
A Novel Machine Learning Model to Predict the Photo-Degradation Performance of Different Photocatalysts on a Variety of Water Contaminants

 ,
,
Abstract
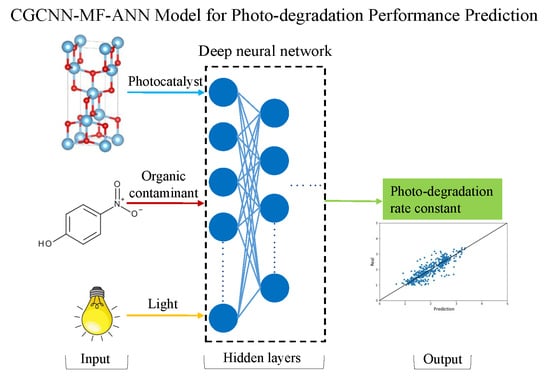
:
1. Introduction
2. Results and Discussion
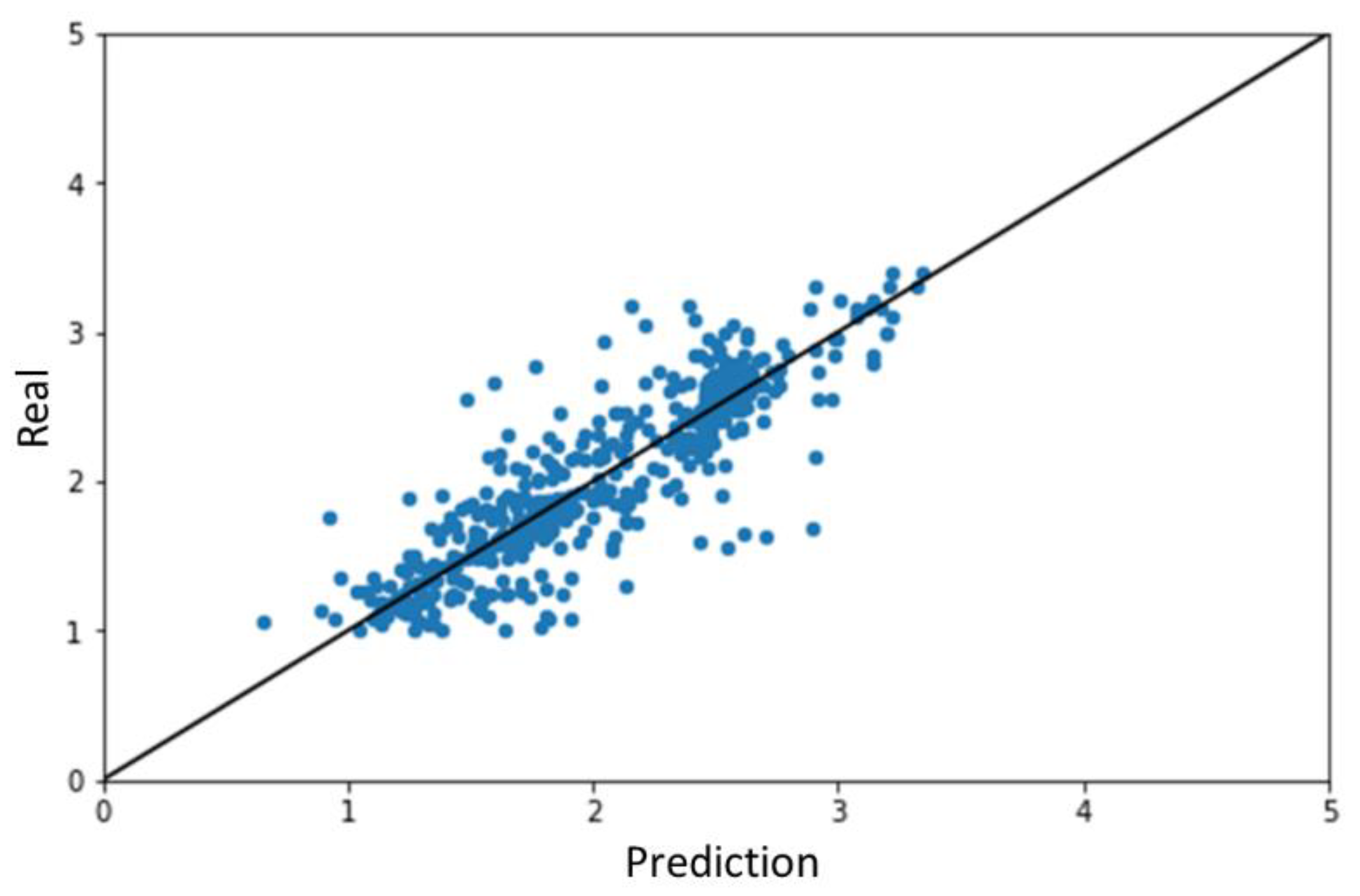
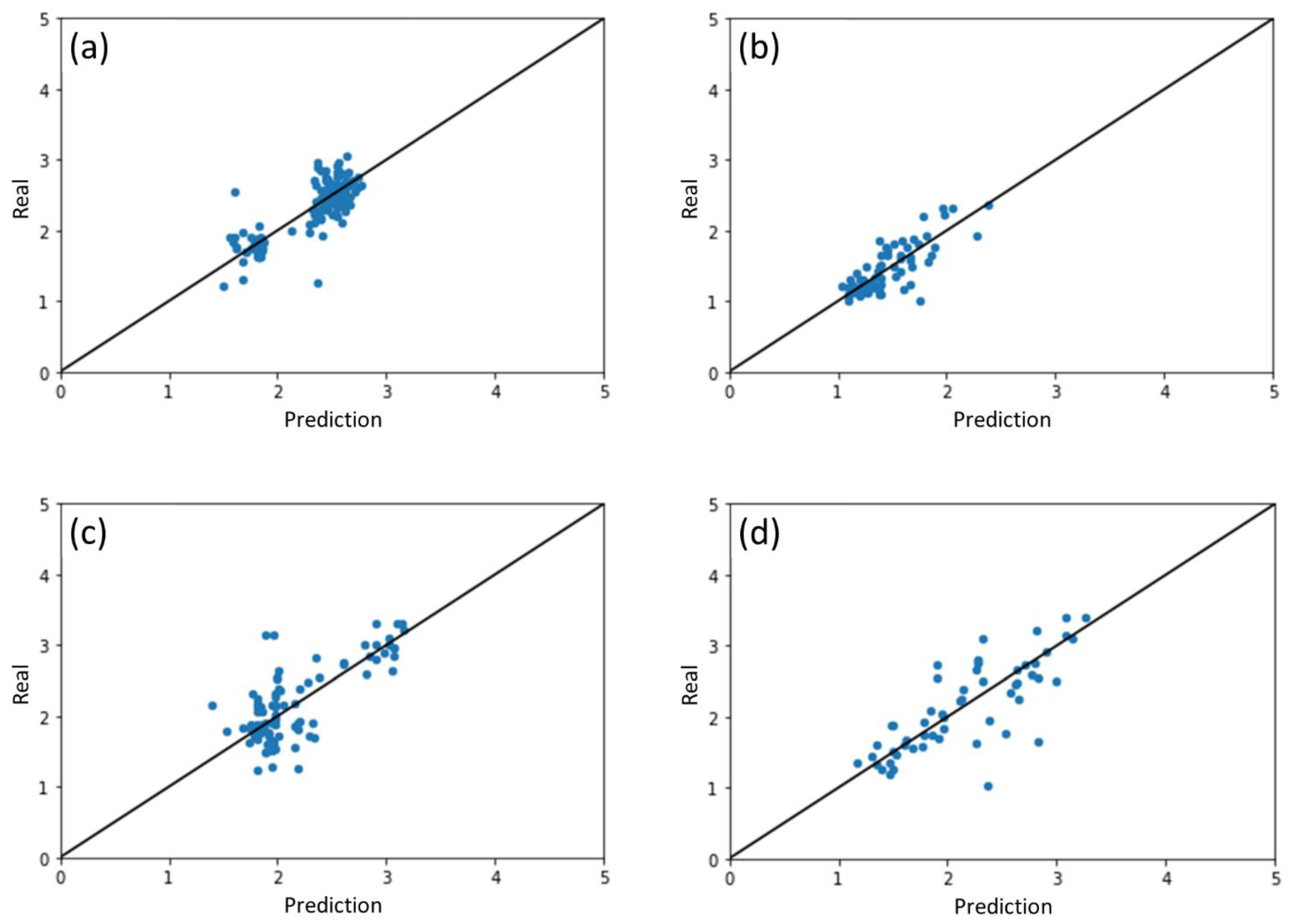
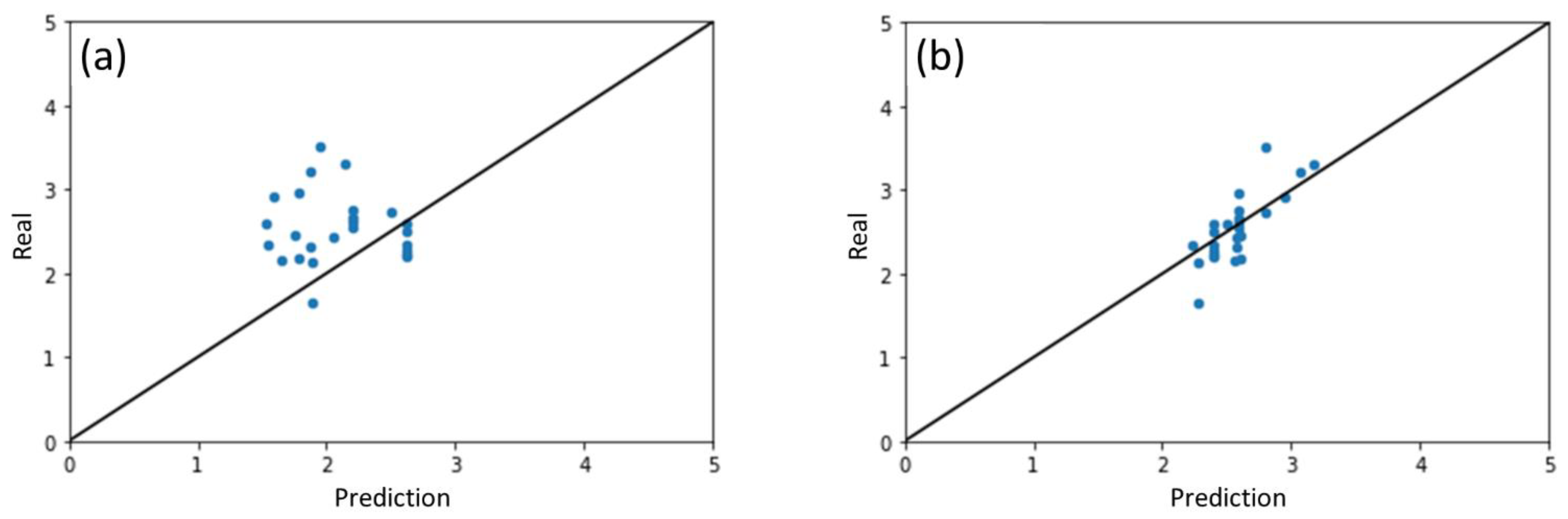
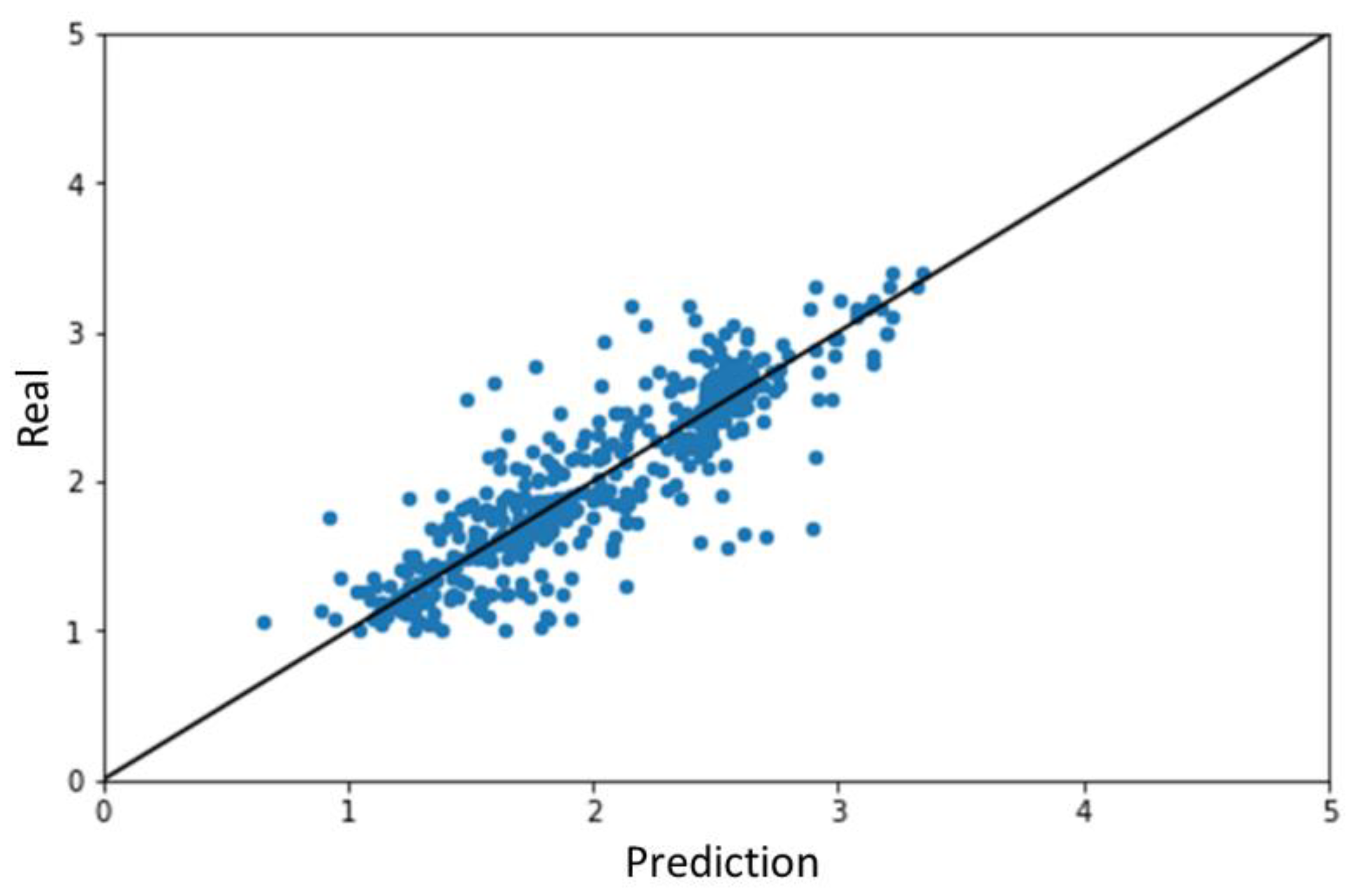
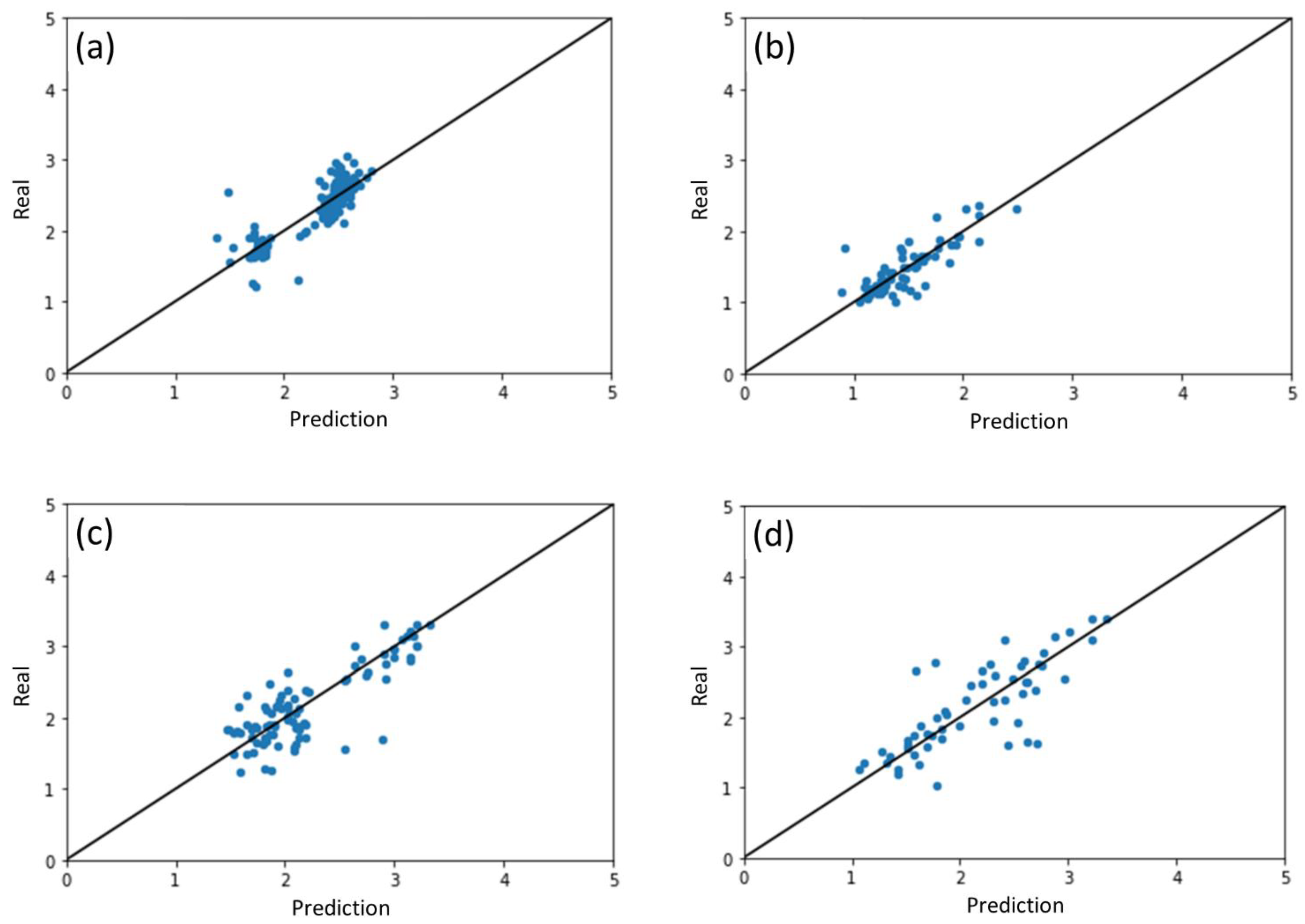
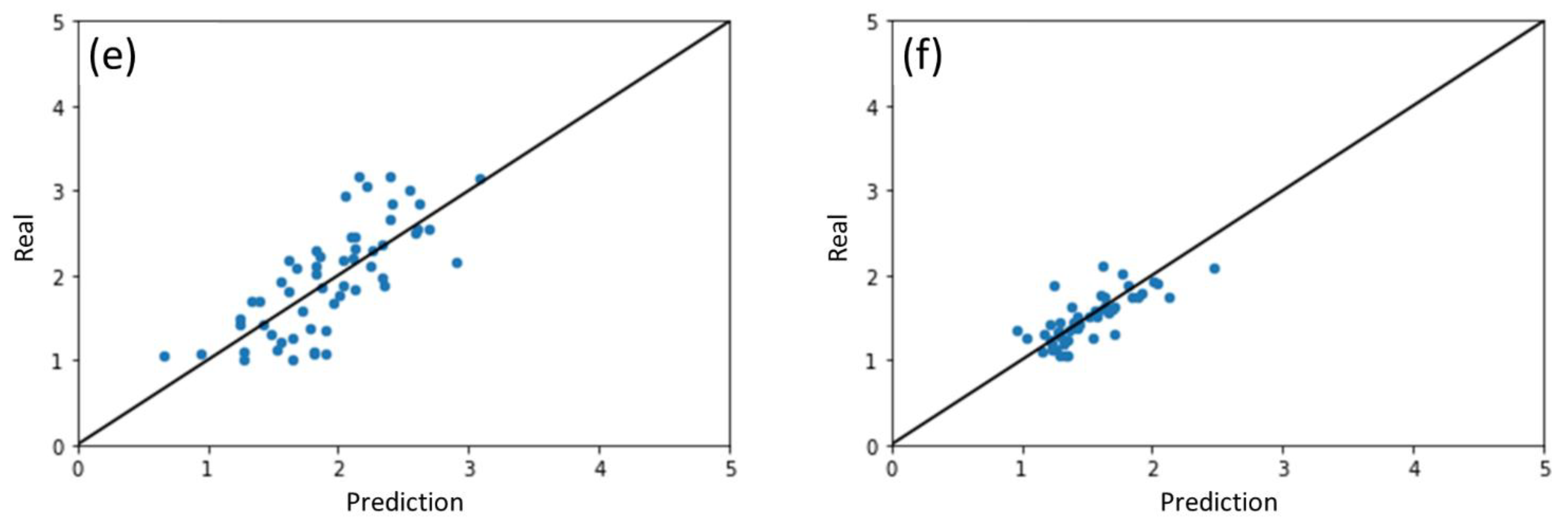
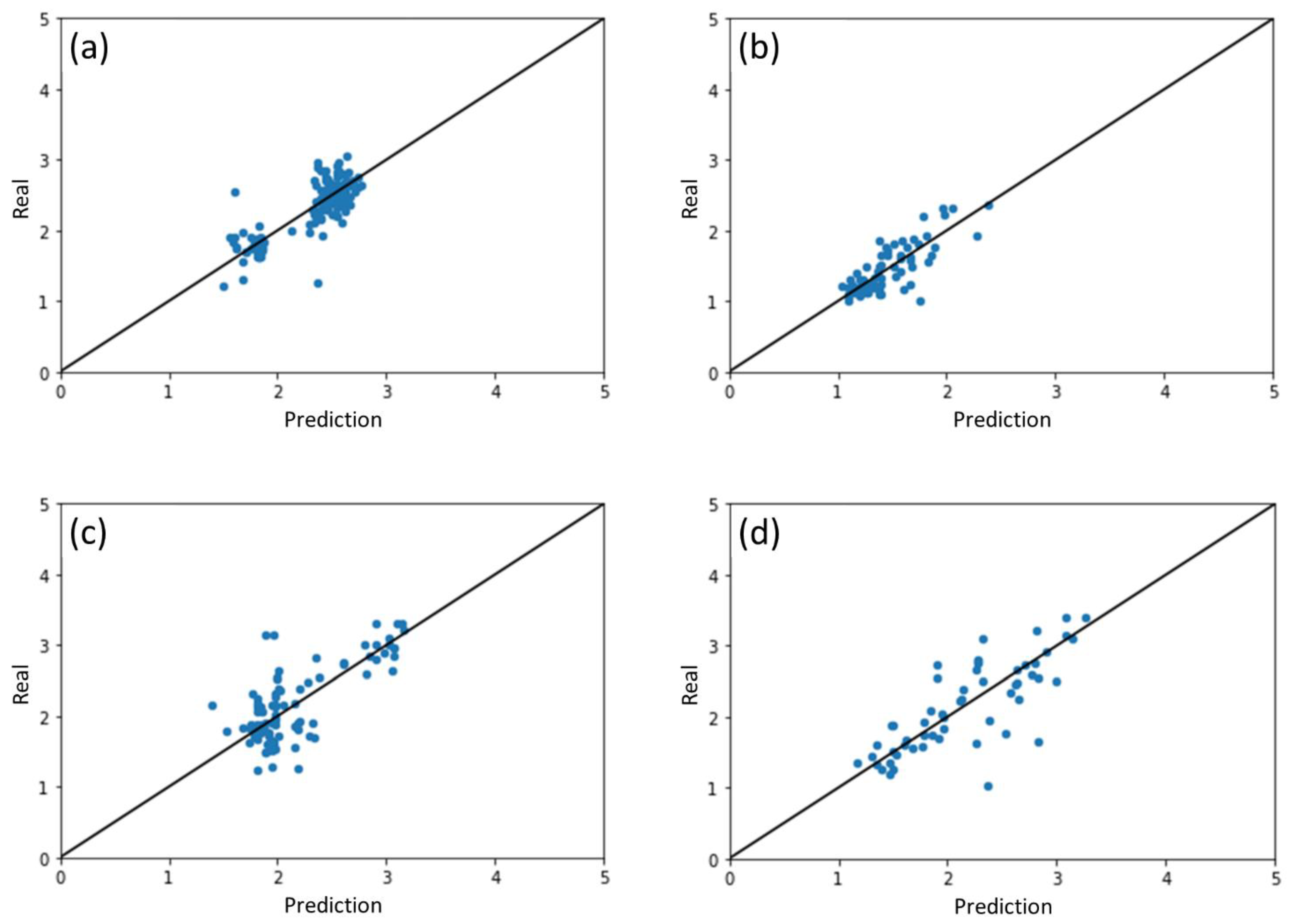
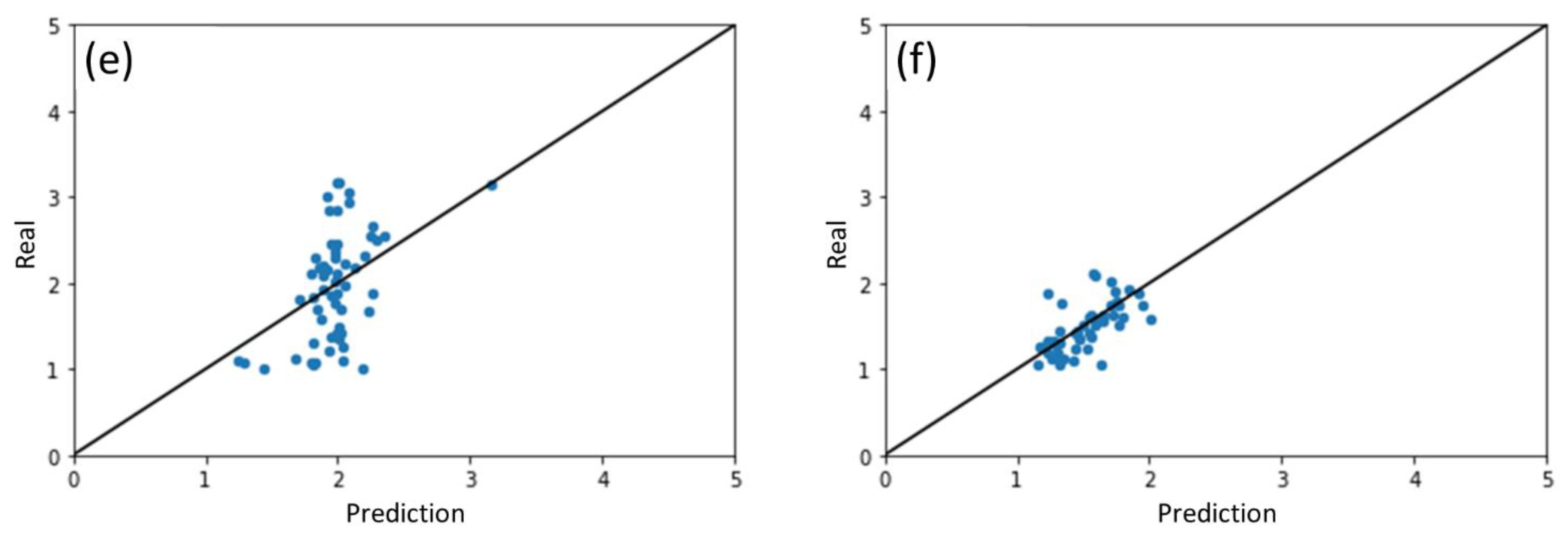
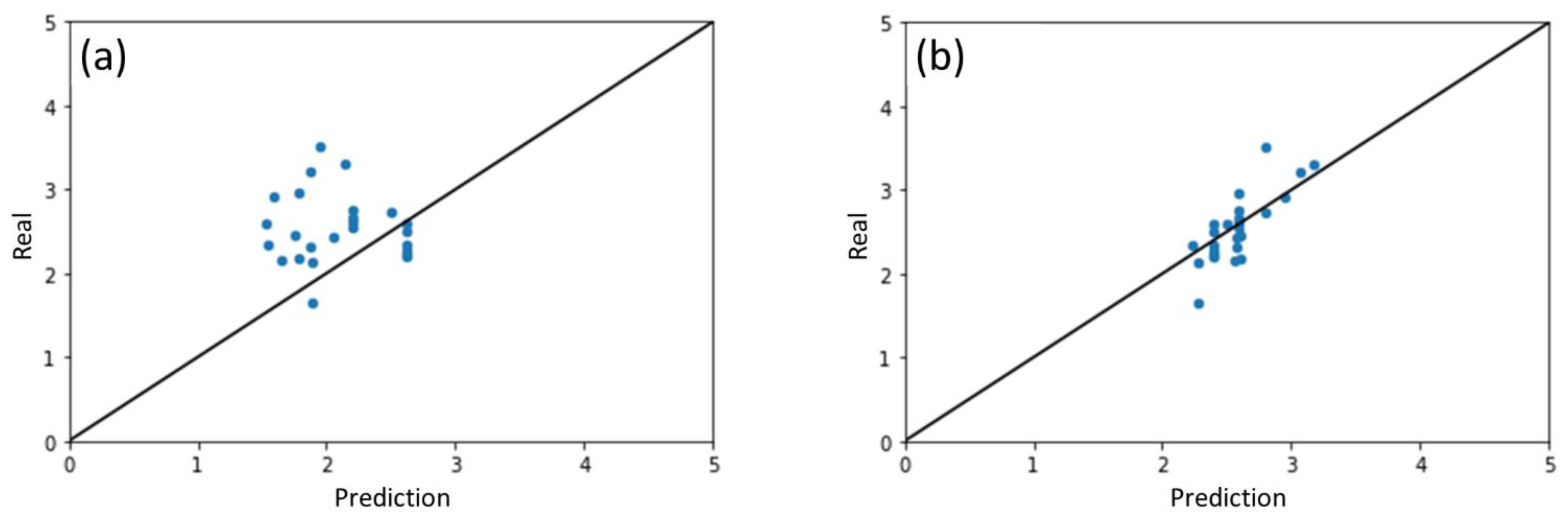
2.1. Results of ML Model Prediction
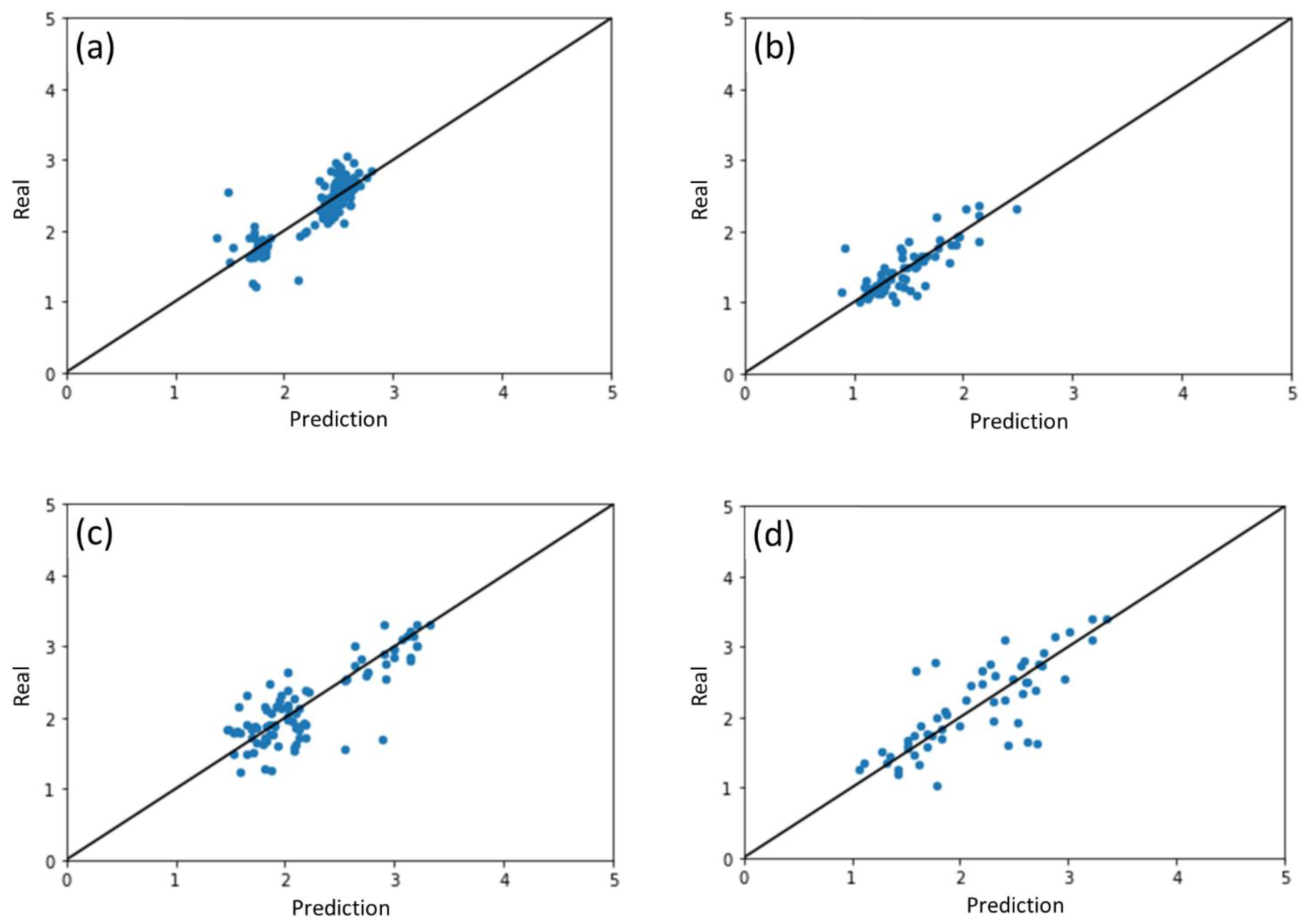
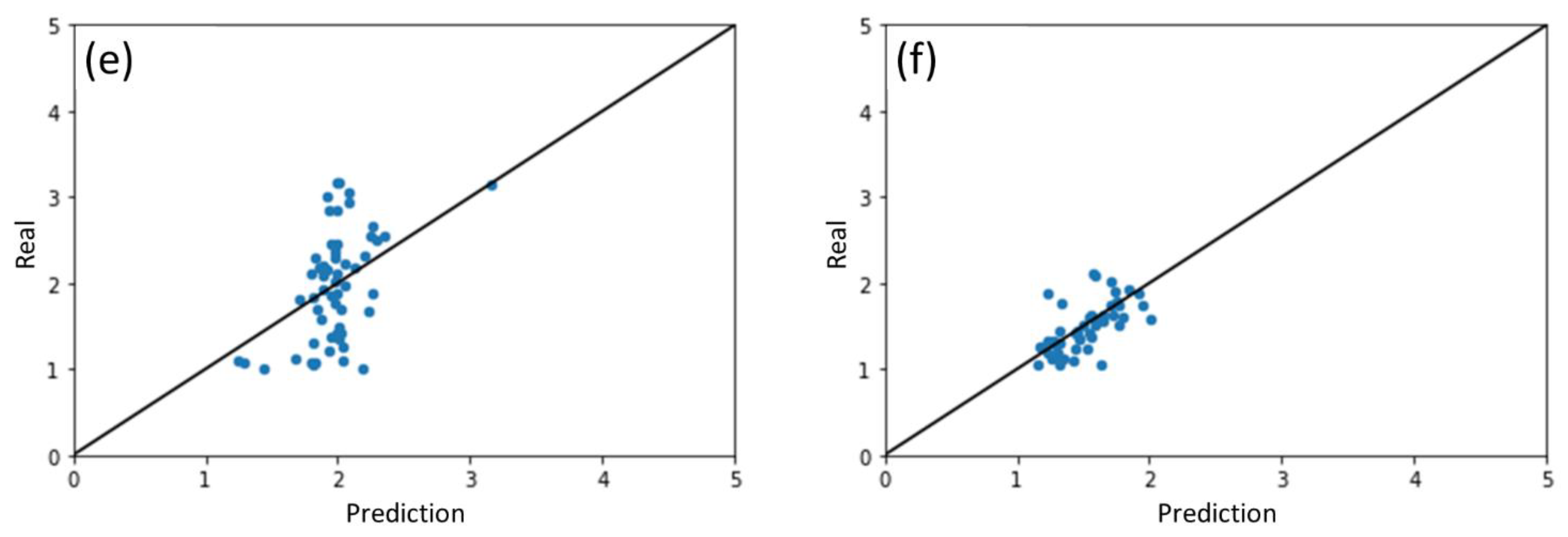
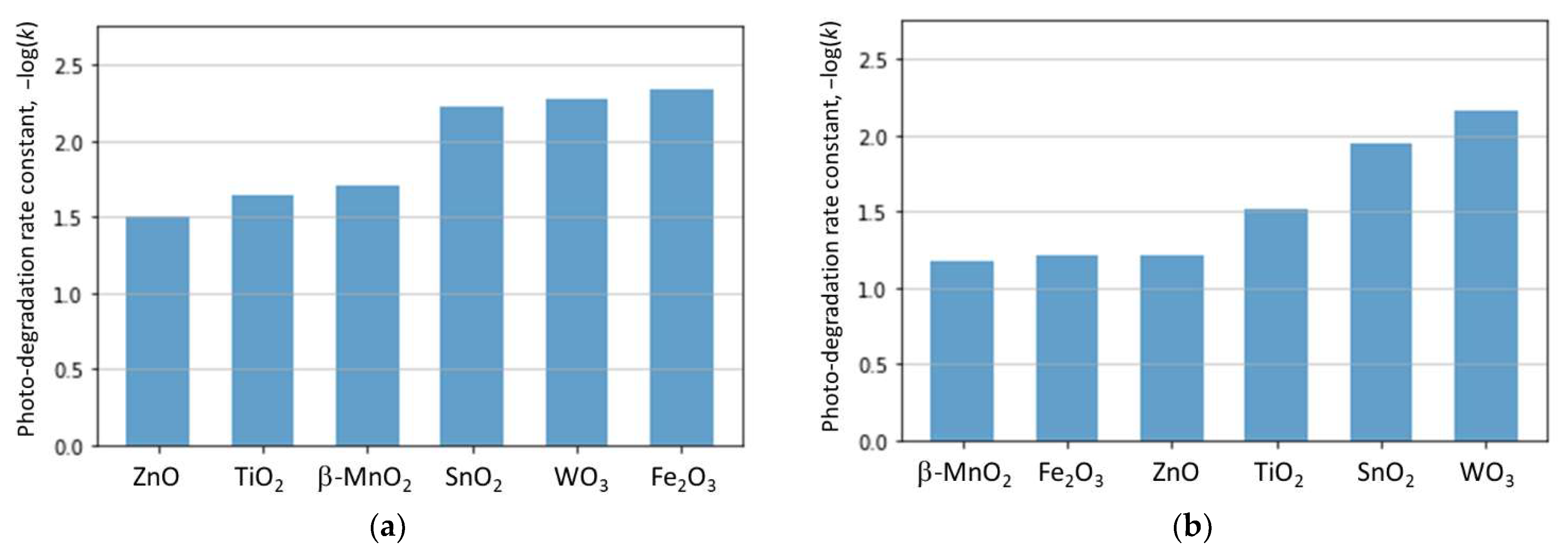
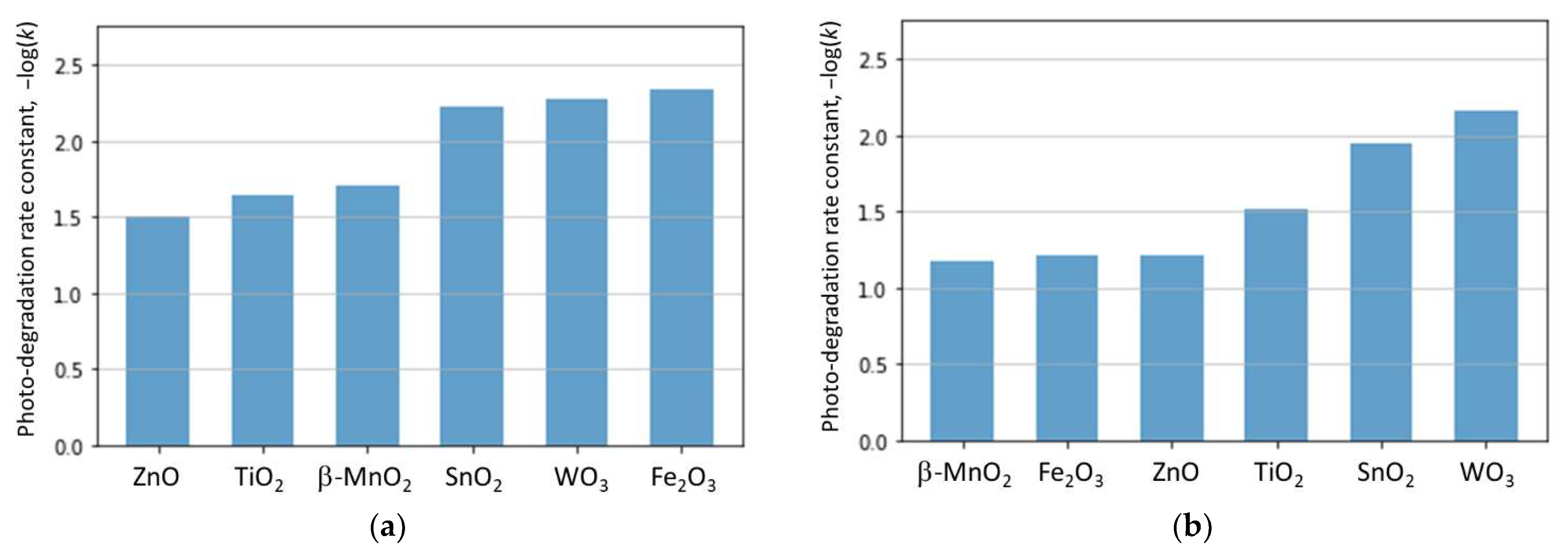
2.2. Performance of ML Model for Different Photocatalysts
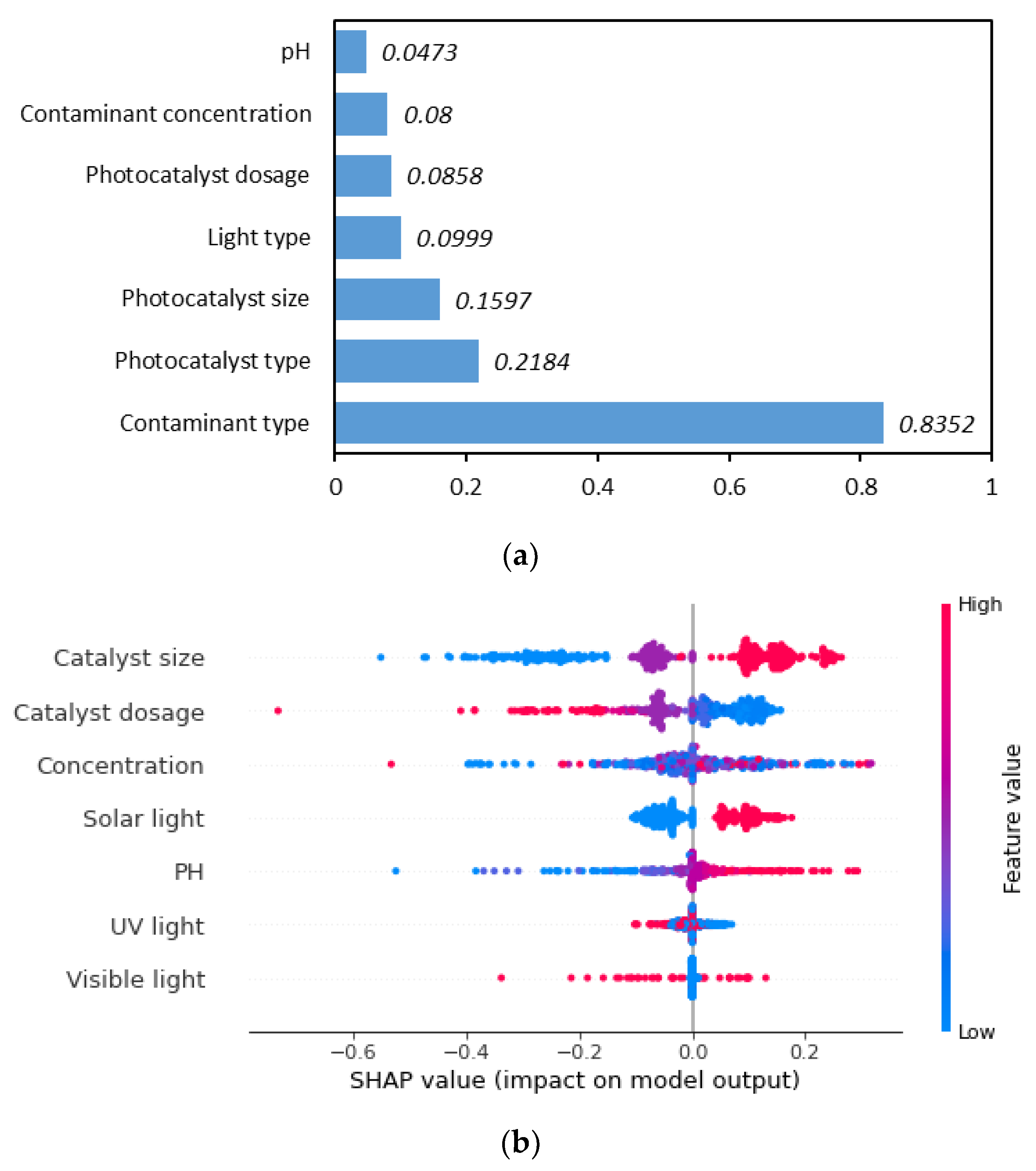
2.3. Model Interpretability via Feature Importance
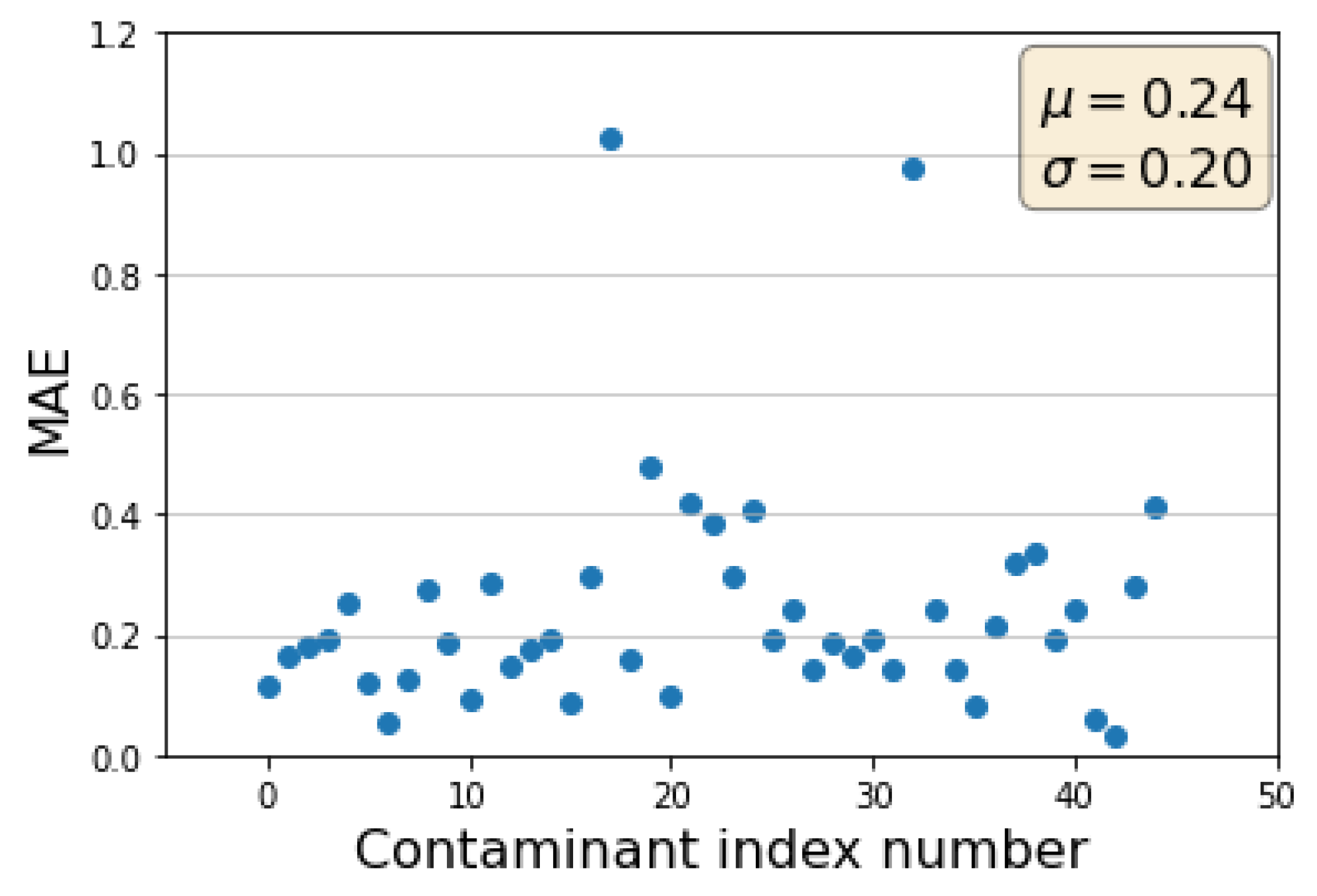
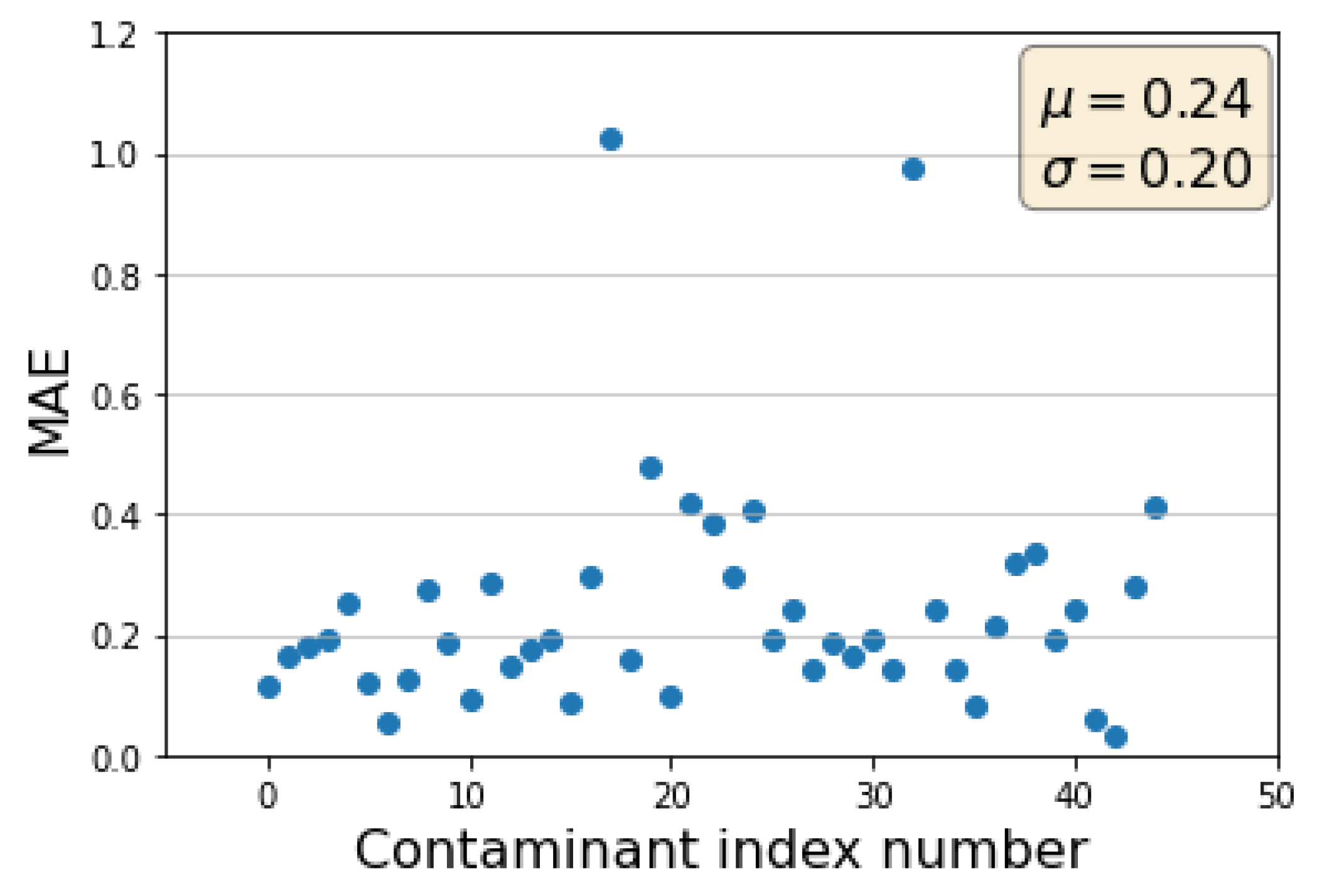
2.4. Performance of CGCNN-MF-ANN ML Model for Different Types of Contaminants
2.5. Application of the CGCNN-MF-ANN ML Model in Selecting the Best Photocatalyst for Contaminant Removal
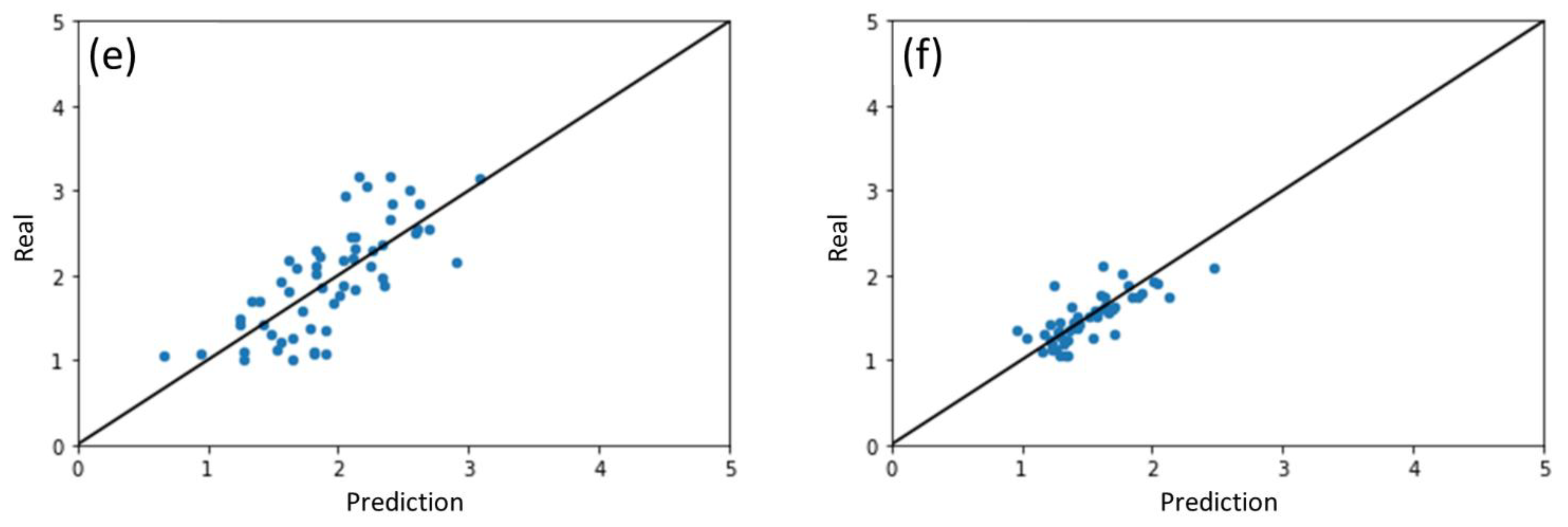
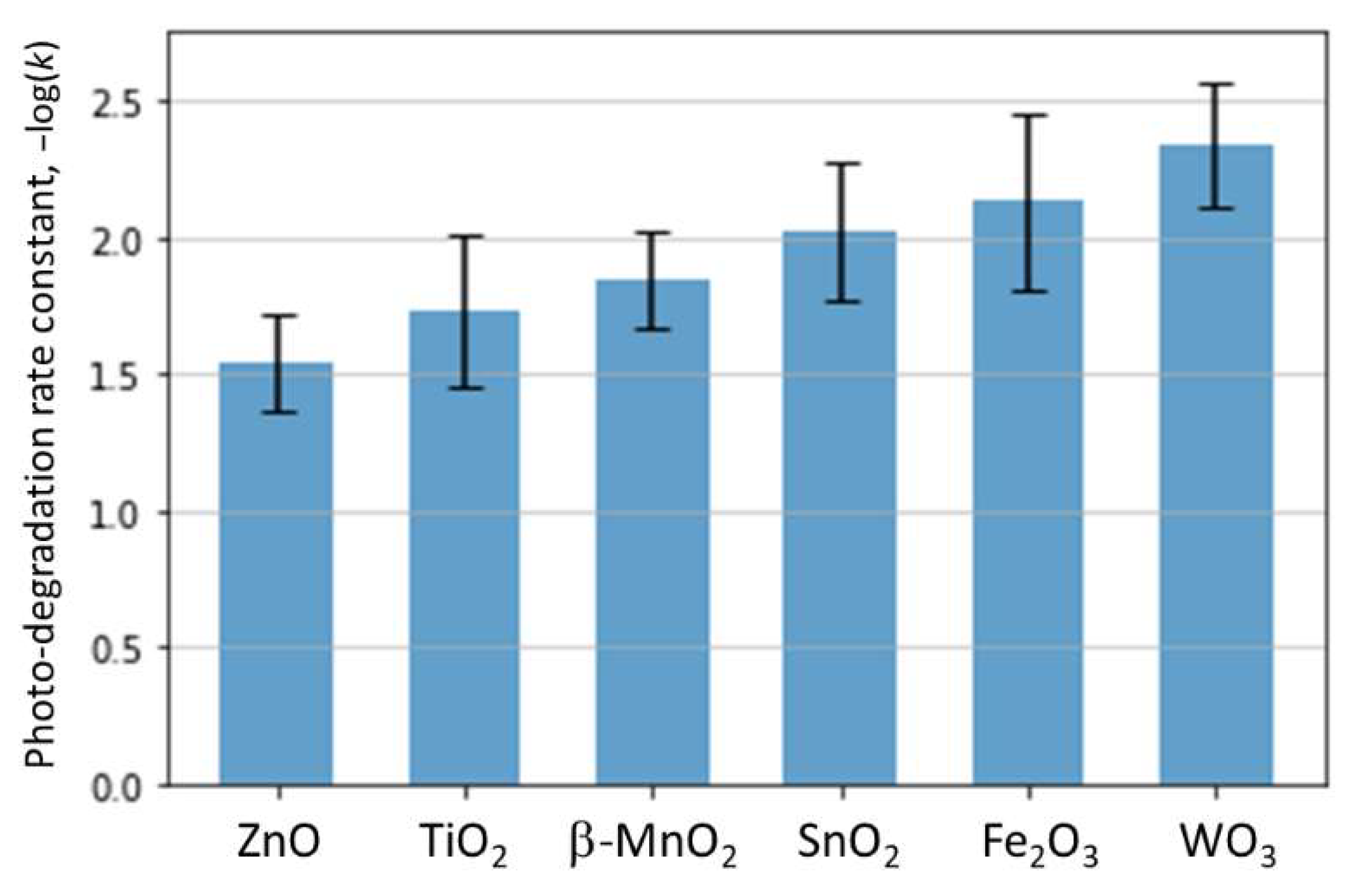
2.6. Predicting the Performance of Other Photocatalysts
3. Materials and Methods
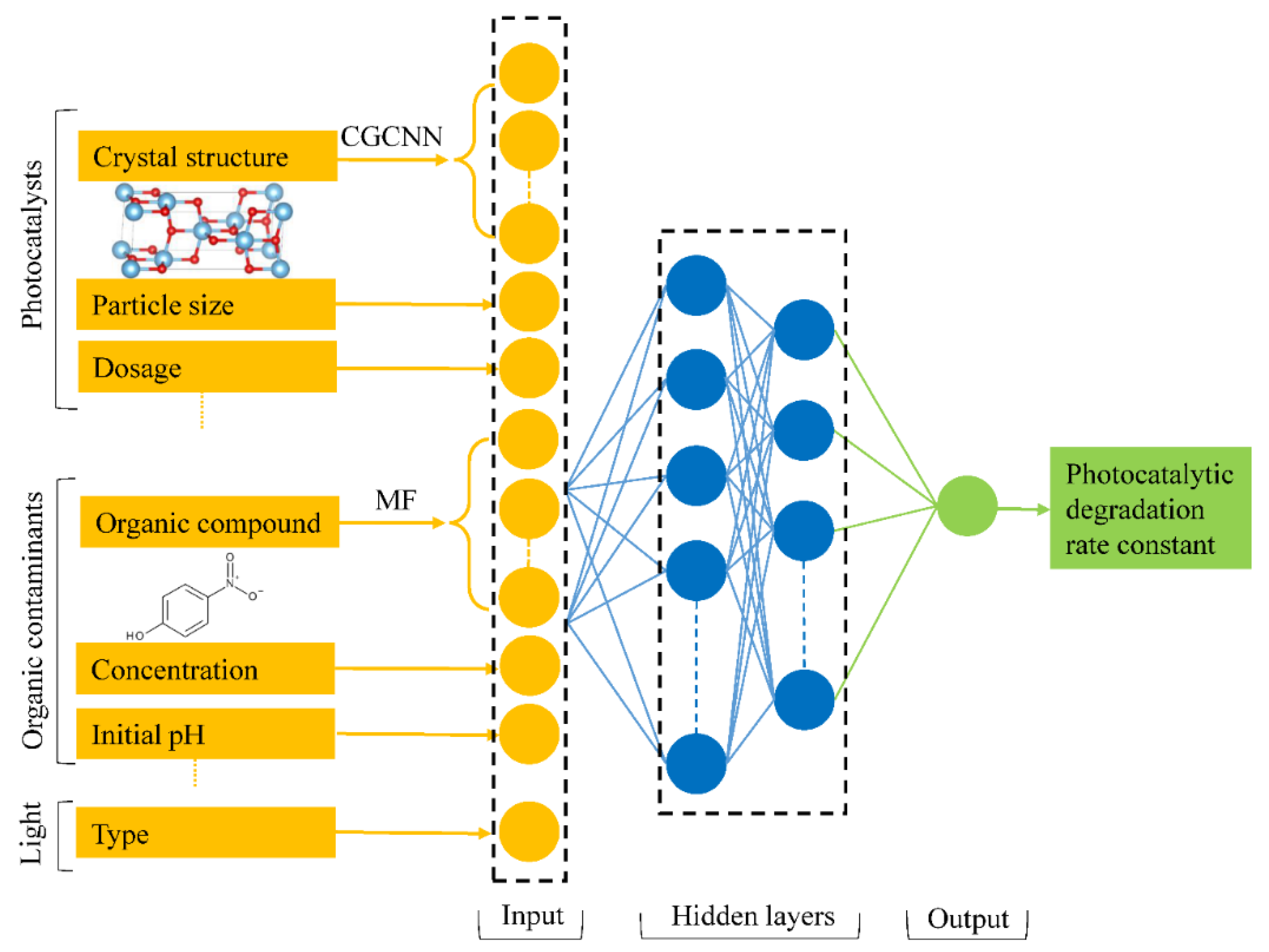
3.1. Data Collection, Preparation, and Encoding
- Six common types of photocatalysts were included in this study, i.e., wurtzite ZnO, rutile SnO2, rhombohedral Fe2O3, anatase TiO2, monoclinic WO3, and tetragonal β-MnO2.
