1. Introduction
Information fusion widely exists in the biological world, and it is an intrinsic feature of organisms from the ancient times to the present [
1]. As a hot field of information science, information fusion technology originated from the military application in the 1970s [
2]. After the continuous research climax from the early 1980s to now, the theory and technology of information fusion have been further developed rapidly [
3,
4]. As an independent discipline, information fusion has been successfully applied to military fields such as military command automation, strategic early warning and defense, multi-target tracking, etc., and gradually radiated to many civil fields such as intelligent transportation, remote sensing monitoring, e-commerce, artificial intelligence, wireless communication, industrial process monitoring and fault diagnosis, etc.
Information fusion is a formal framework, which uses mathematical methods and technical tools to synthesize different information, in order to get high-quality and useful information [
5,
6,
7,
8]. Compared with the single-source independent processing, the advantages of information fusion include: improving detectability and credibility, expanding the space-time sensing range, reducing the degree of reasoning ambiguity, improving the detection accuracy and other performance, increasing the target feature dimension, improving spatial resolution, enhancing the system fault-tolerant ability and white adaptability, so as to improve the whole system performance.
In the past 20 years, scholars have put forward a variety of methods for information fusion, and achieved rich research results [
9,
10,
11,
12]. Among them, p-set theory and method is a unique application. P-sets (P = packet) is a mathematical model with dynamic boundary features [
13,
14,
15]. It is obtained by introducing dynamic features into the finite common element set
X, and improving it. The dynamic boundary features of the p-set are as following: for the given finite set of common elements
X, and the attribute collection
of
X, (a) If the attribute
is added into
,
generates
,
, then some elements are removed from
X, and the
X boundary shrinks inward. We called that the internal p-set
is generated by
X,
. (b) If the attribute
is deleted from
,
generates
,
, then
X is supplemented with some elements, and the
X boundary is expanded outward. We call that
X generates the outer p-set
,
. (c) If you add some attributes into
and delete some other attributes from
at the same time, some elements are deleted from
X and some other elements are added into
X. We call that
X generates a set pair
which is named by p-set. (d) If the above process continues,
X will generate multiple set pair
,
, ⋯,
. We get the dynamic boundary of p-set:
,
. In the p-set, the attribute
of the element
satisfies the expansion or contraction of “conjunctive normal form” in mathematical logic. For given the information
which is defined by
X, inner p-information
, outer p-information
and p-information
are defined by
,
and (
,
) respectively, i.e.,
,
=
,
=
,
=
. We can speculate that p-sets can be used to analyze dynamic information recognition and information fusion. In fact, p-sets are the new mathematical methods and models for researching dynamic information recognition and fusion, because each information
has an attribute set
, that is, the information
is associated with its attribute set
. Given the existing researches that the p-set and p-augmented matrix have many applications in China [
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38] and some applications of function p-sets, the inverse p-sets and the inverse p-sets have made by many researchers [
39,
40,
41].
In the actual data set, redundant information will inevitably appear. For example, the data collected by the sensor at a higher frequency is redundant for data analysis with a longer time span. Similarly, in information fusion, sometimes we need to add some information to improve the accuracy of the analysis. Therefore, we need to pay attention to redundant information fusion and supplementary information fusion. These two kinds of information fusion are more important in the era of big data. In this paper, two kinds of information fusion algorithms are proposed by analyzing p-augmented matrix reasoning from the dynamic boundary of p-set. The purpose of this paper is to improve the dynamic boundary of the p-set and its generated p-augmented matrix for information fusion based on the function p-sets, the inverse p-sets, and the function inverse p-sets. Compared with other traditional methods, p-set theory and method start from the attributes of data, through set operation, matrix reasoning, etc., obtain information equivalent classes, and mine unknown information.
The researches given in this paper are as follows: (a) we give the existing fact of the structure and logical features of p-sets, then we give the structure and generation method of p-augmented matrix. These concepts are preparations for reading this paper. (b) We analyze the dynamic boundary features and the generation of information equivalence classes of p-sets. (c) We give matrix reasoning intelligent acquisition and intelligent acquisition algorithm of information equivalence class generated by p-augmented matrix. (d) We analyze the relationships between the concepts of information equivalence class and information fusion. We find that information equivalence class and information fusion are equivalent. (e) We give the application of intelligent acquisition of information equivalence class on information fusion, which can be used in unknown information discovery.
