Does Imperfect Data Privacy Stop People from Collecting Personal Data?

Abstract
:1. Introduction
2. Theory
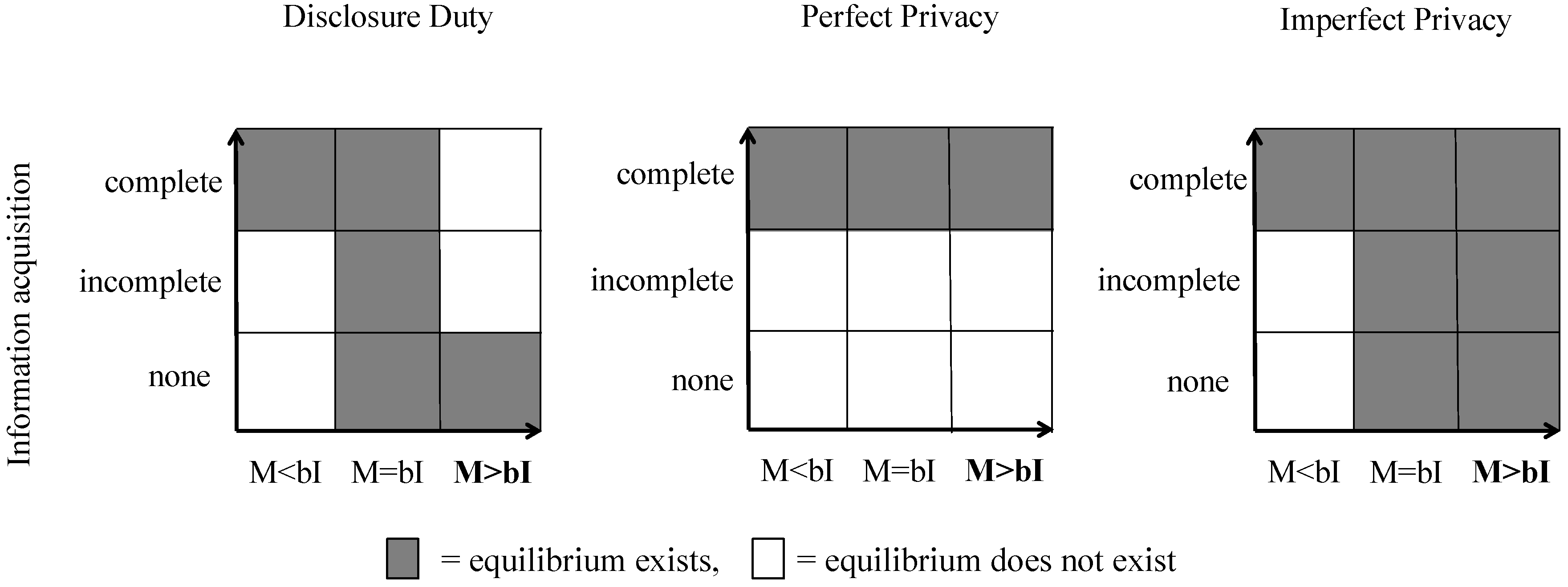
2.1. The Model
- (a)
- For andis a pure strategy equilibrium (complete information acquisition).
- (b)
- For andis a pure strategy equilibrium (no information acquisition).
- (a)
- Foris a pure strategy equilibrium (complete information acquisition).
- (b)
- For andis a pure strategy equilibrium (no information acquisition).
- (a)
- Foris a pure strategy equilibrium (complete information acquisition).
- (b)
- For andis a pure strategy equilibrium (no information acquisition).