- Forty-five different organic compounds, i.e., the names of an organic compound, their initial concentrations, and the pH value if available.
- The properties of light, including a range of wavelengths and intensities. Seventy percent of the light intensity data was missing in the published papers, and only the range of light wavelength was provided. Therefore, the only wavelength of light was used in the ML model.
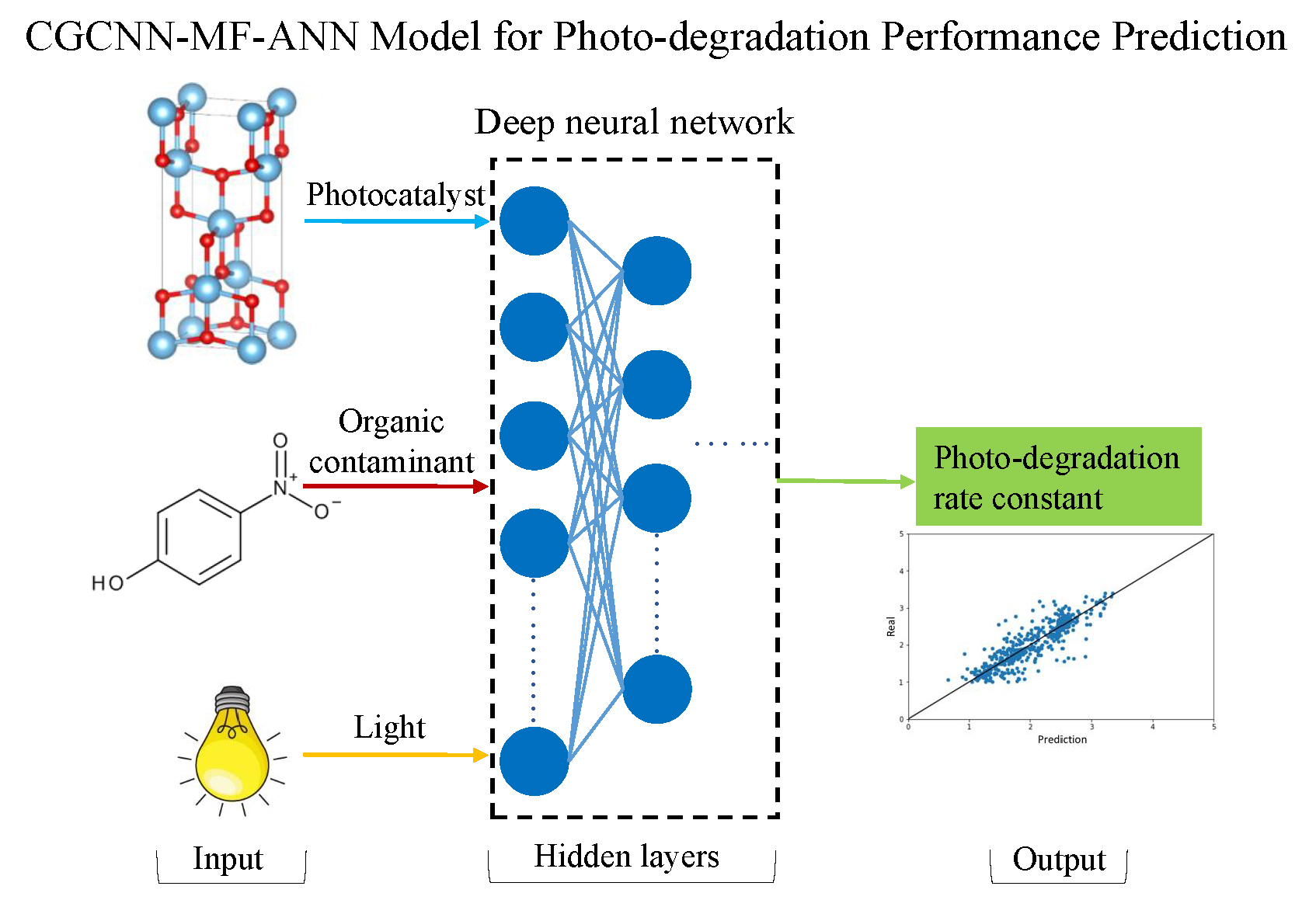
3.2. Machine Learning Model Structure and Optimization
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Orebiyi, O.; Awomeso, A. Water and pollution agents in the 21st century. Nat. Sci. 2008, 6, 16–24. [Google Scholar]
- Mandal, S.; Kunhikrishnan, A.; Bolan, N.S.; Wijesekara, H.; Naidu, R. Application of biochar produced from biowaste materials for environmental protection and sustainable agriculture production. Environ. Mater. Waste 2016, 73–89. [Google Scholar] [CrossRef]
- Poulopoulos, S.G.; Yerkinova, A.; Ulykbanova, G.; Inglezakis, V.J. Photocatalytic treatment of organic pollutants in a synthetic wastewater using UV light and combinations of TiO2, H2O2 and Fe (III). PLoS ONE 2019, 14, e0216745. [Google Scholar] [CrossRef] [PubMed]
- Koe, W.S.; Lee, J.W.; Chong, W.C.; Pang, Y.L.; Sim, L.C. An overview of photocatalytic degradation: Photocatalysts, mechanisms, and development of photocatalytic membrane. Environ. Sci. Pollut. Res. 2019, 27, 2522–2565. [Google Scholar] [CrossRef]