2. Preparatory Concepts
Some preparatory concepts are given in literature [
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41].
2.1. The Structure of P-Sets and Their Logical Characteristics
Given a finite set of ordinary elements
,
, ⋯,
⊂
U,
=
is a attribute set of
X.
is called the internal p-set generated by
X,
where
is called the
-deleted set of
X,
If the attribute set
of
satisfies
where in (
3),
,
,
turns
into
; in (
1),
,
,
,
.
Given a finite set of ordinary elements
,
, ⋯,
} ⊂
U,
=
,
, ⋯
is the attribute set of
X.
is called outer p-set generated by
X,
where
is called
F-supplemented set of
X,
If the attribute set
of
satisfies
where in (
6),
,
turns
into
,
; in (
6),
; in (
4),
,
,
.
The finite ordinary element set pair composed by internal p-set
and outer p-set
is called p-set generated by
X, namely
The finite ordinary element set X is called the base set of p-set .
It is obtained from (
3) that
Internal p-sets can be obtained accordingly from (
1), (
8) as following:
It is obtained from (
6) that
Outer p-sets can be obtained accordingly from (
4) and (
10) as follows:
By using (
9) and (
11), the set is obtained as follow:
which is called the p-set family generated by
X, and (
12) is the general form of the p-set.
Some theorems can be obtained from (
1)–(
7), (
12) as following:
Theorem 1. If , then the p-set is restored to the finite ordinary element set X, namely Theorem 2. If , then the p-set family , is restored to a finite set of ordinary element set X, namely Special notes:
- 1.
U is the finite element universe, and V is the finite attribute universe.
- 2.
, are element or attribute transfer families; , are element or attribute transfer; element (or attribute) transfer is a function concept of transformation.
- 3.
The characteristic of is that, for the element , , turns into ; for the attribute , , turns into .
- 4.
The characteristic of is that: for element , turns into ; for the attribute , turns into .
- 5.
The dynamic feature of the Equation (
1) is the same as the dynamic feature of the inverse accumulator
.
- 6.
The dynamic feature of Equation (
4) is the same as the dynamic feature of the accumulator
. For example, in Equation (
4),
, let
, then
, and so on.
2.2. The Existence Fact of P-Sets and Its Logical Characteristics
Suppose that , , , , is a set of finite ordinary elements in which there are 5 apples, , , } is a attribute set of X, =Red, =Sweet, =Red Fuji; , have the attributes , and . By using the “conjunctive normal form” in mathematical logic, we can obtain the following facts:
Given the attribute for , ,
- 1.
If is added to , generates , , , then , are deleted from X, X generates internal p-set , , , the attribute for satisfies ; .
- 2.
If the attribute is deleted in , generates , , , then , is supplemented to X, X generates an outer p-set , , , the attribute for satisfies , .
- 3.
If you add some attributes into and delete some other attributes from at the same time, generates and , i.e., generates , then X generates and , i.e., X generates a p-set .
- 4.
If the process of adding some attributes into
while deleting other attributes continues from
,
X generates multiple p-sets:
, which are the p-set family which is showed as Equation (
12).
For , , ⋯, , , ⋯, , , ⋯ is the attribute set of X; for , ⋯, , , ⋯, , , ⋯, is the attribute set of ; for , ⋯, , is the attribute set of ; , ; , . Some general conclusions can be obtained from the above facts 1–4 as following:
- 1.
The attribute
for
satisfies the attribute’s conjunctive normal form:
- 2.
The attribute
for
satisfies the expansion of attribute’s conjunctive normal form:
- 3.
The attribute
for
satisfies the contraction of attribute’s conjunctive normal form:
- 4.
The attribute
for
and the attribute
for
satisfies the expansion and contraction of attribute’s conjunctive normal form:
where,
=
,
; Equations (
15)–(
18) are the logical feature of the p-set
.