2.2. Robustness: Risk Aversion, Costs and Benefits from Testing and Equilibrium Refinements
2.2.1. Risk Aversion
2.2.2. Costs and Benefits from Testing
2.2.3. Equilibrium Refinements
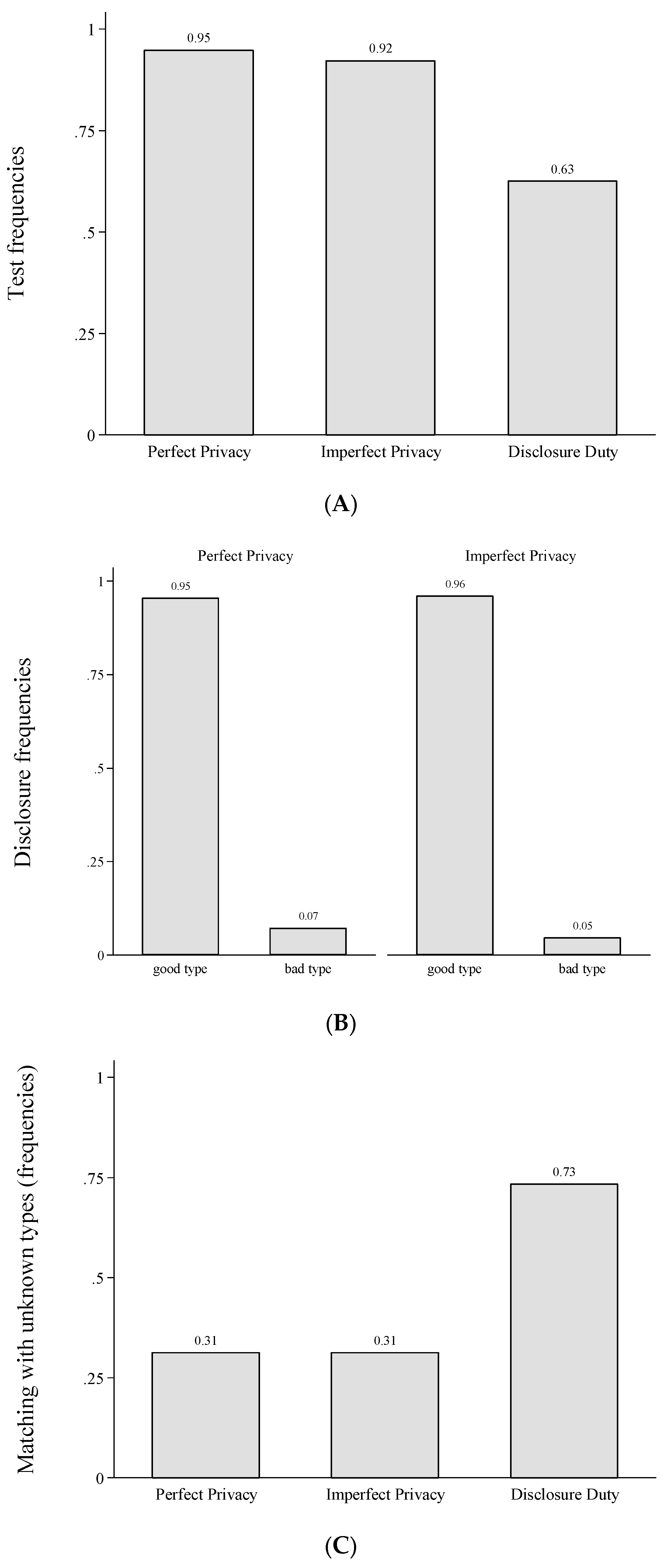
3. Experiment
3.1. Experimental Design (Parameters and Treatments)
3.2. Part 1 (One-Shot)
3.3. Experimental Design for Part 2 (Repeated)
3.4. Experimental Procedures
3.5. Experimental Results
3.5.1. Testing, Disclosing and Matching (Part 1: One-Shot)
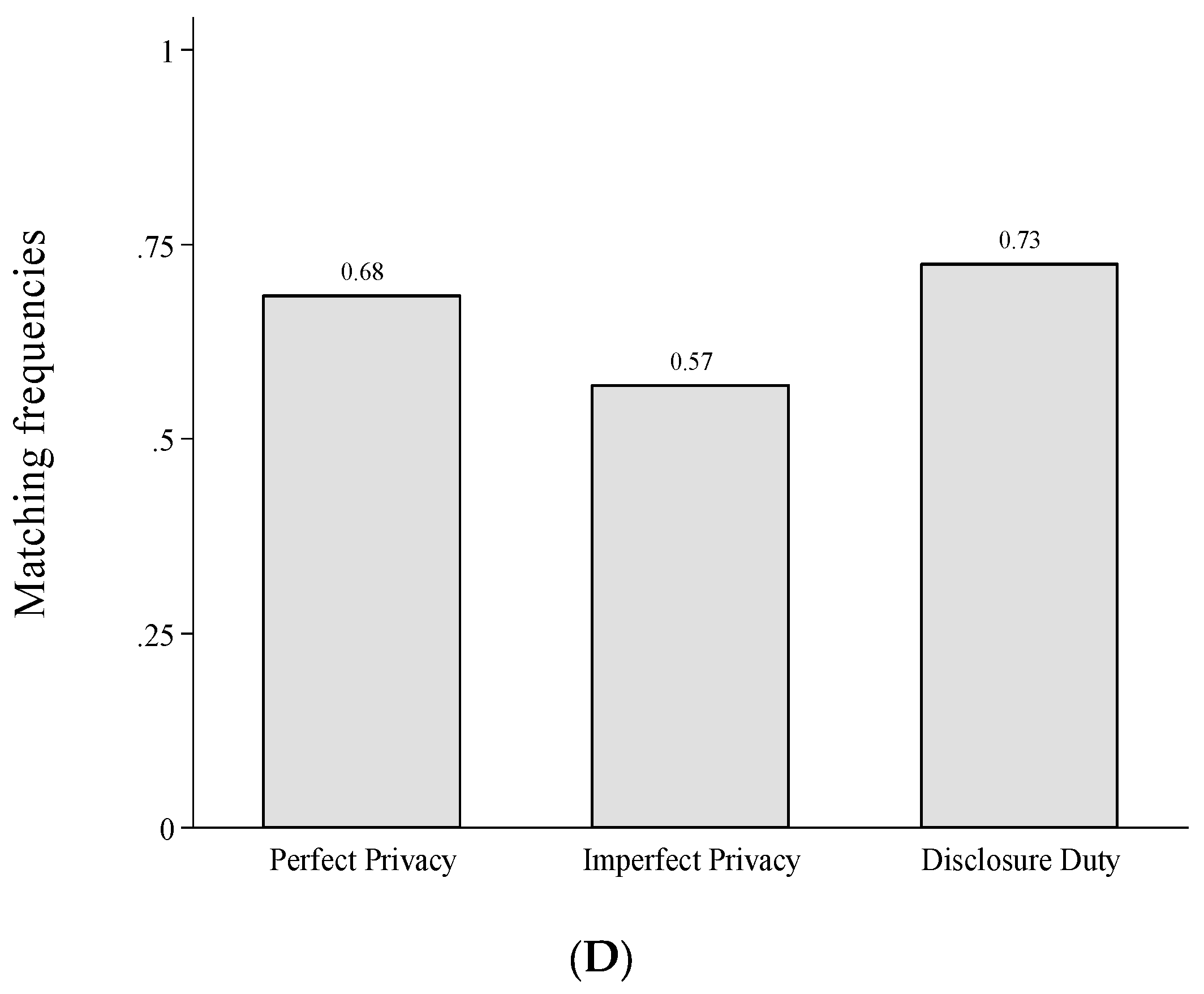
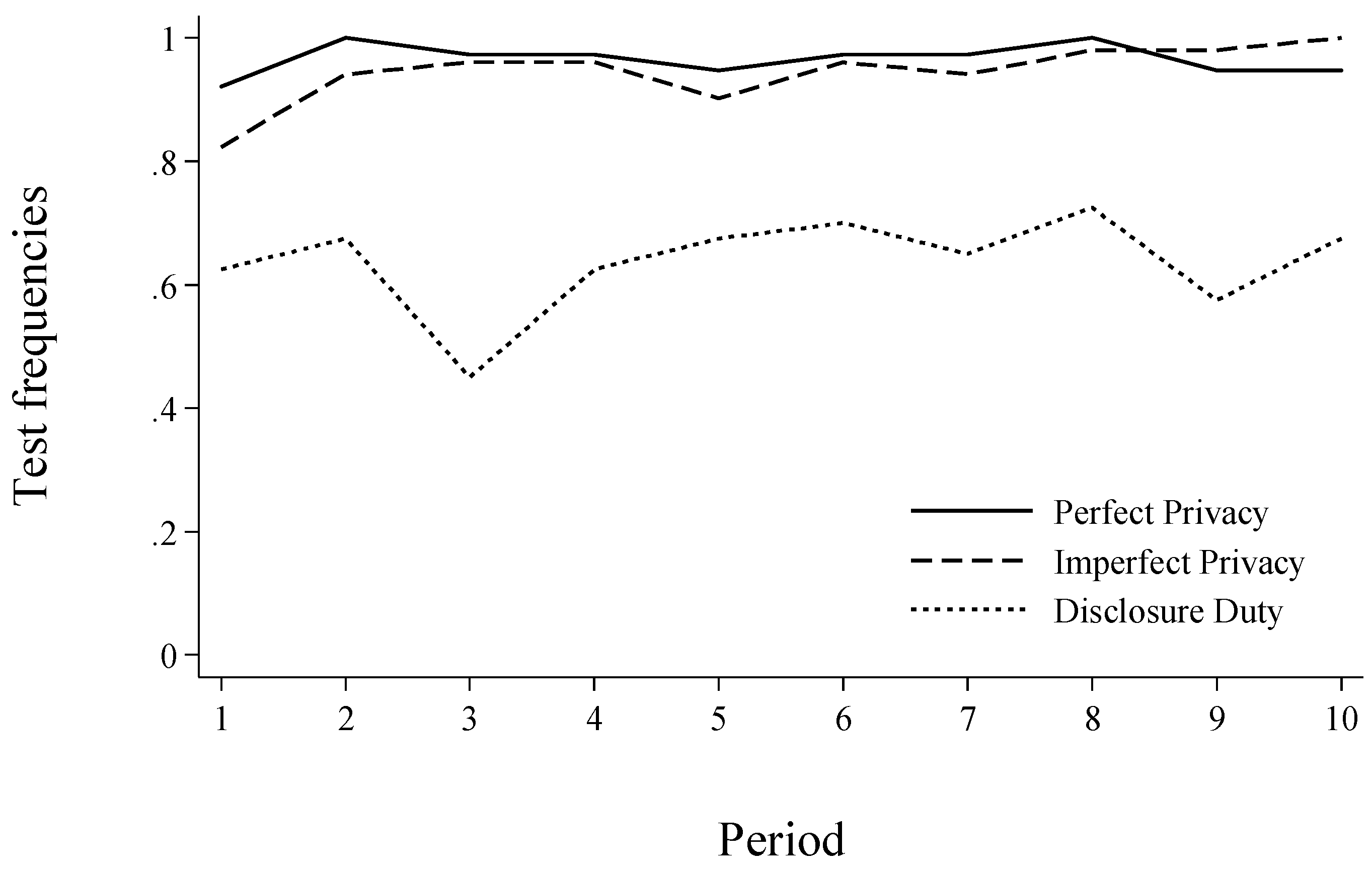
3.5.2. Testing, Disclosing and Matching (Part 2: Repeated)
4. Discussion and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Proofs of Propositions 1 to 3
- (a)
- Assume player 2 will not match with unknown types and . If , player 1 will test, i.e., , because . Player 2’s best response is and if , because and .
- (b)
- Assume player 2 will match with unknown types and . If player 1 will not have herself tested, i.e., player 1 will automatically be disclosed and in case of a bad test result, player 1 would not receive a match. Player 2’s best response is and if because and .
- (a)