- Zhang, F.; Wang, X.; Liu, H.; Liu, C.; Wan, Y.; Long, Y.; Cai, Z. Recent advances and applications of semiconductor photocatalytic technology. Appl. Sci. 2019, 9, 2489. [Google Scholar] [CrossRef] [Green Version]
- Mahlambi, M.M.; Ngila, C.J.; Mamba, B.B. Recent developments in environmental photocatalytic degradation of organic pollutants: The case of titanium dioxide nanoparticles—A review. J. Nanomater. 2015, 2015, 5. [Google Scholar] [CrossRef] [Green Version]
- Sudha, D.; Sivakumar, P. Review on the photocatalytic activity of various composite catalysts. Chem. Eng. Process. Process Intensif. 2015, 97, 112–133. [Google Scholar] [CrossRef]
- Sobczyński, A.; Dobosz, A. Water purification by photocatalysis on semiconductors. Pol. J. Environ. Stud. 2001, 10, 195–205. [Google Scholar]
- Chong, M.N.; Jin, B.; Chow, C.W.; Saint, C. Recent developments in photocatalytic water treatment technology: A review. Water Res. 2010, 44, 2997–3027. [Google Scholar] [CrossRef]
- Ahmed, S.N.; Haider, W. Heterogeneous photocatalysis and its potential applications in water and wastewater treatment: A review. Nanotechnology 2018, 29, 342001. [Google Scholar] [CrossRef] [Green Version]
- Loeb, S.K.; Alvarez, P.J.; Brame, J.A.; Cates, E.L.; Choi, W.; Crittenden, J.; Dionysiou, D.D.; Li, Q.; Li-Puma, G.; Quan, X.; et al. The technology horizon for photocatalytic water treatment: Sunrise or sunset? Environ. Sci. Technol. 2018, 53, 2937–2947. [Google Scholar] [CrossRef] [PubMed]