2.3. Structure and Generation of P-Augmented Matrix
By using the structure of the p-set, the definition and structure of improved general augmentation matrix
are given in literature [
38]:
Given a finite set of ordinary elements
,
, ⋯,
,
(
) has
n values
, ⋯,
;
,
, ⋯,
is a vector generated by
,
, ⋯,
, the matrix
A can be obtained by using
as the column. The
A is called element value matrix generated by
XThe
is called the internal p-augmented matrix of
A generated by internal p-set
,
The
is called the outer p-augmented matrix of
A generated by the outer p-set
,
The matrix pair consisting of the inner p-augmented matrix
and outer p-augmented matrix
is as following
The
is called p-augmented matrix of
A generated by p-set
, where, in Equations (
19)–(
21),
,
. The outer p-augmented matrix
of
A is the same concept as the ordinary augmentation matrix
of
A.
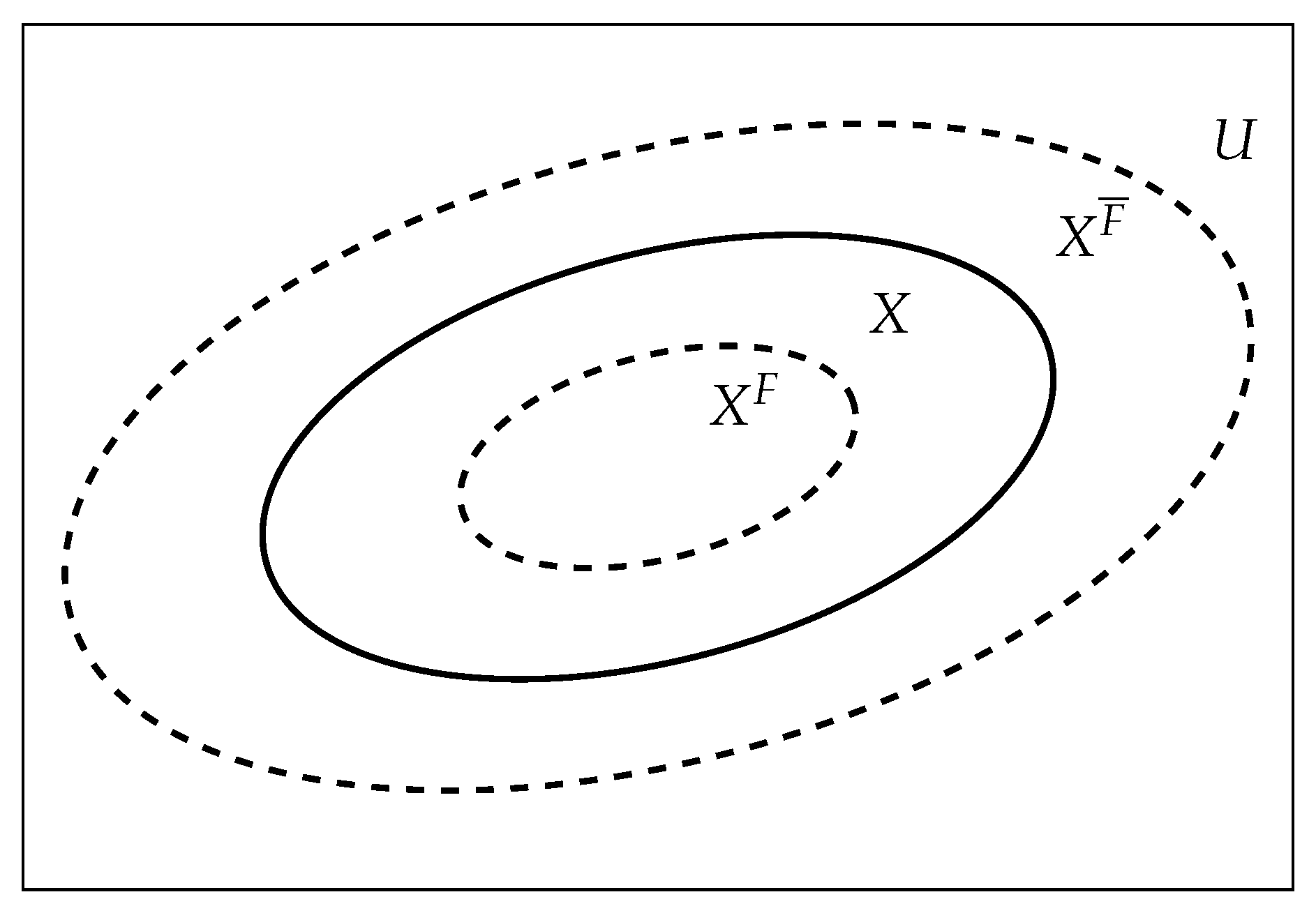
Figure 1 shows a two-dimensional visual representation of the p-set
.