- Assume player 2 will not match with unknown types and . If , player 1 will disclose her type after a good test result because . After a bad test result player 1 is indifferent whether to disclose her type with because Player 2’s best response is because and for all M.
- (b)
- Assume = 0. Assume further that player 1 will never test and player 2 will match with unknown types. Clearly, player 1 cannot gain from testing if player 2 matches with unknown types. The same holds for player 2’s matching strategy and because and .
- (a)
- Analogous to proposition 2a.
- (b)
- Assume player 2 will match with unknown type, i.e., and . If a tested player 1’s best response will be because and because . It follows that. Player 2’s best response is and if because and .
Appendix B. Incomplete Information Acquisition (Mixed Strategy Equilibria)
Appendix C. Instructions
 ,
,  , or
, or  Part 1 will be payoff relevant. If the die shows a
Part 1 will be payoff relevant. If the die shows a  ,
,  , or
, or  , Part 2 will be payoff relevant. Your payoff in the experiment will be calculated in points and later converted into euros. The points you achieve in the payoff relevant part will be converted to Euros and paid out at the end of the experiment. The exchange rate we will use is 10 points = 6 Euros. On the following pages, we will explain the procedures of Part 1. All participants received the same instructions. You will receive the instructions for Part 2 shortly after Part 1 has ended. Before the experiment starts, we will summarize the procedures verbally. After Part 2 we kindly ask you to answer a short questionnaire.
, Part 2 will be payoff relevant. Your payoff in the experiment will be calculated in points and later converted into euros. The points you achieve in the payoff relevant part will be converted to Euros and paid out at the end of the experiment. The exchange rate we will use is 10 points = 6 Euros. On the following pages, we will explain the procedures of Part 1. All participants received the same instructions. You will receive the instructions for Part 2 shortly after Part 1 has ended. Before the experiment starts, we will summarize the procedures verbally. After Part 2 we kindly ask you to answer a short questionnaire.- An interaction yields additional 10 points for participant 1.