- Kucio, K.; Charmas, B.; Pasieczna-Patkowska, S. Structural, thermal and photocatalytic properties of composite materials SiO2/TiO2/C. Adsorption 2019, 25, 501–511. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Jian, H.; Mai, K.; Ren, Z.; Wang, J.; Fu, X.; Fan, C.; Sun, C.; Qian, G.; Wang, Z. Shape-and Size-Controlled Synthesis of Mn3O4 Nanocrystals at Room Temperature. Eur. J. Inorg. Chem. 2014, 2014, 3023–3029. [Google Scholar] [CrossRef]
- Kumar, A.; Pandey, G. A review on the factors affecting the photocatalytic degradation of hazardous materials. Mater. Sci. Eng. Int. J. 2017, 1, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Qamar, M.; Muneer, M. Comparative photocatalytic study of two selected pesticide derivatives, indole-3-acetic acid and indole-3-butyric acid in aqueous suspensions of titanium dioxide. J. Hazard. Mater. 2005, 120, 219–227. [Google Scholar] [CrossRef]
- Fidan, S.; Oktay, H.; Polat, S.; Ozturk, S. An Artificial Neural Network Model to Predict the Thermal Properties of Concrete Using Different Neurons and Activation Functions. Adv. Mater. Sci. Eng. 2019, 2019, 3831813. [Google Scholar] [CrossRef] [Green Version]
- Swaidani, A.M.; Khwies, W.T. Applicability of artificial neural networks to predict mechanical and permeability properties of volcanic scoria-based concrete. Adv. Civ. Eng. 2018, 2018, 5207962. [Google Scholar]
- Zhang, Z.; Barkoula, N.M.; Karger-Kocsis, J.; Friedrich, K. Artificial neural network predictions on erosive wear of polymers. Wear 2003, 255, 708–713. [Google Scholar] [CrossRef]
- Roy, N.K.; Potter, W.D.; Landau, D.P. Polymer property prediction and optimization using neural networks. IEEE Trans. Neural Netw. 2006, 17, 1001–1014. [Google Scholar] [CrossRef] [Green Version]
