Simple Summary
Osteosarcoma is one of the aggressive bone tumors with numerous histologic patterns. Histopathological inspection is a crucial criterion in the medical diagnosis of osteosarcoma. Due to the advancement of computing power and hardware technology, pathological image analysis system based on artificial intelligence were more commonly used. Manual examination of the histopathological images is a difficult and laborious task. The lack of labeling data makes the system difficult to build and costly. Therefore, this study aims to develop an automated computer-aided diagnosis model for osteosarcoma classification. The proposed model uses deep learning, hyperparameter optimizer, and fuzzy logic for the classification process.
Abstract
Osteosarcoma is one of the aggressive bone tumors with numerous histologic patterns. Histopathological inspection is a crucial criterion in the medical diagnosis of Osteosarcoma. Due to the advancement of computing power and hardware technology, pathological image analysis system based on artificial intelligence (AI) were more commonly used. But classifying many intricate pathology images by hand will be challenging for pathologists. The lack of labeling data makes the system difficult to build and costly. This article designs a Honey Badger Optimization with Deep Learning based Automated Osteosarcoma Classification (HBODL-AOC) model. The HBODL-AOC technique’s goal is to identify osteosarcoma’s existence using medical images. In the presented HBODL-AOC technique, image preprocessing is initially performed by contrast enhancement technique. For feature extraction, the HBODL-AOC technique employs a deep convolutional neural network-based Mobile networks (MobileNet) model with an Adam optimizer for hyperparameter tuning. Finally, the adaptive neuro-fuzzy inference system (ANFIS) approach is implemented for the HBO (Honey Badger Optimization) algorithm can tune osteosarcoma classification and the membership function (MF). To demonstrate the enhanced classification performance of the HBODL-AOC approach, a sequence of simulations was performed. The extensive simulation analysis portrayed the improved performance of the HBODL-AOC technique over existing DL models.
1. Introduction
Osteosarcoma is a cancer that originates from the bone and grows quickly to form cancerous bone-like tissue and is an orthopedics disease. Commonly, osteosarcoma arises at the upper end of the humerus, the lower end of the femur, and the upper end of the tibia, particularly around the knee joint [1]. Osteosarcoma mostly occurs in children and adolescents, and its indications consist of fever, mild bone pain, and redness at the cancer site. Constant pain caused by osteogenic sarcoma affects the movement of the patient, and therefore it is a significant cancer that extremely affects labor efficiency and threatens life [2]. Thus, initial treatment and diagnosis have specific importance. Current diagnostic approaches, which include computer tomography (CT), magnetic resonance imaging (MRI), positron emission tomography (PET), and ultrasound, play a vital role in cancer identification [3]. But if such methods cannot earn a precise judgment, clinicians desire to derive tissue samples from cancer for further investigation. Concretely, the derived examples are transformed into smears or slides, and after stained to display some details regarding cells, which is generally time-consuming and leads to great pain in patients [4]. Hence, the growth of automated recognition technology for osteosarcoma has a higher value. Owing to the rise of patient-specific treatment options and cancer incidence, medication and the diagnosis of cancer have become very complex [5]. Diagnosticians should spend a long time analyzing more slides. Identifying the nuances of histologic images was tough. Misdiagnosis frequently happens because of extensive work that declines the precision of diagnosis [6]. The osteoblasts’ morphologies have minute variance in distinguished cells, which makes the image hardly distinguishable. Similarly, a biopsy will be a dynamic and time taking step for determining the existence of malignant tissue [7]. In the meantime, to automatically identify malignancies.
Computer-Aided Detection (CAD) technology renders a solution for radiotherapists. Extraction of features will be the next step in the automatic identification mechanism, and it is executed by deep learning (DL) or manually [8]. Handcrafted (HC) features were picture-specific properties decided by hand depending on targeted features of spaces, and such techniques were broadly used for extraction. The authors made widespread usage of HC characteristics since they were easy to derive, specifically in modest databases. The features are determined with professionals’ help in the appropriate sector [9]. Owing to their difficulty, such characteristics are problematic in deciding if they are associated with complicated images. In this case, DL methods were employed as a feature extraction algorithm. Because of recent advancements in the area of processing, such as the advent of quick and compact processors, the DL model has received significant attention in recent years, enabling experts to quickly and easily train deeper networks [10].
This article designs a Honey Badger Optimization with Deep Learning based Automated Osteosarcoma Classification (HBODL-AOC) model. The goal of the presented HBODL-AOC technique is to identify the existence of osteosarcoma using medical images. In the presented HBODL-AOC technique, image preprocessing is initially performed by contrast enhancement technique. For feature extraction, the HBODL-AOC technique employs deep convolutional neural network-based mobile networks (MobileNet) model with an Adam optimizer for hyperparameter tuning. Finally, the adaptive neuro-fuzzy inference system (ANFIS) approach is implemented for the HBO algorithm can tune osteosarcoma classification and the membership function (MF). To demonstrate the enhanced classification performance of the HBODL-AOC technique, a sequence of simulations was performed. In short, the key contributions of the paper are given as follows.
