

Identification of Scientific Texts Generated by Large Language Models Using Machine Learning
 ,
, 
Abstract
1. Introduction
- identify LLM-generated texts with high accuracy;
- detect covert plagiarism practices using advanced techniques;
- provide accessible tools for academic and professional institutions.
- the creation of a meticulously designed dataset validated through comprehensive experiments;
- the implementation of models ranging from classical techniques to Transformer and LLM architectures.
2. Theoretical Framework
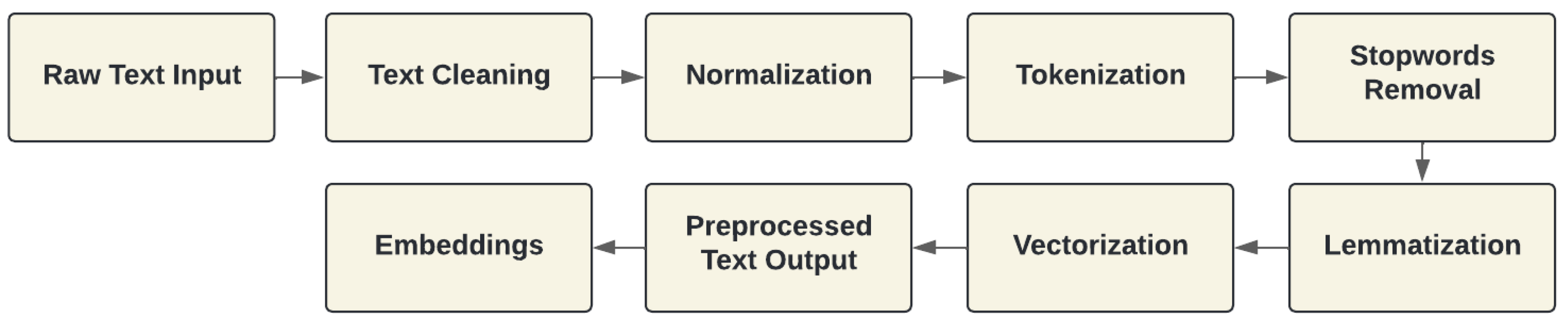
2.1. Preprocessing Techniques
2.2. Overview of Text Vectorization Methods
- One-hot encoding consists of adding a binary vector to each word, where only one element is 1 (representing the word) and the others are 0. It does not identify the semantic relationships between words [2].
- Bag of words represents a document as a list of words; it does not take into account the order of these words, and the resulting vector indicates the frequency at which each word appears in the text [3].
- N-grams expands the bag of words by considering sequences of consecutive words. In this way, it is possible capture information such as the order of the words, which also bring with them the context. These can be uni-grams, bi-grams or tri-grams; this is not limited only to words. They can also be implemented with groups of characters [4].
- TF-IDF compares the frequency of a word in a document with the frequency of the same word in a collection of documents. Less common words are more important and have less weight [5].
- Word2Vec generates dense and low-dimensional vectors for each word according to its context. It uses models such as Skip-Gram or CBOW to train embeddings. It generates a low-dimensional vector for each word; if you want to obtain the vector representation of a sentence, you must add the vectors of each word and divide them by the total number of vectors to obtain a normalized vector containing semantic information and the context of the sentence [6].
- GloVe is an embedding technique that relies on word matches within a large text corpus. It captures semantic patterns using a global matrix of co-occurrences, unlike models such as Word2Vec that train words in close context [7].
- BERT is a language model based on the Transformer architecture that differs in that it is bidirectional, meaning that it takes into account the preceding and following context of a word within a sentence. Compared to unidirectional models that only process text from left to right, being bidirectional allows it to generate much more accurate contextual insertions. Also, the word masking task, in which some words in the text are hidden and the model tries to predict them, helps BERT to learn deep semantic relationships [8].
- RoBERTa is an improved version of BERT, as it was created to overcome some limitations of the original model. This new model was trained with a larger amount of data and employs key adjustments to optimize its performance in various PLN tasks; this model eliminates the “predict the next sentence” method, as the researchers found that it did not provide significant improvements. This new model only receives a masking stage, but it is focused to have a greater attention to scale; this means that it has more data, longer sequences and the use of larger minibatches [9].
- The use of large language models, such as GPT or LLaMA, to create insertions depends on their ability to understand the full context of a text stream. Their Transformer architecture allows these models to process both individual words and their relationship to the rest of the sentence or document. As a result, they produce highly contextualized embeddings, where the meaning of a word depends on the environment in which it is found. This allows the encapsulations to capture complex semantic relationships, representing both the individual meaning of words and the overall context of entire sentences, making them ideal for advanced language processing tasks such as text classification or natural language generation [10].
2.3. Classical Classification Algorithms
- Logistic regression is a linear classification model that is mainly used in binary problems to predict the probability of belonging to a class; unlike linear regression, it uses a sigmoid function that predicts continuous values. In this way, the output can be transformed to values between 0 and 1; for decision-making, normally, a typical threshold of 0.5 is used. If the probability is greater or equal to this value, the model assigns a positive class, otherwise it gives a negative one. The algorithm is efficient when the relationships are approximately linear, but it can be limited when the relationships are more complex. On the other hand, this model can also be implemented for multiclass classification through approaches such as “one vs. rest” or “softmax regression”; in these, the model predicts the probability that an instance belongs to each of the classes that are available, despite being effective in cases where the relationships are linear. Its simplicity and its ability to handle both binary and multiclass problems make it widely used in different tasks [11].
- Random forest is a machine-learning algorithm that is based on the creation of multiple decision trees; each of the trees is trained with a random subset of training data, which produces a diversity among the trees. At the time of classifying a new piece of data, each tree generates a prediction and at the end the final model makes the decision by a majority voting system for classification cases, or the other method is an averaging for regression cases. This approach is not very susceptible to overfitting because individual trees are likely to overfit, but this is mitigated by combining many trees. This model is very effective when dealing with data that do not have linear interactions, as it can work with large datasets of many variables and is able to detect or capture complex relationships between features [12].
- SVMs are a class of powerful classification algorithm that focus mainly on finding an optimal hyperplane that can separate classes in a high dimensionality feature space. The main idea is to maximize the distance between the hyperplane and the points closest to it. These are known as support vectors; having a greater margin can lead to greater confidence in the classification. When talking about nonlinear problems, SVMs use the kernel tool, which allows mapping the data to a higher dimensional feature space, where the classes can be linearly separable; there are several kernels, among which are linear, polynomial and radial basis function (RBF). This algorithm is good in high dimensionality spaces but can be computationally expensive, especially when working with large datasets [13].