- Kumar, G.V.; Pramod, R.; Rao, C.S.P.; Gouda, P.S. Artificial Neural Network Prediction on Wear of Al6061 Alloy Metal Matrix Composites Reinforced with-Al2O3. Mater. Today Proc. 2018, 5, 11268–11276. [Google Scholar] [CrossRef]
- Scott, D.J.; Coveney, P.V.; Kilner, J.A.; Rossiny, J.C.H.; Alford, N.M.N. Prediction of the functional properties of ceramic materials from composition using artificial neural networks. J. Eur. Ceram. Soc. 2007, 27, 4425–4435. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Dong, B.; Guo, H.; Yang, T.; Zhang, Z. Fundamental band gap and alignment of two-dimensional semiconductors explored by machine learning. Chin. Phys. B 2020, 29, 046101. [Google Scholar] [CrossRef] [Green Version]
- Masood, H.; Toe, C.Y.; Teoh, W.Y.; Sethu, V.; Amal, R. Machine Learning for Accelerated Discovery of Solar Photocatalysts. ACS Catal. 2019, 9, 11774–11787. [Google Scholar] [CrossRef]
- Emilio, C.A.; Magallanes, J.F.; Litter, M.I. Chemometric study on the TiO2-photocatalytic degradation of nitrilotriacetic acid. Anal. Chim. Acta 2007, 595, 89–97. [Google Scholar] [CrossRef] [PubMed]
- Toma, F.L.; Guessasma, S.; Klein, D.; Montavon, G.; Bertrand, G.; Coddet, C. Neural computation to predict TiO2 photocatalytic efficiency for nitrogen oxides removal. J. Photochem. Photobiol. A Chem. 2004, 165, 91–96. [Google Scholar] [CrossRef]
- Oliveros, E.; Benoit-Marquie, F.; Puech-Costes, E.; Maurette, M.T.; Nascimento, C.A.O. Neural network modeling of the photocatalytic degradation of 2,4-dihydroxybenzoic acid in aqueous solution. Analusis 1998, 26, 326–332. [Google Scholar] [CrossRef]