- How an interaction affects participant 2 depends on participant 1’s type. If participant 1 is a type A, participant 2 receives additional 10 points. If participant 1 is a type B, participant 2’s points are reduced by 5 points.
- If there is no interaction, points do not change.
- One participant 1 and one participant 2 will be randomly assigned to each other. Participant 1 as well as participant 2 receive 10 points. Participant 1 does not know whether he is of type A or of type B. Participant 2 also does not know participant 1’ type.
- Participant 1 decides whether she wants to learn her type.
- [This bullet point was only included in Perfect Privacy]
- If participant 1 has decided to learn her type, she decides whether to inform participant 2. Please note: If participant 1 knows her type and decided to inform participant 2, participant 2 will learn participant 1’s true type. If participant 1 knows her type but did not inform participant 2, participant 2 will not learn participant 1’s type. If participant 1 does not know her type, participant 2 will also not learn participant 1’s type. If participant 2 does not learn participant 1’s type, she will also not learn whether participant 1 herself knows her type. If participant 2 learns participant 1’s type, he also knows that participant 1 knows her type.
- [This bullet point was only included in Imperfect Privacy]
- If participant 1 decided to learn his type, she decides whether to inform participant 2 about her type. If participant 1 decided to learn her type, but does not inform participant 2, a random mechanism determines whether player 2 learns player 1’s type nevertheless. In this case player 2 learns player 1’s type with a probability of 50%.Please note: If participant 1 knows her type and decided to inform participant 2, participant 2 will learn participant 1’s true type. If participant 1 knows her type but did not inform participant 2, participant 2 will learn participant 1’s type with a probability of 50%. In both cases participant 2 does not know whether he was informed about the type randomly or directly by participant 1. In all other cases, participant 2 does not receive any information about participant 1’s type, i.e., if participant 1 does not know her type, participant 2 will also not learn participant 1’s type. If participant 2 does not learn participant 1’s type, he will also not learn whether participant 1 knows her type. If participant 2 learns participant 1’s type, he also knows that participant 1 knows her type.
- [This bullet point was only included in Disclosure Duty]If participant 1 decides to learn her type, participant 2 will learn participant 1’s type too.Please note: If participant 1 knows that she is type B, participant 2 will also learn that participant 1’s type is B. If participant 1 knows that she is type A, participant 2 will also learn that participant 1’s type is A. If participant 1 does not know her type, participant 2 will also not learn participant 1’s type. But participant 2 knows that participant 1 is of Type A with probability 2/3 (66%) and of Type B with probability 1/3 (33%)
- Participant 2 decides whether he wants to interact with participant 1.
- If participant 2 decides to interact, participant 1 receives an extra 10 points. Participant 2’s points depend on participant 1’ type. If participant 1 is of type A, participant 2 receives an extra 10 points. If participant 1 is of type B, participant 2’s points are reduced by 5 points.
- If participant 2 does decides NOT to interact, both participants receive no extra points, so each of the participants has the 10 points received at the beginning.
- After all participants have made their decision you will receive information about your earnings. At the same time the type of participant 1 and whether an interaction took place will be shown to participants 1 and 2.



- If participant 2 decided to interact and participant 1 is of type A, participant 2 receives___ (10) points.
- If participant 2 decided to interact and participant 1 is of type B, participant 2 loses ___ (5) points.
- If participant 2 decided to interact, participant 1 receives an extra ___ (10) points.
- If participant 2 refused to interact, participant 1 receives an extra ___ (0) points and participant 2 an extra ___ (0) points.
- Experiment 2 consists of 10 periods.
- Every period has the same procedure and rules as Experiment 1.
- You have the same role (participant 1 or participant 2) as in Experiment 1 in all 10 periods.
- Participant 1 decides whether she wants to learn her type (A or B).
- [This bullet point was only included in Perfect Privacy and Imperfect Privacy]. If participant 1 decided to learn her type, she decides whether to inform participant 2 about her type.
- Participant 2 decides whether to interact with participant 1.
- In every period, you will be matched with another participant, i.e., with a participant you have not been matched with before (neither in Part 1 or Part 2).
- In every period for every participant 1 it will be randomly determined whether she is type A or B. The probability to be type A or B are the same as in Part 1.
- ⚪
- The probability of being a type A is 2/3 (or 66.66%).
- ⚪
- The probability of being a type B is 1/3 (or 33.33%).
- At the end of Part 2, i.e., after period 10, one period will be randomly determined to be payoff relevant for Part 2. For this, the participant with seat number 12 will roll a ten-sided die.
