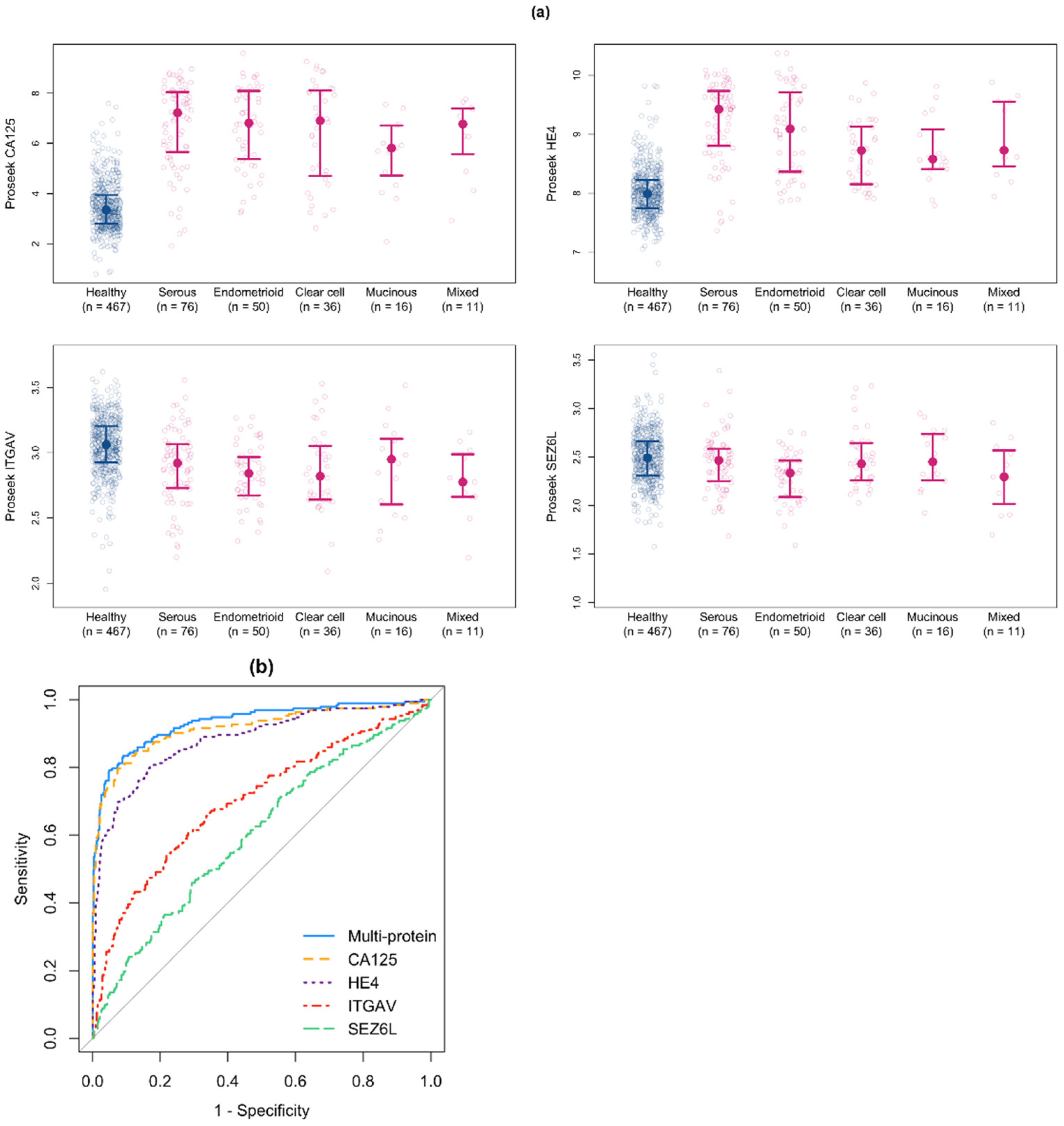
3.5. Validation of the Multiprotein Classifier for Early Stage Ovarian Cancer Using a New Cohort of Early Stage Ovarian Cancer Samples
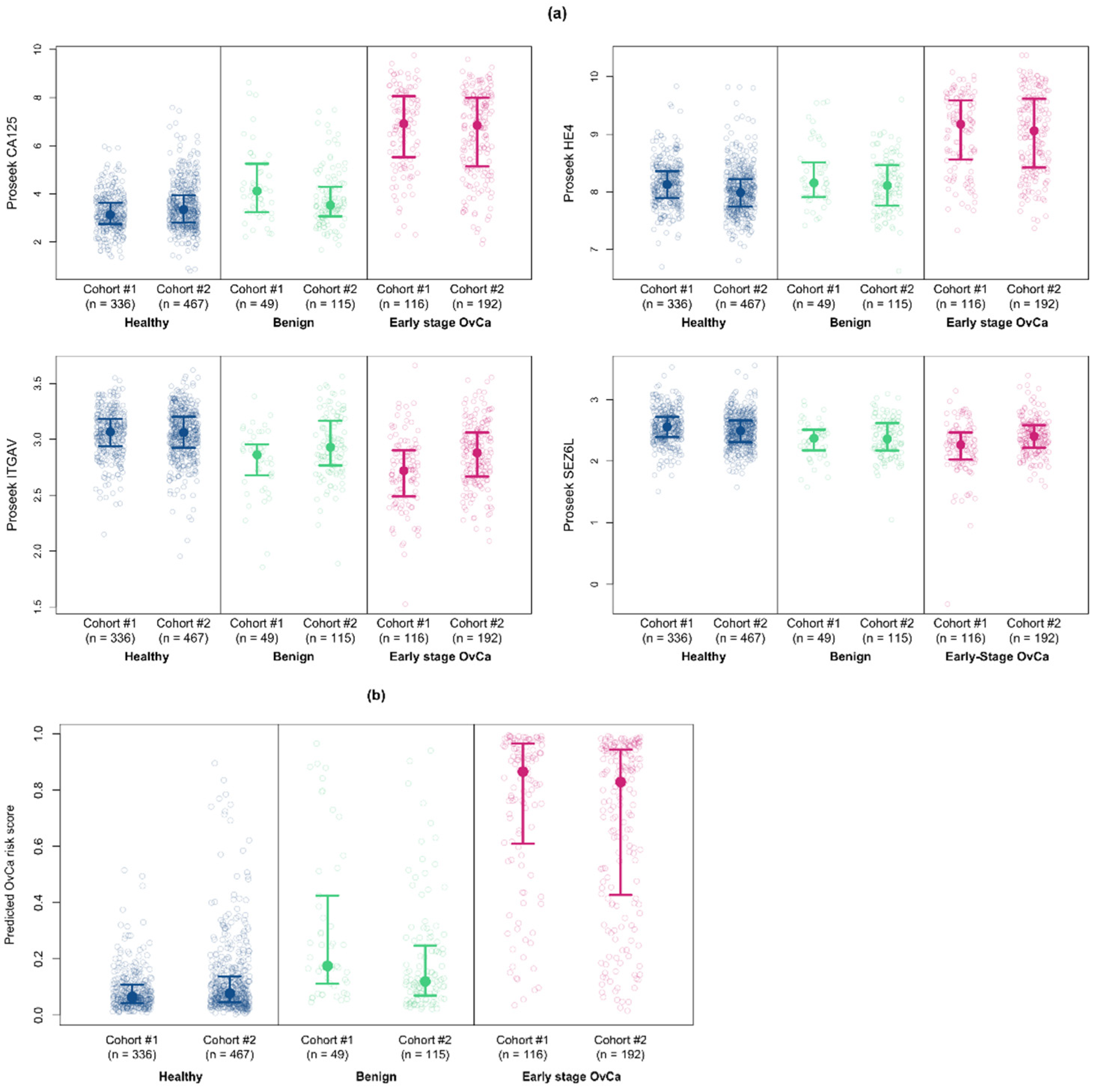
3.6. Validation of the Multiprotein Classifier Using Serum Samples from Women with Benign Ovarian Conditions
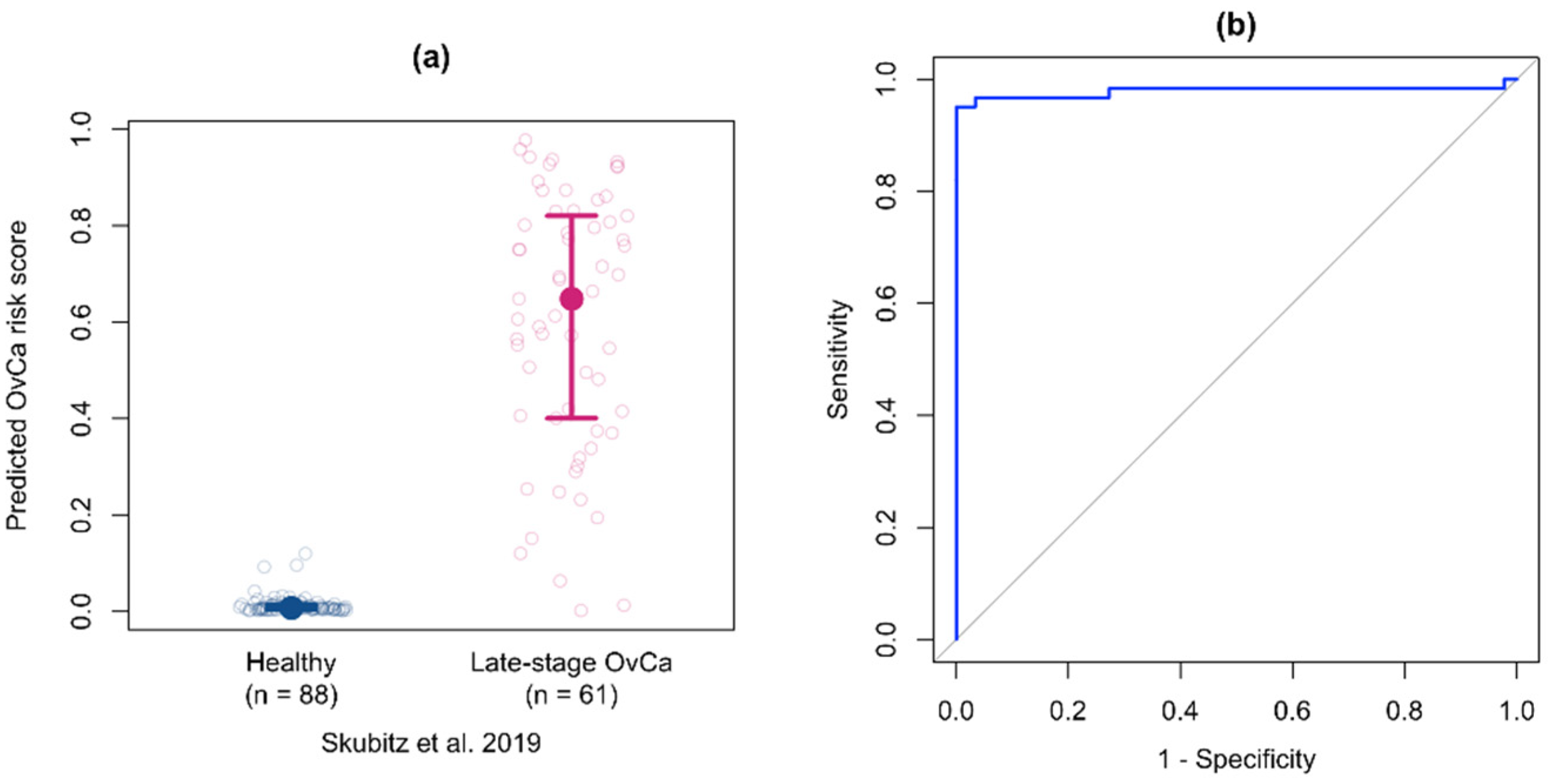
3.7. Validation of the Multiprotein Classifier for Early Stage Ovarian Cancer on Samples from Women with Late Stage Ovarian Cancer
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Siegel, R.L.; Miller, K.D.; Fuchs, H.E.; Jemal, A. Cancer statistics, 2022. CA A Cancer J. Clin. 2022, 72, 7–33. [Google Scholar] [CrossRef]
- Torre, L.A.; Trabert, B.; DeSantis, C.E.; Miller, K.D.; Samimi, G.; Runowicz, C.D.; Gaudet, M.M.; Jemal, A.; Siegel, R.L. Ovarian cancer statistics, 2018. CA A Cancer J. Clin. 2018, 68, 284–296. [Google Scholar] [CrossRef]
- Bast, R.C., Jr.; Klug, T.L.; St John, E.; Jenison, E.; Niloff, J.M.; Lazarus, H.; Berkowitz, R.S.; Leavitt, T.; Griffiths, C.T.; Parker, L.; et al. A radioimmunoassay using a monoclonal antibody to monitor the course of epithelial ovarian cancer. N. Engl. J. Med. 1983, 309, 883–887. [Google Scholar] [CrossRef]
- Kabawat, S.E.; Bast, R.C.; Welch, W.R.; Knapp, R.C.; Colvin, R.B. Immunopathologic characterization of a monoclonal antibody that recognizes common surface antigens of human ovarian tumors of serous, endometrioid, and clear cell types. Am. J. Clin. Pathol. 1983, 79, 98–104. [Google Scholar] [CrossRef] [Green Version]