- Emilio, C.A.; Litter, M.I.; Magallanes, J.F. Semiempirical modeling with application of artificial neural networks for the photocatalytic reaction of ethylenediaminetetraacetic acid (EDTA) over titanium oxide (TiO2). Helv. Chim. Acta 2002, 85, 799–813. [Google Scholar] [CrossRef]
- Hassani, A.; Khataee, A.; Karaca, S. Photocatalytic degradation of ciprofloxacin by synthesized TiO2 nanoparticles on montmorillonite: Effect of operation parameters and artificial neural network modeling. J. Mol. Catal. A Chem. 2015, 409, 149–161. [Google Scholar] [CrossRef]
- Guimarães, O.L.C.; Silva, M.B. Hybrid neural model for decoloration by UV/H2O2 involving process variables and structural parameters characteristics to azo dyes. Chem. Eng. Process. Process Intensif. 2007, 46, 45–51. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4768–4777. [Google Scholar]
- Xie, T.; Grossman, J.C. Crystal graph convolutional neural networks for an accurate and interpretable prediction of material properties. Phys. Rev. Lett. 2018, 120, 145301. [Google Scholar] [CrossRef] [Green Version]
- CGCNN Website. Available online: https://github.com/txie-93/cgcnn (accessed on 14 September 2021).
- Muegge, I.; Mukherjee, P. An overview of molecular fingerprint similarity search in virtual screening. Expert Opin. Drug Discov. 2016, 11, 137–148. [Google Scholar] [CrossRef]
- Yin, Z.; Ai, H.; Zhang, L.; Ren, G.; Wang, Y.; Zhao, Q.; Liu, H. Predicting the cytotoxicity of chemicals using ensemble learning methods and molecular fingerprints. J. Appl. Toxicol. 2019, 39, 1366–1377. [Google Scholar] [CrossRef]