- Afterwards, the participant with seat number 12 will roll a six-sided die to determine whether participants will receive their earnings from part 1 or Part 2.

References
- Acquisti, A.; John, L.K.; Loewenstein, G. What is privacy worth? J. Legal Stud. 2013, 42, 249–274. [Google Scholar] [CrossRef]
- Beresford, A.R.; Kübler, D.; Preibusch, S. Unwillingness to pay for privacy: A field experiment. Econ. Lett. 2012, 117, 25–27. [Google Scholar] [CrossRef]
- Grossklags, J.; Acquisti, A. When 25 Cents is Too Much: An Experiment on Willingness-to-Sell and Willingness-to-Protect Personal Information; WEIS: Pittsburg, PA, USA, 2007. [Google Scholar]
- Huberman, B.A.; Adar, E.; Fine, L.R. Valuating privacy. IEEE Secur. Priv. 2005, 3, 22–25. [Google Scholar] [CrossRef]
- Tsai, J.Y.; Egelman, S.; Cranor, L.; Acquisti, A. The effect of online privacy information on purchasing behavior: An experimental study. Inf. Syst. Res. 2011, 22, 254–268. [Google Scholar] [CrossRef]
- Benndorf, V.; Normann, H.T. The willingness to sell personal data. Scand. J. Econ. 2017. [Google Scholar] [CrossRef]
- Schudy, S.; Utikal, V. ‘You must not know about me’—On the willingness to share personal data. J. Econ. Behav. Organ. 2017, 141, 1–13. [Google Scholar] [CrossRef]
- Hall, J.; Fiebig, D.G.; King, M.T.; Hossain, I.; Louviere, J.J. What influences participation in genetic carrier testing?: Results from a discrete choice experiment. J. Health Econ. 2006, 25, 520–537. [Google Scholar] [CrossRef] [PubMed]
- 5 Steps to Get More out of Your New Oscar Plan. Available online: https://www.hioscar.com/faq/5-steps-to-get-more-out-of-your-new-Oscar-plan (accessed on 2 March 2018).
- Hirshleifer, J. The private and social value of information and the reward to inventive activity. Am. Econ. Rev. 1971, 61, 561–574. [Google Scholar]
- Barigozzi, F.; Henriet, D. Genetic information: Comparing alternative regulatory approaches when prevention matters. J. Pub. Econ. Theory 2011, 13, 23–46. [Google Scholar] [CrossRef]
- Viswanathan, K.S.; Lemaire, J.; Withers, K.; Armstrong, K.; Baumritter, A.; Hershey, J.C.; Pauly, M.V.; Asch, D.A. Adverse selection in term life insurance purchasing due to the brca1/2 genetic test and elastic demand. J. Risk Insur. 2007, 74, 65–86. [Google Scholar] [CrossRef]
- Doherty, N.A.; Thistle, P.D. Adverse selection with endogenous information in insurance markets. J. Pub. Econ. 1996, 63, 83–102. [Google Scholar] [CrossRef]
- Hoy, M.; Polborn, M. The value of genetic information in the life insurance market. J. Pub. Econ. 2000, 78, 235–252. [Google Scholar] [CrossRef]
- Bardey, D.; De Donder, P.; Mantilla, C. Adverse Selection vs Discrimination Risk with Genetic Testing: An Experimental Approach. CESifo Working Paper Series No. 5080. 2014. Available online: http://ssrn.com/abstract=2532921 (accessed on 2 March 2018).
- Peter, R.; Richter, A.; Thistle, P. Endogenous information, adverse selection, and prevention: Implications for genetic testing policy. J. Health Econ. 2017, 55, 95–107. [Google Scholar] [CrossRef] [PubMed]
- Caplin, A.; Eliaz, K. Aids policy and psychology: A mechanism-design approach. RAND J. Econ. 2003, 34, 631–646. [Google Scholar] [CrossRef]
- Philipson, T.J.; Posner, R.A. A theoretical and empirical investigation of the effects of public health subsidies for std testing. Q. J. Econ. 1995, 110, 445–474. [Google Scholar] [CrossRef]
- Tabarrok, A. Genetic testing: An economic and contractarian analysis. J. Health Econ. 1994, 13, 75–91. [Google Scholar] [CrossRef]
- Bardey, D.; De Donder, P. Genetic testing with primary prevention and moral hazard. J. Health Econ. 2013, 32, 768–779. [Google Scholar] [CrossRef] [PubMed]
- Hoel, M.; Iversen, T. Genetic testing when there is a mix of compulsory and voluntary health insurance. J. Health Econ. 2002, 21, 253–270. [Google Scholar] [CrossRef]
- Kierkegaard, P. Electronic health record: Wiring europe’s healthcare. Comput. Law Secur. Rev. 2011, 27, 503–515. [Google Scholar] [CrossRef]
- Peppet, S.R. Unraveling privacy: The personal prospectus and the threat of a full-disclosure future. Northwest. Univ. Law Rev. 2011, 105, 1153. [Google Scholar]
- Nine NHS Trusts Lose Patient Data. Available online: http://news.bbc.co.uk/2/hi/uk_news/7158019.stm (accessed on 1 March 2018).
