
Semi-Automatic Image Labelling Using Depth Information

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
3. New Method for Image Labelling
- Segmentation of RGB and depth images
- Interactive segmentation with ECCL
- Interactive correction to edit the extracted area
4. Fuzzy C-Mean for Segmentation
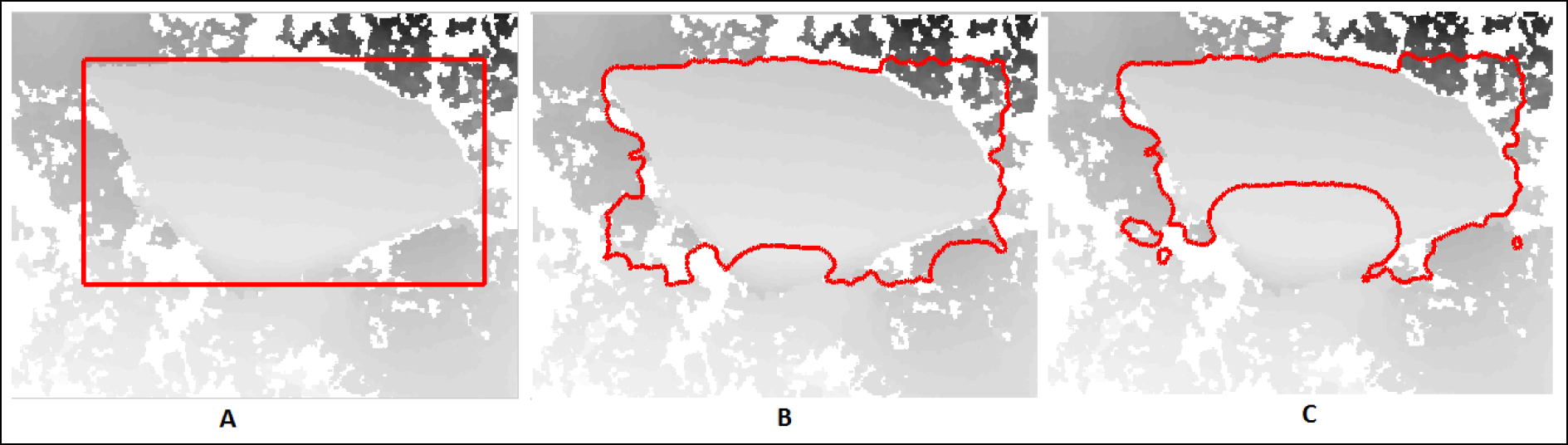
5. Segmentation Correction
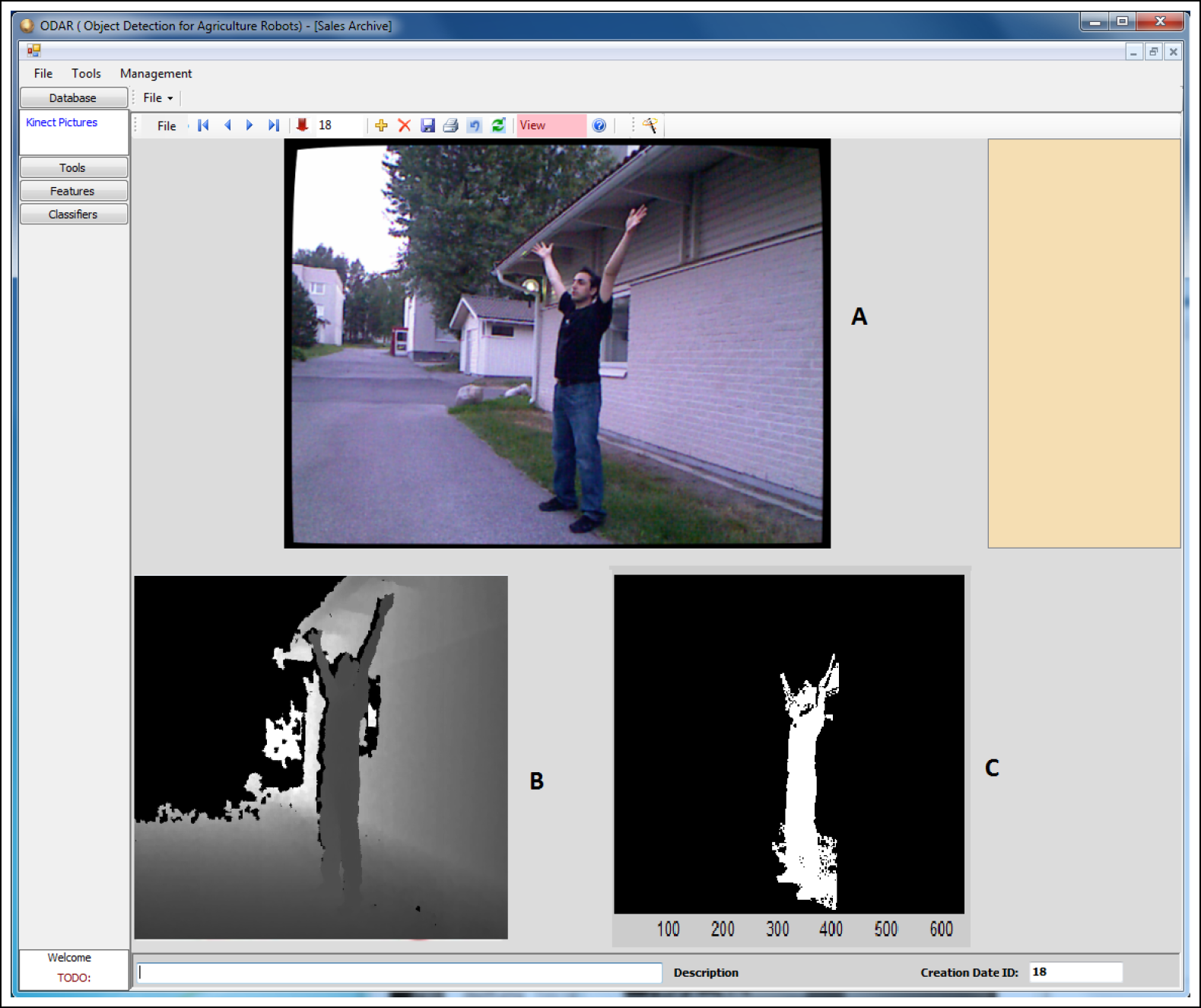
6. Results
7. Conclusions and Future Works
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Yhann, S.R.; Young, T.Y. Boundary localization in texture segmentation. IEEE Trans. Image Process. 1995, 4(6), 849–856. [Google Scholar]
- Tsai, A.; Yezzi, A.; Willsky, A. Curve evolution implementation of the Mumford-Shah functional for image segmentation, denoising, interpolation, and magnification. IEEE Trans. Image Process. 2001, 10, 1169–1186. [Google Scholar]
- Yezzi, A.; Tsai, A.; Willsky, A. A Fully Global Approach to Image Segmentation via Coupled Curve Evolution Equations. J. Vis. Commun. Image Represent. 2002, 13, 195–216. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient graph-based image segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar]
