
A Centralized Routing for Lifetime and Energy Optimization in WSNs Using Genetic Algorithm and Least-Square Policy Iteration


Abstract
:1. Introduction
- (i)
- Formulation of a reward function for the joint optimization of the lifetime and energy consumption for WSNs.
- (ii)
- Design of a centralized routing protocol using a GA and an LSPI for WSNs to improve their lifetimes and energy consumption performances.
2. Literature Review
2.1. Fundamental Concepts
2.1.1. Q-Learning
- (i)
- A large number of iterations are required to learn the optimal routing path; this leads to the degradation of the convergence speed and routing performance.
- (ii)
- It is very sensitive to parameter settings; for example, changes in the learning rate affect the routing performance.
2.1.2. Least-Squares Policy Iteration
2.2. Review of Similar Works
3. Methodology
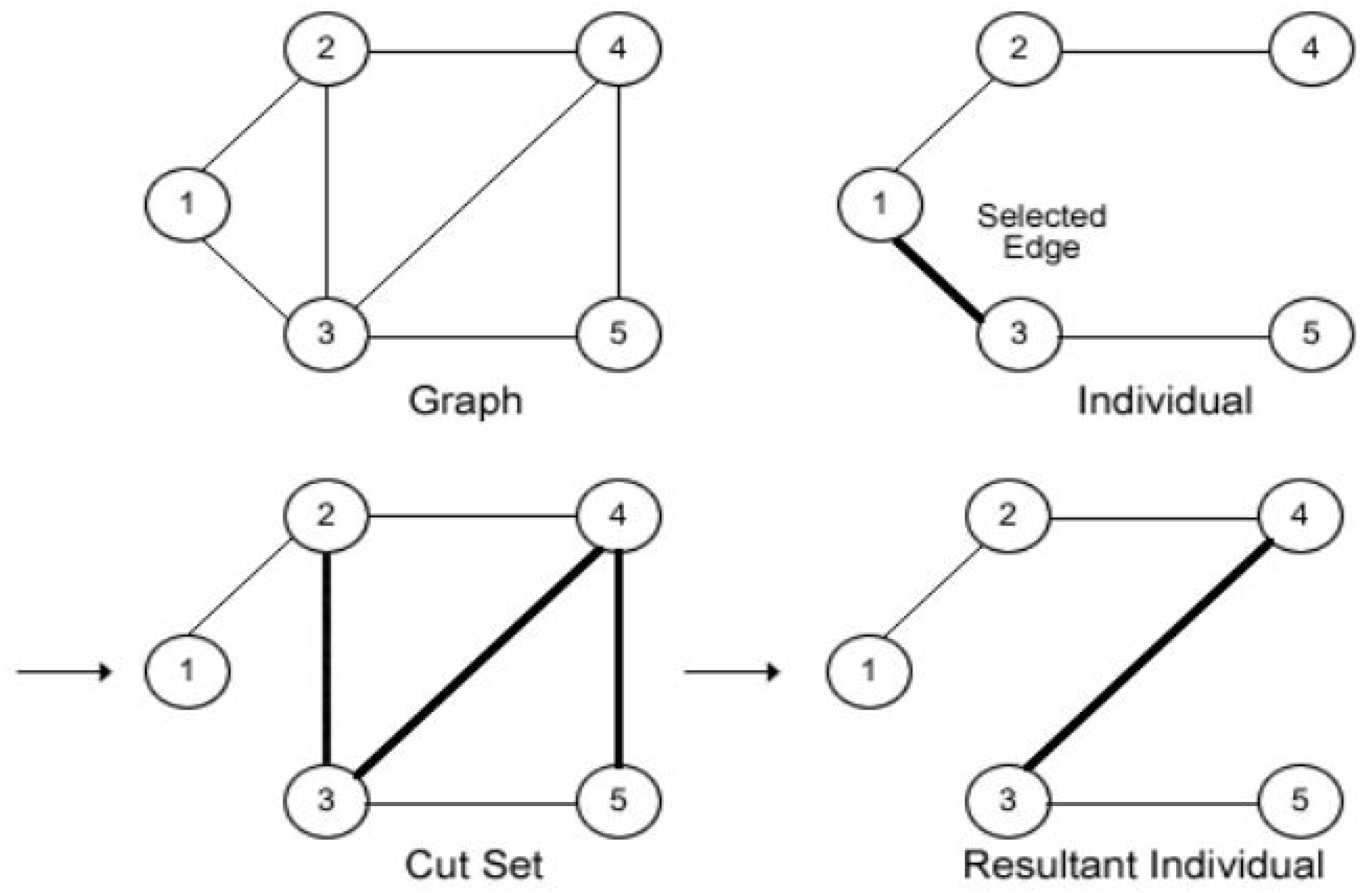
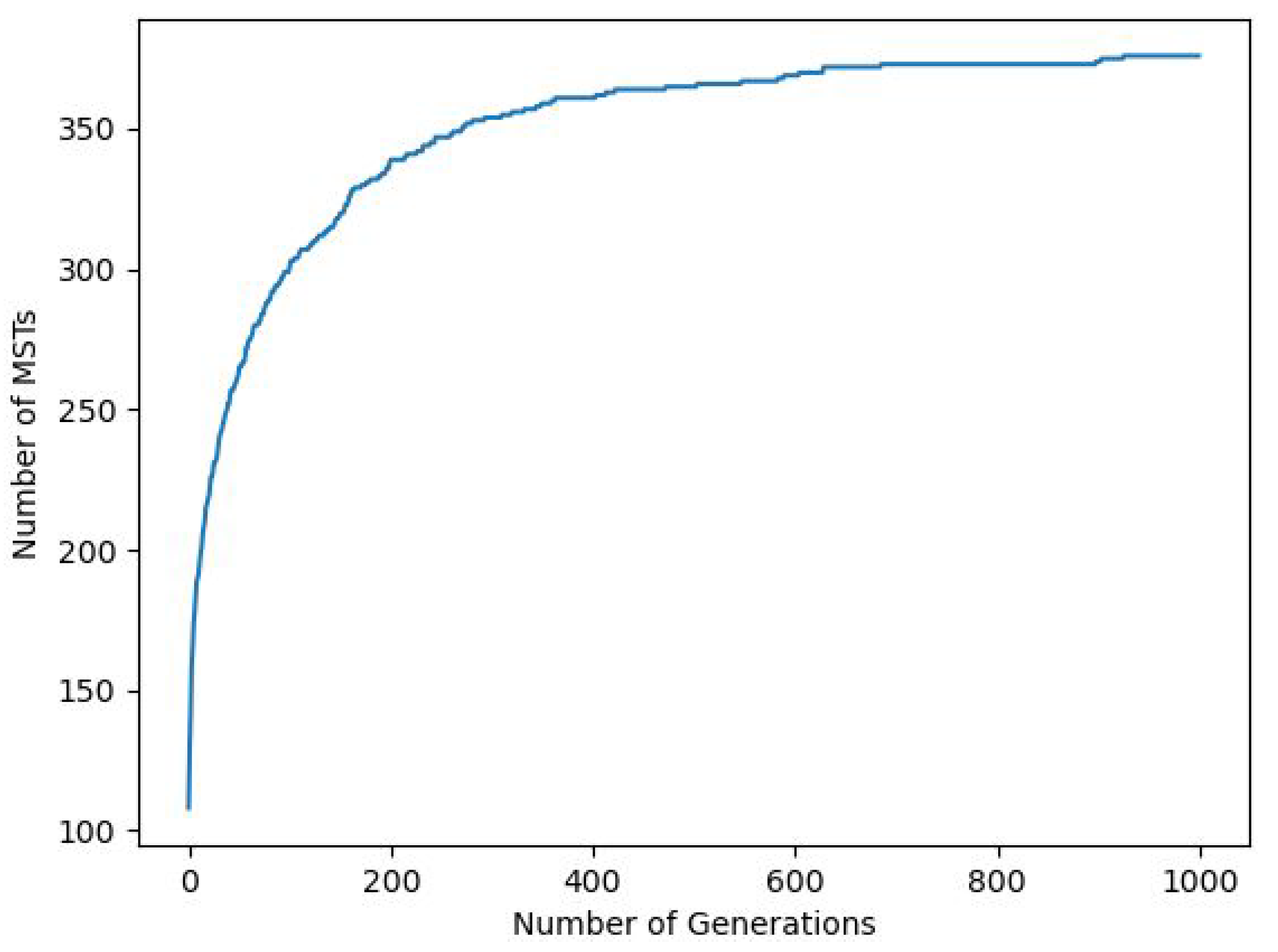
3.1. A GA-Based MSTs
| Algorithm 1 Algorithm to generate initial population for GA-based MSTs. |
Input: Output: while do Select vertex j as the root node if then end if end while Return |
| Algorithm 2 GA for generating MSTs. |
|
3.2. A Centralized Routing Protocol for Lifetime and Energy Optimization Using GA and LSPI
| Algorithm 3 Samples Generation Algorithm. |
|
| Algorithm 4 CRPLEOGALSPI. |
|
3.3. Energy Consumption Model
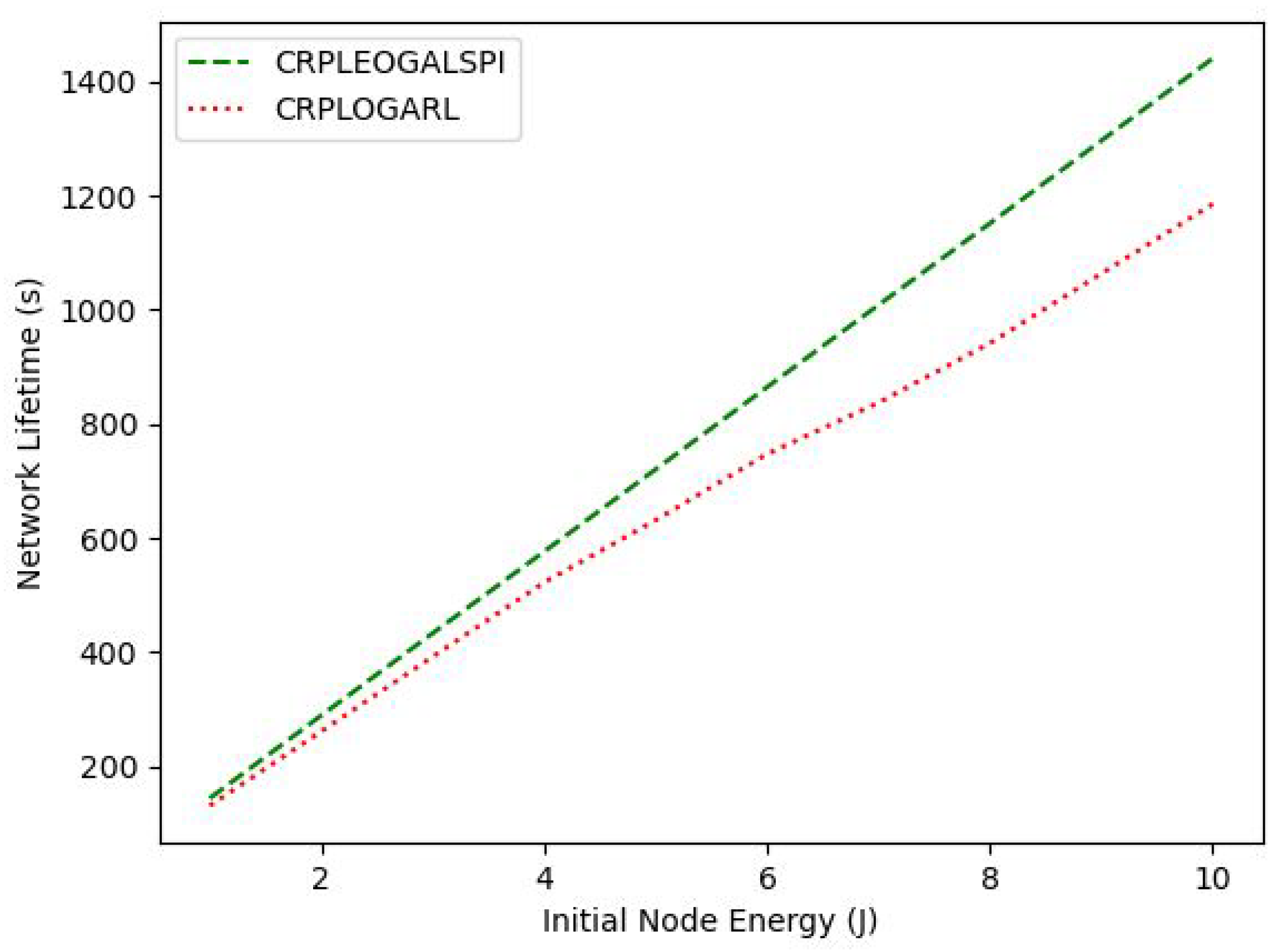
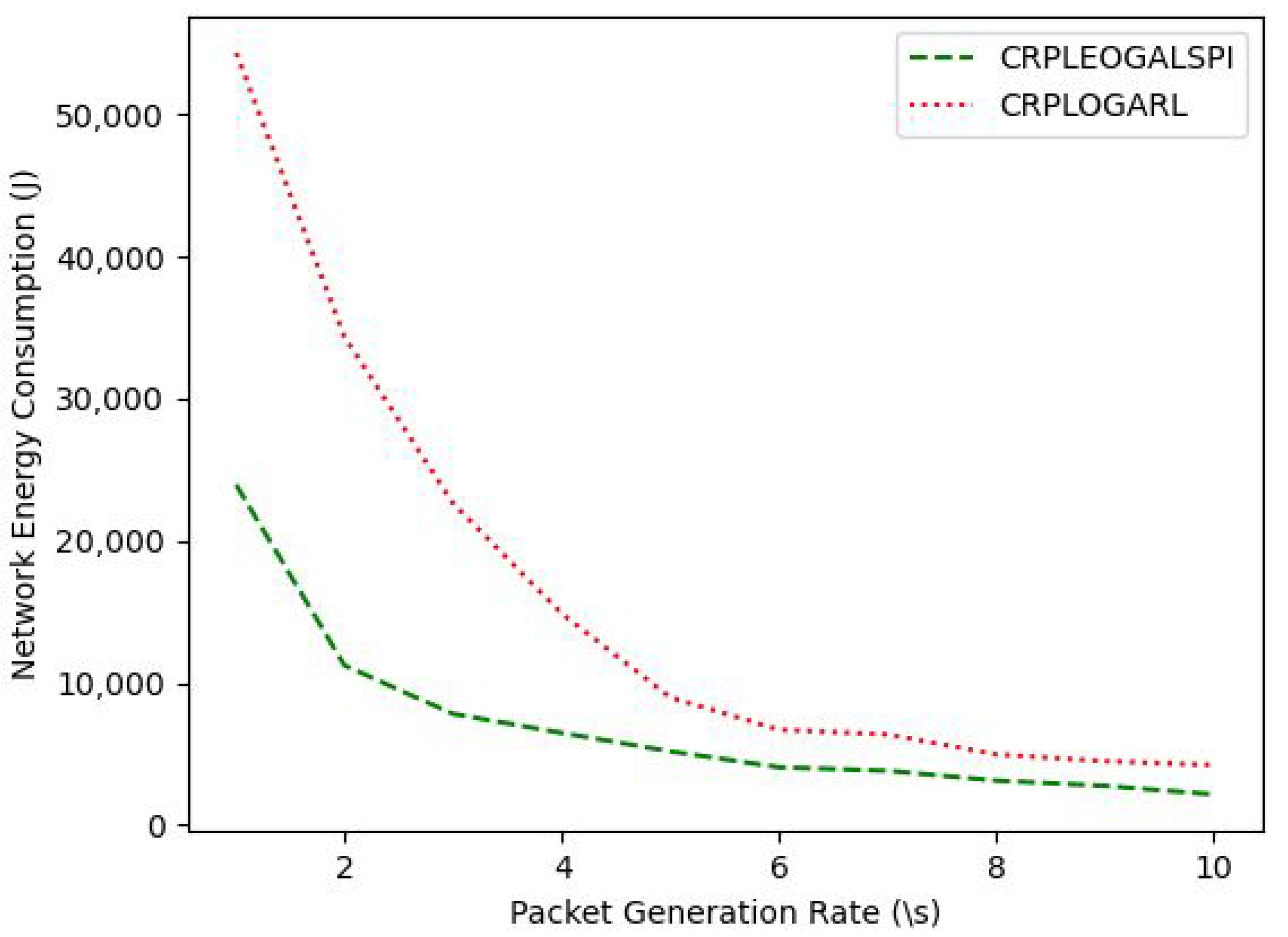
4. Simulation and Results Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Priyadarshi, R.; Gupta, B.; Anurag, A. Deployment techniques in wireless sensor networks: A survey, classification, challenges, and future research issues. J. Supercomput. 2020, 76, 7333–7373. [Google Scholar] [CrossRef]
- Rawat, P.; Singh, K.D.; Chaouchi, H.; Bonnin, J.M. Wireless sensor networks: A survey on recent developments and potential synergies. J. Supercomput. 2014, 68, 1–48. [Google Scholar] [CrossRef]
- Matin, M.A.; Islam, M.M. Overview of wireless sensor network. Wirel. Sens. Netw.-Technol. Protoc. 2012, 1, 1–24. [Google Scholar]
- Xia, F. Wireless sensor technologies and applications. Sensors 2009, 9, 8824–8830. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Engmann, F.; Katsriku, F.A.; Abdulai, J.D.; Adu-Manu, K.S.; Banaseka, F.K. Prolonging the lifetime of wireless sensor networks: A review of current techniques. Wirel. Commun. Mob. Comput. 2018, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Nayak, P.; Swetha, G.K.; Gupta, S.; Madhavi, K. Routing in wireless sensor networks using machine learning techniques: Challenges and opportunities. Measurement 2021, 178, 1–15. [Google Scholar] [CrossRef]