- Matthews, S.; Postlewaite, A. Quality testing and disclosure. RAND J. Econ. 1985, 16, 328–340. [Google Scholar] [CrossRef]
- Myerson, R.B. Refinements of the nash equilibrium concept. Int. J. Game Theory 1978, 7, 73–80. [Google Scholar] [CrossRef]
- Selten, R. Reexamination of the perfectness concept for equilibrium points in extensive games. Int. J. Game Theory 1975, 4, 25–55. [Google Scholar] [CrossRef]
- Rosar, F.; Schulte, E. Imperfect Private Information and the Design of Information–Generating Mechanisms. Discussion Paper. 2010. Available online: http://www.sfbtr15.de/uploads/media/Rosar_Schulte.pdf (accessed on 5 March 2018).
- Schweizer, N.; Szech, N. Optimal revelation of life-changing information. Manag. Sci. 2018. [Google Scholar] [CrossRef]
- Fischbacher, U. Z-tree: Zurich toolbox for ready-made economic experiments. Exp. Econ. 2007, 10, 171–178. [Google Scholar] [CrossRef]
- Greiner, B. An online recruitment system for economic experiments. In Forschung und Wissenschaftliches Rechnen GWDG Bericht 63; Kremer, K., Macho, V., Eds.; Gesellschaft für Wissenschaftliche Datenverarbeitung: Göttingen, Germany, 2004; pp. 79–93. [Google Scholar]
- Engelhardt, B.; Kurt, M.R.; Polgreen, P.M. Sexually transmitted infections with semi-anonymous matching. Health Econ. 2013, 22, 1295–1317. [Google Scholar] [CrossRef] [PubMed]
| 1 | Apart from test based, type specific premiums, insurances nowadays also offer rebates, bonuses (or penalties) based on personal health data collected through health trackers or third parties (see e.g., [9]). |
| 2 | For a similar argument see also Hirshleifer [10]. |
| 3 | Consent Law describes the situation in which consumers “are not required to divulge genetic tests results. But, if they do, insurers may use this information” [12]. |
| 4 | In addition to Consent Law and Disclosure Duty, several other approaches have been discussed in the context of genetic testing. Barigozzi and Henriet [11] consider further the “Laissez-Faire approach”, under which insurers can access test results and require additional tests and “Strict Prohibition” of the use of test results. |
| 5 | |
| 6 | |
| 7 | Matthews and Postlewaite [25] focus on sellers’ testing behavior in the context of product quality when disclosure of test results is mandatory or voluntary and test results may be beneficial to consumers. For Perfect Privacy and Disclosure Duty our model mirrors the logic of their analysis and can be understood as a simplified version of their framework. However, our analysis differs in terms of who acquires information, what quality types are available and includes the additional environment of Imperfect Privacy. |
| 8 | Recently in a different setting, Bardey, De Donder and Mantilla [15] complement their theoretical analysis on different regulatory institutions for genetic testing with an experiment. However, their experimental design focuses on the joint decision of choosing a privacy institution and testing for one’s type using a series of individual lottery choice tasks. |
| 9 | In Section 2.2.2 we provide a robustness analysis on how psychological costs and prevention benefits affect the existence of equilibria derived in the simple model. |
| 10 | Our framework may also be interpreted as a situation in which the insurer offers two tariffs, one for good and one for bad health types. |
| 11 | While these results are derived by modelling patients and insurers as risk neutral and abstaining from modelling direct costs or benefits from testing, we discuss below whether these Proper Equilibria are robustness to common assumptions concerning risk aversion of patients and risk neutrality of insurers. Further, we discuss also the robustness of the different equilibria concerning costs and benefits from testing. |
| 12 | We refrain from modeling a partial internalization of the loss of utility (from a match with a bad type) of player 2 by player 1. Nevertheless modelling this internalization as a loss of I’ for player 1 does not change the model’s predictions as long as for player 1 I’ < M. We thank an anonymous referee for highlighting this aspect. |