- Yair, W. Segmentation using eigenvectors: A unifying view. Proc. IEEE Int. Conf. Comput. Vis. 1999, 2, 975–982. [Google Scholar]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pat. Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Vese, L.A.; Chan, T.F. A multiphase level set framework for image segmentation using the Mumford and Shah model. Int. J. Comput. Vis. 2002, 50, 271–293. [Google Scholar]
- Yushkevich, P.A.; Piven, J.; Heather, C.H.; Rachel, G.S.; Ho, S.; Gee, J.C.; Gerig, G. User-Guided 3D Active Contour Segmentation of Anatomical Structures: Significantly Improved Efficiency and Reliability. Neuroimage 2006, 31, 1116–1128. [Google Scholar]
- Russell, C.; Torralba, A.; Murphy, K.; Freeman, W. LabelMe: A Database and Web-Based Tool for Image Annotation. Int. J. Comput. Vis. 2007, 77, 157–173. [Google Scholar]
- Du, Q.; Gunzburger, M.; Ju, L.; Wang, X. Centroidal voronoi tessellation algorithms for image compression, segmentation, and multichannel restoration. J. Math. Imaging Vis. 2006, 24, 177–194. [Google Scholar]
- Chevrefils, C.; Cheriet, F.; Aubin, C.E.; Grimard, G. Texture analysis for automatic segmentation of intervertebral disks of scoliotic spines from MR images. IEEE Trans. Inf. Technol. Biomed. 2009, 13, 608–620. [Google Scholar]
- Alexe, B.; Deselaers, T.; Ferrari, V. What is an object? Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 73–80.