- The KNN algorithm is a supervised classification model that is mainly based on the similarity of instances; in order to classify new data, the model looks for the closest neighbors to that data within the feature space and assigns the most common class among the neighbors. In order to determine the distance between points, the Euclidean distance is mainly used, although, depending on the nature of the data, other metrics can be used. It is a very simple and effective model where the decision boundaries are complex and nonlinear. It has the main disadvantage of being sensitive to the scale of the features, so it is necessary to apply a normalization process before its application. Also, its performance is affected when there are large datasets; however, KNN is useful when a quick solution is required and there is no parametric model [14].
2.4. Deep-Learning Models
- Fully connected neural networks are the most basic type of neural network; each of the neurons of a layer is completely connected to each neuron of the next layer and the information is propagated in a unidirectional way, from the input to the output, without having any kind of feedback. They can be implemented to solve classification or regression problems. One of their main limitations is that they do not capture the spatial or temporal relationships of the data, which translates into problems to bring good performance in complex problems, such as the analysis of sequences or large images. Despite having a simple architecture, they can become powerful for tasks where the input relationships are linear [15].
- RNN is a type of neural network that has the ability to process data sequences such as text or time series; the rRNN has cyclic connections different from fully connected networks, which allows them to maintain a memory of previous inputs. The reason for this is that they can be useful when modeling temporal dependencies; in each time step, the RNN receives an input and modifies its hidden state based on the input and the current hidden state. This type of neural network usually has problems of gradient fading or splashing; this can make learning difficult when dealing with long data sequences, although they can be useful for tasks such as sequence analysis or machine translation [16].
- LSTM is a type of network is a variant of RNNs but is designed primarily to mitigate the problem of gradient fading when implementing long sequences. This type of network uses a special memory architecture; these memories are composed of cells that can remember and forget information over time. This allows them to capture long-term dependencies more effectively than traditional RNNs. This type of network is widely implemented in sequential tasks such as language modeling, text generation, sentiment analysis and time-series prediction, but despite being computationally more expensive and more complex, LSTMs have proven to be significantly more effective in most sequential problems [16].
- Transformer architecture is an innovative solution presented in 2017 to overcome the limitations that RNNs and LSTMs have, especially in natural language processing and sequence processing tasks. Its main improvements are the attention mechanisms; these allow each part of the input to influence every other part, regardless of the position of the sequence. With that, the need to process data sequentially can be eliminated. This allows for much greater parallelism in training and data processing. This new architecture has proven to have far superior performance than previous architectures for machine translation, language modeling and text generation. Some models that have revolutionized the NLP field, such as BERT or GPT, have their operating principles in the Transformer architecture [17].
2.5. Evaluation Metrics and Visualization Techniques
- Precision is the proportion of instances correctly classified as positive among all instances that were classified as positive. It is a useful metric when the cost of false positives is high. The formula to calculate it is:where are the true positives and are the false positives.
- Recall measures the ability of the model to correctly identify positive instances among all true positive instances. It is particularly important when the cost of false negatives is high. The formula to calculate it is:where are the true positives and are the false negatives.
- F1-Score is the harmonic mean between precision and recall and is useful when there is a balance between false positives and false negatives. The F1-Score provides a single metric that balances these two aspects:
- Accuracy measures the proportion of correct predictions among all predictions made. It is useful in balanced datasets but can be misleading in unbalanced datasets:where are the true negatives.
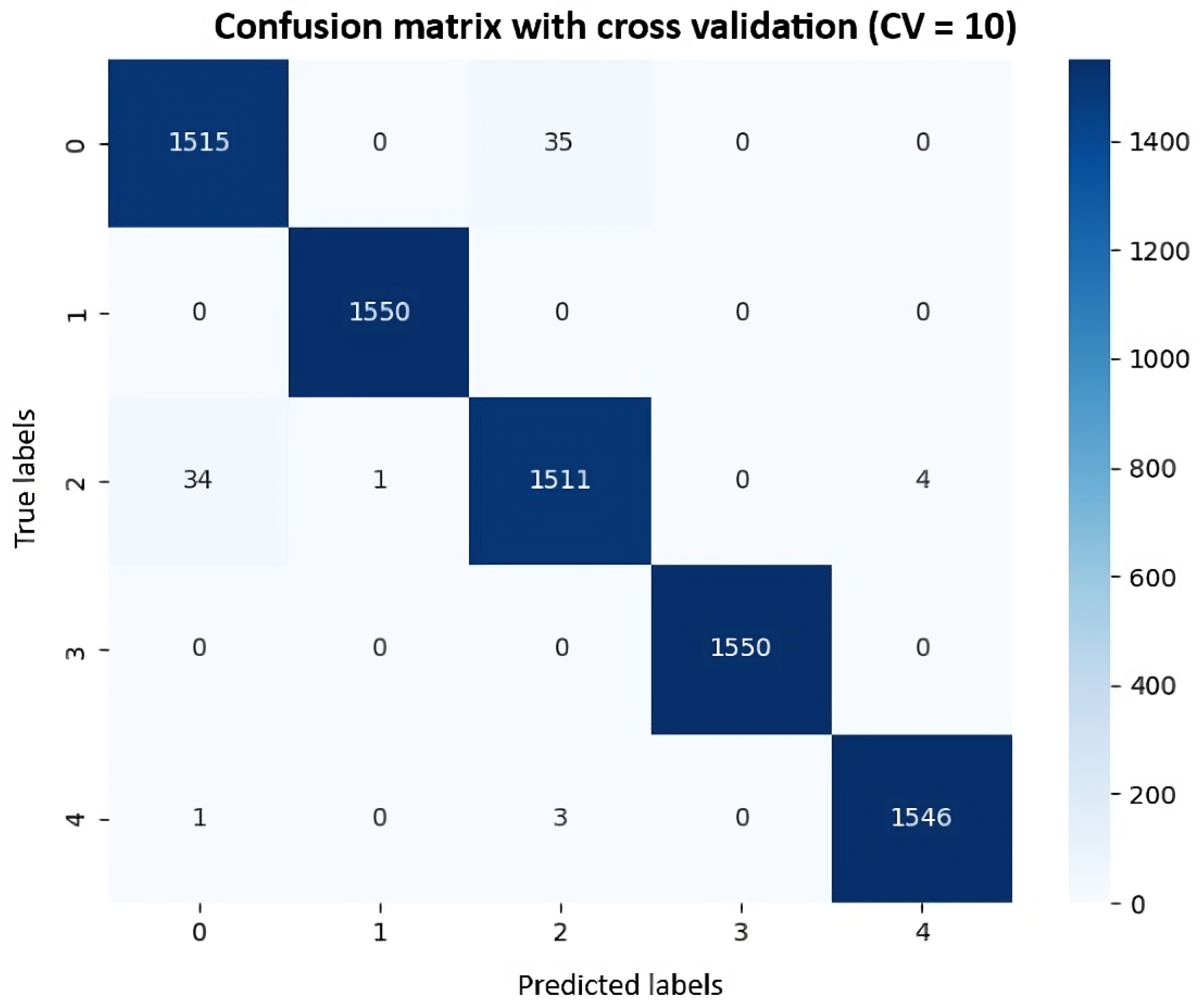
- The confusion matrix is a table that shows the predictions of the model against the original labels; these are broken down into true positives, true negatives, false positives and false negatives. This matrix helps to analyze the performance of our model with each of the classes and better understand the types of errors they are making [19].