- Zhong, S.; Hu, J.; Fan, X.; Yu, X.; Zhang, H. A deep neural network combined with molecular fingerprints (DNN-MF) to develop predictive models for hydroxyl radical rate constants of water contaminants. J. Hazard. Mater. 2020, 383, 121141. [Google Scholar] [CrossRef] [PubMed]
- Chan, H.S.; Shan, H.; Dahoun, T.; Vogel, H.; Yuan, S. Advancing drug discovery via artificial intelligence. Trends Pharmacol. Sci. 2019, 40, 592–604. [Google Scholar] [CrossRef]
- Jiang, Z.; Hu, J.; Zhang, X.; Zhao, Y.; Fan, X.; Zhong, S.; Zhang, H.; Yu, X. A Generalized Predictive Model for TiO2–Catalyzed Photo-degradation Rate Constants of Water Contaminants through Artificial Neural Network. Environ. Res. 2020, 187, 109697. [Google Scholar] [CrossRef] [PubMed]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. Adv. Neural Inf. Process. Syst. 2012, 2, 25. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subgroup | 1 | 2 | 3 | Overall |
|---|---|---|---|---|
| R2 | 0.777 | 0.681 | 0.768 | 0.746 |
| MAE | 0.212 | 0.213 | 0.193 | 0.206 |
| RMSE | 0.299 | 0.311 | 0.266 | 0.293 |
| Photocatalyst Group | β-MnO2 | ZnO | WO3 | SnO2 | Fe2O3 | TiO2 | |
|---|---|---|---|---|---|---|---|
| ML model trained with all datasets and results split by photocatalysts | R2 | 0.721 | 0.658 | 0.648 | 0.607 | 0.555 | 0.490 |
| MAE | 0.152 | 0.137 | 0.236 | 0.279 | 0.347 | 0.148 | |
| RMSE | 0.219 | 0.203 | 0.316 | 0.389 | 0.423 | 0.202 | |
| ML models trained for individual photocatalyst | R2 | 0.662 | 0.621 | 0.524 | 0.593 | 0.206 | 0.374 |
| MAE | 0.178 | 0.163 | 0.277 | 0.281 | 0.452 | 0.156 | |