- Al Aghbari, Z.; Khedr, A.M.; Osamy, W.; Arif, I.; Agrawal, D.P. Routing in wireless sensor networks using optimization techniques: A survey. Wirel. Pers. Commun. 2020, 111, 2407–2434. [Google Scholar] [CrossRef]
- Mostafaei, H.; Menth, M. Software-defined wireless sensor networks: A survey. J. Netw. Comput. Appl. 2018, 119, 42–56. [Google Scholar] [CrossRef]
- Obi, E.; Mammeri, Z.; Ochia, O.E. A Lifetime-Aware Centralized Routing Protocol for Wireless Sensor Networks using Reinforcement Learning. In Proceedings of the 17th International Conference on Wireless and Mobile Computing, Networking and Communications, Bologna, Italy, 11–13 October 2021; pp. 363–368. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT press: Cambridge, MA, USA; London, UK, 2018; pp. 119–138. [Google Scholar]
- Yamada, T.; Kataoka, S.; Watanabe, K. Listing all the minimum spanning trees in an undirected graph. Int. J. Comput. Math. 2010, 87, 3175–3185. [Google Scholar] [CrossRef]
- Whitley, D. A genetic algorithm tutorial. Stat. Comput. 1994, 4, 65–85. [Google Scholar] [CrossRef]
- Obi, E.; Mammeri, Z.; Ochia, O.E. Centralized Routing for Lifetime Optimization Using Genetic Algorithm and Reinforcement Learning for WSNs. In Proceedings of the 16th International Conference on Sensor Technologies and Applications, Lisbon, Portugal, 16–20 October 2022; pp. 5–12. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Lagoudakis, M.G.; Parr, R. Least-squares policy iteration. J. Mach. Learn. Res. 2003, 4, 1107–1149. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef] [Green Version]
- Mammeri, Z. Reinforcement learning based routing in networks: Review and classification of approaches. IEEE Access 2019, 7, 55916–55950. [Google Scholar] [CrossRef]
- Bradtke, S.J.; Barto, A.G. Linear least-squares algorithms for temporal difference learning. Mach. Learn. 1996, 22, 33–57. [Google Scholar] [CrossRef] [Green Version]
- Boyan, J.; Littman, M. Packet routing in dynamically changing networks: A reinforcement learning approach. Adv. Neural Inf. Process. Syst. 1993, 6, 671–678. [Google Scholar]
- Zhang, Y.; Fromherz, M. Constrained flooding: A robust and efficient routing framework for wireless sensor networks. In Proceedings of the 20th International Conference on Advanced Information Networking and Applications-Volume 1, Vienna, Austria, 18–20 April 2006; pp. 1–6. [Google Scholar]