- Yang, W.L.; Gentry-Maharaj, A.; Simmons, A.; Ryan, A.; Fourkala, E.O.; Lu, Z.; Baggerly, K.A.; Zhao, Y.; Lu, K.H.; Bowtell, D.; et al. Elevation of TP53 autoantibody before CA125 in preclinical invasive epithelial ovarian cancer. Clin. Cancer Res. 2017, 23, 5912–5922. [Google Scholar] [CrossRef] [Green Version]
- Elias, K.M.; Fendler, W.; Stawiski, K.; Fiascone, S.J.; Vitonis, A.F.; Berkowitz, R.S.; Frendl, G.; Konstantinopoulos, P.; Crum, C.P.; Kedzierska, M.; et al. Diagnostic potential for a serum miRNA neural network for detection of ovarian cancer. Elife 2017, 6, e28932. [Google Scholar] [CrossRef]
- Hulstaert, E.; Morlion, A.; Levanon, K.; Vandesompele, J.; Mestdagh, P. Candidate RNA biomarkers in biofluids for early diagnosis of ovarian cancer: A systematic review. Gynecol. Oncol. 2021, 160, 633–642. [Google Scholar] [CrossRef]
- Asante, D.B.; Calapre, L.; Ziman, M.; Meniawy, T.M.; Gray, E.S. Liquid biopsy in ovarian cancer using circulating tumor DNA and cells: Ready for prime time? Cancer Lett. 2020, 468, 59–71. [Google Scholar] [CrossRef]
- Assarsson, E.; Lundberg, M.; Holmquist, G.; Bjorkesten, J.; Thorsen, S.B.; Ekman, D.; Eriksson, A.; Rennel Dickens, E.; Ohlsson, S.; Edfeldt, G.; et al. Homogenous 96-plex PEA immunoassay exhibiting high sensitivity, specificity, and excellent scalability. PLoS ONE 2014, 9, e95192. [Google Scholar] [CrossRef] [Green Version]
