

A Deep Learning Approach for Early Detection of Facial Palsy in Video Using Convolutional Neural Networks: A Computational Study


Abstract
:1. Introduction
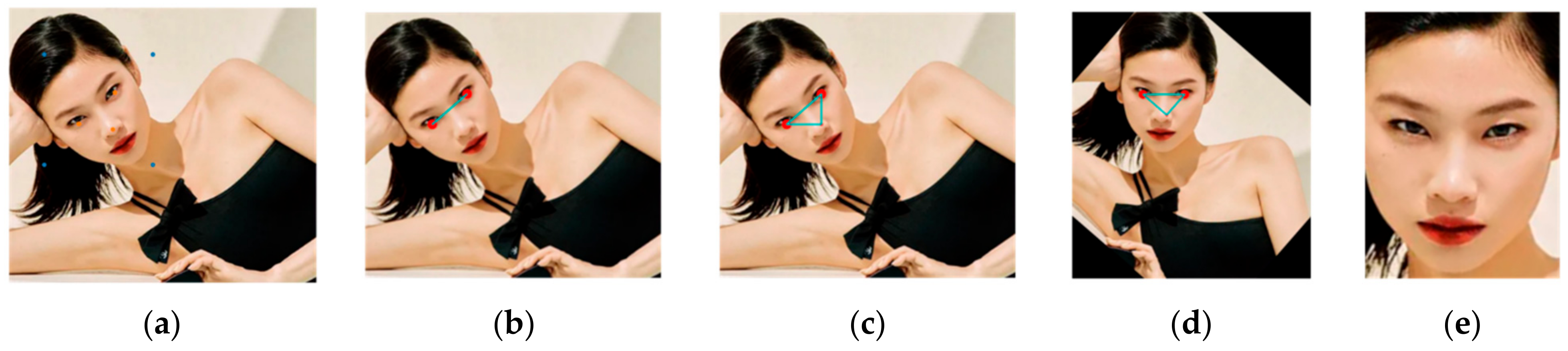
- A multitask cascaded convolutional neural network (MTCNN) model is used for face detection and face landmarks detection. The MTCNN extracted landmark features exploit the facial palsy data preparation and rotate face images lying in frames of video data. Further, data augmentation such as rotation of the face to keep the face aligned and extend the dataset for proper training is performed with the help of extracted face landmark features.
- A convolutional neural network model is used to train palsy-affected and unaffected faces for classification as palsy/no palsy. The model for this task is designed based on parametric experimentation and hyperparameter tuning to optimize accuracy and speed.
2. Literature Study
3. Multi-Model Facial Palsy Detection Framework
3.1. Multi-Task Cascaded Convolutional Network
3.2. Convolutional Neural Network for Facial Classification
4. Dataset Preparation and Experimental Setup
5. Results and Evaluation
5.1. Face Detection, Extraction, and Augmentation Outcome
5.2. Facial Palsy Detection Result
5.3. Ablation Study: Frames Study
5.4. Ablation Study: Validation Set Test Cases
5.5. Limitation
6. Conclusions and Future Scope
- -
- To detect palsy in videos, preprocessing is essential to classify the condition in individual subjects. The selection of shots and frames must be dynamically tailored to target each individual accurately.
- -
- Generate and share enriched video datasets of facial palsy as open data in repositories to support extensive research initiatives.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Guntinas-Lichius, O.; Volk, G.F.; Olsen, K.D.; Mäkitie, A.A.; Silver, C.E.; Zafereo, M.E.; Ferlito, A. Facial nerve electrodiagnostics for patients with facial palsy: A clinical practice guideline. Eur. Arch. Otorhinolaryngol. 2020, 277, 1855–1874. [Google Scholar] [CrossRef] [PubMed]
- Vrochidou, E.; Papić, V.; Kalampokas, T.; Papakostas, G.A. Automatic Facial Palsy Detection—From Mathematical Modeling to Deep Learning. Axioms 2023, 12, 1091. [Google Scholar] [CrossRef]
- Boochoon, K.; Mottaghi, A.; Aziz, A.; Pepper, J.P. Deep Learning for the Assessment of Facial Nerve Palsy: Opportunities and Challenges. Facial Plast. Surg. 2023, 39, 508–511. [Google Scholar] [CrossRef] [PubMed]
- Oo, N.H.Y.; Lee, M.H.; Lim, J.H. Exploring a Multimodal Fusion-Based Deep Learning Network for Detecting Facial Palsy. arXiv 2024, arXiv:2405.16496. [Google Scholar]
- Tiemstra, J.D.; Khatkhate, N. Bell’s Palsy: Diagnosis and Management. Am. Fam. Physician 2007, 76, 997–1002. [Google Scholar] [PubMed]
- Hsu, G.S.J.; Huang, W.F.; Kang, J.H. Hierarchical Network for Facial Palsy Detection. In Proceedings of the CVPR Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 580–586. [Google Scholar]
- Storey, G.; Jiang, R.; Keogh, S.; Bouridane, A.; Li, C.T. 3DPalsyNet: A facial palsy grading and motion recognition framework using fully 3D convolutional neural networks. IEEE Access 2019, 7, 121655–121664. [Google Scholar] [CrossRef]
- Sajid, M.; Shafique, T.; Baig, M.J.A.; Riaz, I.; Amin, S.; Manzoor, S. Automatic grading of palsy using asymmetrical facial features: A study complemented by new solutions. Symmetry 2018, 10, 242. [Google Scholar] [CrossRef]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Swinoujscie, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Evans, R.A.; Harries, M.L.; Baguley, D.M.; Moffat, D.A. Reliability of the House and Brackmann grading system for facial palsy. J. Laryngol. Otol. 1989, 103, 1045–1046. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.S.; Kim, S.Y.; Kim, Y.H.; Park, K.S. A smartphone-based automatic diagnosis system for facial nerve palsy. Sensors 2015, 15, 26756–26768. [Google Scholar] [CrossRef] [PubMed]
- Song, I.; Yen, N.Y.; Vong, J.; Diederich, J.; Yellowlees, P. Profiling bell’s palsy based on House-Brackmann score. In Proceedings of the 2013 IEEE Symposium on Computational Intelligence in Healthcare and E-Health (CICARE), Singapore, 16–19 April 2013; pp. 1–6. [Google Scholar]