- Maroti, M. Directed flood-routing framework for wireless sensor networks. In Proceedings of the ACM/IFIP/USENIX International Conference on Distributed Systems Platforms and Open Distributed Processing, Berlin, Germany, 18–20 October 2004; pp. 99–114. [Google Scholar]
- He, T.; Krishnamurthy, S.; Stankovic, J.A.; Abdelzaher, T.; Luo, L.; Stoleru, R.; Yan, T.; Gu, L.; Hui, J.; Krogh, B. Energy-efficient surveillance system using wireless sensor networks. In Proceedings of the 2nd International Conference on Mobile Systems, Applications, and Services, Boston, MA, USA, 6–9 June 2004; pp. 270–283. [Google Scholar]
- Intanagonwiwat, C.; Govindan, R.; Estrin, D. Directed diffusion: A scalable and robust communication paradigm for sensor networks. In Proceedings of the 6th Annual International Conference on Mobile Computing and Networking, Boston, MA, USA, 6–11 August 2000; pp. 56–67. [Google Scholar]
- Wang, P.; Wang, T. Adaptive routing for sensor networks using reinforcement learning. In Proceedings of the 6th IEEE International Conference on Computer and Information Technology, Seoul, Republic of Korea, 20–22 September 2006; p. 219. [Google Scholar]
- Nurmi, P. Reinforcement learning for routing in ad hoc networks. In Proceedings of the 5th IEEE International Symposium on Modeling and Optimization in Mobile, Ad Hoc and Wireless Networks and Workshops, Limassol, Cyprus, 16–20 April 2007; pp. 1–8. [Google Scholar]
- Dong, S.; Agrawal, P.; Sivalingam, K. Reinforcement learning based geographic routing protocol for UWB wireless sensor network. In Proceedings of the IEEE Global Telecommunications Conference, Washington, DC, USA, 26–30 November 2007; pp. 652–656. [Google Scholar]
- Karp, B.; Kung, H.T. GPSR: Greedy perimeter stateless routing for wireless networks. In Proceedings of the 6th Annual International Conference on Mobile Computing and Networking, Boston MA, USA, 6–11 August 2000; pp. 243–254. [Google Scholar]
- Arroyo-Valles, R.; Alaiz-Rodriguez, R.; Guerrero-Curieses, A.; Cid-Sueiro, J. Q-probabilistic routing in wireless sensor networks. In Proceedings of the IEEE 3rd International Conference on Intelligent Sensors, Sensor Networks and Information, Melbourne, VIC, Australia, 3–6 December 2007; pp. 1–6. [Google Scholar]
- Naruephiphat, W.; Usaha, W. Balancing tradeoffs for energy-efficient routing in MANETs based on reinforcement learning. In Proceedings of the VTC Spring IEEE Vehicular Technology Conference, Marina Bay, Singapore, 11–14 May 2008; pp. 2361–2365. [Google Scholar]