- Lundberg, M.; Eriksson, A.; Tran, B.; Assarsson, E.; Fredriksson, S. Homogeneous antibody-based proximity extension assays provide sensitive and specific detection of low-abundant proteins in human blood. Nucleic Acids Res. 2011, 39, e102. [Google Scholar] [CrossRef]
- Boylan, K.L.M.; Geschwind, K.; Koopmeiners, J.S.; Geller, M.A.; Starr, T.K.; Skubitz, A.P.N. A multiplex platform for the identification of ovarian cancer biomarkers. Clin. Proteom. 2017, 14, 34. [Google Scholar] [CrossRef]
- Skubitz, A.P.N.; Boylan, K.L.M.; Geschwind, K.; Cao, Q.; Starr, T.K.; Geller, M.A.; Celestino, J.; Bast, R.C., Jr.; Lu, K.H.; Koopmeiners, J.S. Simultaneous Measurement of 92 Serum Protein Biomarkers for the Development of a Multiprotein Classifier for Ovarian Cancer Detection. Cancer Prev. Res. 2019, 12, 171–184. [Google Scholar] [CrossRef] [Green Version]
- Shen, Q.; Bjorkesten, J.; Galli, J.; Ekman, D.; Broberg, J.; Nordberg, N.; Tillander, A.; Kamali-Moghaddam, M.; Tybring, G.; Landegren, U. Strong impact on plasma protein profiles by precentrifugation delay but not by repeated freeze-thaw cycles, as analyzed using multiplex proximity extension assays. Clin. Chem. Lab. Med. 2018, 56, 582–594. [Google Scholar] [CrossRef]
- Olink. How Can I Compare Results from Two Different Studies? Available online: https://www.olink.com/faq/how-can-i-compare-results-from-two-different-studies/ (accessed on 14 June 2022).