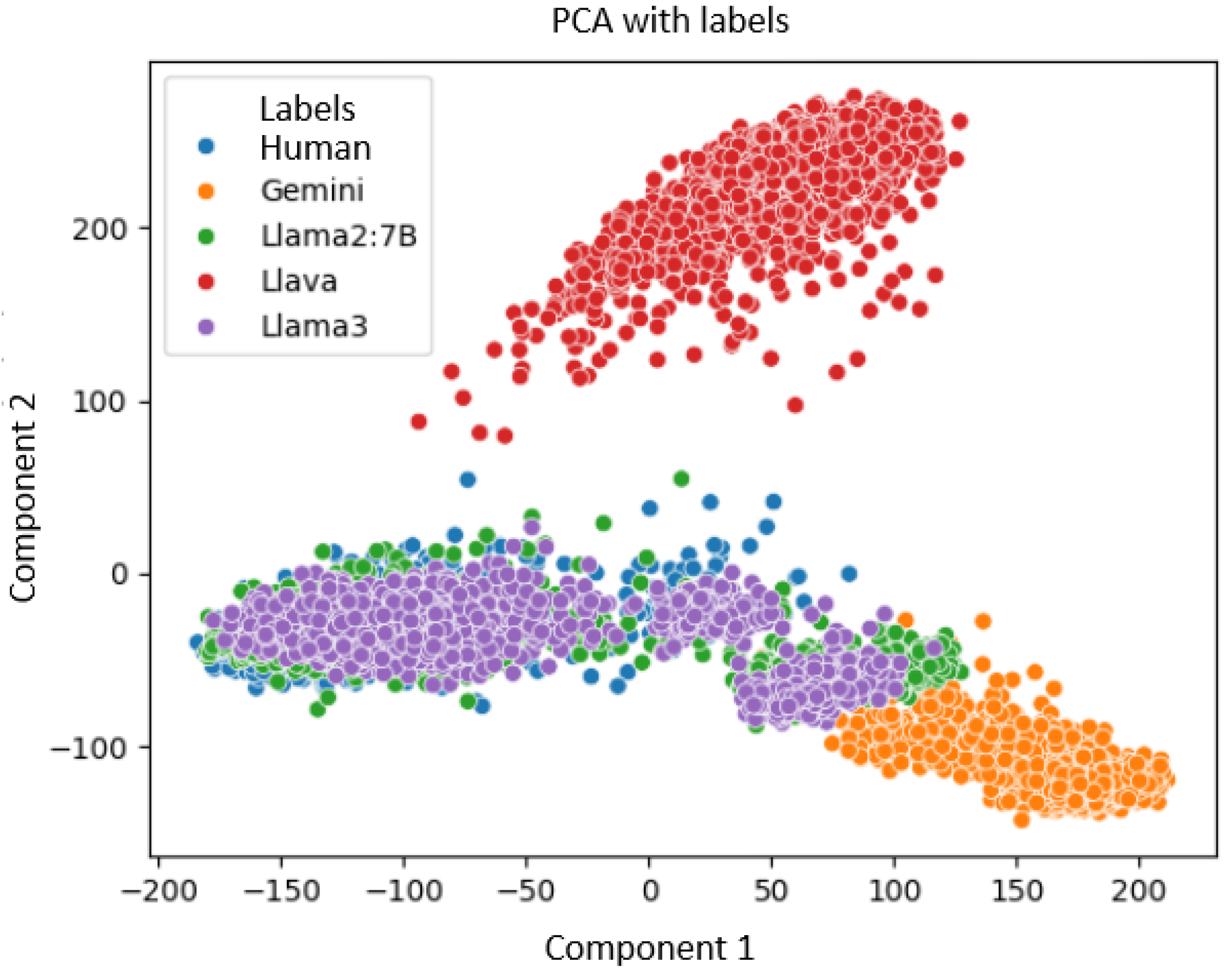
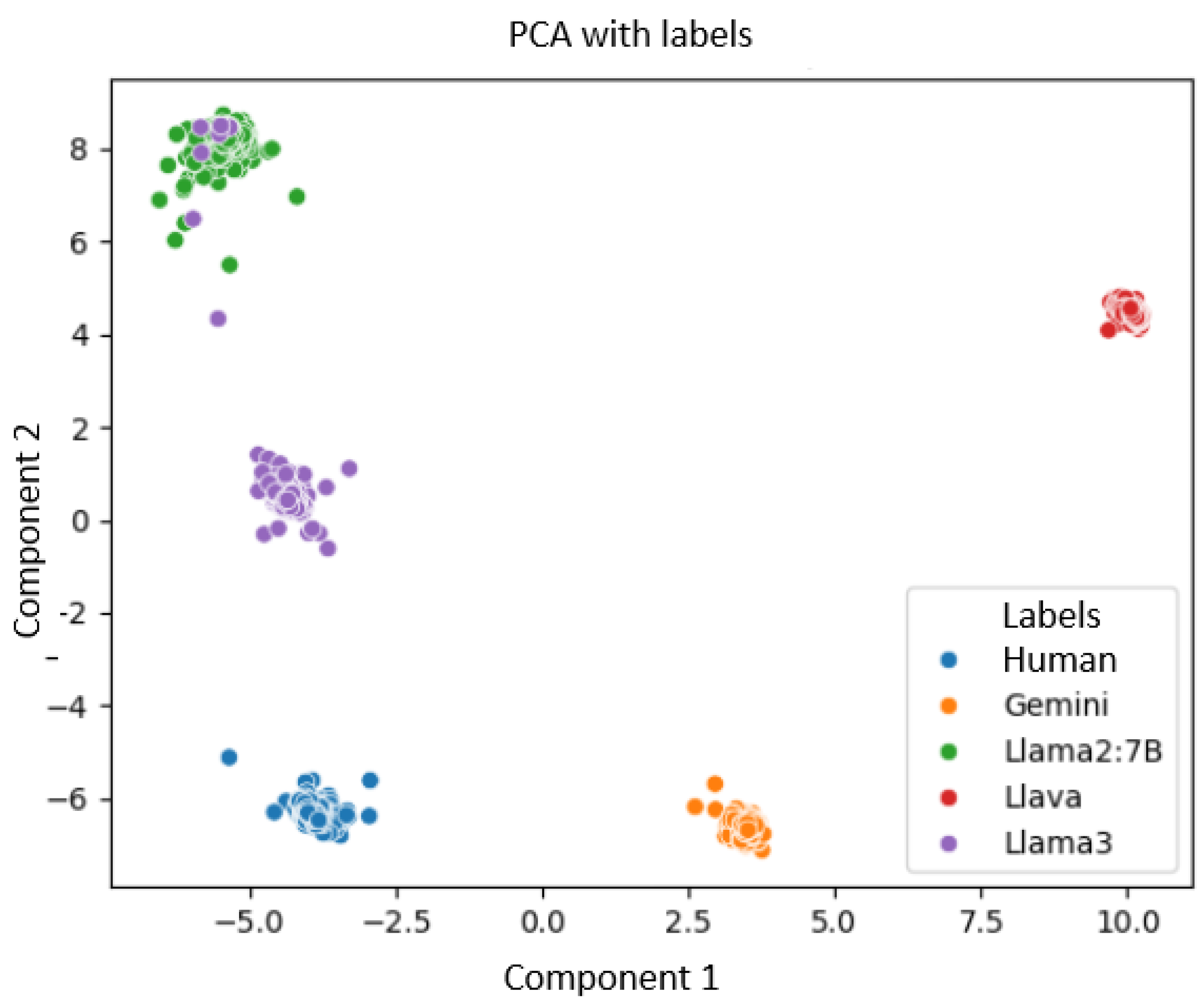
- PCA (Principal Component Analysis) is a dimensionality reduction technique that can transform the data into a new space with fewer dimensions while preserving as much variance as possible. It is mainly implemented to visualize high-dimensional data so that the main features are highlighted in a two-dimensional or three-dimensional plane [20].
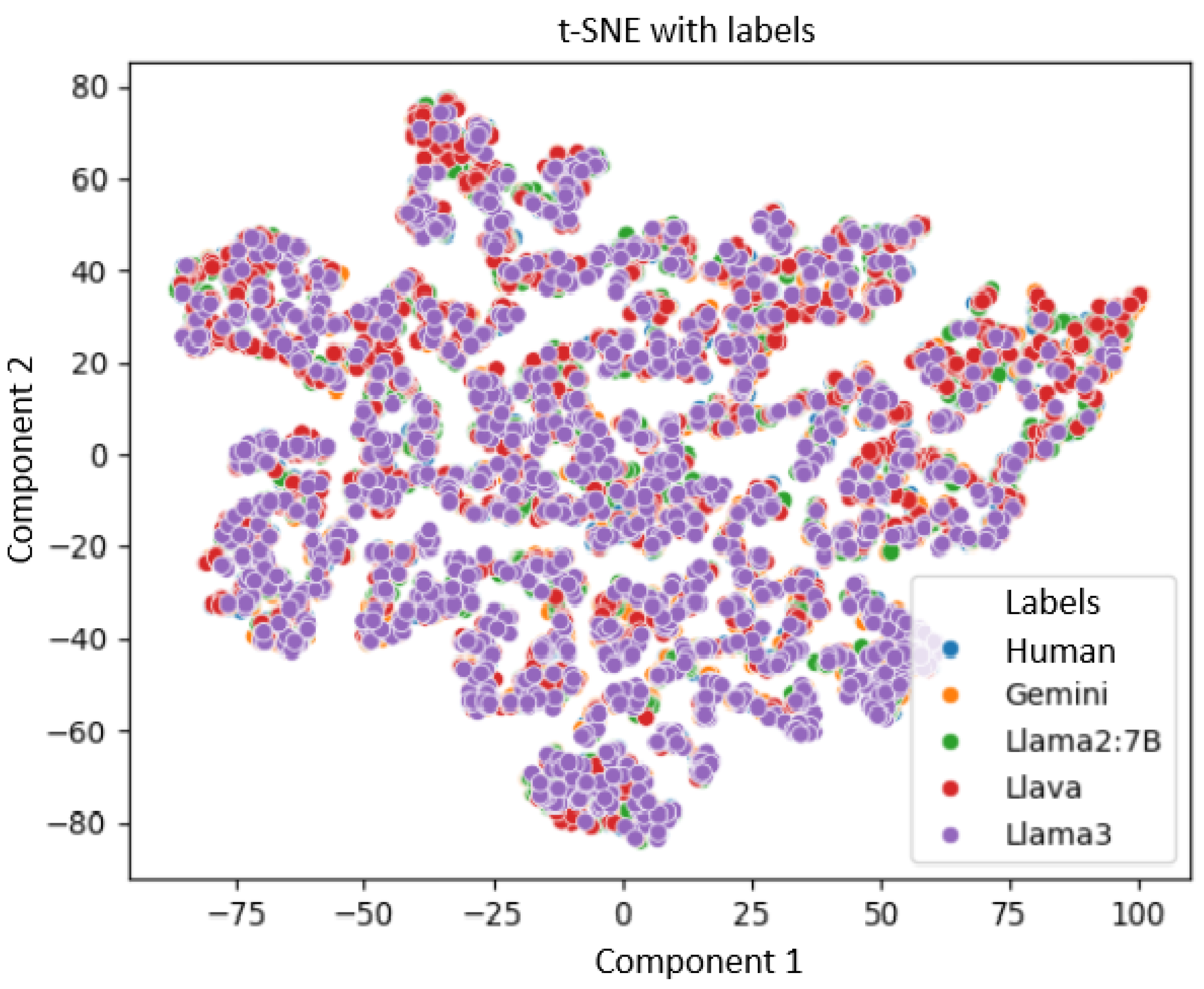
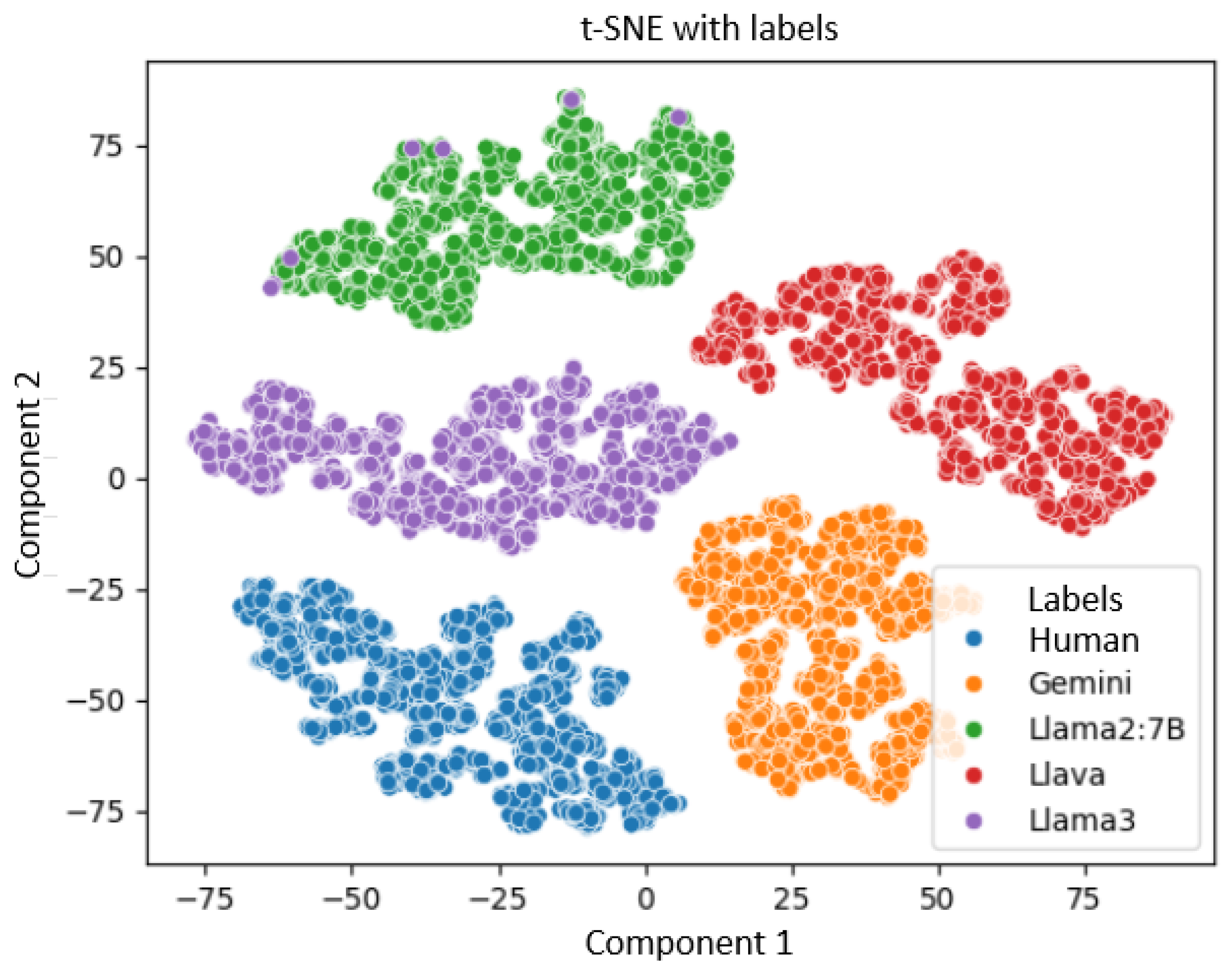