- Förster, A.; Murphy, A.L. Balancing energy expenditure in WSNs through reinforcement learning: A study. In Proceedings of the 1st International Workshop on Energy in Wireless Sensor Networks, Santorini Island, Greece, 11–14 June 2008; pp. 1–7. [Google Scholar]
- Hu, T.; Fei, Y. QELAR: A q-learning-based energy-efficient and lifetime-aware routing protocol for underwater sensor networks. In Proceedings of the IEEE International Performance, Computing and Communications Conference, Austin, TX, USA, 7–9 December 2008; pp. 247–255. [Google Scholar]
- Yang, J.; Zhang, H.; Pan, C.; Sun, W. Learning-based routing approach for direct interactions between wireless sensor network and moving vehicles. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems, The Hague, The Netherlands, 6–9 October 2013; pp. 1971–1976. [Google Scholar]
- Oddi, G.; Pietrabissa, A.; Liberati, F. Energy balancing in multi-hop Wireless Sensor Networks: An approach based on reinforcement learning. In Proceedings of the 2014 NASA/ESA IEEE Conference on Adaptive Hardware and Systems, Leicester, UK, 14–17 July 2014; pp. 262–269. [Google Scholar]
- Jafarzadeh, S.Z.; Moghaddam, M.H.Y. Design of energy-aware QoS routing protocol in wireless sensor networks using reinforcement learning. In Proceedings of the 2014 IEEE 27th Canadian Conference on Electrical and Computer Engineering, Toronto, ON, Canada, 4–7 May 2014; pp. 1–5. [Google Scholar]
- Guo, W.J.; Yan, C.R.; Gan, Y.L.; Lu, T. An intelligent routing algorithm in wireless sensor networks based on reinforcement learning. Appl. Mech. Mater. 2014, 678, 487–493. [Google Scholar] [CrossRef]
- Shah, R.C.; Rabaey, J.M. Energy aware routing for low energy ad hoc sensor networks. In Proceedings of the IEEE Wireless Communications and Networking Conference Record, Orlando, FL, USA, 17–21 March 2002; pp. 350–355. [Google Scholar]
- Yessad, S.; Tazarart, N.; Bakli, L.; Medjkoune-Bouallouche, L.; Aissani, D. Balanced energy-efficient routing protocol for WSN. In Proceedings of the IEEE International Conference on Communications and Information Technology, Hammamet, Tunisia, 26–28 June 2012; pp. 326–330. [Google Scholar]
- Debowski, B.; Spachos, P.; Areibi, S. Q-learning enhanced gradient-based routing for balancing energy consumption in WSNs. In Proceedings of the IEEE 21st International Workshop on Computer Aided Modelling and Design of Communication Links and Networks, Toronto, ON, Canada, 23–25 October 2016; pp. 18–23. [Google Scholar]
- Renold, A.P.; Chandrakala, S. MRL-SCSO: Multi-agent reinforcement learning-based self-configuration and self-optimization protocol for unattended wireless sensor networks. Wirel. Pers. Commun. 2017, 96, 5061–5079. [Google Scholar] [CrossRef]