- Amsalam, A.S.; Al-Naji, A.; Daeef, A.Y. Facial palsy detection using pre-trained deep learning models: A comparative study. In Proceedings of the AIP Conference Proceedings, Jaipur, India, 22–23 May 2024; Volume 3097. [Google Scholar]
- Ikezawa, N.; Okamoto, T.; Yoshida, Y.; Kurihara, S.; Takahashi, N.; Nakada, T.A.; Haneishi, H. Toward an application of automatic evaluation system for central facial palsy using two simple evaluation indices in emergency medicine. Sci. Rep. 2024, 14, 3429. [Google Scholar] [CrossRef] [PubMed]
- Jiang, C.; Wu, J.; Zhong, W.; Wei, M.; Tong, J.; Yu, H.; Wang, L. Automatic facial paralysis assessment via computational image analysis. J. Healthc. Eng. 2020, 2020, 2398542. [Google Scholar] [CrossRef] [PubMed]
- Dice, L.R. Measures of the amount of ecological association between species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Arora, A.; Taneja, A.; Gupta, M.; Mittal, P. Virtual Personal Trainer: Fitness Video Reognition Using Convolution Neural Network and Bidirectional LSTM. IJKSS 2021, 12, 1–21. [Google Scholar] [CrossRef]
- Arora, A.; Jayal, A.; Gupta, M.; Mittal, P.; Satapathy, S.C. Brain tumor segmentation of mri images using processed image driven u-net architecture. Computers 2021, 10, 139. [Google Scholar] [CrossRef]
- Ramprasath, M.; Anand, M.V.; Hariharan, S. Image classification using convolutional neural networks. Int. J. Pure Appl. Math. 2018, 119, 1307–1319. [Google Scholar]
- Sharma, N.; Jain, V.; Mishra, A. An analysis of convolutional neural networks for image classification. Procedia Comput. Sci. 2018, 132, 377–384. [Google Scholar] [CrossRef]
- Arora, A.; Sinha, A.; Bhansali, K.; Goel, R.; Sharma, I.; Jayal, A. SVM and Logistic Regression for Facial Palsy Detection Utilizing Facial Landmark Features. In Proceedings of the 2022 Fourteenth International Conference on Contemporary Computing, Noida, India, 4–6 August 2022; pp. 43–48. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Dataset | Validation Dataset |
|---|---|
| 23 People—Affected | 3 People—Affected |
| 19 People—Unaffected | 3 People—Unaffected |
| 125,825 frames | 10,800 Frames |
| Resource | Details |
|---|---|
| Python | Programming language |
| OpenCV | To read, process and write image and video data |
| PyTorch | Used as the main machine learning library to implement models and train |
| Facenet-pytorch | A pretrained implementation of MTCNN |
| Scikit-learn | Metrics library to evaluate performance of trained models |
| Matplotlib | Used to plot data for analysis and presentation in report |
| Dataset | Accuracy | Precision | Recall | F-Measure |
|---|---|---|---|---|
| Training | 99.2% | 98% | 1 | 98% |
| Validation | 82.2% | 98% | 73.2% | 78.4% |
| Video Name | Number of Frames in Which a Face Was Detected | Number of Frames in Which the Model Detected Palsy | Percentage of Frames with Presence of Palsy Compared to Frames with Faced |
|---|---|---|---|
| affected/1.mp4 | 1800 | 1550 | 86.11% |
| affected/2.mp4 | 1800 | 1799 | 99.94% |
| affected/3.mp4 | 1800 | 1786 | 99.22% |
| Video Name | Number of Frames in Which a Face Was Detected | Number of Frames in Which the Model Detected Palsy | Percentage of Frames with Presence of Palsy Compared to Frames with Faced |
|---|---|---|---|
| unaffected/1.mp4 | 1800 | 164 | 9.11% |
| unaffected/2.mp4 | 1800 | 81 | 4.5% |
| unaffected/3.mp4 | 1800 | 32 | 1.72% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arora, A.; Zaeem, J.M.; Garg, V.; Jayal, A.; Akhtar, Z. A Deep Learning Approach for Early Detection of Facial Palsy in Video Using Convolutional Neural Networks: A Computational Study. Computers 2024, 13, 200. https://doi.org/10.3390/computers13080200
Arora A, Zaeem JM, Garg V, Jayal A, Akhtar Z. A Deep Learning Approach for Early Detection of Facial Palsy in Video Using Convolutional Neural Networks: A Computational Study. Computers. 2024; 13(8):200. https://doi.org/10.3390/computers13080200
Chicago/Turabian StyleArora, Anuja, Jasir Mohammad Zaeem, Vibhor Garg, Ambikesh Jayal, and Zahid Akhtar. 2024. "A Deep Learning Approach for Early Detection of Facial Palsy in Video Using Convolutional Neural Networks: A Computational Study" Computers 13, no. 8: 200. https://doi.org/10.3390/computers13080200