

Detection of Deepfake Media Using a Hybrid CNN–RNN Model and Particle Swarm Optimization (PSO) Algorithm


Abstract
:1. Introduction
2. Related Work
3. Technical Background
3.1. Convolutional Neural Network (CNN)
3.2. Long Short-Term Memory (LSTM)
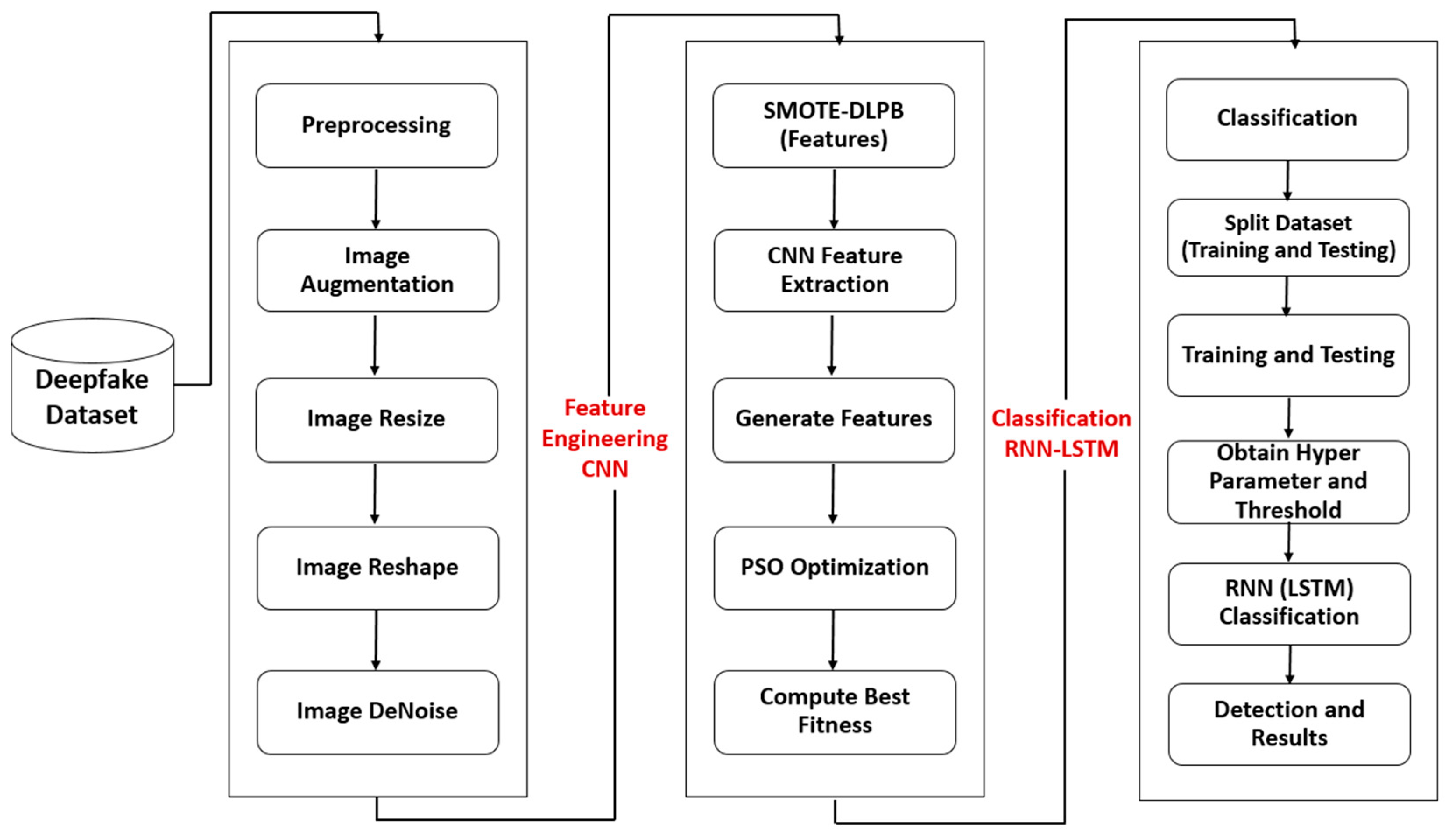
4. Methodology
4.1. Datasets
4.2. Proposed Method
| Algorithm 1. The proposed deepfake detection model. |
| Input: A set of videos, including both real and deepfake videos. |
| Output: The classification of each video as either “real” or “deepfake”. |
|
4.2.1. Preprocessing
4.2.2. PSO
- Number of layers in the CNN (L)
- Number of neurons in each layer of the CNN (N)
- Activation functions used in the CNN (A)
- Number of layers in the RNN (R)
- Number of neurons in each layer of the RNN (M)
- Activation functions used in the RNN (B)
- Initialize the particles in the swarm with random values for the parameters L, N, A, R, M, and B.