- An intelligent HBODL-AOC technique comprising pre-processing, MobileNet feature extraction, an Adam optimizer, ANFIS classifier, and HBO-based parameter tuning is presented. To the best of our knowledge, the HBODL-AOC model has never been presented in the literature;
- Employ the MobileNet model with an Adam optimizer to generate a useful set of feature vectors;
- Present an ANFIS model for osteosarcoma classification with HBO algorithm as a parameter optimization technique. Parameter optimization of the ANFIS model using the HBO algorithm using cross-validation helps to boost the predictive outcome of the HBODL-AOC model for unseen data.
2. Related Works
Pan et al. [11] propose a classical transformer image classification architecture with the integration of feature cross fusion learning (FCFL) and noise reduction convolutional autoencoder (NRCA) for classifying osteosarcoma histological images. NRCA could denoise histological images of osteosarcoma, which leads to more pure images for osteosarcoma segmentation. Furthermore, the research workers presented feature cross fusion learning that incorporates two scale image patches to considerably explore their interaction with other classification tokens. Ling et al. [12] developed an intellectually assisted diagnosis technique for osteosarcoma that could decrease the workload of clinicians in identifying osteosarcoma from three features. Firstly, the research workers constructed a classification-image enhancement method comprising resnet18 and DeepUPE to enhance image clarity and eliminate redundant images that could facilitate doctor observation. Next, the research workers empirically compare the performances of hybrid, serial, and parallel fusion convolution and transformer and present a double U-shaped visual transformer with convolution (DUconViT) for automated classification of osteosarcoma to help doctor diagnoses.
In [13], a robust detection technique has been introduced based on Fractional-Harris Hawks Optimization (F-HHO) related generative adversarial network (GAN) to detect osteosarcoma at an earlier phase. Now, the presented method was intended by the incorporation of HHO and Fractional Calculus, correspondingly. GAN is utilized for performing osteosarcoma recognition on the basis of features derived from the images by using the cell classification method. In [14], proposed a new method for the calculation of tumor stages and grade in long bones relevant to X-ray image analysis. Usually, cancer-affected bone images appear with the variation in bone texture in the affected area. In this work, the author extracts specific feature from bone X-ray image and utilize a support vector machine (SVM) to discriminate between cancerous and healthy bones. Abdelaal and Tobely [15] developed particle swarm-optimized extreme learning neural networks for efficiently forecasting bone cancers. At first, an X-ray image was collected from the oral cancer dataset that should be inspected for noise to remove by means of a non-local median filter. The extracted feature was categorized as a particle swarm optimization-based Extreme Learning Neural Networks Classifier.
Wu et al. [16] developed a boundary-aware grid contextual attention net (BA-GCA Net) to resolve the problems of inadequate performance in osteosarcoma MRI image classification. Firstly, a grid contextual attention (GCA) was intended for capturing texture details of the tumor region. Next, the spatial transformer block (STB) and statistical texture learning block (STLB) are incorporated with the networks to enhance the capability for extracting statistical texture features and locating tumor regions. The author [17] developed an automated bone cancer diagnosis technique to predict cancer at an earlier stage. Firstly, the bone image was gathered from the patients, and noise in the image was removed by means of a median filter. Afterward removing the noise, the affected tumor region can be diagnosed by employing the intuitionistic fuzzy rank correlation. Distinct statistical features were extracted from the diagnosed intuitionistic fuzzy-based clustered images. The obtained feature was processed with the help of a deep neural network (DNN) layer that effectively investigates every feature using the Levenberg–Marquardt learning model.
In spite of the several DL models that existed in the earlier studies, it is still needed to enhance the osteosarcoma classification performance. Due to the incessant deepening of the model, the number of parameters of DL models gets increased, and it leads to model overfitting. Besides, various hyperparameters have a substantial influence on the performance of the CNN model. Principally, hyperparameters such as epoch count, batch size, and learning rate selection are essential to attain effectual outcomes. Since the trial and error method for hyperparameter tuning is a tiresome and inaccurate process, hyperparameter optimizers can be applied. On the other hand, the choice and shape of MFs affect the performance of the fuzzy system irrespective of the significance. Therefore, in this work, an Adam optimizer and HBO algorithm are applied for the parameter optimization of the MobileNet and ANFIS models, respectively.
3. The Proposed Model
In this article, we have introduced an Automated Osteosarcoma Classification model named the HBODL-AOC model. The goal of the presented HBODL-AOC technique is to identify the existence of osteosarcoma using medical images. In the presented HBODL-AOC technique, different sub-processes are involved, namely contrast enhancement, deep convolutional neural network (DCNN) based MobileNet feature extraction, Adam optimizer, ANFIS classification, and HBO-based parameter tuning. Figure 1 depicts the working procedure of the HBODL-AOC approach.