- t-SNE (T-distributed Stochastic Neighbor Embedding) focuses primarily on preserving local relationships between instances, which makes it particularly useful for visualizing data clusters or embeddings in tight spaces. This is another dimensionality reduction technique used for visualization, especially effective for high-dimensional data [21].
- The ROC (receiver operating characteristic) curve shows the relationship between the true positive rate (TPR) and the false positive rate (FPR) for different decision thresholds. An area under the curve (AUC) of 1 indicates a perfect model, while an AUC of 0.5 indicates a random model [22].
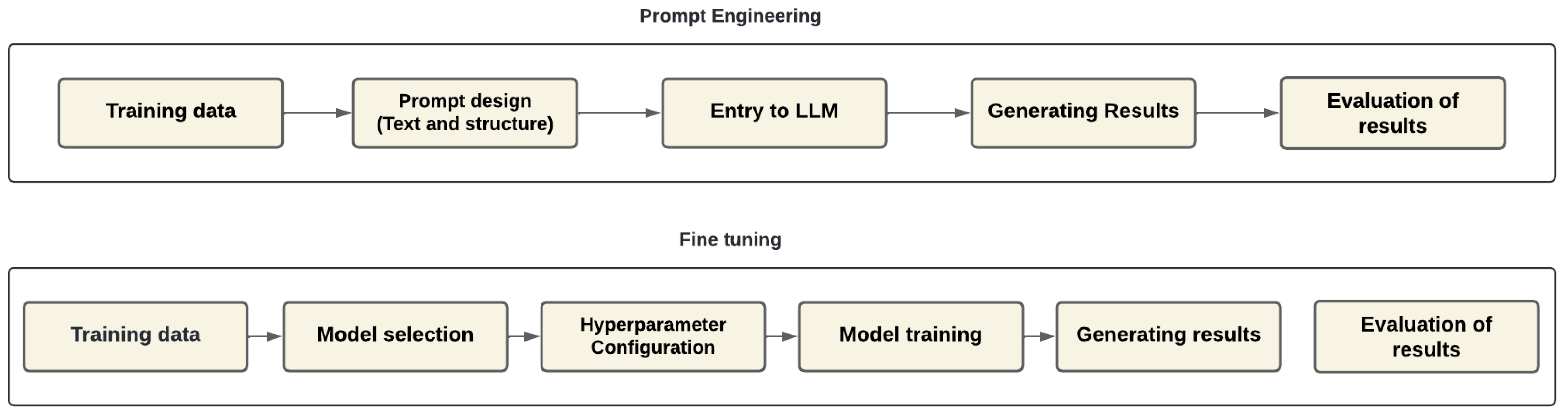
2.6. LLM Implementation Methods
- Prompt Engineering consists of designing prompts in a precise way to guide the language model to generate the most appropriate responses. When using pre-trained LLMs without the need to change their parameters, this technique is particularly useful. Advantages include the fact that it does not require additional training or large computational capacity and that it is fast and efficient for specific tasks. However, its customization for more complex or specific tasks may be limited, and its effectiveness depends on the capability of the LLM [23].