- Olink. Data Normalization and Standardization—White paper. Available online: https://www.olink.com/application/data-normalization-and-standardization/ (accessed on 14 June 2022).
- Meisner, A.; Carone, M.; Pepe, M.S.; Kerr, K.F. Combining biomarkers by maximizing the true positive rate for a fixed false positive rate. Biom. J. Biom. Z 2021, 63, 1223–1240. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Jiang, W.; Varma, S.; Simon, R. Calculating confidence intervals for prediction error in microarray classification using resampling. Stat. Appl. Genet. Mol. Biol. 2008, 7, 8. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Softw. 2010, 33, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Meisner, A.; maxTPR: Maximizing the TPR for a Specified FPR. R Package Version 0.1.0. 2017. Available online: https://CRAN.R-project.org/package=maxTPR (accessed on 14 May 2022).
- Robin, X.; Turck, N.; Hainard, A.; Tiberti, N.; Lisacek, F.; Sanchez, J.C.; Muller, M. pROC: An open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinform. 2011, 12, 77. [Google Scholar] [CrossRef]
- de Hoon, M.J.; Imoto, S.; Nolan, J.; Miyano, S. Open source clustering software. Bioinformatics 2004, 20, 1453–1454. [Google Scholar] [CrossRef] [Green Version]
- Keil, C.; Robert William, L.; Shaik Mohammed, F.; Srikanth, B.; Lance, P.; Anastasia, B. Treeview 3.0 (beta 1)—Visualization and analysis of large data matrices. Zenodo 2018. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Krijthe, J.H. Rtsne: T-Distributed Stochastic Neighbor Embedding Using a Barnes-Hut Implementation; 2015. Available online: https://github.com/jkrijthe/Rtsne (accessed on 14 May 2022).
- Hellstrom, I.; Raycraft, J.; Hayden-Ledbetter, M.; Ledbetter, J.A.; Schummer, M.; McIntosh, M.; Drescher, C.; Urban, N.; Hellstrom, K.E. The HE4 (WFDC2) protein is a biomarker for ovarian carcinoma. Cancer Res. 2003, 63, 3695–3700. [Google Scholar]
- Scholler, N.; Fu, N.; Yang, Y.; Ye, Z.; Goodman, G.E.; Hellstrom, K.E.; Hellstrom, I. Soluble member(s) of the mesothelin/megakaryocyte potentiating factor family are detectable in sera from patients with ovarian carcinoma. Proc. Natl. Acad. Sci. USA 1999, 96, 11531–11536. [Google Scholar] [CrossRef] [Green Version]
- Nakanishi, T.; Kadomatsu, K.; Okamoto, T.; Tomoda, Y.; Muramatsu, T. Expression of midkine and pleiotropin in ovarian tumors. Obs. Gynecol. 1997, 90, 285–290. [Google Scholar] [CrossRef]
- Kishi, T.; Grass, L.; Soosaipillai, A.; Scorilas, A.; Harbeck, N.; Schmalfeldt, B.; Dorn, J.; Mysliwiec, M.; Schmitt, M.; Diamandis, E.P. Human kallikrein 8, a novel biomarker for ovarian carcinoma. Cancer Res. 2003, 63, 2771–2774. [Google Scholar] [PubMed]
- Diamandis, E.P.; Okui, A.; Mitsui, S.; Luo, L.Y.; Soosaipillai, A.; Grass, L.; Nakamura, T.; Howarth, D.J.; Yamaguchi, N. Human kallikrein 11: A new biomarker of prostate and ovarian carcinoma. Cancer Res. 2002, 62, 295–300. [Google Scholar]
- Scorilas, A.; Borgono, C.A.; Harbeck, N.; Dorn, J.; Schmalfeldt, B.; Schmitt, M.; Diamandis, E.P. Human kallikrein 13 protein in ovarian cancer cytosols: A new favorable prognostic marker. J. Clin. Oncol. 2004, 22, 678–685. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Borgono, C.A.; Grass, L.; Soosaipillai, A.; Yousef, G.M.; Petraki, C.D.; Howarth, D.H.; Fracchioli, S.; Katsaros, D.; Diamandis, E.P. Human kallikrein 14: A new potential biomarker for ovarian and breast cancer. Cancer Res. 2003, 63, 9032–9041. [Google Scholar] [PubMed]
- Derycke, M.S.; Pambuccian, S.E.; Gilks, C.B.; Kalloger, S.E.; Ghidouche, A.; Lopez, M.; Bliss, R.L.; Geller, M.A.; Argenta, P.A.; Harrington, K.M.; et al. Nectin 4 overexpression in ovarian cancer tissues and serum: Potential role as a serum biomarker. Am. J. Clin. Pathol. 2010, 134, 835–845. [Google Scholar] [CrossRef]