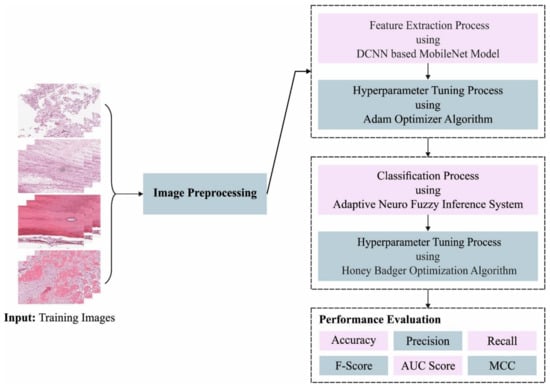
Figure 1.
Working process of HBODL-AOC algorithm. DCNN: deep convolutional neural network; MCC: Mathew Correlation Coefficient.
3.1. Image Pre-Processing
In the presented HBODL-AOC technique, image pre-processing is initially performed by contrast enhancement technique. Contrast enhancement approaches have progressed in the past few decades to address the requirements of its objectives. There were 2 key goals in improving an image’s contrast. One is facilitating or increasing the efficiency of subsequent tasks (for example, image segmentation, image analysis, and object detection), and another one is improving appearance for visual interpretation. Many contrast enhancement methods depend on histogram modifications, which are implemented locally or globally. The method that overcomes the limitations of global techniques by enhancing local contrast is called the Contrast Limited Adaptive Histogram Equalization (CLAHE) technique [18]. CLAHE was a variation of Adaptive histogram equalization (AHE) that thwarts contrast over-amplification. CLAHE operates on smaller areas of an image known as tiles instead of the complete image. The surrounding tiles can be combined through bilinear interpolation to remove the false boundaries. This method is employed for enhancing image contrast.
3.2. Feature Extraction
At this stage, the MobileNet model is applied for feature extraction. CNN is mostly collected from fully connected (FC) input, pooling, output, and convolution layers [18]. As compared to the typical neural network, it features local connection, down-sampling, and weighted sharing. It could efficiently decrease the network parameter, avoid over-fitting, and enhance the efficacy of removing local features. The convolutional layer was a basic element of the convolutional neural network (CNN), and the local extracting feature was recognized by linking the input of all the neurons to the local sensing area of the preceding layer. The convolutional function is classified as convolution and activation, and the computation procedure is demonstrated as:
where and signify the input and resultant of the convolutional layer correspondingly; and represent the serial number of convolutional kernels, and the channel counts correspondingly; and denote the weight as well as the bias of the convolutional kernel; implies the activation function of layers; and , and represent the dimensional of input datasets.
During the activation function, non-linear function like rectified linear unit (ReLU), Sigmoid, Leaky ReLU, and Tanh is implemented for mapping the input later linear transformation for enhancing the non-linear expression capability of networks. Especially, ReLU removes the gradient vanishing outcome of the sigmoid purpose, and the gradient computation speed was very quick; thus, it can be extremely utilized. Thus, the ReLU was executed to the convolutional layer under this work. The pooling layer has a feature mapping layer that decreases the resultant dimensional of the convolutional layer for realizing the down-sampling of local data and efficiently avoiding over-fitting. Overlapping pooling, max pooling, and average pooling can be general pooling approaches. During this case, max pooling was implemented for expressing local features, and several convolutional and pooling layers can be utilized for realizing extracting features.
During the fully connected (FC) layer, all the neurons are FC to every neuron from the front layer, and the predictive value was computed by weight summation of inter-layer weighted co-efficient. To regression procedures, the non-linear activation functions like Sigmoid, ReLU, and Tanh could not be appropriate to the final FC layer. While it maps the outcome in the range of ), , and , correspondingly. So, for improving the expression capability of the method, ReLU and linear activation functions can be executed to FC and output layers correspondingly.
MobileNetV2 is a mobile-enhanced FC network and relies on the inverted residual architecture, which has a bottleneck level interconnected to residual connection [19]. A first FC layer with 32 filters is employed in the MobileNetV2 that can be followed by 19 residual bottleneck layers. Six stages were followed in the model progression, which generates the amplification image generator, fundamental method with MobileNetV2, training the model, building up the model, storing model for forthcoming approximation, and process adding model parameters. A loss of 0.25 assured a random exclusion of 25% of the weight during training. This method significantly reduces overfitting. The major aim is to retain from utilizing too many weights models and from gaining a widespread knowledge of the input. For these datasets, a batch size of 32 images was exploited. Accordingly, 32 images were learned in one cycle. Commonly, the model grows large once the batch size is enhanced. However, this reduces the module’s ability to classify uncommon classes. Over an extensive size of the model, MobileNetV2 enhances efficacy. The MobileNetV2 is encompassed of n times as numerous recurrent layers. In this work, depthwise separable convolutions are used, which consist of depthwise and pointwise convolutions after one another.
The hyperparameter tuning process is performed by the Adam optimizer. It is a kind of typical stochastic gradient descent (SGD) method for upgrading network weighted in trained data [20]. It can be utilized for performing optimization and is the most optimum optimizer at the moment. Adam proceeds in adagrad, and it can be a further adaptable manner. Adagrad and momentum combined are called Adam.