- Fine tuning involves taking a previously trained model and retraining it with a specific dataset. It allows the weights of the model to be adjusted to improve its performance on particular problems. Advantages include the ability to create models that are highly tailored to specific tasks, improving accuracy and performance and being flexible for a wide range of applications. However, disadvantages include the fact that it requires a high quality dataset and significant computational resources, and it can be costly in terms of time and processing [24].
- RAG (Retrieval-augmented generation) combines information retrieval techniques with text generation. First, relevant information is retrieved from a database or search engine, and then the LLM generates text based on that information. Advantages include increasing the accuracy of the LLM by relying on up-to-date and relevant information, improving answers to specific queries and reducing the dependency on model size. However, the disadvantages are that it requires additional systems for information retrieval, which complicates the architecture, and can increase latency in the generation process [25].
- The creation of LLM from scratch implements the initial training of a language model using a large amount of unstructured data without prior training. The design of the model architecture, the selection of training data and the configuration of hyperparameters are all components of this process. Advantages include full control over model design and training, allowing for innovative or extremely customized models for specific needs. However, disadvantages include being very expensive and requiring large amounts of computational resources, storage and time, as well as being complex and requiring a great deal of expertise in language modeling and optimization.
- Quantization is a technique implemented to reduce the size of deep-learning models and also allows us to accelerate their inference, instead of representing the weights of a model with floating point numbers, which are a type of data that consume more memory and require more computation time. Quantization converts this type of data into one of lower precision, for example, converting them into 8-bit data.
- LoRA is a technique that is used to train models that were already pre-trained without the need to adjust all the parameters of the model; instead, LoRA introduces a low-rank matrix that is trained while the model weights are kept fixed so that only a small number of parameters are trained instead of the whole model, which can considerably reduce the training time and also reduces the amount of computational resources needed. This technique is a great advantage when large language models need to be retrained.
- QLoRA combines both quantization and LoRA; that is, this technique applies quantization to the low-rank matrices that are introduced during the fitting process. This allows one to further reduce the size and complexity of the models. QLoRA is a very useful technique when limited computational resources are available.
3. Related Work
4. Methodology
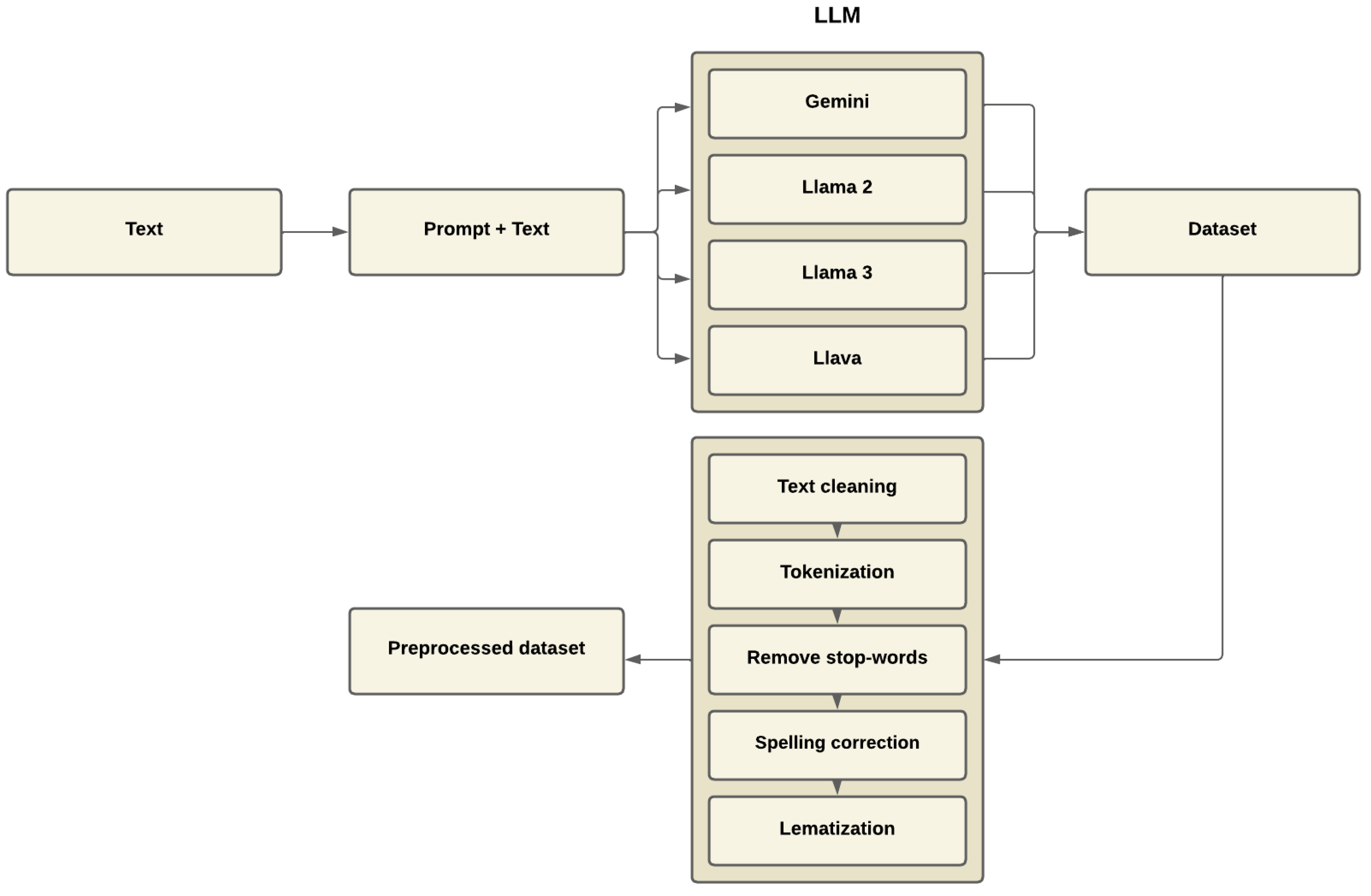
4.1. Formation and Preprocessing of Linguistic Corpus
“Summarize the article. Do not generate any additional text, just provide the summary.”