The following conclusions are directly obtained from Equations (
1)–(
7) and the
Figure 1:
- 1.
The X boundary is contracting inward when some attributes are added into the attribute set of X. That is, the X dynamically generates the internal p-set .
- 2.
The X boundary is expanding outward when some attributes are deleted from the attribute set of X. That is, the X dynamically generates the outer p-set .
- 3.
The boundary of X is contracting inward and expanding outward when some attributes are added and some attributes are deleted in attribute collection of X. That is, the X dynamically generates p-set ; the process of adding attributes and deleting attributes in keeps going, X dynamically generates p-set families.
The concepts in this section are important for accepting the research and results given in
Section 3,
Section 4 and
Section 5. More features and applications of p-sets and p-augmented matrices can be found from the works of literature [
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38].
Convention:
X,
,
and
,
are defined as the information
, the inner p-information
, the outer p-information
and the p-information
,
respectively; i.e.,
,
,
and
,
=
,
. These concepts and symbols are used in
Section 3,
Section 4,
Section 5 and
Section 6.
3. Dynamic Boundary of P-Sets and Dynamic Generation of Information Equivalence Classes
Theorem 3. (The dynamic generation theorem of -information equivalence class ) if some attributes are added into the attribute set α of information , α generates , , then the internal p-information with the attribute set is the -information equivalence class generated by . That is Proof. Suppose that is the internal p-information generated by the information , the attribute set of is the relationship R of , i.e., ; Some equivalence class concepts can be obtained: 1. For , and have the relationship R, i.e., , so the reflexivity is satisfied. 2. For , has a relationship R with , then has a relationship R with ; i.e., if , then could be obtained, so the symmetry is satisfied. 3. For , if has a relationship R with , and has a relationship R with , then has a relationship R with ; i.e., if , and , then the could be obtained. So the transitivity is satisfied. From 1–3 we can obtained that: for , satisfies with the reflexivity ; the symmetry ; and the transitivity . It is easy to get that: internal p-information is the - information equivalence class generated by the information , . □
Theorem 4. (The dynamic generation theorem of -Information equivalence class ) If some attributes are deleted from attribute set α of information , α generates , , then the outer p-information with attribute set is the - Information equivalence class generated by ; that is, The proof is similar to Theorem 1, so the proof of Theorem 2 is omitted.
From Theorems 3 and 4, the Theorem 5 can be obtained directly,
Theorem 5. (The dynamic generation theorem of ,- information equivalence class ) If some attributes are added to and deleted from attribute set α of information at the same time, α generates and , , then the p-information with attribute set is the -Information equivalence class generated by ; that is, Obviously, the information with the attribute set is the -information equivalence class , .
Some propositions can be obtained from Theorems 3–5 and Equations (
1)–(
7) in
Section 2 as following:
Proposition 1. The dynamic generation of - information equivalence class is synchronous with the boundary inward dynamic contraction of the internal p-set .
Proposition 2. The dynamically generation of - information equivalence class is synchronous with the boundary outward expansion of the outer p-set .
Proposition 3. The dynamically generation of -Information equivalence class are synchronous with the boundary inward dynamic contraction and outward dynamic expansion of the p-set .
4. Matrix Reasoning and the Intelligent Acquisition Theorem of Information Equivalence Classes
Conventions: in
Section 2, the internal p-augmented matrix
, outer p-augmented matrix
and p-augmented matrix
are recorded as the internal p-matrix
, the outer p-matrix
and p-matrix
respectively. It will not cause any misunderstanding.