Parameters and , whereas index signifies the present trained iteration, Parameter upgrade in Adam can provide as:
In Equations (2) and (3), and denotes the gradient forgetting features and the second moment of gradients. In Equation (6) implies the smaller scalar utilized for preventing division by 0.
3.3. Osteosarcoma Classification Using Optimal ANFIS Model
For the identification and classification of osteosarcoma, the ANFIS model is exploited. Soft computing techniques like neural networks and fuzzy set concepts are instances of instruments that might be exploited for establishing smart systems [21]. This theory provides a new methodology to resolve the problems that probability theory was incapable of shedding light on. Furthermore, knowledge given by humans was essential for these systems. The fuzzy rule is frequently involved in fuzzy deduction architecture, the most common type of fuzzy examination and fuzzy structure. Mostly, rules might be seen as follows: They comprise fuzzy recommendations and phonetic factors.
Sometimes if the rules are imposed by the regulator in the FIS, but in the ANFIS, such rules establish appropriate conditions. Once the rule cannot be followed for some reason, it should be eliminated. Likewise, the neural network accomplishes its optimum state. Note that the initial stage is represented as training, and the method displays an ideal system with the minimum error that can be remotely possible. Figure 2 showcases the framework of ANFIS.
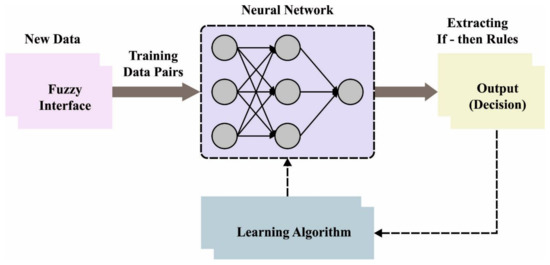
Figure 2.
Architecture of ANFIS.
The aim is to enhance the performance while concurrently decreasing the mistake rate and describing related error indices and functions. Fuzzy if-then rules with one output and two inputs might be formulated by:
The first rule, if and then .
The second rule, if and then .
Where and denote the input; , and designates the phonological labels; and represent the resulting factor, and denotes the output in fuzzy.
Now and characterize the input or passive layer, and membership function, rule, norm, output, and last output layers characterize the first, second, third, fourth, and fifth layers, correspondingly. Finally, the HBO algorithm is used to select the MFs optimally. In HBO, the honey badger’s (HB) dynamic searching performance with digging and honey-search tactics was separate from the exploration and exploitation phases [22]. The HB desires to live apart from the self-dug tunnel and only meets others for mating. But, because of its brave approach, it can be hunted by much greater animals once it is ineffectual to flee. However, an HB climbs a tree to access bird nests and beehives for food. An HB determines its meals by searching for mouse nests and digging, or subsequently, the honeyguide bird that realizes hives then cannot attain honey. The HBO’s mathematical structure was demonstrated as:
- The proposed HBO starts with initialized of the count of HBs dependent upon the population number and the subsequent position:whereas refers to the HB position, and signifies the lower as well as upper limits of all the positions from the searching space, and denotes the arbitrary number betwixt zero and one.
- The intensity (Int) has stated that it will be proportional to concentrates, prey strength, and the length betwixt the HB, as well as prey. The prey moves fast if the smell strength is stronger and different. The subsequent equation was utilized for computing the determining intensity:
In which signifies the source strength, denotes the arbitrary number, and represents the distance betwixt and the badger place. The strength in Equation (10) has assumed that the squared variance betwixt the HB’s present and next position as strength is continuously positive as it refers to intensity. The density factor was definite and upgraded the time-varying randomized controls to ensure a smooth transition from exploration to exploitation. This feature reduces with iterations for decreasing randomized with time as:
In which refers to the maximal iterations number, and stands for constant equivalent to two.
- To enhance the get-away from the local to the optimum area, a flag was created that changes the searching directions. Therefore, agents take availing higher chances of scanning the search space rigorously. It can be defined as:whereas implies the arbitrary number betwixt zero and one. Afterward, the agent positions can be upgraded whereas was upgraded based on 2 stages digging and honey stages, as follows: during the digging stage, an HB carries out activities related to cardioid shape that is simulated as:
In which implies the capability of HB for obtaining food that is superior to or equivalent to 1 (default ) and , and are 3 distinct arbitrary numbers betwixt and one. During the honey stage, an HB monitors a honeyguide bird for reaching a beehive that can be inspired as:
whereas denotes the arbitrary number betwixt zero and one.
4. Performance Validation
The proposed model is simulated using Python 3.6.5 tool. The proposed model was tested using PC i5-8600 k, GeForce 1050Ti 4 GB, 16 GB RAM, 250 GB SSD, and 1 TB HDD. The parameter settings are given as follows: learning rate: 0.01, dropout: 0.5, batch size: five, epoch count: 50, and activation: ReLU. The HBODL-AOC model is tested using a benchmark database [23] containing 1144 images under three classes. It comprises 345 images of viable tumors (VT), 263 images of non-viable tumors (NVT), and 536 images of the non-tumor (NT) class. Figure 3 illustrates the sample images.