“The article discusses how artificial intelligence (AI) is transforming the educational sector. It focuses on the use of AI-based tools to personalize learning, improve teaching through automation and provide more efficient access to educational content. Additionally, it addresses the ethical and social challenges that may arise from the integration of these technologies, such as the potential gap between students with access to AI and those without.”
4.2. Embeddings Generation
4.3. Implementation of Classification Algorithms
5. Experiments and Analysis of Results
6. Limitations
7. Impact and Applicability
8. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hugging Face. Preprocessing Data with Transformers. 2024. Available online: https://huggingface.co/docs/transformers/preprocessing (accessed on 10 April 2024).
- Interactive Chaos. Machine Learning Tutorial: One Hot Encoding. 2024. Available online: https://interactivechaos.com/es/manual/tutorial-de-machine-learning/one-hot-encoding (accessed on 22 April 2024).
- IBM. Bag of Words. 2024. Available online: https://www.ibm.com/topics/bag-of-words (accessed on 24 April 2024).
- Towards Data Science. Understanding Word N-Grams and N-Gram Probability in Natural Language Processing. 2024. Available online: https://towardsdatascience.com/understanding-word-n-grams-and-n-gram-probability-in-natural-language-processing-9d9eef0fa058 (accessed on 24 April 2024).
- Jain, A. TF-IDF in NLP: Term Frequency-Inverse Document Frequency. 2024. Available online: https://medium.com/@abhishekjainindore24/tf-idf-in-nlp-term-frequency-inverse-document-frequency-e05b65932f1d (accessed on 25 April 2024).
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. Available online: https://aclanthology.org/D14-1162/ (accessed on 25 April 2024).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2 June–7 June 2019; Version 2, Last Revised 24 May 2019. Available online: https://arxiv.org/abs/1810.04805 (accessed on 25 April 2024).
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. Available online: https://arxiv.org/abs/1907.11692 (accessed on 25 April 2024).
- LlamaIndex. Ollama Embedding Example. 2024. Available online: https://llamaindex.ai (accessed on 10 April 2024).
- Scikit-Learn. Logistic Regression. 2024. Scikit-Learn Documentation. Available online: https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression (accessed on 23 April 2024).
- Scikit-Learn. Random Forest. 2024. Scikit-Learn Documentation. Available online: https://scikit-learn.org/stable/modules/ensemble.html#random-forests (accessed on 17 April 2024).
- Scikit-Learn. Support Vector Machines. 2024. Scikit-Learn Documentation. Available online: https://scikit-learn.org/stable/modules/svm.html (accessed on 15 April 2024).
- Scikit-Learn. K-Nearest Neighbors. 2024. Scikit-Learn Documentation. Available online: https://scikit-learn.org/stable/modules/neighbors.html (accessed on 23 April 2024).
- BuiltIn. What Is a Fully Connected Layer in Machine Learning? BuiltIn Machine Learning Topics. 2024. Available online: https://builtin.com/machine-learning/fully-connected-layer (accessed on 23 April 2024).
- ScienceDirect. Long Short-Term Memory Networks. 2024. ScienceDirect Topics in Computer Science. Available online: https://www.sciencedirect.com/topics/computer-science/long-short-term-memory-networks (accessed on 23 April 2024).
- Hugging Face. Chapter 1.4–NLP Tasks. 2024. Hugging Face NLP Course. Available online: https://huggingface.co/course/chapter1/4 (accessed on 23 April 2024).
- Analytics Vidhya. Metrics to Evaluate Your Classification Model to Take the Right Decisions. 2021. Analytics Vidhya Blog. Available online: https://www.analyticsvidhya.com/blog/2021/07/metrics-to-evaluate-your-classification-model-to-take-the-right-decisions/ (accessed on 23 April 2024).
- IBM. Confusion Matrix: What It Is and How to Use It. 2024. IBM Topics. Available online: https://www.ibm.com/mx-es/topics/confusion-matrix (accessed on 23 April 2024).
- IBM. Principal Component Analysis: What It Is and How to Use It. 2024. IBM Topics. Available online: https://www.ibm.com/think/topics/principal-component-analysis (accessed on 25 April 2024).
- IBM. Creación de gráficos t-SNE en SPSS Statistics. 2024. IBM Documentation. Available online: https://www.ibm.com/docs/es/spss-statistics/beta?topic=sslvmb-subs-statistics-mainhelp-ddita-spss-base-chart-creation-tsne-html (accessed on 26 April 2024).
- Google Developers. ROC and AUC—Machine Learning Crash Course. Google Machine Learning Crash Course. Available online: https://developers.google.com/machine-learning/crash-course/classification/roc-and-auc?hl=es-419 (accessed on 28 April 2024).
- Pinecone Learning Hub. LangChain Prompt Templates. Pinecone.io Documentation. Available online: https://python.langchain.com/docs/integrations/vectorstores/pinecone/ (accessed on 23 July 2024).
- FreeCodeCamp. Fine-Tuning LLM Models—FreeCodeCamp. FreeCodeCamp News. Available online: https://www.freecodecamp.org/news/fine-tuning-llm-models-course/ (accessed on 30 July 2024).
- Amazon Web Services. What Is Retrieval-Augmented Generation (RAG)? AWS Documentation. Available online: https://aws.amazon.com/what-is/retrieval-augmented-generation/ (accessed on 1 August 2024).
- Sadasivaan, V.S.; Kumar, A.; Balasubramanian, S.; Wang, W.; Feizi, S. Can AI-Generated Text be Reliably Detected? arXiv 2023, arXiv:2303.11156v3. [Google Scholar]
- Wu, J.; Yang, S.; Zhan, R.; Yuan, Y.; Wong, D.F.; Chao, L.S. A Survey on LLM-generated Text Detection: Necessity, Methods, and Future Directions. arXiv 2023, arXiv:2310.14724. [Google Scholar]
- Bv, P.; Ahmed, S.; Sadanandam, M. DistilBERT: A Novel Approach to Detect Text Generated by Large Language Models (LLM). arXiv 2024, arXiv:3909387v1. [Google Scholar]
- Major, A.; Capobianco, M.; Reynolds, M.; Phelan, C.; Shah-Nathwani, K.; Luong, D.; Lee, K.; Kumaravel, M. Supervised Machine Generated Text Detection Using LLM Encoders in Various Data Resource Scenarios. Doctoral Dissertation, Worcester Polytechnic Institute, Worcester, MA, USA, 2023. Available online: https://www.semanticscholar.org/paper/Supervised-Machine-Generated-Text-Detection-Using-Major-Capobianco/a79561bad0a5a3f5b0cb3ba9750ad7851369ff2a (accessed on 25 February 2024).