- Leung, F.; Dimitromanolakis, A.; Kobayashi, H.; Diamandis, E.P.; Kulasingam, V. Folate-receptor 1 (FOLR1) protein is elevated in the serum of ovarian cancer patients. Clin. Biochem. 2013, 46, 1462–1468. [Google Scholar] [CrossRef] [Green Version]
- Berek, J.S.; Chung, C.; Kaldi, K.; Watson, J.M.; Knox, R.M.; Martinez-Maza, O. Serum interleukin-6 levels correlate with disease status in patients with epithelial ovarian cancer. Am. J. Obstet. Gynecol. 1991, 164, 1038–1042, discussion 1042-1033. [Google Scholar] [CrossRef]
- Hamidi, H.; Ivaska, J. Every step of the way: Integrins in cancer progression and metastasis. Nat. Rev. Cancer 2018, 18, 533–548. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goldberg, I.; Davidson, B.; Reich, R.; Gotlieb, W.H.; Ben-Baruch, G.; Bryne, M.; Berner, A.; Nesland, J.M.; Kopolovic, J. Alphav integrin expression is a novel marker of poor prognosis in advanced-stage ovarian carcinoma. Clin. Cancer Res. 2001, 7, 4073–4079. [Google Scholar] [PubMed]
- Boljevic, I.; Malisic, E.; Milovic Kovacevic, M.; Jovanic, I.; Jankovic, R. Expression levels of genes involved in cell adhesion and motility correlate with poor clinicopathological features of epithelial ovarian cancer. J. BUON 2020, 25, 1911–1917. [Google Scholar] [PubMed]
- Leandersson, P.; Akesson, A.; Hedenfalk, I.; Malander, S.; Borgfeldt, C. A multiplex biomarker assay improves the diagnostic performance of HE4 and CA125 in ovarian tumor patients. PLoS ONE 2020, 15, e0240418. [Google Scholar] [CrossRef] [PubMed]
- Davidson, B.; Goldberg, I.; Reich, R.; Tell, L.; Dong, H.P.; Trope, C.G.; Risberg, B.; Kopolovic, J. AlphaV- and beta1-integrin subunits are commonly expressed in malignant effusions from ovarian carcinoma patients. Gynecol. Oncol. 2003, 90, 248–257. [Google Scholar] [CrossRef]
- UniProt Consortium. UniProt: The universal protein knowledgebase in 2021. Nucleic Acids Res. 2021, 49, D480–D489. [Google Scholar] [CrossRef]
- Gorlov, I.P.; Meyer, P.; Liloglou, T.; Myles, J.; Boettger, M.B.; Cassidy, A.; Girard, L.; Minna, J.D.; Fischer, R.; Duffy, S.; et al. Seizure 6-like (SEZ6L) gene and risk for lung cancer. Cancer Res. 2007, 67, 8406–8411. [Google Scholar] [CrossRef] [Green Version]
- Suzuki, H.; Gabrielson, E.; Chen, W.; Anbazhagan, R.; van Engeland, M.; Weijenberg, M.P.; Herman, J.G.; Baylin, S.B. A genomic screen for genes upregulated by demethylation and histone deacetylase inhibition in human colorectal cancer. Nat. Genet. 2002, 31, 141–149. [Google Scholar] [CrossRef]
- Lawicki, S.; Gacuta-Szumarska, E.; Bedkowska, G.E.; Szmitkowski, M. Hematopoietic cytokines as tumor markers in gynecological malignancies. A multivariate analysis in epithelial ovarian cancer patients. Growth Factors 2012, 30, 357–366. [Google Scholar] [CrossRef]
- Arts, H.J.; de Jong, S.; Hollema, H.; Ten Hoor, K.A.; de Vries, E.G.; van der Zee, A.G. Fas and Fas ligand in cyst fluids, serum and tumors of patients with benign and (borderline) malignant ovarian tumors. Int. J. Oncol. 2005, 26, 379–384. [Google Scholar] [CrossRef]
- Lokshin, A.; Bast, R.C.; Rodland, K. Circulating Cancer Biomarkers. Cancers 2021, 13, 802. [Google Scholar] [CrossRef] [PubMed]
- Menon, U.; Gentry-Maharaj, A.; Burnell, M.; Singh, N.; Ryan, A.; Karpinskyj, C.; Carlino, G.; Taylor, J.; Massingham, S.K.; Raikou, M.; et al. Ovarian cancer population screening and mortality after long-term follow-up in the UK Collaborative Trial of Ovarian Cancer Screening (UKCTOCS): A randomised controlled trial. Lancet 2021, 397, 2182–2193. [Google Scholar] [CrossRef]