- Evaluate the fitness of each particle by training the model with the parameters’ current values and measuring the validation set’s accuracy.
- According to each particle’s fitness, update its global best position and personal best position. A particle’s own best position is the optimal combination of parameters it has come across. The optimal combination of characteristics that every particle in the swarm encounters is known as the global best position.
- Update the velocity and position of each particle based on its personal best position and the global best position using the following equations:where v[i,t] is particle i’s velocity at time t; x[i,t] is particle i’s position at time t; w is the inertia weight; c1 and c2 are the acceleration constants; r1 and r2 are random numbers ranging from 0 to 1; pbest[i] are particle i’s personal best positions; and best is the global best.
- The PSO algorithm will continue to update the values of the parameters until the global best position is found, which corresponds to the set of parameters that maximize the model’s accuracy on the validation set.
4.2.3. CNN–RNN Fine-Tuning
4.2.4. CNN
4.2.5. RNN
5. Results
- Swarm size, which denotes the number of particles in the algorithm = 15.
- Number of iterations indicates the precise number of passes the best search algorithm will carry out prior to optimization being finished = 8.
- Cognitive coefficient (c1) indicates the extent to which the particle is affected by its optimal position = 4.
- Social coefficient (c2) indicates the extent to which the particle neighbors’ optimal positions affected it = 4.
- Number of filters in the convolutional layer ranges from 16 to 64.
- The filter size ranges from 3 and 6.
- The stride ranges from 2 to 4
- Drop Out = 0.4.
- Learning Rate = 0.01.
- Epochs = 20.
- Batch Size = 100.
5.1. Results Discussion
5.2. Results Comparison
5.3. Model Complexity
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, W.; Jia, X.; Xie, X. Deepfake: A survey. IEEE Trans. Multimed. 2021, 23, 2250–2269. [Google Scholar]
- Hao, X.; Lu, J.; Cao, X. Deepfake detection using deep learning: A review. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2020, 16, 1–24. [Google Scholar]
- Maras, M.H. Deepfake technology and implications for national security, democracy, and privacy. Int. J. Law Crime Justice 2020, 61, 1–12. [Google Scholar]
- Yarlagadda, P.; Li, Y. Deepfake detection: A review. Comput. Secur. 2021, 107, 102193. [Google Scholar]
- Li, Z.; Li, X.; Wang, Q.; Yang, B.; Zhan, X. Deepfake detection based on improved CNN and Xception networks. IEEE Access 2021, 9, 31664–31673. [Google Scholar]
- Xia, Z.; Liu, X.; Yang, Y. Deepfake detection using particle swarm optimization and machine learning. IEEE Access 2021, 9, 15540–15549. [Google Scholar]
- Natarajan, P.; Garg, N.; Voleti, V. Deepfake detection: A review of techniques and challenges. IEEE Access 2021, 9, 101600–101618. [Google Scholar]
- Li, W.; Sun, L.; Wang, S. Improved deepfake detection with feature fusion and attention mechanism. Neural Comput. Appl. 2022, 34, 649–659. [Google Scholar]
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J. Deepfake detection in the visual and spatial domains with hand-crafted and deep features. Signal Process. Image Commun. 2021, 96, 116231. [Google Scholar]
- Oh, J.; Lee, S.; Lee, S.; Kim, J.; Yang, H. Deepfake detection: Current trends and future directions. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2370–2395. [Google Scholar]
- Anonymous. Deepfake Detection Challenge. 2022. Available online: https://www.deepfakedetectionchallenge.ai/ (accessed on 31 March 2023).