- Blecher, L.; Cucurull, G.; Scialom, T.; Stojnic, R. Nougat: Neural Optical Understanding for Academic Documents. arXiv 2023, arXiv:2308.13418. Available online: https://arxiv.org/abs/2308.13418 (accessed on 25 February 2024).
- Ollama-Llama3. LLaMA3. Ollama Library. Available online: https://ollama.com/library/llama3 (accessed on 25 February 2024).
- Ollama-Llama2. Llama2. Ollama Library. Available online: https://ollama.com/library/llama2 (accessed on 25 February 2024).
- Ollama-Gemma. Gemma. Ollama Library. Available online: https://ollama.com/library/gemma (accessed on 25 February 2024).
- Ollama-Llava. LLaVA. Ollama Library. Available online: https://ollama.com/library/llava (accessed on 25 February 2024).
- Hugging Face-Distilbert. DistilBERT Model Documentation. Hugging Face Transformers. Available online: https://huggingface.co/distilbert (accessed on 20 April 2024).
- Hugging Face. DistilRoBERTa-Base-Distilroberta. Hugging Face Transformers. Available online: https://huggingface.co/distilroberta-base (accessed on 25 April 2024).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Details | Sadasivaan et al. [26] | Wu et al. [27] | Kumar et al. [28] | Capobianco et al. [29] | My Proposal |
|---|---|---|---|---|---|
| Dataset | |||||
| DAIGT-V3, LLM-DetectAI | ✔ | ||||
| HC3 corpus | ✔ | ✔ | ✔ | ||
| New dataset | ✔ | ||||
| Models Used | |||||
| Deep Learning | ✔ | ✔ | ✔ | ||
| Classical algorithms | ✔ | ||||
| Watermarking | ✔ | ||||
| Transformers BERT and RoBERTa | ✔ | ✔ | ✔ | ||
| Main Approach | |||||
| Detection of type 1 and 2 errors | ✔ | ||||
| Classification of texts generated by GPT | ✔ | ||||
| Detection of texts generated by LLMs | ✔ | ✔ | |||
| Detection of texts generated by various LLMs | ✔ | ||||
| Column Name | Column Function |
|---|---|
| Title | Represents the title of the article. |
| Abstract | Provides a concise summary of the article’s content. |
| Category | Indicates the subject area or category assigned to the article in Arxiv. |
| Label | Specifies the label used for classification tasks. |
| Column Name | Description |
|---|---|
| Title | Article title |
| Abstract | Article abstract |
| Category | Arxiv’s category |
| Preprocessed texts | Preprocessed texts |
| Label | Label’s texts |
| One-Hot | One hot coded labels |
| Model | Embedding Sizes |
|---|---|
| LLaMA3 | 4096 |
| LLaMA2 | 4096 |
| Gemini | 2048 |
| LLaVA | 2048 |
| BERT | 768 |
| RoBERTa | 1024 |
| Embeddings | Model | k-Fold | Epochs | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|---|---|
| TF-IDF | Logistic Regression | 10 | - | 0.6981 | 0.7040 | 0.6981 | 0.6938 |
| N-grams | Logistic Regression | 10 | - | 0.7165 | 0.7250 | 0.7132 | 0.7153 |
| Word2Vec | LSTM | - | 1000 | 0.4761 | 0.4549 | 0.4648 | 0.4523 |
| GloVe | Random Forest | 10 | - | 0.5161 | 0.5153 | 0.5161 | 0.5081 |
| BERT | Logistic Regression | 10 | - | 0.7812 | 0.7825 | 0.7812 | 0.7808 |
| RoBERTa | SVM | 9 | - | 0.9233 | 0.9235 | 0.9233 | 0.9234 |
| LLM Gemini | LSTM | - | 500 | 0.7225 | 0.7288 | 0.7120 | 0.7119 |
| LLM LLaMA2 | SVM | 10 | - | 0.9860 | 0.9860 | 0.9860 | 0.9860 |
| LLM LLaMA3 | Logistic Regression | 10 | - | 0.9861 | 0.9862 | 0.9861 | 0.9861 |
| LLM LLaVA | SVM | 10 | - | 0.9899 | 0.9899 | 0.9899 | 0.9899 |
| Model | Epochs | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| DistilBERT | 10 | 0.8077 | 0.8312 | 0.8077 | 0.8097 |
| DistilBERT | 100 | 0.8400 | 0.8517 | 0.8400 | 0.8429 |
| DistilRoBERTa | 10 | 0.9974 | 0.9974 | 0.9974 | 0.9974 |
| DistilRoBERTa | 100 | 0.9954 | 0.9955 | 0.9954 | 0.9954 |
| LLaMA2 | 5 | 0.9932 | 0.9953 | 0.9931 | 0.9935 |
| LLaMA3 | 5 | 0.9952 | 0.9943 | 0.9966 | 0.9963 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Soto-Osorio, D.; Sidorov, G.; Chanona-Hernández, L.; López-Ramírez, B.C. Identification of Scientific Texts Generated by Large Language Models Using Machine Learning. Computers 2024, 13, 346. https://doi.org/10.3390/computers13120346
Soto-Osorio D, Sidorov G, Chanona-Hernández L, López-Ramírez BC. Identification of Scientific Texts Generated by Large Language Models Using Machine Learning. Computers. 2024; 13(12):346. https://doi.org/10.3390/computers13120346
Chicago/Turabian StyleSoto-Osorio, David, Grigori Sidorov, Liliana Chanona-Hernández, and Blanca Cecilia López-Ramírez. 2024. "Identification of Scientific Texts Generated by Large Language Models Using Machine Learning" Computers 13, no. 12: 346. https://doi.org/10.3390/computers13120346
APA StyleSoto-Osorio, D., Sidorov, G., Chanona-Hernández, L., & López-Ramírez, B. C. (2024). Identification of Scientific Texts Generated by Large Language Models Using Machine Learning. Computers, 13(12), 346. https://doi.org/10.3390/computers13120346