| 13 | We discuss the robustness of our results with respect to risk aversion in Section 2.2.1. |
| 14 | We discuss the impact of explicit testing costs in Section 2.2.2. |
| 15 | We relegate formal proofs of all propositions as well as the derivation of mixed strategy equilibria to the appendix. |
| 16 | Assuming a risk neutral insurer but a risk averse consumer (as [13], equilibria with complete information or no information still exist for all institutions. Equilibria with incomplete information acquisition exist only for Disclosure Duty and Imperfect Privacy. |
| 17 | By doing so we implicitly deal with benefits from knowing to be the good type (which are in our model mathematically equivalent to costs from knowing to be the bad type) and costs from not knowing to be the good type (which are mathematically equivalent to benefits from knowing to be the bad type). |
| 18 | One randomly selected participant rolled a six-sided die to determine whether a test result was involuntarily displayed (depending on whether the number was odd or even). The participant was monitored and announced the number publicly. |
| 19 | |
| 20 | A copy of translated instructions can be found in Appendix C. |
| 21 | We cannot reject the hypothesis that disclosure behavior of tested good types is identical in Privacy and Imperfect Privacy (Fisher’s exact test, p-value = 0.926). |
| 22 | We cannot reject the hypothesis that disclosure behavior of tested bad types is identical in Perfect Privacy and Imperfect Privacy (Fisher’s exact test, p-value = 0.740). |
| 23 | More testing eventually reduces the number of mismatches. Engelhardt, et al. [32] for instance argue that on internet platforms for semi-anonymous encounters, provision of information about the own HIV status might result in a directed search and reduce the transmission rate by separating the uninfected and infected, e.g., through the use of condoms. |
| 24 | We carefully note that in the context of HIV testing, social preferences may matter strongly and many people may test and report their result, irrespective of the institutional setup. |
| 25 | Inequality aversion might also be the reason why some players 1 disclose their bad type. By this means they prevent player 2 from matching which would lead to an unequal allocation. |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Decision to… | ||||
|---|---|---|---|---|
| (1) | (2) | (3) | (4) | |
| …Test | …Disclose | …Match with Unknown Type | …Match (Unconditionally) | |
| Perfect Privacy | baseline | baseline | baseline | baseline |
| Imperfect Privacy | −0.056 | −0.035 | 0.180 ** | 0.027 |
| (0.040) | (0.029) | (0.076) | (0.032) | |
| Disclosure Duty | −0.284 *** | n.a. | 0.426 *** | −0.019 |
| (0.058) | (0.035) | (0.016) | ||
| Period | 0.008 ** | 0.002 | −0.011 * | −0.000 |
| (0.004) | (0.003) | (0.006) | (0.002) | |
| Bad Type | −0.319 *** | |||
| (0.040) | ||||
| Imperfect Privacy x | 0.016 | |||
| Bad Type | (0.030) | |||
| Willingness to take | −0.011 * | 0.008 | 0.020 | 0.001 |
| risks in general | (0.007) | (0.006) | (0.017) | (0.014) |
| Male | −0.013 | −0.044 ** | 0.017 | 0.038 * |
| (0.032) | (0.018) | (0.057) | (0.021) | |
| Age | −0.004 ** | 0.001 | −0.025 | −0.024 *** |
| (0.002) | (0.001) | (0.016) | (0.008) | |
| Observations | 1290 | 849 | 373 | 1290 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schudy, S.; Utikal, V. Does Imperfect Data Privacy Stop People from Collecting Personal Data? Games 2018, 9, 14. https://doi.org/10.3390/g9010014
Schudy S, Utikal V. Does Imperfect Data Privacy Stop People from Collecting Personal Data? Games. 2018; 9(1):14. https://doi.org/10.3390/g9010014
Chicago/Turabian StyleSchudy, Simeon, and Verena Utikal. 2018. "Does Imperfect Data Privacy Stop People from Collecting Personal Data?" Games 9, no. 1: 14. https://doi.org/10.3390/g9010014
APA StyleSchudy, S., & Utikal, V. (2018). Does Imperfect Data Privacy Stop People from Collecting Personal Data? Games, 9(1), 14. https://doi.org/10.3390/g9010014