- Ahmed, M.A.; Mahmood, A.N. Deepfake detection: A comprehensive review. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 12989–13007. [Google Scholar]
- Li, M.; Liu, B.; Hu, Y.; Zhang, L.; Wang, S. Deepfake detection using robust spatial and temporal features from facial landmarks. In Proceedings of the IEEE International Workshop on Biometrics and Forensics (IWBF), Rome, Italy, 6–7 May 2021; IEEE: New York, NY, USA, 2021. [Google Scholar]
- Kim, S.W.; Kim, T.H.; Yang, H.; Kim, D.H. Deepfake detection using local spectral analysis of facial components. IEEE Access 2021, 9, 36883–36894. [Google Scholar]
- Wodajo, E.; Hossain, M.S.; Kim, J. Convolutional vision transformer for deepfake detection. IEEE Access 2021, 9, 125634–125643. [Google Scholar]
- Tran, D.T.; Tran, T.T.; Le, T.L. A deepfake detection model for altered video with content-based approach. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 104–112. [Google Scholar]
- Ismail, M.; Mahmood, M.T.; Wahab, A.W. YOLO-CNN-XGBoost: A hybrid approach for deepfake detection. IEEE Access 2021, 9, 97569–97581. [Google Scholar]
- Zhang, J.; Li, Y.; Li, S.; Li, J. Unsupervised detection of deepfake videos using PRNU-based clustering. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1027–1039. [Google Scholar]
- Suratkar, R.; Karia, D.; Patil, P. Deepfake detection using transfer learning in autoencoders and convolutional neural networks. J. Ambient Intell. Humaniz. Comput. 2021, 12, 12649–12667. [Google Scholar]
- Ismail, M.; Mahmood, M.T.; Wahab, A.W. Deepfake detection using You Only Look Once Convolution Recurrent Neural Networks. Neural Comput. Appl. 2021, 33, 13643–13656. [Google Scholar]
- Mitra, S.; Roy, A.; Dubey, S. Deepfake video detection through visual artifact analysis. Multimed. Tools Appl. 2021, 80, 25917–25933. [Google Scholar]
- Ge, Y.; Huang, J.; Zhu, X.; Long, M. Self-distillation fine-tuning for DeepFake video detection. IEEE Trans. Inf. Forensics Secur. 2021, 16, 3045–3058. [Google Scholar]
- Liu, Y.; Wang, J.; He, Q. A portable 3D convolutional neural network for deepfake detection. Neurocomputing 2021, 457, 176–188. [Google Scholar] [CrossRef]
- Heo, J.; Kang, M.J.; Lee, S. Vision transformer for deepfake detection with content-based patch embedding. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 950–964. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Agarwal, A.; Ahmed, S. DeepFake Detection using Machine Learning: A Survey. arXiv 2021, arXiv:2102.06573. [Google Scholar]
- Li, Y.; Yang, X.; Sun, P.; Qi, H. Celeb-DF: A Large-Scale Challenging Dataset for DeepFake Forensics. arXiv 2021, arXiv:1909.12962. [Google Scholar]
- Wang, Y.; Liu, X.; Xie, Z.; Wang, X.; Qiao, Y. Multi-feature fusion with hierarchical attention mechanism for deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 297–298. [Google Scholar]