- Gnawali, O.; Fonseca, R.; Jamieson, K.; Moss, D.; Levis, P. Collection tree protocol. In Proceedings of the 7th ACM Conference on Embedded Networked Sensor Systems, Berkeley, CA, USA, 4–6 November 2009; pp. 1–14. [Google Scholar]
- Guo, W.; Yan, C.; Lu, T. Optimizing the lifetime of wireless sensor networks via reinforcement-learning-based routing. Int. J. Distrib. Sens. Netw. 2019, 15, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Bouzid, S.E.; Serrestou, Y.; Raoof, K.; Omri, M.N. Efficient routing protocol for wireless sensor network based on reinforcement learning. In Proceedings of the 5th IEEE International Conference on Advanced Technologies for Signal and Image Processing, Sousse, Tunisia, 2–5 September 2020; pp. 1–5. [Google Scholar]
- Sapkota, T.; Sharma, B. Analyzing the energy efficient path in Wireless Sensor Network using Machine Learning. ADBU J. Eng. Technol. 2021, 10, 1–7. [Google Scholar]
- Intanagonwiwat, C.; Govindan, R.; Estrin, D.; Heidemann, J.; Silva, F. Directed diffusion for wireless sensor networking. IEEE/ACM Trans. Netw. 2003, 11, 2–16. [Google Scholar] [CrossRef] [Green Version]
- Mutombo, V.K.; Shin, S.Y.; Hong, J. EBR-RL: Energy balancing routing protocol based on reinforcement learning for WSN. In Proceedings of the 36th Annual ACM Symposium on Applied Computing, Virtual Event, 22–26 March 2021; pp. 1915–1920. [Google Scholar]
- Gibbons, A. Algorithmic Graph Theory; Cambridge University Press: New York, NY, USA, 1985; pp. 121–134. [Google Scholar]
- Prim, R.C. Shortest connection networks and some generalizations. Bell Syst. Tech. J. 1957, 36, 1389–1401. [Google Scholar] [CrossRef]
- Kruskal, J.B. On the shortest spanning subtree of a graph and the traveling salesman problem. Proc. Am. Math. Soc. 1956, 7, 48–50. [Google Scholar] [CrossRef]
- Halim, Z. Optimizing the minimum spanning tree-based extracted clusters using evolution strategy. Clust. Comput. 2018, 21, 377–391. [Google Scholar] [CrossRef]
- de Almeida, T.A.; Yamakami, A.; Takahashi, M.T. An evolutionary approach to solve minimum spanning tree problem with fuzzy parameters. In Proceedings of the IEEE International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce, Washington, DC, USA, 28–30 November 2005; Volume 2, pp. 203–208. [Google Scholar]
- Almeida, T.A.; Souza, V.N.; Prado, F.M.S.; Yamakami, A.; Takahashi, M.T. A genetic algorithm to solve minimum spanning tree problem with fuzzy parameters using possibility measure. In Proceedings of the IEEE NAFIPS Annual Meeting of the North American Fuzzy Information Processing Society, Detroit, MI, USA, 26–28 June 2005; pp. 627–632. [Google Scholar]