Given internal p-matrix
and
,
,
are the attribute set of
,
respectively;
,
and
,
satisfy the following equation
Equation (
26) is called internal p-matrix reasoning generated by internal p-matrix;
is called the internal p-matrix reasoning condition,
is called the internal p-matrix reasoning conclusion. Where, in Equation (
26),
is equivalent to
;
is equivalent to
.
Given the outer p-matrix
and
,
and
are the attribute set of
,
, respectively.
,
and
,
satisfy the following equation
Equation (
27) is called outer p-matrix reasoning generated by outer p-matrix;
is called outer p-matrix inference condition,
is called the outer p-matrix reasoning conclusion.
Given p-matrix
,
and
,
,
,
and
,
are the attribute sets of
,
,
,
respectively.
,
,
,
,
,
and
,
satisfy the following equation
Equation (
28) is called p-matrix reasoning generated by p-matrix;
is called the p-matrix reasoning condition,
is called p-matrix reasoning conclusion. Where, in Equation (
28),
means that
,
.
There are some special explanation: from
Section 2,
is generated by the value of
;
does not change the attribute set of
;
and
have the same attribute set
;
is generated by the value of
;
does not change the attribute set of
;
and
have the same attribute set
.
From Equations (
26)–(
28), we can obtain
Theorem 6. (The intelligent acquisition theorem of -Information equivalence class ) if the internal p-matrix , and -Information equivalence class , satisfy Then, under the condition of , -information equivalence class is acquired intelligently from ; .
Proof. From
Section 2, we obtained that:
,
are generated by
,
respectively;
and
satisfy
, that is,
. By using Theorem 3, we get that:
,
are the
-information equivalent equivalence class generated by information
.
and
satisfy
, that is,
. Under the internal p-matrix reasoning condition
,
is obtained, that is,
.
is acquired intelligently in
. □
Theorem 7. (The intelligent acquisition theorem of -Information equivalence class ) If the outer p-matrix , and -Information equivalence class , satisfy Then, under the condition of , - information equivalence class is acquired intelligently by ; .
The proof of Theorem 7 is similar to Theorem 6, so the proof is omitted.
From Theorems 6 and 7, we can obtained directly the following theorem:
Theorem 8. (The intelligent acquisition theorem of -information equivalence class ) If the p-matrix , and -information equivalence class , satisfy Then under the condition of , the , in the -information equivalence class will be acquired intelligently in and respectively. , .
Corollary 1. If is the -information equivalence class generated intelligently by the internal p-matrix reasoning, , then the attribute set α of the must be supplemented with some attributes .
The proof is obtained directly by Theorem 3, and the proof of Corollary 1 is omitted.
Corollary 2. If is the - information equivalence class generated intelligently by outer p-matrix reasoning, , then the attribute set α of information must be deleted some attributes .
The proof of Corollary 2 is similar to Corollary 1, and the proof is omitted.
From Corollaries 1 and 2, we can obtain directly the following corollary:
Corollary 3. If is the -information equivalence class generated intelligently by p-matrix reasoning, , , then the attribute set α of information must be added into the attributes and must be delete the attribute .
The intelligent acquisition algorithm of information acquisition class can be obtained by using the concepts and results given in
Section 4 (showed in
Figure 2). It should be noted that the intelligent algorithm diagram of
- information equivalence class
is similar to
Figure 2. It is omitted.
5. The Relationship between Information Equivalence and Information Fusion
5.1. Two Types of Information Fusion
For example, there are two boxes A and B on the table; there are m grains of soybeans in box A, and n grains of wheat in box B.
- I.
Children w puts n grains of wheat in box B into box A, then the m grains of soybeans mixed with n grains of wheat.
- II.
Children w pour the mixture of m grains and n grains into a sieve. The wheat grains are filtered by a sieve and separated from it, and m grains of soybean are left in the sieve.
If m grains of soybeans in box A are considered as m information elements , n grains of wheat in box B are considered as n information elements , . The two conclusions I and II are obtained by using the concept of information fusion to understand the above facts I and II as following:
- I.