| RMSE | 0.241 | 0.214 | 0.368 | 0.396 | 0.565 | 0.224 | |
| Water Contaminant | No. of Data | Mean Absolute Error | Standard Deviation of Error |
|---|---|---|---|
| Methylene Blue | 67 | 0.286 | 0.233 |
| Rhodamine B | 50 | 0.338 | 0.301 |
| Rose Bengal | 33 | 0.095 | 0.077 |
| Toluidine Blue | 31 | 0.127 | 0.101 |
| Azure B | 31 | 0.142 | 0.100 |
| Carmine Indigo | 22 | 0.275 | 0.194 |
| Phenoxyacetic Acid | 20 | 0.113 | 0.086 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Z.; Hu, J.; Tong, M.; Samia, A.C.; Zhang, H.; Yu, X. A Novel Machine Learning Model to Predict the Photo-Degradation Performance of Different Photocatalysts on a Variety of Water Contaminants. Catalysts 2021, 11, 1107. https://doi.org/10.3390/catal11091107
Jiang Z, Hu J, Tong M, Samia AC, Zhang H, Yu X. A Novel Machine Learning Model to Predict the Photo-Degradation Performance of Different Photocatalysts on a Variety of Water Contaminants. Catalysts. 2021; 11(9):1107. https://doi.org/10.3390/catal11091107
Chicago/Turabian StyleJiang, Zhuoying, Jiajie Hu, Matthew Tong, Anna C. Samia, Huichun (Judy) Zhang, and Xiong (Bill) Yu. 2021. "A Novel Machine Learning Model to Predict the Photo-Degradation Performance of Different Photocatalysts on a Variety of Water Contaminants" Catalysts 11, no. 9: 1107. https://doi.org/10.3390/catal11091107
APA StyleJiang, Z., Hu, J., Tong, M., Samia, A. C., Zhang, H., & Yu, X. (2021). A Novel Machine Learning Model to Predict the Photo-Degradation Performance of Different Photocatalysts on a Variety of Water Contaminants. Catalysts, 11(9), 1107. https://doi.org/10.3390/catal11091107