- Hagberg, A.; Swart, P.; Daniel, S.C. Exploring network structure, dynamics, and function using NetworkX. In Proceedings of the 8th SCIPY Conference, Pasadena, CA, USA, 19–24 August 2008; pp. 11–15. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Routing Protocol | Objective | RL Technique | Control Technique | Drawback |
|---|---|---|---|---|
| Q-Routing [19] | Learns the optimal paths to minimizes the packet delivery delay. | Q-learning | Distributed | i. Requires Q-value freshness. ii. Sensitivity to parameter setting. iii. Slow convergence to optimal routing paths. |
| RL-based constrained flooding [20] | Optimizes the cost of constrained flooding (delivery delay, hop count). | Q-learning | Distributed | Degradation in packet delivery delay when compared with direct routing. |
| AdaR [24] | Maximizes network lifetime taking into consideration the hop count, node residual energy, link reliability, and the number of paths crossing a node. | LSPI | Distributed | i. No explicit definition of the network lifetime. ii. High computation complexity. |
| Energy-aware selfishness RL-based routing [25] | Minimizes the energy consumption. | Q-learning | Distributed | The selfishness and energy functions were not provided. |
| RLGR [26] | Improved the network lifetime by learning the optimal routing paths with factors such as hop count and node residual energy. | Q-learning | Distributed | Slow convergence to the optimal routing paths. |
| Q-PR [28] | Maintains the trade-off between network lifetime and the expected the number of retransmissions while increasing the packet delivery ratio. | Q-learning | Distributed | i. The message’s importance is not balanced with the energy cost of using a constant a discount factor of one. ii. The selection of the next forwarder requires the requisites of neighbors. iii. Non-refinement of the estimation of the residual energy of the sensor nodes. |
| RL-based balancing energy routing [29] | Balancing the trade-off of minimizing energy consumption and maximizing the network lifetime by selecting routing paths based on the energy consumption of paths and residual energy of nodes. | Q-learning | Distributed | The network lifetime is the time when the the first node depletes its energy source, however, sensing is still possible unless the node is the sink. |