The n information elements are merged into A from outside A, which generates information fusion . There are information elements in ; is the first type of information fusion. The first type of information fusion is called information supplementation fusion.
- II.
The n information elements among the information elements in box A are transfer from inside to outside of box A, which generates information fusion . There are m information elements in . is the second type of information fusion. The second type of information fusion is called information redundancy fusion. The characteristics of the two types of information fusion are exactly the same as those of the p-set . P-set is a new model and new method for researching information fusion.
5.2. The Relationship between Two Types of Information Fusion and Information Equivalence Classes
From the above simple example, we analyze the relationship among two types of information fusion and information equivalence class.
The information supplementation fusion is called -information equivalence class on the attribute set , if is the generation of the delete attribute in the attribute set of information .
The information redundancy fusion is called -information equivalence class on the attribute set , if is the generation of the supplementary attribute in the attribute set of information .
The information fusion pair is composed of information redundancy fusion and information supplementation fusion . is called the -information equivalence class on the attribute set .
By using these concepts, we can get the following theorems.
Theorem 9. (The relationship theorem of information supplementation fusion and - information equivalence class) Information supplementation fusion is the - information equivalence class generated by information if and only if ∀, ,∈ satisfy Theorem 10. (The relationship theorem of information redundancy fusion and -information equivalence class) Information redundancy fusion is the -information equivalence class generated by information if and only if , , satisfy Theorems 9 and 10 can be obtained directly by using Theorem 3. The proof of Theorems 9 and 10 is omitted.
Corollary 4. Information redundancy and supplement fusion is the -information equivalence class .
The following Propositions 4–6 are obtained directly by Theorems 9 and 10 and Corollary 4:
Proposition 4. Information redundancy fusion and -information equivalence class are two equivalent concepts.
Proposition 5. Information supplement fusion and -information equivalence class are two equivalent concepts.
Proposition 6. Information redundancy and supplement fusion and the -information equivalence class are two equivalent concepts.
6. Application on Intelligent Acquisition of Information Equivalence Class in Information Fusion and Unknown Information Discovery
In order to be simple and easy to accept the conceptual and theoretical results given in
Section 3,
Section 4 and
Section 5 of this paper, this section only gives the simple application of
-information equivalence intelligence acquisition in information redundancy fusion and unknown information discovery.
Suppose that
,
,
,
,
,
,
are PhD students enrolled in 2018, they will complete their PhD within four years;
come from different provinces in China;
constitutes information
:
has the test scores of math, physics, computer, information technology: mathematics =
, physics =
, computer =
, information technology =
;
, 2, 3, 4, 5, 6, 7.
A is the information value matrix generated by
:
where, for
, the
j column
in A are 4 scores:
,
,
,
, which constitutes the vector
,
,
,
;
,
.
The math, physics, computer, and information technology are defined as attributes
= math,
= physics,
= computer,
= Information Technology respectively.
,
,
,
constitutes the attribute set
of
:
Because each
has the attributes
,
,
and
, the attribute
of
satisfies the attribute “conjunctive normal form” of Equation (
15); that is,
If we want to know which one in
came from Shandong Province, China, we can add the attribute
= Shandong Province to the attribute set
, so
generates
:
We get the
with attribute set
:
The attribute
of
satisfies the attribute “expansion of conjunctive normal form” of Equation (
16), that is,
From Theorem 3, we can obtain that:
is the
-information equivalence class
generated by
; from Theorem 10 and Proposition 4, we obtain that
is the information redundant fusion generated by
by deleting
,
,
,
. The information value matrix
A generate the internal p-matrix
:
From Equations (
35) and (
40), we get that
A and
satisfy
, or
; Equations (
35) and (
40), Equations (
34) and (
39) satisfy the inner p-p-matrix reasoning respectively:
,
. Because the inner p-matrix reasoning condition is satisfied,
, information redundancy fusion
is intelligently acquired in the information
; the students
,
,
who come from the Shandong province are found in
-
.
From this simple example, we conclude that if the attribute is added to the attribute set of the information , the redundant fusion of unknown information is discovered intelligently from ; the unknown information is hidden in before the attribute is added to .