Figure 3.
Sample images.
The confusion matrices of the HBODL-AOC model on OC performance are given in Figure 4. The results implied that the HBODL-AOC model could effectively identify different class labels.
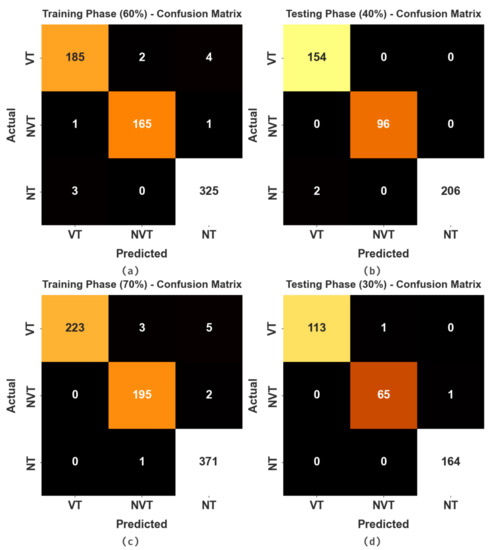
Figure 4.
Confusion matrices of HBODL-AOC approach (a,b) 60:40 of training/testing data and (c,d) 70:30 of training/testing data.
In Table 1 and Figure 5, an overall OC performance of the HBODL-AOC model under 60% of training and 40% of testing datasets is given. The results implied that the HBODL-AOC model has properly identified VT, NVT, and NT classes under both data. On 60% of the training database, the HBODL-AOC model has gained an average of 98.93%, of 98.39%, of 98.25%, of 98.32%, of 98.69%, and Mathew Correlation Coefficient (MCC) of 97.48%. Meanwhile, on 40% of the testing database, the HBODL-AOC method has acquired an average of 99.71%, of 99.57%, of 99.68%, of 99.62%, of 99.73%, and MCC of 99.38%.

Table 1.
OC analysis of HBODL-AOC approach on 60:40 of TR/TS databases.
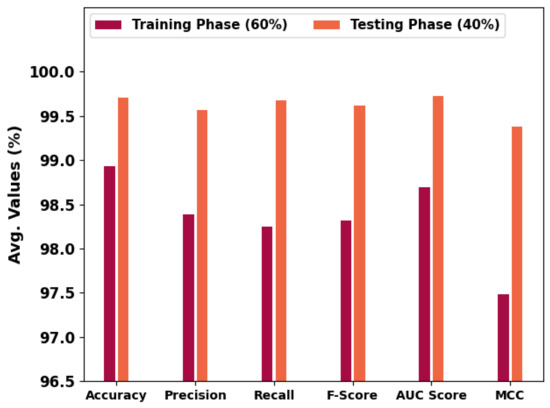
Figure 5.
Average outcome of HBODL-AOC approach on 60:40 of TR/TS databases.
Table 2 and Figure 6 portray the overall OC performance of the HBODL-AOC model under 70% of training and 30% of the testing datasets given. The outcomes exhibited that the HBODL-AOC approach has properly identified VT, NVT, and NT classes under both data. On 70% of the training database, the HBODL-AOC technique has acquired an average of 99.08%, of 98.71%, of 98.42%, of 98.55%, of 98.83%, and MCC of 97.85%. In the meantime, on 30% of the testing database, the HBODL-AOC methodology has obtained an average of 99.61%, of 99.29%, of 99.20%, of 99.25%, of 99.45%, and MCC of 98.96%.
Table 2.
OC analysis of HBODL-AOC approach under 70:30 of TR/TS databases.
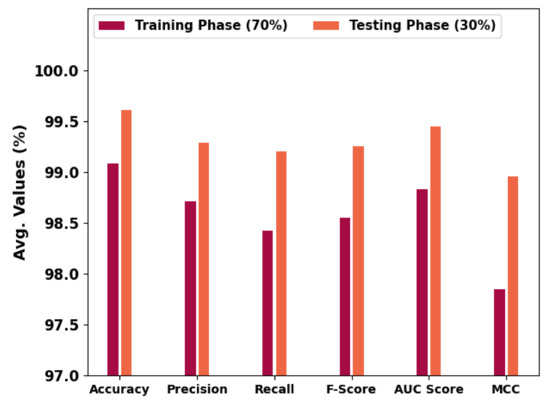
Figure 6.
Average outcome of HBODL-AOC approach on 70:30 of TR/TS databases.
The training accuracy (TACC) and validation accuracy (VACC) of the HBODL-AOC method is inspected on OC performance in Figure 7. The result implied that the HBODL-AOC technique had displayed improved performance with increased values of TACC and VACC. It is seen that the HBODL-AOC method has reached maximum TACC outcomes.