- Bast, R.C.; Han, C.Y.; Lu, Z.; Lu, K.H. Next steps in the early detection of ovarian cancer. Commun. Med. 2021, 1, 36. [Google Scholar] [CrossRef] [PubMed]
- Enroth, S.; Berggrund, M.; Lycke, M.; Broberg, J.; Lundberg, M.; Assarsson, E.; Olovsson, M.; Stalberg, K.; Sundfeldt, K.; Gyllensten, U. High throughput proteomics identifies a high-accuracy 11 plasma protein biomarker signature for ovarian cancer. Commun. Biol. 2019, 2, 221. [Google Scholar] [CrossRef] [Green Version]
- Enroth, S.; Berggrund, M.; Lycke, M.; Lundberg, M.; Assarsson, E.; Olovsson, M.; Stalberg, K.; Sundfeldt, K.; Gyllensten, U. A two-step strategy for identification of plasma protein biomarkers for endometrial and ovarian cancer. Clin. Proteom. 2018, 15, 38. [Google Scholar] [CrossRef] [PubMed]
- Gyllensten, U.; Hedlund-Lindberg, J.; Svensson, J.; Manninen, J.; Ost, T.; Ramsell, J.; Aslin, M.; Ivansson, E.; Lomnytska, M.; Lycke, M.; et al. Next Generation Plasma Proteomics Identifies High-Precision Biomarker Candidates for Ovarian Cancer. Cancers 2022, 14, 1757. [Google Scholar] [CrossRef]
- Mukama, T.; Fortner, R.T.; Katzke, V.; Hynes, L.C.; Petrera, A.; Hauck, S.M.; Johnson, T.; Schulze, M.; Schiborn, C.; Rostgaard-Hansen, A.L.; et al. Prospective evaluation of 92 serum protein biomarkers for early detection of ovarian cancer. Br. J. Cancer 2022, 126, 1301–1309. [Google Scholar] [CrossRef]
- Luo, J.H.; Zhang, C.Y.; Lu, C.Y.; Guo, G.H.; Tian, Y.P.; Li, Y.L. Serum expression level of cytokine and chemokine correlates with progression of human ovarian cancer. Eur. J. Gynaecol. Oncol. 2017, 38, 33–39. [Google Scholar]
- Gorelik, E.; Landsittel, D.P.; Marrangoni, A.M.; Modugno, F.; Velikokhatnaya, L.; Winans, M.T.; Bigbee, W.L.; Herberman, R.B.; Lokshin, A.E. Multiplexed immunobead-based cytokine profiling for early detection of ovarian cancer. Cancer Epidemiol. Biomark. Prev. 2005, 14, 981–987. [Google Scholar] [CrossRef] [Green Version]
- Baron, A.T.; Lafky, J.M.; Boardman, C.H.; Balasubramaniam, S.; Suman, V.J.; Podratz, K.C.; Maihle, N.J. Serum sErbB1 and epidermal growth factor levels as tumor biomarkers in women with stage III or IV epithelial ovarian cancer. Cancer Epidemiol. Biomark. Prev. 1999, 8, 129–137. [Google Scholar]
- Berggrund, M.; Ekman, D.; Gustavsson, I.; Sundfeldt, K.; Olovsson, M.; Enroth, S.; Gyllensten, U. Protein Detection Using the Multiplexed Proximity Extension Assay (PEA) from Plasma and Vaginal Fluid Applied to the Indicating FTA Elute Micro Card. J. Circ. Biomark. 2016, 5, 9. [Google Scholar] [CrossRef] [PubMed]
- Enroth, S.; Johansson, A.; Enroth, S.B.; Gyllensten, U. Strong effects of genetic and lifestyle factors on biomarker variation and use of personalized cutoffs. Nat. Commun. 2014, 5, 4684. [Google Scholar] [CrossRef] [PubMed]
- Gyllensten, U.; Bosdotter Enroth, S.; Stalberg, K.; Sundfeldt, K.; Enroth, S. Preoperative Fasting and General Anaesthesia Alter the Plasma Proteome. Cancers 2020, 12, 2439. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cohort #1 (Discovery) | Cohort #2 (Validation) | |||
|---|---|---|---|---|
| Healthy (n = 336) | Early Stage Ovarian Cancer (n = 116) | Healthy (n = 467) | Early Stage Ovarian Cancer (n = 192) | |
| Location | ||||
| MN | 61 (18%) | 46 (40%) | ||
| TX | 275 (82%) | 70 (60%) | ||
| Fox Chase | 226 (48%) | 55 (29%) | ||
| Italy—Milan | 144 (31%) | 86 (45%) | ||
| OHSU | 7 (1%) | 12 (6%) | ||
| BWH-Harvard | 90 (19%) | 39 (20%) | ||
| Age (years) | ||||
| Mean (SD) | 66.4 (7.6) | 58.5 (12.5) | 55.1 (11.5) | 56.3 (11.5) |
| Median | 67.0 | 58.5 | 54.0 | 56.0 |
| Range | 48–87 | 19–85 | 24–85 | 24–85 |
| CA125 value | ||||
| Median (Q1, Q3) | 10.4 (7.7, 14.3) | 98.3 (42.9, 379) | ND | 143 (42.3, 543) |