For
,
,
,
,
,
,
, we have conducted the survey of students from the provinces respectively, and the results of the survey are the same as those given in Equation (
39).


{kind=link}
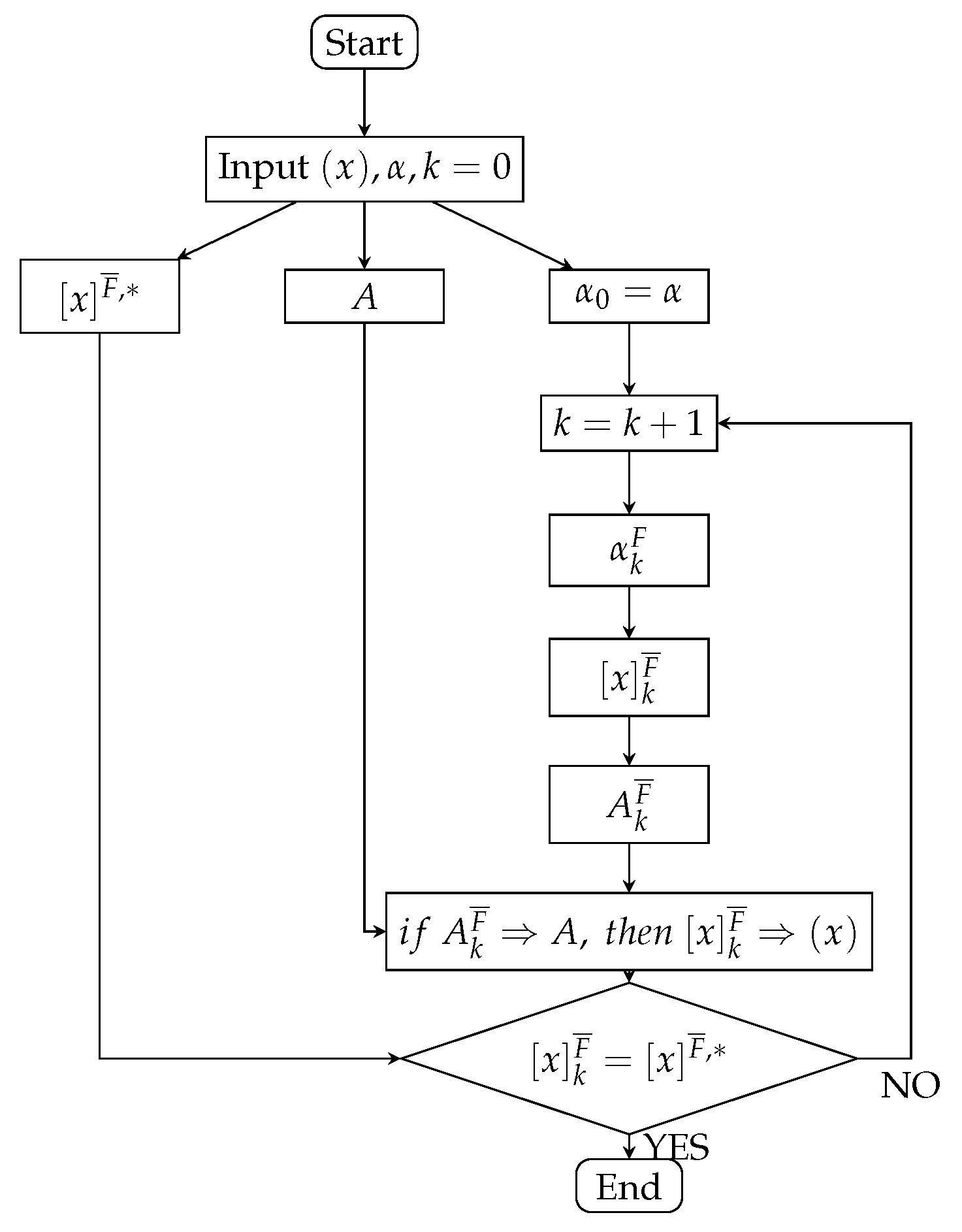{kind=link}