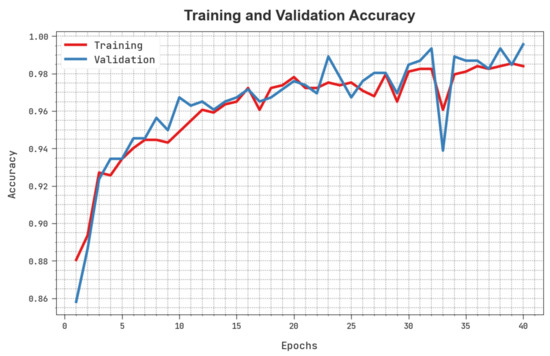
Figure 7.
TACC and VACC analysis of HBODL-AOC approach.
The training loss (TLS) and validation loss (VLS) of the HBODL-AOC technique are tested on OC performance in Figure 8. The figure inferred that the HBODL-AOC approach had revealed better performance with the least values of TLS and VLS. It is noted that the HBODL-AOC technique has resulted in reduced VLS outcomes.
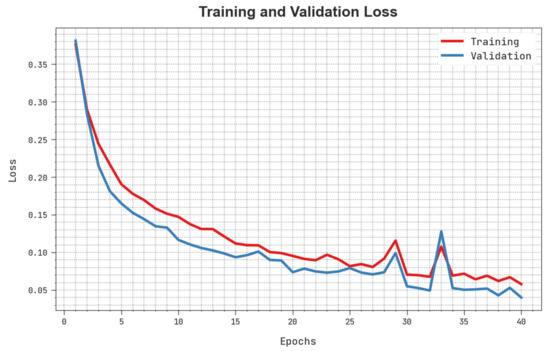
Figure 8.
TLS and VLS analysis of HBODL-AOC approach.
A clear precision-recall study of the HBODL-AOC technique under the test database is portrayed in Figure 9. The figure noted that the HBODL-AOC methodology has resulted in enhanced values of precision-recall values under all classes.
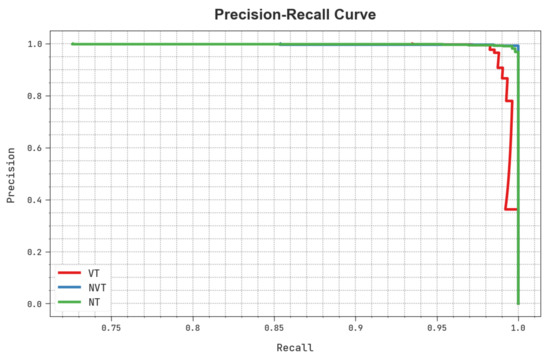
Figure 9.
Precision-recall analysis of HBODL-AOC approach.
In Table 3, an extensive comparative study of the HBODL-AOC model with other DL models on OC classification is provided [24]. Figure 10 represents a comparative and inspection of the HBODL-AOC method with other existing methods. The results show the HBODL-AOC model has attained higher values of and . Based on , the presented HBODL-AOC model has obtained improved of 99.71%, while the wind-driven optimization with deep transfer learning enabled osteosarcoma detection and classification (WDODTL-ODC), EfficientNet, Xception, ResNet-50, and MobileNet-v2 models have reached reduced of 99.22%, 97.70%, 96.85%, 97.85%, and 98.53% respectively.
Table 3.
Comparative analysis of HBODL-AOC technique with other methods.
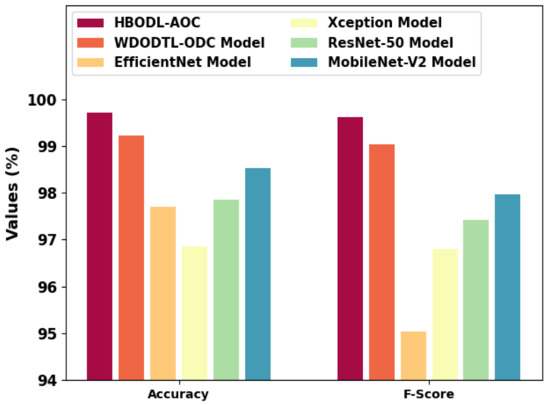
Figure 10.
and analysis of the HBODL-AOC approach with other algorithms.
Moreover, depends on , the presented HBODL-AOC method has acquired improved of 99.62%, while the WDODTL-ODC, EfficientNet, Xception, ResNet-50, and MobileNet-v2 models have reached reduced of 99.04%, 95.03%, 96.80%, 97.42%, and 97.97% correspondingly.
Figure 11 represents a comparative and analysis of the HBODL-AOC technique with other existing methods. The figure exhibited that the HBODL-AOC approach has attained higher values of and . Based on , the presented HBODL-AOC model has obtained improved of 99.57%, while the WDODTL-ODC, EfficientNet, Xception, ResNet-50, and MobileNet-v2 methodologies have reached reduced of 99.13%, 97.94%, 95%, 98.80%, and 98.10% respectively. But based on , the presented HBODL-AOC model has obtained improved of 99.68%, while the WDODTL-ODC, EfficientNet, Xception, ResNet-50, and MobileNet-v2 models have reached reduced of 98.48%, 98.02%, 96.88%, 94.94%, and 98.33%, correspondingly. These results assured the better performance of the HBODL-AOC model over other DL models. The enhanced performance of the proposed model is due to the effective parameter selection of the MobileNet and ANFIS models.