| E-FROMS [30] | Balances the energy consumption in multiple sinks by learning the optimal spanning tree that minimizes the energy-based reward. | Q-learning | Distributed | The state space and action space overhead are high and very high respectively. |
| QELAR [31] | Increases the network lifetime by finding the optimal routing path from each sensor node to the sink and distribute the residual the energy of each sensor node evenly. | Q-learning | Distributed | i. High overhead due to control packets. ii. Slow convergence to the optimal routing paths. |
| RL-based routing interacting with WSN with moving vehicles [32] | Learn the routing paths between sensor nodes and moving sinks taking into consideration of hop count and energy signal strength to maximize the network lifetime. | Q-learning | Distributed | High overhead due to control packets. |
| OPT-EQ-Routing [33] | Optimizes the network lifetime while minimizing the control overhead by balancing the routing load among the sensor nodes taking into consideration the sensor nodes’ current residual energies. | Q-learning | Distributed | Requires too many iterations to converge to the optimal paths. |
| EQR-RL [34] | Minimizing the network energy consumption while ensuring the packet delivery delay by learning the optimal routing path taking into consideration the residual energy of the next forwarder, the ratio of packets between the packet sender to the selected forwarder, and link delay. | Q-learning | Distributed | High convergence time to the optimal route. |
| RLLO [35] | Maximizing the network’s lifetime and packet delay by learning the routing paths using the node residual energy and hop counts to the sink in the reward function. | Q-learning | Distributed | Very high probability of network isolation. |
| QSGrd [38] | Minimizing the energy consumption of the sensor nodes by jointly using Q-learning and transmission gradient. | Q-learning | Distributed | i. Slow convergence to the optimal routing paths. ii. The static parameter of the Q-learning leads to network performance degradation. iii. Increased computation time. |
| MRL-SCSO [39] | Maximizes the network lifetime by learning the next forwarder taking into account buffer lengthand node residual energy. Incorporating a sleeping schedule decreases the energy consumption of nodes. | Q-learning | Distributed | Increased number of episodes to learn the network. |
| RLBR [41] | Search for optimal paths taking into consideration of hop count, link distance, and residual energy. | Q-learning | Distributed | Slow convergence to the optimal routing paths. |