| Range | 0–69 | 7–22,780 | ND | 2–12,219 |
| Subtype | ||||
| HGSOC | 53 (46%) | 76 (40%) | ||
| Endometrioid | 21 (18%) | 50 (26%) | ||
| Clear cell | 14 (12%) | 36 (19%) | ||
| Mucinous | 15 (13%) | 16 (8%) | ||
| Mixed | 13 (11%) | 11 (6%) | ||
| Other | 0 (0%) | 3 (2%) | ||
| Stage | ||||
| I | 73 (63%) | 119 (62%) | ||
| II | 43 (37%) | 73 (38%) | ||
| Protein | UniProt ID | Healthy (n = 336) | Early Stage Ovarian Cancer (n = 116) | p-Value |
|---|---|---|---|---|
| CA125 | Q8WXI7 | 3.21 (0.77) | 6.73 (1.68) | <0.001 |
| HE4 | Q14508 | 8.14 (0.39) | 9.02 (0.65) | <0.001 |
| ITGAV | P06756 | 3.05 (0.21) | 2.70 (0.32) | <0.001 |
| MK | P21741 | 6.40 (0.60) | 7.17 (0.95) | <0.001 |
| SCF | P21583 | 8.89 (0.41) | 8.22 (0.85) | <0.001 |
| IL6 | P05231 | 2.89 (1.26) | 4.21 (1.68) | <0.001 |
| SEZ6L | Q9BYH1 | 2.56 (0.27) | 2.22 (0.44) | <0.001 |
| FASLG | P48023 | 8.97 (0.48) | 8.58 (0.52) | <0.001 |
| ESM-1 | Q9NQ30 | 8.98 (0.57) | 9.44 (0.62) | <0.001 |
| hK11 | Q9UBX7 | 6.18 (0.44) | 6.74 (0.86) | <0.001 |
| ADAM-TS 15 | Q8TE58 | 1.86 (0.63) | 2.41 (0.90) | <0.001 |
| XPNPEP2 | O43895 | 8.06 (0.58) | 7.61 (0.73) | <0.001 |
| SYND1 | P18827 | 6.06 (0.50) | 6.51 (0.82) | <0.001 |
| CXCL13 | O43927 | 7.66 (0.61) | 8.14 (0.86) | <0.001 |
| TFPI-2 | P48307 | 7.57 (0.49) | 7.98 (0.76) | <0.001 |
| TCL1A | P56279 | 4.01 (1.22) | 3.28 (1.31) | <0.001 |
| FR-α | P15328 | 6.57 (0.48) | 7.12 (1.08) | <0.001 |
| KLK13 | Q9UKR3 | 3.41 (0.75) | 3.84 (0.87) | <0.001 |
| VEGFR-2 | P35968 | 6.70 (0.28) | 6.56 (0.30) | <0.001 |
| CEACAM1 | P13688 | 6.02 (0.24) | 5.91 (0.25) | <0.001 |
| TLR3 | O15455 | 4.93 (0.67) | 4.56 (0.87) | <0.001 |
| MSLN | Q13421 | 3.12 (0.66) | 3.55 (1.03) | <0.001 |
| CYR61 | O00622 | 5.70 (0.49) | 5.37 (0.83) | 0.001 |
| GPNMB | Q14956 | 6.07 (0.19) | 5.97 (0.24) | 0.001 |
| CPE | P16870 | 3.95 (0.42) | 3.72 (0.58) | 0.002 |
| LY9 | Q9HBG7 | 5.17 (0.41) | 4.96 (0.53) | 0.003 |
| NECT4 | Q96NY8 | 4.03 (0.47) | 4.36 (0.92) | 0.004 |
| ERBB2 | P04626 | 7.44 (0.31) | 7.27 (0.49) | 0.004 |
| TNFRSF6B | O95407 | 5.10 (0.78) | 5.51 (1.13) | 0.005 |
| FCRLB | Q6BAA4 | 0.92 (0.52) | 1.18 (0.74) | 0.01 |
| GPC1 | P35052 | 4.64 (0.39) | 4.44 (0.55) | 0.01 |
| IFN-γ-R1 | P15260 | 4.68 (0.32) | 4.53 (0.43) | 0.01 |
| CD48 | P09326 | 5.86 (0.32) | 5.73 (0.42) | 0.01 |
| RET | P07949 | 5.35 (0.48) | 5.12 (0.67) | 0.01 |
| ICOSLG | O75144 | 5.94 (0.57) | 5.71 (0.73) | 0.03 |
| CTSV | O60911 | 3.74 (0.48) | 3.54 (0.64) | 0.03 |
| AREG | P15514 | 1.87 (0.57) | 2.07 (0.62) | 0.03 |
| MIA | Q16674 | 9.66 (0.29) | 9.55 (0.37) | 0.03 |
| Single-Protein AUC | Single-Protein Sensitivity at 95% Specificity | Single-Protein Sensitivity at 98% Specificity | ||||
|---|---|---|---|---|---|---|
| Protein | Estimate (95% CI) | Rank | Estimate (95% CI) | Rank | Estimate (95% CI) | Rank |
| CA125 | 0.958 (0.928, 0.982) | 1 | 0.879 (0.802, 0.940) | 1 | 0.810 (0.707, 0.897) | 1 |
| HE4 | 0.857 (0.808, 0.901) | 2 | 0.612 (0.526, 0.716) | 2 | 0.578 (0.302, 0.672) | 2 |
| ITGAV | 0.832 (0.783, 0.878) | 3 | 0.440 (0.302, 0.621) | 3 | 0.276 (0.164, 0.440) | 4 |
| SCF | 0.778 (0.728, 0.825) | 4 | 0.336 (0.233, 0.448) | 6 | 0.293 (0.172, 0.371) | 3 |
| SEZ6L | 0.764 (0.709, 0.816) | 5 | 0.310 (0.207, 0.448) | 9 | 0.164 (0.078, 0.310) | 14 |
| IL6 | 0.762 (0.708, 0.812) | 6 | 0.310 (0.129, 0.474) | 9 | 0.129 (0.000, 0.233) | 22 |
| MK | 0.745 (0.685, 0.802) | 7 | 0.405 (0.310, 0.509) | 4 | 0.250 (0.052, 0.431) | 6 |
| ESM-1 | 0.718 (0.661, 0.772) | 8 | 0.250 (0.129, 0.353) | 17 | 0.121 (0.060, 0.224) | 28 |
| hK11 | 0.713 (0.651, 0.770) | 9 | 0.353 (0.224, 0.466) | 5 | 0.216 (0.138, 0.336) | 9 |
| ADAM-TS 15 | 0.710 (0.649, 0.768) | 10 | 0.259 (0.181, 0.379) | 16 | 0.233 (0.129, 0.310) | 8 |