- Hou, X.; Zhang, L. Saliency detection: A spectral residual approach, Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007.
- Everingham, M.; van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2007 (VOC 2007) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2007/workshop/index.html accessed on 16 April 2015.
- Li, C.; Kao, C.Y.; Gore, J.C.; Ding, Z. Minimization of region-scalable fitting energy for image segmentation. IEEE Trans. Image Process. 2008, 17, 1940–1949. [Google Scholar]
- Friedland, G.; Jantz, K.; Rojas, R. SIOX: Simple interactive object extraction in still images, Proceedings of the Seventh IEEE International Symposium on Multimedia, Irvine, CA, USA, 12–14 December 2005.
- Pordel, M.; Hellstrom, T.; Ostovar, A. Integrating Kinect Depth Data with a Stochastic Object Classification Framework for Forestry Robots, Proceedings of the 9th International Conference on Informatics in Control, Automation and Robotics, Rome, Italy, 28–31 July 2012.
- Zhang, K.; Zhang, L.; Song, H.; Zhou, W. Active contours with selective local or global segmentation: A new formulation and level set method. Image Vis. Comput. 2010, 28, 668–676. [Google Scholar]
- Dillencourt, M.; Samet, H.; Tamminen, M. General approach to connected-component labelling for arbitrary image representations. J. ACM 1992, 39, 253–280. [Google Scholar]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar]
- Lim, Y.W.; Lee, S.U. On the color image segmentation algorithm based on the thresholding and the fuzzy c-means techniques. Pattern Recogn. 1990, 23, 935–952. [Google Scholar]
- Chuang, K.S.; Tzeng, H.L.; Chen, S.; Wu, J.; Chen, T.J. Fuzzy c-means clustering with spatial information for image segmentation. Comput. Med. Imaging Graph. 2006, 30, 9–15. [Google Scholar]
- Pham, D.L.; Prince, J.L. An adaptive fuzzy C-means algorithm for image segmentation in the presence of intensity inhomogeneities. Pattern Recogn. Lett. 1999, 20, 57–68. [Google Scholar]
- Zhang, D.Q.; Chen, S.C. A novel kernelized fuzzy C-means algorithm with application in medical image segmentation. Artif. Intell. Med. 2004, 32, 37–50. [Google Scholar]
- Veksler, O.; Boykov, Y.; Mehrani, P. Superpixels and supervoxels in an energy optimization framework, Proceedings of the 11th European Conference on Computer Vision, Part V, Heraklion, Greece, 5–11 September 2010; pp. 211–224.










© 2015 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pordel, M.; Hellström, T. Semi-Automatic Image Labelling Using Depth Information. Computers 2015, 4, 142-154. https://doi.org/10.3390/computers4020142
Pordel M, Hellström T. Semi-Automatic Image Labelling Using Depth Information. Computers. 2015; 4(2):142-154. https://doi.org/10.3390/computers4020142
Chicago/Turabian StylePordel, Mostafa, and Thomas Hellström. 2015. "Semi-Automatic Image Labelling Using Depth Information" Computers 4, no. 2: 142-154. https://doi.org/10.3390/computers4020142
APA StylePordel, M., & Hellström, T. (2015). Semi-Automatic Image Labelling Using Depth Information. Computers, 4(2), 142-154. https://doi.org/10.3390/computers4020142