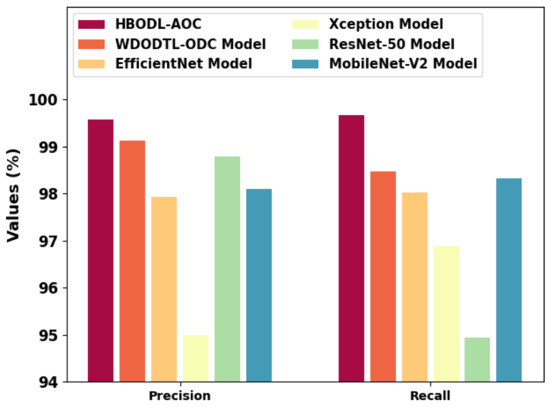
Figure 11.
and analysis of the HBODL-AOC approach with other algorithms.
5. Conclusions
In this article, we have introduced an Automated Osteosarcoma Classification model named the HBODL-AOC model. The goal of the presented HBODL-AOC technique is to identify the existence of osteosarcoma using medical images. In the presented HBODL-AOC technique, image pre-processing is initially performed by contrast enhancement technique. For feature extraction, the HBODL-AOC technique employed the MobileNet model with Adam optimizer for hyperparameter tuning. Finally, the HBO algorithm with the ANFIS model is applied for the osteosarcoma detection and classification process. To demonstrate the enhanced classification performance of the HBODL-AOC approach, a series of simulations were performed. The extensive simulation analysis portrayed the improved performance of the HBODL-AOC technique over existing DL models with maximum accuracy of 99.71%. In the future, the performance of the HBODL-AOC technique can be improved by hybrid DL classification models.
Author Contributions
Conceptualization, T.V. and A.J.; methodology, K.N. and K.K.; software, S.K. and J.K.; validation, T.V., A.J., K.N., K.K., S.K. and J.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Technology Development Program of MSS [No. S3033853].
Institutional Review Board Statement
Not applicable. This article does not contain any studies with human participants performed by any of the authors.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data sharing is not applicable to this article as no datasets were generated during the current study.
Conflicts of Interest
The authors declare that they have no conflict of interest. The manuscript was written through the contributions of all authors. All authors have given approval for the final version of the manuscript.
References
- Arunachalam, H.B.; Mishra, R.; Daescu, O.; Cederberg, K.; Rakheja, D.; Sengupta, A.; Leonard, D.; Hallac, R.; Leavey, P. Viable and necrotic tumor assessment from whole slide images of osteosarcoma using machine-learning and deep-learning models. PLoS ONE 2019, 14, e0210706. [Google Scholar] [CrossRef] [PubMed]
- Tang, H.; Sun, N.; Shen, S. Improving Generalization of Deep Learning Models for Diagnostic Pathology by Increasing Variability in Training Data: Experiments on Osteosarcoma Subtypes. J. Pathol. Inform. 2021, 12, 30. [Google Scholar] [CrossRef] [PubMed]
- Nasir, M.U.; Khan, S.; Mehmood, S.; Khan, M.A.; Rahman, A.U.; Hwang, S.O. IoMT-Based Osteosarcoma Cancer Detection in Histopathology Images Using Transfer Learning Empowered with Blockchain, Fog Computing, and Edge Computing. Sensors 2022, 22, 5444. [Google Scholar] [CrossRef] [PubMed]
- Fu, Y.; Xue, P.; Ji, H.; Cui, W.; Dong, E. Deep model with Siamese network for viable and necrotic tumor regions assessment in osteosarcoma. Med. Phys. 2020, 47, 4895–4905. [Google Scholar] [CrossRef] [PubMed]
- Mahore, S.; Bhole, K.; Rathod, S. Comparative analysis of machine learning algorithm for classification of different osteosarcoma types. In Proceedings of the 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Ho, D.J.; Agaram, N.P.; Schüffler, P.J.; Vanderbilt, C.M.; Jean, M.-H.; Hameed, M.R.; Fuchs, T.J. Deep Interactive Learning: An Efficient Labeling Approach for Deep Learning-Based Osteosarcoma Treatment Response Assessment. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2020; Springer: Cham, Switzerland, 2020; pp. 540–549. [Google Scholar]
- D’Acunto, M.; Martinelli, M.; Moroni, D. From human mesenchymal stromal cells to osteosarcoma cells classification by deep learning. J. Intell. Fuzzy Syst. 2019, 37, 7199–7206. [Google Scholar] [CrossRef]
- Varalakshmi, P.; Priyamvadan, A.V.; Rajakumar, B.R. Predicting Osteosarcoma using eXtreme Gradient Boosting Model. In Proceedings of the 2022 International Conference on Advances in Computing, Communication and Applied Informatics (ACCAI), Chennai, India, 28–29 January 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Wu, J.; Yang, S.; Gou, F.; Zhou, Z.; Xie, P.; Xu, N.; Dai, Z. Intelligent Segmentation Medical Assistance System for MRI Images of Osteosarcoma in Developing Countries. Comput. Math. Methods Med. 2022, 2022, 7703583. [Google Scholar] [CrossRef] [PubMed]