| FASLG | 0.705 (0.647, 0.761) | 11 | 0.284 (0.172, 0.414) | 12 | 0.181 (0.026, 0.267) | 12 |
| Protein + CA125 AUC | Protein + CA125 Sensitivity at 95% Specificity | Protein + CA125 Sensitivity at 98% Specificity | ||||
| Protein | Estimate (95% CI) | Rank | Estimate (95% CI) | Rank | Estimate (95% CI) | Rank |
| CA125 | -- | -- | -- | -- | -- | -- |
| HE4 | 0.966 (0.944, 0.983) | 8 | 0.853 (0.784, 0.914) | 55 | 0.784 (0.664, 0.888) | 55 |
| ITGAV | 0.967 (0.941, 0.987) | 7 | 0.914 (0.845, 0.957) | 1 | 0.862 (0.776, 0.931) | 2 |
| SCF | 0.958 (0.927, 0.982) | 46 | 0.879 (0.802, 0.940) | 36 | 0.810 (0.707, 0.897) | 33 |
| SEZ6L | 0.974 (0.950, 0.992) | 1 | 0.905 (0.845, 0.957) | 3 | 0.897 (0.836, 0.948) | 1 |
| IL6 | 0.963 (0.935, 0.983) | 15 | 0.836 (0.759, 0.914) | 61 | 0.793 (0.707, 0.862) | 51 |
| MK | 0.959 (0.931, 0.982) | 29 | 0.862 (0.776, 0.931) | 52 | 0.784 (0.698, 0.871) | 55 |
| ESM-1 | 0.960 (0.931, 0.983) | 24 | 0.862 (0.802, 0.940) | 52 | 0.802 (0.716, 0.897) | 45 |
| hK11 | 0.953 (0.923, 0.976) | 65 | 0.828 (0.750, 0.914) | 66 | 0.776 (0.672, 0.853) | 60 |
| ADAM-TS 15 | 0.961 (0.931, 0.984) | 21 | 0.888 (0.810, 0.940) | 22 | 0.793 (0.716, 0.905) | 51 |
| FASLG | 0.973 (0.954, 0.988) | 2 | 0.914 (0.853, 0.974) | 1 | 0.836 (0.733, 0.931) | 11 |
| AUC | Sensitivity at 95% Specificity | Sensitivity at 98% Specificity | p-Value 1 | |
|---|---|---|---|---|
| Cohort #1 | ||||
| Multiprotein | 0.974 (0.949, 0.989) | 0.914 (0.852, 0.964) | 0.862 (0.776, 0.933) | -- |
| CA125 | 0.958 (0.928, 0.982) | 0.879 (0.802, 0.940) | 0.810 (0.707, 0.897) | 0.02 |
| HE4 | 0.857 (0.808, 0.901) | 0.612 (0.526, 0.716) | 0.578 (0.302, 0.672) | <0.001 |
| ITGAV | 0.832 (0.783, 0.878) | 0.440 (0.302, 0.621) | 0.276 (0.164, 0.440) | <0.001 |
| SEZ6L | 0.764 (0.709, 0.816) | 0.310 (0.207, 0.448) | 0.164 (0.078, 0.310) | <0.001 |
| Cohort #2 | ||||
| Multiprotein | 0.933 (0.909, 0.955) | 0.792 (0.708, 0.844) | 0.661 (0.526, 0.771) | -- |
| CA125 | 0.916 (0.886, 0.942) | 0.745 (0.672, 0.807) | 0.635 (0.536, 0.750) | <0.001 |
| HE4 | 0.882 (0.850, 0.912) | 0.620 (0.536, 0.703) | 0.516 (0.359, 0.630) | <0.001 |
| ITGAV | 0.700 (0.653, 0.746) | 0.266 (0.172, 0.354) | 0.109 (0.036, 0.224) | <0.001 |
| SEZ6L | 0.603 (0.554, 0.651) | 0.130 (0.068, 0.182) | 0.057 (0.016, 0.115) | <0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boylan, K.L.M.; Petersen, A.; Starr, T.K.; Pu, X.; Geller, M.A.; Bast, R.C., Jr.; Lu, K.H.; Cavallaro, U.; Connolly, D.C.; Elias, K.M.; et al. Development of a Multiprotein Classifier for the Detection of Early Stage Ovarian Cancer. Cancers 2022, 14, 3077. https://doi.org/10.3390/cancers14133077
Boylan KLM, Petersen A, Starr TK, Pu X, Geller MA, Bast RC Jr., Lu KH, Cavallaro U, Connolly DC, Elias KM, et al. Development of a Multiprotein Classifier for the Detection of Early Stage Ovarian Cancer. Cancers. 2022; 14(13):3077. https://doi.org/10.3390/cancers14133077
Chicago/Turabian StyleBoylan, Kristin L. M., Ashley Petersen, Timothy K. Starr, Xuan Pu, Melissa A. Geller, Robert C. Bast, Jr., Karen H. Lu, Ugo Cavallaro, Denise C. Connolly, Kevin M. Elias, and et al. 2022. "Development of a Multiprotein Classifier for the Detection of Early Stage Ovarian Cancer" Cancers 14, no. 13: 3077. https://doi.org/10.3390/cancers14133077
APA StyleBoylan, K. L. M., Petersen, A., Starr, T. K., Pu, X., Geller, M. A., Bast, R. C., Jr., Lu, K. H., Cavallaro, U., Connolly, D. C., Elias, K. M., Cramer, D. W., Pejovic, T., & Skubitz, A. P. N. (2022). Development of a Multiprotein Classifier for the Detection of Early Stage Ovarian Cancer. Cancers, 14(13), 3077. https://doi.org/10.3390/cancers14133077