| R2LTO [42] | Learns the optimal paths to the sink by considering the hop count, residual energy, and transmission energy between nodes. | Q-learning | Distributed | Slow convergence to the optimal routing paths. |
| RL-based routing protocol [43] | Chooses the next forwarder with Q-learning by using the the inverse of the distance between connected sensor nodes. | Q-learning | Distributed | Increased number of episodes to learn the network. |
| EBR-RL [45] | Learns the optimal routing path using hop count and the residual energy of sensor nodes to maximize the network lifetime. | Q-learning | Distributed | Slow convergence to the optimal routing paths. |
| LACQRP [9] | Learn the optimal MST that maximizes the network lifetime. | Q-learning | Centralized | Computational complexity increases exponentially with the number of sensor nodes. |
| CRPLOGARL [13] | Learn the optimal or near-optimal MST that maximizes the network’s lifetime. | Q-learning | Centralized | Slow convergence to the optimal or near-optimal MST. |
| Parameters | Values |
|---|---|
| Number of sink | 1 |
| Number of sensors | 100 |
| Deployment Area of WSN | 1000 m × 1000 m |
| Deployment of Sensor nodes | Random |
| coordinate of sink | |
| Maximum transmission range | 150 m |
| Bandwidth of links | 1 kbps |
| Size of data packet | 1024 bits |
| Sensors initial residual energy | 1 J to 10 J |
| Rate of packet generation | 1/s to 10/s |
| 0.0013 pJ/bit/m | |
| 10 pJ/bit/m | |
| 50 nJ/bit | |
| Discount factor | 0.9 |
| Epsilon | 0.1 |
| Sample size | 100 |
| Maximum generations | 1000 |
| Rate of crossover | 0.1 |
| Rate of Mutation | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Obi, E.; Mammeri, Z.; Ochia, O.E. A Centralized Routing for Lifetime and Energy Optimization in WSNs Using Genetic Algorithm and Least-Square Policy Iteration. Computers 2023, 12, 22. https://doi.org/10.3390/computers12020022
Obi E, Mammeri Z, Ochia OE. A Centralized Routing for Lifetime and Energy Optimization in WSNs Using Genetic Algorithm and Least-Square Policy Iteration. Computers. 2023; 12(2):22. https://doi.org/10.3390/computers12020022
Chicago/Turabian StyleObi, Elvis, Zoubir Mammeri, and Okechukwu E. Ochia. 2023. "A Centralized Routing for Lifetime and Energy Optimization in WSNs Using Genetic Algorithm and Least-Square Policy Iteration" Computers 12, no. 2: 22. https://doi.org/10.3390/computers12020022
APA StyleObi, E., Mammeri, Z., & Ochia, O. E. (2023). A Centralized Routing for Lifetime and Energy Optimization in WSNs Using Genetic Algorithm and Least-Square Policy Iteration. Computers, 12(2), 22. https://doi.org/10.3390/computers12020022