- Mahore, S.; Bhole, K.; Rathod, S. Machine Learning approach to classify and predict different Osteosarcoma types. In Proceedings of the 2021 8th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 26–27 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 641–645. [Google Scholar]
- Pan, L.; Wang, H.; Wang, L.; Ji, B.; Liu, M.; Chongcheawchamnan, M.; Yuan, J.; Peng, S. Noise-reducing attention cross fusion learning transformer for histological image classification of osteosarcoma. Biomed. Signal Process. Control 2022, 77, 103824. [Google Scholar] [CrossRef]
- Ling, Z.; Yang, S.; Gou, F.; Dai, Z.; Wu, J. Intelligent Assistant Diagnosis System of Osteosarcoma MRI Image Based on Transformer and Convolution in Developing Countries. IEEE J. Biomed. Health Inform. 2022, 26, 5563–5574. [Google Scholar] [CrossRef] [PubMed]
- Badashah, S.J.; Basha, S.S.; Ahamed, S.R.; Subba Rao, S.P.V. Fractional-Harris hawks optimization-based generative adversarial network for osteosarcoma detection using Renyi entropy-hybrid fusion. Int. J. Intell. Syst. 2021, 36, 6007–6031. [Google Scholar] [CrossRef]
- Bandyopadhyay, O.; Biswas, A.; Bhattacharya, B.B. Bone-Cancer Assessment and Destruction Pattern Analysis in Long-Bone X-ray Image. J. Digit. Imaging 2019, 32, 300–313. [Google Scholar] [CrossRef] [PubMed]
- Abdelaal, M.; Tobely, T.E.E. Bone Cancer Detection Using Particle Swarm Extreme Learning Machine Neural Networks. J. Med. Imaging Health Inform. 2019, 9, 508–513. [Google Scholar] [CrossRef]
- Wu, J.; Liu, Z.; Gou, F.; Zhu, J.; Tang, H.; Zhou, X.; Xiong, W. BA-GCA Net: Boundary-Aware Grid Contextual Attention Net in Osteosarcoma MRI Image Segmentation. Comput. Intell. Neurosci. 2022, 2022, 3881833. [Google Scholar] [CrossRef] [PubMed]
- Altameem, T. Fuzzy rank correlation-based segmentation method and deep neural network for bone cancer identification. Neural Comput. Appl. 2020, 32, 805–815. [Google Scholar] [CrossRef]
- Alwazzan, M.J.; Ismael, M.A.; Ahmed, A.N. A Hybrid Algorithm to Enhance Colour Retinal Fundus Images Using a Wiener Filter and CLAHE. J. Digit. Imaging 2021, 34, 750–759. [Google Scholar] [CrossRef] [PubMed]
- Gujjar, J.P.; Kumar, H.R.P.; Chiplunkar, N.N. Image classification and prediction using transfer learning in colab notebook. Glob. Transit. Proc. 2021, 2, 382–385. [Google Scholar] [CrossRef]
- Kumar, A.; Sarkar, S.; Pradhan, C. Malaria disease detection using cnn technique with sgd, rmsprop, and adam optimizers. In Deep Learning Techniques for Biomedical and Health Informatics; Springer: Cham, Switzerland, 2020; pp. 211–230. [Google Scholar]
- Rajan, M.S.; Dilip, G.; Kannan, N.; Namratha, M.; Majji, S.; Mohapatra, S.K.; Patnala, T.R.; Karanam, S.R. Diagnosis of fault node in wireless sensor networks using adaptive neuro-fuzzy inference system. Appl. Nanosci. 2021, 1–9. [Google Scholar] [CrossRef]
- El-Sehiemy, R.; Shaheen, A.; Ginidi, A.; Elhosseini, M. A Honey Badger Optimization for Minimizing the Pollutant Environmental Emissions-Based Economic Dispatch Model Integrating Combined Heat and Power Units. Energies 2022, 15, 7603. [Google Scholar] [CrossRef]
- Leavey, P.; Sengupta, A.; Rakheja, D.; Daescu, O.; Arunachalam, H.B.; Mishra, R. Osteosarcoma data from UT Southwestern/UT Dallas for Viable and Necrotic Tumor Assessment [Data set]. Cancer Imaging Arch. 2019, 14. Available online: https://wiki.cancerimagingarchive.net/pages/viewpage.action?pageId=52756935#:~:text=The%20dataset%20consists%20of%201144,30%25)%20viable%20tumor%20tiles (accessed on 18 August 2022).
- Fakieh, B.; AL-Ghamdi, A.S.A.-M.; Ragab, M. Optimal Deep Stacked Sparse Autoencoder Based Osteosarcoma Detection and Classification Model. Healthcare 2022, 10, 1040. [Google Scholar] [CrossRef] [PubMed]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).