- Wu, Y.; Liu, S.; Wang, Y.; Qiao, Y.; Loy, C.C. Learning from synthetic data for crowd counting in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8198–8207. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. FaceForensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar]
- Dang-Nguyen, D.T.; Pasquini, C.; Conotter, V.; Boato, G. The State of the Art in DeepFake Detection: A Review. arXiv 2021, arXiv:2103.01943. [Google Scholar]
- Zhou, X.; Han, X.; Morariu, V.I. Detecting Deepfake through Image Quality Analysis. arXiv 2020, arXiv:2005.07397. [Google Scholar]


{kind=link}
| Author | Dataset | Algorithm | Accuracy Results % |
|---|---|---|---|
| Wodajo [19] | DFDC | CNN | 91.5 |
| Tran [20] | DFDC | CNN | 92.4 |
| Ismail [24] | CelebDF-FaceForencics | YOLO-CNN-XGBoost | 90.62 |
| Mitra [25] | FaceForencies | Resnet50-CNN | 92.33 |
| Ge [26] | CelebDF-FaceForencics | CNN | 95 |
| Liu [27] | FaceForencies | CNN | 92 |
| Heo [28] | CelebDF-FaceForencics | CNN | 96 |
| RUN | Accuracy | Sensitivity | Specificity | F1 Score |
|---|---|---|---|---|
| 1 | 97.40 | 96.84 | 97.94 | 97.35 |
| 2 | 97.12 | 97.14 | 97.09 | 97.14 |
| 3 | 97.25 | 97.39 | 97.09 | 97.39 |
| 4 | 97.17 | 98.36 | 95.24 | 97.17 |
| 5 | 97.35 | 98.36 | 96.15 | 97.56 |
| RUN | Accuracy | Sensitivity | Specificity | F1 Score |
|---|---|---|---|---|
| 1 | 94.42 | 93.75 | 95.24 | 94.86 |
| 2 | 93.99 | 94.40 | 93.52 | 94.40 |
| 3 | 94.12 | 94.62 | 93.52 | 94.62 |
| 4 | 94.47 | 94.57 | 94.34 | 94.94 |
| 5 | 94.02 | 94.53 | 93.40 | 94.53 |
| Author | Dataset | Algorithm | Accuracy Results % |
|---|---|---|---|
| Wodajo [19] | DFDC | CNN | 91.5 |
| Tran [20] | DFDC | CNN | 92.4 |
| Ismail [24] | CelebDF-FaceForencics | YOLO-CNN-XGBoost | 90.62 |
| Mitra [25] | FaceForencies | Resnet50-CNN | 92.33 |
| Ge [26] | CelebDF-FaceForencics | CNN | 95 |
| Liu [27] | FaceForencies | CNN | 92 |
| Heo [28] | CelebDF-FaceForencics | CNN | 96 |
| Proposed method—Celeb | CelebDF | Hybrid (CNN, RNN) with PSO | 97.26 |
| Proposed method—DFEC | DFDC | Hybrid (CNN, RNN) with PSO | 94.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Adwan, A.; Alazzam, H.; Al-Anbaki, N.; Alduweib, E. Detection of Deepfake Media Using a Hybrid CNN–RNN Model and Particle Swarm Optimization (PSO) Algorithm. Computers 2024, 13, 99. https://doi.org/10.3390/computers13040099
Al-Adwan A, Alazzam H, Al-Anbaki N, Alduweib E. Detection of Deepfake Media Using a Hybrid CNN–RNN Model and Particle Swarm Optimization (PSO) Algorithm. Computers. 2024; 13(4):99. https://doi.org/10.3390/computers13040099
Chicago/Turabian StyleAl-Adwan, Aryaf, Hadeel Alazzam, Noor Al-Anbaki, and Eman Alduweib. 2024. "Detection of Deepfake Media Using a Hybrid CNN–RNN Model and Particle Swarm Optimization (PSO) Algorithm" Computers 13, no. 4: 99. https://doi.org/10.3390/computers13040099